
MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 28): GANs überarbeitet mit einer Anleitung zu Lernraten
Einführung
Wir greifen eine Form des neuronalen Netzes wieder auf, die wir bereits in einem früheren Artikel besprochen haben, indem wir uns auf einen bestimmten Hyperparameter konzentrieren. Die „learning-rate“ (Lernrate). Das Generative Adversarial Network ist ein neuronales Netzwerk, das paarweise arbeitet, wobei ein Netzwerk traditionell darauf trainiert wird, die Wahrheit zu erkennen, während ein anderes darauf trainiert wird, die Projektionen des ersteren von realen Ereignissen zu unterscheiden. Diese Dualität impliziert, dass das traditionell trainierte Netz (das erstere) versucht, das letztere zu täuschen, und das stimmt auch, aber die beiden Netze sind im „gleichen Team“, und das gleichzeitige Training beider macht das Generatornetz für den Händler letztlich nützlicher. In diesem Artikel befassen wir uns mit dem Trainingsprozess und konzentrieren uns dabei auf die Lernrate.
Wie immer in diesen Artikeln geht es darum, Signal-Klassen, Trailing-Klassen oder Money-Management-Klassen vorzustellen, die nicht in der Bibliothek vorinstalliert sind und dennoch in irgendeiner Form mit den bestehenden Strategien eines Traders kompatibel sein könnten. Insbesondere der MQL5-Assistent ermöglicht die nahtlose Zusammenstellung und das Testen der gemeinsamen Handelsfunktionen eines Expert Advisors mit minimalen Anforderungen an die Codierung. Daraus lässt sich eine nutzerdefinierte Klasse ableiten, die unabhängig als zusammengesetzter Expert Advisor oder parallel zu anderen Assistenten-Klassen getestet werden kann, da die Assistenten-Assembly dies problemlos ermöglicht. Für alle, die sich noch nicht mit der Montage von Assistenten befasst haben, sind diese Artikel hier und hier eine gute Einführung in das Thema.
In diesem Artikel werden wir daher anhand eines einfachen Generativen Adversarischen Netzes (GAN) untersuchen, ob und welche Bedeutung die Lernrate für die Leistung hat. „Leistung“ selbst ist ein sehr subjektiver Begriff, und streng genommen sollten die Tests über einen viel längeren Zeitraum durchgeführt werden, als wir in diesen Artikeln berücksichtigen. Für unsere Zwecke ist „Leistung“ also einfach der Gesamtgewinn unter Berücksichtigung des Rückgewinnungsfaktors. Es gibt mehrere Arten von Lernraten (oder Zeitplänen), die wir in Betracht ziehen werden, und wir werden uns bemühen, alle erschöpfend zu testen, insbesondere wenn sie sich deutlich von der Masse abheben.
Das Format dieses Artikels wird sich etwas von dem unterscheiden, was wir von früheren Artikeln gewohnt sind. Bei der Vorstellung jedes Formates für Lernraten werden die Berichte über die Strategietests beigefügt. Dies steht im Gegensatz zu früher, wo die Berichte in der Regel am Ende des Artikels, vor der Schlussfolgerung, erschienen. Es handelt sich also um ein exploratives Format, bei dem das Potenzial von Lernraten für die Leistung von Algorithmen des maschinellen Lernens, genauer gesagt von GANs, offen gehalten wird. Da wir mehrere Arten und Formate von Lernquoten betrachten, ist es wichtig, einheitliche Testmetriken zu haben, und deshalb werden wir ein einziges Symbol, einen einzigen Zeitrahmen und einen einzigen Testzeitraum für alle Lernquotenarten verwenden.
Auf dieser Grundlage wird unser Symbol durchgehend EURJPY sein, der Zeitrahmen wird der tägliche sein und der Testzeitraum wird das Jahr 2023 sein. Wir testen auf einem GAN, und dessen Standardarchitektur ist sicherlich ein Faktor. Es gibt immer das Argument, dass ein ausgeklügelteres Design in Bezug auf die Anzahl und Größe der einzelnen Schichten von größter Bedeutung ist, aber obwohl dies alles wichtige Überlegungen sind, liegt unser Schwerpunkt hier auf der Lernrate. Zu diesem Zweck werden unsere GANs relativ einfach mit nur 3 Schichten, einschließlich einer verborgenen Schicht, aufgebaut. Die Gesamtgröße von jedem ist 5-8-1 vom Eingang bis zum Ausgang. Die Einstellungen dafür sind im beigefügten Code angegeben und können vom Leser leicht geändert werden, wenn er eine andere Einstellung verwenden möchte.
Um die Kauf- und Verkaufs-Bedingungen zu generieren, implementieren wir alle verschiedenen Lernratenformate auf die gleiche Weise wie in dem oben erwähnten Artikel, in dem die Verwendung von GANs als nutzerdefinierte Signalklasse in MQL5 untersucht wurde. Der Quellcode ist wie immer beigefügt, wird aber im Folgenden der Vollständigkeit halber vorgestellt:
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalCGAN::LongCondition(void) { int result = 0; double _gen_out = 0.0; bool _dis_out = false; GetOutput(_gen_out, _dis_out); _gen_out *= 100.0; if(_dis_out && _gen_out > 50.0) { result = int(_gen_out); } //printf(__FUNCSIG__ + " generator output is: %.5f, which is backed by discriminator as: %s", _gen_out, string(_dis_out));return(0); return(result); } //+------------------------------------------------------------------+ //| "Voting" that price will fall. | //+------------------------------------------------------------------+ int CSignalCGAN::ShortCondition(void) { int result = 0; double _gen_out = 0.0; bool _dis_out = false; GetOutput(_gen_out, _dis_out); _gen_out *= 100.0; if(_dis_out && _gen_out < 50.0) { result = int(fabs(_gen_out)); } //printf(__FUNCSIG__ + " generator output is: %.5f, which is backed by discriminator as: %s", _gen_out, string(_dis_out));return(0); return(result); }
Feste Lernrate
Für den Anfang ist die feste Lernrate wahrscheinlich das, was die meisten neuen Nutzer von Algorithmen des maschinellen Lernens verwenden, da sie am einfachsten ist. Ein Standardmaß, mit dem die Gewichte und Verzerrungen eines Algorithmus bei jeder Lerniteration angepasst werden; es ändert sich in den verschiedenen Trainingsepochen überhaupt nicht.
Die Vorteile eines festen Zinssatzes ergeben sich aus seiner Einfachheit. Es ist sehr einfach zu implementieren, da man einen einzigen Fließkommawert für alle Epochen verwenden kann. Außerdem wird dadurch die Trainingsdynamik besser vorhersehbar, was zum besseren Verständnis des gesamten Prozesses und zur Fehlerbehebung beiträgt. Außerdem wird dadurch die Reproduzierbarkeit gefördert. Bei vielen neuronalen Netzen, insbesondere solchen, die mit Zufallsgewichten initialisiert werden, sind die Ergebnisse eines bestimmten Testlaufs nicht unbedingt reproduzierbar. In unserem Fall verwenden wir für alle verschiedenen Lernratenformate eine Standardanfangsgewichtung von 0,1 und eine Anfangsverzerrung von 0,01. Durch die Festlegung solcher Werte sind wir besser in der Lage, die Ergebnisse unserer Testläufe zu reproduzieren.
Außerdem bringt eine feste Lernrate Stabilität im frühen Trainingsprozess, da die Lernrate nicht abnimmt oder in den späteren Phasen abfällt, wie es bei den meisten anderen Lernratenformaten der Fall ist. Daten, die später in den Testläufen auftauchen, werden in ähnlichem Maße berücksichtigt wie die ältesten Daten. Dies erleichtert das Benchmarking und den Vergleich in Fällen, in denen ein Netz für einen anderen Hyperparameter, der nicht die Lernrate ist, feinabgestimmt werden soll. Dies könnte zum Beispiel das Anfangsgewicht sein, das das neuronale Netz verwendet. Durch eine feste Lernrate kann eine solche Optimierungssuche schneller zu einem sinnvollen Ergebnis führen.
Das Hauptproblem bei einer festen Lernrate ist die suboptimale Konvergenz. Es besteht die Sorge, dass der Gradientenabstieg beim Training in lokalen Minima hängen bleiben könnte und nicht optimal konvergiert. Dies ist besonders wichtig, bevor die ideale feste Lernrate festgelegt wurde. Außerdem gibt es das Argument der mangelnden Anpassung, das sich aus dem allgemeinen Konsens ergibt, dass das Bedürfnis zu lernen“ nicht gleich bleibt, wenn aufeinanderfolgende Trainingsepochen auftreten. Die allgemeine Auffassung ist, dass sie abnimmt.
Mit diesen Vor- und Nachteilen ergibt sich jedoch das folgende Bild, wenn ein Testlauf für das Jahr 2023 für das Paar EURJPY auf dem täglichen Zeitrahmen durchgeführt wird:


Schrittweise Reduktion
Als nächstes folgt die Schrittweise Reduktion der Lernrate (Step Decay), bei der es sich eigentlich um eine feste Lernrate mit lediglich zwei zusätzlichen Parametern handelt, die bestimmen, wie die anfängliche feste Lernrate mit jeder nachfolgenden Epoche reduziert wird. Dies wird in MQL5 wie folgt umgesetzt:
if(m_learning_type == LEARNING_STEP_DECAY) { int _epoch_index = int(MathFloor((m_epochs - i) / m_decay_epoch_steps)); _learning_rate = m_learning_rate * pow(m_decay_rate, _epoch_index); }
Die Bestimmung der Lernrate in jeder Epoche ist also ein zweistufiger Prozess. Zunächst müssen wir den Epochenindex ermitteln. Dabei handelt es sich einfach um einen Index, der misst, wie weit wir in einer Trainingssitzung durch die Epochen gekommen sind. Unsere for-Schleife zählt abwärts, nicht aufwärts, wie es normalerweise der Fall ist, also subtrahieren wir den aktuellen i-Wert von der Gesamtzahl der Epochen und führen dann eine „Math-Floor-Division“ dieses Wertes durch die zweite Eingabe durch. Das gerundete ganzzahlige Ergebnis dient als Epochenindex, mit dem wir bestimmen, um wie viel wir die anfängliche Lernrate in der aktuellen Epoche reduzieren müssen. Wenn unsere Schrittweite (2. Eingabewert) 5 beträgt, dann warten wir immer und reduzieren die Lernrate erst nach jeweils 5 Epochen. Wenn die Schrittweite 10 beträgt, erfolgt die Reduzierung nach 10 Epochen usw.
Die Gesamtstrategie des „Step Decay“ besteht darin, diese Lernrate allmählich zu verringern, um nicht über das Minimum hinauszuschießen und die optimale Lösung effizient zu erreichen. Es ist stolz darauf, ein Gleichgewicht zwischen schnellem Lernen und späterer Feinabstimmung zu bieten. Sie kann dazu beitragen, lokale Minima und Sattelpunkte in der Verlustlandschaft zu vermeiden, und führt oft zu einer besseren Generalisierung durch die Verringerung der Lernrate (im Gegensatz zur festen Rate), was wiederum dazu beitragen kann, eine Überanpassung zu vermeiden.
Wenn wir die obigen Ausführungen für EURJPY auf dem Tageskurs für das Jahr 2023 durchführen, erhalten wir folgendes Ergebnis:


Exponentielle Reduktion
Die exponentiell abklingende Lernrate (Exponential Decay) ist im Gegensatz zur schrittweise abklingenden Lernrate sanfter in ihrer Reduzierung der Lernrate. Oben haben wir gesehen, dass sich die Lernrate nur verringert, wenn sich der Epochenindex erhöht oder nach einer vordefinierten Anzahl von Epochenschritten. Beim exponentiellen Zerfall wird die Lernrate mit jeder neuen Epoche reduziert. Dies wird durch die nachstehende Formel dargestellt:
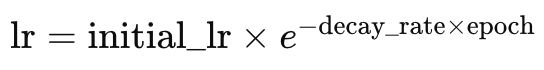
Wobei:
- lr ist die Lernrate,
- initial_lr ist die anfängliche Lernrate,
- e ist die Eulersche Konstante,
- decay_rate und epoch stehen jeweils für ihre Namen.
Dies würde in MQL5 wie folgt kodiert werden:
else if(m_learning_type == LEARNING_EXPONENTIAL_DECAY) { _learning_rate = m_learning_rate * exp(-1.0 * m_decay_rate * (m_epochs - i + 1)); }
Die exponentielle Reduktion ist in der Lage, die Lernrate zu reduzieren, indem sie bei jeder neuen Epoche mit einem Zerfallsfaktor multipliziert wird. Dies gewährleistet eine allmählichere Verringerung der Lernrate im Vergleich zu dem oben beschriebenen stufenweisen Ansatz. Die Vorteile eines schrittweisen Ansatzes entsprechen eher den allgemeinen Ansätzen zur Verringerung der Lerngeschwindigkeit. Diese wurden bereits oben mit der Methode des schrittweisen Abklingens geteilt. Was die exponentielle Reduktion bieten könnte, was bei der schrittweisen Reduktion fehlt, ist die Vermeidung von plötzlichen Einbrüchen der Lernrate, die den Trainingsprozess destabilisieren können.
Wenn wir Testläufe wie oben für EURJPY auf dem täglichen Zeitrahmen für das Jahr 2023 durchführen, erhalten wir die folgenden Ergebnisse:


Auch wenn die exponentielle Reduktion eine sanftere und allmähliche Verringerung der Lernrate ermöglicht, sind nicht alle Reduktionsschritte gleich groß, da die Lernrate in jeder Epoche neu festgelegt wird. Zu Beginn des Trainings sind die Verringerungen der Lernrate deutlich größer, und diese Werte verringern sich mit dem Fortschreiten des Trainings zu den letzten Epochen hin.
Polynomielle Reduktion
Wie beim exponentiellen Reduktion verringert sich auch hier die Lernrate mit fortschreitendem Training. Der Hauptunterschied zum exponentiellen Reduktion besteht darin, dass der polynomielle Reduktion (Polynomial Decay) mit einer langsamen Reduzierung der Lernrate beginnt. Die Reduktionsrate nimmt schließlich zu, wenn sich das Training den letzten Epochen des Prozesses nähert. Dies kann in einer Gleichung wie folgt dargestellt werden:
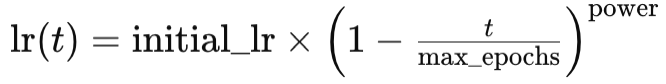
Wobei:
- lr(t) ist die Lernrate zur Epoche t,
- initial_lr ist die anfängliche Lernrate,
- t ist der Index der Epoche,
- max_epochs und power stehen jeweils für ihre Namen.
Die Umsetzung würde also wie folgt aussehen:
else if(m_learning_type == LEARNING_POLYNOMIAL_DECAY) { _learning_rate = m_learning_rate * pow(1.0 - ((m_epochs - i) / m_epochs), m_polynomial_power); }
Die polynomiale Reduktion führt den Eingangsparameter „power“ in unsere Signalklasse ein. Alle Lernratenformate werden in einer einzigen Signalklassendatei zusammengefasst, wobei die Eingabeparameter die Auswahl einer bestimmten Lernrate ermöglichen. Diese Codedatei ist am Ende des Artikels beigefügt. Der polynomiale „power input“ ist ein konstanter Exponent zu einem Faktor, den wir verwenden, um die Lernrate in Abhängigkeit von der Epoche zu reduzieren, wie in der obigen Formel gezeigt.
Die polynomiale Reduktion, die exponentielle Reduktion und die schrittweise Reduktion verringern alle ihre Lernraten. Was die polynomiale Reduktion von diesem Paket unterscheiden könnte, ist, wie bereits erwähnt, die schnelle Verringerung der Lernrate gegen Ende des Trainings. Die letztgenannte schnelle Reduzierung ermöglicht eine „Feinabstimmung“ des Trainingsprozesses, indem die Lernrate so lange wie möglich hoch gehalten wird und erst dann reduziert wird, wenn die Epochen erschöpft sind. Diese „Feinabstimmung“ wird durch die Bestimmung der optimalen polynomialen Potenz über verschiedene Trainingsskits erreicht, und sobald diese bestimmt ist, kann ein optimalerer Lernprozess erwartet werden.
Die Vorteile der polynomialen Reduktion ähneln denen, die wir oben bei den anderen Lernratenformaten erwähnt haben, und konzentrieren sich in erster Linie auf die allmähliche Verringerung, die insgesamt einen sanfteren Prozess ermöglicht. Die erwähnte Feinabstimmung der Lernrate ermöglicht nicht nur die Bestimmung der idealen Lernraten durch die Epochen, sondern auch die Kontrolle der Zeit, die der Trainingsprozess dauert. Eine größere „polynomial power“ kann so verstanden werden, dass der Trainingsprozess beschleunigt wird, während eine niedrige Leistung ihn verlangsamen sollte.
Die Testläufe auf dem täglichen EURJPY-Zeitrahmen über 2023 ergeben folgende Ergebnisse:


Inverser Zeitreduktion
Die inverse Zeitreduktion reduziert auch die Lernrate pro Epoche durch den so genannten Zeitreduktion. Während wir oben eine schnelle anfängliche Verringerung der Lernrate mit exponentiellem Zerfall gegenüber einer langsamen Verringerung der Lernrate mit polynomialem Zerfall betrachtet haben, ermöglicht der Zeitzerfall eine noch langsamere Verringerung der Lernrate, wodurch er bei der Handhabung sehr großer Trainingsdatensätze sogar besser geeignet ist als der polynomiale Zerfall.
Die Formel für die inverse Zeit lautet:
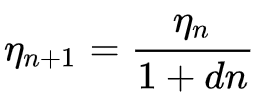
Wobei:
- ηn+1 ist die Lernrate in Epoche n + 1
- ηn die vorherige Lernrate in Epoche n
- d ist die Reduktionsrate (decay rate)
- und n ist der Epochenindex.
Wir implementieren dies in MQL5 wie folgt:
else if(m_learning_type == LEARNING_INVERSE_TIME_DECAY) { _learning_rate = m_prior_learning_rate / (1.0 + (m_decay_rate * (m_epochs - i))); m_prior_learning_rate = _learning_rate; }
Dieser Algorithmus ist ideal für sehr große Trainingsdatensätze, da er die Verringerung der Lernrate stark verlangsamt. Es teilt die meisten der bereits erwähnten Vorteile mit den anderen Lernratenformaten. Sie wird hier als Studienbeispiel aufgenommen, um zu sehen, wie sie im Vergleich zu diesen anderen Lernraten abschneidet, wenn sie mit demselben Symbol, Zeitrahmen und Testzeitraum getestet wird. Der vollständige Quelltext ist beigefügt, sodass der Nutzer Änderungen vornehmen kann, um umfangreichere Tests durchzuführen. Wenn wir jedoch einen Testlauf mit den bisher verwendeten Einstellungen durchführen, erhalten wir die folgenden Ergebnisse:


Kosinus-Annealing
Das Cosinus-Annealing für den Zeitplan der Ratenveränderung reduziert auch die Lernrate schrittweise auf ein vorgegebenes Minimum, indem es einer Cosinusfunktion folgt. Das Ziel der Lernratenreduzierung ähnelt den oben genannten Formaten, allerdings gibt es beim Cosinus-Annealing ein angestrebtes Minimum, und der Prozess wird immer wieder neu gestartet, wenn die minimale Lernrate erreicht ist, bis alle Epochen erschöpft sind.
Die Formel hierfür kann wie folgt dargestellt werden:
![]()
Wobei:
- lr(t) ist die Lernrate zur Epoche t,
- initial_lr ist die anfängliche Lernrate,
- t ist der Index der Epoche,
- T ist die Gesamtzahl der Epochen,
- min_lr ist die minimale Lernrate.
Die Umsetzung in MQL5 kann folgendermaßen aussehen:
else if(m_learning_type == LEARNING_COSINE_ANNEALING) { _learning_rate = m_min_learning_rate + (0.5 * (m_learning_rate - m_min_learning_rate) * (1.0 + MathCos(((m_epochs - i) * M_PI) / m_epochs))); }
Das Cosine Annealing eignet sich besser für große Datensätze, sogar noch besser als das „Inverse Time Decay“. Der Grund dafür ist, dass, während das „Inverse Time Decay“ die großen Einbrüche in der Lernrate hinreichend auf die letzten Trainingsepochen verschiebt, das Cosinus-Annealing einen „Reset“ des Lernens ermöglicht, indem es den Ausgangswert wiederherstellt, sobald eine voreingestellte minimale Lernrate erreicht ist. Dies ist ähnlich, unterscheidet sich aber von einer anderen Technik, die als „warmer Neustart“ bezeichnet wird und bei der die Lernrate nach einem bestimmten Trainingszyklus wieder auf den Ausgangswert zurückgesetzt wird.
„Warme Neustarts“ würden sich in sehr großen Trainingsszenarien eignen, in denen Batches/Zyklen verwendet werden, sodass jeder Batch in Epochen aufgeteilt wird, im Gegensatz zu dem Einzel-Batch-Ansatz, den wir bisher in allen Lernratenformaten betrachtet haben. Bei der Verwendung von Stapeln wird die Lernrate am Ende eines bestimmten Stapels automatisch auf ihren ursprünglichen Wert zurückgesetzt oder wiederhergestellt.
Das Testen der Ergebnisse mit dem Einzel-Batch-Format für Cosinus-Annealing liefert uns den folgenden Bericht:


Darüber hinaus ist eine Feinabstimmung auch mit Cosinus-Annealing möglich, da wir einen zusätzlichen Eingabeparameter für die minimale Lernrate haben. Je nach dem Wert, den wir dieser Rate zuweisen, können wir nicht nur die Qualität/Gründlichkeit des Trainingsprozesses steuern, sondern auch bestimmen, wie lange das Training über alle Epochen hinweg dauern wird. Je nach der Größe der Trainingsdaten, die man vor sich hat, kann dies also von großer Bedeutung sein.
Zu diesem Zweck wird oft argumentiert, dass Cosine Annealing ein Gleichgewicht zwischen Exploration und Ausbeutung bietet. Unter Exploration versteht man die Suche nach der idealen Lernrate, insbesondere durch die Anpassung und Feinabstimmung der minimalen Lernrate, während Exploitation sich darauf bezieht, die besten Netzgewichte und Verzerrungen zu ermitteln und dabei die besten bekannten Lernraten zu nutzen. Dies führt in der Regel zu einer verbesserten Verallgemeinerung des Modells angesichts der zweigleisigen Optimierung.
Zyklische Lernrate
Bei der zyklischen Lernrate wird im Gegensatz zu den bisher betrachteten Formaten die Lernrate zunächst erhöht und schließlich auf das Minimum reduziert. Dies geschieht in einem zyklischen Muster. Das Training beginnt daher immer mit der minimalen Lernrate in jedem Zyklus. Sie orientiert sich an der folgenden Formel:
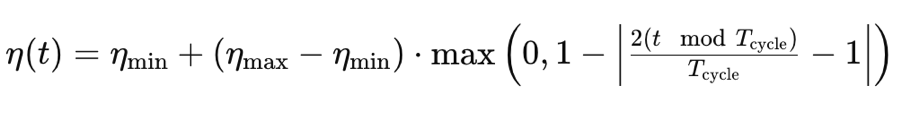
Wobei:
- η(t) ist die Lernrate in der Epoche t
- ηmin ist die minimale Lernrate
- ηmax ist die maximale Lernrate
- Tcycle ist die Gesamtzahl der Epochen in einer bestimmten Charge oder einem Zyklus (wir testen nur mit einzelnen Zyklen)
- (t modTcycle) ist der Rest, der sich aus der Division der Anzahl der Epochen in einem Zyklus durch den Index der Epoche ergibt. Wir multiplizieren diesen Wert mit 2
Dies wird in MQL5 wie folgt umgesetzt:
else if(m_learning_type == LEARNING_CYCLICAL) { double _x = fabs(((2.0 * fmod(m_epochs - i, m_epochs))/m_epochs) - 1.0); _learning_rate = m_min_learning_rate + ((m_learning_rate - m_min_learning_rate) * fmax(0.0, (1.0 - _x))); }
Die Durchführung von Testläufen mit dieser Lernrate unter Beibehaltung derselben Symbol-, Zeitrahmen- und Testperiodeneinstellungen, die wir oben verwendet haben, liefert uns diese Ergebnisse:


Es gibt eine weitere Implementierung der zyklischen Lernrate, die „triangular-2“ genannt wird, bei der die Lernrate zunächst erhöht und dann auf das Minimum reduziert wird. Der Unterschied zu dem, was wir oben betrachtet haben, besteht darin, dass der Wert der maximalen Lernrate, auf den die Rate erhöht wird, mit jedem Zyklus weiter reduziert wird.
Wir werden dieses Lernratenformat sowie weitere Formate wie die adaptive Lernrate, die an sich schon relativ breit gefächert ist, da sie verschiedene Formate aufweist, Warmstart und die Einzelzyklusraten im nächsten Artikel betrachten.
Schlussfolgerung
Abschließend haben wir gesehen, wie die Änderung nur der Lernrate innerhalb eines Algorithmus für maschinelles Lernen, wie z. B. generative adversarische Netze, zu einer Vielzahl unterschiedlicher Ergebnisse führen kann. Es ist klar, dass die Lernrate ein sehr empfindlicher Hyperparameter ist. Der Hauptzweck einer Lernrate, die vielleicht banal erscheinen mag, besteht darin, zu den konkreteren und begehrteren Netzgewichten und Verzerrungen zu gelangen, und doch ist klar, dass der Weg, der gewählt wird, um zu diesen Gewichten und Verzerrungen zu gelangen, wenn innerhalb eines festen Zeit- und Ressourcenrahmens getestet wird, je nach der verwendeten Lernrate erheblich variieren kann.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/15349
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.