Нейросети в трейдинге: Иерархический векторный Transformer (Окончание)

Введение
В предыдущей статье мы познакомились с теоретическим описанием алгоритма Иерархического Векторного Transformer (HiVT), который был предложен для прогнозирования движения нескольких агентов в области автономного вождения транспортных средств. Данный метод предлагает эффективный подход к решению задачи прогнозирования временных рядов путем декомпозиции основной задачи на этапы локального извлечения контекста и глобального моделирования взаимодействий.
Напомню, что задача прогнозирования временных рядов решается авторами метода HiVT в 3 этапа. На первом этапе модель извлекает локальные контекстные признаки объектов. Вся сцена делится на набор локальных областей, каждая из которых центрирована вокруг одного центрального агента.
На втором этапе, осуществляется фиксирование глобальных дальнодействующих зависимостей на сцене путем передачи информации между агентно-центрированными локальными областями.
Полученные локальные и глобальные представления позволяют декодеру прогнозировать будущие траектории всех агентов за один прямой проход модели.
Авторская визуализация метода представлена ниже.
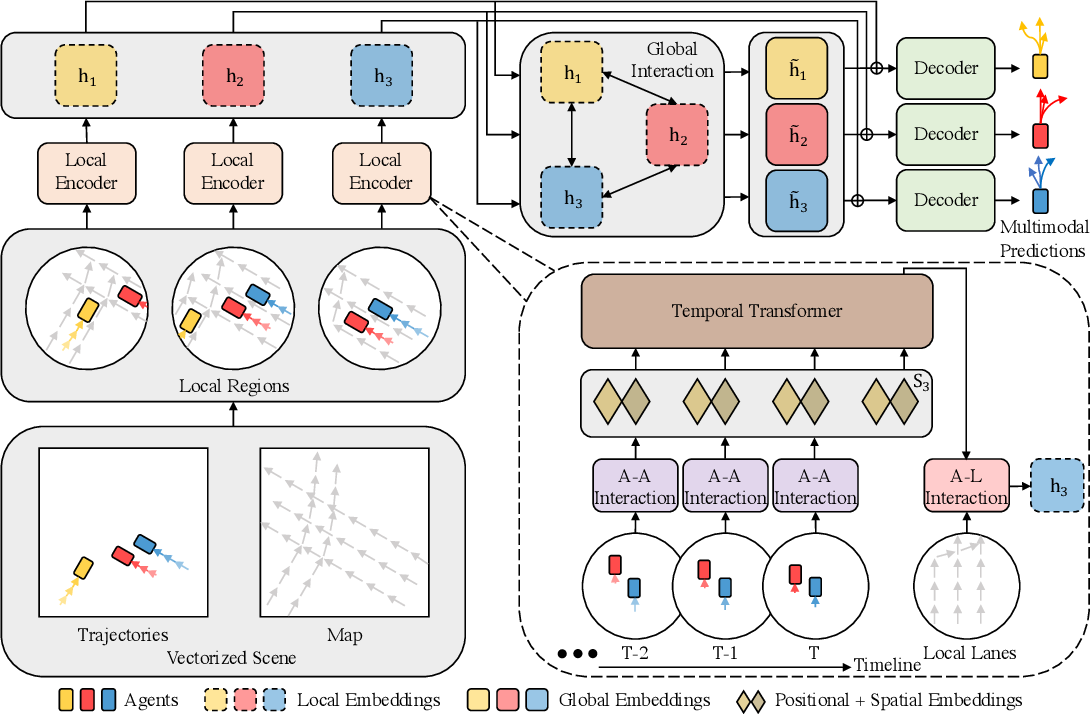
Кроме того, в предыдущей статье мы провели довольно обширную подготовительную работу, в ходе которой были реализованы отдельные блоки предложенного алгоритма. И теперь нам предстоит завершить начатую работу, объединив отдельные разрозненные блоки в единую комплексную структуру.
1. Собираем HiVT
Свое видение реализации подходов, предложенных авторами метода HiVT, мы реализуем в рамках класса CNeuronHiVTOCL. Базовый функционал наш новый класс унаследует от полносвязного слоя CNeuronBaseOCL. А его полная структура представлена ниже.
class CNeuronHiVTOCL : public CNeuronBaseOCL { protected: uint iHistory; uint iVariables; uint iForecast; uint iNumTraj; //--- CNeuronBaseOCL cDataTAD; CNeuronConvOCL cEmbeddingTAD; CNeuronTransposeRCDOCL cTransposeATD; CNeuronHiVTAAEncoder cAAEncoder; CNeuronTransposeRCDOCL cTransposeTAD; CNeuronLearnabledPE cPosEmbeddingTAD; CNeuronMVMHAttentionMLKV cTemporalEncoder; CNeuronLearnabledPE cPosLineEmbeddingTAD; CNeuronPatching cLineEmbeddibg; CNeuronMVCrossAttentionMLKV cALEncoder; CNeuronMLMHAttentionMLKV cGlobalEncoder; CNeuronTransposeOCL cTransposeADT; CNeuronConvOCL cDecoder[3]; // Agent * Traj * Forecast CNeuronConvOCL cProbProj; CNeuronSoftMaxOCL cProbability; // Agent * Traj CNeuronBaseOCL cForecast; CNeuronTransposeOCL cTransposeTA; //--- virtual bool Prepare(const CNeuronBaseOCL *history); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override ; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHiVTOCL(void) {}; ~CNeuronHiVTOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint forecast, uint num_traj, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronHiVTOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
В представленной структуре нашего объекта CNeuronHiVTOCL мы видим объявление уже знакомого нам списка переопределяемых методов и целого ряда внутренних объектов, с функционалом которых мы познакомимся в процессе реализации алгоритмов переопределяемых методов.
Все внутренние объекты мы объявляем статично, что позволяет нам оставить "пустыми" конструктор и деструктор класса. А непосредственная инициализация всех вложенных объектов и переменных осуществляется в методе Init.
bool CNeuronHiVTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint forecast, uint num_traj, ENUM_OPTIMIZATION optimization_type, uint batch) { if(units_count < 2 || !CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * forecast, optimization_type, batch)) return false;
В параметрах метода мы получаем основные константы, позволяющие однозначно идентифицировать архитектуру инициализируемого объекта. А в теле метода мы сразу осуществляем вызов одноименного метода родительского класса. Как вы знаете, в нем осуществляется инициализация всех унаследованных объектов и переменных.
Здесь стоит обратить внимание, что к контролям, реализованным в методе родительского класса, мы добавляем прямую проверку числа элементов в анализируемой последовательности. В данном случае их должно быть не менее 2. Так как в процессе векторизации исходного состояния, который предусмотрен алгоритмом HiVT, мы будем оперировать динамикой показателей. А для вычисления изменения показателя нам нужно 2 его значения: на текущем и предыдущем временном шаге.
После успешного прохождения контрольного блока нашего метода инициализации, мы сохраняем полученные параметры архитектуры блока во внутренние переменные.
iVariables = window; iHistory = units_count - 1; iForecast = forecast; iNumTraj = MathMax(num_traj, 1);
Далее мы осуществляем инициализацию внутренних объектов. Порядок инициализации внутренних объектов будет соответствовать последовательности использования объектов в рамках алгоритма прямого прохода рассматриваемого алгоритма. Такой подход позволит нам ещё раз проработать выстраиваемый алгоритм, а также убедиться как в достаточности, так и в необходимости создания объектов.
Первым мы создадим объект внутреннего слоя для записи векторного представления анализируемого состояния окружающей среды.
Напомню, что здесь вектор описания каждого отдельного элемента унитарной последовательности на отдельном временном шаге равен удвоенному количеству анализируемых унитарных последовательностей. Ведь каждый элемент последовательности характеризуется перемещением в двухмерном пространстве и изменением положения остальных агентов относительно анализируемого элемента.
И такой вектор описания мы создаем для каждого элемента всех анализируемых унитарных последовательностей на каждом временном шаге.
if(!cDataTAD.Init(0, 0, OpenCL, 2 * iVariables * iVariables * iHistory, optimization, iBatch)) return false;
Обратите внимание, что при реализации алгоритма HiVT мы строим работу с трехмерными тензорами, образ которых сохраняем в одномерном буфере данных. И для указания текущей размерности в наименованиях объектов мы добавим суффикс из 3 символов:
- T (Time) — размерность временных шагов;
- A (Agent) — размерность агента (унитарного временного ряда), в нашем случае — анализируемого параметра;
- D (Dimension) — размерность вектора описания одного элемента унитарной последовательности.
Далее мы воспользуемся сверточным слоем для создания эмбедингов полученных векторных описаний.
if(!cEmbeddingTAD.Init(0, 1, OpenCL, 2 * iVariables, 2 * iVariables, window_key, iVariables * iHistory, 1, optimization, iBatch)) return false;
В данном случае, для генерации эмбедингов мы используем 1 матрицу параметров, которую применяем ко всем элементам мультимодальной последовательности. Поэтому количество анализируемых блоков данного слоя укажем как произведение числа унитарных последовательностей на глубину анализируемой истории.
После генерации эмбедингов алгоритмом HiVT предусматривается поведение анализа локальных зависимостей между агентами в рамках одного временного шага. Как обсуждалось в предыдущей статье, перед выполнением этого шага нам необходимо выполнить транспонирование исходных данных.
if(!cTransposeATD.Init(0, 2, OpenCL, iHistory, iVariables, window_key, optimization, iBatch)) return false;
И только потом мы можем воспользоваться имеющимися у нас классами внимания для выявления зависимостей между агентами локальной группы.
if(!cAAEncoder.Init(0, 3, OpenCL, window_key, window_key, heads, (heads + 1) / 2, iVariables, 2, 1, iHistory, optimization, iBatch)) return false;
Здесь следует обратить внимание на 2 момента. Во-первых, после транспонирования данных мы изменили последовательность символов в суффиксе наименования объекта на ATD, что соответствует размерности трехмерного тензора на выходе слоя транспонирования данных.
Во-вторых, посмотрите на функциональность наших блоков внимания. Изначально мы их создавали для работы с 2 мерными тензорами, в которых каждая стока представляет вектор описания одного элемента последовательности. И фактически мы выявляем зависимости между строками анализируемой матрицы. Так сказать, выполняем "вертикальное внимание". Позже мы добавили выявление зависимостей в рамках отдельных унитарных последовательностей мультимодального временного ряда. На практике мы разделили исходную матрицу на несколько одинаковых матриц меньшего по числу анализируемых унитарных рядов. Новые матрицы унаследовали от исходной количество строк, — равномерно разделим между собой её столбцы. По существу, это соответствует размерности нашего трехмерного тензора. Первое измерение представляет собой количество строк в исходной матрице анализируемых данных. Второе измерение укажет на количество матриц меньшего размера для проведения независимого анализа. А третье измерение представляет собой размерность вектора описания одного элемента анализируемой последовательности. С учетом предварительного транспонирования тензора эмбедингов исходных данных, мы укажем количество унитарных последовательностей в качестве размера анализируемой последовательности текущего блока внимания. В то время как глубину анализируемой истории исходных данных мы укажем в параметре количества переменных. Таким образом, мы достигаем эффекта анализа зависимостей между отдельными переменными в рамках 1 временного шага.
В данной реализации блока анализа зависимостей Агент-Агент я использовал 2 слоя внимания с генерацией тензора Key-Value для каждого внутреннего слоя. При этом количество голов внимания тензора Key-Value в 2 раза меньше аналогичного параметра для тензора Query.
И обратите внимание, что в данном случае мы используем блок внимания с функцией управления объединения признаков CNeuronHiVTAAEncoder.
После обогащения эмбединга элементов последовательности зависимостями между агентами локальной группы, алгоритмом HiVT предусмотрен анализ временных зависимостей в рамках отдельных элементов унитарных последовательностей. Здесь нам предстоит вернуть данные в исходное представление.
if(!cTransposeTAD.Init(0, 4, OpenCL, iVariables, iHistory, window_key, optimization, iBatch)) return false;
Затем добавим полностью обучаемое позиционное кодирование.
if(!cPosEmbeddingTAD.Init(0, 5, OpenCL, iVariables * iHistory * window_key, optimization, iBatch)) return false;
И воспользуемся блоком внимания CNeuronMVMHAttentionMLKV для выявления темпоральных зависимостей.
if(!cTemporalEncoder.Init(0, 6, OpenCL, window_key, window_key, heads, (heads + 1) / 2, iHistory, 2, 1, iVariables, optimization, iBatch)) return false;
Несмотря на различия архитектуры блоков внимания локальных и темпоральных зависимостей, для их инициализации мы используем одинаковые параметры.
Следующим шагом авторы метода HiVT предлагают обогатить эмбединги Агентов информацией о дорожной карте. Думаю ни у кого не вызывает сомнение, что состояние дороги, её разметка и изгибы накладывают определенный отпечаток на действия агента. В нашем случае нет явных ориентиров ограничения изменения значений анализируемых параметров. Конечно, есть области допустимых значений отдельных осцилляторов. К примеру RSI может принимать значения только в диапазоне от 0 до 100. Но это скорее частный случай.
Поэтому мы воспользуемся имеющимися у нас историческими данными для определения наиболее вероятного изменения. Представление карты мы подменим эмбедингами фактических малых отрезком траекторий, которые создадим с помощью слоя патчинга данных.
if(!cLineEmbeddibg.Init(0, 7, OpenCL, 3, 1, 8, iHistory - 1, iVariables, optimization, iBatch)) return false;
Обратите внимание, что при векторизации текущего состояния мы использовали динамику изменения параметра за 1 временной шаг. А при эмбединге фактических малых отрезков траектории мы используем блоки из 3 элементов с шагом 1. Таким образом мы хотим выявить зависимости между динамикой показателя на отдельном шаге и возможным продолжением траектории.
К полученным эмбедингам мы добавим полностью обучаемое позиционное кодирование.
if(!cPosLineEmbeddingTAD.Init(0, 8, OpenCL, cLineEmbeddibg.Neurons(), optimization, iBatch)) return false;
И затем обогатим текущие эмбединги Агентов информацией о траекториях. Для этого мы используем блок кросс-внимания CNeuronMVCrossAttentionMLKV с двумя внутренними слоями.
if(!cALEncoder.Init(0, 9, OpenCL, window_key, window_key, heads, 8, (heads + 1) / 2, iHistory, iHistory - 1, 2, 1, iVariables, iVariables, optimization, iBatch)) return false;
Здесь может показаться, что мы последовательно выполняем 2 аналогичные операции: выявление темпоральных зависимостей и анализ зависимостей между агентами и траекториями. В обоих случаях мы анализируем зависимости текущего состояния Агента с представлением параметров того же индикатора на других временных отрезках. Но здесь есть тонкая грань. В первом случае мы сопоставляем аналогичные состояния агента на отдельных временных шагах. А во втором случае мы имеем дело с некими паттернами траекторий, которые охватывают немного больший временной интервал.
На этом завершается блок анализа локальных зависимостей, который, по существу, всесторонне обогащает эмбединг состояния Агента. И следующим этапом алгоритма HiVT является анализ долгосрочных зависимостей сцены в блоке глобального взаимодействия.
if(!cGlobalEncoder.Init(0, 10, OpenCL, window_key*iVariables, window_key*iVariables, heads, (heads+1)/2, iHistory, 4, 2, optimization, iBatch)) return false;
Здесь мы используем блок внимания с 4 внутренними слоями. При этом для анализа зависимостей мы используем представление не отдельных Агентов, а всей сцены.
И далее нам остается смоделировать предстоящую последовательность прогнозных значений. Как и ранее, прогнозирование предстоящей последовательности осуществляется в рамках отдельных унитарных последовательностей. Для этого нам вначале предстоит транспонировать текущие данные.
if(!cTransposeADT.Init(0, 11, OpenCL, iHistory, window_key * iVariables, optimization, iBatch)) return false;
Далее, для прогнозирования последующих значений на всю глубину планирования, авторы метода HiVT предлагают использовать MLP. В нашем случае эта работа выполнятся в блоке из 3 последовательных сверточных слоев, каждый из которых получил уникальное окно анализируемых данных и свою функцию активации.
if(!cDecoder[0].Init(0, 12, OpenCL, iHistory, iHistory, iForecast, window_key * iVariables, optimization, iBatch)) return false; cDecoder[0].SetActivationFunction(SIGMOID); if(!cDecoder[1].Init(0, 13, OpenCL, iForecast * window_key, iForecast * window_key, iForecast * window_key, iVariables, optimization, iBatch)) return false; cDecoder[1].SetActivationFunction(LReLU); if(!cDecoder[2].Init(0, 14, OpenCL, iForecast * window_key, iForecast * window_key, iForecast * iNumTraj, iVariables, optimization, iBatch)) return false; cDecoder[2].SetActivationFunction(TANH);
На первом этапе мы работаем в рамках отдельных элементов эмбединга описания состояния отдельного Агента, изменяя размер последовательности с глубины анализируемой истории до горизонта планирования.
Затем мы анализируем глобальные зависимости в рамках отдельных агентов на весь горизонт планирования без изменения размера тензора.
И только на последнем этапе мы прогнозируем сразу несколько возможных вариантов развития событий по каждому отдельному унитарному временному ряду. Количество вариантов прогнозных траекторий задается внешней программой в параметрах метода.
Здесь стоит отметить, что прогнозирование нескольких вариантов развития событий является отличительной особенностью предложенного подхода. Тем не менее, нам нужен механизм выбора наиболее вероятной траектории. Поэтому мы сначала сделаем проекцию полученных траекторий до размерности количества прогнозных траекторий для каждого агента.
if(!cProbProj.Init(0, 15, OpenCL, iForecast * iNumTraj, iForecast * iNumTraj, iNumTraj, iVariables, optimization, iBatch)) return false;
И с помощью функции SoftMax переведем полученные проекции в область вероятностей.
if(!cProbability.Init(0, 16, OpenCL, iForecast * iNumTraj * iVariables, optimization, iBatch)) return false; cProbability.SetHeads(iVariables); // Agent * Traj
Путем взвешивания ранее спрогнозированных траекторий на их вероятности мы получаем усредненную траекторию предстоящего движения нашего Агента.
if(!cForecast.Init(0, 17, OpenCL, iForecast * iVariables, optimization, iBatch)) return false;
Нам остается лишь привести прогнозные значения к размерности исходных данных. Этот функционал мы выполняем посредством транспонирования данных.
if(!cTransposeTA.Init(0, 18, OpenCL, iVariables, iForecast, optimization, iBatch)) return false;
С целью сокращения операций копирования данных и оптимизации использования ресурсов памяти, мы переопределим указатели буферов результатов и градиентов ошибки нашего блока на аналогичные буфера последнего внутреннего слоя транспонирования данных.
SetOutput(cTransposeTA.getOutput(),true); SetGradient(cTransposeTA.getGradient(),true); //--- return true; }
И завершаем работу метода, вернув вызывающей программе логический результат выполнения операций метода.
После завершения работы по инициализации объекта класса, мы переходим к построению алгоритма прямого прохода нашего класса в методе feedForward.
bool CNeuronHiVTOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!Prepare(NeuronOCL)) return false;
В параметрах метода мы получаем указатель на объект, содержащий исходные данные. Полученный указатель мы сразу передаем в метод подготовки исходных данных Prepare. Данный метод является "оберткой" для вызова кернела векторизации данных HiVTPrepare, алгоритм которого был рассмотрен в предыдущей статье. Мы уже много раз рассматривали различные методы постановки кернелов OpenCL программы в очередь выполнения. И алгоритм метода Prepare не выделяется какими-либо особенностями и "подводными камнями". Поэтому в рамках данной статьи мы опустим описание его алгоритма. Тем не менее вы можете самостоятельно ознакомиться с ним во вложении.
Далее на основании полученных векторных представлений мы генерируем эмбединги Агентов на каждом отдельном временном шаге.
if(!cEmbeddingTAD.FeedForward(cDataTAD.AsObject())) return false;
Транспонируем их.
if(!cTransposeATD.FeedForward(cEmbeddingTAD.AsObject())) return false;
И обогащаем локальными зависимости в рамках анализа представлений Агент-Агент.
if(!cAAEncoder.FeedForward(cTransposeATD.AsObject())) return false;
Следующим шагом мы обогащаем эмбединги состояния агентов путем добавления темпоральных зависимостей. Для этого мы сначала транспонируем текущий тензор данных.
if(!cTransposeTAD.FeedForward(cAAEncoder.AsObject())) return false;
Добавляем к нему метки позиционного кодирования.
if(!cPosEmbeddingTAD.FeedForward(cTransposeTAD.AsObject())) return false;
И вызываем метод прямого прохода нашего модуля темпорального внимания в разрезе отдельных агентов.
if(!cTemporalEncoder.FeedForward(cPosEmbeddingTAD.AsObject())) return false;
После успешного выполнения операций темпорального внимания, мы получаем тензор эмбедингов анализируемых данных, обогащенный локальными и темпоральными зависимости. И теперь нам предстоит обогатить полученные эмбединги информацией о возможных паттернах движения. Для этого мы сначала создаем эмбединги паттернов анализируемого исторического движения.
if(!cLineEmbeddibg.FeedForward(NeuronOCL)) return false;
Добавляем позиционное кодирование к полученным эмбедингам паттернов.
if(!cPosLineEmbeddingTAD.FeedForward(cLineEmbeddibg.AsObject())) return false;
И в модуле кросс-внимания обогатим эмбединги наших агентов информацией о различных паттернах движения.
if(!cALEncoder.FeedForward(cTemporalEncoder.AsObject(), cPosLineEmbeddingTAD.getOutput())) return false;
К тензору обогащенных эмбедингов агентов мы применяем модуль глобального внимания.
if(!cGlobalEncoder.FeedForward(cALEncoder.AsObject())) return false;
За которым следует блок прогнозирования предстоящего движения агентов. Напомню, что мы планируем осуществлять прогнозирование последующих значений анализируемых параметров в разрезе унитарных последовательностей. Поэтому, мы сначала транспонируем имеющийся тензор данных.
if(!cTransposeADT.FeedForward(cGlobalEncoder.AsObject())) return false;
После чего осуществляем прямой проход нашего трехслойного MLP блока прогнозирования данных.
if(!cDecoder[0].FeedForward(cTransposeADT.AsObject())) return false; if(!cDecoder[1].FeedForward(cDecoder[0].AsObject())) return false; if(!cDecoder[2].FeedForward(cDecoder[1].AsObject())) return false;
Здесь следует вспомнить об особенности метода HiVT. На выходе MLP прогнозирования предстоящего движения мы получаем не один, а несколько вариантов возможного продолжения анализируемого исходного ряда. И нам предстоит определить вероятности осуществления каждого варианта прогнозируемого движения. Для этого мы сначала сделаем прогнозные траектории.
if(!cProbProj.FeedForward(cDecoder[2].AsObject())) return false;
И с помощью функции SoftMax переведем полученные проекции в область вероятностных значений.
if(!cProbability.FeedForward(cProbProj.AsObject())) return false;
Теперь нам достаточно умножить тензор прогнозных траекторий на их вероятности.
if(IsStopped() || !MatMul(cDecoder[2].getOutput(), cProbability.getOutput(), cForecast.getOutput(), iForecast, iNumTraj, 1, iVariables)) return false;
В результате данной операции мы получаем тензор средневзвешенных траекторий на весь горизонт планирования для каждого унитарного ряда анализируемой мультимодальной последовательности.
И в завершении операций нашего метода прямого прохода, мы осуществим транспонирование тензора прогнозных значений, чтобы привести его в соответствие с измерениями анализируемых исходных данных.
if(!cTransposeTA.FeedForward(cForecast.AsObject())) return false; //--- return true; }
Как обычно, мы возвращаем вызывающей программе логическое значение результата выполнения операций метода.
На этом мы завершаем работу по реализации алгоритма прямого прохода метода HiVT и переходим к построению методов обратного прохода нашего класса. Как вы знаете, алгоритм обратного прохода состоит из 2 основных блоков:
- Распределение градиента ошибки до всех элементов в соответствии с их влиянием на конечный результат. Данный функционал реализовывается в методе calcInputGradients.
- Корректировка обучаемых параметров модели с целью минимизации общей её работы, которая осуществляется в методе updateInputWeights.
Реализацию алгоритмов обратного прохода мы начнем с построения метода распределения градиента ошибки calcInputGradients. Алгоритм данного метода строится в полном соответствии с алгоритмом прямого прохода, только все операции выполняются в обратном порядке.
bool CNeuronHiVTOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В параметрах данного метода мы получаем указатель на объект предыдущего слоя, который при прямом проходе передавал нам исходные данные. А в данном случае нам предстоит передать в него градиент ошибки в соответствии с влиянием исходных данных на конечный результат.
В теле метода мы сразу проверяем актуальность полученного указателя. Ведь в противном случае выполнение операций данного метода теряет смысл.
После успешного прохождения блока контролей, мы переходим к выполнению операций непосредственного распределения градиента ошибки.
Градиент ошибки на уровне результатов текущего слоя уже содержится в соответствующем буфере нашего класса. Он был туда записан при выполнении операций аналогичного метода последующего слоя. А благодаря осуществленной ранее подмене буферов данных, необходимый нам градиент ошибки уже содержится в буфере последнего слоя транспонирования данных. И мы начинаем работу с передачи градиента ошибки на уровень слоя средневзвешенных прогнозных траекторий унитарных рядов.
if(!cForecast.calcHiddenGradients(cTransposeTA.AsObject())) return false;
Как вы помните, в процессе прямого прохода средневзвешенные траектории мы получили путем умножения тензора нескольких прогнозных траекторий на вектор соответствующих вероятностей. Соответственно, в процессе обратного прохода нам предстоит распределить градиент ошибки как на тензор множества прогнозных траекторий, так и на вектор вероятностей.
if(IsStopped() || !MatMulGrad(cDecoder[2].getOutput(), cDecoder[2].getGradient(), cProbability.getOutput(), cProbability.getGradient(), cForecast.getGradient(), iForecast, iNumTraj, 1, iVariables)) return false;
Градиент ошибки вероятностей мы передадим на слой проекции прогнозных траекторий.
if(!cProbProj.calcHiddenGradients(cProbability.AsObject())) return false;
А для получения проекций мы использовали сами прогнозные траектории. И далее мы должны были бы передать градиент ошибки на уровень прогнозных траекторий.
Но здесь стоит обратить внимание, что на уровень тензора множества прогнозных траекторий мы уже передали градиент ошибки от средневзвешенной траектории шагом ранее. И прямой вызов метода calcHiddenGradients соответствующего слоя удалит ранее переданный градиент ошибки и перезапишет буфер новыми значениями. Обычно в подобных случаях мы используем вспомогательные буфера данных с последующим суммированием значений из 2 потоков данных. Однако в данном случае было принято решение не передавать далее градиент ошибки слоя проекции данных. Тем самым мы бы хотели сохранить "чистым" прогнозирование последующих траекторий без искажения их значений погрешностями вероятностного распределения актуальности отдельных траекторий.
Поэтому через MLP блока прогнозирования мы проводим градиент ошибки прогнозных траекторий.
if(!cDecoder[1].calcHiddenGradients(cDecoder[2].AsObject())) return false; if(!cDecoder[0].calcHiddenGradients(cDecoder[1].AsObject())) return false;
Полученный на выходе тензор градиентов ошибки мы транспонируем и проводим через блок глобального взаимодействия.
if(!cTransposeADT.calcHiddenGradients(cDecoder[0].AsObject())) return false; if(!cGlobalEncoder.calcHiddenGradients(cTransposeADT.AsObject())) return false; if(!cALEncoder.calcHiddenGradients(cGlobalEncoder.AsObject())) return false;
Из блока глобального взаимодействия градиент ошибки передается в блок анализа локальных зависимостей.
Напомню, что в данном блоке осуществляется всесторонний анализ взаимных зависимостей между отдельными локальными объектами. И здесь мы сначала пропускаем полученный градиент ошибки через блок кросс-внимания Агент-Траектория до уровня блока анализа темпоральных зависимостей и позиционного кодирования эмбедингов паттернов движения.
if(!cTemporalEncoder.calcHiddenGradients(cALEncoder.AsObject(), cPosLineEmbeddingTAD.getOutput(), cPosLineEmbeddingTAD.getGradient(), (ENUM_ACTIVATION)cPosLineEmbeddingTAD.Activation())) return false;
Спустим градиент ошибки через операции позиционного кодирования.
if(!cLineEmbeddibg.calcHiddenGradients(cPosLineEmbeddingTAD.AsObject())) return false;
И передадим на уровень исходных данных.
if(!NeuronOCL.calcHiddenGradients(cLineEmbeddibg.AsObject())) return false;
По второму потоку данных мы сначала проведем градиент ошибки через блок анализа темпоральных зависимостей.
if(!cPosEmbeddingTAD.calcHiddenGradients(cTemporalEncoder.AsObject())) return false;
После чего скорректируем полученный градиент ошибки на операции позиционного кодирования.
if(!cTransposeTAD.calcHiddenGradients(cPosEmbeddingTAD.AsObject())) return false;
Транспонируем данные и проведем градиент через блок анализа зависимостей Агент-Агент.
if(!cAAEncoder.calcHiddenGradients(cTransposeTAD.AsObject())) return false; if(!cTransposeATD.calcHiddenGradients(cAAEncoder.AsObject())) return false;
В завершении операций метода транспонируем данные в исходное представление и проведем градиент ошибки через слой генерации эмбеденгов до векторного представления исходных данных.
if(!cEmbeddingTAD.calcHiddenGradients(cTransposeATD.AsObject())) return false; if(!cDataTAD.calcHiddenGradients(cEmbeddingTAD.AsObject())) return false; //--- return true; }
И вернем логический результат выполнения операций вызывающей программе.
На этом этапе мы распределили градиент ошибки до всех элементов модели в соответствии с их влиянием на финальный результат. И теперь нам необходимо скорректировать обучаемые параметры модели в направлении минимизации общей ошибки работы модели. Данный функционал мы реализуем в методе updateInputWeights.
И здесь следует помнить, что все обучаемые параметры нашего нового класса CNeuronHiVTOCL содержатся в его внутренних объектах. Но не все внутренние объекты содержат обучаемые параметры. К примеру, их нет в слоях транспонирования данных. Поэтому в данном методе мы работаем только с объектами, содержащими обучаемые параметры. А для их корректировки нам достаточно лишь вызвать одноименный метод соответствующего внутреннего объекта.
Как видите, алгоритм работы метода довольно прост, поэтому в рамках статьи мы не будем полностью приводить его код. Тем не менее вы можете самостоятельно ознакомиться с ним во вложении. Там же приведен полный код нашего нового класса и всех его методов.
2. Архитектура модели
Мы завершили работу по построению нового класса CNeuronHiVTOCL и его методов. В данном классе реализовано наше видение подходов, предложенных авторами метода HiVT. И теперь пришло время имплементировать новый объект в архитектуру нашей модели.
Как и ранее, объект прогнозирования последующего движения анализируемого мультимодального ряда мы внедряем в модель Энкодера состояния окружающей среды. Архитектурное решение данной модели представлено в методе CreateEncoderDescriptions. В параметрах данного метода мы получаем указатель на объект динамического массива, в который нам и предстоит записать архитектурное решение генерируемой модели.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В теле метода мы проверяем актуальность полученного указателя и, при необходимости, создаем новый экземпляр динамического массива. После чего переходим к последовательному описанию архитектурного решения каждого слоя нашей модели.
Для получения исходных данных мы используем базовый полносвязный слой достаточного размера.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
В модель мы планируем передавать "сырые" необработанные данные. И для приведения их к сопоставимому виду мы используем слои пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
После первичной обработки мы сразу передаем исходные данные в наш новый блок, построенный с использованием подходов метода HiVT.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronHiVTOCL; { int temp[] = {BarDescr, NForecast, 6}; // {Variables, Forecast, NumTraj} ArrayCopy(descr.windows, temp); } descr.window_out = EmbeddingSize; // Inside Dimension descr.count = HistoryBars; // Units descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь мы практически повторяем аналогичные параметры из предыдущих работ. Добавляется лишь 1 новый параметр блока, определяющий количество вариантов прогнозируемых траекторий. В данном случае мы используем 6.
На выходе блока CNeuronHiVTOCL мы ожидаем получить уже готовые прогнозные значения анализируемого мультимодального временного ряда. Но есть один нюанс. Для организации эффективной работы модели с мультимодальным временным рядом, мы привели все его значения в сопоставимый вид. Соответственно, в аналогичном виде мы получили прогнозные значения. Чтобы привести полученные прогнозные значения к привычным показателям исходных данных, мы добавим к ним статистические параметры распределения, изъятые при нормализации "сырых" данных.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
После чего согласуем полученные результаты в частотной области.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Архитектура моделей Актера и Критика не претерпела изменений. То же можно сказать и о программах обучения моделей. Поэтому в рамках данной статьи мы не будем останавливаться на их рассмотрении. Тем не менее полный код всех программ, используемых при подготовке данной статьи приведен во вложении для самостоятельного изучения.
3. Тестирование
Мы завершили работу по имплементации собственного видения подходов, предложенных авторами метода HiVT. И теперь пришло время проверки эффективности реализованных нами решений. Для этого нам предстоит сначала обучить модели на реальных исторических данных, а затем провести тестирование обученных моделей на наборе данных, не входящем в обучающую выборку.
Для обучения моделей мы используем исторические данные инструмента EURUSD таймфрейм H1 за весь 2023 год.
Обучение моделей мы осуществляем офлайн. Поэтому перед началом обучения нам предстоит собрать необходимую обучающую выборку. Подробнее о данном процессе вы можете прочитать в статье, посвященной методу Real-ORL. Мы же для обучения нашего Энкодера состояния окружающей среды использовали обучающую выборку, собранную при работе предыдущими моделями.
Как вы знаете, модель Энкодера состояния счета работает только с историческими данными ценового движения и анализируемых индикаторов, которые не зависят от действий, выполняемых Агентом. Поэтому, на данном этапе обучения моделей нам нет необходимости периодически обновлять обучающую выборку, так как добавленные новые траектории не дают дополнительной информации для нашего Энкодера. И мы выполняем процесс обучения до получения желаемых результатов.
Результаты тестирования обученной модели представлены ниже.
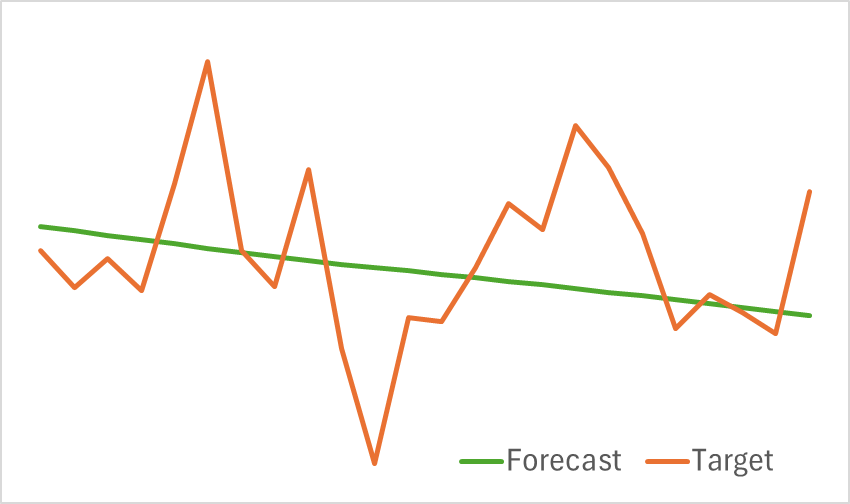
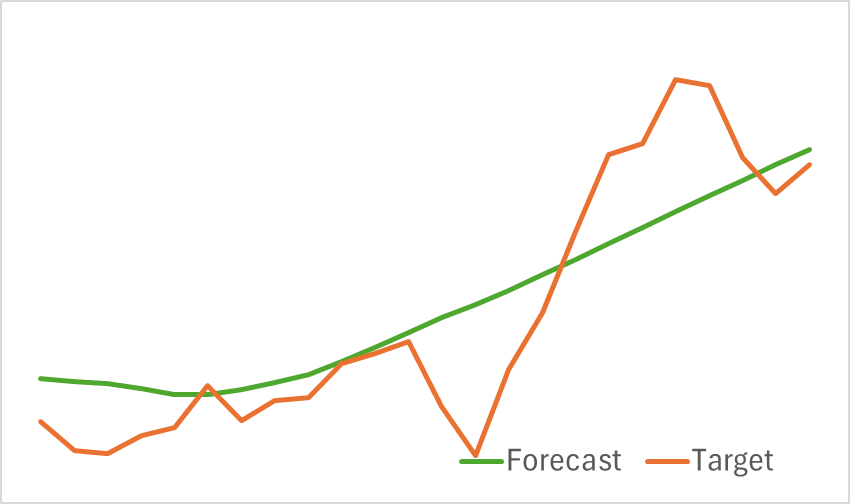
Как видно из приведенных графиков, собранная нами модель может довольно эффективно улавливать основные тенденции предстоящего ценового движения.
Далее мы переходим ко второму этапу обучения моделей — обучению прибыльной политики поведения Актера и функции вознаграждения критика. Очевидно, что в данном случае реальные вознаграждения от окружающей среды будут сильно зависеть от действий, предпринятых Актером. Поэтому для эффективного процесса обучения нам необходимо поддерживать актуальность обучающей выборки. И поэтому мы вынуждены периодически обновлять данные обучающей выборки с учетом текущей политики Актера.
Обучение моделей осуществляется до практического фиксирования ошибки модели на некотором уровне. И очередное обновление обучающей выборки не ведет к оптимизации политики поведения Актера при последующем обучении.
Эффективность работы обученной модели мы проверяем в тестере стратегий MetaTrader 5 на исторических данных Января 2024 года с сохранением прочих параметров. Результаты тестирования обученной модели представлены ниже.
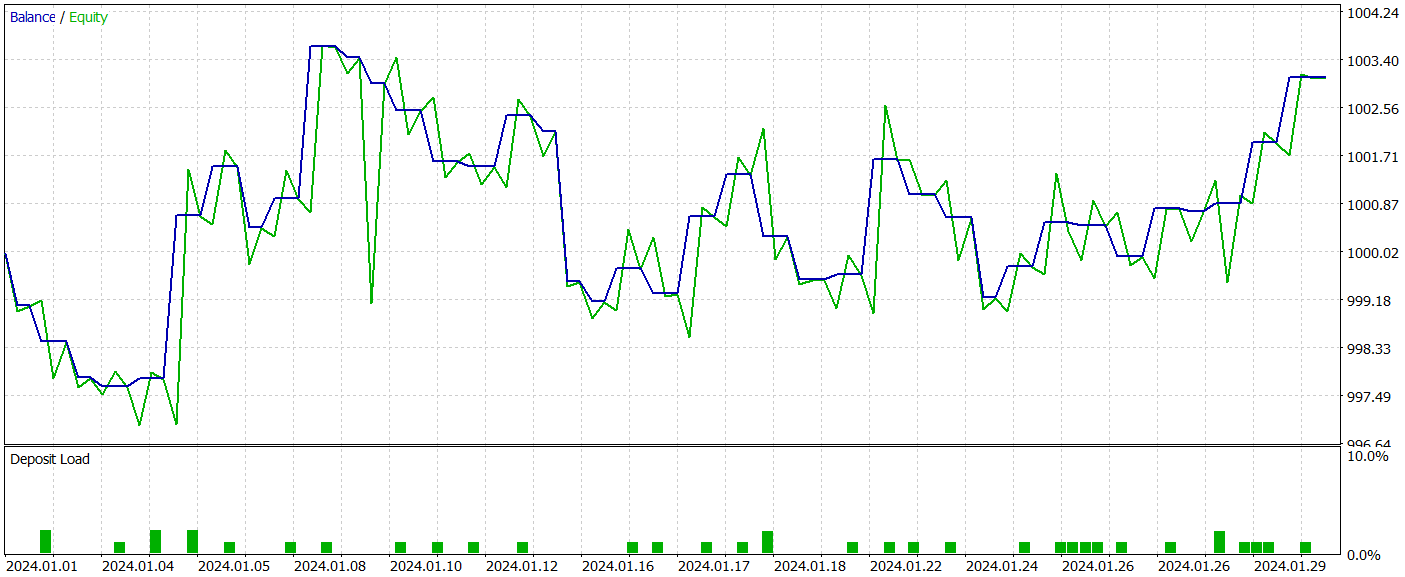
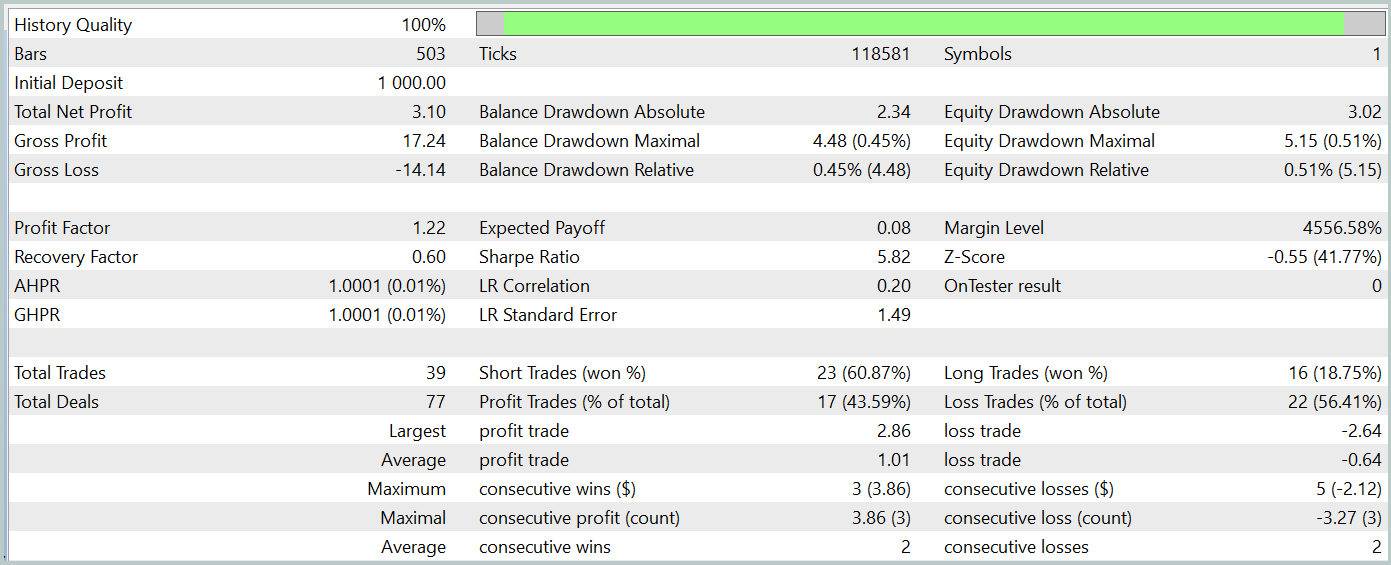
Как можно заметить из приведенных результатов тестирования, в процессе обучения нам удалось получить политику Актера, способную генерировать прибыль как на обучающих, так и на тестовых данных. За период тестирования модель совершила 39 торговых операций и более 43% из них было закрыто с прибылью. Да, доля прибыльных сделок чуть меньше убыточных. Однако, благодаря превышению размера как максимальной, так и средней прибыльной сделки над аналогичным показателем убыточных сделок, нам все же удалось завершить тестирование с небольшой прибылью. При этом профит-фактор был зафиксирован на уровне 1.22.
Тем не менее следует отметить, что ввиду отсутствия явного тренда в наблюдаемой нами линии баланса и малого количества сделок в процессе тестирования, полученные результаты сложно назвать репрезентативными.
Заключение
В данной статье мы завершили работу по реализации подходов, предложенных авторами метода HiVT, средствами MQL5. Мы имплементировали предложенный алгоритм в модель Энкодера состояния окружающей среды. После чего провели обучение и тестирование моделей. Результаты тестирования продемонстрировали способность метода HiVT эффективно улавливать тренды предстоящего ценового движения. И качество прогнозирования предстоящего движения может быть достаточным для обучения прибыльной политики поведения агента.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
 Изучение MQL5 — от новичка до профи (Часть V): Основные операторы перенаправления потока команд
Изучение MQL5 — от новичка до профи (Часть V): Основные операторы перенаправления потока команд
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования