
Самооптимизирующийся советник на языках MQL5 и Python (Часть IV): Стекинг моделей

В этой серии статей мы обсудим различные способы создания торговых приложений, способных динамически подстраиваться под меняющиеся рыночные условия. Существует потенциально бесконечное множество способов решения этой проблемы, но маловероятно, что все возможные решения будут верными. Наша текущая цель — продемонстрировать и эмпирически проанализировать достоинства и недостатки различных возможных решений, чтобы помочь вам улучшить ваши торговые стратегии.
Обзор торговой стратегии
Обратим внимание на прогнозирование валютной пары NZDJPY. Мы хотим алгоритмически изучить торговую стратегию на основе данных по символу, которые соберем из терминала MetaTrader 5. Будучи людьми, мы можем быть по своей природе склонны выбирать торговые стратегии, соответствующие нашим собственным убеждениям и интересам. Модели машинного обучения также предвзяты. Предвзятость модели машинного обучения — это степень, в которой нарушаются предположения, сделанные моделью. Наша торговая стратегия будет основана на ансамбле из двух моделей ИИ. Первая модель будет обучена прогнозировать будущую цену закрытия пары NZDJPY через 20 минут. Вторая будет обучена предсказывать величину ошибки в прогнозе, сделанном первой моделью. Этот метод известен как стекинг (stacking). Мы надеемся, что, объединив две модели, мы сможем преодолеть предвзятость, и этого будет достаточно для получения более высоких результатов.
Обзор методологии
Мы извлекли около 9000 строк рыночных данных M1 по паре NZDJPY из терминала MetaTrader 5 с помощью настроенного скрипта MQL5. Мы создали 2D- и 3D-диаграммы рассеяния рыночных данных. Однако нам не удалось выявить каких-либо заметных взаимосвязей в данных. Мы также выполнили разложение временных рядов на основе набора данных и смогли выявить четкую тенденцию к снижению и наличие сильных сезонных эффектов в данных.
Затем наши данные были разделены на обучающие и тестовые наборы. На обучающей выборке был подобран и оценен набор из 15 различных моделей. Регрессор стохастического градиентного спуска (Stochastic Gradient Descent, SGD) оказался лучшей моделью в группе в плане эффективности.
Впоследствии, когда мы проанализировали показатели важности признаков, мы обнаружили, что максимальная цена оказалась наиболее информативным предиктором, который у нас был для прогнозирования будущей цены закрытия пары NZDJPY. Максимальный цена (High) показала наилучшее значение взаимной информации (Mutual Information, MI). Кроме того, мы использовали реализацию алгоритма рекурсивного исключения признаков (Recursive Feature Elimination, RFE) в scikit-learn. Все имеющиеся у нас предикторы были признаны важными алгоритмом RFE. Однако, как мы увидим в ходе нашего обсуждения, сам факт существования взаимосвязи не гарантирует, что мы успешно ее зафиксируем и смоделируем.
Определив наиболее эффективную модель, мы приступили к настройке ее параметров. Обычно в наших обсуждениях после настройки параметров мы приступаем к тестированию на переобучение, сравнивая производительность нашей настроенной модели с производительностью модели по умолчанию. Однако существует множество различных способов проверки переобучения. В этой статье мы проведем проверку на переобучение, проанализировав остатки (residuals) нашей модели. Мы наблюдали высокий уровень корреляции между остатками нашей модели и ее задержками. Обычно остатки модели, которая достаточно хорошо обучена, не должны иметь корреляции. Таким образом, это навело нас на мысль, что наша наиболее эффективная модель могла неэффективно обучиться или что существуют другие данные, которые могут помочь нам объяснить нашу цель, но мы не включили эти данные.
После этого мы записали остатки нашей модели на обучающем и тестовом наборах. На этом этапе мы не подогнали модель под тестовый набор. Затем мы провели перекрестную проверку нашего набора из 15 моделей на остатках обучения нашего SGD-регрессора. Нашей лучшей моделью оказалась регрессия лассо, однако в качестве возможного решения мы выбрали третью по эффективности модель — глубокую нейронную сеть (Deep Neural Network, DNN). Мы решили сделать это, потому что гибкость, которую предоставляет нам глубокая нейронная сеть, дает нам возможность лучше настраивать ее в соответствии с данными в отличие от ограниченного числа параметров настройки лассо.
Мы настроили наш DNN-регрессор для прогнозирования остатков нашего SGD-регрессора в двухэтапном процессе, что привело к получению двух уникальных моделей. Сначала мы выполнили 100 итераций случайного поиска по параметрам нашего регрессора DNN, таким образом создав первую модель. Наилучшие непрерывные параметры, которые мы определили, были использованы в качестве отправной точки для попытки неограниченной глобальной оптимизации с использованием алгоритма L-BFGS-B с ограниченной памятью, и именно так мы получили нашу вторую модель. Обе модели превзошли стандартный DNN-регрессор на невидимых проверочных данных. Более того, наша последняя модель оказалась наиболее эффективной, а это значит, что мы не тратили время на выполнение дополнительных шагов дважды.
Наконец, мы экспортировали обе наши модели в формат ONNX и приступили к созданию советника на базе ИИ, который научился исправлять собственные ошибки.
Извлечение необходимых данных
Начнем с извлечения необходимых нам данных из терминала MetaTrader 5. Прикрепленный ниже скрипт извлекает из терминала указанное количество баров, а затем записывает эти данные в формат CSV и сохраняет в папке "Файлы".
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int rsi_handler; double rsi_buffer[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator rsi_handler = iRSI(_Symbol,PERIOD_CURRENT,20,PRICE_CLOSE); CopyBuffer(rsi_handler,0,0,size,rsi_buffer); ArraySetAsSeries(rsi_buffer,true); //--- File name string file_name = "Market Data " + Symbol() + ".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Очистка данных
Начнем с форматирования наших данных. Сначала загрузим необходимые нам библиотеки.
#Import the libraries we need import pandas as pd import numpy as np
Теперь считаем рыночные данные.
#Read in the market data
nzd_jpy = pd.read_csv('Market Data NZDJPY.csv') Данные расположены в неправильном порядке. Восстановим их так, чтобы сначала шла самая старая дата, а последней была дата, ближайшая к текущему моменту.
#Format the data nzd_jpy = nzd_jpy[::-1] nzd_jpy.reset_index(inplace=True, drop=True)
Определяем цель.
#Labelling the data nzd_jpy['Target'] = nzd_jpy['Close'].shift(-20) nzd_jpy.dropna(inplace=True)
Также добавим бинарные цели для отображения.
#Add binary target for plotting nzd_jpy['Binary Target'] = np.nan nzd_jpy.loc[nzd_jpy['Close'] > nzd_jpy['Target'],'Binary Target'] = 1 nzd_jpy.loc[nzd_jpy['Close'] <= nzd_jpy['Target'],'Binary Target'] = 0
Проверим данные.
#Current state of our dataframe
nzd_jpy 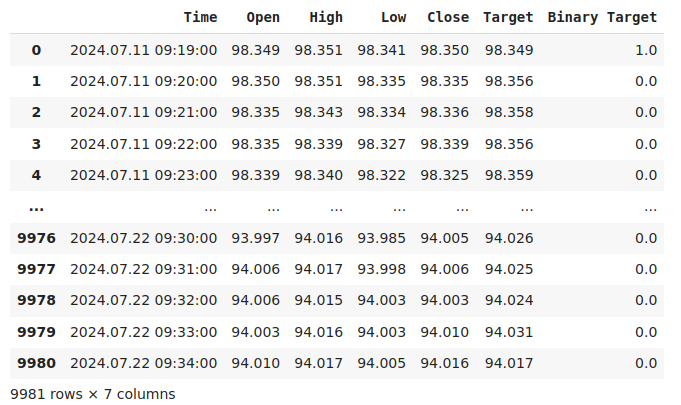
Рис. 1. Текущий фрейм данных
Разведочный анализ данных
Давайте построим диаграммы рассеяния, чтобы определить, существуют ли какие-либо взаимосвязи, которые мы можем наблюдать. К сожалению, наши данные распределены случайным образом, без четкого разделения на восходящие и нисходящие движения рынка.
#Lets perform scatter plots sns.scatterplot(data=nzd_jpy,x=nzd_jpy['Open'], y=nzd_jpy['Close'],hue='Binary Target')
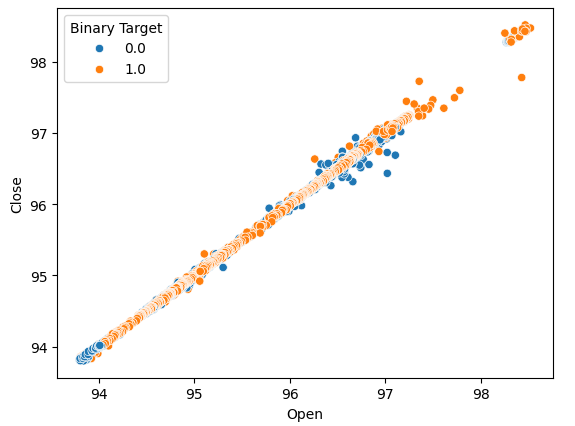
Рис. 2. Диаграмма рассеяния цен открытия и закрытия
Мы задумались о создании диаграмм, суммирующих все случаи, когда цена росла или падала. Мы полагали, что потенциально могут существовать различия в распределении данных в этих двух возможных целях. К сожалению, наши диаграммы показывают, что практически нет никакой разницы между распределением данных при двух возможных результатах.
#Let's create categorical box plots sns.catplot(data=nzd_jpy,x='Binary Target',y='Close',kind='box')
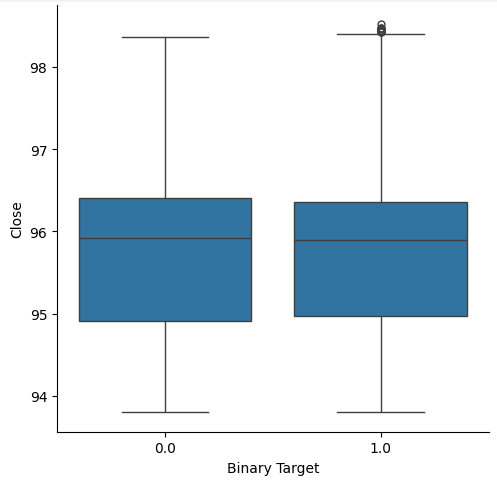
Рис. 3. Диаграмма, суммирующая все случаи, когда уровни цен падали (0) или росли (1)
Мы также можем разложить данные временного ряда на 3 компонента:
- Трендовый
- Сезонный
- Остаточный
Трендовый компонент представляет собой среднее долгосрочное движение ценовых уровней. Сезонный компонент учитывает циклические закономерности, которые неоднократно наблюдаются в данных, в то время как остаточные компоненты представляют собой остаток того, что не удалось объяснить предыдущими двумя компонентами. Поскольку мы используем данные M1 по паре NZDJPY, мы устанавливаем период 1440 или, другими словами, среднюю динамику цены за 1 полный день. Мы можем наблюдать очень четкую и сильную тенденцию к снижению в данных еще до выполнения разложения. Однако, вычитая тренд из исходных данных, мы теперь можем четко наблюдать сезонные эффекты в данных.
#Time series decomposition import statsmodels.api as sm nzd_jpy_decomposition = sm.tsa.seasonal_decompose(nzd_jpy['Close'],period=1440,model='additive') fig = nzd_jpy_decomposition.plot()
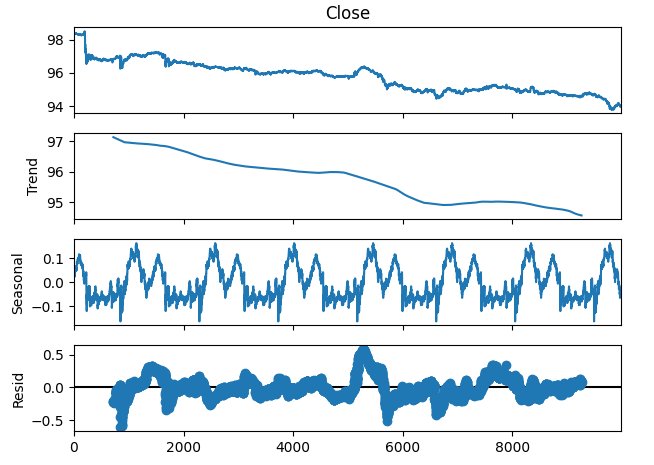
Рис. 4. Разложение данных по временным рядам
Некоторые эффекты могут быть скрыты в более высоких измерениях. Создание трехмерных диаграмм рассеяния наших данных может позволить нам выявить эффекты, скрытые за пределами нашего поля зрения с помощью двухмерной диаграммы рассеяния. К сожалению, этот набор данных не относится к таким случаям. Наши данные по-прежнему довольно сложно разделить, и они не демонстрируют каких-либо заметных взаимосвязей.
#Let's also perform 3D plots #Visualizing our data in 3D import matplotlib.pyplot as plt fig = plt.figure(figsize=(7,7)) ax = fig.add_subplot(111,projection='3d') colors = ['blue' if movement == 0 else 'red' for movement in nzd_jpy.loc[:,"Binary Target"]] ax.scatter(nzd_jpy.loc[:,"Low"],nzd_jpy.loc[:,"High"],nzd_jpy.loc[:,"Close"],c=colors) ax.set_xlabel('NZDJPY Low') ax.set_ylabel('NZDJPY High') ax.set_zlabel('NZDJPY Close')
Рис. 5. Визуализация нашей трехмерной диаграммы рассеяния
Подготовка к моделированию данных
Прежде чем приступить к моделированию данных, нам необходимо масштабировать и стандартизировать данные. Загружаем нужные нам библиотеки.
#Let's prepare the data for modelling from sklearn.preprocessing import RobustScaler
Масштабируем данные.
#Scale the data X = pd.DataFrame(RobustScaler().fit_transform(nzd_jpy.loc[:,['Close']]),columns=['Close']) residuals_X = pd.DataFrame(RobustScaler().fit_transform(nzd_jpy.loc[:,['Open','High','Low']]),columns=['Open','High','Low']) y = nzd_jpy.loc[:,'Target']
Выбор модели
Давайте загрузим библиотеки, необходимые для моделирования данных.
#Cross validating the models from sklearn.model_selection import cross_val_score,train_test_split from sklearn.linear_model import Lasso,LinearRegression,Ridge,ElasticNet,SGDRegressor,HuberRegressor from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor,AdaBoostRegressor,ExtraTreesRegressor,BaggingRegressor from sklearn.svm import LinearSVR from sklearn.neighbors import KNeighborsRegressor from sklearn.tree import DecisionTreeRegressor from sklearn.neural_network import MLPRegressor
Теперь разделим данные на две половины.
#Create train-test splits train_X,test_X,train_y,test_y = train_test_split(nzd_jpy.loc[:,['Close']],y,test_size=0.5,shuffle=False) residuals_train_X,residuals_test_X,residuals_train_y,residuals_test_y = train_test_split(nzd_jpy.loc[:,['Open','High','Low']],y,test_size=0.5,shuffle=False)
Сохраните модели в списке и создайте фрейм данных для хранения уровней ошибок проверки.
#Store the models models = [ Lasso(), LinearRegression(), Ridge(), ElasticNet(), SGDRegressor(), HuberRegressor(), RandomForestRegressor(), GradientBoostingRegressor(), AdaBoostRegressor(), ExtraTreesRegressor(), BaggingRegressor(), LinearSVR(), KNeighborsRegressor(), DecisionTreeRegressor(), MLPRegressor(), ] #Store the names of the models model_names = [ 'Lasso', 'Linear Regression', 'Ridge', 'Elastic Net', 'SGD Regressor', 'Huber Regressor', 'Random Forest Regressor', 'Gradient Boosting Regressor', 'Ada Boost Regressor', 'Extra Trees Regressor', 'Bagging Regressor', 'Linear SVR', 'K Neighbors Regressor', 'Decision Tree Regressor', 'MLP Regressor', ] #Create a dataframe to store our cv error cv_error = pd.DataFrame(columns=model_names,index=np.arange(0,5))
Проведем перекрестную проверку каждой модели.
#Cross validate each model for model in models: cv_score = cross_val_score(model,X,y,cv=5,n_jobs=-1,scoring='neg_mean_squared_error') for i in np.arange(0,5): index = models.index(model) cv_error.iloc[i,index] = cv_score[i]
Визуализируем результаты.
cv_error
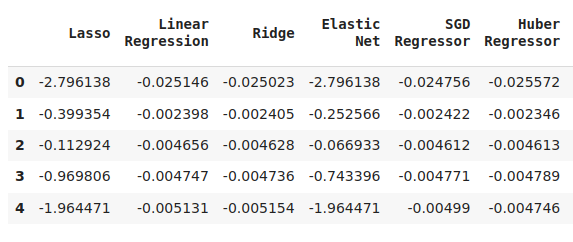
Рис. 6. Некоторые из наших уровней ошибок при прогнозировании будущей цены закрытия NZDJPY
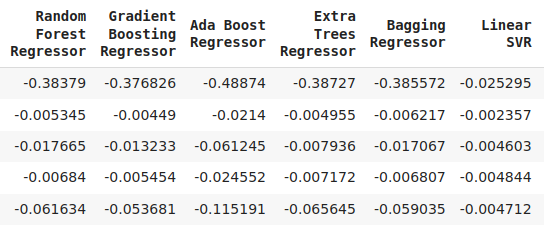
Рис. 7: Продолжение наших уровней ошибок
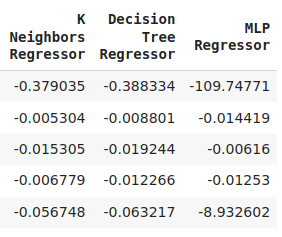
Рис. 8. Окончательные уровни ошибок нашей модели
Мы можем построить графики уровней производительности по всем 5 сверткам. При визуализации данные в этом формате я неожиданно столкнулся с низкой производительностью нейронной сети. Вероятно, настройка параметров пошла бы ей на пользу.
cv_error.plot()
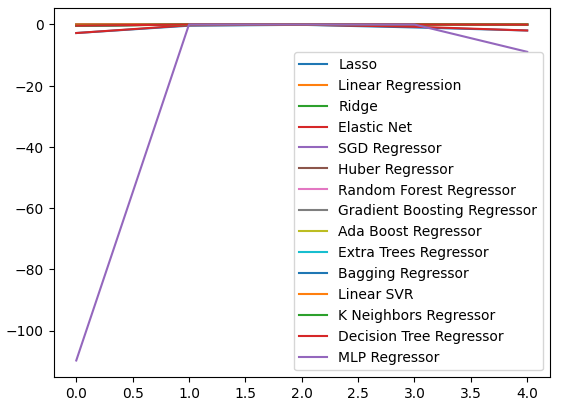
Рис. 9. Визуализация уровней ошибок
Блочная диаграммы помогает нам обобщить большой объем информации на одном графике. Например, на диаграммах ниже мы можем ясно видеть, насколько плохо DNN справилась с этой задачей. Это последняя модель справа, и ее производительность демонстрирует гораздо больший разброс, чем у других моделей.
sns.boxplot(cv_error)

Рис. 10. Визуализация ошибок в виде блочных диаграмм
Мы можем определить наиболее эффективную модель как модель с наименьшим средним уровнем ошибки.
#Our mean validation error
cv_error.mean() 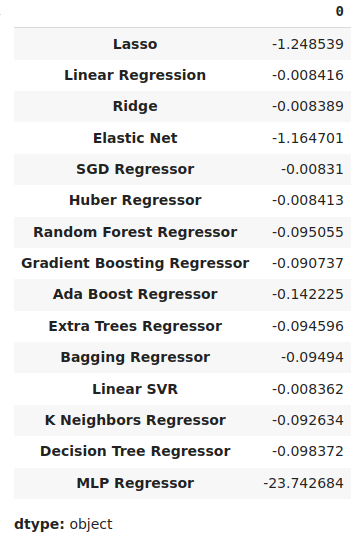
Рис. 11. Визуализация наших средних уровней ошибок
Значимость признаков
Алгоритмы значимости признаков помогают нам понять, усвоила ли наша модель значимые ассоциации или же она усвоила связи, о которых мы, возможно, не знали. Сначала импортируем необходимые библиотеки.
#Feature importance
from sklearn.feature_selection import mutual_info_regression,RFE Начнем с расчета показателей взаимной информации (MI). MI информирует нас о потенциале каждого предиктора, помогая нам предсказать цель. Наконец, MI измеряется по логарифмической шкале. Поэтому показатели MI выше 3 на практике встречаются редко.
mi_score = pd.DataFrame(mutual_info_regression(X,y),columns=['MI Score'],index=X.columns)
Построение графика MI наглядно показывает, что максимальная цена, по-видимому, имеет наибольший потенциал для прогнозирования будущей цены закрытия NZDJPY.
mi_score.plot()
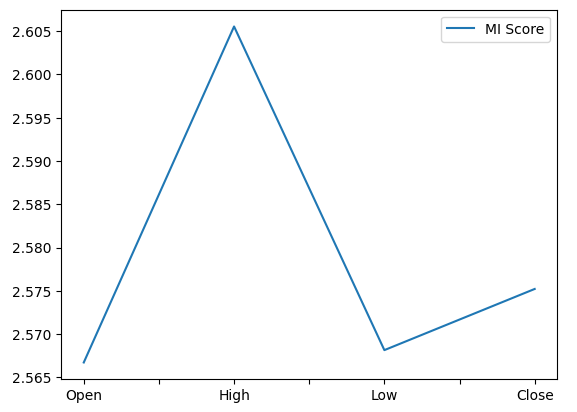
Рис. 12. Построение графика MI
Алгоритм RFE так же прост в использовании, как и почти любой объект из библиотеки scikit-learn. Мы просто создаем экземпляр класса и подгоняем его под данные, прежде чем сможем оценить уровни значимости признаков, которые он присваивает каждому предиктору. Наш алгоритм RFE посчитал, что все предикторы одинаково важны для прогнозирования цены закрытия NZDJPY.
#Select the best features rfe = RFE(model, n_features_to_select=5, step=1) rfe = rfe.fit(X, y) rfe.ranking_
Настройка параметров
Давайте теперь извлечем как можно больше эффективности из нашей модели SGD-регрессора. Мы выполним рандомизированный поиск по выборке пространства параметров модели. Сначала импортируем необходимые библиотеки.
#Parameter tuning
from sklearn.model_selection import RandomizedSearchCV Создадим экземпляр модели по умолчанию.
#Initialize the model
model = SGDRegressor() Создадим объект тюнера и укажем возможные значения параметров, которые мы хотели бы оцифровать.
#Define the tuner
tuner = RandomizedSearchCV(
model,
{
"loss" : ['squared_error', 'huber', 'epsilon_insensitive','squared_epsilon_insensitive'],
"penalty":['l2','l1', 'elasticnet', None],
"alpha":[0.1,0.01,0.001,0.0001,0.00001,0.00001,0.0000001,10,100,1000,10000,100000],
"tol":[0.1,0.01,0.001,0.0001,0.00001,0.000001,0.0000001],
"fit_intercept": [True,False],
"early_stopping": [True,False],
"learning_rate":['constant','optimal','adaptive','invscaling'],
"shuffle": [True,False]
},
n_iter=100,
cv=5,
n_jobs=-1,
scoring="neg_mean_squared_error"
) Установим объект тюнера.
#Fit the tuner
tuner.fit(train_X,train_y) Лучшие параметры, которые мы нашли.
#Our best parameters
tuner.best_params_ 'shuffle': False,
'penalty': 'elasticnet',
'loss': 'huber',
'learning_rate': 'adaptive',
'fit_intercept': True,
'early_stopping': True,
'alpha': 1e-05}
Проверка на переобучение
Мы можем обнаружить переобучение, если наблюдаем корреляцию в остатках модели. Если модель успешно обучилась, ее остатки должны представлять собой случайный белый шум, что указывает на отсутствие предсказуемой закономерности в ошибках, совершаемых нашей моделью. Однако модель, демонстрирующая автокорреляцию в остатках требует внимания. Это может означать, что полученная нами регрессия является ложной или что мы выбрали неподходящую модель для нашей задачи. Для начала нам необходимо зафиксировать остатки нашей настроенной модели.
#Model validation model = SGDRegressor( tol = tuner.best_params_['tol'], shuffle = tuner.best_params_['shuffle'], penalty = tuner.best_params_['penalty'], loss = tuner.best_params_['loss'], learning_rate = tuner.best_params_['learning_rate'], alpha = tuner.best_params_['alpha'], fit_intercept = tuner.best_params_['fit_intercept'], early_stopping = tuner.best_params_['early_stopping'] ) model.fit(train_X,train_y) residuals = test_y - model.predict(test_X)
Мы можем визуализировать остатки нашей модели на графике. К сожалению, мы ясно видим, что в остатках модели присутствует автокорреляция. Другими словами, всякий раз, когда остатки падают, они, как правило, продолжают падать, а когда остатки растут, они, как правило, продолжают расти. Это означает, что будущие значения остатков могут иметь связь с предыдущими значениями, что является явным признаком того, что наша модель, возможно, не обучалась эффективно, даже после выполнения настройки параметров!
#Plot the residuals
residuals.plot() 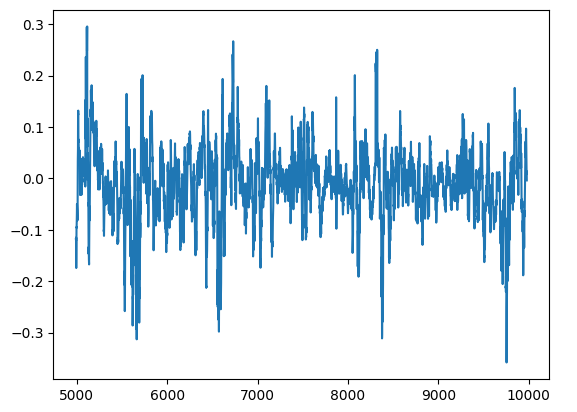
Рис. 13. Остатки модели
Существуют более надежные тесты на автокорреляцию, например, мы можем создать график автокорреляции (ACF). График ACF будет иметь пики при каждом возможном значении задержки. Высота каждого пика отражает уровни корреляции данных временного ряда с их запаздывающим значением. На заднем плане нашего графика также имеется синяя конусообразная структура. Синий конус представляет наши доверительные интервалы. Любые уровни корреляции, выходящие за пределы доверительного интервала, считаются статистически значимыми.
#The residuals appear to have autocorrelation
from statsmodels.graphics.tsaplots import plot_acf
fig = plot_acf(residuals) 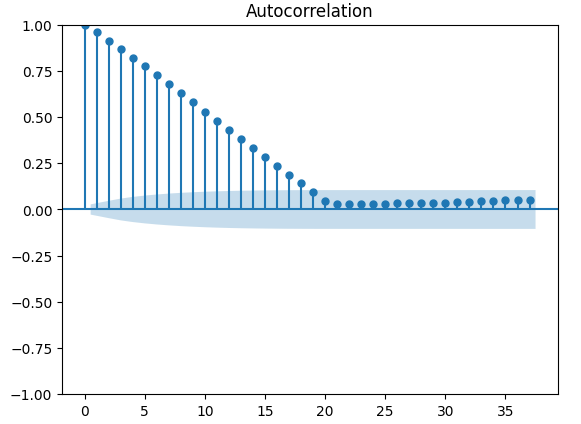
Рис. 14. Автокорреляция остатков модели
Это плохой знак, но мы надеемся, что сможем смягчить проблему, обучив нашу DNN корректировать нашу первую модель. Давайте запишем ошибки нашего SGD-регрессора на обучающих данных, а затем на тестовых данных. Обратите внимание: на этом этапе мы не будем подгонять модель под тестовые данные, а только измерим уровень ее ошибок.
#Prepare the residuals for our second model model = SGDRegressor(tol= 0.001, shuffle=False, penalty= 'elasticnet', loss= 'huber', learning_rate='adaptive', fit_intercept= True, early_stopping= True, alpha= 1e-05) #Store the model residuals model.fit(train_X,train_y) residuals_train_y = train_y - model.predict(train_X) residuals_test_y = test_y - model.predict(test_X)
Теперь мы проверим модели на предмет прогнозирования уровней ошибок SGD-регрессора.
#Cross validate each model for model in models: cv_score = cross_val_score(model,residuals_train_X,residuals_train_y,cv=5,n_jobs=-1,scoring='neg_mean_squared_error') for i in np.arange(0,5): index = models.index(model) cv_error.iloc[i,index] = cv_score[i]
Давайте визуализируем ошибку проверки.
#Cross validaton error levels
cv_error 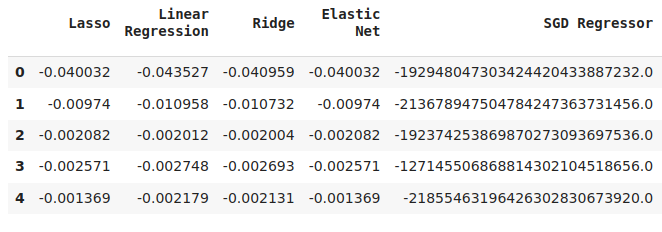
Рис. 15. Некоторые уровни ошибок проверки модели при прогнозировании уровней ошибок первой модели
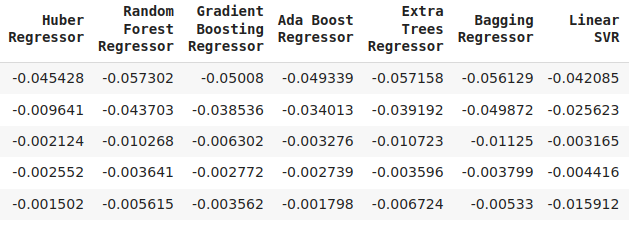
Рис. 16. Продолжение уровней ошибок проверки
Просмотрим наши средние уровни ошибок в порядке убывания, чтобы быстро определить нашу наиболее эффективную модель.
#Store the model's performance cv_error.mean().sort_values(ascending=False)
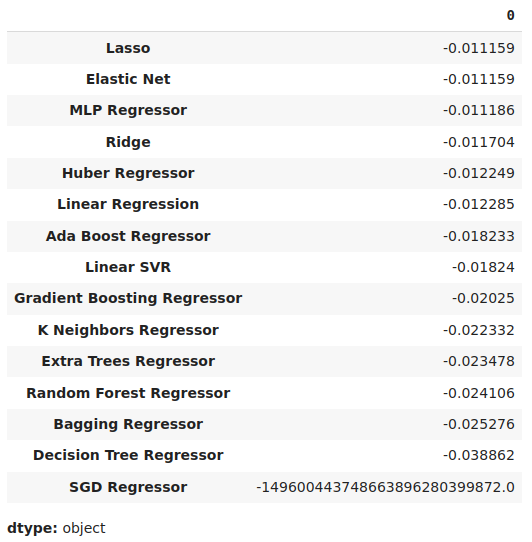
Рис. 17. Средние уровни ошибок проверки ясно показывают, что лассо — самая эффективная модель из всех, что у нас есть
Наши блочные диаграммы показывают, насколько плохо SGD-регрессор справился с попыткой предсказать собственные уровни ошибок.
sns.boxplot(cv_error)
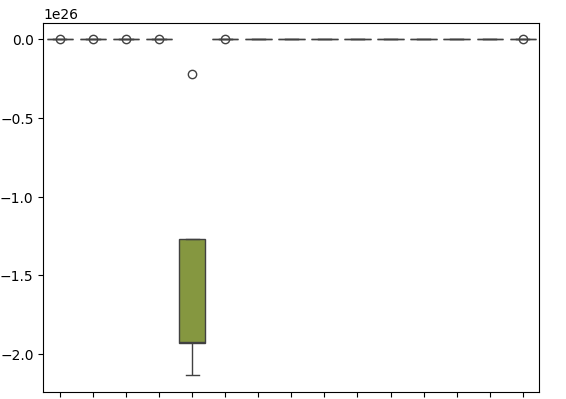
Рис. 18. Диаграммы ошибок проверки при прогнозировании остатков нашей модели
Мы также можем создавать линейные графики для визуализации наших данных.
cv_error.plot()
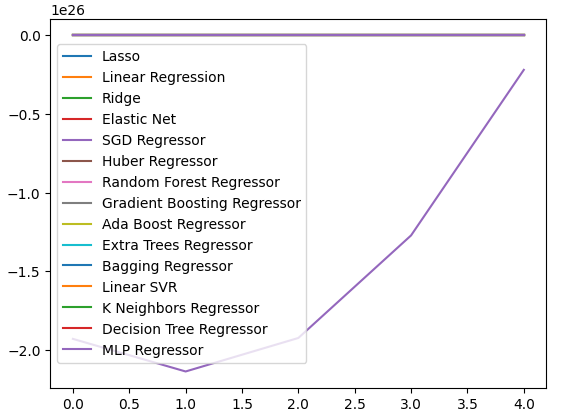
Рис. 19. Визуализация уровней ошибок в виде линейных графиков
Настройка параметров глубокой нейронной сети
Давайте теперь подготовимся к настройке параметров нашего DNN-регрессора. Сначала мы определим объект настройщика (тюнера) и образец пространства параметров, в котором мы хотим выполнить поиск.
#Let's tune the model
#Reinitialize the model
model = MLPRegressor()
#Define the tuner
tuner = RandomizedSearchCV(
model,
{
"activation":["relu","tanh","logistic","identity"],
"solver":["adam","sgd","lbfgs"],
"alpha":[0.1,0.01,0.001,0.00001,0.000001],
"learning_rate": ["constant","invscaling","adaptive"],
"learning_rate_init":[0.1,0.01,0.001,0.0001,0.000001,0.0000001],
"power_t":[0.1,0.5,0.9,0.01,0.001,0.0001],
"shuffle":[True,False],
"tol":[0.1,0.01,0.001,0.0001,0.00001],
"hidden_layer_sizes":[(10,20),(100,200),(30,200,40),(5,20,6)],
"max_iter":[10,50,100,200,300],
"early_stopping":[True,False]
},
n_iter=100,
cv=5,
n_jobs=-1,
scoring="neg_mean_squared_error"
) Теперь займемся установкой тюнера.
#Fit the tuner
tuner.fit(residuals_train_X,residuals_train_y) Наконец мы можем увидеть лучшие найденные нами параметры.
#The best parameters we found
tuner.best_params_ 'solver': 'lbfgs',
'shuffle': False,
'power_t': 0.5,
'max_iter': 300,
'learning_rate_init': 0.01,
'learning_rate': 'constant',
'hidden_layer_sizes': (30, 200, 40),
'early_stopping': False,
'alpha': 1e-05,
'activation': 'identity'}
Более глубокая настройка параметров
Давайте поищем параметры получше. Поскольку мы не знаем, где могут находиться наилучшие входные значения, мы попытаемся выполнить неограниченную глобальную оптимизацию, используя алгоритм L-BFGS-B с ограниченной памятью в библиотеке SciPy. Алгоритм L-BFGS-B может эффективно использоваться для решения глобальных задач оптимизации. Сам численный решатель (numerical solver) реализован на языке Fortran, а библиотека SciPy предоставляет тонкую оболочку для простого взаимодействия с процедурой. Начнем с импорта необходимых нам библиотек.

Рис. 20. Разработчики оригинального алгоритма BFGS, слева направо: Бройден, Флетчер, Гольдфарб и Шанно.
#Deeper optimization
from scipy.optimize import minimize Теперь определим целевую функцию, которую необходимо минимизировать. Мы хотим минимизировать ошибку обучения нашего DNN-регрессора. Мы исправим все остальные входные параметры модели, поскольку наши минимизаторы SciPy могут обрабатывать только задачи непрерывной оптимизации.
#Define the objective function def objective(x): #Create a dataframe to store our accuracy cv_error = pd.DataFrame(index = np.arange(0,5),columns=["Current Error"]) #The parameter x represents a new value for our neural network's settings #In order to find optimal settings, we will perform 10 fold cross validation using the new setting #And return the average RMSE from all 10 tests #We will first turn the model's Alpha parameter, which controls the amount of L2 regularization MLPRegressor(hidden_layer_sizes=(20,5),activation='identity',learning_rate='adaptive',solver='lbfgs',shuffle=True,alpha=x[0],tol=x[1]) model = MLPRegressor( tol = x[0], solver = tuner.best_params_['solver'], power_t = x[1], max_iter = tuner.best_params_['max_iter'], learning_rate = tuner.best_params_['learning_rate'], learning_rate_init = x[2], hidden_layer_sizes = tuner.best_params_['hidden_layer_sizes'], alpha = x[3], early_stopping = tuner.best_params_['early_stopping'], activation = tuner.best_params_['activation'], ) #Cross validate the model cv_score = cross_val_score(model,residuals_train_X,residuals_train_y,cv=5,n_jobs=-1,scoring='neg_mean_squared_error') for i in np.arange(0,5): cv_error.iloc[i,0] = cv_score[i] #Return the Mean CV RMSE return(cv_error.iloc[:,0].mean())
Определим начальную точку птимизации с помощью наилучших параметров, которые мы нашли в результате случайного поиска. Мы также передадим ограничения для нашей процедуры оптимизации. Мы принудительно сделаем все значения положительными и, кроме того, мы разрешим все значения в диапазоне от 10 в степени -100 до 10 в степени 100. Это очень большой домен, и мы надеемся, что он будет содержать оптимальные параметры, которые нам нужны.
#Define the starting point pt = [tuner.best_params_['tol'],tuner.best_params_['power_t'],tuner.best_params_['learning_rate_init'],tuner.best_params_['alpha']] bnds = ((10.0 ** -100,10.0 ** 100), (10.0 ** -100,10.0 ** 100), (10.0 ** -100,10.0 ** 100), (10.0 ** -100,10.0 ** 100))
Ищем наилучшие параметры.
#Searching deeper for better parameters result = minimize(objective,pt,method="L-BFGS-B",bounds=bnds)
Результаты нашей оптимизации.
result
success: True
status: 0
fun: -0.01143352283130129
x: [ 1.000e-04 5.000e-01 1.000e-02 1.000e-05]
nit: 2
jac: [-1.388e+04 -4.657e+04 5.625e+04 -1.033e+04]
nfev: 120
njev: 24
hess_inv: <4x4 LbfgsInvHessProduct with dtype=float64>
Проверка на переобучение
Пора провести проверку на переобучение. На этот раз мы сравним наши две модели с производительностью DNN-регрессора по умолчанию. Давайте создадим экземпляры каждого DNN-регрессора, который мы хотим протестировать.
#Model validation default_model = MLPRegressor() customized_model = MLPRegressor( tol = tuner.best_params_['tol'], solver = tuner.best_params_['solver'], power_t = tuner.best_params_['power_t'], max_iter = tuner.best_params_['max_iter'], learning_rate = tuner.best_params_['learning_rate'], learning_rate_init = tuner.best_params_['learning_rate_init'], hidden_layer_sizes = tuner.best_params_['hidden_layer_sizes'], alpha = tuner.best_params_['alpha'], early_stopping = tuner.best_params_['early_stopping'], activation = tuner.best_params_['activation'], ) lbfgs_customized_model = MLPRegressor( tol = result.x[0], solver = tuner.best_params_['solver'], power_t = result.x[1], max_iter = tuner.best_params_['max_iter'], learning_rate = tuner.best_params_['learning_rate'], learning_rate_init = result.x[2], hidden_layer_sizes = tuner.best_params_['hidden_layer_sizes'], alpha = result.x[3], early_stopping = tuner.best_params_['early_stopping'], activation = tuner.best_params_['activation'], )
Теперь мы создадим список моделей, а также создадим фрейм данных для хранения уровней ошибок проверки.
models = [default_model,customized_model,lbfgs_customized_model] cv_error = pd.DataFrame(index=np.arange(0,5),columns=['Default NN','Random Search NN','L-BFGS-B NN'])
Перекрестная проверка каждой модели.
#Cross validate the model for model in models: model.fit(residuals_train_X,residuals_train_y) cv_score = cross_val_score(model,residuals_test_X,residuals_test_y,cv=5,n_jobs=-1,scoring='neg_mean_squared_error') for i in np.arange(0,5): index = models.index(model) cv_error.iloc[i,index] = cv_score[i]
Наша ошибка перекрестной проверки.
cv_error
| NN по умолчанию | NN случайный поиск | L-BFGS-B NN |
|---|---|---|
| -0.007735 | -0.007708 | -0.007692 |
| -0.00635 | -0.006344 | -0.006329 |
| -0.003307 | -0.003265 | -0.00328 |
| 0.005225 | -0.004803 | -0.004761 |
| -0.004469 | -0.004447 | -0.004492 |
Теперь давайте проанализируем наши средние уровни ошибок.
cv_error.mean().sort_values(ascending=False)
| Модель | Ошибка проверки |
|---|---|
| L-BFGS-B NN | -0.005311 |
| NN случайный поиск | -0.005313 |
| NN по умолчанию | -0.005417 |
Как видим, все наши модели показали результаты в одном и том же диапазоне. Однако наши индивидуальные модели явно обеспечивали нам в среднем более низкие уровни ошибок. К сожалению, дисперсия, отображаемая нашими моделями, практически одинакова по всем направлениям, что видно из наших блочных диаграмм. Уровни дисперсии помогают нам определить уровень мастерства модели,
sns.boxplot(cv_error)
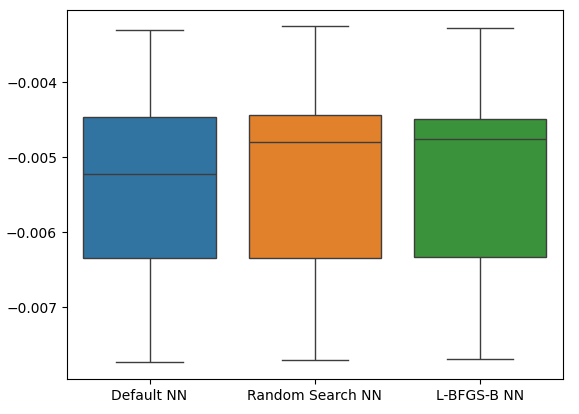
Рис. 21. Наши уровни ошибок проверки на основе сохраненных данных
Давайте теперь посмотрим, является ли наш ансамблевый подход более эффективным, чем просто использование одной модели для прогнозирования уровней цен. Сначала мы подготовим необходимые нам модели.
#Now that we have come this far, let's see if our ensemble approach is worth the trouble baseline = LinearRegression() default_nn = MLPRegressor() #The SGD Regressor will predict the future price sgd_regressor = SGDRegressor(tol= 0.001, shuffle=False, penalty= 'elasticnet', loss= 'huber', learning_rate='adaptive', fit_intercept= True, early_stopping= True, alpha= 1e-05) #The deep neural network will predict the error in the SGDRegressor's prediction lbfgs_customized_model = MLPRegressor( tol = result.x[0], solver = tuner.best_params_['solver'], power_t = result.x[1], max_iter = tuner.best_params_['max_iter'], learning_rate = tuner.best_params_['learning_rate'], learning_rate_init = result.x[2], hidden_layer_sizes = tuner.best_params_['hidden_layer_sizes'], alpha = result.x[3], early_stopping = tuner.best_params_['early_stopping'], activation = tuner.best_params_['activation'], )
Установка моделей на учебный набор.
#Fit the models on the train set baseline.fit(train_X.loc[:,['Close']],train_y) default_nn.fit(train_X.loc[:,['Close']],train_y) sgd_regressor.fit(train_X.loc[:,['Close']],train_y) lbfgs_customized_model.fit(residuals_train_X.loc[:,['Open','High','Low']],residuals_train_y)
Сохраним модели в списке.
#Store the models in a list
models = [baseline,default_nn,sgd_regressor,lbfgs_customized_model] Создадим фрейм данных для хранения наших уровней ошибок.
#Create a dataframe to store our error ensemble_error = pd.DataFrame(index=np.arange(0,5),columns=['Baseline','Default NN','SGD','Customized NN'])
Импортируем необходимые нам библиотеки.
from sklearn.model_selection import TimeSeriesSplit from sklearn.metrics import mean_squared_error
Создадим объект разделения временного ряда.
#Create the time-series object tscv = TimeSeriesSplit(n_splits=5,gap=20)
Сбросим индексы наших данных.
#Reset the indexes so we can perform cross validation
test_y = test_y.reset_index()
residuals_test_y = residuals_test_y.reset_index()
test_X = test_X.reset_index()
residuals_test_X = residuals_test_X.reset_index() Теперь мы выполним перекрестную проверку временных рядов. Обратите внимание, что модель, прогнозирующая остатки, необходимо обучать отдельно от других моделей, которые просто прогнозируют будущую цену закрытия.
#Cross validate the models for j in np.arange(0,4): model = models[j] for i,(train,test) in enumerate(tscv.split(test_X)): #The model predicting the residuals if(j == 3): model.fit(residuals_test_X.loc[train[0]:train[-1],['Open','High','Low']],residuals_test_y.loc[train[0]:train[-1],'Target']) #Measure the loss ensemble_error.iloc[i,j] = mean_squared_error(residuals_test_y.loc[test[0]:test[-1],'Target' ], model.predict(residuals_test_X.loc[test[0]:test[-1],['Open','High','Low']])) elif(j <= 2): #Fit the model model.fit(test_X.loc[train[0]:train[-1],['Close']],test_y.loc[train[0]:train[-1],'Target']) #Measure the loss ensemble_error.iloc[i,j] = mean_squared_error(test_y.loc[test[0]:test[-1],'Target' ],model.predict(test_X.loc[test[0]:test[-1],['Close']]))
Теперь давайте проанализируем наши уровни ошибок проверки. К сожалению, нам не удалось превзойти производительность простой линейной регрессионной модели, что свидетельствует о том, что наша модель может быть слишком чувствительна к дисперсии данных. Хорошей новостью является то, что мы превзошли наш стандартный DNN-регрессор.
ensemble_error.mean().sort_values(ascending=True)
| Модели | Ошибка проверки |
|---|---|
| Базовый уровень | 0.004784 |
| Пользовательский L-BFGS-B NN | 0.004891 |
| SGD | 0.005937 |
| NN по умолчанию | 35.35851 |
Экспорт в формат ONNX
Open Neural Network Exchange (ONNX) — это протокол с открытым исходным кодом для создания и развертывания моделей машинного обучения независимо от языка. ONNX позволяет нам легко интегрировать наши модели scikit-learn в наших советников, полагаясь на поддержку API MQL5 для ONNX. Сначала импортируем необходимые библиотеки. #Prepare to export to ONNX import onnx import netron from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Теперь давайте подогоним модели ко всем имеющимся у нас данным.
#Fit the SGD model on all the data we have close_model = SGDRegressor(tol= 0.001, shuffle=False, penalty= 'elasticnet', loss= 'huber', learning_rate='adaptive', fit_intercept= True, early_stopping= True, alpha= 1e-05) close_model.fit(nzd_jpy.loc[:,['Close']],nzd_jpy.loc[:,'Target'])
Затем, наконец, мы установим наш DNN-регрессор.
#Fit the deep neural network on all the data we have residuals_model = MLPRegressor( tol=0.0001, solver= 'lbfgs', shuffle=False, power_t= 0.5, max_iter= 300, learning_rate_init= 0.01, learning_rate='constant', hidden_layer_sizes=(30, 200, 40), early_stopping=False, alpha=1e-05, activation='identity') #Fit the model on the residuals residuals_model.fit(residuals_train_X,residuals_train_y) residuals_model.fit(residuals_test_X,residuals_test_y)
Давайте определим входные формы наших двух моделей.
# Define the input type close_initial_types = [("float_input",FloatTensorType([1,1]))] residuals_initial_types = [("float_input",FloatTensorType([1,3]))]
Нам необходимо создать ONNX-представления наших моделей.
# Create the ONNX representation close_onnx_model = convert_sklearn(close_model,initial_types=close_initial_types,target_opset=12) residuals_onnx_model = convert_sklearn(residuals_model,initial_types=residuals_initial_types,target_opset=12)
Наконец, нам необходимо сохранить наши модели в формате ONNX.
#Save the ONNX Models onnx.save_model(close_onnx_model,'close_model.onnx') onnx.save_model(residuals_onnx_model,'residuals_model.onnx')
Визуализация наших моделей ONNX
Давайте также визуализируем наши модели, чтобы убедиться, что они имеют указанные нами входные и выходные формы. Начнем с визуализации нашего DNN-регрессора. Сначала импортируем нужную нам библиотеку.
#Import netron
import netron Теперь визуализируем нашу DNN.
#Visualizing the residuals model netron.start("/ENTER/YOUR/PATH/residuals_model.onnx")
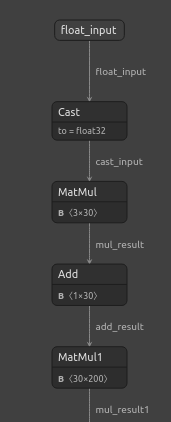
Рис. 22. Визуализация модели DNN-регрессора
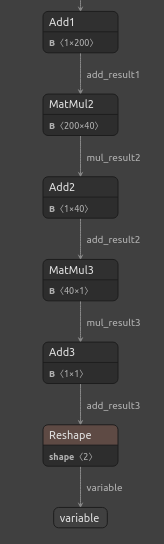
Рис. 23. Визуализация модели DNN-регрессора
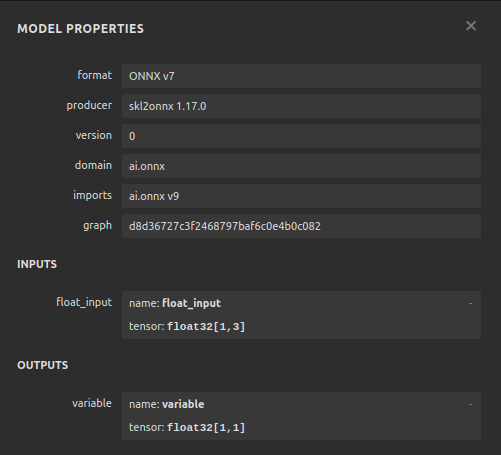
Рис. 24. Форма входных и выходных данных нашего DNN-регрессора соответствует нашим ожиданиям.
Также визуализируем нашу модель SGD-регрессора.
#Visualizing the close model netron.start("/ENTER/YOUR/PATH/close_model.onnx")

Рис 25. Визуализация модели SGD-регрессора
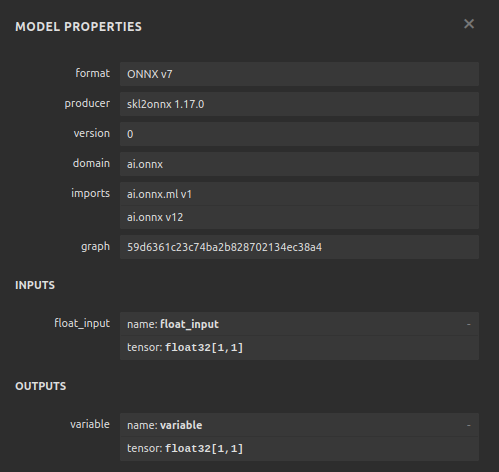
Рис. 26. Визуализация модели SGD-регрессора
Реализация средствами MQL5
Чтобы приступить к созданию нашего советника на базе ИИ, нам сначала необходимо загрузить в приложение файлы ONNX, которые мы только что создали.
//+------------------------------------------------------------------+ //| NZD JPY AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the ONNX models | //+------------------------------------------------------------------+ #resource "\\Files\\residuals_model.onnx" as const uchar residuals_onnx_buffer[]; #resource "\\Files\\close_model.onnx" as const uchar close_onnx_buffer[];
Теперь нам нужна торговая библиотека, которая поможет нам открывать и закрывать позиции.
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
Давайте также создадим глобальные переменные, которые будем использовать во всей нашей программе.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long residuals_model,close_model; vectorf residuals_forecast = vectorf::Zeros(1); vectorf close_forecast = vectorf::Zeros(1); float forecast = 0; int model_state,system_state; int counter = 0; double bid,ask;
В процедуре инициализации нашей модели мы сначала загрузим две наши модели ONNX, а затем проверим, работают ли они.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Load the ONNX models if(!load_onnx_models()) { return(INIT_FAILED); } //--- Validate the model is working model_predict(); if(forecast == 0) { Comment("The ONNX models are not working correctly!"); return(INIT_FAILED); } //--- We managed to load our ONNX models return(INIT_SUCCEEDED); }
Всякий раз, когда наша модель будет удалена из графика, мы освободим все ресурсы, которые больше не используем.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up the resources we no longer need release_resorces(); }
Если мы получим новые цены, мы сначала обновим наши рыночные цены. После этого мы получим прогноз из нашей модели. Получив прогноз, мы проверим, есть ли у нас открытые позиции. Если у нас нет открытых позиций, мы будем следовать прогнозу нашей модели до тех пор, пока изменения цен на более высоких временных интервалах позволят нам это сделать. В противном случае, если у нас уже есть открытая позиция, мы сначала подождем, пока пройдет 20 свечей, прежде чем проверить, предсказывает ли наша модель разворот. Напомним, что мы обучили модель прогнозировать на 20 шагов вперед, поэтому нам следует подождать некоторое время, прежде чем проверять разворот.
//--- If we have no positions, follow the model's forecast if(PositionsTotal() == 0) { //--- Our model is suggesting we should buy if(model_state == 1) { if(iClose(Symbol(),PERIOD_W1,0) > iClose(Symbol(),PERIOD_W1,12)) { Trade.Buy(0.3,Symbol(),ask,0,0,"NZD JPY AI"); system_state = 1; } } //--- Our model is suggesting we should sell if(model_state == -1) { if(iClose(Symbol(),PERIOD_W1,0) < iClose(Symbol(),PERIOD_W1,12)) { Trade.Sell(0.3,Symbol(),bid,0,0,"NZD JPY AI"); system_state = -1; } } } else { //--- We want to wait 20 mins before forecating again. if(time_stamp != time) { time_stamp= time; counter += 1; } if((system_state!= model_state) && (counter >= 20)) { Alert("Reversal detected by our AI system, closing all positions"); Trade.PositionClose(Symbol()); counter = 0; } } }
Давайте определим функцию для получения прогнозов из наших моделей. Напомню, что у нас есть две отдельные модели, каждую из которых нужно вызывать по очереди.
//+------------------------------------------------------------------+ //| Fetch a prediction from our models | //+------------------------------------------------------------------+ void model_predict(void) { //--- Define the inputs vectorf close_inputs = vectorf::Zeros(1); vectorf residuals_inputs = vectorf::Zeros(3); close_inputs[0] = (float) iClose(Symbol(),PERIOD_M1,0); residuals_inputs[0] = (float) iOpen(Symbol(),PERIOD_M1,0); residuals_inputs[1] = (float) iHigh(Symbol(),PERIOD_M1,0); residuals_inputs[2] = (float) iLow(Symbol(),PERIOD_M1,0); //--- Fetch predictions OnnxRun(residuals_model,ONNX_DEFAULT,residuals_inputs,residuals_forecast); OnnxRun(close_model,ONNX_DEFAULT,close_inputs,close_forecast); //--- Our forecast forecast = residuals_forecast[0] + close_forecast[0]; Comment("Model forecast: ",forecast); //--- Remember the model's prediction if(forecast > close_inputs[0]) { model_state = 1; } else { model_state = -1; } }
Нам также нужна функция обновления наших рыночных цен.
//+------------------------------------------------------------------+ //| Update the market data we have | //+------------------------------------------------------------------+ void update_market_data(void) { bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); }
Эта функция освободит ресурсы, которые мы больше не используем.
//+------------------------------------------------------------------+ //| Rlease the resources we no longer need | //+------------------------------------------------------------------+ void release_resorces(void) { OnnxRelease(residuals_model); OnnxRelease(close_model); ExpertRemove(); }
Наконец, эта функция подготовит наши ONNX-модели из ONNX-буферов, которые мы создали в начале нашего приложения.
//+------------------------------------------------------------------+ //| This function will load our ONNX models | //+------------------------------------------------------------------+ bool load_onnx_models(void) { //--- Load the ONNX models from the buffers we created residuals_model = OnnxCreateFromBuffer(residuals_onnx_buffer,ONNX_DEFAULT); close_model = OnnxCreateFromBuffer(close_onnx_buffer,ONNX_DEFAULT); //--- Validate the models if((residuals_model == INVALID_HANDLE) || (close_model == INVALID_HANDLE)) { //--- We failed to load the models Comment("Failed to create the ONNX models: ",GetLastError()); return(false); } //--- Set the I/O shapes of the models ulong residuals_inputs[] = {1,3}; ulong close_inputs[] = {1,1}; ulong model_output[] = {1,1}; //---- Validate the I/O shapes if((!OnnxSetInputShape(residuals_model,0,residuals_inputs)) || (!OnnxSetInputShape(close_model,0,close_inputs))) { //--- We failed to set the input shapes Comment("Failed to set model input shapes: ",GetLastError()); return(false); } if((!OnnxSetOutputShape(residuals_model,0,model_output)) || (!OnnxSetOutputShape(close_model,0,model_output))) { //--- We failed to set the output shapes Comment("Failed to set model output shapes: ",GetLastError()); return(false); } //--- Everything went fine return(true); } //+------------------------------------------------------------------+
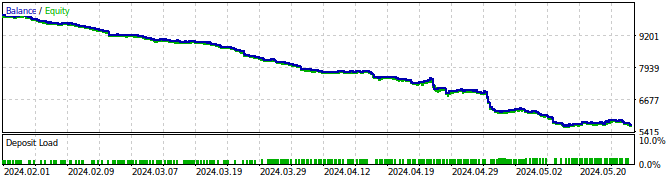
Рис. 27. Тестирование советника на истории
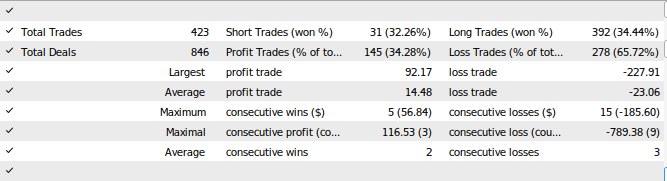
Рис. 28. Результаты тестирования советника
Заключение
В этой статье мы продемонстрировали, как можно создавать самокорректирующиеся торговые приложения. Мы рассмотрели, как анализировать остатки модели, чтобы обнаружить переобучение и смещение в моделях машинного обучения. К сожалению, мы обнаружили, что остатки нашей наиболее эффективной модели вели себя некорректно. Мы могли бы попытаться исправить это, сравнивая данные временного ряда и цель до тех пор, пока не перестанем наблюдать какую-либо автокорреляцию в остатках, однако это также может затруднить интерпретацию нашей модели. Хотя мы не можем гарантировать, что темы, поднятые в этой статье, приведут к постоянному успеху, их определенно стоит рассмотреть, если вы заинтересованы в применении ИИ в своих торговых стратегиях. В следующей статье мы попытаемся устранить обнаруженные подводные камни, одновременно с этим сохраняя интерпретируемость модели.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/15886
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Хорошая статья.
Большое спасибо Киккиху, это много значит.