
Redes neurais de maneira fácil (Parte 42): Procrastinação do modelo, causas e métodos de resolução

Introdução
No campo do aprendizado por reforço de modelos de redes neurais, frequentemente nos deparamos com o problema da procrastinação, quando o processo de aprendizado desacelera ou fica estagnado. A procrastinação do modelo pode ter consequências graves para alcançar os objetivos estabelecidos e exige a adoção de medidas apropriadas para superá-la. Neste artigo, examinaremos as principais causas da procrastinação do modelo e apresentaremos métodos para resolvê-las.
1. O problema da procrastinação
Uma das principais causas da procrastinação do modelo é o ambiente de treinamento insuficiente. O modelo pode enfrentar acesso limitado a dados de treinamento ou recursos insuficientes. A solução desse problema envolve a criação ou atualização do conjunto de dados, o aumento da diversidade dos exemplos de treinamento e a adição de recursos adicionais para treinamento, como poder computacional ou modelos pré-treinados para aprendizado transferido.
Outra causa da procrastinação do modelo pode ser a complexidade da tarefa que ele deve resolver. Ou o uso de um algoritmo de aprendizado que requer uma grande quantidade de recursos computacionais. Nesse caso, a solução pode envolver a simplificação da tarefa ou do algoritmo, otimização dos processos computacionais, utilização de algoritmos mais eficientes ou aprendizado distribuído.
O modelo pode procrastinar se não tiver motivação para alcançar os objetivos estabelecidos. Definir metas claras e relevantes para o modelo, desenvolver uma função de recompensa que estimule o alcance dessas metas e usar técnicas de reforço, como a introdução de recompensas e penalidades, pode ajudar a resolver esse problema.
Se o modelo não receber feedback ou não for atualizado com base em novos dados, ele pode procrastinar em seu desenvolvimento. A solução envolve estabelecer ciclos regulares de atualização do modelo com base em novos dados e feedback, além de desenvolver mecanismos para controlar e monitorar o progresso do treinamento.
É importante avaliar regularmente o progresso do modelo e os resultados do treinamento. Isso ajudará a identificar os sucessos alcançados e a detectar possíveis problemas ou áreas de dificuldade. Avaliações regulares permitirão fazer ajustes no processo de treinamento a tempo e evitar atrasos nas tarefas.
Fornecer à modelagem uma variedade de tarefas e um ambiente estimulante pode ajudar a evitar a procrastinação. A diversidade de tarefas ajuda a manter o interesse e a motivação do modelo, enquanto um ambiente estimulante, como competições ou elementos de jogo, pode incentivar a participação ativa e o progresso do modelo.
A procrastinação do modelo pode estar relacionada à falta de atualização e melhoria. É crucial analisar regularmente os resultados e aprimorar iterativamente o modelo com base no feedback e novas ideias. O desenvolvimento gradual do modelo e o progresso visível podem auxiliar no combate à procrastinação.
Criar um ambiente de aprendizado positivo e de apoio para o modelo é um aspecto importante no treinamento de modelos de aprendizado por reforço. Estudos mostram que exemplos positivos contribuem para um treinamento mais eficaz e direcionado do modelo. Isso ocorre porque o modelo busca a escolha mais ótima, e as penalidades por ações incorretas reduzem a probabilidade de escolher ações errôneas. Ao mesmo tempo, recompensas positivas direcionam claramente o modelo para escolhas corretas e aumentam substancialmente a probabilidade de repetir tais ações.
Quando o modelo recebe uma recompensa positiva por uma ação específica, ele presta mais atenção a ela e tende a repetir essa ação no futuro. Esse mecanismo de motivação ajuda o modelo a buscar e identificar as estratégias mais bem-sucedidas para alcançar os objetivos estabelecidos.
Finalmente, para resolver eficazmente a procrastinação do modelo, é necessário analisar as causas subjacentes. Identificar as razões específicas da procrastinação permitirá tomar medidas direcionadas para superá-las. Isso pode incluir a auditoria dos processos de treinamento, a identificação de pontos fracos, problemas de recursos ou configurações não ideais do modelo.
Levar em consideração e se adaptar às condições em mudança pode ajudar a evitar a procrastinação. Atualizações periódicas do modelo com base em novos dados e mudanças na tarefa de aprendizado o mantêm relevante e eficaz. Além disso, considerar fatores como novos requisitos ou restrições permite que o modelo se adapte e evite estagnação.
Estabelecer metas menores e marcos intermediários pode ajudar a dividir uma grande tarefa em partes mais gerenciáveis e alcançáveis. Isso permite que o modelo visualize o progresso e mantenha a motivação durante o processo de aprendizado.
Para superar a procrastinação com sucesso em modelos de aprendizado por reforço, é necessário empregar abordagens e estratégias diversas. Esse enfoque abrangente auxiliará o modelo a superar a procrastinação de maneira eficaz e alcançar os melhores resultados em sua aprendizagem. Ao combinar diferentes métodos, como melhoria do ambiente de aprendizado, estabelecimento de metas claras, avaliação regular do progresso e uso de motivação, o modelo conseguirá superar a procrastinação e progredir em direção às suas metas de aprendizado.
2. Passos práticos para a solução
Depois de discutirmos os aspectos teóricos do problema, vamos agora abordar a aplicação prática dessas ideias.
No artigo anterior, deixamos nosso modelo com um comentário sobre a necessidade de continuar o treinamento para minimizar negociações deficitárias. No entanto, durante o processo de treinamento contínuo, nos deparamos com uma situação em que o Expert Advisor não realizou nenhuma negociação durante todo o período de treinamento.
Esse fenômeno, conhecido como "procrastinação do modelo", é um problema sério que exige nossa atenção e busca por soluções.

2.1. Análise das causas
Para superar a procrastinação do modelo no aprendizado por reforço, é fundamental começar com uma análise da situação atual e identificar as causas desse fenômeno. A análise nos ajudará a compreender por que o modelo não está realizando negociações e o que pode ser ajustado para melhorar seu desempenho.
Os testes do modelo treinado são realizados usando o Expert Advisor "Test.mq5", que executa uma escolha gananciosa de agente e ação. É importante observar que cada execução subsequente do Expert Advisor com os mesmos parâmetros e período de teste resultará em reprodução da passagem anterior com alta precisão. Isso nos permite adicionar pontos de controle e analisar o desempenho do Expert Advisor a cada execução.
Incorporar pontos de controle e analisar o funcionamento do Expert Advisor a cada execução nos proporciona maior confiabilidade e segurança nos resultados do aprendizado por reforço. Podemos compreender melhor como o modelo aplica seus conhecimentos e previsões aos dados reais, tirando conclusões adequadas e fazendo ajustes para melhorar seu desempenho.
Para avaliar o funcionamento do planejador, introduziremos o vetor ModelsCount, que conterá o número de vezes que cada agente foi escolhido. Para isso, declaramos o vetor ModelsCount no bloco de variáveis globais:
vector<float> ModelsCount;
Em seguida, na função OnInit, inicializamos esse vetor com um tamanho correspondente ao número de agentes usados:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- ModelsCount = vector<float>::Zeros(Models); //--- return(INIT_SUCCEEDED); }
Na função OnTick, após cada propagação do planejador, aumentamos o contador do agente correspondente no vetor ModelsCount:
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ....... //--- if(!Schedule.feedForward(GetPointer(State1), 12, false)) return; Schedule.getResults(Result); int model = GetAction(Result, 0, 1); ModelsCount[model]++; //--- ........ ........ }
Finalmente, ao desinicializar o Expert Advisor, exibiremos os resultados da contagem no log:
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Print(ModelsCount); delete Result; }
Dessa forma, adicionamos funcionalidade para contar a frequência de escolha de cada agente e exibir os resultados no log ao desinicializar o Expert Advisor. Isso nos permite avaliar o funcionamento do planejador e obter informações sobre com que frequência cada agente foi escolhido durante a execução do Expert Advisor.
Após adicionar nosso primeiro ponto de controle, executamos o Expert Advisor no testador de estratégias sem alterar os parâmetros e o período de teste. Os resultados obtidos confirmaram nossas preocupações. Observamos que, durante todo o teste, o planejador utilizou apenas um agente.

Essa observação indica que o planejador pode estar tendencioso a favor de um agente específico, ignorando a exploração de outros agentes disponíveis. Essa tendência pode dificultar a eficácia de nosso modelo de aprendizado por reforço e limitar sua capacidade de descobrir estratégias mais eficazes.
Para resolver esse problema, precisamos investigar as razões pelas quais o planejador prefere usar apenas um agente.
Continuando a analisar as causas desse comportamento do modelo, adicionamos dois pontos de controle adicionais. Agora, vamos focar na dinâmica das mudanças nas distribuições de saída dos modelos conforme o estado do ambiente circundante muda. Para isso, introduzimos dois vetores adicionais: prev_scheduler e prev_actor. Nesses vetores, vamos armazenar os resultados da propagação anterior do planejador e dos agentes, respectivamente.
vector<float> prev_scheduler; vector<float> prev_actor;
Isso nos permitirá comparar as distribuições atuais com as anteriores e avaliar as mudanças nelas. Se descobrirmos que as distribuições estão mudando significativamente ao longo do tempo ou em resposta a mudanças no ambiente circundante, isso pode indicar que o modelo pode ser muito sensível a mudanças ou instável em suas estratégias.
Adicionar esses vetores ao nosso modelo nos permite obter informações mais detalhadas sobre a dinâmica das mudanças nas estratégias e distribuições, o que, por sua vez, nos ajuda a compreender as razões da preferência por um agente específico e tomar medidas para resolver esse problema.
Como no caso anterior, inicializamos os vetores no método OnInit para prepará-los para o controle dos dados.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- ModelsCount = vector<float>::Zeros(Models); prev_scheduler.Init(Models); prev_actor.Init(Result.Total()); //--- return(INIT_SUCCEEDED); }
O controle real dos dados é realizado no método OnTick.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ........ //--- State1.AssignArray(sState.state); if(!Actor.feedForward(GetPointer(State1), 12, false)) return; Actor.getResults(Result); State1.AddArray(Result); if(!Schedule.feedForward(GetPointer(State1), 12, false)) return; vector<float> temp; Schedule.getResults(Result); Result.GetData(temp); float delta = MathAbs(prev_scheduler - temp).Sum(); int model = GetAction(Result, 0, 1); prev_scheduler = temp; Actor.getResults(Result); Result.GetData(temp); delta = MathAbs(prev_actor - temp).Sum(); prev_actor = temp; ModelsCount[model]++; //--- ........ ........ //--- }
Neste caso, queremos avaliar como a mudança no estado do ambiente afeta os resultados do modelo. Como resultado deste experimento, esperamos ver uma distribuição de probabilidade única na saída do modelo para cada vela do conjunto de testes. Ou seja, desejamos observar a mudança nas estratégias do modelo conforme o estado do mercado muda.
Não vamos imprimir os resultados da análise no log, uma vez que isso geraria um grande volume de informações. Em vez disso, usaremos o modo de depuração para observar as mudanças nos valores. Para reduzir a quantidade de valores comparados, vamos verificar apenas o desvio total dos vetores.
Infelizmente, durante o teste, descobrimos a ausência de desvios. Isso significa que a distribuição de probabilidades na saída do modelo permanece praticamente a mesma em todos os estados do ambiente.
Esta observação indica que o modelo não se adapta ao ambiente em mudança e não considera as diferenças nos estados do mercado. Pode haver várias razões para esse comportamento do modelo e diversas abordagens para resolvê-lo:
- Limitação do conjunto de dados de treinamento: Se o conjunto de dados de treinamento não contém situações variadas o suficiente, o modelo pode não aprender a reagir adequadamente a novas condições. Uma solução pode ser expandir e diversificar o conjunto de dados de treinamento, incluindo uma gama mais ampla de cenários e condições de mercado em constante mudança.
- Treinamento insuficiente do modelo: O modelo pode não receber quantidade suficiente de treinamento ou não passar por um número adequado de épocas de treinamento para se adaptar a diferentes condições do ambiente. Nesse caso, aumentar a duração do treinamento ou usar métodos adicionais, como ajuste fino (fine-tuning), pode ajudar o modelo a se adaptar melhor.
- Complexidade insuficiente do modelo: O modelo pode ser insuficientemente complexo para capturar nuances nos estados do ambiente. Nesse cenário, aumentar o tamanho e a complexidade do modelo, por exemplo, adicionando camadas extras ou aumentando o número de neurônios, pode ajudá-lo a capturar e processar melhor as diferenças nos dados.
- Escolha inadequada da arquitetura do modelo: É possível que a arquitetura atual do modelo não seja adequada para resolver a tarefa de adaptação a um ambiente em mudança. Nesse caso, revisar a arquitetura do modelo pode melhorar sua capacidade de se adaptar às mudanças no ambiente.
- Função de recompensa inadequada: A função de recompensa do modelo pode não ser informativa o suficiente ou não atender aos objetivos necessários. Nesse caso, revisar a função de recompensa e considerar fatores mais relevantes pode ajudar o modelo a tomar decisões mais inteligentes em um ambiente em constante mudança.
Todas essas abordagens requerem a realização de experimentos adicionais, testes e ajustes no modelo para alcançar uma adaptação mais eficaz ao ambiente em mudança e melhorar seu desempenho.
Para determinar onde exatamente em nossos modelos a informação sobre a mudança de estado do sistema está sendo perdida, conduziremos uma análise da arquitetura de cada camada. No modo de depuração, verificaremos como os resultados de saída de cada camada de nossos modelos estão mudando.
Começaremos com a camada totalmente conectada CNeuronBaseOCL. Nessa camada, verificaremos se a informação sobre a mudança de estado do sistema está sendo mantida. Em seguida, verificaremos a camada de normalização em lote de dados CNeuronBatchNormOCL para garantir que ela não distorça os dados sobre a mudança de estado. Em seguida, analisaremos a camada convolucional CNeuronConvOCL para entender como ela processa as informações sobre a mudança de estado do sistema. E, por fim, examinaremos a camada totalmente conectada CNeuronMultiModel para determinar como ela considera a mudança de estado em diferentes modelos.
Realizar essa análise nos ajudará a identificar em qual nível da arquitetura do modelo a informação sobre a mudança do estado do sistema está sendo perdida e quais camadas podem ser otimizadas ou modificadas para melhorar o desempenho do modelo na adaptação ao ambiente em mudança.
Para controlar e rastrear os resultados de saída de cada camada no modelo, implementamos o vetor prev_output na classe CNeuronBaseOCL. Lembre-se de que essa classe é a base para todas as outras classes de camadas neurais, e todas as demais camadas a herdam. Ao adicionar esse vetor ao corpo dessa classe, garantimos sua presença em todas as camadas do modelo.
class CNeuronBaseOCL : public CObject { protected: ........ ........ vector<float> prev_output;
No método de inicialização da classe, definiremos o tamanho do vetor, que será igual ao número de neurônios nessa camada.
bool CNeuronBaseOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { ........ ........ //--- prev_output.Init(numNeurons); //--- ........ ........ //--- return true; }
No método feedForward, que realiza a propagação do modelo, adicionaremos um ponto de controle ao final do método, após a conclusão de todas as iterações. É importante observar que todas as operações nesse método são executadas no contexto do OpenCL. Para controlar os dados, precisamos carregar os resultados das operações na memória principal, mas isso pode levar muito tempo. Anteriormente, procuramos minimizar esse carregamento, mantendo apenas o carregamento dos resultados do trabalho do modelo. No caso atual, o carregamento dos resultados de cada camada neural se torna necessário. No entanto, no futuro, esse bloco de código pode ser removido ou comentado se o controle de dados não for necessário.
bool CNeuronBaseOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { ........ ........ //--- vector<float> temp; Output.GetData(temp); float delta=MathAbs(temp-prev_output).Sum(); prev_output=temp; //--- return true; }
Também adicionamos um controle similar aos métodos de propagação de todas as classes de camadas neurais analisadas. Isso nos permite controlar os valores de saída de cada camada e identificar os locais onde a mudança no estado do sistema pode estar sendo "perdida". Ao adicionar blocos de código correspondentes aos métodos de propagação de cada classe de camada, podemos salvar e analisar os resultados do funcionamento da camada a cada iteração do treinamento do modelo.
O controle de dados é realizado no modo de depuração.
Após a análise dos resultados, descobrimos que o bloco de pré-processamento de dados, composto pela camada de dados iniciais, camada de normalização em lote e duas camadas neurais convolucionais e totalmente conectadas em sequência, não está funcionando corretamente. Observamos que após a segunda camada convolucional, o modelo não reage às mudanças no estado do sistema analisado.
CNeuronBaseOCL -> CNeuronBatchNormOCL -> CNeuronConvOCL -> CNeuronBaseOCL -> CNeuronConvOCL -> CNeuronBaseOCL
Isso é observado tanto nos casos dos agentes quanto no caso do planejador, onde usamos um bloco similar de pré-processamento de dados. Os resultados dos testes foram idênticos para ambos os casos.
Apesar de ter tido resultados positivos em experimentos anteriores, essa arquitetura se mostrou ineficaz neste caso Portanto, nos deparamos com a necessidade de fazer alterações na arquitetura dos modelos utilizados.
2.2. Alteração na arquitetura dos modelos
Após a análise realizada, chegamos à conclusão de que a arquitetura atual dos modelos não é eficiente. Agora é necessário dar um passo atrás e revisitar a arquitetura criada anteriormente com uma nova perspectiva, a fim de avaliar possíveis caminhos para otimização.
No modelo atual, fornecemos a situação de mercado e o estado da nossa conta como entrada para os agentes, que analisam a situação e propõem ações possíveis. Os resultados do trabalho dos agentes são acrescentados aos dados iniciais coletados anteriormente e transmitidos como entrada para o planejador, que escolhe um agente para executar uma ação.
Agora, imagine um departamento de investimentos, onde os funcionários analisam a situação de mercado e apresentam os resultados de sua análise ao chefe do departamento. O chefe do departamento, tendo esses resultados, combina-os com os dados iniciais e conduz uma análise adicional para escolher um agente cuja previsão coincide com a sua própria. No entanto, tal abordagem pode reduzir a eficiência do departamento.
Nesse cenário, o chefe do departamento não apenas precisa analisar a situação do mercado por conta própria, mas também avaliar os resultados do trabalho dos funcionários. Isso adiciona uma carga adicional e nem sempre tem um valor prático na tomada de decisões. Tentar fornecer o máximo de informações em cada etapa pode levar a perder o conceito fundamental dos modelos hierárquicos, que consiste em dividir a tarefa em componentes menores.
Nesse contexto, o desempenho desse departamento, com base na analogia de nosso modelo, pode ser inferior ao do próprio chefe do departamento, pois ele precisa lidar não apenas com a análise da situação do mercado, mas também com a verificação do desempenho dos funcionários, o que pode ser menos eficaz na tomada de decisões.
Nesse contexto, fica evidente que a eficiência do trabalho desse departamento, baseado na analogia com o nosso modelo, será maior se dividirmos a análise da situação de mercado entre os agentes e o planejador. Neste modelo, os agentes se especializarão na análise de mercado, enquanto o planejador será responsável por tomar decisões com base nas previsões dos agentes, sem conduzir sua própria análise de mercado.
Os agentes serão responsáveis pela análise dos dados de mercado, incluindo a realização de análise técnica e fundamental Eles irão investigar e avaliar a situação atual do mercado, identificar tendências e sugerir possíveis ações. No entanto, eles não levarão em consideração o estado da conta ao realizar sua análise.
O planejador, por outro lado, será responsável pela gestão de riscos e pela tomada de decisões com base na análise dos agentes. Ele usará as previsões e recomendações fornecidas pelos agentes e conduzirá uma análise adicional do estado da conta e de outros fatores relacionados à gestão de riscos. Com base nessas informações, o planejador tomará a decisão final sobre ações específicas dentro da estratégia de investimento.
Essa divisão de responsabilidades permite que os agentes se concentrem na análise de mercado sem se distraírem com o estado da conta, aumentando sua especialização e precisão nas previsões. O planejador, por sua vez, pode se concentrar na avaliação de riscos e na tomada de decisões com base nas previsões dos agentes, permitindo uma gestão eficaz da carteira e minimização dos riscos.
Essa abordagem melhora o processo de tomada de decisões no departamento de investimentos, pois cada membro da equipe se concentra em sua especialização, levando a análises e previsões mais precisas. Isso pode aumentar a eficiência do nosso modelo de trabalho e levar a decisões de investimento mais fundamentadas e bem-sucedidas.
Com base nas informações apresentadas, iniciaremos a revisão da arquitetura do nosso modelo. Em primeiro lugar, faremos alterações na camada de dados iniciais do agente, para que ela se concentre exclusivamente na análise da situação de mercado, removendo neurônios responsáveis pela análise do estado da conta.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *scheduler) { //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!critic) { critic = new CArrayObj(); if(!critic) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * 12); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
No bloco de pré-processamento de dados, removeremos as camadas totalmente conectadas, mantendo apenas a camada de normalização em lote e 2 camadas convolucionais.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count=descr.count = prev_count-2; descr.window = 3; descr.step = 1; descr.window_out = 2; prev_count*=descr.window_out; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = (prev_count+1)/2; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
O bloco de tomada de decisões permanecerá inalterado.
Decidimos fazer mudanças na arquitetura do Crítico. Como antes, o Crítico analisará tanto a situação de mercado quanto o estado da conta. Isso ocorre porque o valor do próximo estado depende não apenas da última ação realizada, mas também das ações anteriores, expressas em posições abertas e lucros ou perdas acumulados.
Chegamos à conclusão de que o valor do estado subsequente não deve depender da estratégia escolhida. Nosso objetivo é maximizar o potencial de lucro, independentemente da estratégia específica que usamos. Com base nisso, fizemos algumas alterações no modelo do Crítico.
Especificamente, simplificamos a arquitetura do Crítico ao remover as camadas totalmente conectadas de modelos múltiplos. Em vez disso, introduzimos um modelo de tomada de decisão totalmente parametrizado. Isso nos permite adotar uma abordagem mais geral e flexível, em que a estratégia não influencia diretamente a avaliação do valor do estado.
Essa alteração na arquitetura do modelo do Crítico ajuda a separar a análise da situação de mercado da tomada de decisões, simplificando o processo e permitindo um foco na maximização dos lucros, independentemente da estratégia escolhida.
Além disso, fizemos alterações no bloco de pré-processamento de dados, semelhantes às mudanças na arquitetura do agente. Agora, no bloco de pré-processamento de dados, simplificamos a arquitetura, removendo as camadas totalmente conectadas e mantendo apenas a camada de normalização em lote e duas camadas convolucionais.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (int)(HistoryBars * 12 + 9); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count=descr.count = prev_count-2; descr.window = 3; descr.step = 1; descr.window_out = 2; prev_count*=descr.window_out; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = (prev_count+1)/2; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 150; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.optimization = ADAM; descr.activation = TANH; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = TANH; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = 4; descr.window_out = 32; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Em seguida, simplificamos significativamente a arquitetura do planejador. Ao eliminar a análise da situação de mercado, conseguimos reduzir significativamente o tamanho da camada de dados iniciais. Como resultado, praticamente eliminamos o bloco de pré-processamento de dados, mantendo apenas a camada de normalização em lote. Decidimos usar a normalização em lote para analisar os valores absolutos do estado da conta. Atualmente, estamos utilizando os valores totalmente normalizados da saída dos modelos de agentes. No futuro, podemos mudar para valores relativos do estado da conta e abandonar o uso da camada de normalização de dados.
No bloco de tomada de decisões, aplicamos um modelo perceptron simples com uma camada SoftMax na saída. Esse modelo nos permite obter uma distribuição de probabilidade entre diferentes Agentes e escolher a ação mais apropriada com base nessas probabilidades.
Essa simplificação na arquitetura do planejador nos permite tomar decisões de maneira mais eficiente, levando em consideração apenas os resultados da análise dos agentes. Isso reduz a complexidade computacional e diminui a dependência de dados adicionais.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (9 + 40); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 10; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = 10; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
Durante o treinamento do modelo, usamos três Expert Advisors, cada um com sua própria função. Para evitar confusão e reduzir a possibilidade de erros, decidimos mover a função de descrição da arquitetura do modelo para o arquivo "Trajectory.mqh", que faz parte da biblioteca que descreve as classes e estruturas usadas em nosso modelo. Isso nos permite utilizar uma arquitetura de modelos unificada em todos os Expert Advisors e garante a sincronização automática das alterações em todos os três Expert Advisors.
A estrutura dos modelos foi alterada, incluindo a separação do fluxo de dados iniciais, o que exigiu ajustes na estrutura de descrição do estado atual. Criamos um array separado para registrar o estado da conta, de modo que possamos considerá-lo na análise e tomada de decisões. Essa mudança permite gerenciar e utilizar de maneira mais eficaz as informações sobre o estado da conta no processo de treinamento e operação dos modelos.
struct SState { float state[HistoryBars * 12]; float account[9]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); } };
Devido às mudanças na estrutura do modelo, também tivemos que fazer ajustes nos métodos de manipulação de arquivos. O código completo da estrutura atualizada e dos métodos correspondentes está disponível no arquivo anexado para consulta.
2.3. Mudanças no processo de coleta de dados
Na próxima etapa, fizemos alterações no processo de coleta de dados realizado no Expert Advisor "Research.mq5".
Como mencionado anteriormente, o uso de exemplos positivos no treinamento do modelo melhora sua eficácia. Portanto, introduzimos uma restrição mínima de rentabilidade da negociação para que ela seja armazenada no banco de dados de exemplos. O nível mínimo de rentabilidade é determinado pelo parâmetro externo "ProfitToSave".
Além disso, para reduzir casos de posições mantidas por longos períodos, introduzimos parâmetros externos que limitam os níveis de take-profit e stop-loss. Os valores desses parâmetros são definidos na moeda da conta e permitem limitar a duração das posições e indiretamente controlar o tamanho das posições abertas.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input double ProfitToSave = 10; input double MoneyTP = 10; input double MoneySL = 5;
As mudanças na estrutura de armazenamento de dados e na arquitetura dos modelos exigiram ajustes nas operações de coleta e preparação de dados para o processo de propagação dos modelos. Como antes, começamos coletando dados sobre o estado do mercado no array "state".
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- sState.state[b * 12] = (float)Rates[b].close - open; sState.state[b * 12 + 1] = (float)Rates[b].high - open; sState.state[b * 12 + 2] = (float)Rates[b].low - open; sState.state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; sState.state[b * 12 + 4] = (float)sTime.hour; sState.state[b * 12 + 5] = (float)sTime.day_of_week; sState.state[b * 12 + 6] = (float)sTime.mon; sState.state[b * 12 + 7] = rsi; sState.state[b * 12 + 8] = cci; sState.state[b * 12 + 9] = atr; sState.state[b * 12 + 10] = macd; sState.state[b * 12 + 11] = sign; }
Em seguida, salvamos as informações sobre o estado da conta no array "account".
//--- sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); sState.account[2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); sState.account[3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); sState.account[4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } sState.account[5] = (float)buy_value; sState.account[6] = (float)sell_value; sState.account[7] = (float)buy_profit; sState.account[8] = (float)sell_profit;
Para a propagação com a arquitetura atualizada do modelo de Agentes, só precisamos do estado do mercado do array "state".
State1.AssignArray(sState.state); if(!Actor.feedForward(GetPointer(State1), 12, false)) return;
Para fornecer os dados de entrada para a propagação do Planejador, precisamos combinar os dados sobre o estado da conta e os resultados da propagação do modelo dos agentes.
Actor.getResults(Result); State1.AssignArray(sState.account); State1.AddArray(Result); if(!Schedule.feedForward(GetPointer(State1), 12, false)) return;
Após a propagação dos dois modelos, realizamos a amostragem e selecionamos uma ação. Esse processo permanece inalterado. No entanto, adicionamos a análise dos lucros e perdas acumulados. Se o valor dos lucros ou perdas acumulados atingir os valores limite definidos, indicamos uma ação para fechar todas as posições.
É importante notar que nosso modelo prevê apenas ação de fechamento de todas as posições. Portanto, ao analisar os lucros e perdas acumulados, somamos o valor de todas as posições, independentemente de sua direção.
int act = GetAction(Result, Schedule.getSample(), Models); double profit = buy_profit + sell_profit; if(profit >= MoneyTP || profit <= -MathAbs(MoneySL)) act = 2;
Também fizemos alterações na função de recompensa. Decidimos remover a influência das mudanças de patrimônio, resultando em recompensas mais espaçadas. No entanto, estamos cientes de que, no processo de negociação nos mercados financeiros, a mudança no saldo é que possui valor final. Isso foi considerado ao ajustar a função de recompensa.
O código completo de todos os métodos e funções do Expert Advisor pode ser encontrado no anexo.
2.4. Mudanças no processo de treinamento
Também fizemos alterações no processo de treinamento dos modelos, com foco no treinamento paralelo de todos os modelos e agentes. Em particular, mudamos a abordagem para transmitir recompensas durante a retropropagação. Anteriormente, especificávamos a recompensa apenas para um agente selecionado, mas agora gostaríamos de transmitir toda a distribuição de recompensas para todos os agentes. Isso permitirá ao Planejador avaliar mais completamente o possível impacto de cada agente e reduzir a probabilidade de escolher um agente individual para todos os estados, como observado anteriormente.
A partir da teoria das probabilidades, sabemos que a probabilidade de um evento complexo ocorrer é o produto das probabilidades de seus componentes. No nosso caso, temos uma distribuição de probabilidade para a escolha dos agentes e uma distribuição de probabilidade para a escolha das ações por cada agente. Na base de exemplos, também temos ações específicas e suas recompensas correspondentes do sistema. Para preparar os dados para a retropropagação do planejador, multiplicamos os elementos do vetor de probabilidade de escolha do agente pelos elementos do vetor de probabilidade de escolha dessa ação por cada agente.
Para transmitir a recompensa total ao Planejador, aplicamos a função SoftMax para normalizar as probabilidades obtidas e, em seguida, multiplicamos o vetor resultante pela recompensa externa. Nesse processo, ajustamos previamente a recompensa externa com base no valor do estado, permitindo avaliar o desvio da trajetória ideal.
void Train(void) { ........ ........ Actor.getResults(ActorResult); Critic.getResults(CriticResult); State1.AssignArray(Buffer[tr].States[i].account); State1.AddArray(ActorResult); if(!Scheduler.feedForward(GetPointer(State1), 12, false)) return; Scheduler.getResults(SchedulerResult); //--- ulong actions = ActorResult.Size() / Models; matrix<float> temp; temp.Init(1, ActorResult.Size()); temp.Row(ActorResult, 0); temp.Reshape(Models, actions); float reward=(Buffer[tr].Revards[i] - CriticResult.Max())/100; int action=Buffer[tr].Actions[i]; SchedulerResult=SchedulerResult*temp.Col(action); SchedulerResult.Activation(SchedulerResult,AF_SOFTMAX); SchedulerResult = SchedulerResult * reward; Result.AssignArray(SchedulerResult); //--- if(!Scheduler.backProp(GetPointer(Result))) return;
Para treinar o Crítico, simplesmente transmitimos a recompensa externa não ajustada para a ação correspondente.
CriticResult[action] = Buffer[tr].Revards[i]; Result.AssignArray(CriticResult); //--- if(!Critic.backProp(GetPointer(Result), 0.0f, NULL)) return;
Ao lidar com os modelos dos agentes, consideramos que o uso de qualquer estratégia pode levar tanto a lucros quanto a perdas. Em alguns casos, após uma entrada malsucedida em uma posição, é importante ter a decisão de sair a tempo e limitar as perdas. Portanto, não podemos excluir ações com recompensas negativas completamente, já que em alguns casos outras ações podem ter um efeito negativo ainda maior. O mesmo vale para recompensas positivas.
Ao preparar os dados para a retropropagação dos modelos dos agentes, simplesmente ajustamos os resultados da última propagação, levando em consideração a probabilidade de cada agente escolher uma ação e a recompensa externa do sistema. Para manter a integridade da distribuição de probabilidade de cada agente, normalizamos a distribuição ajustada usando a função SoftMax.
//--- for(int r = 0; r < Models; r++) { vector<float> row = temp.Row(r); row[action] += row[action] * reward; row.Activation(row, AF_SOFTMAX); temp.Row(row, r); } temp.Reshape(1, ActorResult.Size()); Result.AssignArray(temp.Row(0)); //--- if(!Actor.backProp(GetPointer(Result))) return;
Nos arquivos anexos, você pode encontrar o código completo de todos os Expert Advisors, bem como suas funções usadas no trabalho.
Para iniciar o processo de treinamento do modelo, executamos o Expert Advisor "Research.mq5" no modo de otimização do testador de estratégias, de forma semelhante ao descrito no artigo sobre o algoritmo Go-Explore. A principal diferença aqui é especificar um nível mínimo de lucratividade para as execuções, que determina os exemplos salvos no banco de dados. Isso ajuda a aumentar a eficácia do treinamento do modelo, concentrando-se em exemplos positivos.
No entanto, vale a pena mencionar um detalhe importante. Para garantir uma exploração ambiental mais diversificada e ampliar a cobertura das estratégias de comportamento, podemos incluir a otimização dos parâmetros de take-profit e stop-loss no processo de coleta de exemplos. Isso permite que nosso modelo explore mais estratégias diferentes e encontre os pontos de saída ideais das posições.

Após criar a base de exemplos, iniciamos o processo de treinamento dos modelos usando o Expert Advisor "Study2.mq5". Para fazer isso, é necessário anexar o Expert Advisor ao gráfico do instrumento selecionado e especificar o número de iterações, que determinará quantas vezes os parâmetros do modelo serão atualizados.
Executar o Expert Advisor "Study2.mq5" no gráfico permite que o modelo use os exemplos coletados para treinamento e ajuste de seus parâmetros. Durante o processo de treinamento, o modelo se aprimorará e se adaptará ao ambiente de mercado para tomar decisões mais precisas e melhorar sua eficácia.
Verificamos os resultados do treinamento do modelo executando-o uma única vez no testador de estratégias, usando o Expert Advisor "Test.mq5". É bastante esperado que após a primeira iteração de treinamento, o resultado do modelo esteja distante do esperado. Pode ser deficitário.


Ou até mesmo gerar lucro. No entanto, o saldo provavelmente estará muito longe de nossas expectativas.

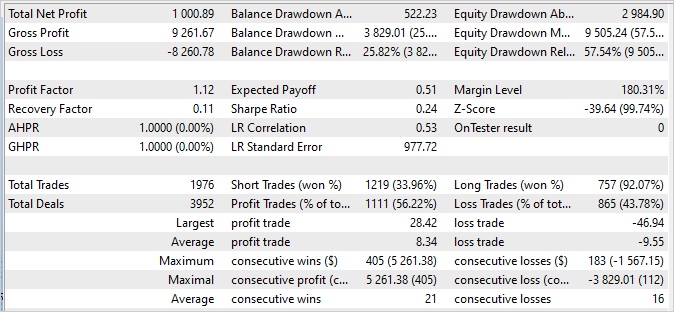
No entanto, podemos observar como nosso Planejador utiliza de forma mais ou menos completa todos os agentes.


Para detectar ações incorretas do modelo, adicionamos um bloco de coleta de informações sobre estados visitados, ações executadas e recompensas externas obtidas em nosso Expert Advisor de teste "Test.mq5". Esse bloco de coleta de dados é semelhante ao que é usado no Expert Advisor para coletar exemplos.
É importante notar que, no Expert Advisor de teste, usamos uma escolha gananciosa de agente e ação. Isso significa que todos os passos executados são determinados pela estratégia do nosso modelo. Portanto, adicionamos todas as execuções à base de exemplos, independentemente de sua lucratividade. Incluir esses dados na base de exemplos nos permitirá ajustar e otimizar a estratégia de negociação do nosso modelo.
Ao coletar informações sobre estados visitados, ações executadas e recompensas obtidas, poderemos analisar o desempenho do modelo e determinar quais ações levam a resultados desejáveis e quais ações levam a resultados indesejáveis. Essas informações nos permitirão melhorar a eficácia dos modelos e a precisão de tomada de decisões em iterações subsequentes de seu treinamento.
Iterações adicionais da execução do Expert Advisor de coleta de exemplos no modo de otimização do testador de estratégias são de grande importância para ampliar a base de exemplos positivos e fornecer mais dados para o treinamento do nosso modelo.
No entanto, é importante notar a necessidade de alternar entre os processos de coleta de exemplos e treinamento do modelo. Durante a coleta de exemplos, amostramos ações a partir da distribuição de probabilidades gerada pelo modelo. Isso significa que a coleta de exemplos tem uma certa direção, e novos exemplos estarão a uma curta distância da escolha gananciosa de ação. Isso permite explorar mais completamente o ambiente em uma direção especificada e enriquecer a base de exemplos com dados úteis.
A alternância entre a coleta de exemplos e o treinamento do modelo permite que o modelo use eficientemente novos dados, melhorando sua estratégia com base nas informações obtidas. Com cada nova iteração, o modelo se torna mais experiente e adaptado à direção de negociação desejada.
3. Teste
Após várias iterações de coleta de exemplos, treinamento e teste, conseguimos um modelo capaz de gerar lucro na amostra de treinamento, com um fator de lucro de 114,53. Nos primeiros 4 meses de 2023, durante os quais o modelo foi treinado, foram realizadas 286 negociações. Dentre elas, apenas 16 foram deficitárias. O fator de recuperação na amostra de treinamento foi de 1,3, indicando a capacidade do modelo de se recuperar rapidamente após perdas.
O tempo de manutenção da posição aberta foi uniformemente distribuído no intervalo de 1 a 198 horas, com uma média de 72 horas e 59 minutos. Isso indica que o modelo pode tomar decisões tanto em intervalos de tempo curtos quanto de longo prazo, dependendo das condições de mercado atuais.
Em geral, esses resultados indicam que o modelo demonstra alta lucratividade, uma baixa proporção de negociações deficitárias, a capacidade de se recuperar rapidamente e flexibilidade na escolha do tempo de manutenção da posição. Isso confirma a eficácia do modelo e seu potencial para aplicação em condições reais de negociação.



É significativo observar que o gráfico de saldo das próximas 2 semanas, que não fazem parte do conjunto de treinamento, demonstra estabilidade e não possui diferenças significativas em relação ao gráfico do conjunto de treinamento. Embora os números sejam um pouco mais baixos, eles ainda são notáveis:
- O fator de lucro é 15,64, o que indica uma boa rentabilidade do modelo em relação ao risco.
- O fator de recuperação é 1,07, o que indica a capacidade do modelo de se recuperar de operações perdedoras.
- Das 89 operações concluídas, 80 foram fechadas com lucro, o que indica uma elevada proporção de transações bem-sucedidas.
Esses resultados confirmam a estabilidade e confiabilidade do modelo nos dados de negociação subsequentes. Embora os valores possam variar ligeiramente em relação ao conjunto de treinamento, eles ainda são impressionantes e confirmam o potencial do modelo para negociação bem-sucedida em condições reais.


Os relatórios do testador de estratégias podem ser encontrados no anexo.
Considerações finais
Neste artigo, abordamos a questão da procrastinação do modelo e propusemos abordagens eficazes para superá-la. Usando o algoritmo Scheduled Auxiliary Control, desenvolvemos uma abordagem para treinar modelos para negociação automatizada nos mercados financeiros.
Apresentamos uma arquitetura hierárquica composta por vários modelos que interagem entre si. Cada modelo é responsável por aspectos específicos da tomada de decisões. Essa estrutura modular nos permite superar eficazmente a procrastinação, dividindo a tarefa em subtarefas menores, mas inter-relacionadas.
Também discutimos métodos de coleta de exemplos, treinamento de modelos e testes, que nos permitem aprender eficazmente com dados reais e se adaptar às mudanças nas condições de mercado.. A inclusão de estratégias diversas e a análise de lucros e perdas acumulados nos permitem tomar decisões fundamentadas e minimizar riscos.
Os resultados dos nossos experimentos mostram que a abordagem proposta é realmente capaz de superar a procrastinação e alcançar negociações estáveis e lucrativas. Nossos modelos demonstram alta lucratividade e estabilidade em dados de treinamento e subsequente, validando sua eficácia em condições reais.
Em geral, nossa abordagem permite que os modelos estudem e se adaptem eficazmente às situações de mercado e tomem decisões fundamentadas. O desenvolvimento contínuo e a otimização dessa abordagem podem levar a uma ainda maior lucratividade e estabilidade na negociação automatizada nos mercados financeiros.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | Study2.mql5 | EA | EA de treinamento de modelo |
| 3 | Test.mq5 | EA | EA de treinamento de modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 5 | FQF.mqh | Biblioteca de classe | Biblioteca de classes de preparação de modelos totalmente parametrizada |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para a criação de uma rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de códigos do programa OpenCL |
…
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/12638
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso