
Нейросети в трейдинге: Инъекция глобальной информации в независимые каналы (InjectTST)

Введение
В последнее время модели прогнозирования мультимодальных временных рядов на основе архитектуры Transformer получили широкое распространение и постепенно становятся одной из самых популярных архитектур для моделирования временных рядов. И все больше моделей используют подходы независимых каналов, когда модель выстраивает последовательность каждого канала отдельно от других.
Независимость от канала имеет два достоинства:
- Подавление шума: независимые от канала модели могут сосредоточиться на прогнозировании отдельных каналов, не отвлекаясь на шум от других каналов.
- Смягчение дрейфа распределения: независимость от канала может облегчить проблему дрейфа распределения временного ряда.
В то же время смешивание каналов оказывается менее эффективным в борьбе с указанными проблемами, что приводит к снижению производительности модели. Тем не менее смешивание каналов обладает некоторыми уникальными преимуществами:
- Высокая информационная емкость: модели микширования каналов превосходны в улавливании зависимостей между каналами и могут дать больше информации для прогнозирования последующих значений.
- Специфичность канала: Оптимизация нескольких каналов в моделях микширования каналов выполняется одновременно, что позволяет модели полностью охватить отличительные характеристики каждого канала.
Кроме того, поскольку подход независимости каналов анализирует отдельные каналы с помощью общей модели, модель не может различать каналы и в основном изучает общие закономерности нескольких каналов. Это приводит к потере специфичности канала и потенциальному влиянию на прогнозирование мультимодального временного ряда.
Таким образом, разработка эффективной модели, обладающей достоинствами как независимости каналов, так и их микширования, которая позволит использовать преимущества обоих подходов (снижения шума, смягчения дрейфа распределения, высокой информационной емкости и специфичности канала) является ключом к дальнейшему повышению эффективности прогнозирования мультимодальных временных рядов.
Однако разработка модели такой модели представляет собой сложную головоломку. Во-первых, независимые от каналов модели по своей сути противоречат канальным зависимостям. Хотя тонкая настройка общей модели для каждого канала может решить проблему специфичности канала, это происходит за счет значительных затрат на обучение. Во-вторых, существующие методы шумоподавления и решения проблемы дрейфа распределения все еще не могут сделать фреймворки микширования каналов такими же надежными, как модели с независимыми каналами.
Один из вариантов решения данных проблем предложен в статье "InjectTST: A Transformer Method of Injecting Global Information into Independent Channels for Long Time Series Forecasting", в которой был представлен метод инъекции глобальной информации мультимодального временного ряда в отдельные каналы (InjectTST). Авторы метода избегают явного моделирования зависимостей между каналами для прогнозирования мультимодального временного ряда. Вместо этого они сохраняют структуры независимости каналов структуру в качестве основы, а глобальная информация (микширование каналов) вводится в каждый канал выборочно. Это позволяет достичь неявного микширования каналов.
Каждый отдельный канал может избирательно получать полезную глобальную информацию и избегать зашумленной, что дает возможность поддерживать высокую информационную емкость и шумоподавление. Поскольку независимость канала сохраняется в качестве основы, дрейф распределения также может быть уменьшен.
Кроме того, авторы метода добавляют идентификатор канала в InjectTST для решения проблемы специфичности канала.
1. Алгоритм InjectTST
С целью построения прогнозных значений Y на заданный горизонт планирования T мы анализируем исторические значения мультимодального временного ряда X, который содержит L временных шагов. И каждый временной шаг является вектором с размерностью M.
Для решения данной задачи с использованием преимуществ как независимости каналов, так и их микширования используется комплексный многоуровневый алгоритм InjectTST.
На первом этапе алгоритма применяем механизм сегментирования исходных данных в независимой от канала магистрали. После чего выполняется линейная проекция с обучаемым позиционным кодированием.
Независимая от каналов платформа обрабатывает каналы с помощью общей модели. В результате модель не может различать каналы и в основном изучает общие закономерности каналов, не имея специфичности канала. Для решения этой проблемы авторы метода InjectTST вводят идентификатор канала, который является обучаемым тензором.
После линейной проекции патчей к токенам добавляются тензоры как с позиционным кодированием, так и с идентификатором канала.
Подготовленные таким образом исходные данные передаются в энкодер Transformer для высокоуровневого представления.
Обратите внимание, что в данном случае в энкодере Transformer работает в магистрали независимых каналов, т.е. анализируются токены только отдельных каналов. Информация между каналами не смешивается.
Идентификатор канала представляет отличительные особенности каждого канала, что позволяет модели различать каналы и получать уникальное представление для каждого из них.
Параллельно с магистралью независимых каналов в маршруте микширования каналов исходная последовательность X сначала проходит через глобальный модуль смешивания для получения глобальной информации. Основной целью InjectTST является внедрение глобальной информации в каждый канал, поэтому получение глобальной информации является критически важной проблемой. Авторы метода в своей работе представили 2 вида глобальных модулей микширования, названных CaT (канал как токен) и PaT (патч как токен).
Модуль CaT напрямую проецирует каждый канал в токен. Если коротко, то линейная проекция применяется ко всем значениям канала.
Глобальный модуль смешивания PaT принимает патчи в качестве входных данных. Сначала группируются патчи, относящиеся к соответствующим временным шагам анализируемой мультимодальной последовательности. А затем к сгруппированным патчам применяется линейная проекция, которая в основном объединяет информацию на уровне патча. После этого добавляется позиционное кодирование и данные передаются в энкодер Transformer для дальнейшего слияния информации между патчами и глобальной информацией.
Эксперименты, проведенные авторами метода, показывают, что PaT более стабилен, в то время как CaT выделяется в некоторых специальных наборах данных.
Одна из проблем метода InjectTST заключается в необходимости внедрения глобальной информации в каждый канал с минимальным влиянием на надежность работы модели. В ванильном Transformer перекрестное внимание заставляет целевую последовательность выборочно и свободно фокусироваться на контекстной информации из другого источника в соответствии с релевантностью. Благодаря этому пониманию конструкция перекрестного внимания может подойти и для инъекции глобальной информации мультимодального временного ряда. Следовательно, глобальную информацию, смешанную из каналов, можно рассматривать как контекст. Авторы метода используют конструкцию перекрестного внимания для введения глобальной информации в каждый канал.
Здесь стоит добавить, что авторы метода вводят необязательное остаточное соединение для модуля контекстуального внимания. В общих случаях остаточное соединение делает модель немного неустойчивой. Однако, оно может значительно улучшить работу в некоторых специальных наборах данных.
В целом, глобальная информация вводится в модуль контекстуального внимания в виде Key и Value. А информация о канале — в виде Query.
После кросс-внимания, данные обогащаются за счет глобальной информации. А для генерации прогнозных значений добавляется линейная головка.
Авторы InjectTST предлагают трех этапный процесс обучения. На этапе предварительного обучения исходные временные ряды случайным образом маскируются, и целью является прогнозирование замаскированных частей. На этапе тонкой настройки головки предварительного обучения InjectTST заменяется головкой прогнозирования, и осуществляется тонкая настройка головки прогнозирования. На данном этапе остальная часть сети замораживается. И на этапе тонкой настройки выполняется тонкая настройка всей сети InjectTST.
Авторская визуализация метода представлена ниже.
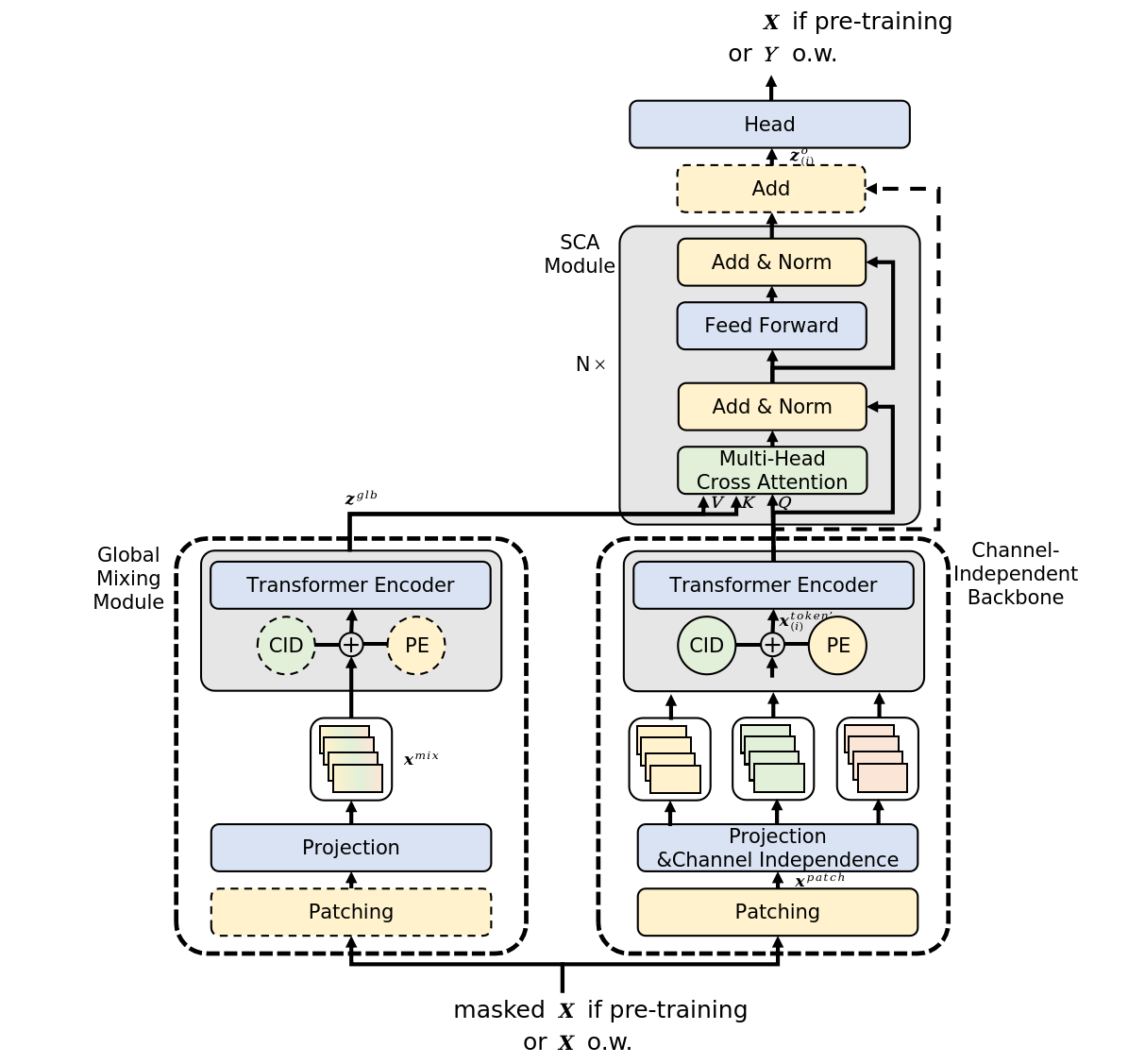
2. Реализация средствами MQL5
После ознакомления с теоретическими аспектами метода InjectTST мы переходим к практической реализации своего видения предложенных подходов средствами MQL5.
Здесь следует обратить внимание, что предложенный в данной статье вариант реализации не является единственно верным. Более того, предложенный вариант реализации является моим личным пониманием изложенных в авторской статье материалов и может отличаться от видения авторов предложенных подходов. То же можно сказать и о полученных результатах.
Начиная работу над реализацией предложенных подходов, стоит отметить, что ранее мы рассматривали несколько моделей на основе Transformer с использованием парадигмы независимых каналов. Но в них лишь прогнозирование осуществлялось для независимых каналов, а блок Transformer использовался для изучения зависимостей между каналами. Что можно сравнить с подходами глобального модуля микширования CaT.
Однако авторы метода используют архитектуру Transformer в магистрали независимых каналов, избегая перетоков информации между каналами на данном этапе. Теоретически мы можем осуществить данный алгоритм, организовав цикл обработки данных отдельных унитарных последовательностей. Однако такой подход является экстенсивным и ведет к росту числа последовательных операций. Которое растет с ростом числа анализируемых переменных в мультимодальных исходных данных.
Мы же в своей работе стремимся осуществлять максимально-возможное количество операций в параллельных потоках. Поэтому в рамках данной реализации мы создадим новый слой с возможностью независимого анализа отдельных каналов.
2.1 Блок независимого анализа отдельных каналов
Функционал независимого анализа отдельных каналов мы реализуем в классе CNeuronMVMHAttentionMLKV, который унаследует базовый функционал от другого многослойного блока многоголового внимания CNeuronMLMHAttentionOCL. Структура нового класса представлена ниже.
class CNeuronMVMHAttentionMLKV : public CNeuronMLMHAttentionOCL { protected: uint iLayersToOneKV; ///< Number of inner layers to 1 KV uint iHeadsKV; ///< Number of heads KV uint iVariables; ///< Number of variables CCollection KV_Tensors; ///< The collection of tensors of Keys and Values CCollection K_Tensors; ///< The collection of tensors of Keys CCollection K_Weights; ///< The collection of Matrix of K weights to previous layer CCollection V_Tensors; ///< The collection of tensors of Values CCollection V_Weights; ///< The collection of Matrix of V weights to previous layer CBufferFloat Temp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool AttentionOut(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *scores, CBufferFloat *out); virtual bool AttentionInsideGradients(CBufferFloat *q, CBufferFloat *q_g, CBufferFloat *kv, CBufferFloat *kv_g, CBufferFloat *scores, CBufferFloat *gradient); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMVMHAttentionMLKV(void) {}; ~CNeuronMVMHAttentionMLKV(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMVMHAttentionMLKV; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
В данном классе мы добавляем 3 переменных:
- iLayersToOneKV — количество слоев для 1 тензора Key-Value;
- iHeadsKV — количество голов внимания в тензоре Key-Value;
- iVariables — количество унитарных последовательностей в мультимодальном временном ряде.
Кроме того, мы добавляем 5 коллекций буферов данных, с назначением которых мы познакомимся в процессе реализации. Все внутренние объекты объявлены статично, что позволяет оставить "пустыми" конструктор и деструктор класса. Непосредственно инициализация всех внутренних переменных и объектов осуществляется в методе Init.
bool CNeuronMVMHAttentionMLKV::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * variables, optimization_type, batch)) return false;
В параметрах данного метода мы ожидаем получить основные константы, позволяющие однозначно идентифицировать архитектуру инициализируемого класса. Среди них:
- window — размер вектора представления одного элемента последовательности одного унитарного временного ряда;
- window_key — размер вектора внутреннего представления сущности Key одного элемента последовательности унитарного временного ряда;
- heads — количество голов внимания сущности Query;
- heads_kv — количество голов внимания в конкатенированном тензоре Key-Value;
- units_count — размер анализируемой последовательности;
- layers — количество вложенных слоев в блоке;
- layers_to_one_kv — количество вложенных слоев, работающих с одним тензором Key-Vakue;
- variables — количество унитарных последовательностей в мультимодальном временном ряде.
В теле метода мы сразу вызываем одноименный метод базового родительского класса, в котором осуществляется инициализация унаследованных переменных и объектов. Кроме того, в данном методе уже реализованы минимально-необходимые контроли данных, полученных от вызывающей программы.
После успешного выполнения метода родительского класса мы осуществляем сохранение полученных параметров во внутренних переменных.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(layers, 1); iHeadsKV = fmax(heads_kv, 1); iLayersToOneKV = fmax(layers_to_one_kv, 1); iVariables = variables;
Тут же мы определим основные константы, определяющие архитектуру вложенных объектов.
uint num_q = iWindowKey * iHeads * iUnits * iVariables; //Size of Q tensor uint num_kv = iWindowKey * iHeadsKV * iUnits * iVariables; //Size of KV tensor uint q_weights = (iWindow * iHeads + 1) * iWindowKey; //Size of weights' matrix of Q tenzor uint kv_weights = (iWindow * iHeadsKV + 1) * iWindowKey; //Size of weights' matrix of K/V tenzor uint scores = iUnits * iUnits * iHeads * iVariables; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits * iVariables; //Size of multi-heads self-attention uint out = iWindow * iUnits * iVariables; //Size of out tensore uint w0 = (iWindowKey * iHeads + 1) * iWindow; //Size W0 weights' matrix uint ff_1 = 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
И здесь, наверное, надо несколько слов сказать о подходах, которые мы предлагаем для реализации в данном классе. Прежде всего, было принято решение о построении нового класса без внесения изменений в OpenCL программу. Иными словами, несмотря на новые требования, мы полностью строим класс на имеющихся кернелах.
Для этого мы прежде всего разделяем генерацию сущностей Key и Value. Напомню, что ранее они генерировались в рамках одного прямого прохода сверточного слоя и записывались в буфер последовательно для каждого элемента последовательности. При построении глобального внимания такой подход приемлем. В случае же организации работы в рамках отдельных каналов мы получим чередующуюся последовательность Key/Value для отдельных каналов, что не совсем удобно для последующего анализа и "не вписывается" в работу созданных нами ранее алгоритмом. Поэтому мы генерируем сущности отдельно, а затем конкатенируем их в единый тензор.
Здесь стоит отметить, что здесь мы разделили генерацию сущностей на 2 этапа, количество которых не зависит ни от числа анализируемых переменных, ни от числа голов внимания.
Второй момент, авторами метода InjectTST предусмотрено использование одного энкодера Transformer для всех каналов. Поэтому мы так же используем одни весовые матрицы для всех каналов. Следовательно, с изменением числа каналов размер весовых матриц не изменяется.
На этом завершается наша подготовительная работа и мы организовываем цикл с числом итераций равным количеству вложенных слоев.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL;
В теле цикла мы организуем вложенный цикл для создания буферов результатов промежуточных операций и соответствующих градиентов ошибки.
for(int d = 0; d < 2; d++) { //--- Initilize Q tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Здесь мы сначала создаем буфер тензора Query. Алгоритм создания идентичен для всех буферов. Сначала мы создаем новый экземпляр объекта буфера. Инициализируем его нулевыми значениями в заданном размере. После чего создаем копию буфера в контексте OpenCL и добавляем указатель на буфер в соответствующую коллекцию. При этом не забываем на каждом шаге контролировать процесс выполнения операций.
Так как мы планируем использование 1 тензора Key-Value для анализа в нескольких вложенных слоях, то и соответствующие буферы мы создаем с заданной периодичностью.
//--- Initilize KV tensor if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!K_Tensors.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!V_Tensors.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(2 * num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Tensors.Add(temp)) return false; }
Стоит отметить, что на данном этапе мы создаем 3 буфера: Key, Value и конкатенированный Key-Value.
Следующим шагом мы создаем буфер коэффициентов внимания.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
За которым идет буфер результатов многоголового внимания.
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
И далее идут буфера сжатия многоголового внимания и блока FeedForward.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
После инициализации буферов промежуточных результатов и их градиентов мы переходим к инициализации весовых матриц. Алгоритм их инициализации аналогичен созданию буферов данных, только матрица заполняется случайными значениями.
Первой генерируется матрица весов сущности Query.
//--- Initilize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(q_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < q_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
Периодичность создания весовых матриц сущностей Key и Value аналогична частоте буферов соответствующих сущностей.
//--- Initilize K weights if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < kv_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!K_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; for(uint w = 0; w < kv_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!V_Weights.Add(temp)) return false; }
Добавим матрицу сжатия голов внимания.
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
И блока FeedForward.
//--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
После чего мы создадим еще один вложенный цикл, в котором добавим буферы моментов на уровне весовых коэффициентов. Количество создаваемых буферов зависит от метода обновления параметров.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? q_weights : iWindowKey * iHeads), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false; if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? kv_weights : iWindowKey * iHeadsKV), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!K_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? kv_weights : iWindowKey * iHeadsKV), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!V_Weights.Add(temp)) return false; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? w0 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? ff_1 : 4 * iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? ff_2 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } }
В завершении метода инициализации мы добавим буфер хранения временных данных и вернем вызывающей программе логический результат выполненных операций.
if(!Temp.BufferInit(MathMax(2 * num_kv, out), 0)) return false; if(!Temp.BufferCreate(OpenCL)) return false; //--- return true; }
После инициализации объекта мы переходим организации алгоритмов прямого прохода. И здесь несколько слов стоит сказать об использовании ранее созданных кернелов. В частности, о кернеле прямого прохода блока кросс-внимания MH2AttentionOut, алгоритм постановки которого в очередь выполнения реализован в методе AttentionOut. Сразу скажем, что алгоритм постановки кернела в очередь выполнения не изменился. Но наша задача реализовать с помощью данного алгоритма анализ независимых каналов.
Для начала давайте посмотрим, как наш кернел работает с отдельными головами внимания. А он их обрабатывает независимо в отдельных потоках. По-моему, это именно то, что нам надо. Так давайте скажем, что отдельные каналы — это такие же головы внимания.
bool CNeuronMVMHAttentionMLKV::AttentionOut(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *scores, CBufferFloat *out) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits/*Q units*/, iUnits/*K units*/, iHeads * iVariables}; uint local_work_size[3] = {1, iUnits, 1};
В остальном алгоритм метода остается прежним. Передадим необходимые параметры кернелу.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_q, q.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_kv, kv.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_score, scores.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_out, out.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Обязательно скорректируем количество голов тензора Key-Value.
if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_heads_kv, (int)(iHeadsKV * iVariables))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
После чего поставим кернел в очередь выполнения.
if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_mask, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionOut, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
И завершим работу метода. Но это лишь часть алгоритма прямого прохода. А полный алгоритм мы выстроим в методе feedForward.
bool CNeuronMVMHAttentionMLKV::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
В параметрах метод получает указатель на объект предшествующего нейронного слоя, который содержит исходные данные для нашего алгоритма. В качестве исходных данных мы ожидаем получить трех мерный тензор — длина последовательности * количество унитарных последовательностей * размер анализируемого окна одного элемента.
В теле метода мы проверяем актуальность полученного указателя и организовываем цикл перебора вложенных слоев модуля.
CBufferFloat *kv = NULL; for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(6 * i - 4));
Здесь мы сначала объявляем локальный указатель на буфер исходных данных, в который сохраним необходимый указатель. После чего извлечем из коллекции соответствующий анализируемому слою буфер сущности Query и запишем в него данные, сгенерированные на основании исходных данных.
CBufferFloat *q = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, q, iWindow, iWindowKey * iHeads, None)) return false;
Следующим шагом мы проверим необходимость генерирования нового тензора Key-Value. При необходимости мы сначала определим смещение в соответствующих коллекциях.
if((i % iLayersToOneKV) == 0) { uint i_kv = i / iLayersToOneKV;
И извлекаем указатели на нужные нам буферы.
kv = KV_Tensors.At(i_kv * 2); CBufferFloat *k = K_Tensors.At(i_kv * 2); CBufferFloat *v = V_Tensors.At(i_kv * 2);
После чего мы последовательно сгенерируем сущности Key и Value.
if(IsStopped() || !ConvolutionForward(K_Weights.At(i_kv * (optimization == SGD ? 2 : 3)), inputs, k, iWindow, iWindowKey * iHeadsKV, None)) return false; if(IsStopped() || !ConvolutionForward(V_Weights.At(i_kv * (optimization == SGD ? 2 : 3)), inputs, v, iWindow, iWindowKey * iHeadsKV, None)) return false;
И конкатенируем полученные тензоры по первому измерению (элементам последовательности).
if(IsStopped() || !Concat(k, v, kv, iWindowKey * iHeadsKV * iVariables, iWindowKey * iHeadsKV * iVariables, iUnits)) return false; }
Обратите внимание, в таком варианте организации данных мы получаем буфер данных, который можно представить в виде пяти мерного тензора данных: Units * [Key, Value] * Variable * HeadsKV * Window_Key. Тензор сущности Query имеет сопоставимую размерность, только вместо [Key, Value] мы имеем [Query]. Собрав измерения Variable и Heads в одно измерение "Variable * Heads" мы получаем размерности тензоров сопоставимые с ванильным Multi-Heads Self-Attention.
Тут надо напомнить, что на стороне OpenCL контекста мы работаем с одномерными буферами данных. И разбиение данных на многомерный тензор носит лишь декларативный характер для понимания последовательности данных. В общем случае последовательность данных в буфере идет от последнего измерения к первому.
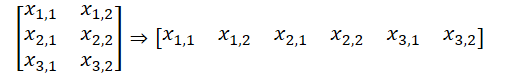
Это позволяет нам использовать ранее созданные кернелы нашей OpenCL программы для анализа независимых каналов. Мы получаем из коллекций указатели на необходимые буфера данных и выполним алгоритм Multi-Heads Self-Attention. Необходимый метод мы скорректировали выше.
//--- Score calculation and Multi-heads attention calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !AttentionOut(q, kv, temp, out)) return false;
Затем мы мысленно переформатируем результаты многоголового внимания в тензор [Units * Variable] * Heads * Window_Key и сделаем проекцию данных до размерности исходных данных.
//--- Attention out calculation temp = FF_Tensors.At(i * 6); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9)), out, temp, iWindowKey * iHeads, iWindow, None)) return false; //--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow, true)) return false;
После чего мы суммируем полученные результаты с исходными данными и нормализуем полученные значения.
Далее мы в том же стиле выполняем операции блока FeedForward и переходим к следующей итерации цикла.
//--- Feed Forward inputs = temp; temp = FF_Tensors.At(i * 6 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), temp, out, 4 * iWindow, iWindow, activation)) return false; //--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } //--- return true; }
После успешного завершения операций всех вложенных слоев блока мы завершаем работу метода и возвращаем логический результат выполнения операций вызывающей программе.
За реализацией методов прямого прохода, обычно, мы переходим к построению алгоритмов обратного прохода. Сегодня я хочу предложить Вам самостоятельно разобрать предложенный вариант реализации, который Вы найдете во вложении. В процессе реализации методов обратного прохода были использованы подходы, описанные выше при реализации методов прямого прохода. Напомню, что операции обратного прохода осуществляются в строгом соответствии с алгоритмом прямого прохода, но в обратном порядке.
Более того, во вложении Вы найдете реализацию класса CNeuronMVCrossAttentionMLKV, алгоритмы которого в большей своей части повторяют аналогичные алгоритмы класса CNeuronMVMHAttentionMLKV, только дополнены средствами кросс-внимания.
Ну а я хочу напомнить, что реализованные нами классы CNeuronMVMHAttentionMLKV и CNeuronMVCrossAttentionMLKV являются лишь составными блоками более сложного алгоритма InjectTST, с теоретическими аспектами мы познакомились выше. И следующим этапом нашей работы будет создание нового класса, в рамках которого мы и реализуем алгоритм InjectTST.
2.2 Реализация InjectTST
Полный алгоритм InjectTST мы соберем в рамках класса CNeuronInjectTST, который унаследует базовый функционал от родительского класса полносвязного нейронного слоя CNeuronBaseOCL. Структура нового класса представлена ниже.
class CNeuronInjectTST : public CNeuronBaseOCL { protected: CNeuronPatching cPatching; CNeuronLearnabledPE cCIPosition; CNeuronLearnabledPE cCMPosition; CNeuronMVMHAttentionMLKV cChanelIndependentAttention; CNeuronMLMHAttentionMLKV cChanelMixAttention; CNeuronMVCrossAttentionMLKV cGlobalInjectionAttention; CBufferFloat cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- public: CNeuronInjectTST(void) {}; ~CNeuronInjectTST(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronInjectTST; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); //--- virtual CBufferFloat *getWeights(void) override; };
В данном классе мы видим довольно большое количество внутренних объектов, но нет ни одной переменной. Это связано с тем, что в данном классе реализована, можно сказать, "крупно узловая сборка" алгоритма, основной функционал которого строится внутренними объектами. И все константы, определяющие архитектуру блока, используются только в методе инициализации класса и сохраняются внутри вложенных объектов. С функционалом которых мы познакомимся в процессе реализации алгоритмов.
Все внутренние объекты класса объявлены статично, что позволяет нам оставить пустыми конструктор и деструктор класса. А инициализация всех вложенных и унаследованных объектов осуществляется в методе Init.
bool CNeuronInjectTST::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * variables, optimization_type, batch)) return false; SetActivationFunction(None);
Как обычно, в параметрах данного метода мы получаем основные константы, определяющие архитектуру создаваемого объекта. В теле метода мы сразу вызываем одноименный метод родительского класса, в котором уже реализованы базовые контроли полученных параметров и инициализация унаследованных объектов.
Далее мы осуществляем инициализацию внутренних объектов в последовательности прямого прохода алгоритма InjectTST. На представленной выше авторской визуализации метода легко заметить, что получаемые исходные данные используются в 2 потоках информации: блоки независимых каналов и глобального смешивания. В обоих блоках исходные данные сначала сегментируются. В своей реализации я решил не дублировать процесс сегментации, а осуществить его 1 раз до разветвления потоков информации.
if(!cPatching.Init(0, 0, OpenCL, window, window, window, units_count, variables, optimization, iBatch)) return false; cPatching.SetActivationFunction(None);
При этом следует отметить, что в данной реализации я использую равные параметры: размер сегмента, шаг окна сегмента и размер эмбединга сегмента. Таким образом размер буфера исходных данных до сегментации и после не изменился. Однако изменилась последовательность данных в буфере. И тензор данных из двух мерного L * V был переформатирован в трех мерный L/p * V * p, где L — длина мультимодальной последовательности исходных данных, V — количество анализируемых переменных, p — размер сегмента.
К токенам сегментов в блоке магистрали независимых каналов авторы метода прибавляют 2 обучаемых тензора: позиционного кодирования и идентификации канала. Сумма 2 числе является числом, поэтому в своей реализации я решил использовать один слой обучаемого позиционного кодирования, который учит позиционную метку каждого отдельного элемента в тензоре исходных данных.
if(!cCIPosition.Init(0, 1, OpenCL, window * units_count * variables, optimization, iBatch)) return false; cCIPosition.SetActivationFunction(None);
В блоке глобального смешивания алгоритмом так же предусмотрено позиционное кодирование. Инициализируем аналогичный слой для магистрали второго потока информации.
if(!cCMPosition.Init(0, 2, OpenCL, window * units_count * variables, optimization, iBatch)) return false; cCMPosition.SetActivationFunction(None);
Магистраль независимых каналов мы построим с использованием выше рассмотренного блока внимания независимых каналов CNeuronMVMHAttentionMLKV.
if(!cChanelIndependentAttention.Init(0, 3, OpenCL, window, window_key, heads, heads_kv, units_count, layers, layers_to_one_kv, variables, optimization, iBatch)) return false; cChanelIndependentAttention.SetActivationFunction(None);
А для организации блока глобального смешивания мы воспользуемся ранее созданным блоком внимания CNeuronMLMHAttentionMLKV.
if(!cChanelMixAttention.Init(0, 4, OpenCL, window * variables, window_key, heads, heads_kv, units_count, layers, layers_to_one_kv, optimization, iBatch)) return false; cChanelMixAttention.SetActivationFunction(None);
Обратите внимание, что в данном случае размер окна анализируемого вектора одного элемента равен произведению размера сегмента на количество анализируемых переменных, что соответствует парадигме смешивания каналов.
Инъекция глобальной информации в независимые каналы осуществляется в рамках блока кросс-внимания.
if(!cGlobalInjectionAttention.Init(0, 5, OpenCL, window, window_key, heads, window * variables, heads_kv, units_count, units_count, layers, layers_to_one_kv, variables, 1, optimization, iBatch)) return false; cGlobalInjectionAttention.SetActivationFunction(None);
Обратите внимание, что в данном случае количество унитарных рядов в контексте мы указываем равным 1, так как здесь мы работаем со смешанными каналами.
В завершении метода инициализации мы осуществляем подмену буферов данных, что позволит нам исключить излишнее копирование между буферами нашего класса и внутренних объектов.
if(!SetOutput(cGlobalInjectionAttention.getOutput(), true) || !SetGradient(cGlobalInjectionAttention.getGradient(), true) ) return false;
Инициализируем вспомогательный буфер для хранения промежуточных данных и вернем логический результат выполнения операций вызывающей программе.
if(!cTemp.BufferInit(cPatching.Neurons(), 0) || !cTemp.BufferCreate(OpenCL) ) return false; //--- return true; }
После инициализации объекта класса мы переходим к построению алгоритма прямого прохода нашего класса. Основные вехи алгоритма мы уже проговорили в процессе реализации метода инициализации. И теперь нам остается описать их в методе feedForward.
bool CNeuronInjectTST::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cPatching.FeedForward(NeuronOCL)) return false;
В параметрах метода мы получаем указатель на объект предыдущего слоя, который передает нам исходные данные. И мы сразу передаем полученный указатель в одноименный метод вложенного слоя сегментации данных.
Обратите внимание, что на данном этапе мы не проверяем актуальность полученного указателя, так как необходимые контроли реализованы в методе слоя сегментации и повторная проверка будет излишней.
Следующим шагом мы добавляем позиционное кодирование к сегментированным данным.
if(!cCIPosition.FeedForward(cPatching.AsObject()) || !cCMPosition.FeedForward(cPatching.AsObject()) ) return false;
После чего проводим данные сначала через блок независимых каналов.
if(!cChanelIndependentAttention.FeedForward(cCIPosition.AsObject())) return false;
А затем через блок глобального смешивания.
if(!cChanelMixAttention.FeedForward(cCMPosition.AsObject())) return false;
Обратите внимание, что несмотря на последовательность выполнения это являются 2 независимых потока информации. И лишь в блоке контекстного внимания осуществляется инъекция глобальных данных в независимые каналы.
if(!cGlobalInjectionAttention.FeedForward(cCIPosition.AsObject(), cCMPosition.getOutput())) return false; //--- return true; }
Голову принятия решений мы вынесли за рамки класса CNeuronInjectTST.
Как видите, метод прямого прохода получился довольно лаконичен и читабелен. В прочем, как и ожидалось от "крупно узловой" реализации алгоритма. Методы обратного прохода построены аналогичным образом. И я предлагаю Вам ознакомиться с ними самостоятельно. Напоминаю, что полный код всех описанных классов и их методов представлен во вложении. Там же Вы найдете и полный код всех программ, используемых при подготовке статьи.
2.3 Архитектура обучаемых моделей
Выше мы реализовали основные алгоритмы метода InjectTST средствами MQL5 и теперь можем внедрить предложенные походы в собственные модели. Рассматриваемый нами метод был предложен для прогнозирования временных рядов. И мы, аналогично ряду рассматриваемых ранее методов прогнозирования временных рядов, попробуем внедрить предложенные подходы в модель Энкодера состояния окружающей среды. Как Вы знаете, описание архитектуры данной модели представлено в методе CreateEncoderDescriptions.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В параметрах данного метода мы получаем указатель на объект динамического массива для записи архитектуры модели. В теле метода мы сразу проверяем актуальность полученного указателя и, при необходимости, создаем новый объект динамического массива. А затем начинаем описывать архитектуру создаваемой модели.
Первый идет базовый полносвязный слой, который служит для записи исходных данных.
//--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Как всегда, в модель мы планируем подавать необработанные исходные данные. И первичную обработку они проходят в слое пакетной нормализации данных, где информация из различных распределений приводится в сопоставимый вид.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Следующим расположился наш новый слой независимых каналов с глобальной инъекцией.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronInjectTST; descr.window = PatchSize; //Patch window descr.window_out = 8; //Window Key
Для указания размера сегмента мы добавляем константу PatchSize. А размер последовательности рассчитываем исходя из глубины анализируемой истории и размере сегмента.
prev_count = descr.count = (HistoryBars + descr.window - 1) / descr.window; //Units
Количество голов внимания для сущностей Query, Key и Value, а также количество унитарных последовательностей мы запишем в массив.
{
int temp[] =
{
4, //Heads
2, //Heads KV
BarDescr //Variables
};
ArrayCopy(descr.heads, temp);
}
Все внутренние блока будут содержать по 4 сложенных слоя.
descr.layers = 4; //Layers
А один тензор Key-Value будет актуален для 2 вложенных слоев.
descr.step = 2; //Layers to 1 KV descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Далее нам предстоит добавить голову прогнозирования последующих значений. Мы помним, что на выходе блока InjectTST мы получаем тензор размерностью L/p * V * p. И для того, чтобы осуществить прогноз данных в рамках независимых каналов нам необходимо сначала транспонировать данные.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = PatchSize * BarDescr; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
А затем мы воспользуемся двухслойным MLP для прогнозирования независимых каналов.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = PatchSize * BarDescr; descr.window = prev_count; descr.window_out = NForecast; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = PatchSize * NForecast; descr.window_out = NForecast; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
При этом мы понижаем размерность данных до Variables * Forecast. Теперь мы можем вернуть прогнозные значения в представление исходных данных.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
И добавим статистические показатели, изъятые из исходных данных при нормализации.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
Кроме того, мы используем подходы метода FreDF для согласования прогнозных значений унитарных рядов в частотной области.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Архитектуры моделей Актера и Критика были перенесены без изменений из предыдущих работ. Поэтому мы не будем сейчас подробно останавливаться на их описании.
Более того, в новой архитектуре Энкодера состояния счета мы не изменяли ни слой исходных данных, ни результатов. Все это позволяет нам использовать без каких-либо изменений все созданные ранее программы взаимодействия с окружающей средой и обучения моделей. Соответственно, мы можем использовать ранее собранную обучающую выборку для первичного обучения моделей.
Напомню, что с полным кодом всех рассмотренных классов и их методов, а так же с полным код всех программ, используемых при подготовке статьи, Вы можете ознакомиться во вложении.
3. Тестирование
Выше мы провели работу по реализации подходов метода InjectTST средствами MQL5. А так же продемонстрировали вариант использования нового класса в модели Энкодера состояния окружающей среды. И теперь мы можем перейти к проверке эффективности модели на реальных исторических данных.
Как и ранее, вначале мы обучаем модель Энкодера состояния окружающей среды прогнозировать предстоящее ценовое движение на заданный горизонт планирования. В ходе эксперимента в качестве обучающей выборки мы используем исторические данные за 2023 год по инструменту EURUSD таймфрейм H1.
Энкодер состояния окружающей среды анализирует только исторические данные ценового инструмента, на которые действия Агента не оказывают влияние. Следовательно, мы осуществляем обучение модели до получения желаемых результатов или выхода ошибки прогнозирования "на плато".
Ниже представлена сравнительная визуализация прогнозной и целевой траектории ценового движения.
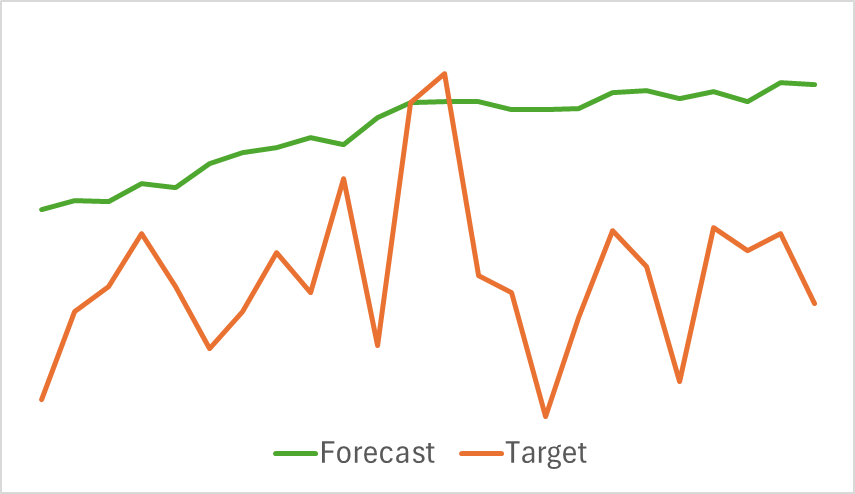
Как можно заметить на представленном графике, прогнозная траектория смещена вверх и колебания на ней менее выражены. При этом можно выделить совпадение направлений общей тенденции. Возможно, это не лучший прогноз последующего ценового движения на уровне рассмотренных нами ранее моделей. Но давайте перейдем ко второму этапу обучения моделей и посмотрим, поможет ли такой Энкодер построить прибыльную стратегию нашему Актеру.
Обучение моделей Актера и Критика осуществляется итерационно. Вначале мы на имеющейся обучающей выборке проводим несколько эпох обучения моделей. А затем в процессе взаимодействия с окружающей средой с использованием текущей политики Актера мы обновляем обучающую выборку. Это позволяет нам обогатить обучающую выборку реальными вознаграждениями за действия из распределения текущей политики Актера. А значит, в ходе дальнейшего обучения моделей мы сможем более качественно обучить функцию вознаграждения Критика и корректнее оценить действия Актера с указанием вектора корректировки действий для повышения эффективности текущей политики. Итерации повторяются до получения желаемого результата.
Для оценки эффективности обученной политики Актера мы проводим тестовый запуск советника взаимодействия с окружающей средой в тестере стратегий MetaTrader 5. Тестирование осуществляется на исторических данных Января 2024 года с сохранением прочих параметров. Результаты тестового прохода представлены ниже.
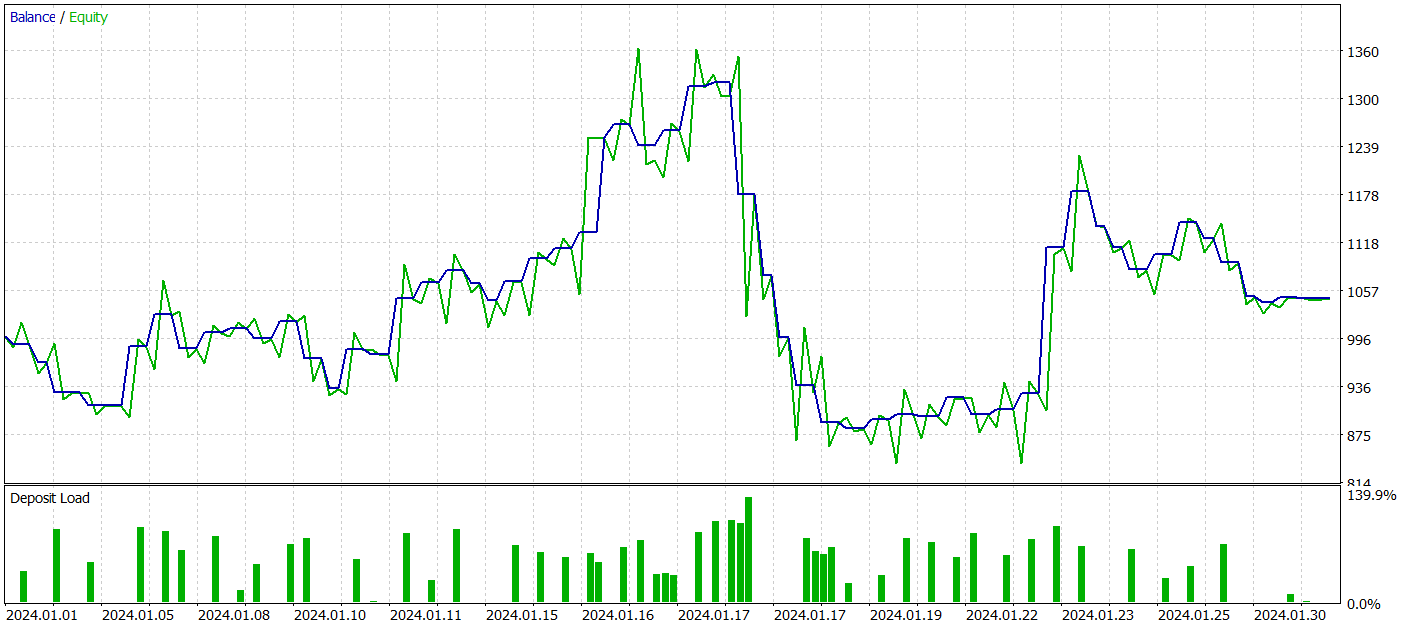
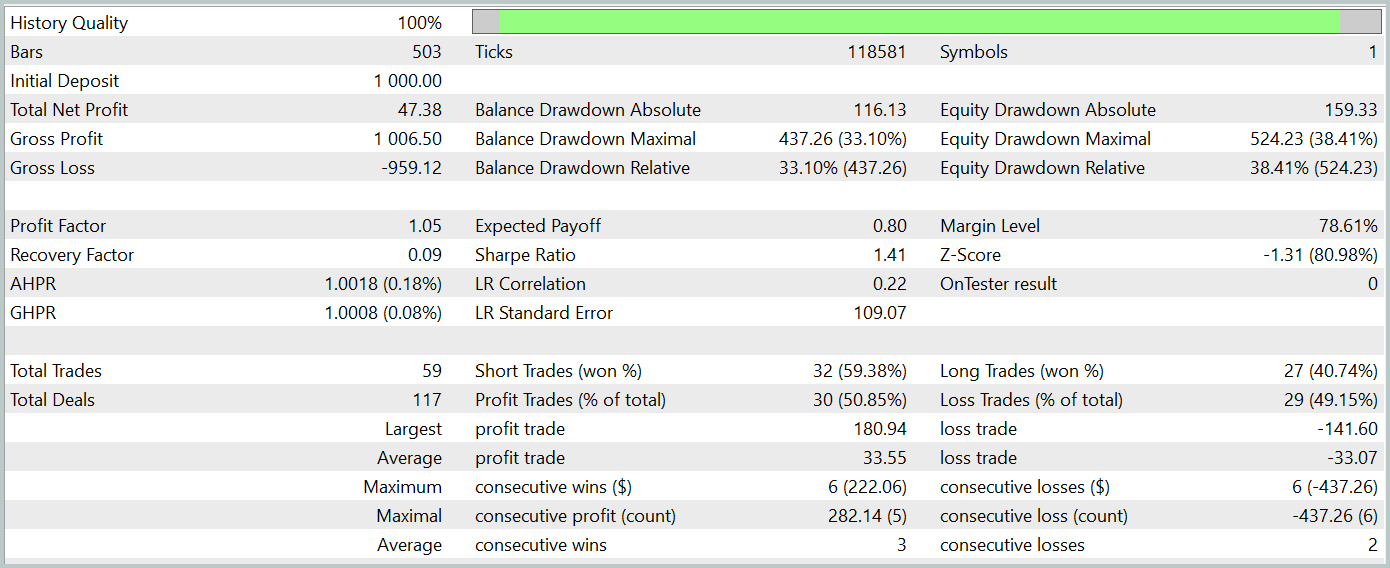
За период тестирования модель смогла получить небольшую прибыль. Было совершено всего 59 сделок и 30 из них было закрыто с прибылью. Максимальная и средняя прибыльная сделка превышают соответствующие показатели убыточных позиций. Это позволило получить профит-фактор на уровне 1.05. Однако график баланса не имеет ярко выраженной направленности. А в ходе тестирования допущена просадка по балансу более 33%.
Заключение
В данной статье мы познакомились с новым методом прогнозирования временных рядов InjectTST, разработанный для повышения качества прогнозирования длинных временных рядов за счёт инъекции глобальной информации в независимые каналы данных.
В практической части статьи мы реализовали предложенные подходы средствами MQL5 и внедрили их в модель Энкодера состояния окружающей среды. Мы проделали большую работу, но результаты оказались далеки от наших ожиданий.
Для поиска причин столь низких результатов необходим детальный анализ. Но вполне возможно, что одной из причин является попытка обучить модель прогнозирования последующих состояний окружающей среды, так сказать, "в лоб". Однако авторы метода рекомендовали трехэтапное обучение модели.
Ссылки
- InjectTST: A Transformer Method of Injecting Global Information into Independent Channels for Long Time Series Forecasting
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования