
因果推論における傾向スコア

はじめに
引き続き、因果推論の世界とその最新ツールに没頭します。もちろん、タスクはより広範です。取引における因果推論手法の活用です。すでに基礎的な勉強から始め、最初のメタ学習器まで書きました。ちなみに、これはかなり堅牢であることが判明しました。というより、その助けを借りて得られたモデルは堅牢であることが判明しました。それらは読者のためだけのものであり、作家にとっては単なる実験に過ぎないと言っておきます。したがって、後戻りはできず、取引における因果推論に関するすべてのトピックが網羅されるまで、最後まで行かなければなりません。結局のところ、因果推論へのアプローチは様々です。私はこの興味深いトピックをできるだけ広く取り上げたいと思っています。
この記事では、前回の記事で簡単に触れたマッチングについて、あるいはその種類の1つである傾向スコアマッチングについて取り上げます。
ラベル付けされたデータが異種であるため、これは重要です。例えば、FXでは、個々の訓練例がボラティリティの高い領域に属することもあれば、低い領域に属することもあります。さらに、サンプルに頻繁に登場する例もあれば、あまり登場しない例もあります。このようなサンプルにおける平均因果効果(ATE)を決定しようとするとき、サンプル内のすべての事例が同じ傾向で処置を生み出すと仮定すると、必然的に偏った推定値に遭遇することになります。条件付き平均処置効果(conditional average treatment effect: CATE)を求めようとすると、「次元の呪い」と呼ばれる問題に遭遇することがあります。
マッチングとは、処置群と対照群の類似した観測(またはユニット)をマッチングさせることによって因果効果を推定する手法のファミリーです。マッチングの目的は、可能な限り正確な真の因果効果の推定を達成するために、類似したユニット間で比較をおこなうことです。
因果推論に関する文献の著者の中には、マッチングはデータの前処理ステップと考えるべきであり、その上で任意の推定量(メタ学習器など)を使用することができると提案している者もいます。いくつかの観測を廃棄する可能性のある十分なデータがある場合、マッチングを前処理として使用することは、通常有用です。
分析すべきデータセットがあるとしましょう。このデータには1000件の観測が含まれています。データセットに18の変数がある場合、各行に少なくとも1つの完全一致が見つかる可能性は何でしょうか。答えは明らかに多くの要因に左右されます。バイナリの変数の数、うち連続変数の数、うちカテゴリ変数の数とそのレベル数、変数が互いに独立しているか相関しているか、などです。
Aleksander Molakは、彼の著書「Causal inference and discovery in Python」の中で、良い視覚的な例を示しています。
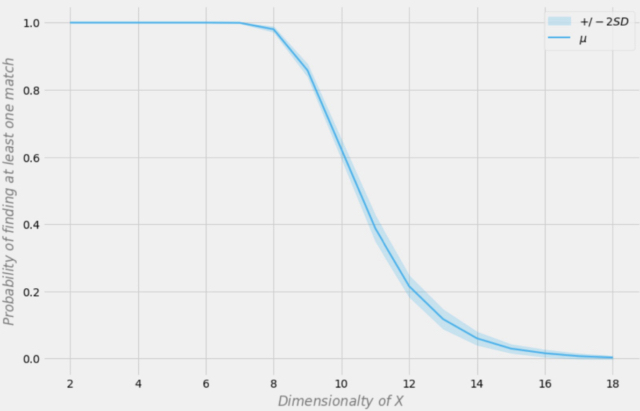
データセットの次元に応じた完全一致を見つける確率
標本に1000の観測があると仮定しましょう。上の図では、X軸はデータセットの次元(データセット中の変数の数)を表し、Y軸は各行で少なくとも1つの完全一致を見つける確率を表します。
青い線は平均確率で、斜線部分は±2標準偏差を表します。データセットは、p=0.5の独立ベルヌーイ分布を用いて作成されました。したがって、各変数はバイナリで独立です。
この本に書いてあることを試してみようと思い、この確率を計算するPythonスクリプトを書きました。
import numpy as np import matplotlib.pyplot as plt def calculate_exact_match_probability(dimensions): num_samples = 1000 num_trials = 1000 match_count = 0 for _ in range(num_trials): dataset = np.random.randint(2, size=(num_samples, dimensions)) row_sums = np.sum(dataset, axis=1) if any(row_sums == dimensions): match_count += 1 return match_count / num_trials def plot_probability_curve(max_dimensions): dimensions_range = list(range(1, max_dimensions + 1)) probabilities = [calculate_exact_match_probability(dim) for dim in dimensions_range] mean_probability = np.mean(probabilities) std_dev = np.std(probabilities) plt.plot(dimensions_range, probabilities, label='Exact Match Probability') plt.axhline(mean_probability, color='blue', linestyle='--', label='Mean Probability') plt.xlabel('Number of Variables') plt.ylabel('Probability') plt.title('Exact Match Probability in Binary Dataset') plt.legend() plt.show()
実際、1000回の観測で確率は一致しました。実験として、データセットの次元についてご自分で計算することもできます。さらなる研究のためには、学習例の数に比べてデータの特徴(共変量)が多すぎる場合、分類器を通してそのようなデータを汎化する能力が制限されることを理解すれば十分です。データ量が多ければ多いほど、統計的推定値はより正確になります。
*実際には、i.i.d((独立同一分布))条件が満たされるはずなので、これは必ずしもそうではありません。
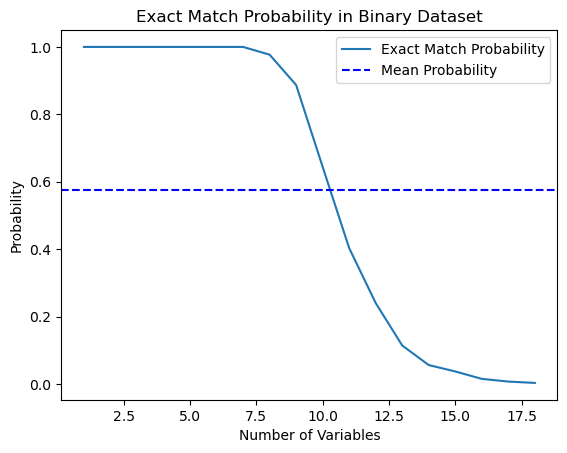
おわかりのように、18次元のバイナリランダムデータセットで完全一致を見つける確率は基本的にゼロです。現実の世界では、純粋なバイナリデータセットを扱うことは稀であり、連続データの場合、多次元マッピングはさらに難しくなります。これは、近似的なケースであっても、マッチングに深刻な問題をもたらします。どうすればこの問題を解決できるのでしょうか。
傾向スコアを用いたデータの次元削減
傾向スコアを用いて次元の呪いの問題を解決することができます。傾向スコアは、あるユニットがその特徴に基づいて実験グループに割り当てられる確率の推定値です。傾向スコアの定理(Rosenbaum and Rubin, 1983)によれば、X形質について無拘束のデータがあれば、陽性と仮定しながら傾向スコアを与えても無拘束となります。陽性とは、処置済みと未処置の分布が重なることを意味します。これが因果推論の積極性の仮定です。これも直感的に理解できます。試験群と対照群が重ならない場合は、両者が大きく異なることを意味し、一方の群の効果をもう一方の群に外挿することはできません。この外挿は不可能ではありませんが(回帰がそうさせる)、非常に危険です。これは、新しい薬を男性だけに投与する実験をして、女性も同じようにその薬に反応すると仮定するのと似ています。形式的には、傾向スコアは以下のように書かれます。
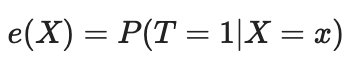
完璧な世界であれば、真の傾向スコアが得られるでしょう。しかし実際には、処置を割り当てるメカニズムは不明であり、真の素因をその評価や予想に置き換える必要があります。これをおこなう一般的な方法の一つはロジスティック回帰を使用することですが、勾配ブースティングのような他の機械学習技術を使用することもできます(ただし、これは過剰適合を避けるためにいくつかの追加ステップを必要とする)。
この方程式を使用して、多次元性の問題を解くことができます。傾向スコアは一変量なので、多変量ベクトルではなく2つの値しかマッチングできません。
従って、処置による潜在的な結果の条件付き独立性
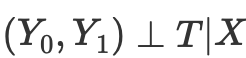
があるとすれば、傾向スコアを用いないマッチングの場合、連続ケースと離散ケースの平均因果効果を計算することができます。
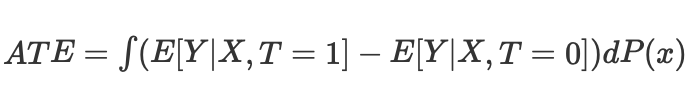
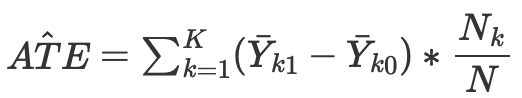
ここで、Nkは各セルの観測数です。セルは、ある近接度測定基準によってマッチングされた観測のサブグループです。
ただし、傾向スコアは、条件付き独立性を達成するためにX交絡因子を直接制御する必要はないという認識から生まれたものです。
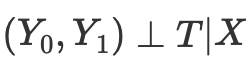
その代わり、バランシング指標
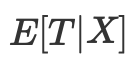
を制御すれば十分です。傾向スコアは、潜在的な結果が処置から独立していることを確実にするために、X全体から独立することを可能にします。傾向スコアであるこの1つの変数に条件をつければ十分です。
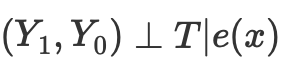
因果推論に関する資料には、このアプローチの問題点がいくつも書かれています。
- 第一に、傾向スコアはデータの次元を減らし、定義上、いくつかの情報を捨てざるを得ません。
- 第2に,元の特徴量空間ではまったく異なる2つの観測が,同じ傾向スコアを持つことがあります。このため、観測結果の一致度が大きく異なり、結果に偏りが生じる可能性があります。
- 第三に、PSM(傾向スコアモデリング)はパラドックスを引き起こす。バイナリの場合、最適な傾向スコアは0.5となります。すべての観測が0.5の最適傾向スコアを持つ完璧なシナリオでは何が起こるでしょうか。傾向スコア空間における各観測の位置は、他のすべての観測と同一になります。これはPSMのパラドックスと呼ばれることもあります。
傾向スコアマッチングと関連手法
傾向スコアに基づくユニットのマッチングには多くの方法があります。主な方法は最近傍法とされ、実験群の各ユニットiと対照群のユニットjを、傾向スコア間の絶対距離が最も近いものでマッチングさせます。
d(i, j) = minj{|e(Xi) – e(Xj)|}.
あるいは、閾値マッチングは、処置グループの各ユニットiと対照グループのユニットjを、あらかじめ指定されたb; 閾値の範囲内でマッチングさせます。
d(i, j) = minj{|e(Xi) – e(Xj)| <b}.
事前に指定したbの閾値は、傾向スコアの標準偏差0.25以下とすることが推奨されます。他の研究者は、傾向スコアの標準偏差のb = 0.20が最適であると主張しています。
閾値マッチングのもう1つの選択肢は半径マッチングです。これは1対多のマッチングであり、処置群の各ユニットiをb個のあらかじめ定義された範囲内の対照群の複数のユニットとマッチングさせます。
d(i, j) = {|e(Xi) – e(Xj)| <b}
他の傾向スコアマッチング法にはマハラノビスメトリックがあります。マハラノビスメトリックを用いたマッチングでは、実験グループの各ユニットiは、制御グループのユニットjと、変数の近接性に基づいて計算された最も近いマハラノビス距離でマッチングされます。
これまで述べてきた傾向スコアマッチング法は、貪欲マッチングアルゴリズムまたは最適マッチングアルゴリズムのいずれかを用いて実装することができます。
- 貪欲マッチングでは、一度マッチングがおこなわれると、マッチしたユニットを変更することはできません。マッチした各ユニットのペアは、現在入手可能な最高のペアです。
- 最適マッチングでは、全体的な最小距離または最適距離を達成するために、現在のマッチングを実行する前に、以前のマッチングユニットを修正することができます。
- どちらのマッチングアルゴリズムも、対照群のサイズが大きい場合には、通常同じマッチングデータを作成します。しかし、最適なマッチングは、マッチしたユニット内の全体的な距離を小さくします。したがって、単によくマッチしたグループを見つけることが目的であれば、貪欲マッチングで十分かもしれません。その代わりに、よくマッチしたペアを見つけることが目的であれば、最適マッチングが望ましいかもしれません。
傾向スコアマッチングには、個々のサンプリング単位を厳密にマッチングさせない方法もあります。例えば、小分類(または層別化)は、傾向スコアパーセンタイルの対応する数に基づいて、標本全体のすべてのユニットをいくつかの層に分類し、層ごとにユニットをマッチングさせます。5つの層は、選択バイアスを最大90%排除することが観察されています。
小分類の特別なタイプは、最適な方法でサブクラスを作成する完全マッチングです。完全にマッチしたサンプルは、マッチしたサブセットで構成され、各マッチセットは、1つの実験ユニットと1つ以上の対照ユニット、または1つの対照ユニットと1つ以上の実験ユニットを含みます。完全マッチングは、各サブクラスにおける各処置対象者と各対照対象者間の推定距離尺度の加重平均を最小化するという点で最適です。
傾向スコアマッチングに関連するもう1つの方法は、カーネルマッチング(または局所線形マッチング)であり、これは1対全マッチングでマッチングと結果分析を1つの手順で組み合わせたものです。
様々な比較方法が提案されていますが、その適用効率は、特定の方法よりも、問題の正しい定式化に依存します。
強い無視の仮定
「強い無視」は、傾向スコアの構築における重要な仮定であり、処置割り付けがランダムである観測における因果効果を推定することを目的としています。基本的に、これは、観察されたベースラインの共変量(形質)があれば、処置割り当ては潜在的な結果から独立していることを意味します。
詳しく見てみましょう。
- 処置の配分:これは、ユニットが処置を受けるかどうか(新しい薬の服用やプログラムへの参加など)です。
- 潜在的な結果:あるユニットが処置条件と対照条件の両方で経験するであろう結果ですが、各ユニットについて1つしか観察することができません。
- ベースラインの共変量:処置を受ける可能性と結果の両方に影響を与える可能性のある、処置配分前に測定されたユニット特性です。
「強く無視できる」という仮定は、次のように述べています。
- 未測定の交絡因子なし:処置配分にも結果にも影響を与える観察されない変数はありません。これは、未観測の交絡因子が推定処置効果にバイアスをかける可能性があるため重要です。
- 積極性:各ユニットは、観察された共変量が与えられた場合、処置と制御の両方を受ける確率がゼロでありません。これにより、意味のある比較をおこなうために比較されるグループに十分な単位があることが保証されます。
これらの条件が満たされていれば、傾向スコア(共変量が与えられた場合に処置を受ける確率の推定値)を条件付けすることで、平均処置効果(ATE)の不偏推定値が得られます。ATEは、処置が無作為に割り当てられていたと仮定した場合の、処置群と対照群間の転帰の平均差を表します。
逆確率重み付け
逆確率重み付けは、処置割り付けの確率の逆数に基づいてデータ集合の観測を再重み付けしようとすることにより、ノイズまたは交絡因子を除去することを意味するアプローチの1つです。この考え方は、処置される可能性が低いと評価された観察をより重視し、一般集団をより代表するようにすることです。
- まず傾向スコアが推定されます。これは観察された共変量が与えられた場合に処置を受ける確率です。
- 各観測について逆傾向スコアが計算されます。
- 各観測と対応する重みが掛け合わされます。つまり、観察された処置を受ける確率がより低い観測には、より多くの重みが与えられます。
- そして、重み付けされたデータセットが分析に使用されます。重み付けは、観察された共変量の潜在的な影響を調整しながら、処置群と対照群の両方に適用されます。
逆確率重み付けは、処置群と対照群の共変量分布のバランスをとるのに役立ち、因果効果の推定におけるバイアスを減らすことができます。しかし、これはすべての関連交絡変数が測定され、傾向スコアを推定するためのモデルに含まれているという仮定に基づいています。さらに、他の統計手法と同様に、IPWの成功は傾向スコアを推定するために使用されるモデルの質に依存します。
逆性向スコア方程式は以下の通りです。
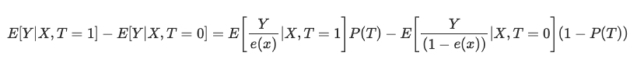
詳細は省きますが、方程式の2つの項を比較することができます。左が処置群、右が対照群です。この式は、単純な平均値の比較が、逆加重平均値の比較と等価であることを示しています。これにより、元の母集団と同じ大きさの母集団が作られますが、左側のすべてが処置を受けることになります。同じ理由で、右側は未処理のものを考慮し、処理したように見えるものを高く評価します。
マッチング後の結果の評価
因果推論では、推定値はATEまたはCATE、すなわち、(傾向スコアで調整された)処置対象値と未処置対象値の加重平均の差として構成されます。
一旦傾向スコアをe(x)として得ると,例えば,X個の特徴量の元の値の代わりに,別の分類器を訓練するためにこれらの値を使用することができます。また、傾向スコアによってサンプルを比較し、階層に分けることもできます。もう1つのオプションは、最終的な評価器を訓練するときにe(x)を別の特徴量として追加することで、サンプルの異なる例が傾向スコアによって異なる推定値を持つ場合に、交絡による偏った推定値を排除するのに役立ちます。
処置(モデルの訓練)に対して良い反応を示すサブグループと悪い反応を示すサブグループを見つけ、最終的な分類器を、うまく訓練できる(分類誤差が最小になる)データに対してのみ訓練することに関心があります。次に、分類が不十分なデータを2番目のサブグループに入れて、2番目の分類器を訓練し、これら2つのサブグループを区別します。つまり、良いデータと悪いデータを分離し、最も処理しやすいサブグループを特定します。したがって、ここでは傾向スコアの方法論全体を採用せず、訓練された分類器の得られた確率に従ってサンプルをマッチングさせることにします。一方、全体的なATE(平均処置効果)評価は私たちにとってあまり関心がありません。
言い換えれば、訓練に参加していない新しいデータ上で実行されたアルゴリズムの結果に基づいて評価をおこないます。さらに、ランダム化されたデータで訓練されたモデルの平均速度にも興味があります。独立したモデルの平均スコアが高ければ高いほど、各モデルに対する信頼度は高くなります。
実験に移る
この記事を始めるにあたり、多くのトレーダー、特に機械学習に馴染みのないトレーダーにとって、この詳細な資料は非常に直感に反するように思えるかもしれないことを承知していました。私の因果推論との最初の出会いを思い出すと、この最初の誤解は私のプライドを傷つけ、詳細を掘り下げずにはいられませんでした。しかも、因果推論のテクニックを勝手に時系列の分類に応用することなど、想像すらできませんでした。
- propensity without matching.pyファイル
傾向スコアを推定器(メタ学習器)に直接組み込む方法から始めましょう。そのためには、2つのモデルを訓練する必要があります。まず、PSM(傾向スコアモデル)自体で、訓練例を処置群またはテスト群に割り当てる確率を求めることができます。得られた確率を、特性(共変量)とともに、結果(買いか売りか)を予測する2番目のモデルの入力とします。
このアプローチの直感的な意味は、メタ学習器は、扱う傾向に基づいてサンプルのサブグループを区別できるようになるということです。これによって、より正確な結果の加重予測が可能になるはずです。この後、前回の記事と同様に、データセットを予測可能なケースと予測不可能なケースに分けます。この場合、メタ学習器が自動的に傾向スコアを考慮して推定するので、明示的なサンプルマッチングは必要ありません。このアプローチは、機械学習がすべての作業を実行してくれるので、私にとっては非常に便利に思えます。
まず、メタモデルを訓練するために、trainとvalのサブサンプルを作成しましょう。メタ学習器は訓練サブサンプルで訓練されるので、ターゲットy_T1、y_T0のペアを作成し、1と0で埋めます。これは、そのユニットが処置(モデル訓練)を受けたかどうかに対応します。次に、目的変数が処置である部分選択をシャッフルし直します。
X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # randomly assign treated and control y_T1 = pd.DataFrame(y_train) y_T1['T'] = 1 y_T1 = y_T1.drop(['labels'], axis=1) y_T0 = pd.DataFrame(y_val) y_T0['T'] = 0 y_T0 = y_T0.drop(['labels'], axis=1) y_TT = pd.concat([y_T1, y_T0]) y_TT = y_TT.sort_index() X_trainT, X_valT, y_trainT, y_valT = train_test_split( X, y_TT, train_size = 0.5, test_size = 0.5, shuffle = True)
次のステップは、サンプルが処理サブサンプルに属するか制御サブサンプルに属するかを予測するためにPSMモデルを訓練することです。
# fit propensity model PSM = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', use_best_model=True, early_stopping_rounds=15, verbose = False).fit(X_trainT, y_trainT, eval_set = (X_valT, y_valT), plot = False)
そして、処置群と対照群に属する予測値を得て、メタ学習器の特徴に加え、それを訓練する必要があります。
# predict probabilities train_proba = PSM.predict_proba(X_train)[:, 1] val_proba = PSM.predict_proba(X_val)[:, 1] # fit meta-learner meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True, early_stopping_rounds=15).fit(X_train.assign(T=train_proba), y_train, eval_set = (X_val.assign(T=val_proba), y_val), plot = False)
最終段階では、メタ学習器の予測値を取得し、予測されたラベルと実際のラベルを比較し、悪い例のブックを埋めます。
# create daatset with predicted values predicted_PSM = PSM.predict_proba(X)[:,1] X_psm = X.assign(T=predicted_PSM) coreset = X.assign(T=predicted_PSM) coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X_psm)[:,1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # add bad samples of this iteration (bad labels indices) coreset_b = coreset[coreset['labels']==0] coreset_s = coreset[coreset['labels']==1] diff_negatives_b = coreset_b['labels'] != coreset_b['labels_pred'] diff_negatives_s = coreset_s['labels'] != coreset_s['labels_pred'] BAD_BUY = BAD_BUY.append(diff_negatives_b[diff_negatives_b == True].index) BAD_SELL = BAD_SELL.append(diff_negatives_s[diff_negatives_s == True].index)
では、25のモデルを訓練し、最良結果と平均結果を見てみましょう。
options = [] best_res = 0.0 for i in range(25): print('Learn ' + str(i) + ' model') options.append(learn_final_models(meta_learners(models_number=5, iterations=25, depth=2, bad_samples_fraction=0.5))) if options[-1][0] > best_res: best_res = options[-1][0] print("BEST: " + str(best_res)) options.sort(key=lambda x: x[0]) test_model(options[-1][1:], plt=True) test_all_models(options)
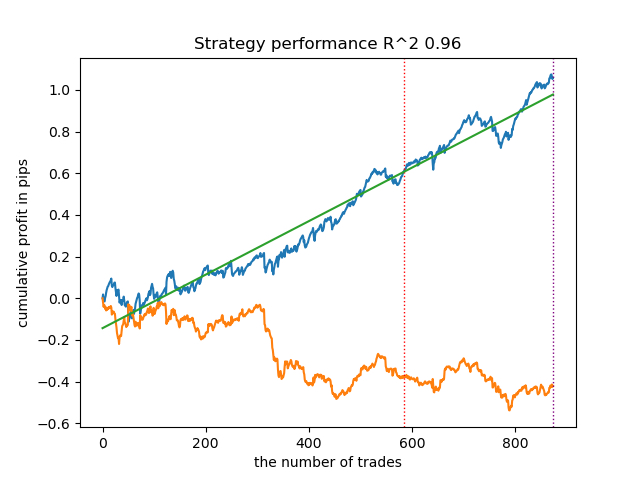
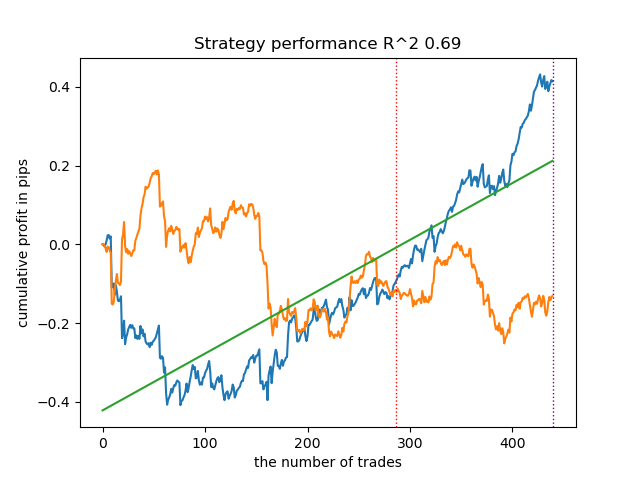
このような訓練を何度も実施し、このアプローチは前回の記事で紹介した私のアプローチとモデルの質において実質的に変わらないと結論づけました。どちらのオプションも、OOSに合格する優れたモデルを生成することができます。これは驚くべきことではありません。e(x)を追加特徴量として使用しただけで他のアルゴリズムに変化はないためです。
- propensity matching naive.pyファイル
実施方法を検討する際、どの方法がより効果的か、事前に知ることはできません。実験として、処置を割り当てる傾向ではなく、目標ラベルを予測する傾向でマッチングをおこなうことにしました。これは読者にとってより直感的に思えるはずです。ここでの主な違いは、1つの(従来から名付けられた)PSMモデルだけを訓練することです。次に、確率を予測し、得られた確率を分割したい層の数に応じてビンのリストを作成します。各層について、正しく推測された結果/誤って推測された結果の数を数え、その後、誤って推測された(比率を乗じた)例の数が正しく推測された例の数を上回る層について、悪例集に悪例を追加する条件が発動されます。
bins = np.linspace(lower_bound, upper_bound, num=bins_number) coreset['bin'] = pd.cut(coreset['propensity'], bins) for val in range(len(coreset['bin'].unique())): values = coreset.loc[coreset['bin'] == coreset['bin'].unique()[val]] diff_negatives = values['labels'] != values['labels_pred'] if len(diff_negatives[diff_negatives == False]) < (len(diff_negatives[diff_negatives == True]) * coefficient): B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index)
このアプローチには追加のパラメータがあります。
- bins_number:ビン数
- lower_bound:層が計算される確率の下限
- upper_bound:層が計算される確率の上限
浅いメタ学習器を使用しているため、確率は通常0.5付近に集まり、極端に達することはほとんどありません。したがって、上限と下限を設定することで、極端な値は参考にならないとして切り捨てることができます。
25のモデルを訓練し、その結果を見てみましょう。どのモデルも同じデータセットで訓練されているので、その比較は非常に正しいことにご注意ください。
options = [] best_res = 0.0 for i in range(25): print('Learn ' + str(i) + ' model') options.append(learn_final_models(meta_learners(models_number=5, iterations=25, depth=2, bad_samples_fraction=0.5, bins_number=25, lower_bound=0.3, upper_bound=0.7, coefficient=1.0))) if options[-1][0] > best_res: best_res = options[-1][0] print("BEST: " + str(best_res)) options.sort(key=lambda x: x[0]) test_model(options[-1][1:], plt=True)
意外なことに、この自然発生的な実装は新しいデータでかなり良い結果を出しました。以下は、最良モデルと全25モデルの取引チャートです。
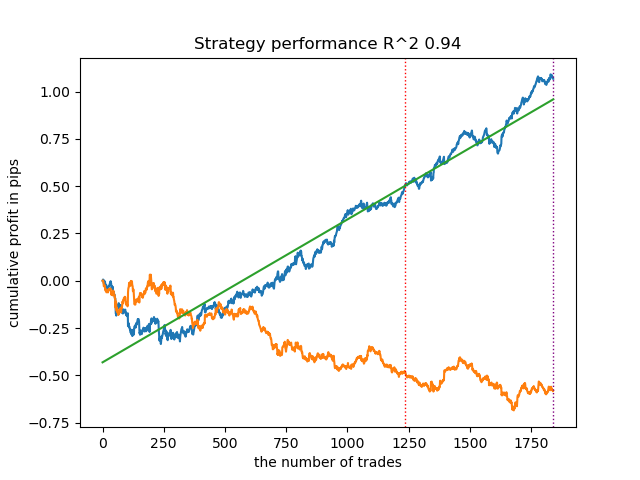
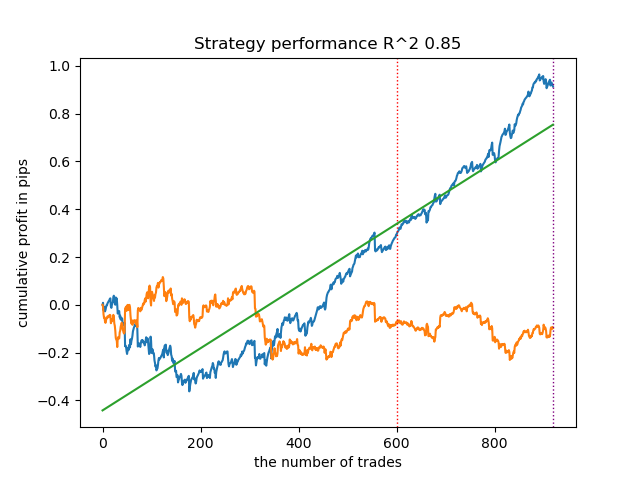
- propensity matching original.pyファイル
強く無視できるという仮定が満たされる、理論に最も近い例の実装に進みます。「強く無視できる」とは、処置の割り当てが潜在的な結果にまったく依存しない場合のことであると思い出してください。つまり、処置割り当ては完全に無作為であり、バイアスに影響する説明不可能な変数が存在しないことを意味します。そのために、ランダムに処置を割り当て、PSMモデルを訓練します。次に、取引の結果(クラスラベル)を予測するためにメタ推定器を訓練します。この後、傾向スコアに従ってサンプルを層別化し、比率を考慮して、失敗した予測の数が成功した予測の数を上回るビンからのみ、悪い例のブックにサンプルを追加します。
また、理論的な部分で説明したIPW(逆確率重み付け)を使用する機能も追加しました。
2つの分類器を訓練した後、以下のコードが実行されます。
# create daatset with predicted values coreset = X.copy() coreset['labels'] = y coreset['propensity'] = PSM.predict_proba(X)[:, 1] if Use_IPW: coreset['propensity'] = coreset['propensity'].apply(lambda x: 1 / x if x > 0.5 else 1 / (1 - x)) coreset['propensity'] = coreset['propensity'].round(3) coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) bins = np.linspace(lower_bound, upper_bound, num=bins_number) coreset['bin'] = pd.cut(coreset['propensity'], bins) for val in range(len(coreset['bin'].unique())): values = coreset.loc[coreset['bin'] == coreset['bin'].unique()[val]] diff_negatives = values['labels'] != values['labels_pred'] if len(diff_negatives[diff_negatives == False]) < (len(diff_negatives[diff_negatives == True]) * coefficient): B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index)
IPWを使用せずに25のモデルを訓練し、以下の設定で、最良の残高グラフと全モデルを平均したグラフを見てみましょう。
options = [] best_res = 0.0 for i in range(25): print('Learn ' + str(i) + ' model') options.append(learn_final_models(meta_learners(models_number=5, iterations=25, depth=2, bad_samples_fraction=0.5, bins_number=25, lower_bound=0.3, upper_bound=0.7, coefficient=1.5, Use_IPW=False))) if options[-1][0] > best_res: best_res = options[-1][0] print("BEST: " + str(best_res))
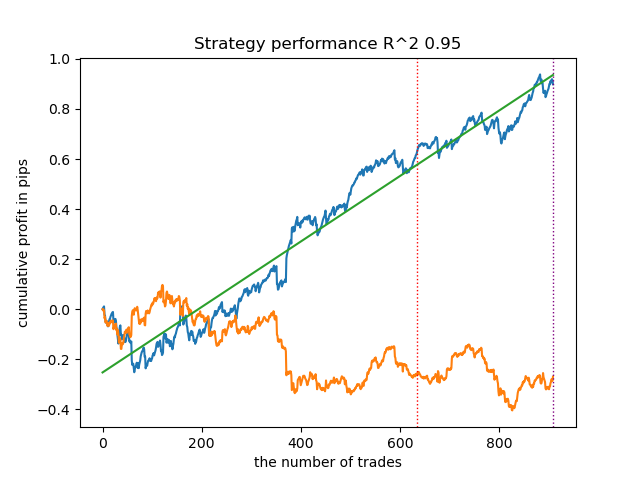
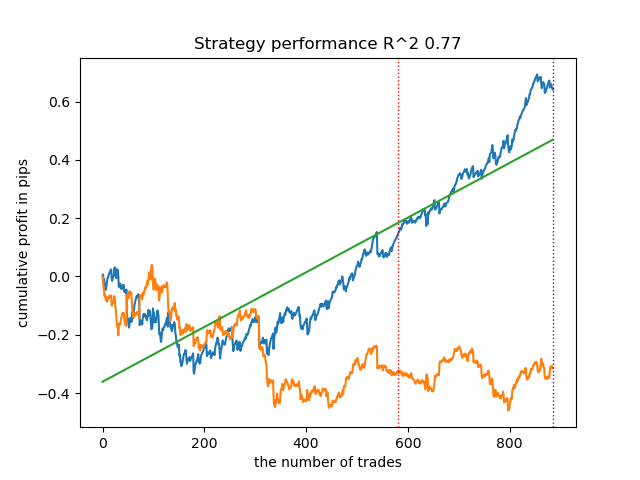
一般的に、結果は以前の実装の結果に匹敵します。では、IPWを有効にして同じことをやってみましょう。
options = [] best_res = 0.0 for i in range(25): print('Learn ' + str(i) + ' model') options.append(learn_final_models(meta_learners(models_number=5, iterations=25, depth=2, bad_samples_fraction=0.5, bins_number=25, lower_bound=0.1, upper_bound=10.0, coefficient=1.5, Use_IPW=True))) if options[-1][0] > best_res: best_res = options[-1][0] print("BEST: " + str(best_res))

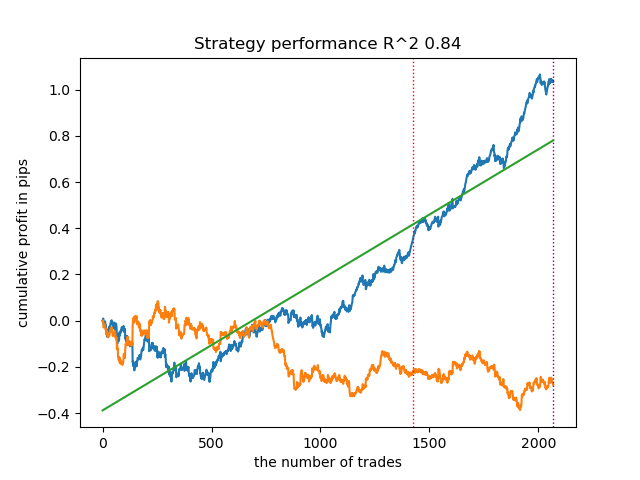
結果は最高のものになりました。もちろん、より詳細な比較のためには、異なる銘柄で複数のテストを実施する必要がありますが、これはただでさえ大きな記事のボリュームを増やすことになります。得られた結果の表を以下に示します。
| アルゴリズム | 最高結果 | 平均結果(25モデル) |
|---|---|---|
| propensity without matching.py | 0.96 | 0.69 |
| propensity matching naive.py | 0.94 | 0.85 |
| propensity matching original.py | 0.95 | 0.77 |
| propensity matching original.py IPW | 0.97 | 0.84 |
結論
金融時系列を分類する問題に傾向スコアを使用する可能性を検討しました。このアプローチは、因果推論の分野では理論的に正当ですが、欠点もあります。一般的には、新しいデータでもその特徴量を維持するモデルを得ることができました。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14360
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索