Квантование в машинном обучении (Часть 1): Теория, пример кода, разбор реализации в CatBoost

Введение
В настоящей статье речь пойдёт о теории применении квантования при построении древовидных моделей. Материал будет подан без сложных математических формул, доступным языком. При подготовкe к написанию статьи было обнаружено отсутствие устоявшейся единой терминологии в научных трудах разных авторов, возможно, это издержки перевода, поэтому я буду выбирать те варианты терминов, которые в наибольшей мере, на мой взгляд, отражают смысл, и буду использовать свою терминологию в тех вопросах, которые остались без должного внимания со стороны других исследователей. В этой статье будут использоваться термины и понятия, о которых я ранее уже писал в статье "Машинное обучение от Яндекс (CatBoost) без изучения Python и R", поэтому, рекомендую, перед прочтением предложенного материала ознакомится с ней.
В данной статье не будет рассматриваться возможность применения квантования к обученным нейронным сетям с целью уменьшения их размера, так как в этом вопросе у меня в настоящий момент нет собственного опыта.
Вот что ждёт читателя в этой статье:
- Первая часть статьи содержит вводный теоретический материал о квантовании, и будет полезна для понимания целей и сути процесса.
- Во второй части статьи будет разобран равномерный метод квантования на примере кода на MQL5.
- В третьей части статьи будет предложено ознакомиться с реализацией процесса квантования на примере CatBoost.
1. Стандартные цели использования
Так что же такое квантование, и зачем его используют – давайте разбираться!
Вначале поговорим немного о данных. Итак, для создания моделей (проведения обучения) требуются данные, которые скрупулёзно собираются в таблицу, источником таких данных может быть любая информация, способная объяснить показание целевой (то - что будет определено моделью, к примеру, торговый сигнал). Источники данных называют по-разному – предикторы, фичи, признаки, факторы. Периодичность появления строки с данными определяется появлением сопоставимого наблюдения процесса явления, о котором собирается информация, и которой будет изучен с помощью машинного обучения. Совокупность полученных данных – называется выборкой.
Выборка может быть репрезентативной – это когда наблюдения, зафиксированные в ней, описывают весь процесс исследуемого явления, а может быть нерепрезентативной – это когда данных столько, сколько удалось собрать, что позволяет только частично описать процесс исследуемого явления. Как правило, мы, занимаясь финансовыми рынками, имеем именно дело с нерепрезентативными выборками в силу того, что ещё не происходило всего, что может произойти, и по этой причине неизвестно, как поведет себя финансовый инструмент при наступлении новых, ранее не происходящих, в своей совокупности, событий. Однако, всем известна мудрость "история повторяется", и именно на это наблюдение опирается алготрейдер при своих изысканиях, надеясь, что среди новых событий будут те, что были похожие на прежние, и исход их будет с выявленной вероятностью аналогичен.
По своему логическому содержанию (по шкале измерения) числовые показатели предикторов могут быть:
- Бинарными – подтверждает или опровергают наличие фиксируемого признака наблюдаемого явления;
- Количественными (метрическая шкала) – описывает явление каким-либо измерительным показателем, к примеру, это может быть скорость, координаты чего либо, размер, время, прошедшее с начала какого-либо события и многие другие характеристики, которые можно измерить, в том числе производные от них.
- Категориальными (номинальная шкала) – сигнализируют о разных наблюдаемых объектах или явлениях, но входящих в одну логическую группу, как правило, выражаются целым числом. К примеру, дни недели, направление тенденции изменения цены, порядковый номер уровня поддержки или сопротивления.
- Ранговыми (порядковая шкала) – характеризуют степень превосходства или упорядочения чего либо. Редко выделяют в отдельную группу, так как в зависимости от контекста и логики можно отнести к другим типам показателей. К примеру, сюда можно отнести очерёдность действий, результат эксперимента в виде оценки его исхода относительно других аналогичных экспериментов.
Итак, выборка содержит в себе разные предикторы со своими числовыми показателями, и эти данные, в своей совокупности, описывают наблюдаемое явление, характеристики или тип которого описан в целевой функции (далее - целевая). Целевая в выборке может быть, как числовым показателем, так и категориальным, и далее я буду в тексте подразумевать именно категориальную целевую функцию, и в большей степени бинарную.
Википедия предлагает следующее определение:
Квантова́ние (англ. quantization) — в обработке сигналов — разбиение диапазона отсчётных значений сигнала на конечное число уровней и округление этих значений до одного из двух ближайших к ним уровней. При этом значение сигнала может округляться либо до ближайшего уровня, либо до меньшего или большего из ближайших уровней в зависимости от способа кодирования. Такое квантование называется скалярным. Существует также векторное квантование — разбиение пространства возможных значений векторной величины на конечное число областей и замена этих значений идентификатором одной из этих областей.
Мне нравится более короткое определение:
Квантование данных – способ сжатия (кодирования) информации о наблюдении с допустимой потерей точности в своей шкале измерения. Сжатие (кодирование) подразумевает дискретность объектов, что подразумевает их однотипность и однородность, или просто - похожесть. Критерий похожести может быть разным, в зависимости от выбранного алгоритма и заложенной в него логики.
Квантование данных используется повсеместно, особенно в преобразовании аналогового сигнала в цифровой сигнал, а так же при последующем сжатии цифрового сигнала. К примеру, полученные с матрицы фотокамеры данные можно записать в виде файла расширения raw, а далее сразу, или уже после на компьютере, сжать в jpg или иной удобный формат хранения данных.
Смотря на графическое представление данных, в виде свечей или баров, в терминале MetaTrader 5, мы видим уже результат работы квантования тиков в выбранную нами временную шкалу. Правда, процесс квантования непрерывного потока данных во времени, принято называть дискретизацией.
Обычно дискретизация – процесс фиксации характеристик наблюдения с заданной частотой по времени. Однако, если считать, что это частота, с которой собираются данные в выборку, то определение надо подкорректировать, на следующие "дискретизация – процесс регистрации характеристик наблюдения, частота которого определяется заданной функцией при её пороговой активации". Под функцией тут подразумевается любой алгоритм, который по собственной заложенной логике даёт сигнал на получение данных. К примеру, в MetaTrader 5 мы видим именно такой подход, ведь в неторговые дни, вместо повторения цены закрытия, как длящегося процесса во времени, на графике просто нет информации, т.е. частота дискретизации падает до нуля.
Простым примером алгоритма квантования является построение гистограммы. Алгоритм данного способа довольно простой:
- Находим максимальное и минимальное значение показателя (в нашем случае предиктора).
- Считаем разницу между максимальным и минимальным показателем.
- Делим получившуюся дельту в пункте 2 на целое число, к примеру, десять, или, как рекомендует Карл Пирсон, в зависимости от числа наблюдений. Получаем шаг деления в начальных единицах измерения, который будет являться отсчетом новой шкалы измерения.
- Теперь нужно построить свою шкалу, со своими делениями, это делается – просто шаг умножаем на порядковый номер отсчета.
- Далее алгоритмом предполагается отнесение каждого значения наблюдения в диапазон новой шкалы измерения и суммирование числа наблюдений в каждом диапазоне по отдельности.
Результатом работы алгоритма будет гистограмма, показанная на рисунке №1.
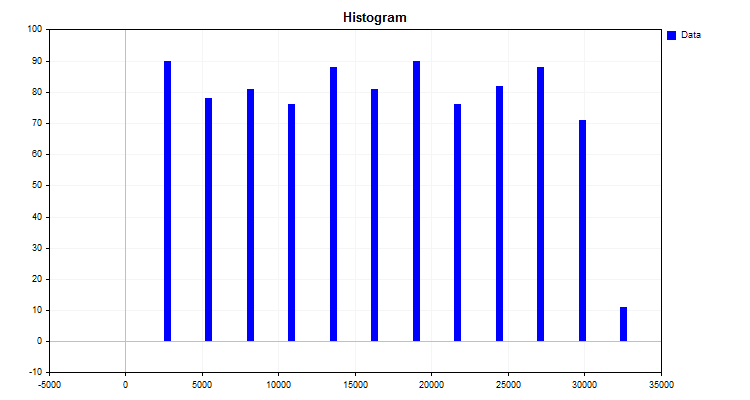
Рисунок № 1.
На гистограмме видно, как распределились данные по новой шкале измерения. По внешнему виду распределения, через аппарат описательной статистики, можно предположить тип плотности распределения, что может быть полезно для выбора способа конечного квантования. Однако, предлагаю с темой плотности распределения ознакомиться в статьях, имеющихся на нашем любимом портале:
- Ядерная оценка неизвестной плотности вероятности;
- Статистические распределения в MQL5 - берем лучшее из R и делаем быстрее;
- Статистические оценки.
Итак, что же мы получили, построив гистограмму:
- Уровни (отсечки) или бордюры, которые разделили данные на группы. Набор уровней называют квантовой сеткой или словарём – именно по этим уровням происходит процесс кодирования данных, который обеспечивает их группировку и сжатие. Бордюры могут устанавливаться по разным правилам, заложенным в алгоритм квантования. Уровни (отсечки) формируют новую шкалу для измерения показателей наблюдений. Диапазон между двумя уровнями я привык называть "квантовый отрезок", хотя в литературе встречается иные названия – "интервал", "диапазон", "шаг квантования";
- Принадлежность каждого значения наблюдения (показателя) к заданной группе (столбцу на гистограмме). Для квантования это работа алгоритма сжатия, суть которой является преобразование исходных данных в сжатые данные в момент отнесения значения наблюдения к определённому диапазону квантовой сетки. Результатом сжатия может быть разное числовое преобразование значения переменной. Часто встречается два варианта: первый вариант - преобразование, при котором переменной присваивается ранг (индекс) по номеру диапазона между значений отсечек (бордюров), в которое попало число, и второй вариант - присвоение переменной значения шкалы уровня, к примеру, числовое значение наблюдения попало в диапазон между 1,2 и 1,4, то присваивается правое значение – 1,4. Однако для применения второго варианта нужно задавать пределы, за которые данные не выйдут, в то время как первый вариант позволяет работать с любыми значениями за пределами границ квантовой таблицы. Для второго варианта хорошим решением может быть принудительное добавление уровней (бордюров/границ) на значительном отдалении, что позволит поместить туда ошибки в виде выбросов или отсутствия данных.
- Возможность восстановления каждого значения числа с потерей точности (деквантование), которое можно произвести следующими способами:
- - По центру интервала, который соответствует индексу числа.
- - По левому или правому значению уровня (границе/отсечке/бордюру) интервала, чаще правому. Учитывая, что для первого и последнего интервала границы в таблице квантования, как правило, не определены, то для их определения можно использовать средний диапазон интервалов или первое и последнее значение ширины интервала.
В зависимости от задачи и области применения квантования приходится сталкиваться с разными обозначениями переменных и стилем написания формул, что делает затруднительным понимание сути алгоритма, так как автор, описывающий их, предполагает знания из конкретной области, где применяется алгоритм. Суть разных алгоритмов сводится к разным способам построения уровней (отсечек), поэтому предлагаю для обобщения их классифицировать по ряду признаков.
Квантование с постоянным интервалом:
- Разбитие на фиксированные интервалы по методу, аналогично гистограмме Пирсона;
- Преобразование для снижения разряда числа.
Квантование с переменным интервалом:
- Накопление фиксированного процента наблюдений для каждого интервала.
- Использование фиксированного значения площади под кривой теоретического или приближённого распределения.
- Использование заданной функции, изменяющей шаг квантования в зависимости от коэффициента. Часто это функции, расширяющие интервал к краю или к центру.
- Использование весовых коэффициентов, влияющих на интервал, в зависимости от плотности значений.
- Итеративные, в том числе адаптивные методы. Для настройки бордюров используется информация о структуре данных, и производятся действия для снижения ошибки.
- Иные методы.
Квантование с эмпирически определённым интервалом:
- Числовые последовательности;
- Знания о природе наблюдения, позволяющие сгруппировать похожие по смыслу показатели;
- Ручной способ разметки.
Снижение ошибки квантования в выбранной метрике может быть итеративным процессом, а может вычисляться единожды по заданной формуле. Для оценки результата удобно использовать средний процент разброса ошибки относительно всего диапазона чисел, принимающих значение предиктора в выборке.
2. Пример реализации алгоритма квантования на MQL5
Ранее мы разобрали простой пример, как происходит квантование, но в нём отсутствует один из этапов, который часто используется при квантовании, а именно повторное разбиение шкалы, полученной после каких-либо вычислений, с целью нахождения среднего значения интервала, которое часто называют центроидом. Именно по половине расстояния между границами двух близлежащих центродов будет окончательно определён интервал для квантования.
Давайте для примера, пошагово сделаем квантование вещественных чисел, типа double, которые в памяти занимают 8 байт, в целый тип данных uchar, который занимает всего 8 бит:
- 1. Находим максимум и минимум во входных данных:
- 1.1.Находим значение максимума и минимума - переменная Max и Min в массиве arr_In_Data.
- 2. Рассчитываем размер окна между интервалами:
- 2.1. Находим разность максимума и минимума - сохраняем в переменную Delta.
- 2.2. Находим размер одного окна Delta/nQ, где nQ - число разделителей (бордюров), результат сохраняем в переменную Interval_Size.
- 3. Производим квантование и подсчет ошибки:
- 3.1. Делаем смещение минимума значения входных данных к нулю arr_In_Data-Min.
- 3.2. Делим результат пункта 3.1. на число интервалов Interval_Size, которых на один больше, чем число разделителей.
- 3.3. Теперь к полученному результату из пункта 3.2. нужно применить функцию round, которая округляет число до ближайшего целого. Результат будем сохранять в массив arr_Output_Q_Interval.
- 3.4. Значение из массива arr_Output_Q_Interval умножим на Interval_Size и прибавим минимум. Вот и получилось преобразованное (отквантованное) значение числа, которое сохраним в массив arr_Output_Q_Data.
- 3.5. Посчитаем ошибку нарастающим итогом, для этого разницу по модулю между исходным значением и полученным в результате квантования разделим на диапазон. Получившийся итог разделим на число элементов в массиве arr_In_Data.
- 4. Сохраним разделители (бордюры) в массив arr_Output_Q_Book:
- 4.1. Для первого интервала делаем поправку - к минимальному значению (Min) прибавляем половину размера интервала (Interval_Size).
- 4.2. Последующие интервалы считаются уже через прибавление значения интервала к значению массива arr_Output_Q_Book на прошлом шаге.
Пример кода функции с описанием переменных и массивов можно посмотреть ниже.
/+---------------------------------------------------------------------------------+ //|Квантование - типа преобразования (кодирования) в заданную целочисленную битность //+---------------------------------------------------------------------------------+ double Q_Bit( double &arr_Input_Data[],//Массив с данными для квантования int &arr_Output_Q_Interval[],//Исходящий массив с интервалами, в которые попали данные double &arr_Output_Q_Data[],//Исходящий массив с восстановленными значениями исходных данных float &arr_Output_Q_Book[],//Исходящий массив - "Книга с границами" или "Таблица квантования" int N_Intervals=2,//Число интервалов, на которые надо разделить (отквантовать) исходные данные bool Use_Max_Min=false,//Использовать входящие значения максимума и минимума или нет double Min_arr=0.0,//Максимальное значение double Max_arr=100.0//Минимальное значение ) { if(N_Intervals<2)return -1;//Минимум интервалом может быть два, тогда разделитель один //---0. Инициализируем переменные и копируем массив arr_Input_Data double arr_In_Data[]; double Max=0.0;//Максимум double Min=0.0;//Минимум int Index_Max=0;//Индекс максимума в массиве int Index_Min=0;//Индекс минимума в массиве double Delta=0.0;//Разница между максимумом и минимумом int nQ=0;//Число разделителей (бордюров) double Interval_Size=0.0;//Размер интервала int Size_arr_In_Data=0;//Размер массива arr_In_Data double Summ_Error=0.0;//Для расчета ошибки/потерь данных nQ=N_Intervals-1;//Число разделителей Size_arr_In_Data=ArrayCopy(arr_In_Data,arr_Input_Data,0,0,WHOLE_ARRAY); ArrayResize(arr_Output_Q_Interval,Size_arr_In_Data); ArrayResize(arr_Output_Q_Data,Size_arr_In_Data); ArrayResize(arr_Output_Q_Book,nQ); //---1. Находим максимум и минимум во входных данных if(Use_Max_Min==false)//Если не используется принудительные пределы массива { Index_Max=ArrayMaximum(arr_In_Data,0,WHOLE_ARRAY); Index_Min=ArrayMinimum(arr_In_Data,0,WHOLE_ARRAY); Max=arr_In_Data[Index_Max]; Min=arr_In_Data[Index_Min]; } else//Иначе установим принудительно максимум и минимум { Max=Max_arr; Min=Min_arr; } //---2. Рассчитываем размер окна между интервалами Delta=Max-Min;//Разница между максимумом и минимумом Interval_Size=Delta/nQ;//Размер одного окна //---3. Производим квантование и подсчет ошибки for(int i=0; i<Size_arr_In_Data; i++) { arr_Output_Q_Interval[i]=(int)round((arr_In_Data[i]-Min)/Interval_Size); arr_Output_Q_Data[i]=arr_Output_Q_Interval[i]*Interval_Size+Min; Summ_Error=Summ_Error+(MathAbs(arr_Output_Q_Data[i]-arr_In_Data[i]))/Delta; } //---4. Сохраним разделители (бордюры) в массив for(int i=0; i<nQ; i++) { switch(i) { case 0: arr_Output_Q_Book[i]=float(Min+Interval_Size*0.5); break; default: arr_Output_Q_Book[i]=float(arr_Output_Q_Book[i-1]+Interval_Size); break; } } return Summ_Error=Summ_Error/(double)Size_arr_In_Data*100.0; }
Что даёт квантование данных в практическом смысле:
- Уменьшение требуемой памяти для хранения и обработки данных. Данный эффект достигается за счет того, что достаточно хранить только индекс квантового отрезка, в который попадает числовое значение числа показателя. При этом есть смысл изменять тип данных с вещественных double или float на целые типы, такие как int или даже на uchar.
- Ускорение вычислений. Достигается за счет работы с целыми числами, и снижением набора используемых чисел, что уменьшает число циклов в алгоритмах.
- Снижение шума. Качество исходных данных может содержать шум, получаемый в виде ошибок измерения, как первичных – потеря данных от брокера, так и в виде задержек, ошибок округления и измерения, квантование, по сути, усредняет показатель в диапазоне квантового отрезка, что сглаживает подобный шум и не позволяет модели акцентировать на него своё внимание.
- Компенсацию отсутствия близких значений наблюдения. Иногда значение предиктора очень редкое в силу нехватки наблюдений, и его нельзя считать выбросом, квантование может дать таким наблюдениям достаточный диапазон рассеивания значения, что сделает пригодность использования модели на новых данных, которых не было в выборке.
- Борьба с проклятием размерности. Снижение числа возможных комбинаций, уменьшает сетку возможных координат пространств измерения, что ускоряет и улучшает процесс обучения.
На двух примерах мы увидели, что есть две основных стратегии квантования:
- Стратегия, направленная на аппроксимацию данных.
- Стратегия, направленная на агрегацию данных.
Первый тип стратегий подходит скорей для метрических шкал, которыми измеряются показатели, имеющие близкие к непрерывному распределению значения признаков. Теоретически тут, чем больше интервалов, разделяющих диапазон значений, тем лучше, так как меньше будет ошибка разброса восстановленного значения по всему диапазону числового ряда. Данный тип хорошо подходит для восстановления математических функций.
Второй тип стратегий направлен на группировку данных, можно представить, что создаются обобщенные категориальные значения признаков, и тут задача с правильной оценкой границ гораздо сложней – по моему опыту нужно стремиться к тому, что бы в интервал попадало не менее 5% наблюдений из выборки.
Стоит отметить, что те признаки, что уже по смыслу категориальные, без каких-либо условностей, стоит квантовать очень осторожно, объединяя только те, которые действительно похожи. При этом похожесть тут подразумевает схожесть выборки, при их разделении на подвыборки.
К статье приложен скрипт "Q_Trans", который служит примером процесса квантования, данные для квантования генерируются случайным образом, он содержит следующие основные функции:
- "Q_Bit" - Квантование - типа преобразования (кодирования) в заданную целочисленную битность
- "Book_to_cifra" - Декодировщик - восстанавливает приближенное значение числа из Таблицы квантования, требуется массив с индексами.
- "Book_to_cifra_v2" - Декодировщик - восстанавливает приближенное значение числа из Таблицы квантования, не требуется массив с индексами.
- "Q_Random" - Квантование – со случайным установлением границ.
Скрипт содержит следующие настройки:
- Число интервалов, на которые надо разделить (отквантовать) исходные данные;
- Инициализирующее число для генерора случайных чисел;
- Сохранять графики;
- Директория для сохранения графиков;
- Ширина графика;
- Высота графика;
- Размер шрифта.
Описание этапов работы скрипта:
- Сгенерируется выборка случайным образом.
-
На графике торгового инструмента будет отображен график гистограммы, построенный так, как было описано ранее в статье (Рисунок №1), а так же график со значениями сгенерированного предиктора, которые распределены в хронологическом порядке и разбиты границами, полученными после квантования (Рисунок №2). Если настройка "Сохранять графики" имеет значение "true", то графики будут сохранены в директории с пользовательскими файлами терминала "Files\Q_Trans\Grafics".
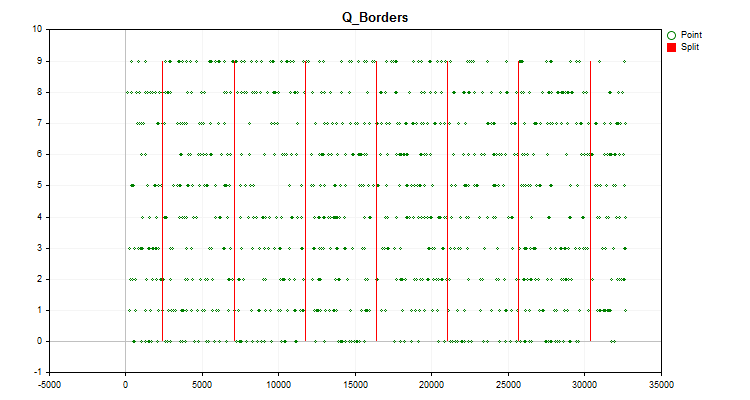 Рисунок №2.
Рисунок №2. - С помощью функции "Q_Bit" будет проведено квантование и подсчитана ошибка в виде смещения восстановленного значения относительно всего диапазона значений выборки.
- С помощью функции "Book_to_cifra" будет проведено деквантование по центроиду и подсчитана ошибка в виде смещения восстановленного значения.
- С помощью функции "Book_to_cifra" будет проведено деквантование по правой границе и подсчитана ошибка в виде смещения восстановленного значения.
- С помощью функции "Book_to_cifra_v2" будет проведено деквантование по центроиду и подсчитана ошибка в виде смещения восстановленного значения.
- С помощью функции "Q_Random" будет осуществлено 1000 попыток найти лучшие интервалы для разбиения предиктора.
- С помощью функции "Book_to_cifra" будет проведено деквантование с помощью полученной случайным образом лучшей сетки по центроиду и подсчитана ошибка в виде смещения восстановленного значения.
Если запустить скрипт с настройками по умолчанию, то в логе терминала "Эксперты" увидим следующую информацию по столбцу "Сообщение"
Средний размер ошибки восстановления данных = 3.52% от всего диапазона, при использовании 8 интервалов Средний размер ошибки через квантовую таблицу для преобразования по центроиду (Book_to_cifra) = 1145.62263 Средний размер ошибки через квантовую таблицу для преобразования по правой границе (Book_to_cifra) = 2513.41952 Средний размер ошибки через квантовую таблицу для преобразования по центроиду (Book_to_cifra_v2) = 1145.62263 Средний размер ошибки через квантовую таблицу для преобразования по центроиду (Q_Random) = 1030.79216
Интересным является то, что случайным метод подбора границ показал результат даже лучше, чем рассмотренный нами ранее – основанный на равномерном квантовании.
3. Квантования с помощью CatBoost
CatBoost, о котором я ранее писал в своей статье "Машинное обучение от Яндекс (CatBoost) без изучения Python и R", использует квантование для предобработки данных, что позволяет значительно ускорить работу алгоритма градиентного бустинга. Как и раньше, я буду пользоваться консольной версией CatBoost, так как она не требует установки дополнительного программного обеспечения при выполнении работы на центральном процессоре компьютера.
Нам понадобятся следующие настройки:
1. Метод квантования (разделения) – ключ "--feature-border-type":
- Median
- Uniform
- UniformAndQuantiles
- MaxLogSum
- MinEntropy
- GreedyLogSum
2. Число разделителей от 1 до 65535 – ключ "--border-count"
3. Сохранение таблиц квантования в указанный файл – ключ " --output-borders-file"
4. Загрузка таблиц квантования из указанного файла – ключ " --input-borders-file"
Если не указывать выше описанные ключи, то по умолчанию для построения используемых в статье моделей применяются настройки:
- Для вычисления на CPU метод квантования "GreedyLogSum", число разделителей "254";
- Для вычислений на GPU метод квантования "GreedyLogSum", число разделителей "128".
Приведу примеры, как прописывать эти ключи:
Настроим квантование, установив метод "Uniform" и число разделителей 30, сохраним таблицу квантования в файл "Quant_CB.csv"
catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description Test_CB_Setup_0_000000000 --has-header --delimiter ; --train-dir ..\Rezultat --feature-border-type Uniform --border-count 30 --output-borders-file Quant_CB.csv
Загрузим таблицу квантования из файла "Quant_CB.csv" и обучим модель
catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description Test_CB_Setup_0_000000000 --has-header --delimiter ; --train-dir ..\Rezultat --input-borders-file Quant_CB.csv
С разделом инструкции от разработчика, относящейся к настройкам квантования можно ознакомиться по следующей ссылке.
Давайте посмотрим, как отличаются методы квантования, применительно к конкретным данным. Ниже представлены графики в виде gif файлов, каждый новый кадр следующий метод, число разделителей я взял 16.
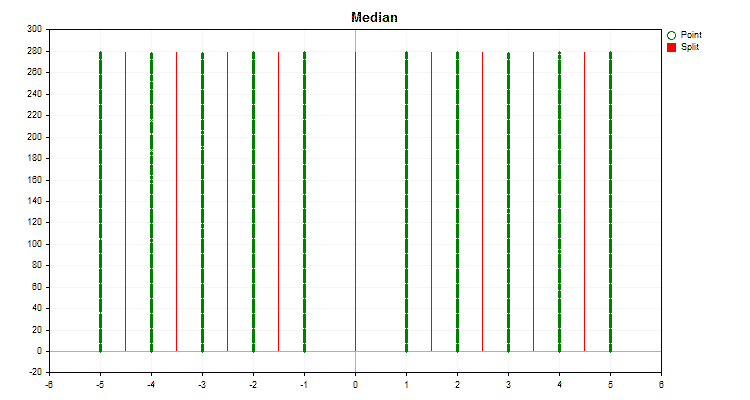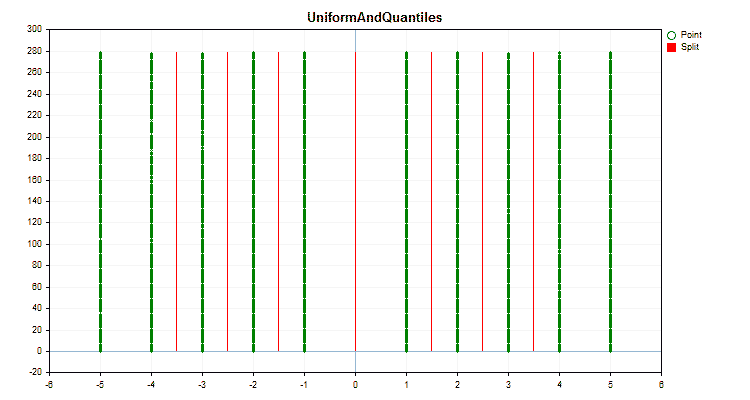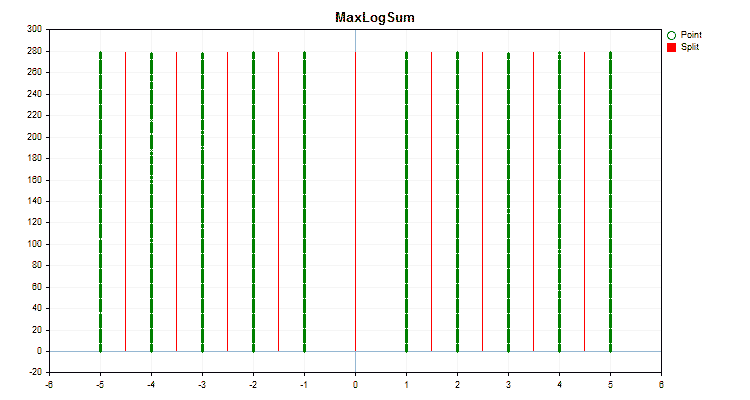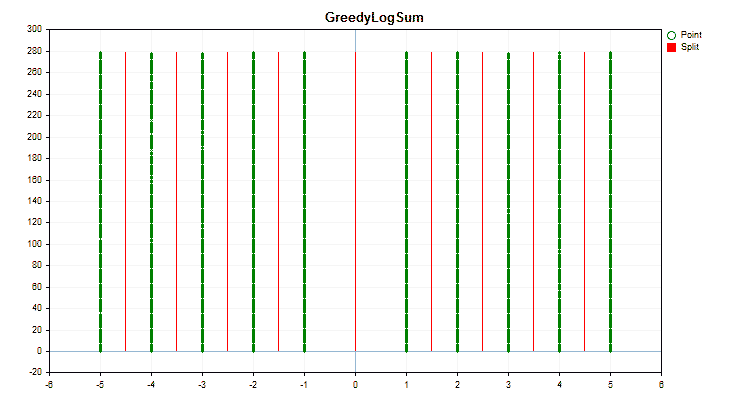
Рисунок №2 "График данных для категориального предиктора"
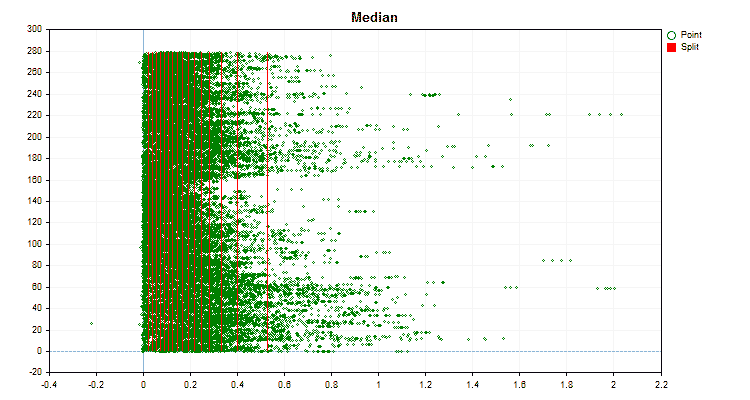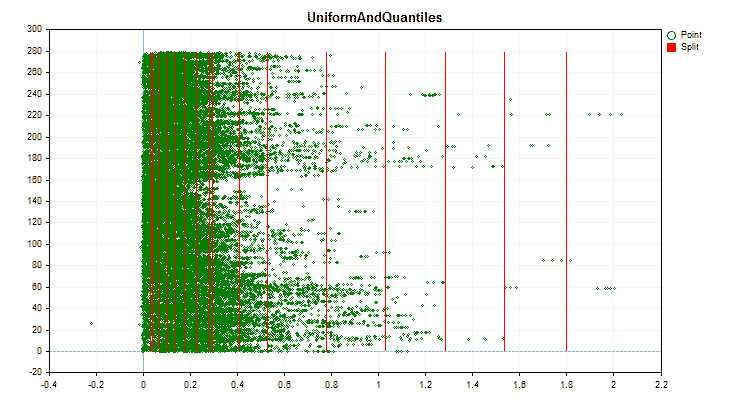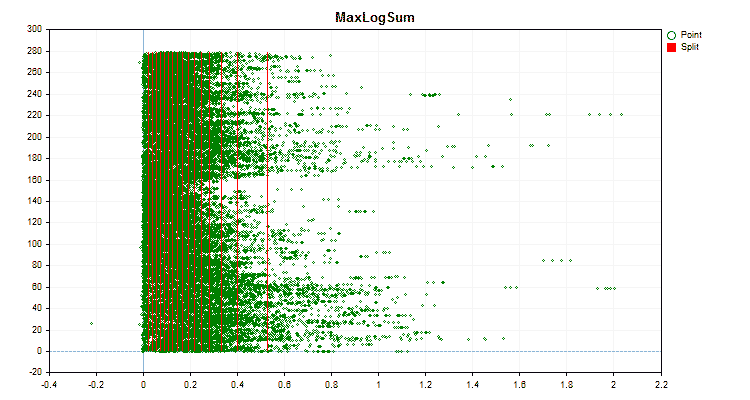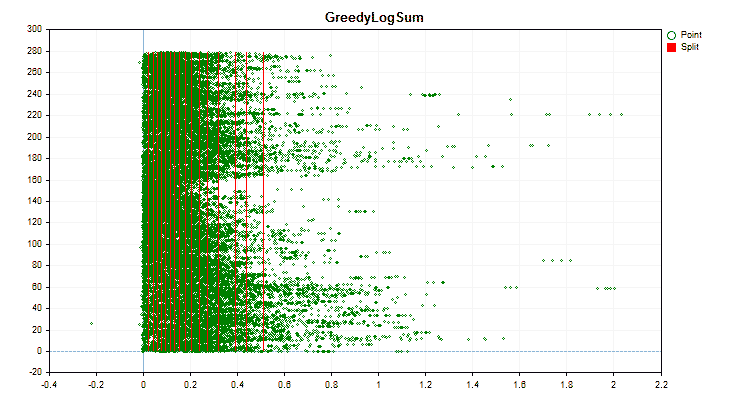
Рисунок №3 "График данных для предиктора со смещением значений в левую область"
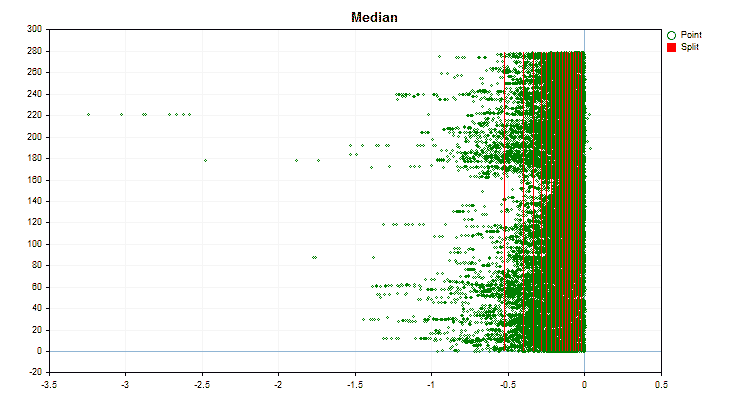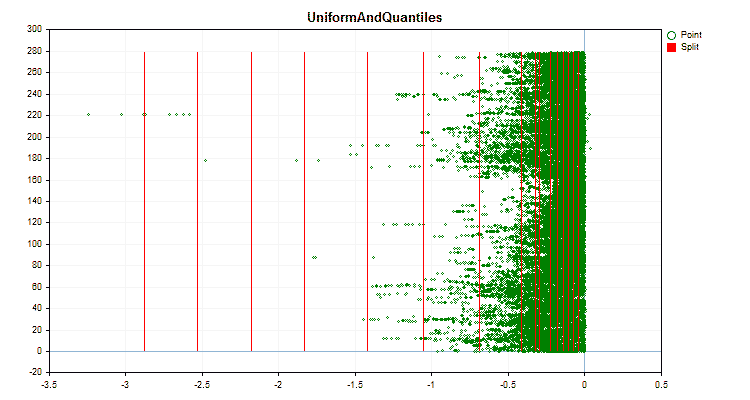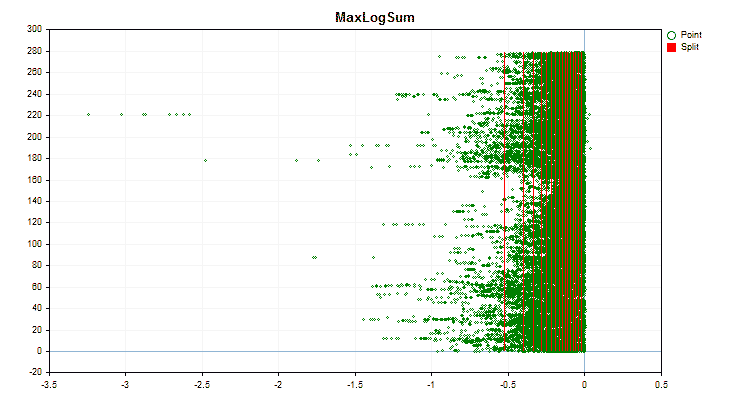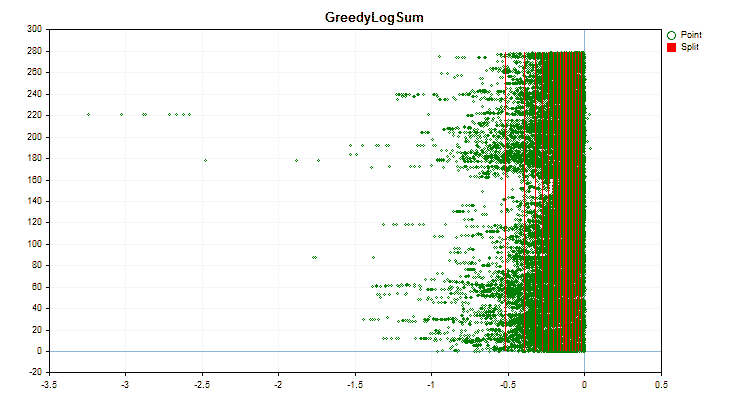
Рисунок №4 "График данных для предиктора со смещением значений в правую область"
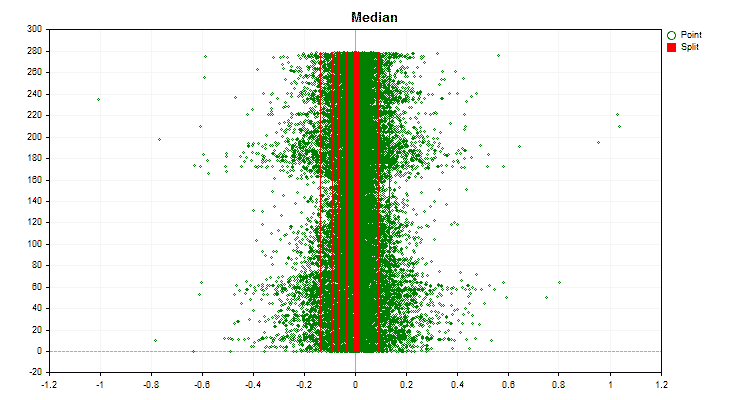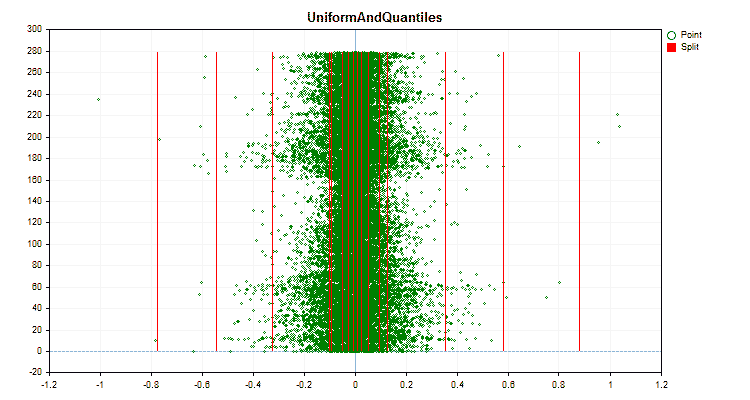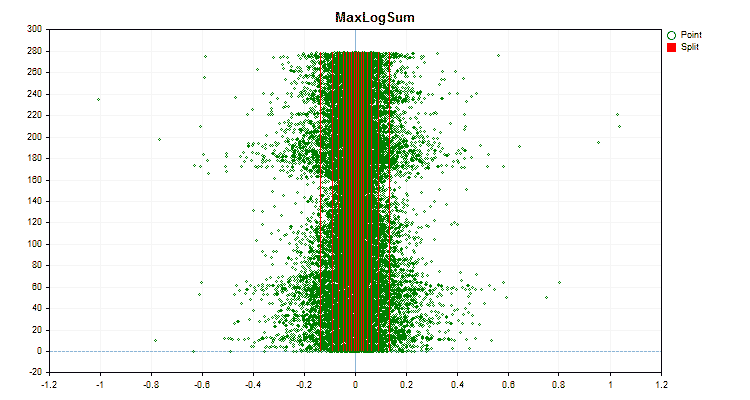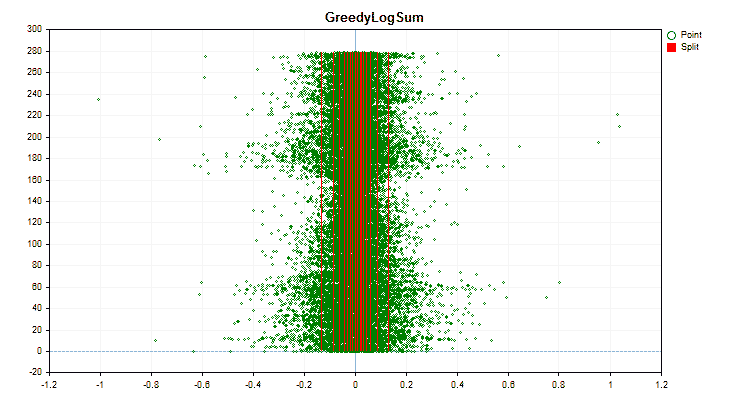
Рисунок №5 "График данных для предиктора с размещением значений в центральной области"
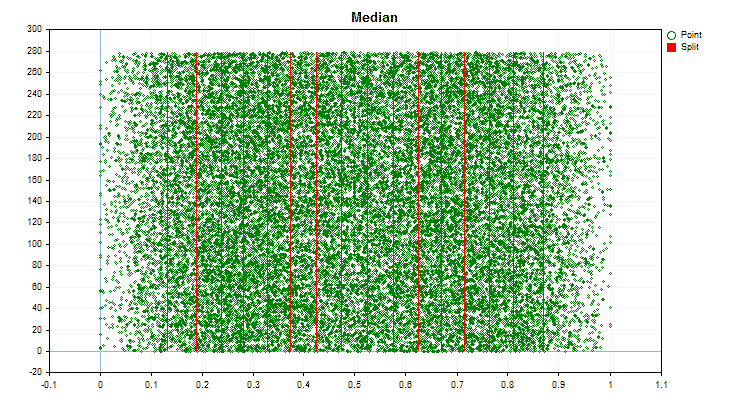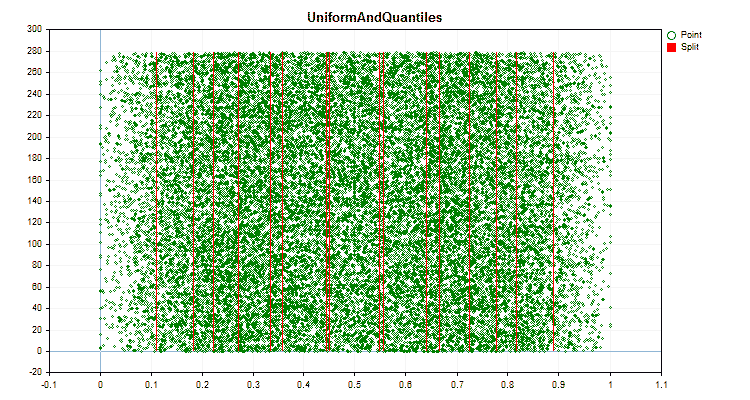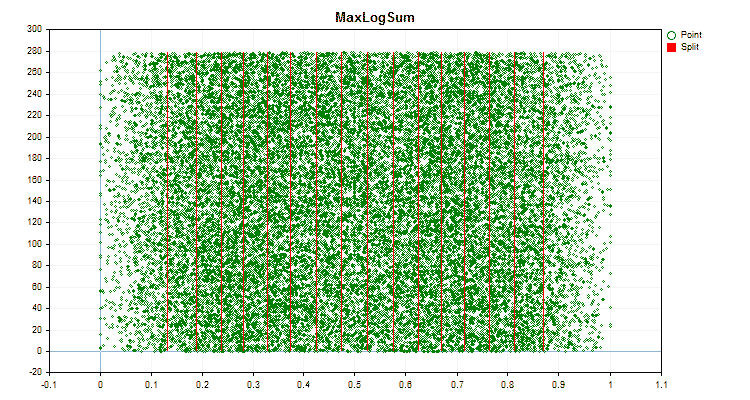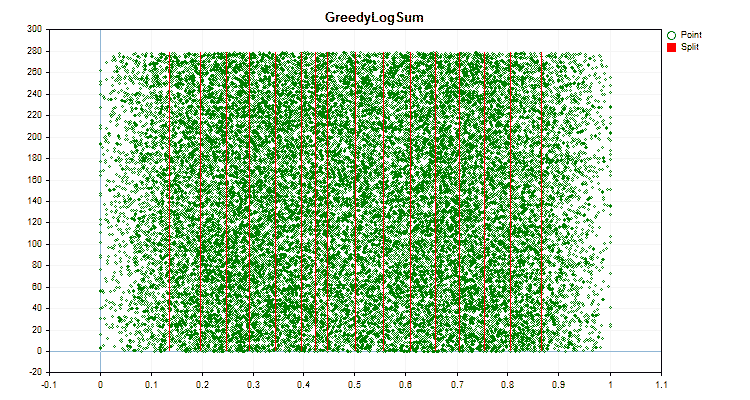
Рисунок №6 "График данных для предиктора с равномерным распределением значений"
Если рассмотреть структуру файла с таблицей квантования, в нашем случае это будет файл "Quant_CB.csv", мы увидим два столбца и множество строк. В первый столбец сохраняется порядковый номер предиктора, который будет использован при обучении модели, а во второй разделитель (бордюр/уровень). Число строк соответствует совокупной сумме разделителей, а номер в первом столбце меняется после того, как будут перечислены все разделители.
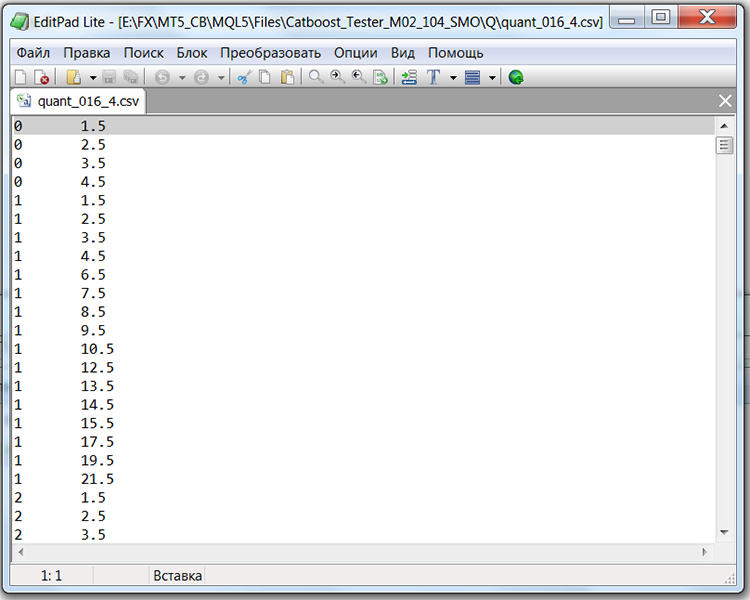
Таблица 1 "Содержимое сохраненного файла CatBoost с разделителями"
Заключение
В данной статье мы познакомились с понятием квантование, на примере кода на языке MQL5 разобрали процесс получения отквантованных значений предиктора, рассмотрели реализацию квантования в CatBoost.
Если, уважаемый читатель нашёл ошибки в терминах или суждениях, изложенных в статье, то обязательно пишите об этом - в Ваших силах улучшить приведённый текст на благо нашему сообществу.
В следующей статье разберёмся, как можно отбирать квантовые таблицы для конкретного предиктора, а так же проведём эксперимент для оценки целесообразности этого занятия.
| № | Приложение | Описание |
|---|---|---|
| 1 | Q_Trans.mq5 | Скрипт, содержащий пример равномерного квантования на случайной выборке. |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Квантование в машинном обучении - это не квантовая нейросеть (и не квантовое обучение нейросети).
Где это утверждается? Похоже, что слово "квантование" вводит в заблуждение и искажает ожидания?
Спасибо за статью, интересно!
Очень рад!
Очень интересная статья!
Спасибо!
Можно я добавлюсь к вам в друзья? Я новичок в ML. Пытаюсь кодить модели и сохранять их в ONNX, но получается сливная ерунда или же просто элементарное запоминание исторических данных(
Добавил Вас, хотя мне могут писать все, кто хочет - нет ограничения программного.