
SP500 Handelsstrategie in MQL5 für Anfänger

Einführung
In diesem Artikel wird erörtert, wie wir eine intelligente Handelsstrategie für den Handel mit dem Standard & Poor's 500 (S&P 500) Index mit MQL5 erstellen können. Unsere Diskussion wird zeigen, wie man die Flexibilität von MQL5 nutzen kann, um einen dynamischen Expert Advisor zu erstellen, der auf einer Kombination aus künstlicher Intelligenz und technischer Analyse beruht. Unser Grundgedanke ist, dass das alleinige Vertrauen in die KI zu instabilen Strategien führen kann. Wenn wir jedoch die KI mit den bewährten Prinzipien der technischen Analyse anleiten, können wir einen zuverlässigeren Ansatz erreichen. Diese hybride Strategie zielt darauf ab, in den riesigen Datenmengen, die auf unseren MetaTrader 5-Terminals zur Verfügung stehen, verborgene Muster aufzudecken. Dabei werden die Stärken von KI, traditioneller Analyse und der MQL5-Sprache genutzt, um die Handelsleistung und die Entscheidungsfindung zu verbessern.
Nach der Lektüre dieses Artikels werden Sie gewinnen:
- Gute Programmiergrundsätze für MQL5
- Einblicke in die Art und Weise, wie Händler große Datensätze von mehreren Symbolen gleichzeitig mit linearen Algebra-Befehlen in der MQL5-API leicht analysieren können.
- Techniken zur Aufdeckung von verborgenen Mustern in Marktdaten, die nicht sofort erkennbar sind.
Geschichte: Was ist der Standard & Poor's 500?
Der S&P 500, der 1957 eingeführt wurde, ist eine wichtige Benchmark, die die breite Performance der US-Wirtschaft widerspiegelt. Im Laufe der Jahre wurden zahlreiche Unternehmen in den Index aufgenommen oder aus ihm entfernt, um die Dynamik des Marktes widerzuspiegeln. Zu den ältesten Mitgliedern gehören General Electric, J.P. Morgan und Goldman Sachs, die ihre Positionen im Index seit seiner Gründung beibehalten haben.
Der S&P 500 stellt den Durchschnittswert der 500 größten Unternehmen in den Vereinigten Staaten von Amerika dar. Der Wert eines jeden Unternehmens wird auf der Grundlage seiner Marktkapitalisierung gewichtet. Daher kann der S&P 500 auch als ein nach der Marktkapitalisierung gewichteter Index der 500 größten börsennotierten Unternehmen der Welt betrachtet werden.
Heutzutage haben bahnbrechende Unternehmen wie Tesla und Nvidia den Benchmark von Grund auf neu definiert. Der größte Teil des S&P 500 wird heute von großen Technologieunternehmen gehalten, darunter Google, Apple und Microsoft, die zu den genannten Giganten gehören. Diese Tech-Titanen haben die Landschaft des Indexes verändert und spiegeln die Verlagerung der Wirtschaft hin zu Technologie und Innovation wider.
Überblick über unsere Handelsstrategie
Eine Liste der in den Index aufgenommenen Unternehmen ist im Internet leicht zugänglich. Wir können unser Wissen über die Zusammensetzung des Index nutzen, um eine Handelsstrategie zu entwickeln. Wir werden eine Handvoll der größten Unternehmen im Index auswählen und den jeweiligen Kurs jedes Unternehmens als Input für ein KI-Modell verwenden, das den Schlusskurs des Index auf der Grundlage unserer Stichprobe von Unternehmen mit einer verhältnismäßig großen Gewichtung vorhersagen wird. Unser Ziel ist es, eine Strategie zu entwickeln, die KI mit bewährten Techniken verbindet.
Unser technisches Analysesystem verwendet Trendfolgeprinzipien, um Handelssignale zu generieren. Wir müssen mehrere Schlüsselindikatoren einbeziehen:
- Der Commodity Channel Index (CCI) als unser Volumenindikator. Wir wollen nur Geschäfte tätigen, die durch ein bestimmtes Volumen gestützt sind.
- Der Relative Strength Index (RSI) und der Williams Percent Range (WPR), um den Kauf- oder Verkaufsdruck auf dem Markt zu messen.
- Ein gleitender Durchschnitt (MA) als unser letzter Bestätigungsindikator.
Der Commodity Channel Index (CCI) bewegt sich um 0. Ein Wert über 0 deutet auf ein starkes Volumen für eine Kaufgelegenheit hin, während ein Wert unter 0 auf ein unterstützendes Volumen für einen Verkauf hindeutet. Für die Handelsbestätigung ist eine Abstimmung mit anderen Indikatoren erforderlich, wodurch sich die Chancen verbessern, Setups mit hoher Wahrscheinlichkeit zu finden.
Damit wir kaufen können, sollte also gelten:
- Der CCI-Wert muss größer als 0 sein.
- Der RSI-Wert muss größer als 50 sein.
- Der WPR-Wert muss größer als -50 sein.
- MA muss unter dem Schlusskurs liegen.
Und umgekehrt für einen Verkauf gilt:
- Der CCI-Wert muss kleiner als 0 sein.
- Der RSI-Wert muss kleiner als 50 sein.
- Der WPR-Wert muss weniger als -50 betragen.
- MA muss über dem Schlusskurs liegen.
Um unser KI-System aufzubauen, müssen wir zunächst die historischen Kurse von 12 Aktien mit hoher Marktkapitalisierung, die im S&P 500 enthalten sind, und die Schlusskurse des S&P 500 ermitteln. Dies werden unsere Trainingsdaten sein, die wir zur Erstellung unseres multiplen linearen Regressionsmodells verwenden, um zukünftige Preise des Index zu prognostizieren.
Von dort aus prognostiziert das KI-System mit Hilfe der Regression der kleinsten Quadrate den Schlusswert des S&P 500.

Abb. 1: Unser Modell wird den S&P500 als Ergebnis der Gruppe dieser Aktien betrachten.
Sobald wir die Daten vorliegen haben, können wir die Modellparameter für unser lineares Regressionsmodell anhand der folgenden Formel schätzen.
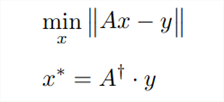
Abb. 2: Die obige Gleichung zeigt einen von vielen möglichen Wegen zur Schätzung der Parameter eines multiplen linearen Regressionsmodells.
Der Ausdruck „Ax - y“, der von zwei senkrechten Linien umgeben ist, wird als L2-Norm eines Vektors bezeichnet und als „ell 2“ ausgesprochen. Wenn wir in der Alltagssprache bei physischen Objekten fragen: „Wie groß ist es?“, sprechen wir über ihre Größe oder Magnitude. Wenn wir fragen, „wie groß“ ein Vektor ist, beziehen wir uns auf seine Norm. Ein Vektor ist im Wesentlichen eine Liste von Zahlen. Es gibt zwar verschiedene Arten von Normen, aber die L1-Norm und die L2-Norm sind am weitesten verbreitet. Heute werden wir uns auf die L2-Norm konzentrieren, die als Quadratwurzel aus der Summe der quadrierten Werte innerhalb des Vektors berechnet wird.
In diesem Zusammenhang:
- Die Matrix „A“ stellt die Eingangsdaten dar, die aus den Schlusskursen von 12 verschiedenen Aktien bestehen.
- Das Symbol „x“ kennzeichnet die Koeffizientenwerte für unser multiples lineares Regressionsmodell, mit einem Koeffizienten pro Aktie.
- Das Produkt „Ax“ stellt unsere Prognosen für den zukünftigen Kurs des S&P 500 Index auf der Grundlage unserer Trainingsdaten dar.
- Die Notation „y“ symbolisiert den Vektor der tatsächlichen Schlusskurse, die wir beim Training vorhersagen wollten.
Im Wesentlichen besagt die erste Gleichung, dass wir nach Werten für x suchen, die die L2-Norm von Ax - y minimieren. Mit anderen Worten, wir suchen die Werte von x, die unseren Prognosefehler bei der Vorhersage des Schlusskurses des S&P 500 minimieren.
Die zweite Gleichung zeigt, dass die Werte von x, die den geringsten Fehler ergeben, durch Multiplikation der Pseudo-Inverse von A mit den Ausgabedaten (y) aus unserem Trainingssatz gefunden werden können. Die Pseudo-Inverse Operation ist in MQL5 bequem implementiert.
Wir können die pseudo-inverse Lösung in MQL5 mit nur wenigen Zeilen Code effizient finden.
Umsetzung: SP500 Handelsstrategie
Die ersten Schritte
Zunächst müssen wir die Eingaben für unseren Expert Advisor definieren. Wir benötigen Eingaben, die es dem Nutzer ermöglichen, die Zeiträume unserer technischen Indikatoren zu ändern.
//+------------------------------------------------------------------+ //| SP500 Strategy EA.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com" #property version "1.00" /* The goal of this application is to implement a strategy to trade the SP500 based on the performance of a sample of stocks that hold proportionally large weights in the index and classical technical analysis. We will use the following stocks: 1)Microsoft 2)Apple 3)Google 4)Meta 5)Visa 6)JPMorgan 7)Nvidia 8)Tesla 9)Johnsons N Johnsons 10)Home Depot 11)Proctor & Gamble 12)Master Card A strategy that relies solely on AI may prove to be unstable. We want to use a combination of AI guided by trading strategies that have been trusted over time. Our AI will be a linear system mapping the price of each stock to the closing price of the index. Recall that financial time series data can be very noisy. Using simpler models may be beneficial. We will attempt to find linear coefficients using ordinary least squares. We will use the pseudo inverse solution to find our model parameters. Our technical analysis will be based on trend following principles: 1)We must observe increasing volume backing a trade before we enter. 2)We want 2 confirmation indicators, RSI and WPR, confirming the trend. 3)We want price to break above the previous week high or low. 4)We want price above or below our MA before we trade. Our goal is to find an optimal combination of statistical insight, and classical technical analysis to hopefully build a strategy with an edge. Gamuchirai Zororo Ndawana Selebi Phikwe Botswana Monday 8 July 2024 21:03 */ //Inputs //How far ahead into the future should we forecast? input int look_ahead = 10; //Our moving average period input int ma_period = 120; //Our RSI period input int rsi_period = 10; //Our WPR period input int wpr_period = 30; //Our CCI period input int cci_period = 40; //How big should our lot sizes be? int input lot_multiple = 20;
Als Nächstes müssen wir unsere Handelsbibliothek importieren, damit wir unsere Positionen verwalten können.
//Libraries //Trade class #include <Trade/Trade.mqh> CTrade Trade;
Nun müssen wir globale Variablen definieren, die in unserem Programm verwendet werden.
//Global variables //Smallest lot size double minimum_volume; //Ask double ask_price; //Bid double bid_price; //How much data should we fetch? int fetch = 20; //Determine the starting date for our inputs int inupt_start; //Determine the starting date for our outputs int output_start; //Which symbols are we going to use to forecast the SP500 close? string desired_symbols[] = {"MSFT","AAPL","NVDA","GOOG","TSLA","META","JPM","JNJ","V","PG","HD","MA"}; //Define our input matrix matrix input_matrix = matrix::Ones(fetch,(ArraySize(desired_symbols))-1); //Define our output matrix, our output matrix has one column matrix output_matrix = matrix::Ones(fetch,1); //A vector to store the initial values of each column vector initiall_input_values = vector::Ones((ArraySize(desired_symbols))); //A variable to store the initial value of the output double initiall_output_value = 0.0; //Defining the matrix that will store our model parameters matrix b; //Define our target symbol string target_symbol = "US_500"; //A vector to temporarily store the historic closing price of each stock vector symbol_history = vector::Zeros(fetch); //A flag to let us know when our model is ready bool model_initialized = false; //A flag to let us know if the training process has started bool model_being_trained = false; //Our model's prediction double model_forecast = 0; //Handlers for our technical indicators int cci_handler,rsi_handler,wpr_handler,ma_handler; //Buffers for our technical indicator values double cci_buffer[],rsi_buffer[],wpr_buffer[],ma_buffer[];
Nachdem wir nun so weit gekommen sind, müssen wir unsere technischen Indikatoren in OnInit()) einrichten.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- //Let's setup our technical indicators rsi_handler = iRSI(target_symbol,PERIOD_CURRENT,rsi_period,PRICE_CLOSE); ma_handler = iMA(target_symbol,PERIOD_CURRENT,ma_period,0,MODE_EMA,PRICE_CLOSE); wpr_handler = iWPR(target_symbol,PERIOD_CURRENT,wpr_period); cci_handler = iCCI(target_symbol,PERIOD_CURRENT,cci_period,PRICE_CLOSE); //Get market data minimum_volume = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); //--- return(INIT_SUCCEEDED); }
Wir benötigen Hilfsfunktionen. Zunächst definieren wir ein Verfahren zur Initialisierung unseres multiplen linearen Regressionsmodells. Unsere Anpassungsprozedur beginnt mit dem Setzen eines Flags, das anzeigt, dass sich unser Modell in der Training befindet. Zusätzliche Funktionen übernehmen Aufgaben wie das Abrufen von Trainingsdaten und die Anpassung des Modells. Indem wir unseren Code in kleinere Funktionen aufteilen, vermeiden wir es, dieselben Codezeilen mehrfach zu schreiben.
//+------------------------------------------------------------------+ //This function defines the procedure for fitting our model void model_initialize(void) { /* Our function will run the initialization procedure as follows: 1)Update the training flag to show that the model has been trained 2)Fetch the necessary input and output data 3)Preprocess the data, normalization and scaling etc. 4)Fit the model 5)Update the flags to show that the model has been trained. From there our application will have the ability to begin trading. */ //First let us set our flag to denote that the model is being trained model_being_trained = true; //Defining the input start time and the output start time //Remember the input data should not contain the most recent bars //The most recent bars must only be included in the output start time //The input data should be older than the output data. inupt_start = 1+look_ahead; output_start = 1; //Fetch the input data fetch_input_data(inupt_start,fetch); //Fetch the output data fetch_output_data(output_start,fetch); //Prepare the data prepare_data(0); //Fit our model fit_linear_model(); //The model is ready model_ready(); }
Nun definieren wir die Funktion, die für das Abrufen unserer Eingabedaten zuständig ist. Unsere Eingabematrix enthält in der ersten Spalte eine Spalte mit Einsen, die den Abfangpunkt oder den durchschnittlichen Schlusskurs des S&P 500 darstellt, wenn alle Aktienwerte Null sind. Obwohl dieses Szenario in der Finanzwelt keinen Sinn macht, denn wenn alle Aktienwerte 0 wären, würde auch der Schlusskurs des S&P 500 0 sein.
Davon abgesehen ist unser Verfahren zum Abrufen von Eingabedaten einfach:
- Wir initialisieren die Eingabematrix mit Einsen,
- bilden die Matrix um,
- geben den Schlusswert jeder Aktie ein, beginnend mit der zweiten Spalte und
- wir achten darauf, dass die erste Spalte mit Einsen gefüllt ist.
//This function will get our input data ready void fetch_input_data(int f_input_start,int f_fetch) { /* To get the input data ready we will to cycle through the symbols available and copy the requested amount of data to the globally scoped input matrix. Our function parameters are: 1)f_input_start: this is where we should get our input data, for the current data pass 0 and only fetch 1. 2)f_fetch: this is how much data should be fetched and copied into the input matrix. */ Print("Preparing to fetch input data"); //Let's observe the original state of our input matrix Print("We will reset the input matrix before fetching the data we need: "); input_matrix = matrix::Ones(f_fetch,(ArraySize(desired_symbols))-1); Print(input_matrix); //We need to reshape our matrix input_matrix.Reshape(f_fetch,13); //Filling the input matrix //Then we need to prepare our input matrix. //The first column must be full of 1's because it represents the intercept. //Therefore we will skip 0, and start filling input values from column 1. This is not a mistake. for(int i=1; i <= ArraySize(desired_symbols);i++) { //Copy the input data we need symbol_history.CopyRates(desired_symbols[i-1],PERIOD_CURRENT,COPY_RATES_CLOSE,f_input_start,f_fetch); //Insert the input data into our input matrix input_matrix.Col(symbol_history,i); } //Ensure that the first column is full of ones for our intercept vector intercept = vector::Ones(f_fetch); input_matrix.Col(intercept,0); //Let us see what our input matrix looks like now. Print("Final state of our input matrix: "); Print(input_matrix); }Das Verfahren zum Abrufen der Ausgabedaten ist mehr oder weniger dasselbe wie das Verfahren zum Abrufen der Eingabedaten.
//This function will get our output data ready void fetch_output_data(int f_output_start, int f_fetch) { /* This function will fetch our output data for training our model and copy it into our globally defined output matrix. The model has only 2 parameters: 1)f_output_start: where should we start copying our output data 2)f_fetch: amount of data to copy */ Print("Preparing to fetch output data"); //Let's observe the original state of our output matrix Print("Ressetting output matrix before fetching the data we need: "); //Reset the output matrix output_matrix = matrix::Ones(f_fetch,1); Print(output_matrix); //We need to reshape our matrix output_matrix.Reshape(f_fetch,1); //Output data //Copy the output data we need symbol_history.CopyRates(target_symbol,PERIOD_CURRENT,COPY_RATES_CLOSE,f_output_start,f_fetch); //Insert the output data into our input matrix output_matrix.Col(symbol_history,0); //Let us see what our input matrix looks like now. Print("Final state of our output matrix: "); Print(output_matrix); }
Bevor wir unser Modell anpassen, müssen wir unsere Daten standardisieren und skalieren. Dies ist ein wichtiger Schritt, da unsere Anwendung dadurch die versteckten Beziehungen in den Veränderungsraten leichter erkennen kann.
In Phase 1, wenn das Modell zum ersten Mal trainiert wird, müssen wir die Werte, die wir zur Skalierung jeder Spalte verwendet haben, in einem Vektor speichern. Jede Spalte wird durch den ersten Wert in ihr geteilt, d. h. der erste Wert in jeder Spalte ist eins.
Wenn wir nun in dieser Spalte einen Wert kleiner als eins beobachten, ist der Preis gefallen, und Werte größer als eins bedeuten, dass der Preis gestiegen ist. Bei einem Wert von 0,72 ist der Preis um 28 % gefallen, bei einem Wert von 1,017 ist er um 1,7 % gestiegen.
Wir sollten den Anfangswert jeder Spalte nur einmal speichern, von da an sollten alle zukünftigen Eingaben durch den gleichen Betrag geteilt werden, um Konsistenz zu gewährleisten.
//This function will normalize our input data so that our model can learn better //We will also scale our output so that it shows the growth in price void prepare_data(int f_flag) { /* This function is responsible for normalizing our inputs and outputs. We want to first store the initial value of each column. Then we will divide each column by its first value, so that the first value in each column is one. The above steps are performed only once, when the model is initialized. All subsequent inputs will simply be divided by the initial values of that column. */ Print("Normalizing and scaling the data"); //This part of the procedure should only be performed once if(f_flag == 0) { Print("Preparing to normalize the data for training the model"); //Normalizing the inputs //Store the initial value of each column for(int i=0;i<ArraySize(desired_symbols);i++) { //First we store the initial value of each column initiall_input_values[i] = input_matrix[0][i+1]; //Now temporarily copy the column, so that we can normalize the entire column at once vector temp_vector = input_matrix.Col(i+1); //Now divide that entire column by its initial value, if done correctly the first value of each column should be 1 temp_vector = temp_vector / initiall_input_values[i]; //Now reinsert the normalized column input_matrix.Col(temp_vector,i+1); } //Print the initial input values Print("Our initial input values for each column "); Print(initiall_input_values); //Scale the output //Store the initial output value initiall_output_value = output_matrix[0][0]; //Make a temporary copy of the entire output column vector temp_vector_output = output_matrix.Col(0); //Divide the entire column by its initial value, so that the first value in the column is one //This means that any time the value is less than 1, price fell //And every time the value is greater than 1, price rose. //A value of 1.023... means price increased by 2.3% //A value of 0.8732.. would mean price fell by 22.67% temp_vector_output = temp_vector_output / initiall_output_value; //Reinsert the column back into the output matrix output_matrix.Col(temp_vector_output,0); //Shpw the scaled data Print("Data has been normlised and the output has been scaled:"); Print("Input matrix: "); Print(input_matrix); Print("Output matrix: "); Print(output_matrix); } //Normalize the data using the initial values we have allready calculated if(f_flag == 1) { //Divide each of the input values by its corresponding input value Print("Preparing to normalize the data for prediction"); for(int i = 0; i < ArraySize(desired_symbols);i++) { input_matrix[0][i+1] = input_matrix[0][i+1]/initiall_input_values[i]; } Print("Input data being used for prediction"); Print(input_matrix); } }
Als Nächstes müssen wir eine Funktion definieren, die die notwendigen Flag-Bedingungen setzt, damit unsere Anwendung mit dem Handel beginnen kann.
//This function will allow our program to switch states and begin forecasting and looking for trades void model_ready(void) { //Our model is ready. //We need to switch these flags to give the system access to trading functionality Print("Giving the system permission to begin trading"); model_initialized = true; model_being_trained = false; }
Um eine Vorhersage von unserem Expert Advisor zu erhalten, müssen wir zunächst die aktuellsten Daten abrufen, die uns zur Verfügung stehen, die Daten vorverarbeiten und dann die lineare Regressionsgleichung verwenden, um eine Vorhersage von unserem Modell zu erhalten.
//This function will obtain a prediction from our model double model_predict(void) { //First we have to fetch current market data Print("Obtaining a forecast from our model"); fetch_input_data(0,1); //Now we need to normalize our data using the values we calculated when we initialized the model prepare_data(1); //Now we can return our model's forecast return((b[0][0] + (b[1][0]*input_matrix[0][0]) + (b[2][0]*input_matrix[0][1]) + (b[3][0]*input_matrix[0][2]) + (b[4][0]*input_matrix[0][3]) + (b[5][0]*input_matrix[0][4]) + (b[6][0]*input_matrix[0][5]) + (b[7][0]*input_matrix[0][6]) + (b[8][0]*input_matrix[0][7]) + (b[9][0]*input_matrix[0][8]) + (b[10][0]*input_matrix[0][9]) + (b[11][0]*input_matrix[0][10])+ (b[12][0]*input_matrix[0][11]))); }
Wir müssen ein Verfahren zur Anpassung unseres linearen Modells anhand der oben definierten und erläuterten Gleichungen implementieren. Beachten Sie, dass unsere MQL5-API uns die Flexibilität bietet, unsere linearen Algebra-Befehle auf flexible und nutzerfreundliche Weise auszuführen, wir können leicht Operationen miteinander verketten, was unsere Produkte sehr leistungsfähig macht.
Dies ist besonders wichtig, wenn Sie Ihre Produkte auf dem Markt verkaufen wollen. Vermeiden Sie for-Schleifen, wenn wir stattdessen Vektoroperationen durchführen können, da Vektoroperationen schneller sind als Schleifen. Ihre Endnutzer werden eine sehr reaktionsschnelle Anwendung erleben, die nicht verzögert, und sie werden ihre Nutzererfahrung genießen.
//This function will fit our linear model using the pseudo inverse solution void fit_linear_model(void) { /* The pseudo inverse solution finds a list of values that maps our training data inputs to the output by minimizing the error, RSS. These coefficient values can easily be estimated using linear algebra, however these coefficients minimize our error on training data and on not unseen data! */ Print("Attempting to find OLS solutions."); //Now we can estimate our model parameters b = input_matrix.PInv().MatMul(output_matrix); //Let's see our model parameters Print("Our model parameters "); Print(b); }
Im weiteren Verlauf benötigen wir eine Funktion, die für die Aktualisierung unserer technischen Indikatoren und das Abrufen aktueller Marktdaten zuständig ist.
//Update our technical indicator values void update_technical_indicators() { //Get market data ask_price = SymbolInfoDouble(_Symbol,SYMBOL_ASK); bid_price = SymbolInfoDouble(_Symbol,SYMBOL_BID); //Copy indicator buffers CopyBuffer(rsi_handler,0,0,10,rsi_buffer); CopyBuffer(cci_handler,0,0,10,cci_buffer); CopyBuffer(wpr_handler,0,0,10,wpr_buffer); CopyBuffer(ma_handler,0,0,10,ma_buffer); //Set the arrays as series ArraySetAsSeries(rsi_buffer,true); ArraySetAsSeries(cci_buffer,true); ArraySetAsSeries(wpr_buffer,true); ArraySetAsSeries(ma_buffer,true); }
Dann werden wir eine Funktion schreiben, die unsere Handels-Setups für uns ausführt. Unsere Funktion wird nur dann in der Lage sein, Geschäfte auszuführen, wenn unsere beiden Systeme aufeinander abgestimmt sind.
//Let's try find an entry signal void find_entry(void) { //Our sell setup if(bearish_sentiment()) { Trade.Sell(minimum_volume * lot_multiple,_Symbol,bid_price); } //Our buy setup else if(bullish_sentiment()) { Trade.Buy(minimum_volume * lot_multiple,_Symbol,ask_price); } }
Dies ist möglich, weil wir über Funktionen verfügen, die die Abwärts-Stimmung gemäß unseren obigen Beschreibungen definieren.
//This function tells us if all our tools align for a sell setup bool bearish_sentiment(void) { /* For a sell setup, we want the following conditions to be satisfied: 1) CCI reading should be less than 0 2) RSI reading should be less than 50 3) WPR reading should be less than -50 4) Our model forecast should be less than 1 5) MA reading should be below the moving average */ return((iClose(target_symbol,PERIOD_CURRENT,0) < ma_buffer[0]) && (cci_buffer[0] < 0) && (rsi_buffer[0] < 50) && (wpr_buffer[0] < -50) && (model_forecast < 1)); }
Das Gleiche gilt für unsere Funktion zur Definition der Aufwärts-Stimmung.
//This function tells us if all our tools align for a buy setup bool bullish_sentiment(void) { /* For a sell setup, we want the following conditions to be satisfied: 1) CCI reading should be greater than 0 2) RSI reading should be greater than 50 3) WPR reading should be greater than -50 4) Our model forecast should be greater than 1 5) MA reading should be above the moving average */ return((iClose(target_symbol,PERIOD_CURRENT,0) > ma_buffer[0]) && (cci_buffer[0] > 0) && (rsi_buffer[0] > 50) && (wpr_buffer[0] > -50) && (model_forecast > 1)); }
Schließlich benötigen wir eine Hilfsfunktion, um unsere Werte von Stop-Loss und Take-Profit zu aktualisieren.
//+----------------------------------------------------------------------+ //|This function is responsible for calculating our SL & TP values | //+----------------------------------------------------------------------+ void update_stoploss(void) { //First we iterate over the total number of open positions for(int i = PositionsTotal() -1; i >= 0; i--) { //Then we fetch the name of the symbol of the open position string symbol = PositionGetSymbol(i); //Before going any furhter we need to ensure that the symbol of the position matches the symbol we're trading if(_Symbol == symbol) { //Now we get information about the position ulong ticket = PositionGetInteger(POSITION_TICKET); //Position Ticket double position_price = PositionGetDouble(POSITION_PRICE_OPEN); //Position Open Price long type = PositionGetInteger(POSITION_TYPE); //Position Type double current_stop_loss = PositionGetDouble(POSITION_SL); //Current Stop loss value //If the position is a buy if(type == POSITION_TYPE_BUY) { //The new stop loss value is just the ask price minus the ATR stop we calculated above double atr_stop_loss = NormalizeDouble(ask_price - ((min_distance * sl_width)/2),_Digits); //The new take profit is just the ask price plus the ATR stop we calculated above double atr_take_profit = NormalizeDouble(ask_price + (min_distance * sl_width),_Digits); //If our current stop loss is less than our calculated ATR stop loss //Or if our current stop loss is 0 then we will modify the stop loss and take profit if((current_stop_loss < atr_stop_loss) || (current_stop_loss == 0)) { Trade.PositionModify(ticket,atr_stop_loss,atr_take_profit); } } //If the position is a sell else if(type == POSITION_TYPE_SELL) { //The new stop loss value is just the ask price minus the ATR stop we calculated above double atr_stop_loss = NormalizeDouble(bid_price + ((min_distance * sl_width)/2),_Digits); //The new take profit is just the ask price plus the ATR stop we calculated above double atr_take_profit = NormalizeDouble(bid_price - (min_distance * sl_width),_Digits); //If our current stop loss is greater than our calculated ATR stop loss //Or if our current stop loss is 0 then we will modify the stop loss and take profit if((current_stop_loss > atr_stop_loss) || (current_stop_loss == 0)) { Trade.PositionModify(ticket,atr_stop_loss,atr_take_profit); } } } }
Alle unsere Hilfsfunktionen werden zu gegebener Zeit von unserem OnTick-Handler aufgerufen, der für die Steuerung des Ereignisflusses innerhalb unseres Terminals verantwortlich ist, sobald sich der Preis ändert.
void OnTick() { //Our model must be initialized before we can begin trading. switch(model_initialized) { //Our model is ready case(true): //Update the technical indicator values update_technical_indicators(); //If we have no open positions, let's make a forecast using our model if(PositionsTotal() == 0) { //Let's obtain a prediction from our model model_forecast = model_predict(); //Now that we have sentiment from our model let's try find an entry find_entry(); Comment("Model forecast: ",model_forecast); } //If we have an open position, we need to manage it if(PositionsTotal() > 0) { //Update our stop loss update_stoploss(); } break; //Default case //Our model is not yet ready. default: //If our model is not being trained, train it. if(!model_being_trained) { Print("Our model is not ready. Starting the training procedure"); model_initialize(); } break; } }

Abb. 3: Unsere Anwendung in Aktion.
Beschränkungen
Der Modellierungsansatz, den wir für unsere KI-Modelle gewählt haben, weist einige Einschränkungen auf, von denen wir einige wichtige hervorheben wollen:
1.1 Korrelierte Eingaben
Die Probleme, die durch korrelierte Eingaben verursacht werden, treten nicht nur bei linearen Modellen auf, sondern betreffen viele Modelle des maschinellen Lernens. Einige der Aktien in unserer Eingabematrix sind in derselben Branche tätig, und ihre Kurse neigen dazu, gleichzeitig zu steigen und zu fallen. Dies kann es unserem Modell erschweren, die Auswirkungen der einzelnen Aktien auf die Performance des Index zu isolieren, da sich die Kursbewegungen gegenseitig überlagern können.
1.2 Nichtlineare Zielfunktion
Finanzdatensätze, die von Natur aus verrauscht sind, eignen sich in der Regel besser für einfachere Modelle wie die multiple lineare Regression. In den meisten realen Fällen sind die zu approximierenden Funktionen jedoch nur selten linear. Je weiter die wahre Funktion von der Linearität entfernt ist, desto größer ist die Varianz in der Genauigkeit des Modells.
1.3 Beschränkungen eines direkten Modellierungsansatzes
Würden wir schließlich alle Aktien des S&P 500 in unser Modell einbeziehen, hätten wir ein Modell mit 500 Parametern. Die Optimierung eines solchen Modells würde erhebliche Rechenressourcen erfordern, und die Interpretation der Ergebnisse wäre eine Herausforderung. Direkte Modellierungslösungen lassen sich in diesem Zusammenhang nicht gut skalieren; wenn wir in Zukunft weitere Bestände hinzufügen, könnte die Anzahl der zu optimierenden Parameter schnell unüberschaubar werden.
Schlussfolgerung
In diesem Artikel haben wir gezeigt, wie einfach es ist, KI-Modelle zu erstellen, die technische Analysen für fundierte Handelsentscheidungen integrieren. Bei der Weiterentwicklung zu fortgeschritteneren Modellen werden die meisten der heute behandelten Schritte unverändert bleiben. Dies sollte Anfängern Selbstvertrauen geben, da sie wissen, dass sie ein maschinelles Lernprojekt von Anfang bis Ende abgeschlossen und hoffentlich die Gründe für jede Entscheidung verstanden haben.
Unsere gesamte Anwendung verwendet nativen MQL5-Code und nutzt die technischen Standardindikatoren, die in jeder Installation von MetaTrader 5 verfügbar sind. Wir hoffen, dass dieser Artikel Sie dazu inspiriert, weitere Möglichkeiten mit Ihren vorhandenen Tools zu erforschen und bei der Beherrschung von MQL5 weiter voranzukommen.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/14815
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.