
ニューラルネットワークが簡単に(第64回):ConserWeightive Behavioral Cloning (CWBC)法

はじめに
Decision Transformerと、最近の記事で取り上げたそのすべての改良は、行動クローニング(BC、BehaviorCloning)の手法に属します。環境の状態や目標とする結果に応じて、「エキスパートアドバイザー(EA)」の軌道から行動を繰り返すようにモデルを訓練します。このように、目標を達成するために、現在の環境状態におけるEAの行動を模倣するようにモデルに教えます。
しかし、現実の環境では、同じ環境状態でもEAの評価が異なれば、かなり大きく異なります。時には正反対になることもあります。さらに、以前の作業では、訓練セットの作成にEAを関与させなかったことを思い出してください。エージェントの行動を様々な手法で標本化し、最適な軌道を選択しました。これらの軌道は必ずしも最適なものではありませんでした。
行動とエピソードの連続空間で軌跡を標本化する過程で、可能な選択肢をすべて保存することはほとんど不可能です。標本化された軌跡のごく一部だけが、少なくとも部分的に私たちの要求を満たすことができます。このような軌跡はむしろ外れ値のようなもので、モデルは訓練過程で単純に捨てることができます。
この状況に対抗するため、Go-Explore法のアプローチを用いました。そして、小さなピースを使用して、成功裏の軌跡を次々と描いていきました。このような軌跡は、最適とは言えません。私たちの期待に近いものですが、その最適性はまだ証明されていません。
もちろん、過去のデータを使用して手動で最適な軌道をマークすることもできます。このアプローチでは教師あり学習に近づきますが、その長所も短所もあります。
同時に、最適なパスを選択すると、モデルが理想的な状態になり、モデルの過剰適合につながる可能性があります。この場合、訓練サンプルの経路を訓練したモデルは、得られた経験を新しい環境状態に一般化することができません。
行動クローニング法の2つ目の問題点は、モデルの目標(ReturnToGo、RTG)の設定です。この問題については、過去の記事でもすでに論じています。ある研究では、訓練セットからの最大結果に対する係数を使用することを推奨しており、その方が良い結果が得られることが多いです。しかし、このアプローチは静的な問題を解く場合にしか適用できません。このような係数は、タスクごとに個別に選択されます。コントロールの二分法は、この問題に対するもう1つの解決策を提供します。他のアプローチもあります。
上記の問題点は、「Reliable Conditioning of Behavioral Cloning for Offline Reinforcement Learning」という論文の著者が取り上げています。このような問題を解決するために、著者らはConserWeightive Behavioral Cloning (CWBC)という興味深い手法を提案しています。
1.アルゴリズム
目標報酬に依存する強化学習法の信頼性に影響する要因を特定するために、論文「Reliable Conditioning of Behavioral Cloning for Offline Reinforcement Learning」の著者らは、2つの例示的な実験を計画しました。
最初の実験では、ほぼ無作為なものから専門家による最適でないものまで、さまざまなレベルのリターンを持つ軌道のデータセットに対して、異なるアーキテクチャのモデルを実行しました。実験の結果、モデルの信頼性は訓練データセットの質に大きく依存することが示されました。平均的なリターン軌跡と熟練者のリターン軌跡のデータでモデルを訓練すると、RTGが高い条件下で信頼性の高い結果を示します。同時に、低得点の軌道でモデルを訓練すると、RTGが増加するある時点を境に、その性能は急速に低下します。低品質なデータでは、大きな報酬を条件とする方策を訓練するのに十分な情報が得られないからです。これは、出来上がったモデルの信頼性に悪影響を及ぼします。
モデルの信頼性の理由はデータの質だけではありません。モデルアーキテクチャも重要な役割を果たします。実施した実験では、DTは3つのデータセットすべてで信頼性を示しました。DTの信頼性はTransformerアーキテクチャの使用によって達成されると仮定されています。エージェントの次の行動予測方策は、環境状態とRTGラベルのシーケンスに基づいているため、Attention層は訓練データセット分布外のRTGラベルを無視することができます。これもまた、予測精度の高さを示しています。同時に、MLPアーキテクチャで構築されたモデルは、行動を生成するための入力データとして現在の状態とRTGを受け取りますが、希望する報酬に関する情報を無視することはできません。この仮説を検証するために、著者らは、環境ベクトルとRTGベクトルを各時間ステップで連結するDTを少し修正したバージョンで実験をおこないました。したがって、このモデルはシーケンス内のRTG情報を無視することはできません。実験結果は、RTGが訓練セットの分布から外れた後、このようなモデルの信頼性が急速に低下することを示しています。これは、上記の仮定を裏付けるものです。
モデル訓練プロセスを最適化し、上記の要因の影響を最小化するために、著者らはConserWeightive Behavioral Cloning (CWBC)フレームワークの使用を提案しています。CWBCは、行動クローニングモデルを訓練する既存の手法の信頼性を向上させる、極めてシンプルで効果的な手法です。CWBCは2つの要素から成ります。
- 軌道の重み付け
- 保守的なRTG正則化
軌跡の重み付けは、高リターンの軌跡の重みを増やすことによって、最適でないデータ分布を変換し、最適な分布をより正確に推定する体系的な方法を提供します。保守的な損失正則化器は、大きな目標値のもとで、元のデータ分布に近い状態を保つように方策を促します。
1.1軌跡の重み付け
オフラインでの最適な軌跡の分布は、単に最適な方策によって生成されたデモンストレーションの分布であることがわかっています。通常、オフラインの軌道分布は最適なものに比べて偏る。なぜなら、モデルを評価運用する際には、エージェントのリターンが最大になるようにエージェントを調整したいが、訓練中は偏ったデータ分布に対する経験的リスクを最小化せざるを得ないからです。
この手法の主なアイデアは、軌道の訓練サンプルを、最適な軌道をよりよく推定する新しい分布に変換することです。新しい分布は、直感的に訓練とテストのギャップを緩和する高リターンの軌道に焦点を当てるべきです。元のデータセットには高リターンの軌跡はほとんど含まれていないと予想されるため、低リターンの軌跡を削除するだけで、訓練データの大半が削除されることになります。これではデータ効率が悪くなります。著者が提案する手法は、リターンに基づいて軌跡を重み付けすることです。
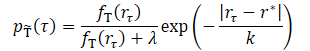
ここで、λ、kは変換された分布の形状を決定する2つのハイパーパラメータです。
平滑化パラメータkは、リターンに基づく軌道の重み付けを制御します。直感的には、kが小さいほど高リターンの軌道に重みが増します。パラメータ値が大きくなるにつれて、変換された分布はより均一になります。著者らは、k値を訓練データセットの結果の最大値とz番目のパーセンタイル値との差に設定することを提案しています。
![]()
これにより、kの実際の値を異なるデータセットに適応させることができます。この手法の作成者は、集合{99, 90, 50, 0}から4つのz値をテストしました。これは4つのk値の増加に対応します。各データセットの実験結果によると、小さなkを用いた変換分布は、高い報酬に非常に集中しています。kが増加するにつれて、低リターン軌道の密度が増加し、分布がより均一になります。集合{99,90,50}からのパーセンタイルに基づく比較的小さなkの値で、モデルはすべてのデータセットで良好な性能を示します。しかし、パーセンタイル0に基づくkの値が大きいと、EA軌跡データセットの性能が低下します。
パラメータλも変換後の分布に影響を与えます。λ=0のとき、変換された分布は高いリターンに集中します。λが大きくなるにつれて、変換された分布は元の分布に近づく傾向にあるが、指数項の影響により、依然として高リターン領域に偏っています。λの値を変えたモデルの実際の性能は、オリジナルのデータセットで訓練した場合よりも良い、あるいは同等の同様の結果を示しています。
1.2保守的正則化
上述したように、アーキテクチャも訓練済みモデルの信頼性に重要な役割を果たします。理想化されたシナリオを実現するのは難しいし、不可能でさえあります。しかし、CWBC法の著者は、分布外のRTGを指定した場合の壊滅的な失敗を避けるために、少なくとも元のデータ分布に近いモデルを要求しています。つまり、方策は保守的でなければなりません。しかし、保守性は必ずしもアーキテクチャに由来する必要はなく、状態や遷移のコスト推定に基づく保守的な手法で一般的なように、適切なモデル訓練の損失関数から生じることもあります。
この手法の著者らは、戻り条件付き行動クローン法に対して、元のデータ分布に近づくよう明示的に方策を奨励する新しい保守的正則化を提案しています。このアイデアは、大きな分布外リターンを条件とするときに予測される行動を、分布内行動に近づけるように強制することです。これは、高いリターンを持つ軌道のRTGに正のノイズを追加し、予測された行動とグランドトゥルースとの間のL2距離にペナルティを課すことで達成されます。大きなリターンが分布の外に生成されることを保証するために、調整後のRTG値が訓練セットの中で最も高いリターンを下回らないようにノイズを生成します。
著者らは、リターンが訓練セットの報酬のqパーセンタイルを超える軌道に対して、保守的な正則化を適用することを提案しています。これにより、訓練分布の外でRTGを指定する場合、方策は無作為な軌道ではなく、高リターンの軌道と同様の振る舞いをすることが保証されます。各時間ステップでノイズを追加し、RTGをオフセットします。
この手法の著者がおこなった実験では、95パーセンタイルを使用することで、様々な環境やデータセットで一般的にうまく機能することが実証されています。
この手法の著者は、提案する保守的正則化器が、状態や遷移のコストの推定に基づくオフラインRL手法の他の保守的構成要素とは異なることに注目しています。後者が一般的に外挿誤差を防ぐためにコスト関数の推定を調整しようとするのに対し、提案された手法は分布外条件を作り出すためにReturn-to-Goを歪め、行動の予測を調整します。
軌跡の重み付けと保守的な正則化を併用することで、両者の長所を併せ持つConserWeightive Behavioral Cloning (CWBC)が得られます。
2.MQL5を使用した実装
ConserWeightive Behavioral Cloning (CWBC)法の理論的側面を検討した後、提案されたアプローチの解釈の実装に移ります。今回は2つのモデルを訓練します。
- 行動を予測するためのDecision Transformer
- RTG生成のための環境の現状のコストを見積もるモデル
学習プロセスを最適化するために、軌跡の重み付けと保守的な正則化を追加します。CWBC法の著者は、提案されたアルゴリズムによってDTの訓練効率を平均8%向上させることができると主張しています。
モデルの訓練過程は独立しています。並行して訓練することも可能です。これを使用するつもりです。その前に、モデルのアーキテクチャを説明します。ここでは、アーキテクチャを記述するプロセスを2つの手法に分けて説明します。CreateDescriptionsメソッドでは、5つのエンティティからなる分析シーケンスの1ステップを入力として受け取る、エージェントのアーキテクチャの記述を作成します。
- енруの値動きと分析されたディケータの履歴データ
- 口座状態と未決済ポジション
- タイムスタンプ
- エージェントの最後の行動
- RTG
これはモデルのソースデータ層に反映されています。
bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions + NRewards); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
通常通り、受信したデータはバッチ正規化層で前処理されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
次に、すべてのエンティティを比較可能な形に変換します。そのためにまず、すべてを単一のN次元空間に転送する埋め込み層を使用します。埋め込み層には、分析された履歴の深さまで以前に取得されたデータがメモリ内に含まれていることを思い出してください。収集されたシーケンスに新しいデータが追加されます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, NRewards}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
次にSoftMax層を使用して、すべての埋め込みを比較可能な分布に変換します。SoftMaxは個々の埋め込みごとに適用されます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count * 5; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
すべての埋め込みを比較可能な形に変換した後、結果のシーケンスを分析するAttentionブロックを使用します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
次に2つの畳み込み層のブロックが来ますが、これはデータ中の安定したパターンを探し、同時にデータの次元を2分の1にします。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
別個の埋め込みの枠組みの中でデータを処理しています。SoftMax関数を使用して、すべてのエンティティを比較可能な形に変換することで、この段階を完了しましょう。これはシーケンス内の各エンティティにも個別に適用します。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
処理され、完全に比較可能なデータは、全結合層で構成される意思決定ブロックに転送されます。出力では、生成されたエージェントの予測行動が得られます。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
次のステップは、CreateRTGDescriptionsメソッドで環境原価計算モデルアーキテクチャの記述を作成することです。このモデルに、過去の価格変動と分析された指標データのあるシーケンスを投入します。この場合、数バーのシーケンスについて話しています。
bool CreateRTGDescriptions(CArrayObj *rtg) { //--- CLayerDescription *descr; //--- if(!rtg) { rtg = new CArrayObj(); if(!rtg) return false; } //--- RTG rtg.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = ValueBars * BarDescr; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
受信データはバッチ正規化層で前処理されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
次に、畳み込み層とSoftMax関数を使用して、各バーの埋め込みを作成します。この場合、各バーのデータ構造は同じであり、受信データを蓄積する必要がないため、埋め込み層を使用しません。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count + BarDescr - 1) / BarDescr; descr.window = BarDescr; descr.step = BarDescr; int prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
処理されたデータはAttentionブロックに転送されます。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
その後、データは畳み込み層のブロックに入り、上述したモデルと同様に、SoftMaxによって正規化されます。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
その後、全結合層から意思決定ブロックを作成します。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
モデルの出力では、変分オートエンコーダブロックを使用して、RTG生成方策の確率性を生成します。このように、学習された分布の枠組みの中で、環境の確率性と可能な遷移のコストをシミュレートします。
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NRewards; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- return true; }
モデルアーキテクチャの説明を作成した後、モデルの訓練EAの作業に移ります。訓練サンプルの初期収集には、EA「...\CWBC\Faza1.mq5」を使用して標本化された最適な無作為軌道を選択します。このEAのアルゴリズムとデータ収集の原則は、コントロールTransformerの記事で説明しています。
次に、エージェントを訓練するためのEA「...\CWBC\StudyAgent.mq5」を作成します。このEAは、オリジナルのDecision Transformerの訓練EAの構造をほぼ受け継いでいると言わざるを得ません。さらに、CWBC法からのアプローチも追加しています。まず、GetProbTrajectoriesという軌跡重み付けメソッドを作り、軌跡を標本化する累積確率のベクトルを返します。メソッドの本文では、すぐに、経験再生バッファの最大リターン、必要な分位のレベル、リターンの標準偏差のベクトルを決定します。このデータは、その後の保守的な正則化のために必要となります。
メソッドのパラメータには、経験再生バッファと必要な変数を渡します。
vector<float> GetProbTrajectories(STrajectory &buffer[], float &max_reward, float &quantile, vector<float> &std, double quant, float lanbda) { ulong total = buffer.Size();
メソッドの本体では、再生バッファ内の軌跡の数を決定し、パスで報酬を収集するための行列を準備します。
matrix<float> rewards = matrix<float>::Zeros(total, NRewards); vector<float> result;
軌跡を再生バッファに保存する際、パス終了までの累積報酬を再計算します。したがって、パス全体の報酬の合計は、インデックス0の要素に格納されます。ループを構成し、各パスの総報酬を用意した行列にコピーします。
for(ulong i = 0; i < total; i++) { result.Assign(buffer[i].States[0].rewards); rewards.Row(result, i); }
行列演算を使用して、報酬ベクトルの各要素の標準偏差を求めます。
std = rewards.Std(0);
以下は、各パスの総報酬のベクトルと最大報酬の値です。
result = rewards.Sum(1);
max_reward = result.Max();
各パスの報酬ベクトルの単純な合計を使用しました。しかし、分解された報酬の平均値や、その額や平均値に対する加重オプションにはばらつきがあります。アプローチは特定のタスクに依存します。
次に、必要な分位のレベルを決定します。Quantileベクトル演算に関するMQL5のドキュメントには、正しい計算には並び替えられたシーケンスベクトルが必要であると記載されています。総報酬のベクトルのコピーを作成し、昇順に並び替えます。
vector<float> sorted = result; bool sort = true; int iter = 0; while(sort) { sort = false; for(ulong i = 0; i < sorted.Size() - 1; i++) if(sorted[i] > sorted[i + 1]) { float temp = sorted[i]; sorted[i] = sorted[i + 1]; sorted[i + 1] = temp; sort = true; } iter++; } quantile = sorted.Quantile(quant);
次に、ベクトル関数Quantileを呼び出し、結果を保存します。
その後の操作に必要なデータを収集した後、各軌道の重みを決定する作業に直接進みます。係数λの使い方を統一するためには、報酬のすべての可能な標本を単一の分布にするアルゴリズムが必要です。そのために、すべての報酬を範囲(0,1)に正規化します。
正規化値の範囲には0を含めません。なぜなら、各軌跡は0とは異なる確率を持たなければならないからです。そこで、報酬範囲の最小値を平均二乗報酬の10%下げます。
相対値を最大限に利用することで、計算を真に統一したものにすることができます。
float min = result.Min() - 0.1f * std.Sum();
しかし、すべてのパスで同じ報酬値が得られる確率は低いです。これにはさまざまな理由があるでしょう。そのような事態が起こる可能性は低いにもかかわらず、チェックはおこないます。アルゴリズムのメインブランチでは、まず指数成分を計算します。次に、報酬を正規化し、軌道の重みを再計算します。
if(max_reward > min) { vector<float> multipl=exp(MathAbs(result - max_reward) / (result.Percentile(90)-max_reward)); result = (result - min) / (max_reward - min); result = result / (result + lanbda) * multipl; result.ReplaceNan(0); }
報酬が等しいという特殊なケースについては、確率ベクトルを定数値で埋めることにします。
else result.Fill(1);
次に、すべての確率の和を1に減らし、累積和のベクトルを計算します。
result = result / result.Sum(); result = result.CumSum(); //--- return result; }
各反復で軌道を標本化するために、SampleTrajectoryメソッドを使用し、そのパラメータに上記で得られた累積確率のベクトルを渡します。繰り返しの結果は、経験再生バッファ内の軌跡インデックスとなります。
int SampleTrajectory(vector<float> &probability) { //--- check ulong total = probability.Size(); if(total <= 0) return -1;
メソッド本体では、出来上がった確率ベクトルのサイズを確認し、空であれば即座に不正なインデックス「-1」を返します。
次に、一様分布から[0,1]の範囲の乱数を発生させ、その結果得られる乱数値の範囲に選択確率の範囲が入る要素を探します。
まず、極値(確率ベクトルの最初と最後の要素)を確認します。
//--- randomize float rnd = float(MathRand() / 32767.0); //--- search if(rnd <= probability[0] || total == 1) return 0; if(rnd > probability[total - 2]) return int(total - 1);
標本化された値が極端な範囲に収まらない場合は、必要な値を求めてベクトルの要素を繰り返し処理します。
直感的には、軌道の確率分布は一様になる傾向があると考えることができます。目的の方向に移動しながら、ベクトルの途中から要素を反復し始めると、最初から配列全体を反復するよりもはるかに速くなります。そこで、標本化された値にベクトルのサイズを掛け合わせ、要素のインデックスを得ます。選択された要素の確率を、標本化された値と照合します。その確率が低ければ、ループの中で、必要な要素が見つかるまでインデックスを増やしていきます。そうでない場合は、インデックスを減らして同じことをします。
int result = int(rnd * total); if(probability[result] < rnd) while(probability[result] < rnd) result++; else while(probability[result - 1] >= rnd) result--; //--- return result return result; }
結果は呼び出し側プログラムに返されます。
CWBC法を実装するのに必要なもう1つの補助関数は、ノイズ生成関数Noiseです。関数のパラメータには、報酬ベクトルの要素の標準偏差のベクトルと、最大ノイズレベルを決定するスカラー係数を渡します。この関数はノイズベクトルを返します。
vector<float> Noise(vector<float> &std, float multiplyer) { //--- check ulong total = std.Size(); if(total <= 0) return vector<float>::Zeros(0);
関数本体では、まず標準偏差ベクトルのサイズを確認します。もし空なら、空のノイズベクトルを返します。
コントロールのブロックを渡すことに成功したら、ゼロ値のベクトルを作成します。次に、ループの中で、報酬ベクトルの各要素に対して個別のノイズ値を生成します。
vector<float> result = vector<float>::Zeros(total); for(ulong i = 0; i < total; i++) { float rnd = float(MathRand() / 32767.0); result[i] = std[i] * rnd * multiplyer; } //--- return result return result; }
CWBCメソッドを実装するために別々のブロックを作成し、Trainメソッドに実装されている完全なエージェントモデル訓練アルゴリズムの実装に移ります。
メソッド本体では、必要なローカル変数を宣言し、軌跡を計量するためのGetProbTrajectoriesメソッドを呼び出します。
void Train(void) { float max_reward = 0, quantile = 0; vector<float> std; vector<float> probability = GetProbTrajectories(Buffer, max_reward, quantile, std, 0.95, 0.1f); uint ticks = GetTickCount();
そして、モデルの訓練ループのシステムを組織します。ループ本体では、まずSampleTrajectoryメソッドを呼び出して軌道を標本化し、選択された軌道上の状態を無作為に選択して学習プロセスを開始します。
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars - ValueBars, MathMin(Buffer[tr].Total, 20))); if(i < 0) { iter--; continue; }
次に、ネストされたループを構成し、連続する環境状態に対してモデルを訓練します。Decision Transformerモデルを正しく訓練し、機能させるためには、出来事を歴史的な順序に従って厳密に使用する必要があります。このモデルは、受信したデータが内部バッファに到着すると、そのデータを収集し、分析のための履歴シーケンスを生成します。
Actions = vector<float>::Zeros(NActions); Agent.Clear(); for(int state = i; state < MathMin(Buffer[tr].Total - 1 - ValueBars, i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
ループ本体では、データをソースデータバッファに収集します。まず、過去の値動きデータをダウンロードし、指標値を分析します。
続いて、口座状態や未決済ポジションに関する情報が表示されます。
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
その後、タイムスタンプを生成します。
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
そして、エージェントの最後の行動のベクトルをバッファに追加します。
//--- Prev action if(state > 0) State.AddArray(Buffer[tr].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions));
次に、RTGの形で目標指定をバッファに追加するだけです。このブロックでは、峠の終わりまで目標指定を使わず、小さなローカル区間でのみ使用します。ここでは、保守的な正則化のプロセスも作成します。そのために、まず使用した軌道の収益性を確認し、必要であればノイズベクトルを生成します。CWBC方式によれば、ノイズはリターンの高いパスだけに追加されることを思い出してください。
//--- Return to go vector<float> target, result; vector<float> noise = vector<float>::Zeros(NRewards); target.Assign(Buffer[tr].States[0].rewards); if(target.Sum() >= quantile) noise = Noise(std, 100);
次に、その地域の過去の期間における実際のリターンを計算します。出来上がったノイズベクトルを追加します。結果の値をソースデータバッファに追加します。
target.Assign(Buffer[tr].States[state + 1].rewards); result.Assign(Buffer[tr].States[state + ValueBars].rewards); target = target - result * MathPow(DiscFactor, ValueBars) + noise; State.AddArray(target);
必要なデータの完全なセットを生成したので、行動のベクトルを形成するためにエージェントのフィードフォワードパスを実行します。
//--- Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
フィードフォワードパスが成功した後、エージェントのバックプロパゲーション法を呼び出し、エージェントの予測行動と実際の行動との不一致を最小化します。このプロセスは、オリジナルのDTを訓練するのと似ています。
//--- Policy study Result.AssignArray(Buffer[tr].States[state].action); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
最後に、モデル訓練プロセスの進捗状況をユーザーに知らせ、モデル訓練ループシステムの次の反復に移る必要があります。
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
モデル訓練の反復のフルループが完了したら、チャートのコメントフィールドをクリアします。訓練結果をログに出力し、EAのシャットダウンを開始します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); ExpertRemove(); //--- }
以上で、エージェント訓練アルゴリズムの紹介を終了します。EA「...\CWBC\StudyRTG.mq5」でも同様の原理で環境状態評価モデルの訓練を構築します。添付ファイルでよく理解されることをお勧めします。また、添付ファイルにはこの記事で使用したすべてのプログラムが含まれています。
もう一点、触れておきたいことがあります。標本化された軌跡の中から最良のものを選択することにより、一次訓練データセットを形成しました。これらは、私たちの要求のいくつかを満たしているため、条件付きで準最適と分類することができます。次に、このようなデータに基づいて訓練されたエージェントの方策を最適化します。そのためには、訓練したモデルのパフォーマンスを過去のデータでテストし、同時に方策の最適化の可能性に関する情報を収集する必要があります。そこで、訓練サンプルの履歴セグメントに対するストラテジーテスターの次のパスの間に、エージェントによって予測されたデータから一定の信頼区間内で行動を実行し、そのようなパスの結果を経験再生バッファに追加します。その後、モデルのダウンストリーム訓練を繰り返し実行します。
ダウンストリームパスを収集する機能は、EA「...\CWBCResearch.mq5」に実装されます。この記事では、EAのすべてのメソッドについて詳しく説明することはしません。環境との相互作用を実装するOnTickティック処理メソッドだけを考えてみましょう。
メソッド本体では、新しいバーを開くイベントの発生を確認し、必要であれば履歴データを読み込みます。
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), History, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
得られたデータから、まず状態を推定するための入力データのベクトルを形成し、対応するモデルのフィードフォワードパスを呼び出します。
//--- History data float atr = 0; bState.Clear(); for(int b = ValueBars - 1; b >= 0; b--) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- bState.Add((float)(Rates[b].close - open)); bState.Add((float)(Rates[b].high - open)); bState.Add((float)(Rates[b].low - open)); bState.Add((float)(Rates[b].tick_volume / 1000.0f)); bState.Add(rsi); bState.Add(cci); bState.Add(atr); bState.Add(macd); bState.Add(sign); } if(!RTG.feedForward(GetPointer(bState), 1, false)) return;
次に、エージェントの初期データのテンソルを形成します。モデルを訓練する際に使用したデータの順序に従ってください。ここでは経験再生バッファの代わりに、環境からのデータを使用します。
for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
並行して、データを構造体に収集し、経験再生バッファに格納します。
また、環境調査(端末への問い合わせ)をおこない、口座状態や未決済ポジションに関する情報を収集します。
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
タイムスタンプは、学習プロセスのアルゴリズムに完全に準拠して生成されます。
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
最初のデータベクトル収集プロセスの最後に、エージェントの最新の行動と、モデルによって生成されたreturn to goを追加します。
//--- Prev action bState.AddArray(AgentResult); //--- Latent representation RTG.getResults(Result); bState.AddArray(Result);
収集されたデータは、エージェントのフィードフォワードメソッドに転送され、その後の行動のベクトルを形成します。
//--- if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat *)NULL)) return;
無作為なノイズを追加しることで、エージェントの予測行動のベクトルをわずかに歪めます。これは、予測された行動というある環境下での環境の探索を促すものです。
Agent.getResults(AgentResult); for(ulong i = 0; i < AgentResult.Size(); i++) { float rnd = ((float)MathRand() / 32767.0f - 0.5f) * 0.03f; float t = AgentResult[i] + rnd; if(t > 1 || t < 0) t = AgentResult[i] - rnd; AgentResult[i] = t; } AgentResult.Clip(0.0f, 1.0f);
その後、後続のローソク足に必要なデータをローカル変数に保存します。
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
多方向ポジションのオーバーラップボリュームを調整しましょう。
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(AgentResult[0] >= AgentResult[3]) { AgentResult[0] -= AgentResult[3]; AgentResult[3] = 0; } else { AgentResult[3] -= AgentResult[0]; AgentResult[0] = 0; }
次に、結果として得られるエージェントの行動のベクトルをデコードします。その後、環境に実装します。
//--- buy control if(AgentResult[0] < 0.9*min_lot || (AgentResult[1] * MaxTP * Symb.Point()) <= stops || (AgentResult[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(AgentResult[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + AgentResult[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - AgentResult[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(AgentResult[3] < 0.9*min_lot || (AgentResult[4] * MaxTP * Symb.Point()) <= stops || (AgentResult[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(AgentResult[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - AgentResult[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + AgentResult[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
次に、現在の状態への遷移(エージェントの以前の行動)に対して環境から報酬を受け取り、収集したデータを経験再生バッファに転送する必要があります。
int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
EAの完全なコードとすべてのメソッドは添付ファイルにあります。
訓練済みモデルテストEA「...\CWBCTest.mq5」は、エージェントが予測する行動のベクトルを歪める以外は、同様のアルゴリズムに従っています。そのコードも記事の添付ファイルに含まれています。
そして、必要なプログラムをすべて作成した後、出来上がった仕事のテストに移ります。
3.テスト
この記事の実践編では、MQL5を使用したConserWeightive Behavioral Cloning (CWBC)法のビジョンを実現するために、かなり多くの作業をおこないました。では、努力の成果を実際に評価してみましょう。いつものように、EURUSDH1の履歴データを使用して、モデルの訓練とテストをおこないます。2023年の最初の7ヶ月間の過去の期間を訓練データとして使用します。テストは2023年8月からのデータを用いておこなわれます。
前述のように、「Control Transformer」稿で標本化したデータを使用して初期訓練をおこないます。そのため、このプロセスは省略して、すぐにモデルの訓練プロセスに移ります。
この記事では、2つのモデルを訓練するために2つのEAを作成しました。これにより、2つのモデルを並行して訓練することができます。このプロセスは、異なるデバイス上で独立して実行することができます。
モデルの初期訓練後、訓練データセットで訓練済みモデルの性能を確認し、訓練データセットの履歴期間でストラテジーテスターのEA「...\CWBC\Research.mq5」と「...\CWBC\Test.mq5」を実行して追加軌道を収集します。この場合、EAを起動する順序は、モデルの訓練プロセスには影響しません。
次に、更新された経験再生バッファのデータを使用して、ダウンストリーム訓練を実行します。
ここで注意しなければならないのは、私の場合、モデル性能の向上はダウンストリーム学習の最初の反復後にのみ観察されたということです。さらに軌跡の追加収集とモデルの再訓練を繰り返したが、望ましい結果は得られませんでした。ただし、これは特殊なケースかもしれません。
訓練の過程で、訓練サンプルの過去のセグメントで利益を生み出すモデルを得ることができました。


訓練期間中、モデルは141回の取引をおこないました。そのうちの約40%は黒字決算でした。最大利益の取引は、最大損失の4倍以上です。そして、平均的な勝ち取引は、平均的な負け取引のほぼ2倍です。さらに、平均勝ち取引は最大損失より13%大きいです。この結果、プロフィットファクターは1.11となりました。新しいデータでも同様の結果が見られます。
しかし、得られた結果については否定的なトーンもあります。このモデルはロングポジションのみを建てており、これは概ねこの歴史的間隔の全域的トレンドに対応しています。その結果、残高曲線は商品のチャートと非常によく似ています。


詳細なテスト分析によると、2023年2月と5月に損失が発生し、それ以降の月も重複しています。月が最も収益性の高い月となりました。週単位では、水曜日が最大の収益性を示しました。
結論
本稿では、学習された戦略のロバスト性を向上させるために、軌跡の重み付けと保守的な正則化を組み合わせたConserWeightive Behavioral Cloning (CWBC)を紹介しました。MQL5を用いて提案手法を実装し、実際の過去のデータでテストしました。
その結果、CWBCはオフラインのモデル訓練においてかなり高い安定性を示すことがわかりました。特に、この手法は、リターンの大きい軌道が訓練データセットのごく一部を占めるような条件にもうまく対処できます。しかし、必要なハイパーパラメータを注意深く選択することが重要です。これはCWBCの有効性において重要な役割を果たします。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Faza1.mq5 | EA | コレクションEAの例 |
| 2 | Research.mq5 | EA | 追加軌道を収集するEA |
| 3 | StudyAgentmq5 | EA | 局所的方策モデルを訓練するEA |
| 4 | StudyRTG.mq5 | EA | コスト関数を訓練するEA |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13742
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索