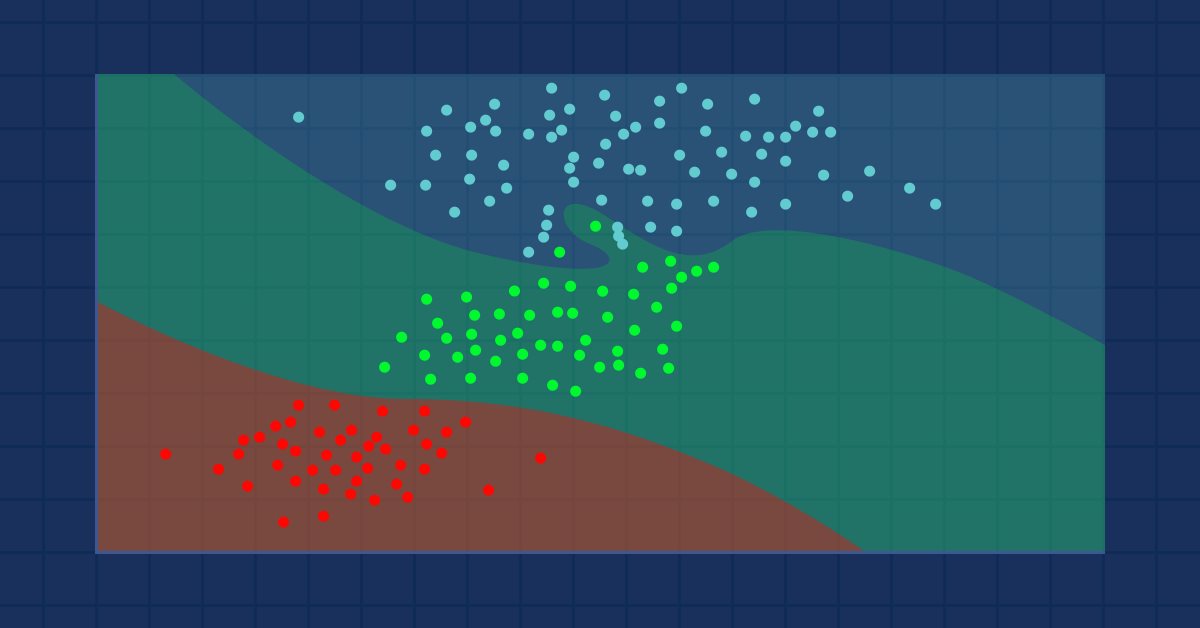
Машинное обучение и Data Science (Часть 9): Алгоритм k-ближайших соседей (KNN)

Птицы одного оперения собираются вместе (английская пословица) — идея, лежащая в основе алгоритма KNN.
Алгоритм K-ближайших соседей — это непараметрический классификатор обучения с учителем, который классифицирует данные или предсказывает принадлежность их к классам на основе близости. Алгоритм в основном используется для задач классификации, однако его можно использовать и для решения задачи регрессии. Он часто используется для классификации на основе предположения, что схожие точки в наборе данных могут находиться рядом. Метод k-ближайших соседей — один из самых простых алгоритмов в машинном обучении с учителем. В этой статье мы построим свой алгоритм для классификации.

Источник изображения: skicit-learn.org
Несколько замечаний:
- Часто используется как классификатор, но можно использовать и для регрессии.
- K-NN — непараметрический алгоритм, что означает, что он не делает никаких предположений относительно исходных данных.
- Его часто называют алгоритмом ленивого обучения, потому что он не учится на тренировочной выборке. Метод хранит все данные и использует их.
- Алгоритм KNN предполагает сходство между новыми данными и доступным набором данных. На основе этого он помещает новые данные в категорию с наиболее похожими данными.
Ка работает алгоритм KNN?
Прежде чем углубимся в написание кода, давайте разберемся, как работает алгоритм KNN:- Шаг 1: выбор числа k соседей
- Шаг 2: находим евклидово расстояние от точки до всех членов набора данных
- Шаг 3: берем K ближайших соседей по евклидову расстоянию
- Шаг 4: среди этих ближайших соседей считаем количество точек данных в каждой категории
- Шаг 5: относим новые данные к той категории, для которой количество соседей максимально
Шаг 1: выбор количества k соседей
Это простой шаг. Все, что нам нужно сделать, это выбрать число k, которое будем использовать в классе CKNNnearestNeighbours. Теперь возникает вопрос, как факторизовать k.
Факторизация K
K — это количество ближайших соседей, которых будем использовать для голосования относительно того, куда отнести данное значение/точку. Выбор маленького значения k приведет к большому количеству шума в классифицированных данных, что может привести к большему числу смещений, а очень большее значение k делает алгоритм значительно медленнее. 
Такое чаще всего происходит, когда для классификации используются 2 категории. Позже мы увидим, что можно сделать в подобных ситуациях, когда есть много категорий для k соседей.
Внутри библиотеки кластеризации создадим функцию для получения доступных классов из матрицы наборов данных и сохранения их в глобальном векторе классов m_classesVector
vector CKNNNearestNeighbors::ClassVector() { vector t_vectors = Matrix.Col(m_cols-1); //целевые переменные находятся в последнем столбце матрицы vector temp_t = t_vectors, v = {t_vectors[0]}; for (ulong i=0, count =1; i<m_rows; i++) //подсчет разных соседей { for (ulong j=0; j<m_rows; j++) { if (t_vectors[i] == temp_t[j] && temp_t[j] != -1000) { bool count_ready = false; for(ulong n=0;n<v.Size();n++) if (t_vectors[i] == v[n]) count_ready = true; if (!count_ready) { count++; v.Resize(count); v[count-1] = t_vectors[i]; temp_t[j] = -1000; //изменим, чтобы больше нельзя было считать } else break; //Print("t vectors vector ",t_vectors); } else continue; } } return(v); }
CKNNNearestNeighbors::CKNNNearestNeighbors(matrix<double> &Matrix_) { Matrix.Copy(Matrix_); k = (int)round(MathSqrt(Matrix.Rows())); k = k%2 ==0 ? k+1 : k; //проверим, является ли k нечетным m_rows = Matrix.Rows(); m_cols = Matrix.Cols(); m_classesVector = ClassVector(); Print("classes vector | Neighbors ",m_classesVector); }
Выводимая информация:
2022.10.31 05:40:33.825 TestScript classes vector | Neighbors [1,0]
Если вы обратили внимание, в конструкторе есть строка, которая гарантирует, что значение k является нечетным числом. Оно генерируется по умолчанию как квадратный корень из общего количества строк в наборе данных/количестве точек данных. Это тот случай, когда мы не заморачиваемся со значением K, то есть не настраиваем алгоритм. Есть и другой конструктор, который позволяет настраивать значение k, но после этого все-равно проверяется, является ли k нечетным. Значение в данном случае равно 3, для 9 строк: √9 = 3 (нечетное число).
CKNNNearestNeighbors:: CKNNNearestNeighbors(matrix<double> &Matrix_, uint k_) { k = k_; if (k %2 ==0) printf("K %d is an even number, It will be added by One so it becomes an odd Number %d",k,k=k+1); Matrix.Copy(Matrix_); m_rows = Matrix.Rows(); m_cols = Matrix.Cols(); m_classesVector = ClassVector(); Print("classes vector | Neighbors ",m_classesVector); }
Для начала при создании библиотеки будем использовать приведенный ниже набор данных. Далее посмотрим, как можно использовать торговую информацию и применить алгоритм в MetaTrader 5.

Вот как данные выглядят в MetaEditor:
matrix Matrix = {//weight(kg) | height(cm) | class {51, 167, 1}, //underweight {62, 182, 0}, //Normal {69, 176, 0}, //Normal {64, 173, 0}, //Normal {65, 172, 0}, //Normal {56, 174, 1}, //Underweight {58, 169, 0}, //Normal {57, 173, 0}, //Normal {55, 170, 0} //Normal };
Шаг 2: находим евклидово расстояние от точки до всех членов набора данных
Предполагая, что мы не знаем, как рассчитать индекс массы тела, нужно узнать, к какой категории относится человек с весом 57 кг и ростом 170 см — к категории недостаточного веса или нормального веса.
vector v = {57, 170}; nearest_neighbors = new CKNNNearestNeighbors(Matrix); //вызовем конструктор и передадим матрицу nearest_neighbors.KNNAlgorithm(v); //передаем новые точки в алгоритм
Первое, что делает функция KNNAlgorithm, — это находит евклидово расстояние между заданной точкой и всеми точками в наборе данных.
vector vector_2; vector euc_dist; euc_dist.Resize(m_rows); matrix temp_matrix = Matrix; temp_matrix.Resize(Matrix.Rows(),Matrix.Cols()-1); //удаляем последний столбец независимых переменных for (ulong i=0; i<m_rows; i++) { vector_2 = temp_matrix.Row(i); euc_dist[i] = Euclidean_distance(vector_,vector_2); }
Сама функция для вычисления евклидова расстояния выглядит так:
double CKNNNearestNeighbors:: Euclidean_distance(const vector &v1,const vector &v2) { double dist = 0; if (v1.Size() != v2.Size()) Print(__FUNCTION__," v1 and v2 not matching in size"); else { double c = 0; for (ulong i=0; i<v1.Size(); i++) c += MathPow(v1[i] - v2[i], 2); dist = MathSqrt(c); } return(dist); }
Для измерения расстояния между двумя точками в этой библиотеке я выбрал Евклидово расстояние, но это не единственный способ. Можно также использовать прямолинейное расстояние и Манхэттенское расстояние, о некоторых мы говорили в предыдущей статье.
Print("Euclidean distance vector\n",euc_dist); Output -----------> CS 0 19:29:09.057 TestScript Euclidean distance vector CS 0 19:29:09.057 TestScript [6.7082,13,13.41641,7.61577,8.24621,4.12311,1.41421,3,2]
Теперь давайте заполним последний столбец матрицы евклидовым расстоянием:
if (isdebug) { matrix dbgMatrix = Matrix; //временная матрица отладки dbgMatrix.Resize(dbgMatrix.Rows(),dbgMatrix.Cols()+1); dbgMatrix.Col(euc_dist,dbgMatrix.Cols()-1); Print("Matrix w Euclidean Distance\n",dbgMatrix); ZeroMemory(dbgMatrix); }
Выводимая информация:
CS 0 19:33:48.862 TestScript Matrix w Euclidean Distance CS 0 19:33:48.862 TestScript [[51,167,1,6.7082] CS 0 19:33:48.862 TestScript [62,182,0,13] CS 0 19:33:48.862 TestScript [69,176,0,13.41641] CS 0 19:33:48.862 TestScript [64,173,0,7.61577] CS 0 19:33:48.862 TestScript [65,172,0,8.24621] CS 0 19:33:48.862 TestScript [56,174,1,4.12311] CS 0 19:33:48.862 TestScript [58,169,0,1.41421] CS 0 19:33:48.862 TestScript [57,173,0,3] CS 0 19:33:48.862 TestScript [55,170,0,2]]
Чтобы лучше объяснить, покажу эти данные в виде изображения:
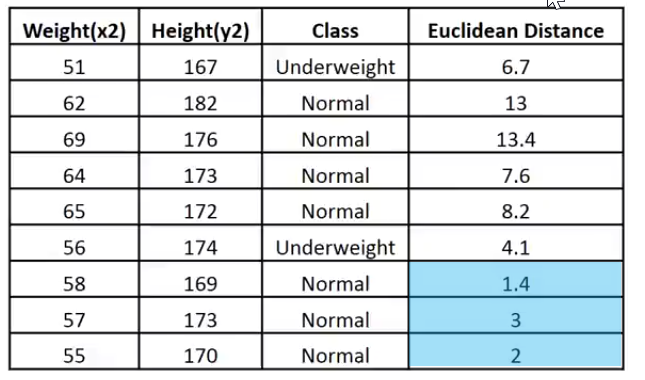
Учитывая, что значение k равно 3, все 3 ближайших соседа попадают в класс Normal, поэтому визуально мы понимаем, что данная точка попадает в категорию Normal. Теперь давайте напишем код для принятия этого решения.
Определять ближайших соседей и отслеживать их с помощью векторов будет очень сложно. Массивы — более гибкий вариант для разделения и изменения формы. Давайте воспользуемся массивами в нашем процессе.
int size = (int)m_target.Size(); double tarArr[]; ArrayResize(tarArr, size); double eucArray[]; ArrayResize(eucArray, size); for(ulong i=0; i<m_target.Size(); i++) //преобразуем векторы в массивы { tarArr[i] = m_target[i]; eucArray[i] = euc_dist[i]; } double track[], NN[]; ArrayCopy(track, tarArr); int max; for(int i=0; i<(int)m_target.Size(); i++) { if(ArraySize(track) > (int)k) { max = ArrayMaximum(eucArray); ArrayRemove(eucArray, max, 1); ArrayRemove(track, max, 1); } } ArrayCopy(NN, eucArray); Print("NN "); ArrayPrint(NN); Print("Track "); ArrayPrint(track);
В коде выше мы определяем ближайших соседей и сохраняем их в массиве NN, мы также отслеживаем их значения класса/какой класс они занимают в глобальном векторе целевых значений. Кроме того, мы удаляем максимальные значения в массиве, пока не останется массив меньших значений размером k (ближайшие соседи).
Результат будет таким:
CS 0 05:40:33.825 TestScript NN CS 0 05:40:33.825 TestScript 1.4 3.0 2.0 CS 0 05:40:33.825 TestScript Track CS 0 05:40:33.825 TestScript 0.0 0.0 0.0
Процесс голосования:
//--- процесс голосования vector votes(m_classesVector.Size()); for(ulong i=0; i<votes.Size(); i++) { int count = 0; for(ulong j=0; j<track.Size(); j++) { if(m_classesVector[i] == track[j]) count++; } votes[i] = (double)count; if(votes.Sum() == k) //все участники проголосовали break; } Print("votes ", votes);
Выводимая информация:
2022.10.31 05:40:33.825 TestScript votes [0,3]
Помните, что вектор голосов упорядочивает голоса на основе глобального вектора классов в наборе данных?
2022.10.31 06:43:30.095 TestScript classes vector | Neighbors [1,0]
Здесь из 3 соседей, которые были выбраны для голосования, 3 проголосовали за то, что данные принадлежат классу нулей (0), и ни один член не проголосовал за класс единиц (1).
Давайте посмотрим, что могло бы произойти, если бы для голосования было выбрано 5 соседей, т. е. значение K было бы равно 5.
CS 0 06:43:30.095 TestScript NN CS 0 06:43:30.095 TestScript 6.7 4.1 1.4 3.0 2.0 CS 0 06:43:30.095 TestScript Track CS 0 06:43:30.095 TestScript 1.0 1.0 0.0 0.0 0.0 CS 0 06:43:30.095 TestScript votes [2,3]
Теперь окончательное решение принять легко: класс с наибольшим количеством голосов выиграет. В этом случае вес относится к классу нормального, индекс которого 0.
if(isdebug) Print(vector_, " belongs to class ", (int)m_classesVector[votes.ArgMax()]);
Выводимая информация:
2022.10.31 06:43:30.095 TestScript [57,170] belongs to class 0
Теперь все отлично работает. Давайте изменим тип KNNAlgorithm с void на int, чтобы функция возвращала значение класса, к которому принадлежит данное значение. Это может пригодиться в реальной торговле, мы будем подавать новые значения, для которых будет ожидать немедленный вывод от алгоритма.
int KNNAlgorithm(vector &vector_);
Тестируем модель и определяем ее точность.
Наша модель готова. Теперь, как и с любым другим методом машинного обучения с учителем, нужно обучить ее и протестировать на новых для нее данных. Тестирование поможет понять, как наша модель работает на разных наборах данных.
float TrainTest(double train_size=0.7)
По умолчанию 70% набора данных будут использоваться для обучения, а остальные 30% — для тестирования.
Напишем код функции для разделения набора данных на этап обучения и этап тестирования:
//--- Разделим матрицу matrix default_Matrix = Matrix; int train = (int)MathCeil(m_rows*train_size), test = (int)MathFloor(m_rows*(1-train_size)); if (isdebug) printf("Train %d test %d",train,test); matrix TrainMatrix(train,m_cols), TestMatrix(test,m_cols); int train_index = 0, test_index =0; //--- for (ulong r=0; r<Matrix.Rows(); r++) { if ((int)r < train) { TrainMatrix.Row(Matrix.Row(r),train_index); train_index++; } else { TestMatrix.Row(Matrix.Row(r),test_index); test_index++; } } if (isdebug) Print("TrainMatrix\n",TrainMatrix,"\nTestMatrix\n",TestMatrix);
Выводимая информация:
CS 0 09:51:45.136 TestScript TrainMatrix CS 0 09:51:45.136 TestScript [[51,167,1] CS 0 09:51:45.136 TestScript [62,182,0] CS 0 09:51:45.136 TestScript [69,176,0] CS 0 09:51:45.136 TestScript [64,173,0] CS 0 09:51:45.136 TestScript [65,172,0] CS 0 09:51:45.136 TestScript [56,174,1] CS 0 09:51:45.136 TestScript [58,169,0]] CS 0 09:51:45.136 TestScript TestMatrix CS 0 09:51:45.136 TestScript [[57,173,0] CS 0 09:51:45.136 TestScript [55,170,0]]
Таким образом, обучение для алгоритма ближайших соседей очень простое. Можно подумать, что обучения и вовсе нет, потому что, как было сказано ранее, этот алгоритм сам по себе не пытается понять закономерности в наборе данных, в отличие от таких методов, как логистическая регрессия или SVM — он просто сохраняет данные во время обучения, эти данные затем будут использоваться для целей тестирования.
Обучение:
Matrix.Copy(TrainMatrix); //That's it ??? Тестирование:
//--- тестирование алгоритма vector TestPred(TestMatrix.Rows()); vector v_in = {}; for (ulong i=0; i<TestMatrix.Rows(); i++) { v_in = TestMatrix.Row(i); v_in.Resize(v_in.Size()-1); //Удаляем независимую переменную TestPred[i] = KNNAlgorithm(v_in); Print("v_in ",v_in," out ",TestPred[i]); }
Выводимая информация:
CS 0 09:51:45.136 TestScript v_in [57,173] out 0.0 CS 0 09:51:45.136 TestScript v_in [55,170] out 0.0
Все тесты были бы напрасными без измерения того, насколько точна наша модель на данном наборе данных.
Матрица путаницы
Об этом мы говорили ранее, во второй статье из этой серии.
matrix CKNNNearestNeighbors::ConfusionMatrix(vector &A,vector &P) { ulong size = m_classesVector.Size(); matrix mat_(size,size); if (A.Size() != P.Size()) Print("Cant create confusion matrix | A and P not having the same size "); else { int tn = 0,fn =0,fp =0, tp=0; for (ulong i = 0; i<A.Size(); i++) { if (A[i]== P[i] && P[i]==m_classesVector[0]) tp++; if (A[i]== P[i] && P[i]==m_classesVector[1]) tn++; if (P[i]==m_classesVector[0] && A[i]==m_classesVector[1]) fp++; if (P[i]==m_classesVector[1] && A[i]==m_classesVector[0]) fn++; } mat_[0][0] = tn; mat_[0][1] = fp; mat_[1][0] = fn; mat_[1][1] = tp; } return(mat_); }
Внутри TrainTest() в конце функции я добавил следующий код, чтобы завершить функцию и вернуть точность:
matrix cf_m = ConfusionMatrix(TargetPred,TestPred); vector diag = cf_m.Diag(); float acc = (float)(diag.Sum()/cf_m.Sum())*100; Print("Confusion Matrix\n",cf_m,"\nAccuracy ------> ",acc,"%"); return(acc);
Выводимая информация:
CS 0 10:34:26.681 TestScript Confusion Matrix CS 0 10:34:26.681 TestScript [[2,0] CS 0 10:34:26.681 TestScript [0,0]] CS 0 10:34:26.681 TestScript Accuracy ------> 100.0%
Разумеется, точность должна была быть стопроцентной, модель давала для проверки только две точки данных, при этом все они относились к классу нуля (нормальному классу), что верно.
На данный момент у нас есть полнофункциональная библиотека K-Nearest Neighbours. Давайте посмотрим, как можно использовать ее для прогнозирования цен на различные форекс-символы и акции.
Подготовка набора данных
Помните, что это обучение с учителем, то есть должно быть вмешательство человека для создания данных и присвоения им меток, чтобы модели знали, каковы их цели, чтобы они могли понять взаимосвязь между независимыми и целевыми переменными.
Независимыми переменными являются показатели индикатора ATR и Индикатор объемов. Целевая переменная будет равна 1, если рынок пошел вверх, и 0, если рынок пошел вниз. Это будет сигналом на покупку и сигналом на продажу соответственно при тестировании и использовании модели для торговли.
int OnInit() { //--- подготовка набора данных atr_handle = iATR(Symbol(),timeframe,period); volume_handle = iVolumes(Symbol(),timeframe,applied_vol); CopyBuffer(atr_handle,0,1,bars,atr_buffer); CopyBuffer(volume_handle,0,1,bars,volume_buffer); Matrix.Col(atr_buffer,0); //Независимая переменная 1 Matrix.Col(volume_buffer,1); //Независимая переменная 2 //--- целевые переменные vector Target_vector(bars); MqlRates rates[]; ArraySetAsSeries(rates,true); CopyRates(Symbol(),PERIOD_D1,1,bars,rates); for (ulong i=0; i<Target_vector.Size(); i++) //устанавливаем метки { if (rates[i].close > rates[i].open) Target_vector[i] = 1; //bullish else Target_vector[i] = 0; } Matrix.Col(Target_vector,2); //---
Логика поиска независимых переменных такая: если свеча закрылась выше уровня закрытия, то есть это бычья свеча, целевая переменная для независимых переменных равна 1, в противоположном случае — 0.
Но когда мы работает на дневной свече, внутри этих 24 часов одной свечи может происходить множество ценовых движений. Эта логика не подойдет для создания скальпера или робота, торгующего на более коротких периодах. Есть еще один небольшой недостаток в логике: если цена закрытия выше цены открытия, мы обозначаем целевую переменную как 1, в противном случае мы обозначаем 0, но часто бывают ситуации, когда цена открытия равна цене закрытия. Но такая ситуация редко случается на старших таймфреймах, так что это мой способ избежать ошибок.
Информация не является финансовым или торговым советом.
Давайте выведем последние 10 значений баров, 10 строк нашей матрицы набора данных:
CS 0 12:20:10.449 NearestNeighorsEA (EURUSD,D1) ATR,Volumes,Class Matrix CS 0 12:20:10.449 NearestNeighorsEA (EURUSD,D1) [[0.01139285714285716,12295,0] CS 0 12:20:10.449 NearestNeighorsEA (EURUSD,D1) [0.01146428571428573,12055,0] CS 0 12:20:10.449 NearestNeighorsEA (EURUSD,D1) [0.01122142857142859,10937,0] CS 0 12:20:10.449 NearestNeighorsEA (EURUSD,D1) [0.01130000000000002,13136,0] CS 0 12:20:10.449 NearestNeighorsEA (EURUSD,D1) [0.01130000000000002,15305,0] CS 0 12:20:10.449 NearestNeighorsEA (EURUSD,D1) [0.01097857142857144,13762,1] CS 0 12:20:10.449 NearestNeighorsEA (EURUSD,D1) [0.0109357142857143,12545,1] CS 0 12:20:10.449 NearestNeighorsEA (EURUSD,D1) [0.01116428571428572,18806,1] CS 0 12:20:10.449 NearestNeighorsEA (EURUSD,D1) [0.01188571428571429,19595,1] CS 0 12:20:10.449 NearestNeighorsEA (EURUSD,D1) [0.01137142857142859,15128,1]]
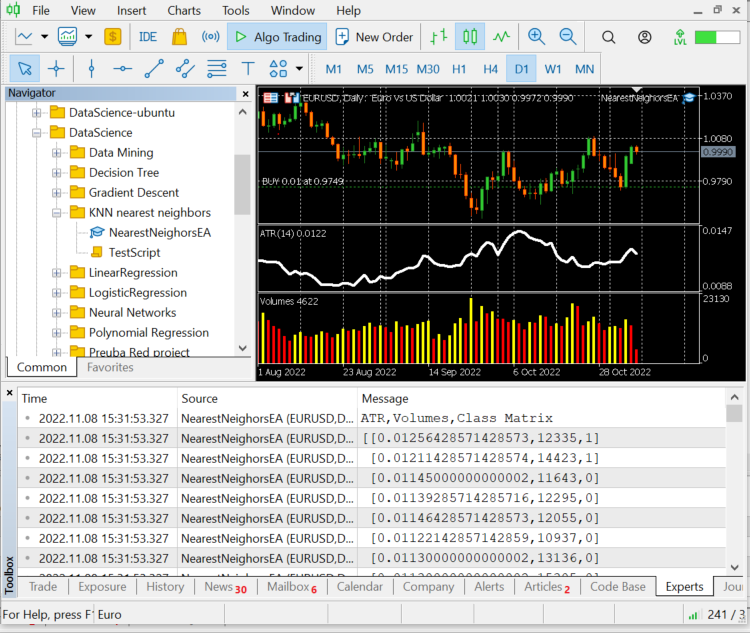
Данные сгруппированы по соответствующим свечам и индикаторам, теперь передадим их алгоритму.
nearest_neigbors = new CKNNNearestNeighbors(Matrix,k);
nearest_neigbors.TrainTest();
Выводимая информация:
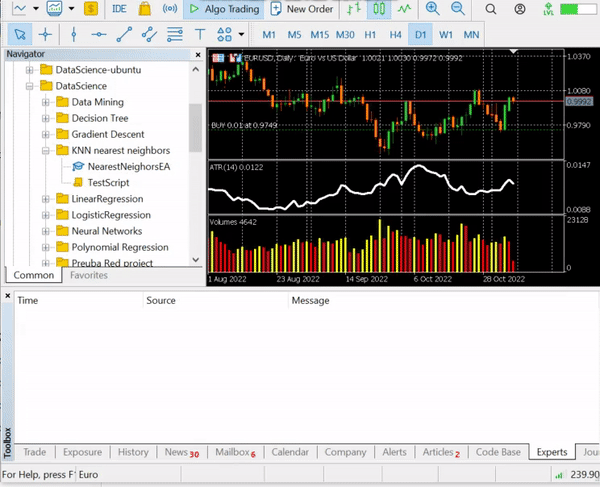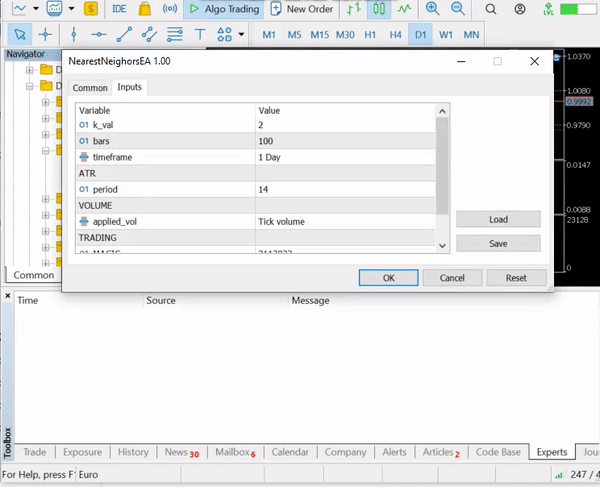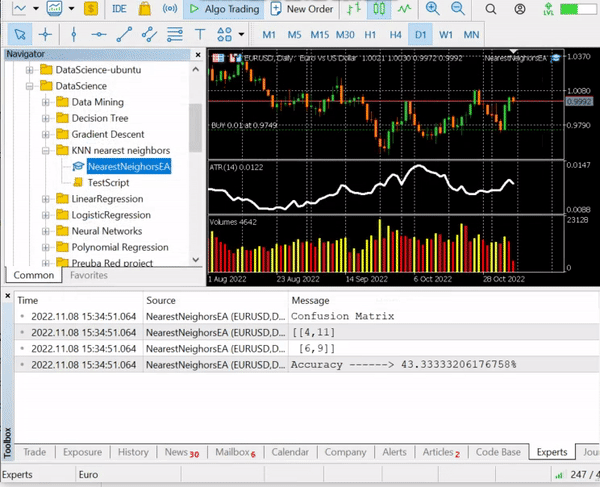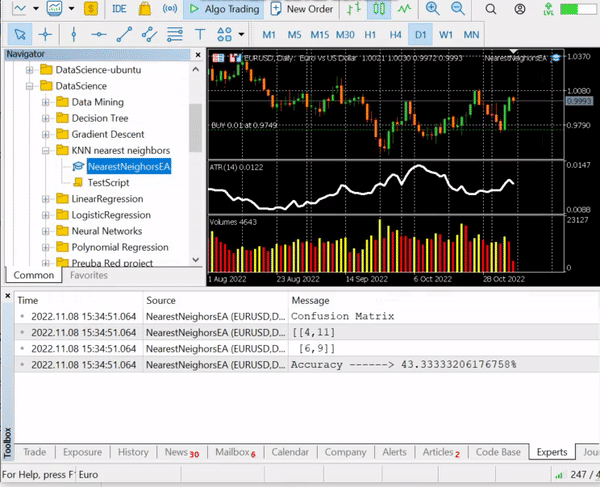
Получилась точность около 43,33%, что неплохо, учитывая, что мы не искали оптимальное значение k. Пройдемся в цикле по разным значениям k и выберем то, которое обеспечивает лучшую точность.
for(uint i=0; i<bars; i++) { printf("<<< k %d >>>",i); nearest_neigbors = new CKNNNearestNeighbors(Matrix,i); nearest_neigbors.TrainTest(); delete(nearest_neigbors); }
Выводимая информация:
...... CS 0 16:22:28.013 NearestNeighorsEA (EURUSD,D1) <<< k 24 >>> CS 0 16:22:28.013 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 46.66666793823242% CS 0 16:22:28.014 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 46.66666793823242% CS 0 16:22:28.014 NearestNeighorsEA (EURUSD,D1) <<< k 26 >>> CS 0 16:22:28.014 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 40.0% CS 0 16:22:28.014 NearestNeighorsEA (EURUSD,D1) <<< k 27 >>> CS 0 16:22:28.015 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 40.0% CS 0 16:22:28.015 NearestNeighorsEA (EURUSD,D1) <<< k 28 >>> CS 0 16:22:28.015 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 56.66666793823242% CS 0 16:22:28.016 NearestNeighorsEA (EURUSD,D1) <<< k 29 >>> CS 0 16:22:28.016 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 56.66666793823242% CS 0 16:22:28.016 NearestNeighorsEA (EURUSD,D1) <<< k 30 >>> ..... ..... CS 0 16:22:28.017 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 60.000003814697266% CS 0 16:22:28.017 NearestNeighorsEA (EURUSD,D1) <<< k 31 >>> CS 0 16:22:28.017 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 60.000003814697266% CS 0 16:22:28.017 NearestNeighorsEA (EURUSD,D1) <<< k 32 >>> CS 0 16:22:28.018 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 56.66666793823242% CS 0 16:22:28.018 NearestNeighorsEA (EURUSD,D1) <<< k 33 >>> CS 0 16:22:28.018 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 56.66666793823242% CS 0 16:22:28.018 NearestNeighorsEA (EURUSD,D1) <<< k 34 >>> CS 0 16:22:28.019 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 50.0% CS 0 16:22:28.019 NearestNeighorsEA (EURUSD,D1) <<< k 35 >>> CS 0 16:22:28.019 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 50.0% CS 0 16:22:28.019 NearestNeighorsEA (EURUSD,D1) <<< k 36 >>> CS 0 16:22:28.020 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 53.333335876464844% CS 0 16:22:28.020 NearestNeighorsEA (EURUSD,D1) <<< k 37 >>> CS 0 16:22:28.020 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 53.333335876464844% CS 0 16:22:28.020 NearestNeighorsEA (EURUSD,D1) <<< k 38 >>> CS 0 16:22:28.021 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 56.66666793823242% CS 0 16:22:28.021 NearestNeighorsEA (EURUSD,D1) <<< k 39 >>> CS 0 16:22:28.021 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 56.66666793823242% CS 0 16:22:28.021 NearestNeighorsEA (EURUSD,D1) <<< k 40 >>> CS 0 16:22:28.022 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 56.66666793823242% CS 0 16:22:28.022 NearestNeighorsEA (EURUSD,D1) <<< k 41 >>> ..... .... CS 0 16:22:28.023 NearestNeighorsEA (EURUSD,D1) <<< k 42 >>> CS 0 16:22:28.023 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 63.33333206176758% CS 0 16:22:28.023 NearestNeighorsEA (EURUSD,D1) <<< k 43 >>> CS 0 16:22:28.024 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 63.33333206176758% CS 0 16:22:28.024 NearestNeighorsEA (EURUSD,D1) <<< k 44 >>> CS 0 16:22:28.024 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 66.66667175292969% CS 0 16:22:28.024 NearestNeighorsEA (EURUSD,D1) <<< k 45 >>> CS 0 16:22:28.025 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 66.66667175292969% CS 0 16:22:28.025 NearestNeighorsEA (EURUSD,D1) <<< k 46 >>> CS 0 16:22:28.025 NearestNeighorsEA (EURUSD,D1) Accuracy ------> 56.66666793823242% CS 0 16:22:28.025 NearestNeighorsEA (EURUSD,D1) <<< k 47 >>> .... ....
Это не лучший метод для определения значения k. Для нахождения оптимальных значений можно использовать метод перекрестной проверки. Итак, у нас пик производительности был при значении k в районе сорока. Теперь давайте попробуем этот алгоритм в торговой среде.
void OnTick() { vector x_vars(2); //вектор для хранения значений atr и volumes double atr_val[], volume_val[]; CopyBuffer(atr_handle,0,0,1,atr_val); CopyBuffer(volume_handle,0,0,1,volume_val); x_vars[0] = atr_val[0]; x_vars[1] = volume_val[0]; //--- int signal = 0; double volume = SymbolInfoDouble(Symbol(),SYMBOL_VOLUME_MIN); MqlTick ticks; SymbolInfoTick(Symbol(),ticks); double ask = ticks.ask, bid = ticks.bid; if (isNewBar() == true) //мы на новой свече { signal = nearest_neigbors.KNNAlgorithm(x_vars); //вызов алгоритма if (signal == 1) { if (!CheckPosionType(POSITION_TYPE_BUY)) { m_trade.Buy(volume,Symbol(),ask,0,0); if (ClosePosType(POSITION_TYPE_SELL)) printf("Failed to close %s Err = %d",EnumToString(POSITION_TYPE_SELL),GetLastError()); } } else { if (!CheckPosionType(POSITION_TYPE_SELL)) { m_trade.Sell(volume,Symbol(),bid,0,0); if (ClosePosType(POSITION_TYPE_BUY)) printf("Failed to close %s Err = %d",EnumToString(POSITION_TYPE_BUY),GetLastError()); } } } }
Советник научился открывать сделки и закрывать их, теперь проверим его в тестере стратегий. Но для начала взглянем на вызов всего алгоритма в эксперте:
#include "KNN_nearest_neighbors.mqh"; CKNNNearestNeighbors *nearest_neigbors; matrix Matrix; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // сбор данных в матрицу проигнорирован nearest_neigbors = new CKNNNearestNeighbors(Matrix,_k); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- delete(nearest_neigbors); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { vector x_vars(2); //вектор для хранения значений atr и volumes //добавление живых значений индикатора с рынка проигнорировано //--- int signal = 0; if (isNewBar() == true) //мы на новой свече { signal = nearest_neigbors.KNNAlgorithm(x_vars); //торговые действия } }
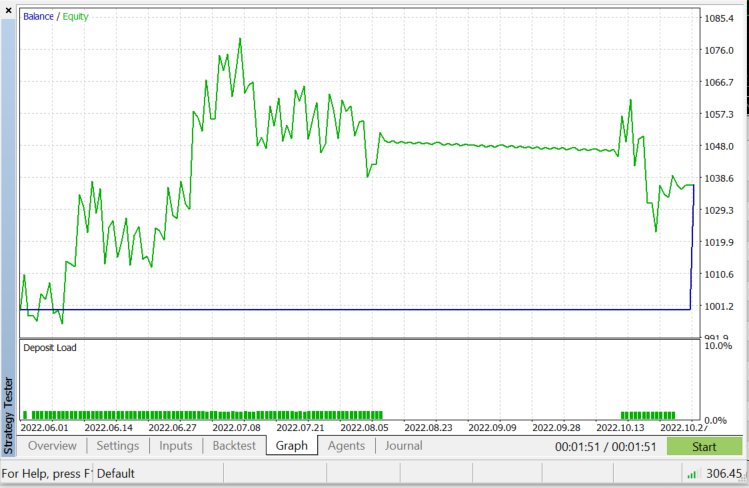
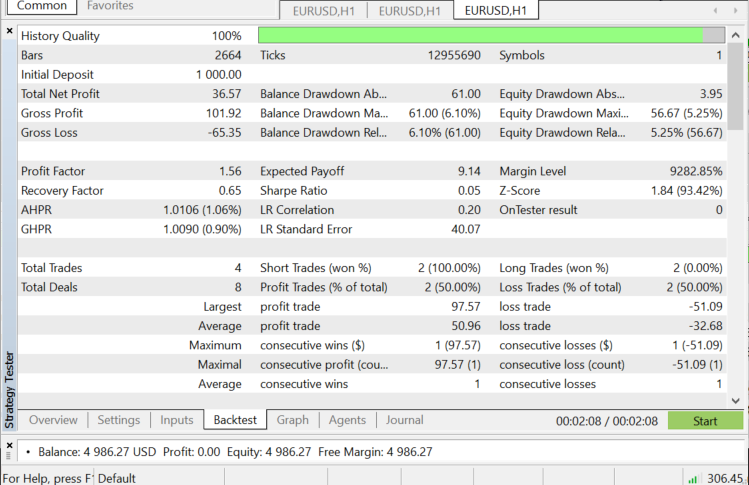
Тестирование в тестере стратегий на паре EURUSD с 01.06.2022 по 03.11.2022 (в режиме "Все тики"):
Когда использовать алгоритм KNN?
Очень важно знать, где использовать этот алгоритм, потому что не каждую проблему можно решить с его помощью, впрочем, как и в случае любой другой техники машинного обучения.
- Когда набор данных размечен
- Когда в наборе данных нет шума
- Когда набор данных небольшой (это также нужно для производительности)
Преимущества:
- Очень легко понять и реализовать
- Основан на локальных точках данных, что хорошо для наборов данных, включающих множество групп с локальными кластерами.
Недостатки
Каждый раз для предсказания используются все имеющиеся обучающие данные, это означает, что все данные должны быть сохранены и готовы к использованию каждый раз, когда появляется новая точка для классификации.
Заключительные мысли
Как было сказано ранее, этот алгоритм является хорошим классификатором, но не для сложного набора данных. Поэтому я думаю, что он будет лучше предсказывать акции и индексы, но и вы поэкспериментируйте с инструментами. При тестировании алгоритма в советнике появились проблемы с производительностью в тестере стратегий. Я выбрал 50 баров, советник работает на новом баре. При этом тестер застревает на каждой свече примерно на 20-30 секунд — это нужно, чтобы алгоритм запустил весь процесс. Это проблема тестера, а при реальной торговле все происходит быстрее. Всегда есть место для улучшения, особенно в следующих строках кода. Я не смог получить значении индикатора в функции Init, поэтому пришлось получать их и использовать для прогнозирования рынка в одном месте.
if (isNewBar() == true) //new candlestick { if (MQLInfoInteger(MQL_TESTER) || MQLInfoInteger(MQL_OPTIMIZATION)) { gather_data(); nearest_neigbors = new CKNNNearestNeighbors(Matrix,_k); signal = nearest_neigbors.KNNAlgorithm(x_vars); delete(nearest_neigbors); }
Спасибо за внимание!
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/11678
 Горная карта, или График "Айсберг"
Горная карта, или График "Айсберг"
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования