
MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 29): Fortsetzung zu Lernraten mit MLPs
Einführung
Wir wiederholen und schließen unseren Blick auf die Rolle, die verschiedene Formate von Lernraten auf die Leistung von Expert Advisor haben, indem wir die adaptiven Lernraten und die Lernrate mit einem Zyklus untersuchen. Das Format für diesen Artikel folgt dem Ansatz, den wir im letzten Artikel hatten, indem wir Testberichte in jedem Abschnitt über das Lernratenformat und nicht am Ende des Artikels aufführen.
Bevor wir beginnen, möchten wir einige andere wichtige Überlegungen zum Design des maschinellen Lernens anführen, die die Leistung eines Modells erheblich beeinflussen können. Eine davon ist die Batch-Normalisierung der Eingabedaten. Ich hatte bereits in früheren Artikeln darauf hingewiesen, warum dies so wichtig ist, aber unser nächster Artikel wird sich genau damit befassen. Bei der Entwicklung des Modus und des Formats eines Netzes wird die Stapelnormalisierung jedoch in Verbindung mit den Aktivierungsalgorithmen betrachtet, die das Modell oder das Netz verwenden soll. Bisher haben wir die Soft-Plus-Aktivierung verwendet, die die Tendenz hat, ungebundene Ergebnisse zu produzieren, d. h. im Gegensatz zu den TANH- oder Sigmoid-Aktivierungen, die Ausgaben in den Bereichen -1,0 bis +1,0 bzw. 0,0 bis 1,0 produzieren, kann Soft-Plus ziemlich oft Ergebnisse produzieren, die den den Gültigkeitstest nicht bestehen und somit den Trainings- und Vorhersageprozess ungültig machen.
Als Vorlauf zum nächsten Artikel nehmen wir daher nicht nur einige Änderungen an den von unseren Netzen verwendeten Aktivierungsalgorithmen vor, sondern auch am getesteten Devisensymbol. Wir verwenden den output-gebundenen Aktivierungsalgorithmus Sigmoid für alle Schichtaktivierungen, aber darüber hinaus liegen die Eingaben unseres Test-Forex-Symbolpaars (in unserem Fall sind es immer noch Rohpreise, da wir keine Batch-Normalisierung durchführen) im Bereich von 0,0 bis 1,0. Es gibt nicht viele Devisenpaare, deren Preise für unseren Testzeitraum, das Jahr 2023, in diesem Bereich liegen; der NZDUSD jedoch schon, und deshalb werden wir ihn verwenden.
Dies macht einen Vergleich der Leistungsergebnisse mit den Ergebnissen des vorherigen Artikels unpraktisch, da sich die Grundlage geändert hat. Mit diesem neuen Netz, Aktivierungsalgorithmus und Devisenpaar können die im letzten Artikel untersuchten Lernratenformate jedoch weiterhin vom Leser getestet werden, um einen Vergleich zu erhalten, während man seine bevorzugte Lernratenmethode eingrenzt. Außerdem stammen die hier und in diesen Artikeln im Allgemeinen vorgestellten Testergebnisse nicht von den besten Einstellungen, und das sollen sie auch gar nicht sein. Sie sind ausschließlich für explorative Zwecke gezeigt, sodass es immer die Aufgabe des Lesers ist, die Feinabstimmung der Eingaben des Expert Advisors für sein Optimum, nicht nur mit hochwertigen, historischen Daten, sondern auch vorzugsweise in Vorwärtstests nach dem Zeitraum des Strategie-Testers auf Demo-Konten, bevor er eingesetzt wird.
Was hier vorgestellt wird, ist also nur das Potenzial. Und zu diesem Zweck hat sich gezeigt, dass die Lernrate ein sehr empfindlicher Maßstab für die Leistung ist, wie aus den unterschiedlichen Testergebnissen hervorgeht, die wir im letzten Artikel vorgestellt haben. Die adaptive Lernrate soll das Problem angehen, dass zu viele Parameter die ideale Lernrate für ein Modell bestimmen sollen. Erinnern Sie sich daran, dass die Lernrate selbst nur ein Mittel ist, um die idealen Netzgewichte und Verzerrungen zu erreichen, sodass die Verwendung zusätzlicher Parameter wie die polynomische Potenz, die wir im letzten Artikel gesehen haben, oder die minimale Lernrate mit diesen Methoden vermieden werden soll. Um die Parametrisierung zu minimieren, generiert das adaptive Lernen im Prinzip die Lernrate für jeden Schichtparameter auf der Grundlage seines Trainingsgradienten. Dies hat zur Folge, dass fast alle Parameter ihre eigene Lernrate haben und die dafür erforderlichen Eingaben minimal sind. Vier Formate von adaptiven Lernraten sind üblich: adaptiver Gradient, adaptiver RMS, adaptiver exponentieller Mittelwert und adaptives Delta. Wir werden einen nach dem anderen besprechen.
Adaptive Gradienten-Lernrate
Dies ist wahrscheinlich das einfachste Format unter den adaptiven Lernraten, aber es hält sich immer noch an die angepasste Lernrate pro Parameter über alle Schichten hinweg, obwohl es nur eine einzige Eingabe hat, die anfängliche Lernrate. Die Implementierung der Lernrate auf der Basis einzelner Parameter erfordert Anpassungen, die über die nutzerdefinierte Signalklasse hinaus auf unsere übergeordnete Expertenklasse ausgedehnt werden, wie dies bei den Lernraten im letzten Artikel der Fall war. Dies liegt daran, dass die Trainingsgradienten, die als Eingaben zur Bestimmung der Lernrate dienen, nur über die Schnittstelle der übergeordneten Netzklasse zugänglich sind. Wir können zwar Änderungen an der Klasse vornehmen und diese veröffentlichen, aber angesichts der zusätzlichen Anpassungen (bei denen potenziell jede Schichtgewichtung und jeder Bias eine eigene Lernrate haben könnte) ist der Aufruf der Backpropagation möglicherweise nicht mehr so effizient, wie er eigentlich sein sollte. Durch die Ausarbeitung jeder einzelnen Lernrate während des Trainingsprozesses wird das Netz darauf vorbereitet, fast genauso effizient zu arbeiten, wenn eine einzige Lernrate für alle Parameter verwendet wird, da die berechnete Lernrate sofort auf den spezifischen Parameter angewendet wird, anstatt zuerst eine nutzerdefinierte Struktur zu entwickeln, um die neuen Lernraten für alle Parameter unterzubringen, dann den iterativen Prozess der Berechnung jeder einzelnen Lernrate zu durchlaufen und dann mit einem weiteren iterativen Prozess der Anwendung jeder einzelnen Lernrate abzuschließen. Dies wäre zwar nicht umständlicher zu programmieren, aber es wäre sicherlich rechenintensiver. Wir nehmen jedoch Änderungen an der übergeordneten Netzwerkklasse vor, indem wir zunächst zwei Vektor-Array-Parameter „adaptive_gradients“ und „adaptive_deltas“ einführen, wie in der neuen Klassenschnittstelle unten dargestellt:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ enum ENUM_ADAPTIVE { ADAPTIVE_NONE = -1, ADAPTIVE_GRAD = 0, ADAPTIVE_RMS = 1, ADAPTIVE_ME = 2, ADAPTIVE_DELTA = 3, }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Cmlp { protected: matrix weights[]; vector biases[]; vector adaptive_gradients[]; vector adaptive_deltas[]; .... bool validated; void AdaptiveGradientUpdate(double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs); void AdaptiveRMSUpdate(double DecayRate, double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs); void AdaptiveMEUpdate(double DecayRate, double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs); void AdaptiveDeltaUpdate(double DecayRate, double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs); public: ... void Forward(); void Backward(double LearningRate = 0.1, ENUM_ADAPTIVE AdaptiveType = ADAPTIVE_NONE, double DecayRate = 0.9); .... void ~Cmlp(void) { }; };
Nachdem diese in der Klassenschnittstelle deklariert wurden, müssen wir erhebliche Änderungen an der Backpropagation-Funktion vornehmen, die wir „Backward“ genannt haben. Die Änderungen betreffen in erster Linie das Hinzufügen von Eingaben und die Überprüfung dieser Eingaben, um den geeigneten Typ der zu verwendenden Lernrate zu bestimmen. Wir fügen der Funktion „Backward“ nur zwei Parameter hinzu, nämlich „AdaptiveType“ und „DecayRate“. Der adaptive Typ ist, wie der Name schon sagt, einer der vier adaptiven Lernratentypen, die zur Verfügung gestellt werden, wenn die adaptiven Lernraten verwendet werden sollen. Unser Netzwerk lässt immer noch die Option offen, keine adaptiven Lernraten zu verwenden, weshalb diesem Parameter der Standardwert „ADAPTIVE_NONE“ zugewiesen wurde, der das impliziert, was sein Tag suggeriert. Darüber hinaus erfordern die nächsten drei Formate der adaptiven Lernrate, die wir im Folgenden betrachten werden, eine Reduktionsrate (decay rate), sodass der dritte und letzte Eingabeparameter für unsere Backpropagation-Funktion dieser Wert sein wird, und da den beiden vorherigen Parametern Standardwerte zugewiesen wurden, folgt daraus, dass auch diesem Parameter ein Wert zugewiesen wird.
Innerhalb dieser Funktion finden die wichtigsten Änderungen an den beiden „Lernpunkten“ statt, d. h. dort, wo wir die Ausgangsgewichte und Vorspannungen aktualisieren, sowie im skalierbaren Teil, wo wir die versteckten Gewichte und versteckten Vorspannungen jeder versteckten Schicht aktualisieren, falls das Netz über solche verfügt. Diese Aktualisierungsabschnitte sind getrennt, da die Einbeziehung von verborgenen Schichten bei der Konstruktion dieses Netzes eine Option und nicht obligatorisch ist. Es ist insofern skalierbar, als es alle versteckten Schichten auf einmal aktualisiert, wenn sie vorhanden sind, unabhängig von ihrer Anzahl. Die Änderungen, die im Vergleich zum alten Netz vorgenommen wurden, bestehen also lediglich darin, zu überprüfen, ob an jedem dieser Punkte adaptives Lernen eingesetzt wird. Es gibt 4 Arten von adaptiven Lernraten, die im Folgenden der Vollständigkeit halber vorgestellt werden, sodass sie im weiteren Verlauf des Artikels nicht wiederholt werden. Unser erster Punkt wird nun wie folgt aussehen:
//+------------------------------------------------------------------+ //| Backward pass through the neural network to update weights | //| and biases using gradient descent | //+------------------------------------------------------------------+ void Cmlp::Backward(double LearningRate = 0.1, ENUM_ADAPTIVE AdaptiveType = ADAPTIVE_NONE, double DecayRate = 0.9) { if(!validated) { printf(__FUNCSIG__ + " invalid network settings! "); return; } // Calculate output layer gradients vector _output_error = target - output; vector _output_gradients; _output_gradients.Init(output.Size()); for (int i = 0; i < int(output.Size()); i++) { _output_gradients[i] = _output_error[i] * ActivationDerivative(output[i]); } // Update output layer weights and biases if(AdaptiveType == ADAPTIVE_NONE) { for (int i = 0; i < int(output.Size()); i++) { for (int j = 0; j < int(weights[hidden_layers].Cols()); j++) { weights[hidden_layers][i][j] += LearningRate * _output_gradients[i] * hidden_outputs[hidden_layers - 1][j]; } biases[hidden_layers][i] += LearningRate * _output_gradients[i]; } } // Adaptive updates else if(AdaptiveType != ADAPTIVE_NONE) { if(AdaptiveType == ADAPTIVE_GRAD) { AdaptiveGradientUpdate(LearningRate, hidden_layers, _output_gradients, hidden_outputs[hidden_layers - 1]); } else if(AdaptiveType == ADAPTIVE_RMS) { AdaptiveRMSUpdate(DecayRate, LearningRate, hidden_layers, _output_gradients, hidden_outputs[hidden_layers - 1]); } else if(AdaptiveType == ADAPTIVE_ME) { AdaptiveMEUpdate(DecayRate, LearningRate, hidden_layers, _output_gradients, hidden_outputs[hidden_layers - 1]); } else if(AdaptiveType == ADAPTIVE_DELTA) { AdaptiveDeltaUpdate(DecayRate, LearningRate, hidden_layers, _output_gradients, hidden_outputs[hidden_layers - 1]); } } // Calculate hidden layer gradients ... }
Die Änderungen an den versteckten Gewichten und die Aktualisierungen der Verzerrungen sind wie folgt:
//+------------------------------------------------------------------+ //| Backward pass through the neural network to update weights | //| and biases using gradient descent | //+------------------------------------------------------------------+ void Cmlp::Backward(double LearningRate = 0.1, ENUM_ADAPTIVE AdaptiveType = ADAPTIVE_NONE, double DecayRate = 0.9) { if(!validated) { printf(__FUNCSIG__ + " invalid network settings! "); return; } // Calculate output layer gradients ... // Calculate hidden layer gradients vector _hidden_gradients[]; ArrayResize(_hidden_gradients, hidden_layers); for(int h = hidden_layers - 1; h >= 0; h--) { vector _hidden_target; _hidden_target.Init(hidden_outputs[h].Size()); _hidden_target.Fill(0.0); _hidden_gradients[h].Init(hidden_outputs[h].Size()); if(h == hidden_layers - 1) { for(int j = 0; j < int(hidden_outputs[h].Size()); j++) { double _sum = 0.0; for(int i = 0; i < int(target.Size()); i++) { if(weights[h + 1][i][j] != 0.0) { _sum += (target[i] / weights[h + 1][i][j]); } } _hidden_target[j] = ActivationDerivative(_sum - biases[h][j]); } } else if(h < hidden_layers - 1) { for(int j = 0; j < int(hidden_outputs[h].Size()); j++) { double _sum = 0.0; for(int i = 0; i < int(hidden_outputs[h + 1].Size()); i++) { if(weights[h][i][j] != 0.0) { _sum += (hidden_outputs[h + 1][i] / weights[h][i][j]); } } _hidden_target[j] = ActivationDerivative(_sum - biases[h][j]); } } vector _hidden_error = _hidden_target - hidden_outputs[h]; for (int i = 0; i < int(_hidden_target.Size()); i++) { _hidden_gradients[h][i] = _hidden_error[i] * ActivationDerivative(hidden_outputs[h][i]); } } // Adaptive updates if(AdaptiveType != ADAPTIVE_NONE) { for(int h = hidden_layers - 1; h >= 0; h--) { vector _outputs = inputs; if(h > 0) { _outputs = hidden_outputs[h - 1]; } if(AdaptiveType == ADAPTIVE_GRAD) { AdaptiveGradientUpdate(LearningRate, h, _hidden_gradients[h], _outputs); } else if(AdaptiveType == ADAPTIVE_RMS) { AdaptiveRMSUpdate(DecayRate, LearningRate, h, _hidden_gradients[h], _outputs); } else if(AdaptiveType == ADAPTIVE_ME) { AdaptiveMEUpdate(DecayRate, LearningRate, h, _hidden_gradients[h], _outputs); } else if(AdaptiveType == ADAPTIVE_DELTA) { AdaptiveDeltaUpdate(DecayRate, LearningRate, h, _hidden_gradients[h], _outputs); } } } // Update hidden layer weights and biases else if(AdaptiveType == ADAPTIVE_NONE) { for(int h = hidden_layers - 1; h >= 0; h--) { for (int i = 0; i < int(weights[h].Rows()); i++) { for (int j = 0; j < int(weights[h].Cols()); j++) { if(h == 0) { weights[h][i][j] += LearningRate * _hidden_gradients[h][i] * inputs[j]; } else if(h > 0) { weights[h][i][j] += LearningRate * _hidden_gradients[h][i] * hidden_outputs[h - 1][j]; } } biases[h][i] += LearningRate * _hidden_gradients[h][i]; } } } }
Alle Funktionen, die in diesen Änderungen erwähnt werden, werden in den jeweiligen Abschnitten hervorgehoben. Die adaptive Gradientenaktualisierungsfunktion wird wie folgt implementiert:
//+------------------------------------------------------------------+ // Adaptive Gradient Update function //+------------------------------------------------------------------+ void Cmlp::AdaptiveGradientUpdate(double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs) { for (int i = 0; i < int(weights[LayerIndex].Rows()); i++) { adaptive_gradients[LayerIndex][i] += (Gradients[i] * Gradients[i]); double _learning_rate = LearningRate / (MathSqrt(adaptive_gradients[LayerIndex][i]) + __NON_ZERO); for (int j = 0; j < int(weights[LayerIndex].Cols()); j++) { weights[LayerIndex][i][j] -= (_learning_rate * Gradients[i] * Outputs[j]); } // biases[LayerIndex][i] -= _learning_rate * Gradients[i]; } }
Das hinzugefügte Vektorarray der adaptiven Gradienten akkumuliert die quadrierten Werte der Gradienten für jeden Parameter in jeder Schicht. Diese quadrierten Werte, die für jeden Parameter spezifisch sind, reduzieren dann die Lernrate in unterschiedlichem Maße, je nach dem betroffenen Parameter und seiner Geschichte der Gradienten während des Trainingsprozesses. Die Summe der quadrierten Gradienten dient als Nenner für die Lernrate, d. h. je größer die Gradienten sind, desto kleiner ist die Lernrate.
Wir haben einige Testläufe mit den adaptiven Gradienten-Lernraten durchgeführt und einige unserer Testergebnisse sind wie folgt:


Diese Testläufe werden für das Jahr 2023 auf dem täglichen Zeitrahmen für das Devisenpaar NZDUSD durchgeführt. Die Verwendung des NZDUSD dient der Batch-Normalisierung, auf die wir im nächsten Artikel näher eingehen werden. Im Moment verwenden wir jedoch, wie oben erwähnt, die Sigmoid-Aktivierung, die ihre Ausgaben im Bereich von 0,0 bis 1,0 hält, was für Testzwecke bei der Erkundung idealer Lernraten gut geeignet ist. Sobald jeder Parameter seine eigene Lernrate hat, werden die Gewichte und Verzerrungen durch die adaptive Gradientenaktualisierungsfunktion aktualisiert, deren Auflistung bereits oben mitgeteilt wurde.
Da unsere Eingabedaten, die Rohpreise, im Bereich von 0,0 bis 1,0 liegen und wir nach dem Sigmoid-Prinzip aktivieren, sollten auch unsere Netzausgaben im Bereich von 0,0 bis 1,0 liegen. Wir haben es mit Rohpreisen zu tun, und da wir unser Netzwerk mit historischen Preisdaten füttern und es auf sequenziellen Preisdaten trainieren, können wir erwarten, dass unser Netzwerk den nächsten Schlusskurs vorhersagen wird. Wir tun dies alles ohne Batch-Normalisierung, was sehr riskant ist, denn obwohl die Ausgabe im gewünschten Bereich von 0,0 bis 1,0 liegen könnte, kann sie leicht über den aktuellen Geldkurs (oder darunter) verzerrt werden, was zu permanenten Kauf- oder Verkaufssignalen führen würde. Dies zeigt sich bereits in unseren obigen „idealen“ Testergebnissen. Ich habe zwar Läufe gemacht, bei denen sowohl Kauf- und Verkaufs-Positionen eröffnet wurden, aber das Fehlen einer Batch-Normalisierung ist mit Vorsicht zu genießen. Um Signale oder Bedingungswerte aus unseren Kauf- und Verkaufs-Bedingungsfunktionen in der nutzerdefinierten Signalklasse zu generieren, müssen wir den prognostizierten Preis so normalisieren, dass er im ganzzahligen Bereich von 0 bis 100 liegt.
Wie immer gibt es viele Möglichkeiten, dies zu erreichen, aber in unserem Fall vergleichen wir einfach den prognostizierten Preis mit der Reihe von Inputpreisen und erhalten einen Perzentilwert vom Typ double. Wir wandeln diesen Perzentilwert in eine ganze Zahl zwischen 0 und 100 um, und wir haben eine Ausgabebedingung. Diese Normalisierung wird in jeder der Kauf- und Verkaufs-Konditionsfunktionen nur dann vorgenommen, wenn der prognostizierte Preis des Netzes über bzw. unter dem aktuellen Angebotspreis liegt. Der Quellcode dazu ist weiter unten zu finden:
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalCMLP::LongCondition(void) { int result = 0; double _mlp_output = 0.0; GetOutput(_mlp_output); m_symbol.Refresh(); m_symbol.RefreshRates(); if(_mlp_output > m_symbol.Bid()) { vector _scale; _scale.CopyRates(m_symbol.Name(), m_period, 8, 0, __MLP_INPUTS); result = int(round(100.0 * (fmin(_mlp_output, _scale.Max()) - _scale.Min()) / fmax(m_symbol.Point(), _scale.Max() - _scale.Min()))); } //printf(__FUNCSIG__ + " output is: %.5f, change is: %.5f, and result is: %i", _mlp_output, m_symbol.Bid()-_mlp_output, result);return(0); return(result); } //+------------------------------------------------------------------+ //| "Voting" that price will fall. | //+------------------------------------------------------------------+ int CSignalCMLP::ShortCondition(void) { int result = 0; double _mlp_output = 0.0; GetOutput(_mlp_output); m_symbol.Refresh(); m_symbol.RefreshRates(); if(_mlp_output < m_symbol.Bid()) { vector _scale; _scale.CopyRates(m_symbol.Name(), m_period, 8, 0, __MLP_INPUTS); result = int(round(100.0 * (fmin(_mlp_output, _scale.Max()) - _scale.Min()) / fmax(m_symbol.Point(), _scale.Max() - _scale.Min()))); } //printf(__FUNCSIG__ + " output is: %.5f, change is: %.5f, and result is: %i", _mlp_output, m_symbol.Bid()-_mlp_output, result);return(0); return(result); }
Die Verwendung dieses Codes, der am Ende dieses Artikels angehängt ist, erfolgt durch die Zusammenstellung eines Expert Advisors über den MQL5-Assistenten. Eine Anleitung dazu finden Sie hier und hier.
Adaptive RMS-Lernrate
Die adaptive Lernrate der RMS-Prop führt einen zusätzlichen Parameter ein, um den schnellen Abfall der Lernrate zu bewältigen, der bei großen Trainingsgradienten häufig auftritt, da sich diese im Laufe des Trainingsprozesses akkumulieren. Bei diesem Parameter handelt es sich um die Reduktionsrate, die wir bereits weiter oben als einen der neuen zusätzlichen Eingangsparameter für die modifizierte Rückverteilungsfunktion eingeführt haben. Im vorangegangenen Artikel haben wir jedoch eine Reduktionsrate in der Schrittreduktions-Lernrate, der exponentiellen Reduktions-Lernrate und der inversen Zeitreduktions-Lernrate verwendet, und sie diente einem ähnlichen Zweck. In unserer nutzerdefinierten Signalklasse haben wir einen einzelnen Eingabeparameter namens Reduktionsrate, der all diese Zwecke erfüllt, da in jeder Trainingssitzung nur ein Lernratenformat ausgewählt werden kann. Die Reduktionsrate dient also dem gewählten Lernkurventyp.
Um mit den adaptiven Lernraten fortzufahren, begrenzt RMS-prop jedoch die Akkumulation historischer Gradienten, was bei den adaptiven Gradienten ein Problem darstellen kann, da sie den Lernprozess erheblich verlangsamen, bis zu einem Punkt, an dem er praktisch zum Stillstand kommt. Dies ist auf die bereits erwähnte umgekehrte Beziehung zwischen den historischen Gradienten und der Lernrate zurückzuführen. Die Innovation der RMS-Stütze besteht darin, diesen Abfall der Lernrate dank des Abklingfaktors wirksam zu verlangsamen:
//+------------------------------------------------------------------+ // Adaptive RMS Update function //+------------------------------------------------------------------+ void Cmlp::AdaptiveRMSUpdate(double DecayRate, double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs) { for (int i = 0; i < int(weights[LayerIndex].Rows()); i++) { adaptive_gradients[LayerIndex][i] += (DecayRate * adaptive_gradients[LayerIndex][i]) + ((1.0 - DecayRate)*(Gradients[i] * Gradients[i])); double _learning_rate = LearningRate / (MathSqrt(adaptive_gradients[LayerIndex][i]) + __NON_ZERO); for (int j = 0; j < int(weights[LayerIndex].Cols()); j++) { weights[LayerIndex][i][j] -= (_learning_rate * Gradients[i] * Outputs[j]); } biases[LayerIndex][i] -= _learning_rate * Gradients[i]; } }
Ein weiteres Problem des adaptiven Gradienten besteht darin, dass sich bei nicht-stationären Daten die zugrunde liegende Verteilung und die Merkmale der Daten im Laufe der Zeit ändern, sodass die akkumulierten Gradienten selbst bei einem Trainingssatz veraltet und weniger relevant werden können, was zu suboptimalen Lernraten führt. RMS prop hingegen sorgt dafür, dass die neueren Gradienten im Spiel sind und somit einen größeren Einfluss auf die Lernrate haben. Dies macht den Lernprozess anpassungsfähiger und wohl auch nützlicher für Szenarien, die für Händler relevanter sind, wie z. B. die Prognose von Zeitreihen.
Darüber hinaus können adaptive Gradienten in Fällen, in denen auf spärlichen Datensätzen trainiert wird, die außerhalb unserer Kernkompetenz des Handels liegen, wie z. B. bei der Verarbeitung natürlicher Sprache oder bei Empfehlungssystemen, die Gradienten übermäßig reduzieren, wenn sie selten verwendete Merkmale oder Datenpunkte lesen. RMS prop ermöglicht daher einen ausgewogeneren Trainingsprozess, indem die Lernrate über längere Zeiträume auf einem relativ hohen Niveau gehalten wird, sodass diese Netze (die für Händler in bestimmten Situationen immer noch nützlich sein können) optimalere Gewichte und Verzerrungen aufweisen können.
Schließlich sind adaptive Gradienten sehr anfällig und empfindlich gegenüber verrauschten Daten, da der Gradient im Wesentlichen positiv mit dem Rauschen korreliert. In Situationen, in denen die Trainingsdaten nicht ordnungsgemäß nach diesen Ausreißern gefiltert werden, würde eine rasche Verringerung der Lernrate im Wesentlichen bedeuten, dass das Netz mehr aus den Ausreißern und dem Rauschen lernt als aus den Kern- oder Idealdaten. Der Glättungseffekt des RMS-Prop mit dem Decay-Faktor bedeutet, dass die Lernrate die wilden Ausreißer „überleben“ kann und weiterhin effektiv zu den Netzgewichten und Verzerrungen beiträgt, wenn die Kern- oder Idealdaten schließlich in der Trainingsmenge gefunden werden.
Wir haben einige Testläufe mit dem adaptiven RMS-Lernverfahren durchgeführt, und im Folgenden finden Sie ein Beispiel für unsere Testergebnisse:


Da die Eingaben unseres Netzwerks nicht im Einklang mit der Wahl der Aktivierungsfunktion für dieses Netzwerk normalisiert sind (wir verwenden Sigmoid vs. Soft Max), sind unsere Testergebnisse so verzerrt, dass nur Kaufpositionen platziert werden, da der prognostizierte Ausgabepreis immer über dem aktuellen Geldkurs lag. Es könnte Möglichkeiten geben, den Ausgabepreis zu normalisieren, um ein Gleichgewicht zwischen Kauf- und Verkaufspositionen zu erreichen, was bei unserem Ansatz hier nicht berücksichtigt wurde, aber ich würde es vorziehen, dass wir mit einer ordnungsgemäßen Batch-Normalisierung der Eingabedaten beginnen, bevor wir solche Ansätze in Betracht ziehen. Dies ist also ein Problem, das wir, wie oben erwähnt, in dem Netzartikel besser angehen werden.
Adaptive Momentum-Schätzung (oder mittlere exponentielle) Lernrate
Adaptive Moment Estimation (auch bekannt als ADAM) ist eine weitere Variante der adaptiven Lernraten, die darauf abzielt, Ansätze wie den oben genannten RMS durch eine doppelte Berücksichtigung von Gradientenmittelwert und Gradientenvarianz (Momentum) noch glatter zu machen. Dies wird in MQL5 wie folgt umgesetzt:
//+------------------------------------------------------------------+ // Adaptive Mean Exponential(ME) Update function //+------------------------------------------------------------------+ void Cmlp::AdaptiveMEUpdate(double DecayRate, double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs) { for (int i = 0; i < int(weights[LayerIndex].Rows()); i++) { adaptive_gradients[LayerIndex][i] = (DecayRate * adaptive_gradients[LayerIndex][i]) + ((1.0 - DecayRate)*(Gradients[i] * Gradients[i])); double _learning_rate = LearningRate / (fabs(adaptive_gradients[LayerIndex][i]) + __NON_ZERO); for (int j = 0; j < int(weights[LayerIndex].Cols()); j++) { weights[LayerIndex][i][j] -= (_learning_rate * Gradients[i] * Outputs[j]); } // biases[LayerIndex][i] -= _learning_rate * Gradients[i]; } }
Wir haben soeben gesehen, dass die RMS-Lernraten einen Schritt weiter gehen als die Gradientenraten, da sie die Verringerung der Lernrate verlangsamen, was eine Reihe von Vorteilen mit sich bringen kann, von denen einige bereits erwähnt wurden. ADAM geht weiter in diese Richtung, insbesondere wenn es um hochdimensionale Daten geht. Mit zunehmender Größe der bearbeiteten Datensätze steigt auch die Anzahl der Parameter in einem Gradientenfeld. In solchen Situationen, z. B. bei der Bild- und Spracherkennung, hilft die Berücksichtigung des Impulses zusätzlich zum Mittelwert, die Lernrate empfindlicher an den Datensatz anzupassen, als wenn nur der Mittelwert berücksichtigt wird. Je nach Netzdesign könnte ein solches Szenario mit hoher Dimension bei der Prognose von Finanzzeitreihen auftreten.
Die relativ instabile und langsame Konvergenz, wenn nur der Mittelwert der quadratischen Gradienten verwendet wird, macht RMS prop bei verrauschten Daten weniger zuverlässig als ADAM. Die Kombination der quadrierten Mittelwerte und der Varianz ermöglicht eine gleichmäßigere, robustere, stabilere und schnellere Konvergenz. Auch spärliche Gradienten in der Verarbeitung natürlicher Sprache und in Empfehlungssystemen werden, obwohl sie von RMS prop besser gehandhabt werden als von adaptiven Gradienten, mit ADAM dank der Impulsgewichtung in der Lernrate noch besser gehandhabt. Darüber hinaus kann in Situationen, in denen sich Parameter häufig ändern, z. B. wenn ein neues Netz mit zufälligen Gewichten und Verzerrungen initialisiert wird, die Konzentration von RMS prop auf die jüngste Gradientenhistorie zu übermäßig konservativen Aktualisierungen führen, während ADAM durch die Berücksichtigung des Momentums auch in solchen Situationen besser reagieren kann.
Bei nicht-stationären Zielen, bei denen sich die Zielfunktion im Laufe der Zeit ändert, kann sich RMS prop, obwohl es durch einen Mittelwert unterstützt wird, nicht so gut anpassen wie ADAM. Nehmen wir als Beispiel eine Situation, in der Ihr Netz für die Vorhersage von Immobilienpreisen modelliert wird und Eingaben oder Merkmale wie die Größe des Hauses, die Anzahl der Schlafzimmer und den Standort verarbeitet. Die Zielfunktion, die wir für unser MLP-Netz während der Backpropagation verwenden, ist einfach die Vektordifferenz zwischen dem Ziel und der Vorhersage, aber typischerweise kann dieses Ziel viele Formen annehmen, wie z. B. den mittleren quadratischen Fehler (MSE), was in dieser Situation die folgende Formel ergibt:
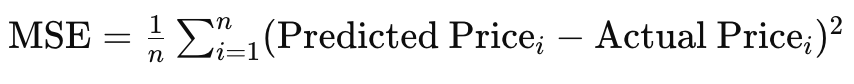
Wobei:
- n ist die Anzahl der Häuser in der Datenstichprobe
- MSE ist der mittlere quadratische Fehler
Dies wäre eine Backpropagation-Fehlerfunktion, deren Ergebnis im Laufe der Zeit abnimmt, wenn das Netz lernt, indem es seine Gewichte und Verzerrungen entsprechend aktualisiert, wobei niedrigere MSE-Werte eine verbesserte Netzleistung bedeuten. Nehmen wir nun an, dass sich der untersuchte Immobilienmarkt drastisch verändert, sodass sich die Beziehung zwischen den Netzmerkmalen (Inputs) und den prognostizierten Preisen erheblich ändert, wenn beispielsweise eine neue U-Bahn in der Region eingeführt wird, in der sich die untersuchten Immobilien befinden. Dadurch würde sich das Preismodell für die Immobilien in diesem Gebiet sicherlich ändern, was die Zielfunktion bei der Anpassung an diese Änderungen weniger nützlich machen würde. Eine Überarbeitung des Netzes durch Hinzufügen weiterer relevanter Merkmale (Eingabefelder) könnte zu einem optimaleren Ergebnis führen, da die Gewichte und Verzerrungen aktualisiert werden. ADAM bewältigt diesen Übergang von der Überarbeitung und Aktualisierung eines Netzmodells durch das Hinzufügen neuer Merkmale besser, da der Prozess der Gewichtsaktualisierung die Dynamik berücksichtigt.
Die Testergebnisse mit ADAM geben uns folgenden Bericht:


Dies ist nicht die beste oder ideale Einstellung, sondern zeigt nur, wie die ADAM-Lernrate in einem MLP-Netz angewendet wird. Im letzten Artikel hatten wir ein Paar GAN-Netze verwendet, während wir hier etwas rudimentäreres, aber immer noch intuitives verwenden, nämlich das Multi-Layer-Perceptron mit nur drei Schichten in einer 5-8-1-Formation.
Adaptive Delta-Lernrate
Unsere endgültige adaptive Lernrate ist die ADADELTA, und obwohl sie keine neuen Eingangsparameter annimmt, fördert sie die Bemühungen um eine optimale Anpassung der Lernrate beim Training. Die Formel dafür ist relativ kompliziert, aber im Prinzip wird neben der Berücksichtigung einer zerfallenden Akkumulation von Gradienten auch eine zerfallende Akkumulation von Gewichten berücksichtigt. Dies wird in MQL5 wie folgt realisiert:
//+------------------------------------------------------------------+ // Adaptive Delta Update function //+------------------------------------------------------------------+ void Cmlp::AdaptiveDeltaUpdate(double DecayRate, double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs) { for (int i = 0; i < int(weights[LayerIndex].Rows()); i++) { adaptive_gradients[LayerIndex][i] = (DecayRate * adaptive_gradients[LayerIndex][i]) + ((1.0 - DecayRate)*(Gradients[i] * Gradients[i])); double _delta = (MathSqrt(adaptive_deltas[LayerIndex][i] + __NON_ZERO) / MathSqrt(adaptive_gradients[LayerIndex][i] + __NON_ZERO)) * Gradients[i]; adaptive_deltas[LayerIndex][i] = (DecayRate * adaptive_deltas[LayerIndex][i]) + ((1.0 - DecayRate) * _delta * _delta); for (int j = 0; j < int(weights[LayerIndex].Cols()); j++) { weights[LayerIndex][i][j] -= (_delta * Outputs[j]); } // Bias update with AdaDelta biases[LayerIndex][i] -= _delta; } }
Die meisten der oben für RMS prop und ADAM genannten Vorteile einer weniger schnellen Absenkung der Lernrate gelten auch für ADADELTA. Erwähnenswert wären nun die Vorteile des zusätzlichen Puffers an adaptiven Deltas, den ADADELTA bei der Schätzung der Lernrate einführt.
ADAM verwendet gleitende Mittelwerte des Mittelwerts und der Varianz des quadrierten Gradienten bei der Anpassung der Lernraten für jeden Parameter. Dies ist zwar eine effektive Verbesserung gegenüber RMS Prop, aber es gibt Fälle, in denen die Konzentration auf historische Gradienten zu einem Überschreiten von Minima führt, was beim Training zu Instabilität führt, insbesondere bei der Verarbeitung verrauschter Daten. Die Einbeziehung eines Puffers von quadratischen Aktualisierungen, die als „adaptive Deltas“ bezeichnet werden. Diese Akkumulation trägt dazu bei, die Aktualisierungen der Lernrate besser auszubalancieren, sodass sie sowohl auf der Größe der jüngsten Gradienten als auch auf der Wirksamkeit der jüngsten Delta-Aktualisierungen basiert.
Durch die Verfolgung der quadrierten Aktualisierungen kann ADADELTA die Schrittgrößen dynamisch anpassen, indem es die jüngste Wirksamkeit dieser Aktualisierungen berücksichtigt. Dies ist für den Lernprozess von Vorteil, denn es verhindert, dass er zu konservativ wird, was passieren kann, wenn die Gradienten deutlich abnehmen. Darüber hinaus bietet die zusätzliche Akkumulation von Gewichtsaktualisierungen einen Mechanismus zur Normalisierung von Aktualisierungen unter Verwendung der Skala der jüngsten Aktualisierungen, wodurch die Fähigkeit des Optimierers zur Anpassung an Veränderungen in der Gradientenlandschaft verbessert wird. Dies ist in Szenarien mit instationären Datensatzverteilungen oder stark variablen Gradienten von entscheidender Bedeutung.
Weitere Neuerungen von ADADELTA sind die Verringerung der Empfindlichkeit der Hyperparameter und die Vermeidung von abnehmenden Lernraten. Wir führen Tests mit einer ADADELTA-Lernrate mit ähnlichem Symbol, Testzeitraum und Zeitrahmen wie oben durch und erhalten eine Vielzahl profitabler Ergebnisse. Nachstehend finden Sie einen der Berichte:


Ein-Zyklus-Lernrate
Dieser Ansatz zur Anpassung der Lernrate ist nicht so ausgeklügelt wie die adaptiven Lernratenmethoden und ähnelt eher dem Cosinus-Annealing-Format, das wir im letzten Artikel betrachtet haben. Es ist jedoch etwas einfacher als das Cosinus-Annealing, da die Lernrate gegen Ende des Trainings erhöht und dann reduziert wird. Dies wird wie folgt umgesetzt:
else if(m_learning_type == LEARNING_ONE_CYCLE) { double _cycle_position = (double)((m_epochs - i) % (2 * m_epochs)) / (2.0 * m_epochs); if (_cycle_position <= 0.5) { _learning_rate = m_min_learning_rate + (2.0 * _cycle_position * (m_learning_rate - m_min_learning_rate)); } else { _learning_rate = m_learning_rate - (2.0 * (_cycle_position - 0.5) * (m_learning_rate - m_min_learning_rate)); } }
Im Gegensatz zu den relativ komplexen Ansätzen, die wir in diesem Artikel für die Anpassung der Lernrate untersucht haben, wird die Lernrate für einen Zyklus zunächst einfach in einer so genannten Aufwärmphase erhöht, um dann in der Abkühlungsphase, dem letzten Teil des Trainingsprozesses, die maximale Lernrate zu erreichen und dann zu reduzieren. Mit Ausnahme von Cosinus-Annealing sind die meisten Lernratenansätze darauf bedacht, mit einer großen Lernrate zu beginnen und diesen Wert dann zu reduzieren, wenn mehr Daten verarbeitet werden.
Die Lernrate für einen Zyklus verhält sich ein wenig umgekehrt, indem sie mit der minimalen Lernrate beginnt. Die minimale Lernrate und die maximale Lernrate sind vordefinierte Eingabeparameter, und der Pfad oder die Änderungsrate der Lernrate wird durch die Anzahl der Epochen oder die Länge der Trainingssitzung beeinflusst. Wie bei den adaptiven Lernraten führen wir auch hier Testläufe mit der Lernrate von einem Zyklus durch; einer unserer Testberichte wird im Folgenden vorgestellt:


Aus unseren obigen Ergebnissen geht hervor, dass wir trotz eines Mangels an angemessener Batch-Normalisierung durch bloße Anpassung der Lernrate in der Lage sind, endlich einige Short-Trades zu eröffnen. Dies geschieht bei der Vorhersage von Rohsymbolpreisen (ohne Batch-Normalisierung) und bei der Normalisierung der Long- und Short-Bedingungen auf die gleiche Weise, wie wir es beim Testen der adaptiven Lernratenmethoden getan haben. Dies zeigt einmal mehr, wie empfindlich sich der Ansatz zur Verwendung und Anpassung der Lernrate auf die Leistung eines neuronalen Netzes auswirkt.
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass Lernraten ein entscheidender und sehr sensibler Aspekt von Algorithmen für maschinelles Lernen sind. Wir haben die Variationen bei der Umsetzung der verschiedenen Formate untersucht, wobei wir uns auf die sequenziellen Innovationen in jedem Format konzentriert haben, da die meisten Lernratenansätze entwickelt wurden, um frühere Methoden und Ansätze zu verbessern. Der Weg zur Verbesserung dieser Lernraten ist sicherlich noch in Bewegung und wird fortgesetzt, aber auch einfachere Ansätze wie die Lernrate von einem Zyklus sollten nicht vernachlässigt werden, da sie sehr wirkungsvoll sein können, wie einige unserer Testergebnisse gezeigt haben.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/15405
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.