
Нейросети в трейдинге: Комплексный метод прогнозирования траекторий (Traj-LLM)

Введение
Прогнозирование предстоящего ценового движения на финансовых рынках играет критическую роль для принятия решения трейдером. Качественные прогнозы позволяют принимать более обоснованные решения и минимизировать риски. Однако прогнозирование будущих ценовых траекторий сталкивается с множеством вызовов из-за хаотичности и стохастичности рынков. Даже самые продвинутые модели прогнозирования часто не могут адекватно учитывать все факторы, влияющие на рыночную динамику, такие как внезапные изменения в поведении участников рынка или неожиданные внешние события.
В последние годы развитие искусственного интеллекта, особенно в области больших языковых моделей (LLM), открыло новые возможности для решения различных задач. LLM продемонстрировали удивительные способности к обработке сложной информации и моделированию сценариев, приближенных к человеческому мышлению. Такие модели успешно применяются в различных областях, от обработки естественного языка до прогнозирования временных рядов, что делает их перспективными инструментами для анализа и прогнозирования рыночных движений.
Я предлагаю вам познакомиться с алгоритмом Traj-LLM, который был описан в статье "Traj-LLM: A New Exploration for Empowering Trajectory Prediction with Pre-trained Large Language Models". Модель Traj-LLM была представлена для решения задач в области автономного управления транспортных средств. Авторы метода предлагают использовать возможности LLM для улучшения точности и адаптивности прогнозирования будущих траекторий участников движения.
Более того, Traj-LLM сочетает мощь больших языковых моделей с новыми подходами к моделированию временных зависимостей и взаимодействий между объектами, что позволяет ей более точно прогнозировать траектории даже в сложных и динамичных условиях. Данная модель не только улучшает точность прогнозирования, но и предлагает новые пути для анализа и понимания возможных сценариев развития. Мы ожидаем, что использование предложенного авторами метода будет эффективно в решении наших задач и позволит нам повысить качество прогнозов предстоящего ценового движения.
1. Алгоритм Traj-LLM
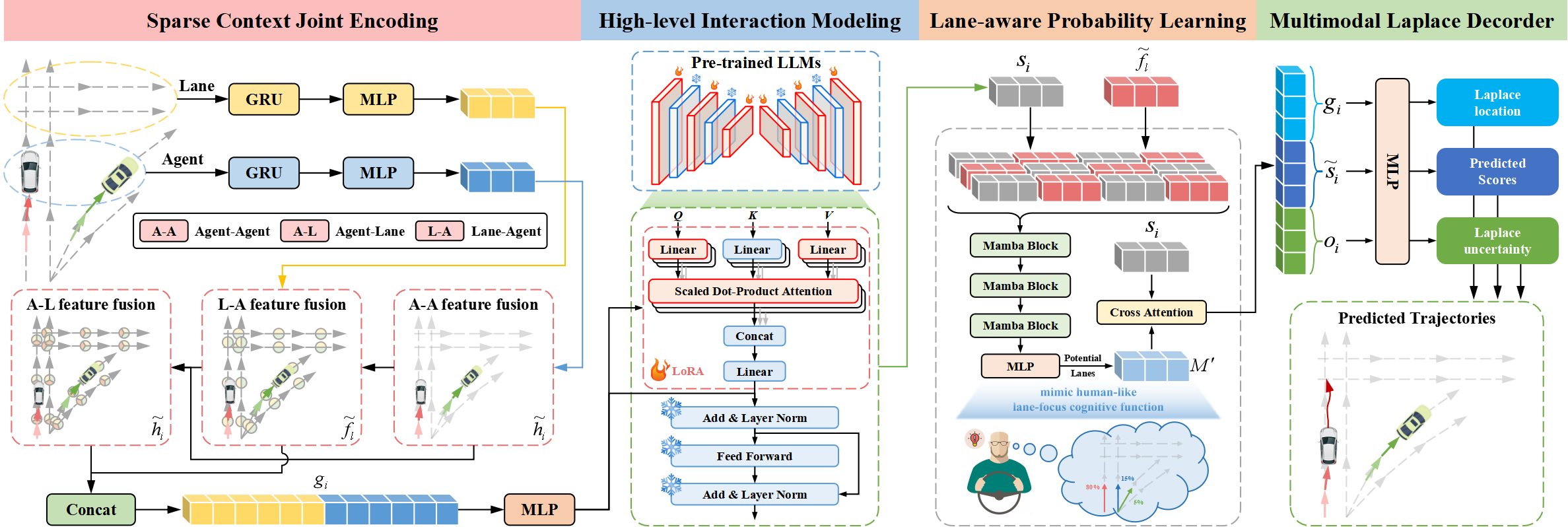
Архитектура Traj-LLM содержит четыре неотъемлемых компонента:
- разреженное контекстное совместное кодирование,
- высокоуровневое моделирование взаимодействия,
- обучение вероятности с учетом полосы движения,
- мультимодальный декодер Лапласа.
Авторы метода Traj-LLM предлагают использовать способности LLM для решения задачи прогнозирования траекторий, что позволяет избавиться от необходимости явного оперативного проектирования. Совместное кодирование с разреженным контекстом первоначально включает в себя разбор особенностей агентов и сцен в форму, понятную для LLM. Впоследствии полученные представления вводятся в предварительно обученные LLM для решения задач взаимодействия высокого уровня. Чтобы имитировать когнитивную функцию, подобную человеческой, и еще больше улучшить понимание сцены в Traj-LLM, вводится вероятностное обучение с учетом полосы на основе модуля Mamba. А мультимодальный декодер Лапласа используется для создания надежных прогнозов.
Первым шагом Traj-LLM является кодирование пространственно-временных исходных данных сцены, таких как состояния агента и полосы. Для каждого из них мы используем встраиваемую модель, состоящую из рекуррентного слоя и MLP для извлечения многомерных признаков. После этого результирующие тензоры hi и fl направляются в подмодуль Fusion, облегчая сложный обмен информацией между состояниями агентов и полосами движения в локализованных областях. Этот процесс выполняется по принципу встраивания токенов, чтобы соответствовать архитектуре LLM.
В частности, процесс синтеза влечет за собой использование многоголового механизма Self-Attention для слияния функций Aгент-Aгент. Кроме того, слияние функций Агент-Полоса и Полоса-Агент включает в себя обновление представлений Агента и Полосы с помощью механизма многоголового перекрестного внимания с пропуском соединений. Формально этот процесс можно выразить следующим образом:

После чего объединяем hi и fl для создания разреженных контекстных совместных кодировок gi, которые интуитивно переносят зависимости, относящиеся к локальным рецептивным полям векторизованных сущностей. Совместное кодирование с разреженным контекстом предназначено для того, чтобы позволить LLM понимать данные о траекториях, тем самым расширяя возможности LLM.
Переходы траекторий подчиняются шаблонам, управляемым высокоуровневыми ограничениями, исходящими от различных элементов сцены. Чтобы изучить эти высокоуровневые взаимодействия, авторы метода исследуют способность LLM моделировать ряд зависимостей, присущих задачам прогнозирования траекторий. Несмотря на сходство между данными траекторий и текстами на естественном языке, прямое использование LLM для обработки разреженных контекстных совместных кодировок считается нецелесообразным. Так как предварительно обученные LLM в первую очередь предназначены для обработки текстовых данных. Одним из альтернативных предложений является всесторонняя переподготовка всех LLM. Процесс, требующий значительных вычислительных ресурсов, что делает его в некоторой степени неосуществимым. Другое более эффективное решение заключается в применении метода Parameter-Efficient Fine-Tuning (PEFT) для тонкой настройки предварительно обученных LLM.
В своей работе авторы Traj-LLM используют параметры из предварительно обученных архитектур трансформеров NLP, уделяя особое внимание модели GPT2, для высокоуровневого моделирования взаимодействия. Они предлагают замораживать все предварительно обученные параметры и внедрять новые, пригодные для обучения, используя технику адаптации низкого ранга (LoRA). LoRA применяется к сущностям Query и Key механизма внимания LLM.
Таким образом разреженные контексты совместного кодирования gi передаются в LLM, которая содержит серию предварительно обученных блоков Transformer, оснащенных LoRA. Эта процедура завершается генерацией высокоуровневых представлений взаимодействия zi.
![]()
Результаты работы предварительно обученной LLM преобразуются с помощью MLP в соответствии с размерами gi, таким образом получаем конечные состояния высокоуровневого взаимодействия si.
Подавляющее большинство опытных водителей обращают внимание лишь на несколько потенциальных участков полосы движения, которые оказывают заметное влияние на их дальнейшее движение. Чтобы имитировать эту человекоподобную когнитивную функцию и еще больше улучшить понимание сцены в Traj-LLM, авторы метода используют вероятностное обучение с учетом полосы движения для непрерывной оценки вероятности выравнивания состояний движения с сегментами полосы. Точнее, они синхронизируют движение целевого агента с информацией о полосе движения на каждом временном шаге t∈{1,…,tf} с введением слоя Mamba. Функционируя как селективная структурированная модель пространства состояний (SSM), Mamba позволяет уточнить и обобщить релевантную информацию. Это аналогично сложному принятию решений водителями-людьми, которые разумно взвешивают ключевые информационные сигналы, такие как потенциальные полосы движения, чтобы сделать свой выбор.
В предложенной архитектуре слой Mamba состоит из блока Mamba, трехслойной нормализации и сети прямой связи по позициям. В частности, блок Mamba сначала расширяет исходную размерность с помощью линейных проекций, дающих различные представления для двух параллельных ветвей потока информации. Затем одна ветвь обрабатывается с помощью свертки и активации SiLU для захвата зависимостей с учетом полосы движения. Ядро блока Mamba включает в себя селективную модель пространства состояний с дискретизированными параметрами на основе исходных данных. Чтобы повысить надежность, авторы метода дополнительно включают нормализацию экземпляров и остаточное соединение для получения неявных состояний.
После чего используется сеть FeedForward по позициям для улучшения моделирования оценки с учетом полосы движения в скрытом измерении. И снова выполняется нормализация экземпляра и остаточное соединение для получения векторов обучения, учитывающих полосы движения, которые затем подаются в слой MLP.
Как уже говорилось выше, опытные водители уделяют пристальное внимание нескольким потенциальным сегментам полосы движения, что способствует эффективному принятию решений. С этой целью тщательно отбираются сегменты верхней линии в качестве полос кандидатов-движения, которые в дальнейшем объединяются в форму ℳ.
Обучение вероятности с учетом полосы движения моделируется как задача классификации, в которой двоичная ошибка перекрестной энтропии ℒlane применяется для оптимизации оценки вероятности.
Авторская визуализация метода Traj-LLM представлена ниже.
2. Реализация средствами MQL5
После рассмотрения теоретического описания метода Traj-LLM мы переходим к практической части нашей статьи, в которой реализуем свое видение предложенных подходов средствами MQL5. Алгоритм Traj-LLM представляет собой комплексную структуру, объединяющую блоки различных архитектурных решений, с отдельным использованием которых мы уже встречались. А значит, при построении алгоритма мы можем воспользоваться существующими наработками. Однако, нам не обойтись без отдельных доработок.
2.1 Корректировка алгоритма LSTM-блока
Давайте посмотрим на представленную выше визуализацию метода Traj-LLM. Исходные данные сначала поступают в блок разреженного контекстного совместного кодирования, который состоит из рекуррентного слоя и MLP. В нашей библиотеке уже реализован рекуррентный слой CNeuronLSTMOCL. Однако он использует массив исходных данных в качественного целостного представления состояния окружающей среды. В данном же случае авторы метода предполагают осуществить независимое кодирование состояния отдельных агентов и полос движения. Иными словами, нам необходимо организовать независимое кодирование унитарных каналов данных. Конечно, мы можем создать отдельный объект CNeuronLSTMOCL для каждого канала анализируемой информации. Но такой подход характеризуется неконтролируемым увеличением числа внутренних объектов и их последовательной обработкой, что не лучшим образом скажется на производительности нашей модели.
Второй вариант решения — внесение правок в алгоритм существующего класса рекуррентного слоя CNeuronLSTMOCL. Здесь мы сначала вносим изменения на стороне OpenCL программы. Алгоритм прямого прохода нашего рекуррентного слоя организован в кернеле LSTM_FeedForward. Для организации работы в рамках независимых унитарных последовательностей мы не будем вносить правки во внешние параметры кернела. А для организации параллельной обработки данных отдельных унитарных последовательностей мы добавим ещё одно измерение в пространстве задач.
__kernel void LSTM_FeedForward(__global const float *inputs, int inputs_size, __global const float *weights, __global float *concatenated, __global float *memory, __global float *output) { uint id = (uint)get_global_id(0); uint total = (uint)get_global_size(0); uint id2 = (uint)get_local_id(1); uint idv = (uint)get_global_id(2); uint total_v = (uint)get_global_size(2);
Напомню, что работа LSTM-блока построена на 4 сущностях, значения которых вычисляются внутренними слоями:
- Forget Gate — врата забвения;
- Input Gate — входные врата;
- Output Gate — врата выходного сигнала;
- New Content — новый контент.
Алгоритм вычисления данных сущностей одинаков и идентичен полносвязному слою. Отличие лишь в функции активации. Поэтому в своей реализации мы построили процесс вычисления значений данных сущностей в параллельных потоках рабочей группы. А для обмена данными между потоками используется массив, созданный в локальной памяти.
__local float Temp[4];
Далее мы определяем константы смешения в глобальных буферах данных.
float sum = 0; uint shift_in = idv * inputs_size; uint shift_out = idv * total; uint shift = (inputs_size + total + 1) * (id2 + id);
И здесь стоит обратить внимание на один момент. Мы организовываем процесс работы рекуррентного блока с независимыми каналами. Однако по логике построения алгоритма Traj-LLM, все независимые каналы информации содержат сопоставимые данные, будь то информация о состоянии различных агентов или существующих полос движения. Поэтому вполне логично использовать одну матрицу весов для кодирования информации из разных каналов данных, что позволит получить на выходе сопоставимые эмбединги.
Таким образом, идентификатор канала оказывает влияние на смещение в буферах исходных данных и результатов. Но не влияет на смещение в матрице весов.
Далее мы организовываем цикл расчета взвешенной суммы скрытого состояния.
for(uint i = 0; i < total; i += 4) { if(total - i > 4) sum += dot((float4)(output[shift_out + i], output[shift_out + i + 1], output[shift_out + i + 2], output[shift_out + i + 3]), (float4)(weights[shift + i], weights[shift + i + 1], weights[shift + i + 2], weights[shift + i + 3])); else for(uint k = i; k < total; k++) sum += output[shift_out + k] * weights[shift + k]; }
И добавим влияние исходных данных.
shift += total; for(uint i = 0; i < inputs_size; i += 4) { if(total - i > 4) sum += dot((float4)(inputs[shift_in + i], inputs[shift_in + i + 1], inputs[shift_in + i + 2], inputs[shift_in + i + 3]), (float4)(weights[shift + i], weights[shift + i + 1], weights[shift + i + 2], weights[shift + i + 3])); else for(uint k = i; k < total; k++) sum += inputs[shift_in + k] * weights[shift + k]; } sum += weights[shift + inputs_size];
К полученному значению применим соответствующую функцию активации.
if(isnan(sum) || isinf(sum)) sum = 0; if(id2 < 3) sum = Activation(sum, 1); else sum = Activation(sum, 0);
После чего сохраним результат операций и синхронизируем потоки рабочей группы.
Temp[id2] = sum; concatenated[4 * shift_out + id2 * total + id] = sum; //--- barrier(CLK_LOCAL_MEM_FENCE);
И теперь нам остается лишь вычислить результат работы LSTM-блока, который одновременно является скрытым состоянием данной ячейки.
if(id2 == 0) { float mem = memory[shift_out + id + total_v * total] = memory[shift_out + id]; float fg = Temp[0]; float ig = Temp[1]; float og = Temp[2]; float nc = Temp[3]; //--- memory[shift_out + id] = mem = mem * fg + ig * nc; output[shift_out + id] = og * Activation(mem, 0); } }
Результаты операций сохраняем в соответствующие элементы глобальных буферов данных.
Аналогичные правки мы внесли в кернелы обратного прохода. И наиболее существенными они были в кернеле LSTM_HiddenGradient. Как и в кернеле прямого, мы не изменяем состав внешних параметров и корректируем лишь пространство задач.
__kernel void LSTM_HiddenGradient(__global float *concatenated_gradient, __global float *inputs_gradient, __global float *weights_gradient, __global float *hidden_state, __global float *inputs, __global float *weights, __global float *output, const int hidden_size, const int inputs_size) { uint id = get_global_id(0); uint total = get_global_size(0); uint idv = (uint)get_global_id(1); uint total_v = (uint)get_global_size(1);
Здесь стоит вспомнить, что все независимые каналы работают с одной матрицей весов. Следовательно, для весовых коэффициентов нам предстоит собрать градиенты ошибок со всех независимых каналов. Каждый канал данных работает в своем потоке, которые мы объединим в рабочие группы. А для обмена данными между потоками воспользуемся массивом в локальной памяти.
__local float Temp[LOCAL_ARRAY_SIZE]; uint ls = min(total_v, (uint)LOCAL_ARRAY_SIZE);
Далее определим смещения в буферах данных.
uint shift_in = idv * inputs_size; uint shift_out = idv * total; uint weights_step = hidden_size + inputs_size + 1;
И организуем цикл перебора конкатенированного буфера исходных данных. Вначале мы просто обновим скрытое состояние.
for(int i = id; i < (hidden_size + inputs_size); i += total) { float inp = 0; if(i < hidden_size) { inp = hidden_state[shift_out + i]; hidden_state[shift_out + i] = output[shift_out + i]; }
А затем определим градиент ошибки на уровне исходных данных.
else { inp = inputs[shift_in + i - hidden_size]; float grad = 0; for(uint g = 0; g < 3 * hidden_size; g++) { float temp = concatenated_gradient[4 * shift_out + g]; grad += temp * (1 - temp) * weights[i + g * weights_step]; } for(uint g = 3 * hidden_size; g < 4 * hidden_size; g++) { float temp = concatenated_gradient[4 * shift_out + g]; grad += temp * (1 - pow(temp, 2.0f)) * weights[i + g * weights_step]; } inputs_gradient[shift_in + i - hidden_size] = grad; }
Тут же мы посчитаем градиент ошибки на уровне весовых коэффициентов. Вначале обнулим значения локального массива.
for(uint g = 0; g < 3 * hidden_size; g++) { float temp = concatenated_gradient[4 * shift_out + g]; if(idv < ls) Temp[idv % ls] = 0; barrier(CLK_LOCAL_MEM_FENCE);
При этом мы в обязательном порядке синхронизируем потоки рабочей группы.
Далее мы соберем суммарный градиент ошибки со всех каналов данных. На первом этапе мы сохраним отдельные значения в локальном массиве.
for(uint v = 0; v < total_v; v += ls) { if(idv >= v && idv < v + ls) Temp[idv % ls] += temp * (1 - temp) * inp; barrier(CLK_LOCAL_MEM_FENCE); }
Мы предполагаем, что в анализируемых данных будет сравнительно небольшое количество независимых каналов. Поэтому сумму значений массива мы соберем в одном потоке с последующим сохранением полученного значения в глобальном буфере данных.
if(idv == 0) { temp = Temp[0]; for(int v = 1; v < ls; v++) temp += Temp[v]; weights_gradient[i + g * weights_step] = temp; } barrier(CLK_LOCAL_MEM_FENCE); }
Аналогичным образом соберем градиент ошибки для весовых коэффициентов New Content.
for(uint g = 3 * hidden_size; g < 4 * hidden_size; g++) { float temp = concatenated_gradient[4 * shift_out + g]; if(idv < ls) Temp[idv % ls] = 0; barrier(CLK_LOCAL_MEM_FENCE); for(uint v = 0; v < total_v; v += ls) { if(idv >= v && idv < v + ls) Temp[idv % ls] += temp * (1 - pow(temp, 2.0f)) * inp; barrier(CLK_LOCAL_MEM_FENCE); } if(idv == 0) { temp = Temp[0]; for(int v = 1; v < ls; v++) temp += Temp[v]; weights_gradient[i + g * weights_step] = temp; } barrier(CLK_LOCAL_MEM_FENCE); } }
Здесь стоит обратить внимание, что в процессе выполнения операций основного цикла из нашего внимания выпали весовые коэффициенты байесовского смещения. Для вычисления соответствующих градиентов ошибки, мы организуем дополнительные операции по вышеприведенной схеме.
for(int i = id; i < 4 * hidden_size; i += total) { if(idv < ls) Temp[idv % ls] = 0; barrier(CLK_LOCAL_MEM_FENCE); float temp = concatenated_gradient[4 * shift_out + (i + 1) * hidden_size]; if(i < 3 * hidden_size) { for(uint v = 0; v < total_v; v += ls) { if(idv >= v && idv < v + ls) Temp[idv % ls] += temp * (1 - temp); barrier(CLK_LOCAL_MEM_FENCE); } } else { for(uint v = 0; v < total_v; v += ls) { if(idv >= v && idv < v + ls) Temp[idv % ls] += 1 - pow(temp, 2.0f); barrier(CLK_LOCAL_MEM_FENCE); } } if(idv == 0) { temp = Temp[0]; for(int v = 1; v < ls; v++) temp += Temp[v]; weights_gradient[(i + 1) * weights_step] = temp; } barrier(CLK_LOCAL_MEM_FENCE); } }
Здесь особое внимание стоит уделить точкам синхронизации потоков. Их количество должно быть минимально-достаточным для корректной работы алгоритма. Избыточные точки синхронизации потоков снизят скорость выполнения операций. А наличие точек синхронизации, в которые попадают не все потоки и вовсе приводит к "зависанию" программы.
На этом мы завершаем рассмотрение корректировок программы OpenCL для организации работы LSTM-блока в условиях независимых каналов. А с точечными правками на стороне основной программы я предлагаю вам ознакомиться самостоятельно. Полный код обновленного класса CNeuronLSTMOCL и всех его методов представлен во вложении.
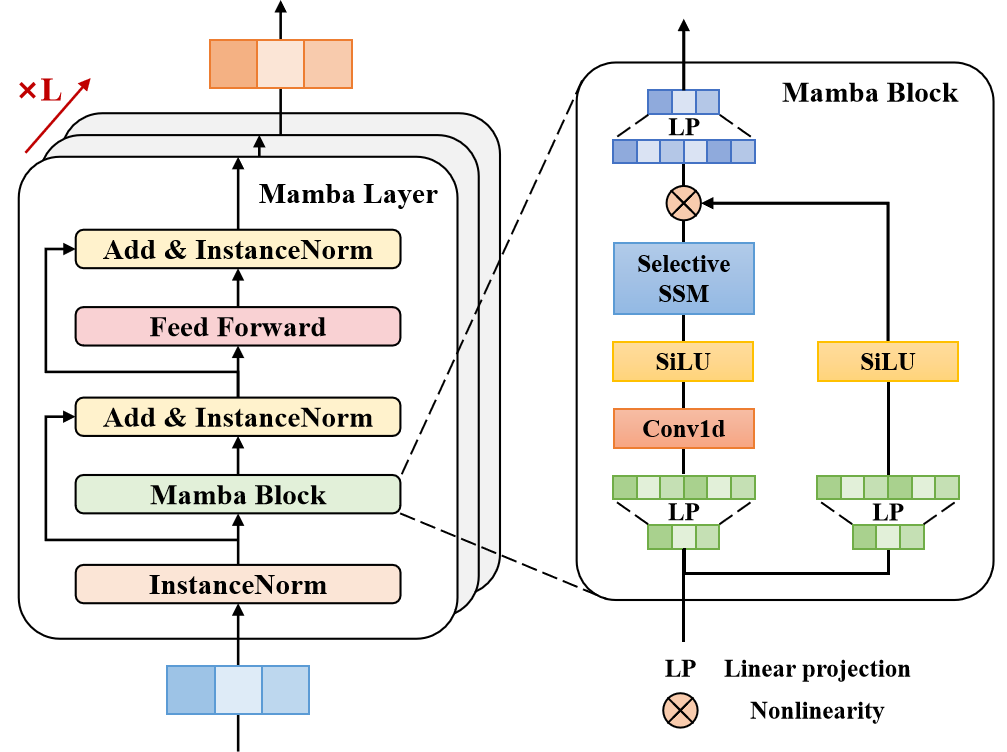
2.2 Построение блока Mamba
Следующим шагом нашей подготовительной работы является построение блока Mamba. Название блока не случайно созвучно с методом, рассмотренным нами в предыдущей статье. Авторы метода Traj-LLM расширяют использование моделей пространства состояний и предлагают архитектуру блока, которую можно сравнить с Энкодером Transformer. Только механизм Self-Attention заменяется архитектурой Mamba.
Для реализации предложенного алгоритма мы создадим новый класс CNeuronMambaBlockOCL, структура которого представлена ниже.
class CNeuronMambaBlockOCL : public CNeuronBaseOCL { protected: uint iWindow; CNeuronMambaOCL cMamba; CNeuronBaseOCL cMambaResidual; CNeuronConvOCL cFF[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- public: CNeuronMambaBlockOCL(void) {}; ~CNeuronMambaBlockOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMambaBlockOCL; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Базовый функционал мы унаследуем от класса полносвязного слоя CNeuronBaseOCL. При этом переопределим уже привычный список виртуальных методов.
В структуре нашего нового класса можно выделить внутренние объекты, с функционалом которых мы познакомимся в процессе реализации методов. Все объекты объявлены статично, что позволяет нам оставить "пустыми" конструктор и деструктор класса. А инициализация всех внутренних объектов и переменных осуществляется в методе Init.
Как уже было сказано выше, блок Mamba по своей архитектуре напоминает Энкодер Transformer. Сходство можно найти и в параметрах метода инициализации, которые дают однозначное представление об архитектуре инициализируемого блока.
bool CNeuronMambaBlockOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
В теле метода мы вызываем одноименный метод родительского класса, в котором уже организован минимально-необходимый блок контроля полученных параметров и инициализация всех унаследованных объектов.
После успешного выполнения метода инициализации родительского класса, мы сохраняем в локальную переменную размер окна анализа данных.
iWindow = window;
И переходим к инициализации объявленных внутренних объектов. Первым мы инициализируем слой пространства состояний Mamba.
if(!cMamba.Init(0, 0, OpenCL, window, window_key, units_count, optimization, iBatch)) return false;
За ним следует полносвязный слой, в буфер которого мы планируем сохранять нормализованное значения результатов селективного анализа пространства состояний с остаточной связью.
if(!cMambaResidual.Init(0, 1, OpenCL, window * units_count, optimization, iBatch)) return false; cMambaResidual.SetActivationFunction(None);
После чего мы добавим блок FeedForward.
if(!cFF[0].Init(0, 2, OpenCL, window, window, 4 * window, units_count, 1, optimization, iBatch)) return false; cFF[0].SetActivationFunction(LReLU); if(!cFF[1].Init(0, 2, OpenCL, 4 * window, 4 * window, window, units_count, 1, optimization, iBatch)) return false; cFF[1].SetActivationFunction(None);
И организуем подмену указателей на буфера данных с целью исключения излишних операций копирования.
SetActivationFunction(None); SetGradient(cFF[1].getGradient(), true); //--- return true; }
Обратите внимание, что здесь мы осуществляем подмену указателя только на буфер градиентов ошибки. Это связано с тем, что при прямом проходе перед передачей результатов на выход слоя будут организованы дополнительное остаточное соединение и нормализация полученных результатов.
Не забываем контролировать результат выполнения операций на каждом шаге. А в завершении метода мы возвращаем логический результат выполненных операций вызывающей программе.
После инициализации объекта класса, мы переходим к построению алгоритма прямого прохода, который реализован в методе feedForward. Надо сказать, что здесь все лаконично и просто.
bool CNeuronMambaBlockOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cMamba.FeedForward(NeuronOCL)) return false;
В параметрах метода мы, как обычно, получаем указатель на объект предшествующего слоя, который передает нам исходные данные. И в теле метода мы сразу передаем полученный указатель в селективную модель пространства состояния.
После успешного выполнения операций метода прямого прохода внутреннего слоя, мы осуществляем суммирование полученных результатов и исходных данных с последующей нормализацией значений.
if(!SumAndNormilize(cMamba.getOutput(), NeuronOCL.getOutput(), cMambaResidual.getOutput(), iWindow, true)) return false;
Далее идет прямой проход блока FeedForward.
if(!cFF[0].FeedForward(cMambaResidual.AsObject())) return false; if(!cFF[1].FeedForward(cFF[0].AsObject())) return false;
И организуем остаточное соединение с последующей нормализацией данных.
if(!SumAndNormilize(cMambaResidual.getOutput(), cFF[1].getOutput(), getOutput(), iWindow, true)) return false; //--- return true; }
Методы обратного прохода также не выделяются сложностью алгоритма, и я предлагаю их оставить для самостоятельного изучения. Напомню, что во вложении вы найдете полный код данного класса и всех его методов.
А мы на этом завершаем подготовительную работу и переходим к построению общего алгоритма метода Traj-LLM.
2.3 Собираем отдельные блоки в целостный алгоритм
Выше мы провели подготовительную работу и дополнили нашу библиотеку недостающими "кирпичиками", которыми воспользуемся для построения алгоритма Traj-LLM в раках класса CNeuronTrajLLMOCL. Структура нового класса представлена ниже.
class CNeuronTrajLLMOCL : public CNeuronBaseOCL { protected: //--- State Encoder CNeuronLSTMOCL cStateRNN; CNeuronConvOCL cStateMLP[2]; //--- Variables Encoder CNeuronTransposeOCL cTranspose; CNeuronLSTMOCL cVariablesRNN; CNeuronConvOCL cVariablesMLP[2]; //--- Context Encoder CNeuronLearnabledPE cStatePE; CNeuronLearnabledPE cVariablesPE; CNeuronMLMHAttentionMLKV cStateToState; CNeuronMLCrossAttentionMLKV cVariableToState; CNeuronMLCrossAttentionMLKV cStateToVariable; CNeuronBaseOCL cContext; CNeuronConvOCL cContextMLP[2]; //--- CNeuronMLMHAttentionMLKV cHighLevelInteraction; CNeuronMambaBlockOCL caMamba[3]; CNeuronMLCrossAttentionMLKV cLaneAware; CNeuronConvOCL caForecastMLP[2]; CNeuronTransposeOCL cTransposeOut; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- public: CNeuronTrajLLMOCL(void) {}; ~CNeuronTrajLLMOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint forecast, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronTrajLLMOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Как можно заметить, в структуре класса мы переопределяем те же виртуальные методы. Однако данный класс выделяется большим количеством внутренних объектов, что вполне ожидаемо для столь комплексной архитектуры. С назначением объявленных объектов мы познакомимся в процессе реализации методов нашего класса.
Все внутренние объекты класса мы объявили статично. Как следствие, конструктор и деструктор класса остались пустыми. Инициализацию всех объявленных объектов мы осуществляем в методе Init.
В параметрах метода мы получаем основные константы, которые будут использованы для инициализации вложенных объектов. Здесь мы видим уже знакомые нам наименования параметров. Однако стоит обратить внимание, что некоторые из них могут нести различный функционал для отдельных внутренних объектов.
bool CNeuronTrajLLMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint forecast, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * forecast, optimization_type, batch)) return false;
По уже сложившейся традиции, в теле метода мы первым делом вызываем одноименный метод родительского класса. Как вы знаете, в нем уже реализованы некоторые контроли полученных параметров и инициализация всех унаследованных объектов. И после успешного выполнения метода родительского класса мы переходим к инициализации объявленных внутренних объектов.
Исходя из опыта построения предыдущих моделей, мы предполагаем, что на вход модели подается матрица описания текущей рыночной ситуации. Каждая строка этой матрицы содержит ряд параметров описания отдельной рыночной свечи с соответствующими значениями анализируемых индикаторов.
Согласно алгоритму Traj-LLM полученные исходные данные вначале подаются на вход блока разреженного контекстного кодировщика, который включает кодировщик агентов и полос движения. В нашем случае это кодировщики состояний окружающей среды (данных отдельных баров) и исторических траекторий анализируемых параметров (индикаторов).
Кодировщик состояний мы построим из рекуррентного блока анализа отдельных баров и 2 последующих сверточных слоев, которые организуют работу MLP в рамках независимых каналов информации.
//--- State Encoder if(!cStateRNN.Init(0, 0, OpenCL, window_key, units_count, optimization, iBatch) || !cStateRNN.SetInputs(window)) return false; if(!cStateMLP[0].Init(0, 1, OpenCL, window_key, window_key, 4 * window_key, units_count, optimization, iBatch)) return false; cStateMLP[0].SetActivationFunction(LReLU); if(!cStateMLP[1].Init(0, 2, OpenCL, 4 * window_key, 4 * window_key, window_key, units_count, optimization, iBatch)) return false;
Кодировщик исторических траекторий анализируемых индикаторов имеет аналогичную архитектуру. Только на вход он получает транспонированный тензор исходных данных, что отражается на размере окна анализируемых данных и количестве независимых каналов.
//--- Variables Encoder if(!cTranspose.Init(0, 3, OpenCL, units_count, window, optimization, iBatch)) return false; if(!cVariablesRNN.Init(0, 4, OpenCL, window_key, window, optimization, iBatch) || !cVariablesRNN.SetInputs(units_count)) return false; if(!cVariablesMLP[0].Init(0, 5, OpenCL, window_key, window_key, 4 * window_key, window, optimization, iBatch)) return false; cVariablesMLP[0].SetActivationFunction(LReLU); if(!cVariablesMLP[1].Init(0, 6, OpenCL, 4 * window_key, 4 * window_key, window_key, window, optimization, iBatch)) return false;
Обратите внимание, что алгоритмом Traj-LLM далее предусматривается совместный анализ Агентов и Полос. Поэтому на выходе кодировщиков мы получаем векторы описания одного элемента последовательности (состояния окружающей среды или исторической траектории анализируемого индикатора) одинакового размера. При этом допускается различие в размерах последовательностей, так как количество анализируемых состояний окружающей среды далеко не всегда равно количеству анализируемых параметров описания таких состояний.
Следуя алгоритму Traj-LLM далее, результаты работы кодировщиков передаются в блок Fusion, где осуществляется всесторонний анализ взаимных зависимостей между отдельными элементами последовательностей с использованием алгоритмов Self-Attention и Cross-Attention. Однако мы знаем, что для повышения эффективности работы блоков внимания необходимо добавить к элементам последовательности метки позиционного кодирования. Для выполнения этого функционала мы добавим 2 слоя обучаемого позиционного кодирования.
//--- Position Encoder if(!cStatePE.Init(0, 7, OpenCL, cStateMLP[1].Neurons(), optimization, iBatch)) return false; if(!cVariablesPE.Init(0, 8, OpenCL, cVariablesMLP[1].Neurons(), optimization, iBatch)) return false;
И только затем мы осуществим анализ зависимостей между отдельными состояниями в блоке Self-Attention.
//--- Context if(!cStateToState.Init(0, 9, OpenCL, window_key, window_key, heads, heads / 2, units_count, 2, 1, optimization, iBatch)) return false;
А затем осуществим анализ перекрестных зависимостей в 2 последующих блоках кросс-внимания.
if(!cStateToVariable.Init(0, 10, OpenCL, window_key, window_key, heads, window_key, heads / 2, units_count, window, 2, 1, optimization, iBatch)) return false; if(!cVariableToState.Init(0, 11, OpenCL, window_key, window_key, heads, window_key, heads / 2, window, units_count, 2, 1, optimization, iBatch)) return false;
Обогащенные представления состояний и траекторий конкатенируются в единый тензор.
if(!cContext.Init(0, 12, OpenCL, window_key * (units_count + window), optimization, iBatch)) return false;
После чего данные проходят через ещё один MLP.
if(!cContextMLP[0].Init(0, 13, OpenCL, window_key, window_key, 4 * window_key, window + units_count, optimization, iBatch)) return false; cContextMLP[0].SetActivationFunction(LReLU); if(!cContextMLP[1].Init(0, 14, OpenCL, 4 * window_key, 4 * window_key, window_key, window + units_count, optimization, iBatch)) return false;
Далее идет блок высокоуровневого моделирования взаимодействия. Здесь авторы метода Traj-LLM используют предварительно обученную языковую модель, которую мы заменим блоком Transformer.
if(!cHighLevelInteraction.Init(0, 15, OpenCL, window_key, window_key, heads, heads / 2, window + units_count, 4, 2, optimization, iBatch)) return false;
Следующим идет когнитивный блок обучения вероятностей последующего движения с учетом существующих полос движения. Здесь мы используем 3 последовательных блока Mamba одинаковой архитектуры.
for(int i = 0; i < int(caMamba.Size()); i++) { if(!caMamba[i].Init(0, 16 + i, OpenCL, window_key, 2 * window_key, window + units_count, optimization, iBatch)) return false; }
Полученные значения сопоставляются с историческими траекториями в блоке кросс-внимания.
if(!cLaneAware.Init(0, 19, OpenCL, window_key, window_key, heads, window_key, heads / 2, window, window + units_count, 2, 1, optimization, iBatch)) return false;
И в завершении мы используем MLP для прогнозирования последующих траекторий независимых каналов данных.
if(!caForecastMLP[0].Init(0, 20, OpenCL, window_key, window_key, 4 * forecast, window, optimization, iBatch)) return false; caForecastMLP[0].SetActivationFunction(LReLU); if(!caForecastMLP[1].Init(0, 21, OpenCL, 4 * forecast, 4 * forecast, forecast, window, optimization, iBatch)) return false; caForecastMLP[1].SetActivationFunction(TANH); if(!cTransposeOut.Init(0, 22, OpenCL, window, forecast, optimization, iBatch)) return false;
Обратите внимание, что тензор прогнозных траекторий транспонируется для приведения информации в представление исходных данных.
SetOutput(cTransposeOut.getOutput(), true); SetGradient(cTransposeOut.getGradient(), true); SetActivationFunction((ENUM_ACTIVATION)caForecastMLP[1].Activation()); //--- return true; }
Мы так же используем подмену указателей на буфера данных с целью исключения излишних операций копирования. После чего возвращаем вызывающей программе логический результат выполненных операций метода.
После завершения работы над методом инициализации класса, мы переходим к построению алгоритма прямого прохода, который реализуем в методе feedForward.
bool CNeuronTrajLLMOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- State Encoder if(!cStateRNN.FeedForward(NeuronOCL)) return false; if(!cStateMLP[0].FeedForward(cStateRNN.AsObject())) return false; if(!cStateMLP[1].FeedForward(cStateMLP[0].AsObject())) return false;
В параметрах метода мы получаем указатель на объект с исходными данными, которые мы сразу проводим через блок кодирования состояний.
Затем транспонируем исходные данные и кодируем исторические траектории анализируемых параметров описания состояния окружающей среды.
//--- Variables Encoder if(!cTranspose.FeedForward(NeuronOCL)) return false; if(!cVariablesRNN.FeedForward(cTranspose.AsObject())) return false; if(!cVariablesMLP[0].FeedForward(cVariablesRNN.AsObject())) return false; if(!cVariablesMLP[1].FeedForward(cVariablesMLP[0].AsObject())) return false;
К полученным данным добавляем позиционное кодирование.
//--- Position Encoder if(!cStatePE.FeedForward(cStateMLP[1].AsObject())) return false; if(!cVariablesPE.FeedForward(cVariablesMLP[1].AsObject())) return false;
После чего обогащаем данные контекстом взаимозависимостей.
//--- Context if(!cStateToState.FeedForward(cStatePE.AsObject())) return false; if(!cStateToVariable.FeedForward(cStateToState.AsObject(), cVariablesPE.getOutput())) return false; if(!cVariableToState.FeedForward(cVariablesPE.AsObject(), cStateToVariable.getOutput())) return false;
Обогащенные данные конкатенируются в единый тензор.
if(!Concat(cStateToVariable.getOutput(), cVariableToState.getOutput(), cContext.getOutput(), cStateToVariable.Neurons(), cVariableToState.Neurons(), 1)) return false;
И обрабатываются MLP.
if(!cContextMLP[0].FeedForward(cContext.AsObject())) return false; if(!cContextMLP[1].FeedForward(cContextMLP[0].AsObject())) return false;
Далее идет блок анализа высокоуровневых зависимостей.
//--- Lane aware if(!cHighLevelInteraction.FeedForward(cContextMLP[1].AsObject())) return false;
И модель пространства состояний.
if(!caMamba[0].FeedForward(cHighLevelInteraction.AsObject())) return false; for(int i = 1; i < int(caMamba.Size()); i++) { if(!caMamba[i].FeedForward(caMamba[i - 1].AsObject())) return false; }
Сопоставим исторические траектории с результатами нашего анализа.
if(!cLaneAware.FeedForward(cVariablesPE.AsObject(), caMamba[caMamba.Size() - 1].getOutput())) return false;
И на основании полученных данных сделаем прогноз наиболее вероятного предстоящего изменения анализируемых параметров.
//--- Forecast if(!caForecastMLP[0].FeedForward(cLaneAware.AsObject())) return false; if(!caForecastMLP[1].FeedForward(caForecastMLP[0].AsObject())) return false;
После чего приведем прогнозные значения в представление исходных данных.
if(!cTransposeOut.FeedForward(caForecastMLP[1].AsObject())) return false; //--- return true; }
И вернем вызывающей программе логический результат выполнения операций метода.
Следующим этапом нашей работы является построение алгоритмов обратного прохода. Здесь нам предстоит реализовать распределение градиентов ошибки до всех объектов в соответствии с их влиянием на конечный результат и последующую корректировку обучающих параметров в сторону минимизации ошибки.
И если с обновлением параметров все довольно просто — обучаемые параметры содержатся только во вложенных объектах. И для организации процесса нам предстоит последовательно вызывать методы корректировки параметров вложенных объектов. То "запутанный клубок" распределения градиентов ошибки нам предстоит распутать.
Распределение градиентов ошибки осуществляется в полном соответствии с алгоритмом прямого прохода, но в обратном порядке. И здесь надо заметить, что не такой уж и "прямой" наш прямой проход. Прошу прощения за тавтологию. В алгоритме прямого прохода можно отследить несколько параллельных потоков информации. И нам предстоит собрать градиенты ошибок со всех этих потоков.
Алгоритм распределения градиентов ошибки мы построим в методе calcInputGradients. В параметрах метода мы получаем указатель на объект предыдущего слоя, в который нам предстоит передать градиент ошибки в соответствии с влиянием исходных данных на конечный результат работы модели. И в теле метода мы сразу проверяем актуальность полученного указателя, так как при отсутствии корректного указателя весь дальнейший процесс теряет смысл.
bool CNeuronTrajLLMOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Здесь надо напомнить, что на момент вызова данного метода градиент ошибки текущего слоя уже сохранен в его буфере градиентов. Он был записан туда в процессе выполнения аналогичного метода последующего слоя нашей модели. А благодаря организованной нами ранее подмене указателей на буферы данных, этот же градиент ошибки содержится в буфере нашего внутреннего слоя транспонирования результатов прогнозирования. И мы начинаем распределение градиента ошибки с проведения его через MLP прогнозирования предстоящего движения.
//--- Forecast if(!caForecastMLP[1].calcHiddenGradients(cTransposeOut.AsObject())) return false; if(!caForecastMLP[0].calcHiddenGradients(caForecastMLP[1].AsObject())) return false;
После чего передадим градиент ошибки на слой сопоставления исторического движения анализируемых параметров с результатами когнитивного анализа.
//--- Lane aware if(!cLaneAware.calcHiddenGradients(caForecastMLP[0].AsObject())) return false;
Заметьте, что блок кросс-внимания сопоставляет данные из 2 потоков информации. Следовательно, нам необходимо распределить градиент ошибки на 2 потока в соответствии с их влиянием на конечный результат.
if(!cVariablesPE.calcHiddenGradients(cLaneAware.AsObject(), caMamba[caMamba.Size() - 1].getOutput(), caMamba[caMamba.Size() - 1].getGradient(), (ENUM_ACTIVATION)caMamba[caMamba.Size() - 1].Activation())) return false;
Далее мы проведем градиент ошибки через модель пространства состояний.
for(int i = int(caMamba.Size()) - 2; i >= 0; i--) if(!caMamba[i].calcHiddenGradients(caMamba[i + 1].AsObject())) return false;
И блок анализа высокоуровневых зависимостей.
if(!cHighLevelInteraction.calcHiddenGradients(caMamba[0].AsObject())) return false;
Через MLP контекста мы опустим градиент ошибки на уровень ниже. До буфера конкатенированных данных состояний и траекторий.
if(!cContextMLP[1].calcHiddenGradients(cHighLevelInteraction.AsObject())) return false; if(!cContextMLP[0].calcHiddenGradients(cContextMLP[1].AsObject())) return false; if(!cContext.calcHiddenGradients(cContextMLP[0].AsObject())) return false;
А далее начинается самое интересное. И здесь надо быть особенно внимательными, чтобы ничего не упустить.
Нам предстоит разделить градиент конкатенированного буфера на 2 потока. В этом нет ничего сложного. Достаточно выполнить метод деконкатенации, указав соответствующие буферы данных. В данном случае это 2 слоя кросс-внимания: траекторий анализируемых переменных к состояниям окружающей среды и наоборот. Но дело в том, что следующим шагом мы будем проводить градиент ошибки через блок кросс-внимания траекторий к состояниям, который так же передаст градиент ошибки на уровень слоя кросс-внимания состояний к траекториям. Следовательно, чтобы на следующем шаге мы не потеряли часть информации, нам предстоит сохранить её в некоем вспомогательном буфере. Но в рамках данного класса у нас и без вспомогательных буферов создано довольно много объектов. И среди этих объектов многие только ожидают своей очереди. Воспользуемся ими для временного хранения информации. И градиент ошибки на уровне блока кросс-внимания состояний к траекториям сохраним в слой соответствующего позиционного кодирования.
if(!DeConcat(cStatePE.getGradient(), cVariableToState.getGradient(), cContext.getGradient(), cStateToVariable.Neurons(), cVariableToState.Neurons(), 1)) return false;
Более того, мы вспоминаем, что в буфере градиентов слоя позиционного кодирования траекторий уже хранится часть полезных градиентов ошибки. И чтобы не потерять данную информацию, мы перенесем её временно в буфер MLP соответствующего кодировщика.
if(!SumAndNormilize(cVariablesPE.getGradient(), cVariablesPE.getGradient(), cVariablesMLP[1].getGradient(), 1, false)) return false;
Теперь, когда мы побеспокоились о сохранности всей необходимой информации, мы выполняем распределение градиента ошибки через блок кросс-внимания траекторий к состояниям.
if(!cVariablesPE.calcHiddenGradients(cVariableToState.AsObject(), cStateToVariable.getOutput(), cStateToVariable.getGradient(), (ENUM_ACTIVATION)cStateToVariable.Activation())) return false;
Теперь мы можем суммировать градиент ошибки на уровне блока кросс-внимания состояний к траекториям из 2 потоков данных.
if(!SumAndNormilize(cStateToVariable.getGradient(), cStatePE.getGradient(), cStateToVariable.getGradient(), 1, false, 0, 0, 0, 1)) return false;
Однако, на следующем шаге нам вновь предстоит передать градиент ошибки на уровень позиционного кодирования траекторий уже в третий раз. Поэтому мы сначала суммируем уже имеющийся градиент ошибки из 2 потоков данных.
if(!SumAndNormilize(cVariablesPE.getGradient(), cVariablesMLP[1].getGradient(), cVariablesMLP[1].getGradient(), 1, false, 0, 0, 0, 1)) return false;
И только потом вызываем метод распределения градиента ошибки через блок кросс-внимания состояний к траекториям.
if(!cStateToState.calcHiddenGradients(cStateToVariable.AsObject(), cVariablesPE.getOutput(), cVariablesPE.getGradient(), (ENUM_ACTIVATION)cVariablesPE.Activation())) return false;
Теперь мы можем суммировать градиент ошибки на уровне слоя позиционного кодирования траекторий уже из 3 потоков информации.
if(!SumAndNormilize(cVariablesPE.getGradient(), cVariablesMLP[1].getGradient(), cVariablesPE.getGradient(), 1, false, 0, 0, 0, 1)) return false;
И опустим градиент ошибки до слоя позиционного кодирования состояний.
if(!cStatePE.calcHiddenGradients(cStateToState.AsObject())) return false;
Обратите внимание, что слои позиционного кодирования используются в 2 независимых параллельных потоках информации. И мы спускаем градиент ошибки до уровня соответствующих кодировщиков.
//--- Position Encoder if(!cStateMLP[1].calcHiddenGradients(cStatePE.AsObject())) return false; if(!cVariablesMLP[1].calcHiddenGradients(cVariablesPE.AsObject())) return false;
Следующим этапом нам предстоит провести градиент ошибки через 2 параллельных кодировщика, которые используют общий тензор исходных данных. Здесь мы опять сталкиваемся с необходимостью записи градиентов ошибки из 2 потоков информации в один буфер. Нам опять необходим вспомогательный буфер данных, который мы не создавали. И более того, на момент записи данных в буфер предыдущего слоя все наши внутренние объекты уже будут заполнены полезной информацией, которую мы не можем потерять.
Но есть один нюанс. Слой транспонирования данных, который мы используем для изменения порядка исходных данных перед кодированием траекторий, не содержит обучаемых параметров. И данные его буфера градиентов ошибки используются только в процессе передачи данных на уровень предыдущего слоя. Более того, размер указанного буфера нам идеально подходит, ведь нам необходимо сохранить те же данные, но в другой последовательности. Прекрасно. Выполняем проведение градиента ошибки через блок кодирования траекторий.
//--- Variables Encoder if(!cVariablesMLP[0].calcHiddenGradients(cVariablesMLP[1].AsObject())) return false; if(!cVariablesRNN.calcHiddenGradients(cVariablesMLP[0].AsObject())) return false; if(!cTranspose.calcHiddenGradients(cVariablesRNN.AsObject())) return false; if(!NeuronOCL.FeedForward(cTranspose.AsObject())) return false;
И переносим полученный градиент ошибки в буфер слоя транспонирования данных.
if(!SumAndNormilize(NeuronOCL.getGradient(), NeuronOCL.getGradient(), cTranspose.getGradient(), 1, false)) return false;
Аналогичным образом проводим градиент ошибки через блок кодирования состояний.
//--- State Encoder if(!cStateMLP[0].calcHiddenGradients(cStateMLP[1].AsObject())) return false; if(!cStateRNN.calcHiddenGradients(cStateMLP[0].AsObject())) return false; if(!NeuronOCL.calcHiddenGradients(cStateRNN.AsObject())) return false;
И суммируем градиенты ошибок из 2 потоков информации.
if(!SumAndNormilize(cTranspose.getGradient(), NeuronOCL.getGradient(), NeuronOCL.getGradient(), 1, false, 0, 0, 0, 1)) return false; //--- return true; }
И далее нам остается лишь вернуть логический результат выполнения операций метода вызывающей программе.
На этом мы завершаем рассмотрение алгоритмов организации работы класса CNeuronTrajLLMOCL. С полным кодом данного класса и всех его методов вы можете самостоятельно ознакомиться во вложении.
2.4 Архитектура моделей
После реализации алгоритмов нового класса нам предстоит лаконично добавить его в нашу модель для проведения анализа эффективности предложенных подходов на реальных исторических данных. Алгоритм Traj-LLM предложен для прогнозирования предстоящих траекторий. Подобные методы мы используем в Энкодере состояния окружающей среды.
Здесь стоит отметить, что свое видение практического использования предложенных подходов мы реализовали в рамках одного комплексного блока. Это позволяет нам сделать внешнюю архитектур модели максимально простой без потери её функциональности.
На вход модели мы, как обычно, подаем "сырые" необработанные данные описания текущей рыночной ситуации.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } //--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Первичная обработка данных осуществляется в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
После чего данные сразу передаются в наш новый блок Traj-LLM. Сложно назвать нейронным слоем столь комплексное архитектурное решение.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTrajLLMOCL; descr.window = BarDescr; //window descr.window_out = EmbeddingSize; //Inside Dimension descr.count = HistoryBars; //Units prev_count = descr.layers = NForecast; //Forecast descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
На выходе блока мы уже имеем прогнозные значения, к которым добавляем статистические параметры исходных значений.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
И согласовываем результаты в частотной области.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Архитектура прочих моделей осталась без изменений. Равно как и код всех используемых программ. С ними вы можете самостоятельно ознакомиться во вложении. Ну а мы переходим к заключительному этапу нашей работы.
3. Тестирование
Мы провели большую работу по имплементации подходов метода Traj-LLM средствами MQL5. И теперь пришло время посмотреть на практические результаты нашей работы. Нам предстоит обучить модели на реальных исторических данных и проверить их эффективность на данных, не входящих в обучающую выборку.
Как было сказано выше, изменение архитектуры модели не повлияло на структуру исходных данных и результатов её работы. Что позволяет нам использовать для предварительного обучения ранее собранные обучающие выборки.
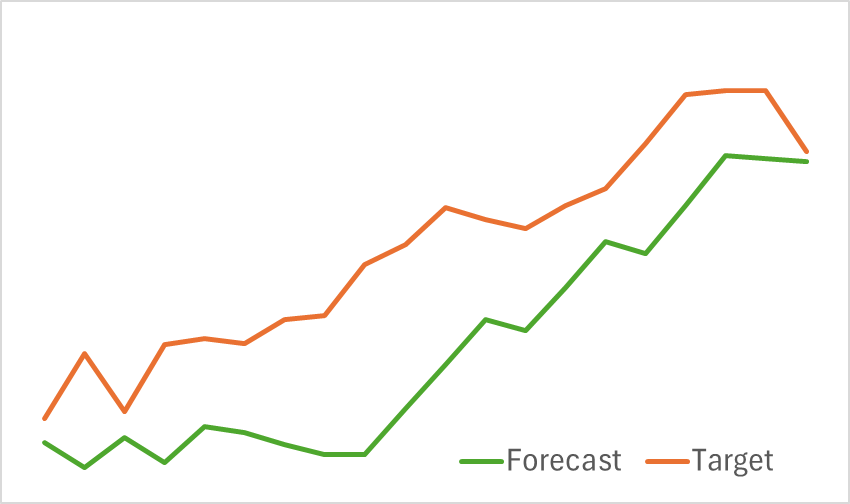
На первом этапе мы обучаем модель Энкодера состояния окружающей среды на предмет прогнозирования предстоящего ценового движения. Обучения осуществляется до практической фиксации ошибки прогнозирования на некотором уровне. При этом в процессе обучения модели мы не обновляем обучающую выборку. На данном этапе мы получили довольно неплохие результаты. Модель корректно определяет тенденции предстоящего ценового движения.
На втором этапе мы осуществляем итерационное обучение политики поведения Актера и функции вознаграждения Критика. Обучение модели Критика носит вспомогательный характер. Она используется только для корректировки действий Актера. Основная же наша цель — обучение прибыльной политики Актера. Тем не менее, для корректной оценки его действий в процессе обучения мы периодически осуществляем обновление обучающей выборки. После нескольких итераций обучения, нам удалось получить политику, способную генерировать прибыль на тестовой выборке.
Напомню, что обучение моделей осуществляется на исторических данных инструмента EURUSD за 2023 года, таймфрейм Н1. А тестирование на данных Января 2024 года с сохранением всех прочих параметров.
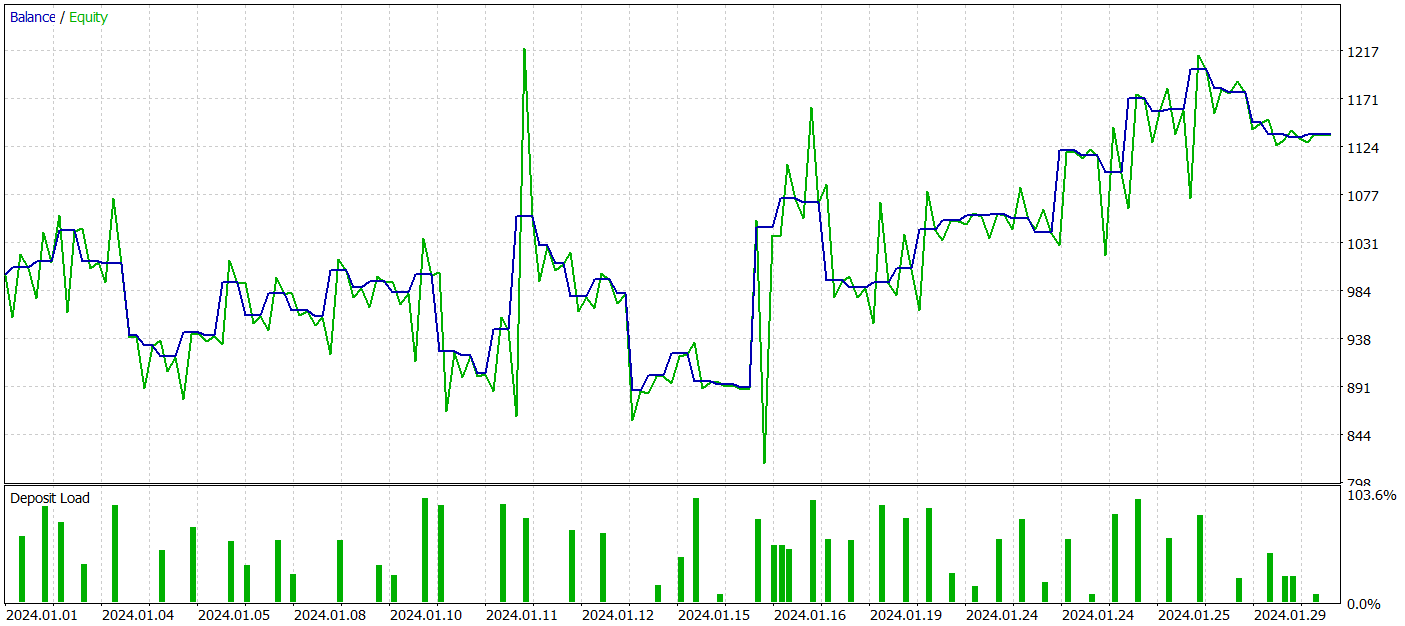
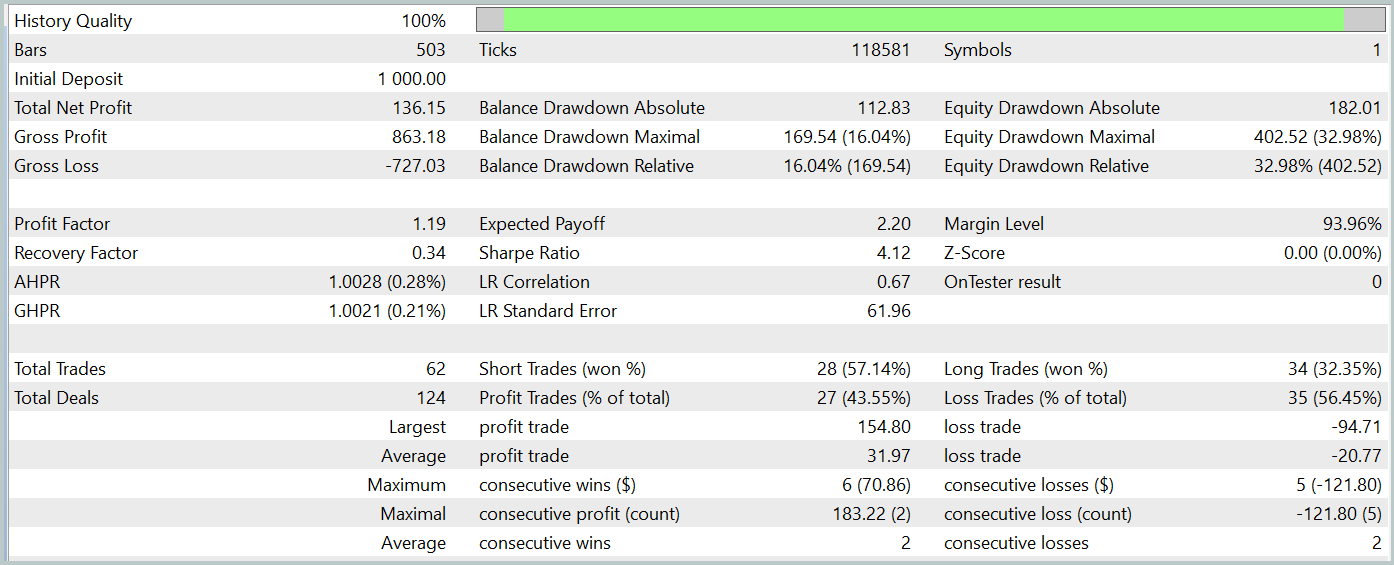
За период тестирования наша модель совершила 62 сделки и 27 из них (43.55%) были закрыты с прибылью. Однако благодаря тому, что максимальная и средняя прибыльная сделки более чем в половину превышают аналогичные показатели убыточных сделок, в целом за период тестирования была получена прибыль в размере 13.6%. А профит-фактор зафиксировался на отметке 1.19. Тем не менее вызывает беспокойство просадка по Эквити, которая достигает почти 33%. Очевидно, что в таком виде модель не может быть использована для реальной торговли и требует доработок.
Заключение
В данной статье мы познакомились с новым методом Traj-LLM, авторы которого предлагают новое видение использования больших языковых моделей. Он демонстрирует, как возможности LLM могут быть адаптированы для прогнозирования последующих значений различных временных рядов, обеспечивая более точное и адаптивное прогнозирование в условиях неопределенности и хаотичности.
В практической части данной статьи мы реализовали свое видение предложенных подходов и провели их тестирование на реальных исторических данных. Полученные результаты не идеальны, но носят многообещающий характер.
Ссылки
- Traj-LLM: A New Exploration for Empowering Trajectory Prediction with Pre-trained Large Language Models
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования