
Нейросети в трейдинге: Модели пространства состояний

Введение
В последнее время широкое распространение получила парадигма адаптации к новым задачам больших моделей, предварительно обученных на больших массивах произвольных исходных данных из широкого спектра областей, таких как текст, изображения, аудио, временные ряды и прочее.
Хотя эта концепция не зависит от конкретного выбора архитектуры, но большинство моделей основано на одно типе архитектуры — Transformer и его основном слое Self-Attention. Эффективность Self-Attention объясняется способностью плотно направлять информацию в контекстное окно, что позволяет моделировать сложные данные. Однако это свойство имеет принципиальные недостатки — невозможность моделировать что-либо за пределами конечного окна, и квадратичное масштабирование по отношению к длине окна.
В задачах моделирования последовательностей альтернативным решением может стать использование структурированных моделей последовательностей в пространстве состояний (Space Sequence Models — SSM). Эти модели можно интерпретировать как комбинацию рекуррентных нейронных сетей (RNN) и сверточных нейронных сетей (CNN). Данный класс моделей может быть очень эффективно вычислен с линейным или почти линейным масштабированием длины последовательности. Кроме того, у него есть принципиальные механизмы моделирования дальних зависимостей в определенных модальностях данных.
Один из алгоритмов, который позволяет использовать модели пространства состояний для прогнозирования временных рядов, был предложен в статье "Mamba: Linear-Time Sequence Modeling with Selective State Spaces". В ней представлен новый класс выборочных моделей пространства состояний.
Авторы статьи определяют ключевое ограничение существующих моделей: способность эффективно отбирать информацию в зависимости от исходных данных (т.е. фокусироваться на конкретных исходных данных или игнорировать их). И разрабатывают простой механизм выбора, делая параметры SSM зависимыми от исходных данных. Это позволяет модели отфильтровывать нерелевантную информацию и запоминать релевантную информацию на неопределенный срок.
Авторы метода упрощают предыдущие архитектуры моделей глубоких последовательностей, объединяя дизайн архитектур SSM с MLP в один блок, что приводит к простому и однородному дизайну архитектуры (Mamba), включающему выборочные пространства состояний.
Выборочные SSM и, как следствие, архитектура Mamba являются полностью рекуррентными моделями с ключевыми свойствами, которые делают их пригодными в качестве основы общих базовых моделей, работающих с последовательностями.
- Высокое качество: селективность обеспечивает высокую производительность в плотных модальностях.
- Быстрое обучение и вывод: вычисления и память линейно масштабируются по длине последовательности во время обучения, а авторегрессионное развертывание модели во время вывода требует только постоянного времени на шаг, поскольку для этого не требуется кэш предыдущих элементов.
- Долгосрочный контекст: качество и эффективность в совокупности обеспечивают повышение производительности при работе с последовательностями больших размеров.
1. Алгоритм Mamba
Авторы метода Mamba утверждают, что фундаментальной проблемой моделирования последовательностей является сжатие контекста в меньшее состояние. Можно рассматривать компромиссы популярных моделей последовательностей с этой точки зрения. Например, внимание одновременно эффективно и неэффективно, потому что оно явно не сжимает контекст вообще. Это видно из того факта, что авторегрессионный вывод требует явного сохранения всего контекста (т.е. кэша Key-Value), что непосредственно вызывает медленный вывод в линейном времени и обучение Transformer в квадратичном времени.
С другой стороны, рекуррентные модели эффективны, потому что они имеют конечное состояние, что подразумевает вывод с постоянным временем и обучение с помощью линейного времени. Однако их эффективность ограничена тем, насколько хорошо это состояние спрессовало контекст.
Для понимания этого принципа авторы метода в своей работе уделяют особое внимание решению двух синтетических задач:
- Задача Выборочное копирование. Она требует рассуждения с учетом содержимого, чтобы иметь возможность запоминать релевантные токены и отфильтровывать нерелевантные.
- Задача Индукционные головы — этот механизм объясняет большинство способностей LLM к контекстному обучению. Решение задачи требует контекстно-зависимого рассуждения, чтобы знать, когда следует получить правильный вывод в соответствующем контексте.
Эти задачи выявляют режим отказа моделей LTI. С рекуррентного взгляда их постоянная динамика не позволяет им выбирать правильную информацию из своего контекста или влиять на скрытое состояние, передаваемое по последовательности, зависящим от исходных данных. С точки зрения свертки известно, что глобальные свертки могут решить ванильную задачу копирования, потому что она требует только осознания времени, но они испытывают трудности с задачей выборочного копирования из-за недостаточной осведомленности о содержимом. Если говорить более конкретно, то расстояние между исходными данными и результатами варьируется, и не может быть смоделировано ядрами статической свертки.
Таким образом, компромисс эффективности моделей последовательностей характеризуется тем, насколько хорошо они сжимают свое состояние. В свою очередь, авторы метода предполагают, что фундаментальным принципом построения моделей последовательностей является избирательность, или контекстно-зависимая способность фокусироваться на исходных данных или отфильтровывать их в последовательном состоянии. В частности, механизм выбора контролирует, как информация распространяется или взаимодействует по размерности последовательности.
Один из методов включения механизма отбора в модели заключается в том, чтобы позволить их параметрам, влияющим на взаимодействие вдоль последовательности, быть зависимыми от исходных данных. Основное отличие заключается в том, чтобы просто сделать несколько параметров Δ B, C функциями от исходных данных, а также связанные с ними изменения форм тензоров. В частности, эти параметры теперь имеют размерность длины L. Это означает, что модель изменилась с инвариантной во времени на изменяющуюся во времени.
Авторы метода специально выбирают:
- SB(x) = LinearN(x)
- SC(x) = LinearN(x)
- SΔ(x) = BroadcastD(Linear1(x))
- τΔ = SoftPlus
Выбор SΔ и τΔ возникает из подключения к механизмам вентилей RNN.
Авторы метода стремятся сделать выборочные SSM эффективными на современном оборудовании (GPU). На высоком уровне рекуррентные модели такие, как SSM, всегда балансируют между эффективностью и скоростью: модели с большей размерностью скрытого состояния должны быть более эффективными, но более медленными. Таким образом, перед авторами метода Mamba стояла задача максимизировать размерность скрытого состояния без потери скорости работы модели и увеличения потребления памяти.
Механизм выбора призван преодолеть ограничения моделей LTI. Однако необходимо вернуться к проблеме вычисления SSM. Авторы метода решают эту проблему с помощью трех классических методов: слияния ядер, параллельного сканирования и повторного вычисления. Они делают два основных наблюдения:
- Наивные рекуррентные вычисления используют O(BLDN) FLOP, в то время как при использовании сверточных вычислений O(BLD log(L)) FLOP. И первый имеет меньший постоянный коэффициент. Таким образом, для длинных последовательностей и не слишком большой размерности состояния N, рекуррентный режим на самом деле может использовать меньше FLOP.
- Две проблемы — это последовательный характер повторения и большое использование памяти. Чтобы решить последнюю, как и в случае со сверточным режимом, мы можем попытаться на самом деле не вычислять полное состояние h.
Основная идея состоит в том, чтобы использовать свойства современных ускорителей (GPU) для вычисления состояния h только на более эффективных уровнях иерархии памяти. В частности, большинство операций ограничены пропускной способностью памяти. Это относится и к операции сканирования. Авторы метода используют слияние ядра для уменьшения количества операций ввода-вывода в памяти, что приводит к значительному ускорению по сравнению со стандартной реализацией.
Кроме того, авторы метода осторожно применяют классическую технику пересчета для снижения требований к памяти: промежуточные состояния не сохраняются, а пересчитываются в обратном направлении при загрузке исходных данных.
Выборочные SSM представляют собой автономные преобразования последовательностей, которые можно гибко встраивать в нейронные сети.
Механизм отбора — это более широкое понятие, которое может применяться по-разному к другим параметрам или с использованием различных преобразований.
Избирательность позволяет отсеивать нерелевантные токены шума, которые могут возникать между интересующими исходными данными. Примером этого является задача выборочного копирования, но она встречается повсеместно в обычных модальностях данных, особенно для дискретных данных. Это свойство возникает из-за того, что модель может механически отфильтровывать любые конкретные исходные данные Xt.
Эмпирически было замечено, что многие модели последовательностей не улучшаются при более длительном контексте, несмотря на принцип, что большее количество контекста должно приводить к строго лучшей производительности. Объяснение заключается в том, что многие модели последовательностей не могут эффективно игнорировать нерелевантный контекст, когда это необходимо.
С другой стороны, модели выбора могут просто сбросить свое состояние в любой момент, чтобы удалить постороннюю историю, и, таким образом, их производительность в принципе монотонно улучшается с увеличением длины контекста.
Авторская визуализация метода представлена ниже.
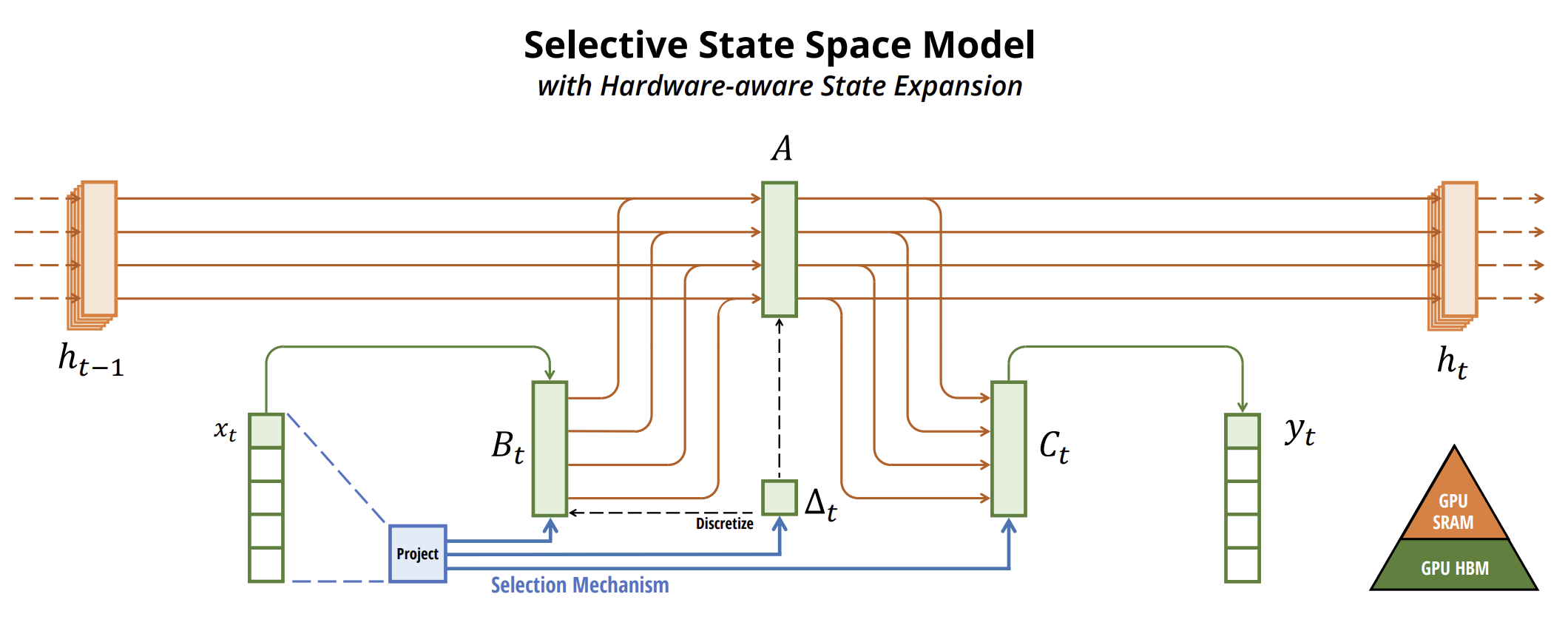
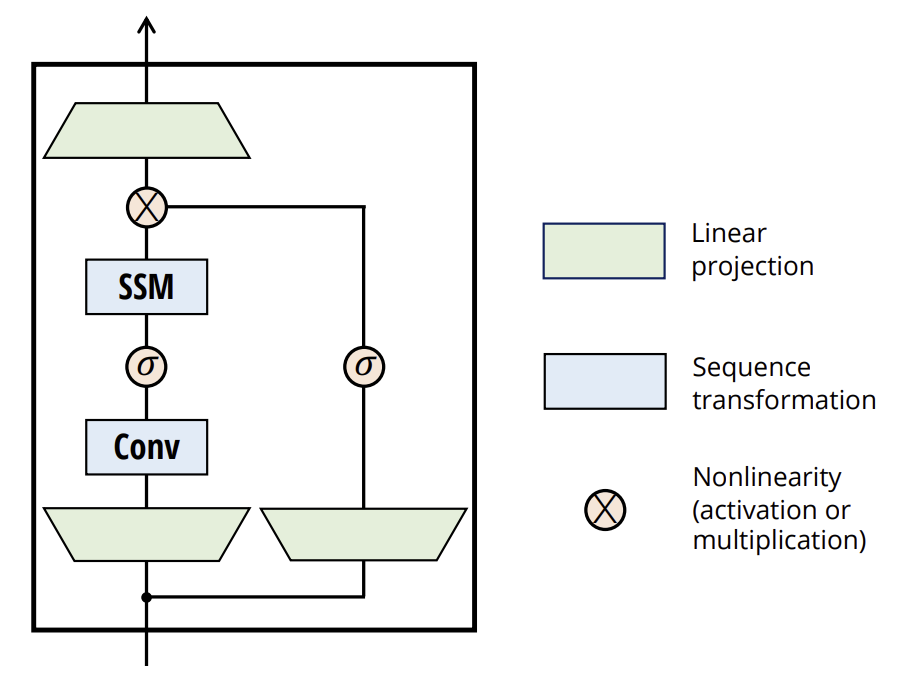
2. Реализация средствами MQL5
После ознакомления с теоретическими аспектами метода Mamba, мы переходим к практической реализации предложенных подходов средствами MQL5. И здесь мы разделим работу на два этапа. Вначале мы построим класс реализации алгоритма SSM, который является одним из вложенных слоев комплексного метода Mamba. А затем построим процессы алгоритма верхнего уровня.
2.1 Реализация SSM
Сразу надо сказать, что существует довольно много различных алгоритмов построения SSM. И в рамках данного эксперимента я немного отступил от алгоритма, реализованного авторами метода Mamba, построив одну из наиболее простых моделей отбора пространства состояний. Его мы реализовали в классе CNeuronSSMOCL. В качестве родительского объекта мы используем базовый класс полносвязного нейронного слоя CNeuronBaseOCL. Структура нового класса представлена ниже.
class CNeuronSSMOCL : public CNeuronBaseOCL { protected: uint iWindowHidden; CNeuronBaseOCL cHiddenStates; CNeuronConvOCL cA; CNeuronConvOCL cB; CNeuronBaseOCL cAB; CNeuronConvOCL cC; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- public: CNeuronSSMOCL(void) {}; ~CNeuronSSMOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronSSMOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
В представленной структуре мы видим объявление одной константы, определяющей размерность скрытого состояния одного элемента (iWindowHidden), и 5 внутренних нейронных слоев с функционалом которых мы познакомимся в процессе реализации.
Набор переопределяемых методов в нашем классе довольно привычен. И я думаю, что вы уже догадались об их функциональной нагрузке.
Все внутренние объекты класса объявлены статично, что позволяет нам оставить "пустыми" конструктор и деструктор класса. Инициализация всех объявленных и унаследованных объектов, как обычно, осуществляется в методе Init. В параметрах данного метода мы получаем константы, которые нам позволяют однозначно определить, какой объект хотел создать пользователь.
bool CNeuronSSMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Таких параметров здесь всего 3:
- window — размер вектора одного элемента последовательности;
- window_key — размер вектора внутреннего представления одного элемента последовательности;
- units_count — размер анализируемой последовательности.
Как я уже сказал, в данном эксперименте мы используем упрощенный алгоритм SSM. В частности, в нем не реализовано разделение мультимодальной последовательности на независимые каналы.
В теле метода мы сразу вызываем одноименный метод родительского класса, в котором уже реализована инициализация унаследованных объектов и переменных. А так же он выполняет минимально-необходимый контроль полученных от внешней программы параметров.
После успешного выполнения метода родительского класса мы переходим к инициализации объектов, объявленных в данном классе. Здесь мы сначала инициализируем внутренний слой хранения скрытого состояния.
if(!cHiddenStates.Init(0, 0, OpenCL, window_key * units_count, optimization, iBatch)) return false; cHiddenStates.SetActivationFunction(None); iWindowHidden = window_key;
И сразу сохраняем в локальной переменной размер вектора внутреннего состояния одного элемента последовательности.
Обратите внимание, что мы смело сохраняем значение параметра без проверки его значения. Фокус заключается в том, что мы осознанно сначала инициализировали объект внутреннего слоя, размер которого определяется через данный параметр. И в случае указания пользователем некорректного значения, мы бы получили ошибки на стадии инициализации класса. Таким образом, предусмотрительно проведенная инициализация внутреннего слоя косвенно выполняет функцию контроля параметров. Следовательно, мы не выполняем излишних операций на данном этапе.
Сразу надо сказать, что объект cHiddenStates используется только для временного хранения данных и мы принудительно отключаем в нем функцию активации.
Далее мы инициализируем два слоя проекции данных, которые при этом контролируют влияние данных на результат. Первым мы инициализируем слой проекции скрытого состояния.
if(!cA.Init(0, 1, OpenCL, iWindowHidden, iWindowHidden, iWindowHidden, units_count, 1, optimization, iBatch)) return false; cA.SetActivationFunction(SIGMOID);
Здесь мы используем сверточный слой, который позволяет нам сделать независимые проекции скрытого состояния каждого элемента последовательности. А для регулирования влияния элемента на результат мы используем сигмоиду в качестве функции активации данного слоя. Как вы знаете, область значений данной функции [0, 1]. При "0" элемент не оказывает влияние на общий результат.
И аналогичным образом инициализируем слой проекции исходных данных.
if(!cB.Init(0, 2, OpenCL, window, window, iWindowHidden, units_count, 1, optimization, iBatch)) return false; cB.SetActivationFunction(SIGMOID);
Обратите внимание, что оба слоя проекции возвращают тензор в размере скрытого состояния, хотя на вход получают тензоры различного размера. Это можно заметить по размеру анализируемого окна данных и его шага при инициализации объектов.
Для получения совместного влияния исходных данных и скрытого состояния на результат мы планируем использовать взвешенное суммирование. А для сокращения числа выполняемых операций мы решили совместить данный процесс с проекцией данных к требуемой размерности результатов. Поэтому мы сначала конкатенируем данные в общий тензор по размерности элементов последовательности.
if(!cAB.Init(0, 3, OpenCL, 2 * iWindowHidden * units_count, optimization, iBatch)) return false; cAB.SetActivationFunction(None);
А затем воспользуемся ещё одним внутренним сверточным слоем.
if(!cC.Init(0, 4, OpenCL, 2*iWindowHidden, 2*iWindowHidden, window, units_count, 1, optimization, iBatch)) return false; cC.SetActivationFunction(None);
В завершении метода инициализации мы осуществим подмену указателей на буфера результатов и градиентов ошибки нашего класса аналогичными буферами внутреннего слоя проекции результатов. Такой простой шаг позволяет нам исключить излишние операции копирования данных при осуществлении прямого и обратного проходов.
SetActivationFunction(None); if(!SetOutput(cC.getOutput()) || !SetGradient(cC.getGradient())) return false; //--- return true; }
Ну и конечно же, не забываем контролировать процесс выполнения операций, а в завершении метода вернем логическое значение выполненных операций вызывающей программе.
После завершения процесса инициализации класса, мы переходим к построению алгоритмов прямого прохода. Как вы знаете, данный функционал мы реализуем в переопределяемом методе feedForward. И здесь все довольно прозаично и просто.
bool CNeuronSSMOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cA.FeedForward(cHiddenStates.AsObject())) return false; if(!cB.FeedForward(NeuronOCL)) return false;
В параметрах метода мы получаем указатель на объект предшествующего нейронного слоя, который нам предоставляет исходные данные.
А в теле метода мы сразу осуществляем две проекции (исходных данных и скрытого состояния) до сопоставимого вида. Для этого мы воспользуемся методами прямого прохода соответствующих внутренних сверточных слоев.
Полученные проекции мы конкатенируем в единый тензор по размерности элементов последовательности.
if(!Concat(cA.getOutput(), cB.getOutput(), cAB.getOutput(), iWindowHidden, iWindowHidden, cA.Neurons() / iWindowHidden)) return false;
И в завершение метода мы осуществим проекцию конкатенированного слоя до требуемой размерности результатов.
if(!cC.FeedForward(cAB.AsObject())) return false;
Здесь следует обратить внимание на два момента. Во-первых, мы не передаем полученный результат в буфер результатов текущего слоя — эту операцию нам удалось исключить, благодаря подмене указателей буферов данных.
И второй момент: вы, наверное, заметили, что мы не обновили скрытое состояние. И в таком виде метод прямого прохода выглядит незавершенным. Но проблема в том, что текущие данные скрытого состояния нам ещё понадобятся для целей обратного прохода. И в таком случае есть смысл обновить скрытое состояние в процессе обратного прохода, так как оно используется только в алгоритме текущего слоя.
Но есть и обратная сторона медали — в процессе эксплуатации модели мы не используем методы обратного прохода. И если мы вынесем обновление скрытого состояния в методы обратного прохода, то оно вообще не будет обновляться в процессе эксплуатации модели, что нарушает весь алгоритм.
Поэтому мы сначала проверяем текущий режим работы модели и только в случае эксплуатации модели обновляем скрытое состояние. Для этого мы суммируем и нормализуем проекции предыдущего скрытого состояния и исходных данных.
if(!bTrain) if(!SumAndNormilize(cA.getOutput(), cB.getOutput(), cHiddenStates.getOutput(), iWindowHidden, true)) return false; //--- return true; }
Теперь наш метод прямого прохода получил завершенный вид. И мы возвращаем вызывающей программе логическое значение выполненных операций.
После выполнения алгоритма прямого прохода, мы переходим к работе с методами обратного прохода. Как обычно, здесь мы переопределяем два метода:
- calcInputGradients — распределение градиентов ошибки;
- updateInputWeights — обновление параметров модели.
Алгоритм метода распределения градиента ошибки повторяет метод прямого прохода в обратном порядке. И я предлагаю вам ознакомиться с ним самостоятельно во вложении. А вот о методе обновления параметров модели надо сказать пару слов. Именно в него мы вынесли обновление скрытого состояния в процессе обучения модели.
bool CNeuronSSMOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cA.UpdateInputWeights(cHiddenStates.AsObject())) return false; if(!SumAndNormilize(cA.getOutput(), cB.getOutput(), cHiddenStates.getOutput(), iWindowHidden, true)) return false;
Здесь мы сначала скорректируем параметры внутреннего слоя проекции скрытого состояния. И лишь потом обновим значения скрытого состояния.
Обратите внимание, что здесь мы не проверяем режим работы модели, так как вызов данного метода возможен только в процессе обучения.
Далее мы вызываем одноименные методы оставшихся внутренних объектов с обучаемыми параметрами.
if(!cB.UpdateInputWeights(NeuronOCL)) return false; if(!cC.UpdateInputWeights(cAB.AsObject())) return false; //--- return true; }
И по завершении всех операций метода мы вернем их логический результат вызывающей программе.
На этом мы завершаем рассмотрение методов класса реализации SSM. А с полным кодом всех его методов вы можете самостоятельно ознакомиться во вложении.
2.2 Класс метода Mamba
Выше мы реализовали класс для реализации слоя SSM. И теперь мы можем перейти к реализации алгоритма верхнего уровня метода Mamba. Для его реализации мы создадим класс CNeuronMambaOCL, который, как и предыдущий, унаследует базовый функционал от полносвязного слоя CNeuronBaseOCL. Структура нового класса представлена ниже.
class CNeuronMambaOCL : public CNeuronBaseOCL { protected: CNeuronConvOCL cXProject; CNeuronConvOCL cZProject; CNeuronConvOCL cInsideConv; CNeuronSSMOCL cSSM; CNeuronBaseOCL cZSSM; CNeuronConvOCL cOutProject; CBufferFloat Temp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- public: CNeuronMambaOCL(void) {}; ~CNeuronMambaOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMambaOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Здесь мы видим уже знакомый нам набор переопределяемых методов и объявление внутренних нейронных слоев, с функционалом которых мы познакомимся в процессе реализации методов класса.
При этом здесь не объявляется ни одна внутренняя переменная для хранения констант. О решениях, которые позволили отказаться от сохранения констант, мы так же поговорим в процессе реализации.
Как обычно, все внутренние объекты объявлены статично и, следовательно, конструктор и деструктор класса остаются пустыми. А инициализации объектов осуществляется в методе Init.
bool CNeuronMambaOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Здесь мы видим список параметров аналогичный одноименному методу выше рассмотренному классу CNeuronSSMOCL. Несложно догадаться, что они имеют схожий функционал.
В теле метода мы сразу вызываем метод инициализации родительского класса, в котором осуществляется работа с унаследованными объектами и переменными.
Как вы помните из теоретического описания метода Mamba, исходные данные здесь проходят два параллельных потока. И для обоих потоков мы выполняем проекцию данных, которая будет выполняться сверточными слоями.
if(!cXProject.Init(0, 0, OpenCL, window, window, window_key + 2, units_count, 1, optimization, iBatch)) return false; cXProject.SetActivationFunction(None); if(!cZProject.Init(0, 1, OpenCL, window, window, window_key, units_count, 1, optimization, iBatch)) return false; cZProject.SetActivationFunction(SIGMOID);
В первом потоке мы будем использовать сверточный слой и SSM. А во втором используется функция активации, и данные идут на слияние потоков информации. Соответственно, на выходе двух потоков должны быть тензоры сопоставимого размера. Для достижения такого результата мы немного увеличим размер проекции первого потока, что компенсируется сжатием данных при свертке.
Обратите внимание, что функцию активации мы используем только для проекции второго потока.
Следующим шагом мы инициализируем сверточный слой.
if(!cInsideConv.Init(0, 2, OpenCL, 3, 1, 1, window_key, units_count, optimization, iBatch)) return false; cInsideConv.SetActivationFunction(SIGMOID);
Здесь мы осуществляем независимую свертку в рамках отдельных элементов последовательности. Поэтому мы укажем размер тензора скрытого состояния в качестве количества элементов свертки. И тут же добавим количество элементов последовательности в качестве числа независимых переменных.
Размер окна свертки и его шаг корреспондируют с нашим увеличением проекции первого потока данных.
И тут мы уже добавляем функцию активации, что делает сопоставимыми данными в обоих потоках информации.
Далее следует наш блок SSM, в котором осуществляется селекция состояний.
if(!cSSM.Init(0, 3, OpenCL, window_key, window_key, units_count, optimization, iBatch)) return false;
В завершении алгоритма для придания нелинейности объединению двух потоков информации мы, как и в предыдущем случае, конкатенируем информацию потоков в единый тензор.
if(!cZSSM.Init(0, 4, OpenCL, 2 * window_key * units_count, optimization, iBatch)) return false; cZSSM.SetActivationFunction(None);
И осуществим проекцию данных до требуемого размера в рамках отдельных элементов последовательности с помощью сверточного слоя.
if(!cOutProject.Init(0, 5, OpenCL, 2*window_key, 2*window_key, window, units_count, 1, optimization, iBatch)) return false; cOutProject.SetActivationFunction(None);
Добавим буфер для хранения промежуточных результатов.
if(!Temp.BufferInit(window * units_count, 0)) return false; if(!Temp.BufferCreate(OpenCL)) return false;
И выполним операцию подмены указателей на буферы данных.
if(!SetOutput(cOutProject.getOutput())) return false; if(!SetGradient(cOutProject.getGradient())) return false; SetActivationFunction(None); //--- return true; }
Ну и в завершении метода вернем логический результат выполненных операций вызывающей программе.
После завершения работы с методом инициализации класса, мы начинаем построение алгоритмов прямого прохода в методе feedForward. Частично алгоритм метода был озвучен при создании метода инициализации. Теперь посмотрим на реализацию алгоритма в коде.
bool CNeuronMambaOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cXProject.FeedForward(NeuronOCL)) return false; if(!cZProject.FeedForward(NeuronOCL)) return false;
В параметрах метода мы получаем указатель на объект предыдущего слоя, в буфере которого содержатся наши исходные данные. И в теле метода мы сразу осуществляем проекцию полученных данных, путем вызова методов прямого прохода наших сверточных слоев проекции данных.
На этом, можно сказать, выполнены операции второго потока информации. Но нам еще предстоит выполнить операции основного потока данных. Здесь мы сначала осуществляем свертку данных.
if(!cInsideConv.FeedForward(cXProject.AsObject())) return false;
После чего выполним селекцию состояний.
if(!cSSM.FeedForward(cInsideConv.AsObject())) return false;
Теперь, когда выполнены операции обоих потоков данных, мы объединяем результаты в единый тензор.
if(!Concat(cSSM.getOutput(), cZProject.getOutput(), cZSSM.getOutput(), 1, 1, cSSM.Neurons())) return false;
И тут мы вспоминаем, что не сохранили размерность внутреннего состояния одного элемента последовательности. Не беда. Мы знаем, что тензоры обоих потоков информации имеют одинаковую размерность. Значит, если мы последовательно будем брать по одному элементу каждого тензора, то мы не нарушим общей структуры.
И теперь нам остается лишь осуществить проекцию данных до требуемой размерности результатов.
if(!cOutProject.FeedForward(cZSSM.AsObject())) return false; //--- return true; }
В завершении метода мы возвращаем вызывающей программе логический результат выполнения операций.
Как можно заметить, алгоритм метода прямого прохода не выделяется особой сложностью. То же самое можно сказать о методах обратного прохода. Поэтому я предлагаю не останавливаться сейчас на рассмотрении их алгоритмов, а оставить для самостоятельного обучения. Полный код данного класса и всех его методов вы найдете во вложении.
2.3 Архитектура моделей
Выше мы реализовали свое видение подходов, предложенных авторами метода Mamba. Но проделанная работа должна приносить результат. Чтобы оценить эффективность реализованных алгоритмов, нам необходимо внедрить их в нашу модель. Вы наверное, уже догадались, что добавлять вновь созданные слои мы будем в модель Энкодера состояния окружающей среды. Ведь именно эту модель мы обучаем в парадигме прогнозирования последующего ценового движения.
Архитектура указанной модели представлена в методе CreateEncoderDescriptions.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В параметрах метода мы получаем указатель на динамический массив, в который нам предстоит записать описание архитектуры создаваемой модели.
В теле метода мы проверяем актуальность полученного указателя и, при необходимости, создаем новый экземпляр объекта. На этом завершается наша подготовительная работа, и мы переходим к созданию описания архитектуры модели.
Первый слой предназначен для передачи в модель исходных данных. Здесь мы, как всегда, используем полносвязный слой достаточного размера.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Обычно в модель мы передаем "сырые" исходные данные в том виде, в котором получаем их от терминала. Вполне естественно, что такие данные относятся к разным распределениям. А мы знаем, что эффективность любой модели значительно повышается при работе с сопоставимыми значениями в исходных данных. Чтобы привести разнообразные исходные данные к сопоставимому виду, мы используем слой пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Далее мы создадим блок из 3 слоев метода Mamba с идентичной архитектурой. Для этого мы создадим одно описание архитектуры блока. После чего добавим его в массив нужное количество раз.
if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMambaOCL; descr.window = BarDescr; //window descr.window_out = 4 * BarDescr; //Inside Dimension prev_count = descr.count = HistoryBars; //Units descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; for(int i = 2; i <= 4; i++) if(!encoder.Add(descr)) { delete descr; return false; }
Обратите внимание, что размер анализируемого окна данных равен количеству элементов описания одного элемента последовательности, а размер внутреннего представления мы сделали в 4 раза больше. Ведь в методе Mamba авторы рекомендуют осуществлять расширяющуюся проекцию.
Число элементов последовательности равно глубине анализируемой истории.
Как я говорил в процессе реализации классов, в данной реализации мы не выделили отдельные каналы информации. Однако, наш алгоритм работает с независимыми элементами последовательности. И в случае необходимости анализа независимых каналов, вы можете предварительно транспонировать данные и соответствующим образом изменить параметры слоя. Но это мы оставим для другого эксперимента.
Тем не менее, прогнозировать последовательности мы будем в разрезе независимых каналов. Для этого мы уже после блока Mamba добавим транспонирование данных.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = BarDescr; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
И воспользуемся двумя сверточными слоями для прогнозирования последующих значений независимых каналов.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = prev_count; descr.window_out = 4 * NForecast; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = 4 * NForecast; descr.window_out = NForecast; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
После чего вернем уже прогнозные значения в исходное представление.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
И добавим к ним статистические характеристики распределения исходных данных, изъятые при нормализации.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
Последним штрихом нашей модели будет согласование результатов в частотной области.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Архитектура моделей Актера и Критика остались без изменений. Нет изменений и в программах взаимодействия с окружающей средой. А вот в программы обучения моделей нам потребовалось внести некоторые точечные правки. Ведь использование скрытого состояния в SSM блоке требует изменения в последовательности подачи исходных данных, свойственное рекуррентным моделям. Подобные изменения мы вносим каждый раз при использовании моделей со скрытыми состояниями, информация в которых накапливается со временем работы модели. И я предлагаю вам самостоятельно посмотреть на них во вложении. Напомню, что там представлен код всех программ и классов, используемых при подготовке статьи. А мы на этом завершаем рассмотрение реализации предложенных подходов и переходим к практическим тестам на реальных исторических данных.
3. Тестирование
Наша работа подходит к завершению, и мы переходим к финальному этапу — обучению моделей и тестированию достигнутых результатов. Обучение моделей мы осуществляем на исторических данных за 2023 год инструмента EURUSD таймфрейм H1. Параметры всех индикаторов используются по умолчанию.
На первом этапе мы обучаем модель Энкодера состояния окружающей среды в попытках прогнозирования последующего ценового движения на заданный горизонт планирования. Данная модель анализирует только исторические данные ценового движения и полностью игнорирует действия Актера. Это позволяет нам провести полное обучение модели с использованием ранее собранных обучающих данных без необходимости их актуализации. Однако такая актуализация может потребоваться при изменении или увеличении исторического периода обучения.
Первое, что можно отметить — модель получилась довольно компактной и быстрой. Процесс обучения проходил относительно стабильно и устойчиво. При этом модель показала интересные результаты.
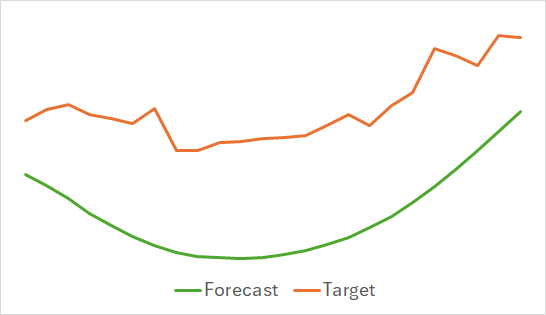
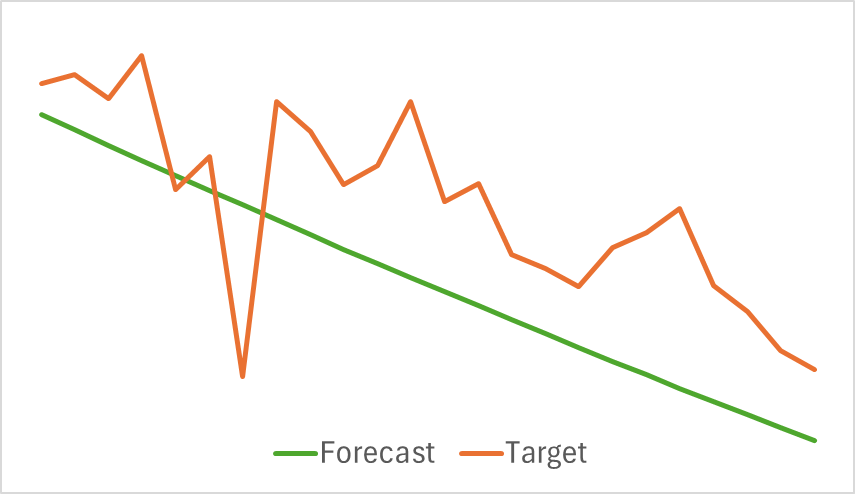
Выше представлены результаты прогноза предстоящего ценового движения на последующие 24 часа. Можно заметить, что прогнозная линия в первом довольно плавно описывает точку изменения тенденции. А во втором случае практически линейно указывает текущую тенденцию.
На втором этапе мы осуществляли итерационное обучение политики Актера. А вместе с ним мы обучаем функцию стоимости Критика. Роль Критика — указать направлению Актеру для повышения эффективности его политики.
Как уже было сказано выше, второй этап обучения итерационный. Это значит, что в процессе обучения моделей мы периодически будем осуществлять обновление обучающей выборки с целью наполнить её данными, актуальными для текущей политики Актера. Именно актуальное состояние обучающей выборки является залогом корректного обучения моделей.
Однако, в процессе обучения мы не получили политику с ярко выраженной тенденцией к росту депозита. Да, наша модель смогла получить прибыль на тестовом историческом отрезке Января 2024 года, но четко выраженной тенденции не наблюдается.
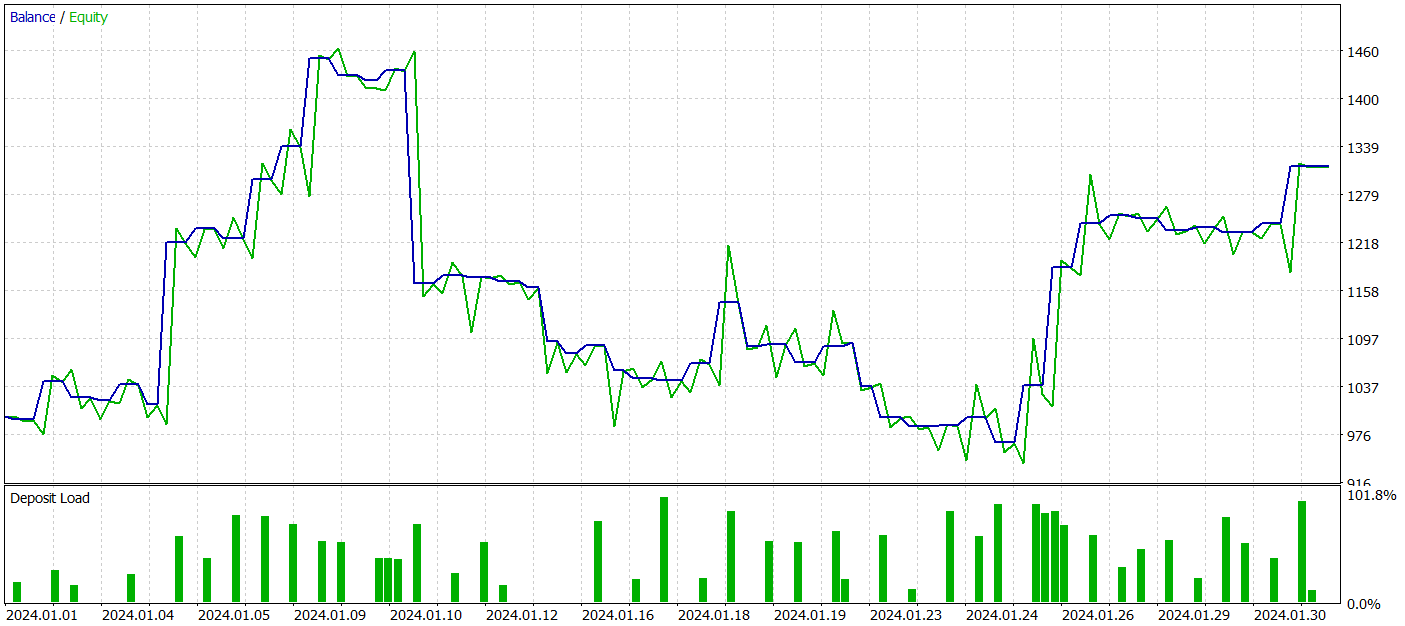
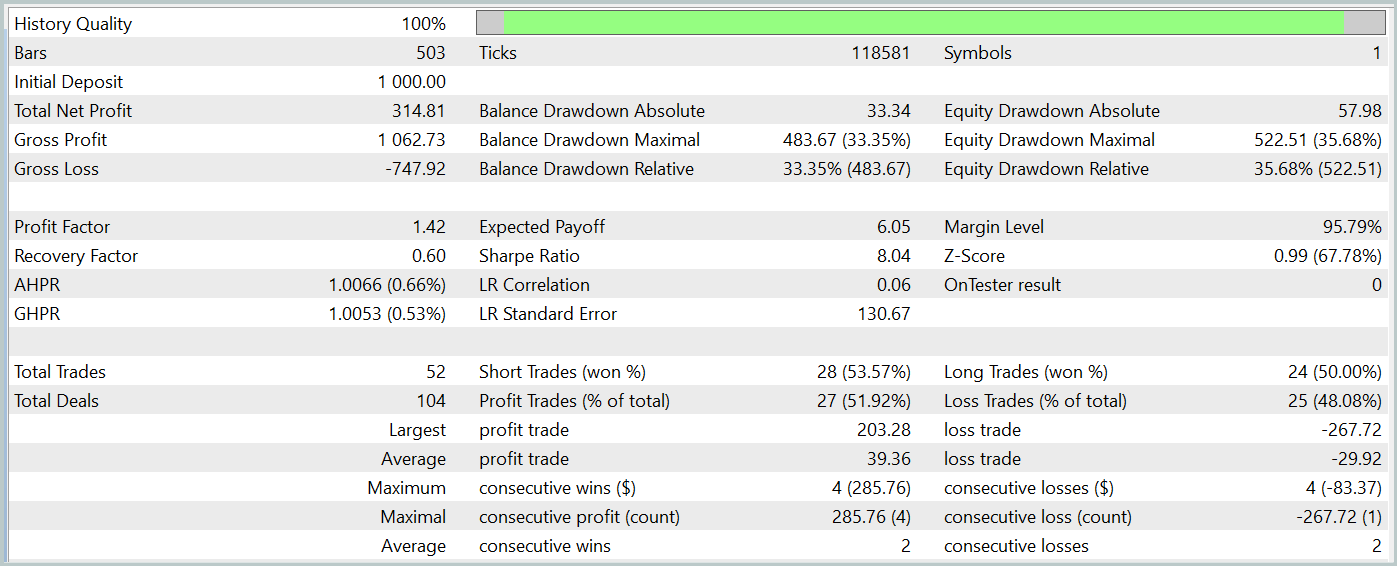
За период тестирования модель совершила 52 сделки и 27 из них были закрыты с прибылью, что составило почти 52%. Средняя прибыльная сделка превышает аналогичный показатель по убыточных сделок (39,36 против -29,82). Однако максимальный убыток на 30% превышает максимальную прибыльную сделку. Кроме того, мы видим просадку по Эквити более 35%. Такая модель однозначно требует дальнейшей работы.
Интерес вызывают графики прибыли и убытков по часам и дням.
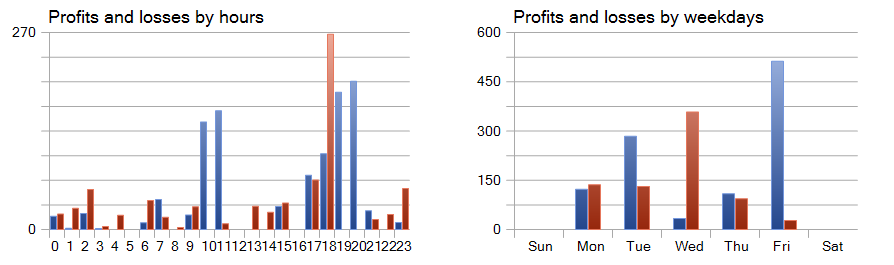
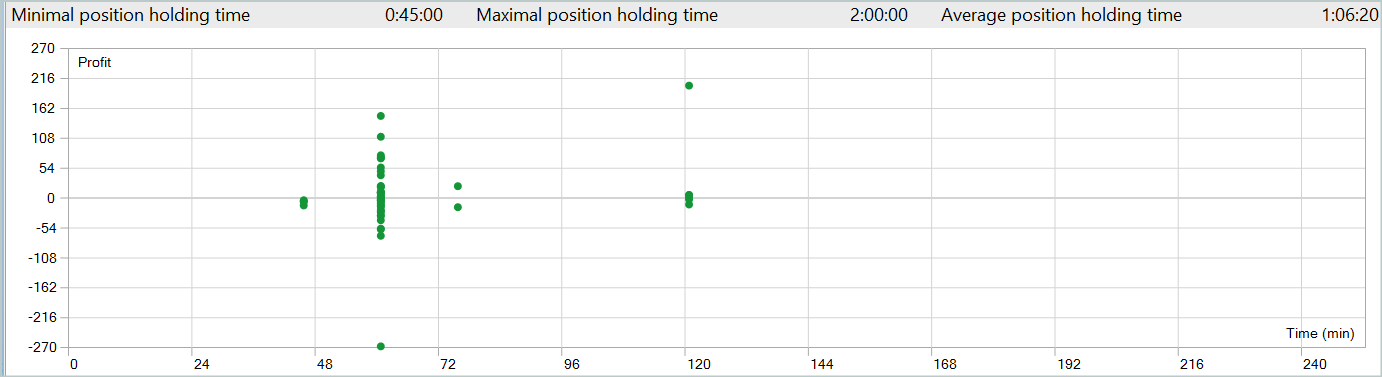
Здесь резко позитивно выделяется пятница, а среда, наоборот, убыточная. Так же можно выделить периоды внутри дня с большим количеством прибыльных и убыточных сделок. Здесь есть над чем подумать. Тем более средняя продолжительность удержания позиции чуть больше часа, а максимальная 2 часа.
Заключение
В данной статье мы познакомились с новым методом прогнозирования временных рядов Mamba, который предлагает эффективную и производительную альтернативу традиционным архитектурам, таким как Transformer. Благодаря интеграции выборочных моделей пространства состояний (SSM), Mamba обеспечивает высокую пропускную способность и линейное масштабирование по длине последовательности.
В практической части нашей статьи мы реализовали свое видение предложенных подходов средствами MQL5. Мы обучили модели на реальных данных и получили неоднозначные результаты.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования