
Нейросети в трейдинге: Иерархический векторный Transformer (HiVT)

Введение
Проблемы, решаемые в области автономного вождения, во многом пересекаются с задачами, которые стоят перед трейдерами. Навигация в динамичных условиях безопасным маневром — это критическая задача для автономных транспортных средств. Для достижения этой цели такие автомобили должны понимать окружающую обстановку и прогнозировать будущие события на дороге. Однако точное прогнозирование маневров ближайших участников дорожного движения, таких как автомобили, велосипеды и пешеходы, является сложной задачей, особенно когда их цели или намерения неизвестны. В многопользовательских сценариях дорожного движения поведение агента формируется под влиянием сложных взаимодействий с другими агентами, что дополнительно усложняется правилами дорожного движения, зависящими от карты, что делает понимание разнообразного поведения нескольких агентов на сцене чрезвычайно сложным.
В последних исследованиях используют векторизованный подход для более компактного представления сцен, извлекая набор векторов или точек из траекторий и элементов карты. Однако существующие векторизованные подходы сталкиваются с проблемами при необходимости выполнения прогнозирования движения в реальном времени в условиях быстро меняющегося дорожного трафика. Поскольку такие методы обычно неустойчивы к изменениям положения и ориентации системы координат. Для смягчения этой проблемы сцены нормализуются так, чтобы они были центрированы на целевом агенте и выровнены по направлению его движения. Этот подход становится проблематичным, когда необходимо прогнозировать движение большого числа агентов на сцене, из-за высоких вычислительных затрат на повторную нормализацию сцены и повторное вычисление признаков для каждого целевого агента. Кроме того, существующие работы моделируют взаимосвязи всех элементов во всех измерениях пространства и времени, чтобы зафиксировать детализированные взаимодействия между векторизованными элементами, что неизбежно приводит к чрезмерным вычислительным затратам по мере увеличения количества элементов. Поскольку точное прогнозирование в реальном времени критически важны для безопасности автономного вождения, многие исследователи стремятся вывести этот процесс на новый уровень, разработав новую структуру, позволяющую быстрее и точнее прогнозировать движение множества агентов.
Один из таких подходов был представлен в статье "HiVT: Hierarchical Vector Transformer for Multi-Agent Motion Prediction". Он использует симметрии и иерархическую структуру задачи прогнозирования движения множества агентов. Авторы HiVT рассматривают задачу прогнозирования движения в несколько этапов и иерархически моделируют взаимосвязи между элементами с помощью Transformer.
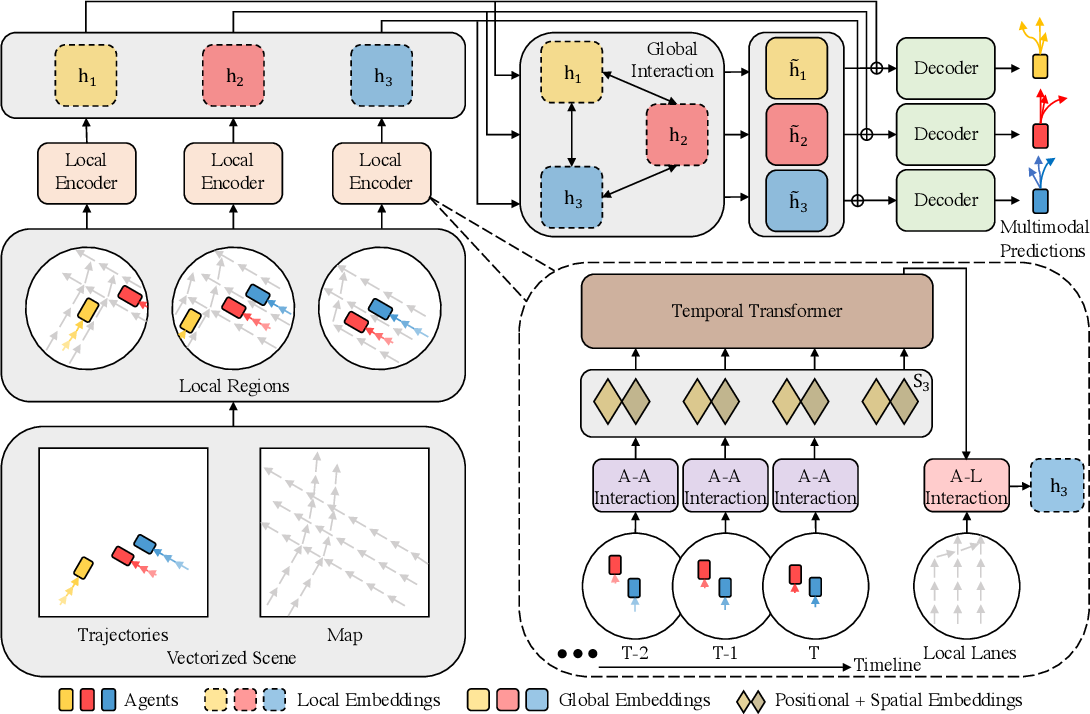
На первом этапе модель избегает дорогостоящего моделирования взаимодействий всех элементов между собой и вместо этого извлекает контекстные признаки локально. Вся сцена делится на набор локальных областей, каждая из которых центрирована на моделируемом агенте. Для каждой агентно-центрированной локальной области извлекаются контекстные признаки из локальных векторизованных элементов, которые содержат богатую информацию, связанную с центральным агентом.
На втором этапе, для компенсации ограничений локальных полей зрения и фиксирования дальнодействующих зависимостей на сцене, осуществляется глобальная передача информации между агентно-центрированными локальными областями. Для этого авторы метода используют Transformer, оснащенный геометрическими связями между локальными системами отсчета.
Полученные локальные и глобальные представления позволяют декодеру прогнозировать будущие траектории всех агентов за один прямой проход модели. А для дополнительного использования симметрии задачи, авторы метода вводят представление сцены, не зависящее от сдвига глобальной системы координат, в котором для характеристики всех векторизованных элементов используются относительные положения. Исходя из этого представления сцены, вводятся модули вращательно-инвариантного перекрестного внимания для пространственного обучения, которые могут изучать локальные и глобальные представления, не зависящие от поворота сцены.
1. Алгоритм HiVT
Алгоритм метода HiVT начинается с представления дорожной сцены в виде совокупности векторизованных элементов. На основе этого представления сцены модель иерархически агрегирует пространственно-временную информацию о сцене. Дорожная сцена состоит из агентов и информации о карте. Для структурированного представления сцены вначале извлекаем векторизованные элементы, включая сегменты траекторий дорожных агентов и сегменты полос в данных карты.
Векторизованный элемент ассоциирован с семантическими и геометрическими атрибутами. В отличие от предыдущих векторизованных методов, где геометрические атрибуты агентов или полос включают абсолютные позиции точек, авторы метода избегают использования абсолютных позиций и предлагают описывать геометрические атрибуты с помощью относительных позиций. Это делает сцену полностью набором векторов. В частности, траектория агента i представляется как "pt,i — pt-1,i", где pt,i — это местоположение агента i на шаге времени t.
Для сегмента полосы xi геометрический атрибут задается как p1,xi — p0,xi, где p0,xi и p1,xi — начальные и конечные координаты xi. Преобразовав набор точек в набор векторов, такое представление естественно гарантирует инвариантность к трансляции. Однако информация об относительных позициях между элементами также теряется. Чтобы сохранить пространственные отношения, мы вводим векторы относительных позиций для пар агент-агент и агент-полоса. Например, вектор позиции агента j относительно агента i на шаге времени t равен ptj — pti, что полностью описывает пространственные отношения между двумя агентами и также является инвариантным к трансляции. Без потери информации подобное представление сцены гарантирует, что любые применяемые к нему обучаемые функции будут соблюдать инвариантность к трансляции.
Для точного прогнозирования будущих траекторий агентов в высокодинамичной среде модель должна эффективно изучать пространственно-временные зависимости между большим числом векторизованных элементов. Transformer продемонстрировал потенциал в захвате долгосрочных зависимостей между элементами в различных задачах. Однако прямое применение трансформеров к пространственно-временным элементам сталкивается со сложностью O((NT + L)^2), где N, T и L — числа агентов, исторических временных шагов и сегментов полос, соответственно. С целью эффективного извлечения информации из большого числа элементов, авторы HiVT предлагают факторизовать пространственные и временные размеры с изучением пространственных отношений только локально на каждом временном шаге. В частности, они делят пространство на N локальных регионов, каждый из которых сосредоточен вокруг одного агента в сцене. Внутри каждого локального региона находятся сегменты траекторий и локальная среда центрального агента, где информация о среде включает сегменты траекторий соседних агентов и локальные сегменты полос, окружающие центрального агента. Для каждого локального региона мы агрегируем локальную информацию в один вектор признаков, последовательно моделируя взаимодействие агент-агент на каждом временном шаге, временные зависимости для каждого агента и взаимодействия агент-полоса на текущем временном шаге. После агрегации вектор признаков содержит богатую информацию, связанную с центральным агентом. При этом вычислительная сложность снижается с O((NT + L)^2) до O(NT^2 + TN^2 + NL) за счет факторизации пространственных и временных размеров и дополнительно уменьшается до O(NT^2 + TNk + Nl) за счет ограничения радиуса локальных регионов, где k < N и l < L.
Хотя локальный энкодер может извлекать богатые представления, объем информации ограничен диапазоном локальных регионов. Чтобы избежать потерь в качестве прогнозов, авторы метода дополнительно используют глобальный модуль взаимодействия для компенсации ограниченных локальных рецептивных полей и захвата динамики на уровне сцены, в котором выполняется обмен сообщениями между локальными регионами. Глобальный модуль взаимодействия значительно усиливает выразительность модели при стоимости сложности O(N^2), что относительно легковесно по сравнению с локальным энкодером.
Проблема прогнозирования движения нескольких агентов демонстрирует симметрии перевода и вращения. Существующие методы перенормируют все векторизованные элементы относительно каждого агента и делают прогнозы для одного агента несколько раз, чтобы достичь инвариантности. Эта парадигма масштабируется линейно относительно числа агентов. Для сравнения, модель HiVT может делать прогнозы для всех агентов за один прямой проход без потери инвариантности, используя инвариантное представление сцены и модули пространственного обучения, устойчивые к вращению.
Модуль взаимодействия Агент-Агент предназначен для изучения отношений между центральным и соседними агентами в каждом локальном регионе на каждом временном шаге. С целью использования симметрий проблемы, авторы метода предлагают блок перекрестного внимания, устойчивый к вращению, который позволяет агрегировать пространственную информацию. В частности, они принимают последний сегмент траектории центрального агента pT,i — pT-1,i в качестве вектора отсчета локального региона и вращают все локальные векторы в соответствии с ориентацией вектора отсчета ʘi. Повернутые вектора и их связанные семантические атрибуты обрабатываются многослойным перцептроном (MLP), чтобы получить эмбединг центрального агента zti и эмбединг любого соседнего агента ztij на любом временном шаге t.
Поскольку все геометрические атрибуты нормализованы относительно центрального агента перед подачей в MLP, эти эмбединги не зависят от вращения глобальной системы координат. Кроме сегментов траекторий, исходные данные функции фnbr(•) так же содержат векторы позиций соседних агентов относительно центрального агента, что делает эмбединги соседей пространственное осведомленными. Эмбединг центрального агента далее преобразуется в вектор Query, а эмбединги соседних агентов используются для вычисления сущностей Key и Value. Полученные сущности используются в блоке внимания.
В отличие от классического Transformer, авторы HiVT предлагают использовать функцию управления объединением признаков окружающей среды с признаками центрального агента zti. Это позволяет блоку внимания лучше контролировать обновление признаков. Как и в оригинальной архитектуре Transformer, предложенный блок внимания может быть расширен до нескольких голов внимания. Результаты блока многоголового внимания проходят через MLP-блок для получения пространственного встраивания sti агента i на временном шаге t.
Кроме того, авторы метода используют нормализацию данных по слою перед каждым блоком и остаточные соединения после каждого блока. На практике этот модуль можно реализовать с использованием эффективных операций параллелизма обучения по всем локальным регионам и временным шагам.
Дальнейший захват темпоральной информации каждого локального региона осуществляется с использованием энкодера временного Transformer, который следует за модулем взаимодействия Агент-Агент. Для любого центрального агента i исходная последовательность этого модуля состоит из эмбедингов sti, полученных от модуля взаимодействия Агент-Агент на разных временных шагах. Авторы метода добавляют дополнительный обучаемый токен sT+1 в конец исходной последовательности. После чего добавляют обучаемое позиционное кодирование ко всем токенам и укладывают токены в матрицу Si, которая подается на вход блоку временного внимания.
Темпоральный обучающий модуль также состоит из чередующихся блоков многоголового внимания и MLP-блоков.
Локальная структура карты может указать на будущие намерения центрального агента. Поэтому информация о локальной карте добавляется в эмбединг центрального агента. Для этого сначала вращаем локальные сегменты дороги и векторы относительных позиций агента-дороги на текущем временном шаге T. Повернутые векторы затем кодируются с помощью MLP. Используя пространственно-временные признаки центрального агента в качестве Query и признаки сегментов дороги, закодированные с помощью MLP, в качестве Key-Value векторов, кросс-внимание Агент-Дорога осуществляется аналогично описанным выше подходам.
Авторы метода дополнительно применяют MLP-блок для получения окончательного локального эмбединга hi центрального агента i. После последовательного моделирования взаимодействий Агент-Агент, темпоральных зависимостей и взаимодействий Агент-Дорога эмбединг содержат обогащенную информацию, связанную с центральными агентами локальных регионов.
На следующем этапе алгоритма HiVT локальные эмбединги обрабатываются в модуле глобального взаимодействия для захвата долгосрочных зависимостей в сцене. Поскольку локальные признаки извлекаются в координатных системах, ориентированных на агента, глобальный модуль взаимодействия должен учитывать геометрические отношения между отдельными кадрами при обмене информацией локальными регионами. Для этого авторы метода расширяют энкодер Transformer, чтобы он учитывал различия между локальными координатными системами. При передаче сообщения от агента j к агенту i авторы метода используют MLP для получения парного встраивания, которое затем включается в преобразование векторов.
Для захвата парных взаимодействий глобально используется тот же пространственный механизм внимания, что и в локальном энкодере, за которым следует блок MLP и выводит глобальное представление для любого агента.
Прогнозные движения транспортных агентов по своей сути мультимодальны. Поэтому авторы метода предлагают параметризировать распределение будущих траекторий как смесь моделей, где каждая компонента является распределением Лапласа. Прогнозы выполняются для всех агентов за один проход. И для каждого агента i каждой компоненты f MLP получает локальные и глобальные представления в качестве исходных данных. А возвращает местоположение и его ассоциированную неопределенность агента на каждый будущий временной шаг в локальной координатной системе. Тензор результатов головы регрессии имеет размерность [F, N, H, 4], где F — количество компонент смеси, N — количество агентов в сцене, а H — горизонт прогнозирования будущих временных шагов. Здесь также используется MLP. За ним следует функция SoftMax, которая позволяет получить коэффициенты смеси модели для каждого агента.
Авторская визуализация метода HiVT представлена ниже.
2. Реализация средствами MQL5
Выше мы рассмотрели довольно объемное описание комплексного алгоритма, предложенного авторами метода HiVT. И теперь пришло время перейти к практической части нашей работы, в которой мы реализуем свое видение предложенных подходов средствами MQL5.
И здесь стоит отметить, что предложенные авторами метода подходы сильно отличаются от используемых нами ранее механизмов. Поэтому впереди нам предстоит выполнить большой объем работы.
2.1 Векторизация исходного состояния
А начнем мы работы с организации процесса векторизации состояния. Конечно, ранее мы рассматривали различные алгоритмы векторизации исходного состояния. Сюда можно отнести кусочно-линейное представление временных рядов, сегментацию данных, различные подходы эмбединга. Но в данном случае, авторы метода предложили кардинально другой подход. И мы реализуем его на стороне OpenCL в кернеле HiVTPrepare.
__kernel void HiVTPrepare(__global const float *data, __global float2 *output ) { const size_t t = get_global_id(0); const size_t v = get_global_id(1); const size_t total_v = get_global_size(1);
В параметрах кернела мы используем лишь 2 указателя на глобальные буферы данных: исходные значения и результаты операций.
Здесь следует обратить внимание, что, в отличие от исходных данных, для буфера результатов мы используем векторный тип float2. Ранее мы уже использовали его для комплексных величин. Но в данном случае мы не будем использовать математику комплексных чисел. А использование указанного типа данных связано с вращением сцены в двухмерном пространстве. И в векторе из 2 элементов нам будет удобнее сохранять координаты и смещение на плоскости.
Как вы уже заметили, в параметрах кернела мы не передаем константы, определяющие размерность тензоров исходных данных и результатов. Эту информацию мы планируем получать из двухмерного пространства задач. По первому измерению мы укажем глубину анализируемой истории, а по второму — количество унитарных временных рядов в мультимодальной анализируемой последовательности.
Здесь мы исходим из допущения, что наша мультимодальная последовательность является совокупностью одномерных унитарных временных рядов.
В теле кернела мы идентифицируем текущий поток по всем измерениям пространства задач. После чего определяем константы смещения в глобальных буферах данных.
const int shift_data = t * total_v; const int shift_out = shift_data * total_v;
Для внесения ясности о смещении в буфере результатов, стоит немного рассказать об алгоритме, который мы планируем реализовать в данном кернеле.
Как было сказано в теоретической части, авторы метода HiVT предложили заменить абсолютные величины на относительные с вращением сцены вокруг центрального агента.
Следуя этой логике, мы сначала определяем смещение каждого агента на отдельно взятом временном шаге.
float value = data[shift_data + v + total_v] - data[shift_data + v];
Далее мы находим угол наклона полученного перемещения. Разумеется, для получения угла наклона на плоскости нам нужно 2 координаты смещения. Но в исходных данных имеется только 1 показатель. Однако мы имеем дело с временным рядом. Следовательно, для смещения по второй оси мы можем взять "1", как смещение по оси времени на 1 шаг.
const float theta = atan(value);
И теперь мы можем определить синус и косинус угла для построения матрицы вращения.
const float cos_theta = cos(theta); const float sin_theta = sin(theta);
После чего можно осуществить вращение вектора перемещения центрального агента.
const float2 main = Rotate(value, cos_theta, sin_theta);
Так как вращение нам предстоит выполнять для всех агентов, то я вынес данную операцию в отдельную функцию.
Обратите внимание, что в результате вращения мы получаем смещение по 2 координатным осям. И для сохранения данных мы используем векторную переменную float2.
Далее мы организуем цикл перебора всех агентов, присутствующих на данном временном шаге.
for(int a = 0; a < total_v; a++) { float2 o = main; if(a != v) o -= Rotate(data[shift_data + a + total_v] - data[shift_data + a], cos_theta, sin_theta); output[shift_out + a] = o; } }
В теле цикла для центрального агента мы сохраним его перемещение, а для остальных агентов мы посчитаем их перемещение относительно центрального. Для этого мы сначала определяем смещение каждого агента. Вращаем его в соответствии с матрицей вращения центрального агента. И вычтем полученное перемещение из вектора движения центрального агента.
Таким образом, для каждого агента на каждом временном шаге мы получаем тензор описания сцены из 2 столбцов (координаты на плоскости) с количеством строк равным числу анализируемых унитарных рядов.
Здесь стоит сказать, что авторы метода ограничивали число агентов радиусом локального сегмента. Мы же не стали этого делать, так как дивергенция значений индикаторов часто дает довольно хорошие торговые сигналы.
2.2 Внимание в рамках отдельного временного шага
Следующий вопрос, который стал перед нами в процессе реализации предложенных подходов — организация механизмов внимания между агентами в рамках отдельного временного шага.
Ранее мы уже реализовали механизмы внимания в рамках отдельных переменных. Но это, так сказать, анализ "по вертикали". А в данном случае нам необходим анализ "по горизонтали". Мы, конечно, могли бы решить данный вопрос созданием нового класса "горизонтального внимания", но это довольно трудоемкий подход.
Однако есть и более быстрое решение. Мы могли бы транспонировать исходные данные и воспользоваться имеющимися решениями "вертикального внимания". Но есть один нюанс. В данном случае имеющийся алгоритм транспонирования двухмерных матриц не подходит. Поэтому мы создадим алгоритм транспонирования трехмерного тензора. При этом в процессе транспонирования мы меняем местами 1 и 2 измерение, а 3 остается неизменным.
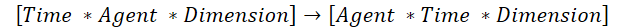
Именно это нам необходимо для использования имеющихся алгоритмов "вертикального внимания".
Для организации этого процесса мы создадим кернел TransposeRCD.
__kernel void TransposeRCD(__global const float *matrix_in, ///<[in] Input matrix __global float *matrix_out ///<[out] Output matrix ) { const int r = get_global_id(0); const int c = get_global_id(1); const int d = get_global_id(2); const int rows = get_global_size(0); const int cols = get_global_size(1); const int dimension = get_global_size(2); //--- matrix_out[(c * rows + r)*dimension + d] = matrix_in[(r * cols + c) * dimension + d]; }
Должен сказать, что алгоритм кернела практически полностью повторяет аналогичный кернел транспонирования двухмерной матрицы. Добавляется лишь ещё 1 измерение пространства задач. И соответственно, корректируется смещение в буферах данных с учетом добавленного измерения.
То же можно сказать о структуре класса CNeuronTransposeRCDOCL. Здесь мы осознанно использовали класс транспортирования двухмерной матрицы CNeuronTransposeOCL в качестве родительского.
class CNeuronTransposeRCDOCL : public CNeuronTransposeOCL { protected: virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronTransposeRCDOCL(void){}; ~CNeuronTransposeRCDOCL(void){}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, uint dimension, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronTransposeRCDOCL; } };
Обратите внимание, что в теле класса мы не объявляем дополнительных переменных и объектов. Для организации процесса нам вполне достаточно унаследованных. И это позволяет нам переопределить лишь методы вызова кернела, а весь остальной функционал покрывается методами родительского класса. Поэтому мы не будем сейчас подробно останавливаться на разборе алгоритмов методов данного класса. Я предлагаю вам разобрать их самостоятельно. Полный код данного класса и всех его методов вы найдете во вложении.
2.3 Блок внимания Агент-Агент
Далее мы переходим к реализации блока внимания Агент-Агент. Напомню, что в рамках данного блока предполагается построение внимания между локальными эмбедингами агентов в рамках одного временного шага. Созданный выше класс транспонирования трехмерного тензора нам значительно упростил работу. Однако, использование предложенного авторами метода механизма управления объединением признаков требует корректировки алгоритма.
Для организации процессов указанного блока внимания мы создадим новый класс CNeuronHiVTAAEncoder. В качестве родительского класса в данном случае мы будем использовать слой внимания независимых переменных CNeuronMVMHAttentionMLKV.
class CNeuronHiVTAAEncoder : public CNeuronMVMHAttentionMLKV { protected: virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHiVTAAEncoder(void){}; ~CNeuronHiVTAAEncoder(void){}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMVMHAttentionMLKV; } };
Как можно заметить, в структуре данного класса мы так же не объявляем дополнительных переменных и объектов. На этот раз к нам благосклонна структура родительского класса. Напомню, что в классе CNeuronMVMHAttentionMLKV используются динамические коллекции буферов данных, с которыми, в свою очередь, работают методы класса. И мы можем добавить необходимое количество буферов данных в существующие коллекции.
Инициализация нового экземпляра объекта нашего класса осуществляется в методе Init.
bool CNeuronHiVTAAEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * variables, optimization_type, batch)) return false;
В параметрах метода мы получаем основные константы, которые позволяют нам безошибочно определить архитектуру объекта, заданную пользователем. В теле метода, уже по сложившейся традиции, мы вызываем одноименный метод базового класса нейронного слоя.
Обратите внимание, что мы вызываем метод не прямого родительского класса, а базового. Так как далее нам еще предстоит переопределить некоторые буфера данных.
После успешного выполнения метода родительского класса, мы сохраняем полученные от внешней программы константы определения архитектуры объекта во внутренние переменные.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(layers, 1); iHeadsKV = fmax(heads_kv, 1); iLayersToOneKV = fmax(layers_to_one_kv, 1); iVariables = variables;
И сразу вычислим константы, определяющие размеры внутренних объектов.
uint num_q = iWindowKey * iHeads * iUnits * iVariables; //Size of Q tensor uint num_kv = iWindowKey * iHeadsKV * iUnits * iVariables; //Size of KV tensor uint q_weights = (iWindow * iHeads + 1) * iWindowKey; //Size of weights' matrix of Q tenzor uint kv_weights = (iWindow * iHeadsKV + 1) * iWindowKey; //Size of weights' matrix of KV tenzor uint scores = iUnits * iUnits * iHeads * iVariables; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits * iVariables; //Size of multi-heads self-attention uint out = iWindow * iUnits * iVariables; //Size of attention out tensore uint w0 = (iWindowKey * iHeads + 1) * iWindow; //Size W0 weights matrix uint gate = (2 * iWindow + 1) * iWindow; //Size of weights' matrix gate layer uint self = (iWindow + 1) * iWindow; //Size of weights' matrix self layer
Алгоритм в целом унаследован от родительского класса, внесены лишь некоторые точечные правки.
После завершения подготовительной работы мы организовываем цикл с числом итераций, равным заданному количеству вложенных слоев. В теле данного цикла мы на каждой итерации будем создавать объекты, необходимые для выполнения функционала каждого отдельно взятого вложенного слоя.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- Initilize Q tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Здесь мы сначала создадим буфера промежуточных данных и результатов отдельных блоков, а также для записи соответствующих градиентов ошибки.
Обратите внимание, что буфер данных и соответствующих градиентов ошибки имеют одинаковые размеры. Поэтому с целью сокращения ручного труда мы создадим вложенный цикл из 2 итераций. На первой итерации цикла будут созданы буфера данных, а на второй — буфера соответствующих градиентов ошибки.
Первым мы создаем буфер для записи сущностей Query. А за ним идет очередь буферов для Key и Value.
//--- Initilize KV tensor if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!K_Tensors.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!V_Tensors.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(2 * num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Tensors.Add(temp)) return false; }
Алгоритмы создания и инициализации буферов данных полностью идентичны. Только нашим алгоритмом предоставляется возможность использования одного тензора Key-Value для нескольких вложенных слоев. Поэтому перед созданием буферов, мы проверяем необходимость данного действия на текущем слое.
Далее мы инициализируем буфер коэффициентов зависимости между объектами.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
И буфер результатов многоголового внимания.
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
В соответствии с алгоритмом Multi-Haed Self-Attention, результаты многоголового внимания сжимаются до уровня исходных данных с помощью слоя проекции. Создадим буфер для сохранения полученной проекции.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Описанный до этого момента алгоритм практически полностью повторяет метод родительского класса. Но дальше идут изменения, внесенные для организации механизма управления объединением признаков. Здесь, согласно предложенному алгоритму, нам предстоит сначала конкатенировать исходные данные с результатами блока внимания.
//--- Initialize Concatenate temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(2 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
И на их основе будут рассчитаны управляющие коэффициенты.
//--- Initialize Gate temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
После чего мы сделаем проекцию исходных данных.
//--- Initialize Self temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
И в завершении вложенного цикла мы создадим буфер результатов текущего вложенного слоя.
//--- Initialize Out if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
Здесь следует обратить внимание, что буфера результатов и градиентов мы создаем только для промежуточных внутренних слоев. Для последнего вложенного слоя мы просто скопируем указатели на соответствующие буфера нашего класса.
После создания буферов промежуточных результатов и соответствующих градиентов ошибки, мы инициализируем матрицы обучающих параметров. У нас их будет несколько. Во-первых, это матрица генерации сущности Query.
//--- Initilize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(q_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < q_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
Здесь мы сначала создаем буфер, а затем заполняем его случайными параметрами. Данные параметры будут оптимизированы в процессе обучения модели.
Аналогичным образом создаем параметры генерации сущностей Key и Value. Однако, данные матрицы мы генерируем не для каждого вложенного слоя.
//--- Initilize K weights if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; for(uint w = 0; w < kv_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!K_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; for(uint w = 0; w < kv_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!V_Weights.Add(temp)) return false; }
Кроме того нам понадобится матрица проекции результатов многоголового внимания.
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Тут же мы добавим параметры для блока управления объединения признаков.
//--- Initilize Gate Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(gate)) return false; k = (float)(1 / sqrt(2 * iWindow + 1)); for(uint w = 0; w < gate; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
И проекции исходных данных.
//--- Self temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(self)) return false; k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < self; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Далее нам остается добавить буфера данных для записи моментов на уровне матрицы весов, которые будут использоваться в процессе оптимизации параметров.
//--- for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? q_weights : iWindowKey * iHeads), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false; if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? kv_weights : iWindowKey * iHeadsKV), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!K_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? kv_weights : iWindowKey * iHeadsKV), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!V_Weights.Add(temp)) return false; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? w0 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize Gate Momentum temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? gate : 2 * iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize Self Momentum temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? self : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } }
После успешной инициализации объектов вложенных слоев, мы создадим дополнительный буфер, который будет использоваться для временной записи промежуточных результатов.
if(!Temp.BufferInit(MathMax(2 * num_kv, out), 0)) return false; if(!Temp.BufferCreate(OpenCL)) return false; //--- return true; }
И завершаем работу метода. При этом мы возвращаем вызывающей программе логический результат выполнения операций метода.
Следующим этапом, после инициализации объекта, мы переходим к построению алгоритма прямого прохода, который реализован в методе feedForward.
bool CNeuronHiVTAAEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
В параметрах данного метода мы получаем указатель на объект с исходными данными и сразу проверяем актуальность полученного указателя. И при успешном прохождении данного контроля, мы организовываем цикл, в котором организуем последовательное выполнение операций каждого вложенного слоя.
CBufferFloat *kv = NULL; for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(10 * i - 6)); CBufferFloat *q = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, q, iWindow, iWindowKey * iHeads, None)) return false;
Сначала мы генерируем сущности Query. А затем, при необходимости, формируем тензор Key-Value.
if((i % iLayersToOneKV) == 0) { uint i_kv = i / iLayersToOneKV; kv = KV_Tensors.At(i_kv * 2); CBufferFloat *k = K_Tensors.At(i_kv * 2); CBufferFloat *v = V_Tensors.At(i_kv * 2); if(IsStopped() || !ConvolutionForward(K_Weights.At(i_kv * (optimization == SGD ? 2 : 3)), inputs, k, iWindow, iWindowKey * iHeadsKV, None)) return false; if(IsStopped() || !ConvolutionForward(V_Weights.At(i_kv * (optimization == SGD ? 2 : 3)), inputs, v, iWindow, iWindowKey * iHeadsKV, None)) return false; if(IsStopped() || !Concat(k, v, kv, iWindowKey * iHeadsKV * iVariables, iWindowKey * iHeadsKV * iVariables, iUnits)) return false; }
После формирования тензоров необходимых сущностей, мы можем вычислить результаты многоголового внимания.
//--- Score calculation and Multi-heads attention calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !AttentionOut(q, kv, temp, out)) return false;
И сожмем их до размерности исходных данных.
//--- Attention out calculation temp = FF_Tensors.At(i * 10); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9)), out, temp, iWindowKey * iHeads, iWindow, None)) return false;
Для целей вычисления управляющих коэффициентов, мы сначала конкатенируем результаты блока внимания и исходные данные.
//--- Concat out = FF_Tensors.At(i * 10 + 1); if(IsStopped() || !Concat(temp, inputs, out, iWindow, iWindow, iUnits)) return false;
А затем вычислим управляющие коэффициенты.
//--- Gate if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), out, FF_Tensors.At(i * 10 + 2), 2 * iWindow, iWindow, SIGMOID)) return false;
Нам остается сделать проекцию исходных данных.
//--- Self if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), inputs, FF_Tensors.At(i * 10 + 3), iWindow, iWindow, None)) return false;
После чего объединим полученную проекцию с результатами блока внимания с учетом управляющих коэффициентов.
//--- Out if(IsStopped() || !GateElementMult(FF_Tensors.At(i * 10 + 3), temp, FF_Tensors.At(i * 10 + 2), FF_Tensors.At(i * 10 + 4))) return false; } //--- return true; }
И переходим к работе со следующим вложенным слоем на новой итерации цикла.
После успешного выполнения операций всех вложенных слоев, мы завершаем работу метода и возвращаем вызывающей программе логический результат выполнения операций метода.
На этом мы завершаем работу с методами прямого прохода. А с алгоритмами методов обратного прохода я предлагаю вам ознакомиться самостоятельно. Напомню, что полный код данного класса и его методов, как и всех программ, используемых при подготовке статьи, вы можете найти во вложении.
Заключение
В данной статье мы познакомились с довольно интересным и многообещающим методом иерархического векторного Transformet (HiVT), который был предложен для прогнозирования движения нескольких агентов. Данный метод предлагает эффективный подход к решению задачи прогнозирования, декомпозируя задачу на этапы локального извлечения контекста и глобального моделирования взаимодействий.
Авторы метода подошли комплексно к решению поставленной задачи и предложили целый ряд подходов для повышения эффективности предложенной модели. К сожалению, объем работы по реализации предложенных подходов превышает формат статьи. И в данной работе мы смогли лишь провести подготовительную работу. Начатая работа будет завершена в следующей статье. Там же будут представлены результаты тестирования предложенных подходов на реальных исторических данных.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования