
Переосмысливаем классические стратегии в MQL5 (Часть III): Прогнозирование индекса FTSE 100

Искусственный интеллект (ИИ) открывает потенциально бесконечные возможности для использования в стратегии современного инвестора. К сожалению, ни у одного индивидуального инвестора не будет достаточно времени для тщательного анализа каждой стратегии, прежде чем решить, какой из них доверить свой капитал. В настоящей серии статей мы поможем вам разобраться в огромном количестве основанных на ИИ возможных стратегий, чтобы помочь вам определить стратегию, соответствующую вашему профилю инвестора.
Обзор торговой стратегии
Лондонская фондовая биржа (LSE) - одна из старейших фондовых бирж в развитых странах мира. Она основана в 1801 году и является основной фондовой биржей Соединенного Королевства. Она считается частью "большой тройки" наряду с Нью-Йоркской фондовой биржей и Токийской фондовой биржей. Лондонская фондовая биржа является крупнейшей фондовой биржей в Европе, и, согласно ее официальному веб-сайту, текущая общая рыночная капитализация всех компаний, котирующихся на бирже, составляет примерно 4,4 трлн. британских фунтов стерлингов.
Financial Times Stock Exchange (FTSE) 100 - это индекс, производный от LSE, отслеживающий 100 крупнейших компаний, котирующихся на LSE. Эти компании обычно называют "голубыми фишками" и считаются относительно безопасными инвестициями, учитывая репутацию, заработанную компаниями с течением времени, и их проверенный послужной список. Мы можем воспользоваться нашим пониманием того, как рассчитывается индекс FTSE 100, и потенциально создать новую торговую стратегию, которая будет прогнозировать будущую цену закрытия FTSE 100, учитывая текущую цену закрытия индекса, а также динамику акций 10 крупных компаний, включенных в индекс.
Обзор методологии
Мы создали наш советник на базе искусственного интеллекта полностью на MQL5. Это дает нам гибкость, поскольку нашу модель можно использовать на разных таймфреймах без необходимости постоянной корректировки. Кроме того, мы можем динамически настраивать параметры модели, например, на какое отдаленное будущее она должна прогнозировать. Наша модель использовала в общей сложности 12 входных данных для прогнозирования будущей цены закрытия FTSE 100, на 20 шагов вперед.
Мы выполнили Z-стандартизацию, чтобы нормализовать и масштабировать каждые из входных данных нашей модели, используя среднее значение по столбцу и стандартное значение отклонения. Нашей целью была будущая цена закрытия индекса FTSE100 на 20 шагов вперед, и мы создали модель множественной линейной регрессии для прогнозирования будущей цены закрытия индекса.
Не все модели машинного обучения созданы одинаково, это особенно заметно в задачах, касающихся прогнозирования. Давайте рассмотрим деревья решений; древовидные алгоритмы обычно работают путем разбиения данных на группы, а затем, когда модели требуется сделать прогноз, она просто возвращает среднее значение по группе для той группы, которая наилучшим образом соответствует текущим входным данным. Следовательно, древовидные алгоритмы не выполняют экстраполяцию, другими словами, они не обладают умением заглядывать вперед и делать прогнозы на будущее. Следовательно, если бы древовидной модели были даны 5 одинаковых входных данных из 5 разных моментов, она могла бы предсказать одинаковую цену закрытия для всех 5, если бы они были достаточно похожи, в то время как наша модель линейной регрессии способна к экстраполяции и может дать нам прогноз о будущей цене закрытия ценной бумаги.
Первоначальная разработка в виде скрипта
Изначально мы представим нашу идею в виде простого скрипта на MQL5, чтобы оценить, как части нашей системы работают вместе. Начнем с определения наших глобальных переменных.//+------------------------------------------------------------------+ //| UK100.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ //1) ADM.LSE - Admiral //2) AAL.LSE - Anglo American //3) ANTO.LSE - Antofagasta //4) AHT.LSE - Ashtead //5) AZN.LSE - AstraZeneca //6) ABF.LSE - Associated British Foods //7) AV.LSE - Aviva //8) BARC.LSE - Barclays //9) BP.LSE - BP //10) BKG.LSE - Berkeley Group //11) UK100 - FTSE 100 Index //+-------------------------------------------------------------------+ //| Global variables | //+-------------------------------------------------------------------+ int fetch = 2000; int look_ahead = 20; double mean_values[11],std_values[11]; string list_of_companies[11] = {"ADM.LSE","AAL.LSE","ANTO.LSE","AHT.LSE","AZN.LSE","ABF.LSE","AV.LSE","BARC.LSE","BP.LSE","BKG.LSE","UK100"}; vector intercept = vector::Ones(fetch); matrix target = matrix::Zeros(1,fetch); matrix coefficients; matrix input_matrix = matrix::Zeros(12,fetch);
Первая задача, которую мы выполним, - это извлечение и нормализация входных данных. Мы будем хранить входные данные в одной матрице, а целевые данные будут храниться в отдельной матрице
void OnStart() { //--- Fetch the target target.CopyRates("UK100",PERIOD_CURRENT,COPY_RATES_CLOSE,1,fetch); //--- Fill in the input matrix for(int i = 0; i < 11; i++) { //--- Add the symbol to market watch SymbolSelect(list_of_companies[i],true); //--- Fetch historical data vector temp = vector::Zeros(fetch); temp.CopyRates(list_of_companies[i],PERIOD_CURRENT,COPY_RATES_CLOSE,1+look_ahead,fetch); //--- Store the mean value and standard deviation, also scale the data mean_values[i] = temp.Mean(); std_values[i] = temp.Std(); temp = ((temp - mean_values[i]) / std_values[i]); //--- Add the data to the matrix input_matrix.Row(temp,i); } //--- Add the intercept input_matrix.Row(intercept,11); //--- Show the input data Print("Input data:"); Print(input_matrix);
Рис 1: Пример выходных данных, сгенерированных нашим скриптом
После получения наших входных данных мы можем приступить к расчету параметров нашей модели. К счастью, коэффициенты модели множественной линейной регрессии можно рассчитать с помощью формулы замкнутой формы. Ниже приведён пример модельных коэффициентов.
//--- Calculating coefficient values coefficients = target.MatMul(input_matrix.PInv()); //--- Display the coefficient values Print("UK100 Coefficients:"); Print(coefficients.Transpose());

Рис 2: Параметры нашей модели
Давайте интерпретируем результаты вместе, первое значение коэффициента представляет собой среднее значение целевого показателя, когда все входные данные модели равны 0. Это математическое определение параметра смещения. Однако в нашем торговом приложении он имеет очень мало интуитивного смысла. С технической точки зрения, если бы все акции в FTSE 100 оценивались в 0 британских фунтов, то средняя будущая стоимость FTSE 100 также составляла бы 0 британских фунтов. Второй коэффициент представляет собой незначительное изменение будущей стоимости FTSE 100 при условии, что все остальные акции закрываются по той же цене. Поэтому всякий раз, когда акции Admiral растут на одну единицу, мы наблюдаем, что будущая цена закрытия индекса, по-видимому, несколько снижается.
Получить прогноз на основе нашей модели так же просто, как умножить текущую цену каждой акции на рассчитанное значение коэффициента и просуммировать все эти продукты. Теперь, когда у нас есть представление о том, как можно построить нашу модель, мы готовы приступить к созданию нашего советника.
Реализация нашего советника
Начнем с определения входных данных, которые пользователь может изменять, чтобы изменить поведение программы.
//+------------------------------------------------------------------+ //| FTSE 100 AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int look_ahead = 20; // How far into the future should we forecast? input int rsi_period = 20; // The period of our RSI input int profit_target = 20; // After how much profit should we close our positions? input bool ai_auto_close = true; // Should the AI automatically close positions?
Затем импортируем торговую библиотеку, которая поможет нам управлять нашими позициями.
//+------------------------------------------------------------------+ //| Libraries we need | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
Теперь определим несколько глобальных переменных, которые нам понадобятся на протяжении всего нашего советника.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double position_profit = 0; int fetch = 20; matrix coefficients; matrix input_matrix = matrix::Zeros(12,fetch); double mean_values[11],std_values[11],rsi_buffer[1]; string list_of_companies[11] = {"ADM.LSE","AAL.LSE","ANTO.LSE","AHT.LSE","AZN.LSE","ABF.LSE","AV.LSE","BARC.LSE","BP.LSE","BKG.LSE","UK100"}; ulong open_ticket;
Теперь определим функцию для получения наших обучающих данных. Напомним, что мы стремимся получить обучающие данные, а затем нормализовать и стандартизировать наши данные, прежде чем добавлять их во входную матрицу.
//+------------------------------------------------------------------+ //| This function will fetch our training data | //+------------------------------------------------------------------+ void fetch_training_data(void) { //--- Fetch the target target.CopyRates("UK100",PERIOD_CURRENT,COPY_RATES_CLOSE,1,fetch); //--- Add the intercept input_matrix.Row(intercept,0); //--- Fill in the input matrix for(int i = 0; i < 11; i++) { //--- Add the symbol to market watch SymbolSelect(list_of_companies[i],true); //--- Fetch historical data vector temp = vector::Zeros(fetch); temp.CopyRates(list_of_companies[i],PERIOD_CURRENT,COPY_RATES_CLOSE,1+look_ahead,fetch); //--- Store the mean value and standard deviation, also scale the data mean_values[i] = temp.Mean(); std_values[i] = temp.Std(); temp = ((temp - mean_values[i]) / std_values[i]); //--- Add the data to the matrix input_matrix.Row(temp,i+1); } }
После получения наших обучающих данных мы также должны определить функцию для подгонки коэффициентов нашей модели.
//+---------------------------------------------------------------------+ //| This function will fit our multiple linear regression model | //+---------------------------------------------------------------------+ void model_fit(void) { //--- Calculating coefficient values coefficients = target.MatMul(input_matrix.PInv()); }
Как только обучим и адаптируем нашу модель, мы, наконец, сможем получать с помощью неё прогнозы. Чтобы начать работу, сначала извлечем и нормализуем текущие рыночные данные из нашей модели. После получения данных мы применяем формулу линейной регрессии для получения прогноза из нашей модели. Затем, наконец, мы сохраним прогноз модели в виде двоичного флага, который поможет нам отслеживать возможные развороты.
//+---------------------------------------------------------------------+ //| This function will fetch a prediction from our model | //+---------------------------------------------------------------------+ void model_predict(void) { //--- Add the intercept intercept = vector::Ones(1); input_matrix.Row(intercept,0); //--- Fill in the input matrix for(int i = 0; i < 11; i++) { //--- Fetch historical data vector temp = vector::Zeros(1); temp.CopyRates(list_of_companies[i],PERIOD_CURRENT,COPY_RATES_CLOSE,0,1); //--- Normalize and scale the data temp = ((temp - mean_values[i]) / std_values[i]); //--- Add the data to the matrix input_matrix.Row(temp,i+1); } //--- Calculate the model forecast forecast = ( (1 * coefficients[0,0]) + (input_matrix[0,1] * coefficients[0,1]) + (input_matrix[0,2] * coefficients[0,2]) + (input_matrix[0,3] * coefficients[0,3]) + (input_matrix[0,4] * coefficients[0,4]) + (input_matrix[0,5] * coefficients[0,5]) + (input_matrix[0,6] * coefficients[0,6]) + (input_matrix[0,7] * coefficients[0,7]) + (input_matrix[0,8] * coefficients[0,8]) + (input_matrix[0,9] * coefficients[0,9]) + (input_matrix[0,10] * coefficients[0,10]) + (input_matrix[0,11] * coefficients[0,11]) ); //--- Store the model's state //--- Whenever the system and model state aren't the same, we may have a potential reversal if(forecast > iClose("UK100",PERIOD_CURRENT,0)) { model_state = 1; } else if(forecast < iClose("UK100",PERIOD_CURRENT,0)) { model_state = -1; } } //+------------------------------------------------------------------+
Нам также понадобится функция, отвечающая за получение текущих рыночных данных из нашего терминала.
//+------------------------------------------------------------------+ //| Update our market data | //+------------------------------------------------------------------+ void update_market_data(void) { //--- Update the bid and ask prices bid = SymbolInfoDouble("UK100",SYMBOL_BID); ask = SymbolInfoDouble("UK100",SYMBOL_ASK); //--- Update the RSI readings CopyBuffer(rsi_handler,0,1,1,rsi_buffer); }
Теперь создадим функции, которые будут анализировать рыночные настроения, чтобы определить, согласуются ли они с нашей моделью. Всякий раз, когда наша модель предлагает нам покупать, мы сначала проверяем изменение цены на недельном таймфрейме в течение 1 бизнес-цикла, если уровни цен повысились, то мы также проверяем, указывает ли наш индикатор RSI на бычьи настроения на рынке. Если это так, то мы откроем нашу позицию на покупку. В противном случае мы уйдем без настройки какой-либо позиции.
//+------------------------------------------------------------------+ //| Check if we have an opportunity to sell | //+------------------------------------------------------------------+ void check_sell(void) { if(iClose("UK100",PERIOD_W1,0) < iClose("UK100",PERIOD_W1,12)) { if(rsi_buffer[0] < 50) { Trade.Sell(0.3,"UK100",bid,0,0,"FTSE 100 AI"); //--- Remeber the ticket open_ticket = PositionGetTicket(0); //--- Whenever the system and model state aren't the same, we may have a potential reversal system_state = -1; } } } //+------------------------------------------------------------------+ //| Check if we have an opportunity to buy | //+------------------------------------------------------------------+ void check_buy(void) { if(iClose("UK100",PERIOD_W1,0) > iClose("UK100",PERIOD_W1,12)) { if(rsi_buffer[0] > 50) { Trade.Buy(0.3,"UK100",ask,0,0,"FTSE 100 AI"); //--- Remeber the ticket open_ticket = PositionGetTicket(0); //--- Whenever the system and model state aren't the same, we may have a potential reversal system_state = 1; } } }
Когда наше приложение будет инициализировано, сначала мы подготовим наш индикатор RSI. После этого мы проверим наш индикатор RSI. Если этот тест будет пройден, мы приступим к созданию нашей модели множественной линейной регрессии. Мы начинаем с получения обучающих данных, а затем вычисляем коэффициенты нашей модели. Затем, наконец, мы проверим вводимые пользователем данные, чтобы убедиться, что пользователь определил меру для контроля уровней риска.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Prepare the technical indicator rsi_handler = iRSI(Symbol(),PERIOD_CURRENT,rsi_period,PRICE_CLOSE); //--- Validate the indicator handler if(rsi_handler == INVALID_HANDLE) { //--- We failed to load the indicator Comment("Failed to load the RSI indicator"); return(INIT_FAILED); } //--- This function will fetch our training data and scaling factors fetch_training_data(); //--- This function will fit our multiple linear regression model model_fit(); //--- Ensure the user's inputs are valid if((ai_auto_close == false && profit_target == 0)) { Comment("Either set AI auto close true, or define a profit target!") return(INIT_FAILED); } //--- Everything went well return(INIT_SUCCEEDED); }
Всякий раз, когда наш советник не используется, мы освобождаем ресурсы, которые больше не используем. В частности, мы уберем индикатор RSI и советник с основного графика.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up the resources we are no longer using IndicatorRelease(rsi_handler); ExpertRemove(); }
Наконец, всякий раз при получении обновленных цен, мы сначала выбираем символ FTSE 100, прежде чем получать обновленные рыночные данные и значения технических индикаторов. Исходя из этого, мы можем получить новый прогноз от нашей модели и принять меры. Если в нашей системе нет открытых позиций, мы проверим, соответствуют ли текущие рыночные настроения прогнозам наших моделей, прежде чем открывать какие-либо позиции. Если у нас уже есть открытые позиции, мы проверим их на потенциальные развороты, которые можно легко обнаружить по частоте встречаемости, поскольку состояние нашей модели и состояние системы не являются одним и тем же.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Since we are dealing with a lot of different symbols, be sure to select the UK1OO (FTSE100) //--- Select the symbol SymbolSelect("UK100",true); //--- Update market data update_market_data(); //--- Fetch a prediction from our AI model model_predict(); //--- Give the user feedback Comment("Model forecast: ",forecast,"\nPosition Profit: ",position_profit); //--- Look for a position if(PositionsTotal() == 0) { //--- We have no open positions open_ticket = 0; //--- Check if our model's prediction is validated if(model_state == 1) { check_buy(); } else if(model_state == -1) { check_sell(); } } //--- Do we have a position allready? if(PositionsTotal() > 0) { //--- Should we close our positon manually? if(PositionSelectByTicket(open_ticket)) { if((profit_target > 0) && (ai_auto_close == false)) { //--- Update the position profit position_profit = PositionGetDouble(POSITION_PROFIT); if(profit_target < position_profit) { Trade.PositionClose("UK100"); } } } //--- Should we close our positon using a hybrid approach? if(PositionSelectByTicket(open_ticket)) { if((profit_target > 0) && (ai_auto_close == true)) { //--- Update the position profit position_profit = PositionGetDouble(POSITION_PROFIT); //--- Check if we have passed our profit target or if we are expecting a reversal if((profit_target < position_profit) || (model_state != system_state)) { Trade.PositionClose("UK100"); } } } //--- Are we closing our system just using AI? else if((system_state != model_state) && (ai_auto_close == true) && (profit_target == 0)) { Trade.PositionClose("UK100"); } } } //+------------------------------------------------------------------+

Рис. 3: Бэк-тестирование нашего советника
Оптимизация нашего советника
Пока что наше торговое приложение работает нестабильно. Мы можем попытаться улучшить стабильность нашего торгового приложения, используя идеи, изложенные американским экономистом Гарри Марковицем (Harry Markowitz). Марковицу приписывают концептуализацию основ современной портфельной теории (СПТ) в том виде, в каком мы ее знаем сегодня. По сути, он понял, что эффективность любого отдельного актива ничтожно мала по сравнению с эффективностью всего портфеля инвестора.

Рис. 4: Фотография нобелевского лауреата Гарри Марковица (Harry Markowitz)
Давайте попробуем применить некоторые идеи Марковица, чтобы, как мы надеемся, стабилизировать работу нашего торгового приложения. Начнем с импорта необходимых нам библиотек.
#Import the libraries we need import pandas as pd import numpy as np import seaborn as sns import MetaTrader5 as mt5 import matplotlib.pyplot as plt from scipy.optimize import minimize
Нам нужно составить список акций, которые мы будем рассматривать.
#Create the list of stocks stocks = ["ADM.LSE","AAL.LSE","ANTO.LSE","AHT.LSE","AZN.LSE","ABF.LSE","AV.LSE","BARC.LSE","BP.LSE","BKG.LSE","UK100"]
Инициализируем терминал.
#Initialize the terminal
if(!mt5.initialize()):
print('Failed to load the MT5 Terminal') Теперь нам нужно создать фрейм данных для хранения значений доходности каждого символа.
#Create a dataframe to store our returns amount = 10000 returns = pd.DataFrame(columns=stocks,index=np.arange(0,amount))
Извлекаем необходимые нам данные из нашего терминала MetaTrader 5.
#Fetch the data for stock in stocks: temp = pd.DataFrame(mt5.copy_rates_from_pos(stock,mt5.TIMEFRAME_M1,0,amount)) returns[[stock]] = temp[['close']]
Для решения этой задачи мы будем использовать доходность каждой акции вместо обычной цены закрытия.
#Store the data as returns returns = returns.pct_change() returns.dropna(inplace=True)
По умолчанию, для получения фактического процента доходности мы должны умножить каждую запись на 100.
#Let's look at our dataframe returns = returns * (10.0 ** 2)
Давайте теперь рассмотрим данные, которые у нас есть.
returns
Рис. 5: Некоторые из доходов по акциям из нашей корзины акций FTSE100
Теперь построим график рыночной доходности каждой имеющейся у нас акции. Мы ясно видим, что некоторые акции, такие как Ashtead Group (AHT.LSE), имеют сильные хвосты, которые отличаются от средних показателей портфеля из 11 имеющихся у нас акций. По сути, алгоритм Марковица поможет нам эмпирически отобрать меньше акций с высокой дисперсией и больше акций с меньшей дисперсией. Подход Марковица является аналитическим и исключает с нашей стороны любые догадки в процессе.
#Let's visualize our market returns returns.plot()
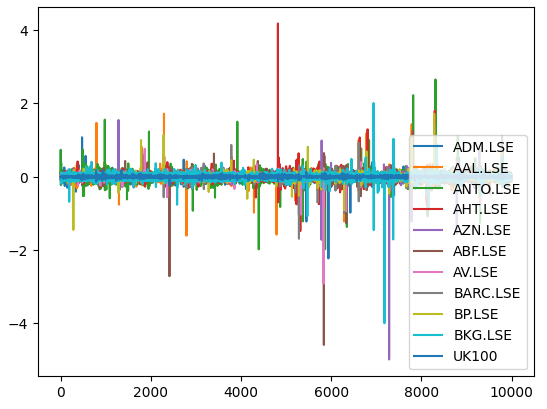
Рис. 6: Рыночная доходность от нашей корзины акций на FTSE 100
Давайте посмотрим, есть ли в наших данных какие-либо значимые уровни корреляции. К сожалению, существенных уровней корреляции, которые показались бы нам интересными обнаружено не было.
#Let's analyze the correlation coefficients fig, ax = plt.subplots(figsize=(8,8)) sns.heatmap(returns.corr(),annot=True,linewidths=.5, ax=ax)
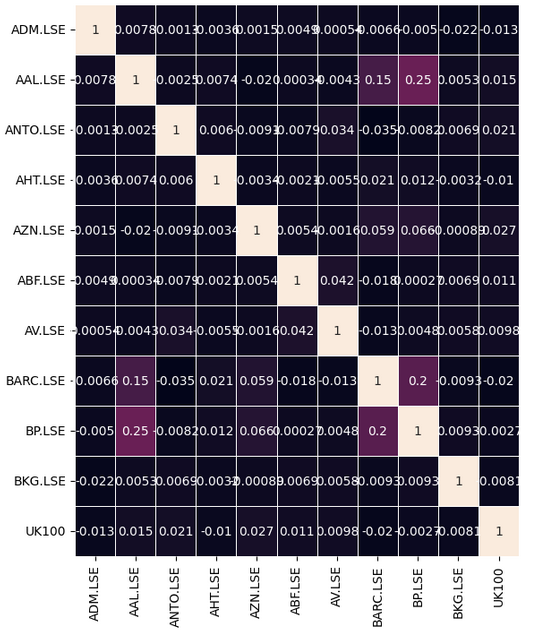
Рис. 7: Наша корреляционная тепловая карта по FTSE 100
Некоторые взаимосвязи будет нелегко найти, и для их выявления потребуются некоторые этапы предварительной обработки. Вместо того чтобы просто искать корреляцию непосредственно между имеющейся у нас корзиной акций, мы также можем искать корреляцию между текущей стоимостью каждой акции и будущей стоимостью символа UK100. Это классический метод, известный как корреляция опережения и запаздывания.
Мы начнем с того, что отодвинем нашу корзину акций на 20 позиций назад, а символ UK100 - на 20 позиций вперед.
# Let's also analyze for lead-lag correlation look_ahead = 20 lead_lag = pd.DataFrame(columns=stocks,index=np.arange(0,returns.shape[0] - look_ahead)) for stock in stocks: if stock == 'UK100': lead_lag[[stock]] = returns[[stock]].shift(-20) else: lead_lag[[stock]] = returns[[stock]].shift(20) # Returns lead_lag.dropna(inplace=True)
Посмотрим, были ли какие-либо изменения в корреляционной матрице. К сожалению, эта процедура не принесла нам каких-либо улучшений.
#Let's see if there are any stocks that are correlated with the future UK100 returns fig, ax = plt.subplots(figsize=(8,8)) sns.heatmap(lead_lag.corr(),annot=True,linewidths=.5, ax=ax)
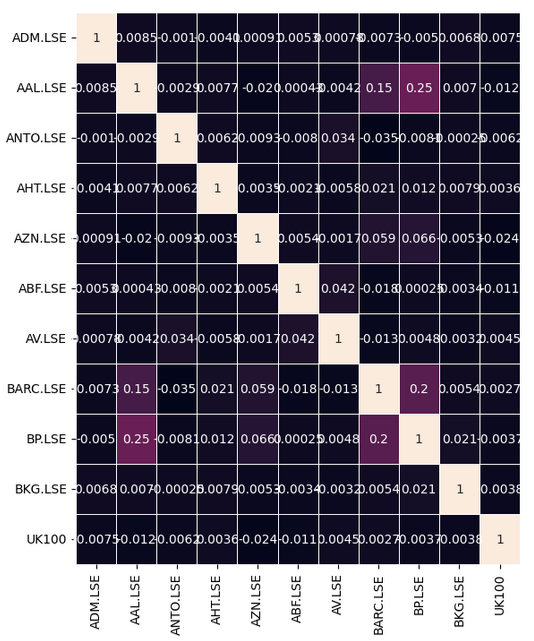
Рис. 8: Наша тепловая карта корреляции опережения и запаздывания
Теперь попытаемся свести к минимуму различия во всем нашем портфолио. Мы будем моделировать наш портфель таким образом, чтобы нам было разрешено покупать и продавать различные акции для минимизации рисков для нашего портфеля. Для достижения нашей цели мы будем использовать библиотеку оптимизации SciPy. У нас будет 11 различных весов, которые необходимо оптимизировать; каждый вес представляет собой распределение капитала, которое должно быть произведено для каждой соответствующей акции. Коэффициент каждого веса будет символизировать, следует ли нам покупать (положительный коэффициент) или продавать (отрицательный коэффициент) каждую конкретную акцию. Чтобы быть более конкретными, нам надо быть уверенными, что все наши коэффициенты находятся в диапазоне от -1 до 1 включительно, или в интервальной записи [-1,1].
Вдобавок ко всему, мы хотели бы использовать весь имеющийся у нас капитал, и не более того. Следовательно, мы должны установить ограничения для нашей процедуры оптимизации. В частности, мы должны обеспечить, чтобы сумма всех весов в портфеле равнялась 1. Это будет означать, что мы выделили весь имеющийся у нас капитал. Напомним, что некоторые из наших коэффициентов будут отрицательными, поэтому может возникнуть проблема с тем, чтобы сумма всех наших коэффициентов равнялась 1. Следовательно, мы должны изменить это ограничение, чтобы учитывать только абсолютные значения каждого веса. Другими словами, если мы храним наши 11 весов в векторе, мы хотим убедиться, что L1-norm равен 1.
Для начала мы сперва инициализируем наши веса случайными значениями и вычисляем ковариацию матрицы наших доходов.
#Let's attempt to minimize the variance of the portfolio weights = np.array([0,0,0,0,0,0,-1,1,1,0,0]) covariance = returns.cov()
Давайте теперь проследим за начальными уровнями дисперсии.
#Store the initial portfolio variance
initial_portfolio_variance = np.dot(weights.T,np.dot(covariance,weights))
initial_portfolio_variance При выполнении оптимизации мы ищем оптимальные входные данные для функции, которые приводят к наименьшим выходным данным из функции. Данная функция известна как функция стоимости. Наша функция стоимости будет представлять собой дисперсию портфеля при текущих весах. К счастью, это легко вычислить с помощью команд линейной алгебры.
#Cost function def cost_function(x): return(np.dot(x.T,np.dot(covariance,x)))
Теперь мы определим наши ограничения, которые указывают, что вес нашего портфеля должен быть равен 1.
#Constraints
def l1_norm(x):
return(np.sum(np.abs(x))) - 1
constraints = {'type': 'eq', 'fun':l1_norm} SciPy ожидает, что при выполнении оптимизации мы предоставим ему первоначальное предположение.
#Initial guess
initial_guess = weights Напомним, что мы хотим, чтобы все наши веса находились в диапазоне от -1 до 1; мы передаем эти инструкции SciPy, используя набор границ.
#Add bounds bounds = [(-1,1)] * 11
Теперь мы сведем к минимуму дисперсию нашего портфеля, используя алгоритм последовательного программирования методом наименьших квадратов (SLSQP). Алгоритм SLSQP был первоначально разработан выдающимся немецким инженером Дитером Крафтом (Dieter Kraft) в 1980-х годах. Первоначальная программа была реализована на языке FORTRAN. Оригинальную научную статью Крафта с описанием алгоритма можно найти по этой ссылке, здесь. SLSQP - это квазиньютоновский алгоритм, который означает, что он оценивает вторую производную (матрицу Гесса) целевой функции, чтобы найти оптимумы целевой функции.
#Minimize the portfolio variance result = minimize(cost_function,initial_guess,method="SLSQP",constraints=constraints,bounds=bounds)
Мы успешно выполнили эту процедуру оптимизации, давайте посмотрим на наши результаты.
result
success: True
status: 0
fun: 0.0004706570068070814
x: [ 5.845e-02 -1.057e-01 8.800e-03 2.894e-02 -1.461e-01
3.433e-02 -2.625e-01 6.867e-02 1.653e-01 3.450e-02
8.675e-02]
nit: 12
jac: [ 3.820e-04 -9.886e-04 3.242e-05 4.724e-04 -1.544e-03
4.151e-04 -1.351e-03 5.850e-04 8.880e-04 4.457e-04
4.392e-05]
nfev: 154
njev: 12
Давайте сохраним оптимальные веса, найденные для нас нашим решателем SciPy.
#Store the optimal weights
optimal_weights = result.x Проверим, что ограничение L1-norm не было нарушено. Обратите внимание, что из-за ограниченной точности измерения в памяти компьютеров наши веса не будут точно равны 1.
#Validating the weights add up to one
np.sum(np.abs(optimal_weights)) Сохраним новую дисперсию портфеля.
#Store the new portfolio variance otpimal_variance = cost_function(optimal_weights)
Создадим фрейм данных, который позволит нам сравнить нашу эффективность.
#Portfolio variance portfolio_var = pd.DataFrame(columns=['Old Var','New Var'],index=[0])
Сохраним наши уровни дисперсии во фрейме данных.
portfolio_var.iloc[0,0] = initial_portfolio_variance * (10.0 ** 7) portfolio_var.iloc[0,1] = otpimal_variance * (10.0 ** 7)
Изобразим дисперсию нашего портфеля. Как мы видим, наши уровни дисперсии значительно снизились.
portfolio_var.plot.bar()
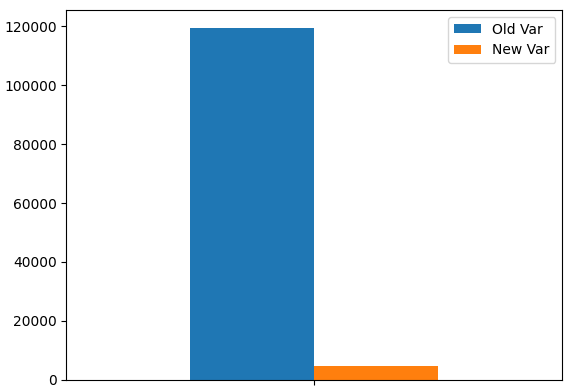
Рис. 9: Новая дисперсия нашего портфеля
Теперь подсчитаем количество позиций, которые мы должны открыть на каждом рынке, в соответствии с нашими оптимальными весами. Наши данные свидетельствуют о том, что всякий раз, когда мы открываем 1 долгосрочную позицию по символу UK100, мы не должны открывать каких-либо позиций в Admiral Group (ADM.LSE) и должны открывать 2 эквивалентные краткосрочные позиции в Anglo-American (AAL.LSE).
int_weights = (optimal_weights / optimal_weights[-1]) // 1 int_weights
Обновление нашего советника
Теперь мы можем обратить наше внимание на обновление нашего торгового алгоритма, чтобы воспользоваться преимуществами нашего нового понимания рынка FTSE 100. Давайте сначала загрузим оптимальные веса, которые мы рассчитали с помощью SciPy.
int optimization_weights[11] = {0,-2,0,0,-2,0,-4,0,1,0,1};
Нам также нужна настройка для запуска нашей процедуры оптимизации, мы установим лимит убытков. Всякий раз, когда убыток по нашей открытой сделке превышает установленный лимит убытков, мы открываем сделки на других рынках FTSE100, чтобы попытаться минимизировать уровни риска.
input double loss_limit = 20; // After how much loss should we optimize our portfolio?
Теперь определим функцию, которая будет отвечать за вызов процедуры минимизации уровней риска нашего портфеля. Напомним, что мы будем выполнять эту процедуру только в том случае, если счет превысил ограничение убытков или существует риск превышения порога капитала.
//--- Should we optimize our portfolio variance using the optimal weights we have calculated if((loss_limit > 0)) { //--- Update the position profit position_profit = AccountInfoDouble(ACCOUNT_EQUITY) - AccountInfoDouble(ACCOUNT_BALANCE); //--- Check if we have passed our profit target or if we are expecting a reversal if(((loss_limit * -1) < position_profit)) { minimize_variance(); } }
Данная функция фактически выполнит оптимизацию портфеля, выполнит итерацию по нашему списку акций, а затем проверит количество и тип позиции, которую она должна открыть.
//+------------------------------------------------------------------+ //| This function will minimize the variance of our portfolio | //+------------------------------------------------------------------+ void minimize_variance(void) { risk_minimized = true; if(!risk_minimized) { for(int i = 0; i < 11; i++) { string current_symbol = list_of_companies[i]; //--- Add that stock to the portfolio to minimize our variance, buy if(optimization_weights[i] > 0) { for(int i = 0; i < optimization_weights[i]; i++) { Trade.Buy(0.3,current_symbol,ask,0,0,"FTSE Optimization"); } } //--- Add that stock to the portfolio to minimize our variance, sell else if(optimization_weights[i] < 0) { for(int i = 0; i < optimization_weights[i]; i--) { Trade.Sell(0.3,current_symbol,bid,0,0,"FTSE Optimization"); } } } } }
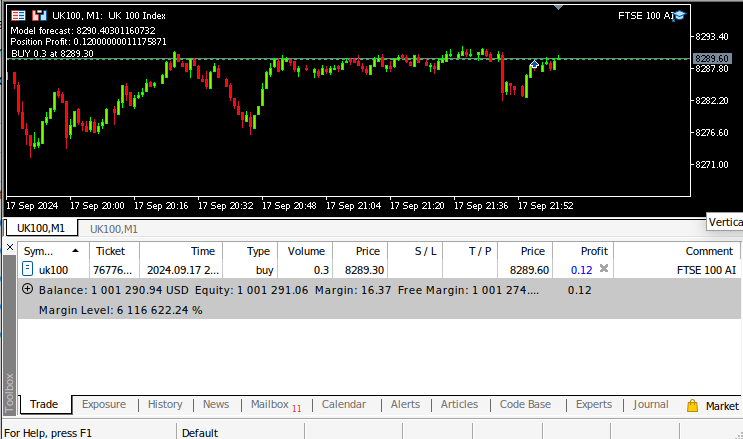
Рис. 10: Форвард-тестирование нашего алгоритма
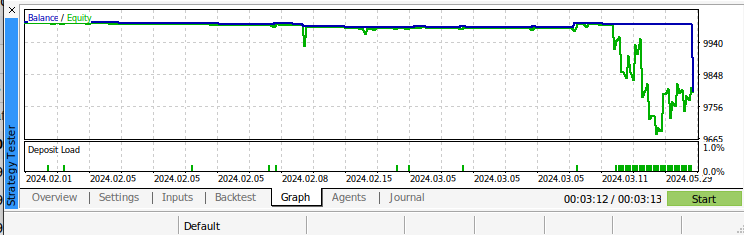
Рис. 11: Бэк-тестирование нашего алгоритма
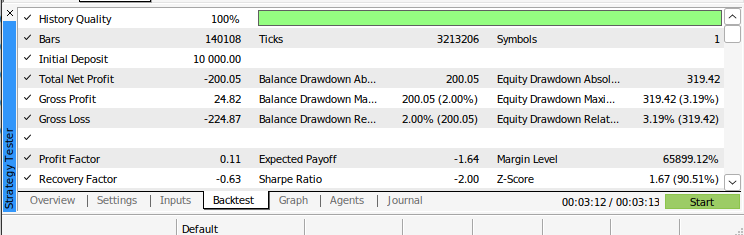
Рис. 12: Результаты бэк-тестирования нашего алгоритма
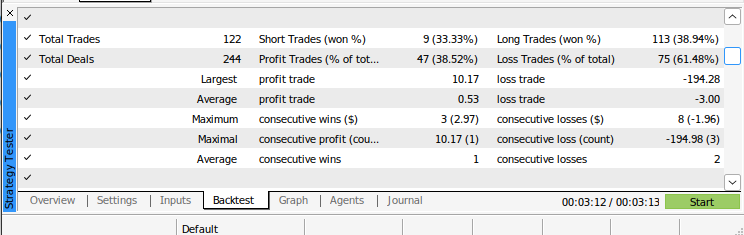
Рис. 13: Дополнительные результаты бэк-тестирования нашего алгоритма
Заключение
В настоящей статье мы продемонстрировали, как легко можно создать комплекс технического анализа и искусственного интеллекта, используя Python и MQL5. Наше приложение способно динамически подстраиваться под все таймфреймы, доступные в терминале MetaTrader 5. Мы изложили основные принципы современной оптимизации портфеля ценных бумаг с использованием современных алгоритмов оптимизации. Мы продемонстрировали, как свести к минимуму необъективность со стороны человека в процессе выбора портфолио. Кроме того, мы продемонстрировали, как использовать рыночные данные для принятия оптимальных решений. В нашем алгоритме еще есть возможности для совершенствования, например, в будущих статьях мы продемонстрируем, как оптимизировать 2 критерия одновременно, например, оптимизация уровней риска с учетом безрисковой нормы доходности. Однако большинство принципов, которые мы изложили сегодня, останутся неизменными, даже если мы будем выполнять более тонкие процедуры оптимизации, нам нужно будет только скорректировать наши функции стоимости, ограничения и определить соответствующий нашим потребностям алгоритм оптимизации.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/15818
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Статья призвана информировать, обучать или развлекать читателей. Если в ней повторяется одно и то же, только меняются индикаторы или названия акций, это не помогает и просто тратит время читателя.
Я думаю, вы найдете в каждой статье еще один увлекательный способ анализа данных в попытке установить движущие связи. Я лично ценю усилия и понимание того, как применять принципы больших данных к каждому новому аспекту. Да, структура одна и та же, но каждый раз находится еще одна кроличья нора, чтобы спуститься вниз и рассмотреть отношения по-другому, в данном случае, как использовать опережение и отставание. Пожалуйста, продолжайте искать дырявый грааль, спасибо за ваши перспективы.
Статья призвана информировать, обучать или развлекать читателей. Если в ней повторяются одни и те же вещи, только меняются названия индикаторов или акций, это не помогает и просто тратит время читателя.
Я пишу 3 разных цикла статей. Я хотел бы понять, когда вы говорите, что статьи повторяются, вы имеете в виду все 3 серии, или в пределах одной серии? Кроме того, что бы вы хотели сделать по-другому?
Я думаю, что в каждой статье вы найдете еще один увлекательный способ анализа данных, пытающихся установить движущие силы взаимосвязи. Я лично ценю усилия и понимание того, как применять принципы больших данных к каждому новому аспекту. Да, структура одна и та же, но каждый раз находится еще одна кроличья нора, чтобы спуститься вниз и рассмотреть отношения по-другому, в данном случае, как использовать опережение и отставание. Пожалуйста, продолжайте искать дырявый грааль, спасибо за ваши перспективы.
Спасибо, Нил. Я верю, что мы найдем его. Он не может прятаться от нас вечно.