
Desenvolvendo um EA multimoeda (Parte 9): Coleta dos resultados de otimização de instâncias individuais da estratégia de trading
Introdução
Já fizemos em artigos anteriores várias coisas valiosas por si só. Temos uma ou mais estratégias de trading que podemos implementar no EA. Desenvolvemos um esquema de conexão de várias instâncias de estratégias de trading em um único EA. Adicionamos ferramentas para gerenciar o máximo rebaixamento permitido. Exploramos maneiras possíveis de automatizar a seleção de conjuntos de parâmetros das estratégias para seu melhor desempenho em grupo. Aprendemos a montar o EA a partir de grupos de instâncias de estratégias e até mesmo de grupos de diferentes grupos de instâncias de estratégias. No entanto, o valor dos resultados já obtidos aumentará significativamente se conseguirmos unificá-los.
Neste artigo, tentaremos esboçar um esquema geral do processo: as estratégias de trading individuais são inseridas, e o resultado é um EA finalizado, onde são usadas instâncias selecionadas e agrupadas das estratégias de trading originais, que oferecem os melhores resultados.
Após mapear um esboço, olharemos mais de perto para uma de suas partes, analisaremos o que será necessário para a implementação dessa etapa escolhida, e então nos dedicaremos diretamente à sua execução.
Principais Etapas
Vamos listar as principais etapas que enfrentaremos no processo de desenvolvimento do EA:
- Implementação da estratégia de trading. Desenvolvemos uma classe, herdeira de CVirtualStrategy, que implementa a lógica de trading para a abertura, acompanhamento e fechamento de posições e ordens virtuais. Foi isso que fizemos nas primeiras quatro partes do ciclo.
- Otimização da estratégia de trading. Selecionamos bons conjuntos de parâmetros de entrada para a estratégia de trading, que mostram resultados dignos de atenção. Se não forem encontrados, voltamos ao ponto 1.
Geralmente, é mais conveniente realizar a otimização em um único símbolo e período. Para a otimização genética, provavelmente precisaremos rodá-la várias vezes com diferentes critérios de otimização, incluindo algum critério personalizado. Usar a otimização por busca exaustiva só será viável em estratégias com um número muito pequeno de parâmetros. Mesmo em nossa estratégia modelo, a busca exaustiva é muito custosa. Portanto, daqui em diante, quando falarmos de otimização,
nos referiremos especificamente à otimização genética no testador de estratégias do MetaTrader 5. O processo de otimização não foi descrito em detalhes nos artigos, pois é padrão. - Clusterização dos conjuntos. Esta etapa não é obrigatória, mas permite economizar algum tempo na próxima etapa. Aqui, reduzimos significativamente o número de conjuntos de parâmetros das instâncias da estratégia de trading, entre os quais selecionaremos bons grupos. Mencionado na sexta parte.
- Seleção de grupos de conjuntos de parâmetros. Com base nos resultados da etapa anterior, realizamos uma otimização que seleciona
os conjuntos de parâmetros mais compatíveis das instâncias da estratégia de trading, obtendo os melhores resultados. Isto também é descrito principalmente na sexta parte e desenvolvido na sétima. - Seleção de grupos a partir de grupos de conjuntos de parâmetros. Agora agrupamos os resultados da etapa anterior seguindo o mesmo princípio de como agrupamos os conjuntos de parâmetros de instâncias individuais no modo de coleta de quadros da estratégia.
- Iteração de símbolos e períodos. Repetimos as etapas 2 a 5 para todos os símbolos e períodos desejados. Talvez, além do símbolo e do período, para algumas estratégias de trading, seja possível realizar uma otimização separada para determinadas classes de outros parâmetros de entrada.
- Outras estratégias. Se houver outras estratégias de trading em mente, repetimos as etapas 1 a 6 para cada uma delas.
- Montagem do EA. Todas as melhores combinações de grupos para diferentes estratégias de trading, símbolos, períodos e outros parâmetros são reunidas em um único EA final.
Cada etapa, após ser concluída, gera dados que precisam ser armazenados e utilizados nas próximas etapas. Até agora, temos usado soluções temporárias, convenientes o suficiente para uso uma ou duas vezes, mas não ideais para uso repetido.
Por exemplo, salvamos os resultados da otimização da segunda etapa em um arquivo Excel, adicionamos manualmente as colunas ausentes e, após salvar como arquivo CSV, usamos na terceira etapa.
Os resultados da terceira etapa foram usados diretamente na interface do testador de estratégias ou novamente salvos em arquivos Excel, onde realizamos algum processamento e usamos os resultados mais uma vez na interface do testador.
A quinta etapa não foi realizada de fato, apenas destacamos a possibilidade de sua execução. Portanto, não chegamos aos seus resultados.
Gostaríamos de implementar um esquema unificado de armazenamento e utilização para todos esses dados gerados.
Opções de implementação
Basicamente, o principal tipo de dado que precisamos armazenar e usar são os resultados de otimização de vários EAs. Como é sabido, todos os resultados de otimização são gravados pelo testador de estratégias em um arquivo de cache separado com a extensão *.opt, que pode ser reaberto no testador posteriormente ou até mesmo em outro terminal MetaTrader 5. O nome do arquivo é definido a partir de um hash, calculado com base no nome do EA otimizado e nos parâmetros de otimização. Isso permite não perder informações sobre as execuções já realizadas ao continuar a otimização após uma interrupção antecipada ou mudança no critério de otimização.
Portanto, uma das opções consideradas é o uso de arquivos de cache de otimização para armazenar resultados intermediários. Para trabalhar com eles, existe uma boa biblioteca de fxsaber, que nos permite acessar todas as informações salvas a partir de programas em MQL5.
No entanto, à medida que o número de otimizações realizadas aumenta, também aumentará o número de arquivos com seus resultados. Para não nos perdermos com esses arquivos, será necessário desenvolver um esquema adicional de organização para o armazenamento e manipulação desses arquivos de cache. Se a otimização for realizada em mais de um servidor, será preciso implementar a sincronização ou o armazenamento de todos os arquivos de cache em um único local. Além disso, para a próxima etapa, ainda precisaremos processar os resultados para exportá-los para o EA.
Assim, vamos aborar o armazenamento de todos os resultados em um banco de dados. À primeira vista, isso pode exigir um esforço significativo de tempo para implementação. No entanto, esse trabalho pode ser dividido em etapas menores, e seus resultados podem ser utilizados imediatamente, sem a necessidade de esperar pela implementação completa. Essa abordagem oferece uma grande liberdade na escolha dos meios mais convenientes para o processamento intermediário dos resultados armazenados. Por exemplo, parte do processamento pode ser realizada por consultas SQL simples, outra parte pode ser calculada em MQL5, e alguns cálculos podem ser feitos em programas escritos em Python ou R. Dessa forma, podemos testar diferentes métodos de processamento e escolher o mais adequado.
O MQL5 oferece funções embutidas para trabalhar com o banco de dados SQLite. Além disso, há bibliotecas de terceiros que permitem trabalhar com MySQL, por exemplo. Ainda não está claro se as funcionalidades do SQLite serão suficientes para nós, mas provavelmente essa base de dados será adequada para nossas necessidades. Se não for, então pensaremos na migração para outro SGBD.
Iniciando o projeto do banco de dados
Primeiro, precisamos identificar as entidades sobre as quais queremos armazenar informações. Certamente, uma dessas entidades é a execução do testador. Os campos dessa entidade incluirão os dados de entrada do teste e os resultados obtidos. Esses campos podem ser divididos em entidades separadas. A entidade de dados de entrada pode ser subdividida em entidades menores: EA, configurações de otimização e parâmetros de uma execução individual do EA. Mas vamos continuar seguindo o princípio da ação mínima. Inicialmente, uma tabela com os campos para os resultados da execução que usamos nos artigos anteriores, juntamente com um ou dois campos de texto para os parâmetros de entrada, será suficiente.
Essa tabela pode ser criada com a seguinte consulta SQL:
CREATE TABLE passes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
pass INT, -- pass index
inputs TEXT, -- pass input values
params TEXT, -- additional pass data
initial_deposit REAL, -- pass results...
withdrawal REAL,
profit REAL,
gross_profit REAL,
gross_loss REAL,
max_profittrade REAL,
max_losstrade REAL,
conprofitmax REAL,
conprofitmax_trades REAL,
max_conwins REAL,
max_conprofit_trades REAL,
conlossmax REAL,
conlossmax_trades REAL,
max_conlosses REAL,
max_conloss_trades REAL,
balancemin REAL,
balance_dd REAL,
balancedd_percent REAL,
balance_ddrel_percent REAL,
balance_dd_relative REAL,
equitymin REAL,
equity_dd REAL,
equitydd_percent REAL,
equity_ddrel_percent REAL,
equity_dd_relative REAL,
expected_payoff REAL,
profit_factor REAL,
recovery_factor REAL,
sharpe_ratio REAL,
min_marginlevel REAL,
deals REAL,
trades REAL,
profit_trades REAL,
loss_trades REAL,
short_trades REAL,
long_trades REAL,
profit_shorttrades REAL,
profit_longtrades REAL,
profittrades_avgcon REAL,
losstrades_avgcon REAL,
complex_criterion REAL,
custom_ontester REAL,
pass_date DATETIME DEFAULT (datetime('now') )
NOT NULL
);
Vamos criar uma classe auxiliar CDatabase, que conterá os métodos para trabalhar com o banco de dados. Ela pode ser estática, já que não precisaremos de muitas instâncias dela em um único programa, apenas uma será suficiente. Como estamos planejando armazenar todas as informações em um único banco de dados, o nome do arquivo do banco de dados pode ser definido diretamente no código-fonte.
Essa classe incluirá um campo s_db para armazenar o handle do banco de dados aberto. Seu valor será atribuído pelo método de abertura do banco de dados Open(). Se o banco de dados ainda não tiver sido criado no momento da abertura, ele será criado pelo método Create(). Após a abertura, poderemos executar consultas SQL individuais ao banco de dados usando o método Execute(), ou consultas SQL em massa dentro de uma única transação com o método ExecuteTransaction(). No final, vamos fechar o banco de dados utilizando o método Close().
Também podemos declarar um pequeno macro que permite usar um nome mais curto DB em vez do nome completo da classe CDatabase.
#define DB CDatabase //+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { static int s_db; // DB connection handle static string s_fileName; // DB file name public: static bool IsOpen(); // Is the DB open? static void Create(); // Create an empty DB static void Open(); // Opening DB static void Close(); // Closing DB // Execute one query to the DB static bool Execute(string &query); // Execute multiple DB queries in one transaction static bool ExecuteTransaction(string &queries[]); }; int CDatabase::s_db = INVALID_HANDLE; string CDatabase::s_fileName = "database.sqlite";
No método de criação do banco de dados, por enquanto, apenas criaremos um array com as consultas SQL para a criação das tabelas e as executaremos em uma única transação:
//+------------------------------------------------------------------+ //| Create an empty DB | //+------------------------------------------------------------------+ void CDatabase::Create() { // Array of DB creation requests string queries[] = { "DROP TABLE IF EXISTS passes;", "CREATE TABLE passes (" "id INTEGER PRIMARY KEY AUTOINCREMENT," "pass INT," "inputs TEXT," "params TEXT," "initial_deposit REAL," "withdrawal REAL," "profit REAL," "gross_profit REAL," "gross_loss REAL," ... "pass_date DATETIME DEFAULT (datetime('now') ) NOT NULL" ");" , }; // Execute all requests ExecuteTransaction(queries); }
No método de abertura do banco de dados, primeiro tentamos abrir o arquivo de banco de dados existente. Se ele não existir, então o criaremos e o abriremos, depois criaremos a estrutura do banco de dados chamando o método Create():
//+------------------------------------------------------------------+ //| Is the DB open? | //+------------------------------------------------------------------+ bool CDatabase::IsOpen() { return (s_db != INVALID_HANDLE); } ... //+------------------------------------------------------------------+ //| Open DB | //+------------------------------------------------------------------+ void CDatabase::Open() { // Try to open an existing DB file s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | DATABASE_OPEN_COMMON); // If the DB file is not found, try to create it when opening if(!IsOpen()) { s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | DATABASE_OPEN_CREATE | DATABASE_OPEN_COMMON); // Report an error in case of failure if(!IsOpen()) { PrintFormat(__FUNCTION__" | ERROR: %s open failed with code %d", s_fileName, GetLastError()); return; } // Create the database structure Create(); } PrintFormat(__FUNCTION__" | Database %s opened successfully", s_fileName); }
No método de execução de várias consultas ExecuteTransaction(), criamos uma transação e começamos a executar todas as consultas SQL em loop, uma após a outra. Se ocorrer um erro ao executar qualquer consulta, interrompemos o loop, relatamos o erro e cancelamos todas as consultas anteriores dentro dessa transação. Se nenhum erro ocorrer, confirmamos a transação:
//+------------------------------------------------------------------+ //| Execute multiple DB queries in one transaction | //+------------------------------------------------------------------+ bool CDatabase::ExecuteTransaction(string &queries[]) { // Open a transaction DatabaseTransactionBegin(s_db); bool res = true; // Send all execution requests FOREACH(queries, { res &= Execute(queries[i]); if(!res) break; }); // If an error occurred in any request, then if(!res) { // Report it PrintFormat(__FUNCTION__" | ERROR: Transaction failed, error code=%d", GetLastError()); // Cancel transaction DatabaseTransactionRollback(s_db); } else { // Otherwise, confirm transaction DatabaseTransactionCommit(s_db); PrintFormat(__FUNCTION__" | Transaction done successfully"); } return res; }
Salvamos as alterações feitas no arquivo Database.mqh na pasta atual.
Modificação do EA para coletar dados de otimização
Ao usar apenas agentes no computador local durante o processo de otimização, podemos realizar a gravação dos resultados no banco de dados tanto no manipulador de evento OnTester() quanto no manipulador de evento OnDeinit(). Ao usar agentes na rede local ou na MQL5 Cloud Network, conseguir salvar os resultados será muito difícil, se não impossível. Felizmente, o MQL5 oferece uma excelente maneira padrão de obter qualquer informação dos agentes de teste, independentemente de onde eles estejam, por meio da criação, envio e recebimento de frames de dados.
Esse mecanismo é descrito detalhadamente na documentação e no tutorial sobre algotrading. Para usá-lo, precisamos adicionar ao EA otimizado três manipuladores de eventos adicionais: OnTesterInit(), OnTesterPass() e OnTesterDeinit().
A otimização sempre é iniciada a partir de algum terminal MetaTrader 5, que chamaremos de principal a partir de agora. Ao iniciar a otimização de um EA com esses manipuladores a partir do terminal principal, antes de distribuir as instâncias do EA para os agentes de teste para realizar os ciclos de otimização com diferentes conjuntos de parâmetros, um novo gráfico é aberto no terminal principal, e uma nova instância do EA é lançada nesse gráfico.
Essa instância é iniciada em um modo especial: nela, os manipuladores padrão OnInit(), OnTick() e OnDeinit() não são executados, sendo executados apenas esses três novos manipuladores. Esse modo até tem um nome próprio - modo de coleta de frames de resultados de otimização. Se necessário, nas funções do EA, podemos verificar se o EA foi iniciado nesse modo usando uma chamada à função MQLInfoInteger():
// Check if the EA is running in data frame collection mode bool isFrameMode = MQLInfoInteger(MQL_FRAME_MODE);
Como os nomes sugerem, no modo de coleta de frames, o manipulador OnTesterInit() é executado uma vez antes do início do processo de otimização, OnTesterPass() é executado toda vez que um dos agentes de teste conclui um ciclo, e OnTesterDeinit() é executado uma vez após todos os ciclos de otimização planejados serem concluídos ou interrompidos.
É precisamente a instância do EA, iniciada no gráfico do terminal principal no modo de coleta de frames, que será responsável pela coleta dos frames de dados de todos os agentes de teste. "Frame de dados" é apenas um nome conveniente para descrever os processos de troca de informações entre os agentes de teste e o EA no terminal principal. Ele representa um conjunto de dados com um nome e um identificador numérico, que o agente de teste criou e enviou ao terminal principal após a conclusão de mais um ciclo de otimização.
Vale ressaltar que faz sentido criar frames de dados apenas nas instâncias do EA que operam no modo normal nos agentes de teste, enquanto a coleta e o processamento dos frames de dados são realizados apenas na instância do EA no terminal principal, funcionando no modo de coleta de frames. Portanto, vamos começar com o processo de criação dos frames.
A criação dos frames pode ser incluída no EA dentro do manipulador OnTester() ou em qualquer função ou método chamado a partir de OnTester(). Esse manipulador é acionado após a conclusão de um ciclo, e podemos obter nele os valores de todas as características estatísticas do ciclo concluído e, se necessário, calcular o valor de um critério personalizado para avaliar os resultados do ciclo.
Atualmente, temos nele um código que calcula o critério personalizado, mostrando o lucro previsto que poderia ser obtido sob a condição de um rebaixamento máximo de 10%:
//+------------------------------------------------------------------+ //| Test results | //+------------------------------------------------------------------+ double OnTester(void) { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = fixedBalance_ * 0.1 / balanceDrawdown; // Recalculate the profit double fittedProfit = profit * coeff; return fittedProfit; }
Vamos mover esse código do arquivo do EA SimpleVolumesExpertSingle.mq5 para um novo método da classe CVirtualAdvisor, e no EA deixaremos apenas o retorno do resultado da chamada desse método:
//+------------------------------------------------------------------+ //| Test results | //+------------------------------------------------------------------+ double OnTester(void) { return expert.Tester(); }
Ao mover, devemos considerar que dentro do método não podemos mais usar a variável fixedBalance_, pois em outro EA ela pode não existir. Mas podemos obter seu valor da classe estática CMoney através da chamada do método CMoney::FixedBalance(). Paralelamente, faremos outra alteração no cálculo do nosso critério personalizado. Após determinar o lucro previsto, o recalcularemos para uma unidade de tempo, como lucro anual, por exemplo. Isso nos permitirá comparar aproximadamente os resultados dos ciclos de diferentes durações.
Para isso, precisaremos registrar no EA a data de início do teste. Adicionaremos uma nova propriedade m_fromDate, onde gravaremos o tempo atual no construtor do objeto EA.
//+------------------------------------------------------------------+ //| Class of the EA handling virtual positions (orders) | //+------------------------------------------------------------------+ class CVirtualAdvisor : public CAdvisor { protected: ... datetime m_fromDate; public: ... virtual double Tester() override; // OnTester event handler ... }; //+------------------------------------------------------------------+ //| OnTester event handler | //+------------------------------------------------------------------+ double CVirtualAdvisor::Tester() { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = CMoney::FixedBalance() * 0.1 / balanceDrawdown; // Calculate the profit in annual terms long totalSeconds = TimeCurrent() - m_fromDate; double fittedProfit = profit * coeff * 365 * 24 * 3600 / totalSeconds ; // Perform data frame generation on the test agent CTesterHandler::Tester(fittedProfit, ~((CVirtualStrategy *) m_strategies[0])); return fittedProfit; }
É possível que, no futuro, façamos vários critérios personalizados de otimização, e então esse código será movido novamente para outro local. Mas, por enquanto, não nos desviaremos do extenso tema da pesquisa de diferentes funções de fitness para a otimização de EAs e deixaremos esse código como está.
Agora, vamos adicionar novos manipuladores ao arquivo do EA SimpleVolumesExpertSingle.mq5: OnTesterInit(), OnTesterPass() e OnTesterDeinit(). Como planejamos que a lógica dessas funções seja a mesma para todos os EAs, implementaremos inicialmente essas funções no nível do expert (objeto da classe CVirtualAdvisor).
Ao mesmo tempo, é importante levar em consideração que, quando o EA for iniciado no terminal principal no modo de coleta de frames, a função OnInit(), que cria a instância do expert, não será executada. Portanto, para evitar a necessidade de adicionar a criação/remoção da instância do expert nos novos manipuladores, faremos com que os métodos de tratamento desses eventos na classe CVirtualAdvisor sejam estáticos. Assim, no EA, precisaremos adicionar o seguinte código:
//+------------------------------------------------------------------+ //| Initialization before starting optimization | //+------------------------------------------------------------------+ int OnTesterInit(void) { return CVirtualAdvisor::TesterInit(); } //+------------------------------------------------------------------+ //| Actions after completing the next optimization pass | //+------------------------------------------------------------------+ void OnTesterPass() { CVirtualAdvisor::TesterPass(); } //+------------------------------------------------------------------+ //| Actions after optimization is complete | //+------------------------------------------------------------------+ void OnTesterDeinit(void) { CVirtualAdvisor::TesterDeinit(); }
Outra mudança que podemos fazer com vistas ao futuro é eliminar a chamada separada do método de adição de estratégias de trading ao expert CVirtualAdvisor::Add() após a criação do expert. Em vez disso, passaremos diretamente as informações sobre as estratégias para o construtor do expert, e ele chamará o método Add() internamente. Com isso, o método poderá ser removido da parte pública.
Com essa abordagem, a função de inicialização do EA OnInit() ficará assim:
int OnInit() { CMoney::FixedBalance(fixedBalance_); // Create an EA handling virtual positions expert = new CVirtualAdvisor( new CSimpleVolumesStrategy( symbol_, timeframe_, signalPeriod_, signalDeviation_, signaAddlDeviation_, openDistance_, stopLevel_, takeLevel_, ordersExpiration_, maxCountOfOrders_, 0), // One strategy instance magic_, "SimpleVolumesSingle", true); return(INIT_SUCCEEDED); }
Salvemos as alterações feitas no arquivo SimpleVolumesExpertSingle.mq5 na pasta atual.
Modificação da classe expert
Para não sobrecarregar o código da classe expert CVirtualAdvisor, vamos mover o código dos manipuladores de eventos TesterInit, TesterPass e OnTesterDeinit para uma classe separada CTesterHandler, onde criaremos métodos estáticos para lidar com cada um desses eventos. Assim, na classe CVirtualAdvisor, precisaremos adicionar um código semelhante ao do arquivo principal do EA:
//+------------------------------------------------------------------+ //| Class of the EA handling virtual positions (orders) | //+------------------------------------------------------------------+ class CVirtualAdvisor : public CAdvisor { ... public: ... static int TesterInit(); // OnTesterInit event handler static void TesterPass(); // OnTesterDeinit event handler static void TesterDeinit(); // OnTesterDeinit event handler }; //+------------------------------------------------------------------+ //| Initialization before starting optimization | //+------------------------------------------------------------------+ int CVirtualAdvisor::TesterInit() { return CTesterHandler::TesterInit(); } //+------------------------------------------------------------------+ //| Actions after completing the next optimization pass | //+------------------------------------------------------------------+ void CVirtualAdvisor::TesterPass() { CTesterHandler::TesterPass(); } //+------------------------------------------------------------------+ //| Actions after optimization is complete | //+------------------------------------------------------------------+ void CVirtualAdvisor::TesterDeinit() { CTesterHandler::TesterDeinit(); }
Faremos também algumas modificações no código do construtor do objeto expert. Com vistas ao futuro, moveremos todas as ações do construtor para um novo método de inicialização Init(). Isso nos permitirá adicionar vários construtores com diferentes conjuntos de parâmetros, que usarão o mesmo método de inicialização após uma pequena pré-processamento dos parâmetros.
Adicionaremos construtores cujo primeiro argumento será um objeto de estratégia ou um objeto de grupo de estratégias. Dessa forma, a adição das estratégias ao expert poderá ser feita diretamente no construtor. Nesse caso, não será mais necessário chamar o método Add() na função OnInit() do EA.
//+------------------------------------------------------------------+ //| Class of the EA handling virtual positions (orders) | //+------------------------------------------------------------------+ class CVirtualAdvisor : public CAdvisor { protected: ... datetime m_fromDate; public: CVirtualAdvisor(CVirtualStrategy *p_strategy, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false); // Constructor CVirtualAdvisor(CVirtualStrategyGroup *p_group, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false); // Constructor void CVirtualAdvisor::Init(CVirtualStrategyGroup *p_group, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false ); ... }; ... //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualAdvisor::CVirtualAdvisor(CVirtualStrategy *p_strategy, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false ) { CVirtualStrategy *strategies[] = {p_strategy}; Init(new CVirtualStrategyGroup(strategies), p_magic, p_name, p_useOnlyNewBar); }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualAdvisor::CVirtualAdvisor(CVirtualStrategyGroup *p_group, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false ) { Init(p_group, p_magic, p_name, p_useOnlyNewBar); }; //+------------------------------------------------------------------+ //| EA initialization method | //+------------------------------------------------------------------+ void CVirtualAdvisor::Init(CVirtualStrategyGroup *p_group, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false ) { // Initialize the receiver with a static receiver m_receiver = CVirtualReceiver::Instance(p_magic); // Initialize the interface with the static interface m_interface = CVirtualInterface::Instance(p_magic); m_lastSaveTime = 0; m_useOnlyNewBar = p_useOnlyNewBar; m_name = StringFormat("%s-%d%s.csv", (p_name != "" ? p_name : "Expert"), p_magic, (MQLInfoInteger(MQL_TESTER) ? ".test" : "") ); m_fromDate = TimeCurrent(); Add(p_group); delete p_group; };
Salvemos as alterações feitas no arquivo VirtualExpert.mqh na pasta atual.
Classe de tratamento de eventos de otimização
Agora, vamos nos concentrar diretamente na implementação das ações realizadas antes do início, após a conclusão de um ciclo, e após o término da otimização. Criaremos a classe CTesterHandler e adicionaremos métodos de tratamento para os eventos necessários, além de alguns métodos auxiliares colocados na parte privada da classe:
//+------------------------------------------------------------------+ //| Optimization event handling class | //+------------------------------------------------------------------+ class CTesterHandler { static string s_fileName; // File name for writing frame data static void ProcessFrames(); // Handle incoming frames static string GetFrameInputs(ulong pass); // Get pass inputs public: static int TesterInit(); // Handle the optimization start in the main terminal static void TesterDeinit(); // Handle the optimization completion in the main terminal static void TesterPass(); // Handle the completion of a pass on an agent in the main terminal static void Tester(const double OnTesterValue, const string params); // Handle completion of tester pass for agent }; string CTesterHandler::s_fileName = "data.bin"; // File name for writing frame data
Os manipuladores de eventos para o terminal principal serão bem simples, pois o código principal será movido para funções auxiliares:
//+------------------------------------------------------------------+ //| Handling the optimization start in the main terminal | //+------------------------------------------------------------------+ int CTesterHandler::TesterInit(void) { // Open / create a database DB::Open(); // If failed to open it, we do not start optimization if(!DB::IsOpen()) { return INIT_FAILED; } // Close a successfully opened database DB::Close(); return INIT_SUCCEEDED; } //+------------------------------------------------------------------+ //| Handling the optimization completion in the main terminal | //+------------------------------------------------------------------+ void CTesterHandler::TesterDeinit(void) { // Handle the latest data frames received from agents ProcessFrames(); // Close the chart with the EA running in frame collection mode ChartClose(); } //+--------------------------------------------------------------------+ //| Handling the completion of a pass on an agent in the main terminal | //+--------------------------------------------------------------------+ void CTesterHandler::TesterPass(void) { // Handle data frames received from the agent ProcessFrames(); }
As ações realizadas após a conclusão de um ciclo existirão em dois formatos:
- Para o agente de teste. Aqui, após o ciclo, serão coletadas as informações necessárias e criado o frame de dados para envio ao terminal principal. Essas ações serão reunidas no manipulador de evento Tester().
- Para o terminal principal. Aqui, poderão ser realizadas ações para receber os frames de dados dos agentes de teste, analisar as informações contidas nos frames e inseri-las no banco de dados. Essas ações serão reunidas no manipulador TesterPass().
As ações de criação do frame de dados para o agente de teste precisam ser executadas no EA dentro do manipulador OnTester. Como o código foi movido para o nível do objeto expert (classe CVirtualAdvisor), é lá que o método CTesterHandler::Tester() deve ser chamado. Os parâmetros que passaremos para esse método serão o valor recém-calculado do critério de otimização personalizado e uma string com a descrição dos parâmetros da estratégia utilizada no EA otimizado. Para criar essa string, utilizaremos o operador ~ (til) que já foi implementado para os objetos da classe CVirtualStrategy.
//+------------------------------------------------------------------+ //| OnTester event handler | //+------------------------------------------------------------------+ double CVirtualAdvisor::Tester() { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = CMoney::FixedBalance() * 0.1 / balanceDrawdown; // Calculate the profit in annual terms long totalSeconds = TimeCurrent() - m_fromDate; double fittedProfit = profit * coeff * 365 * 24 * 3600 / totalSeconds ; // Perform data frame generation on the test agent CTesterHandler::Tester(fittedProfit, ~((CVirtualStrategy *) m_strategies[0])); return fittedProfit; }
Dentro do método CTesterHandler::Tester(), iteraremos sobre todos os possíveis nomes das características estatísticas disponíveis, obteremos seus valores, os converteremos em strings e adicionaremos essas strings ao array stats. Por que precisamos converter características numéricas em strings? Isso é necessário para podermos enviar todas essas informações em um único frame, juntamente com a string que descreve os parâmetros da estratégia. Em um frame, só é possível enviar um array de valores de tipos simples (o que não inclui strings), ou então um arquivo criado previamente com quaisquer dados. Portanto, para evitar o envio de dois frames separados (um contendo números e outro contendo strings de um arquivo), converteremos todos os dados em strings, escreveremos em um arquivo, e enviaremos o conteúdo desse arquivo em um único frame:
//+------------------------------------------------------------------+ //| Handling completion of tester pass for agent | //+------------------------------------------------------------------+ void CTesterHandler::Tester(double custom, // Custom criteria string params // Description of EA parameters in the current pass ) { // Array of names of saved statistical characteristics of the pass ENUM_STATISTICS statNames[] = { STAT_INITIAL_DEPOSIT, STAT_WITHDRAWAL, STAT_PROFIT, ... }; // Array for values of statistical characteristics of the pass as strings string stats[]; ArrayResize(stats, ArraySize(statNames)); // Fill the array of values of statistical characteristics of the pass FOREACH(statNames, stats[i] = DoubleToString(TesterStatistics(statNames[i]), 2)); // Add the custom criterion value to it APPEND(stats, DoubleToString(custom, 2)); // Screen the quotes in the description of parameters just in case StringReplace(params, "'", "\\'"); // Open the file to write data for the frame int f = FileOpen(s_fileName, FILE_WRITE | FILE_TXT | FILE_ANSI); // Write statistical characteristics FOREACH(stats, FileWriteString(f, stats[i] + ",")); // Write a description of the EA parameters FileWriteString(f, StringFormat("'%s'", params)); // Close the file FileClose(f); // Create a frame with data from the recorded file and send it to the main terminal if(!FrameAdd("", 0, 0, s_fileName)) { PrintFormat(__FUNCTION__" | ERROR: Frame add error: %d", GetLastError()); } }
Finalmente, o método auxiliar que irá receber os frames de dados e salvar as informações deles no banco de dados. Nesse método, em um loop, processamos todos os frames recebidos que ainda não foram tratados até o momento. De cada frame, extraímos os dados como um array de caracteres e os convertemos em uma string. Em seguida, formamos uma string contendo os nomes e os valores dos parâmetros do ciclo com um índice específico. Esses valores serão usados para formar uma consulta SQL para inserir uma nova linha na tabela passes no nosso banco de dados. A consulta SQL criada é adicionada ao array de consultas SQL.
Após processar todos os frames de dados recebidos até o momento, executamos todas as consultas SQL do array dentro de uma única transação.
//+------------------------------------------------------------------+ //| Handling incoming frames | //+------------------------------------------------------------------+ void CTesterHandler::ProcessFrames(void) { // Open the database DB::Open(); // Variables for reading data from frames string name; // Frame name (not used) ulong pass; // Frame pass index long id; // Frame type ID (not used) double value; // Single frame value (not used) uchar data[]; // Frame data array as a character array string values; // Frame data as a string string inputs; // String with names and values of pass parameters string query; // A single SQL query string string queries[]; // SQL queries for adding records to the database // Go through frames and read data from them while(FrameNext(pass, name, id, value, data)) { // Convert the array of characters read from the frame into a string values = CharArrayToString(data); // Form a string with names and values of the pass parameters inputs = GetFrameInputs(pass); // Form an SQL query from the received data query = StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %s,\n'%s',\n'%s');", pass, values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); // Add it to the SQL query array APPEND(queries, query); } // Execute all requests DB::ExecuteTransaction(queries); // Close the database DB::Close(); }
O método auxiliar que forma a string com os nomes e valores das variáveis de entrada do ciclo, GetFrameInputs(), foi retirado do manual de algotrading e adaptado para nossas necessidades.
O código gerado será salvo no arquivo TesterHandler.mqh na pasta atual.
Verificação do funcionamento
Para verificar o funcionamento, executaremos a otimização com um pequeno número de parâmetros a serem testados em um período de tempo não muito extenso. Após a conclusão do processo de otimização, poderemos verificar os resultados no testador de estratégias e no banco de dados criado.
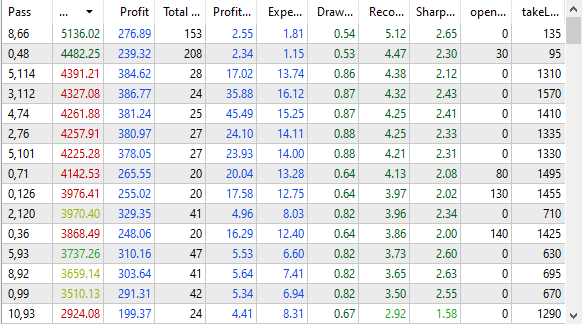
Figura 1. Resultados da otimização no testador de estratégias
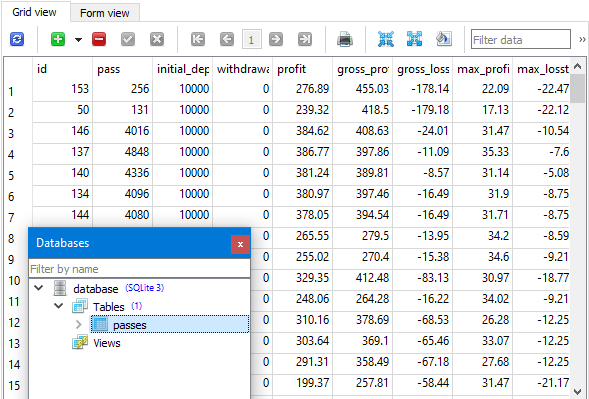
Figura 2. Resultados da otimização no banco de dados
Como pode ser observado, os resultados no banco de dados coincidem com os resultados no testador: com a mesma ordenação pelo critério personalizado, vemos a mesma sequência de valores de lucro (profit) em ambos os lugares. O melhor ciclo indica que, em um ano, o lucro esperado pode ultrapassar $5000 com um depósito inicial de $10000 e um rebaixamento máximo permitido de 10% do saldo inicial ($1000). No entanto, neste momento, não são tão importantes as características quantitativas dos resultados da otimização quanto esses resultados agora podem ser armazenados no banco de dados.
Considerações finais
Assim, demos mais um passo em direção ao objetivo estabelecido. Conseguimos armazenar os resultados das otimizações dos parâmetros do EA em nosso banco de dados. Com isso, estabelecemos a base para a futura implementação automatizada da segunda etapa de desenvolvimento do Expert Advisor.
Muitas questões ainda ficaram em aberto. Muitas coisas durante o trabalho neste artigo tiveram que ser deixadas para o futuro, pois sua implementação demandaria esforços consideráveis. Mas, com os resultados obtidos, podemos formular com mais clareza o direcionamento do desenvolvimento futuro do projeto.
O armazenamento realizado funciona até agora para um único processo de otimização, no sentido de que salvamos as informações dos ciclos, mas ainda é difícil agrupar as linhas relacionadas a um único processo de otimização. Para isso, será necessário fazer modificações na estrutura do banco de dados, que atualmente é bastante simples. No futuro, tentaremos automatizar a execução de vários processos de otimização consecutivos com a definição prévia de diferentes variantes dos parâmetros a serem otimizados.
Obrigado pela atenção e até a próxima!
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14680
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso