
Возможности Мастера MQL5, которые вам нужно знать (Часть 20): Символьная регрессия
Введение
Мы продолжаем серию статей, в которых рассматриваем алгоритмы, которые можно быстро реализовать, протестировать и, возможно, даже запустить, благодаря Мастеру MQL5, содержащему не только библиотеку стандартных торговых функций и классов, но и альтернативные торговые сигналы и методы, которые можно использовать параллельно с любой реализацией пользовательского класса.
Символьная регрессия - вариант регрессионного анализа, который начинается с более "чистого листа" по сравнению со стандартной регрессией. Лучшим способом проиллюстрировать это будет рассмотрение типичной задачи регрессии, которая заключается в поиске наклона и пересечения с осью Y линии, которая наилучшим образом соответствует набору точек данных.

y = mx + c
где:
- y — прогнозируемое и зависимое значение
- m — наклон линии наилучшего соответствия
- c - точка пересечения оси Y
- x — независимая переменная
В приведенной выше задаче предполагается, что точки данных в идеале должны располагаться на прямой линии, поэтому решение(я) ищутся для пересечения оси Y и наклона. В качестве альтернативы нейронные сети, по сути, также стремятся найти волнистую линию или квадратное уравнение, которое наилучшим образом отображает 2 набора данных (то есть модель), предполагая сеть с предустановленной архитектурой (количество слоев, размеры слоев, типы активации и т.д.). Эти и другие подобные подходы изначально имеют указанную предвзятость, и есть случаи, когда она оправданна (например, в глубоком обучении), однако символьная регрессия позволяет построить описательную модель, которая сопоставляет два набора данных, в виде дерева выражений, начиная со случайно назначенных узлов.
Теоретически этот подход может оказаться эффективным для выявления сложных рыночных взаимоотношений, которые можно было бы скрыть с помощью обычных средств. Символьная регрессия (Symbolic Regression, SR) имеет ряд преимуществ по сравнению с традиционными подходами. Она более адаптируема к новым рыночным данным и меняющимся условиям, поскольку каждый анализ начинается без предвзятости, с использованием случайного распределения узлов дерева выражений, которые затем оптимизируются. Кроме того, SR может использовать несколько источников данных, в отличие от линейной регрессии, которая предполагает, что на значение y влияет одна переменная x. Такая гибкость позволяет SR выдавать более точные и комплексные модели для сложных сценариев обработки данных. Адаптивность предполагает, что больше переменных, помимо единственного x, собираются в дереве выражения, которое лучше определяет значение y. Это более гибкий подход, поскольку дерево выражения осуществляет больший контроль над обучающими данными, разрабатывая систематические узлы, которые обрабатывают данные в заданной последовательности с определенными коэффициентами, что позволяет ему фиксировать более сложные взаимосвязи, в отличие, скажем, от линейной регрессии (как указано выше), где фиксировались бы только линейные взаимосвязи. Даже если y зависел исключительно от x, эта связь может быть не линейной, а квадратичной, и SR позволяет установить это с помощью генетической оптимизации. Наконец, она снимает завесу тайны со связи модели черного ящика между изучаемыми наборами данных, вводя объясняемость (explainability), поскольку построенные деревья выражений по своей сути "объясняют" более точно, как входные данные фактически сопоставляются с целью. Объясняемость присуща большинству уравнений, однако SR, возможно, добавляет "простоту", выполняя генетическую эволюцию от более сложных выражений и переходя к более простым, при условии, что их наилучшие оценки соответствия выше.
Определение
SR представляет собой модель сопоставления между независимыми переменными и зависимой (или прогнозируемой) переменной в виде дерева выражений. Итак, схематическое изображение, подобное приведенному ниже:
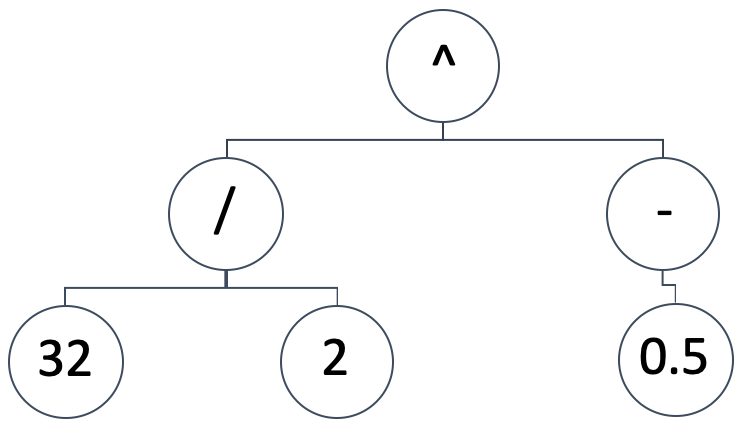
подразумевает математическое выражение:
(32/2) ^ (-0,5)
Это эквивалентно 0,25. Деревья выражений могут принимать различные формы и конструкции, мы хотим сохранить основополагающую предпосылку SR, которая начинается со случайной и непредвзятой конфигурации. В то же время нам необходимо иметь возможность запускать генетическую оптимизацию на любом размере изначально сгенерированного дерева выражений, имея при этом возможность сравнивать его результат (или метрику наилучшего соответствия) с деревьями выражений разного размера.
Чтобы добиться этого, мы будем запускать нашу генетическую оптимизацию в "эпохах". В то время как эпохи широко используются в терминологии машинного обучения при пакетной обработке сеансов обучения, например, в нейронных сетях, здесь мы используем этот термин для обозначения различных итераций генетической оптимизации, где каждый запуск использует деревья выражений одинакового размера. Почему мы сохраняем размер в каждой эпохе? Потому что генетическая оптимизация использует кроссоверы (cross-overs). Если же деревья выражений имеют разную длину, то это неоправданно усложняет процесс. Как же тогда сохранить случайность исходных деревьев выражений? Пусть каждая эпоха представляет определенный размер деревьев. Таким образом, мы проводим оптимизацию по всем эпохам и сравниваем их все с одним и тем же эталоном или метрикой наилучшего соответствия.
Параметры измерения функции соответствия, доступные в векторных/матричных типах данных MQL5, которые мы могли бы использовать, - regression и loss. Эти встроенные функции будут применимы, поскольку мы будем сравнивать идеальный вывод из обучающего набора данных в виде одного вектора с выводами, полученными с помощью тестируемого дерева выражений также в векторном формате. Таким образом, чем длиннее или больше тестовый набор данных, тем больше наши сравниваемые векторы. Эти большие наборы данных, вероятно, подразумевают, что достижение идеального нулевого значения наилучшего соответствия будет очень сложным, и поэтому необходимо предусмотреть достаточное количество поколений оптимизации в каждой эпохе.
При получении наилучшего дерева выражений на основе наилучшей оценки соответствия мы будем оценивать деревья выражений от самого длинного (и, следовательно, самого сложного) до самого простого и предположительно самого легкого для "объяснения". Наши форматы дерева выражений могут принимать множество форм, однако мы остановимся на основных:
coeff, x-exponent, sign, coeff, x-exponent, sign, …
где:
- Coeff представляет собой коэффициент x
- x-exponent — это степень x
- sign — это оператор (знак) в выражении (-, +, * или /)
Последнее значение любого выражения не будет являться оператором, поскольку такой оператор не будет ни с чем связан, а это значит, что операторов всегда будет меньше, чем значений x в любом выражении. Размер такого выражения будет варьироваться от 1, где мы указываем только один коэффициент x и показатель степени без знака, до 16 (16 используется здесь строго в целях тестирования). Как было отмечено выше, этот максимальный размер напрямую коррелирует с количеством эпох, которые будут использоваться при генетической оптимизации. Это просто означает, что мы начинаем оптимизацию для идеального выражения с деревом выражений длиной 16 единиц. Как упоминалось выше, эти 16 единиц подразумевают 15 операторов, и "каждая единица" — это просто коэффициент x и его экспонента.
Таким образом, при выборе первых случайных деревьев выражений мы всегда будем следовать формату двух случайных цифровых "узлов", за которыми следует случайный "узел" знака, если дерево выражения имеет длину более одной единицы, и мы не завершаем выражение, то есть у нас есть единица для отслеживания. Необходимый листинг приведен ниже:
//+------------------------------------------------------------------+ // Get Expression Tree //+------------------------------------------------------------------+ void CSignalSR::GetExpressionTree(int Size, string &ExpressionTree[]) { if(Size < 1) { return; } ArrayFree(ExpressionTree); ArrayResize(ExpressionTree, (2 * Size) + Size - 1); int _digit[]; GetDigitNode(2 * Size, _digit); string _sign[]; if(Size >= 2) { GetSignNode(Size - 1, _sign); } int _di = 0, _si = 0; for(int i = 0; i < (2 * Size) + Size - 1; i += 3) { ExpressionTree[i] = IntegerToString(_digit[_di]); ExpressionTree[i + 1] = IntegerToString(_digit[_di + 1]); _di += 2; if(Size >= 2 && _si < Size - 1) { ExpressionTree[i + 2] = _sign[_si]; _si ++; } } }
Наша функция выше начинается с проверки того, что размер дерева выражений равен по крайней мере единице. Если этот тест пройден, нам необходимо определить фактический размер массива дерева. Из вышеизложенного мы видим, что деревья следуют коэффициенту формата, экспоненте, а затем знаку, если применимо. Это означает, что при размере s общее количество цифровых узлов в этом дереве будет равно 2 x s, поскольку каждая единица размера должна иметь коэффициент и показатель степени. Эти узлы выбираются случайным образом с помощью функции получения цифрового узла. Листинг приведен ниже:
//+------------------------------------------------------------------+ // Get Digit //+------------------------------------------------------------------+ void CSignalSR::GetDigitNode(int Count, int &Digit[]) { ArrayFree(Digit); ArrayResize(Digit, Count); for(int i = 0; i < Count; i++) { Digit[i] = __DIGIT_NODE[MathRand() % __DIGITS]; } }
Числа выбираются случайным образом из статического глобального массива цифровых узлов. Однако узлы знаков будут различаться в зависимости от того, превышает ли размер дерева единицу. Если размер дерева - единица, то никакой знак не применим, поскольку остается место только для коэффициента x и его экспоненты. Если размер дерева превышает единицу, то количество узлов знака будет эквивалентно размеру входных данных минус один. Ниже приведена функция для случайного выбора знака для заполнения слота знака в выражении:
//+------------------------------------------------------------------+ // Get Sign //+------------------------------------------------------------------+ void CSignalSR::GetSignNode(int Count, string &Sign[]) { ArrayFree(Sign); ArrayResize(Sign, Count); for(int i = 0; i < Count; i++) { Sign[i] = __SIGN_NODE[MathRand() % __SIGNS]; } }
Как и в массиве цифровых узлов, знаки выбираются случайным образом из массива знаковых узлов. Массив может иметь несколько вариантов, но для краткости мы оставим только знаки "+" и "-". К ним можно было бы добавить знак "*" (умножение), однако знак деления "/" был специально опущен, поскольку мы не обрабатываем деления на ноль, что может оказаться весьма затруднительным, когда мы начнем генетическую оптимизацию и придется выполнять кроссоверы и т. д. Читатель может свободно исследовать этот вопрос, при условии, что проблема деления на ноль будет должным образом решена, поскольку она может исказить результаты оптимизации.
Получив начальную популяцию случайных деревьев выражений, мы можем начать процесс генетической оптимизации для конкретной эпохи. Также следует отметить простую структуру, которую мы используем для хранения и доступа к информации дерева выражений. По сути, это строковая матрица с дополнительной возможностью гибко менять размер (функции, которые должен предоставлять стандартный тип данных, такой как матрица, который обрабатывает дубли?). Ниже приведен необходимый листинг:
//+------------------------------------------------------------------+ //| //+------------------------------------------------------------------+ struct Stree { string tree[]; Stree() { ArrayFree(tree); }; ~Stree() {}; }; struct Spopulation { Stree population[]; Spopulation() {}; ~Spopulation() {}; };
Мы используем эту структуру для создания и отслеживания популяций в каждом поколении оптимизации. Каждая эпоха использует заданное количество поколений для оптимизации. Как уже упоминалось, чем больше набор тестовых данных, тем больше потребуется поколений оптимизации. С другой стороны, если тестовых данных слишком мало, это может привести к появлению деревьев выражений, которые в основном будут получены из белого шума, а не из базовых закономерностей в тестируемых наборах данных, поэтому необходимо соблюдать баланс.
Как только мы начнем оптимизацию для каждого поколения, нам нужно будет получить показатели приспособленности каждого дерева, и поскольку у нас несколько деревьев, эти показатели записываются в вектор. Как только у нас появится этот вектор, следующим шагом станет установление порогового значения для обрезки этой популяции, учитывая, что это дерево совершенствуется и сужается с каждым последующим поколением в пределах данной эпохи. Мы назвали этот порог _fit. Он основан на целочисленном входном параметре, который действует как процентильный маркер. Параметр варьируется от 0 до 100.
Мы приступаем к созданию еще одной выборочной популяции из начальной, где мы выбираем только те деревья выражений, приспособленность которых ниже или равна пороговому значению. Функция для вычисления нашей оценки приспособленности, использованная выше, будет иметь следующий листинг:
//+------------------------------------------------------------------+ // Get Fitness //+------------------------------------------------------------------+ double CSignalSR::GetFitness(matrix &XY, vector &Y, string &ExpressionTree[]) { Y.Init(XY.Rows()); for(int r = 0; r < int(XY.Rows()); r++) { Y[r] = 0.0; string _sign = ""; for(int i = 0; i < int(ExpressionTree.Size()); i += 3) { double _yy = pow(XY[r][0], StringToDouble(ExpressionTree[i + 1])); _yy *= StringToDouble(ExpressionTree[i]); if(_sign == "+") { Y[r] += _yy; } else if(_sign == "-") { Y[r] -= _yy; } else if(_sign == "/" && _yy != 0.0)//un-handled { Y[r] /= _yy; } else if(_sign == "*") { Y[r] *= _yy; } else if(_sign == "") { Y[r] = _yy; } if(i + 2 < int(ExpressionTree.Size())) { _sign = ExpressionTree[i + 2]; } } } return(Y.RegressionMetric(XY.Col(1), m_regressor)); //return(_y.Loss(XY.Col(1),LOSS_MAE)); }
Функция получения приспособленности берет матрицу входных данных XY и фокусируется на столбце x матрицы (мы используем одномерные данные как для входных, так и для выходных данных) для вычисления прогнозируемого значения дерева входных выражений. Входная матрица имеет несколько строк данных, поэтому на основе значения x в каждой строке (первый столбец) создается проекция, и все эти проекции для каждой строки сохраняются в векторе Y. После обработки всех строк вектор Y сравнивается с фактическими значениями во втором столбце с использованием либо встроенной функции регрессии, либо функции потерь. Мы выбираем регрессию, в качестве метрики которой используется среднеквадратическая ошибка.
Величина этого значения представляет собой значение приспособленности входного дерева выражения. Чем оно меньше, тем лучше приспособленность. Получив это значение для каждой выборочной совокупности, нам необходимо сначала проверить, является ли размер выборки четным. Если нет, уменьшаем размер на единицу. Размер должен быть четным, поскольку на следующем этапе мы скрещиваем эти деревья, а полученные скрещивания добавляются парами, и они должны соответствовать родительской популяции (выборкам), поскольку мы уменьшаем популяцию только при выборке в каждом поколении. Пересечение деревьев выражений в выборках осуществляется случайным образом путем выбора индекса. Ниже приведена функция, отвечающая за пересечение:
//+------------------------------------------------------------------+ // Set Crossover //+------------------------------------------------------------------+ void CSignalSR::SetCrossover(string &ParentA[], string &ParentB[], string &ChildA[], string &ChildB[]) { if(ParentA.Size() != ParentB.Size() || ParentB.Size() == 0) { return; } int _length = int(ParentA.Size()); ArrayResize(ChildA, _length); ArrayResize(ChildB, _length); int _cross = 0; if(_length > 1) { _cross = rand() % (_length - 1) + 1; } for(int c = 0; c < _cross; c++) { ChildA[c] = ParentA[c]; ChildB[c] = ParentB[c]; } for(int l = _cross; l < _length; l++) { ChildA[l] = ParentB[l]; ChildB[l] = ParentA[l]; } }
Функция начинается с проверки того, что два родительских выражения имеют одинаковый размер и ни одно из них не равно нулю. Если проверка пройдена, то два выходных дочерних массива изменяют размер в соответствии с длинами родительских массивов, а затем выбирается точка пересечения. Это скрещивание также является случайным и имеет значение только в том случае, если родительский размер больше единицы. После установки точки пересечения значения двух родительских элементов меняются местами и выводятся в два дочерних массива. Тут нам пригодятся соответствующие длины, потому что, например, если бы они были разными, то потребовался бы дополнительный код для обработки (или избежания) случаев, когда цифры заменяются знаками. Очевидно, что эти усложнения не нужны, поскольку все размеры можно протестировать независимо, в своей собственной эпохе, для наилучшего соответствия.
После того, как мы завершим скрещивание, мы можем провести мутацию потомков. "Может", потому что мы используем порог вероятности в 5% для выполнения этих мутаций, так как они не гарантированы, но обычно являются частью процесса генетической оптимизации. Затем мы копируем эту новую скрещенную популяцию, чтобы перезаписать нашу начальную, из которой мы производили выборку в начале, и в качестве маркера мы регистрируем наилучшую оценку соответствия наилучшего дерева выражений из новой скрещенной популяции. Мы используем записанную оценку не только для определения наиболее подходящего дерева, но и в некоторых редких случаях для остановки оптимизации, если мы получим нулевое значение.
Пользовательский класс сигнала
При разработке класса сигнала наши основные шаги не сильно отличаются от того, что мы делали в предыдущих пользовательских классах сигналов в этой серии статей. Во-первых, нам необходимо подготовить набор данных для нашей модели. Это данные, которые заполняют нашу входную матрицу XY для рассмотренной выше функции получения приспособленности. Это также входные данные для функции, которая объединяет все описанные выше шаги и называется "получить лучшее дерево". Исходный код этой функции приведен ниже:
//+------------------------------------------------------------------+ // Get Best Fit //+------------------------------------------------------------------+ void CSignalSR::GetBestTree(matrix &XY, vector &Y, string &BestTree[]) { double _best_fit = DBL_MAX; for(int e = 1 + m_epochs; e >= 1; e--) { Spopulation _p; ArrayResize(_p.population, m_population); int _e_size = 2 * e; for(int p = 0; p < m_population; p++) { string _tree[]; GetExpressionTree(e, _tree); _e_size = int(_tree.Size()); ArrayResize(_p.population[p].tree, _e_size); for(int ee = 0; ee < _e_size; ee++) { _p.population[p].tree[ee] = _tree[ee]; } } for(int g = 0; g < m_generations; g++) { vector _fitness; _fitness.Init(int(_p.population.Size())); for(int p = 0; p < int(_p.population.Size()); p++) { _fitness[p] = GetFitness(XY, Y, _p.population[p].tree); } double _fit = _fitness.Percentile(m_fitness); Spopulation _s; int _samples = 0; for(int p = 0; p < int(_p.population.Size()); p++) { if(_fitness[p] <= _fit) { _samples++; ArrayResize(_s.population, _samples); ArrayResize(_s.population[_samples - 1].tree, _e_size); for(int ee = 0; ee < _e_size; ee++) { _s.population[_samples - 1].tree[ee] = _p.population[p].tree[ee]; } } } if(_samples % 2 == 1) { _samples--; ArrayResize(_s.population, _samples); } if(_samples == 0) { break; } Spopulation _g; ArrayResize(_g.population, _samples); for(int s = 0; s < _samples - 1; s += 2) { int _a = rand() % _samples; int _b = rand() % _samples; SetCrossover(_s.population[_a].tree, _s.population[_b].tree, _g.population[s].tree, _g.population[s + 1].tree); if (rand() % 100 < 5) // 5% chance { SetMutation(_g.population[s].tree); } if (rand() % 100 < 5) { SetMutation(_g.population[s + 1].tree); } } // Replace old population ArrayResize(_p.population, _samples); for(int s = 0; s < _samples; s ++) { for(int ee = 0; ee < _e_size; ee++) { _p.population[s].tree[ee] = _g.population[s].tree[ee]; } } // Print best individual for(int s = 0; s < _samples; s ++) { _fit = GetFitness(XY, Y, _p.population[s].tree); if (_fit < _best_fit) { _best_fit = _fit; ArrayCopy(BestTree,_p.population[s].tree); } } } } }
Входная матрица объединяет одномерные значения x и одномерные значения y. Независимые переменные и зависимые переменные. Многомерность также может быть реализована путем преобразования входного вектора Y в матрицу и дерево выражений для каждого значения x во входном векторе и для каждого значения y в выходном векторе. Эти деревья выражений также должны быть в матричном или более многомерном формате хранения.
Однако мы используем отдельные измерения, и наша строка данных состоит просто из последовательных цен закрытия. Таким образом, в верхней или самой последней строке данных у нас будет предпоследняя цена закрытия в качестве значения x и текущая цена закрытия в качестве значения y. Подготовка и заполнение нашей матрицы XY этими данными выполняется с помощью исходного кода, представленного ниже:
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalSR::LongCondition(void) { int result = 0; m_close.Refresh(-1); matrix _xy; _xy.Init(m_data_set, 2); for(int i = 0; i < m_data_set; i++) { _xy[i][0] = m_close.GetData(StartIndex()+i+1); _xy[i][1] = m_close.GetData(StartIndex()+i); } ... return(result); }
После завершения подготовки данных будет полезно четко определить метод оценки приспособленности, который будет использоваться в нашей модели. Мы выбираем regression вместо loss, но даже в рамках регрессии есть довольно много метрик, из которых можно выбирать. Таким образом, для обеспечения оптимального выбора тип используемой метрики регрессии является входным параметром, который можно оптимизировать для лучшего соответствия тестируемым наборам данных. Однако нашим значением по умолчанию является обычная среднеквадратичная ошибка.
Реализацией генетического алгоритма занимается функция получения наилучшего дерева, исходный код которой приведен выше. Он возвращает ряд выходных данных, среди которых находится лучшее дерево выражений. С помощью этого дерева мы можем обработать текущую цену закрытия как входные данные (значение x) для получения следующей цены закрытия (значение y), используя функцию получения пригодности, поскольку она также возвращает больше, чем просто пригодность запрошенного выражения, поскольку входной вектор Y содержит наш целевой прогноз. Ниже приведена реализация в коде:
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalSR::LongCondition(void) { ... vector _y; string _best_fit[]; GetBestTree(_xy, _y, _best_fit); ... return(result); }
Получив ориентировочную цену закрытия, следующим шагом будет преобразование этой цены в полезный сигнал для советника. Прогнозируемые значения часто лишь указывают на рост или падение, но их абсолютные значения выходят за пределы диапазона по сравнению с недавними ценовыми значениями закрытия. Это означает, что нам придется нормализовать их, прежде чем их можно будет использовать. Нормализация и генерация сигнала реализованы в следующем коде:
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalSR::LongCondition(void) { int result = 0; ... double _cond = (_y[0]-m_close.GetData(StartIndex()))/fmax(fabs(_y[0]),m_close.GetData(StartIndex())); _cond *= 100.0; //printf(__FUNCSIG__ + " cond: %.2f", _cond); //return(result); if(_cond > 0.0) { result = int(fabs(_cond)); } return(result); }
Целочисленный вывод как длинных, так и коротких условий в стандартном классе сигналов Expert должен находиться в диапазоне от 0 до 100, и именно в него мы преобразуем наш сигнал в приведенном выше коде.
Функции длинного и короткого условий являются зеркальными версиями друг друга, а сборка классов сигналов в советники рассматривается в статьях здесьи здесь.
Тестирование на истории и оптимизация
При выполнении тестового прогона с некоторыми из "лучших настроек" собранного советника мы получаем следующий отчет и кривую эквити:


Однако для любых заданных настроек, поскольку деревья выражений получаются путем случайного отбора, скрещиваются и мутируют также случайным образом, маловероятно, что какой-либо конкретный тестовый запуск в точности воспроизведет свои результаты. Что интересно, если тестовый прогон оказался прибыльным, то последующие прогоны с теми же настройками будут показывать другие результаты, но в целом также будут прибыльными. Наше тестирование проводилось для 2022 года на EURJPY H4. Как всегда, мы проводим тесты без целевых уровней стоп-лосса или тейк-профита, поскольку это может помочь лучше определить идеальные настройки советника.
Заключение
Мы представили символьную регрессию как модель, которую можно использовать в пользовательском экземпляре класса сигнала советника для взвешивания условий на покупку и продажу. В этом анализе мы использовали очень скромный набор данных, поскольку как входные, так и выходные значения модели были одномерными. Это не означает, что модель нельзя расширить для охвата многомерных наборов данных. Кроме того, природа генетической оптимизации алгоритма модели затрудняет получение идентичных результатов в каждом тестовом прогоне. Это означает, что советники, основанные на этой модели, следует использовать на достаточно больших таймфреймах и в сочетании с другими торговыми сигналами, чтобы они могли выступать в качестве подтверждения независимо сгенерированных сигналов.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/14943
 Особенности написания Пользовательских Индикаторов
Особенности написания Пользовательских Индикаторов

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования