
Нейросети в трейдинге: Универсальная модель генерации траекторий (UniTraj)

Введение
Анализ поведения нескольких агентов имеет огромное значение в разнообразных сферах, таких как финансы, автономное вождение и системы видеонаблюдения. Для понимания действий агентов необходимо решить ряд ключевых задач: отслеживание объектов, их идентификация, моделирование траекторий и распознавание действий. Моделирование траекторий играет важную роль в процессе анализа движений агентов. Несмотря на сложности, связанные с динамикой среды и тонкими взаимодействиями между агентами, недавно был достигнут значительный прогресс в решении этой задачи. Основные достижения сосредоточены в трех ключевых направлениях: прогнозирование траекторий, восстановление пропущенных данных и пространственно-временное моделирование.
Однако большинство подходов являются специализированными для конкретных задач. И их трудно обобщить до решения других задач. Решение одних задач требует использования как прямых, так и обратных пространственно-временных зависимостей, которые обычно не рассматриваются в моделях, ориентированных на прогнозирование. Другие алгоритмы решили проблему условного расчета многоагентных траекторий, но часто упускают из виду будущие траектории агентов. Что ограничивает их практическую полезность в полном понимании движения, где прогнозирование будущих траекторий имеет решающее значение для планирования последующих этапов, а не просто для реконструкции исторических траекторий.
В статье "Deciphering Movement: Unified Trajectory Generation Model for Multi-Agent" представлена универсальная модель Unified TrajectoryGeneration (UniTraj), которая интегрирует различные задачи работы с траекториями в общую схему. В частности, авторы метода объединяют разные типы исходных данных в единую унифицированную форму: произвольную неполную траекторию с маской, которая указывает на видимость каждого агента на каждом временном шаге. Модель равномерно обрабатывает исходные данные каждой задачи в виде замаскированных траекторий, стремясь создать полные траектории на основе незавершенных.
Для моделирования пространственно-временных зависимостей в различных представлениях траекторий авторы метода предложили модуль Ghost Spatial Masking (GSM), встроенный в кодировщик на основе Transformer. Используя возможности последних популярных моделей пространства состояний (SSM), особенно модели Mamba, авторы метода адаптируют и улучшают ее в двунаправленный темпоральный кодировщик Mamba для долгосрочной генерации многоагентных траекторий. Кроме того, они предложили простой, но эффективный модуль Bidirectional Temporal Scaled (BTS), который всесторонне сканирует траектории, сохраняя при этом целостность временных отношений в последовательности. Представленные в авторской статье результаты экспериментов подтверждают стабильную и исключительную производительность предложенного метода.
1. Алгоритм UniTraj
Для обработки различных исходных условий в рамках одной структуры авторы метода предлагают унифицированную генеративную модель траектории, которая рассматривает любой произвольный ввод как замаскированную последовательность траектории. Видимые области траектории используются в качестве ограничений или исходных данных, в то время как недостающие области являются целями для решения генеративной задачи. И таким образом формируется следующее определение проблемы:
Необходимо определить полную траекторию X[N, T, D], где N — количество агентов, T представляет собой длину траектории, а D — размерность состояний агентов. Обозначим состояния агента i в момент времени t как xi,t[D]. Кроме того используется двоичная матрица маскирования M[N, T]. Переменная mi,t имеет значение 1, если местонахождение агента i известно во времени t и 0 в противном случае. Таким образом, траектория делится маской на два сегмента: видимая область, определяется как Xv=X⊙M, и отсутствующая область, определенная как Xm=X⊙(1−M). Задача направлена на создание полной траектории Y'={X'v,X'm}, где X'v — реконструированная траектория и X'm — вновь сгенерированная траектория. Для согласованности авторы метода ссылаются на исходную траекторию как на основную истину Y=X={Xv, Xm}.
Более формально, цель — обучить генеративную модель f(⋅) с параметрами θ, что выводить полную траекторию Y'.
Общий подход к оценке параметров модели θ включает в себя разложение на множители совместного распределения траектории и максимизацию логарифмического правдоподобия.
Рассмотрим использование агента i на временном шаге t с позицией xi,t. Сначала вычисляем относительную скорость 𝒗i,t, вычитая координаты смежных временных шагов. Для отсутствующих местоположений мы заполняем значения с помощью 0, путем поэлементного умножения на маску. Кроме того, определяем вектор одной категории 𝒄i,t для представления категорий агентов. Эта категоризация имеет решающее значение в спортивных играх, где игроки могут использовать определенные наступательные или оборонительные стратегии. Признаки агента проецируются на вектор признаков высокой размерности 𝒇i,xt. Векторы исходных признаков вычисляются следующим образом:
![]()
где φx(⋅) — проекционная функция с весами 𝐖x, ⊙ представляет собой поэлементное умножение, а ⊕ указывает на конкатенацию.
Авторы метода внедрили φx(⋅) с использованием MLP. Этот подход позволяет включать информацию о местоположении, скорости, видимости и категориях для извлечения пространственных объектов и их последующего анализа.
В отличие от других задач последовательного моделирования, нам крайне важно учитывать плотные социальные взаимодействия. Существующие исследования человеческих взаимодействий преимущественно используют механизмы внимания, такие как перекрестное внимание и графическое внимание, чтобы зафиксировать эту динамику. Однако, учитывая, что в UniTraj решается единая задача с произвольными неполными исходными данными, для предложенной модели важно изучить пространственно-временные отсутствующие закономерности. И авторы метода предлагают новый и эффективный модуль Ghost Spatial Masking (GSM) для абстрагирования и обобщения пространственных структур отсутствующих данных. Этот модуль может быть плавно интегрирован в Transformer без усложнения структуры модели.
Transformer был первоначально предложен для моделирования временных зависимостей для последовательных данных, и авторы UniTraj применяют многоголовый дизайн Self-Attention в пространственном измерении. На каждом временном шаге рассматривается эмбединг каждого из N агентов и передается в качестве исходных данных Энкодера Transformer. Этот подход предназначен для извлечения инвариантных по порядку пространственных особенностей агентов, учитывая любую возможную расстановку порядка агентов, которая может иметь место на практике. Следовательно, в данном случае предпочтительнее заменить синусоидальное позиционное кодирование на полностью обучаемое.
В результате, энкодер Transformer выводит пространственные объекты Fs,xt для всех агентов на каждом временном шаге t. Затем эти объекты конкатенируются по временному измерению, чтобы получить пространственные признаки на всей траектории.
Учитывая способность модели Mamba фиксировать долгосрочные временные зависимости, авторы UniTraj адаптировали ее для интеграции в предложенную инфраструктуру. Тем не менее адаптация модели Mamba к генерации единой траектории является сложной задачей, в первую очередь из-за отсутствия архитектуры, специально адаптированной к траекториям модели. Эффективное моделирование траектории требует тщательного захвата пространственно-временных особенностей, что осложняется неполнотой траекторий.
Для повышения эффективности извлечения временных объектов при сохранении отсутствующих отношений, вводится двунаправленная временная мамба. Эта адаптация включает в себя несколько остаточных блоков Mamba в паре с инновационным модулем Bidirectional Temporal Scaled (BTS).
Изначально обрабатывается маска M для всей траектории. Разворачиваем ее вдоль временного измерения, чтобы произвести M', которая облегчает обучение модели временным отсутствующим отношениям за счет использования как исходной, так и перевернутой масок в модуле BTS. Этот процесс генерирует матрицу масштабирования S и соответствующую ей обратную версию S'. В частности, для агента i на временном шаге t, si,t вычисляется следующим образом:
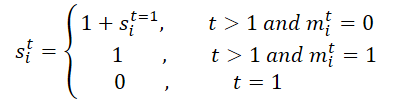
Затем проецируем матрицу масштабирования S и её перевернутую версию S' в матрицу признаков следующим образом:
![]()
где φs(⋅) — проекционные функции с весами 𝐖s.
Авторы метода реализуют φs(⋅) с использованием MLP и функцией активации ReLU. Предложенная матрица масштабирования предназначена для вычисления расстояния от последнего наблюдения до текущего временного шага, что помогает количественно оценить влияние временных разрывов, особенно при работе со сложными пропущенными закономерностями. Суть в том, что влияние переменной, которая отсутствовала в течение определенного периода, со временем уменьшается. А использование отрицательной экспоненциальной функции и ReLU может гарантировать, что влияние монотонно затухает в разумном диапазоне между 0 и 1.
Описанный выше процесс кодирования предназначен для определения параметров гауссова распределения для приближенного апостериора. В частности, среднее значение μq и стандартное отклонение σq апостериорного гауссова распределения вычисляются следующим образом:
![]()
Мы делаем выборку латентных переменных 𝒁 из априорного гауссова распределения 𝒩(0, I).
Чтобы улучшить способность модели генерировать правдоподобные траектории, мы объединяем эту функцию Fz,x с латентной переменной 𝒁 перед подачей его в декодер. Затем процесс генерации траектории рассчитывается следующим образом:
![]()
где φdec — функция декодера, реализованная с помощью MLP.
При наличии произвольной неполной траектории модель UniTraj генерирует полную траекторию. В процессе обучения вычисляется ошибка реконструкцию для видимых областей и ошибка восстановления маскированных данных.
Авторская визуализация метода представлена UniTraj ниже.
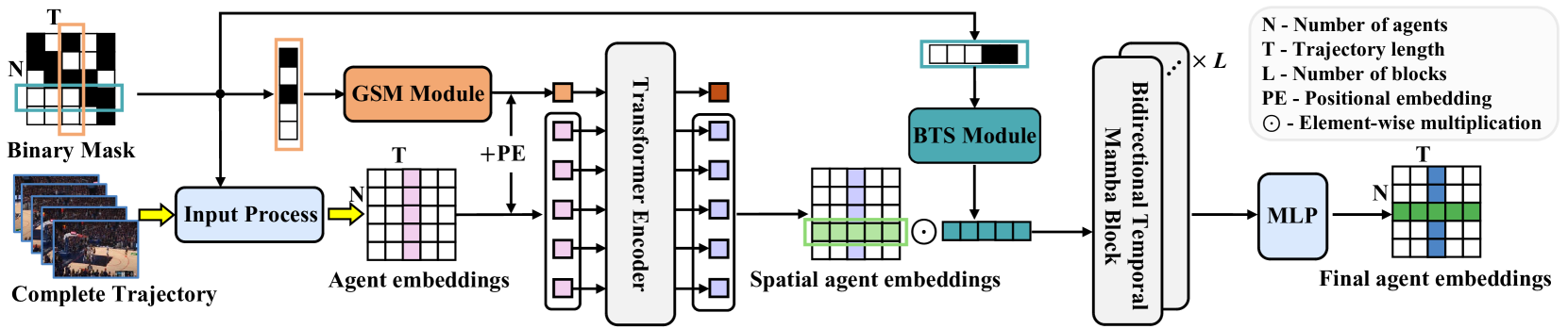
2. Реализация средствами MQL5
После рассмотрения теоретического описания предложенного метода UniTraj, мы, как обычно, переходим к практической части нашей статьи, в которой реализуем свое видение предложенных подходов средствами MQL5. И здесь мы должны сразу обратить внимание, что предложенный алгоритм конструктивно отличается от рассмотренных нами ранее методов.
Первое, это конечно процесс маскирования. При передаче исходных данных в модель, авторы метода предлагают нам дополнительно подготовить маску, которая бы определяла какие данные видит модель, а какие должна сгенерировать. Это немного добавляет нам работы. И при этом увеличивается время принятия решения, что нежелательно. Поэтому, хотелось бы организовать генерацию маски внутри модели.
Второй момент — это передача полной траектории в модель. Если в процессе тестирования мы можем её получить, то в процессе эксплуатации нет. Конечно, модель допускает маскирование недостающих данных с последующим восстановлением. Но в любом случае нам необходимо передать в модель тензор большего объема. Что ведет к увеличению потребления памяти и накладным расходам на передачу дополнительного объема. А это опять отражается на времени принятия решения.
Конечно, мы можем ограничиться передачей только исторических данных в процессе обучения и эксплуатации. Но тогда теряется значительная часть функционала предложенного метода.
И нами было принято решение разделить объем передачи данных на 2 части: исторические данные и будущая траектория. Последняя подается только в процессе обучения модели для извлечения пространственно-временных зависимостей. В режиме эксплуатации модели тензор будущих значений не передается, и модель работает в режиме прогнозирования данных.
И конечно, в данной работе нам пришлось сделать некоторые дополнения на стороне OpenCL программы.
2.1 Дополнение OpenCL программы
На первом этапе нашей работы мы подготовим новые кернелы на стороне OpenCL программы. Вначале мы создадим кернел подготовки данных UniTrajPrepare. В теле данного кернела мы конкатенируем исторические данные и известную нам информацию о последующем движении с учетом маскирования.
В параметрах кернела мы получаем указатели на 5 буферов данных: 4 исходных данных и 1 результатов. А также размеры глубины анализируемой истории и горизонта планирования.
__kernel void UniTrajPrepare(__global const float *history, __global const float *h_mask, __global const float *future, __global const float *f_mask, __global float *output, const int h_total, const int f_total ) { const size_t i = get_global_id(0); const size_t v = get_global_id(1); const size_t variables = get_global_size(1);
Выполнение кернела мы планируем в двухмерном пространстве задач. Первое измерение имеет размер большего из 2 временных отрезков (глубина истории и горизонт планирования). Второе измерение укажет на количество анализируемых параметров.
В теле кернела мы сначала идентифицируем поток в заданном пространстве задач. И определим смещение в буферах данных.
const int shift_in = i * variables + v; const int shift_out = 3 * shift_in; const int shift_f_out = 3 * (h_total * variables + v);
Далее мы работаем с историческими данными. Здесь мы сначала определяем скорость изменения параметра с учетом маски. А затем сохраняем в буфере результатов значение параметра с учетом макси, вычисленную ранее скорость и саму маску.
//--- history if(i < h_total) { float mask = h_mask[shift_in]; float h = history[shift_in]; float v = (i < (h_total - 1) && mask != 0 ? (history[shift_in + variables] - h) * mask : 0); if(isnan(v) || isinf(v)) v = h = mask = 0; output[shift_out] = h * mask; output[shift_out + 1] = v; output[shift_out + 2] = mask; }
Аналогичные параметры мы вычисляем и для будущих значений.
//--- future if(i < f_total) { float mask = f_mask[shift_in]; float f = future[shift_in]; float v = (i < (f_total - 1) && mask != 0 ? (future[shift_in + variables] - f) * mask : 0); if(isnan(v) || isinf(v)) v = f = mask = 0; output[shift_f_out + shift_out] = f * mask; output[shift_f_out + shift_out + 1] = v; output[shift_f_out + shift_out + 2] = mask; } }
Далее мы сохраним кернел обратного прохода вышеуказанных операций UniTrajPrepareGrad.
__kernel void UniTrajPrepareGrad(__global float *history_gr, __global float *future_gr, __global const float *output, __global const float *output_gr, const int h_total, const int f_total ) { const size_t i = get_global_id(0); const size_t v = get_global_id(1); const size_t variables = get_global_size(1);
Обратите внимание, что в параметрах метода обратного прохода мы не указываем указатели на буферы исходных данных и масок. Вместо них мы воспользуемся буфером результатов кернела прямого прохода UniTrajPrepare, в котором сохранены указанные данные. Кроме того, мы не передаем градиент ошибки на уровень масок, так как это не имеет смысла.
Пространство задач кернела обратного прохода идентично рассмотренному выше для кернела прямого прохода.
В теле кернела мы идентифицируем текущий поток в пространстве задач и определим смещение в буферах данных.
const int shift_in = i * variables + v; const int shift_out = 3 * shift_in; const int shift_f_out = 3 * (h_total * variables + v);
Аналогично кренелу прямого прохода, работу мы организуем в 2 этапа. Сначала распределим градиент ошибки до уровня исторических данных.
//--- history if(i < h_total) { float mask = output[shift_out + 2]; float grad = 0; if(mask > 0) { grad = output_gr[shift_out] * mask; grad -= (i < (h_total - 1) && mask != 0 ? (output_gr[shift_out + 1]) * mask : 0); grad += (i > 0 ? output[shift_out + 1 - 3 * variables] * output[shift_out + 2 - 3 * variables] : 0); if(isnan(grad) || isinf(grad)) grad = 0; //--- } history_gr[shift_in] = grad; }
А затем передадим градиент ошибки известным прогнозным значениям.
//--- future if(i < f_total) { float mask = output[shift_f_out + shift_out + 2]; float grad = 0; if(mask > 0) { grad = output_gr[shift_f_out + shift_out] * mask; grad -= (i < (h_total - 1) && mask != 0 ? (output_gr[shift_f_out + shift_out + 1]) * mask : 0); grad += (i > 0 ? output[shift_f_out + shift_out + 1 - 3 * variables] * output[shift_f_out + shift_out + 2 - 3 * variables] : 0); if(isnan(grad) || isinf(grad)) grad = 0; //--- } future_gr[shift_in] = grad; } }
Ещё один алгоритм, который нам предстоит реализовать на стороне OpenCL — создание матрицы масштабирования. В кернеле UniTrajBTS мы вычислим прямую и обратную матрицы масштабирования.
Здесь в качестве исходных данных мы также используем результаты прямого прохода кернела подготовки данных. На основании его данных мы посчитаем смещение от последнего немаскированного значения в прямом и обратном направлении, которые сохраним в соответствующие буфера данных.
__kernel void UniTrajBTS(__global const float * concat_inp, __global float * d_forw, __global float * d_bakw, const int total ) { const size_t i = get_global_id(0); const size_t v = get_global_id(1); const size_t variables = get_global_size(1);
Пространство задач мы используем двухмерное. Но в первом измерении у нас будет лишь 2 потока, которые соответствуют вычислению прямой и обратной матрицы масштабирования. А во втором измерении мы, как и ранее, укажем количество анализируемых переменных.
После идентификации потока в пространстве задач мы разделим алгоритм кернела, в зависимости от значения первого измерения.
if(i == 0) { const int step = variables * 3; const int start = v * 3 + 2; float last = 0; d_forw[v] = 0; for(int p = 1; p < total; p++) { float m = concat_inp[start + p * step]; d_forw[p * variables + v] = last = 1 + (1 - m) * last; } }
При вычислении прямой матрицы масштабирования, мы определяем смещение до маски первого элемента анализируемой переменной и шаг до следующего элемента. После чего организуем цикл последовательного перебора масок анализируемого элемента с вычислением коэффициентов масштабирования по заданной формуле.
Для обратной матрицы масштабирования алгоритм идентичен. Только определяем смещение до последнего элемента и движемся в обратном порядке.
else { const int step = -(variables * 3); const int start = (total - 1) * variables + v * 3 + 2; float last = 0; d_bakw[(total - 1) + v] = 0; for(int p = 1; p < total; p++) { float m = concat_inp[start + p * step]; d_bakw[(total - 1 - p) * variables + v] = last = 1 + (1 - m) * last; } } }
Обратите внимание, что представленный алгоритм работает только с масками, распределение градиента ошибки на которые не имеет смысла. По этому мы не создаем кернел обратного прохода данного алгоритма. И завершаем на этом работу на стороне OpenCL программы. А с её полным кодом вы можете ознакомиться во вложении.
2.2 Реализация алгоритма UniTraj
После проведения подготовительной работы на стороне OpenCL программы, мы переходим к реализации предложенных подходов на стороне основной программы. Здесь алгоритм UniTraj мы организуем в рамках класса CNeuronUniTraj, структура которого представлена ниже.
class CNeuronUniTraj : public CNeuronBaseOCL { protected: uint iVariables; float fDropout; //--- CBufferFloat cHistoryMask; CBufferFloat cFutureMask; CNeuronBaseOCL cData; CNeuronLearnabledPE cPE; CNeuronMVMHAttentionMLKV cEncoder; CNeuronBaseOCL cDForw; CNeuronBaseOCL cDBakw; CNeuronConvOCL cProjDForw; CNeuronConvOCL cProjDBakw; CNeuronBaseOCL cDataDForw; CNeuronBaseOCL cDataDBakw; CNeuronBaseOCL cConcatDataDForwBakw; CNeuronMambaBlockOCL cSSM[4]; CNeuronConvOCL cStat; CNeuronTransposeOCL cTranspStat; CVAE cVAE; CNeuronTransposeOCL cTranspVAE; CNeuronConvOCL cDecoder[2]; CNeuronTransposeOCL cTranspResult; //--- virtual bool Prepare(const CBufferFloat* history, const CBufferFloat* future); virtual bool PrepareGrad(CBufferFloat* history_gr, CBufferFloat* future_gr); virtual bool BTS(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return feedForward(NeuronOCL, NULL); } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return calcInputGradients(NeuronOCL, NULL, NULL, None); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return updateInputWeights(NeuronOCL, NULL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *second) override; //--- public: CNeuronUniTraj(void) {}; ~CNeuronUniTraj(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint forecast, float dropout, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronUniTrajOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Как можно заметить, в структуре класса объявляется большое количество внутренних объектов, с функционалом которых мы познакомимся в процессе реализации методов. При этом, все объекты объявлены статично. Это позволяет нам оставить конструктор и деструктор класса пустыми, а работу с памятью переложить на систему.
Инициализация всех внутренних объектов осуществляется в методе Init, в параметрах которого мы получаем основные константы, позволяющие однозначно идентифицировать архитектуру объекта.
bool CNeuronUniTraj::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint forecast, float dropout, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * (units_count + forecast), optimization_type, batch)) return false;
В теле метода мы, по сложившейся традиции, сначала вызываем одноименный метод родительского класса, в котором уже реализованы минимально необходимые контроли инициализации унаследованных объектов.
После успешного выполнения операций родительского класса, мы сохраним полученные от внешней программы константы, среди которых количество анализируемых переменных в исходных данных и доля маскируемых в процессе обучения элементов.
iVariables = window; fDropout = MathMax(MathMin(dropout, 1), 0);
А затем мы переходим к инициализации объявленных объектов. Здесь мы в первую очередь создадим буферы маскирования исторических и прогнозных данных.
if(!cHistoryMask.BufferInit(iVariables * units_count, 1) || !cHistoryMask.BufferCreate(OpenCL)) return false; if(!cFutureMask.BufferInit(iVariables * forecast, 1) || !cFutureMask.BufferCreate(OpenCL)) return false;
Затем инициализируем внутренний слой конкатенированных исходных данных.
if(!cData.Init(0, 0, OpenCL, 3 * iVariables * (units_count + forecast), optimization, iBatch)) return false;
И создадим аналогичного размера слой обучаемого позиционного кодирования.
if(!cPE.Init(0, 1, OpenCL, cData.Neurons(), optimization, iBatch)) return false;
И далее идет Энкодер Transformer для извлечения пространственно-временных зависимостей.
if(!cEncoder.Init(0, 2, OpenCL, 3, window_key, heads, (heads + 1) / 2, iVariables, 1, 1, (units_count + forecast), optimization, iBatch)) return false;
Здесь стоит отметить, что авторы метода провели ряд экспериментов и пришли к выводу, что оптимальная производительность метода достигается при использовании 1 блока Энкодера Transformer и 4 блоков Mamba. Поэтому в данном случае мы используем только 1 слой Энкодера.
И обратите внимание, что размер окна исходных данных равен "3", что соответствует 3 параметрам 1 показателя на каждом временном шаге (значение, скорость и маска). При этом количество элементов в последовательности мы устанавливаем на уровне количества анализируемых переменных, а число независимых каналов равно суммарной глубине анализируемой истории и прогнозирования. Таким образом мы организовываем оценку зависимостей между анализируемыми показателями в рамках 1 временного шага.
Далее мы переходим к блоку BTS и создадим объекты прямой и обратной матрицы масштабирования.
if(!cDForw.Init(0, 3, OpenCL, iVariables * (units_count + forecast), optimization, iBatch)) return false;; if(!cDBakw.Init(0, 4, OpenCL, iVariables * (units_count + forecast), optimization, iBatch)) return false;
И тут же добавим сверточные слои проекции данных матриц.
if(!cProjDForw.Init(0, 5, OpenCL, 1, 1, 3, iVariables, (units_count + forecast), optimization, iBatch)) return false; cProjDForw.SetActivationFunction(SIGMOID); if(!cProjDBakw.Init(0, 6, OpenCL, 1, 1, 3, iVariables, (units_count + forecast), optimization, iBatch)) return false; cProjDBakw.SetActivationFunction(SIGMOID);
Полученные проекции будут поэлементно умножены на результаты работы Энкодера и результаты операций будут записаны в следующие объекты.
if(!cDataDForw.Init(0, 7, OpenCL, cData.Neurons(), optimization, iBatch)) return false; if(!cDataDBakw.Init(0, 8, OpenCL, cData.Neurons(), optimization, iBatch)) return false;
Затем мы планируем конкатенировать полученные данные в единый тензор.
if(!cConcatDataDForwBakw.Init(0, 9, OpenCL, 2 * cData.Neurons(), optimization, iBatch)) return false;
Который мы и передадим в SSM блок. Как было сказано ранее, в данном блоке инициализируем 4 последовательных слоя Mamba.
for(uint i = 0; i < cSSM.Size(); i++) { if(!cSSM[i].Init(0, 10 + i, OpenCL, 6 * iVariables, 12 * iVariables, (units_count + forecast), optimization, iBatch)) return false; }
Здесь авторы метода предлагают использовать остаточные связи к слою Mamba. Мы же пойдем немного дальше и воспользуемся классом CNeuronMambaBlockOCL, который мы создали при работе с методом TrajLLM.
Полученные результаты мы проецируем на статистические показатели целевого распределения.
uint id = 10 + cSSM.Size(); if(!cStat.Init(0, id, OpenCL, 6, 6, 12, iVariables * (units_count + forecast), optimization, iBatch)) return false;
Но перед семплированием и репараметризацией значений нам необходимо немного изменить порядок данных. Для этого мы воспользуемся слоем транспонирования.
id++; if(!cTranspStat.Init(0, id, OpenCL, iVariables * (units_count + forecast), 12, optimization, iBatch)) return false; id++; if(!cVAE.Init(0, id, OpenCL, cTranspStat.Neurons() / 2, optimization, iBatch)) return false;
Сэмплированные значения мы переведем в размерность независимых информационных каналов.
id++; if(!cTranspVAE.Init(0, id, OpenCL, cVAE.Neurons() / iVariables, iVariables, optimization, iBatch)) return false;
И пропустим данные через декодер, на выходе которого получим сгенерированную целевую последовательность.
id++; uint w = cTranspVAE.Neurons() / iVariables; if(!cDecoder[0].Init(0, id, OpenCL, w, w, 2 * (units_count + forecast), iVariables, optimization, iBatch)) return false; cDecoder[0].SetActivationFunction(LReLU); id++; if(!cDecoder[1].Init(0, id, OpenCL, 2 * (units_count + forecast), 2 * (units_count + forecast), (units_count + forecast), iVariables, optimization, iBatch)) return false; cDecoder[1].SetActivationFunction(TANH);
И теперь нам остается привести полученный результат в размерность исходных данных.
id++; if(!cTranspResult.Init(0, id, OpenCL, iVariables, (units_count + forecast), optimization, iBatch)) return false;
С целью исключения излишних операций копирования данных, мы осуществим подмену указателей на буфера данных.
if(!SetOutput(cTranspResult.getOutput(), true) || !SetGradient(cTranspResult.getGradient(), true)) return false; SetActivationFunction((ENUM_ACTIVATION)cDecoder[1].Activation()); //--- return true; }
Не забываем на каждом этапе контролировать процесс выполнения операций, и в завершении метода возвращаем логическое значение работы метода вызывающей программе.
После завершения работы по инициализации экземпляра класса, мы переходим к реализации методов прямого прохода. Вначале мы проводим небольшую подготовительную работу по организации постановки в очередь выполнения вышесозданных кернелов. Здесь мы используем уже отработанные алгоритмы, с которыми вы можете ознакомиться самостоятельно во вложении. А в рамках статьи я предлагаю рассмотреть метод верхнего уровня feedForward, в котором "крупными мазками" мы опишем весь алгоритм.
bool CNeuronUniTraj::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!NeuronOCL) return false;
В параметрах метода мы получаем указатели на 2 объекта, которые содержат исторические и прогнозные значения. В теле метода мы сразу проверяем актуальность указателя на исторические данные. Как вы помните, по нашей логике исторические данные есть всегда. А вот прогнозных значений может и не быть.
Далее мы организуем процесс генерации тензора случайного маскирования исторических данных.
//--- Create History Mask int total = cHistoryMask.Total(); if(!cHistoryMask.BufferInit(total, 1)) return false; if(bTrain) { for(int i = 0; i < int(total * fDropout); i++) cHistoryMask.Update(RND(total), 0); } if(!cHistoryMask.BufferWrite()) return false;
Обратите внимание, что маскирование осуществляется только в процессе обучения. В режиме промышленной эксплуатации мы используем всю имеющуюся информацию.
После чего организуем аналогичный процесс для прогнозных значений. Но здесь есть нюанс. При наличии прогнозных значений мы генерируем тензор случайного маскирования. А вот в случае отсутствия информации о предстоящем движении, мы заполняем весь тензор маскирования нулевыми значениями.
//--- Create Future Mask total = cFutureMask.Total(); if(!cFutureMask.BufferInit(total, (!SecondInput ? 0 : 1))) return false; if(bTrain && !!SecondInput) { for(int i = 0; i < int(total * fDropout); i++) cFutureMask.Update(RND(total), 0); } if(!cFutureMask.BufferWrite()) return false;
После генерации тензоров маскирования мы можем выполнить этап подготовки и конкатенации данных.
//--- Prepare Data if(!Prepare(NeuronOCL.getOutput(), SecondInput)) return false;
Затем добавим позиционное кодирование и передадим в энкодер Transformer/
//--- Encoder if(!cPE.FeedForward(cData.AsObject())) return false; if(!cEncoder.FeedForward(cPE.AsObject())) return false;
Далее, согласно алгоритму UniTraj, используется блок BTS. Создадим прямую и обратную матрицы масштабирования.
//--- BTS if(!BTS()) return false;
Сделаем их проекции.
if(!cProjDForw.FeedForward(cDForw.AsObject())) return false; if(!cProjDBakw.FeedForward(cDBakw.AsObject())) return false;
Умножим на результаты работы Энкодера.
if(!ElementMult(cEncoder.getOutput(), cProjDForw.getOutput(), cDataDForw.getOutput())) return false; if(!ElementMult(cEncoder.getOutput(), cProjDBakw.getOutput(), cDataDBakw.getOutput())) return false;
И объединим полученные значения в единый тензор.
if(!Concat(cDataDForw.getOutput(), cDataDBakw.getOutput(), cConcatDataDForwBakw.getOutput(), 3, 3, cData.Neurons() / 3)) return false;
Проанализируем данные в модели пространства состояний.
//--- SSM if(!cSSM[0].FeedForward(cConcatDataDForwBakw.AsObject())) return false; for(uint i = 1; i < cSSM.Size(); i++) if(!cSSM[i].FeedForward(cSSM[i - 1].AsObject())) return false;
После чего получим проекцию статистических показателей целевого распределения.
//--- VAE if(!cStat.FeedForward(cSSM[cSSM.Size() - 1].AsObject())) return false;
И сэмплируем значения из заданного распределения.
if(!cTranspStat.FeedForward(cStat.AsObject())) return false; if(!cVAE.FeedForward(cTranspStat.AsObject())) return false;
Декодер сгенерирует целевую последовательность.
//--- Decoder if(!cTranspVAE.FeedForward(cVAE.AsObject())) return false; if(!cDecoder[0].FeedForward(cTranspVAE.AsObject())) return false; if(!cDecoder[1].FeedForward(cDecoder[0].AsObject())) return false; if(!cTranspResult.FeedForward(cDecoder[1].AsObject())) return false; //--- return true; }
Которую мы приведем в размерность исходных данных.
Как вы помните, в методе инициализации объекта мы осуществили подмену указателей на буфера данных, поэтому на данном этапе копирование полученных значений из внутренних объектов в унаследованные буфера нашего класса не требуется. И для завершения работы метода прямого прохода нам остается лишь передать логический результат работы метода вызывающей программе.
Мы выполнили работу по построению алгоритма прямого прохода. И следующим шагом, обычно, мы переходим к организации процессов обратного прохода. Они полностью соответствуют прямому проходу, но поток информации идет в обратном направлении. Но сегодня нас ещё ждет определенный объем работы, а формат статьи имеет свои размеры. Поэтому я оставляю методы обратного прохода для самостоятельного изучения. Напомню, что полный код данного класса и всех его методов вы найдете во вложении.
2.3 Архитектура моделей
После реализации нашего видения алгоритмов метода UniTraj, мы переходим к их имплементации в рамках своих моделей. Как и другие методы анализа траекторий исторических данных, предложенный алгоритм мы будем использовать в рамках модели Энкодера состояния окружающей среды. Напомню, что архитектура указанной модели задается в методе CreateEncoderDescriptions.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
От внешней программы метод получает указатель на объект динамического массива, в который нам предстоит записать архитектуру создаваемой модели. В теле метода мы сразу проверяем актуальность полученного указателя и, при необходимости, создаем новый объект. После чего переходим к описанию архитектурного решения.
Первым мы используем полносвязный слой, в который запишем исходные данные.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь мы записываем информацию исторического ценового движения и значения анализируемых индикаторов на заданную глубину истории. Данные мы получаем от терминала "как есть" без какой-либо предварительной обработки. Очевидно, что такие данные будут весьма несопоставимы. Поэтому мы приведем их сопоставимый вид с помощью слоя пакетной нормализации данных.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Нормализованные данные мы сразу передаем в наш новый блок UniTraj. При этом установим коэффициент маскирования на уровне 50% полученных данных.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronUniTrajOCL; descr.window = BarDescr; //window descr.window_out = EmbeddingSize; //Inside Dimension descr.count = HistoryBars; //Units descr.layers = NForecast; //Forecast descr.step=4; //Heads descr.probability=0.5f; //DropOut descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
На выходе блока мы получаем вольную целевую траекторию, содержащую как восстановленные исторические данные, так и прогнозные значения на заданный горизонт планирования. К полученным данным мы добавим статистические показатели исходных данных, изъятые при нормализации данных.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * (NForecast+HistoryBars); descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
И согласуем прогнозные значения в частотной области.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast+HistoryBars; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Благодаря комплексной архитектуре нашего нового блока CNeuronUniTraj, мы получили довольно краткое и лаконичное описание создаваемой модели, что никак не уменьшает её возможности.
Следует сказать, что увеличение размера тензора результатов модели Энкодера окружающей среды потребовало точечных правок и моделей Актера и Критика. Но эти изменения столь незначительные, что вы можете самостоятельно ознакомиться с ними во вложении. А вот корректировки программы обучения модели Энкодера более значительные.
2.4 Программа обучения модели
Внесенные изменения в архитектуру модели Энкодера состояния окружающей среды наряду с подходами к обучению, предложенными авторами метода UniTraj привели к необходимости корректировки советника обучения данной модели "...\Experts\UniTraj\StudyEncoder.mq5".
Первое, что мы сделали — это скорректировали блок контроля модели в части проверки размера слоя результатов. Это точечная правка в методе инициализации советника.
Encoder.getResults(Result); if(Result.Total() != (NForecast+HistoryBars) * BarDescr) { PrintFormat("The scope of the Encoder does not match the forecast state count (%d <> %d)", (NForecast+HistoryBars) * BarDescr, Result.Total()); return INIT_FAILED; }
Но как вы догадываетесь, основная работа нас ждала в методе обучения модели Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Как и ранее, в теле метода мы сначала генерируем вектор вероятностей выбора траекторий в процессе обучения на основе полученных доходностей. Суть данной операции — в более частом использовании прибыльных траекторий, что позволит обучать более прибыльную стратегию.
Затем мы объявляем необходимые переменные.
vector<float> result, target, state; bool Stop = false; const int Batch = 1000; int b = 0; //--- uint ticks = GetTickCount();
И организовываем систему циклов обучения моделей.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += b) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 5 - NForecast)); if(start <= 0) continue;
Напомню, что блок Mamba имеет рекуррентный характер, что накладывает отпечаток на процесс его обучения. Сначала мы сэмплируем одну траекторию из буфера воспроизведения опыта и выбираем на ней состояние начала обучения. После чего организовываем вложенный цикл последовательного перебора состояний на выбранной траектории.
for(b = 0; (b < Batch && (iter + b) < Iterations); b++) { int i = start + b; if(i >= MathMin(Buffer[tr].Total, Buffer_Size) - NForecast) break;
Мы сначала загружаем из буфера воспроизведения опыта исторические данные анализируемых параметров.
state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum() == 0) break; bState.AssignArray(state);
И тут же загружаем истинные последующие значения.
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
После чего мы случайным образом разделяем процесс обучения на 2 потока с вероятностью 50%.
//--- State Encoder if((MathRand() / 32767.0) < 0.5) { if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
В первом случае мы, как и ранее, на вход модели подаем только исторические данные и осуществляем прямой проход. А во втором случае мы также даем модели истинные последующие значения предстоящего ценового движения. Таким образом, на вход модели мы подаем полную реальную информацию об исторических и последующих состояниях системы.
else { if(Result.GetIndex()>=0) Result.BufferWrite(); if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Напомню, что в нашем алгоритме предусмотрено 50% случайное маскирование полученных данных в процессе обучения. Поэтому в таком режиме модель учится восстанавливать замаскированные данные.
На выходе модели мы получаем полную траекторию в виде единого тензора, поэтому мы объединим 2 буфера исходных данных в единый тензор и воспользуемся для обратного прохода модели. В ходе которого мы скорректируем обучаемые параметры модели с целью минимизации общей ошибки восстановления и прогнозирования данных.
//--- Collect target data if(!bState.AddArray(Result)) continue; if(!Encoder.backProp((CBufferFloat*)GetPointer(bState), (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Теперь нам остается лишь проинформировать пользователя о ходе обучения и перейти к следующей итерации системы циклов.
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter + b) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
А после успешного выполнения всех итераций циклов обучения модели, мы очищаем поле комментариев на графике инструмента. Выводим результаты обучения в журнал терминала и инициализируем процесс завершения работы модели.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
В процессе эксплуатации модели мы не планируем подавать прогнозных значений на вход модели. Поэтому программа обучения политики Актера осталась без изменений. С полным кодом всех программ и классов, используемых при подготовке данной статьи вы можете ознакомиться во вложении.
3. Тестирование
Выше мы познакомились с теоретическим описанием нового метода работы с мультимодальными временными последовательностями UniTraj. И реализовали свое видение предложенных подходов средствами MQL5. И теперь мы переходим к завершающему этапу нашей работы, в котором оценим эффективность предложенных подходов для решения наших задач.
Несмотря на внесение изменений в архитектуру модели и программу обучения модели Энкодера состояния окружающей среды, структура используемой обучающей выборки не изменилась. И это позволяет нам начать обучение модели с использованием ранее собранных обучающих выборок.
Напомню, что для обучения моделей мы используем реальные исторические данные инструмента EURUSD таймфрейм H1 за полный 2023 год. Параметры всех анализируемых индикаторов используются по умолчанию.
На первом этапе мы обучаем модель Энкодера состояния окружающей среды. Мы уже не раз говорили, что в процессе обучения Энкодера состояния нам нет необходимости обновлять обучающую выборку. И мы обучаем модель до получения желаемых результатов. Надо сказать, что полученная модель не отличается легкостью. И её обучение требует времени. Тем не менее процесс обучения идет довольно гладко. И после её обучения мы получили визуально неплохую проекцию прогнозного ценового движения.
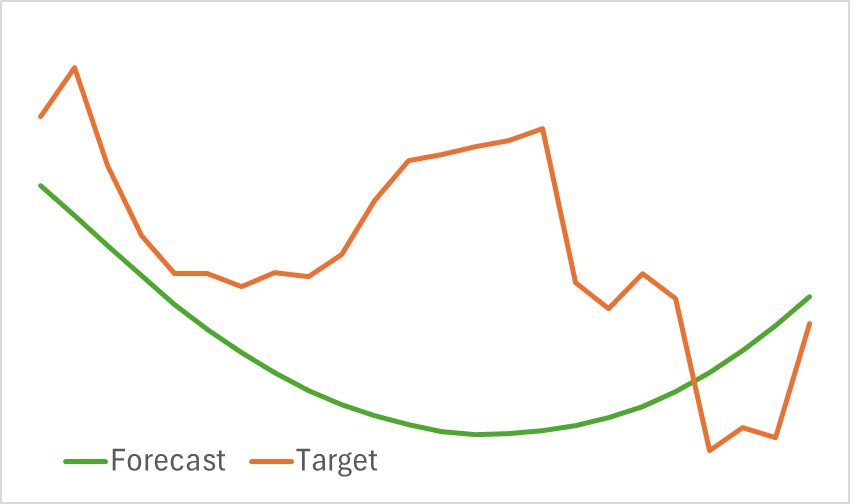
При этом надо сказать, что линия прогнозного движения сильно сглажена. То же самое можно сказать и о восстановленной траектории. На лицо значительное удаление шума из исходных данных. Насколько это полезно для обучения прибыльной политики Актера мы узнаем на следующем этапе обучения моделей.
Второй этап нашего тестирования включает итерационный процесс обучения моделей Актера и Критика. На данном этапе мы ищем прибыльную политику Актера, которая строится на анализе прогнозного ценового движения, полученного от Энкодера состояния окружающей среды. В данном случае Энкодер возвращает как прогнозное, так и восстановленное историческое ценовое движение.
Для тестирования работы обученных моделей мы использовали исторические данные Января 2024 года с сохранением всех прочих параметров.
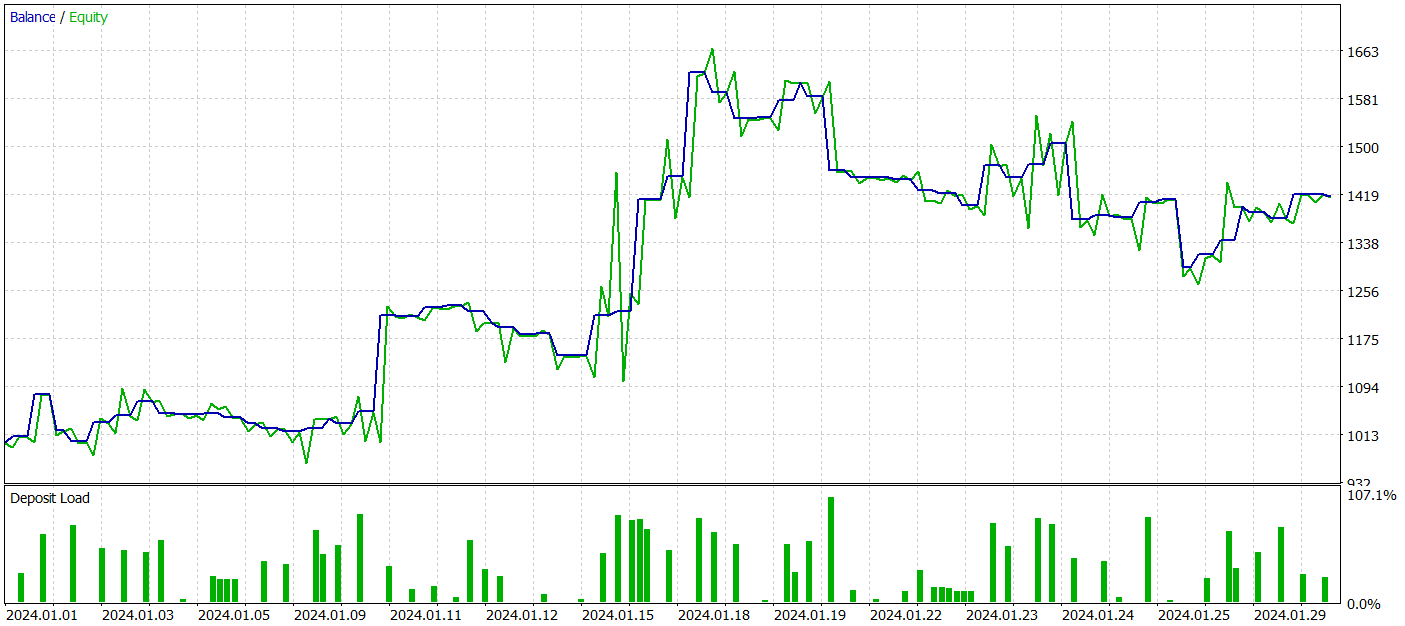
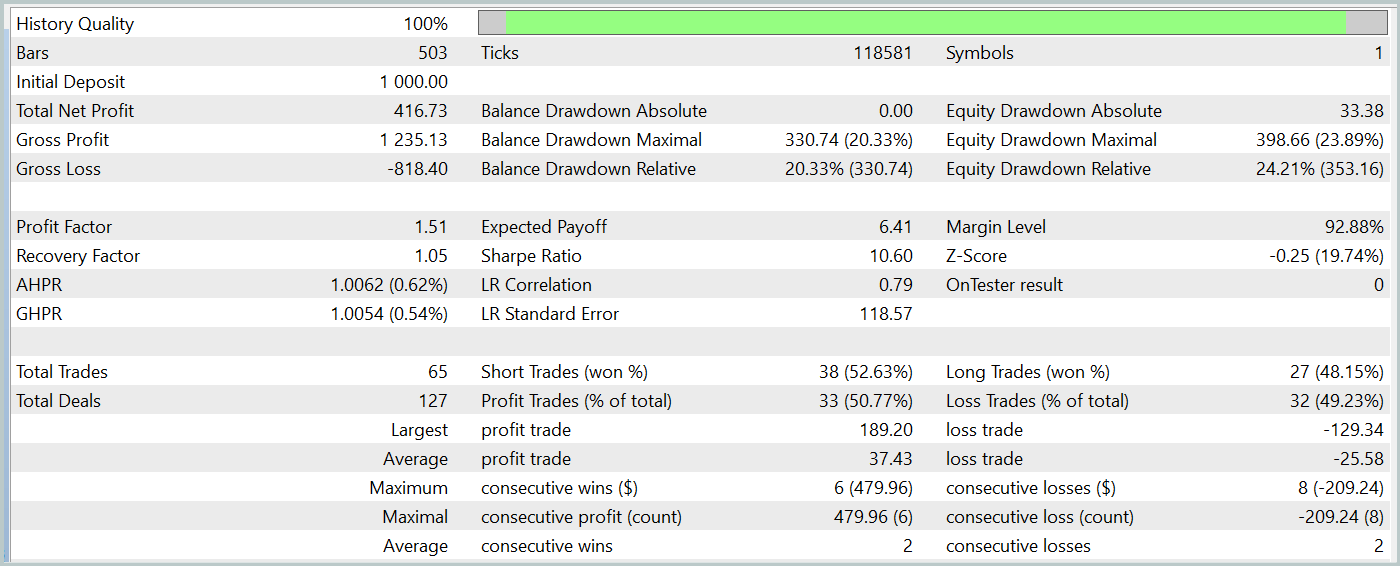
За период тестирования наша обученная модель Актера смогла сгенерировать более 40% прибыли с максимальной просадкой по эквити чуть более 24%. Всего было совершено 65 торговых операций и примерно половина из них (33 трейда) было закрыто с прибылью. А благодаря значительному превышению максимальной и средней прибыльной сделки над аналогичным убыточным показателем, профит фактор был зафиксирован на уровне 1.51. Конечно, период тестирования в 1 месяц и 65 совершенных сделки не позволяют говорить о стабильном доходе в будущем. Но в целом полученный результат выше полученного методом Traj-LLM.
Заключение
Рассмотренный в данной статье метод UniTraj демонстрирует потенциал как универсальный инструмент для обработки траекторий агентов в различных сценариях. Данный подход решает ключевую проблему адаптации модели к множественным задачам, что улучшает производительность по сравнению с традиционными методами. Унифицированная обработка замаскированных исходных данных делает UniTraj гибким и эффективным решением.
В практической части статьи мы реализовали предложенные подходы средствами MQL5. Имплементировали их в модель Энкодера состояния окружающей среды. Обучили и провели тестирование обученных моделей на реальных исторических данных. Полученные результаты позволяют судить об эффективности предложенных подходов, что позволяет их использовать при построении реальных торговых стратегий.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
 Особенности написания Пользовательских Индикаторов
Особенности написания Пользовательских Индикаторов

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования