
Redes neurais de maneira fácil (Parte 63): pré-treinamento do transformador de decisões não supervisionado (PDT)

Introdução
O decision transformer (DT) é uma ferramenta bastante eficiente para resolver uma diversidade de problemas práticos. E muito disso é obtido por meio da abordagem de atenção do transformador. Pela experiência de trabalhos anteriores, vimos que o uso da arquitetura do transformador também exige um treinamento longo e completo do modelo. Durante esse processo, enfrentamos o problema de preparar dados de treinamento rotulados. Ao resolver problemas práticos, às vezes acontece que é muito difícil obter recompensas e expandir a amostra de treinamento pois os dados rotulados não são bem dimensionados. Entretanto, evitar recompensas durante o pré-treinamento também permite que o modelo adquira padrões gerais de comportamento que podem ser facilmente adaptados para serem usados nas diferentes tarefas posteriores.
Neste artigo, apresento a você um método de pré-treinamento de RL chamado pretrained decision transformer (PDT), que foi descrito no artigo Unsupervised Pre-training for Decision Transformer" (maio de 2023). Esse método oferece ao DT a capacidade de treinar com dados sem rótulos de recompensa e com dados abaixo do ideal. Em particular, os autores do método consideram um cenário de pré-treinamento no qual o modelo é, primeiro, treinado off-line com trajetórias coletadas sem rótulos de recompensa e, em seguida, ajustado à tarefa-alvo por meio de interação on-line.
Para um pré-treinamento eficaz, o modelo deve ser capaz de extrair sinais de aprendizado multifacetados e universais na ausência de recompensas. Durante o pré-treinamento, o modelo deve se adaptar rapidamente à questão das recompensas, determinando quais sinais de aprendizado podem ser associados às mesmas.
O PDT explora o espaço de incorporação da trajetória futura e a probabilidade futura a priori condicionada apenas a informações passadas. Treinada para prever ações para alcançar um investimento futuro desejado, o PDT é dotada da capacidade de "raciocinar sobre o futuro". Essa capacidade é independente da tarefa e pode ser generalizada para diferentes aplicativos.
Para obter um pré-treinamento on-line eficiente em tarefas posteriores, a estrutura se adapta prontamente a novas condições associando cada investimento futuro ao seu retorno, o que é obtido por meio do treinamento de uma rede para prever a recompensa esperada para cada investimento-alvo.
Proponho que passemos para a próxima seção do nosso artigo e nos iniciemos no método pretrained decision transformer.
1. Método pretrained decision transformer
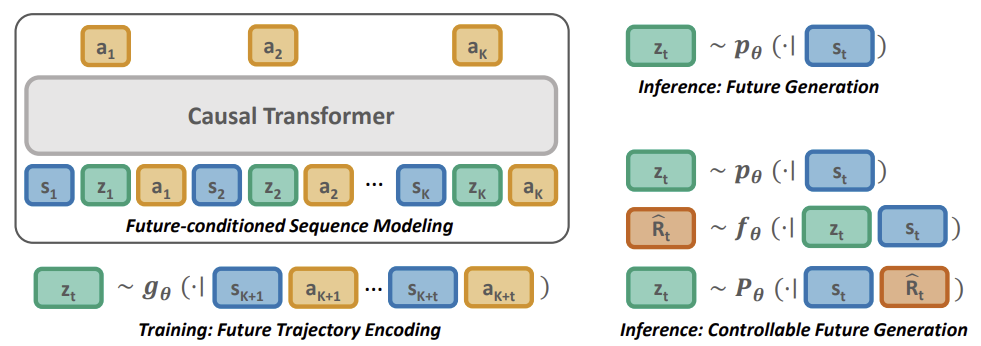
O método PDT se baseia nos princípios do DT. Ele também prevê as ações do Agente após analisar a sequência de estados visitados e ações executadas. Além disso, o PDT introduz acréscimos ao algoritmo DT que permitem que o modelo seja pré-treinado com dados não rotulados, ou seja, sem análise de recompensa. Isso parece impossível, porque a recompensa futura esperada (Return To Go) é um dos membros da sequência analisada pelo modelo e serve como uma espécie de bússola para a orientação do modelo no espaço.
Os autores do método PDT propuseram substituir o RTG por algum vetor de estado latente Z. Essa ideia não é nova, mas os autores deram uma interpretação bastante interessante a isso. No processo de pré-treinamento, treinaremos 3 modelos com dados não rotulados:
- Ator, que é essencialmente um DT clássico com previsão de ação baseada na análise da trajetória anterior;
- O modelo de previsão de metas P(-|St) realiza a previsão de metas DT (estado latente Z) com base na análise do estado atual;
- O modelo de codificador do futuro G(-|τt+1:t+k) "olha para o futuro" e o incorpora como um vetor de estado latente Z.
Observe que os dois últimos modelos analisam dados diferentes, mas ambos retornam o vetor de estado latente Z. Dessa forma, é criado um tipo de autocodificador entre os estados atuais e futuros. E seu estado latente é usado como alvo para o DT (do Ator).
No entanto, o treinamento do modelo é diferente do processo de treinamento do autocodificador. Primeiro, treinamos o codificador do futuro e o ator, criando dependências entre a trajetória futura e as ações executadas. Permitimos que o PDT olhe para o futuro em algum horizonte de planejamento. Compactamos as informações da trajetória posterior em um estado latente. Dessa forma, permitimos que o modelo tome uma decisão com base nas informações disponíveis sobre o futuro. E esperamos criar uma política de Ator com uma ampla gama de habilidades comportamentais, sem restrições impostas pelas recompensas do ambiente durante o pré-treinamento.
Em seguida, treinamos um modelo de previsão de metas que procura dependências entre o estado atual e a incorporação aprendida da trajetória futura.
Essa abordagem nos permite dissociar as recompensas dos resultados desejados, abrindo oportunidades para o pré-aprendizado contínuo em larga escala. Ao fazer isso, ele reduz o problema de comportamento inconsistente, em que o comportamento do Agente se desvia significativamente das metas desejadas.
Embora seja útil usar o modelo de previsão de metas P(Z|St) para obter amostras de variáveis latentes futuras e gerar comportamentos que imitem a distribuição da amostra de treinamento, ele não codifica nenhuma informação específica da tarefa. Por isso, é necessário direcionar P(Z|St) para obter amostras de futuras incorporações que levem a altas recompensas futuras durante o pré-treinamento.
Assim é que são criados comportamentos especializados para DTs condicionados com o objetivo de maximizar a recompensa. Em contraste com as políticas de gerenciamento condicionadas à maximização do resultado por meio da atribuição de uma recompensa de meta escalar, precisamos ajustar a distribuição do modelo de previsão de meta P(Z|St). Como essa distribuição é desconhecida, usamos um modelo adicional de previsão de recompensa F(-|Z,St) para prever a trajetória ideal. O modelo de previsão de recompensa é treinado junto com todos os outros durante o pré-treinamento.
Semelhante ao pré-treinamento para recuperar o estado latente, usamos um codificador do futuro, que permite que os gradientes se propaguem para trás, ajustando a codificação das informações de recompensa na representação latente. Isso permite que as especificidades da tarefa em questão sejam abordadas durante o pré-treinamento.
Abaixo é apresentada uma representação do método pretrained decision transformer do artigo original.
2. Implementação usando MQL5
Depois de considerar os aspectos teóricos do método pretrained decision transformer, passaremos para a parte prática do nosso artigo e revisaremos uma variante da implementação do método usando MQL5. E deixe-me dizer desde já que, neste artigo, vamos nos concentrar no EA de coleta de amostras de treinamento. Em artigos anteriores, foram vistas várias opções para construir algoritmos da família decision transformer. Todos eles são semelhantes no que diz respeito ao buffer de reprodução de experiência. E podemos usá-los para a coleta inicial da amostra de treinamento. Em meu trabalho, usarei o buffer de reprodução de experiência montado no artigo anterior. Deixe-me lembrá-lo de que coletamos essa informação por meio de amostragem aleatória de ações sem vinculação a um modelo específico (método Go-Explore).
2.1. Descrição da arquitetura do modelo
Como já temos um conjunto de dados de treinamento, passamos para a próxima etapa, o pré-treinamento não supervisionado. Conforme mencionado acima, treinaremos 3 modelos nesta etapa. E começaremos com a descrição da arquitetura dos modelos, que é coletada no método CreateDescriptions.
bool CreateDescriptions(CArrayObj *agent, CArrayObj *planner, CArrayObj *future_embedding) { //--- CLayerDescription *descr;
Nos parâmetros, o método recebe ponteiros para 3 arrays dinâmicos aos quais serão adicionadas as descrições da arquitetura da camada neural dos modelos.
No corpo do método, declaramos uma variável local com o objetivo de registrar um ponteiro para o objeto de descrição de uma camada neural. Nele, "manteremos" um ponteiro para o objeto com o qual estamos trabalhando em um bloco separado.
Começaremos descrevendo a arquitetura do nosso Agente. Lembre-se de que, nesse caso, seu papel é desempenhado pelo decision transformer (DT). Ele usa uma descrição passo a passo da trajetória como entrada e acumula as incorporações de toda a sequência no buffer de resultados da camada de incorporação. Mas, diferentemente do trabalho anterior, durante a retropropagação, temos que passar o gradiente de erro para o modelo de codificador do futuro. Para fazer isso, vamos nos complicar um pouco. Dividimos todo o array de dados brutos em dois fluxos. Transferiremos a maior parte dos dados para o modelo, como de costume, por meio do buffer da camada de dados brutos. E passaremos como segundo fluxo a incorporação do futuro para mesclar na camada de concatenação. Os dados brutos não processados com que alimentamos o buffer da camada de dados brutos serão normalizados usando a camada de normalização de lote. A incorporação do futuro, por outro lado, é o resultado do modelo e pode ser usada sem normalização.
//--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = prev_count + EmbeddingSize; descr.step = EmbeddingSize; descr.optimization = ADAM; descr.activation = None; if(!agent.Add(descr)) { delete descr; return false; }
A camada de incorporação neural das informações apresentadas é alimentada com os dados coletados em um único fluxo .
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, EmbeddingSize}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
Em seguida, os dados são transmitidos para o bloco do transformador. Usei um "bolo" de 4 camadas com 16 cabeças de self-attention.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 16; descr.window_out = 64; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Após o bloco do transformador, usei duas camadas de convolução para identificar padrões consistentes.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 16; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
Essas são seguidas por 3 camadas totalmente conectadas do bloco de decisão.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
E, na saída do modelo, temos uma camada totalmente conectada com o número de elementos igual ao espaço de ação do Agente.
Em seguida, criamos uma descrição do modelo de previsão de metas P(Z|St). Conforme a terminologia de modelos hierárquicos, podemos chamá-lo de Agendador. Afinal, estruturalmente, sua funcionalidade é muito semelhante, embora as abordagens de treinamento dos modelos sejam muito diferentes.
A camada de dados inicial do modelo deve ser alimentada com a descrição dos dados históricos e valores de indicadores de um padrão. Em nosso caso, são dados de apenas 1 barra.
Concordo que essas informações são muito escassas para analisar a situação do mercado e prever os próximos estados e ações, especialmente no caso de várias etapas à frente. Mas vamos analisar a situação de outra forma. Durante a utilização prática, alimentamos nosso Ator com a previsão futura gerada na forma de uma incorporação, Ator esse cujas camadas internas contêm informações com uma determinada profundidade do histórico. E, nesse contexto, é mais relevante prestarmos atenção às mudanças que ocorreram e corrigir o comportamento do Ator. Analisar o histórico mais profundo ao elaborar a incorporação do futuro pode "borrar" as mudanças localizadas. No entanto, essa é minha opinião subjetiva e não é um requisito do algoritmo pretrained decision transformer.
if(!planner) { planner = new CArrayObj(); if(!planner) return false; } //--- Planner planner.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = BarDescr * NBarInPattern; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
Executamos os dados brutos resultantes por meio de uma camada de normalização em lote para colocá-los em um formato que se possa comparar.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
Em seguida, não compliquei muito o modelo e coloquei um bloco de decisão de 3 camadas totalmente conectadas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
Na saída do modelo, reduzimos a escala do vetor para o tamanho da incorporação e normalizamos os resultados por meio da função SoftMax.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
Já descrevemos a arquitetura dos dois modelos. E resta-nos acrescentar uma descrição do codificador do futuro. Embora o resultado do modelo, em princípio, implique consistência com o resultado do modelo anterior, isso só ficará evidente nas últimas camadas do modelo. A própria arquitetura do codificador é um pouco mais complexa. Em primeiro lugar, ao incorporar o futuro, incluímos o planejamento com certa profundidade. Isso significa que alimentamos a camada de dados brutos com informações sobre algumas velas posteriores.
Neste ponto, é importante notar que, quanto às informações sobre o futuro, incluí apenas dados sobre o movimento do preço do instrumento e indicadores. Não incluí informações sobre o status da conta e as próximas etapas do Agente. As ações do Agente estão sujeitas às suas políticas. E eu gostaria de enfatizar que é necessário entender os processos no ambiente. Mas os estados da conta, até certo ponto, já contêm informações sobre a recompensa recebida do ambiente, o que é um pouco contrário ao princípio referente aos dados não rotulados.
//--- Future Embedding if(!future_embedding) { future_embedding = new CArrayObj(); if(!future_embedding) return false; } //--- future_embedding.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = BarDescr * NBarInPattern * ValueBars; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
Como antes, executamos os dados brutos sem pré-processamento por meio de uma camada de normalização em lote para colocá-los em um formato comparável.
Em seguida, usei um bloco do transformador de 4 camadas e 16 cabeças self-attention. Nesse caso, o bloco de atenção analisa as dependências entre as barras individuais em uma tentativa de identificar as principais tendências ao longo do horizonte de planejamento e de filtrar o componente de ruído.
Pela lógica do método PDT, é a incorporação do estado futuro que deve indicar ao Ator a habilidade que está sendo usada e a direção da ação futura. Por isso, a saída do codificador deve ser o mais informativa e precisa possível.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = ValueBars; descr.window = BarDescr * NBarInPattern; descr.step = 16; descr.window_out = 64; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
As camadas de atenção são seguidas pelas camadas totalmente conectadas do bloco de decisão.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
E na saída do modelo, usamos uma camada totalmente conectada com normalização por meio da função SoftMax, como foi feito acima no modelo de previsão futura.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- return true; }
Assim concluímos nossa descrição da arquitetura do modelo para o EA de pré-treinamento. Mas antes de prosseguir com o próprio EA, gostaria de concluir o trabalho iniciado na descrição da arquitetura dos modelos. Lembre-es de que a fase de ajuste fino do método PDT envolve a adição de outro modelo, nomeadamente a previsão de recompensa. E como ele é adicionado em um estágio posterior do treinamento, decidi colocar a descrição de sua arquitetura em um método CreateValueDescriptions separado.
De acordo com a metodologia PDT, esse modelo deve estimar as tendências futuras codificadas no estado latente e no estado atual. A recompensa do ambiente precisa ser prevista com base nos resultados da análise.
O objetivo do pré-treinamento do modelo, por outro lado, é incorporar informações sobre recompensas prováveis durante futuras incorporações. Por isso, assim como na fase de pré-treinamento, agora precisamos passar o gradiente de erro de previsão de recompensa para o modelo do codificador do futuro. E aqui usaremos a separação do fluxo de informações testada acima. Um fluxo de dados de entrada será o estado atual e o outro, a incorporação do futuro.
A segunda questão que temos de abordar agora é o que incluímos na compreensão do estado atual nesta etapa. É claro que, na fase de ajuste fino, usamos os dados rotulados da amostra de treinamento e podemos incluir, se desejado, a quantidade total de informações disponíveis. Mas a grande quantidade de dados de entrada complica muito o modelo e aumenta o custo de processamento. E qual é praticidade de usar essa quantidade de dados no estágio atual?
A análise dos estados antecedentes do ambiente é necessária para prever seus estados posteriores. Mas já temos informações sobre estados futuros na forma de incorporação.
A análise das ações anteriores do Agente pode indicar a política em uso. Mas precisamos fornecer informações ao Agente para que ele decida se a habilidade e a política comportamental usadas precisam ser alteradas.
Mas as informações sobre o status atual da conta podem ser úteis. A presença de margem livre nos indicará se podemos abrir posições adicionais em caso de tendências favoráveis. Ou talvez as tendências mudem e teremos de fechar posições abertas anteriormente com a fixação de lucros e perdas acumulados. Além disso, não se esqueça das penalidades por não ter posições abertas, que também afetarão a recompensa.
Assim, a camada de dados de entrada deve ser alimentada com a descrição atual do status da conta e das posições abertas.
bool CreateValueDescriptions(CArrayObj *value) { //--- CLayerDescription *descr; //--- if(!value) { value = new CArrayObj(); if(!value) return false; } //--- Value value.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
Os dados resultantes passam por uma camada de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
Além disso, combinamos os dois fluxos de informações na camada de concatenação.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.step = EmbeddingSize; descr.optimization = ADAM; descr.activation = SIGMOID; if(!value.Add(descr)) { delete descr; return false; }
Então o bloco de tomada de decisão é alimentado com informações a partir das camadas totalmente conectadas.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- return true; }
E na saída do modelo, obtemos um vetor de recompensas esperadas.
2.2. EA de pré-treinamento
Depois de criar a arquitetura dos modelos usados, prosseguimos com a implementação do algoritmo do método PDT. E, é claro, começamos com o EA de pré-treinamento "...\PDT\Pretrain.mq5". Como mencionado acima, esse EA é pré-treinado com 3 modelos: Ator, planejador e codificador do futuro.
CNet Agent; CNet Planner; CNet FutureEmbedding;
No método de inicialização do EA, primeiro carregamos a amostra de treinamento.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Tentamos carregar os modelos pré-treinados e, se necessário, inicializamos novos modelos de acordo com a arquitetura acima.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Planner.Load(FileName + "Pln.nnw", temp, temp, temp, dtStudied, true) || !FutureEmbedding.Load(FileName + "FEm.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *agent = new CArrayObj(); CArrayObj *planner = new CArrayObj(); CArrayObj *future_embedding = new CArrayObj(); if(!CreateDescriptions(agent, planner, future_embedding)) { delete agent; delete planner; delete future_embedding; return INIT_FAILED; } if(!Agent.Create(agent) || !Planner.Create(planner) || !FutureEmbedding.Create(future_embedding)) { delete agent; delete planner; delete future_embedding; return INIT_FAILED; } delete agent; delete planner; delete future_embedding; //--- }
Depois disso, movemos todos os modelos para um contexto OpenCL.
//---
COpenCL *opcl = Agent.GetOpenCL();
Planner.SetOpenCL(opcl);
FutureEmbedding.SetOpenCL(opcl); Aqui também realizamos um controle mínimo da arquitetura dos modelos.
Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the worker does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
E inicializar o início o pré-treinamento, implementado no método Train.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Sempre salvamos os modelos treinados no método de desinicialização do EA.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Agent.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); Planner.Save(FileName + "Pln.nnw", 0, 0, 0, TimeCurrent(), true); FutureEmbedding.Save(FileName + "FEm.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
O treinamento do modelo é implementado no método Train. No corpo do método, primeiro definimos o tamanho do buffer de reprodução da experiência.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
E, em seguida, fazemos os sistemas de laços de aprendizado de modelos aninhados. O laço externo é limitado ao número de iterações de treinamento especificadas no parâmetro externo do EA. Para iniciar o processo de aprendizado, no corpo desse laço, primeiro amostramos uma trajetória (do buffer de repetição de experiência) e um estado do ambiente separado na trajetória selecionada.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars - ValueBars, MathMin(Buffer[tr].Total, 20 + ValueBars))); if(i < 0) { iter--; continue; }
Em seguida, realizamos um laço aninhado para treinar o modelo DT sequencialmente.
Actions = vector<float>::Zeros(NActions); for(int state = i; state < MathMin(Buffer[tr].Total - ValueBars, i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state); if(!Planner.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
No corpo do ciclo, gravamos dados históricos sobre movimentos de preços e indicadores no buffer de dados brutos. E aqui vale a pena observar que esses dados já são suficientes para realizar uma propagação do modelo de previsão (Planejador). Essa operação é a primeira que realizamos. Depois disso, continuamos a preencher o buffer de dados inicial para o nosso Ator. Adicionamos o status da conta.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
O rótulo de tempo e as ações recentes do Agente.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action State.AddArray(Actions);
Agora, a única coisa que nos falta para realizar uma propagação do Ator é uma incorporação do futuro. Temos, é claro, o buffer de resultados do Agendador, mas, nesse estágio, o resultado do modelo não treinado não é orientado por nada. De acordo com o algoritmo PDT, precisamos fazer o carregamento das informações sobre os estados posteriores e gerar a incorporação dos dados obtidos.
//--- Target Result.AssignArray(Buffer[tr].States[state + 1].state); for(int s = 1; s < ValueBars; s++) Result.AddArray(Buffer[tr].States[state + 1].state); if(!FutureEmbedding.feedForward(Result, 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
A entrada 2 do modelo Ator deve ser alimentada com o resultado do codificador, e chamamos sua propagação.
FutureEmbedding.getResults(Result); //--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Depois de realizar uma propagação de todos os modelos usados, passamos a treiná-los. E o primeiro método de retropropagação que chamamos é para o modelo do Planejador (previsão do futuro). Essa sequência é orientada pela presteza do vetor de resultado de destino com o qual acabamos de alimentar o Ator.
//--- Planner Study if(!Planner.backProp(Result, NULL, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Em seguida, passamos a preparar os resultados-alvo do nosso Ator. Para isso, usamos as ações do buffer de reprodução da experiência que levaram às consequências conhecidas.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result);
Depois de preparar os valores-alvo, realizamos uma retropropagação do Ator e executamos imediatamente o gradiente de erro através do modelo do codificador do futuro.
if(!Agent.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Depois disso, tudo o que precisamos fazer é informar o usuário sobre o progresso das operações e passar para uma nova iteração.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Planner", iter * 100.0 / (double)(Iterations), Planner.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Quando todas as iterações do sistema de laços são concluídas, limpamos o campo de comentários no gráfico. Exibimos os resultados do treinamento no log e iniciamos a conclusão do trabalho do Expert Advisor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Planner", Planner.getRecentAverageError()); ExpertRemove(); //--- }
Todos os outros métodos do Expert Advisor são transferidos sem alterações dos EAs de treinamento "...\Study.mq5" discutido nos artigos anteriores. E não vamos nos alongar sobre eles agora. Você mesmo pode ler o código completo do programa disponível no anexo. E agora vamos para a próxima etapa.
2.3. Ajuste fino do Expert Advisor
Depois de concluir a implementação do algoritmo de pré-treinamento, passamos a trabalhar na criação de um Expert Advisor de ajuste fino "...\PDT\FineTune.mq5", no qual criaremos um algoritmo para modelos de pré-treinamento.
Note desde já que o Expert Advisor é aproximadamente 90% igual ao anterior. Por isso, não faremos uma análise completa de seus métodos. E vamos nos concentrar apenas nas mudanças que foram feitas.
Conforme já mencionado na parte teórica, o método PDT nesta etapa permite a otimização de modelos para a solução do problema em questão. Isso implica que usaremos dados rotulados e recompensas do ambiente para otimizar as políticas do nosso Agente. Para isso, adicionamos outro modelo para prever a recompensa externa ao processo de aprendizado.
CNet RTG;
É aqui que adicionamos um modelo, deixando inalterado o uso de modelos do EA anterior.
Observe que deixei o mecanismo para criar novos modelos de Agente, Planejador e Codificador do futuro no EA de ajuste fino quando os modelos pré-treinados não puderem ser carregados. Assim, o usuário pode treinar modelos do zero. Nesse caso, o carregamento e, se necessário, a inicialização de um novo modelo de previsão de recompensa externa presente no método de inicialização EA são colocados em um bloco separado. Afinal, quando passarmos do pré-treinamento para o ajuste fino, teremos os padrões treinados no EA anterior. Mas inicializaremos o modelo de previsão de recompensa com parâmetros aleatórios.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- if(!RTG.Load(FileName + "RTG.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *rtg = new CArrayObj(); if(!CreateValueDescriptions(rtg)) { delete rtg; return INIT_FAILED; } if(!RTG.Create(rtg)) { delete rtg; return INIT_FAILED; } delete rtg; //--- } //--- COpenCL *opcl = Agent.GetOpenCL(); Planner.SetOpenCL(opcl); FutureEmbedding.SetOpenCL(opcl); RTG.SetOpenCL(opcl); //--- RTG.getResults(Result); if(Result.Total() != NRewards) { PrintFormat("The scope of the RTG does not match the rewards count (%d <> %d)", NRewards, Result.Total()); return INIT_FAILED; } //--- ........ ........ //--- return(INIT_SUCCEEDED); }
Também adaptamos todos os modelos em um único contexto OpenCL e verificamos se a camada de resultado do modelo adicionado corresponde à dimensionalidade do vetor de recompensa decomposto.
Também fizemos acréscimos pontuais ao método de treinamento do modelo Train. Após a propagação do agente, adicionamos uma chamada à propagação do modelo de previsão de recompensa. Conforme discutido acima, alimentamos o modelo com um vetor de descrição do estado da conta e com a incorporação do futuro.
........ ........ //--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } //--- Return-To-Go Account.AssignArray(Buffer[tr].States[state + 1].account); if(!RTG.feedForward(GetPointer(Account), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } ........ ........
Os parâmetros do modelo são atualizados da mesma forma depois que os parâmetros do Agente são atualizados. O algoritmo para otimizar os modelos é praticamente idêntico. Ao invocar o método de retropropagação do modelo, realizamos uma transferência de gradiente de erro para o modelo de codificação do futuro, seguida de uma atualização de seus parâmetros. A única diferença são os valores-alvo. Essa abordagem nos permite treinar a dependência das ações do agente e da recompensa externa resultante em relação à incorporação do futuro.
........ ........ //--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } //--- Return To Go study vector<float> target; target.Assign(Buffer[tr].States[state + 1].rewards); result.Assign(Buffer[tr].States[state + ValueBars].rewards); target = target - result * MathPow(DiscFactor, ValueBars); Result.AssignArray(target); if(!RTG.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } ........ ........
Assim concluímos nossas mudanças pontuais. Você pode encontrar o código completo do Expert Advisor, bem como todos os programas usados no artigo, no anexo.
2.4. EA para testar modelos treinados
Depois de treinar os modelos nos Expert Advisors discutidos acima, precisaremos testar o desempenho dos modelos obtidos com base nos dados históricos que não estão incluídos na amostra de treinamento. Para implementar essa funcionalidade, criaremos um Expert Advisor "...\PDT\Test.mq5". Ao contrário dos EAs discutidos acima, em que o treinamento de modelos off-line foi realizado, o EA de teste interage com o ambiente on-line. Isso se reflete na construção de seu algoritmo.
No método de inicialização do EA OnInit, primeiro inicializamos os objetos dos indicadores analisados.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(NBarInPattern) || !CCI.BufferResize(NBarInPattern) || !ATR.BufferResize(NBarInPattern) || !MACD.BufferResize(NBarInPattern)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
Criamos um objeto de operações de trading.
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
E carregamos os modelos treinados. Aqui usamos apenas dois modelos: Ator e Planejador. E, diferentemente dos Expert Advisors anteriores, o erro de carregamento de modelos leva à interrupção do Expert Advisor. Afinal de contas, não implementamos o treinamento de modelos on-line nele.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Planner.Load(FileName + "Pln.nnw", temp, temp, temp, dtStudied, true)) { PrintFormat("Can't load pretrained model"); return INIT_FAILED; }
Após o carregamento bem-sucedido dos modelos, nós os adaptamos em um único contexto OpenCL e realizamos um controle de arquitetura mínimo ou nulo.
Planner.SetOpenCL(Agent.GetOpenCL()); Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the Actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Agent.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } Agent.Clear();
No final do método, inicializamos as variáveis com seus valores iniciais.
AgentResult = vector<float>::Zeros(NActions); PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
O processo de interação direta com o ambiente é implementado no método de tratamento de ticks OnTick. No corpo do método, primeiro verificamos a ocorrência do evento de abertura da nova barra. Gostaria de lembrá-lo de que todos os nossos modelos analisam candlesticks fechados e negociam na abertura de uma nova barra.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Em seguida, solicitamos ao terminal os dados necessários com base na profundidade do histórico analisado. Nesse caso, por profundidade do histórico, queremos dizer o tamanho de um padrão, que, em nosso caso, é uma barra. A profundidade do histórico analisado pelo Agente está contida em seu estado latente como embeddings (incorporações) e não é reprocessada em cada barra.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Em seguida, temos que transferir os dados recebidos para um buffer para serem transferidos para o modelo.
//--- History data float atr = 0; for(int b = 0; b < NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Os dados históricos obtidos são suficientes para realizarmos uma propagação do Planejador, o que fizemos.
if(!Planner.feedForward(GetPointer(bState), 1, false)) return;
No entanto, precisamos de informações adicionais para que o Agente funcione plenamente. Primeiro, adicionamos ao buffer as informações de status da conta que solicitamos anteriormente ao terminal.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Em seguida, adicionamos um rótulo de tempo e as últimas ações do Agente.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(AgentResult);
Em um buffer separado, obtemos os resultados da propagação do Planejador realizada anteriormente e chamamos o método de propagação do Agente.
//--- Return to go Planner.getResults(Result); //--- if(!Agent.feedForward(GetPointer(bState), 1, false, Result)) return;
Depois disso, atualizamos as variáveis necessárias para realizar operações na próxima barra.
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Assim concluímos a primeira etapa da análise dos dados brutos. E passamos para o estágio de interação com o ambiente. Aqui, pegamos os resultados da propagação do agente e os decodificamos em um vetor de operações futuras. Como de costume, excluímos os volumes sobrepostos e deixamos a diferença na direção do movimento mais provável.
vector<float> temp; Agent.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp;
Em seguida, ajustamos nossa posição no mercado de acordo com os valores previstos. Primeiro, ajustamos nossa posição longa.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
E quanto à direção oposta repetimos as operações.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Compomos os resultados da interação com o ambiente em uma estrutura e os armazenamos em uma trajetória, que será posteriormente adicionada ao buffer de reprodução de experiência para otimização adicional da política de modelos.
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
Assim concluímos a implementação do método pretrained decision transformer usando as ferramentas MQL5. E você pode ver o código completo de todos os programas usados no artigo no anexo.
3. Teste
Uma vez concluída a implementação do método considerado, precisamos treinar o modelo e testar seu desempenho com base em dados históricos. Como de costume, usamos um dos instrumentos mais voláteis, o EURUSD, e o período de tempo H1 para treinar e testar os modelos. Os modelos são treinados com base em dados históricos dos primeiros 7 meses de 2023. E para testar o desempenho dos modelos treinados, usei dados históricos de agosto de 2023.
E antes de iniciar a fase de pré-treinamento dos modelos, precisamos coletar um conjunto de dados de treinamento. Conforme mencionado anteriormente, neste artigo, usei o conjunto de dados de treinamento do artigo anterior, no qual todo o processo é descrito. Tudo o que fiz foi criar uma cópia do arquivo de amostra de treinamento chamado "PDT.bd".
Depois disso, executei o EA de pré-treinamento em tempo real.
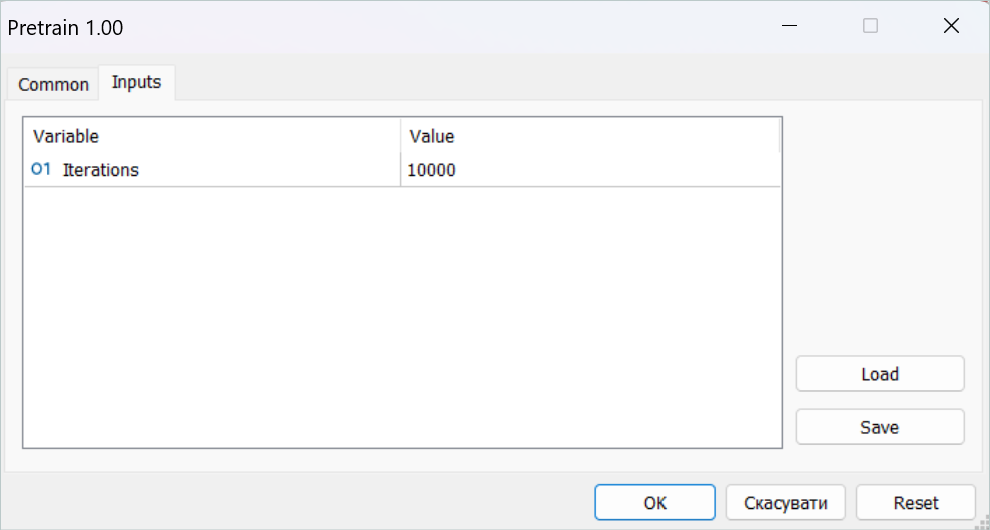
Gostaria de lembrá-lo de que todos os EAs de treinamento de modelos trabalham com gráficos on-line. Ao mesmo tempo, todo o processo de aprendizado ocorre off-line, sem operações de negociação.
Nesse estágio, você precisa ser paciente. O processo de pré-treinamento é bastante demorado. E deixei meu computador ligado por mais de 24 horas.
Em seguida, passamos para o processo de ajuste fino. Em seguida, os autores do método falam sobre o aprendizado on-line. Alternei entre não treinar o modelo por um longo período e testá-lo no intervalo de treinamento no testador de estratégias. Mas o principal era "aquecer" o modelo usando uma amostra de treinamento coletada anteriormente.
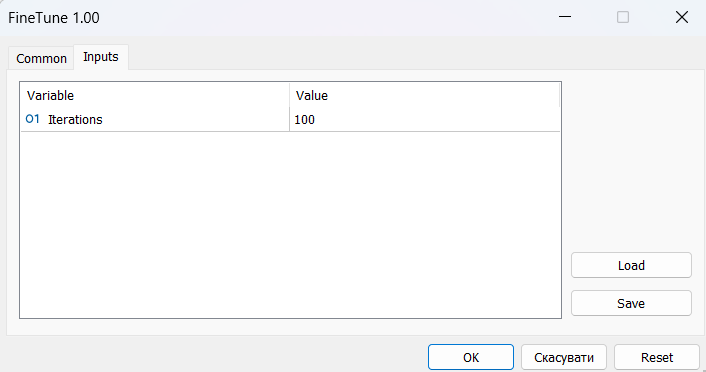
Para o período de ajuste fino, precisei de várias dezenas de iterações sucessivas de pré-treinamento e teste de modelos, o que também exigiu tempo e esforço.
No entanto, os resultados do treinamento não foram tão animadores. Como resultado do treinamento, obtive um modelo de negociação de volume mínimo com sucesso variável. Em algumas partes do histórico, a linha de equilíbrio mostrou uma clara tendência de aumento. Outros estão sofrendo um declínio. Em geral, os resultados do modelo nos dados de treinamento e nos novos dados foram próximos de "0".
Os aspectos positivos incluem a capacidade do modelo de transferir a experiência aprendida para novos dados, o que é confirmado pela comparabilidade dos resultados dos testes tanto na seção de dados históricos da amostra de treinamento como no intervalo de histórico subsequente. Além disso, podemos observar um excesso significativo do tamanho de uma operação positiva em relação a outra com prejuízo. Em ambos os gráficos de dados históricos, observamos que o tamanho da operação lucrativa média excede a perda máxima. No entanto, todos os aspectos positivos são nivelados pela baixa participação de operações com lucro, que é um pouco menor que 40% em ambos os intervalos históricos.


Assim, ao testar o modelo com dados históricos para agosto de 2023 (novos dados), o modelo fez 18 operações. E apenas 39% delas foram fechadas com lucro. Ao mesmo tempo, a operação máxima lucrativa foi de 11,26, o que é quase três vezes mais do que a perda máxima de 4,76. E a operação lucrativa média foi de 5,15, com uma perda média de 3,19. O fator de lucro para o período de teste foi de 1,03.
Obviamente, para aumentar a parcela de operações boas, é necessária uma análise adicional dos resultados obtidos e o ajuste fino do modelo. O método mostra potencial, mas é necessário treinar o modelo por um longo período.
Considerações finais
Neste artigo, apresentamos o pretrained decision transformer (PDT), que fornece um algoritmo de pré-treinamento não supervisionado para o aprendizado por reforço com o decision transformer (DT). Com base no conhecimento de estados futuros durante o treinamento do modelo, o PDT é capaz de extrair um rico conhecimento a priori dos dados de treinamento. Esse conhecimento pode ser ainda mais ajustado na fase de pré-treinamento dos modelos, pois o PDT associa cada oportunidade futura a um retorno apropriado e seleciona a recompensa máxima prevista. Isso permite que você tome as melhores decisões possíveis.
No entanto, o PDT exige mais tempo de treinamento e recursos computacionais em comparação com o DT e o ODT discutidos anteriormente, o que pode levar a dificuldades práticas devido à limitação dos recursos disponíveis. Além disso, o treinamento de modelos gera uma compensação entre a diversidade de comportamentos estudados e sua consistência. Os experimentos práticos realizados pelos autores do método indicam que o valor ideal depende do conjunto de dados específico. E para aprimorar a codificação de estados futuros, podemos aplicar técnicas adicionais.
Não poderia estar mais de acordo com as conclusões dos autores do método. Nossa experiência prática confirma totalmente o que foi dito. O treinamento de modelos é bastante longo e consome muito tempo. Para desenvolver a maior variedade possível de habilidades de Agente, é necessária uma amostra de treinamento bastante extensa. Obviamente, usamos dados não rotulados para o pré-treinamento, o que facilita o processo de coleta de dados. Ainda assim a questão permanece quanto à disponibilidade de recursos para coleta de dados, ao processamento de dados e ao treinamento de modelos.
Referências
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Faza1.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | Pretrain.mq5 | Expert Advisor | EA de pré-treinamento |
| 3 | FineTune.mq5 | Expert Advisor | Ajuste fino do Expert Advisor |
| 4 | Test.mq5 | Expert Advisor | EA para testar o modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura para descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13712
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso