
Возможности Мастера MQL5, которые вам нужно знать (Часть 16): Метод главных компонент с собственными векторами
Введение
Метод главных компонент (Principal Component Analysis, PCA) фокусируется только на "главных компонентах" среди многих измерений набора данных, при котором измерения этого набора данных сокращаются за счет игнорирования "неглавных" частей. Возможно, простейшим примером снижения размерности может служить матрица, подобная представленной ниже:

Если бы это была точка данных, ее можно было бы представить как одно значение:
Таким образом, это одно значение подразумевает уменьшение размерности с 9 до 1. Наша иллюстрация выше сводит матрицу к ее детерминанту, и это примерно эквивалентно уменьшению размерности.
PCA предлагает более глубокий подход, используя собственные значения и векторы. Обычно наборы данных, обрабатываемые в рамках PCA, имеют матричную структуру, а главные компоненты, которые ищутся в матрице, представляют собой один векторный столбец (или строку), который является наиболее значимым среди других векторов матрицы и может быть достаточным в качестве представителя всей матрицы. Как упоминалось во введении выше, этот вектор сам по себе будет содержать главные компоненты всей матрицы, отсюда и название PCA. Однако идентификация этого вектора не обязательно должна осуществляться с помощью собственных векторов и значений. Альтернативные варианты - сингулярное разложение (singular value decomposition, SVD) и степенной метод.
SVD позволяет добиться снижения размерности путем разбиения набора матричных данных на три отдельные матрицы, одна из которых, матрица Σ, определяет наиболее важные направления дисперсии в данных. Эта матрица, также известная как диагональная матрица, содержит сингулярные значения, которые представляют собой величины дисперсии вдоль каждого заранее определенного направления (записанные в другой из трех матриц, часто называемой U). Чем больше сингулярное значение, тем более значимо соответствующее направление в объяснении изменчивости данных. Это приводит к тому, что столбец U с наивысшим сингулярным значением выбирается в качестве репрезентативного для всей матрицы, что фактически приводит к уменьшению размерности матрицы до одного вектора.
Наоборот, степенной метод итеративно уточняет оценку вектора, стремясь к доминирующему собственному вектору. Этот собственный вектор фиксирует направление с наиболее значительными изменениями в данных и представляет собой уменьшенную размерность исходной матрицы.
Однако, поскольку в данной статье мы сосредоточимся на собственных векторах и значениях, мы можем преобразовать матрицу n x n в n возможных векторов размера n, при этом каждому из этих векторов будет присвоено собственное значение. Это собственное значение затем определяет выбор одного собственного вектора для наилучшего представления матрицы, причем более высокое значение снова указывает на более высокую положительную корреляцию при объяснении изменчивости данных.
Так в чем же смысл уменьшения размерности наборов данных? Если коротко, я считаю, что это управление белым шумом. Однако более содержательным ответом было бы улучшение визуализации, поскольку данные высокой размерности сложнее отображать и представлять в таком привычном виде, как точечная диаграмма и другие обычные графические форматы. В этом случае может помочь сокращение измерений (координат участка) до 2 или 3. Еще одним важным преимуществом является снижение затрат на вычисления при сравнении точек данных при прогнозировании.
Такое сравнение выполняется при обучении моделей, что позволяет экономить время на обучение моделей и вычислительную мощность. Это приводит к "проклятию размерности", когда данные с высокой размерностью, как правило, дают точные результаты при тестировании на выборке во время обучения, но эта эффективность снижается быстрее, чем в случае с данными с низкой размерностью при перекрестной проверке. Уменьшение размеров может помочь справиться с этой проблемой. Кроме того, уменьшение размерности приводит к снижению уровня шума в наборах данных, что теоретически должно повысить производительность. И наконец, данные меньшей размерности занимают меньше места и, следовательно, более эффективны в управлении, особенно при обучении больших моделей.
PCA и собственные векторы
Формально собственные векторы определяются уравнением:
Av =λv
где:
- A — матрица преобразования
- v — вектор, который необходимо преобразовать
- a и λ — коэффициент масштабирования, применяемый к вектору.
Центральный принцип собственных векторов заключается в том, что для многих (но не всех) квадратных матриц A размера n x n существует n векторов, каждый из которых имеет размер n, таких, что при применении матрицы A к любому из этих векторов направление результирующего произведения сохраняет то же направление, что и исходный вектор, с единственным изменением, заключающимся в пропорциональном масштабе значений в исходном векторе. В приведенном выше уравнении эта шкала обозначена как лямбда и ее правильнее называть собственным значением. Для каждого собственного вектора существует одно собственное значение.
Не все матрицы производят необходимое количество собственных векторов, поскольку некоторые из них деформированы, однако для каждого полученного вектора существует кандидат на уменьшенную размерность исходной матрицы. Выбор среди этих векторов победителя осуществляется на основе собственного значения, причем более высокие значения соответствуют лучшему охвату дисперсии набора данных и меньшему охвату его шума.
Процесс определения собственного вектора начинается с нормализации матрицы набора данных. Это можно сделать несколькими способами. В этой статье я использую z-нормализацию. После нормализации матричных данных вычисляется эквивалент ковариационной матрицы. Каждый элемент матрицы отражает ковариацию между любыми двумя элементами, при этом диагональ отражает ковариацию каждого элемента с самим собой. Помимо большей вычислительной эффективности при расчете собственных векторов и значений при использовании ковариационной матрицы, значения данных, полученные с помощью ковариационной матрицы, отражают линейные соотношения между точками данных в матрице и дают четкую картину того, как каждая точка данных в матрице соизмеряется с другими точками данных.
Вычисление ковариационной матрицы для матричных типов данных выполняется встроенными функциями MQL5, в данном случае - функцией Cov(). После получения ковариационной матрицы, собственные векторы и значения можно вычислить с помощью встроенной функции Eig(). Получив собственные векторы и их соответствующие значения, мы транспонируем матрицу собственных векторов и умножаем ее на исходную матрицу возвратов. Строки в матрице представляют дисперсионные веса каждого портфеля, поэтому выбранный портфель будет зависеть от этих весов. Это связано с тем, что его направление отражает максимальную дисперсию данных в пределах выборочного набора данных.
Простую иллюстрацию, поясняющую суть фиксации максимальной дисперсии, можно создать, если взять координаты x и y вдоль кривой эллипса в качестве набора данных, причем каждая точка данных имеет два измерения x и y. Если бы мы изобразили этот эллипс на графике, он выглядел бы так:
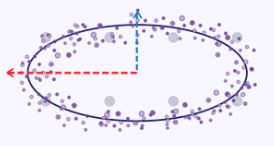
Таким образом, если поставить задачу сведения этих измерений x и y к одному (меньшему числу) измерений, как можно увидеть на изображении графика выше, то значения координаты x будут более репрезентативными из двух, поскольку эллипс имеет тенденцию сильнее вытягиваться вдоль своей оси x, чем вдоль оси y.
Однако в целом необходимо найти компромисс между уменьшением измерений и сохранением информации. Хотя уменьшение размерности имеет свои преимущества, перечисленные выше, следует помнить о его интерпретации и простоте объяснения.
Реализация средствами MQL5
Торговая система, использующая PCA с собственными векторами, обычно делает это путем оптимального выбора портфеля из набора(ов) различных итераций. Чтобы проиллюстрировать это, мы можем взять матрицу, которую мы рассматривали во введении выше, просто как составную часть векторов, где каждый вектор представляет собой доходность на один доллар, инвестированный в каждый актив при трех различных режимах распределения. Фактическое распределение веса каждого вектора (портфеля) становится важным только после того, как выбран собственный вектор, и распределение активов, которое должно быть принято в соответствии с этим вектором, затем требуется для будущих инвестиций.

Если наши активы - SPY,TLT и PDBC, то его предполагаемое распределение, основанное на 5-летней доходности каждого из этих ETF, составляет:

Итак, PCA с собственными векторами поможет нам выбрать идеальный портфель (распределение активов) среди этих 3 вариантов на основе их эффективности за последние 5 лет. Если перечислить шаги, описанные выше, первое, что нам нужно сделать, это всегда нормализовать набор данных, и, как уже упоминалось, для этого мы используем z-нормализацию. Исходный код приведен ниже:
//+------------------------------------------------------------------+ //| Z-Normalization | //+------------------------------------------------------------------+ matrix ZNorm(matrix &M) { matrix _z; _z.Init(M.Rows(), M.Cols()); _z.Copy(M); if(M.Rows() > 0 && M.Cols() > 0) { double _std_min = (M.Max() - M.Min()) / (M.Rows() * M.Cols()); if(_std_min > 0.0) { double _mean = M.Mean(); double _std = fmax(_std_min, M.Std()); for(ulong i = 0; i < M.Rows(); i++) { for(ulong ii = 0; ii < M.Cols(); ii++) { _z[i][ii] = (M[i][ii] - _mean) / _std; } } } } return(_z); }
После того, как мы нормализуем матрицу возвратов, мы вычисляем ковариационную матрицу того, что мы нормализовали. Встроенный тип данных MQL5 для матриц может сделать это для нас одной строкой:
matrix _z = ZNorm(_m); matrix _cov_col = _z.Cov(false);
Вооружившись ковариационными соотношениями каждой точки данных в матрице, мы можем вычислить собственные векторы и собственные значения. Вычисление также занимает одну строку:
matrix _e_vectors; vector _e_values; _cov_col.Eig(_e_vectors, _e_values);
Выходные данные вышеуказанной функции являются двойственными. Нас в первую очередь интересуют собственные векторы, которые возвращаются в виде матрицы. Эта матрица, транспонированная и умноженная на исходную матрицу доходности, дает нам то, что мы ищем, — проекционную матрицу P. Это матрица со строками для каждого из возможных портфелей, где столбец в каждой строке представляет собой весовой коэффициент для каждого из трех сгенерированных собственных векторов. Например, в первой строке наибольшее значение находится в первом столбце. Это означает, что большая часть дисперсии доходности этого портфеля обусловлена первым собственным вектором. Если мы посмотрим на собственное значение этого собственного вектора, то увидим, что оно наибольшее из трех. Таким образом, это означает, что среди всех трех портфелей первый портфель отвечает за большинство значимых закономерностей (или тенденций), представленных в матрице данных.
В нашем случае все портфели приносили положительную доходность, если их значения суммировать по столбцам, поскольку каждый столбец представляет собой портфель. Фактически, единственная отрицательная доходность возникает при вложении в облигации ETF PDBC независимо от распределения. Это означает, что если кто-то хочет "увековечить" эту хеджированную, диверсифицированную или имеющую хорошую бету доходность, ему нужно будет придерживаться портфеля 1. Опять же, общая тенденция матрицы данных о доходности заключается в положительной доходности акций и товаров и отрицательной доходности облигаций. Таким образом, PCA с собственными векторами может отсортировать портфель из тех, которые с наибольшей вероятностью продолжат эту тенденцию, как в случае с портфелем 1, или даже сделать обратное, что в нашем случае будет портфелем 3, поскольку в матрице проекции максимальное значение в 3-ей строке - в столбце 3 и 3-й собственный вектор имел наименьшее значение.
Примечательно, что этот портфель не имеет самой высокой доходности, и сам процесс не выбирает ее как таковую. Все, что он делает, — это дает ориентировочные оценки сохранения статуса-кво. Все это выглядит неоправданно сложным для выбора, который можно было бы легко сделать при проверке, и тем не менее, по мере того, как возвращаемые данные или анализируемые матрицы становятся больше с большим количеством строк и столбцов (PCA с собственными векторами требует квадратных матриц), этот процесс начинает приносить свои плоды.
Для демонстрации PCA в классе сигналов, мы ограничены тем, что по умолчанию можно протестировать только один символ на одном таймфрейме, а это значит, что приведенные выше понятия о выборе портфеля не применимы изначально. Существуют обходные пути для этих ограничений, и, возможно, мы могли бы рассмотреть их в другой статье в будущем, но сейчас мы будем работать в рамках этих ограничений.
Мы проанализируем изменения цены за каждый день недели по одному символу на дневном таймфрейме. Поскольку в неделе 5 торговых дней, наша матрица будет иметь 5 столбцов, и для того, чтобы получить 5 строк, необходимых для анализа собственных векторов PCA, мы рассмотрим 5 различных типов цен, а именно: открытия (Open), максимальную (High), минимальную (Low), закрытия (Close) и типичную (Typical). Определение собственных векторов и значений будет осуществляться по уже упомянутым выше шагам.
То же самое относится к получению проекционной матрицы, и как только она у нас появится, мы сможем легко определить торговый день недели и примененный тип цены, которые отражают наибольшую дисперсию. Если следовать приведенному ниже коду скрипта:
matrix _t = _e_vectors.Transpose(); matrix _p = _m * _t; //Print(" projection: \n", _p); vector _max_row = _p.Max(0); vector _max_col = _p.Max(1); double _days[]; _max_row.Swap(_days); PrintFormat(" best trade day is: %s", EnumToString(ENUM_DAY_OF_WEEK(ArrayMaximum(_days)+1))); ENUM_APPLIED_PRICE _price[__SIZE]; _price[0] = PRICE_OPEN; _price[1] = PRICE_WEIGHTED; _price[2] = PRICE_MEDIAN; _price[3] = PRICE_CLOSE; _price[4] = PRICE_TYPICAL; double _prices[]; _max_col.Swap(_prices); PrintFormat(" best applied price is: %s", EnumToString(_price[ArrayMaximum(_prices)])); PrintFormat(" worst trade day is: %s", EnumToString(ENUM_DAY_OF_WEEK(ArrayMinimum(_days)+1))); PrintFormat(" worst applied price is: %s", EnumToString(_price[ArrayMinimum(_prices)]));
Сообщения в журнале приводятся в разделе "Тестирование стратегии и результаты".
Итак, из приведенных выше журналов мы видим, что большая часть колебаний цен символа, к графику которого прикреплен скрипт (EURJPY), происходит по четвергам на ценах закрытия. Что это значит? Это значит, что если кто-то находит общий тренд и ценовое поведение EURJPY интересными и хочет вести аналогичную игру в будущем, то ему лучше сосредоточить свои сделки на четверге и использовать ряд цен закрытия. Предположим, что EURJPY является частью установленной позиции в чьем-то портфеле, и в дальнейшем воздействие EURJPY сокращается. Как может помочь матрица позиций? "Худшие" торговые дни и ценовые ряды можно использовать при определении того, когда и как закрывать позиции по EURJPY.
Итак, наша матрица позиций рекомендует торговые дни и ценовые ряды, поэтому давайте воспользуемся простым классом сигналов ниже, который учитывает их.
int _buffer_size = CopyRates(Symbol(), Period(), __start, __stop, _rates); PrintFormat(__FUNCSIG__+" buffered: %i",_buffer_size); if(_buffer_size >= 1) { for(int i = 1; i < _buffer_size - 1; i++) { TimeToStruct(_rates[i].time,_datetime); int _iii = int(_datetime.day_of_week)-1; if(_datetime.day_of_week == SUNDAY || _datetime.day_of_week == SATURDAY) { _iii = 0; } for(int ii = 0; ii < __SIZE; ii++) { ... ... } } }
Тестирование стратегии и результаты
Чтобы провести тестирование на истории с помощью советника, собранного в Мастере MQL5, нам сначала необходимо запустить скрипт на графике и таймфрейме символа, который мы будем тестировать. В нашем примере это EURUSD H4. Если мы запустим скрипт на графике, то получим пятницу и взвешенную цену в качестве "идеальных" или определяющих дисперсию параметров для EURUSD H4. Сообщения в журнале представлены ниже:
2024.04.15 14:55:51.297 ev_5 (EURUSD.ln,H4) best trade day is: FRIDAY 2024.04.15 14:55:51.297 ev_5 (EURUSD.ln,H4) best applied price is: PRICE_WEIGHTED 2024.04.15 14:55:51.297 ev_5 (EURUSD.ln,H4) worst trade day is: TUESDAY 2024.04.15 14:55:51.297 ev_5 (EURUSD.ln,H4) worst applied price is: PRICE_OPEN
В нашем скрипте также есть два входных параметра, определяющих анализируемый период, а именно время начала и время окончания. Обе являются переменными типа datetime. Мы устанавливаем их на 2022.01.01 и 2023.01.01, чтобы сначала протестировать нашего советника на этом периоде, а затем провести перекрестную проверку с теми же настройками на периоде с 2023.01.01 по 2024.01.01. Скрипт рекомендует пятницу и взвешенную цену в качестве лучших переменных, определяющих дисперсию. Как нам использовать эту информацию при разработке класса сигнала? Как всегда, существует ряд вариантов, которые можно рассмотреть, однако мы рассмотрим простой индикатор пересечения цены со скользящей средней. Используя скользящую среднюю рекомендуемой применяемой цены, а также размещая сделки только в рекомендуемый день недели, мы попытаемся провести перекрестную проверку логики нашего скрипта. Таким образом, код для нашего класса сигналов будет очень простым:
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalPCA::LongCondition(void) { int _result = 0; m_MA.Refresh(-1); m_close.Refresh(-1); m_time.Refresh(-1); // if(m_MA.Main(StartIndex()+1) > m_close.GetData(StartIndex()+1) && m_MA.Main(StartIndex()) < m_close.GetData(StartIndex())) { _result = 100; //PrintFormat(__FUNCSIG__); } if(m_pca) { TimeToStruct(m_time.GetData(StartIndex()),__D); if(__D.day_of_week != m_day) { _result = 0; } } // return(_result); } //+------------------------------------------------------------------+ //| "Voting" that price will fall. | //+------------------------------------------------------------------+ int CSignalPCA::ShortCondition(void) { int _result = 0; m_MA.Refresh(-1); m_close.Refresh(-1); // if(m_MA.Main(StartIndex()+1) < m_close.GetData(StartIndex()+1) && m_MA.Main(StartIndex()) > m_close.GetData(StartIndex())) { _result = 100; //PrintFormat(__FUNCSIG__); } if(m_pca) { TimeToStruct(m_time.GetData(StartIndex()),__D); if(__D.day_of_week != m_day) { _result = 0; } } // return(_result); }
Как всегда, мы не используем ценовые уровни для тейк-профита или стоп-лосса и строго используем лимитные ордера. Это означает, что после того, как позиция открыта нашим советником, она закрывается только при развороте. Возможно, это высокорискованный подход, но для наших целей его будет достаточно. Если мы проведем тестирование на истории по первому периоду, то получим следующий отчет и кривую капитала:


Приведенные выше результаты относятся к периоду с 01.01.2022 по 01.01.2023. Если мы попытаемся провести тестирование с теми же настройками в течение более длительного периода, выходящего за рамки периода анализа скрипта, с 2022.01.01 по 2024.01.01, мы получим следующие результаты:


Наш сигнал содержит довольно много ограничений, и сделок совершается не так уж много, что ставит эффективность тестирования под сомнение. Тем не менее, тестовые периоды продолжительностью в несколько лет не являются надежными. В качестве контроля, помимо перекрестной проверки, описанной выше, мы также можем проводить тесты с различными применяемыми ценами во время торговли в любой день недели с теми же настройками советника. Это дает следующие результаты:


Общая производительность явно страдает, как только мы выходим за рамки рекомендаций сценария PCA, но почему? Почему торговля только в рамках параметров, определяющих дисперсию, дает нам лучшие результаты, чем неограниченные настройки? Я считаю, что это уместный вопрос, поскольку влияние на дисперсию не обязательно подразумевает большую прибыльность, поскольку общая тенденция изучаемого набора данных может быть искажена. Вот почему выбор наиболее определяющих дисперсию настроек следует осуществлять только в том случае, если базовые и общие тенденции в изучаемом наборе данных соответствуют общим целям трейдера.
Если мы рассмотрим график EURUSD, то увидим, что в период анализа PCA с 2022.01.01 по 2023.01.01 пара в основном демонстрировала тенденцию к снижению, прежде чем в октябре на короткое время развернулась. Однако в период перекрестной проверки, в 2023 году, пара сильно колебалась, не формируя каких-либо серьезных трендов, как в 2022 году. Это может означать, что, выполняя анализ по основным периодам тренда, можно лучше уловить параметры дисперсии, задающие тренд, и они могут оказаться полезными даже в ситуациях резкого разворота, как это стало очевидно в 2023 году.
Заключение
Мы увидели, что PCA по своей сути является аналитическим инструментом, направленным на снижение размерности набора(ов) данных путем выявления измерений (или компонентов набора данных), которые в наибольшей степени отвечают за определение его базовых тенденций. Существует множество доступных инструментов для снижения размерности данных, и на первый взгляд PCA может показаться примитивным, но он требует осторожного анализа и интерпретации, учитывая, что он всегда основан на базовых тенденциях изучаемого набора данных.
В примере, который мы рассмотрели при тестировании, базовые тенденции для изучаемого символа были медвежьими, и на основании этого при перекрестной проверке большинство размещенных сделок вне выборки были короткими. Если бы гипотетически мы изучали бычий рынок для рассматриваемого символа, то любые торговые стратегии, которые будут приняты на основе рекомендуемых настроек PCA, должны были бы извлекать выгоду из бычьей среды. И наоборот, в таких ситуациях имеет смысл выбирать настройки, которые в наименьшей степени объясняют дисперсию, если вы намерены извлечь выгоду из медвежьего рынка, поскольку медвежий рынок и бычий рынок являются полярными противоположностями. Кроме того, PCA выдает более одной пары настроек, каждая из которых имеет весовое значение, или собственное значение, что подразумевает возможность принятия более одной настройки, если их весовые значения превышают достаточный порог. В данной статье этот вопрос не рассматривался, и читатель может самостоятельно с этим ознакомиться, поскольку исходный код приложен ниже. Использование этого кода в Мастере MQL5 для сборки советника можно посмотреть здесь.
Однако один из подходов, который можно использовать для размещения большего количества настроек PCA в скрипте анализа и советнике, заключается в простой нормализации собственных значений таким образом, чтобы, например, все они были положительными и находились в диапазоне от 0,0 до 1,0. После этого вы сможете определить пороговые значения отбора для собственных векторов, которые вы будете выбирать из каждого анализа. Например, если анализ PCA матрицы 3 x 3 изначально дает значения 2,94, 1,92, 0,14, то мы нормализуем эти значения до диапазона 0–1 следующим образом: 0,588, 0,384 и 0,028. При использовании нормализованных значений пороговое значение, например 0,3, может позволить беспристрастно выбирать собственные векторы для нескольких анализов. Повторный анализ с другим набором данных и даже другим размером матрицы может по-прежнему иметь собственные векторы, выбранные аналогичным образом. Для скрипта это будет означать итерацию по собственным значениям и добавление двух перекрестных свойств для каждого совпавшего значения в выходной список или массив. Этот массив может быть структурой, которая регистрирует свойства x и y в матрице набора данных. При использовании советника необходимо ввести свойства фильтра в виде строковых значений, разделенных запятой, для масштабируемости. Для этого потребуется проанализировать строку и извлечь свойства в стандартный формат, понятный советнику.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/14743
 Особенности написания Пользовательских Индикаторов
Особенности написания Пользовательских Индикаторов

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Весьма полезная информация, спасибо.
Однако для матрицы "_m" почему бы вам не итерировать индекс "_rates" до тех пор, пока "i<=_buffer_size"?
Весьма полезная информация, спасибо.
Однако для матрицы "_m" почему бы вам не итерировать индекс "_rates" до тех пор, пока "i<=_buffer_size"?
Должно было быть так, но учитывая большой размер буфера, я думаю, мы скопировали данные за год, эффект от этой ошибки был минимальным. Спасибо, что указали.
Должно было быть так, но, учитывая большой размер буфера, я думаю, мы скопировали данные за год, эффект от этой ошибки был минимальным. Спасибо, что указали на это.