Статьи по машинному обучению в трейдинге
Создание торговых роботов на основе искусственного интеллекта: нативная интеграция с Python, операции с матрицами и векторами, библиотеки математики и статистики и многое другое.
Узнайте, как использовать машинное обучение в трейдинге. Нейроны, перцептроны, сверточные и рекуррентные сети, модели прогнозирования — начните с основ и продвигайтесь к созданию собственного ИИ. Вы научитесь обучать и применять нейронные сети для алгоритмической торговли на финансовых рынках.
Новая статья

Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь

Нейросети — это просто (Часть 66): Проблематика исследования в офлайн обучении
Обучение моделей в офлайн режиме осуществляется на данных ранее подготовленной обучающей выборки. Это дает нам ряд преимуществ, но при этом информация об окружающей среде сильно сжимается до размеров обучающей выборки. Что, в свою очередь, ограничивает возможности исследования. В данной статье хочу предложить познакомиться с методом, позволяющем наполнить обучающую выборку максимально разнообразными данными.

Python, ONNX и MetaTrader 5: Создаем модель RandomForest с предварительной обработкой данных RobustScaler и PolynomialFeatures
В этой статье мы создадим модель случайного леса на языке Python, обучим модель и сохраним ее в виде конвейера ONNX с препроцессингом данных. Модель мы далее используем в терминале MetaTrader 5.

Теория категорий в MQL5 (Часть 15): Функторы с графами
Статья продолжает серию о реализации теории категорий в MQL5, рассматривая функторы как мост между графами и множеством. Мы вновь обратимся к календарным данным и, несмотря на их ограничения в использовании тестера стратегий, обоснуем использование функторов в прогнозировании волатильности с помощью корреляции.

Популяционные алгоритмы оптимизации: Дифференциальная эволюция (Differential Evolution, DE)
В этой статье поговорим об алгоритме, который демонстрирует самые противоречивые результаты из всех рассмотренных ранее, алгоритм дифференциальной эволюции (DE).

Нейросети — это просто (Часть 65): Дистанционно-взвешенное обучение с учителем (DWSL)
В данной статье я предлагаю Вам познакомиться с интересным алгоритмом, который построен на стыке методов обучения с учителем и подкреплением.
Популяционные алгоритмы оптимизации: Алгоритм оптимизации спиральной динамики (Spiral Dynamics Optimization, SDO)
В статье представлен алгоритм оптимизации, основанный на закономерностях построения спиральных траекторий в природе, таких как раковины моллюсков - алгоритм оптимизации спиральной динамики, SDO. Алгоритм, предложенный авторами, был мной основательно переосмыслен и модифицирован, в статье будет рассмотрено, почему эти изменения были необходимы.

Популяционные алгоритмы оптимизации: Алгоритм интеллектуальных капель воды (Intelligent Water Drops, IWD)
В статье рассматривается интересный алгоритм - интеллектуальные капли воды, IWD, подсмотренный у неживой природы, симулирующий процесс формирования русла реки. Идеи этого алгоритма позволили значительно улучшить прошлого лидера рейтинга - SDS, а нового лидера (модифицированный SDSm), как обычно, найдёте в архиве к статье.

Нейросети — это просто (Часть 64): Метод Консервативного Весового Поведенческого Клонирования (CWBC)
В результате тестов, проведенных в предыдущих статьях, мы пришли к выводу, что оптимальность обученной стратегии во многом зависит от используемой обучаемой выборки. В данной статье я предлагаю вам познакомиться с довольно простым и эффективном методе выбора траекторий для обучения моделей.

Нейросети — это просто (Часть 63): Предварительное обучение Трансформера решений без учителя (PDT)
Продолжаем рассмотрение семейства методов Трансформера решений. Из предыдущих работ мы уже заметили, что обучение трансформера, лежащего в основе архитектуры данных методов, довольно сложная задача и требует большого количества размеченных обучающих данных. В данной статье мы рассмотрим алгоритм использования не размеченных траекторий для предварительного обучения моделей.

Регрессионные модели библиотеки Scikit-learn и их экспорт в ONNX
В данной статье мы рассмотрим применение регрессионных моделей пакета Scikit-learn, попробуем их сконвертировать в ONNX-формат и использовать полученные модели в программах на MQL5. Также мы сравним точность работы оригинальных моделей и их ONNX-версий для float и double. Кроме того, мы рассмотрим ONNX-представление регресионных моделей, это позволит лучше понять их внутреннее устройство и принцип работы.

Квантование в машинном обучении (Часть 2): Предобработка данных, отбор таблиц, обучение моделий CatBoost
В настоящей статье речь пойдёт о практическом применении квантования при построении древовидных моделей. Рассмотрены методы отбора квантовых таблиц и предобработки данных. Материал будет подан без сложных математических формул, доступным языком.

Нейросети — это просто (Часть 62): Использование Трансформера решений в иерархических моделях
В последних статьях мы познакомились с несколькими вариантами использования метода Decision Transformer. Который позволяет анализировать не только текущее состояние, но и траекторию предшествующих состояний и, совершенных в них, действий. В данной статье я предлагаю Вам познакомиться с вариантом использования данного метода в иерархических моделях.

Популяционные алгоритмы оптимизации: Алгоритм поиска системой зарядов (Charged System Search, CSS)
В этой статье рассмотрим ещё один алгоритм оптимизации, инспирированный неживой природой - алгоритм поиска системой зарядов (CSS). Цель этой статьи - представить новый алгоритм оптимизации, основанный на принципах физики и механики.
Квантование в машинном обучении (Часть 1): Теория, пример кода, разбор реализации в CatBoost
В настоящей статье речь пойдёт о теоретическом применении квантования при построении древовидных моделей. Рассмотрены реализованные методы квантования в CatBoost. Материал будет подан без сложных математических формул, доступным языком.

Нейросети — это просто (Часть 61): Проблема оптимизма в офлайн обучении с подкреплением
В процессе офлайн обучения мы оптимизируем политику Агента по данным обучающей выборки. Полученная стратегия придает Агенту уверенность в его действиях. Однако такой оптимизм не всегда оправдан и может привести к увеличению рисков в процессе эксплуатации модели. Сегодня мы рассмотрим один из методов снижения этих рисков.
Эксперименты с нейросетями (Часть 7): Передаем индикаторы
Примеры передачи индикаторов в перцептрон. В статье даются общие понятия, представлен простейший готовый советник, результаты его оптимизации и форвард тестирования.

Нейросети — это просто (Часть 60): Онлайн Трансформер решений (Online Decision Transformer—ODT)
Последние 2 статьи были посвящены методу Decision Transformer, который моделирует последовательности действий в контексте авторегрессионной модели желаемых вознаграждений. В данной статье мы рассмотрим ещё один алгоритм оптимизации данного метода.

Популяционные алгоритмы оптимизации: Стохастический диффузионный поиск (Stochastic Diffusion Search, SDS)
В статье рассматривается стохастический диффузионный поиск, SDS, это очень мощный и эффективный алгоритм оптимизации, основанный на принципах случайного блуждания. Алгоритм позволяет находить оптимальные решения в сложных многомерных пространствах, обладая высокой скоростью сходимости и способностью избегать локальных экстремумов.

Нейросети — это просто (Часть 59): Дихотомия контроля (Dichotomy of Control — DoC)
В предыдущей статье мы познакомились с Трансформером решений. Но сложная стохастическая среда валютного рынка не позволила в полной мере раскрыть потенциал представленного метода. Сегодня я хочу представить Вам алгоритм, который направлен на повышение производительности алгоритмов в стохастических средах.

Классификационные модели библиотеки Scikit-learn и их экспорт в ONNX
В данной статье мы рассмотрим применение всех классификационных моделей пакета Scikit-learn для решения задачи классификации ирисов Фишера, попробуем их сконвертировать в ONNX-формат и использовать полученные модели в программах на MQL5. Также мы сравним точность работы оригинальных моделей и их ONNX-версий на полном наборе Iris dataset.

Теория категорий в MQL5 (Часть 14): Функторы с линейным порядком
Эта статья из серии статей о реализации теории категорий в MQL5 посвящена функторам. Мы исследуем, как линейный порядок может быть отображен на множестве благодаря функторам при рассмотрении двух множеств данных, между которыми на первый взгляд отсутствует всякая связь.

Нейросети — это просто (Часть 58): Трансформер решений (Decision Transformer—DT)
Мы продолжаем рассмотрение методов обучения с подкреплением. И в данной статье я предлагаю вам познакомиться с несколько иным алгоритмом, который рассматривает политику Агента в парадигме построения последовательности действий.

Теория категорий в MQL5 (Часть 13): События календаря со схемами баз данных
В статье рассматривается, как схемы баз данных могут быть включены для классификации в MQL5. Мы кратко рассмотрим, как концепции схемы базы данных могут сочетаться с теорией категорий при идентификации текстовой (строковой) информации, имеющей отношение к торговле. В центре внимания будут находиться события календаря.

Популяционные алгоритмы оптимизации: Алгоритм эволюции разума (Mind Evolutionary Computation, MEC)
В данной статье рассматривается алгоритм семейства MEC, называемый простым алгоритмом эволюции разума (Simple MEC, SMEC). Алгоритм отличается красотой заложенной идеи и простотой реализации.

Популяционные алгоритмы оптимизации: Тасующий алгоритм прыгающих лягушек (Shuffled Frog-Leaping, SFL)
Статья представляет подробное описание алгоритма прыгающих лягушек (SFL) и его возможности в решении задач оптимизации. SFL-алгоритм вдохновлен поведением лягушек в естественной среде и предлагает новый подход к оптимизации функций. SFL-алгоритм является эффективным и гибким инструментом, способным обрабатывать разнообразные типы данных и достигать оптимальных решений.

Нейросети — это просто (Часть 57): Стохастический маргинальный актор-критик (SMAC)
Предлагаем познакомиться с довольно новым алгоритмом Stochastic Marginal Actor-Critic (SMAC), который позволяет строить политики латентных переменных в рамках максимизации энтропии.
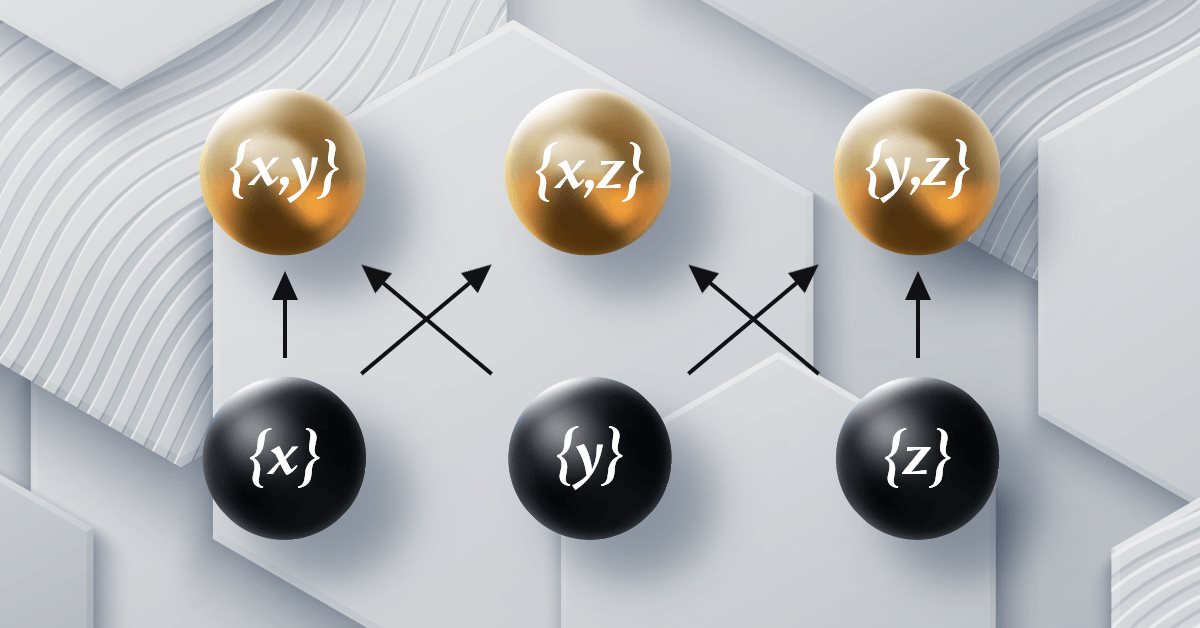
Теория категорий в MQL5 (Часть 12): Порядок
Статья является частью серии о реализации графов средствами теории категорий в MQL5 и посвящена отношению порядка (Order Theory). Мы рассмотрим два основных типа упорядочения и исследуем, как концепции отношения порядка могут поддерживать моноидные множества при принятии торговых решений.
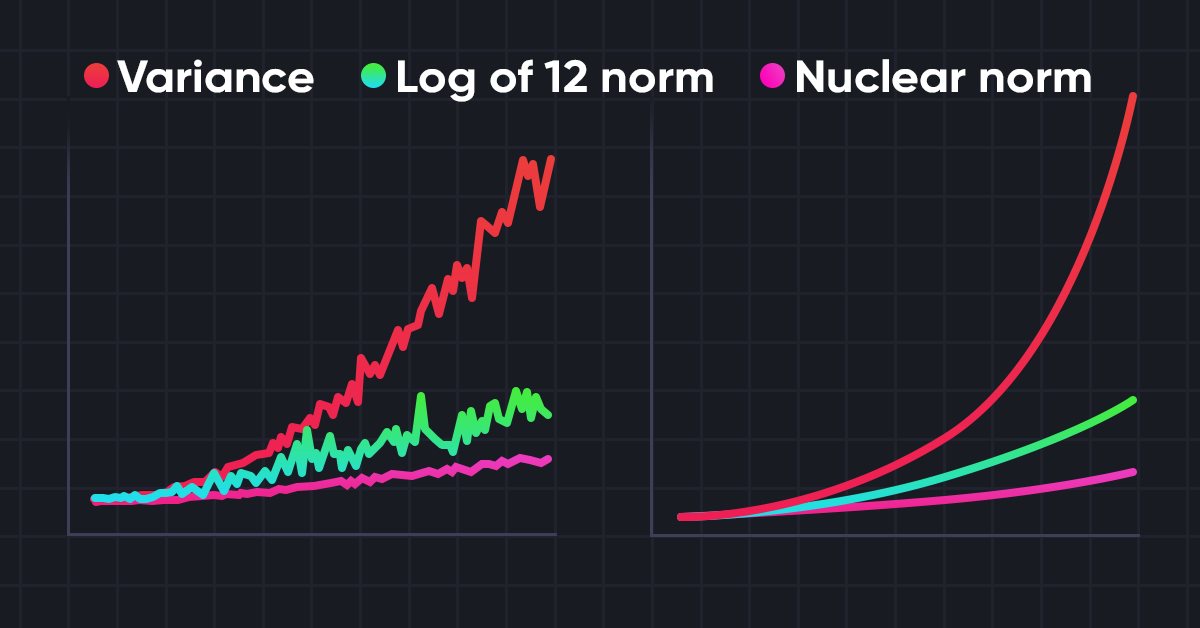
Нейросети — это просто (Часть 56): Использование ядерной нормы для стимулирования исследования
Исследование окружающей среды в задачах обучения с подкреплением является актуальной проблемой. Ранее мы уже рассматривали некоторые подходы. И сегодня я предлагаю познакомиться с ещё одним методом, основанным на максимизации ядерной нормы. Он позволяет агентам выделять состояния среды с высокой степенью новизны и разнообразия.
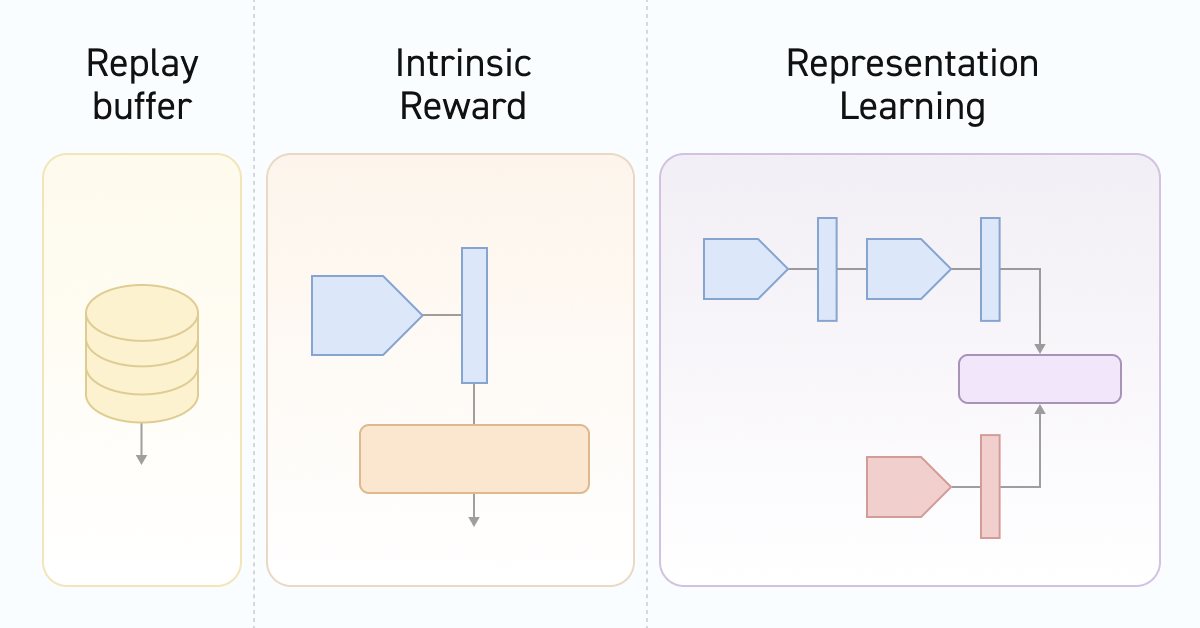
Нейросети — это просто (Часть 55): Контрастный внутренний контроль (CIC)
Контрастное обучение (Contrastive learning) - это метод обучения представлению без учителя. Его целью является обучение модели выделять сходства и различия в наборах данных. В данной статье мы поговорим об использовании подходов контрастного обучения для исследования различных навыков Актера.

Нейросети — это просто (Часть 54): Использование случайного энкодера для эффективного исследования (RE3)
Каждый раз, при рассмотрении методов обучения с подкреплением, мы сталкиваемся с вопросом эффективного исследования окружающей среды. Решение данного вопроса часто приводит к усложнению алгоритма и обучению дополнительных моделей. В данной статье мы рассмотрим альтернативный подход к решению данной проблемы.

Нейросети — это просто (Часть 53): Декомпозиция вознаграждения
Мы уже не раз говорили о важности правильного подбора функции вознаграждения, которую используем для стимулирования желательного поведения Агента, добавляя вознаграждения или штрафы за отдельные действия. Но остается открытым вопрос о дешифровке наших сигналов Агентом. В данной статье мы поговорим о декомпозиции вознаграждения в части передачи отдельных сигналов обучаемому Агенту.

Нейросети — это просто (Часть 52): Исследование с оптимизмом и коррекцией распределения
По мере обучения модели на базе буфера воспроизведения опыта текущая политика Актера все больше отдаляется от сохраненных примеров, что снижает эффективность обучения модели в целом. В данной статье мы рассмотрим алгоритм повышения эффективности использования образцов в алгоритмах обучения с подкреплением.

Нейросети — это просто (Часть 51): Актор-критик, управляемый поведением (BAC)
В последних двух статьях рассматривался алгоритм Soft Actor-Critic, который включает энтропийную регуляризацию в функцию вознаграждения. Этот подход позволяет балансировать исследование среды и эксплуатацию модели, но он применим только к стохастическим моделям. В данной статье рассматривается альтернативный подход, который применим как для стохастических, так и для детерминированных моделей.

Нейросети — это просто (Часть 50): Soft Actor-Critic (оптимизация модели)
В предыдущей статье мы реализовали алгоритм Soft Actor-Critic, но не смогли обучить прибыльную модель. В данной статье мы проведем оптимизацию ранее созданной модели для получения желаемых результатов её работы.

Машинное обучение и Data Science (Часть 14): Применение карт Кохонена на рынках
Хотите найти новый подход в торговле, который поможет ориентироваться на сложных и постоянно меняющихся рынках? Взгляните на карты Кохонена — инновационную форму искусственных нейронных сетей, которая поможет выявить скрытые закономерности и тренды в рыночных данных. В этой статье мы рассмотрим, как работают карты Кохонена и как их использовать для разработки эффективных торговых стратегий. Думаю, этот новый подход будет интересен как опытным трейдерам, так и начинающим.

Теория категорий (Часть 9): Действия моноидов
Статья продолжает серию о реализации теории категорий в MQL5. В статье рассматриваются действия моноидов (monoid actions) как средство преобразования моноидов, описанных в предыдущей статье, для увеличения областей их применения.

Представления частотной области временных рядов: Спектральная функция
В этой статье мы рассмотрим методы, связанные с анализом временных рядов в частотной области. Также будет уделено внимание пользе изучения спектральных функций временных рядов при построении прогностических моделей. Кроме того, мы обсудим некоторые многообещающие перспективы анализа временных рядов в частотной области с использованием дискретного преобразования Фурье (ДПФ).

Нейросети — это просто (Часть 49): Мягкий Актор-Критик (Soft Actor-Critic)
Мы продолжаем рассмотрение алгоритмов обучения с подкреплением в решении задач непрерывного пространства действий. И в данной статье предлагаю познакомиться с алгоритмом Soft Аctor-Critic (SAC). Основное преимущество SAC заключается в способности находить оптимальные политики, которые не только максимизируют ожидаемую награду, но и имеют максимальную энтропию (разнообразие) действий.

Нейросети — это просто (Часть 48): Методы снижения переоценки значений Q-функции
В предыдущей статье мы познакомились с методом DDPG, который позволяет обучать модели в непрерывном пространстве действий. Однако, как и другие методы Q-обучения, DDPG склонен к переоценки значений Q-функции. Эта проблема часто приводит к обучению агента с неоптимальной стратегией. В данной статье мы рассмотрим некоторые подходы преодоления упомянутой проблемы.

Нейросети — это просто (Часть 47): Непрерывное пространство действий
В данной статье мы расширяем спектр задач нашего агента. В процесс обучения будут включены некоторые аспекты мани- и риск-менеджмента, которые являются неотъемлемой частью любой торговой стратегии.