Статьи по машинному обучению в трейдинге
Создание торговых роботов на основе искусственного интеллекта: нативная интеграция с Python, операции с матрицами и векторами, библиотеки математики и статистики и многое другое.
Узнайте, как использовать машинное обучение в трейдинге. Нейроны, перцептроны, сверточные и рекуррентные сети, модели прогнозирования — начните с основ и продвигайтесь к созданию собственного ИИ. Вы научитесь обучать и применять нейронные сети для алгоритмической торговли на финансовых рынках.
Новая статья

Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
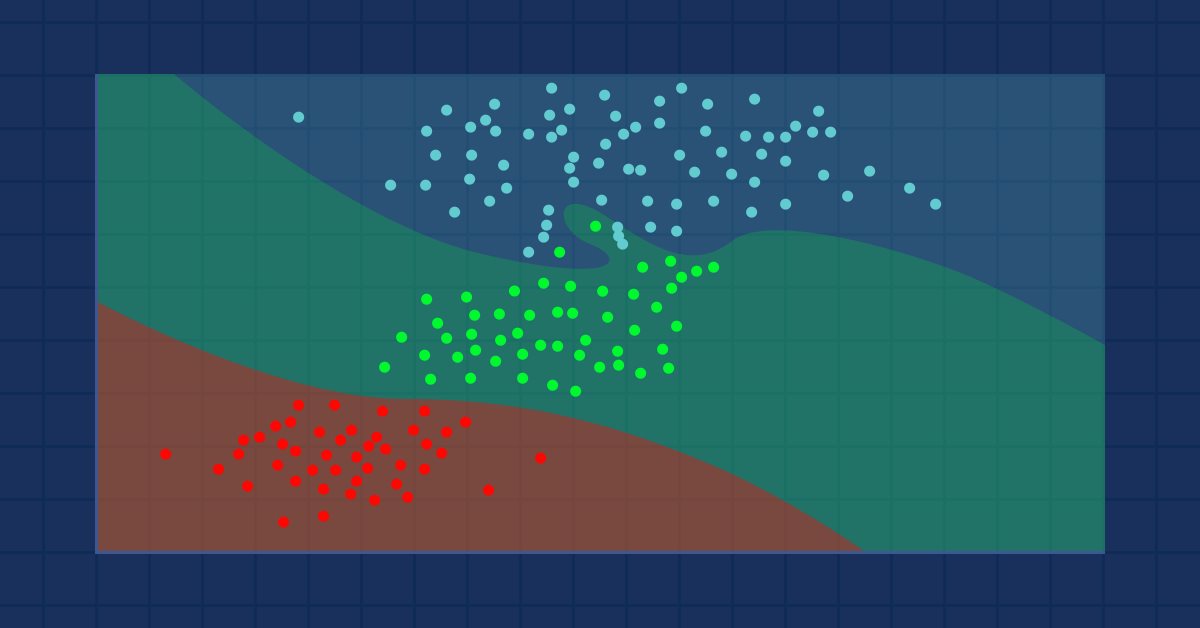
Машинное обучение и Data Science (Часть 9): Алгоритм k-ближайших соседей (KNN)
Это ленивый алгоритм, который не учится на обучающей выборке, а хранит все доступные наблюдения и классифицирует данные сразу же, как только получает новую выборку. Несмотря на простоту, этот метод используется во множестве реальных приложений.
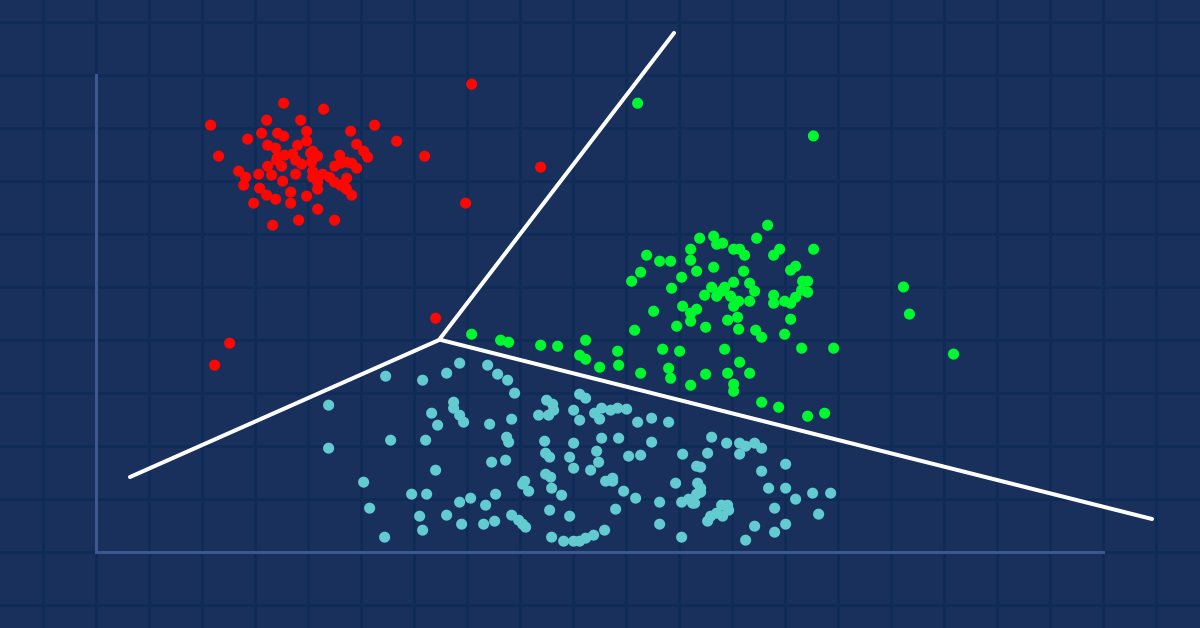
Машинное обучение и Data Science (Часть 8): Кластеризация методом k-средних в MQL5
Для всех, кто работает с данными, включая трейдеров, data mining может открыть совершенно новые возможности, ведь зачастую данные не такие простые, какими кажутся. Человеческому глазу сложно увидеть глубинные закономерности и отношения в наборе данных. Одно из решений — алгоритм К-средних. Давайте посмотрим, полезен ли он.

Популяционные алгоритмы оптимизации: Светлячковый алгоритм (Firefly Algorithm - FA)
Рассмотрим метод оптимизации "Поиск с помощью светлячкового алгоритма" (FA). Из аутсайдера путем модификации алгоритм превратился в настоящего лидера рейтинговой таблицы.

Популяционные алгоритмы оптимизации: Поиск косяком рыб (Fish School Search — FSS)
Поиск косяком рыб (FSS) — новый современный алгоритм оптимизации, вдохновленный поведением рыб в стае, большинство из которых, до 80%, плавают организовано в сообществе сородичей. Доказано, что объединения рыб играют важную роль в эффективности поиска пропитания и защиты от хищников.

Популяционные алгоритмы оптимизации: Алгоритм оптимизации с кукушкой (Cuckoo Optimization Algorithm — COA)
Следующий алгоритм, который рассмотрим — оптимизация поиском кукушки с использованием полётов Леви. Это один из новейших алгоритмов оптимизации и новый лидер в рейтинговой таблице.

Нейросети — это просто (Часть 35): Модуль внутреннего любопытства (Intrinsic Curiosity Module)
Продолжаем изучение алгоритмов обучения с подкреплением. Все ранее рассмотренные нами алгоритмы требовали создания политики вознаграждения таким образом, чтобы агент мог оценить каждое свое действие на каждом переходе из одного состояния системы в другое. Но такой подход довольно искусственный. На практике же между действием и вознаграждением существует некоторый временной лаг. В данной статье я предлагаю Вам познакомиться с алгоритмом обучения модели, способным работать с различными временными задержками от действия до вознаграждения.
Машинное обучение и Data Science (Часть 07): Полиномиальная регрессия
Полиномиальная регрессия — это гибкая модель, предназначенная для эффективного решения задач, с которыми не справляется модель линейной регрессии. В этой статье узнаем, как создавать полиномиальные модели на MQL5 и извлекать из них выгоду.

Популяционные алгоритмы оптимизации: Оптимизация Стаей Серых Волков (Grey Wolf Optimizer - GWO)
Рассмотрим один из новейших современных алгоритмов оптимизации "Стаи серых волков". Оригинальное поведение на тестовых функциях делает этот алгоритм одним из самых интересных среди рассмотренных ранее. Один из лидеров для применения в обучении нейронных сетей, гладких функций с многими переменными.
Нейросети — это просто (Часть 34): Полностью параметризированная квантильная функция
Продолжаем изучение алгоритмов распределенного Q-обучения. В предыдущих статьях мы рассмотрели алгоритмы распределенного и квантильного Q-обучения. В первом мы учили вероятности заданных диапазонов значений. Во втором учили диапазоны с заданной вероятностью. И в первом, и во втором алгоритме мы использовали априорные знания одного распределения и учили другое. В данной статье мы рассмотрим алгоритм, позволяющей модели учить оба распределения.

Популяционные алгоритмы оптимизации: Искуственная Пчелиная Колония (Artificial Bee Colony - ABC)
Сегодня изучим алгоритм искусственной пчелиной колонии. Дополним наши знания новыми принципами исследования функциональных пространств. В данной статье я расскажу о моей интерпретации классического варианта алгоритма.

Нейросети — это просто (Часть 33): Квантильная регрессия в распределенном Q-обучении
Продолжаем изучение распределенного Q-обучение. И сегодня мы посмотрим на данный подход с другой стороны. О возможности использования квантильной регрессии в решение вопрос прогнозирования ценовых движений.

Возможности Мастера MQL5, которые вам нужно знать (Часть 3): Энтропия Шеннона
Современный трейдер почти всегда находится в поиске новых идей. Он постоянно пробует новые стратегии, модифицирует их и отбрасывает те, что не оправдали себя. В этой серии статей я постараюсь доказать, что Мастер MQL5 является настоящей опорой трейдера.

Нейросети — это просто (Часть 32): Распределенное Q-обучение
В одной из статей данной серии мы с вами уже познакомились с методом Q-обучения. Данный метод усредняет вознаграждения за каждое действие. В 2017 году были представлены сразу 2 работы, в которых большего успеха добиваются при изучении функции распределения вознаграждения. Давайте рассмотрим возможность использования подобной технологии для решения наших задач.
Машинное обучение и Data Science. Нейросети (Часть 02): архитектура нейронных сетей с прямой связью
В предыдущей статье мы начали изучать нейросети с прямой связью, однако остались неразобранными некоторые моменты. Один из них — проектирование архитектуры. Поэтому в этой статье мы рассмотрим, как спроектировать гибкую нейронную сеть с учетом входных данных, количества скрытых слоев и узлов для каждой сети.

Популяционные алгоритмы оптимизации: Муравьиная Колония (Ant Colony Optimization - ACO)
В этот раз разберём алгоритм оптимизации Муравьиная Колония. Алгоритм очень интересный и неоднозначный. Попытка создания нового типа ACO.

Нейросети — это просто (Часть 31): Эволюционные алгоритмы
В предыдущей статье мы начали изучение безградиентных методов оптимизации. И познакомились с генетическим алгоритмом. Сегодня мы продолжаем начатую тему. И рассмотрим ещё один класс эволюционных алгоритмов.
Машинное обучение и Data Science — Нейросети (Часть 01): Разбираем нейронные сети с прямой связью
Многие любят, но немногие понимают все операции, лежащие в основе нейронных сетей. В этой статье я постараюсь простым языком объяснить все, что происходит за закрытыми дверями многоуровневого перцептрона с прямой связью Feed Forward.

Популяционные алгоритмы оптимизации: Рой частиц (PSO)
В данной статье рассмотрим популярный алгоритм "Рой Частиц" (PSO — particle swarm optimisation). Ранее мы обсудили такие важные характеристики алгоритмов оптимизации как сходимость, скорость сходимости, устойчивость, масштабируемость, разработали стенд для тестирования, рассмотрели простейший алгоритм на ГСЧ.

Нейросети — это просто (Часть 30): Генетические алгоритмы
Сегодня я хочу познакомить Вас с немного иным методом обучения. Можно сказать, что он заимствован из теории эволюции Дарвина. Наверное, он менее контролируем в сравнении с рассмотренными ранее методами. Но при этом позволяет обучать и недифференцируемые модели.

Нейросети — это просто (Часть 29): Алгоритм актор-критик с преимуществом (Advantage actor-critic)
В предыдущих статьях данной серии мы познакомились с 2-мя алгоритмами обучения с подкреплением. Каждый из них обладает своими достоинствами и недостатками. Как часто бывает в таких случаях, появляется идея совместить оба метода в некий алгоритм, который бы вобрал в себя лучшее из двух. И тем самым компенсировать недостатки каждого из них. О таком методе мы и поговорим в этой статье.

Нейросети — это просто (Часть 28): Policy gradient алгоритм
Продолжаем изучение методов обучение с подкреплением. В предыдущей статье мы познакомились с методом глубокого Q-обучения. В котором мы обучаем модель прогнозирования предстоящей награды в зависимости от совершаемого действия в конкретной ситуации. И далее совершаем действие в соответствии с нашей политикой и ожидаемой наградой. Но не всегда возможно аппроксимировать Q-функцию. Или её аппроксимация не даёт желаемого результата. В таких случаях используют методы аппроксимации не функции полезности, а на прямую политику (стратегию) действий. Именно к таким методам относится policy gradient.

Нейросети — это просто (Часть 27): Глубокое Q-обучение (DQN)
Продолжаем изучение обучения с подкреплением. И в этой статье мы познакомимся с методом глубокого Q-обучения. Использование данного метода позволило команде DeepMind создать модель, способную превзойти человека при игре в компьютерные игры Atari. Думаю, будет полезно оценить возможности подобной технологии для решения задач трейдинга.

Машинное обучение и Data Science (Часть 06): Градиентный спуск
Градиентный спуск играет важную роль в обучении нейронных сетей и различных алгоритмов машинного обучения — это быстрый и умный алгоритм. Однако несмотря на его впечатляющую работу, многие специалисты по данным все еще неправильно его понимают. Давайте в этой статье посмотрим, о чем идет речь.

Нейросети — это просто (Часть 26): Обучение с подкреплением
Продолжаем изучение методов машинного обучения. Данной статьей мы начинаем еще одну большую тему "Обучение с подкреплением". Данный подход позволяет моделям выстаивать определенные стратегии для решения поставленных задач. И мы рассчитываем, что это свойство обучения с подкреплением откроет перед нами новые горизонты построения торговых стратегий.
Нейросети — это просто (Часть 25): Практикум Transfer Learning
В последних двух статьях мы создали инструмент, позволяющий создавать и редактировать модели нейронных сетей. И теперь пришло время оценить потенциальные возможности использования технологии Transfer Learning на практических примерах.

Машинное обучение и Data Science (Часть 05): Деревья решений на примере погодных условий для игры в теннис
Деревья решений классифицируют данные, имитируя то, каким образом размышляют люди. В этой статье посмотрим, как строить деревья и использовать их для классификации и прогнозирования данных. Основная цель алгоритма деревьев решений состоит в том, чтобы разделить выборку на данные с "примесями" и на "чистые" или близкие к узлам.

Нейросети — это просто (Часть 24): Совершенствуем инструмент для Transfer Learning
В прошлой статье мы создали инструмент для создания и редактирования архитектуры нейронных сетей. И сегодня я хочу Вам предложить продолжить работу над этим инструментом. Чтобы сделать его более дружелюбным к пользователю. В чем-то это шаг в сторону от нашей темы. Но согласитесь, организация рабочего пространства играет не последнюю роль в достижении результата.

Машинное обучение и Data Science (Часть 04): Предсказание биржевого краха
В этой статье я попытаюсь использовать нашу логистическую модель, чтобы спрогнозировать крах фондового рынка на основе главнейших акций для экономики США: NETFLIX и APPLE. Мы проанализируем эти акции, будем использовать информацию о предыдущих падениях рынка 2019 и 2020 годов. Посмотрим, как наша модель будет работать в нынешних мрачных условиях.
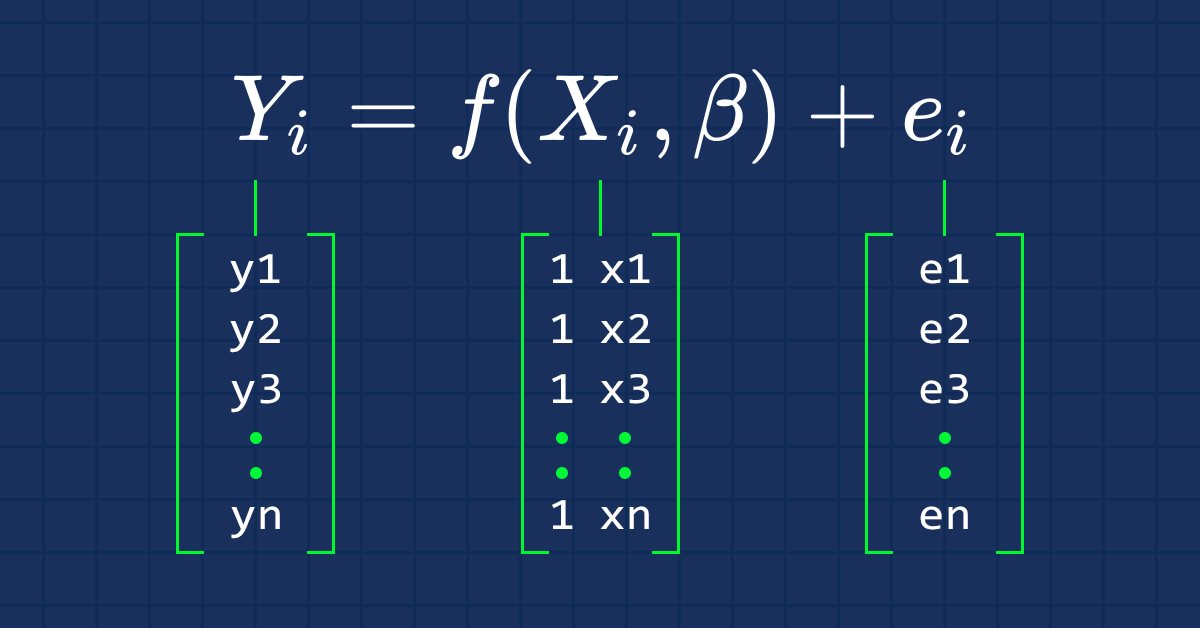
Машинное обучение и Data Science (Часть 03): Матричная регрессия
В этот раз мы будем создавать модели с помощью матриц — они дают большую гибкость и позволяют создавать мощные модели, которые могут обрабатывать не только пять независимых переменных, но и множество других, насколько позволяют пределы вычислительных возможностей компьютера. Статья будет очень интересной, это точно.

Нейросети — это просто (Часть 23): Создаём инструмент для Transfer Learning
В данной серии статей мы уже не один раз упоминали о Transfer Learning. Но дальше упоминаний пока дело не шло. Я предлагаю заполнить этот пробел и посмотреть поближе на Transfer Learning.
Нейросети — это просто (Часть 22): Обучение без учителя рекуррентных моделей
Мы продолжаем рассмотрение алгоритмов обучения без учителя. И сейчас я предлагаю обсудить особенности использования автоэнкодеров для обучения рекуррентных моделей.

Нейросети — это просто (Часть 21): Вариационные автоэнкодеры (VAE)
В прошлой статье мы познакомились с алгоритмом работы автоэнкодера. Как и любой другой алгоритм, он имеет свои достоинства и недостатки. В оригинальной реализации автоэнкодер выполняет задачу максимально разделить объекты из обучающей выборки. А о том, как бороться с некоторыми его недостатками мы поговорим в этой статье.

Эксперименты с нейросетями (Часть 2): Хитрая оптимизация нейросети
Нейросети наше все. Проверяем на практике, так ли это. MetaTrader 5 как самодостаточное средство для использования нейросетей в трейдинге. Простое объяснение.

Нейросети — это просто (Часть 20): Автоэнкодеры
Мы продолжаем изучение алгоритмов обучения без учителя. Возможно, у читателя может возникнуть вопрос об соответствии последних публикаций теме нейронных сетей. В новой статье мы возвращаемся к использованию нейронных сетей.
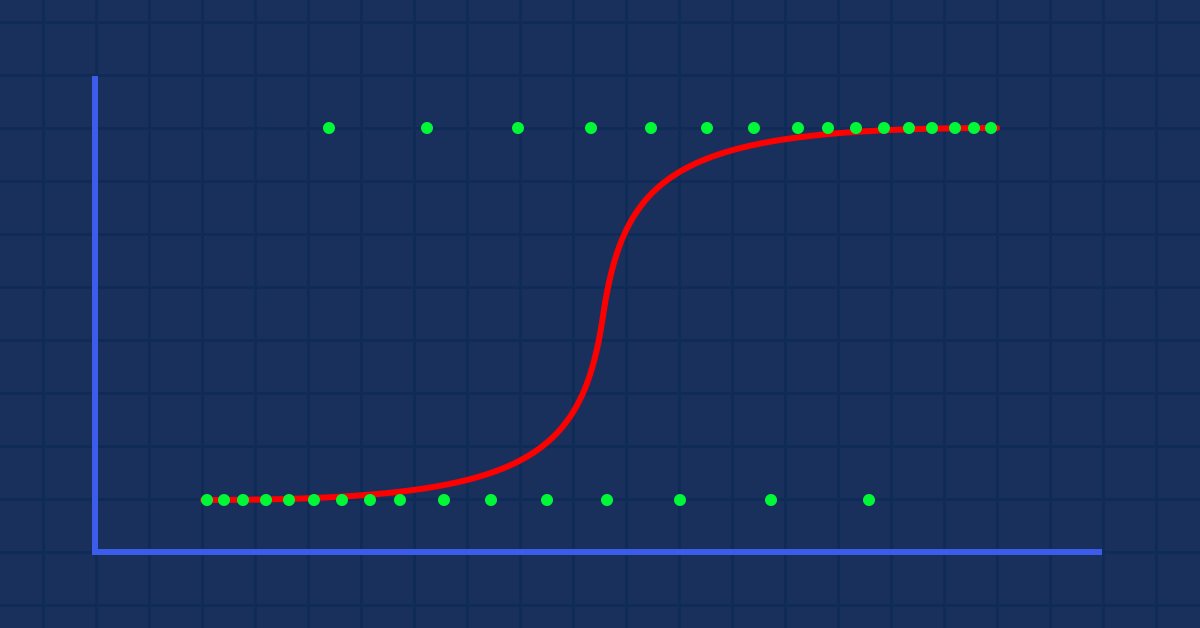
Машинное обучение и Data Science (Часть 02): Логистическая регрессия
Классификация данных — важнейшая вещь для алготрейдера и программиста. В этой статье мы рассмотрим в подробностях один из классификационных логистических алгоритмов, который может помочь нам определить «да» или «нет», рост или падение, покупки или продажи.

Нейросети — это просто (Часть 19): Ассоциативные правила средствами MQL5
Продолжаем тему поиска ассоциативных правил. В предыдущей статье мы рассмотрели теоретические аспекты данного типа задач. В этой статье я продемонстрирую реализацию метода FP-Growth средствами MQL5. А также мы протестируем нашу реализацию на реальных данных.

Нейросети — это просто (Часть 18): Ассоциативные правила
В продолжение данной серии статей предлагаю познакомиться ещё с одним типом задач из методов обучения без учителя — поиск ассоциативных правил. Данный тип задач впервые был применен в ритейле для анализа корзин покупателей. О возможностях использования подобных алгоритмов в рамках трейдинга мы и поговорим в этой статье.

Метамодели в машинном обучении и трейдинге: Оригинальный тайминг торговых приказов
Метамодели в машинном обучении: Автоматическое создание торговых систем практически без участия человека — Модель сама принимает решение как торговать и когда торговать.

Эксперименты с нейросетями (Часть 1): Вспоминая геометрию
Нейросети наше все. Проверяем на практике, так ли это. Экспериментируем и используем нестандартные подходы. Пишем прибыльную торговую систему. Простое объяснение.

Нейросети — это просто (Часть 17): Понижение размерности
Мы продолжаем рассмотрение моделей искусственного интеллекта. И, в частности, алгоритмов обучения без учителя. Мы уже познакомились с одним из алгоритмов кластеризации. А в этой статье я хочу поделиться с Вами вариантом решения задач понижения размерности.