
Redes neuronales: así de sencillo (Parte 63): Entrenamiento previo del Transformador de decisiones no supervisado (PDT)

Introducción
El Decision Transformer es una herramienta muy potente para resolver diversos problemas prácticos, y gran parte de esto se logra usando las técnicas de atención del Transformer. La experiencia de trabajos anteriores ha demostrado que el uso de la arquitectura del Transformer también requiere un entrenamiento largo y exhaustivo del modelo. Al hacerlo, nos enfrentamos al problema de preparar los datos de entrenamiento marcados. Al resolver problemas prácticos, a veces resulta bastante difícil obtener recompensas. Y los datos marcados no se escalan bien para ampliar la muestra de entrenamiento. No obstante, evitar las recompensas durante el entrenamiento previo también permite al modelo adquirir patrones generales de comportamiento que pueden adaptarse fácilmente para su uso en diversas tareas posteriores.
En este artículo, veremos un método de entrenamiento previo RL llamado Pretrained Decision Transformer (PDT), introducido en el artículo "Future-conditioned Unsupervised Pretraining for Decision Transformer" (mayo de 2023). Este método proporciona al DT la capacidad de entrenarse con datos sin etiquetas de recompensa y utilizando datos subóptimos. En concreto, los autores del método consideran un escenario de entrenamiento previo en el que el modelo se entrena primero offline con trayectorias recogidas previamente sin etiquetas de recompensa, y luego se ajusta a la tarea objetivo usando la interacción online.
Para que el entrenamiento previo sea eficaz, el modelo deberá ser capaz de extraer señales de entrenamiento polifacéticas y universales en ausencia de recompensas. Durante el entrenamiento previo, el modelo deberá adaptarse rápidamente a la tarea de recompensa determinando qué señales de entrenamiento pueden asociarse a recompensas.
El PDT explora el espacio de incorporación de la trayectoria futura y la probabilidad futura a priori condicionada únicamente por la información pasada. Entrenado para predecir acciones encaminadas a lograr un objetivo de inversión futura, el PDT está dotado de la capacidad de "razonar sobre el futuro". Esta capacidad es independiente de la tarea y podrá generalizarse a diferentes aplicaciones.
Para lograr un entrenamiento previo online eficaz en tareas posteriores, el marco se adaptará fácilmente a las nuevas condiciones asociando cada inversión futura con su rentabilidad, lo que se logrará entrenando una red para predecir la recompensa esperada de cada inversión objetivo.
Le proponemos pasar a la siguiente sección de nuestro artículo y familiarizarnos con el método Pretrained Decision Transformer.
1. El método Pretrained Decision Transformer
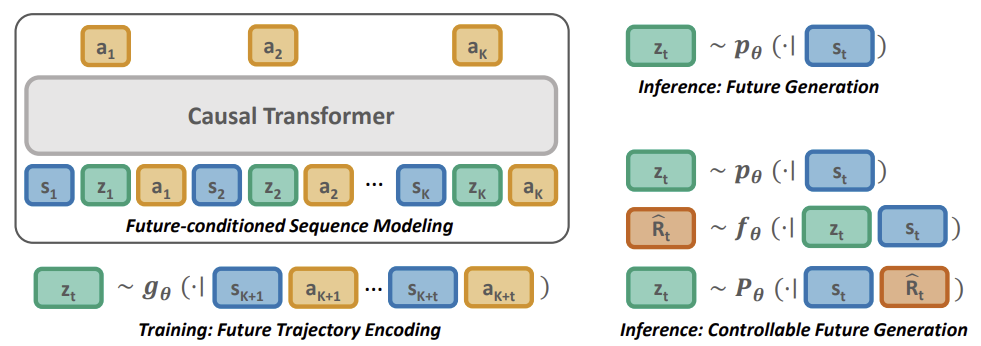
El método PDT se basa en los principios del DT. También predice las acciones del Agente tras analizar la secuencia de estados visitados y las acciones realizadas. Al mismo tiempo, el PDT introduce adiciones al algoritmo DT que permiten preentrenar el modelo con datos no marcados, es decir, sin análisis de recompensa. Esto parece imposible, porque la recompensa futura esperada (Return To Go) supone uno de los miembros de la secuencia analizada por el modelo y sirve como una especie de brújula para orientar el modelo en el espacio.
Los autores del método PDT propusieron sustituir el RTG por algún vector de estado latente Z. Esta idea no resulta nueva, pero los autores le han dado una interpretación bastante interesante. Durante el entrenamiento previo, entrenaremos 3 modelos con datos sin etiquetar:
- El Actor, que es esencialmente un DT clásico con predicción de acciones basada en el análisis de la trayectoria previa;
- El modelo de predicción de objetivos P(•|St) - realiza la predicción de los objetivos de DT (estado latente Z) basándose en el análisis del estado actual;
- El modelo codificador del futuro G(•|τt+1:t+k) - "mira hacia el futuro" y lo incorpora como un vector de estado latente Z.
Obsérvese que los 2 últimos modelos analizan datos diferentes, pero ambos retornan el vector de estado latente Z. De este modo, se construirá una especie de autocodificador entre estados actuales y futuros. Y su estado latente se utilizará como objetivo para el DT (Actor).
No obstante, el entrenamiento del modelo será diferente del proceso de entrenamiento del autocodificador. Primero entrenaremos al codificador de futuro y al Actor, construyendo dependencias entre la trayectoria futura y las acciones realizadas. Permitiremos que el PDT mire al futuro con cierto horizonte de planificación. Luego comprimiremos la información de la trayectoria descendente hasta un estado latente. De este modo, permitiremos que el modelo tome una decisión basándose en la información disponible sobre el futuro. Así, esperaremos crear una política de Actor con una amplia gama de habilidades de comportamiento, sin restricciones por las recompensas del entorno en el proceso de entrenamiento previo.
Y después entrenaremos un modelo de predicción de objetivos que busque dependencias entre el estado actual y la incorporación aprendida de la trayectoria futura.
Este planteamiento nos permitirá desvincular las recompensas de los resultados previstos, lo cual nos ofrecerá oportunidades de realizar un entrenamiento previo continuo a gran escala. Al hacerlo, reduciremos el problema del comportamiento incoherente, en el que el comportamiento del Agente se desvía significativamente de los objetivos deseados.
Aunque el uso el modelo de predicción de objetivos P(Z|St) resulta útil para muestrear futuras variables latentes y generar comportamientos que imiten la distribución de la muestra de entrenamiento, este no codifica ninguna información específica de la tarea. Por consiguiente, deberemos dirigir P(Z|St) para muestrear incorporaciones futuras que conduzcan a recompensas futuras altas durante el entrenamiento previo.
Esto conllevará la creación de comportamientos expertos para los DT condicionados a maximizar la recompensa. A diferencia de las políticas de control condicionadas a maximizar el resultado asignando una recompensa objetivo escalar, necesitaremos ajustar la distribución del modelo de predicción objetivo P(Z|St). Como esta distribución es desconocida, utilizaremos un modelo adicional de predicción de la recompensa F(•|Z, St) para predecir la trayectoria óptima. El modelo de predicción de recompensa se entrenará junto con todos los demás durante el entrenamiento previo.
De manera similar al entrenamiento previo para la recuperación del estado latente, utilizaremos un codificador de futuro, que permitirá que los gradientes se propaguen hacia atrás ajustando la codificación de la información de la recompensa en la representación latente. Esto permitirá abordar los aspectos específicos de la tarea en cuestión durante el proceso de entrenamiento previo.
A continuación veremos una visualización del método Pretrained Decision Transformer del artículo original.
2. Implementación con los recursos de MQL5
Tras considerar los aspectos teóricos del método Pretrained Decision Transformer, pasaremos a la parte práctica de nuestro artículo y analizaremos una variante de la implementación del método utilizando MQL5. Y permítanme decir de inmediato que en este artículo nos centraremos en el asesor de recopilación de muestras de entrenamiento. En artículos anteriores, hemos analizado varias opciones para construir algoritmos de la familia del Decision Transformer. Todos ellos contienen una composición similar del búfer de reproducción de la experiencias. Y para la recogida inicial de la muestra de entrenamiento, podremos utilizarlas. En el presente artículo, utilizaremos el búfer de reproducción de experiencias montado en el artículo anterior. Permítanme recordarles que la hemos realizado la recopilación mediante el muestreo aleatorio de acciones sin vincularlas a un modelo concreto (método Go-Explore).
2.1. Descripción de la arquitectura del modelo
Como ya tenemos un conjunto de datos de entrenamiento, procederemos al siguiente paso, el entrenamiento previo no supervisado. Como ya hemos mencionado, en esta fase entrenaremos 3 modelos. Y comenzaremos nuestro trabajo describiendo la arquitectura de los modelos, que se recoge en el método CreateDescriptions.
bool CreateDescriptions(CArrayObj *agent, CArrayObj *planner, CArrayObj *future_embedding) { //--- CLayerDescription *descr;
En los parámetros, el método obtendrá los punteros a 3 arrays dinámicos a los que se añadirán las descripciones de la arquitectura de las capas neuronales de los modelos.
En el cuerpo del método, declararemos una variable local para registrar el puntero a un único objeto de descripción de la capa neuronal. En él "mantendremos" el puntero al objeto con el que estamos trabajando en un bloque aparte.
Comenzaremos nuestro trabajo describiendo la arquitectura de nuestro Agente. Permítanme recordarles que en este caso su papel lo desempeñará el Decision Transformer. Este tomará como entrada una descripción paso a paso de la trayectoria y acumulará las incorporaciones de toda la secuencia en el búfer de resultados de la capa de incorporación. Pero a diferencia del artículo anterior, durante la pasada inversa, tendremos que pasar el gradiente de error al modelo de codificador de futuro. Para ello, complicaremos un poco la situación. Dividiremos el array de datos de origen al completo en 2 flujos. Como de costumbre, transferiremos el grueso de los datos al modelo a través del búfer de la capa de datos de origen. Y transmitiremos la incorporación de futuro al segundo flujo para su fusión en la capa de concatenación. Los datos de origen sin procesar que introduzcamos en el búfer de la capa de datos de origen se normalizarán usando la capa de normalización por lotes. En cambio, la incorporación futura será el resultado del modelo y podrá utilizarse sin normalización.
//--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = prev_count + EmbeddingSize; descr.step = EmbeddingSize; descr.optimization = ADAM; descr.activation = None; if(!agent.Add(descr)) { delete descr; return false; }
Suministraremos la capa de incorporación neuronal de la información presentada con los datos recopilados en un único flujo.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, EmbeddingSize}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
A continuación, los datos se transmitirán a la unidad del Transformador. Hemos utilizado un "pastel" de 4 capas con 16 cabezas Self-Attention.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 16; descr.window_out = 64; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Después del bloque del Transformador, hemos usado 2 capas de convolución para identificar patrones coherentes.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 16; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
Le siguen las 3 capas totalmente conectadas del bloque de decisión.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Y a la salida del modelo obtendremos una capa totalmente conectada con un número de elementos igual al espacio de acciones del Agente.
A continuación, crearemos una descripción del modelo de predicción de objetivos P(Z|St). Usando la terminología de los modelos jerárquicos, podremos llamarlo con el Planificador. Después de todo, estructuralmente su funcionalidad resulta muy similar, aunque los enfoques para entrenar los modelos difieren drásticamente.
En la capa de datos inicial del modelo solo describiremos los datos históricos y los valores de los indicadores de un patrón. En nuestro caso, se tratará de los datos de una sola barra.
Estoy de acuerdo en que es muy poca información para analizar la situación del mercado y predecir estados y acciones posteriores, sobre todo unos pasos por delante. Pero veamos la situación de otra forma. Durante la explotación, suministraremos la previsión de futuro generada como incorporación a la entrada de nuestro Actor, cuyas capas internas contendrán información a una profundidad determinada de la historia. Y en ese contexto, resultará más pertinente que prestemos atención a los cambios que se han producido y que corrijamos el comportamiento del Actor. Un análisis más profundo de la historia al trazar la incorporación del futuro tiene el potencial de "difuminar" los cambios localizados. No obstante, esta es mi opinión subjetiva y no supone un requisito del algoritmo Pretrained Decision Transformer.
if(!planner) { planner = new CArrayObj(); if(!planner) return false; } //--- Planner planner.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = BarDescr * NBarInPattern; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
Los datos de origen resultantes los pasaremos por una capa de normalización por lotes para que resulten comparables.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
A continuación, no complicaremos demasiado el modelo y pondremos un bloque de decisión de 3 capas totalmente conectadas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
En la salida del modelo, reduciremos la escala del vector al tamaño de incorporación y normalizaremos los resultados con la función SoftMax.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
Ya hemos descrito la arquitectura de los 2 modelos. Solo nos queda añadir una descripción del codificador de futuro. Aunque en principio la salida del modelo implica coherencia con la salida del modelo anterior, esto solo resultará evidente en las últimas capas del modelo. La propia arquitectura del codificador es un poco más compleja. En primer lugar, al integrar el futuro, incluiremos la planificación de cierta profundidad. Lo cual significa que suministraremos a la capa de datos de origen información sobre varias velas posteriores.
Aquí debemos decir que en la información sobre el futuro solo hemos incluido los datos sobre el movimiento de los precios de los instrumentos e indicadores. No hemos incluido información sobre el estado de la cuenta y los próximos pasos del agente. Las acciones del Agente estarán sujetas a sus políticas. Y querríamos hacer hincapié en la comprensión de los procesos del entorno. Pero los estados de la cuenta ya contienen en cierta medida información sobre la recompensa recibida del entorno, lo cual es algo contrario al principio de los datos no marcados.
//--- Future Embedding if(!future_embedding) { future_embedding = new CArrayObj(); if(!future_embedding) return false; } //--- future_embedding.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = BarDescr * NBarInPattern * ValueBars; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
Como antes, transmitiremos los datos de origen sin preprocesar usando una capa de normalización por lotes para ponerlos en un formato comparable.
A continuación, utilizaremos un bloque del Transformador de 4 capas y 16 cabezas Self-Attention. En este caso, la unidad de atención analiza las dependencias entre barras individuales en un intento de identificar las principales tendencias a lo largo del horizonte de planificación y de descartar el componente de ruido.
Según la lógica del método PDT, es la incorporación del estado futuro lo que deberá indicar al Actor la habilidad que se está utilizando y la dirección de la acción posterior. Por lo tanto, la salida del codificador deberá ser lo más informativa y precisa posible.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = ValueBars; descr.window = BarDescr * NBarInPattern; descr.step = 16; descr.window_out = 64; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
Las capas de atención irán seguidas de las capas totalmente conectadas de la unidad de decisión.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
Y en la salida del modelo, utilizaremos una capa totalmente conectada con normalización usando la función SoftMax, como hemos hecho antes en el modelo de predicción de futuro.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- return true; }
Con esto concluiremos nuestra descripción de la arquitectura del modelo para el asesor de entrenamiento previo. Pero antes de pasar a trabajar en el propio asesor, querríamos completar el trabajo iniciado sobre la descripción de la arquitectura de los modelos. Queremos recordarles que la fase de ajuste del método PDT implica la adición de otro modelo: la predicción de recompensas. Y puesto que se añade en una etapa posterior del entrenamiento, hemos decidido poner la descripción de su arquitectura en un método CreateValueDescriptions aparte.
Según la metodología PDT, este modelo deberá estimar las tendencias futuras codificadas en el estado latente y el estado actual. Partiendo de los resultados del análisis, habrá que predecir la recompensa del entorno.
Por otra parte, el objetivo del proceso de entrenamiento previo del modelo es incorporar información sobre las recompensas probables en la incorporación de la futura. Por consiguiente, al igual que en la fase de entrenamiento previo, necesitaremos transmitir el gradiente de error de predicción de la recompensa al modelo del codificador de futuro. Y aquí utilizaremos el enfoque de separación del flujos de información probado anteriormente. Con un flujo de datos de entrada tendremos el estado actual, mientras que el segundo supondrá la incorporación del futuro.
La segunda cuestión que debemos abordar ahora es qué incluiremos en la comprensión del estado actual en esta fase. Por supuesto, en la fase de ajuste usaremos los datos marcados de la muestra de entrenamiento y podríamos haber incluido toda la información disponible. Pero la gran cantidad de datos de entrada complicará mucho el modelo y aumentará el coste de procesarlos. ¿Y cuál será la eficacia de utilizar esta cantidad de datos en la fase actual?
Analizar los estados antecedentes del entorno será necesario para predecir sus estados posteriores. Sin embargo, ya tenemos información sobre los estados futuros en forma de incorporación.
El análisis de las acciones anteriores del Agente puede indicar la política en uso, pero necesitaremos ofrecer información al Agente para que decida si es necesario cambiar la política de habilidades y comportamientos utilizada.
Pero la información sobre el estado actual de la cuenta puede ser útil. La presencia de margen libre nos indicará la posibilidad de abrir posiciones adicionales si existen tendencias favorables. O puede que se prevea un cambio de tendencia y haya que cerrar posiciones abiertas anteriormente fijando las ganancias y pérdidas acumuladas. Además, no deberemos olvidar las penalizaciones por no tener posiciones abiertas, que también afectarán a la recompensa.
Así, introduciremos la descripción actual del estado de la cuenta y las posiciones abiertas en la capa de datos de entrada.
bool CreateValueDescriptions(CArrayObj *value) { //--- CLayerDescription *descr; //--- if(!value) { value = new CArrayObj(); if(!value) return false; } //--- Value value.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
Los datos resultantes pasarán por una capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
Y además combinaremos los 2 flujos de información en la capa de concatenación.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.step = EmbeddingSize; descr.optimization = ADAM; descr.activation = SIGMOID; if(!value.Add(descr)) { delete descr; return false; }
A continuación, la información se introducirá en la unidad de toma de decisiones desde las capas totalmente conectadas.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- return true; }
Y en la salida del modelo, obtendremos el vector de recompensas esperadas.
2.2. Asesor de entrenamiento previo
Tras crear la arquitectura de los modelos utilizados, comenzaremos con la implementación directa del algoritmo del método PDT. Y, por supuesto, empezaremos con el asesor de entrenamiento previo "...\PDT\Pretrain.mq5". Como ya hemos mencionado, este asesor estará previamente entrenado con 3 modelos: Actor, planificador y codificador de futuro.
CNet Agent; CNet Planner; CNet FutureEmbedding;
En el método de inicialización del asesor, primero cargaremos la muestra de entrenamiento.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Intentaremos cargar los modelos preentrenados y, si es necesario, inicializaremos nuevos modelos según la arquitectura anterior.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Planner.Load(FileName + "Pln.nnw", temp, temp, temp, dtStudied, true) || !FutureEmbedding.Load(FileName + "FEm.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *agent = new CArrayObj(); CArrayObj *planner = new CArrayObj(); CArrayObj *future_embedding = new CArrayObj(); if(!CreateDescriptions(agent, planner, future_embedding)) { delete agent; delete planner; delete future_embedding; return INIT_FAILED; } if(!Agent.Create(agent) || !Planner.Create(planner) || !FutureEmbedding.Create(future_embedding)) { delete agent; delete planner; delete future_embedding; return INIT_FAILED; } delete agent; delete planner; delete future_embedding; //--- }
Después moveremos todos los modelos a un contexto OpenCL.
//---
COpenCL *opcl = Agent.GetOpenCL();
Planner.SetOpenCL(opcl);
FutureEmbedding.SetOpenCL(opcl); Aquí también realizaremos un control mínimo de la arquitectura de los modelos.
Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the worker does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
Y pondremos en marcha el inicio del proceso de entrenamiento previo, que se implementará en el método Train.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
En el método de desinicialización del asesor, guardaremos necesariamente los modelos entrenados.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Agent.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); Planner.Save(FileName + "Pln.nnw", 0, 0, 0, TimeCurrent(), true); FutureEmbedding.Save(FileName + "FEm.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
El proceso de entrenamiento del modelo se realizará mediante el método Train. En el cuerpo del método, primero definiremos el tamaño del búfer de reproducción de experiencias.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Y luego organizaremos sistemas de ciclos anidados de entrenamiento de modelos. El ciclo externo estará limitado al número de iteraciones de entrenamiento especificado en el parámetro externo del asesor. En el cuerpo de este ciclo, primero muestrearemos una trayectoria del búfer de reproducción de experiencias y un estado de entorno independiente en la trayectoria seleccionada para iniciar el proceso de aprendizaje.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars - ValueBars, MathMin(Buffer[tr].Total, 20 + ValueBars))); if(i < 0) { iter--; continue; }
A continuación, organizaremos un ciclo anidado para entrenar secuencialmente el modelo DT.
Actions = vector<float>::Zeros(NActions); for(int state = i; state < MathMin(Buffer[tr].Total - ValueBars, i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state); if(!Planner.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
En el cuerpo del ciclo escribiremos los datos históricos sobre los movimientos de precios e indicadores en el búfer de datos de origen. Y aquí cabe destacar que estos datos ya serán suficientes para realizar una pasada directa del modelo de predicción (Planificador). Esta operación es la primera que realizaremos. Después continuaremos rellenando el búfer de datos inicial para nuestro Actor. Añadiremos el estado de la cuenta.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
La marca de tiempo y las acciones recientes del Agente.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action State.AddArray(Actions);
Ahora, lo único que nos faltará para realizar una pasada directa del Actor será una incorporación de futuro. Tenemos, por supuesto, el búfer de resultados del Planificador, pero en esta fase el resultado del modelo no entrenado no estará dirigido por nada. Según el algoritmo PDT, necesitaremos descargar la información sobre los estados posteriores y generar la incorporación de los datos obtenidos.
//--- Target Result.AssignArray(Buffer[tr].States[state + 1].state); for(int s = 1; s < ValueBars; s++) Result.AddArray(Buffer[tr].States[state + 1].state); if(!FutureEmbedding.feedForward(Result, 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Luego suministraremos el resultado del codificador a la entrada 2 del modelo del Actor y llamaremos su pasada directa.
FutureEmbedding.getResults(Result); //--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Tras realizar una pasada directa de todos los modelos utilizados, procederemos a entrenarlos. Y el primer método de pasada inversa que llamaremos será para el modelo del Planificador (predicción del futuro). Esta secuencia viene dictada por la disponibilidad del vector de resultados objetivo que acabamos de introducir en la entrada del Actor.
//--- Planner Study if(!Planner.backProp(Result, NULL, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
A continuación, comenzaremos a preparar los resultados previstos de nuestro Actor. Para ello, utilizaremos las acciones del búfer de reproducción de experiencias que han conducido a las consecuencias conocidas.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result);
Después de preparar los valores objetivo, realizaremos una pasada inversa del Actor e inmediatamente ejecutaremos el gradiente de error a través del modelo del codificador de futuro.
if(!Agent.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Después, bastará con informar al usuario sobre el progreso de las operaciones y pasar a una nueva iteración.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Planner", iter * 100.0 / (double)(Iterations), Planner.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Una vez completadas todas las iteraciones del sistema de ciclos, borraremos el campo de comentarios del gráfico. Luego enviaremos los resultados del entrenamiento al registro e inicializaremos el proceso de finalización del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Planner", Planner.getRecentAverageError()); ExpertRemove(); //--- }
Todos los demás métodos del asesor se transferirán sin cambios desde los asesores de entrenamiento "...\Study.mq5" discutidos en los artículos anteriores. No nos detendremos en ellos ahora. Podrá leer usted mismo el código completo del programa en el archivo adjunto. Vamos a pasar a la siguiente fase de nuestro trabajo.
2.3. Ajuste del asesor
Tras completar la implementación del algoritmo de entrenamiento previo, comenzaremos a trabajar en la creación del asesor de ajuste fino "...\PDT\FineTune.mq5", en el que construiremos un algoritmo para el entrenamiento previo de modelos.
Permítanme decir de inmediato que el asesor es aproximadamente un 90% igual al anterior, así que no analizaremos en profundidad sus métodos. Nos detendremos únicamente en los cambios que se han producido.
Como ya hemos mencionado en la parte teórica de este artículo, el método PDT prevé en esta fase la optimización de los modelos para solucionar el problema planteado. Esto significa que utilizaremos datos marcados y recompensas del entorno para optimizar las políticas de nuestro Agente. Para ello, añadiremos al proceso de entrenamiento otro modelo de predicción de la recompensa externa.
CNet RTG;
Y aquí añadiremos exactamente un modelo, dejando sin cambios el uso de modelos del asesor anterior.
Tenga en cuenta que hemos dejado en el asesor de ajuste fino el mecanismo para crear nuevos modelos del Agente, el Planificador y el codificador de futuro cuando no se pueden cargar los modelos preentrenados. De este modo, el usuario podrá entrenar modelos desde cero. En ese momento, la carga y, si fuera necesario, la inicialización de un nuevo modelo de previsión de la recompensa externa en el método de inicialización asesor se colocarán en un bloque aparte. Al fin y al cabo, cuando pasemos del entrenamiento previo al ajuste fino, dispondremos de los patrones entrenados en el asesor anterior, mientras que el modelo de predicción de la recompensa lo inicializaremos con parámetros aleatorios.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- if(!RTG.Load(FileName + "RTG.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *rtg = new CArrayObj(); if(!CreateValueDescriptions(rtg)) { delete rtg; return INIT_FAILED; } if(!RTG.Create(rtg)) { delete rtg; return INIT_FAILED; } delete rtg; //--- } //--- COpenCL *opcl = Agent.GetOpenCL(); Planner.SetOpenCL(opcl); FutureEmbedding.SetOpenCL(opcl); RTG.SetOpenCL(opcl); //--- RTG.getResults(Result); if(Result.Total() != NRewards) { PrintFormat("The scope of the RTG does not match the rewards count (%d <> %d)", NRewards, Result.Total()); return INIT_FAILED; } //--- ........ ........ //--- return(INIT_SUCCEEDED); }
También tranferiremos todos los modelos a un único contexto OpenCL y verificaremos que la capa resultante del modelo añadido coincida con la dimensionalidad del vector de recompensa descompuesto.
Asimismo, hemos realizado adiciones puntuales al método de entrenamiento del modelo Train. Después de la pasada directa del Agente, hemos agregado una llamada a la pasada directa del modelo de predicción de la recompensa. Como ya hemos comentado, suministraremos a la entrada del modelo un vector de descripción del estado de la cuenta y de incorporación de futuro.
........ ........ //--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } //--- Return-To-Go Account.AssignArray(Buffer[tr].States[state + 1].account); if(!RTG.feedForward(GetPointer(Account), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } ........ ........
Los parámetros del modelo se actualizarán de la misma manera tras la actualización de los parámetros del Agente. Al mismo tiempo, el algoritmo de optimización de los modelos será casi idéntico. Al invocar el método de pasada inversa del modelo, realizaremos una transferencia del gradiente de error al futuro modelo de codificación, seguida de una actualización de sus parámetros. La única diferencia serán los valores objetivo. Este enfoque nos permitirá entrenar la dependencia de las acciones del Agente y la recompensa externa resultante en la incorporación de futuro.
........ ........ //--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } //--- Return To Go study vector<float> target; target.Assign(Buffer[tr].States[state + 1].rewards); result.Assign(Buffer[tr].States[state + ValueBars].rewards); target = target - result * MathPow(DiscFactor, ValueBars); Result.AssignArray(target); if(!RTG.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } ........ ........
Con esto concluiremos nuestros cambios puntuales. En el archivo adjunto encontrará el código completo del asesor, así como todos los programas utilizados en el artículo.
2.4. Asesor para probar los modelos entrenados
Tras entrenar los modelos con los asesores comentados anteriormente, tendremos que probar el rendimiento de los modelos obtenidos con datos históricos que no estén incluidos en la muestra de entrenamiento. Para implementar esta funcionalidad, crearemos el asesor "...\PDT\Test.mq5". A diferencia de los asesores analizados anteriormente, en los que el entrenamiento del modelo se realizaba fuera offline, el asesor de prueba interactuará con el entorno online. Esto se reflejará en la construcción de su algoritmo.
En el método de inicialización del asesor OnInit, primero inicializaremos los objetos de los indicadores analizados.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(NBarInPattern) || !CCI.BufferResize(NBarInPattern) || !ATR.BufferResize(NBarInPattern) || !MACD.BufferResize(NBarInPattern)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
Luego crearemos un objeto de operaciones comerciales.
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
Y cargaremos los modelos entrenados. Aquí solo utilizaremos 2 modelos: Actor y Planificador. Y, a diferencia de los asesores anteriores, el error de carga de los modelos provocará la interrupción del asesor. Al fin y al cabo, no hemos implantado en este el entrenamiento online de modelos.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Planner.Load(FileName + "Pln.nnw", temp, temp, temp, dtStudied, true)) { PrintFormat("Can't load pretrained model"); return INIT_FAILED; }
Una vez los modelos se hayan cargado correctamente, los transferiremos a un único contexto OpenCL y realizaremos el control mínimo imprescindible de la arquitectura.
Planner.SetOpenCL(Agent.GetOpenCL()); Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the Actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Agent.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } Agent.Clear();
Al final del método, inicializaremos las variables con sus valores iniciales.
AgentResult = vector<float>::Zeros(NActions); PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
El proceso de interacción directa con el entorno se implementará en el método de procesamiento de ticks OnTick. En el cuerpo del método primero comprobaremos la aparición del evento de apertura de nueva barra. Permítame recordarle que todos nuestros modelos analizan velas cerradas y comercian con la apertura de una nueva barra.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
A continuación, solicitaremos al terminal los datos necesarios para la profundidad de la historia analizada. En este caso, por profundidad de la historia entenderemos el tamaño de un patrón, que en nuestro caso será una barra. La profundidad de la historia analizada por el Agente estará contenida en su estado latente como incorporaciones y no se volverá a procesar en cada barra.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
A continuación, deberemos transferir los datos recibidos a un búfer para transferirlos al modelo.
//--- History data float atr = 0; for(int b = 0; b < NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Los datos históricos obtenidos nos bastarán para realizar una pasada directa del Planificador, cosa que haremos.
if(!Planner.feedForward(GetPointer(bState), 1, false)) return;
No obstante, necesitaremos información adicional para que el Agente funcione plenamente. En primer lugar, añadiremos al búfer la información sobre el estado de la cuenta, que solicitamos previamente al terminal.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
A continuación, añadiremos una marca de tiempo y las últimas acciones del Agente.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(AgentResult);
En un búfer aparte obtendremos los resultados de la pasada directa realizada previamente por el Planificador y llamaremos al método de pasada directa del Agente.
//--- Return to go Planner.getResults(Result); //--- if(!Agent.feedForward(GetPointer(bState), 1, false, Result)) return;
Después actualizaremos las variables necesarias para las operaciones de la siguiente barra.
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Con esto se completará la primera fase del análisis de los datos de origen. Y pasaremos a la fase de interacción con el entorno. Aquí tomaremos los resultados de la pasada directa del Agente y los decodificaremos en un vector de operaciones próximas. Como de costumbre, excluiremos los volúmenes superpuestos y dejaremos la diferencia en la dirección del movimiento más probable.
vector<float> temp; Agent.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp;
A continuación, ajustaremos nuestra posición en el mercado según los valores previstos. Primero, ajustaremos nuestra posición larga.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Y repetiremos las operaciones para el sentido contrario.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Los resultados de la interacción con el entorno los compondremos en una estructura, y luego los almacenaremos en una trayectoria que más tarde se añadirá al búfer de reproducción de experiencias para seguir optimizando la política de modelos.
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
Con esto completaremos la implementación del método Pretrained Decision Transformer utilizando los recursos de MQL5. Podrá ver el código completo de todos los programas utilizados en el artículo en el archivo adjunto.
3. Simulación
Una vez completada la implementación del método analizado, tendremos que entrenar el modelo y probar su rendimiento con datos históricos. Como de costumbre, utilizaremos uno de los instrumentos más volátiles EURUSD y el marco temporal H1 para entrenar y probar los modelos. Los modelos se entrenarán con datos históricos de los 7 primeros meses de 2023. Para probar el rendimiento de los modelos entrenados, hemos usado datos históricos de agosto de 2023.
Y antes de iniciar la fase de entrenamiento previo de los modelos, necesitaremos recopilar un conjunto de datos de entrenamiento. Como ya hemos mencionado, en este artículo hemos utilizado el conjunto de datos de entrenamiento del artículo anterior, donde se describe todo el proceso. Todo lo que hemos hecho ha sido crear una copia del archivo de muestra de entrenamiento, llamado "PDT.bd".
Después hemos ejecutado el asesor de entrenamiento previo en tiempo real.
Permítame recordarle que todos los asesores de entrenamiento de modelos trabajan con gráficos online. Al mismo tiempo, el proceso completo de entrenamiento tiene lugar offline, sin operaciones comerciales.
Debemos decir que en esta fase debemos tener paciencia. El proceso de entrenamiento previo es bastante largo. Hemos dejado el ordenador encendido más de 24 horas.
A continuación, pasaremos al proceso de ajuste. Y aquí los autores del método nos hablan del aprendizaje online. Nosotros hemos alternado entre no entrenar el modelo durante mucho tiempo y probarlo en el intervalo de entrenamiento en el simulador de estrategias. Pero lo principal era "calentar" el modelo con una muestra de entrenamiento recogida previamente.
Para el periodo de ajuste, hemos necesitado varias docenas de iteraciones sucesivas de entrenamiento previo y pruebas de modelos, lo cual también ha requerido tiempo y esfuerzo.
Sin embargo, los resultados del entrenamiento no han sido tan halagüeños. Como resultado del entrenamiento, hemos logrado un modelo comercial de volumen mínimo con éxito variable. En algunas partes de la historia, la línea de balance ha mostrado una clara tendencia al alza. En otras, la línea ha experimentando un declive. En general, los resultados del modelo tanto con los datos de entrenamiento como con los nuevos se han aproximado a "0".
Los aspectos positivos incluyen la capacidad del modelo para transferir la experiencia aprendida a nuevos datos, lo cual se ve confirmado por la comparabilidad de los resultados de las pruebas en la sección de datos históricos de la muestra de entrenamiento y en el intervalo histórico posterior. Además, podemos observar un exceso significativo del tamaño de las operaciones rentables con respecto a las perdedoras. En ambos gráficos de datos históricos, observamos que el tamaño de la operación rentable media supera la pérdida máxima. No obstante, todos los aspectos positivos se ven nivelados por el bajo porcentaje de operaciones rentables, que es algo inferior al 40% en ambos intervalos históricos.


Así, al probar el modelo con datos históricos para agosto de 2023 (nuevos datos), el modelo ha realizado 18 operaciones. Y solo el 39% de ellas se han cerrado con beneficios. Al mismo tiempo, la operación rentable máxima ha sido de 11,26, es decir, casi 3 veces más que la pérdida máxima de 4,76, mientras que la media de operaciones rentables ha sido de 5,15, con una media de pérdidas de 3,19. El factor de beneficio para el periodo de prueba ha sido de 1,03.
Evidentemente, para aumentar la proporción de operaciones rentables, deberemos realizar un análisis adicional de los resultados obtenidos y afinar el modelo. El método muestra potencial, pero se requerirá un largo periodo de entrenamiento del modelo.
Conclusión
En este trabajo, nos hemos familiarizado con el Pretrained Decision Transformer (PDT), que ofrece un algoritmo de preentrenamiento no supervisado para el aprendizaje por refuerzo con el Decision Transformer. Basándose en el conocimiento de los estados futuros durante el entrenamiento del modelo, el PDT es capaz de extraer un rico conocimiento a priori de los datos de entrenamiento. Este conocimiento puede afinarse y ajustarse aún más en la fase de entrenamiento previo de los modelos, ya que el PDT vincula cada oportunidad futura con la rentabilidad correspondiente y realiza la selección con la máxima recompensa prevista, lo cual le permite tomar las mejores decisiones posibles.
Sin embargo, el PDT requiere más tiempo de entrenamiento y recursos computacionales en comparación con el DT y el ODT anteriormente analizados, lo cual puede provocar dificultades prácticas debido a la limitación de los recursos disponibles. Además, el objetivo, el aprendizaje de modelos crea un equilibrio entre la diversidad de comportamientos aprendidos y su coherencia. Los experimentos prácticos de los autores del método indican que el valor óptimo dependerá del conjunto de datos concreto. Y para mejorar la codificación de los estados futuros, pueden aplicarse técnicas adicionales.
No podría estar más de acuerdo con las conclusiones de los autores del método. Nuestra experiencia práctica confirma plenamente lo expuesto. El entrenamiento de modelos resulta bastante largo y requiere mucho tiempo. Para desarrollar la máxima variedad de habilidades del Agente, se requerirá una muestra de entrenamiento bastante amplia. Obviamente, utilizaremos datos sin marcar para el entrenamiento previo, lo cual facilitará el proceso de recopilación de datos. Pero la cuestión de la disponibilidad de recursos para la recogida de datos, su procesamiento y el entrenamiento de modelos sigue abierta.
Enlaces
Programas utilizados en el artículo:
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Faza1.mq5 | Asesor | Asesor de recopilación de ejemplos |
| 2 | Pretrain.mq5 | Asesor | Asesor de entrenamiento previo |
| 3 | FineTune.mq5 | Asesor | Ajuste del asesor |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clase | Estructura de la descripción del estado del sistema |
| 6 | NeuroNet.mqh | Biblioteca de clase | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13712
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso