
Características del Wizard MQL5 que debe conocer (Parte 10). El RBM no convencional
Introducción

Las máquinas de Boltzmann restringidas (RBMs) son una forma de red neuronal que tienen una estructura bastante simple, pero que, no obstante, son veneradas en ciertos círculos por lo que pueden lograr en cuanto a revelar propiedades y características ocultas en conjuntos de datos. Esto se consigue aprendiendo los pesos en una dimensión más pequeña a partir de unos datos de entrada de mayor dimensión, y estos pesos suelen denominarse distribuciones de probabilidad. Como siempre se puede leer más aquí, pero por lo general su estructura se puede ilustrar con la siguiente imagen:
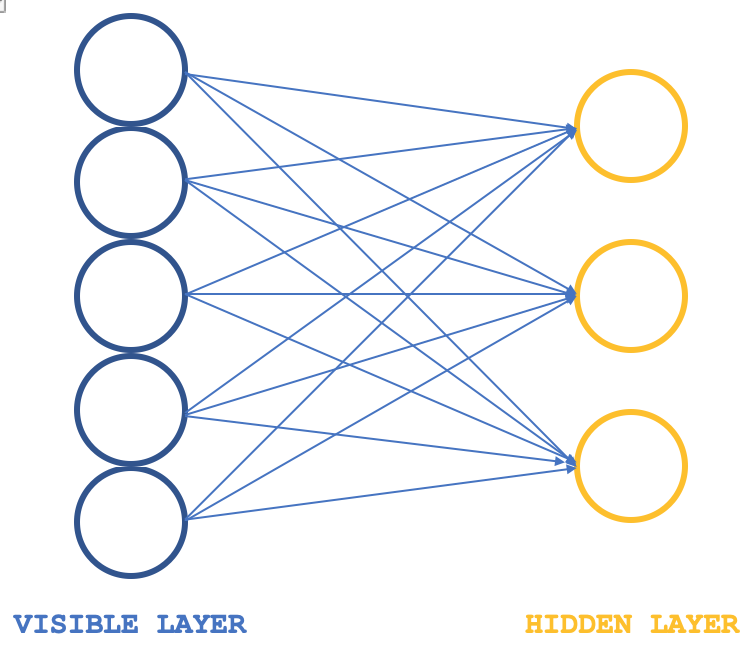
Típicamente las RBM constan de 2 capas, (digo típicamente porque hay algunas redes que las apilan en transformadores), una capa visible y una capa oculta, siendo la capa visible más grande (con más neuronas) que la oculta. Cada neurona de la capa visible se conecta a cada neurona de la capa oculta durante lo que se denomina la fase positiva, de modo que durante esta fase, como es habitual en la mayoría de las redes neuronales, los valores de entrada en la capa visible se multiplican por los valores de peso en las neuronas de conexión y la suma de estos productos se añade a un sesgo para determinar los valores en las respectivas neuronas ocultas. La fase negativa, que es la inversa, es la que sigue y, a través de diferentes conexiones neuronales, pretende restaurar los datos de entrada a su estado original a partir de los valores calculados en la capa oculta.
Por lo tanto, con los primeros ciclos, como era de esperar, los datos de entrada reconstruidos no coinciden con los de entrada iniciales, ya que a menudo el RBM se inicializa con pesos aleatorios. Esto implica que los pesos deben ajustarse para que la salida reconstruida se acerque más a los datos de entrada y ésta es la fase adicional que seguiría a cada ciclo. El resultado final y el objetivo de este ciclo de fase positiva seguida de una fase negativa y de ajuste de los pesos es llegar a conectar los pesos de las neuronas que, cuando se aplican a los datos de entrada, pueden darnos valores "intuitivos" de las neuronas en la capa oculta. Estos valores neuronales en la capa oculta son lo que se denomina la distribución de probabilidad de los datos de entrada a través de las neuronas ocultas.
Las fases positiva y negativa de un ciclo RBM suelen denominarse colectivamente Muestreo de Gibbs. Y con el fin de llegar a los pesos de conexión que mapean con precisión a la distribución de probabilidad de los datos, los pesos de conexión se ajustan a través de lo que se llama Divergencia contrastiva. Por lo tanto, si tuviéramos una clase simple que ilustra esto en MQL5, entonces nuestra interfaz podría tener el siguiente aspecto:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Crbm { protected: ... public: bool init; matrix weights_v_to_h; matrix weights_h_to_v; vector bias_v_to_h; vector bias_h_to_v; matrix old_visible; matrix old_hidden; matrix new_hidden; matrix new_visible; matrix output; void GibbsSample(matrix &Input); void ContrastiveDivergence(); Crbm(int Visible, int Hidden, int Sample, double LearningRate, ENUM_LOSS_FUNCTION Loss); ~Crbm(); };
Las variables notables aquí son las matrices que registran los pesos cuando se propagan de la capa visible a la capa oculta y también cuando se propagan en la dirección inversa, estas se denominan acertadamente 'weights_v_to_h' ('pesos_v_a_h') y 'weights_h_to_v' ('pesos_h_a_v'), respectivamente. También deben incluirse los vectores que registran los sesgos y, lo que es más importante, los 4 conjuntos de neuronas que se utilizan en el muestreo de Gibbs para almacenar los valores de las neuronas en cada muestreo; 2 para la capa visible y 2 para la capa oculta. El muestreo de Gibbs tanto para la fase positiva como para la negativa podría tener su función definida como sigue:
//+------------------------------------------------------------------+ //| Feed through network using Gibbs Sampling | //+------------------------------------------------------------------+ void Crbm::GibbsSample(matrix &Input) { old_visible.Fill(0.0); old_visible.Copy(Input); //old_hidden = old_visible * weights_v_to_h; //new_hidden = Sigmoid(old_hidden) + bias_v_to_h; for (int GibbsStep = 0; GibbsStep < sample; GibbsStep++) { // Positive phase... Upward pass with biases for (int j = 0; j < hidden; j++) { old_hidden[GibbsStep][j] = 0.0; for (int i = 0; i < visible; i++) { old_hidden[GibbsStep][j] += (old_visible[GibbsStep][i] * weights_v_to_h[i][j]); } new_hidden[GibbsStep][j] = 1.0 / (1.0 + exp(-(old_hidden[GibbsStep][j] + bias_v_to_h[j]))); } } //new_visible = new_hidden * weights_h_to_v; //output = Sigmoid(new_visible) + bias_v_to_h; for (int GibbsStep = 0; GibbsStep < sample; GibbsStep++) { // Negative phase... Downward pass with biases for (int i = 0; i < visible; i++) { new_visible[GibbsStep][i] = 0.0; for (int j = 0; j < hidden; j++) { new_visible[GibbsStep][i] += (new_hidden[GibbsStep][j] * weights_h_to_v[j][i]); } output[GibbsStep][i] = 1.0 / (1.0 + exp(-(new_visible[GibbsStep][i] + bias_h_to_v[i]))); } } }
Y de forma similar la actualización de los pesos y sesgos de las neuronas podría realizarse con la función que se muestra a continuación:
//+------------------------------------------------------------------+ //| Update weights using Contrastive Divergence | //+------------------------------------------------------------------+ void Crbm::ContrastiveDivergence() { // Update weights based on the difference between positive and negative phase matrix _weights_v_to_h_update; _weights_v_to_h_update.Init(visible, hidden); _weights_v_to_h_update.Fill(0.0); matrix _weights_h_to_v_update; _weights_h_to_v_update.Init(hidden, visible); _weights_h_to_v_update.Fill(0.0); for (int i = 0; i < visible; i++) { for (int j = 0; j < hidden; j++) { _weights_v_to_h_update[i][j] = learning_rate * ( (old_visible[0][i] * weights_v_to_h[i][j]) - old_hidden[0][j] ); _weights_h_to_v_update[j][i] = learning_rate * ( (new_hidden[0][j] * weights_h_to_v[j][i]) - new_visible[0][i] ); } } // Apply weight updates for (int i = 0; i < visible; i++) { for (int j = 0; j < hidden; j++) { weights_v_to_h[i][j] += _weights_v_to_h_update[i][j]; weights_h_to_v[j][i] += _weights_h_to_v_update[j][i]; } } // Bias updates vector _bias_v_to_h_update; _bias_v_to_h_update.Init(hidden); vector _bias_h_to_v_update; _bias_h_to_v_update.Init(visible); // Compute bias updates for (int j = 0; j < hidden; j++) { _bias_v_to_h_update[j] = learning_rate * ((old_hidden[0][j] + bias_v_to_h[j]) - new_hidden[0][j]); } for (int i = 0; i < visible; i++) { _bias_h_to_v_update[i] = learning_rate * ((new_visible[0][i] + bias_h_to_v[i]) - output[0][i]); } // Apply bias updates for (int i = 0; i < visible; ++i) { bias_h_to_v[i] += _bias_h_to_v_update[i]; } for (int j = 0; j < hidden; ++j) { bias_v_to_h[j] += _bias_v_to_h_update[j]; } }
Con la antigua estructura RBM, aunque esquemáticamente sólo se muestran 2 capas en la ilustración, el código tiene valores neuronales para 5 capas porque los valores neuronales de fase negativa y positiva se registran después de cada producto y también después de cada activación. Así, la antigua capa visible registra los valores brutos de los datos de entrada, la antigua capa oculta registra el primer producto de las entradas y los pesos, y la nueva capa oculta registra los valores sigmoidales activados de este producto. La nueva capa visible registra el segundo producto entre la nueva capa oculta y los pesos de la fase negativa y, por último, la capa "de salida" registra la activación de este producto.
Este enfoque ortodoxo de los RBM se presenta aquí sólo con fines de exploración, ya que está compilado pero no probado, puesto que este artículo se centra en un enfoque alternativo del diseño y el entrenamiento de los RBMs. Sin embargo, a efectos de análisis, la salida clave de la función de muestreo de Gibbs serían los valores de las neuronas en la primera y segunda "capas ocultas". Los valores dobles de estos dos conjuntos de neuronas captarían las propiedades de los datos de entrada una vez que la red se haya entrenado lo suficiente.
Entonces, ¿qué RBM no convencional podemos considerar que mantenga los preceptos básicos pero en una estructura diferente? Un perceptrón de 3 capas que tiene su capa de entrada y su capa de salida con tamaños coincidentes y su única oculta un tamaño menor que estas dos capas externas. ¿Cómo se puede garantizar que el entrenamiento siga siendo no supervisado, ya que los perceptrones suelen tener un aprendizaje supervisado? Al tener cada fila de datos de entrada también sirve como la salida de destino, que es esencialmente lo que Gibbs Sampling está realizando en cada bucle de tal manera que nuestro objetivo de obtener pesos para todas las conexiones a la capa oculta se puede lograr como lo haría normalmente a través de la retropropagación. Por lo tanto, la estructura de nuestro RBM se parecería a la siguiente imagen:
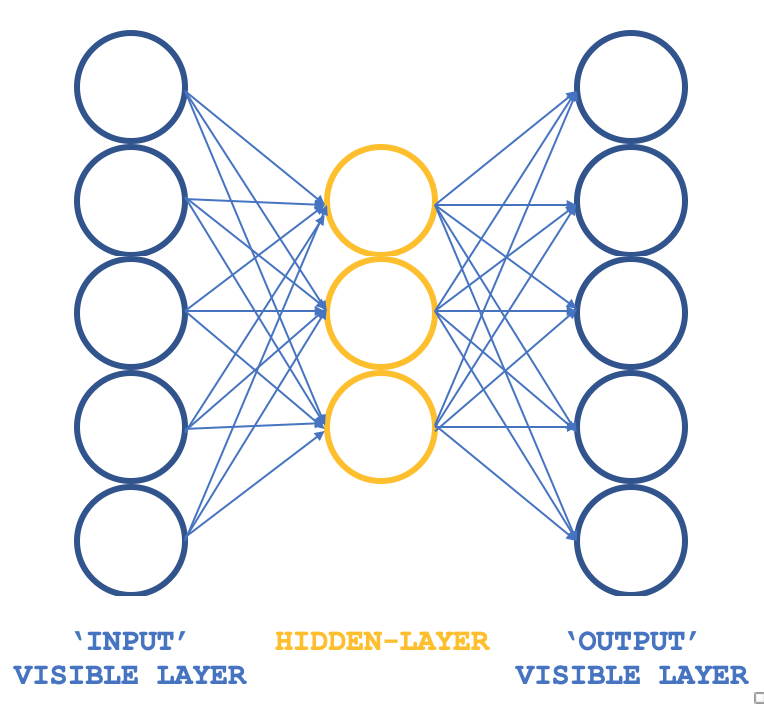
Este enfoque, cuando se utiliza con las clases ALGLIB, proporciona un enfoque compacto y eficiente en la prueba de RBMs en lugar de codificar todo desde cero, que es el tema que estamos explorando en esta serie. Una vez que se tienen ideas viables, se puede considerar la personalización y quizás la codificación desde cero.
El objetivo del entrenamiento, para resumir, será obtener pesos de red que puedan mapear con precisión las características de los datos de entrada en la capa oculta. Se extraerían y utilizarían en la siguiente fase del modelo y, a nuestros efectos, pueden considerarse un formato normalizado de los datos de entrada.
El origen de las RBMs
En referencia a un artículo que estaba en deeplearning.net y que desgraciadamente ya no está subido, los RBMs suelen definirse como modelos basados en energía debido a su capacidad para asociar una energía escalar a cada configuración de un conjunto de datos de interés. El aprendizaje se realiza modificando esa función de energía para que su forma tenga propiedades deseables. La "función de energía" es un término coloquial para referirse a la función que interviene en la transformación del conjunto de datos de entrada en un formato diferente (de tránsito) y, por último, de vuelta a los datos de entrada, de forma que la "energía" es la diferencia entre el conjunto de datos de entrada y los datos de salida. Por lo tanto, el objetivo de entrenar los RBMs es tener configuraciones deseables de "baja energía" en las que la diferencia entre las entradas iniciales y las salidas finales sea mínima. Los modelos probabilísticos basados en la energía definirían una distribución de probabilidad obtenida mediante esta función de energía, como siendo el vector de neuronas ocultas una fracción la suma de los valores de las neuronas ocultas para todos los datos de entrada muestreados.
En general, los modelos basados en la energía se entrenan realizando un descenso de gradiente (estocástico) sobre la verosimilitud negativa de logaritmo empírica de los datos de entrenamiento. Y las máquinas de Boltzmann generales no tienen capas ocultas y todas las neuronas están interconectadas.
Por lo tanto, el primer paso para que este cálculo sea manejable es estimar la expectativa utilizando un número fijo de muestras del modelo. Las muestras utilizadas para estimar el gradiente de fase positiva se denominan pesos, y un producto de estos pesos matriciales y el vector del conjunto de datos de entrada debe proporcionar un vector de valores de neuronas. (por ejemplo, al hacer un Monte-Carlo). Con esto, casi tendríamos un algoritmo estocástico práctico para aprender un EBM. El único ingrediente que falta es cómo extraer estos pesos. Aunque en la literatura estadística abundan los métodos de muestreo, los métodos Markov Chain Monte Carlo son especialmente adecuados para modelos como las máquinas de Boltzmann (BMs, Boltzmann Machines), un tipo específico de EBM.
Las máquinas de Boltzmann (BMs, Boltzmann Machines) son una forma particular de "Campo aleatorio de Markov" (MRF, Markov Random Field) logarítmico-lineal, es decir, en las cuales la función de energía es lineal en sus parámetros libres. Para que sean lo suficientemente potentes como para representar distribuciones complicadas (es decir, pasar del entorno paramétrico limitado a uno no paramétrico), consideramos que algunas de las variables nunca se observan (se denominan ocultas, como se ha indicado anteriormente). Al tener más variables ocultas (también llamadas unidades ocultas), podemos aumentar la capacidad de modelado de la máquina de Boltzmann (BM). Las máquinas de Boltzmann restringidas, un derivado de ésta, restringen aún más las BMs a aquellas sin conexiones visibles-visibles y ocultas-ocultas, como se ilustra en la imagen introductoria anterior.
En la práctica, por tanto, es un hecho que no todos los aspectos de un conjunto de datos son fácilmente "visibles", o tendemos a necesitar introducir algunas variables no observadas para aumentar la capacidad expresiva de un modelo. Esto puede considerarse como una presunción de que hay aspectos del conjunto de datos de entrada que se desconocen y que, por lo tanto, deben investigarse. Esta presunción implica un gradiente para estas incógnitas, donde "gradiente" es el cambio o diferencia entre los datos conocidos y los datos desconocidos u "ocultos".
El gradiente contendría dos fases, que se denominan fase positiva y fase negativa . Los términos positivo y negativo reflejan su efecto en la densidad de probabilidad o en los desconocidos mapeados definidos por el modelo. La fase positiva, también conocida como primera fase, aumenta la probabilidad de los datos de entrenamiento (al reducir la energía libre correspondiente), mientras que la segunda fase disminuye la probabilidad de que las muestras generadas por el modelo vuelvan al conjunto de datos muestreado.
En resumen, cuando el tamaño de los conjuntos de datos conocidos y ocultos no está definido, como en las máquinas de Boltzmann no restringidas, suele ser difícil determinar este gradiente analíticamente, ya que implica muchos cálculos. Por ello, los RBMs, al predefinir el número de conocidos e incógnitos, pueden determinar de forma factible la distribución de probabilidad.
Arquitectura de red y entrenamiento
Nuestra estructura de 3 capas ilustrada anteriormente se va a implementar utilizando tamaños de capa de entrada y salida de 5 y un tamaño de capa oculta de 3. Las entradas de los valores de las 5 neuronas serán los valores actuales de los indicadores. Estos pueden ser sustituidos por el lector, ya que se adjuntan todas las fuentes, pero para este artículo vamos a utilizar las lecturas de los valores de los indicadores para la Media Móvil, MACD, Oscilador Estocástico, Williams Percent Range, y el Índice de Vigor Relativo (RVI, Relative Vigor Index). La salida normalizada, como se mencionó anteriormente, captura los valores de las neuronas de la primera y segunda capa oculta, lo que significa que el tamaño de este vector de salida es el doble del tamaño de nuestra capa oculta.
Todos los productos de peso y las activaciones son manejados por las clases de ALGLIB y estos son personalizables neurona por neurona y el código fue compartido que muestra esto en un artículo anterior. Para este artículo utilizamos los valores por defecto, que sin duda habrá que ajustar una vez que se dé un paso más, pero por ahora puede servir para ilustrar la recuperación de la distribución de probabilidad de los datos.
Así pues, las conexiones a través de esta red se asemejan más a una mariposa que a una flecha, como se ilustra en el diagrama anterior
La retropropagación en una red neuronal convencional ajusta los pesos de conexión por descenso de gradiente mediante la regla de la cadena multivariante. Esto no es como la divergencia contrastiva y no sólo está obligado a ser más intenso computacionalmente, sino que podría dar lugar a pesos drásticamente diferentes (distribuciones de probabilidad) de lo que se supone que se obtiene en un RBM regular. En este artículo lo utilizamos para realizar pruebas y, dado que el código fuente completo es compartido, se pueden personalizar las modificaciones de esta fase.
Como se mencionó anteriormente, la retropropagación suele ser supervisada porque se necesitan valores objetivo para obtener los gradientes y, en nuestro caso, dado que la entrada sirve como objetivo, nuestro RBM modificado podría considerarse no supervisado.
Durante el entrenamiento, los pesos de nuestra red se ajustarán de modo que la salida sea lo más parecida posible a la entrada. De este modo, cualquier nuevo conjunto de datos que se introduzca en la red proporcionará información clave a las neuronas de la capa oculta. Esta información procedente de las neuronas está en formato de matriz, como cabría esperar. Sin embargo, el tamaño de esta matriz es el doble del número de neuronas de la capa oculta. En el formato que estamos adaptando para las pruebas, las neuronas de la capa oculta son tres, lo que implica que nuestra matriz de salida que captura las propiedades de los 5 indicadores que buscamos tiene un tamaño de 6.
Estos valores de las neuronas ocultas pueden tomarse como un formato de normalización de los 5 valores de los indicadores. No tenemos una reducción de dimensionalidad en este caso ya que el vector de propiedades tiene un tamaño de 6 y sin embargo utilizamos 5 valores de indicadores de entrada, sin embargo si utilizáramos más indicadores digamos 8 y mantuviéramos el número de neuronas en la capa oculta en 3, tendríamos una reducción.
¿Cómo utilizar estos valores? Si nos atenemos a la opinión de que son simplemente una normalización de los valores de los indicadores, pueden servir como un vector de clasificación que podría ser útil en comparación si ahora los utilizamos en un modelo diferente en el que añadimos supervisión en forma de un eventual cambio en el precio tras cada conjunto de valores de los indicadores. Así pues, todo lo que hacemos es comparar el vector de valores actuales cuyo cambio eventual de precio se desconoce con otros vectores cuyos cambios se conocen y una media ponderada en la que la similitud del coseno entre estos vectores puede actuar como peso proporcionaría la previsión media del próximo cambio.
Codificar la red en MQL5
La interfaz para implementar nuestro extraño RBM podría tener el aspecto que se indica a continuación:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Crbm { protected: int visible; int hidden; int sample; double loss; string file; public: bool init; ... CArrayDouble losses; void Train(matrix &W); void Process(matrix &W, matrix &XY, bool Compare = false); bool ReadWeights(); bool WriteWeights(); bool Writer(); Crbm(int Visible, int Hidden, int Sample, double Loss, string File); ~Crbm(); };
En la interfaz declaramos y utilizamos las clases básicas mínimas que necesitaríamos para ejecutar un perceptrón como hemos hecho en artículos anteriores. La única adición notable es la matriz doble de 'pérdidas' que nos ayuda a rastrear la diferencia entre la capa de entrada y la capa de salida y en el proceso de guiar qué redes obtienen sus parámetros exportables escritos en un archivo porque como se ha enfatizado en el pasado, los perceptrones deben ser probados con la capacidad de exportar parámetros ajustables de tal manera que cuando se despliega o se mueve el experto a un entorno de producción los pesos aprendidos se pueden utilizar fácilmente en lugar de volver a entrenar a partir de pesos aleatorios iniciales cada vez.
Así, la matriz de pérdidas simplemente registra la similitud del coseno entre el conjunto de datos de entrada y el conjunto de datos de salida para cada fila de datos en cada barra de precios. Al final de una ejecución de prueba, los pesos de las redes o los parámetros exportables se escriben en un archivo si el número de semejanzas del coseno por debajo de un umbral de entrada (el valor predeterminado para esto es 0,9, pero se puede ajustar) es menor que lo que se escribió la última vez que se registró el archivo. Este parámetro umbral se denomina "loss" (pérdida).
La sintaxis utilizada para multiplicar los pesos y los valores de entrada es probablemente más complicado de lo que debería ser teniendo en cuenta "matriz" y "vector" son ahora los tipos de datos incrustados en MQL5. Una simple multiplicación de estas asociaciones de seguimiento y de los respectivos tamaños de fila y columna podría lograr el mismo resultado con menos memoria y, por tanto, menos recursos informáticos.
La función de red utiliza clases ALGLIB para iniciar, entrenar y procesar conjuntos de datos. Las personalizaciones fuera de esto, con el propio perceptrón codificado, podría conducir a una mayor eficiencia en las pruebas y en el despliegue, ya que el código de ALGLIB es bastante complejo y "enrevesado" porque al ser una biblioteca tiende a atender a una mayor variedad de escenarios. Sin embargo, incluso con la implementación "out of box", listo para usar, se pueden realizar algunas personalizaciones básicas, como con la activación y los sesgos, y su influencia en el rendimiento de la red puede ser muy significativa. Esto puede ser útil para una fase inicial de pruebas, que es lo que estamos explorando aquí.
Así, con esta configuración de prueba entrenamos nuestro RBM no convencional, en cada nueva barra o cada vez que obtenemos un nuevo punto de precio, lo que implica que los pesos de los que dependemos para hacer la clasificación de cada punto de datos de entrada se están refinando y ajustando con cada pasada. También podrían explorarse enfoques alternativos para el ajuste de las ponderaciones, como ajustar las ponderaciones una vez al trimestre o dos veces al año, siempre que, por supuesto, se haya realizado un entrenamiento durante un número decente de años antes de utilizar la red. En este artículo no se tienen en cuenta, pero se mencionan como posibles vías que el lector podría seguir. Las funciones de entrenamiento y proceso están definidas como se indica a continuación:
//+------------------------------------------------------------------+ //| Train Data Matrix | //+------------------------------------------------------------------+ void Crbm::Train(matrix &W) { for(int s = 0; s < sample; s++) { for(int i = 0; i < visible; i++) { xy.Set(s, i, W[s][i]); xy.Set(s, i + visible, W[s][i]); } } train.MLPTrainLM(model, xy, sample, 0.001, 2, info, report); }
Es bastante rudimentario porque las clases ALGLIB se encargan de la codificación. La función de proceso se codifica del siguiente modo:
//+------------------------------------------------------------------+ //| Process New Vector | //+------------------------------------------------------------------+ void Crbm::Process(matrix &W, matrix &XY, bool Compare = false) { for(int w = 0; w < int(W.Rows()); w++) { CRowDouble _x = CRowDouble(W.Row(w)), _y; base.MLPProcess(model, _x, _y); for(int i = 6; i < visible + 7; i++) { XY[w][i - 6] = model.m_neurons[i]; } //Comparison vector _input = _x.ToVector(); vector _output = _y.ToVector(); if(Compare) { for(int i = 0; i < int(_input.Size()); i++) { printf(__FUNCSIG__ + " at: " + IntegerToString(i) + " we've input: " + DoubleToString(_input[i]) + " & y: " + DoubleToString(_y[i]) ); } //Loss printf(__FUNCSIG__ + " loss is: " + DoubleToString(_output.Loss(_input, LOSS_COSINE)) ); } losses.Add(_output.Loss(_input, LOSS_COSINE)); } }
En cierto sentido, esta función presenta la "salsa secreta" del algoritmo, ya que muestra cómo recuperamos los valores de las neuronas ocultas del perceptrón para cada valor de los datos de entrada. En cada barra recuperamos estos pesos como una forma de muestreo. Por lo tanto, los emitimos en un formato matricial en el que la fila de datos de entrada nos da un vector de pesos.
Las ponderaciones que se extraen para cada punto de datos de entrada sirven como formas normalizadas de los 5 valores indicadores y la comparación de vectores ponderados mencionada anteriormente puede realizarse del siguiente modo:
//+------------------------------------------------------------------+ //| RBM Output. | //+------------------------------------------------------------------+ double CSignalRBM::GetOutput(void) { m_close.Refresh(-1); MA.Refresh(-1); MACD.Refresh(-1); STOCH.Refresh(-1); WPR.Refresh(-1); RVI.Refresh(-1); double _output = 0.0; int _i=StartIndex(); matrix _w; _w.Init(m_sample,__VISIBLE); matrix _xy; _xy.Init(m_sample,7); if(RBM.init) { for(int s=0;s<m_sample;s++) { for(int i=0;i<5;i++) { if(i==0){ _w[s][i] = MA.GetData(0,_i+s); } else if(i==1){ _w[s][i] = MACD.GetData(0,_i+s); } else if(i==2){ _w[s][i] = WPR.GetData(0,_i+s); } else if(i==3){ _w[s][i] = STOCH.GetData(0,_i+s); } else if(i==4){ _w[s][i] = RVI.GetData(0,_i+s); } } if(s>0){ _xy[s][2*__HIDDEN] = m_close.GetData(_i+s)-m_close.GetData(_i+s+1); } } RBM.Train(_w); RBM.Process(_w,_xy); double _w=0.0,_w_sum=0.0; vector _x0=_xy.Row(0); _x0.Resize(6); for(int s=1;s<m_sample;s++) { vector _x=_xy.Row(s); _x.Resize(6); double _weight=fabs(1.0+_x.Loss(_x0,LOSS_COSINE)); _w+=(_weight*_xy[s][6]); _w_sum+=_weight; } if(_w_sum>0.0){ _w/=_w_sum; } _output=_w; } return(_output); }
Con el último bucle "for" obtenemos la previsión media probable basada en la ponderación de la similitud del coseno con otros puntos de datos que tienen una Y conocida (cambio eventual del precio)
Optimizamos esta instancia personalizada de la clase de señal experta en el símbolo GBPUSD en el marco temporal de 4 horas desde 2023.07.01 hasta 2023.10.01 con una prueba de avance desde 2023.10.01 hasta 2023.12.25 y obtuvimos los siguientes informes.


Por lo que se ve, podría ser prometedor. Las pruebas, como es habitual, se realizarían idealmente con los ticks reales del broker con el que se pretende operar. Y esto sería ideal después de realizar los cambios y personalizaciones adecuados no sólo en las fuentes de datos de entrada, sino probablemente en el diseño y la eficiencia del perceptrón. La última parte es importante porque los resultados de prueba confiables deberían basarse en períodos extendidos de datos históricos, por lo que esto podría ser un desafío con la fuente ALGLIB tal como está.
Conclusión
En resumen, hemos examinado la definición tradicional de una red RBM y cómo se podría programar en MQL5. Pero lo más importante es que hemos explorado una variante poco habitual de esta red, estructurada y entrenada como un simple perceptrón multicapa, y hemos examinado si la "distribución de probabilidades", a la que nos referimos como pesos de salida, podría utilizarse para construir otra instancia personalizada de la clase de señales expertas. Los resultados del backtesting y del forward testing indican que podría haber potencial en utilizar el sistema, sujeto a pruebas más extensas y quizás a un ajuste fino en la elección de la entrada de datos.
Notas
El código adjunto es utilizable una vez ensamblado con el Asistente MQL5 (MQL5 Wizard). He mostrado cómo se puede hacer esto en artículos anteriores dentro de esta serie sin embargo este artículo también puede servir como guía para aquellos que son nuevos con el Asistente MQL5 (MQL5 Wizard).
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/13988
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso