
Datenwissenschaft und maschinelles Lernen (Teil 21): Neuronale Netze entschlüsseln, Optimierungsalgorithmen entmystifiziert

Ich will damit nicht sagen, dass neuronale Netze einfach sind. Man muss schon ein Experte sein, damit diese Dinge funktionieren. Aber dieses Fachwissen kommt Ihnen bei einem breiteren Spektrum von Anwendungen zugute. In gewissem Sinne fließen alle Bemühungen, die zuvor in die Entwicklung von Funktionen flossen, nun in die Entwicklung von Architekturen, Verlustfunktionen und Optimierungsschemata. Die manuelle Arbeit wurde auf eine höhere Abstraktionsebene gehoben.
Stefano Soatto
Einführung
Es scheint so, als ob heutzutage jeder an Künstlicher Intelligenz interessiert ist, sie ist überall, und die Großen der Tech-Industrie wie Google und Microsoft, die hinter openAI stehen, drängen auf die Anpassung von KI in verschiedenen Aspekten und Branchen wie Unterhaltung, Gesundheitswesen, Kunst, Kreativität usw.
Ich sehe diesen Trend auch in der MQL5-Community, warum nicht? Nachdem Metatrader5 Matrizen und Vektoren und ONNX eingeführt hat, ist es nun möglich, künstliche Intelligenz Handelsmodelle von beliebiger Komplexität zu machen. Sie müssen nicht einmal ein Experte in der linearen Algebra oder ein Nerd sein, um alles, was in das System geht zu verstehen.
Trotz alledem sind die Grundlagen des maschinellen Lernens heute schwieriger zu finden als je zuvor, und doch sind sie so wichtig, um Ihr Verständnis von KI zu festigen. Sie lassen Sie wissen, warum Sie tun, was Sie tun, was Sie flexibel macht und Sie Ihre Optionen ausüben lässt. Heute werden wir sehen, welche Optimierungsalgorithmen es gibt, wie sie gegeneinander abschneiden, wann und welchen Optimierungsalgorithmus Sie für eine bessere Leistung und Genauigkeit Ihrer neuronalen Netzwerke wählen sollten.

Der in diesem Artikel besprochene Inhalt wird Ihnen helfen, Optimierungsalgorithmen im Allgemeinen zu verstehen, d.h. dieses Wissen wird Ihnen auch bei der Arbeit mit Python-Modellen wie Scikit-Learn, Tensorflow oder Pytorch helfen, da diese Optimierer für alle neuronalen Netze universell sind, egal welche Programmiersprache Sie verwenden.
Was sind die Optimierer eines Neuronalen Netzes?
Per Definition sind Optimierer Algorithmen, die während des Trainings eine Feinabstimmung der Parameter des neuronalen Netzes vornehmen. Ihr Ziel ist es, die Verlustfunktion zu minimieren, was letztlich zu einer verbesserten Leistung führt.
Einfach ausgedrückt: Neuronale Netzoptimierer tun es:
- Dies sind die Schlüsselparameter, die das neuronale Netz beeinflussen. Die Optimierer legen fest, wie jeder Parameter in jeder Trainingsiteration geändert werden soll.
- Optimierer messen die Diskrepanz zwischen den tatsächlichen Werten und den Vorhersagen des neuronalen Netzes und bemühen sich, diesen Fehler schrittweise zu verringern.
Ich empfehle die Lektüre eines früheren Artikels Neural Networks Demystified, falls Sie das noch nicht getan haben. In diesem Artikel werden wir das Modell des neuronalen Netzes, das wir in diesem Artikel von Grund auf neu erstellt haben, verbessern, indem wir ihm die Optimierer hinzufügen.
Bevor wir sehen, was die verschiedenen Arten von Optimierern sind, müssen wir die Algorithmen für die Backpropagation verstehen, Es gibt im Allgemeinen drei Algorithmen;
- Stochastischer Gradientenabstieg (SGD)
- Batch-Gradientenabstieg (BGD)
- Mini-Batch-Gradientenabstieg
01: Stochastischer Gradientenabstiegsalgorithmus (SGD)
Der stochastische Gradientenabstieg (SGD) ist ein grundlegender Optimierungsalgorithmus, der zum Training neuronaler Netze verwendet wird. Dabei werden die Gewichte und Verzerrungen des Netzes in einer Weise aktualisiert, die die Verlustfunktion minimiert. Die Verlustfunktion misst die Diskrepanz zwischen den Vorhersagen des Netzes und den tatsächlichen Kennzeichnungen (Zielwerten) in den Trainingsdaten.
Die wichtigsten Prozesse, die bei diesen Optimierungsalgorithmen ablaufen, sind die gleichen;
- Iteration
- Backpropagation
- Gewichte und Aktualisierung der Vorspannung
Diese Algorithmen unterscheiden sich darin, wie Iterationen gehandhabt werden und wie oft die Gewichte und Verzerrungen aktualisiert werden. Der SGD-Algorithmus aktualisiert die Parameter des neuronalen Netzes (Gewichte und Verzerrungen) für ein Trainingsbeispiel (Datenpunkt) nach dem anderen.
void CRegressorNets::backpropagation(const matrix& x, const vector &y) { for (ulong epoch=0; epoch<epochs && !IsStopped(); epoch++) { for (ulong iter=0; iter<rows; iter++) //iterate through all data points { for (int layer=(int)mlp.hidden_layers-1; layer>=0 && !IsStopped(); layer--) //Loop through the network backward from last to first layer { // find partial derivatives of each layer WRT the loss function dW and dB //--- Weights updates optimizer_weights.update(W, dW); optimizer_bias.update(B, dB); this.W_tensor.Add(W, layer); this.B_tensor.Add(B, layer); } } } }
Seine Vorteile:
- Effiziente Berechnungen für große Datensätze.
- Kann manchmal schneller konvergieren als BGD und Mini-Batch-Gradientenabstieg, insbesondere für nicht-konvexe Verlustfunktionen, da jeweils nur ein Trainingsbeispiel verwendet wird.
- Gut darin, die lokalen Minima zu vermeiden: Aufgrund der verrauschten Aktualisierungen in SGD hat er die Fähigkeit, aus lokalen Minima zu entkommen und zu globalen Minima zu konvergieren
Nachteile:
- Aktualisierungen können verrauscht sein, was zu einem Zick-Zack-Verhalten beim Training führt.
- Er konvergiert möglicherweise nicht immer zum globalen Minimum.
- Langsame Konvergenz, kann mehr Epochen zur Konvergenz benötigen, da die Parameter für jedes Trainingsbeispiel einzeln aktualisiert werden.
- Empfindlich gegenüber der Lernrate: Die Wahl der Lernrate kann für diesen Algorithmus von entscheidender Bedeutung sein; eine höhere Lernrate kann dazu führen, dass der Algorithmus über die globalen Minima hinausschießt, während eine niedrigere Lernrate den Konvergenzprozess verlangsamt.
02: Batch-Gradientenabstiegs-Algorithmus (BGD):
Im Gegensatz zu SGD werden beim Batch Gradient Descent (BGD) die Gradienten in jeder Iteration anhand des gesamten Datensatzes berechnet.
Vorteile:
Theoretisch konvergiert er zu einem Minimum, wenn die Verlustfunktion glatt und konvex ist.
Nachteile:
Kann bei großen Datensätzen rechenintensiv sein, da der gesamte Datensatz wiederholt verarbeitet werden muss.
Ich werde ihn nicht in das neuronale Netz implementieren, das wir im Moment haben, aber er kann leicht implementiert werden, genau wie der Mini-Batch-Gradientenabstieg unten, Sie können ihn implementieren, wenn Sie möchten.
03: Mini-Batch-Gradientenabstieg:
Dieser Algorithmus ist ein Kompromiss zwischen SGD und BGD. Er aktualisiert die Parameter des Netzes unter Verwendung einer kleinen Teilmenge (Mini-Batch) der Trainingsdaten in jeder Iteration.
Vorteile:
- Bietet im Vergleich zu SGD und BGD ein gutes Gleichgewicht zwischen Berechnungseffizienz und Aktualisierungsstabilität.
- Kann größere Datenmengen effektiver verarbeiten als BGD.
Nachteile:
- Kann im Vergleich zu SGD eine stärkere Abstimmung der Mini-Batch-Größe erfordern.
- Rechenintensiv im Vergleich zu SGD, verbraucht viel Speicher für die Stapelspeicherung und -verarbeitung
- Es kann lange dauern, viele große Chargen zu trainieren.
Im Folgenden ist der Pseudocode des Mini-Batch-Gradientenabstiegs-Algorithmus dargestellt:
void CRegressorNets::backpropagation(const matrix& x, const vector &y, OptimizerSGD *sgd, const uint epochs, uint batch_size=0, bool show_batch_progress=false) { //.... for (ulong epoch=0; epoch<epochs && !IsStopped(); epoch++) { for (uint batch=0, batch_start=0, batch_end=batch_size; batch<num_batches; batch++, batch_start+=batch_size, batch_end=(batch_start+batch_size-1)) { matrix batch_x = MatrixExtend::Get(x, batch_start, batch_end-1); vector batch_y = MatrixExtend::Get(y, batch_start, batch_end-1); rows = batch_x.Rows(); for (ulong iter=0; iter<rows ; iter++) //replace to rows { pred_v[0] = predict(batch_x.Row(iter)); actual_v[0] = y[iter]; // Find derivatives WRT weights dW and bias dB //.... //--- Updating the weights using a given optimizer optimizer_weights.update(W, dW); optimizer_bias.update(B, dB); this.Weights_tensor.Add(W, layer); this.Bias_tensor.Add(B, layer); } } } }
Diese beiden Algorithmen verfügen standardmäßig über eine einfache Aktualisierungsregel für den Gradientenabstieg, die oft als SGD- oder Mini-BGD-Optimierer bezeichnet wird.
class OptimizerSGD { protected: double m_learning_rate; public: OptimizerSGD(double learning_rate=0.01); ~OptimizerSGD(void); virtual void update(matrix ¶meters, matrix &gradients); }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ OptimizerSGD::OptimizerSGD(double learning_rate=0.01): m_learning_rate(learning_rate) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ OptimizerSGD::~OptimizerSGD(void) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void OptimizerSGD::update(matrix ¶meters, matrix &gradients) { parameters -= this.m_learning_rate * gradients; //Simple gradient descent update rule } //+------------------------------------------------------------------+ //| Batch Gradient Descent (BGD): This optimizer computes the | //| gradients of the loss function on the entire training dataset | //| and updates the parameters accordingly. It can be slow and | //| memory-intensive for large datasets but tends to provide a | //| stable convergence. | //+------------------------------------------------------------------+ class OptimizerMinBGD: public OptimizerSGD { public: OptimizerMinBGD(double learning_rate=0.01); ~OptimizerMinBGD(void); }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ OptimizerMinBGD::OptimizerMinBGD(double learning_rate=0.010000): OptimizerSGD(learning_rate) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ OptimizerMinBGD::~OptimizerMinBGD(void) { }
Lassen Sie uns nun ein Modell mit diesen beiden Optimierern trainieren und das Ergebnis beobachten, um sie besser zu verstehen;
#include <MALE5\MatrixExtend.mqh> #include <MALE5\preprocessing.mqh> #include <MALE5\metrics.mqh> #include <MALE5\Neural Networks\Regressor Nets.mqh> CRegressorNets *nn; StandardizationScaler scaler; vector open_, high_, low_; vector hidden_layers = {5}; input uint nn_epochs = 100; input double nn_learning_rate = 0.0001; input uint nn_batch_size =32; input bool show_batch = false; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- string headers; matrix dataset = MatrixExtend::ReadCsv("airfoil_noise_data.csv", headers); matrix x_train, x_test; vector y_train, y_test; MatrixExtend::TrainTestSplitMatrices(dataset, x_train, y_train, x_test, y_test, 0.7); nn = new CRegressorNets(hidden_layers, AF_RELU_, LOSS_MSE_); x_train = scaler.fit_transform(x_train); nn.fit(x_train, y_train, new OptimizerMinBGD(nn_learning_rate), nn_epochs, nn_batch_size, show_batch); delete nn; }
Wenn der Eingabe nn_batch_size ein Wert größer als Null zugewiesen wird, wird der Mini-Batch-Gradientenabstieg aktiviert, unabhängig davon, welcher Optimierer auf die Fit/Backpropagation-Funktion angewendet wird.
backprop CRegressorNets::backpropagation(const matrix& x, const vector &y, OptimizerSGD *optimizer, const uint epochs, uint batch_size=0, bool show_batch_progress=false) { //... //... //--- Optimizer use selected optimizer when batch_size ==0 otherwise use the batch gradient descent OptimizerSGD optimizer_weights = optimizer; OptimizerSGD optimizer_bias = optimizer; if (batch_size>0) { OptimizerMinBGD optimizer_weights; OptimizerMinBGD optimizer_bias; } //--- Cross validation CCrossValidation cross_validation; CTensors *cv_tensor; matrix validation_data = MatrixExtend::concatenate(x, y); matrix validation_x; vector validation_y; cv_tensor = cross_validation.KFoldCV(validation_data, 10); //k-fold cross validation | 10 folds selected //--- matrix DELTA = {}; double actual=0, pred=0; matrix temp_inputs ={}; matrix dB = {}; //Bias Derivatives matrix dW = {}; //Weight Derivatives for (ulong epoch=0; epoch<epochs && !IsStopped(); epoch++) { double epoch_start = GetTickCount(); uint num_batches = (uint)MathFloor(x.Rows()/(batch_size+DBL_EPSILON)); vector batch_loss(num_batches), batch_accuracy(num_batches); vector actual_v(1), pred_v(1), LossGradient = {}; if (batch_size==0) //Stochastic Gradient Descent { for (ulong iter=0; iter<rows; iter++) //iterate through all data points { pred = predict(x.Row(iter)); actual = y[iter]; pred_v[0] = pred; actual_v[0] = actual; //--- DELTA.Resize(mlp.outputs,1); for (int layer=(int)mlp.hidden_layers-1; layer>=0 && !IsStopped(); layer--) //Loop through the network backward from last to first layer { //..... backpropagation and finding derivatives code //-- Observation | DeLTA matrix is same size as the bias matrix W = this.Weights_tensor.Get(layer); B = this.Bias_tensor.Get(layer); //--- Derivatives wrt weights and bias dB = DELTA; dW = DELTA.MatMul(temp_inputs.Transpose()); //--- Weights updates optimizer_weights.update(W, dW); optimizer_bias.update(B, dB); this.Weights_tensor.Add(W, layer); this.Bias_tensor.Add(B, layer); } } } else //Batch Gradient Descent { for (uint batch=0, batch_start=0, batch_end=batch_size; batch<num_batches; batch++, batch_start+=batch_size, batch_end=(batch_start+batch_size-1)) { matrix batch_x = MatrixExtend::Get(x, batch_start, batch_end-1); vector batch_y = MatrixExtend::Get(y, batch_start, batch_end-1); rows = batch_x.Rows(); for (ulong iter=0; iter<rows ; iter++) //iterate through all data points { pred_v[0] = predict(batch_x.Row(iter)); actual_v[0] = y[iter]; //--- DELTA.Resize(mlp.outputs,1); for (int layer=(int)mlp.hidden_layers-1; layer>=0 && !IsStopped(); layer--) //Loop through the network backward from last to first layer { //..... backpropagation and finding derivatives code } //-- Observation | DeLTA matrix is same size as the bias matrix W = this.Weights_tensor.Get(layer); B = this.Bias_tensor.Get(layer); //--- Derivatives wrt weights and bias dB = DELTA; dW = DELTA.MatMul(temp_inputs.Transpose()); //--- Weights updates optimizer_weights.update(W, dW); optimizer_bias.update(B, dB); this.Weights_tensor.Add(W, layer); this.Bias_tensor.Add(B, layer); } } pred_v = predict(batch_x); batch_loss[batch] = pred_v.Loss(batch_y, ENUM_LOSS_FUNCTION(m_loss_function)); batch_loss[batch] = MathIsValidNumber(batch_loss[batch]) ? (batch_loss[batch]>1e6 ? 1e6 : batch_loss[batch]) : 1e6; //Check for nan and return some large value if it is nan batch_accuracy[batch] = Metrics::r_squared(batch_y, pred_v); if (show_batch_progress) printf("----> batch[%d/%d] batch-loss %.5f accuracy %.3f",batch+1,num_batches,batch_loss[batch], batch_accuracy[batch]); } } //--- End of an epoch vector validation_loss(cv_tensor.SIZE); vector validation_acc(cv_tensor.SIZE); for (ulong i=0; i<cv_tensor.SIZE; i++) { validation_data = cv_tensor.Get(i); MatrixExtend::XandYSplitMatrices(validation_data, validation_x, validation_y); vector val_preds = this.predict(validation_x);; validation_loss[i] = val_preds.Loss(validation_y, ENUM_LOSS_FUNCTION(m_loss_function)); validation_acc[i] = Metrics::r_squared(validation_y, val_preds); } pred_v = this.predict(x); if (batch_size==0) { backprop_struct.training_loss[epoch] = pred_v.Loss(y, ENUM_LOSS_FUNCTION(m_loss_function)); backprop_struct.training_loss[epoch] = MathIsValidNumber(backprop_struct.training_loss[epoch]) ? (backprop_struct.training_loss[epoch]>1e6 ? 1e6 : backprop_struct.training_loss[epoch]) : 1e6; //Check for nan and return some large value if it is nan backprop_struct.validation_loss[epoch] = validation_loss.Mean(); backprop_struct.validation_loss[epoch] = MathIsValidNumber(backprop_struct.validation_loss[epoch]) ? (backprop_struct.validation_loss[epoch]>1e6 ? 1e6 : backprop_struct.validation_loss[epoch]) : 1e6; //Check for nan and return some large value if it is nan } else { backprop_struct.training_loss[epoch] = batch_loss.Mean(); backprop_struct.training_loss[epoch] = MathIsValidNumber(backprop_struct.training_loss[epoch]) ? (backprop_struct.training_loss[epoch]>1e6 ? 1e6 : backprop_struct.training_loss[epoch]) : 1e6; //Check for nan and return some large value if it is nan backprop_struct.validation_loss[epoch] = validation_loss.Mean(); backprop_struct.validation_loss[epoch] = MathIsValidNumber(backprop_struct.validation_loss[epoch]) ? (backprop_struct.validation_loss[epoch]>1e6 ? 1e6 : backprop_struct.validation_loss[epoch]) : 1e6; //Check for nan and return some large value if it is nan } double epoch_stop = GetTickCount(); printf("--> Epoch [%d/%d] training -> loss %.8f accuracy %.3f validation -> loss %.5f accuracy %.3f | Elapsed %s ",epoch+1,epochs,backprop_struct.training_loss[epoch],Metrics::r_squared(y, pred_v),backprop_struct.validation_loss[epoch],validation_acc.Mean(),this.ConvertTime((epoch_stop-epoch_start)/1000.0)); } isBackProp = false; if (CheckPointer(optimizer)!=POINTER_INVALID) delete optimizer; return backprop_struct; }
Ergebnisse:
Stochastischer Gradientenabstieg (SGD): Lernrate = 0,0001

Batch-Gradientenabstieg (BGD): Lernrate = 0,0001, Losgröße = 16

SGD konvergierte schneller, bereist in der Nähe von lokalen Minima um die 10. Epoche, während die BGD erst um die 20. Epoche dort war. SGD konvergierte zu ca. 60% Genauigkeit in beiden Ausbildung und Validierung, während BGD Genauigkeit von 15% während der Ausbildung Probe und 13% auf Validierung Probe. Wir können noch nicht abschließend urteilen, wie wir nicht sicher sind, dass BGD die beste Lernrate und die Batch-Größe hat, die für diesen Datensatz geeignet ist. Verschiedene Optimierer funktionieren am besten bei unterschiedlichen Lerngeschwindigkeiten. Dies kann eine der Ursachen dafür sein, dass SGD nicht funktioniert. Allerdings konvergiert es gut, ohne dass es zu Oszillationen um die lokalen Minima kommt, was bei SGD nicht zu sehen ist. Das BGD-Diagramm ist glatt, was auf einen stabilen Trainingsprozess hindeutet .
backprop_struct.training_loss[epoch] = batch_loss.Mean(); backprop_struct.training_loss[epoch] = MathIsValidNumber(backprop_struct.training_loss[epoch]) ? (backprop_struct.training_loss[epoch]>1e6 ? 1e6 : backprop_struct.training_loss[epoch]) : 1e6; //Check for nan and return some large value if it is nan backprop_struct.validation_loss[epoch] = validation_loss.Mean(); backprop_struct.validation_loss[epoch] = MathIsValidNumber(backprop_struct.validation_loss[epoch]) ? (backprop_struct.validation_loss[epoch]>1e6 ? 1e6 : backprop_struct.validation_loss[epoch]) : 1e6; //Check for nan and return some large value if it is nan
Vielleicht haben Sie in den Diagrammen gesehen, dass der Wert von log10 auf die Verlustwerte für das Diagramm angewendet wurde. Diese Normalisierung stellt sicher, dass die Verlustwerte gut gezeichnet werden, da in frühen Epochen die Verlustwerte manchmal größer sein können. Dadurch sollen die größeren Werte bestraft werden, damit sie in einem Diagramm gut aussehen. Die tatsächlichen Verlustwerte sind in der Registerkarte Experten und nicht im Diagramm zu sehen.
void CRegressorNets::fit(const matrix &x, const vector &y, OptimizerSGD *optimizer, const uint epochs, uint batch_size=0, bool show_batch_progress=false) { trained = true; //The fit method has been called vector epochs_vector(epochs); for (uint i=0; i<epochs; i++) epochs_vector[i] = i+1; backprop backprop_struct; backprop_struct = this.backpropagation(x, y, optimizer, epochs, batch_size, show_batch_progress); //Run backpropagation CPlots plt; backprop_struct.training_loss = log10(backprop_struct.training_loss); //Logarithmic scalling plt.Plot("Loss vs Epochs",epochs_vector,backprop_struct.training_loss,"epochs","log10(loss)","training-loss",CURVE_LINES); backprop_struct.validation_loss = log10(backprop_struct.validation_loss); plt.AddPlot(backprop_struct.validation_loss,"validation-loss",clrRed); while (MessageBox("Close or Cancel Loss Vs Epoch plot to proceed","Training progress",MB_OK)<0) Sleep(1); isBackProp = false; }
Der SGD-Optimierer ist ein allgemeines Werkzeug zur Minimierung von Verlustfunktionen, während der SGD-Algorithmus für Backpropagation eine spezielle Technik innerhalb von SGD ist, die auf die Berechnung von Gradienten in neuronalen Netzen zugeschnitten ist.
Betrachten Sie den SGD-Optimierer als Zimmermann und die SGD- oder Min-BGD-Algorithmen für die Backpropagation als ein spezialisiertes Werkzeug in ihrem Werkzeugkasten.
Arten von Optimierern für neuronale Netze
Abgesehen von den SGD-Optimierern, die wir gerade besprochen haben, gibt es noch andere verschiedene neuronale Netzoptimierer, die jeweils unterschiedliche Strategien einsetzen, um optimale Parameterwerte zu erreichen. Im Folgenden werden einige der am häufigsten verwendeten neuronalen Netzoptimierer vorgestellt;
- Propagation des quadratischen Mittelwerts (RMSProp)
- Adaptiver Gradientenabstieg (AdaGrad)
- Adaptive Momentabschätzung (Adam)
- Adadelta
- Nesterov-beschleunigte adaptive Moment-Schätzung (Nadam)
01: Propagation des mittleren Quadrats (RMSProp)
Dieser Optimierungsalgorithmus zielt darauf ab, die Grenzen des stochastischen Gradientenabstiegs (SGD) zu überwinden, indem die Lernrate für jedes Gewicht und jeden Bias-Parameter auf der Grundlage ihrer historischen Gradienten angepasst wird.Problem mit SGD:
SGD aktualisiert Gewichte und Verzerrungen anhand des aktuellen Gradienten und einer festen Lernrate. Bei komplexen Funktionen wie neuronalen Netzen kann die Größe der Gradienten für verschiedene Parameter jedoch erheblich variieren. Dies kann zu einer langsamen Konvergenz führen, da Parameter mit kleinen Gradienten nur sehr langsam aktualisiert werden, was den Lernprozess insgesamt behindert. Außerdem kann SGD zu starken Oszillationen führen, da Parameter mit großen Gradienten während der Aktualisierung übermäßige Schwankungen erfahren können, was den Lernprozess instabil macht.Theorie:
Das ist der Kerngedanke von RMSprop:
- Behalte den Exponential Moving Average (EMA) der quadratischen Steigungen: Für jeden Parameter verfolgt RMSprop einen exponentiell absteigenden Durchschnitt der quadrierten Gradienten. Dieser Durchschnittswert spiegelt die jüngste Entwicklung wider, wie oft der Parameter aktualisiert werden sollte.

- Normalisiere den Gradienten: Der aktuelle Gradient für jeden Parameter wird durch die Quadratwurzel des EMA der quadrierten Gradienten geteilt, zusammen mit einem kleinen Glättungsausdruck (normalerweise mit ε bezeichnet), um eine Division durch Null zu vermeiden.
- Aktualisiere den Parameter: Der normalisierte Gradient wird mit der Lernrate multipliziert, um die Aktualisierung für den Parameter zu bestimmen.

wobei:
![]() EMA der quadrierten Gradienten im Zeitschritt t
EMA der quadrierten Gradienten im Zeitschritt t
![]() Absenkrate (Hyperparameter, normalerweise zwischen 0,9 und 0,999) - sie steuert den Einfluss vergangener Gradienten
Absenkrate (Hyperparameter, normalerweise zwischen 0,9 und 0,999) - sie steuert den Einfluss vergangener Gradienten
![]() Gradient der Verlustfunktion in Bezug auf den Parameter w im Zeitschritt t
Gradient der Verlustfunktion in Bezug auf den Parameter w im Zeitschritt t
![]() Parameterwert zum Zeitschritt t
Parameterwert zum Zeitschritt t
![]() Aktualisierter Parameterwert im Zeitschritt t+1
Aktualisierter Parameterwert im Zeitschritt t+1
η: Lernrate (Hyperparameter)
ε: Glättungsterm (normalerweise ein kleiner Wert wie 1e-8)
class OptimizerRMSprop { protected: double m_learning_rate; double m_decay_rate; double m_epsilon; matrix<double> cache; //Dividing double/matrix causes compilation error | this is the fix to the issue matrix divide(const double numerator, const matrix &denominator) { matrix res = denominator; for (ulong i=0; i<denominator.Rows(); i++) res.Row(numerator / denominator.Row(i), i); return res; } public: OptimizerRMSprop(double learning_rate=0.01, double decay_rate=0.9, double epsilon=1e-8); ~OptimizerRMSprop(void); virtual void update(matrix& parameters, matrix& gradients); }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ OptimizerRMSprop::OptimizerRMSprop(double learning_rate=0.01, double decay_rate=0.9, double epsilon=1e-8): m_learning_rate(learning_rate), m_decay_rate(decay_rate), m_epsilon(epsilon) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ OptimizerRMSprop::~OptimizerRMSprop(void) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void OptimizerRMSprop::update(matrix ¶meters,matrix &gradients) { if (cache.Rows()!=parameters.Rows() || cache.Cols()!=parameters.Cols()) { cache.Init(parameters.Rows(), parameters.Cols()); cache.Fill(0.0); } //--- cache += m_decay_rate * cache + (1 - m_decay_rate) * MathPow(gradients, 2); parameters -= divide(m_learning_rate, cache + m_epsilon) * gradients; }
Mit 100 Epochen und 0,0001, denselben Standardwerten, die für die vorherigen Optimierer verwendet wurden, konnte das neuronale Netzwerk bei 100 Epochen nicht konvergieren, da es eine Genauigkeit von etwa -319 bzw. -324 in den Trainings- und Validierungsproben lieferte. Es scheint, dass es bei seinem Tempo mehr als 1000 Epochen benötigen könnte, vorausgesetzt, dass wir bei dieser großen Anzahl von Epochen nicht über die lokalen Minima hinausgehen.
HK 0 15:10:15.632 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [90/100] training -> loss 15164.85487215 accuracy -320.064 validation -> loss 15164.99272 accuracy -325.349 | Elapsed 0.031 Seconds HQ 0 15:10:15.663 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [91/100] training -> loss 15161.78717397 accuracy -319.999 validation -> loss 15161.92323 accuracy -325.283 | Elapsed 0.031 Seconds DO 0 15:10:15.694 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [92/100] training -> loss 15158.07142844 accuracy -319.921 validation -> loss 15158.20512 accuracy -325.203 | Elapsed 0.031 Seconds GE 0 15:10:15.727 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [93/100] training -> loss 15154.92004326 accuracy -319.854 validation -> loss 15155.05184 accuracy -325.135 | Elapsed 0.032 Seconds GS 0 15:10:15.760 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [94/100] training -> loss 15151.84229952 accuracy -319.789 validation -> loss 15151.97226 accuracy -325.069 | Elapsed 0.031 Seconds DH 0 15:10:15.796 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [95/100] training -> loss 15148.77653633 accuracy -319.724 validation -> loss 15148.90466 accuracy -325.003 | Elapsed 0.031 Seconds MF 0 15:10:15.831 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [96/100] training -> loss 15145.56414236 accuracy -319.656 validation -> loss 15145.69033 accuracy -324.934 | Elapsed 0.047 Seconds IL 0 15:10:15.869 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [97/100] training -> loss 15141.85430749 accuracy -319.577 validation -> loss 15141.97859 accuracy -324.854 | Elapsed 0.031 Seconds KJ 0 15:10:15.906 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [98/100] training -> loss 15138.40751503 accuracy -319.504 validation -> loss 15138.52969 accuracy -324.780 | Elapsed 0.032 Seconds PP 0 15:10:15.942 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [99/100] training -> loss 15135.31136641 accuracy -319.439 validation -> loss 15135.43169 accuracy -324.713 | Elapsed 0.046 Seconds NM 0 15:10:15.975 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [100/100] training -> loss 15131.73032246 accuracy -319.363 validation -> loss 15131.84854 accuracy -324.636 | Elapsed 0.032 Seconds
Verlust vs. Epochendiagramm: 100 Epochen, 0,0001 Lernrate
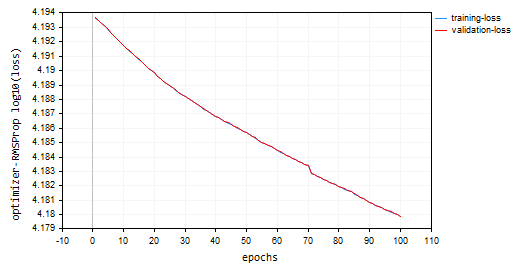
Wo wird RMSProp verwendet?
Gut für nicht-stationäre Ziele, spärliche Gradienten, einfacher als Adam
02: Adagrad (Adaptiver Gradientenalgorithmus)
Adagrad ist ein Optimierer für neuronale Netze, der ähnlich wie RMSprop eine adaptive Lernrate verwendet. Allerdings weisen Adagrad und RMSprop einige wesentliche Unterschiede in ihrem Ansatz auf:
Die Mathematik dahinter:
- Er akkumuliert vergangene Gradienten: Adagrad verfolgt die Summe der quadrierten Gradienten für jeden Parameter während des gesamten Trainingsprozesses. Dieser kumulierte Wert gibt an, wie oft ein Parameter in der Vergangenheit aktualisiert wurde.
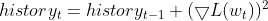
cache += MathPow(gradients, 2);
- Er normalisiert den Gradienten: der aktuelle Gradient für jeden Parameter wird durch die Quadratwurzel der akkumulierten Summe der quadrierten Gradienten geteilt, zusammen mit einem kleinen Glättungsausdruck (normalerweise mit ε bezeichnet), um eine Division durch Null zu vermeiden.
- Er aktualisiert den Parameter: Der normalisierte Gradient wird mit der Lernrate multipliziert, um die Aktualisierung des Parameters zu bestimmen.
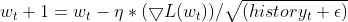
parameters -= divide(this.m_learning_rate, MathSqrt(cache + this.m_epsilon)) * gradients;
nn_learning_rate = 0.0001, Epochen = 100
nn.fit(x_train, y_train, new OptimizerAdaGrad(nn_learning_rate), nn_epochs, nn_batch_size, show_batch); Verlust vs. Epochendiagramm:
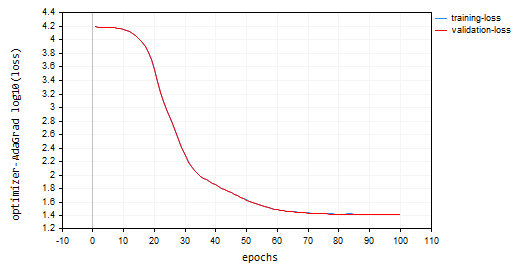
Adagrad hatte eine steilere Lernkurve und war während der Aktualisierungen sehr stabil, benötigte aber mehr als 100 Epochen, um zu konvergieren, da es am Ende eine Genauigkeit von etwa 44 % sowohl bei den Trainings- als auch bei den Validierungsstichproben erreichte.
RK 0 15:15:52.202 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [90/100] training -> loss 26.22261537 accuracy 0.445 validation -> loss 26.13118 accuracy 0.440 | Elapsed 0.031 Seconds ER 0 15:15:52.239 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [91/100] training -> loss 26.12443561 accuracy 0.447 validation -> loss 26.03635 accuracy 0.442 | Elapsed 0.047 Seconds NJ 0 15:15:52.277 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [92/100] training -> loss 26.11449352 accuracy 0.447 validation -> loss 26.02561 accuracy 0.442 | Elapsed 0.032 Seconds IQ 0 15:15:52.316 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [93/100] training -> loss 26.09263184 accuracy 0.448 validation -> loss 26.00461 accuracy 0.443 | Elapsed 0.046 Seconds NH 0 15:15:52.354 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [94/100] training -> loss 26.14277865 accuracy 0.447 validation -> loss 26.05529 accuracy 0.442 | Elapsed 0.032 Seconds HP 0 15:15:52.393 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [95/100] training -> loss 26.09559950 accuracy 0.448 validation -> loss 26.00845 accuracy 0.443 | Elapsed 0.047 Seconds PO 0 15:15:52.442 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [96/100] training -> loss 26.05409769 accuracy 0.448 validation -> loss 25.96754 accuracy 0.443 | Elapsed 0.046 Seconds PG 0 15:15:52.479 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [97/100] training -> loss 25.98822082 accuracy 0.450 validation -> loss 25.90384 accuracy 0.445 | Elapsed 0.032 Seconds PN 0 15:15:52.519 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [98/100] training -> loss 25.98781231 accuracy 0.450 validation -> loss 25.90438 accuracy 0.445 | Elapsed 0.047 Seconds EE 0 15:15:52.559 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [99/100] training -> loss 25.91146212 accuracy 0.451 validation -> loss 25.83083 accuracy 0.446 | Elapsed 0.031 Seconds CN 0 15:15:52.595 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [100/100] training -> loss 25.87412572 accuracy 0.452 validation -> loss 25.79453 accuracy 0.447 | Elapsed 0.047 Seconds
Vorteile von Adagrad:
Es konvergiert schneller bei spärlichen Merkmalen. In Situationen, in denen viele Parameter aufgrund spärlicher Merkmale in den Daten nur selten aktualisiert werden, kann Adagrad die Lernraten effektiv reduzieren und so eine schnellere Konvergenz für diese Parameter ermöglichen.
Beschränkungen von Adagrad:
Im Laufe der Zeit wächst die Summe der quadrierten Gradienten in Adagrad immer weiter an, sodass die Lernraten für alle Parameter kontinuierlich sinken. Dies kann den Trainingsfortschritt aufhalten.
Wann ist Adagrad zu verwenden:
Bei Datensätzen mit wenigen Merkmalen, bei denen viele Merkmale nur selten aktualisiert werden, kann Adagrad die Konvergenz dieser Parameter wirksam beschleunigen.
In den frühen Phasen der Ausbildung: In einigen Szenarien können die anfänglichen Lernratenanpassungen von Adagrad hilfreich sein, bevor später im Training zu einem anderen Optimierer gewechselt wird.
03: Adaptive Momentabschätzung (Adam)
Ein hocheffektiver Optimierungsalgorithmus, der häufig beim Training neuronaler Netze eingesetzt wird. Es kombiniert die Stärken von AdaGrad und RMSprop, um deren Grenzen zu überwinden, und bietet effizientes und stabiles Lernen.
Theorie:
Adam hat zwei Hauptmerkmale;
- Exponentieller gleitender Durchschnitt (EMA) der Gradienten: Ähnlich wie bei RMSprop unterhält Adam eine EMA der quadrierten Gradienten (Cache), um die jüngste Geschichte der für jeden Parameter erforderlichen Aktualisierungen zu erfassen.
- Exponentieller gleitender Durchschnitt der Momente: Adam führt einen weiteren EMA (Moment) ein, der den laufenden Durchschnitt der Gradienten selbst verfolgt. Dadurch wird das Problem der verschwindenden Gradienten, das bei einigen Netzarchitekturen auftreten kann, gemildert.
Normalisierung und Aktualisierung:
- Moment Update: Der aktuelle Gradient wird zur Aktualisierung der EMA der Momente (m_t) verwendet
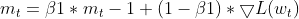
this.moment = this.m_beta1 * this.moment + (1 - this.m_beta1) * gradients;
- Aktualisierung des quadratischen Gradienten: Der aktuelle quadratische Gradient wird zur Aktualisierung der EMA der quadratischen Gradienten (cache_t) verwendet.
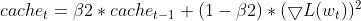
this.cache = this.m_beta2 * this.cache + (1 - this.m_beta2) * MathPow(gradients, 2);
- Korrektur der Verzerrung: Beide EMAs (moment_t und cache_t) werden mit exponentiellen Zerfallsfaktoren (β1 und β2) korrigiert, um sicherzustellen, dass sie unverzerrte Schätzungen der wahren Momente sind.
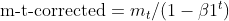
matrix moment_hat = this.moment / (1 - MathPow(this.m_beta1, this.time_step));
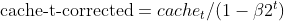
matrix cache_hat = this.cache / (1 - MathPow(this.m_beta2, this.time_step));
- Normalisierung: Ähnlich wie bei RMSprop wird der aktuelle Gradient anhand der korrigierten EMAs und eines kleinen Glättungsfaktors (ε) normalisiert.
- Parameteraktualisierungen; Der normalisierte Gradient wird mit der Lernrate (η) multipliziert, um die Aktualisierung des Parameters zu bestimmen.
parameters -= (this.m_learning_rate * moment_hat) / (MathPow(cache_hat, 0.5) + this.m_epsilon);
So sieht der Konstruktor des Optimizers von Adam aus;
OptimizerAdam(double learning_rate=0.01, double beta1=0.9, double beta2=0.999, double epsilon=1e-8);
Ich habe es mit der Lernrate genannt:
nn.fit(x_train, y_train, new OptimizerAdam(nn_learning_rate), nn_epochs, nn_batch_size, show_batch); Das resultierende Diagramm Verlust vs. Epoche:

Adam schnitt besser ab als die vorherigen Optimierer, abgesehen von SGD, und lieferte eine Genauigkeit von ca. 53 % bzw. 52 % bei den Trainings- und Validierungsproben.
MD 0 15:23:37.651 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [90/100] training -> loss 22.05051037 accuracy 0.533 validation -> loss 21.92528 accuracy 0.529 | Elapsed 0.047 Seconds DS 0 15:23:37.703 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [91/100] training -> loss 22.38393234 accuracy 0.526 validation -> loss 22.25178 accuracy 0.522 | Elapsed 0.046 Seconds OK 0 15:23:37.756 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [92/100] training -> loss 22.12091827 accuracy 0.532 validation -> loss 21.99456 accuracy 0.528 | Elapsed 0.063 Seconds OR 0 15:23:37.808 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [93/100] training -> loss 21.94438889 accuracy 0.535 validation -> loss 21.81944 accuracy 0.532 | Elapsed 0.047 Seconds NI 0 15:23:37.862 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [94/100] training -> loss 22.41965082 accuracy 0.525 validation -> loss 22.28371 accuracy 0.522 | Elapsed 0.062 Seconds LQ 0 15:23:37.915 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [95/100] training -> loss 22.27254037 accuracy 0.528 validation -> loss 22.13931 accuracy 0.525 | Elapsed 0.047 Seconds FH 0 15:23:37.969 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [96/100] training -> loss 21.93193893 accuracy 0.536 validation -> loss 21.80427 accuracy 0.532 | Elapsed 0.047 Seconds LG 0 15:23:38.024 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [97/100] training -> loss 22.41523220 accuracy 0.525 validation -> loss 22.27900 accuracy 0.522 | Elapsed 0.063 Seconds MO 0 15:23:38.077 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [98/100] training -> loss 22.23551304 accuracy 0.529 validation -> loss 22.10466 accuracy 0.526 | Elapsed 0.046 Seconds QF 0 15:23:38.129 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [99/100] training -> loss 21.96662717 accuracy 0.535 validation -> loss 21.84087 accuracy 0.531 | Elapsed 0.063 Seconds GM 0 15:23:38.191 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [100/100] training -> loss 22.29715377 accuracy 0.528 validation -> loss 22.16686 accuracy 0.524 | Elapsed 0.062 Seconds
Vorteile von Adam:
- Er konvergiert schneller. Adam konvergiert oft schneller als SGD und kann in verschiedenen Szenarien effizienter sein als RMSprop.
- Weniger empfindlich gegenüber der Lernrate: Im Vergleich zu SGD reagiert Adam weniger empfindlich auf die Wahl der Lernrate, was es robuster macht.
- Geeignet für nicht-konvexe Verlustfunktionen: Es kann effektiv mit nicht-konvexen Verlustfunktionen umgehen, die bei Deep-Learning-Aufgaben üblich sind.
- Breite Anwendbarkeit: Die Kombination der Funktionen von Adam macht es zu einem breit einsetzbaren Optimierer für verschiedene Netzwerkarchitekturen und Datensätze.
Nachteile:
- Abstimmung der Hyperparameter: Adam ist zwar im Allgemeinen weniger empfindlich, erfordert aber immer noch eine Abstimmung der Hyperparameter wie Lernrate und Abklingraten, um eine optimale Leistung zu erzielen.
- Speicherverbrauch: Die Pflege der EMAs kann im Vergleich zu SGD zu einem etwas höheren Speicherverbrauch führen.
Wo soll Adam eingesetzt werden?
Verwenden Sie Adam (Adaptive Moment Estimation) für das Training Ihres neuronalen Netzes, wenn Sie wollen:
Schnellere Konvergenz, Sie möchten, dass Ihr Netz weniger empfindlich auf die Lernrate reagiert, und wenn Sie eine adaptive Lernrate mit Impuls wünschen.
04: Adadelta (Adaptives Lernen mit delta)
Dies ist ein weiterer Optimierungsalgorithmus, der in neuronalen Netzen verwendet wird. Er weist einige Ähnlichkeiten mit SGD und RMSProp auf und bietet eine adaptive Lernrate mit einem spezifischen Impulsterm.
Adadelta zielt darauf ab, die feste Lernrate von SGD, die zu langsamer Konvergenz und Oszillationen führt, zu beseitigen. Er verwendet eine adaptive Lernrate, die sich auf der Grundlage vergangener quadratischer Gradienten anpasst, ähnlich wie bei RMSProp
Mathe dahinter:
- Um einen Exponential Moving Average (EMA) der quadrierten Deltas zu erhalten, berechnet Adadelta für jeden Parameter einen EMA der quadrierten Differenzen zwischen aufeinanderfolgenden Parameteraktualisierungen (Deltas). Dies zeigt, wie sehr sich der Parameter in der jüngsten Vergangenheit verändert hat
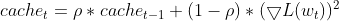
this.cache = m_decay_rate * this.cache + (1 - m_decay_rate) * MathPow(gradients, 2);
- Adaptive Lernrate: Der aktuelle quadratische Gradient für einen Parameter wird durch die EMA der quadratischen Deltas (mit einem Glättungsfaktor) geteilt. Dies dient als adaptive Lernrate und steuert die Aktualisierungsgröße für jeden Parameter
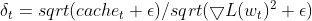
matrix delta = lr * sqrt(this.cache + m_epsilon) / sqrt(pow(gradients, 2) + m_epsilon);
-
Momentum: Adadelta enthält einen Momentum-Term, der die vorherige Aktualisierung des Parameters berücksichtigt, ähnlich wie bei Momentum SGD. Dadurch können Gradienten akkumuliert und lokale Minima möglicherweise umgangen werden.

matrix momentum_term = this.m_gamma * parameters + (1 - this.m_gamma) * gradients; parameters -= delta * momentum_term;
wobei:
![]() : EMA der quadrierten Deltas im Zeitschritt t
: EMA der quadrierten Deltas im Zeitschritt t
![]() : Absenkrate (Hyperparameter, normalerweise zwischen 0,9 und 0,999)
: Absenkrate (Hyperparameter, normalerweise zwischen 0,9 und 0,999)
![]() : Gradient der Verlustfunktion in Bezug auf den Parameter w im Zeitschritt t
: Gradient der Verlustfunktion in Bezug auf den Parameter w im Zeitschritt t
![]() : Parameterwert zum Zeitschritt t
: Parameterwert zum Zeitschritt t
![]() : Aktualisierter Parameterwert im Zeitschritt t+1
: Aktualisierter Parameterwert im Zeitschritt t+1
ε: Glättungsterm (normalerweise ein kleiner Wert wie 1e-8)
γ: Impulskoeffizient (Hyperparameter, normalerweise zwischen 0 und 1)
Vorteile von Adadelta:
- Schnellere Konvergenz: Im Vergleich zu SGD mit fester Lernrate kann Adadelta oft schneller konvergieren, insbesondere bei Problemen mit nichtstationären Gradienten.
- Es verwendet Momentum zur Überwindung lokaler Minima: Der Impulsterm hilft dabei, Gradienten zu akkumulieren und möglicherweise lokale Minima in der Verlustfunktion zu umgehen.
- Weniger empfindlich gegenüber der Lernrate: Ähnlich wie RMSprop ist Adadelta weniger empfindlich auf die gewählte Lernrate als SGD.
Nachteile von Adadelta:
- Erfordert die Abstimmung von Hyperparametern wie der Absenkrate (ρ) und dem Impulskoeffizienten (γ) für optimale Leistung
OptimizerAdaDelta(double learning_rate=0.01, double decay_rate=0.95, double gamma=0.9, double epsilon=1e-8);
- Die Beibehaltung der EMA und die Einbeziehung des Impulses erhöhen die Rechenkosten im Vergleich zur SGD geringfügig.
Wo Adadelta zu verwenden ist:
Adadelta kann in bestimmten Szenarien eine wertvolle Alternative sein:
- Nicht-stationäre Gradienten, Wenn Ihr Problem nicht-stationäre Gradienten aufweist, könnte die adaptive Lernrate von Adadelta mit Momentum von Vorteil sein.
- In Situationen, in denen es entscheidend ist, lokalen Minima zu entgehen, könnte der Impulsbegriff von Adadelta von Vorteil sein.
Ich habe das Modell mit adadelta trainiert, für 100 Epochen, 0,0001 Lernrate. Alles war so, wie es auch in anderen Optimierern verwendet wird:
nn.fit(x_train, y_train, new OptimizerAdaDelta(nn_learning_rate), nn_epochs, nn_batch_size, show_batch); Verlust/Epoche-Diagramm:

Der Adadelta-Optimierer konnte nichts lernen, da er denselben Verlustwert von 15625 und eine Genauigkeit von etwa -335 bei den Trainings- und Validierungsstichproben lieferte. Es sieht so aus, als ob das mit RMSProp gemacht wurde
NP 0 15:32:30.664 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [90/100] training -> loss 15625.71263806 accuracy -329.821 validation -> loss 15626.09899 accuracy -335.267 | Elapsed 0.062 Seconds ON 0 15:32:30.724 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [91/100] training -> loss 15625.71263806 accuracy -329.821 validation -> loss 15626.09899 accuracy -335.267 | Elapsed 0.063 Seconds IK 0 15:32:30.788 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [92/100] training -> loss 15625.71263806 accuracy -329.821 validation -> loss 15626.09899 accuracy -335.267 | Elapsed 0.062 Seconds JQ 0 15:32:30.848 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [93/100] training -> loss 15625.71263806 accuracy -329.821 validation -> loss 15626.09899 accuracy -335.267 | Elapsed 0.063 Seconds RO 0 15:32:30.914 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [94/100] training -> loss 15625.71263806 accuracy -329.821 validation -> loss 15626.09899 accuracy -335.267 | Elapsed 0.062 Seconds PE 0 15:32:30.972 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [95/100] training -> loss 15625.71263806 accuracy -329.821 validation -> loss 15626.09899 accuracy -335.267 | Elapsed 0.063 Seconds CS 0 15:32:31.029 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [96/100] training -> loss 15625.71263806 accuracy -329.821 validation -> loss 15626.09899 accuracy -335.267 | Elapsed 0.047 Seconds DI 0 15:32:31.086 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [97/100] training -> loss 15625.71263806 accuracy -329.821 validation -> loss 15626.09899 accuracy -335.267 | Elapsed 0.062 Seconds DG 0 15:32:31.143 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [98/100] training -> loss 15625.71263806 accuracy -329.821 validation -> loss 15626.09899 accuracy -335.267 | Elapsed 0.063 Seconds FM 0 15:32:31.202 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [99/100] training -> loss 15625.71263806 accuracy -329.821 validation -> loss 15626.09899 accuracy -335.267 | Elapsed 0.046 Seconds GI 0 15:32:31.258 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [100/100] training -> loss 15625.71263806 accuracy -329.821 validation -> loss 15626.09899 accuracy -335.267 | Elapsed 0.063 Seconds
05: Nadam: Nesterov-beschleunigte adaptive Moment-Schätzung
Dieser Optimierungsalgorithmus kombiniert die Stärken von zwei beliebten Optimierern, Adam (Adaptive Moment Estimation) und Nesterov Momentum. Er zielt darauf ab, eine schnellere Konvergenz und eine potenziell bessere Leistung im Vergleich zu Adam zu erreichen, insbesondere in Situationen mit verrauschten Gradienten.
Der Ansatz von Nadam:
Er erbt die Kernfunktionen von Adam:
class OptimizerNadam: protected OptimizerAdam { protected: double m_gamma; public: OptimizerNadam(double learning_rate=0.01, double beta1=0.9, double beta2=0.999, double gamma=0.9, double epsilon=1e-8); ~OptimizerNadam(void); virtual void update(matrix ¶meters, matrix &gradients); }; //+------------------------------------------------------------------+ //| Initializes the Adam optimizer with hyperparameters. | //| | //| learning_rate: Step size for parameter updates | //| beta1: Decay rate for the first moment estimate | //| (moving average of gradients). | //| beta2: Decay rate for the second moment estimate | //| (moving average of squared gradients). | //| epsilon: Small value for numerical stability. | //+------------------------------------------------------------------+ OptimizerNadam::OptimizerNadam(double learning_rate=0.010000, double beta1=0.9, double beta2=0.999, double gamma=0.9, double epsilon=1e-8) :OptimizerAdam(learning_rate, beta1, beta2, epsilon), m_gamma(gamma) { }
Einschließlich:
-
Beibehaltung der EMAs (Exponential Moving Averages): Er verfolgt den EMA der quadrierten Gradienten (cache_t) und den EMA der Momente (m_t), ähnlich wie Adam.
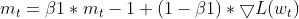
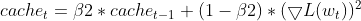
- Berechnung der adaptiven Lernrate: Auf der Grundlage dieser EMAs wird eine adaptive Lernrate berechnet, die sich an jeden Parameter anpasst.
- Sie umfasst das Nesterov-Momentum: Nadam leiht sich das Konzept des Nesterov-Momentums von SGD mit Nesterov-Momentum. Dies beinhaltet:
- Gradient „Peek“: Bevor der Parameter auf der Grundlage des aktuellen Gradienten aktualisiert wird, schätzt Nadam einen „Peek“-Gradienten unter Verwendung des aktuellen Gradienten und des Impulsterms.“
- Aktualisierung mit „Peek“-Farbverlauf: Die Parameteraktualisierung wird dann unter Verwendung dieses „Peek“-Gradienten durchgeführt, was zu einer schnelleren Konvergenz und einer besseren Handhabung verrauschter Gradienten führen kann.
Die Mathematik hinter Nadam:
- Aktualisierung der EMA der Momente (wie bei Adam)
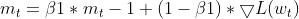
- Aktualisierung der EMA der quadrierten Gradienten (wie bei Adam)
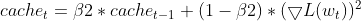
- Verzerrungskorrektur für Momente (wie bei Adam)
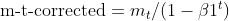
- Verzerrungskorrektur für quadrierte Gradienten (wie bei Adam)
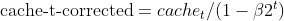
- Nesterov-Dynamik (unter Verwendung der vorherigen Gradientenschätzung)
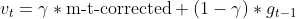
- Aktualisierung der vorherigen Gradientenschätzung
- Parameter mit Nesterov-Dynamik aktualisieren

matrix nesterov_moment = m_gamma * moment_hat + (1 - m_gamma) * gradients; // Nesterov accelerated gradient parameters -= m_learning_rate * nesterov_moment / sqrt(cache_hat + m_epsilon); // Update parameters
Vorteile von Nadam:
- Er ist schneller: Im Vergleich zu Adam kann Nadam potenziell eine schnellere Konvergenz erreichen, insbesondere bei Problemen mit verrauschten Gradienten.
- Er kann besser mit verrauschten Gradienten umgehen: der Nesterov-Term in Nadam kann dazu beitragen, verrauschte Gradienten zu glätten und zu einer besseren Leistung zu führen.
- Er hat die Vorteile von Adam: Ee behält die Vorteile von Adam, wie Anpassungsfähigkeit und geringere Empfindlichkeit gegenüber der Auswahl der Lernrate.
Nachteile:
- Er erfordert die Abstimmung von Hyperparametern wie Lernrate, Absenkraten und Impulskoeffizient für optimale Leistung.
- Nadam ist zwar vielversprechend, wird aber nicht in allen Fällen besser abschneiden als Adam. Weitere Forschung und Experimente sind erforderlich.
Wo kann man Nadam verwenden?
Kann bei Problemen mit verrauschten Gradienten eine gute Alternative zu Adam sein.
Ich habe Nadam mit Standardparametern und der gleichen Lernrate aufgerufen, die wir für alle zuvor besprochenen Optimierer verwendet haben. Mit einer Genauigkeit von ca. 47 % sowohl bei den Trainings- als auch bei den Validierungssätzen landete ich hinter Adam auf dem zweiten Platz. Nadam hat im Vergleich zu den anderen in diesem Artikel besprochenen Methoden eine Menge Oszillationen um die lokalen Minima herum verursacht.
IL 0 15:37:56.549 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [90/100] training -> loss 25.23632476 accuracy 0.466 validation -> loss 25.06902 accuracy 0.462 | Elapsed 0.062 Seconds LK 0 15:37:56.619 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [91/100] training -> loss 24.60851222 accuracy 0.479 validation -> loss 24.44829 accuracy 0.475 | Elapsed 0.078 Seconds RS 0 15:37:56.690 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [92/100] training -> loss 24.68657614 accuracy 0.477 validation -> loss 24.53442 accuracy 0.473 | Elapsed 0.078 Seconds IJ 0 15:37:56.761 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [93/100] training -> loss 24.89495551 accuracy 0.473 validation -> loss 24.73423 accuracy 0.469 | Elapsed 0.063 Seconds GQ 0 15:37:56.832 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [94/100] training -> loss 25.25899364 accuracy 0.465 validation -> loss 25.09940 accuracy 0.461 | Elapsed 0.078 Seconds QI 0 15:37:56.901 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [95/100] training -> loss 25.17698272 accuracy 0.467 validation -> loss 25.01065 accuracy 0.463 | Elapsed 0.063 Seconds FP 0 15:37:56.976 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [96/100] training -> loss 25.36663261 accuracy 0.463 validation -> loss 25.20273 accuracy 0.459 | Elapsed 0.078 Seconds FO 0 15:37:57.056 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [97/100] training -> loss 23.34069092 accuracy 0.506 validation -> loss 23.19590 accuracy 0.502 | Elapsed 0.078 Seconds OG 0 15:37:57.128 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [98/100] training -> loss 23.48894694 accuracy 0.503 validation -> loss 23.33753 accuracy 0.499 | Elapsed 0.078 Seconds ON 0 15:37:57.203 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [99/100] training -> loss 23.03205165 accuracy 0.512 validation -> loss 22.88233 accuracy 0.509 | Elapsed 0.062 Seconds ME 0 15:37:57.275 Optimization Algorithms testScript (EURUSD,H1) --> Epoch [100/100] training -> loss 24.98193438 accuracy 0.471 validation -> loss 24.82652 accuracy 0.467 | Elapsed 0.079 Seconds
Unten sehen Sie das Diagramm Verlust vs. Epoche:

Abschließende Überlegungen
Die Wahl des besten Optimierers hängt von Ihrem spezifischen Problem, dem Datensatz, der Netzarchitektur und den Parametern ab. Experimentieren ist der Schlüssel, um den effektivsten Optimierer für die Trainingsaufgabe Ihres neuronalen Netzes zu finden. Adam erweist sich als der beste Optimierer für viele neuronale Netze, da er schneller konvergiert, weniger empfindlich auf die Lernrate reagiert und seine Lernrate mit der Dynamik anpasst. Er ist eine gute Wahl, um ihn zuerst auszuprobieren, besonders bei komplexen Problemen oder wenn Sie nicht sicher sind, welchen Optimierer Sie zuerst verwenden sollen.
Beste Wünsche.
Verfolgen Sie die Entwicklung von Modellen für maschinelles Lernen und vieles mehr in dieser Artikelserie auf diesem GitHub repo.
Anhänge:
| Datei | Beschreibung/Verwendung |
|---|---|
| MatrixExtend.mqh | Verfügt über zusätzliche Funktionen für Matrixmanipulationen. |
| metrics.mqh | Enthält Funktionen und Code zur Messung der Leistung von ML-Modellen. |
| preprocessing.mqh | Die Bibliothek für die Vorverarbeitung von rohen Eingabedaten, um sie für die Verwendung von Modellen des maschinellen Lernens geeignet zu machen. |
| plots.mqh | Bibliothek zum Zeichnen von Vektoren und Matrizen |
| optimizers.mqh | Eine Include-Datei, die alle in diesem Artikel besprochenen Optimierer für neuronale Netze enthält |
| cross_validation.mqh | Eine Bibliothek mit Kreuzvalidierungstechniken |
| Tensors.mqh | Eine Bibliothek mit Tensoren, algebraischen 3D-Matrizen-Objekten, programmiert in einfacher MQL5-Sprache |
| Regressor Nets.mqh | Enthält neuronale Netze zur Lösung eines Regressionsproblems |
| Optimization Algorithms testScript.mq5 | Ein Skript zur Ausführung des Codes aus allen Include-Dateien und dem Datensatz/Dies ist die Hauptdatei |
| airfoil_noise_data.csv | Daten des Regressionsproblems bei Tragflächen |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/14435
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.