
Neuronale Netze leicht gemacht (Teil 39): Go-Explore, ein anderer Ansatz zur Erkundung

Einführung
Wir setzen das Thema der Umgebungserkundung beim Verstärkungslernen fort. In früheren Artikeln dieser Reihe haben wir uns bereits mit Algorithmen zur Erkundung der Umgebung durch Neugier und Uneinigkeit in einem Ensemble von Modellen beschäftigt. Beide Ansätze nutzten intrinsische Belohnungen, um den Agenten zu motivieren, in ähnlichen Situationen unterschiedliche Aktionen auszuführen und gleichzeitig neue Gebiete zu erkunden. Das Problem ist jedoch, dass die intrinsische Belohnung abnimmt, je besser die Umgebung erforscht wird. In komplexen Fällen mit seltenen Belohnungen oder wenn der Agent auf dem Weg zur Belohnung Strafen erhalten kann, ist dieser Ansatz möglicherweise nicht sehr effektiv. In diesem Artikel schlage ich vor, sich mit einem etwas anderen Ansatz zur Untersuchung der Umgebung vertraut zu machen – dem Go-Explore-Algorithmus.
1. Der Algorithmus Go-Explore
Go-Explore ist ein Verstärkungslernalgorithmus, der entwickelt wurde, um optimale Lösungen für komplexe Probleme zu finden, die einen großen Aktions- und Zustandsraum haben. Der Algorithmus wurde von Adrien Ecoffet entwickelt und wurde in dem Artikel Go-Explore: a New Approach for Hard-Exploration Problems beschrieben.
Er nutzt evolutionäre Algorithmen und Techniken des maschinellen Lernens, um effizient optimale Lösungen für komplexe und schwer lösbare Probleme zu finden.
Der Algorithmus beginnt mit der Erkundung einer großen Anzahl zufälliger Pfade, den so genannten „Basisexplorationen“. Dann speichert es mit Hilfe eines evolutionären Algorithmus die besten gefundenen Lösungen und kombiniert sie, um neue Pfade zu erstellen. Diese neuen Pfade werden dann mit den bisherigen besten Lösungen verglichen, und wenn sie besser sind, werden sie gespeichert. Dieser Vorgang wird so lange wiederholt, bis die optimale Lösung gefunden ist.
Go-Explore verwendet auch eine Technik namens „Recorder“, um die besten gefundenen Lösungen zu speichern und sie für die Erstellung neuer Pfade wiederzuverwenden. Auf diese Weise kann der Algorithmus bessere Lösungen finden, als wenn er einfach weiter zufällige Pfade erkunden würde.
Einer der Hauptvorteile von Go-Explore ist seine Fähigkeit, optimale Lösungen für komplexe und schwer lösbare Probleme zu finden, bei denen andere Algorithmen des Reinforcement Learning versagen könnten. Er ist auch in der Lage, effizient unter verringerter Belohnungen zu lernen, was für andere Algorithmen eine Herausforderung darstellen kann.
Insgesamt ist Go-Explore ein leistungsfähiges Werkzeug zur Lösung von Reinforcement-Learning-Problemen und kann in verschiedenen Bereichen, einschließlich Robotik, Computerspiele und künstliche Intelligenz im Allgemeinen, effektiv eingesetzt werden.
Die Hauptidee von Go-Explore besteht darin, sich an vielversprechende Zustände zu erinnern und zu ihnen zurückzukehren. Dies ist von grundlegender Bedeutung für einen effektiven Betrieb, wenn die Anzahl der Belohnungen begrenzt ist. Diese Idee ist so flexibel und breit gefächert, dass sie auf vielfältige Weise umgesetzt werden kann.
Im Gegensatz zu den meisten Reinforcement-Learning-Algorithmen konzentriert sich Go-Explore nicht auf die direkte Lösung des Zielproblems, sondern darauf, relevante Zustände und Aktionen im Zustandsraum zu finden, die zum Erreichen des Zielzustands führen können. Um dies zu erreichen, hat der Algorithmus zwei Hauptphasen: Suche und Wiederverwendung.
Die erste Phase besteht darin, alle Zustände im Zustandsraum zu durchlaufen und jeden besuchten Zustand in einer Zustands-“Karte“ festzuhalten. Danach beginnt der Algorithmus, jeden besuchten Zustand genauer zu untersuchen und Informationen über Aktionen zu sammeln, die zu anderen interessanten Zuständen führen können.
In der zweiten Phase geht es darum, bereits gelernte Zustände und Aktionen wiederzuverwenden, um neue Lösungen zu finden. Der Algorithmus speichert die erfolgreichsten Trajektorien und verwendet sie, um neue Zustände zu erzeugen, die zu noch erfolgreicheren Lösungen führen können.
Der Go-Explore-Algorithmus funktioniert wie folgt:
- Sammeln eines Archivs von Beispielen: Der Agent startet das Spiel, zeichnet jede Leistung auf und speichert sie im Archiv. Anstatt die Zustände selbst zu speichern, enthält das Archiv Beschreibungen der Aktionen, die zum Erreichen eines bestimmten Zustands geführt haben.
- Iterative Erkundung: Bei jeder Iteration wählt der Agent einen zufälligen Zustand aus dem Archiv aus und spielt das Spiel ab diesem Zustand erneut. Es speichert alle neuen Zustände, die es erreicht, und fügt sie dem Archiv zusammen mit einer Beschreibung der Aktionen hinzu, die zu diesen Zuständen geführt haben.
- Beispielbasiertes Lernen: Nach der iterativen Erkundung lernt der Algorithmus aus den gesammelten Beispielen mit Hilfe einer Art von Verstärkungslernalgorithmus.
- Wiederholungen: Der Algorithmus wiederholt die iterative Erkundung und das beispielbasierte Lernen, bis er das gewünschte Leistungsniveau erreicht.
Das Ziel des Go-Explore-Algorithmus ist es, die Anzahl der erforderlichen Spielwiederholungen zu minimieren, um ein hohes Leistungsniveau zu erreichen. Es ermöglicht dem Agenten, einen großen Zustandsraum mit Hilfe einer Beispieldatenbank zu erkunden, was den Lernprozess beschleunigt und eine bessere Leistung ermöglicht.
Go-Explore ist ein leistungsfähiger und effizienter Algorithmus, der bei der Lösung komplexer Reinforcement-Learning-Probleme gut abschneidet.
2. Implementierung mittels MQL5
In unserer Implementierung werden wir, anders als bei den bisher betrachteten, nicht den gesamten Algorithmus in einem Programm zusammenfassen. Die Stufen des Go-Explore-Algorithmus sind so unterschiedlich, dass es effizienter wäre, für jede Stufe ein eigenes Programm zu erstellen.
2.1. Erste Phase: Erkundung
Zunächst erstellen wir ein Programm, um die erste Phase des Algorithmus zu implementieren, nämlich die Erkundung der Umgebung und das Sammeln eines Archivs von Beispielen. Bevor wir mit der Implementierung beginnen, müssen wir die Grundlagen des zu entwickelnden Algorithmus festlegen.
Wenn wir mit der Untersuchung der Umgebung beginnen, müssen wir alle ihre Zustände so vollständig wie möglich erforschen. In diesem Stadium haben wir nicht das Ziel, eine optimale Strategie zu finden. So seltsam es klingen mag, wir werden hier kein neuronales Netz verwenden, da wir nicht nach einer Strategie oder Optimierungspolitik suchen. Dies wird die Aufgabe der zweiten Phase sein. In diesem Stadium führen wir einfach zufällige Aktionen mit mehreren Agenten durch und zeichnen alle Systemzustände auf, die jeder Agent besucht.
Aber auf diese Weise erhalten wir einen Haufen zufälliger, nicht zusammenhängender Zustände. Wie sieht es mit der Erforschung der Umgebung aus? Was hilft es, wenn jeder Agent nur eine Handlung in jedem Zustand ausführt, ohne die positiven und negativen Seiten der anderen Handlungen zu lernen? Deshalb brauchen wir den zweiten Schritt des Algorithmus. Wir wählen nach dem Zufallsprinzip oder nach einer vordefinierten Richtlinie Zustände aus dem Archiv aus. Wir wiederholen alle Schritte, bis dieser Zustand erreicht ist. Und dann bestimmen wir wieder zufällig die Aktionen des Agenten, bis wir das Ende der untersuchten Episode erreichen. Wir fügen auch neue Zustände zu unserem Beispielarchiv hinzu.
Diese beiden Schritte des Algorithmus bilden die erste Phase – die Erkundung.
Bitte beachten Sie einen weiteren Punkt. Für eine wirksame Forschung müssen wir mehrere Mittel einsetzen. Um mehrere unabhängige Agenten parallel laufen zu lassen, werden wir den Multithreading-Optimierer des Strategy Testers verwenden. Basierend auf den Ergebnissen jedes Durchlauf überträgt der Agent sein akkumuliertes Zustandsarchiv an ein einziges Zentrum zur Generalisierung.
Nachdem wir die wichtigsten Punkte des Algorithmus festgelegt haben, können wir mit seiner Umsetzung beginnen. Wir werden unsere Arbeit damit beginnen, eine Struktur für die Erfassung des Zustands und des Weges dorthin zu schaffen. Hier stoßen wir auf die erste Einschränkung: Um die Ergebnisse jeder Iteration zu übergeben, können Sie im Strategy Tester ein Array beliebigen Typs verwenden. Sie sollte jedoch keine komplexen Strukturen enthalten, die String-Werte und dynamische Arrays verwenden. Dies bedeutet, dass wir keine dynamischen Arrays verwenden können, um den Pfad und den Zustand des Systems zu beschreiben. Wir müssen sofort ihre Dimensionen bestimmen. Um die Programmorganisation flexibel zu gestalten, werden wir die wichtigsten Werte als Konstanten ausgeben. In diesen Konstanten werden die Tiefe des analysierten Verlaufs in Balken (HistoryBars) und die Größe des Pfadpuffers (Buffer_Size) festgelegt. Sie können Ihre eigenen Werte verwenden, die zu Ihren spezifischen Problemen passen.
#define HistoryBars 20 #define Buffer_Size 600 #define FileName "GoExploer"
Außerdem geben wir gleich den Dateinamen für die Aufzeichnung des Beispielarchivs an.
Die Daten werden im Format der Zellstruktur aufgezeichnet. Wir erstellen zwei Arrays in der Struktur: ein Array mit ganzen Zahlen, um die Pfade zur Erreichung des Zustands zu schreiben – actions; und das zweite für echte Arrays, um die Beschreibung des erreichten Zustands aufzuzeichnen – state. Da wir statische Datenarrays verwenden müssen, führen wir die Variable total_actions ein, um die Größe des vom Agenten zurückgelegten Weges anzugeben. Zusätzlich fügen wir einen realen Variablenwert hinzu, um den Wert des Zustandsgewichts zu erfassen. Sie wird verwendet, um die Auswahl von Zuständen für die anschließende Erkundung zu priorisieren.
//+------------------------------------------------------------------+ //| Cell | //+------------------------------------------------------------------+ struct Cell { int actions[Buffer_Size]; float state[HistoryBars * 12 + 9]; int total_actions; float value; //--- Cell(void); //--- bool Save(int file_handle); bool Load(int file_handle); };
Wir initialisieren die erstellten Variablen und Arrays im Strukturkonstruktor. Bei der Erstellung der Struktur füllen wir das Pfad-Array mit dem Wert „-1“. Wir füllen auch das Zustandsfeld und die Variablen mit Nullwerten.
Cell::Cell(void) { ArrayInitialize(actions, -1); ArrayInitialize(state, 0); value = 0; total_actions = 0; }
Es sei daran erinnert, dass wir die gesammelten Zustände in einer Beispiel-Archivdatei speichern werden. Daher müssen wir Methoden für die Arbeit mit Dateien entwickeln. Die Methode der Datenspeicherung basiert auf dem uns bereits bekannten Algorithmus. Wir haben mehr als einmal die Daten der erstellten Klassen aufgezeichnet.
Die Methode erhält als Parameter den Handle der Datei für die Datenaufzeichnung. Wir prüfen den Wert sofort. Wird ein falsches Handle empfangen, wird die Methode mit dem Ergebnis „false“ beendet.
Nach erfolgreicher Übergabe des Kontrollblocks schreiben wir „999“ in die Datei, um unsere Struktur zu identifizieren. Danach werden wir die Werte der Variablen und Arrays speichern. Um später das korrekte Lesen von Arrays zu gewährleisten, müssen wir vor dem Schreiben ihrer Daten die Array-Dimension angeben. Um Speicherplatz zu sparen, speichern wir nur die tatsächlichen Pfaddaten und nicht das gesamte Array „actions“. Da wir den Wert der Variablen total_actions bereits gespeichert haben, geben wir die Größe dieses Arrays nicht mehr an. Beim Speichern des Arrays „state“ geben wir zunächst die Größe des Arrays an und speichern dann seinen Inhalt. Achten Sie darauf, dass Sie den Ablauf jedes Vorgangs kontrollieren. Nachdem alle Daten erfolgreich gespeichert wurden, schließen wir die Methode mit dem Ergebnis „true“ ab.
bool Cell::Save(int file_handle) { if(file_handle <= 0) return false; if(FileWriteInteger(file_handle, 999) < INT_VALUE) return false; if(FileWriteFloat(file_handle, value) < sizeof(float)) return false; if(FileWriteInteger(file_handle, total_actions) < INT_VALUE) return false; for(int i = 0; i < total_actions; i++) if(FileWriteInteger(file_handle, actions[i]) < INT_VALUE) return false; int size = ArraySize(state); if(FileWriteInteger(file_handle, size) < INT_VALUE) return false; for(int i = 0; i < size; i++) if(FileWriteFloat(file_handle, state[i]) < sizeof(float)) return false; //--- return true; }
Die Methode zum Lesen von Daten aus der Datei „Load“ ist ähnlich aufgebaut. Es führt Datenlesevorgänge unter strikter Einhaltung der Reihenfolge der Schreibvorgänge durch. Der vollständige Code der Methode ist in der Anlage unten zu finden.
Nach der Erstellung einer Struktur zur Beschreibung eines Systemzustands und der Art und Weise, wie dieser erreicht wird, gehen wir zur Erstellung eines Expert Advisors über, um die erste Phase des Go-Explore-Algorithmus zu implementieren. Nennen wir den Advisor Faza1.mq5. Auch wenn wir zufällige Aktionen durchführen, ohne die Marktsituation zu analysieren, werden wir dennoch Indikatoren verwenden, um den Zustand des Systems zu beschreiben. Daher werden wir ihre Parameter von früheren Expert Advisors übernehmen. Die externe Variable „Start“ wird verwendet, um den Zustand des Beispielarchivs anzuzeigen. Wir werden etwas später darauf zurückkommen.
input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; input int Start = 100; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod = 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price bool TrainMode = true;
Nach der Angabe der externen Parameter werden wir globale Variablen erstellen. Hier erstellen wir 2 Arrays von Strukturen, die den Zustand des Systems beschreiben. Der Erste (Base) wird verwendet, um die Zustände des aktuellen Durchlaufs zu erfassen. Der Zweite (Total) wird für die Aufzeichnung eines vollständigen Archivs von Beispielen verwendet.
Hier deklarieren wir auch Objekte für die Durchführung von Handelsoperationen und das Laden von historischen Daten. Sie sind denen, die bisher verwendet wurden, völlig ähnlich.
Für den aktuellen Algorithmus werden wir folgendes erstellen:
- action_count — Zähler der Vorgänge;
- actions — ein Array zur Aufzeichnung der während der Sitzung durchgeführten Aktionen;
- StartCell — Zustandsbeschreibungsstruktur für den Beginn einer Erkundung;
- bar — Zähler der Schritte seit dem Start des Expert Advisors.
Cell Base[Buffer_Size]; Cell Total[]; CSymbolInfo Symb; CTrade Trade; //--- MqlRates Rates[]; CiRSI RSI; CiCCI CCI; CiATR ATR; CiMACD MACD; //--- int action_count = 0; int actions[Buffer_Size]; Cell StartCell; int bar = -1;
In der Funktion OnInit werden zunächst die Objekte Indikator und Handelsoperation initialisiert. Diese Funktionalität ist völlig identisch mit den zuvor besprochenen EAs.
int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
Dann versuchen wir, das Archiv mit den Beispielen zu laden, die während des vorherigen Betriebs des EA erstellt worden sein könnten. Beide Optionen sind hier zulässig. Wenn es uns gelingt, das Beispielarchiv zu laden, versuchen wir, daraus das Element mit dem in der externen Variablen „Start“ angegebenen Index zu lesen. Wenn es kein solches Element gibt, nehmen wir ein zufälliges Element und kopieren es in die „StartCell“-Struktur. Dies ist der Ausgangspunkt unserer Erkundung. Wenn die Datenbank mit den Beispielen nicht geladen ist, beginnen wir mit der Studie von vorne.
//--- if(LoadTotalBase()) { int total = ArraySize(Total); if(total > Start) StartCell = Total[Start]; else { total = (int)(((double)MathRand() / 32768.0) * (total - 1)); StartCell = Total[total]; } } //--- return(INIT_SUCCEEDED); }
Ich habe ein so umfangreiches System zur Erstellung eines Ausgangspunkts für die Erkundung verwendet, um verschiedene Szenarien organisieren zu können, ohne den EA-Code zu ändern.
Nachdem alle Operationen abgeschlossen sind, beenden wir die EA-Initialisierungsfunktion mit dem Ergebnis INIT_SUCCEEDED.
Um das Beispielarchiv zu laden, haben wir die Funktion LoadTotalBase verwendet. Um die Beschreibung des Initialisierungsprozesses zu vervollständigen, lassen Sie uns seinen Algorithmus betrachten. Diese Funktion hat keine Parameter. Stattdessen wird die zuvor definierte Dateinamenkonstante FileName verwendet.
Achten Sie darauf, dass die Datei sowohl in der ersten als auch in der zweiten Phase des Algorithmus verwendet wird. Aus diesem Grund haben wir die Konstante FileName in der Strukturdatei der Zustandsbeschreibung angegeben.
Im Hauptteil der Funktion wird zunächst die Datei geöffnet, um Daten zu lesen und das Ergebnis der Operation anhand des Handle-Wertes zu überprüfen.
Wenn die Datei erfolgreich geöffnet wurde, lesen wir die Anzahl der Elemente im Beispielarchiv. Wir ändern die Größe des Arrays zum Lesen von Daten und implementieren eine Schleife zum Lesen von Daten aus der Datei. Um jede einzelne Struktur zu lesen, verwenden wir die zuvor erstellte Methode „Load“ unserer Systemstatus-Speicherstruktur.
Bei jeder Iteration kontrollieren wir den Ablauf der Operationen. Bevor wir die Funktion in einer der Optionen beenden, müssen wir die zuvor geöffnete Datei schließen.
bool LoadTotalBase(void) { int handle = FileOpen(FileName + ".bd", FILE_READ | FILE_BIN | FILE_COMMON); if(handle < 0) return false; int total = FileReadInteger(handle); if(total <= 0) { FileClose(handle); return false; } if(ArrayResize(Total, total) < total) { FileClose(handle); return false; } for(int i = 0; i < total; i++) if(!Total[i].Load(handle)) { FileClose(handle); return false; } FileClose(handle); //--- return true; }
Nachdem wir den EA-Initialisierungsalgorithmus erstellt haben, gehen wir zur Methode der Tick-Verarbeitung OnTick über. Diese Methode wird vom Terminal aufgerufen, wenn ein neues Tick-Ereignis im Chart des EA auftritt. Wir müssen nur das Ereignis der Eröffnung eines neuen Balkens verarbeiten. Um eine solche Kontrolle zu implementieren, verwenden wir die Funktion IsNewBar. Der Algorithmus wurde vollständig vom vorherigen EA kopiert und wird daher hier nicht weiter erläutert.
void OnTick() { //--- if(!IsNewBar()) return;
Als Nächstes erhöhen wir den Zähler der Schritte ab dem Start des EA und vergleichen seinen Wert mit der Anzahl der Schritte vor dem Start der Erkundung. Wenn wir den Zustand des Beginns der Erkundung noch nicht erreicht haben, dann nehmen wir die nächste Aktion aus dem Pfad zum Zielzustand und führen sie aus. Danach warten wir auf die Eröffnung einer neuen Kerze.
bar++; if(bar < StartCell.total_actions) { switch(StartCell.actions[bar]) { case 0: Trade.Buy(Symb.LotsMin(), Symb.Name()); break; case 1: Trade.Sell(Symb.LotsMin(), Symb.Name()); break; case 2: for(int i = PositionsTotal() - 1; i >= 0; i--) if(PositionGetSymbol(i) == Symb.Name()) Trade.PositionClose(PositionGetInteger(POSITION_IDENTIFIER)); break; } return; }
Nach Erreichen des Startzustands der Erkundung kopieren wir den vorherigen Pfad in das Array der Aktionen des aktuellen Agenten.
if(bar == StartCell.total_actions) ArrayCopy(actions, StartCell.actions, 0, 0, StartCell.total_actions);
Anschließend aktualisieren wir die historischen Daten der Indikatoren.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Danach erstellen wir ein Array mit der aktuellen Beschreibung des Systemzustands. In dieser Datei werden wir historische Daten von Indikatoren und Kurswerten sowie Informationen über den Kontostatus und offene Positionen aufzeichnen.
float state[249]; MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- state[b * 12] = (float)Rates[b].close - open; state[b * 12 + 1] = (float)Rates[b].high - open; state[b * 12 + 2] = (float)Rates[b].low - open; state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; state[b * 12 + 4] = (float)sTime.hour; state[b * 12 + 5] = (float)sTime.day_of_week; state[b * 12 + 6] = (float)sTime.mon; state[b * 12 + 7] = rsi; state[b * 12 + 8] = cci; state[b * 12 + 9] = atr; state[b * 12 + 10] = macd; state[b * 12 + 11] = sign; } //--- state[240] = (float)AccountInfoDouble(ACCOUNT_BALANCE); state[240 + 1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); state[240 + 2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); state[240 + 3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); state[240 + 4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } state[240 + 5] = (float)buy_value; state[240 + 6] = (float)sell_value; state[240 + 7] = (float)buy_profit; state[240 + 8] = (float)sell_profit;
Danach führen wir eine zufällige Aktion durch.
//--- int act = SampleAction(4); switch(act) { case 0: Trade.Buy(Symb.LotsMin(), Symb.Name()); break; case 1: Trade.Sell(Symb.LotsMin(), Symb.Name()); break; case 2: for(int i = PositionsTotal() - 1; i >= 0; i--) if(PositionGetSymbol(i) == Symb.Name()) Trade.PositionClose(PositionGetInteger(POSITION_IDENTIFIER)); break; }
Und wir speichern den aktuellen Zustand in einem Array der besuchten Zustände des aktuellen Agenten.
Bitte beachten Sie, dass wir als Anzahl der Schritte zum aktuellen Zustand die Summe der Schritte zum Zustand zu Beginn der Erkundung und der zufälligen Schritte der Erkundung angeben. Wir haben die Zustände vor Beginn der Erkundung gespeichert, da sie bereits in unserem Beispielarchiv gespeichert sind. Gleichzeitig müssen wir den vollständigen Pfad zu jedem Zustand speichern.
Als Zustandswert geben wir den umgekehrten Wert der Veränderung des Kontokapitals an. Wir werden sie als Leitfaden für die Festlegung von Prioritäten bei der Erkundung von Staaten verwenden. Ziel dieser Prioritätensetzung ist es, Maßnahmen zur Minimierung der Verluste zu finden. Dies kann zu einer Steigerung der Gesamtgewinne führen. Außerdem können wir später den Kehrwert dieses Wertes als Belohnung beim Training der Strategie in der zweiten Phase des Go-Explore-Algorithmus verwenden.
//--- copy cell actions[action_count] = act; Base[action_count].total_actions = action_count+StartCell.total_actions; if(action_count > 0) { ArrayCopy(Base[action_count].actions, actions, 0, 0, Base[action_count].total_actions+1); Base[action_count - 1].value = Base[action_count - 1].state[241] - state[241]; } ArrayCopy(Base[action_count].state, state, 0, 0); //--- action_count++; }
Nachdem wir die Daten über den aktuellen Stand gespeichert haben, erhöhen wir den Schrittzähler und warten auf die nächste Kerze.
Wir haben einen Agentenalgorithmus zur Erkundung der Umgebung entwickelt. Nun müssen wir den Prozess der Datensammlung von allen Bearbeitern in einem einzigen Archiv von Beispielen organisieren. Zu diesem Zweck muss jeder Agent nach Abschluss der Tests die gesammelten Daten an das Generalisierungszentrum senden. Wir organisieren diese Funktionalität in der Methode OnTester. Sie wird vom Strategietester nach Abschluss eines jeden Durchlaufs aufgerufen.
Ich habe beschlossen, nur die rentablen Durchläufe zu behalten. Dadurch wird der Umfang des Beispielarchivs erheblich reduziert und der Lernprozess beschleunigt. Wenn Sie die Politik mit der höchstmöglichen Genauigkeit trainieren wollen und Sie nicht in den Ressourcen begrenzt sind, dann können Sie alle Durchläufe speichern. Dies wird Ihrer Politik helfen, die Umgebung besser zu erkunden.
Wir prüfen zunächst den Erfolg des Durchlaufes. Falls erforderlich, senden wir die Daten mit der Funktion FrameAdd.
//+------------------------------------------------------------------+ //| Tester function | //+------------------------------------------------------------------+ double OnTester() { //--- double ret = 0.0; //--- double profit = TesterStatistics(STAT_PROFIT); action_count--; if(profit > 0) FrameAdd(MQLInfoString(MQL_PROGRAM_NAME), action_count, profit, Base); //--- return(ret); }
Bitte beachten Sie, dass wir vor dem Senden die Anzahl der Schritte um 1 reduzieren, da uns die Ergebnisse der letzten Aktion nicht bekannt sind.
Um den Prozess der Datensammlung in einem gemeinsamen Archiv von Beispielen zu organisieren, werden wir 3 Funktionen verwenden. Bei der Initialisierung des Optimierungsprozesses laden wir zunächst das Beispielarchiv, falls zuvor eines angelegt wurde. Dieser Vorgang wird in der Funktion OnTesterInit durchgeführt.
//+------------------------------------------------------------------+ //| TesterInit function | //+------------------------------------------------------------------+ void OnTesterInit() { //--- LoadTotalBase(); }
Anschließend wird jeder Durchlauf in der Funktion OnTesterPass verarbeitet. Hier implementieren wir die Sammlung von Daten aus allen verfügbaren Frames und fügen sie dem Array des gemeinsamen Beispielarchivs hinzu. Die Funktion FrameNext liest den nächsten Frame. Wurden die Daten erfolgreich geladen, wird true zurückgegeben. Wenn jedoch ein Fehler beim Lesen der Rahmendaten auftritt, wird false zurückgegeben. Mit dieser Eigenschaft können wir eine Schleife organisieren, um Daten zu lesen und sie zu unserem gemeinsamen Array hinzuzufügen.
//+------------------------------------------------------------------+ //| TesterPass function | //+------------------------------------------------------------------+ void OnTesterPass() { //--- ulong pass; string name; long id; double value; Cell array[]; while(FrameNext(pass, name, id, value, array)) { int total = ArraySize(Total); if(name != MQLInfoString(MQL_PROGRAM_NAME)) continue; if(id <= 0) continue; if(ArrayResize(Total, total + (int)id, 10000) < 0) return; ArrayCopy(Total, array, total, 0, (int)id); } }
Am Ende des Optimierungsprozesses wird die Funktion OnTesterDeinit aufgerufen. Hier sortieren wir zunächst unsere Datenbank in absteigender Reihenfolge nach dem „Wert“ der Zustandsbeschreibung. Dadurch können wir die Elemente, die den größten Verlust verursachen, an den Anfang des Arrays verschieben.
//+------------------------------------------------------------------+ //| TesterDeinit function | //+------------------------------------------------------------------+ void OnTesterDeinit() { //--- bool flag = false; int total = ArraySize(Total); printf("total %d", total); Cell temp; Print("Start sorting..."); do { flag = false; for(int i = 0; i < (total - 1); i++) if(Total[i].value < Total[i + 1].value) { temp = Total[i]; Total[i] = Total[i + 1]; Total[i + 1] = temp; flag = true; } } while(flag); Print("Saving..."); SaveTotalBase(); Print("Saved"); }
Danach speichern wir das Beispielarchiv mit der Methode SaveTotalBase in einer Datei. Der Algorithmus ist ähnlich wie bei der oben beschriebenen LoadTotalBase-Methode. Der vollständige Code aller Funktionen ist im Anhang enthalten.
Damit ist unsere Arbeit an der ersten Phase der EA abgeschlossen. Kompilieren Sie ihn und gehen Sie zum Strategietester. Wählen Sie den EA Faza1.ex5, ein Symbol, einen Testzeitraum (in unserem Fall Training), langsame Optimierung mit allen Optionen.
Es wird ein Parameter des EAs optimiert – Start. Sie wird verwendet, um die Anzahl der laufenden Agenten zu ermitteln. In der Anfangsphase habe ich den EA mit einer kleinen Anzahl von Agenten gestartet. Auf diese Weise können wir im Handumdrehen ein erstes Archiv mit Beispielen erstellen.
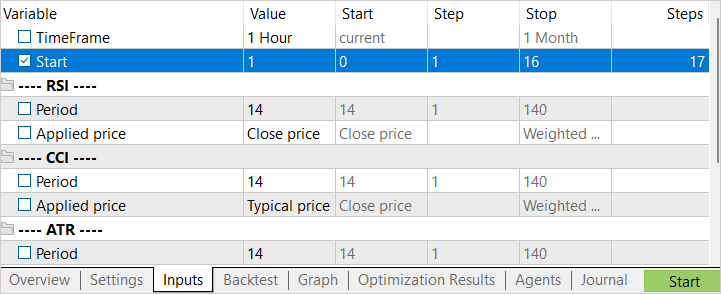
Nach Abschluss der ersten Optimierungsphase erhöhen wir die Anzahl der Testagnten. Hier haben wir 2 Ansätze für den nächsten Start. Wenn wir versuchen wollen, die beste Aktion in den unrentabelsten Zuständen zu finden, dann sollte das Optimierungsintervall für den Parameter Start von „0“ aus angegeben werden. Um zufällige Zustände zu wählen, setzen wir einen absichtlich großen Anfangswert für die Parameteroptimierung als Ausgangspunkt für die Erkundung. Der endgültige Optimierungswert des Parameters hängt von der Anzahl der zu startenden Agenten ab. Der Wert in der Spalte Schritte entspricht der Anzahl der Agenten, die während des Optimierungsprozesses (Training) gestartet wurden.
2.2. Zweite Phase: Training der Politik anhand von Beispielen
Während unser erster EA daran arbeitet, eine Datenbank mit Beispielen zu erstellen, gehen wir zur Arbeit an der zweiten Phase des EA über.
Bei meiner Umsetzung wich ich in Phase 2 ein wenig von dem von den Autoren des Artikels vorgeschlagenen Verfahren zum Training der Politik ab. In dem Artikel wird der Einsatz einer Simulationsmethode zum Trainieren der Politik vorgeschlagen. Dabei wird ein modifizierter Ansatz für die Algorithmen des verstärkten Lernens verwendet. In einem separaten Abschnitt wird der Agent darauf trainiert, die Aktionen einer erfolgreichen Strategie aus dem Beispielarchiv zu wiederholen, und dann wird ein Standardverstärkungslernverfahren angewendet. In der ersten Phase ist das Demonstrationssegment des „Lehrers“ maximal. Der Agent darf keine schlechteren Ergebnisse erzielen als der „Lehrer“. Mit fortschreitendem Training verringert sich das „Lehrer“-Intervall. Der Agent muss lernen, die Strategie des Lehrers zu optimieren.
Bei meiner Umsetzung habe ich diese Phase in 2 Stufen unterteilt. In der ersten Phase trainieren wir den Agenten auf ähnliche Weise wie beim überwachten Lernprozess. Wir geben jedoch nicht die richtige Aktion an. Stattdessen passen wir den prognostizierten Belohnungswert an. Für diese Phase erstellen wir den EA Faza2.mq5.
In den EA-Code fügen wir ein Element zur Beschreibung des Systemzustands und eine Klasse eines vollständig parametrisierten FQF-Modells ein.
//+------------------------------------------------------------------+ //| Includes | //+------------------------------------------------------------------+ #include "Cell.mqh" #include "..\RL\FQF.mqh" //+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input int Iterations = 100000;
Sie hat ein Minimum an externen Parametern. Wir geben nur die Anzahl der Trainingsiterationen des Modells an.
Zu den globalen Parametern gehören eine Modellklasse, ein Objekt zur Zustandsbeschreibung und ein Array von Belohnungen. Wir müssen auch ein Array deklarieren, um das Archiv der Beispiele zu laden.
CNet StudyNet; //--- float dError; datetime dtStudied; bool bEventStudy; //--- CBufferFloat State1; CBufferFloat *Rewards; Cell Base[];
Bei der EA-Initialisierungsmethode laden wir zunächst das Beispielarchiv hoch. In diesem Fall ist dies einer der wichtigsten Punkte. Wenn beim Laden des Beispielarchivs ein Fehler auftritt, stehen uns keine Quelldaten zum Trainieren des Modells zur Verfügung. Im Falle eines Ladefehlers wird die Funktion daher mit dem Ergebnis INIT_FAILED beendet.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!LoadTotalBase()) return(INIT_FAILED); //--- if(!StudyNet.Load(FileName + ".nnw", dError, dError, dError, dtStudied, true)) { CArrayObj *model = new CArrayObj(); if(!CreateDescriptions(model)) { delete model; return INIT_FAILED; } if(!StudyNet.Create(model)) { delete model; return INIT_FAILED; } delete model; } if(!StudyNet.TrainMode(true)) return INIT_FAILED; //--- bEventStudy = EventChartCustom(ChartID(), 1, 0, 0, "Init"); //--- return(INIT_SUCCEEDED); }
Nach dem Laden des Archivs mit Beispielen wird das Modell für das Training initialisiert. Wie üblich versuchen wir zunächst, ein vortrainiertes Modell zu laden. Wenn das Modell aus irgendeinem Grund nicht geladen werden kann, wird ein neues Modell mit Zufallsgewichten erstellt. Die Modellbeschreibung wird mit der Funktion CreateDescriptions festgelegt.
Nach erfolgreicher Modellinitialisierung erstellen wir ein nutzerdefiniertes Ereignis, um den Modelllernprozess zu starten. Wir haben den gleichen Ansatz für das überwachte Lernen verwendet.
Hier schließen wir die Initialisierungsfunktion des EA ab.
Bitte beachten Sie, dass wir in diesem EA keine Objekte zum Laden von historischen Kursdaten und Indikatoren erstellt haben. Der gesamte Lernprozess basiert auf Beispielen. Das Beispielarchiv speichert alle Beschreibungen des Systemzustands, einschließlich Informationen über das Konto und die offenen Positionen.
Das von uns erstellte nutzerdefinierte Ereignis wird in der Funktion OnChartEvent verarbeitet. Hier prüfen wir nur das Auftreten des erwarteten Ereignisses und rufen die Trainingsfunktion des Modells auf.
//+------------------------------------------------------------------+ //| ChartEvent function | //+------------------------------------------------------------------+ void OnChartEvent(const int id, const long &lparam, const double &dparam, const string &sparam) { //--- if(id == 1001) Train(); }
Das eigentliche Modelltraining ist in der Funktion Train implementiert. Diese Funktion hat keine Parameter. Im Hauptteil der Funktion bestimmen wir zunächst die Größe des Beispielarchivs und speichern die Anzahl der Millisekunden ab dem Systemstart in einer lokalen Variablen. Wir werden diesen Wert verwenden, um den Nutzer regelmäßig über den Fortschritt des Modelltrainings zu informieren.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total = ArraySize(Base); uint ticks = GetTickCount();
Nach ein wenig Vorarbeit organisieren wir eine Trainingsschleife des Modells. Die Anzahl der Schleifeniterationen entspricht dem Wert der externen Variablen. Wir werden auch für eine erzwungene Unterbrechung der Schleife und das Beenden des Programms auf Wunsch des Nutzers sorgen. Dies kann mit der Funktion IsStopped geschehen. Wenn der Nutzer das Programm schließt, gibt die angegebene Funktion true zurück.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int i = 0; int count = 0; int total_max = 0; i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (total - 1)); State1.AssignArray(Base[i].state); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; }
Im Schleifenkörper wählen wir zufällig ein Beispiel aus dem Archiv aus und kopieren den Zustand in den Datenpuffer. Dann führen wir den Feedforward-Durchlauf des Modells durch.
if(!StudyNet.feedForward(GetPointer(State1), 12, true)) return;
Anschließend wird die ausgeführte Aktion im aktuellen Beispiel abgerufen, die Ergebnisse des Feedforward-Verfahrens abgeglichen und die Belohnung für die ausgeführte Aktion aktualisiert.
int action = Base[i].total_actions; if(action < 0) { iter--; continue; } action = Base[i].actions[action]; if(action < 0 || action > 3) action = 3; StudyNet.getResults(Rewards); if(!Rewards.Update(action, -Base[i].value)) return;
Achten Sie auf die folgenden beiden Momente. Wenn es in dem Beispiel keine Aktion gibt (der Ausgangszustand ist ausgewählt), dann verringern wir den Iterationszähler und wählen ein neues Beispiel. Bei der Aktualisierung der Belohnung wird der Wert mit dem umgekehrten Vorzeichen genommen. Erinnern Sie sich? Bei der Sicherung des Zustandes haben wir einen positiven Wert angesetzt, um das Kapital zu verringern. Und das ist ein negativer Punkt.
Nach der Aktualisierung der Belohnung führen wir einen Backpropagation-Durchlauf durch und aktualisieren die Gewichte.
if(!StudyNet.backProp(GetPointer(Rewards))) return; if(GetTickCount() - ticks > 500) { Comment(StringFormat("%.2f%% -> Error %.8f", iter * 100.0 / (double)(Iterations), StudyNet.getRecentAverageError())); ticks = GetTickCount(); } }
Am Ende der Schleifeniterationen wird geprüft, ob die Lernprozessinformationen für den Nutzer aktualisiert werden müssen. In diesem Beispiel wird das Kommentarfeld des Diagramms alle 0,5 Sekunden aktualisiert.
Damit sind die Operationen im Schleifenkörper abgeschlossen, und wir fahren mit einem neuen Beispiel aus der Datenbank fort.
Nachdem alle Iterationen der Schleife abgeschlossen sind, wird das Kommentarfeld gelöscht. Wir geben die Informationen in das Protokoll aus und leiten das Herunterfahren des EA ein.
Comment(""); //--- PrintFormat("%s -> %d -> %10.7f", __FUNCTION__, __LINE__, StudyNet.getRecentAverageError()); ExpertRemove(); //--- }
Wenn wir den EA schließen, löschen wir die verwendeten dynamischen Objekte in seiner Deinitialisierungsmethode und speichern das trainierte Modell auf der Festplatte.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if(!!Rewards) delete Rewards; //--- StudyNet.Save(FileName + ".nnw", 0, 0, 0, 0, true); }
Nachdem der EA der ersten Phase das Archiv mit den Beispielen gesammelt hat, müssen wir nur noch den EA der zweiten Phase auf dem Diagramm ausführen, und das Modelltraining kann beginnen. Bitte beachten Sie, dass wir im Gegensatz zum EA der ersten Phase den EA der zweiten Phase nicht im Strategietester laufen lassen, sondern ihn an einen realen Chart anhängen. In den EA-Parametern geben wir die Anzahl der Iterationen der Lernprozessschleife an und überwachen den Prozess.
Um optimale Ergebnisse zu erzielen, können die erste und die zweite Phase wiederholt werden. In diesem Fall ist es möglich, zunächst die erste Phase N-mal und dann die zweite Phase M-mal zu wiederholen. Oder Sie können die Schleife aus erster Phase + zweiter Phase mehrmals wiederholen.
Zur Feinabstimmung der Politik verwenden wir den dritten EA GE-learning.mq5. Er implementiert einen klassischen Algorithmus des verstärkten Lernens. Wir werden jetzt nicht im Detail auf alle Funktionen des EAs eingehen. Der vollständige Code des EAs befindet sich im Anhang. Betrachten wir nur die Verarbeitungsfunktion der Ticks OnTick.
Wie in der ersten EA-Phase verarbeiten wir nur das Eröffnungsereignis einer neuen Kerze. Wenn es keine gibt, führen wir die Funktion einfach aus und warten auf den richtigen Moment.
Wenn das neue Eröffnungsereignis einer neuen Kerze eintritt, speichern wir zunächst den letzten Status, die durchgeführte Aktion und die Änderung des Kapitals im Erfahrungswiedergabepuffer. Und wir schreiben den Aktienindikator in eine globale Variable um, um Änderungen bei der nächsten Kerze zu verfolgen.
void OnTick() { if(!IsNewBar()) return; //--- float current = (float)AccountInfoDouble(ACCOUNT_EQUITY); if(Equity >= 0 && State1.Total() == (HistoryBars * 12 + 9)) cReplay.AddState(GetPointer(State1), Action, (double)(current - Equity)); Equity = current;
Dann aktualisieren wir die Historie der Preise und Indikatoren.
//--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Wir erstellen eine Beschreibung des aktuellen Zustands des Systems. Hier müssen wir darauf achten, dass die generierte Beschreibung des Systemzustands vollständig einem ähnlichen Prozess in der ersten Phase des EA entspricht. Denn der Betrieb und die Feinabstimmung sollten mit Daten durchgeführt werden, die mit den Daten der Trainingsstichprobe vergleichbar sind.
State1.Clear(); for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State1.Add((float)Rates[b].close - open) || !State1.Add((float)Rates[b].high - open) || !State1.Add((float)Rates[b].low - open) || !State1.Add((float)Rates[b].tick_volume / 1000.0f) || !State1.Add(sTime.hour) || !State1.Add(sTime.day_of_week) || !State1.Add(sTime.mon) || !State1.Add(rsi) || !State1.Add(cci) || !State1.Add(atr) || !State1.Add(macd) || !State1.Add(sign)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } } //--- if(!State1.Add((float)AccountInfoDouble(ACCOUNT_BALANCE)) || !State1.Add((float)AccountInfoDouble(ACCOUNT_EQUITY)) || !State1.Add((float)AccountInfoDouble(ACCOUNT_MARGIN_FREE)) || !State1.Add((float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL)) || !State1.Add((float)AccountInfoDouble(ACCOUNT_PROFIT))) return; //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); return; } } if(!State1.Add((float)buy_value) || !State1.Add((float)sell_value) || !State1.Add((float)buy_profit) || !State1.Add((float)sell_profit)) return;
Danach führen wir den Feed-Forward-Durchlauf aus. Auf der Grundlage der Ergebnisse des Feedforward-Durchlaufs bestimmen wir eine Aktion und führen sie durch.
if(!StudyNet.feedForward(GetPointer(State1), 12, true)) return; Action = StudyNet.getAction(); switch(Action) { case 0: Trade.Buy(Symb.LotsMin(), Symb.Name()); break; case 1: Trade.Sell(Symb.LotsMin(), Symb.Name()); break; case 2: for(int i = PositionsTotal() - 1; i >= 0; i--) if(PositionGetSymbol(i) == Symb.Name()) Trade.PositionClose(PositionGetInteger(POSITION_IDENTIFIER)); break; }
Bitte beachten Sie, dass wir in diesem Fall keine Explorationspolitik betreiben. Wir halten uns streng an die erlernte Politik.
Am Ende der Tick-Verarbeitungsfunktion wird die Uhrzeit überprüft. Einmal am Tag, um Mitternacht, aktualisieren wir die Richtlinie des Agenten anhand des Erfahrungswiedergabepuffers.
MqlDateTime time; TimeCurrent(time); if(time.hour == 0) { int repl_action; double repl_reward; for(int i = 0; i < 10; i++) { if(cReplay.GetRendomState(pstate1, repl_action, repl_reward, pstate2)) return; if(!StudyNet.feedForward(pstate1, 12, true)) return; StudyNet.getResults(Rewards); if(!Rewards.Update(repl_action, (float)repl_reward)) return; if(!StudyNet.backProp(GetPointer(Rewards), DiscountFactor, pstate2, 12, true)) return; } } //--- }
Die vollständigen Codes aller EAs finden Sie im Anhang.
3. Tests
Alle drei EAs wurden in Übereinstimmung mit dem Go-Explore-Algorithmus nacheinander getestet:
- Mehrere aufeinanderfolgende Starts des EA der ersten Phase im Optimierungsmodus des Strategietesters, um ein Archiv von Beispielen zu erstellen.
- Mehrere Iterationen der Politiktraining durch die zweite Phase der EA.
- Abschließende Feinabstimmung im Strategietester mit Hilfe von Algorithmen des verstärkten Lernens.
Alle Tests wurden, wie in der gesamten Artikelserie, mit historischen Daten des EURUSD, Zeitrahmen H1, durchgeführt. Die Indikatorparameter wurden standardmäßig ohne Anpassungen verwendet.
Die Tests ergaben recht gute Ergebnisse, die in den nachstehenden Screenshots zu sehen sind.


Hier sehen wir ein ziemlich gleichmäßiges Schaubild des Saldenwachstums. Die Testdaten ergaben einen Gewinnfaktor von 6,0 und einen Erholungsfaktor von 3,34. Von den 30 durchgeführten Geschäften waren 22 gewinnbringend, was einem Anteil von 73,3 % entspricht. Der durchschnittliche Gewinn eines Handels ist mehr als 2-mal höher als der durchschnittliche Verlust. Der maximale Gewinn pro Handel ist 3,5 Mal höher als der maximale Verlust pro Handel.
Bitte beachten Sie, dass der EA nur Kaufgeschäfte ausführte und diese ohne signifikante Verluste schloss. Der Grund für das Fehlen von Verkaufsgeschäfte ist Gegenstand weiterer Untersuchungen.
Die Testergebnisse sind vielversprechend, aber sie wurden nur über einen kurzen Zeitraum erzielt. Um die Ergebnisse des Algorithmus zu bestätigen, sind weitere Experimente über einen längeren Zeitraum erforderlich.
Schlussfolgerung
In diesem Artikel stellen wir den Go-Explore-Algorithmus vor, einen neuen Ansatz zur Lösung komplexer Verstärkungslernprobleme. Es basiert auf der Idee, sich an vielversprechende Zustände im Zustandsraum zu erinnern und diese erneut aufzurufen, um die gewünschte Leistung schneller zu erreichen. Der Hauptunterschied zwischen Go-Explore und anderen Algorithmen besteht darin, dass der Schwerpunkt auf der Suche nach relevanten Zuständen und Aktionen liegt und nicht auf der direkten Lösung des Zielproblems.
Wir haben drei Expert Advisors entwickelt, die nacheinander ausgeführt werden. Jeder von ihnen führt seine eigene Algorithmus aus, um das gemeinsame Ziel des Policy Lernens zu erreichen. Policy bedeutet hier die Handelsstrategie.
Der Algorithmus wurde anhand historischer Daten getestet und zeigte eines der besten Ergebnisse. Allerdings wurden die Ergebnisse im Strategietester innerhalb eines kurzen Zeitraums erzielt. Bevor der EA auf realen Konten eingesetzt werden kann, muss er daher umfassend getestet und das Modell über einen längeren, repräsentativen Zeitraum trainiert werden.
Referenzen
- Go-Explore: a New Approach for Hard-Exploration Problems
- Neuronale Netze leicht gemacht (Teil 35): Modul für intrinsische Neugierde
- Neuronale Netze leicht gemacht (Teil 36): Relationales Verstärkungslernen
- Neuronale Netze leicht gemacht (Teil 37): Sparse Attention (Verringerte Aufmerksamkeit)
- Neuronale Netze leicht gemacht (Teil 38): Selbstüberwachte Erkundung bei Unstimmigkeit (Self-Supervised Exploration via Disagreement)
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Faza1.mq5 | Expert Advisor | Expert Advisor der ersten Phase |
| 2 | Faza2.mql5 | Expert Advisor | Expert Advisor der zweiten Phase |
| 3 | GE-lerning.mq5 | Expert Advisor | Expert Advisor für die Feinabstimmung der Strategie |
| 4 | Cell.mqh | Klassenbibliothek | Aufbau der Systemzustandsbeschreibung |
| 5 | FQF.mqh | Klassenbibliothek | Klassenbibliothek für die Organisation der Arbeit eines vollständig parametrisierten Modells |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/12558
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Der erste Einsatz des MetaTrader VPS: eine Schritt-für-Schritt-Anleitung
Der erste Einsatz des MetaTrader VPS: eine Schritt-für-Schritt-Anleitung
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Ich habe diesen Fehler.
2023.05.07 20:04:44.281 Core 01 pass 359 tested with error "critical runtime error 502 in OnTester function(array out of range, module Experts\GoExploer\Faza1.ex5, file Faza1.mq5, line 223, col 12)" in 0:00:00.202
//--- Zelle kopieren
actions[action_count] = act;
Base[action_count].total_actions = action_count+StartCell.total_actions;
Wie kann man das Problem lösen?
Wenn der Fehler ständig zunimmt, versuchen Sie, den Trainingskoeffizienten zu verringern.
Ich habe diesen Fehler.
2023.05.07 20:04:44.281 Core 01 pass 359 tested with error "critical runtime error 502 in OnTester function (array out of range, module Experts\GoExploer\Faza1.ex5, file Faza1.mq5, line 223, col 12)" in 0:00:00.202
//--- Zelle kopieren
actions[action_count] = act;
Base[action_count].total_actions = action_count+StartCell.total_actions;
Wie ist das Problem zu lösen?
Wie lange dauert das Studium?
Wie lange dauert das Studium?
H1 Daten, von 1 Apr 2023~ 30 Apr 2023