
Vantagens do Assistente MQL5 que você precisa saber (Parte 12): Polinômio de Newton
Introdução
A análise de séries temporais desempenha um papel importante não apenas como parte da análise fundamental. Em mercados muito líquidos, como o forex, pode ser um fator chave na tomada de decisões. Os indicadores técnicos tradicionais tendem a estar muito atrasados em relação ao mercado, o que levou ao surgimento de alternativas. Talvez as mais populares até o momento sejam as redes neurais. Mas e a interpolação polinomial?
Ela apresenta algumas vantagens, principalmente porque é fácil de entender e implementar, pois a interpolação representa claramente a relação entre observações passadas e previsões futuras em uma equação simples. Isso ajuda a entender como os dados passados influenciam os valores futuros, o que, por sua vez, leva ao desenvolvimento de conceitos amplos e possíveis teorias sobre o comportamento das séries temporais estudadas.
Além disso, a capacidade de adaptação tanto a relações lineares quanto quadráticas a torna flexível para várias séries temporais e, possivelmente, mais adequada para traders que trabalham com diferentes tipos de mercados (por exemplo, lateralizado versus tendência ou volatilidade versus mercado calmo).
Além disso, a interpolação geralmente não requer grandes recursos computacionais e é relativamente simples em comparação com abordagens alternativas, como redes neurais. De fato, os modelos discutidos neste artigo não têm requisitos de memória, o que não se pode dizer de uma rede neural, que, dependendo de sua arquitetura, requer espaço para armazenar um grande número de pesos e desvios ótimos após cada sessão de treinamento.
Formalmente, o polinômio de interpolação de Newton N(x) é definido pela equação:

onde todos os x j são únicos na série, a j representa a soma das diferenças divididas, enquanto n j (x) é soma dos produtos dos coeficientes base para x, o que pode ser formalmente apresentado da seguinte maneira:

As fórmulas das diferenças divididas e dos coeficientes base podem ser facilmente encontradas de forma independente, no entanto, vamos tentar revelar suas definições de forma menos rigorosa.
As diferenças divididas são um processo repetitivo de divisão, no qual os coeficientes para x são definidos em cada expoente até que todos os expoentes de x sejam esgotados a partir do conjunto de dados fornecido. Para ilustrar isso, vamos considerar o exemplo abaixo com três pontos de dados:
(1,2), (3,4) e (5,6)
Para utilizar a diferença dividida, todos os valores de x devem ser únicos. O número de pontos de dados fornecidos determina o grau máximo de x no polinômio de Newton resultante. Por exemplo, se tivéssemos apenas dois pontos, nossa equação seria linear:
y = mx + c.
Presume-se que o grau máximo seja um. Assim, em nosso exemplo com três pontos, o maior expoente é 2, o que significa que precisamos obter 3 coeficientes diferentes para o nosso polinômio derivado.
Obter cada um desses três coeficientes é um processo iterativo passo a passo, até chegarmos ao terceiro. As fórmulas estão nas referências acima, mas talvez a melhor maneira de entender todo o processo seja usar uma tabela, como mostrado abaixo:
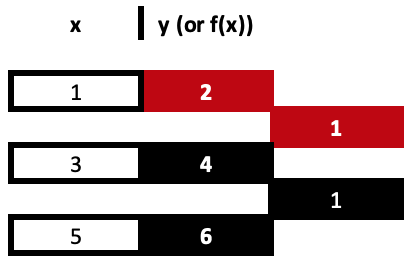
Portanto, nossa primeira coluna de diferenças divididas é obtida dividindo a diferença entre os valores de y e a mudança correspondente nos valores de x. Lembre-se de que todos os valores de x devem ser únicos. Esses cálculos são muito simples e diretos, mas são mais fáceis de acompanhar em uma tabela, como mostrado acima, do que nas fórmulas típicas indicadas nas referências gerais. Ambas as abordagens levam ao mesmo resultado.
= (4 - 2) / (3 - 1)
Obtemos nosso primeiro coeficiente, que é 1.
= (6 - 4) / (5 - 3)
Nos dá o segundo coeficiente similar. Os coeficientes estão destacados em vermelho.
No nosso exemplo com três pontos de dados, o valor final das diferenças y será obtido a partir dos valores recém-calculados. Mas seus denominadores x serão os dois valores extremos na série x, pois sua diferença será o divisor, então nossa tabela ficará assim:

Na nossa tabela preenchida acima, temos 3 valores derivados, mas apenas 2 deles são usados para obter coeficientes. Isso nos leva às somas dos produtos dos "polinômios base". Por mais peculiar que isso possa parecer, na verdade são mais simples que as diferenças divididas. Para ilustrar isso com base nos nossos coeficientes derivados da tabela acima, nossa equação para três pontos terá a seguinte forma:
y = 2 + 1*(x – 1) + 0*(x – 1)*(x – 3)
o que se resume a:
y = x + 1
Os parênteses adicionados são tudo o que constitui os polinômios base. O valor x n representa o valor correspondente de x para cada ponto da amostra de dados. Voltando aos coeficientes. Em geral, usamos apenas os valores superiores da tabela como prefixo dos valores entre parênteses. À medida que avançamos para a direita, obtendo colunas mais curtas na tabela, os valores superiores atuam como prefixos de sequências mais longas entre parênteses até que todos os pontos de dados disponíveis sejam considerados. Como mencionado anteriormente, quanto mais pontos de dados precisarem ser interpolados, mais expoentes de x e, portanto, mais colunas teremos em nossa tabela derivada.
Antes de passar para a implementação, vamos dar mais um exemplo. Suponha que temos 7 pontos de dados para os preços de títulos financeiros, onde os valores de x são simplesmente o índice da barra de preços, como mostrado abaixo:
| 0 | 1,25590 |
| 1 | 1,26370 |
| 2 | 1,25890 |
| 3 | 1,25395 |
| 4 | 1,25785 |
| 5 | 1,26565 |
| 6 | 1,26175 |
Nossa tabela, que espalha os valores dos coeficientes, será expandida para 8 colunas da seguinte forma:

Com os coeficientes fornecidos (destacados em vermelho), a equação será a seguinte:
y = 1.2559 + 0.0078*(x – 0) – 0.0063*(x – 0)*(x – 1) + …
A equação vai até o grau 6, considerando os sete pontos de dados, e sua função principal pode ser prever o próximo valor inserindo um novo índice x na equação. Se os dados da amostra foram "dados como série", o próximo índice será -1, caso contrário, será 8.
Implementação em MQL5
A implementação com MQL5 pode ser alcançada com a escrita mínima de código, embora eu não tenha encontrado nenhuma biblioteca que permitisse implementar essas ideias, por exemplo, a partir de instâncias de classes já prontas.
No entanto, para isso, precisamos fazer duas coisas. Primeiro, precisamos de uma função para calcular os coeficientes x para nossa equação, considerando nosso conjunto de dados amostrais. Em segundo lugar, também precisamos de uma função para processar o valor previsto usando nossa equação, apresentada com o valor x. Tudo isso parece bastante simples, mas, considerando que queremos alcançar escalabilidade, precisamos levar em conta alguns nuances na etapa de processamento.
O que se entende por "escalabilidade" aqui? São funções que podem usar diferenças divididas para obter coeficientes para conjuntos de dados cujo tamanho não é definido previamente. Isso pode parecer óbvio, mas vamos considerar nosso primeiro exemplo com três pontos de dados. Sua implementação em MQL5 para obter coeficientes é mostrada abaixo.
O código abaixo contém as equações para obter a diferença dividida para dois pares nos dados da amostra, repetindo este procedimento para obter o valor final. Agora, se tivéssemos uma amostra de 4 pontos de dados, a interpolação de sua equação exigiria uma função diferente, pois precisaríamos fazer mais passos do que o mostrado no exemplo com 3 pontos acima.
Então, se tivéssemos uma função escalável, ela seria capaz de lidar com conjuntos de dados de tamanho n e produzir coeficientes n-1. Isso é mostrado no seguinte código:
//+------------------------------------------------------------------+ //| INPUT PARAMETERS | //| X - vector with x values of sampled data | //| Y - vector with y values of sampled data | //| OUTPUT PARAMETERS | //| W - vector with coefficients. | | //+------------------------------------------------------------------+ void Cnewton::Set(vector &W, vector &X, vector &Y) { vector _w[]; ArrayResize(_w, int(X.Size() - 1)); int _x_scale = 1; int _y_scale = int(X.Size() - 1); for(int i = 0; i < int(X.Size() - 1); i++) { _w[i].Init(_y_scale); for(int ii = 0; ii < _y_scale; ii++) { if(X[ii + _x_scale] != X[ii]) { if(i == 0) { _w[i][ii] = (Y[ii + 1] - Y[ii]) / (X[ii + _x_scale] - X[ii]); } else if(i > 0) { _w[i][ii] = (_w[i - 1][ii + 1] - _w[i - 1][ii]) / (X[ii + _x_scale] - X[ii]); } } else { printf(__FUNCSIG__ + " ERR!, identical X value: " + DoubleToString(X[ii + _x_scale]) + ", at: " + IntegerToString(ii + _x_scale) + ", and: " + IntegerToString(ii)); return; } } _x_scale++; _y_scale--; W[i + 1] = _w[i][0]; if(_y_scale <= 0) { break; } } }
Esta função trabalha com dois loops for aninhados e dois inteiros que rastreiam os índices para os valores de x e y. Pode não ser a maneira mais eficiente de implementação, mas funciona. Ela pode ser aprimorada dependendo do caso de uso.
A função para processar o próximo y considerando o sinal de entrada x e todos os coeficientes de nossas equações também é apresentada abaixo:
//+------------------------------------------------------------------+ //| INPUT PARAMETERS | //| W - vector with pre-computed coefficients | //| X - vector with x values of sampled data | //| XX - query x value with unknown y | //| OUTPUT PARAMETERS | //| YY - solution for unknown y. | //+------------------------------------------------------------------+ void Cnewton::Get(vector &W, vector &X, double &XX, double &YY) { YY = W[0]; for(int i = 1; i < int(W.Size()); i++) { double _y = W[i]; for(int ii = 0; ii < i; ii++) { _y *= (XX - X[ii]); } YY += _y; } }
Ela parece mais simples do que nossa função anterior, embora também tenha um loop aninhado. Tudo o que fazemos é rastrear os coeficientes que obtivemos na função set e atribuir a eles o polinômio básico de Newton correspondente.
Áreas de aplicação
Neste artigo, veremos como o método pode ser usado como sinal e trailing stop, bem como na gestão de capital. Antes de começar a escrever o código, geralmente é recomendado preparar uma classe de ligação com duas funções que implementam a interpolação. O código da classe é apresentado acima. Para a classe, teremos a seguinte interface:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Cnewton { private: public: Cnewton(); ~Cnewton(); void Set(vector &W, vector &X, vector &Y); void Get(vector &W, vector &X, double &XX, double &YY); };
Sinal
Os arquivos de classes padrão de sinais de EA, apresentados na biblioteca MQL5, como sempre, servem como um guia útil para seus próprios desenvolvimentos. No nosso caso, a primeira escolha óbvia de dados amostrais de entrada para gerar o polinômio serão os preços de fechamento brutos dos títulos financeiros. Para gerar o polinômio com base nos preços de fechamento, primeiro preenchemos os vetores x e y com os índices das barras de preços e os preços de fechamento reais, respectivamente. Esses dois vetores são os dados de entrada principais para nossa função set, que é responsável por obter os coeficientes. Simplesmente usamos os índices das barras de preços para x no nosso sinal, mas alternativas como sessões diárias ou semanais podem ser usadas, desde que nenhuma delas se repita no conjunto de dados, ou seja, todas apareçam apenas uma vez. Por exemplo, se em um dia de negociação houver 4 sessões, você pode fornecer no máximo 4 pontos de dados, e os índices das sessões 0, 1, 2 e 3 podem aparecer no conjunto de dados apenas uma vez.
Depois de preencher nossos vetores x e y, a chamada da função set deve fornecer os coeficientes preliminares para nossa equação polinomial. Se executarmos esta equação com os coeficientes e o próximo valor x usando a função get, obteremos a projeção de qual será o próximo valor y. Como nossos valores de entrada y na função set foram preços de fechamento, estaremos procurando o próximo preço de fechamento. O código correspondente é mostrado abaixo:
double _xx = -1.0;//m_length + 1.0, double _yy = 0.0; __N.Get(_w, _xx, _yy);
Além de obter o próximo preço de fechamento previsto, as funções de verificação de abertura da classe de sinais de EA geralmente produzem um número inteiro na faixa de 0 a 100 como um indicador de quão forte é o sinal de compra ou venda. Portanto, no nosso caso, precisamos encontrar uma maneira de representar o preço de fechamento previsto como um número inteiro simples que se encaixe nessa faixa.
Para obter essa normalização, a alteração prevista do preço de fechamento é expressa como uma porcentagem da faixa atual de preços altos e baixos. Em seguida, essa porcentagem é expressa como um número inteiro na faixa de 0 a 100. Isso significa que mudanças negativas no preço de fechamento na função "verificação de abertura de posição longa" automaticamente serão zero, assim como mudanças positivas na previsão na função "verificação de abertura de posição curta".
m_high.Refresh(-1); m_low.Refresh(-1); m_close.Refresh(-1); int _i = StartIndex(); double _h = m_high.GetData(m_high.MaxIndex(_i,m_length)); double _l = m_low.GetData(m_low.MinIndex(_i,m_length)); double _c = m_close.GetData(0); // if(_yy > _c) { _result = int(round(((_yy - _c) / (fmax(_h, fmax(_yy, _c)) - fmin(fmin(_yy, _c), _l))) * 100.0)); }
Ao fazer previsões usando a equação polinomial, a única variável que usamos é a duração do período de backtesting (que define o tamanho do conjunto de dados amostrais). Esta é a variável m_length. Ao executar a otimização apenas para este parâmetro no símbolo EURJPY H1 em 2023, obteremos os seguintes relatórios.


Uma análise completa para todo o ano nos dá o seguinte quadro de equidade:

Trailing Stop
Além da classe de sinal do EA, podemos montar um EA usando o assistente, selecionando também o método de configuração e ajuste do trailing stop para posições abertas. A biblioteca fornece métodos que utilizam Parabolic Sar e médias móveis, e geralmente seu número é bem menor do que na biblioteca de sinais. Se quisermos melhorar essa contagem adicionando uma classe que use o polinômio de Newton, então talvez nossos dados amostrais devam ser os intervalos das barras de preços.
Assim, se seguirmos os mesmos passos que tomamos acima ao prever o próximo preço de fechamento, com a principal mudança sendo os dados do vetor y, que neste caso agora será o intervalo das barras de preços, nossa fonte será a seguinte:
//+------------------------------------------------------------------+ //| Checking trailing stop and/or profit for long position. | //+------------------------------------------------------------------+ bool CTrailingNP::CheckTrailingStopLong(CPositionInfo *position, double &sl, double &tp) { //--- check ... //--- m_high.Refresh(-1); m_low.Refresh(-1); vector _x, _y; _x.Init(m_length); _y.Init(m_length); for(int i = 0; i < m_length; i++) { _x[i] = i; _y[i] = (m_high.GetData(StartIndex()+i)-m_low.GetData(StartIndex()+i)); } vector _w; _w.Init(m_length); _w[0] = _y[0]; __N.Set(_w, _x, _y); double _xx = -1.0; double _yy = 0.0; __N.Get(_w, _x, _xx, _yy); //--- ... //--- return(sl != EMPTY_VALUE); }
Parte desse intervalo de barras previstas é então usada para definir o tamanho do stop-loss da posição. A proporção utilizada representa um parâmetro otimizável, m_stop_level, e antes de definir o novo stop-loss, adicionamos a esse delta a distância mínima do stop para evitar erros da corretora. Essa normalização é mostrada no código abaixo:
//+------------------------------------------------------------------+ //| Checking trailing stop and/or profit for long position. | //+------------------------------------------------------------------+ bool CTrailingNP::CheckTrailingStopLong(CPositionInfo *position, double &sl, double &tp) { //--- check ... //--- sl = EMPTY_VALUE; tp = EMPTY_VALUE; delta = (m_stop_level * _yy) + (m_symbol.Point() * m_symbol.StopsLevel()); //--- if(price - base > delta) { sl = price - delta; } //--- return(sl != EMPTY_VALUE); }
Se montarmos um EA usando o Assistente MQL5 que utilize a classe de sinais da biblioteca Awesome Oscillator e tentarmos otimizar apenas para o comprimento polinomial ideal, para o mesmo símbolo, timeframe e período de 1 ano mencionados acima, obteremos o seguinte relatório no melhor cenário:


Os resultados, no melhor dos casos, são insatisfatórios. Curiosamente, se executarmos o mesmo EA, mas com trailing stop baseado na média móvel, os resultados "melhoram":


Esses resultados podem ser explicados pela otimização de um maior número de parâmetros, ao invés de apenas um, como ao trabalhar com o polinômio. Combinar com outro sinal pode resultar em resultados radicalmente diferentes. No entanto, para fins de experimento de controle, esses relatórios podem servir como um guia para o potencial do polinômio de Newton na gestão de stop-loss.
Gestão de Capital
Finalmente, consideremos como os polinômios de Newton podem ajudar na determinação do tamanho da posição usando o terceiro tipo de classes integradas do Assistente, CExpertMoney. Como nosso polinômio pode ajudar aqui? Claro, existem muitas maneiras pelas quais o polinômio pode ser melhor aplicado, mas consideraremos as mudanças no intervalo das barras como um indicador de volatilidade e, portanto, um guia sobre como devemos ajustar o tamanho da posição com margem fixa. Nosso simples pressuposto será que, se prevemos um aumento no intervalo das barras de preços, reduziremos proporcionalmente o tamanho da nossa posição; no entanto, se o intervalo não aumentar, não faremos nada. Não haverá crescimento devido à previsão de queda na volatilidade.
O código fonte é fornecido abaixo. Trechos não relacionados à gestão de capital foram removidos.
//+------------------------------------------------------------------+ //| Optimizing lot size for open. | //+------------------------------------------------------------------+ double CMoneySizeOptimized::Optimize(double lots) { double lot = lots; //--- 0 factor means no optimization if(m_decrease_factor > 0) { m_high.Refresh(-1); m_low.Refresh(-1); vector _x, _y; _x.Init(m_length); _y.Init(m_length); for(int i = 0; i < m_length; i++) { _x[i] = i; _y[i] = (m_high.GetData(StartIndex() + i) - m_low.GetData(StartIndex() + i)) - (m_high.GetData(StartIndex() + i + 1) - m_low.GetData(StartIndex() + i + 1)); } vector _w; _w.Init(m_length); _w[0] = _y[0]; __N.Set(_w, _x, _y); double _xx = -1.0; double _yy = 0.0; __N.Get(_w, _x, _xx, _yy); //--- if(_yy > 0.0) { double _range = (m_high.GetData(StartIndex()) - m_low.GetData(StartIndex())); _range += (m_decrease_factor*m_symbol.Point()); _range += _yy; lot = NormalizeDouble(lot*(1.0-(_yy/_range)), 2); } } //--- normalize and check limits ... //--- return(lot); }
Se executarmos a otimização APENAS para o período de backtesting do polinômio para o EA, que usa a mesma classe de sinal que para trailing para o mesmo símbolo e timeframe pelo mesmo período, obteremos os seguintes relatórios:


No Assistente deste EA, o método trailing stop não foi selecionado, e ele basicamente usa os sinais brutos do Awesome Oscillator, com a única alteração sendo a redução do tamanho da posição se a volatilidade for prevista.
Como controle, usamos a classe de gestão de capital embutida, otimizada pelo tamanho no EA com um sinal semelhante e sem trailing stop. O EA permite ajustar apenas o coeficiente de redução, formando o denominador, para um valor fracionário, reduzindo o tamanho da posição proporcionalmente às perdas sofridas pelo EA. Se executarmos testes com as melhores configurações, obteremos os seguintes relatórios:


Os resultados claramente não são tão bons em comparação com os que obtivemos com a gestão de capital baseada no polinômio de Newton. Como vimos no exemplo das classes finais, isso por si só não é uma condenação para os EAs otimizados pelo tamanho da posição. Para nossos fins comparativos, a gestão de capital baseada no polinômio de Newton, da forma como implementamos, é a melhor alternativa.
Considerações finais
Analisamos o polinômio de Newton — um método que gera uma equação polinomial com base em um conjunto de vários pontos de dados. O polinômio, a parede digital abordada no artigo anterior, bem como a máquina de Boltzmann restrita abordada anteriormente, representam ideias que podem ser usadas de várias maneiras, incluindo aquelas não descritas nesta série.
O artigo não se posiciona contra os métodos estabelecidos e testados de análise de mercado, mas, considerando que estamos em uma situação em que tudo - desde bitcoin até ações, títulos e até commodities - está amplamente correlacionado, podemos falar sobre padrões sistêmicos. Em tempos de dinheiro fácil, é fácil perder a vantagem, por isso esta série pode ser vista como uma forma de popularizar abordagens novas e muitas vezes pouco comuns, que podem fornecer alguma proteção necessária quando todos nós nos aventuramos no desconhecido.
Os polinômios de Newton realmente têm limitações, como mostrado nos relatórios de teste acima. Eles estão principalmente relacionados à sua incapacidade de filtrar o ruído branco, o que significa que eles têm potencial para funcionar bem em combinação com outros indicadores que resolvem esse problema. O Assistente MQL5 permite combinar vários sinais em um único EA, por isso é possível usar um filtro ou até vários filtros para obter um sinal de EA melhor. Os módulos da classe trailing e da gestão de capital não permitem isso, então testes adicionais são necessários para determinar quais classes de trailing e gestão de capital funcionam melhor com o sinal.
A incapacidade de filtrar o ruído branco pode ser explicada pela tendência dos polinômios de ajustar excessivamente os dados amostrais, capturando todas as oscilações em vez de processar os padrões principais. Isso é frequentemente chamado de ruído de memória, que leva à diminuição do desempenho ao processar dados fora da amostra. As séries temporais financeiras geralmente também têm propriedades estatísticas mutáveis (média, variância...) e dinâmica não linear, onde mudanças abruptas de preços podem ser normais. Os polinômios de Newton, baseados em curvas polinomiais suaves, têm dificuldade em lidar com essas complexidades. Finalmente, como mencionado acima, sua incapacidade de levar em conta os sentimentos econômicos e os indicadores fundamentais significa que devem ser combinados com indicadores financeiros adequados.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/14273
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso