
Теория категорий в MQL5 (Часть 14): Функторы с линейным порядком
Введение
Согласно определению Сэмюэля Эйленберга и Сондерса Маклейна, данному в 1950-х годах, теорию категорий можно рассматривать как средство изучения систем с упором на трансформацию на каждой фазе, а не на сами фазы. Она применяется во многих областях человеческих знаний, включая функциональное программирование на таких языках, как Haskell; изучение структуры и состава естественных языков в лингвистике; алгебраическую топологию (обеспечение единого подхода к пониманию различных топологических конструкций и инвариантов), и многое другое.
В этой серии статей теория категорий до сих пор касалась информации и структуры уровня подкатегорий; в нашем случае - множеств (объектов). Мы рассмотрели их отношения и свойства внутри категории.
Цель этой статьи и нескольких подобных ей в будущем — отойти от категории и начать рассматривать отношения, которые различные категории могут иметь между собой. Формально они называются функторы. Итак, мы собираемся рассмотреть различные категории и их возможные отношения. В наборе данных трейдера есть несколько кандидатов на категории, которые стоит изучить. Однако, чтобы подчеркнуть выдающиеся качества теории категорий, мы выйдем за рамки привычных понятий и в этой статье рассмотрим связь данных об океанских приливах у побережья Калифорнии с волатильностью индекса NASDAQ. Есть ли что-нибудь в океанских приливах, что предвещает волатильность этого индекса? Мы надеемся, что сможем в некоторой степени ответить на этот вопрос к концу статьи.
Эта статья и несколько подобных ей в будущем не будут вводить новых концепций как таковых, а будут рассматривать то, что уже было рассмотрено, и пытаться применить имеющиеся знания по-другому, возможно, в более широком масштабе.
Океанский приливы и индекс NASDAQ
Данные об океанских приливах публикуются Национальным управлением по исследованию океанов и атмосферы (NOAA) на их сайте. Данные регистрируют высоту океанского прилива от исходной точки четыре раза в день. Время и высота прилива в каждый момент времени — это все, что регистрируется каждый день в течение всего года. Пример приведен ниже:

Все океаны разделены на четыре региона, значения приливов и приливов собираются с множества измерительных станций в каждом регионе. Например, на западном побережье Северной и Южной Америки - от Аляски до Чили - имеется 33 станции. Для нашего анализа мы возьмем данные, собранные на станции Монтерей в Калифорнии за 2020 год.
NASDAQ — это прежде всего американская фондовая биржа, но мы рассматриваем ее здесь прежде всего как индекс, состоящий из довольно большого количества высокотехнологичных компаний, таких как MSFT, AAPL, GOOG и AMZN, штаб-квартиры которых находятся в Калифорнии. Этот индекс можно торговать у большинства брокеров, поэтому его ценовой поток будет информировать нашу категорию, поскольку мы увидим, связана ли рыночная капитализация этих компаний, которые произвели революцию в отраслях и олицетворяют инновационный дух Калифорнии, каким-либо образом связаны с данными океанских приливов, собранными у ее побережья.
Сопоставление данных с использованием функторов теории категорий
До сих пор мы явно не говорили о функторах в этой серии, однако в статьях, где мы рассматривали моноиды, группы моноидов, графы и порядки, подразумевалось, что мы имеем дело с функторами, поскольку каждое из этих понятий можно рассматривать как категорию, и их отношения часто ложились в основу статей. Так, например, морфизмы между моноидами были де-факто функторами.
Формально функтор — это сопоставление категорий, которое сохраняет их структуру и отношения, определенные объектами и их морфизмами внутри каждой категории. Если C и D — категории, то функтор F из C в D
Состоит из двух вещей, а именно: для каждого объекта c в C существует связанный объект F(c) в D и для каждых двух объектов в b, c в C с морфизмом f.
![]()
существует ассоциированный морфизм F(f)
в D. Функторы также имеют дополнительные аксиомы сохранения смысла композиции, если у нас есть морфизмы
![]()
и
в C, то F сохраняет композицию в C такую, что
и тождественные морфизмы в C сохраняются для каждого отображаемого объекта в D, так что если
то
Важность связи различных категорий проистекает из открытий. Для каждой системы, которая классифицируется как категория, часто по умолчанию не существует способа не только перевести одну категорию в другую, но и установить "относительное положение" и, возможно, важность каждой категории в более широком контексте. Вот почему функторы могут, например, сопоставить категорию торгуемых ценных бумаг с собственным портфелем взвешенных морфизмов с другой категорией торговых стратегий. Польза от такого функтора для трейдеров может быть сведена к перспективе, но если функтор отображает временной лаг, мы можем либо установить, какие стратегии использовать с учетом ценных бумаг нашего портфеля, либо, например, какие ценные бумаги держать следующими, учитывая нашу текущую стратегию.
Напомним, что линейный порядок или полный порядок, помимо соответствия аксиомам транзитивности и рефлексивности, также отвечает требованиям антисимметрии и сопоставимости. Обычно это означает, что все данные в линейном порядке должны быть числовыми или, если это текст, быть дискретными, чтобы бинарную операцию "<=" можно было применять без двусмысленности или получения неопределенного результата. Данные об океанских приливах, представленные на веб-сайте NOAA, являются многомерными, если мы принимаем день за одну точку данных. Он имеет 4 записи даты и времени для каждой высоты, 4 значения высот с плавающей запятой и запись даты и времени для дня. Если мы воспользуемся нашим линейным порядком для сравнения значения даты и времени дня для каждой точки данных, тогда данные о приливах станут простым временным рядом с двумя частями данных в каждой точке - дата в качестве datetime и высота прилива в качестве данных с плавающей запятой.
Представление этого линейного порядка в виде категории означало бы, что бинарная операция между любыми двумя последовательными точками данных становится морфизмом, и каждая точка данных становится объектом, который содержит 4 фрагмента данных, 4 даты и время регистрации высот и 4 значения высоты, если мы должны сгруппировать эти данные по дням, поскольку значения приливов регистрировались ежедневно. Однако нам необходимо немного больше нормализовать эти данные, поскольку не во все дни есть 4 точки данных. У некоторых их всего 3. Поскольку наша категория будет иметь простые изоморфные отношения, важно, чтобы мы были последовательны в количестве элементов в каждом домене (дне).
Категория волатильности NASDAQ будет следовать тому же принципу, что и океанские приливы, в том смысле, что мы связываем точки ценовых данных, основанные на последовательности во времени, как морфизмы.
Сравнительный анализ и идеи
Если мы сопоставим нашу категорию приливов с категорией индекса NASDAQ, нам придется сделать это с задержкой во времени, чтобы получить от этого какую-либо прогнозную выгоду. Но сначала нам нужно будет создать экземпляр категории класса океанских приливов, и это можно представить, как показано ниже:
protected:
...
CCategory _category_ocean,_category_nasdaq;
CDomain<string> _domain_ocean,_domain_nasdaq;
CHomomorphism<string,string> _hmorph_ocean,_hmorph_nasdaq; Поскольку мы заинтересованы в использовании этого функтора для прогнозирования, наша категория будет динамической, поскольку она будет переопределяться на каждом новом баре, но функтор от нее к категории NASDAQ будет постоянным. Таким образом, поскольку наша задержка составляет один день, три вышеупомянутых морфизма, связывающие зарегистрированные высоты океана, могут быть определены путем считывания данных о приливах океана из файла csv следующим образом:
void CTrailingCT::SetOcean(int Index)
{
...
if(_handle!=INVALID_HANDLE)
{
...
while(!FileIsLineEnding(_handle))
{
...
if(_date>_data_time)
{
_category_ocean.SetDomain(_category_ocean.Domains(),_domain_ocean);
break;
}
else if(__DATETIME.day_of_week!=6 && __DATETIME.day_of_week!=0 && datetime(int(_data_time)-int(_date))<=PeriodSeconds(PERIOD_D1))//_date<=_data_time && datetime(int(_data_time)-(1*PeriodSeconds(PERIOD_D1)))<=_date)
{
_element_value.Let();_element_value.Cardinality(1);_element_value.Set(0,DoubleToString(_value));
_domain_ocean.Cardinality(_elements);_domain_ocean.Set(_elements-1,_element_value);
_elements++;
}
}
FileClose(_handle);
}
else
{
printf(__FUNCSIG__+" failed to load file. Err: "+IntegerToString(GetLastError()));
}
} Аналогичным образом мы построим наше множество волатильности NASDAQ, используя листинг ниже:
void CTrailingCT::SetNasdaq(int Index)
{
m_high.Refresh(-1);
m_low.Refresh(-1);
_value=0.0;
_value=(m_high.GetData(Index+StartIndex()+m_high.MaxIndex(Index,_category_ocean.Homomorphisms()))-m_low.GetData(Index+StartIndex()+m_low.MinIndex(Index,_category_ocean.Homomorphisms())))/m_symbol.Point();
_element_value.Let();_element_value.Cardinality(1);_element_value.Set(0,DoubleToString(_value));
_domain_nasdaq.Cardinality(1);_domain_nasdaq.Set(0,_element_value);
_category_nasdaq.SetDomain(_category_nasdaq.Domains(),_domain_nasdaq);
} Его морфизмы также собраны весьма схожим образом. Теперь функтор, как уже отмечалось в определении, отображает не только объекты двух категорий, но и морфизмы. Это подразумевает, что одно проверяет другое. Если мы начнем с отображения объекта, части нашего функтора для данных об океанских приливах в NASDAQ, он инициализируется следующим образом:
double CTrailingCT::GetOutput()
{
...
...
_domain.Init(3+1,3);
for(int r=0;r<4;r++)
{
CDomain<string> _d;_d.Let();
_category_ocean.GetDomain(_category_ocean.Domains()-r-1,_d);
for(int c=0;c<_d.Cardinality();c++)
{
CElement<string> _e; _d.Get(c,_e);
string _s; _e.Get(0,_s);
_domain[r][c]=StringToDouble(_s);
}
}
_codomain.Init(3);
for(int r=0;r<3;r++)
{
CDomain<string> _d;
_category_nasdaq.GetDomain(_category_nasdaq.Domains()-r-1,_d);
CElement<string> _e; _d.Get(0,_e);
string _s; _e.Get(0,_s);
_codomain[r]=StringToDouble(_s);
}
_inputs.Init(3);_inputs.Fill(m_consant_morph);
M(_domain,_codomain,_inputs,_output,1);
return(_output);
} Подобным же образом конструкция функтора морфизма примет следующий вид:
double CTrailingCT::GetOutput()
{
...
...
_domain.Init(3+1,3);
for(int r=0;r<4;r++)
{
...
if(_category_ocean.Domains()-r-1-1>=0){ _category_ocean.GetDomain(_category_ocean.Domains()-r-1-1,_d_old); }
for(int c=0;c<_d_new.Cardinality();c++)
{
...
CElement<string> _e_old; _d_old.Get(c,_e_old);
string _s_old; _e_old.Get(0,_s_old);
_domain[r][c]=StringToDouble(_s_new)-StringToDouble(_s_old);
}
}
_codomain.Init(3);
for(int r=0;r<3;r++)
{
...
if(_category_nasdaq.Domains()-r-1-1>=0){ _category_nasdaq.GetDomain(_category_nasdaq.Domains()-r-1-1,_d_old); }
...
CElement<string> _e_old; _d_old.Get(0,_e_old);
string _s_old; _e_old.Get(0,_s_old);
_codomain[r]=StringToDouble(_s_new)-StringToDouble(_s_old);
}
_inputs.Init(3);_inputs.Fill(m_consant_morph);
M(_domain,_codomain,_inputs,_output,1);
return(_output);
} Основная часть работы здесь заключается в том, чтобы сделать данные об океанских приливах доступными для MQL5. Для этого доступ к данным осуществляется из файла csv в общей папке данных в табличном формате, который аналогичен нашему элементу в категории океанских приливов. Формат данных включает поле datetime для синхронизации со временем нашего торгового сервера при выборе правильных значений. В MQL5 IDE есть другие альтернативы доступа к таким вторичным данным, и одна из них — через базу данных, поскольку в IDE возможно создание собственного соединения. Если у вас есть база данных на локальном компьютере или облачное соединение с ней, можно организовать доступ. Однако для наших целей, поскольку я хотел бы, чтобы читатели могли легко воспроизвести результаты тестов, опубликованные здесь, используется файл csv в общей папке.
Наш функтор сопоставляет два элемента, что означает, что во избежание дублирования одно соединение проверит другое. Поскольку вначале мы не знаем, какая из этих настроек будет идеальной для нашей торговой системы, мы протестируем обе.
Итак, в первой настройке у нас будет функтор по объектам, подтверждающий или проверяющий морфизмы между объектами в кодомене (набор NASDAQ). Схематически это можно представить следующим образом:
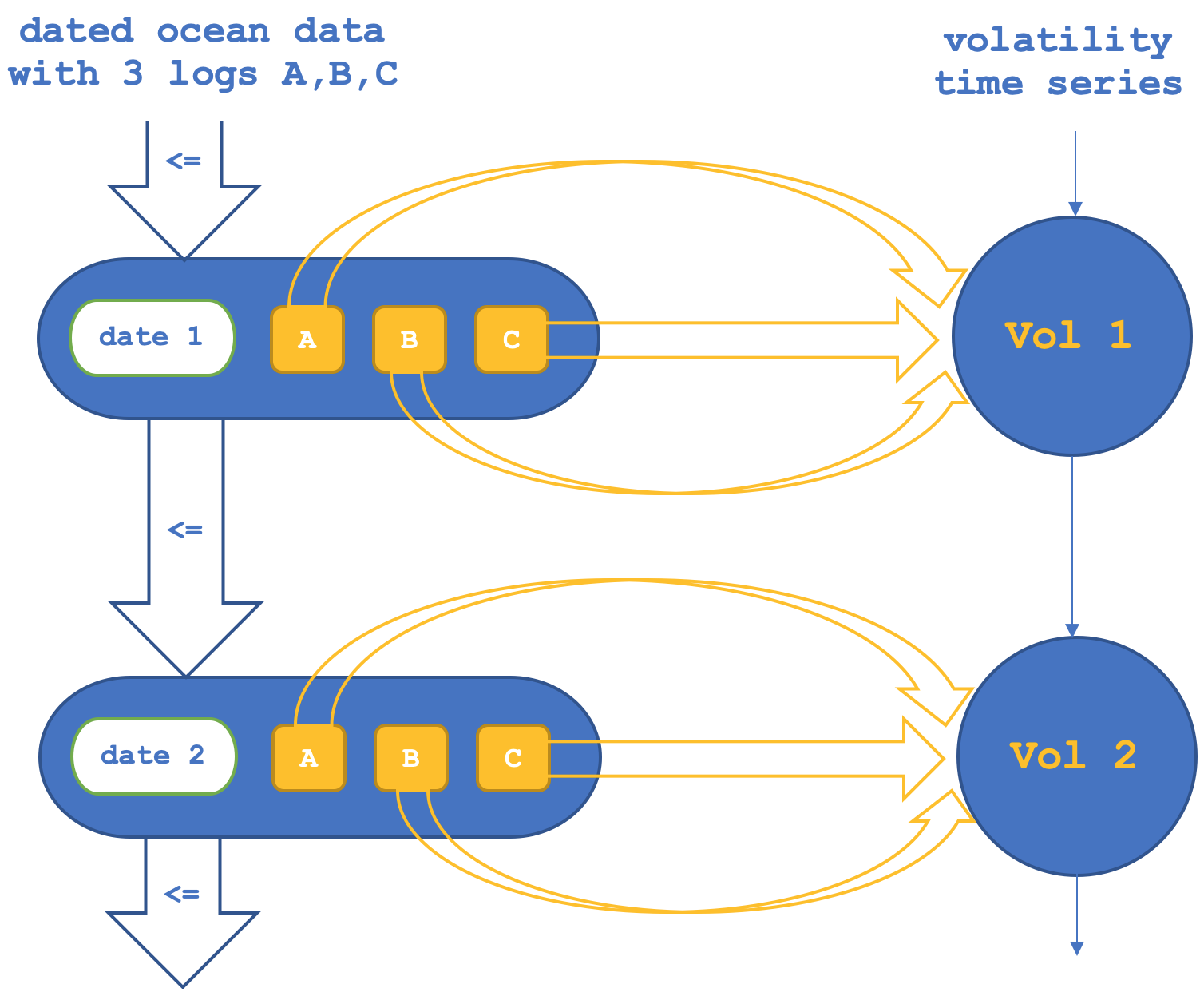
Если мы запустим тесты, чтобы попытаться спрогнозировать волатильность NASDAQ, основываясь только на объектных функторах, мы получим отчеты, подобные приведенному ниже (необходимый код прикреплен в виде файла TraillingCT_14_1a):

Если, как уже упоминалось, мы пойдем от обратного и сосредоточимся на функторах морфизмов, а затем подтвердим объекты, это можно представить следующим образом:
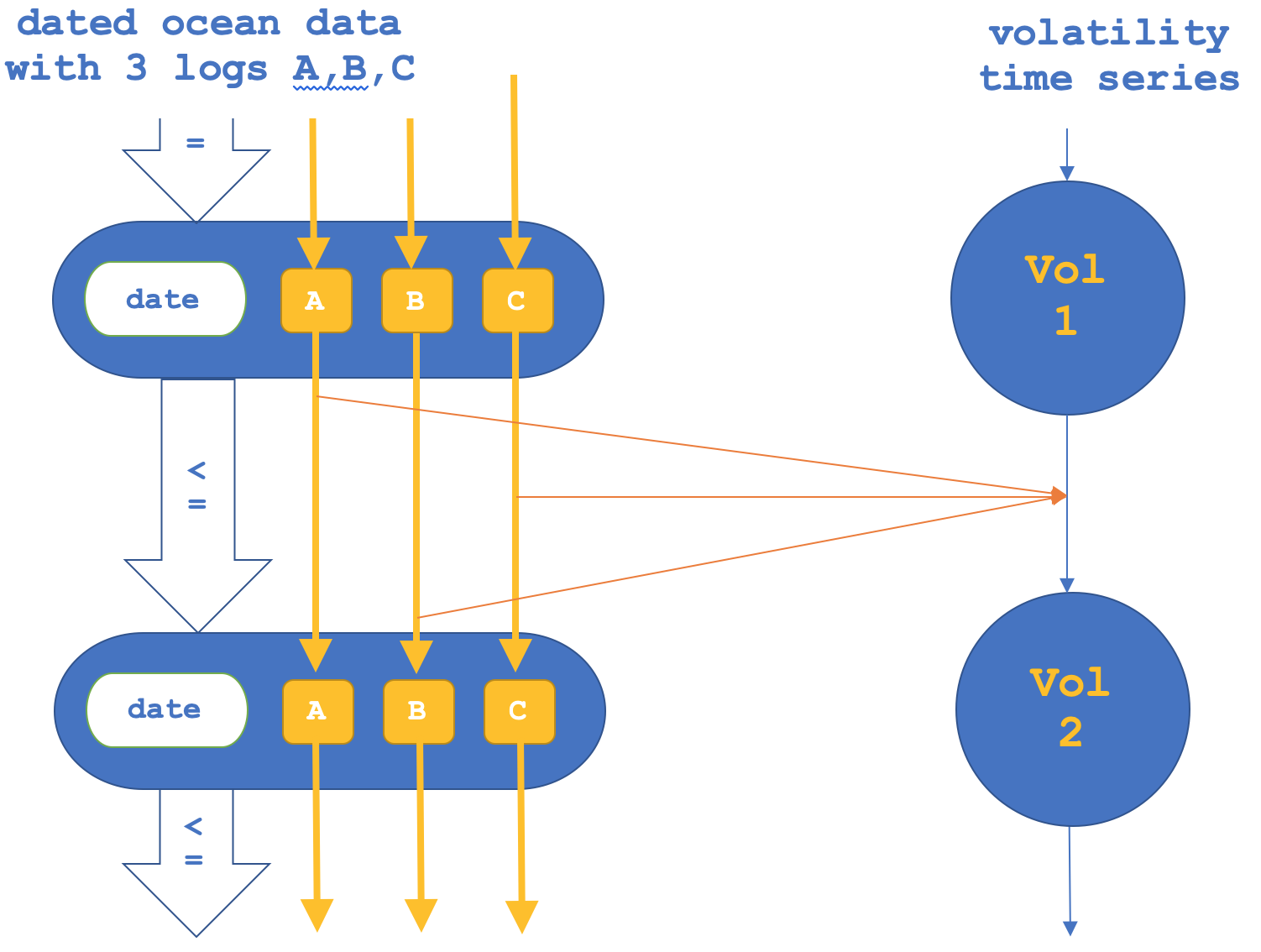
Отчет тестера только для функторов морфизма указан ниже:

Два наших варианта тестирования, описанные выше, сопоставление объектов и сопоставление морфизмов, дали разные результаты даже в очень коротком окне тестирования, начиная с 1 января 2020 года по 15 марта того же года на дневном графике. Какой же из двух вариантов полезнее для трейдеров при составлении прогнозов любого рода, а не только прогнозов волатильности? Чтобы ответить на этот вопрос, понадобится тестирование на более длительных периодах времени по конкретному аспекту тестируемой торговой системы, будь то сигнал входа, управление капиталом или трейлинг-стоп.
Период, выбранный для тестирования, хотя и был очень коротким, на самом деле был важным для NASDAQ, поскольку именно тогда индекс достиг своего исторического максимума, а затем, в разгар пандемии, довольно резко снизился. Таким образом, хотя это тестирование действительно предполагает возможную корреляцию с данными об океанских приливах, оно, конечно, не подразумевает какой-либо причинно-следственной связи.
Как и в случае с этими сериями, используемый входной сигнал является очень простым. В данном случае это был встроенный осциллятор Awesome с настройками по умолчанию соответствующего файла сигналов. Размер позиции также, как обычно, был фиксированным. Мы тестировали NASDAQ на ежедневном временном интервале, поскольку данные о категориях наших доменов собирались ежедневно, через три интервала. Таким образом, при форматировании линейного порядка, эквивалентного категории, каждый день представлял собой домен (объект), который имел три элемента. Как уже упоминалось, они представляли собой три точки данных каждого дня.
Главный вывод здесь заключается в том, что разрозненные и, казалось бы, несвязанные наборы данных могут быть изучены и проверены на наличие полезных запаздывающих связей, которые могут помочь в принятии торговых решений. В нашем тестировании отставание составляло один день, у вас оно может быть больше. Вместо океанских приливов можно было бы выбрать возможные альтернативные множества данных. Вариантов довольно много. Но, возможно, было бы полезно поделиться несколькими примерами множеств данных, которые могут заменить данные об океанских приливах, использованные выше, что также позволит лучше понять, насколько взаимосвязаны наши рынки и экзогенные системы.
Альтернативные множества данных могут включать цены на сырьевые товары; новости о технологиях, где количество статей о новых технологических тенденциях, например, таких как искусственный интеллект, по сравнению с альтернативными новостными статьями, например, о развлечениях, можно отслеживать с задержкой для возможной связи; данные о настроениях в социальных сетях о тоне сообщений в социальных сетях, количественно выраженные лексикологическими методами также могут быть проверены на предмет их связи с волатильностью NASDAQ (или любой торгуемой ценной бумаги), особенно если она связана с акциями технологических компаний. Примеры довольно эзотерические, но можно рассмотреть множества данных, более близких к нашей теме, такие как цены на другие ценные бумаги или значения их индикаторов.
Заключение
Мы изучили, как данные в категории формата линейного порядка могут быть связаны с помощью функтора с ценами ценных бумаг. В данном случае наши доменные данные представляли собой маловероятное множество данных о высоте океанских приливов, взятых у побережья Калифорнии. Была сделана попытка связать их с волатильностью NASDAQ с дневным лагом через функтор. Эта связь может принимать два формата: от объектов к объектам или от морфизмов к морфизмам. В результате нашего тестирования, которое включало использование одинаковых сигналов входа и методов определения размера позиции, оба формата дали существенно разные результаты, учитывая короткое окно тестирования.
Функторы теории категорий могут сыграть важную роль в сопоставлении различных типов данных. Для этой статьи мы использовали довольно сложный набор данных для сортировки и составления, но читатель может найти более приемлемые варианты. Хотя они не обязательно дадут ему преимущество, но в целях тестирования они могут быть полезны.
Будущие возможности в связывании линейного порядка с множествами с точки зрения трейдера могут иметь несколько направлений. Они могут включать в себя прогнозирование погоды, интеграцию данных и графики в таких областях, как искусственный интеллект, машинное обучение и трансферное обучение, в которых линейные порядки, которые являются функторами, связанными с финансовыми данными, могут быть развиты дальше, например, веса функторов, полученные между двумя категориями, можно будет протестировать или даже применить в разных областях, что потенциально улучшит модели машинного обучения и их эффективность.
Существует множество других возможностей, включая статистический анализ и объединение данных, случайные выводы и корреляционные исследования, количественное финансирование с алгоритмическим финансированием, принятие решений на основе данных и многое другое. Выбор приложения будет зависеть от точки зрения или подхода к торговле.
Читателю предлагается изучить эту область с учетом своей специализации и подхода к рынкам. Предметная область имеет большой потенциал, включая междисциплинарный анализ данных.
Поместите файлы TrailingCT_14_1a.mqh и TrailingCT_14_1b.mqh в папку MQL5\include\Expert\Trailing\, файл ct_14_1s.mqh можно поместить в папку Include.
Возможно, вам будут полезны рекомендации, приведенные здесь о том, как собрать советник с помощью Мастера. Как указано в статье, я использовал Awesome Oscillator в качестве сигнала входа и фиксированную маржу для управления капиталом. Обе составляющие являются частью библиотеки MQL5. Как всегда, цель статьи – не представить вам Грааль, а скорее, предложить идею, которую вы можете адаптировать к своей собственной стратегии. Приложенные файлы собраны в Мастере. Вы можете скомпилировать их или создать самостоятельно.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/13018
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования