
因果推論における時系列クラスタリング

はじめに
ボラティリティのクラスタリング
クラスタリングを利用したマッチングトレード:
はじめに
クラスタリングとは、データセットをオブジェクトのグループ(クラスタ)に分割し、同一クラスタ内のオブジェクト同士は類似し、異なるクラスタ間のオブジェクトは異なるように分ける機械学習手法です。クラスタリングは、データ構造を明らかにし、隠れたパターンを特定し、類似性に基づいてオブジェクトをグループ化するのに役立ちます。
クラスタリングは因果推論に利用できます。この文脈でクラスタリングを適用する1つの方法は、特定の原因に関連付けることができる類似したオブジェクトやイベントのグループを識別することです。データがクラスタ化されると、クラスタと原因の関係を分析し、潜在的な因果関係を特定することができます。
さらに、クラスタリングは、同じ影響を受ける可能性のあるオブジェクトや共通の原因を持つオブジェクトのグループを識別するのに役立ち、因果関係を分析する際にも役立ちます。
因果推論におけるクラスタリングの使用は、データを分析し、潜在的な因果関係を特定する上で特に有用です。この記事では、この文脈でクラスタリングがどのように利用できるかを考えます。
- 類似したオブジェクトのグループを識別する:クラスタリングは、類似した特性や動作を持つオブジェクトのグループを識別することができます。そして、これらのグループを分析し、それらに関連すると思われる共通の原因や要因を探すことができます。
- 因果関係を見極める:データがクラスタに分割されると、クラスタ間の関係を探索し、潜在的な因果関係を特定することができます。たとえば、あるオブジェクトのクラスタが特定の動作や特性を示す場合、その原因となっている可能性のある要因を見つけるために分析をおこなうことができます。
- 隠れたパターンを見つける:クラスタリングは、因果関係に関連すると思われるデータの隠れたパターンを明らかにするのに役立ちます。クラスタの構造を分析し、その中に共通するオブジェクトの特徴量を特定することで、ある現象の発生に重要な役割を果たすと思われる要因を発見することができます。
- 将来の出来事を予測する:クラスタと因果関係が特定されれば、得られた知識は将来の出来事や傾向を予測するために使用することができます。データ分析と特定されたパターンに基づいて、どのような要因が将来の出来事に影響を及ぼす可能性があり、それを管理するためにどのような対策を講じることができるかについて仮定することができます。
クラスタリングは因果推論におけるマッチングに利用できます。マッチングとは、異なるデータセットに含まれるオブジェクトを、それらの類似性や特定の基準への適合性に基づいてマッチングするプロセスです。因果推論の文脈では、マッチングは、原因と結果の関係を確立し、ある現象の原因である可能性のある共通の特徴や要因を特定するために使用することができます。
マッチングにおいて、クラスタリングは以下のような場合に有効です。
- オブジェクトのグループ化:クラスタリングは、データセットを類似した特性や動作を持つオブジェクトのグループに分割することができます。この後、各クラスタ内でマッチングを実行し、オブジェクト間のマッチングを見つけ、オブジェクト間の接続を確立することができます。
- 類似性の識別:オブジェクトがクラスタに分割されると、各クラスタ内のオブジェクト間の類似性を調べ、マッチングに使用することができます。例えば、あるオブジェクトのクラスタが似たような動作や特性を示す場合、これらのオブジェクトに関連する可能性のある共通要因を見つけるためにマッチングをおこなうことができます。
- ノイズ減少:クラスタリングは、データのノイズを減らし、オブジェクトの主要なグループを強調し、マッチングプロセスを容易にするのに役立ちます。データをクラスタに分割することで、最も重要で類似したオブジェクトに焦点を当てることができ、マッチングの質が向上し、より明確な因果関係を特定することができます。
その結果、時系列クラスタリングは、異質な治療効果、つまり時系列の異なるグループにおける効果の違いを識別するのに役立ちます。分類や予測をおこなう時系列分析の文脈では、異質な処理効果とは、時系列の挙動がその特性や他の要因によって異なる可能性があることを意味します。
このように、時系列をクラスタリングすることで、以下のような効果が得られます。
- 時系列のグループ化:クラスタリングは、時系列をその特性、傾向、またはその他の要因に基づいてグループに分けることを可能にします。その後、各グループの動作を個別に調べ、異なる時系列クラスタ間で予測や分類に違いがあるかどうかを判断することができます。
- 効果の異なるサブグループの特定:時系列をクラスタリングすることで、異なる行動や変化の軌跡を持つサブグループを特定することができます。これによって研究者は、どのような特徴や要因が分類や予測結果に影響を与えるかを判断し、異なる分析アプローチを必要とする時系列のサブセットを特定することができます。
- モデルのパーソナライズ:クラスタリングの結果と、異なる振る舞いをする時系列の特定されたサブグループを使用して、分類または予測モデルをパーソナライズし、各グループに最適な戦略を選択することができます。これにより、予測と分類の精度を向上させ、モデルをさまざまなタイプの時系列に適応させることができます。
クラスタリングは、例えばボラティリティに基づく市場レジームの識別という観点からも見ることができます。
市場のボラティリティ分析は、投資家やトレーダーにとって、市場の現状を理解し、予想される値動きに基づいて情報に基づいた意思決定をおこなうための重要なツールです。金融分析の文脈では、ボラティリティ基本のクラスタリングアルゴリズムは、異なるトレンド、統合の段階、または不確実性の高い期間を示す可能性のある、異なる市場の「レジーム」を強調するのに役立ちます。
ボラティリティに基づく市場レジームの決定という問題において、クラスタリングアルゴリズムがどのように機能するのでしょうか。
- データの準備:資産の生の価格ボラティリティ時系列は、価格の標準偏差または価格分布の変動に基づいてボラティリティを計算するなどの前処理がおこなわれます。
- クラスタリングアルゴリズムの適用:その後、クラスタリングアルゴリズムをボラティリティデータに適用し、隠れた構造や市場レジームのグループを特定します。クラスタリングアルゴリズムとしては、k平均法、DBSCAN、あるいは時系列分析用に特別に設計されたアルゴリズム(例えば時間依存性を考慮したアルゴリズム)など、様々な手法を使用することができます。
- 結果の解釈:その結果得られたクラスタは、取引戦略の文脈で解釈できるさまざまな市場体制を表しています。例えば、ボラティリティの低いクラスタは横ばいトレンドの時期に対応し、ボラティリティの高いクラスタは市場の急騰やトレンドの変化を示している可能性があります。
ボラティリティに基づく市場レジーム決定問題におけるクラスタリングアルゴリズムの利点は、次の通りです。
- 市場構造の判定:クラスタリングアルゴリズムにより、市場構造を浮き彫りにし、隠れたモードを特定することが可能になり、投資家やトレーダーが市場の現状を理解するのに役立ちます。
- 分析の自動化:クラスタリングアルゴリズムの使用により、市場のボラティリティを分析し、異なるモードを特定するプロセスを自動化することができます。
- 意思決定支援:ボラティリティに基づく市場パターンを特定することは、将来の値動きを予測し、十分な情報に基づいた取引や投資の意思決定をおこなうのに役立ちます。
ボラティリティに基づく市場レジーム決定問題におけるクラスタリングアルゴリズムの欠点は次の通りです。
- パラメータ選択に対する感度:クラスタリングの結果は、クラスタ数や距離メトリックなどのアルゴリズムパラメータの選択に依存することがあり、慎重なチューニングが必要です。
- アルゴリズムの限界:クラスタリングアルゴリズムによっては、大量のデータを処理する際に効率的でなかったり、時間依存性を考慮していなかったりする場合があります。
クラスタリングアルゴリズムの種類
私たちのタスクには、さまざまなクラスタリングアルゴリズムを使うことができます。クラスタリングの主な種類は、Pythonで実装された既製のライブラリとして利用できます。クラスタリングの実験を始めるには、ライブラリを使うのが一番です。これにより、実験のセットアップと実施プロセスが大幅にスピードアップします。
有用と思われる主なクラスタリングアルゴリズムを簡単に見て、それらをタスクに適用します。
- k平均法(K-Means):その単純さと効率性で際立っているが、初期条件への依存やクラスタ数を知る必要があるなどの限界がある
- 親和性伝播(Affinity Propagation):クラスタ数を事前に決定する必要がなく、様々な形状のデータでうまく機能するが、計算が複雑になる可能性がある
- Mean Shift:任意の形状のクラスタを検出でき、クラスタ数を指定する必要はない。大量のデータを扱う場合、計算コストが高くなる可能性がある
- スペクトルクラスタリング(Spectral Clustering):非線形構造を持つデータに適しており、普遍的である。しかし、パラメータを調整するのは難しく、計算量も多くなる
- 凝集型クラスタリング(Agglomerative Clustering):階層的なクラスタを作成し、未知のクラスタ数を扱うのに適している
- GMM:クラスタリングに確率的なアプローチを提供し、異なる形状と密度を持つクラスタのモデリングを可能にする
- HDBSCANおよびBIRCH:ともに、大量のデータを効率的に処理し、クラスタ数を自動的に決定することができるが、計算の複雑さやパラメータに対する感度の高さといった欠点もある
時系列クラスタリング(ボラティリティクラスタリング)の実装
ここでは、市場レジームを決定する手段として、また異質な処理効果をマッチングし決定する手段として、金融時系列をクラスタリングする可能性に関心があります。まず、市場体制のクラスタリングを試みます。
以下のコードは、メタ訓練モデルを訓練し、その後、金融データのボラティリティに基づくクラスタリングの結果に基づいて、最終モデルとメタモデルを訓練します。
def meta_learner(models_number: int, iterations: int, depth: int, bad_samples_fraction: float, n_clusters: int, algorithm: int) -> pd.DataFrame: dataset = get_labels(get_prices()) data = dataset[(dataset.index < FORWARD) & (dataset.index > BACKWARD)].copy() X = data[data.columns[1:-2]] X = X.loc[:, ~X.columns.str.contains('std')] meta_X = data.loc[:, data.columns.str.contains('std')] y = data['labels'] B_S_B = pd.DatetimeIndex([]) for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # learn debias model with train and validation subsets meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # add bad samples of this iteration (bad labels indices) diff_negatives = coreset['labels'] != coreset['labels_pred'] B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index) to_mark = B_S_B.value_counts() marked_idx = to_mark[to_mark > to_mark.mean() * bad_samples_fraction].index data.loc[data.index.isin(marked_idx), 'meta_labels'] = 0.0 if algorithm==0: data['clusters'] = KMeans(n_clusters=n_clusters).fit(meta_X).labels_ elif algorithm==1: data['clusters'] = AffinityPropagation().fit(meta_X).predict(meta_X) elif algorithm==2: data['clusters'] = SpectralClustering(n_clusters=n_clusters, assign_labels='discretize', random_state=0).fit_predict(meta_X) elif algorithm==3: data['clusters'] = MeanShift().fit_predict(meta_X) elif algorithm==4: data['clusters'] = AgglomerativeClustering(n_clusters=n_clusters).fit_predict(meta_X) elif algorithm==5: data['clusters'] = mixture.GaussianMixture(n_components=n_clusters, covariance_type='full').fit(meta_X).predict(meta_X) elif algorithm==6: data['clusters'] = HDBSCAN(min_cluster_size=150).fit_predict(meta_X) elif algorithm==7: data['clusters'] = Birch(threshold=0.01, n_clusters=n_clusters).fit_predict(meta_X) return data[data.columns[1:]]
機能の説明
meta_learner関数は、データセット内の誤ったラベル付けされたサンプルを識別し修正するために、分類モデルをメタ訓練するように設計されています。CatBoostClassifierモデルのアンサンブルを使用してそのようなサンプルを識別し、クラスタリングアルゴリズムを適用してデータをさらに処理します。以下は、そのプロセスの詳細です。
1. データの準備:この関数は、まずタイムスタンプでフィルタリングされたデータセット(特定の期間のデータを除く)を取得します。次に、データを特徴量(X)、標準偏差に基づくメタ特徴量(meta_X)、ターゲットラベル(y)に分割します。
2. 変数の初期化:空の日付インデックスB_S_Bは、誤ったラベルのサンプルのインデックスを格納するために作成されます。
3. モデルの訓練と誤ったラベルの識別:models_numberモデルごとに、データを訓練セットと検証セットに分けます。そして、与えられたパラメータでCatBoostClassifierモデルが訓練されます。訓練が完了すると、モデルは特徴セットX全体のラベルを予測するために使用されます。予測されたラベルを元のラベルと比較することにより、この関数は誤ってラベル付けされたサンプルを特定し、そのインデックスをB_S_Bに追加します。
4. 不良サンプルにラベルを付ける:すべてのモデルを訓練した後、この関数は、B_S_Bに格納されている不良サンプルのインデックスを分析し、bad_samples_fractionによって決定されるよりも頻繁に発生するものにフラグを立て、ソースデータのmeta_labels列に0.0としてマークします。
5.クラスタリング:algorithmパラメータの値に応じて、この関数はメタフィーチャ(meta_X)にクラスタリングアルゴリズムのいずれかを適用し、結果のクラスタラベルをソースデータに追加します。
6. 結果を返す:この関数は、ラベルとクラスタが割り当てられた更新されたデータセットを返します.
このアプローチは、データラベルの誤りを特定し修正するだけでなく、さらなる分析やモデル訓練のためにデータをグループ化することを可能にします。これは、誤ってラベル付けされたサンプルが多数ある問題で特に役立ちます。
以下は、最終モデルの訓練関数です。
def fit_final_models(dataset) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = dataset[dataset['meta_labels']==1], dataset[dataset.columns[:-3]] X = X[X.columns[:-3]] X = X.loc[:, ~X.columns.str.contains('std')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('std')] # labels for model\meta models y, y_meta = dataset[dataset['meta_labels']==1], dataset[dataset.columns[-1]] y = y[y.columns[-3]] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.8, test_size=0.2, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.8, test_size=0.2, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=200, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=100, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU') meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False) R2 = test_model([model, meta_model]) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) return [R2, model, meta_model]
fit_final_models関数は、提供されたデータセットでメインモデルとメタモデルを訓練するように設計されています。以下は、その操作の詳細です。
1. データの準備
- メインモデル(X, y)を訓練するためにmeta_labelsが1に等しい行をデータセットから選択します。
- データセットのすべての行(X_meta, y_meta)がメタモデルの訓練に使用されます。
- 名前にstdを含む列と最後の3列は、メインモデルを訓練するための特徴量から除外されます。
- メタモデルでは、この関数は名前にstdを含む特徴量だけを使用します。
- メインモデルのターゲット変数(y)は、最後から3列目から取り出され、int16型にキャストされます。
- メタモデルのターゲット変数(y_meta)は最後の列から取り出され、int16にキャストされます。
2. データを訓練サンプルとテストサンプルに分ける
- メインモデルとメタモデルでは、データを訓練サンプルとテストサンプルに80%対20%の割合で分割します。
3. 基本的なモデルの訓練
- CatBoostClassifier分類器を200回繰り返し、Accuracy損失関数とAccuracy評価指標を使用します。訓練の進捗に関する情報は出力されず、最適なモデルが選択され、タスクタイプは「CPU」に設定されます。
- モデルは訓練データセットで訓練されます。また、測定値が改善されない場合は、25ラウンド後に早期停止します。
4. メタモデルの訓練
- 主モデルと似ていますが、反復回数100回、損失関数F1、評価指標F1、15ラウンド後で早期停止
5.モデルのテスト
- 訓練されたモデルはtest_model関数を使ってテストされ、R2メトリックの値を返します。
- 結果のR2値がNaNの場合、-1.0に置き換えられ、対応するメッセージが表示されます。
6. 戻り値
- この関数は、R2値、メインモデル、メタモデルを含むリストを返します。
この関数は機械訓練プロセスの一部であり、メインモデルはフィルタリングされたデータ(ラベルが検証または調整されたと仮定される)で訓練され、メタモデルは選択されたボラティリティクラスタを予測するために訓練されます。
アルゴリズム全体はループで訓練されます
この関数は、入力データセットに基づいてモデルとメタモデルを訓練します。そして、R2値、メインモデル、メタモデルを含むリストを返します。
# LEARNING LOOP models = [] for i in range(1): data = meta_learner(5, 25, 2, 0.9, n_clusters=N_CLUSTERS, algorithm=6) for clust in data['clusters'].unique(): print(f'Iteration: {i}, Cluster: {clust}') filtered_data = data.copy() filtered_data['clusters'] = filtered_data['clusters'].apply(lambda x: 1 if x == clust else 0) models.append(fit_final_models(filtered_data))
このコードは、meta_learner関数を使用してモデルをメタ訓練し、その結果得られたクラスタに基づいて最終モデルを訓練する訓練ループです。以下は、そのプロセスの詳細です。
1. モデルリストの初期化:空のリストmodelsが作成され、訓練された最終モデルを格納するのに使用されます。
2. 訓練ループを走る:forループは1反復(range(1))に設定されており、これは全処理が1回実行されることを意味します。これはデモンストレーションやテストの目的でおこなわれるもので、これらのループは通常、学習アルゴリズムのランダム化により、より多くの反復を使用するためです。
3. meta_learnerを使ったメタ学習:meta_learner関数が与えられたパラメータで呼び出されます。
- models_number=5:メタ学習に5つの基本モデルを使用
- iterations=25:各基本モデルは25回の反復で訓練される
- depth=2:基本モデルの分類器木の深さが2に設定される
- bad_samples_fraction=0.9:誤ってフラグが付けられたサンプルの割合は90%
- n_clusters=N_CLUSTERS:クラスタリングアルゴリズムのクラスタ数で、N_CLUSTERSは事前に定義しておく必要がある
- アルゴリズム=6:HDBSCANクラスタリングアルゴリズムを使用
meta_learner関数は、ラベルと割り当てられたクラスタを持つ更新されたデータセットを返します。
4. ユニークなクラスタを繰り返し処理:データセット内のユニークなクラスタごとに、反復とクラスタ番号のメッセージが表示されます。そして、現在のクラスタに属するレコードはすべて1とマークされ、それ以外はすべて0とマークされるようにデータがフィルタリングされます。これにより、各クラスタの2値分類が作成されます。
5.最終モデルの訓練:各クラスタについて、fit_final_models関数が呼び出され、フィルタリングされたデータに基づいてモデルを訓練して返します。訓練されたモデルは「モデル」リストに追加されます。
このアプローチでは、特定のデータクラスタに特化したモデルを複数訓練することができ、それぞれが異なるデータグループの特性をより正確に考慮することで、全体的なモデリングのパフォーマンスを向上させることができます。
提案されたすべてのクラスタリングアルゴリズムを分析し、市場レジームを決定し ました。いくつかのアルゴリズムは好成績を収めましたが、他のアルゴリズムは振るいませんでした。
以下は、異なるクラスタリングアルゴリズムを使用した訓練結果です。
まず、クラスタリングのスピードに興味がありました。Affinity Propagation、Spectral Clustering、Agglomerative Clustering、Mean Shiftの各アルゴリズムは非常に時間がかかることがわかりました。標準的な設定ではクラスタリングの結果が得られなかったので、これらのアルゴリズムの結果は示していません。
Webでこれを確認しました。

アルゴリズム内のランダム化によって訓練の反復ごとに結果が異なるため、より有益な結果を得るために、訓練プロセス全体を10回繰り返しました。
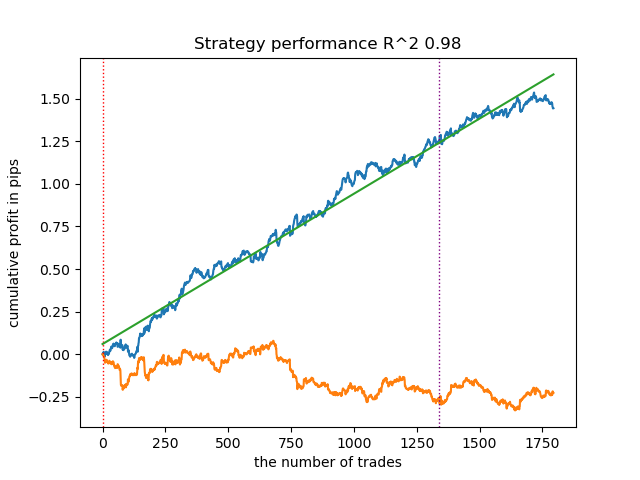
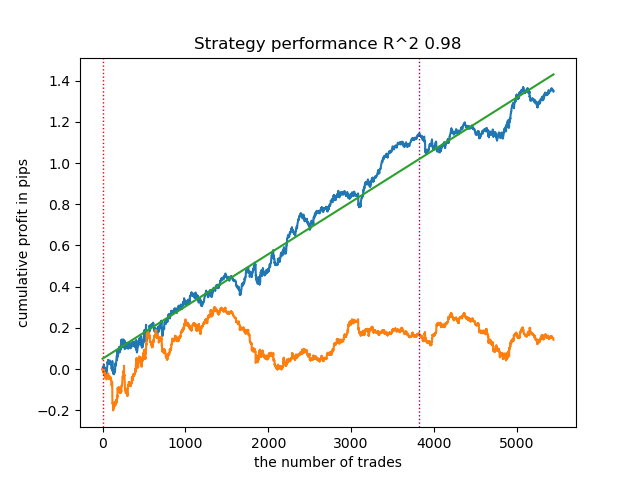
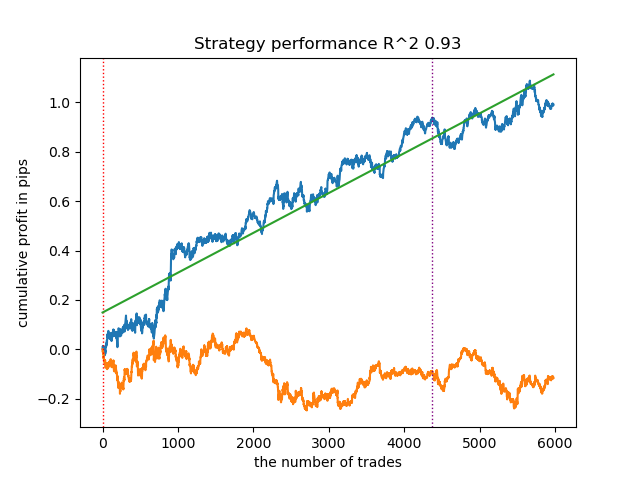
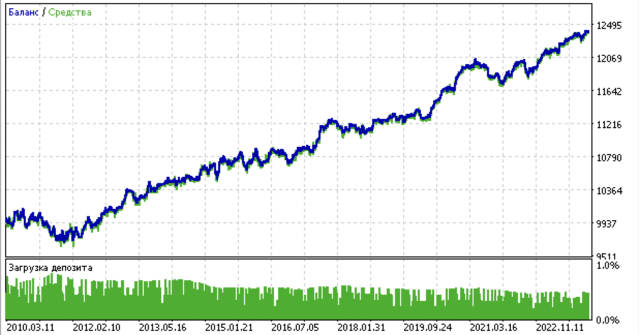
- 青い線はバランスグラフ
- 橙色の線は金融商品チャート(この場合はEURUSD)
1. 残る4つのアルゴリズムの中で、HDBSCANを評価のトップに据えることにしました。データをうまく分離し、クラスタ数を設定する必要がありません。
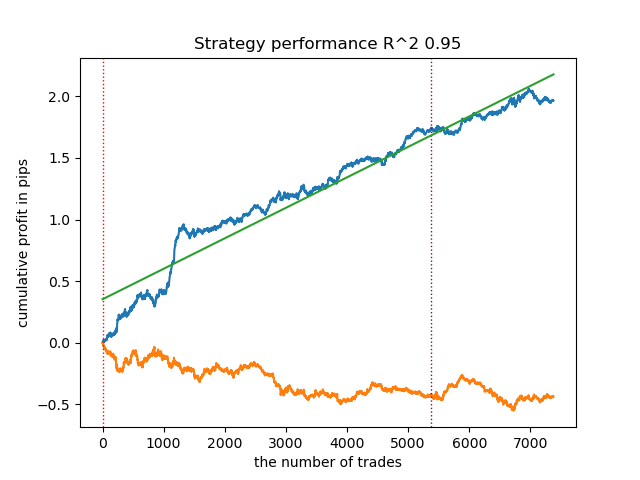
2. k平均法は良好な性能を示し、テスト結果もかなり良好でした。欠点はクラスタ数に敏感なことで、この場合は10です。
3. BIRCHは良い結果を示しましたが、以前のアルゴリズムよりも計算がやや遅くなります。また、クラスタ数の初期設定も必要ありません。
4. 最後はガウス混合です。テスト結果は、他のクラスタリングアルゴリズムを使ったときよりも悪いように思えました。視覚的には、これは「ノイズの多い」バランスグラフで表現されます。k平均法と同様、10個のクラスタを定義しました。
このように、選択した市場体制に応じて、さまざまな取引システムを手に入れることができます。訓練プロセス中、モデルのテスト結果は、指定されたクラスタ数に基づいて、レジームごとに表示されます。
クラスタリングの質は、入力パラメータのセットに影響されます。以下は、使用したパラメータです。
- 通貨ペア
- 時間枠
- 訓練の開始日と終了日
- メインモデルの特徴量数
- メタモデルの特徴量数(ボラティリティ)
- クラスタ数n_clusters
- get_labels(min,max)関数のパラメータminとmax
例えば、以下のパラメータを使った別のクラスタリング結果です。
SYMBOL = 'EURUSD' MARKUP = 0.00010 PERIODS = [i for i in range(10, 100, 10)] PERIODS_META = [20] BACKWARD = datetime(2019, 1, 1) FORWARD = datetime(2023, 1, 1) n_clusters = 40 def get_labels(dataset, min = 5, max = 5) Timeframe = H1
クラスタ探索アルゴリズムもランダム化されるため、何度か実行するのが良い方法です。
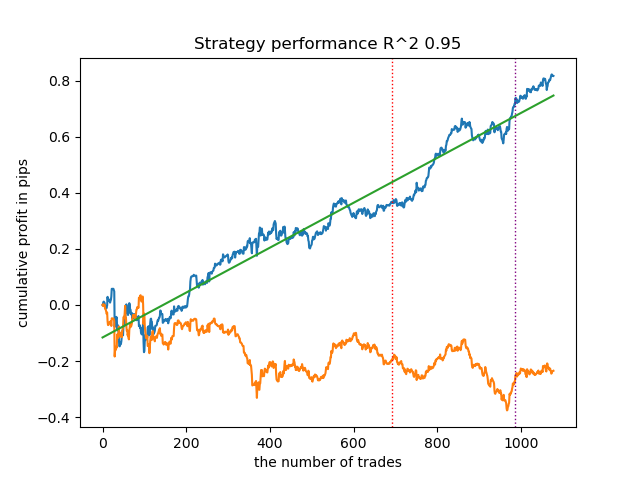
クラスタリングを用いたマッチング取引
では、最後の部分に移りましょう。実はこれが記事の主要部分です。因果推論にクラスタリングの要素を加えることで、因果推論の理解を深めたかったのです。この記事では因果推論について説明し、別の記事では傾向スコアによるマッチングについて取り上げます。ここで、傾向スコアによるマッチングを独自のアプローチ、すなわちクラスタリングによるマッチングに置き換えてみましょう。この目的のために、最初の記事のアルゴリズムを使用し、それを修正します。
def meta_learners(models_number: int, iterations: int, depth: int, bad_samples_fraction: float, n_clusters: int): dataset = get_labels(get_prices()) data = dataset[(dataset.index < FORWARD) & (dataset.index > BACKWARD)].copy() X = data[data.columns[1:-2]] y = data['labels'] clusters = KMeans(n_clusters=n_clusters).fit(X[X.columns[0:1]]).labels_ BAD_CLUSTERS = [] for _ in range(n_clusters): sublist = [pd.DatetimeIndex([]), pd.DatetimeIndex([])] BAD_CLUSTERS.append(sublist) for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # learn debias model with train and validation subsets meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) coreset['clusters'] = clusters # add bad samples of this iteration (bad labels indices) coreset_b = coreset[coreset['labels']==0] coreset_s = coreset[coreset['labels']==1] for clust in range(n_clusters): diff_negatives_b = (coreset_b['labels'] != coreset_b['labels_pred']) & (coreset['clusters'] == clust) diff_negatives_s = (coreset_s['labels'] != coreset_s['labels_pred']) & (coreset['clusters'] == clust) BAD_CLUSTERS[clust][0] = BAD_CLUSTERS[clust][0].append(diff_negatives_b[diff_negatives_b == True].index) BAD_CLUSTERS[clust][1] = BAD_CLUSTERS[clust][ 1].append(diff_negatives_s[diff_negatives_s == True].index) for clust in range(n_clusters): to_mark_b = BAD_CLUSTERS[clust][0].value_counts() to_mark_s = BAD_CLUSTERS[clust][1].value_counts() marked_idx_b = to_mark_b[to_mark_b > to_mark_b.mean() * bad_samples_fraction].index marked_idx_s = to_mark_s[to_mark_s > to_mark_s.mean() * bad_samples_fraction].index data.loc[data.index.isin(marked_idx_b), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_s), 'meta_labels'] = 0.0 return data[data.columns[1:]]
私の過去の記事を読んでいない人のために、アルゴリズムの簡単な説明をしましょう。
- データ処理
- 最初に、get_prices()関数とget_labels()関数を使用してデータセットを取得します。これらの関数はそれぞれ価格情報とクラスラベルを返します。
- get_labels()は、価格データとラベルを関連付けます。これは、金融データに関連するMLでは一般的なタスクです。
- その後、FORWARD定数とBACKWARD定数で定義された時間間隔でデータがフィルタリングされます。
- データの準備
- データは特徴量(X)とラベル(y)に分けられます。
- 次に、K平均クラスタリングアルゴリズムを使ってデータクラスタを作成します。
- モデル訓練
- forループで、モデルの数をmodels_numberとします。各反復において、モデルはデータセットの半分(train_size = 0.5)で訓練され、後半(検証セット)で検証されます。
- CatBoostClassifierモデルを特定のパラメータで使用します。この勾配ブースティング法は、特にカテゴリ特徴を扱うように設計されています。
- アルゴリズムは、カスタム損失関数Accuracyと評価指標Accuracyを使用することに注意してください。これは予測精度を重視していることを示しています。
- そしてメタモデルは、主要モデルの予測値を評価調整するために適用されます。これにより、一次モデルで起こりうる偏りや誤差を考慮することができます。
- 不良サンプルの特定
- アルゴリズムは、各クラスタ内の不良サンプルに関する情報を含むBAD_CLUSTERSリストを作成します。不良サンプルは、モデルが有意な数の誤差を生じるサンプルと定義されます。
- 各訓練反復において、アルゴリズムは不良サンプルを特定し、そのインデックスを対応するリストに保存します。
- メタ分析と補正
- 前のステップで特定された不良サンプルのインデックスは集計され、マスターデータ内の対応するサンプルにフラグを立てるために使用されます。
- これは、不良サンプルを除去または修正することによって、モデル訓練の質を向上させるのに役立つと考えられています。
- データを返す
- この関数は、準備されたデータからタイムスタンプを含む最初の列を除いたものを返します。
このアルゴリズムは、不良サンプルを検出して修正し、メタモデルを使用して主要モデルのエラーを考慮することで、機械学習モデルの品質を向上させようとするものです。複雑で、効果的に機能させるにはパラメータを慎重に調整する必要があります。
このコードでは、クラスタリングはいくつかの方法でデータの異質性を説明するのに役立ちます。
- データクラスタの特定
- K平均クラスタリングアルゴリズムを使うことで、データを類似したオブジェクトのグループに分けることができます。各クラスタには、似たような特徴を持つデータが含まれています。これは、オブジェクトが異なるカテゴリーに属していたり、異なる構造を持っていたりする異種データの場合に特に有効です。
- クラスタを個別に分析処理
- 各クラスタは他のクラスタとは別に処理されるため、各グループ内のデータ特性や構造を考慮することが可能になります。これは、データの異質性を理解し、各クラスタの特定の条件に学習アルゴリズムを適応させるのに役立ちます。
- クラスタ内のエラー訂正
- モデルを訓練した後、各クラスタの不良サンプルをループで分析します。これらのサンプルは、モデルがかなりの数のエラーを起こすサンプルです。これにより、各クラスタ内のエラー補正を個別に集中的におこなうことができ、同じ補正を全データに適用するよりも効果的です。
- メタモデル訓練におけるデータ特徴量の考慮
- クラスタリングは、メタモデルを訓練する際にクラスタ間の違いを考慮するためにも使用されます。これにより、各クラスタ内のデータの構造に関する情報を取り込むことで、メタモデルがデータの異質性にうまく適応できるようになります。
このように、クラスタリングはデータの異質性を考慮する上で重要な役割を果たし、アルゴリズムがより効果的にオブジェクトやデータ構造の多様性に適応できるようにします。
モデルの訓練結果を以下に示します。新しいデータによってモデルがより安定したことがわかるでしょう。
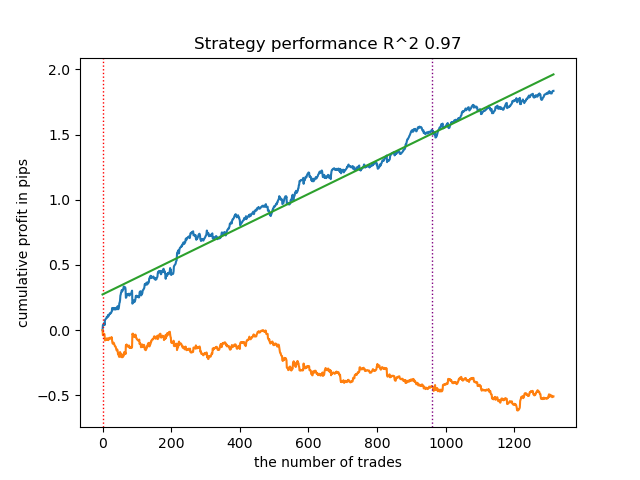
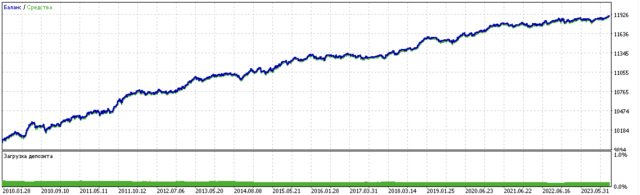
このモデルはONNX形式にエクスポートでき、ONNXトレーダーEAと完全に互換性があります。
結論
本稿では、時系列クラスタリングに対する筆者独自のアプローチについて説明しました。市場レジームをボラティリティに基づいてクラスタリングするために、様々なアルゴリズムを検証しました。その結果、複雑なアルゴリズムが必ずしも期待通りに機能するわけではないことが判明しました。k平均法のようなシンプルかつ高速なクラスタリングアルゴリズムが、十分に優れたパフォーマンスを発揮する場合もあります。同時に、HDBSCANアルゴリズムは非常に有望であると感じました。
第2部では、クラスタリングを用いて異質な処理効果を特定する方法について検討しました。実験結果に基づき、クラスタリングを活用して不良取引を考慮することで、値のばらつきが減少し(バランス曲線が滑らかになり)、新しいデータに対するモデルの予測精度が向上することが示されました。一般的に、これはかなり複雑で深いテーマであり、アルゴリズムを微調整するためにはハイパーパラメータの設定が必要となります。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14548
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索