
Neuronale Netze leicht gemacht (Teil 63): Unüberwachtes Pretraining für Decision Transformer (PDT)

Einführung
Decision Transformer ist ein leistungsfähiges Werkzeug für die Lösung verschiedener praktischer Probleme. Dies wird größtenteils durch den Einsatz von Methoden der Transformer Attention erreicht. Frühere Experimente haben gezeigt, dass die Verwendung der Transformer-Architektur auch ein langes und gründliches Modelltraining erfordert. Dies wiederum erfordert die Aufbereitung von gekennzeichneten Trainingsdaten. Bei der Lösung praktischer Probleme ist es mitunter recht schwierig, Belohnungen zu erhalten, und die Skalierbarkeit der gekennzeichneten Daten reicht nicht aus, um die Trainingsmenge zu erweitern. Wenn wir beim Pretraining keine Belohnungen einsetzen, kann das Modell allgemeine Verhaltensmuster erlernen, die später leicht für verschiedene Aufgaben angepasst werden können.
In diesem Artikel lade ich Sie ein, sich mit der RL-Pretraining-Methode namens Pretrained Decision Transformer (PDT) vertraut zu machen, die in dem Artikel „Future-conditioned Unsupervised Pretraining for Decision Transformer“ im Mai 2023 vorgestellt wurde. Diese Methode bietet DT die Möglichkeit, auf Daten ohne Kennzeichnung der Belohnung und mit suboptimalen Daten zu trainieren. Die Autoren der Methode ziehen insbesondere ein Pretrainingsszenario in Betracht, bei dem das Modell zunächst offline auf zuvor gesammelten Trajektorien ohne Belohnungskennzeichnung trainiert und dann durch Online-Interaktion auf die Zielaufgabe feinabgestimmt wird.
Für ein effektives Pretraining muss das Modell in der Lage sein, vielfältige und universelle Lernsignale zu extrahieren, ohne Belohnungen zu verwenden. Während des Pretrainings muss sich das Modell schnell an die Belohnungsaufgabe anpassen, indem es bestimmt, welche Lernsignale mit Belohnungen verbunden werden können.
PDT erlernt gemeinsam einen Einbettungsraum der zukünftigen Trajektorie sowie eine zukünftige Priorität, die nur von vergangenen Informationen abhängt. Durch die Konditionierung der Handlungsvorhersage auf die Einbettung des Ziels in die Zukunft wird die PDT mit der Fähigkeit ausgestattet, „über die Zukunft nachzudenken“. Diese Fähigkeit ist natürlich aufgabenunabhängig und kann auf verschiedene Aufgabenspezifikationen verallgemeinert werden.
Um eine effiziente Online-Feinabstimmung bei nachgelagerten Aufgaben zu erreichen, können Sie den Rahmen leicht an neue Bedingungen anpassen, indem Sie jede zukünftige Einbettung mit ihrem Ertrag verknüpfen, was durch das Training eines Belohnungsvorhersagenetzwerks für jede zukünftige Einbettung realisiert wird.
Ich schlage vor, mit dem nächsten Abschnitt unseres Artikels fortzufahren und die Methode des Pretrained Decision Transformer im Detail zu betrachten.
1. Pretrained Decision Transformer Methode (PDT)
Die PDT-Methode basiert auf den Prinzipien der DT. Es sagt auch die Aktionen des Agenten voraus, nachdem es die Abfolge der besuchten Zustände und abgeschlossenen Aktionen analysiert hat. Gleichzeitig führt PDT Ergänzungen zum DT-Algorithmus ein, die ein vorläufiges Modelltraining auf ungekennzeichneten Daten, d. h. ohne Analyse der Rückgabe, ermöglichen. Dies scheint unmöglich zu sein, da die zukünftige Belohnung mit „Return-To-Go“ (RTG, Zurück auf Los) eines der Elemente der vom Modell analysierten Sequenz ist und als eine Art Kompass für die Orientierung des Modells im Raum dient.
Die Autoren der PDT-Methode schlugen vor, das RTG durch einen latenten Zustandsvektor Z zu ersetzen. Dieser Gedanke ist nicht neu, aber die Autoren haben ihn recht interessant interpretiert. Im Zuge des vorläufigen Trainings mit ungekennzeichneten Daten werden wir 3 Modelle trainieren:
- Akteur (Actor), ein klassisches DT mit Handlungsvorhersage auf der Grundlage der Analyse der vorherigen Trajektorie;
- Zielvorhersagemodell P(-|St) — prognostiziert DT-Ziele (latenter Zustand Z) auf der Grundlage der Analyse des aktuellen Zustands;
- Modell des Zukunftskodierers G(•|τt+1:t+k) — „schaut in die Zukunft“ und bettet sie in den latenten Zustand Z ein.
Beachten Sie, dass die letzten beiden Modelle unterschiedliche Daten analysieren, aber beide den latenten Vektor Z liefern. Dadurch wird eine Art Autoencoder zwischen dem aktuellen und dem zukünftigen Zustand gebildet. Sein latenter Zustand wird als Zielbezeichnung für den DT (Akteur) verwendet.
Das Modelltraining unterscheidet sich jedoch vom Autoencoder-Training. Zunächst trainieren wir den Encoder der Zukunft und den Akteur, indem wir Abhängigkeiten zwischen der zukünftigen Trajektorie und den durchgeführten Aktionen herstellen. Wir erlauben dem PDT, für einen gewissen Planungshorizont in die Zukunft zu schauen. Wir komprimieren Informationen über den weiteren Verlauf in einen latenten Zustand. Auf diese Weise ermöglichen wir es dem Modell, eine Entscheidung auf der Grundlage der verfügbaren Informationen über die Zukunft zu treffen. Wir gehen davon aus, dass wir in der Pretraining eine Akteurspolitik mit einer breiten Palette von Verhaltensfähigkeiten entwickeln werden, die durch Belohnungen aus der Umwelt nicht eingeschränkt werden.
Dann trainieren wir ein Zielvorhersagemodell, das nach Abhängigkeiten zwischen dem aktuellen Zustand und der gelernten Einbettung der zukünftigen Trajektorie sucht.
Dieser Ansatz ermöglicht es uns, die Belohnungen von den angestrebten Ergebnissen zu trennen, wodurch sich Möglichkeiten für ein umfassendes kontinuierliches Vorlernen eröffnen. Gleichzeitig verringert es das Problem des inkonsistenten Verhaltens, wenn das Verhalten des Agenten erheblich vom gewünschten Ziel abweicht.
Obwohl die Verwendung des Zielvorhersagemodells P(Z|St) hilft, um zukünftige latente Variablen zu sampeln und Verhaltensweisen zu erzeugen, die die Verteilung des Trainingsdatensatzes nachahmen, kodiert es keine aufgabenspezifischen Daten. Daher ist es notwendig, P(Z|St) an einen Datensatz zukünftiger Einbettungen zu senden, die beim nachgelagerten Lernen zu hohen zukünftigen Belohnungen führen.
Dies führt dazu, dass die DT ein Expertenverhalten an den Tag legt, das auf eine Maximierung der Erträge ausgerichtet ist. Im Gegensatz zur Steuerung der renditemaximierenden Politik durch Zuweisung einer skalaren Zielbelohnung müssen wir die Verteilung des Zielvorhersagemodells P(Z|St) anpassen. Da diese Verteilung unbekannt ist, verwenden wir ein zusätzliches Belohnungsvorhersagemodell F(•|Z, St), um die optimale Trajektorie vorherzusagen. Das Belohnungsvorhersagemodell lernt zusammen mit allen anderen während des nachgelagerten Trainingsprozesses.
Ähnlich wie beim Pretraining verwenden wir einen Future-Encoder, um den latenten Zustand zu erhalten, der es ermöglicht, dass sich Gradienten zurück ausbreiten und die Kodierung der Belohnungsdaten in der latenten Repräsentation anpassen. Dies ermöglicht es, die Besonderheiten der Aufgabe während des nachgelagerten Lernprozesses zu lösen.
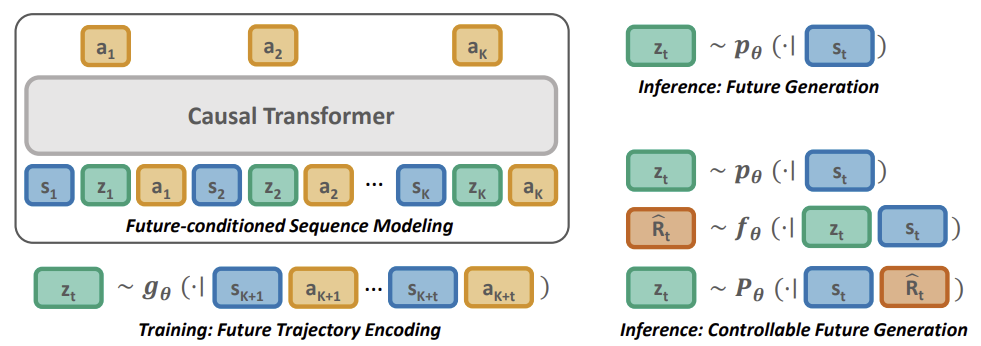
Nachfolgend sehen Sie eine Visualisierung der Pretrained Decision Transformer-Methode aus dem Originalartikel.
2. Implementierung mit MQL5
Nachdem wir nun die theoretischen Aspekte der Pretrained Decision Transformer-Methode besprochen haben, können wir zum praktischen Teil unseres Artikels übergehen und die Implementierung der Methode in MQL5 diskutieren. In diesem Artikel werden wir uns auf den EA konzentrieren, der den Trainingsdatensatz sammelt. In den vorangegangenen Artikeln haben wir verschiedene Möglichkeiten zur Konstruktion von Algorithmen aus der Familie der Entscheidungstransformatoren untersucht. Sie alle enthalten einen ähnlichen Erfahrungswiedergabepuffer. Wir werden die für die anfängliche Sammlung des Trainingsdatensatzes verwenden. In meiner Arbeit werde ich den im vorherigen Artikel erstellten Erfahrungswiedergabepuffer verwenden. Wir haben ihn durch Stichproben von Aktionen ohne Bezug zu einem bestimmten Modell gesammelt (implementiert für die Methode Go-Explore).
2.1. Modell der Architektur
Da wir bereits über einen Satz von Trainingsdaten verfügen, gehen wir zum nächsten Schritt über, dem unüberwachten Pretraining. Wie bereits erwähnt, werden wir in dieser Phase 3 Modelle trainieren. Beginnen wir unsere Arbeit mit einer Beschreibung der Modellarchitektur, die in der Methode CreateDescriptions gesammelt wird.
bool CreateDescriptions(CArrayObj *agent, CArrayObj *planner, CArrayObj *future_embedding) { //--- CLayerDescription *descr;
In den Parametern erhält die Methode Zeiger auf 3 dynamische Arrays, in die wir die Architekturbeschreibungen der neuronalen Schichten des Modells einfügen werden.
Im Hauptteil der Methode deklarieren wir eine lokale Variable, um einen Zeiger auf ein Objekt zu schreiben, das eine neuronale Schicht beschreibt. In dieser Variablen wird ein Zeiger auf das Objekt, mit dem wir arbeiten, in einem separaten Block „aufbewahrt“.
Zunächst werden wir die Architektur unseres Agenten beschreiben. In diesem Fall handelt es sich um Decision Transformer. Sie nimmt als Eingabe eine schrittweise Beschreibung der Trajektorie und akkumuliert die Einbettungen der gesamten Sequenz im Ergebnispuffer der Einbettungsschicht. Im Gegensatz zu früheren Arbeiten müssen wir jedoch während des Backpropagation-Durchgangs den Fehlergradienten an das zukünftige Encoder-Modell weitergeben. Dazu werden wir einen kleinen Trick anwenden. Wir werden das gesamte Quelldatenfeld in 2 Streams aufteilen. Die Hauptmenge der Daten wird wie üblich über den Puffer der Quelldatenschicht an das Modell übergeben. Die Einbettung der Zukunft wird als zweiter Stream übergeben, der in der Verkettungsschicht kombiniert wird. Die unverarbeiteten Quelldaten, die wir in den Puffer der Quelldatenschicht einspeisen, werden mit Hilfe einer Batch-Normalisierungsschicht normalisiert. Die Einbettung des Futures ist das Ergebnis der Arbeit des Modells und kann ohne Normalisierung verwendet werden.
//--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = prev_count + EmbeddingSize; descr.step = EmbeddingSize; descr.optimization = ADAM; descr.activation = None; if(!agent.Add(descr)) { delete descr; return false; }
Die zu einem einzigen Datenstrom zusammengefassten Daten werden in die neuronale Schicht der vorgestellten Informationseinbettung eingespeist.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, EmbeddingSize}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
Anschließend werden die Daten an den Transformer-Block übergeben. Ich habe einen 4-lagigen „Kuchen“ mit 16 Self-Attention-Köpfen verwendet.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 16; descr.window_out = 64; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Nach dem Transformer-Block habe ich 2 Faltungsschichten verwendet, um stabile Muster zu erkennen.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 16; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
Es folgen 3 vollständig verbundene Schichten des Entscheidungsblocks.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Am Ausgang des Modells befindet sich eine vollständig verbundene Schicht, deren Anzahl der Elemente dem Aktionsraum des Agenten entspricht.
Als Nächstes wird eine Beschreibung des Zielvorhersagemodells P(Z|St) erstellt. In der Terminologie der hierarchischen Modelle können wir es den Planer (planner) nennen. Ihre Funktionalität ist strukturell sehr ähnlich, auch wenn die Ansätze zum Trainieren von Modellen grundverschieden sind.
Als Input für die Quelldatenschicht des Modells geben wir eine Beschreibung von ausschließlich historischen Daten und Indikatorwerten für ein Muster ein. In unserem Fall handelt es sich um Daten von nur 1 Balken.
Ich stimme zu, dass dies zu wenig Informationen sind, um die Marktsituation zu analysieren und zukünftige Zustände und Handlungen vorherzusagen. Vor allem, wenn wir über Vorhersagen sprechen, die ein paar Schritte nach vorne gehen. Aber lassen Sie uns die Situation anders betrachten. Während des Betriebs füttern wir unseren Akteur mit der generierten Zukunftsprognose in Form einer Einbettung als Eingabe. Die internen Schichten speichern Daten bis zu einer bestimmten Tiefe der Handelshistorie. In diesem Zusammenhang ist es für uns wichtiger, auf die eingetretenen Veränderungen zu achten und das Verhalten des Akteurs anzupassen. Die Analyse einer tieferen Handelshistorie bei der Erstellung der zukünftigen Einbettung kann lokale Veränderungen „verwischen“. Dies ist jedoch meine subjektive Meinung und keine Voraussetzung für den Pretrained Decision Transformer-Algorithmus.
if(!planner) { planner = new CArrayObj(); if(!planner) return false; } //--- Planner planner.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = BarDescr * NBarInPattern; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
Die resultierenden Rohdaten werden durch eine Batch-Normalisierungsschicht geleitet, um sie in eine vergleichbare Form zu bringen.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
Als Nächstes beschloss ich, das Modell nicht zu verkomplizieren, und verwendete einen Entscheidungsblock mit 3 vollständig verbundenen Schichten.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
Am Ausgang des Modells reduzieren wir die Vektorgröße auf die Einbettungsgröße und normalisieren die Ergebnisse mit den SoftMax-Funktionen.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
Wir haben bereits die architektonische Lösung von 2 Modellen beschrieben. Und alles, was wir tun müssen, ist, eine Beschreibung des zukünftigen Encoders hinzuzufügen. Obwohl der Output des Modells grundsätzlich mit dem Output des vorherigen Modells übereinstimmen soll, wird dies nur in den letzten Schichten des Modells spürbar sein. Die Architektur des Encoders ist ein wenig komplizierter. Zunächst einmal ermöglichen wir in der zukünftigen Einbettung die Planung in einer gewissen Tiefe. Das bedeutet, dass wir Informationen über mehrere nachfolgende Kerzen in die Quelldatenschicht einspeisen.
Beachten Sie, dass ich in die Daten über die Zukunft nur Daten über die Preisbewegung des Symbols und die Indikatorwerte aufgenommen habe. Ich habe keine Informationen über den Kontostand und die nachfolgenden Aktionen des Agenten aufgenommen. Das Handeln des Agenten wird durch seine Politik bestimmt. Ich wollte mich darauf konzentrieren, Prozesse in der Umwelt zu verstehen. Zwar enthält der Kontostand in gewissem Maße bereits Informationen über die von der Umwelt erhaltene Belohnung, was dem Prinzip der ungekennzeichneten Daten etwas widerspricht.
//--- Future Embedding if(!future_embedding) { future_embedding = new CArrayObj(); if(!future_embedding) return false; } //--- future_embedding.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = BarDescr * NBarInPattern * ValueBars; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
Wie zuvor werden die unverarbeiteten Rohdaten durch eine Batch-Normalisierungsschicht geleitet, um sie in eine vergleichbare Form zu bringen.
Als Nächstes habe ich einen Transformer-Block mit 4 Schichten und 16 Self-Attention-Köpfe verwendet. In diesem Fall analysiert der Aufmerksamkeitsblock die Abhängigkeiten zwischen den einzelnen Balken, um die Haupttrends am Planungshorizont zu erkennen und den Rauschanteil herauszufiltern.
Nach der Logik der PDT-Methode ist es die Einbettung des zukünftigen Zustands, die dem Akteur die eingesetzte Fähigkeit und die Richtung der weiteren Handlungen anzeigen soll. Daher sollte das Ergebnis des Encoderbetriebs so informativ und genau wie möglich sein.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = ValueBars; descr.window = BarDescr * NBarInPattern; descr.step = 16; descr.window_out = 64; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
Auf die Aufmerksamkeitsschichten folgen die vollständig verknüpften Schichten des Entscheidungsblocks.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
Am Ausgang des Modells verwenden wir eine vollständig verknüpfte Schicht mit SoftMax-Normalisierung, wie dies bereits beim Modell für die Zukunftsprognose geschehen ist.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- return true; }
Damit ist die Beschreibung der Modellarchitektur für den Pretraining Expert Advisor abgeschlossen. Bevor ich jedoch mit der Arbeit am Expert Advisor fortfahre, möchte ich die Arbeit an der Beschreibung der Architektur der Modelle abschließen. Ich möchte Sie daran erinnern, dass es in der Phase der Feinabstimmung mit der PDT-Methode möglich ist, ein weiteres Modell hinzuzufügen, nämlich die Belohnungsvorhersage. Da sie in einer späteren Phase des Trainings hinzugefügt wird, habe ich beschlossen, eine Beschreibung ihrer Architektur in eine separate Methode CreateValueDescriptions aufzunehmen.
Nach der PDT-Methodik muss dieses Modell die im latenten Zustand und im aktuellen Zustand kodierten zukünftigen Trends abschätzen. Ausgehend von den Ergebnissen der Analyse müssen die Belohnungen aus der Umwelt vorhergesagt werden.
Der Zweck des nachgelagerten Trainingsprozesses besteht darin, Informationen über die wahrscheinliche Belohnung in die zukünftige Einbettung einzubeziehen. Daher müssen wir, wie in der Pretrainingsphase, den Gradienten des Belohnungsvorhersagefehlers an das zukünftige Encoder-Modell weitergeben. Hier werden wir den oben getesteten Ansatz zur Trennung der Informationsflüsse verwenden. Einer der anfänglichen Datenströme wird der aktuelle Zustand sein. Die zweite wird die zukünftige Einbettung sein.
Die zweite Frage, die wir uns nun stellen müssen, ist, was zum Verständnis des gegenwärtigen Zustands in dieser Phase gehört. In der Phase der Feinabstimmung verwenden wir natürlich gekennzeichnete Daten aus dem Trainingsdatensatz und könnten die gesamte verfügbare Datenmenge einbeziehen. Eine große Menge an Eingabedaten verkompliziert das Modell jedoch erheblich und erhöht die Kosten der Modellverarbeitung. Wie effizient ist die Verwendung einer solchen Datenmenge zum jetzigen Zeitpunkt?
Um nachfolgende Zustände vorherzusagen, müssen wir die vorherigen Zustände der Umgebung analysieren. Aber wir haben bereits Informationen über zukünftige Zustände in Form von Einbettungen.
Die Analyse der früheren Aktionen des Agenten kann Aufschluss über die angewandte Politik geben. Aber wir müssen dem Agenten Informationen zur Verfügung stellen, damit er eine Entscheidung über die Notwendigkeit einer Änderung der angewandten Kompetenz- und Verhaltenspolitik treffen kann.
Informationen über den aktuellen Kontostand können nützlich sein. Das Vorhandensein einer freien Marge zeigt an, dass zusätzliche Positionen eröffnet werden können, wenn der Trend günstig ist. Oder wenn eine Trendwende zu erwarten ist und wir zuvor offene Positionen schließen und schwebende Gewinne und Verluste festschreiben müssen. Darüber hinaus sollten wir an die Strafen für das Fehlen offener Stellen denken, die sich auch auf die Vergütung auswirken werden.
Daher speisen wir die aktuelle Beschreibung des Kontostands und der offenen Positionen in die Quelldatenschicht ein.
bool CreateValueDescriptions(CArrayObj *value) { //--- CLayerDescription *descr; //--- if(!value) { value = new CArrayObj(); if(!value) return false; } //--- Value value.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
Die Ausgabe wird durch eine Batch-Normalisierungsschicht geleitet.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
Anschließend werden die beiden Datenströme in der Verkettungsschicht kombiniert.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.step = EmbeddingSize; descr.optimization = ADAM; descr.activation = SIGMOID; if(!value.Add(descr)) { delete descr; return false; }
Anschließend werden die Daten von den vollständig verknüpften Schichten an den Entscheidungsblock weitergeleitet.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- return true; }
Am Ausgang des Modells erhalten wir einen Vektor der erwarteten Belohnungen.
2.2. Pretraining Expert Advisor
Nachdem wir die Architektur der verwendeten Modelle erstellt haben, fahren wir mit der Implementierung des PDT-Algorithmus fort. Wir beginnen mit dem Pretraining Expert Advisor „...\PDT\Pretrain.mq5“. Wie bereits erwähnt, führte diese EA ein vorläufiges Training von 3 Modellen durch: Akteur, Planer und Zukunfts-Encoder.
CNet Agent; CNet Planner; CNet FutureEmbedding;
Bei der EA-Initialisierungsmethode laden wir zunächst den Trainingsdatensatz.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Wir versuchen, die trainierten Modelle zu laden und, falls erforderlich, neue Modelle entsprechend der oben beschriebenen Architektur zu initialisieren.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Planner.Load(FileName + "Pln.nnw", temp, temp, temp, dtStudied, true) || !FutureEmbedding.Load(FileName + "FEm.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *agent = new CArrayObj(); CArrayObj *planner = new CArrayObj(); CArrayObj *future_embedding = new CArrayObj(); if(!CreateDescriptions(agent, planner, future_embedding)) { delete agent; delete planner; delete future_embedding; return INIT_FAILED; } if(!Agent.Create(agent) || !Planner.Create(planner) || !FutureEmbedding.Create(future_embedding)) { delete agent; delete planner; delete future_embedding; return INIT_FAILED; } delete agent; delete planner; delete future_embedding; //--- }
Dann übertragen wir alle Modelle in einen OpenCL-Kontext.
//---
COpenCL *opcl = Agent.GetOpenCL();
Planner.SetOpenCL(opcl);
FutureEmbedding.SetOpenCL(opcl);
Hier führen wir die minimal erforderliche Kontrolle über die Modellarchitektur durch.
Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the worker does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
Wir initialisieren den Start des vorläufigen Trainingsprozesses, der in der Methode Train implementiert ist.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Bei der EA-Deinitialisierungsmethode müssen wir die trainierten Modelle speichern.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Agent.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); Planner.Save(FileName + "Pln.nnw", 0, 0, 0, TimeCurrent(), true); FutureEmbedding.Save(FileName + "FEm.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
Das Modelltraining wird mit der Train-Methode durchgeführt. Im Hauptteil der Methode wird zunächst die Größe des Erfahrungswiedergabepuffers bestimmt.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Als Nächstes haben wir ein System aus verschachtelten Schleifen für die Modelltraining erstellt. Die externe Schleife ist auf die in den externen Parametern von EA angegebene Anzahl von Trainingsiterationen begrenzt. Im Hauptteil dieser Schleife nehmen wir zunächst eine Trajektorie aus dem Erfahrungswiedergabepuffer und einen separaten Umgebungszustand entlang der ausgewählten Trajektorie, um den Lernprozess zu beginnen.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars - ValueBars, MathMin(Buffer[tr].Total, 20 + ValueBars))); if(i < 0) { iter--; continue; }
Danach führen wir eine verschachtelte Schleife aus, um das DT-Modell sequentiell zu trainieren.
Actions = vector<float>::Zeros(NActions); for(int state = i; state < MathMin(Buffer[tr].Total - ValueBars, i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state); if(!Planner.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Im Hauptteil der Schleife schreiben wir historische Kursbewegungsdaten und Indikatorwerte in den Quelldatenpuffer. Es ist zu beachten, dass diese Daten ausreichen, um einen Feedforward-Durchlauf des Planer-Modells durchzuführen. Dieser Vorgang wird zuerst ausgeführt. Danach fahren wir damit fort, den Quelldatenpuffer unseres Akteurs zu füllen. Fügen wir den Kontozustand hinzu
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
und jetzt den Zeitstempel und die letzten Aktionen des Agenten.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action State.AddArray(Actions);
Um den Akteur einen Vorwärtsdurchgang machen zu lassen, brauchen wir nur die Einbettung der Zukunft. Nun, wir haben einen Puffer von Planer-Ergebnissen, aber in diesem Stadium ist das Ergebnis des untrainierten Modells durch nichts bedingt. Nach dem PDT-Algorithmus müssen wir Informationen über nachfolgende Zustände laden und eine Einbettung der empfangenen Daten erzeugen.
//--- Target Result.AssignArray(Buffer[tr].States[state + 1].state); for(int s = 1; s < ValueBars; s++) Result.AddArray(Buffer[tr].States[state + 1].state); if(!FutureEmbedding.feedForward(Result, 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Das Ergebnis der Encoder-Operation wird in das zweite Akteursmodell eingegeben. Als Nächstes rufen wir seinen direkten Durchgang auf.
FutureEmbedding.getResults(Result); //--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Nach dem Vorwärtsdurchlauf durch alle verwendeten Modelle werden diese trainiert. Zunächst rufen wir die Backpropagation-Methode für das Planer-Modell auf (Vorhersage der Zukunft). Diese Sequenz hängt mit der Bereitschaft des Vektors der Zielergebnisse zusammen, den wir gerade in den Akteur eingegeben haben.
//--- Planner Study if(!Planner.backProp(Result, NULL, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Als Nächstes bereiten wir die Zielrenditen unseres Akteurs vor. Dazu verwenden wir Aktionen aus dem Erfahrungswiedergabepuffer, die zu bekannten Konsequenzen führten.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result);
Nachdem wir die Zielwerte vorbereitet haben, führen wir einen Backpropagation-Lauf des Akteurs durch und leiten den Fehlergradienten sofort durch das zukünftige Encoder-Modell.
if(!Agent.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Danach müssen wir den Nutzer nur noch über den Fortschritt der Operationen informieren und zu einer neuen Iteration übergehen.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Planner", iter * 100.0 / (double)(Iterations), Planner.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Wenn alle Iterationen des Schleifensystems abgeschlossen sind, löschen wir das Feld für die Chartkommentare. Anzeige der Trainingsergebnisse im Journal und Einleitung der Beendigung des EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Planner", Planner.getRecentAverageError()); ExpertRemove(); //--- }
Alle anderen EA-Methoden wurden unverändert aus den bereits in anderen Artikeln betrachteten Trainingsexpert Advisors „...\Study.mq5“ übernommen. Deshalb werden wir uns jetzt nicht mit ihnen befassen. Den vollständigen Code des Programms finden Sie in der Anlage. Wir gehen nun zur nächsten Phase unserer Arbeit über.
2.3. Feinabstimmung EA
Nach Abschluss der Implementierung des Pretrainingsalgorithmus arbeiten wir an der Erstellung des Feinabstimmungs-EA „...\PDT\FineTune.mq5“, in dem wir einen Algorithmus für das nachgelagerte Training von Modellen erstellen.
Der Expert Advisor ist zu etwa 90% identisch mit dem vorherigen. Daher werden wir nicht auf alle Methoden im Einzelnen eingehen. Wir werden uns nur die vorgenommenen Änderungen anschauen.
Wie im theoretischen Teil dieses Artikels erwähnt, ermöglicht die PDT-Methode in diesem Stadium die Optimierung von Modellen zur Lösung des Problems. Das bedeutet, dass wir ungekennzeichnete Daten und Umweltprämien nutzen werden, um die Politik unseres Agenten zu optimieren. Daher fügen wir dem Lernprozess ein weiteres externes Belohnungsvorhersagemodell hinzu.
CNet RTG;
Bitte beachten Sie, dass wir nur ein Modell hinzufügen und die Verwendung von Modellen aus dem vorherigen Expert Advisor unverändert lassen.
Im Fine-Tuning Expert Advisor habe ich einen Mechanismus zur Erstellung neuer Modelle des Agenten, des Planers und des Future Encoders belassen, wenn es nicht möglich ist, vortrainierte Modelle zu laden. So können die Nutzer Modelle von Grund auf neu trainieren. Gleichzeitig wird das Laden und ggf. die Initialisierung eines neuen externen Reward-Prognosemodells in der Expert Advisor Initialisierungsmethode in einem separaten Block durchgeführt. Wenn wir vom Pretraining zur Feinabstimmung übergehen, haben wir Modelle, die im vorherigen EA trainiert wurden. Das Belohnungsvorhersagemodell wird mit zufälligen Parametern initialisiert.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- if(!RTG.Load(FileName + "RTG.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *rtg = new CArrayObj(); if(!CreateValueDescriptions(rtg)) { delete rtg; return INIT_FAILED; } if(!RTG.Create(rtg)) { delete rtg; return INIT_FAILED; } delete rtg; //--- } //--- COpenCL *opcl = Agent.GetOpenCL(); Planner.SetOpenCL(opcl); FutureEmbedding.SetOpenCL(opcl); RTG.SetOpenCL(opcl); //--- RTG.getResults(Result); if(Result.Total() != NRewards) { PrintFormat("The scope of the RTG does not match the rewards count (%d <> %d)", NRewards, Result.Total()); return INIT_FAILED; } //--- ........ ........ //--- return(INIT_SUCCEEDED); }
Als Nächstes übertragen wir alle Modelle in einen einzigen OpenCL-Kontext und prüfen, ob die Ergebnisschicht des hinzugefügten Modells mit der Dimension des zerlegten Reward-Vektors übereinstimmt.
Einige Ergänzungen wurden auch bei der Trainingsmethode des Modells Train vorgenommen. Nach dem Vorwärtsdurchgang des Agenten fügen wir einen Aufruf zum Vorwärtsdurchgang des Belohnungsvorhersagemodells hinzu. Wie bereits erwähnt, wird dem Modell ein Vektor zugeführt, der den Kontostand und die zukünftige Einbettung beschreibt.
........ ........ //--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } //--- Return-To-Go Account.AssignArray(Buffer[tr].States[state + 1].account); if(!RTG.feedForward(GetPointer(Account), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } ........ ........
Die Modellparameter werden ebenfalls aktualisiert, nachdem die Parameter des Agenten aktualisiert wurden. Die Algorithmen zur Modelloptimierung sind nahezu identisch. Durch den Aufruf der Backpropagation-Methode des Modells wird der Fehlergradient auf das zukünftige Kodierungsmodell übertragen und dessen Parameter aktualisiert. Der einzige Unterschied liegt in den Zielwerten. Dieser Ansatz ermöglicht es uns, die Abhängigkeit der Handlungen des Agenten und der erhaltenen externen Belohnung von der zukünftigen Einbettung zu trainieren.
........ ........ //--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } //--- Return To Go study vector<float> target; target.Assign(Buffer[tr].States[state + 1].rewards); result.Assign(Buffer[tr].States[state + ValueBars].rewards); target = target - result * MathPow(DiscFactor, ValueBars); Result.AssignArray(target); if(!RTG.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } ........ ........
Damit sind unsere lokalen Änderungen abgeschlossen. Der vollständige Code des EA und alle im Artikel verwendeten Programme sind im Anhang verfügbar.
2.4. Expert Advisor zum Testen trainierter Modelle
Nach dem Training der Modelle in den oben beschriebenen Expert Advisors müssen wir die Leistung der resultierenden Modelle mit historischen Daten testen, die nicht im Trainingsdatensatz enthalten sind. Um diese Funktionalität zu implementieren, erstellen wir einen neuen Expert Advisor „...\PDT\Test.mq5“. Im Gegensatz zu den oben beschriebenen EAs, bei denen die Modelle offline trainiert wurden, interagiert der Test-EA online mit der Umgebung. Dies spiegelt sich auch in der Konstruktion des Algorithmus wider.
In der Initialisierungsmethode OnInit EA werden zunächst die Objekte der analysierten Indikatoren initialisiert.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(NBarInPattern) || !CCI.BufferResize(NBarInPattern) || !ATR.BufferResize(NBarInPattern) || !MACD.BufferResize(NBarInPattern)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
Erstellen eines Objekts für Handelsoperationen.
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
Laden der trainierten Modelle. Hier verwenden wir nur 2 Modelle: Akteur und Planer. Im Gegensatz zu früheren EAs führt ein Fehler beim Laden von Modellen zur Unterbrechung des EAs. Denn wir haben keine Online-Modelltraining darin implementiert.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Planner.Load(FileName + "Pln.nnw", temp, temp, temp, dtStudied, true)) { PrintFormat("Can't load pretrained model"); return INIT_FAILED; }
Nach dem erfolgreichen Laden der Modelle übertragen wir sie in einen einzigen OpenCL-Kontext und führen die minimal notwendige Architekturkontrolle durch.
Planner.SetOpenCL(Agent.GetOpenCL()); Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the Actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Agent.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } Agent.Clear();
Am Ende der Methode initialisieren wir die Variablen mit Anfangswerten.
AgentResult = vector<float>::Zeros(NActions); PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
Der Prozess der Interaktion mit der Umgebung ist in der Tick-Verarbeitungsmethode OnTick implementiert. Im Hauptteil der Methode wird zunächst geprüft, ob ein neues Ereignis zur Öffnung eines Taktes eingetreten ist. Das liegt daran, dass alle unsere Modelle geschlossene Kerzen analysieren und Handelsoperationen bei der Eröffnung einer neuen Kerze ausführen.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Als Nächstes fordern wir vom Terminal die erforderlichen Daten für die analysierte Verlaufstiefe an. Mit der Tiefe der Handelshistorie meine ich in diesem Fall die Größe eines Musters, in unserem Fall eines Balkens. Die Tiefe der vom Agenten analysierten Handelshistorie ist in seinem latenten Zustand in Form von Einbettungen enthalten und wird nicht bei jedem Takt neu verarbeitet.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Als Nächstes müssen wir die empfangenen Daten in einen Puffer übertragen, um sie an das Modell weiterzuleiten.
//--- History data float atr = 0; for(int b = 0; b < NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Die empfangenen historischen Daten reichen aus, um einen Feedforward-Durchlauf des Planers durchzuführen.
if(!Planner.feedForward(GetPointer(bState), 1, false)) return;
Damit der Agent jedoch in vollem Umfang funktionieren kann, benötigen wir zusätzliche Daten. Zunächst fügen wir dem Puffer Informationen über den Kontostand hinzu, die wir zunächst vom Terminal abfragen.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Als Nächstes fügen wir einen Zeitstempel und die letzten Aktionen des Agenten hinzu.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(AgentResult);
In einem separaten Puffer erhalten wir die Ergebnisse des zuvor durchgeführten Vorwärtsdurchgangs des Planers und rufen die Vorwärtsdurchgangsmethode des Agenten auf.
//--- Return to go Planner.getResults(Result); //--- if(!Agent.feedForward(GetPointer(bState), 1, false, Result)) return;
Dann aktualisieren wir die Variablen, die für die Operationen im nächsten Balken erforderlich sind.
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Die erste Phase der ersten Datenanalyse ist abgeschlossen. Kommen wir nun zur Phase der Interaktion mit der Umwelt. Hier erhalten wir die Ergebnisse des Feed-Forward-Passes des Agenten und entschlüsseln sie in einen Vektor der kommenden Operationen. Wie üblich schließen wir Überschneidungen aus und belassen die Differenz in der Richtung der wahrscheinlicheren Bewegung.
vector<float> temp; Agent.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp;
Dann passen wir unsere Position auf dem Markt entsprechend den Prognosewerten an. Zunächst passen wir unsere Long-Position an.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Dann wiederholen wir die Vorgänge für die andere Richtung.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Wir stellen eine Struktur auf der Grundlage der Ergebnisse der Interaktion mit der Umwelt zusammen und speichern sie in einer Trajektorie, die später dem Erfahrungswiedergabepuffer für die anschließende Optimierung der Modellpolitik hinzugefügt wird.
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
Damit ist unsere Arbeit zur Implementierung der Pretrained Decision Transformer-Methode mit MQL5 abgeschlossen. Den vollständigen Code aller verwendeten Programme finden Sie im Anhang.
3. Tests
Nach Abschluss der Implementierung der betrachteten Methode müssen wir das Modell trainieren und seine Leistung anhand historischer Daten testen. Wie üblich verwenden wir eines der volatilsten Instrumente EURUSD und den H1-Zeitrahmen zum Trainieren und Testen der Modelle. Die Modelle werden mit historischen Daten für die ersten 7 Monate des Jahres 2023 trainiert. Um die Leistung der trainierten Modelle zu testen, habe ich historische Daten vom August 2023 verwendet.
Bevor wir mit dem vorläufigen Modelltraining beginnen, müssen wir einen Trainingsdatensatz sammeln. Wie bereits erwähnt, verwenden wir hier den Trainingsdatensatz aus dem vorherigen Artikel. Weitere Einzelheiten können Sie darin nachlesen. Ich habe eine Kopie der Trainingsdatendatei erstellt und sie als „PDT.bd“ gespeichert.
Danach habe ich den Pretraining EA in Echtzeit gestartet.
Ich möchte Sie daran erinnern, dass alle Modell-Trainings-EAs auf Online-Charts laufen. Der gesamte Lernprozess findet jedoch offline statt, ohne dass Handelsoperationen durchgeführt werden.
Bitte beachten Sie, dass Sie in dieser Phase Geduld haben müssen. Der Prozess des Pretrainings ist recht zeitaufwändig. Ich habe den Computer mehr als einen Tag lang laufen lassen.
Als Nächstes geht es an die Feinabstimmung. Hier sprechen die Autoren der Methode über Online-Lernen. Ich habe ein kurzes Downstream-Training mit dem Testen des Trainingsintervalls im Strategie-Tester abgewechselt. Doch zunächst mussten wir das Modell mit dem zuvor gesammelten Trainingsdatensatz „aufwärmen“.
Für die Feinabstimmung benötigte ich mehrere Dutzend aufeinanderfolgende Iterationen des nachgelagerten Trainings und Testens, was ebenfalls Zeit und Mühe erforderte.
Die Lernergebnisse waren jedoch nicht so vielversprechend. Als Ergebnis des Trainings habe ich ein Modell erhalten, das mit unterschiedlichem Erfolg mit einer Mindestmenge handelt. In einigen Abschnitten der Handelshistorie zeigte die Saldenlinie einen klaren Aufwärtstrend. Bei anderen war es ein deutlicher Rückgang. Im Allgemeinen lagen die Modellergebnisse sowohl bei den Trainingsdaten als auch bei einem neuen Datensatz nahe bei 0.
Zu den positiven Aspekten gehört die Fähigkeit des Modells, die gewonnenen Erfahrungen auf neue Daten zu übertragen, was durch die Vergleichbarkeit der Testergebnisse auf dem historischen Datensatz des Trainingssatzes und auf dem folgenden Historienintervall bestätigt wird. Außerdem können Sie sehen, dass der Umfang eines gewinnbringenden Handels erheblich größer ist als der eines Verlusthandels. In beiden historischen Datensegmenten ist zu beobachten, dass die Höhe des durchschnittlichen Gewinns den maximalen Verlust übersteigt. Allen positiven Aspekten steht jedoch der geringe Anteil profitabler Handelsgeschäfte gegenüber, der in beiden historischen Zeiträumen bei knapp 40 % liegt.


Beim Test des Modells mit historischen Daten für August 2023 (neue Daten) führte das Modell 18 Handelsgeschäfte aus. Nur 39 % von ihnen wurden mit Gewinn abgeschlossen. Gleichzeitig lag der maximale Gewinn bei 11,26, was fast dreimal so hoch ist wie der maximale Verlust von 4,76. Der durchschnittliche Gewinn lag bei 5,15, der durchschnittliche Verlust bei 3,19. Der Gewinnfaktor für den Testzeitraum betrug 1,03.
Um den Anteil der gewinnbringenden Geschäfte zu erhöhen, müssen wir natürlich die erzielten Ergebnisse zusätzlich analysieren und das Modell feinabstimmen. Die Methode hat Potenzial, erfordert aber eine lange Einarbeitungszeit des Modells.
Schlussfolgerung
In diesem Artikel haben wir die Pretrained Decision Transformer (PDT) Methode vorgestellt, die einen unbeaufsichtigten Pretraining-Algorithmus für Decision Transformer Reinforcement Learning bietet. Basierend auf der Kenntnis zukünftiger Zustände während des Modelltrainings ist PDT in der Lage, umfangreiches Vorwissen aus Trainingsdaten zu extrahieren. Dieses Wissen kann während des Downstream-Trainings des Modells weiter verfeinert und angepasst werden, da PDT jede zukünftige Chance mit einer entsprechenden Rendite verknüpft und diejenige mit der höchsten vorhergesagten Rendite auswählt. Das hilft dabei, optimale Entscheidungen zu treffen.
Die PDT erfordert jedoch im Vergleich zu den zuvor diskutierten DT und ODT mehr Trainingszeit und Rechenressourcen, was aufgrund der begrenzten verfügbaren Ressourcen zu praktischen Schwierigkeiten führen kann. Darüber hinaus führt das Ziel, Modelle zu trainieren, zu einem Zielkonflikt zwischen der Vielfalt der zu lernenden Verhaltensweisen und ihrer Konsistenz. Praktische Experimente der Autoren der Methode zeigen, dass der optimale Wert von dem jeweiligen Datensatz abhängt. Außerdem können zusätzliche Techniken angewandt werden, um die Kodierung zukünftiger Zustände zu verbessern.
Ich kann den Schlussfolgerungen der Autoren der Methode nur zustimmen. Unsere praktischen Erfahrungen bestätigen sie voll und ganz. Das Trainings von Modellen ist ein recht zeit- und arbeitsintensiver Prozess. Um die größtmögliche Vielfalt an Agentenfähigkeiten zu entwickeln, benötigen wir einen ziemlich großen Trainingsdatensatz. Natürlich verwenden wir für das Pretraining ungekennzeichnete Daten, was den Prozess der Datenerfassung erleichtert. Es stellt sich jedoch die Frage nach der Verfügbarkeit von Ressourcen für die Sammlung und Verarbeitung von Daten und das Training der Modelle.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Faza1.mq5 | EA | Beispielsammlung EA |
| 2 | Pretrain.mq5 | EA | Pretraining Expert Advisor |
| 3 | FineTune.mq5 | EA | Feinabstimmung EA |
| 4 | Test.mq5 | EA | Modeltraining-EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13712
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.