
知っておくべきMQL5ウィザードのテクニック(第29回):MLPの学習率についての続き
はじめに
本記事では、適応学習率と1サイクル学習率を検証し、異なる形式の学習率がEAのパフォーマンスに与える影響を再評価します。形式は前回の記事のアプローチに沿っており、各学習率形式のセクションにテストレポートを配置しています。
本題に入る前に、モデルのパフォーマンスに大きな影響を与える機械学習設計の他の重要な要素に触れておきます。その1つが、入力データのバッチ正規化です。以前の記事でその重要性を述べましたが、次回はこのトピックをさらに詳しく扱います。現時点では、ネットワークのモードや形式を設計する際、バッチ正規化はモデルが採用する活性化アルゴリズムと併せて考慮されるべきです。これまで、無制限の出力を生成する傾向があるソフトプラス活性化を使用してきました。つまり、それぞれ -1.0 ~ +1.0 および 0.0 ~ 1.0 の範囲の出力を生成するTANHまたはシグモイド活性化とは異なり、ソフトプラスは有効なテストに合格しない結果を生成することが非常に多く、結果として訓練や予測のプロセスが無効になる場合がありました。
次回の記事の予告として、ネットワークで使用する活性化アルゴリズムに加え、テストに使用するFX銘柄にも変更を加えています。すべての層の活性化にはシグモイドを使用し、テスト対象のFX銘柄ペアの入力(バッチ正規化を行っていないため生の価格)は、0.0から1.0の範囲となります。2023年のテスト期間中、この範囲に収まる外国為替ペアは少ないですが、NZDUSDはこの条件を満たすため使用します。
このため、前回の記事のパフォーマンス結果と直接比較するのは難しいですが、新しいネットワークと活性化アルゴリズム、および異なる外国為替ペアを使うことで、前回説明した学習率形式のテストを通じて、読者は自身に適した学習率方法を比較検討することができます。また、この記事や一般的にこの手の記事で紹介されるテスト結果は、最良の設定に基づいたものではなく、あくまで探索的な目的で提供されています。読者には、高品質な履歴データだけでなく、デモ口座などの環境でEAのパフォーマンスを最適化する責任があります。
要するに、ここで提示しているのは可能性の一例にすぎません。そして、学習率がパフォーマンスに非常に敏感な要素であることは、前回のテスト結果の違いからも明らかです。適応学習率(英語)は、多数のパラメータがモデルの最適な学習率を決定する問題に対応するために用いられます。学習率自体は、理想的なネットワークの重みやバイアスを調整するための手段に過ぎません。そのため、前回の記事で触れた多項式パワーや最小学習率などの余分なパラメータは、これらの手法では避けられるよう設計されています。パラメータ化を最小限に抑えるために、適応学習では各層のパラメータに基づいて学習率を自動的に調整します。これにより、ほとんどのパラメータが独自の学習率を持ち、必要な入力も最小限に抑えられます。適応学習率には、適応勾配、適応RMS、適応指数平均、適応デルタの4つの主要形式があり、これらを順次検討していきます。
適応勾配学習率
これはおそらく適応学習率の中で最も単純な形式であるが、初期学習率という1つの入力を持つにもかかわらず、すべての層でパラメータごとにカスタマイズされた学習率を守っています。パラメータごとに学習率を実装するには、前回の記事の学習率でおこなったように、カスタムシグナルクラスを越えて親Expertクラスにまで及ぶカスタマイズが必要です。これは、学習率を決定する入力となる訓練勾配は、親ネットワークのクラスインターフェイス内からしかアクセスできないからです。クラスを変更して公開することはできますが、カスタマイズが必要になる(各層の重みとバイアスが独自の学習率を持つ可能性がある)ことを考えると、バックプロパゲーションを呼び出すことは、本来あるべき効率的なものではなくなってしまうかもしれません。訓練の過程で個々の学習率を計算することで、最初にすべてのパラメータの新しい学習率を格納するカスタム構造体を開発し、次に各学習率を個別に計算する反復プロセスを経て、最後に個々の学習率を適用する別の反復プロセスをおこなうのではなく、計算された学習率を特定のパラメータに即座に適用するため、すべてのパラメータで単一の学習率を使用した場合とほぼ同じ効率でネットワークが実行されるようになります。明らかにコーディングが面倒になることはないでしょうが、計算量は多くなるに違いません。しかし、まず親ネットワーククラスに変更を加え、以下の新しいクラスインターフェイスに示すように、adaptive_gradientsとadaptive_deltasという2つのベクトル配列パラメータを導入します。
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ enum ENUM_ADAPTIVE { ADAPTIVE_NONE = -1, ADAPTIVE_GRAD = 0, ADAPTIVE_RMS = 1, ADAPTIVE_ME = 2, ADAPTIVE_DELTA = 3, }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Cmlp { protected: matrix weights[]; vector biases[]; vector adaptive_gradients[]; vector adaptive_deltas[]; .... bool validated; void AdaptiveGradientUpdate(double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs); void AdaptiveRMSUpdate(double DecayRate, double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs); void AdaptiveMEUpdate(double DecayRate, double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs); void AdaptiveDeltaUpdate(double DecayRate, double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs); public: ... void Forward(); void Backward(double LearningRate = 0.1, ENUM_ADAPTIVE AdaptiveType = ADAPTIVE_NONE, double DecayRate = 0.9); .... void ~Cmlp(void) { }; };
クラスインターフェイス内でこれらの宣言がなされたので、次にバックプロパゲーション関数に大きな変更を加えなければなりません。主な変更点は、入力を追加し、これらの入力をチェックして、使用する学習率の適切なタイプを決定することです。Backward関数には、AdaptiveTypeとDecayRateという2つのパラメータのみを追加します。アダプティブタイプは、その名が示すように、4つのアダプティブ学習率タイプのうちの1つで、アダプティブ学習率を使用する場合に提供されます。私たちのネットワークでは、適応学習率を使わないという選択肢もまだ残されています。そのため、このパラメータにはデフォルト値としてADAPTIVE_NONEが割り当てられています。さらに、これから見ていく適応学習率の次の3つの形式は減衰率を必要とするので、バックプロパゲーション関数への3番目と最後の入力パラメータはこの値になります。前の2つのパラメータはすべてデフォルト値が割り当てられているので、このパラメータにも値が割り当てられることになります。
この関数の中で主な変更は、2つの「学習ポイント」、つまり出力重みとバイアスを更新するところと、スケーラブルな部分で、ネットワークに隠れ層がある場合、各隠れ層の隠れ重みと隠れバイアスを更新するところです。隠れ層の追加はオプションであり、このネットワークを構築する際に必須ではないからです。スケーラブルなのは、隠れ層の数に関係なく、すべての隠れ層が存在する場合に一気に更新する点です。つまり、旧ネットワークのバックプロパゲーションからの変更は、これらの各ポイントで適応学習が使われているかどうかのチェックだけです。4つの適応学習率タイプがあり、この後の記事で繰り返されないように、完全を期すためにすべてを以下に示します。最初のポイントは次のようになります。
//+------------------------------------------------------------------+ //| Backward pass through the neural network to update weights | //| and biases using gradient descent | //+------------------------------------------------------------------+ void Cmlp::Backward(double LearningRate = 0.1, ENUM_ADAPTIVE AdaptiveType = ADAPTIVE_NONE, double DecayRate = 0.9) { if(!validated) { printf(__FUNCSIG__ + " invalid network settings! "); return; } // Calculate output layer gradients vector _output_error = target - output; vector _output_gradients; _output_gradients.Init(output.Size()); for (int i = 0; i < int(output.Size()); i++) { _output_gradients[i] = _output_error[i] * ActivationDerivative(output[i]); } // Update output layer weights and biases if(AdaptiveType == ADAPTIVE_NONE) { for (int i = 0; i < int(output.Size()); i++) { for (int j = 0; j < int(weights[hidden_layers].Cols()); j++) { weights[hidden_layers][i][j] += LearningRate * _output_gradients[i] * hidden_outputs[hidden_layers - 1][j]; } biases[hidden_layers][i] += LearningRate * _output_gradients[i]; } } // Adaptive updates else if(AdaptiveType != ADAPTIVE_NONE) { if(AdaptiveType == ADAPTIVE_GRAD) { AdaptiveGradientUpdate(LearningRate, hidden_layers, _output_gradients, hidden_outputs[hidden_layers - 1]); } else if(AdaptiveType == ADAPTIVE_RMS) { AdaptiveRMSUpdate(DecayRate, LearningRate, hidden_layers, _output_gradients, hidden_outputs[hidden_layers - 1]); } else if(AdaptiveType == ADAPTIVE_ME) { AdaptiveMEUpdate(DecayRate, LearningRate, hidden_layers, _output_gradients, hidden_outputs[hidden_layers - 1]); } else if(AdaptiveType == ADAPTIVE_DELTA) { AdaptiveDeltaUpdate(DecayRate, LearningRate, hidden_layers, _output_gradients, hidden_outputs[hidden_layers - 1]); } } // Calculate hidden layer gradients ... }
同様に、隠れ重みとバイアスの更新の変更は以下の通りです。
//+------------------------------------------------------------------+ //| Backward pass through the neural network to update weights | //| and biases using gradient descent | //+------------------------------------------------------------------+ void Cmlp::Backward(double LearningRate = 0.1, ENUM_ADAPTIVE AdaptiveType = ADAPTIVE_NONE, double DecayRate = 0.9) { if(!validated) { printf(__FUNCSIG__ + " invalid network settings! "); return; } // Calculate output layer gradients ... // Calculate hidden layer gradients vector _hidden_gradients[]; ArrayResize(_hidden_gradients, hidden_layers); for(int h = hidden_layers - 1; h >= 0; h--) { vector _hidden_target; _hidden_target.Init(hidden_outputs[h].Size()); _hidden_target.Fill(0.0); _hidden_gradients[h].Init(hidden_outputs[h].Size()); if(h == hidden_layers - 1) { for(int j = 0; j < int(hidden_outputs[h].Size()); j++) { double _sum = 0.0; for(int i = 0; i < int(target.Size()); i++) { if(weights[h + 1][i][j] != 0.0) { _sum += (target[i] / weights[h + 1][i][j]); } } _hidden_target[j] = ActivationDerivative(_sum - biases[h][j]); } } else if(h < hidden_layers - 1) { for(int j = 0; j < int(hidden_outputs[h].Size()); j++) { double _sum = 0.0; for(int i = 0; i < int(hidden_outputs[h + 1].Size()); i++) { if(weights[h][i][j] != 0.0) { _sum += (hidden_outputs[h + 1][i] / weights[h][i][j]); } } _hidden_target[j] = ActivationDerivative(_sum - biases[h][j]); } } vector _hidden_error = _hidden_target - hidden_outputs[h]; for (int i = 0; i < int(_hidden_target.Size()); i++) { _hidden_gradients[h][i] = _hidden_error[i] * ActivationDerivative(hidden_outputs[h][i]); } } // Adaptive updates if(AdaptiveType != ADAPTIVE_NONE) { for(int h = hidden_layers - 1; h >= 0; h--) { vector _outputs = inputs; if(h > 0) { _outputs = hidden_outputs[h - 1]; } if(AdaptiveType == ADAPTIVE_GRAD) { AdaptiveGradientUpdate(LearningRate, h, _hidden_gradients[h], _outputs); } else if(AdaptiveType == ADAPTIVE_RMS) { AdaptiveRMSUpdate(DecayRate, LearningRate, h, _hidden_gradients[h], _outputs); } else if(AdaptiveType == ADAPTIVE_ME) { AdaptiveMEUpdate(DecayRate, LearningRate, h, _hidden_gradients[h], _outputs); } else if(AdaptiveType == ADAPTIVE_DELTA) { AdaptiveDeltaUpdate(DecayRate, LearningRate, h, _hidden_gradients[h], _outputs); } } } // Update hidden layer weights and biases else if(AdaptiveType == ADAPTIVE_NONE) { for(int h = hidden_layers - 1; h >= 0; h--) { for (int i = 0; i < int(weights[h].Rows()); i++) { for (int j = 0; j < int(weights[h].Cols()); j++) { if(h == 0) { weights[h][i][j] += LearningRate * _hidden_gradients[h][i] * inputs[j]; } else if(h > 0) { weights[h][i][j] += LearningRate * _hidden_gradients[h][i] * hidden_outputs[h - 1][j]; } } biases[h][i] += LearningRate * _hidden_gradients[h][i]; } } } }
これらの変更点における上記のすべての関数は、それぞれのセクションで強調表示されます。適応勾配更新関数の実装は以下の通りです。
//+------------------------------------------------------------------+ // Adaptive Gradient Update function //+------------------------------------------------------------------+ void Cmlp::AdaptiveGradientUpdate(double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs) { for (int i = 0; i < int(weights[LayerIndex].Rows()); i++) { adaptive_gradients[LayerIndex][i] += (Gradients[i] * Gradients[i]); double _learning_rate = LearningRate / (MathSqrt(adaptive_gradients[LayerIndex][i]) + __NON_ZERO); for (int j = 0; j < int(weights[LayerIndex].Cols()); j++) { weights[LayerIndex][i][j] -= (_learning_rate * Gradients[i] * Outputs[j]); } // biases[LayerIndex][i] -= _learning_rate * Gradients[i]; } }
追加された適応勾配のベクトル配列は、各層における各パラメータの勾配の2乗値を累積します。これらの2乗値は各パラメータに固有の値であり、その後、関係するパラメータと学習プロセス全体を通しての勾配の履歴に応じて、様々な量の学習率を減少させます。勾配の二乗和は学習率の分母として働くので、勾配が大きいほど学習率は小さくなることが理解できます。
適応勾配学習率を用いていくつかのテストをおこないました。


これらのテストは、FXペアNZDUSDの日足時間枠で2023年についておこなわれました。NZDUSDを使用するのは、次回の記事で詳しく説明するバッチ正規化のためです。ただし、現時点では、前述のように、出力を0.0 ~ 1.0の範囲に保つシグモイド活性化を使用しており、これは理想的な学習率を調査する際のテスト目的に適しています。各パラメータがそれぞれの学習率を持つと、重みとバイアスは適応勾配更新関数によって更新されます。
入力データである生価格は0.0から1.0の範囲にあり、シグモイドで活性化しているので、ネットワークの出力も0.0から1.0の範囲にあるはずです。ここでは生の価格を扱っており、ネットワークに過去の価格データを与え、連続した価格データで学習させているため、ネットワークが次の終値を予測することが期待できます。出力が望ましい0.0から1.0の範囲にあっても、現在の買値より上(または下)に偏る可能性があるため、永久的な買いまたは永久的な売りのシグナルを与えることになります。これは上記の「理想的な」テスト結果ですでに明らかです。さて、ロングとショートの両方のポジションを建てましたが、バッチ正常化の欠如は注意すべき点です。カスタムシグナルクラスのロングとショートの条件関数からシグナルや条件値を生成するには、予測価格を0から100の整数範囲になるように正規化する必要があります。
いつものように、これを実現する方法はいくらでもありますが、今回のケースでは、単純に予測価格と投入価格の配列を比較し、2倍のパーセンタイル値を算出します。このパーセンタイル値を0から100までの整数に変換し、出力条件とします。この正規化は、ロングとショートの各条件関数において、それぞれネットワークの予測価格が現在のビッド価格を上回っている場合、または下回っている場合にのみおこなわれます。そのソースコードを以下に掲載します。
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalCMLP::LongCondition(void) { int result = 0; double _mlp_output = 0.0; GetOutput(_mlp_output); m_symbol.Refresh(); m_symbol.RefreshRates(); if(_mlp_output > m_symbol.Bid()) { vector _scale; _scale.CopyRates(m_symbol.Name(), m_period, 8, 0, __MLP_INPUTS); result = int(round(100.0 * (fmin(_mlp_output, _scale.Max()) - _scale.Min()) / fmax(m_symbol.Point(), _scale.Max() - _scale.Min()))); } //printf(__FUNCSIG__ + " output is: %.5f, change is: %.5f, and result is: %i", _mlp_output, m_symbol.Bid()-_mlp_output, result);return(0); return(result); } //+------------------------------------------------------------------+ //| "Voting" that price will fall. | //+------------------------------------------------------------------+ int CSignalCMLP::ShortCondition(void) { int result = 0; double _mlp_output = 0.0; GetOutput(_mlp_output); m_symbol.Refresh(); m_symbol.RefreshRates(); if(_mlp_output < m_symbol.Bid()) { vector _scale; _scale.CopyRates(m_symbol.Name(), m_period, 8, 0, __MLP_INPUTS); result = int(round(100.0 * (fmin(_mlp_output, _scale.Max()) - _scale.Min()) / fmax(m_symbol.Point(), _scale.Max() - _scale.Min()))); } //printf(__FUNCSIG__ + " output is: %.5f, change is: %.5f, and result is: %i", _mlp_output, m_symbol.Bid()-_mlp_output, result);return(0); return(result); }
この記事の下部に添付されているこのコードを使用するには、MQL5ウィザードを使用してEAを組み立てます。そのためのガイダンスは、こちらとこちらにあります。
適応RMS学習率
RMSprop適応学習率は、訓練プロセス全体を通じて蓄積されるため、大きな訓練勾配に直面したときに頻繁に発生する学習率の急激な低下を管理するための追加パラメータを導入します。このパラメータは減衰率であり、修正されたバックプロパゲーション関数への新しい追加入力パラメータの1つとして、すでに上で紹介しました。前回の記事では、ステップ減衰学習率、指数減衰学習率、逆時間減衰学習率で減衰率を使いましたが、それはほぼ同様の目的を果たしました。カスタムシグナルクラスには、減衰率という単一の入力パラメータがあり、これはこれらすべての目的に使用できます。これは、どの訓練セッションでも1つの学習率形式しか選択できないためです。そのため、減衰率は選択された学習率タイプに対応します。
ただし、適応学習率を継続するために、RMSpropは履歴勾配の蓄積を制限します。これは、適応勾配によって学習が大幅に遅くなり、事実上停止してしまうため、問題となる可能性があります。すでに述べたように、過去の勾配と学習率の間に逆相関があるためです。RMSpropの革新は、減衰ファクターのおかげで、この学習率の低下を効果的に遅らせることであり、これは以下のように達成されます。
//+------------------------------------------------------------------+ // Adaptive RMS Update function //+------------------------------------------------------------------+ void Cmlp::AdaptiveRMSUpdate(double DecayRate, double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs) { for (int i = 0; i < int(weights[LayerIndex].Rows()); i++) { adaptive_gradients[LayerIndex][i] += (DecayRate * adaptive_gradients[LayerIndex][i]) + ((1.0 - DecayRate)*(Gradients[i] * Gradients[i])); double _learning_rate = LearningRate / (MathSqrt(adaptive_gradients[LayerIndex][i]) + __NON_ZERO); for (int j = 0; j < int(weights[LayerIndex].Cols()); j++) { weights[LayerIndex][i][j] -= (_learning_rate * Gradients[i] * Outputs[j]); } biases[LayerIndex][i] -= _learning_rate * Gradients[i]; } }
適応勾配のもう1つの問題は、非定常データを扱う場合、データの基本的な分布や特性が時間とともに変化するため、学習セットを通してでさえ、蓄積された勾配が古くなり、最適な学習率ではなくなる可能性があることです。一方、RMSpropは、より新しい勾配が有効であることを確認し、したがって学習率により大きな影響を与えます。これにより、学習プロセスがより適応的になり、時系列予測のようなトレーダーにとってより適切なシナリオにおいて、間違いなくより有用になります。
さらに、自然言語処理や推薦システムのように、私たちが得意とする取引の対象外のような疎なデータセットで学習がおこなわれる場合、適応的勾配は、使用頻度の低い特徴やデータポイントを読み取る際に、勾配を過度に減少させる可能性があります。したがって、RMSpropは、学習率を比較的高いレベルに長期間維持することで、よりバランスの取れた学習プロセスを可能にし、このようなネットワーク(トレーダーは、特定の状況ではまだ有用であると考える可能性がある)は、より最適な重みとバイアスを持つことができます。
最後に、適応勾配はノイズの多いデータに対して非常に敏感で、影響を受けやすいです。したがって、学習データがこれらの異常値に対して適切にフィルタされていない状況では、学習率の急激な低下は、本質的に、ネットワークがコアデータや理想的なデータよりも異常値やノイズから多くを学習していることを意味します。RMSpropの減衰ファクターによる平滑化効果は、学習率が乱暴な異常値を「生き残る」ことができ、最終的に訓練セットでコアまたは理想的なデータが満たされたときに、依然として効果的にネットワークの重みとバイアスに寄与し続けることを意味します。
RMSprop適応学習ではいくつかのテストをおこなっているので、以下にテスト結果のサンプルを示します。


ネットワークの入力は、このネットワークの活性化関数の選択(シグモイドとソフトマックスを使い分けている)に沿ってバッチ正規化されていないため、テスト結果は、出力予測価格が常に現在の買値を上回っているため、ロング取引のみをおこなうように偏っています。出力価格を正規化してロングポジションとショートポジションのバランスをとる方法があるかもしれませんが、ここでのアプローチでは考慮していません。しかし、そのようなアプローチを検討する前に、入力データを適切にバッチ正規化することから始めることをお勧めします。したがって、この問題は、前述のように、ネット記事でより効果的に取り組むことになります。
適応モーメント推定(または平均指数)学習率
適応モーメント推定(ADAM; Adaptive Moment Estimation)は、上記のRMSのようなアプローチを、勾配平均と勾配分散(モーメンタム)の両方を考慮することによって、さらに滑らかにすることを目的とした、アダプティブ学習率のもうひとつのバリエーションです。これはMQL5では以下のように実装されています。
//+------------------------------------------------------------------+ // Adaptive Mean Exponential(ME) Update function //+------------------------------------------------------------------+ void Cmlp::AdaptiveMEUpdate(double DecayRate, double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs) { for (int i = 0; i < int(weights[LayerIndex].Rows()); i++) { adaptive_gradients[LayerIndex][i] = (DecayRate * adaptive_gradients[LayerIndex][i]) + ((1.0 - DecayRate)*(Gradients[i] * Gradients[i])); double _learning_rate = LearningRate / (fabs(adaptive_gradients[LayerIndex][i]) + __NON_ZERO); for (int j = 0; j < int(weights[LayerIndex].Cols()); j++) { weights[LayerIndex][i][j] -= (_learning_rate * Gradients[i] * Outputs[j]); } // biases[LayerIndex][i] -= _learning_rate * Gradients[i]; } }
上で、RMSprop学習率は、学習率の低下率を遅くするという点で勾配率よりも優れていることを説明しました。これにより、上で説明したいくつかの利点が得られます。ADAMは、特に高次元データに直面したときに、この方向性を継続します。扱うデータセットの次元が大きくなると、勾配配列のパラメータ数も増えます。画像認識や音声認識のような状況では、平均値に加えて運動量も考慮することで、平均値だけを考慮した場合よりも、学習率がより敏感にデータセットに適応できるようになります。ネットワークの設計にもよりますが、金融時系列予測ではこのような高次元のシナリオに遭遇する可能性があります。
二乗勾配の平均値のみを使用する場合、比較的不安定で収束が遅いため、ノイズの多いデータではADAMよりもRMSpropの信頼性が低くなります。二乗平均と分散の両方を組み合わせることで、よりスムーズでロバスト、安定した高速な収束処理が可能になります。また、自然言語処理や推薦システムにおける疎な勾配は、適応勾配よりもRMSpropの方がうまく扱えますが、学習率における運動量重み付けのおかげで、ADAMの方がさらにうまく扱えます。さらに、新しいネットワークがランダムな重みとバイアスで初期化される場合など、パラメータが頻繁に変化する状況では、RMSpropは最近の勾配の履歴に注目するため、過度に保守的な更新になる可能性があります。
最後に、目的関数が時間と共に変化する非定常目的関数を扱う場合、RMSpropは平均によって支援されるとはいえ、ADAMほど適応しない可能性があります。この例として、ネットワークが不動産価格を予測するためにモデル化され、家の大きさ、寝室の数、場所などの入力や特徴を扱う状況を考えてみましょう。バックプロパゲーションの間、MLPネットワークに使用している目的関数は、単純にターゲットと予測の間のベクトルの差ですが、一般的にこの目的は、平均二乗誤差 (MSE)のような多くの形をとることができ、この状況では以下の式になります。
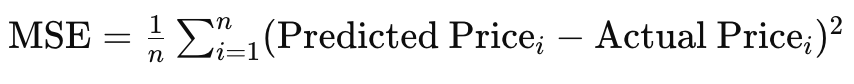
ここで
- nはデータサンプルの家屋数
- MSEは平均二乗誤差
これは、ネットワークが重みとバイアスを適切に更新して学習するにつれて、その結果が時間の経過とともに減少するバックプロパゲーション誤差関数であり、MSE値が低いほどネットワークのパフォーマンスが向上していることを意味します。ここで、調査対象の不動産市場が劇的に変化し、ネットワーク機能 (入力) と予測価格の関係が大きく変化したと仮定します。たとえば、調査対象の不動産が占める地域に新しい地下鉄が導入された場合です。そうなれば、その地域の不動産物件の価格モデルは確実に変化し、目的関数がこうした変化に適応する上で役に立たなくなります。より適切な特徴(入力フィールド)を追加することによってネットワークを修正すれば、重みとバイアスが更新され、より最適な結果が得られる可能性があります。ADAMは、重みの更新プロセスが運動量を考慮するため、新機能の追加によるネットワークモデルの修正と更新の移行をよりうまく管理できます。
ADAMのテスト結果は次のようなものでした。


これは最良あるいは理想的な設定からではなく、MLPネットワークにおいてADAM学習率がどのように適用されるかを示しているにすぎません。前回の記事では2つのGANネットワークを使いましたが、今回はもっと初歩的だが直感的な、5-8-1の3層だけの多層パーセプトロンを使います。
適応デルタ学習率
私たちの最終的な適応学習率はADADELTAです。新しい入力パラメータを取らないにもかかわらず、学習時に学習率を最適に調整する努力をさらに進めています。この計算式は比較的複雑だが、原理的には、勾配の減衰蓄積を考慮するほかに、重みの減衰蓄積も考慮します。これはMQL5で以下のように実現されています。
//+------------------------------------------------------------------+ // Adaptive Delta Update function //+------------------------------------------------------------------+ void Cmlp::AdaptiveDeltaUpdate(double DecayRate, double LearningRate, int LayerIndex, vector &Gradients, vector &Outputs) { for (int i = 0; i < int(weights[LayerIndex].Rows()); i++) { adaptive_gradients[LayerIndex][i] = (DecayRate * adaptive_gradients[LayerIndex][i]) + ((1.0 - DecayRate)*(Gradients[i] * Gradients[i])); double _delta = (MathSqrt(adaptive_deltas[LayerIndex][i] + __NON_ZERO) / MathSqrt(adaptive_gradients[LayerIndex][i] + __NON_ZERO)) * Gradients[i]; adaptive_deltas[LayerIndex][i] = (DecayRate * adaptive_deltas[LayerIndex][i]) + ((1.0 - DecayRate) * _delta * _delta); for (int j = 0; j < int(weights[LayerIndex].Cols()); j++) { weights[LayerIndex][i][j] -= (_delta * Outputs[j]); } // Bias update with AdaDelta biases[LayerIndex][i] -= _delta; } }
RMSpropやADAMについて前述した、学習率をあまり急激に下げないという利点のほとんどは、ADADELTAにも当てはまります。今、言及する価値があるのは、ADADELTAが学習率を推定する際に導入する、適応デルタの余分なバッファの利点でしょう。
ADAMは、各パラメータの学習率を適応させる際に、2乗勾配の平均と分散の移動平均を使用します。RMSpropよりも効果的な改善ですが、履歴勾配に注目すると、特にノイズの多いデータを扱う場合に、訓練時にオーバーシュートして不安定になる場合があります。「適応デルタ」と呼ばれる2乗更新のバッファが含まれます。この蓄積は、最近の勾配の大きさと最近のデルタ更新の有効性の両方に基づくように、学習率更新の更新のバランスをより良くするのに役立ちます。
ADADELTAは、2乗更新を追跡することで、これらの更新の最近の有効性を考慮して、ステップサイズを動的に調整することができます。これは学習プロセスにとって有益で、勾配の大きさが著しく減少した場合に起こりうる、学習プロセスが過度に保守的になるのを防ぎます。さらに、重みの更新の追加的な蓄積は、最近の更新のスケールを使用しながら更新を正規化するメカニズムを提供し、オプティマイザが勾配ランドスケープの変化に適応する能力を向上させます。これは、データセットの分布が非定常であったり、勾配が大きく変動したりするシナリオでは極めて重要です。
ADADELTAの他の革新的な点は、ハイパーパラメータ感度の低減と学習率の逓減の回避です。ADADELTAの学習率を用いて、上記と同様の銘柄、テスト期間、時間枠でテストをおこない、様々な有益な結果を得ています。以下はその報告のひとつです。


1サイクル学習率
この学習率調整法は、適応学習率法の洗練性を欠いており、前回の記事で検討したcosine annealing形式に近いです。しかし、cosine annealingに比べると、学習率を上げていき、訓練の終盤に下げるという点で少し単純です。これは以下のように実装されます。
else if(m_learning_type == LEARNING_ONE_CYCLE) { double _cycle_position = (double)((m_epochs - i) % (2 * m_epochs)) / (2.0 * m_epochs); if (_cycle_position <= 0.5) { _learning_rate = m_min_learning_rate + (2.0 * _cycle_position * (m_learning_rate - m_min_learning_rate)); } else { _learning_rate = m_learning_rate - (2.0 * (_cycle_position - 0.5) * (m_learning_rate - m_min_learning_rate)); } }
そのため、この記事で検討した学習率を調整する比較的複雑なアプローチとは異なり、1サイクルの場合、学習率はウォームアップ段階と呼ばれる初期段階で単純に上げられ、その後、学習率がピークに達した後、訓練の後半部分であるクーリングダウン段階で下げられます。cosine annealingを除いて、ほとんどの学習率アプローチは、大きな学習率で開始し、より多くのデータを処理するにつれてこの値を小さくすることに重点を置いています。
1サイクル学習率は、最小の学習率からスタートするという点で、少し逆のことをします。最小学習率と最大学習率は、あらかじめ定義された入力パラメータであり、学習率の変化経路や変化率は、エポック数や学習セッションの長さに影響されます。適応学習率でおこなったように、1サイクル学習率でテストランをおこない、テストレポートの1つを以下に示します。


上記の結果から、適切なバッチ正規化がおこなわれていないにもかかわらず、学習率を微調整するだけで、最終的にいくつかのショート取引を建てることができました。これは、生の銘柄価格を予測し(バッチ正規化なし)、適応学習率法をテストしたときと同じ方法でロングとショートの条件を正規化した場合です。これは、学習率の使用と調整に対するアプローチが、ニューラルネットワークのパフォーマンスにいかに敏感であるかを改めて示しています。
結論
まとめると、学習率は機械学習アルゴリズムにおいて非常に重要かつ繊細な要素です。多くの学習率手法は、従来のアプローチを改良するために開発されており、それぞれの革新に着目しながら、さまざまな実装バリエーションを検討してきました。これらの改善の試みは今も進行中であり、さらなる発展が期待されていますが、1サイクル学習率のようなシンプルな基本アプローチも見逃せません。いくつかのテスト結果から明らかなように、このような手法が大きな効果を発揮する可能性があります。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/15405
 エラー 146 (「トレードコンテキスト ビジー」) と、その対処方法
エラー 146 (「トレードコンテキスト ビジー」) と、その対処方法
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索