
ニューラルネットワークが簡単に(第79回):状態の文脈におけるFeature Aggregated Queries (FAQ)

はじめに
先に説明した方法のほとんどは、環境の状態を静的なものとして分析するもので、マルコフ過程の定義に完全に対応しています。当然ながら、環境状態の記述には過去のデータを詰め込み、モデルに必要な情報を可能な限り提供しましたが、このモデルは状態の変化のダイナミクスを評価するものではありません。これは前回の記事で紹介した方法にも通じます。DFFTは静止画像中の物体を検出するために開発されました。
しかし、値動きの観察から、変化のダイナミクスが十分な確率で次の動きの強さと方向を示すことがあることがわかります。論理的に、次にビデオ内の物体を検出する方法に注目します。
ビデオにおける物体検出には多くの特徴があり、画像領域では遭遇しない、動きによって生じる物体の特徴の変化の問題を解決しなければなりません。解決策の1つは、時間情報を利用し、隣接するフレームの特徴を組み合わせることです。「FAQ:Feature Aggregated Queries for Transformer-based Video Object Detectors」では、ビデオ内のオブジェクトを検出するための新しいアプローチを提案しています。この論文の著者は、Transformerベースのモデルに対するクエリを集約することで、クエリの質を向上させています。この目標を達成するために、入力フレームの特徴に従ってクエリを生成し、集約する実用的な方法が提案されています。本論文で提供されている広範な実験結果は、提案手法の有効性を検証するものです。提案されたアプローチは、画像やビデオ内のオブジェクトを検出するための幅広い手法に拡張し、その効率を向上させることができます。
1. Feature Aggregated Queriesアルゴリズム
ビデオ内のオブジェクトを検出するためにTransformerアーキテクチャを使用するのは、FAQ法が初めてではありません。しかし、Transformerを使用した既存のビデオオブジェクト検出器は、クエリを集約することでオブジェクトの特徴表現を改善しています。 素朴なアイデアは、隣接するフレームからのクエリを平均化することです。クエリはランダムに初期化され、訓練プロセスで使用されます。隣接クエリは現在のフレーム𝑰に対してΔ𝑸に集約され、以下のように表されます。
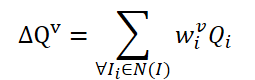
ここで、wは集約のための学習可能な計量です。
学習可能な重みを作成するという単純なアイデアは、入力フレームの特徴の余弦類似度に基づいています。既存のビデオオブジェクト検出器に倣い、FAQメソッドの著者は数式を用いて集約重みを生成します。
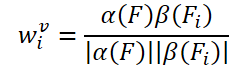
α、βは写像関数、||は正規化を表します。
現在のフレーム𝑰とその隣接フレーム𝑰の関連する特徴量iを𝑭と𝑭iとします。その結果、オブジェクトを特定する確率は次のように表すことができます。
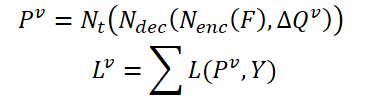
ここで𝑷vは、集約されたクエリΔ𝑸vを用いた予測確率です。
バニラクエリ集約モジュールには問題があります。これらの隣接クエリ𝑸iはランダムに初期化され、対応するフレーム𝑰iと関連付けられていません。したがって、隣接クエリ𝑸iは、速い動きによる性能劣化の問題を克服するのに十分な時間的または意味的な情報を提供しません。集計に使用される重みwiは、関数𝑭と𝑭iに関係します。ランダムに開始されるクエリの数に対する制約が十分ではありません。そのため、FAQメソッドの著者は、集約モジュールQueryを、Queryに制約を追加し、隣接するフレームに応じて重みを調整できる動的バージョンに更新することを提案しています。単純な実装のアイデアは、入力フレームの特徴𝑭iから直接クエリ𝑸iを生成することです。しかし、この手法の著者がおこなった実験によれば、この手法は訓練が難しく、常に悪い結果を生みます。上記の素朴な考えとは対照的に、この手法の著者は、ランダムに初期化されたクエリから、元のデータに適応した新しいクエリを生成することを提案しています。まず、Queryベクトルとして、基本と動的の2種類を定義します。学習と操作の過程で、入力フレームの特徴𝑭i、𝑭に従って基本クエリから動的クエリが生成されます。
![]()
ここで、Mは、特徴𝑭と 𝑭iに従って基本クエリQbと動的クエリQdの関係を構築するための写像関数です。
まず、基本クエリをrクエリごとにグループ分けしてみましょう。次に、各グループについて、同じ重みを使用して、現在のグループの加重平均クエリを決定します。
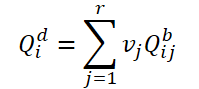
動的クエリ𝑸の関係を構築するためにdと対応するフレーム𝑰iとの関係を構築するために、この手法の著者は大域的な特徴量を用いて重み𝑽を生成することを提案しています。
![]()
ここで、Aは特徴量テンソルの次元を変更し、グローバルレベルの特徴量を作成するための大域的なプーリング操作です。
Gは、大域的な特徴量を動的テンソルQueryの次元に投影できる写像関数です。
このように、ソースデータの特徴に基づく動的なクエリ集約のプロセスは、次のように更新することができます。
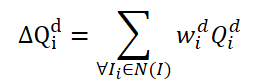
訓練の間、この手法の著者は動的なクエリと基本的なクエリの両方を集約することを提案しています。どちらのタイプのクエリも、同じ重みと対応する予測値𝑷で集約され、対応する予測𝑷dと 𝑷bが生成されます。ここでは、両予測の双方向の一致誤差も計算します。ハイパーパラメータγは、誤差の影響のバランスをとるために使用されます。
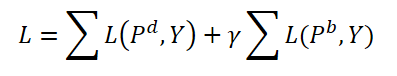
操作中は、元のモデルをわずかに複雑にするだけの動的クエリ𝑸dとそれに対応する予測𝑷dのみを最終結果として使用します。
以下は、著者の手法の可視化です。

2.MQL5を使用した実装
アルゴリズムの理論的側面について考察しました。では、MQL5を使用して提案されたアプローチを実践してみましょう。
上記のFAQ法の説明からわかるように、FAQ法の主な貢献は、Transformerデコーダで動的クエリテンソルを生成し、集約するためのモジュールを作成することです。DFFT法の著者は、デコーダが無効であることを理由にこの方式を除外したことを思い出してください。今回の研究では、デコーダを追加し、FAQ法の著者によって提案された動的Queryエンティティを使用するコンテキストで、その有効性を評価します。
2.1 動的Queryクラス
動的なクエリを生成するために、新しいクラスCNeuronFAQOCLを作成します。新しいオブジェクトはニューラル層の基本クラスCNeuronBaseOCLを継承します。
class CNeuronFAQOCL : public CNeuronBaseOCL { protected: //--- CNeuronConvOCL cF; CNeuronBaseOCL cWv; CNeuronBatchNormOCL cNormV; CNeuronBaseOCL cQd; CNeuronXCiTOCL cDQd; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronFAQOCL(void) {}; ~CNeuronFAQOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint heads, uint units_count, uint input_units, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronFAQOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
新しいメソッドでは、オーバーライドされたメソッドの基本セットに加えて、5つの内部ニューラル層を追加します。それぞれの目的については、実施時に説明します。すべての内部オブジェクトを静的に宣言したので、クラスのコンストラクタとデストラクタを空にしておくことができます。
クラスオブジェクトはCNeuronFAQOCL::Initメソッドで初期化されます。メソッドのパラメータには、内部オブジェクトを初期化するための主要なパラメータがすべて含まれています。メソッド本体では、親クラスの関連メソッドを呼び出します。すでにご存知のように、このメソッドは、受け取ったパラメータの必要最小限の制御と、継承されたオブジェクトの初期化を実装しています。
bool CNeuronFAQOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint heads, uint units_count, uint input_units, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
このクラスには活性化関数は指定されていません。
activation = None;
次に、内部オブジェクトを初期化します。ここで、Queryメソッドの著者によって提案された、動的Queryを生成するアプローチに目を向けます。ソースデータの特徴に基づいて基本クエリの集約重みを生成するために、3つの層を作成しましょう。まず、ソースデータの特徴量を畳み込み層に通し、隣接する環境状態のパターンを分析します。
if(!cF.Init(0, 0, OpenCL, 3 * window, window, 8, fmax((int)input_units - 2, 1), optimization_type, batch)) return false; cF.SetActivationFunction(None);
モデルの訓練と運用プロセスの安定性を高めるため、受信データを正規化します。
if(!cNormV.Init(8, 1, OpenCL, fmax((int)input_units - 2, 1) * 8, batch, optimization_type)) return false; cNormV.SetActivationFunction(None);
そして、基本クエリ集計の重みテンソルのサイズにデータを圧縮します。結果として得られる重みが[0,1]の範囲になるように、シグモイド活性化関数を使用します。
if(!cWv.Init(units_count * window_out, 2, OpenCL, 8, optimization_type, batch)) return false; cWv.SetActivationFunction(SIGMOID);
FAQアルゴリズムによれば、結果として得られる集約係数のベクトルに、訓練の最初にランダムに生成される基本クエリの行列を掛け合わせる必要があります。私の実装では、もう少し踏み込んで基本クエリを訓練することにしました。全結合層を使用するよりいい方法は思いつきません。この層には集約係数のベクトルを与え、 全結合層の重み行列は訓練中の基本クエリのテンソルです。
if(!cQd.Init(0, 4, OpenCL, units_count * window_out, optimization_type, batch)) return false; cQd.SetActivationFunction(None);
次に来るのは動的クエリーの集約です。FAQ法の著者は、その論文の中で、さまざまな集計方法の実験結果を紹介しています。最も効果的だったのは、Transformerアーキテクチャを使用した動的Queryの集約でした。上記の結果を受けて、動的クエリの集約にCNeuronXCiTOCLクラスオブジェクトを使用します。
if(!cDQd.Init(0, 5, OpenCL, window_out, 3, heads, units_count, 3, optimization_type, batch)) return false; cDQd.SetActivationFunction(None);
不必要なデータコピー操作を排除するために、クラスと誤差勾配の結果バッファを置き換えます。
if(Output != cDQd.getOutput()) { Output.BufferFree(); delete Output; Output = cDQd.getOutput(); } if(Gradient != cDQd.getGradient()) { Gradient.BufferFree(); delete Gradient; Gradient = cDQd.getGradient(); } //--- return true; }
オブジェクトを初期化した後、CNeuronFAQOCL::feedForwardメソッドでフィードフォワードプロセスの編成に移ります。ここではすべてがシンプルでわかりやすいです。メソッドのパラメータでは、環境の状態を記述するためのパラメータを持つソースデータレイヤへのポインタを受け取ります。メソッド本体では、内部オブジェクトに関連するフィードフォワードメソッドを交互に呼び出します。
bool CNeuronFAQOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- if(!cF.FeedForward(NeuronOCL)) return false;
まず、畳み込み層を通して環境の記述を転送し、得られたデータを正規化します。
if(!cNormV.FeedForward(GetPointer(cF))) return false;
次に、基となるクエリの集約係数を生成します。
if(!cWv.FeedForward(GetPointer(cNormV))) return false;
動的クエリを作成します。
if(!cQd.FeedForward(GetPointer(cWv))) return false;
それらをCNeuronXCiTOCLクラスオブジェクトに集約します。
if(!cDQd.FeedForward(GetPointer(cQd))) return false; //--- return true; }
データバッファの置換をおこなっているため、不要なコピー操作をおこなうことなく、内部層cDQdの結果がCNeuronFAQOCLクラスの結果バッファに反映されます。これで、このメソッドは完成します。
次に、バックプロパゲーションメソッドCNeuronFAQOCL::calcInputGradientsとCNeuronFAQOCL::updateInputWeightsを作成します。フィードフォワードメソッドと同様に、ここでは内部オブジェクトの関連メソッドを呼び出しますが、順序は逆です。したがって、本稿では彼らのアルゴリズムについては詳しく検討しません。動的クエリ生成クラスCNeuronFAQOCLのすべてのメソッドの完全なコードは、記事の添付ファイルを使用して調べることができます。
2.2 Cross-Attentionクラス
次のステップは、Cross-Attentionクラスの作成です。先に、ADAPTメソッドの実装の枠組みの中で、すでにCross-Attention層CNeuronMH2AttentionOCLを作成しました。しかしその時は、1つのテンソルの異なる次元間の関係を分析しました。今のタスクは少し違います。CNeuronFAQOCLクラスから生成された動的クエリと、私たちのモデルのエンコーダから圧縮された環境の状態との依存関係を評価する必要があります。つまり、2つの異なるテンソルの関係を評価する必要があります。
この機能を実装するために、必要な機能の一部を前述のCNeuronMH2AttentionOCLクラスから継承した新しいクラスCNeuronCrossAttentionを作成します。
class CNeuronCrossAttention : public CNeuronMH2AttentionOCL { protected: uint iWindow_K; uint iUnits_K; CNeuronBaseOCL *cContext; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context); virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); virtual bool attentionOut(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context); virtual bool AttentionInsideGradients(void); public: CNeuronCrossAttention(void) {}; ~CNeuronCrossAttention(void) { delete cContext; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_k, uint units_k, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); //--- virtual int Type(void) const { return defNeuronCrossAttenOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); };
標準的なオーバーライドされたメソッドに加えて、ここでは2つの新しい変数に注目してください。
- iWindow_K:2番目のテンソルの1つの要素に対する説明ベクトルのサイズ
- iUnits_K:2番目のテンソルのシーケンスの要素数
さらに、必要に応じてソースオブジェクトとして初期化される補助ニューラル層cContextへの動的ポインタを追加します。このオブジェクトはオプションで補助的な役割を果たすので、このクラスのコンストラクタは空のままです。しかし、クラスのデストラクタでは、動的オブジェクトを削除する必要があります。
~CNeuronCrossAttention(void) { delete cContext; }
いつものように、オブジェクトはCNeuronCrossAttention::Initメソッドで初期化されます。メソッドのパラメータでは、作成された層のアーキテクチャに関する必要なデータを取得します。メソッド本体では、基本ニューラル層クラスCNeuronBaseOCL::Initの関連メソッドを呼び出します。
bool CNeuronCrossAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_k, uint units_k, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
初期化メソッドを呼び出しているのは、直接の親クラスCNeuronMH2AttentionOCLではなく、基本クラスCNeuronBaseOCLであることに注意してください。これは、CNeuronCrossAttentionと CNeuronMH2AttentionOCLクラスのアーキテクチャの違いによるものです。そのため、メソッド本体ではさらに、新規オブジェクトだけでなく継承オブジェクトも初期化します。
まず、層の設定を保存します。
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iWindow_K = fmax(window_k, 1); iUnits_K = fmax(units_k, 1); iHeads = fmax(heads, 1); activation = None;
次に、Queryエンティティ生成層を初期化します。
if(!Q_Embedding.Init(0, 0, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, optimization_type, batch)) return false; Q_Embedding.SetActivationFunction(None);
KeyエンティティとValueエンティティについても同様におこないます。
if(!KV_Embedding.Init(0, 0, OpenCL, iWindow_K, iWindow_K, 2 * iWindowKey * iHeads, iUnits_K, optimization_type, batch)) return false; KV_Embedding.SetActivationFunction(None);
ここで生成されるQueryエンティティを、CNeuronFAQOCLクラスで生成される動的Queryと混同しないでください。
FAQメソッドの実装の一部として、生成された動的クエリを初期データとしてこのクラスに入力します。ここでは、Q_Embedding層がAttentionヘッドにそれらを分配すると言うことができます。そしてKV_Embedding層は、エンコーダから受け取った環境状態の圧縮表現からエンティティを生成します。
クラスの初期化メソッドに戻りましょう。エンティティ生成層を初期化した後、依存係数行列バッファScoreを作成します。
ScoreIndex = OpenCL.AddBuffer(sizeof(float) * iUnits * iUnits_K * iHeads, CL_MEM_READ_WRITE); if(ScoreIndex == INVALID_HANDLE) return false;
ここでは、Multi-Head Attention結果の層も作成します。
if(!MHAttentionOut.Init(0, 0, OpenCL, iWindowKey * iUnits * iHeads, optimization_type, batch)) return false; MHAttentionOut.SetActivationFunction(None);
そして、Attentionヘッドの集合体の層を作成します。
if(!W0.Init(0, 0, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, optimization_type, batch)) return false; W0.SetActivationFunction(None); if(!AttentionOut.Init(0, 0, OpenCL, iWindow * iUnits, optimization_type, batch)) return false; AttentionOut.SetActivationFunction(None);
次はFeedForwardブロックです。
if(!FF[0].Init(0, 0, OpenCL, iWindow, iWindow, 4 * iWindow, iUnits, optimization_type, batch)) return false; if(!FF[1].Init(0, 0, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iUnits, optimization_type, batch)) return false; for(int i = 0; i < 2; i++) FF[i].SetActivationFunction(None);
初期化メソッドの最後に、バッファの置換を整理します。
Gradient.BufferFree(); delete Gradient; Gradient = FF[1].getGradient(); //--- return true; }
クラスを初期化した後、いつものようにフィードフォワードパスの編成に進みます。このクラスでは、OpenCLプログラム側で新しいカーネルを作成することはありません。この場合、親クラスのプロセスを実装するために作成されたカーネルを使用します。しかし、カーネルを呼び出すためのメソッドに若干の調整を加える必要があります。例えば、CNeuronCrossAttention::attentionOutメソッドでは、タスク空間とローカルグループを示す配列をKeyエンティティシーケンスのサイズ(コード内で赤くハイライトされている)だけ変更します。
bool CNeuronCrossAttention::attentionOut(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits/*Q units*/, iUnits_K/*K units*/, iHeads}; uint local_work_size[3] = {1, iUnits_K, 1}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_q, Q_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_kv, KV_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_out, MHAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionOut, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
フィードフォワードアルゴリズム全体は、CNeuronCrossAttention::feedForwardメソッドのトップレベルで記述されています。親クラスの関連メソッドとは異なり、このメソッドはニューラル層の2つのオブジェクトへのポインタをパラメータとして受け取ります。これらのデータには2つのテンソルのデータが含まれており、依存性を分析することができます。
bool CNeuronCrossAttention::feedForward(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context) { //--- if(!Q_Embedding.FeedForward(NeuronOCL)) return false; //--- if(!KV_Embedding.FeedForward(Context)) return false;
メソッド本体では、まず受信したデータからエンティティを生成します。そこで、Multi-Head Attentionメソッドを呼び出します。
if(!attentionOut()) return false;
注目の結果を集計します。
if(!W0.FeedForward(GetPointer(MHAttentionOut))) return false;
そして、それらをソースデータと合計します。その後、シーケンスの要素内で結果を正規化します。FAQ法の実装のコンテキストでは、正規化は個々の動的クエリのコンテキストで実行されます。
if(!SumAndNormilize(W0.getOutput(), NeuronOCL.getOutput(), AttentionOut.getOutput(), iWindow)) return false;
その後、データはFeedForwardブロックを通過します。
if(!FF[0].FeedForward(GetPointer(AttentionOut))) return false; if(!FF[1].FeedForward(GetPointer(FF[0]))) return false;
そして、再びデータを合計し、正規化します。
if(!SumAndNormilize(FF[1].getOutput(), AttentionOut.getOutput(), Output, iWindow)) return false; //--- return true; }
以上の操作がすべて成功したら、メソッドを終了します。
これでフィードフォワードメソッドの説明は終わったので、バックプロパゲーションのパスの整理に移ります。ここでは、親クラスの実装の一部として作成されたカーネルも使用し、カーネル呼び出しメソッドCNeuronCrossAttention::AttentionInsideGradientsに特定の変更を加えます。
bool CNeuronCrossAttention::AttentionInsideGradients(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits, iWindowKey, iHeads}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_q, Q_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_qg, Q_Embedding.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kv, KV_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kvg, KV_Embedding.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_outg, MHAttentionOut.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kunits, (int)iUnits_K)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Cross-Attention層を通して誤差勾配を伝播するプロセスは、CNeuronCrossAttention::calcInputGradientsメソッドで実装されています。フィードフォワードメソッドと同様に、このメソッドのパラメータには、2つのデータスレッドを持つ2つの層へのポインタを渡します。
bool CNeuronCrossAttention::calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Context) { if(!FF[1].calcInputGradients(GetPointer(FF[0]))) return false; if(!FF[0].calcInputGradients(GetPointer(AttentionOut))) return false;
データバッファの置換のおかげで、後続の層から得られた誤差勾配は、フィードフォワードブロックの第2層の誤差勾配バッファに直ちに伝搬されます。したがって、データをコピーする必要はありません。次に、FeedForwardブロックの内部層の誤差勾配を分配するメソッドをすぐに呼び出します。
この段階で、FeedForwardブロックとそれに続くニューラル層から受け取った誤差勾配を加えなければなりません。
if(!SumAndNormilize(FF[1].getGradient(), AttentionOut.getGradient(), W0.getGradient(), iWindow, false)) return false;
次に、Attentionヘッドに誤差勾配を分布させます。
if(!W0.calcInputGradients(GetPointer(MHAttentionOut))) return false;
メソッドを呼び出して、誤差勾配をQuery、Key、Valueエンティティに伝搬します。
if(!AttentionInsideGradients()) return false;
KeyとValueエンティティの勾配は、Context(Encoder)層に転送されます。
if(!KV_Embedding.calcInputGradients(Context)) return false;
Queryからの勾配は前の層に転送されます。
if(!Q_Embedding.calcInputGradients(prevLayer)) return false;
誤差勾配を合計することを忘れないでください。
if(!SumAndNormilize(prevLayer.getGradient(), W0.getGradient(), prevLayer.getGradient(), iWindow, false)) return false; //--- return true; }
そしてメソッドを完成させます。
内部オブジェクトパラメータを更新するためのCNeuronCrossAttention::updateInputWeightsメソッドはとてもシンプルです。内部オブジェクトの関連メソッドを1つずつ呼び出すだけです。添付ファイルをご覧ください。また、添付ファイルには必要なファイル操作方法が記載されています。さらに、この記事で使用されているすべてのプログラムとクラスの完全なコードも含まれています。
これで新しいクラスの作成は完了し、モデルアーキテクチャの記述に移ります。
2.3 モデルアーキテクチャ
モデルアーキテクチャはCreateDescriptionsメソッドで示されます。現在のモデルのアーキテクチャは、DFFT法の実装からほぼコピーされています。ただし、デコーダを追加しました。したがって、ActorとCriticはデコーダからデータを受け取ります。モデルの説明を作成するには、4つの動的配列が必要です。
bool CreateDescriptions(CArrayObj *dot, CArrayObj *decoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!dot) { dot = new CArrayObj(); if(!dot) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
エンコーダのモデル(ドット)は、前回の記事からそのままコピーしています。詳しい説明はこちらをご覧ください。
デコーダは、エンコーダの潜在データを位置符号化層のレベルで入力データとして使用します。
//--- Decoder decoder.Clear(); //--- Input layer CLayerDescription *po = dot.At(LatentLayer); if(!po || !(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = po.count * po.window; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
このレベルでは、ローカルスタックに格納されているいくつかの環境状態の埋め込みを、位置符号化ラベルを追加して削除していることを思い出してください。実際には、これらの埋め込みは、GPTBarsローソク足の環境の状態を記述する一連のサインを含んでいます。これはビデオシリーズのフレームと比較することができます。このデータに基づいて、動的なクエリを生成します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFAQOCL; { int temp[] = {QueryCount, po.count}; ArrayCopy(descr.units, temp); } descr.window = po.window; descr.window_out = 16; descr.optimization = ADAM; descr.step = 4; descr.activation = None; if(!decoder.Add(descr)) { delete descr; return false; }
そしてCross-Attentionを実施します。
//--- layer 2 CLayerDescription *encoder = dot.At(dot.Total() - 1); if(!encoder || !(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {QueryCount, encoder.count}; ArrayCopy(descr.units, temp); } { int temp[] = {16, encoder.window}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Actorはデコーダからデータを受け取ります。
//--- Actor actor.Clear(); //--- Input layer encoder = decoder.At(decoder.Total() - 1); if(!encoder || !(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = encoder.units[0] * encoder.windows[0]; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
そして、それを口座ステータスの説明と組み合わせます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
その後、データは2つの全結合層を通過します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
出力では、Actorの方策に確率を加えます。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Criticのモデルはほぼそのままコピーされています。唯一の変更点は、初期データのソースがエンコーダからデコーダに変わったことです。
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(0)); if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(1)); descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.4 環境相互作用EA
この記事を書くにあたり、3つの環境相互作用EAを使用しました。
- Research.mq5
- ResearchRealORL.mq5
- Test.mq5
EA「...\Experts\FAQ\ResearchRealORL.mq5」はモデルアーキテクチャにリンクされていません。すべてのEAは、環境を記述する同じ初期データを分析することによって訓練され、テストされるので、このEAは、異なる記事で何の変更もなく使用されます。そのコードと使用方法の詳細については、こちらをご覧ください。
EA「...\Experts\FAQ\Research.mq5」のコードに、Decoderモデルを追加します。
CNet DOT; CNet Decoder; CNet Actor;
したがって、初期化メソッドでは、このモデルの読み込みを追加し、必要に応じてランダムなパラメータで初期化します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- load models float temp; //--- if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *dot = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, decoder, actor, critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Decoder.Create(decoder) || !Actor.Create(actor)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } delete dot; delete decoder; delete actor; delete critic; } //--- Decoder.SetOpenCL(DOT.GetOpenCL()); Actor.SetOpenCL(DOT.GetOpenCL()); //--- ........ ........ //--- return(INIT_SUCCEEDED); }
この場合、Criticモデルを使用していないことに注意してください。その機能は、環境との相互作用や訓練のためのデータ収集のプロセスには関与しません。
実際の環境との相互作用のプロセスは、OnTickメソッドの中で整理されます。メソッド本体では、まず新しいバーの開始イベントの発生を確認します。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
すべてのプロセスは、クローズ済みのローソク足の分析に基づいています。
必要なイベントが発生すると、まず履歴データをダウンロードします。
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
現在の環境状態を記述するバッファにデータを転送します。
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
そして、口座ステータスとポジションのデータを収集します。
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
受信したデータは口座ステータスバッファにまとめられます。
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
タイムスタンプのハーモニクスもここに加えます。
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
収集されたデータは、まずエンコーダ入力に送られます。
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
エンコーダの動作結果はデコーダに転送されます。
if(!Decoder.feedForward((CNet*)GetPointer(DOT), LatentLayer,(CNet*)GetPointer(DOT))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
その後、Actorに移されます。
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(Decoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } //--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Actorが予測したアクションを読み込み、カウンタ操作は除外します。
vector<float> temp; Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
そして、予測行動を解読し、必要な取引行動を実行します。まず、ロングポジションを実装します。
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
次にショートポジションを実装します。
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
メソッドの最後に、環境とのインタラクションの結果を経験再生バッファに保存します。
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
その他のEAのメソッドに変更はありません。
EA「...\Experts\FAQ\Test.mq5」にも同様の変更を加えました。添付のコードを使用して、両方のEAの完全なコードをご自分で勉強することができます。
2.5 モデル訓練EA
モデルは「...\Experts\FAQ\Study.mq5」EAで訓練されます。以前に開発されたEAと同様、EAの構造は過去の作品からコピーしたものです。モデルアーキテクチャの変更に伴い、デコーダを追加しました。
CNet DOT; CNet Decoder; CNet Actor; CNet Critic;
ご覧の通り、Criticもモデルの訓練プロセスに参加しています。
EA初期化メソッドでは、まず訓練データを読み込みます。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
次に、事前に訓練されたモデルを読み込んでみます。モデルを読み込めない場合は、新しいモデルを作成し、ランダムなパラメータで初期化します。
//--- load models float temp; if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Decoder.Load(FileName + "Dec.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic.Load(FileName + "Crt.nnw", temp, temp, temp, dtStudied, true) ) { CArrayObj *dot = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, decoder, actor, critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Decoder.Create(decoder) || !Actor.Create(actor) || !Critic.Create(critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } delete dot; delete decoder; delete actor; delete critic; }
すべてのモデルを1つのOpenCLコンテキストに転送します。
OpenCL = DOT.GetOpenCL(); Decoder.SetOpenCL(OpenCL); Actor.SetOpenCL(OpenCL); Critic.SetOpenCL(OpenCL);
モデルアーキテクチャのコンプライアンスに対する最小限の制御を実装しています。
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- DOT.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
補助的なデータバッファを作成します。
if(!bGradient.BufferInit(MathMax(AccountDescr, NForecast), 0) || !bGradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
学習過程開始のカスタムイベントを生成します。
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
EAの非初期化メソッドでは、訓練済みモデルを保存し、動的オブジェクトのメモリをクリアします。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); DOT.Save(FileName + "DOT.nnw", 0, 0, 0, TimeCurrent(), true); Decoder.Save(FileName + "Dec.nnw", 0, 0, 0, TimeCurrent(), true); Critic.Save(FileName + "Crt.nnw", 0, 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
モデルを訓練する過程は、Trainメソッドで実装されています。メソッドの本体では、まず、収益性に応じて軌道を選択する確率を決定します。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
次にローカル変数を宣言します。
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
そして、学習プロセスのために入れ子のループのシステムを作ります。
エンコーダアーキテクチャは、履歴データを蓄積するための内部バッファを持つEmbedding層を提供します。この種のアーキテクチャソリューションは、受信したソースデータの履歴シーケンスに非常に敏感です。そのため、モデルを訓練するために、入れ子ループのシステムを構成します。外側のループは訓練バッチの数を数えます。訓練バッチ内の入れ子されたループでは、初期データが過去の時系列で供給されます。
外側ループの本体では、軌道と状態をサンプリングして訓練バッチを開始します。
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
内部バッファをクリアすることで、履歴データの蓄積を訴えました。
DOT.Clear();
訓練パッケージの終了状態を決定します。
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
そして、入れ子の学習ループを構成します。本体では、まず経験再生バッファから環境状態の履歴記述を読み込みます。
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
利用可能なデータを使用して、エンコーダとデコーダにフィードフォワードパスを通します。
//--- Trajectory if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!Decoder.feedForward((CNet*)GetPointer(DOT), LatentLayer, (CNet*)GetPointer(DOT))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
また、口座状態に対応する記述を経験再生バッファから読み込み、データを適切なバッファに転送します。
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
タイムスタンプハーモニクスを追加します。
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
このプロセスは、環境との相互作用に関するEAと完全に同じです。ただし、端末をポーリングするのではなく、経験再生バッファからすべてのデータを読み込みます。
データを受け取った後、ActorとCriticに対して逐次フィードフォワードパスを実行することができます。
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(Decoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- Critic if(!Critic.feedForward((CNet *)GetPointer(Decoder), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
フィードフォワードパスに続いてバックプロパゲーションパスがおこなわれ、その間にモデルパラメータが最適化されます。まず、Actorのバックプロパゲーションパスをおこない、経験再生バッファからのアクションまでの誤差を最小化します。
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, (CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) ||
Actorからの誤差勾配はデコーダに転送されます。
!Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) ||
デコーダは次に、誤差勾配をエンコーダに送信します。デコーダは、エンコーダの2つの層から初期データを受け取り、対応する2つの層に誤差勾配を送信することに注意してください。モデルのパラメータを正しく更新するためには、まず潜在層から勾配を伝播させる必要があります。
!DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) ||
そして初めて、エンコーダモデル全体を通します。
!DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
次に、次のトランジションの報酬を決めます。
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result);
そして、Criticのパラメータを最適化し、その後に誤差勾配をすべての参加モデルに伝達します。
if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) || !DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) || !DOT.backPropGradient((CBufferFloat*)NULL) || !Actor.backPropGradient((CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient), -1, false) || !Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) || !DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) || !DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
ループシステム内での操作が終わたら、訓練の進捗状況をユーザーに知らせ、次の反復に移ります。
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
モデル訓練ループシステムのすべての反復が成功したら、チャートのコメントフィールドを消去します。
Comment("");
また、モデルの訓練結果をログに出力し、EAの終了を開始します。
PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
これで、使用したプログラムのアルゴリズムの説明は終わりです。これらのEAの全コードを以下に添付します。さて、この記事の最終章に移りますが、そこではアルゴリズムをテストします。
3.テスト
この記事では、特徴量集約クエリの手法を学び、MQL5を使用してそのアプローチを実装しました。さて、次はおこなった作業の結果を評価する番です。いつものように、H1時間枠 EURUSDの履歴データでモデルを訓練し、テストしました。モデルは、2023年の最初の7ヶ月間の過去の期間で訓練されています。訓練済みモデルをテストするために、2023年8月からの過去データを使用します。
この記事で取り上げたモデルは、以前の記事で取り上げたモデルと同様に入力データを分析します。Actorのアクションのベクトルと、新しい状態への遷移が完了したときの報酬も、前回の記事と同じです。そのため、モデルの訓練には、過去の記事からモデルの訓練時に収集した経験再生バッファを使用することができます。このため、ファイル名を「FAQ.bd」に変更します。
しかし、過去に作成したファイルがない場合や、何らかの理由で新しいファイルを作成したい場合は、まず実際のシグナルの取引履歴を使用して、いくつかのパスを保存することをお勧めします。これについては、RealORL法を説明した記事で述べました。
EA「...\Experts\FAQ\Research.mq5」を使用して、ランダムパスで経験再生バッファを補完できます。そのためには、MetaTrader 5ストラテジーテスターで、訓練期間の履歴データに対して、このEAの低速最適化を実行してください。
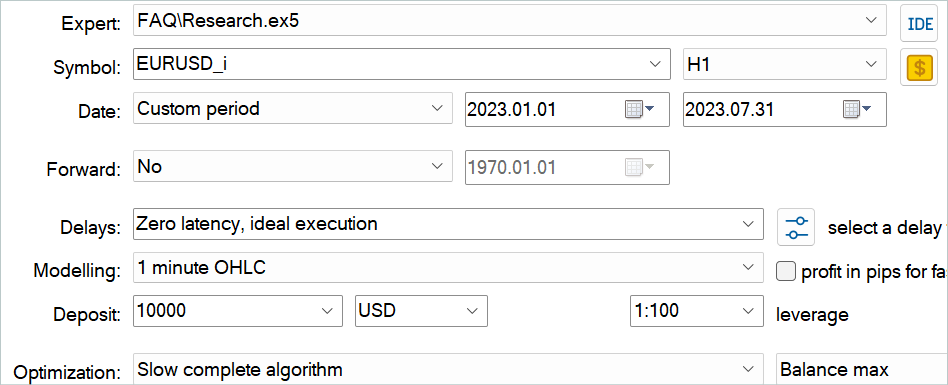
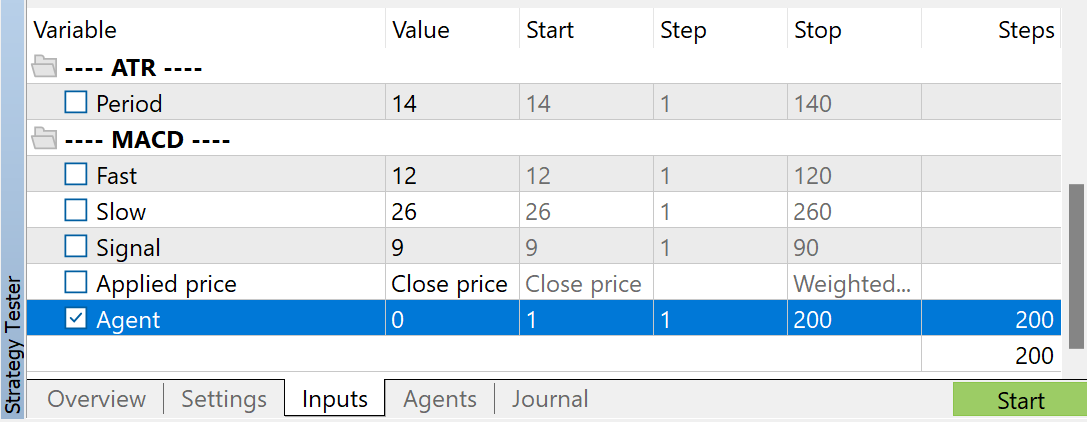
指標のパラメータは何でもいいですが、訓練データセットを収集するときと訓練済みモデルをテストするときには、必ず同じパラメータを使用してください。また、モデル操作のパラメータを保存してください。この記事を作成する際、すべての指標のデフォルト設定を使用しました。
収集したパスの数を調整するために、Agentパラメータに最適化を使用しています。このパラメータは、最適化パスを調整するためだけにEAに追加されたものであり、EAのコードでは使用されていません。
訓練データを収集した後、リアルタイムでチャート上でEA「...\Experts\FAQ\Study.mq5」を実行します。EAは、収集した訓練データセットを使用して、取引操作をおこなうことなくモデルを訓練します。したがって、実際のチャート上でEAを操作しても、口座残高に影響はありません。
通常、私は反復的なアプローチでモデルを訓練します。この過程で、モデルの訓練と、訓練セットへの追加データの収集を交互におこないます。このアプローチでは、訓練データセットのサイズは限られており、環境におけるエージェントの多様な行動をすべてカバーすることはできません。EA「...\Experts\FAQ\Research.mq5」の次回の起動中、環境との対話プロセスでは、ランダムな方策によってガイドされなくなります。代わりに私たちの訓練された方策が使用されます。こうして、私たちの方策に近い状態や行動で経験再生バッファを補充します。そうすることで、オンライン学習のプロセスと同じように、私たちの方策を取り巻く環境を探ることができます。つまり、その後の訓練では、補間された報酬ではなく、実際の報酬を受け取ることになります。これは、私たちのActorが方策を正しい方向に調整するのに役立つでしょう。
同時に、訓練データセットに含まれていないデータでの訓練結果も定期的にモニターします。
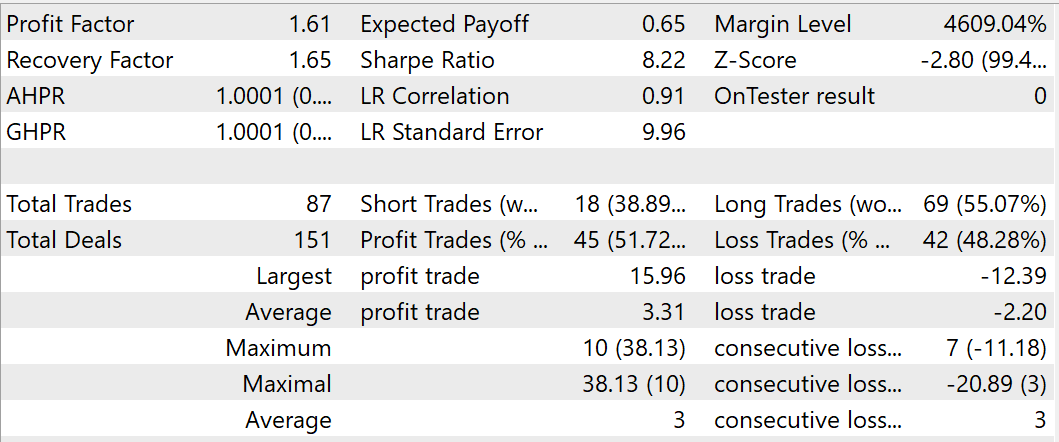
訓練の過程で、訓練データセットとテストデータセットで利益を生み出すことができるモデルを得ることができました。2023年8月に訓練済みモデルをテストしている間、EAは87回の取引をおこない、そのうち45回は利益で決済されました。これは51.72%に相当します。最高と平均の利益を上げた取引の利益は、負け取引の対応する値を上回ります。テスト期間中、EAはプロフィットファクター1.61、リカバリーファクタ1.65に達しました。
結論
この記事では、ビデオ内のオブジェクトを検出するためのFeature Aggregated Queries (FAQ) メソッドについて説明しました。この手法の著者は、モデルの効率と性能のバランスをとるために、Transformerアーキテクチャに基づく検出器の入力データに基づいてクエリを初期化し、それらを集約することに焦点を当てました。彼らは、その表現をオブジェクト検出器に拡張するクエリ集約モジュールを開発しました。これによって、ビデオ課題のパフォーマンスが向上します。
さらに、FAQ法の作者は、クエリ集約モジュールを動的バージョンに拡張し、クエリの初期化を適応的に生成し、ソースデータに応じてクエリ集約の重みを調整できるようにしました。
提案された手法は、ビデオや他のタイムシーケンスにおける問題を解決するために、ほとんどの最新のTransformerベースのオブジェクト検出器に統合できるプラグアンドプレイモジュールです。
本稿の実践編では、MQL5を用いて提案されたアプローチを実装しました。実際の履歴データでモデルを訓練し、訓練セット以外の期間でテストしました。テスト結果は、提案したアプローチの有効性を確認しています。ただし、具体的な結論を出すには、訓練とテストの期間が短かすぎます。この記事で紹介したプログラムはすべて、提案するアプローチのデモンストレーションとテストのみを目的としています。
参照文献
記事で使用されているプログラム
| # | ファイル名 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14394

 エラー 146 (「トレードコンテキスト ビジー」) と、その対処方法
エラー 146 (「トレードコンテキスト ビジー」) と、その対処方法
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索