
Python, ONNX и MetaTrader 5: Создаем модель RandomForest с предварительной обработкой данных RobustScaler и PolynomialFeatures

Какую основу мы будем использовать? Что такое случайный лес?
История разработки метода случайного леса (Random Forest) уходит в прошлое и связана с работами нескольких выдающихся ученых в области машинного обучения и статистики. Однако для лучшего понимания принципов и применения этого метода, давайте представим его, как огромную группу "людей" (деревьев решений), собравшихся вместе и работающих совместно.
Метод случайного леса имеет свои корни в деревьях решений. Деревья решений - это графическое представление алгоритма принятия решений, где каждый узел представляет собой тест на одном из признаков, каждая ветвь - результат этого теста, а листья дерева - предсказанный вывод. Деревья решений были разработаны в середине 20-го века и стали популярными инструментами для классификации и регрессии.
Следующим важным шагом была концепция бэггинга, предложенная Лео Брейманом в 1996 году. Бэггинг заключается в создании нескольких подвыборок (bootstrap samples) из обучающего набора данных и обучении отдельных моделей на каждой из них. Затем результаты моделей усредняются или объединяются для получения более устойчивых и точных прогнозов. Этот метод позволил уменьшить дисперсию моделей и улучшить их обобщающую способность.
Сам метод случайного леса был предложен Лео Брейманом и Адель Катлер в начале 2000-х годов. Он основан на идее комбинирования множества деревьев решений с использованием бэггинга и дополнительной случайности. Каждое дерево строится на основе случайной подвыборки обучающих данных, и при построении каждого узла дерева выбирается случайный набор признаков. Это делает каждое дерево уникальным и уменьшает корреляцию между деревьями, что приводит к улучшению обобщающей способности.
Случайный лес быстро стал одним из наиболее популярных методов в машинном обучении благодаря своей высокой производительности и способности работать как с задачами классификации, так и с задачами регрессии. В классификации он используется для принятия решений о принадлежности объектов к различным классам, а в регрессии - для предсказания численных значений.
Сегодня случайный лес широко применяется в различных областях, включая финансы, медицину, анализ данных и многие другие, благодаря своей надежности и способности обрабатывать сложные задачи машинного обучения.
Случайный лес, или RandomForest, представляет собой мощный инструмент в арсенале машинного обучения. Для того чтобы лучше понять его принцип работы, давайте визуализируем его как огромную группу людей, собравшихся вместе и принимающих коллективные решения. Однако вместо реальных людей, каждый человек в этой группе является независимым классификатором или предсказателем текущей ситуации. Внутри этой группы, люди - это деревья решений, каждое из которых способно принимать решения на основе определенных признаков. Когда случайный лес принимает решение, он использует демократический принцип и голосование - каждое дерево выражает свое мнение, и решение принимается на основе множественных голосов.
Случайный лес широко применяется в множестве областей, и его гибкость делает его подходящим для задач как классификации, так и регрессии. При задаче классификации, модель решает, к какому из предопределенных классов отнести текущее состояние. Например, на финансовом рынке, это может означать решение о покупке (класс 1) или продаже (класс 0) актива, основываясь на множестве признаков.
Однако, в данной статье мы углубимся в задачу регрессии. Регрессия в машинном обучении - это попытка прогнозировать будущие численные значения временного ряда, основываясь на его прошлых значениях. Вместо классификации, где мы относим объекты к определенным классам, в регрессии мы стремимся предсказать конкретные числа. Это может быть, например, прогнозирование цен акций на финансовом рынке, предсказание температуры или любой другой численной переменной.
Создаем базовую модель RF
Для создания базовой модели случайного леса, мы будем использовать библиотеку sklearn (Scikit-learn) в Python. Приведен ниже простой шаблон кода для обучения регрессионной модели случайного леса. Прежде чем запустить этот код, вам нужно установить библиотеки, необходимые для работы с sklearn, MetaTrader 5, с помощью инструмента установки пакетов в Python.
pip install onnx
pip install skl2onnx
pip install MetaTrader5 Далее по плану - импорт библиотек и настройка параметров. Мы импортируем необходимые библиотеки, такие как pandas для работы с данными, gdown для загрузки данных из Google Drive, а также библиотеки для обработки данных и создания модели случайного леса. Также мы задаем количество временных шагов (n_steps) в последовательности данных, которое определяется в зависимости от конкретных требований:
import pandas as pd import gdown import numpy as np import joblib import random import onnx import os import shutil from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score from sklearn.utils import shuffle from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.pipeline import Pipeline from sklearn.preprocessing import RobustScaler, MinMaxScaler, PolynomialFeatures, PowerTransformer import MetaTrader5 as mt5 from datetime import datetime # Задать количество временных шагов по требованиям n_steps = 100
Следующий шаг - загрузка и обработка данных. В этой части кода мы загружаем данные о котировках из MetaTrader 5 и обрабатываем их. Мы устанавливаем индекс времени и выбираем только цены закрытия (это то, с чем мы будем работать):
Вот часть кода, отвечающая за разделение наших данных на тренировочный и тестовый наборы, а также за разметку меток для обучения модели. Мы разделяем данные на тренировочный и тестовый наборы. Затем мы создаем метки для регрессии, что означает, что каждая метка представляет собой фактическое будущее значение цены. Функция labelling_relabeling_regression используется для создания маркированных данных .mt5.initialize() SYMBOL = 'EURUSD' TIMEFRAME = mt5.TIMEFRAME_H1 START_DATE = datetime(2000, 1, 1) STOP_DATE = datetime(2023, 1, 1) # Задаем количество временных шагов по вашим требованиям n_steps = 100 # Обрабатываем данные data = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START_DATE, STOP_DATE), columns=['time', 'close']).set_index('time') data.index = pd.to_datetime(data.index, unit='s') data = data.dropna() data = data[['close']] # Работаем только с закрытием
# Определить train_data_initial training_size = int(len(data) * 0.70) train_data_initial = data.iloc[:training_size] test_data_initial = data.iloc[training_size:] # Функция для создания и присвоения меток для регрессии (изменения внесены для регрессии, а не классификации) def labelling_relabeling_regression(dataset, min_value=1, max_value=1): future_prices = [] for i in range(dataset.shape[0] - max_value): rand = random.randint(min_value, max_value) future_pr = dataset['close'].iloc[i + rand] future_prices.append(future_pr) dataset = dataset.iloc[:len(future_prices)].copy() dataset['future_price'] = future_prices return dataset # Применить функцию labelling_relabeling_regression к исходным данным, чтобы получить маркированные данные train_data_labeled = labelling_relabeling_regression(train_data_initial) test_data_labeled = labelling_relabeling_regression(test_data_initial)
Далее создаем наборы обучающих данных, из определенных последовательностей. Важно то, чтобы модель брала в качестве признаков все цены закрытия в нашей последовательности. Этот же размер последовательности уходит в качестве размера подаваемых на вход ONNX модели данных, Нормализации на данном этапе нет - она будет выполнена в конвейере обучения, в рамках работы конвейера модели.
# Создаем наборы данных признаков и целевых переменных для тестирования
x_test = np.array([test_data_labeled['close'].iloc[i - n_steps:i].values[-n_steps:] for i in range(n_steps, len(test_data_labeled))])
y_test = test_data_labeled['future_price'].iloc[n_steps:].values
# После создания x_train и x_test, можно определить n_features так:
n_features = x_train.shape[1]
# Теперь можно использовать n_features для определения типа входных данных ONNX
initial_type = [('float_input', FloatTensorType([None, n_features]))]
Пишем конвейер Pipeline для препроцессинга данных
Следующий наш шаг - создание модели, модели случайного леса, при этом важно сделать модель в виде конвейера.
Конвейер (Pipeline) в библиотеке scikit-learn (sklearn) представляет собой способ создания последовательной цепочки преобразований и моделей для анализа данных и машинного обучения. Конвейер позволяет объединить несколько этапов обработки данных и моделирования в единый объект, который можно использовать для удобного и последовательного выполнения операций на данных.
В нашем примере кода мы создаем следующий конвейер:
# Создаем конвейер с MinMaxScaler, RobustScaler, PolynomialFeatures и RandomForestRegressor
pipeline = Pipeline([
('MinMaxScaler', MinMaxScaler()),
('robust', RobustScaler()),
('poly', PolynomialFeatures()),
('rf', RandomForestRegressor(
n_estimators=20,
max_depth=20,
min_samples_split=5000,
min_samples_leaf=5000,
random_state=1,
verbose=2
))
])
# Обучение конвейера
pipeline.fit(x_train, y_train)
# Сделать прогнозы
predictions = pipeline.predict(x_test)
# Оценка модели с помощью R2
r2 = r2_score(y_test, predictions)
print(f'R2 score: {r2}') Конвейер (pipeline) - это последовательность шагов обработки данных и моделирования, объединенных в одну цепочку. В данном коде конвейер создается с использованием библиотеки scikit-learn (sklearn) и включает в себя следующие этапы:
-
MinMaxScaler: Этот этап масштабирует данные, приводя их к диапазону от 0 до 1. Это полезно для обеспечения одинакового масштаба всех признаков.
-
RobustScaler: RobustScaler также выполняет масштабирование данных, но более устойчив к выбросам в данных. Он использует медиану и интерквартильный диапазон для масштабирования.
-
PolynomialFeatures: На этом этапе применяется полиномиальное преобразование к признакам. Это добавляет полиномиальные признаки, которые могут помочь модели учесть нелинейные зависимости в данных.
-
RandomForestRegressor: Этот этап определяет модель случайного леса с набором гиперпараметров:
- n_estimators (Количество деревьев в лесу): Допустим, у вас есть группа "экспертов", каждый из которых специализируется на прогнозировании цен на финансовом рынке. Количество деревьев в случайном лесу (n_estimators) определяет, сколько таких "экспертов" будет в вашей группе. Чем больше деревьев, тем более разнообразные мнения и прогнозы будут учтены при принятии решения моделью.
- max_depth (Максимальная глубина каждого дерева): Этот параметр ограничивает, насколько глубоко каждый "эксперт" (дерево) может "погружаться" в анализ данных. Если вы установите максимальную глубину, например, равной 20, то каждое дерево будет принимать решения, учитывая не более 20 признаков или характеристик.
- min_samples_split (Минимальное количество образцов для разделения узла дерева): Этот параметр говорит о том, сколько образцов (наблюдений) должно быть в узле дерева, чтобы дерево продолжило его деление на более мелкие узлы. Например, если вы установите минимальное количество образцов для разделения равным 5000, то дерево будет разделять узлы только в том случае, если в узле есть более 5000 наблюдений.
- min_samples_leaf (Минимальное количество образцов в листовом узле дерева): Этот параметр определяет, сколько образцов должно находиться в листовом узле дерева, чтобы этот узел стал "листом" и не разделялся дальше. Например, если установить минимальное количество образцов в листовом узле равным 5000, то каждый лист дерева будет содержать не менее 5000 наблюдений.
- random_state (Задает начальное состояние для случайной генерации, обеспечивая воспроизводимость результатов): Этот параметр используется для контроля случайных процессов внутри модели. Если вы установите фиксированное значение (например, 1), то при каждом запуске модели результаты будут одинаковыми. Это полезно для воспроизводимости результатов.
- verbose (Включает вывод информации о процессе обучения модели): При обучении модели может быть полезно видеть информацию о процессе. Параметр verbose позволяет управлять уровнем подробности этой информации. Чем выше значение (например, 2), тем больше информации будет выведено в процессе обучения.
После создания конвейера, мы используем метод fit для обучения его на обучающих данных. Затем с помощью метода predict делаем прогнозы на тестовых данных. Наконец, оцениваем качество модели с помощью метрики R2, которая измеряет соответствие модели данным.
Конвейер обучается, а затем оценивается по метрике R2. Мы используем нормализацию, удаление выбросов из данных, а также создание полиноминальных признаков. Это самые простые методы препроцессинга данных. В будущих статьях мы будем разбирать создание собственной функции препроцессинга с помощью Function Transformer.
Используем экспорт модели в ONNX, пишем функцию экспорта
После обучения конвейера мы сохраняем его в формате joblib, который при помощи библиотеки skl2onnx мы сохраняем в формат ONNX.
# Сохраняем конвейер
joblib.dump(pipeline, 'rf_pipeline.joblib')
# Конвертация конвейера в ONNX
onnx_model = convert_sklearn(pipeline, initial_types=initial_type)
# Сохраняем модель в формате ONNX
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Сохраняем модель в формате ONNX
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Подключить Google Диск (если работаете в Colab и это необходимо)
from google.colab import drive
drive.mount('/content/drive')
# Указать путь к Google Диск, куда вы хотите переместить модель
drive_path = '/content/drive/My Drive/' # Убедитесь, что путь указан правильно
rf_pipeline_onnx_drive_path = os.path.join(drive_path, 'rf_pipeline.onnx')
# Переместить модель ONNX на Google Диск
shutil.move(model_onnx_path, rf_pipeline_onnx_drive_path)
print('Модель rf_pipeline сохранена в формате ONNX на Google Drive:', rf_pipeline_onnx_drive_path) Вот так выглядит процесс обучения модели и сохранения модели в ONNX. Такую картинку мы увидим после окончания обучения:
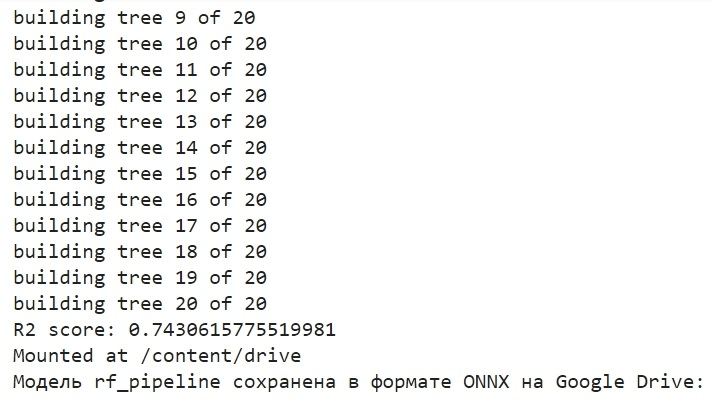
Модель сохраняется в базовую директорию Гугл-Диска,в формате ONNX. ONNX можно рассматривать как своеобразную "дискету" для моделей машинного обучения. Этот формат позволяет сохранять обученные модели и конвертировать их для использования в различных приложениях. Это подобно тому, как вы сохраняете файлы на флешку-накопитель и затем можете читать их на других устройствах. В нашем случае, ONNX модель будет использоваться в среде MetaTrader 5 для прогнозирования цен на финансовых рынках. Саму "дискету" ONNX можно прочитать на стороне, к примеру в MetaTrader 5 - чем мы сейчас и займемся.
Проверяем модель в тестере MetaTrader 5
ONNX модель сохранилась к нам на Google Drive, скачиваем ее оттуда. После сохранения ONNX модели на Google Drive, мы загружаем её оттуда. Для использования этой модели в MetaTrader 5, мы создаем эксперта, который будет читать и применять эту модель для принятия решений о торговле. В представленном коде советника, мы устанавливаем параметры торговли, такие как объем лота, использование стоп-заказов, уровни Take Profit и Stop Loss. Вот код советника, который будет "читать" нашу ONNX модель:
//+------------------------------------------------------------------+ //| ONNX Random Forest.mq5 | //| Copyright 2023 | //| Evgeniy Koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com" #property version "0.90" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; input double InpLots = 1.0; // Объем лота для открытия позиции input bool InpUseStops = true; // Использовать стоп-заказы при торговле input int InpTakeProfit = 500; // Уровень Take Profit input int InpStopLoss = 500; // Уровень Stop Loss #resource "Python/rf_pipeline.onnx" as uchar ExtModel[] #define SAMPLE_SIZE 100 long ExtHandle=INVALID_HANDLE; int ExtPredictedClass=-1; datetime ExtNextBar=0; datetime ExtNextDay=0; CTrade ExtTrade; #define PRICE_UP 1 #define PRICE_SAME 2 #define PRICE_DOWN 0 // Функция для закрытия всех позиций void CloseAll(int type=-1) { for(int i=PositionsTotal()-1; i>=0; i--) { if(PositionSelectByTicket(PositionGetTicket(i))) { if(PositionGetInteger(POSITION_TYPE)==type || type==-1) { trade.PositionClose(PositionGetTicket(i)); } } } } // Инициализация эксперта int OnInit() { if(_Symbol!="EURUSD" || _Period!=PERIOD_H1) { Print("Модель должна работать с EURUSD, H1"); return(INIT_FAILED); } ExtHandle=OnnxCreateFromBuffer(ExtModel,ONNX_DEFAULT); if(ExtHandle==INVALID_HANDLE) { Print("Ошибка при создании модели OnnxCreateFromBuffer ",GetLastError()); return(INIT_FAILED); } const long input_shape[] = {1,100}; if(!OnnxSetInputShape(ExtHandle,ONNX_DEFAULT,input_shape)) { Print("Ошибка при установке формы входных данных OnnxSetInputShape ",GetLastError()); return(INIT_FAILED); } const long output_shape[] = {1,1}; if(!OnnxSetOutputShape(ExtHandle,0,output_shape)) { Print("Ошибка при установке формы выходных данных OnnxSetOutputShape ",GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Деинициализация эксперта void OnDeinit(const int reason) { if(ExtHandle!=INVALID_HANDLE) { OnnxRelease(ExtHandle); ExtHandle=INVALID_HANDLE; } } // Обработка тиковой функции void OnTick() { if(TimeCurrent()<ExtNextBar) return; ExtNextBar=TimeCurrent(); ExtNextBar-=ExtNextBar%PeriodSeconds(); ExtNextBar+=PeriodSeconds(); PredictPrice(); if(ExtPredictedClass>=0) if(PositionSelect(_Symbol)) CheckForClose(); else CheckForOpen(); } // Проверка условий открытия позиции void CheckForOpen(void) { ENUM_ORDER_TYPE signal=WRONG_VALUE; if(ExtPredictedClass==PRICE_DOWN) signal=ORDER_TYPE_SELL; else { if(ExtPredictedClass==PRICE_UP) signal=ORDER_TYPE_BUY; } if(signal!=WRONG_VALUE && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { double price,sl=0,tp=0; double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); if(signal==ORDER_TYPE_SELL) { price=bid; if(InpUseStops) { sl=NormalizeDouble(bid+InpStopLoss*_Point,_Digits); tp=NormalizeDouble(ask-InpTakeProfit*_Point,_Digits); } } else { price=ask; if(InpUseStops) { sl=NormalizeDouble(ask-InpStopLoss*_Point,_Digits); tp=NormalizeDouble(bid+InpTakeProfit*_Point,_Digits); } } ExtTrade.PositionOpen(_Symbol,signal,InpLots,price,sl,tp); } } // Проверка условий закрытия позиции void CheckForClose(void) { if(InpUseStops) return; bool tsignal=false; long type=PositionGetInteger(POSITION_TYPE); if(type==POSITION_TYPE_BUY && ExtPredictedClass==PRICE_DOWN) tsignal=true; if(type==POSITION_TYPE_SELL && ExtPredictedClass==PRICE_UP) tsignal=true; if(tsignal && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { ExtTrade.PositionClose(_Symbol,3); CheckForOpen(); } } // Функция для получения текущего спреда double GetSpreadInPips(string symbol) { double spreadPoints = SymbolInfoInteger(symbol, SYMBOL_SPREAD); double spreadPips = spreadPoints * _Point / _Digits; return spreadPips; } // Функция для прогнозирования цены void PredictPrice() { static vectorf output_data(1); static vectorf x_norm(SAMPLE_SIZE); double spread = GetSpreadInPips(_Symbol); if (!x_norm.CopyRates(_Symbol, _Period, COPY_RATES_CLOSE, 1, SAMPLE_SIZE)) { ExtPredictedClass = -1; return; } if (!OnnxRun(ExtHandle, ONNX_NO_CONVERSION, x_norm, output_data)) { ExtPredictedClass = -1; return; } float predicted = output_data[0]; if (spread < 0.000005 && predicted > iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_UP; } else if (spread < 0.000005 && predicted < iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_DOWN; } else { ExtPredictedClass = PRICE_SAME; } }
Особенно хотелось бы отметить, что вот эта размерность входных данных:
const long input_shape[] = {1,100};
Должна соответствовать размерности в нашей Python-модели:
# Задаем количество временных шагов по вашим требованиям n_steps = 100
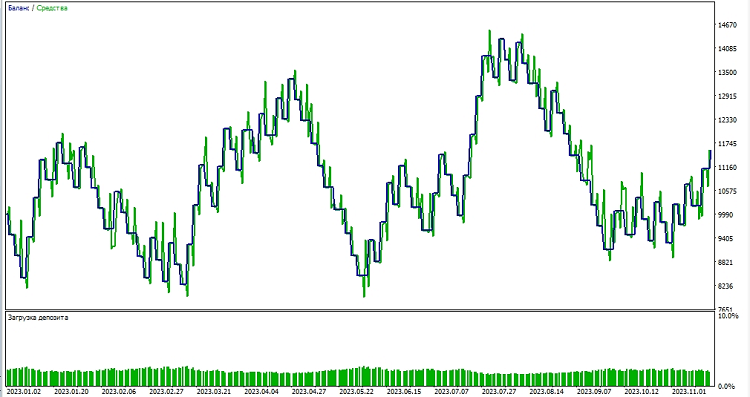
Далее мы приступаем к тестированию модели в среде MetaTrader 5. Мы используем предсказания модели для определения направления движения цен на рынке. Если модель предсказывает, что цена поднимется, мы готовимся к открытию длинной позиции (покупки), и наоборот, если модель предсказывает, что цена снизится, мы готовимся к открытию короткой позиции (продаже). Проведем тестирование модели с тейк-профитом 1000, и стоп-лоссом в 500:
Заключение
Итак, мы рассмотрели создание и обучение модели случайного леса в Python, предобработку данных прямо в рамках модели, а также ее экспорт в ONNX-стандарт, и последующее открытие и использование модели в MetaTrader 5.
ONNX — отличная система импорта-экспорта моделей, универсальная и простая. Сохранение модели в ONNX на самом деле намного проще, чем кажется, и препроцессинг данных также очень прост.
Конечно, наша модель из всего 20 решающих деревьев - очень простая, да и сама модель случайного леса уже достаточно старое решение, модель прошлого века. В будущем мы создадим более сложные и современные модели, и будем использовать более сложную предобработку данных. Отдельно хотелось бы отметить возможность создания ансамбля моделей сразу в виде конвейера sklearn, одновременно вместе с препроцессингом. Это существенно расширит наши возможности, в том числе и для задач классификации.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Почему не был использован градиентный бустинг как более современный алгоритм (раз уж вы жалуетесь, что random forest уже устарел)? Это просто произошло или была какая-то причина? Я думаю, что бустинг есть в sklearn.
Просто лес был выбран в качестве простого примера)Бустинг в следующей статье, сейчас я его немного дорабатываю)
Просто лес был выбран в качестве простого примера)Бустинг в следующей статье, сейчас я его немного дорабатываю)
Хорошо)
Было бы интересно дальнейшее развитие темы конвейеров и их конвертирования в ONNX с последующим использованием в метатрейдере. Например, есть ли возможность добавлять в конвейер кастомные преобразования и будет ли полученная из такого конвейера ONNX модель открываться в метатрейдере? Имхо, тема достойная нескольких статей.
Было бы интересно дальнейшее развитие темы конвейеров и их конвертирования в ONNX с последующим использованием в метатрейдере. Например, есть ли возможность добавлять в конвейер кастомные преобразования и будет ли полученная из такого конвейера ONNX модель открываться в метатрейдере? Имхо, тема достойная нескольких статей.