
Нейросети в трейдинге: Практические результаты метода TEMPO

Введение
В предыдущей статье мы познакомились с теоретическими аспектами метода TEMPO, который предлагает оригинальный подход использования предварительно обученных языковых моделей для решения задач прогнозирования временных рядов. Кратко напомню основные новшества предложенного алгоритма.
Метод TEMPO построен на использовании предварительно обученной языковой модели. В частности, авторы метода в своих экспериментах используют предварительно обученную GPT-2. И основная идея подхода лежит в использовании знаний модели, полученных при предварительном обучении для прогнозирования временных рядов. Здесь, конечно, стоит провести неочевидные параллели между речью и временным рядом. Ведь, по существу, наша речь — это временной ряд звуков, которые записываются с помощью букв. А различные интонации фиксируются знаками препинания.
Второй момент, большая языковая модель (Long Language Model — LLM), такая, как GPT-2, была предварительно обучена на большом наборе данных (часто на нескольких языках) и выучила большое количество различных зависимостей во временной последовательности слов, которые мы бы хотели использовать при прогнозировании временных рядов. Но последовательности букв и слов сильно отличаются от данных анализируемых временных рядов. А мы всегда говорили, что для корректности работы любой модели очень важно соблюдение распределения данных в обучающей и тестовой выборках. Тем более данных, анализируемых в процессе эксплуатации модели. И здесь надо вспомнить, что любая языковая модель не работает с привычным нам текстом в чистом виде. Сначала он проходит стадию эмбединга (кодирования), в ходе которого привычный нам текст преобразовывается в некий числовой код (скрытое состояние). С которым уже работает модель. На выходе модели генерируются вероятности последующего использования букв и знаков пунктуации. Из символов с наибольшей вероятностью формируется читаемый нами текст.
Этим свойством и воспользовались авторы метода TEMPO. В процессе обучения модели прогнозирования временных рядов они "замораживают" параметры языковой модели и оптимизируют параметры преобразования исходных данных в эмбединги, понятные используемой модели. Здесь авторы метода TEMPO предлагают комплексный подход, позволяющей предоставить модели максимум полезной информации. Вначале анализируемый временной ряд раскладывается на составляющие его компоненты: тренд, сезонность и прочее. Затем каждая компонента сегментируется и преобразовывается в эмбединги, понятные языковой модели. А чтобы направить языковую модель в нужном направлении (анализ трендов или сезонности), авторами метода разрабатывается система "мягких подсказок".
В целом, такой подход делает модель максимально интерпретируемой и позволяет судить о влиянии той или иной компоненты на результат прогнозирования последующих значений.
Авторская визуализация метода представлена ниже.
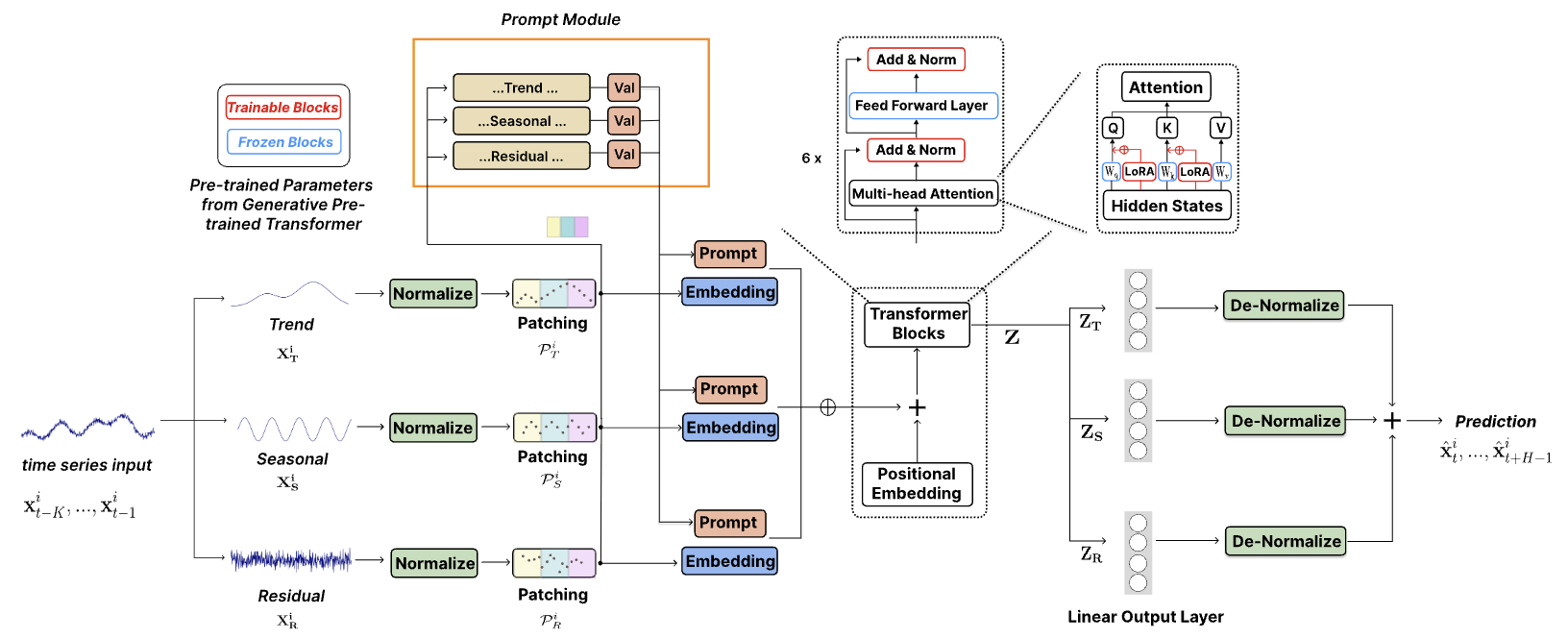
1. Архитектура моделей
Архитектура предложенной модели довольно комплексная. Она содержит целый ряд разветвлений и параллельных потоков данных, которые суммируются на выходе модели. Такой алгоритм довольно сложно реализовать в рамках используемой нами линейной модели. Поэтому мы провели большую работу по реализации всего алгоритма в рамках одного блока, который, по существу, является одним слоем нашей модели. Такая реализация, в кокой-то мере, ограничивает возможности пользователя экспериментировать с моделями различной сложности. Ведь вариативность структуры модуля ограничивается параметрами метода Init, созданного нами класса CNeuronTEMPOOCL. Но есть и другая сторона медали — мы максимально упрощаем процесс создания новой модели. Пользователю не обязательно погружаться во все тонкости архитектуры рассмотренного метода. Ему достаточно лишь указать несколько параметров для построения комплексной и мощной архитектуры. На мой взгляд это более приемлемый вариант для большинства пользователей.
И, конечно, стоит обратить внимание ещё на один довольно важный момент. Авторы метода в своих экспериментах использовали предварительно обученную языковую модель GPT-2. При реализации на Python такие модели можно найти. К примеру, в библиотеке Hugging Face. Но в нашем варианте реализации нет такой предварительно обученной модели. Поэтому мы заменили её блоком кросс-внимания. И будем обучать его вместе с моделью.
Метод TEMPO позиционируется авторами в качестве модели прогнозирования временных рядов. Следовательно, мы, как и ранее в подобных случаях, внедряем предложенные подходы в нашу модель Энкодера состояния окружающей среды. Архитектура данной модели представлена в методе CreateEncoderDescriptions.
В параметрах указанного метода мы передаем указатель на динамический массив, в элементы которого будут записаны архитектурные параметры нейронных слоев создаваемой модели.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В теле метода мы проверяем актуальность полученного указателя и, при необходимости, создаем новый экземпляр объекта.
Далее идет описание модели. И первым мы указываем полносвязный слой для записи исходных данных. Размер создаваемого слоя должен соответствовать размеру тензора исходных данных.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Напомню, что в модель мы передаем тензор не обработанных исходных данных в том виде, в котором получаем из терминала. И следующим шагом во всех наших предыдущих моделях мы использовали слой пакетной нормализации данных, в котором осуществлялась первичная обработка данных и приведение их в сопоставимый вид.
Однако в данном случае мы исключили слой пакетной нормализации. И причиной тому, как ни странно, послужила архитектура метода TEMPO. Как можно заметить на представленной выше визуализации метода, исходные данные сразу попадают в блок декомпозиции. В котором анализируемый временной ряд раскладывается на составляющие его 3 компоненты: тренд, сезонность и прочее. Разложение на компоненты осуществляется независимо для каждого унитарного временного ряда — анализируемого параметра мультимодального временного ряда. Сопоставимость значений в рамках отдельного унитарного ряда гарантируется природой происхождения значений.
Вначале из исходных данных извлекается трендовая составляющая. В нашей реализации эту операцию мы выполняем с помощью метода кусочно-линейного представления временного ряда. Как Вы знаете, алгоритм данного метода позволяет извлекать сопоставимы сегменты не зависимо от масштабирования и смещения распределения исходных данных, которое осуществляется в процессе нормализации.
На следующем мы берем исходные данные за вычетом трендовой составляющей и определяем компоненту сезонности. Для этого мы при помощи дискретного преобразования Фурье раскладываем сигнал на спектр частот, по амплитуде которых можно выделить наиболее значимые периодичные зависимости. Частотное разложение так же не чувствительно к масштабированию и смещению исходных данных.
А для определения третьей компоненты нам достаточно вычесть их исходных данных 2 выше найденные составляющие.
Думаю, здесь становится очевидно, что с точки зрения логики построения модели предварительная нормализация данных нам не даст дополнительных преимуществ. С другой стороны, нормализация данных потребует дополнительных вычислительных ресурсов, что само по себе уже не желательно.
Но посмотрите далее. Авторы метода вводят нормализацию выделенных компонент, которая, очевидно, важна для последующих операций с мультимодальными данными. Может мы могли изменить точку нормализации данных? Провести нормализацию исходных данных до разделения на компоненты и затем исключить последующую нормализацию данных отдельных компонент? Ведь очевидно, что объем исходных данных в 3 раза меньше суммарного объема 3 компонент. Моё мнение: скорее "нет", чем "да".
Для примера возьмем некий абстрактный график и выделим на нем основные тенденции. Очевидно, что трендовая составляющая "поглотит" больший объем информации.
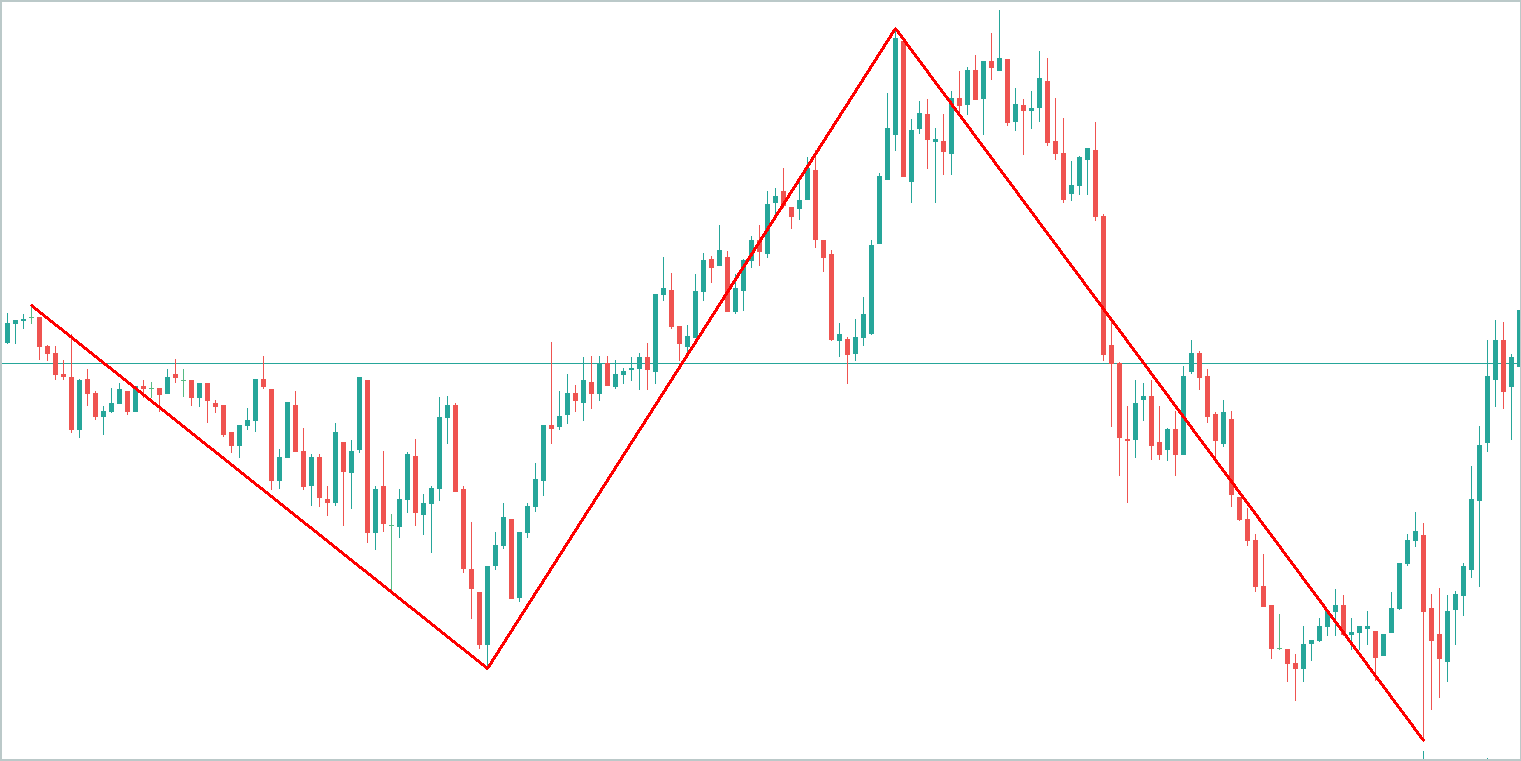
Сезонная составляющая представляет собой волновые колебания около линии тренда. Амплитуда её значений будет значительно ниже трендовой компоненты.
Третья компонента прочих значений получит ещё меньшую амплитуду значений, которые в большей степени представляют собой шум. Однако их нельзя игнорировать, ведь среди этого шума находят свое отражения новостной фон и прочие неучтенные факторы, которые носят несистемный характер.
Нормализация исходных данных до разделения сигналы на компоненты позволит решить вопрос сопоставимости данных отдельных унитарных рядов. Но она не способна решить проблему сопоставимости данных отдельных компонент, выделенных из анализируемого сигнала. Поэтому, для стабильности работы модели предпочтительнее последующая нормализация данных отдельных компонент.
Следуя выше представленным рассуждениям, мы исключаем слой пакетной нормализации исходных данных. Сразу за слоем исходных данных мы устанавливаем наш новый блок метода TEMPO.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTEMPOOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = NForecast;
Размер анализируемой мультимодальной последовательности, количество унитарных временных рядов в ней и горизонт планирования мы указываем через ранее заданные константы.
В рамках эксперимент при подготовке данной статьи я указал 4 головы внимания.
descr.window_out = 4;
И 4 вложенных слоя в блоке внимания.
descr.layers = 4;
Здесь я хочу напомнить, что данные параметры используются во 2 вложенных блоках внимания:
- блок внимания в частотной области, используемый для выявления зависимостей между частотными характеристиками отдельных унитарных последовательностей;
- блок кросс-внимания выявления зависимостей в последовательности временных рядов.
Далее мы указываем размер пакета нормализации и метод оптимизации модели.
descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
На этом можно было бы считать модель завершенной, так как на выходе блока CNeuronTEMPOOCL мы уже получаем желаемые прогнозные значения анализируемого временного ряда. Но мы добавим последний штрих в виде слоя согласования частотных характеристик прогнозного временного ряда CNeuronFreDFOCL.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
В результате мы получаем краткую и лаконичную архитектуру модели в виде 3 нейронных слоев. Однако под ней скрывается сложный комплексный алгоритм. Ведь мы знаем, что под "верхушкой айсберга" CNeuronTEMPOOCL скрывается 24 вложенных слоя, 12 из которых содержат обучаемые параметры. Более того, 2 из этих вложенных слоев являются блоками внимания, для которых мы указали создание четырехслойной архитектуры Self-Attention с 4 головами внимания в каждом. И это делает нашу модель поистине сложной и глубокой.
Полученные прогнозные значения предстоящего ценового движения мы будем использовать для обучения политики поведения Актера. Здесь мы во многом сохранили архитектуры из предыдущих статей, но ввиду сложности Энкодера состояния окружающей и ожидаемого повышения затрат на его обучение было принято решение о снижении числа вложенных слоев в блоках кросс-внимания моделей Актера и Критика. Напомню, что описание архитектуры указанных моделей представлено в методе CreateDescriptions, в параметрах которого мы передаем указатели на 2 динамических массива. В этих массивы мы и запишем описание архитектуры наших моделей.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
В теле метода мы проверяем актуальность полученных указателей и, при необходимости, создаем новые экземпляры объектов.
Первой мы описываем архитектуру Актера, на вход которого мы подаем тензор описания состояния счета.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Обратите внимание, что здесь мы говорим именно о состоянии счета, а не окружающей среды. Под понятие "состояние окружающей среды" мы подразумеваем параметры динамики ценового движения и анализируемых индикаторов. А в понятие "состояние счета" вкладываем текущее значение баланса счета, объем и направление открытых позиций, а так же накопленную на них прибыль или убыток.
Полученную на вход модели информацию мы преобразовываем в скрытое состояние с помощью базового полносвязного слоя.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
И далее мы используем блок кросс-внимания, в котором сопоставляем текущее состояние счета с прогнозным значением предстоящего ценового движения, полученного от Энкодера состояния окружающей среды.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLCrossAttentionMLKV; { int temp[] = {1, NForecast}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, BarDescr}; ArrayCopy(descr.windows, temp); } { int temp[] = {4, 2}; ArrayCopy(descr.heads, temp); } descr.layers = 4; descr.step = 1; descr.window_out = 32; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
И здесь следует обратить внимание на один момент — подпространство значений данных, получаемых от Энкодера состояния счета. Да, точно такой же подход мы использовали и ранее, но тогда нас это не смущало. Что же произошло?
А "дьявол кроется в деталях". Ранее на входе Энкодера состояния окружающей среды мы использовали слой пакетной нормализации для приведения исходных данных в сопоставимый вид. А на выходе модели с помощью слоя CNeuronRevINDenormOCL проводили обратную операцию, возвращая данные в исходное подпространство. Для целей Актера и Критика мы использовали скрытое значение прогнозных значений в сопоставимом виде до операций смещения и масштабирования в подпространства исходных данных. И в таком случае для последующего анализа мы получаем сопоставимые данные, с которыми привычно работает модель.
В случае же CNeuronTEMPOOCL мы отказались от предварительной нормализации исходных данных, что обсуждалось выше. Но теперь на выходе модели ожидается получение ненормализованных значений прогнозируемого ценового движения, что может усложнить работу Актера и Критика. И, как следствие, снизить их эффективность. Одним из вариантов решения является предварительная нормализация значений прогнозируемого временного ряда перед их последующим использованием. Наиболее простой способ это сделать — создать небольшую дополнительную модель предварительной обработки данных с одним слоем нормализации. Однако мы этого не сделали.
Я хочу напомнить Вам, что на выходе блока CNeuronTEMPOOCL вместо простого сложения прогнозных значений 3 компонент (тренд, сезонность и прочее) мы использовали сверточный слой без функции активации, который заменяет простое на взвешенное сложение полученных данных.
if(!cSum.Init(0, 24, OpenCL, 3, 3, 1, iVariables, iForecast, optimization, iBatch)) return false; cSum.SetActivationFunction(None);
А ограничение максимального значения параметров модели меньше 1 позволяет нам исключить заведомо большие значения на выходе модели.
#define MAX_WEIGHT 1.0e-3f
Конечно, такой подход заведомо ограничивает точность работы нашего Энкодера состояния окружающей среды. Ведь как сопоставить, к примеру, реальные показатели индикатора RSI (диапазон его значений от 0 до 100), с прогнозными результатами, абсолютное значение которых менее 1. В таком случае при использовании MSE в качестве функции потерь мы с большой вероятностью можем получить прогнозные значения на уровне максимально возможного. Именно по этому мы добавили на выходе Энкодера состояния окружающей среды блок частотного согласования результатов CNeuronFreDFOCL, который менее чувствителен к масштабированию данных. И позволит нам выучить структуру предстоящего ценового движение, которая в данном случае более важна, чем абсолютные значения.
Здесь я должен согласиться, что предложенное решение не очевидно и в какой-то мере может быть сложно для понимания. А его эффективность мы оценим на практических результатах наших моделей.
Но вернемся к архитектуре нашего Актера. После блока кросс-внимания для принятия решения мы используем перцептрон из 3 полносвязных слоев.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
На выходе которого добавляем стохастичности политике нашего Актера.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
И согласуем частотные характеристики принятого решения.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Архитектура Критика практически полностью повторяет представленную выше архитектуру построения Актера. Есть лишь точечные отличия. В частности, на вход модели мы подаем не состояние счета, а тензор действий Актера.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
А на выходе модели мы не используем стохастичность, давая четкую оценку предложенных действий.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NRewards; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
Ну а с полным кодом архитектурного решения всех используемых моделей Вы можете ознакомиться самостоятельно во вложении.
2. Обучение моделей
Как можно заметить из представленного выше описания архитектурного решения обучаемых моделей, внедрение подходов рассмотренного метода TEMPO не внесло изменений в структуру исходных данных или результатов обучаемых моделей. Поэтому мы можем смело использовать собранные ранее обучающие выборки для первичного обучения моделей. Более того, мы можем собирать данные в обучающую выборку, обучать модели и обновлять обучающую выборку с помощью ранее созданных программ взаимодействия с окружающей средой и обучения моделей.
Напомню, что для взаимодействия с окружающей средой и сбора данных обучающей выборки мы используем 2 программы:
- "...\Experts\TEMPO\ResearchRealORL.mq5" — используется для сбора данных по набору истории реальных сделок. Метод подробно описан в статье по ссылке.
- "...\Experts\TEMPO\Research.mq5" — советник в большей мере предназначен для анализа результативности предварительно обученной политики и обновления данных обучающей выборки в некотором окружении текущей политики. Что в последующем позволяет проводить более тонкую настройку политики Актера на основании реальных вознаграждений за его действия. Тем не менее, данный советник может быть использован и для сбора первичного набора обучающих данных на основе политики поведения Актера, инициализированной случайными параметрами.
Независимо от наличия у нас ранее собранных данных взаимодействия с окружающей средой мы можем запустить в тестере стратегий MetaTrader 5 любой из указанных выше советников для создания новой или обновления существующей обучающей выборки.
Собранные данные обучающей выборки вначале используются для обучения модели Энкодера состояния окружающей среды на предмет прогнозирования последующего ценового движения. Для этого мы запускаем в режиме реального времени в MetaTrader 5 советник "...\Experts\TEMPO\StudyEncoder.mq5".
Здесь надо сказать, что в процессе обучения Энкодер состояния окружающей среды работает только параметрами динамики ценового движения и анализируемых индикаторов, на которые не оказывают влияние действия Агента. Поэтому, все проходы в обучающей выборке на одном историческом отрезке для модели являются идентичными. И в процессе обучения Энкодера обновление обучающей выборки не даст дополнительной информации. Следовательно, мы запасаемся терпением и обучаем модель до получения желаемых результатов.
Еще раз хочу напомнить, что в связи с особенностями нашего архитектурного решения, которые были обсуждены выше, на данном этапе мы не ждем "низких" значений ошибки. Но все же добиваемся минимально возможных результатов. И останавливаем процесс обучения модели, когда ошибка прогнозирования стабилизируется в узком диапазоне.
На втором этапе у нас осуществляется итерационное обучение моделей Актера и Критика. На данном этапе мы используем советник "...\Experts\TEMPO\Study.mq5", который так же запускается в режиме реального времени. На этот раз мы "замораживаем" параметры Энкодера состояния окружающей среды и осуществляем параллельное обучение 2 моделей (Актера и Критика).
Критик на данных обучающей выборки учит функцию вознаграждения окружающей среды, сопоставляя прогнозное состояние среды и действия Агента из обучающей выборки в попытке спрогнозировать вознаграждение от окружающей среды. Данный этап соответствует принципам обучения с учителем, так как реальное вознаграждение за совершенные действия у нас сохранены в обучающей выборке.
Затем Актер, по "подсказкам" Критика, оптимизирует свою политику в попытке максимизировать общую доходность.
Данный процесс носит итерационный характер, так как в процессе обучения подпространство действий Актера смещается. И нам необходимо актуализировать обучающую выборку с целью получения реальных вознаграждений в новом подпространстве действий. Это позволит Критику скорректировать функцию вознаграждения и дать более корректную оценку действий Актера. Что, в свою очередь, позволит скорректировать политику Актера в нужном направлении.
Для целей обновления обучающей выборки мы повторно запускаем процесс медленной оптимизации советника "...\Experts\TEMPO\Research.mq5".
На данном этапе может возникнуть вопрос о целесообразность обучения Энкодера состояния счета отдельно от других моделей. С одной стороны, предварительно обученный Энкодер состояния счета дает нам наиболее вероятное последующее движение рынка. И таким образом выступает в роли цифрового фильтра, снижая шум, присущий исходным данным. В то же время, мы используем горизонт планирования значительно ниже глубины анализируемой истории. Таким образом, Энкодер ещё и сжимает данные для последующего анализа. Что в целом, потенциально, повышает эффективность работы Актера и Критика.
С другой стороны, насколько нам нужен именно прогноз предстоящего ценового движения. Ведь мы не раз говорили, что для нас более важно четкая интерпретация текущего состояния, позволяющая с максимальной точностью выбрать оптимальное действие Агента. Для ответа на этот вопрос мы создали ещё один советник обучения моделей "...\Experts\TEMPO\Study2.mq5". Данная программа была создана на базе советника "...\Experts\TEMPO\Study.mq5". Поэтому мы рассмотрим лишь метод непосредственного обучения моделей Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false;
В теле метода мы сначала генерируем вектор вероятностей выбора траекторий из буфера воспроизведения опыта на основе суммарной доходности проходов. После чего инициализируем необходимые локальные переменные.
На этом мы завершаем подготовительную работу и организовываем цикл непосредственного обучения моделей.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter --; continue; } state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum() == 0) { iter --; continue; }
В теле цикла мы сэмплируем одну траекторию из буфера воспроизведения опыта и случайным образом выбираем на ней состояние окружающей среды.
Описание выбранного состояния окружающей среды из обучающей выборки мы переносим в буфер данных и осуществляем прямой проход Энкодера состояния окружающей среды.
bState.AssignArray(state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Затем мы берем из буфера воспроизведения опыта действия Агента, совершенные в выбранном состоянии при взаимодействии с окружающей средой, и осуществляем их оценку Критиком.
//--- Critic bActions.AssignArray(Buffer[tr].States[i].action); if(bActions.GetIndex() >= 0) bActions.BufferWrite(); Critic.TrainMode(true); if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Заметьте, что в буфере воспроизведения опыта есть фактическая оценка данных действий и мы можем скорректировать функцию вознаграждения выученную, Критиком в сторону минимизации ошибки. Для этого мы извлекаем из буфера воспроизведения опыта фактически полученное вознаграждение и осуществляем обратный проход Критика.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
На этом этапе мы добавим обратный проход Энкодера состояния окружающей среды, чтобы обратить внимание модели на реперные точки, позволяющее дать более точные оценки действий.
Следующим этапом мы корректируем политику Актера. Сначала мы подготовим из буфера воспроизведения опыта описание состояния счета, соответствующее выбранному ранее состоянию окружающей среды.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
И осуществим прямой проход Актера для генерации вектора действий с учетом текущей политики.
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
После чего мы отключим режим обучения Критика и проведем оценку действий, сгенерированных Актером.
Critic.TrainMode(false); if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Корректировать политику Актера мы будем в 2 этапа. Вначале мы проверим результативность текущего прохода. Если в процессе взаимодействия с окружающей средой данный проход оказался прибыльным, то мы скорректируем политику действий Актера в сторону действий, сохраненных в буфере воспроизведения опыта.
if(Buffer[tr].States[0].rewards[0] > 0) if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder), LatentLayer) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
При этом мы так же скорректируем параметры Энкодера состояния окружающей среды с целью выделить точки исходных данных, влияющие на эффективность политики Актера.
На втором этапе обучения политики Актера мы предложим Критику указать направление корректировки действий агента для повышения доходности / снижения убыточности на 1%. Для этого мы возьмем текущую оценку действий Актера и улучшим её на 1%.
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); }
Полученный результат мы будем использовать в качестве эталонного для обратного прохода Критика. Напомню, что на данном этапе мы отключили процесс обучения Критика. Поэтому при осуществлении обратного прохода его параметры не будут корректироваться. Зато Актер получит градиент ошибки. И мы сможем скорректировать параметры Актера в сторону повышения эффективности его политики.
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), LatentLayer, -1, true) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Далее нам остается лишь проинформировать пользователя о ходе обучения моделей и перейти к следующей итерации цикла.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После завершения процесса обучения мы очищаем поле комментариев на графике инструмента.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Выводим в журнал терминала результаты обучения моделей и инициализируем процесс завершения работы программы.
С полным кодом данного советника, как и всех программ, используемых при подготовке данной статьи, Вы можете ознакомиться во вложении.
3. Тестирование
После проведенной работы мы пришли к кульминационному моменту, практической оценке результатов обученных моделей.
Напомню, что модели были обучены на исторических данных за весь 2023 год инструмента EURUDS таймфрейм H1. Параметры всех анализируемых индикаторов используются по умолчанию.
Тестирование обученных моделей осуществляется на исторических данных Января 2024 года с сохранением всех прочих параметрах. Таким образом мы достигаем максимального приближения к условиям реальной эксплуатации моделей.
На первом этапе мы обучили модель Энкодера состояния окружающей среды. Ниже представлен график визуализации фактического и прогнозного ценового движения на 24 часа с шагом прогноза в 1 шаг. Что соответствует последующим суткам на таймфрейме H1. Именно данные этого таймфрейма мы использовали для анализа.
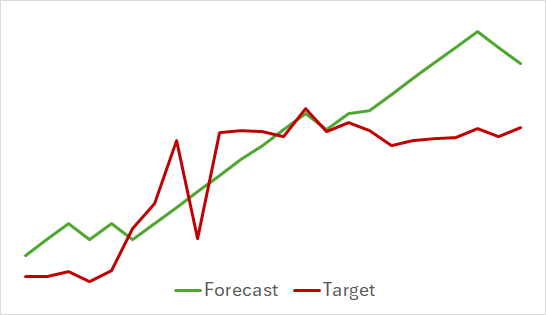
На представленном графике можно отметить, что полученный прогноз в целом уловил главное направление предстоящего движения. Можно даже отметить совпадение по времени и направлению некоторых локальных экстремумов. При этом график прогнозного движения более ровный и больше напоминает линии тренда, нанесенные на график ценового движения инструмента.
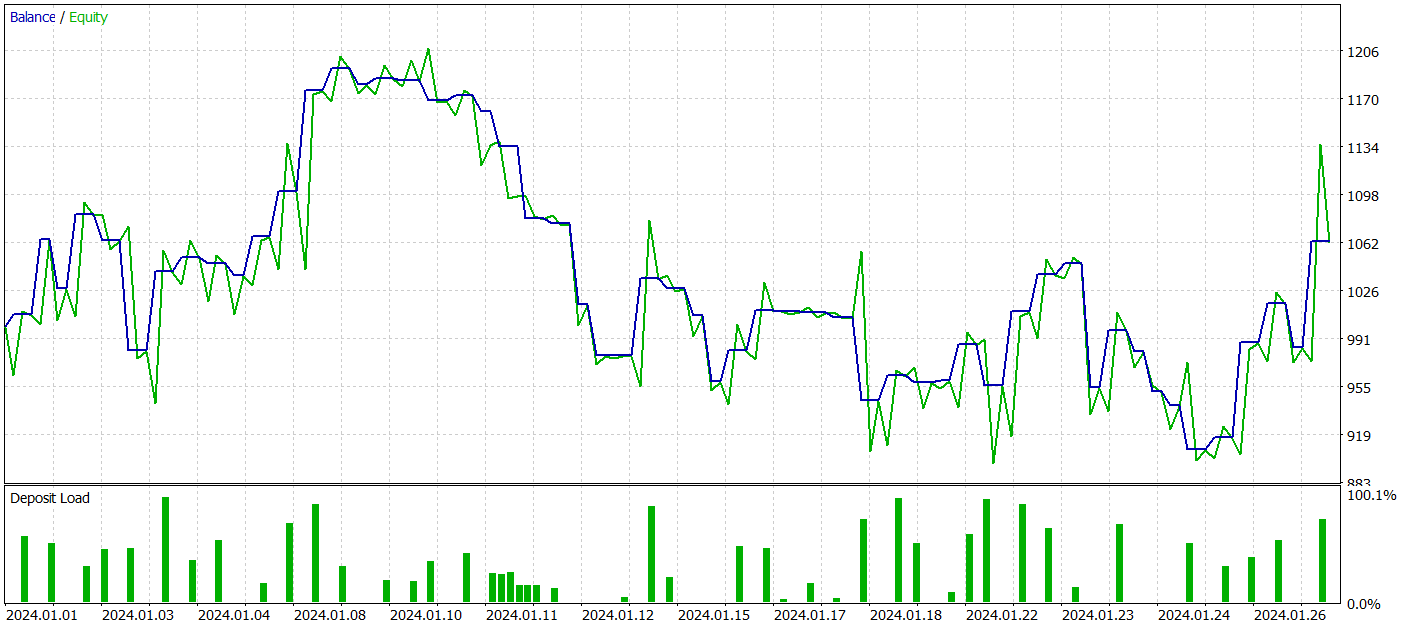
На втором этапе мы обучили модели Актера и Критика. Мы не будем смотреть на качество оценки действий Критиком. Ведь его основная задача направить обучение политики Актера в нужном русле. Посмотрим на доходность выученной политики Актера на тестовом временном интервале. Результаты действий Актера в тестере стратегий представлены ниже.
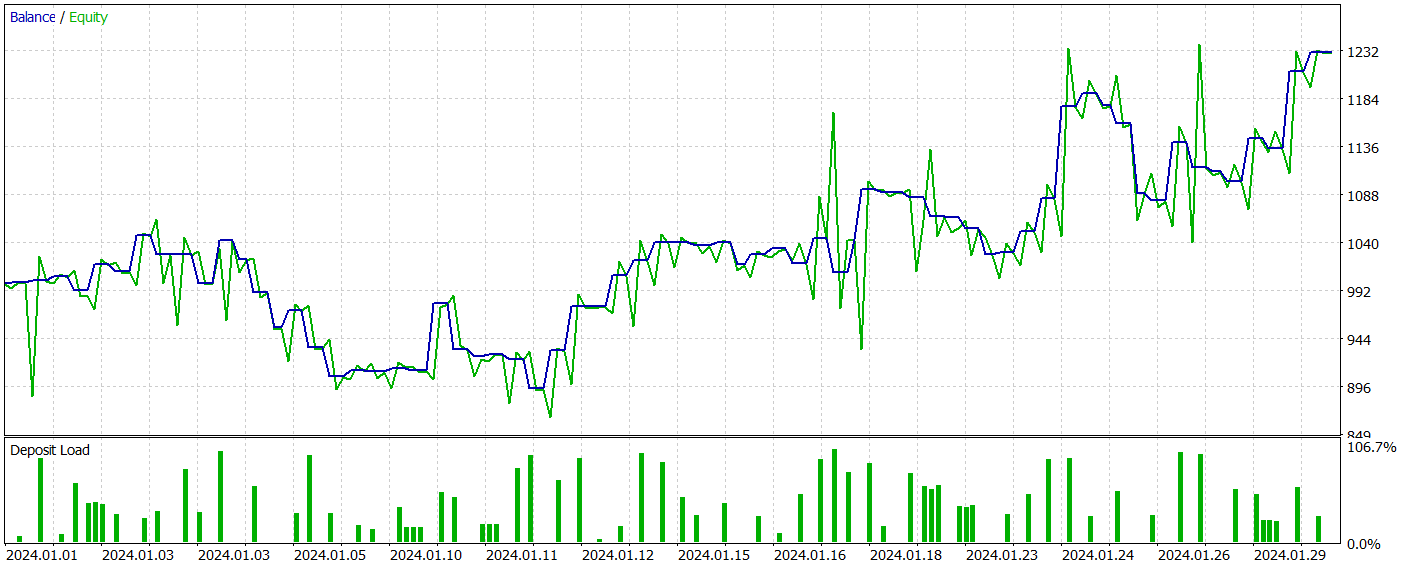
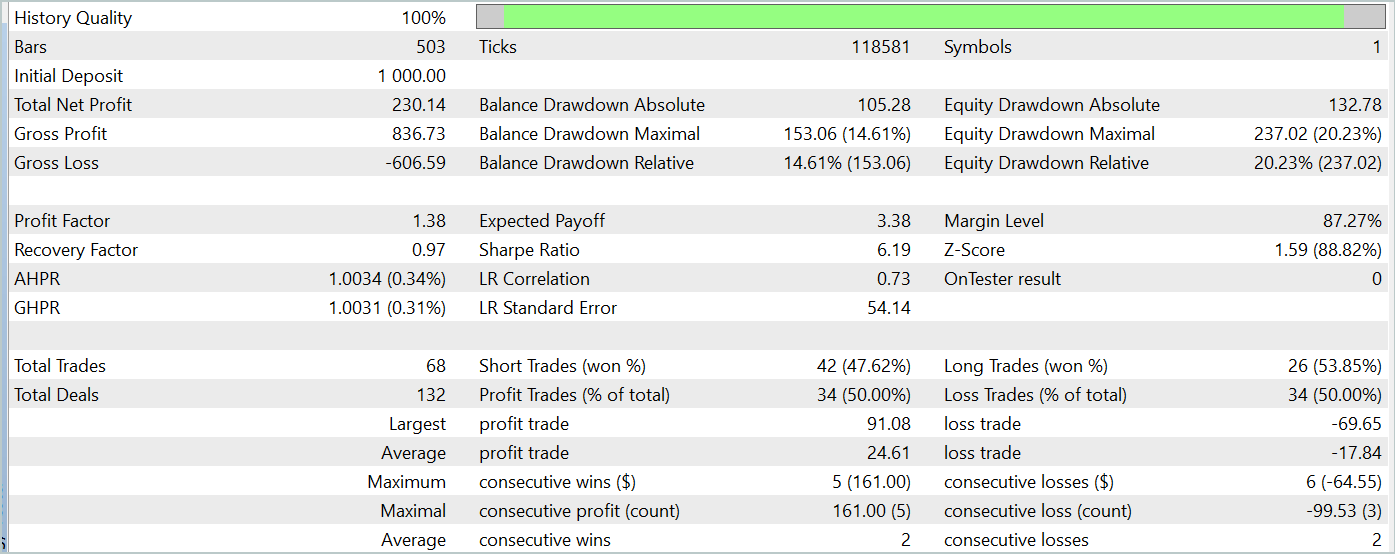
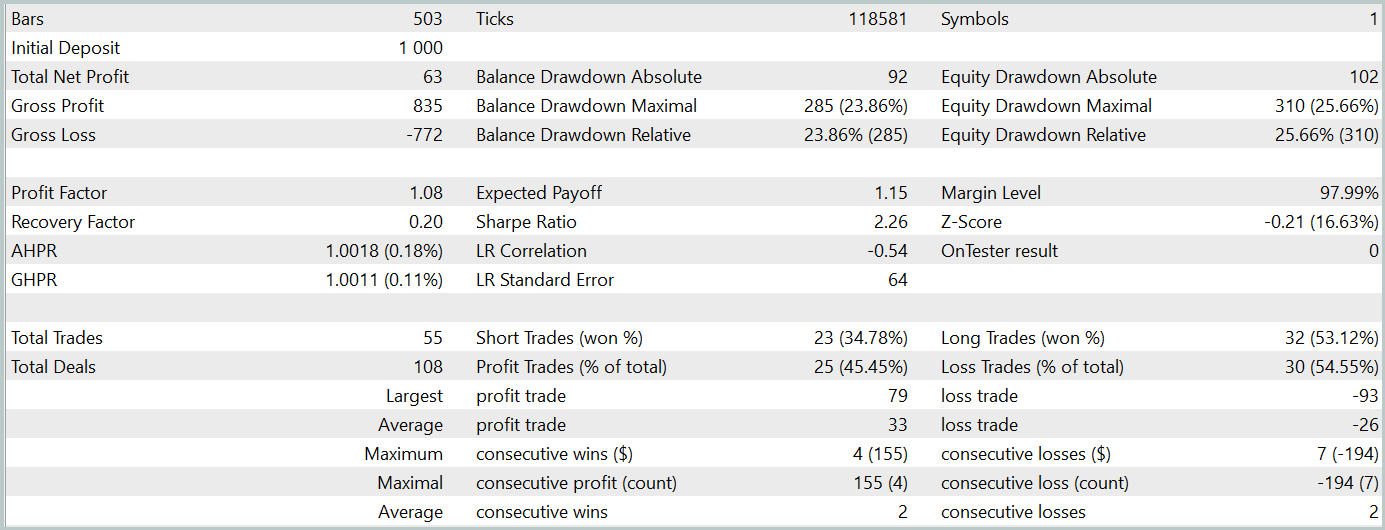
За период тестирования (Январь 2024 года) Актер совершил 68 сделок. Половина из которых была закрыта с прибылью. И благодаря тому, что как максимальная, так и средняя прибыльная сделка превышали соответствующие убыточные показатели (91.08 и 24.61 против -69.85 и -17.84 соответственно) модель достигла прибыль 23%.
Однако на графике баланса можно заметить значительные пики эквити как выше, так и ниже линии баланса. Первая мысль о "пересиживании убытков" и позднем выходе из позиции. Но если обратить внимание, что в такие моменты загрузка депозита близка к 100%, то можно уже задуматься и о завышенных рисках. Об этом же свидетельствует максимальная просадка по эквити более 20%.
Следующим этапом мы провели дообучение политики Актера с корректировкой параметров Энкодера состояния окружающей среды. Здесь стоит отметить, что дообучение проводилось без обновления обучающей выборки. Иными словами, база обучения осталась прежней. Однако такое обучение оказала негативный эффект. Эффективность модели снизилась. Количество совершенных сделок стало меньше. И доля прибыльных уменьшилась до 45%. Общая доходность модели уменьшилась, а просадка по эквити превысила 25%.
Примечательно, что изменилось и качество прогнозов предстоящих траекторий ценового движения.
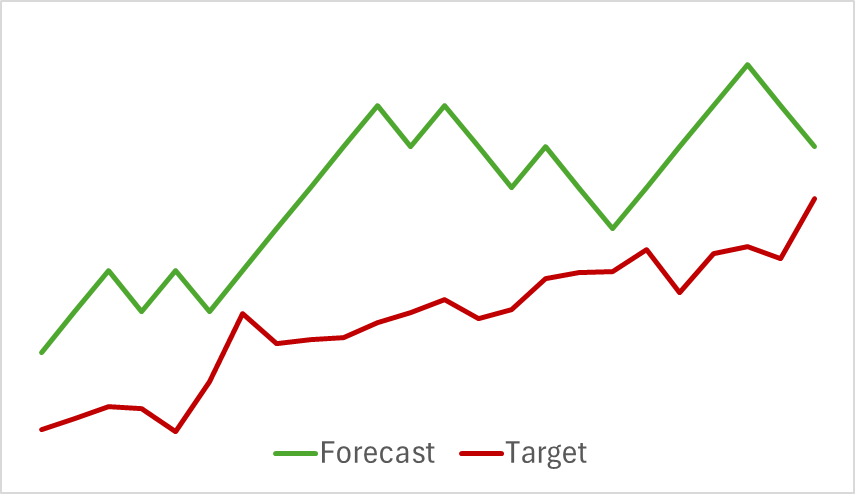
Мое мнение, что, когда мы начинаем оптимизировать параметры Энкодера состояния окружающей среды под цели Актера и Критика, тем самым мы добавляем шум на выходе Энкодера. Ведь если в процессе обучения модели прогнозирования предстоящего движения мы имели четкое соответствие исходных данных и результатов. А в процессе обучения модель учила и обобщала эти закономерности. То градиент ошибки, полученный от Актера и Критика, добавляет разнонаправленный шум, когда модель пытается минимизировать свою погрешность за счет исходных данных, полученных от Энкодера состояния окружающей среды. В результате Энкодер уже не выполняет роль фильтра исходных данных, и мы получаем снижение эффективности моделей по всем направлениям.
Заключение
Мы познакомились с интересным и комплексным методом прогнозирования временных рядов TEMPO, авторы которого предложили использовать предварительно обученные языковые модели для решения задач прогнозирования временных рядов. В предложенном алгоритме реализован новый подход в декомпозиции временных рядов, который позволяет повысить эффективность обучения представления исходных данных.
Мы провели серьезную работу про реализации предложенных подходов средствами MQL5. И несмотря на то, что в нашем распоряжении не было предварительно обученной языковой модели, в ходе экспериментов были получены довольно интересные результаты.
В целом, предложенные подходя могут быть использованы при построении реальных торговых моделей. Но нужно быть готовым, что обучение моделей, использующих архитектуру Transformer, требует предварительный сбор значительных объемов данных и может быть затратным в процессе обучения.
Ссылки
- TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
| 9 | Study2.mq5 | Советник | Советник обучения моделей Актера и Критика с корректировкой параметров Энкодера |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Отношение к пользователям
Ясно
Только к тем, кто думает, что автор ему что-то должен...
Аферист тоже никому ничего не должен.
Но люди почему-то ведутся на него.
Если бы в статьях не было бы триггеров и откровенной мотивации по типу «...модель способна генерировать прибыль», то наздоровье. Наши проблемы.
А когда манипулируют непротестированной инфой - это не совсем наши проблемы.
Учитывая, что первого пользователя забанили за критику, я тоже закончу по добру по здорову. Можете парировать контраргументами, оставлю лучше без ответа.
...Если бы в статьях не было бы триггеров и откровенной мотивации по типу «...модель способна генерировать прибыль», то наздоровье. Наши проблемы.
А когда манипулируют непротестированной инфой - это не совсем наши проблемы...
Я под какой-то статьёй Дмитрия в коментах просил его написать статью конкретно про обучение его советников. Чтобы он взял любую свою модель из любой статьи и полностью объяснил в статье как он её учит. Вот с нуля и до результата, подробно, со всеми нюансами. На что смотреть, в какой последовательности учит, сколько раз, на каком оборудовании, что делает если не учится, на какие ошибки смотрит. Вот максимально подробно про обучение в стиле "для чайников". Но Дмитрий почему-то проигнорировал или не заметил эту просьбу и статьи такой до сих пор так и не написал. Я думаю много народу ему за это будет благодарно.
Дмитрий напиши такую статью пожалуйста.
Есть же книга от Дмитрия - Встречайте книгу «Нейросети в алготрейдинге на MQL5»