
Нейросети — это просто (Часть 97): Обучение модели с использованием MSFformer

Введение
В предыдущей статье мы построили основные модули модели MSFformer: CSCM и Skip-PAM. В CSCM модуле происходит построение дерева признаков анализируемого временного ряда. А Skip-PAM извлекает информацию из временных рядов на нескольких масштабах через механизм внимания, построенный на основе дерева временных признаков. В данной статье мы продолжим начатую работу: обучим модель и оценим эффективность её работы на реальных данных в тестере стратегий MetaTrader 5.
1. Архитектура моделей
И прежде, чем приступить к обучению моделей нам предстоит выполнить целый ряд подготовительных работ. Вначале нам необходимо определить архитектуру моделей. Метод MSFformer был разработан для решения задач прогнозирования временных рядов. Следовательно, мы внедрим его в модель Энкодера состояния окружающей среды, как и ряд других аналогичных методов.
1.1 Архитектура Энкодера состояния окружающей среды
Архитектура Энкодера состояния окружающей среды задается в методе CreateEncoderDescriptions. В параметрах данный метод получает указатель на объект динамического массива, в который нам предстоит записать архитектуру модели.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В теле метода мы проверяем актуальность полученного указателя и, при необходимости, создаем новый экземпляр динамического массива.
Далее мы переходим к непосредственному описанию архитектуры модели. На вход Энкодера мы подаем "сырые" данные описания текущего состояния окружающей среды. Как обычно, в качестве слоя исходных данных мы используем объект базового полносвязного слоя без функции активации. Её применение в данном случае излишне, так как получаемые исходные данные мы будем записывать напрямую в буфер результатов указанного слоя.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь следует обратить внимание, что размер создаваемого слоя исходных данных должен точно соответствовать размеру тензора описания состояния окружающей среды. Более того, описание состояния окружающей среды должно быть идентично на всех стадиях обучения и эксплуатации модели. Поэтому, для удобства синхронизации параметров программ, используемых в процессе обучения и эксплуатации моделей, мы вынесем в константы 2 параметры: количество элементов описания одной свечи (BarDescr) и глубину анализируемой истории (HistoryBars). Произведением указанных констант мы и воспользуемся для задания размера создаваемого слоя исходных данных.
Как уже было сказано выше, на вход модели мы планируем подавать "сырые" (не обработанные) исходные данные. С одной стороны, это позволяет нам не акцентировать внимание на синхронизации блоков подготовки исходных данных в программах обучения и эксплуатации модели. Это хорошая новость.
С другой стороны, использование не обработанных данных обычно снижает эффективность обучения моделей. Это вызывается сильным различием статистических показателей различных элементов в используемых исходных данных. Для минимизации влияния данного фактора мы проведем первичную обработку исходных данных прямо в нашей модели. Данный функционал выполнит слой пакетной нормализации данных. Его алгоритм построен таким образом, что на выходе мы получим все данные со средним значением близким к "0" и единичной дисперсией.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Подготовленные исходные данные, уже нормализованного временного ряда, мы подаем на вход модуля извлечения признаков CSCM.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCSCMOCL; descr.count = HistoryBars; descr.window = BarDescr;
Обратите внимание, что извлекать признаки мы будем в рамках унитарных временных рядов. И здесь мы указываем длину последовательности равной глубине анализируемой истории, а количество унитарных последовательностей равно размеру вектора описания одной свечи. Однако при составлении тензора описания состояния окружающей среды в предыдущих работах мы обычно собираем матрицу данных, в которой строки соответствуют анализируемым барам, а столбцы — признакам. Поэтому мы укажем в параметрах CSCM необходимость предварительного транспонирования данных.
descr.step = int(true);
Извлекать признаки мы будем в 3 уровнях с размерами окон анализа 6, 5 и 4 бара.
{
int temp[] = {6, 5, 4};
if(!ArrayCopy(descr.windows, temp))
return false;
}
Функцию активации мы не используем, а оптимизировать параметры модели мы будем с использованием метода Adam.
descr.step = int(true); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Далее согласно алгоритму метода MSFformer следует модуль Skip-PAM. В нашей реализации мы добавим 3 последовательных слоя Skip-PAM с одинаковой конфигурацией.
//--- layer 3 - 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSPyrAttentionMLKV; descr.count = HistoryBars; descr.window = BarDescr;
Здесь мы указываем аналогичный размер анализируемой последовательности, только в данном случае мы уже работаем с мультимодальной последовательности.
Размер внутреннего вектора описания сущностей Query, Key и Value мы укажем в 32 элемента. При этом количество голов внимания для тензора Key-Value будет в 2 раза меньше.
descr.window_out = 32; { int temp[] = {8, 4}; if(!ArrayCopy(descr.heads, temp)) return false; } descr.layers = 3; descr.activation = None; descr.optimization = ADAM; for(int l = 0; l < 3; l++) if(!encoder.Add(descr)) { delete descr; return false; }
Пирамида внимания каждого из Skip-PAM будет содержать 3 уровня. Здесь мы так же используем метод Adam для оптимизации параметров модели.
На выходе модуля Skip-PAM мы получаем тензор, размер которого соответствует исходным данным. При этом его содержимое скорректировано зависимостями между элементами анализируемой последовательности. И далее нам предстоит построить прогнозные траектории продолжения мультимодального временного ряда исходных данных. Мы планируем строить отдельные прогнозные траектории для каждого унитарного ряда в анализируемой мультимодальной последовательности. Для этого мы сначала транспонируем тензор данных, полученный от модуля Skip-PAM.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; }
После чего воспользуемся 2 последовательными сверточными слоями, которые выполнят роль MLP для отдельных унитарных последовательностей.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; descr.window_out = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = LatentCount; descr.step = LatentCount; descr.window_out = NForecast; descr.optimization = ADAM; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Обратите внимание, что для организации подобия MLP в выше представленных сверточных слоях мы указываем равными размеры анализируемого окна и его шага. В первом случае на уровне глубины анализируемой последовательности. А во втором случае равным количеству фильтров предыдущего слоя. При этом количество блоков свертки равно количеству анализируемых унитарных последовательностей. Для создания нелинейности между сверточными слоями мы используем функцию активации LReLU.
Для второго сверточного слоя мы устанавливаем количество фильтров равное размеру прогнозируемой последовательности. Которое в нашем случае задано константой NForecast.
Кроме того, для второго сверточного слоя в качестве функции активации мы используем гиперболический тангенс (TANH). Надо сказать, что выбор функции активации не случаен. Как вы помните, на входе модели для предварительной обработки исходных данных мы использовали слой пакетной нормализации, который приводит данные к единичной дисперсии и среднее значение близкое к "0". Согласно правилу "3 сигм" около 2/3 значений нормально распределенной случайной величины лежат не далее 1 стандартного отклонения от среднего значения. Таким образом, использование гиперболического тангенса с диапазоном значений (-1, 1) в качестве функции позволяет покрыть 68% значений анализируемой величины. И при этом отфильтровать "выбросы", которые лежат далее стандартного отклонения от средней величины.
Здесь надо понимать, что мы не ставим перед собой цель выучить и спрогнозировать все колебания анализируемого временного ряда, так как он полон различного шума. Нам лишь нужен прогноз достаточной точности, чтобы построить прибыльную торговую стратегию.
Далее, с помощью слоя транспонирования данных мы возвращаем прогнозные значения в представление исходных данных.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
И добавляем к ним статистические показатели, которые мы изъяли ранее в слое пакетной нормализации.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr*NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers=1; if(!encoder.Add(descr)) { delete descr; return false; }
На этом можно уже считать законченной архитектуру модели Энкодера состояния окружающей среды. Действительно, в таком виде она уже соответствует модели, представленной авторами метода MSFformer. Но все же мы добавим последний штрих. В предыдущих работах мы уже говорили, что парадигма прямого прогнозирования предполагает независимость отдельных шагов в прогнозной последовательности. А это, как Вы сами понимаете, противоречит сущности временного ряда. Поэтому мы воспользуемся наработками метода FreDF для согласования отдельных шагов в построенной нами прогнозной последовательности анализируемого временного ряда.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
В таком виде архитектура Энкодера имеет более законченный вид. И я надеюсь, что, данные мной, комментарии помогли Вам понять логику, которую мы вложили в построенную модель.
На данном этапе мы описали архитектуры модели прогнозирования предстоящего ценового движения и могли бы идти далее по пути обучения модели. Но наша цель выходит за рамки только прогнозирования временного ряда. Мы хотим обучить модель, способную совершать сделки на финансовых рынках и генерировать прибыль. А значит, нам предстоит ещё создать модель Актера, который будет генерировать торговые действия и совершать их от нашего имени. А также модель Критика, который будет оценивать сгенерированные Актером торговые операции и поможет нам выстроить прибыльную торговую стратегию.
1.2 Архитектуры Актера и Критика
Описание архитектуры моделей Актера и Критика мы создадим в методе CreateDescriptions. В параметрах указанный метод получает 2 указателя на динамические массивы, в которые мы и сохраним описание создаваемых архитектурных решений.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Как и в предыдущем случае, в теле метода сначала мы проверяем актуальность полученных указателей и, при необходимости, создаем новые экземпляры объектов динамических массивов. После чего переходим к непосредственному описанию архитектур создаваемых моделей.
Первой мы создадим модель Актера. И прежде, чем приступить к описанию архитектурного решения давайте не много поговорим о целях, которые мы ставим перед моделью Актера. Конечно, основная его цель сгенерировать оптимальные действия для совершения торговой операции. Но как модель должна это сделать? Очевидно, что Актер должен посмотреть на прогнозное ценовое движение, которое сгенерирует Энкодер состояния окружающей среды, и определить направление сделки. Затем необходимо посмотреть на текущее состояние счета и определить наши возможности. И уже из совокупности проведенных анализов Актер определяет объем сделки, риски и цели в виде стоп-лосса и тейк-профита. Именно в такой парадигме мы и опишем архитектуру Актера.
На вход модели мы сначала подаем вектор описания состояния счета.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Который мы пропустим через полносвязный слой.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
А затем мы поставим блок кросс-внимания из 9 вложенных слоев, в котором сопоставим текущее состояние счета и прогнозное ценовое движение.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLCrossAttentionMLKV; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); } { int temp[] = {8, 4}; ArrayCopy(descr.heads, temp); } descr.layers = 9; descr.step = 1; descr.window_out = 32; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Как и в Энкодере состояния окружающей среды, мы используем:
- Размер вектора описания внутренних сущностей в 32 элемента;
- Количество голов внимания тензора Key-Value в 2 раза меньше тензора Query.
При этом каждый тензор Key-Value действует в рамках только одного вложенного слоя.
Далее мы анализируем полученные данные с помощью 3 слойного MLP.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
И на выходе модели генерируем вектор действий с помощью стохастической головы.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Напомню, что создаваемая нами стохастическая голова генерирует "случайные" действия Актера. Допустимая область этих случайных значений строго ограничена параметрами нормального распределения в виде среднего значения и стандартного отклонения, которые учатся предшествующим слоем. Таким образом, в идеальных условиях, когда действие может быть четко определено, дисперсия распределения случайной величины генерируемого действия стремится к "0". Следовательно, на выходе Актера мы получим результат близкий к выученному среднему значению. По мере роста неопределенности, растет и дисперсия генерируемых действий. Как следствие, мы получаем случайные действия на выходе Актера. Поэтому, при использовании стохастической политики следует больше внимания уделить процессу тестирования обученной модели. При прочих равных условиях, обученная политика должна генерировать близкие результаты. Значительный разброс 2 тестовых проходов может свидетельствовать о недостаточности обучения модели.
И, конечно, генерируемые Актером действия должны быть согласованы между собой. Уровень стоп-лосса должен соответствовать допустимому риску при заявленном объеме сделки. При этом мы стремимся исключить разнонаправленные сделки. Согласовывать действия Актера мы будем с помощью слоя FreDF.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Модель Критика имеет схожую архитектуру, только вектор описания состояния счета, подаваемый на вход Актеру, мы заменяет тензором действий, которые Актер сгенерировал в анализируемом состоянии окружающей среды. Отсутствие данных о состоянии счета на входе Критика легко объяснить. Ведь получаемый нами доход или убыток зависит не от объема средств на счете, а от объема и направления открытой позиции.
Более подробно с архитектурой Критика я предлагаю Вам ознакомиться самостоятельно. Полный код всех программ, используемых при подготовке данной статьи, Вы можете найти во вложении.
2. Советники обучения моделей
После описания архитектуры обучаемых моделей я предлагаю поговорить о программах обучения моделей. В данном случае мы будем использовать 2 советника:
- StudyEncoder.mq5 — советник обучения Энкодера состояния окружающей среды.
- Study.mq5 — обучение политики Актера.
2.1 Программа обучения Энкодера
В рамках "StudyEncoder.mq5" мы будем обучать модель Энкодера прогнозировать предстоящее ценовое движение и значения анализируемых индикаторов. Пусть Вас не удивляет, что мы будем расходовать ресурсы на прогнозирование, казалось бы, излишних показателей анализируемых индикаторов. Мы привыкли, что индикаторы используются для выявления зон перекупленности и перепроданности, определения силы тренды, поиска точек разворота ценового движения. Однако при построении индикаторов обычно используются различные цифровые фильтры, призванные минимизировать влияние шума, присущего исходным данным ценового движения. Это делает значения индикаторов боле сглаженными и, часто, более предсказуемыми. Таким образом, прогнозируя последующие значения индикаторов мы стремимся в какой-то мере уточнить и подтвердить свои прогнозы ценового движения.
В методе инициализации "StudyEncoder.mq5" мы сначала загружаем данные обучающей выборки, о методах сбора которой мы поговорим чуть позже.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
После чего мы пробуем загрузить предварительно обученную модель Энкодера состояния окружающей среды. Здесь мы понимаем, что не всегда мы будем обучать полностью новую модель, инициализированную случайными параметрами. Гораздо чаще придется дообучать модель, при первичном обучении которой нам не удалось достигнуть желаемых результатов.
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { Print("Create new model"); CArrayObj *encoder = new CArrayObj(); if(!CreateEncoderDescriptions(encoder)) { delete encoder; return INIT_FAILED; } if(!Encoder.Create(encoder)) { delete encoder; return INIT_FAILED; } delete encoder; }
Если же нам не удалось загрузить предварительно обученную модель по каким-либо причинам, то мы вызываем метод генерирования архитектуры новой модели CreateEncoderDescriptions. После чего инициализируем новую модель заданной архитектуры случайными параметрами.
//--- Encoder.getResults(Result); if(Result.Total() != NForecast * BarDescr) { PrintFormat("The scope of the Encoder does not match the forecast state count (%d <> %d)", NForecast * BarDescr, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Следующим этапом мы организуем небольшой блок контроля архитектуры модели, в котором проверим размеры слоя исходных данных и тензора результатов. Конечно, мы понимаем, что при создании новой модели отклонения здесь практически невозможны. Ведь для проверки размеров мы используем те же константы, которыми ранее задавали размеры слоев при описании архитектуры модели. Данный блок контролей больше направлен на выявление случаем загрузки предварительно обученных моделей, которые не соответствуют используемой обучающей выборке.
После успешного прохождения контрольного блока нам остается лишь сгенерировать пользовательское событие начала процесса обучения модели и завершить работу метода инициализации советника.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Непосредственно процесс обучения модели построен в методе Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
В теле метода мы сначала генерируем вектор вероятностей выбора траекторий из обучающей выборки. Здесь алгоритм построен таким образом, чтобы проходы с максимальной доходностью получили большую вероятность. Конечно, это более актуально при обучении политики Актера. Ведь модель Энкодера состояния счета не анализирует ни текущий баланс, ни открытые позиции. Она работает только с показателями анализируемых индикаторов и ценового движения. Тем не менее, мы оставили данный функционал для сохранения единства архитектуры решения всех используемых программ.
Затем мы объявим необходимые локальные переменные.
vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
И организуем цикл обучения модели. Количество итераций обучения модели указывается во внешних параметрах программы.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter--; continue; }
В теле цикла мы сэмплируем одну траекторию и состояние на ней из обучающей выборки. Проверяем выбранное состояние на наличие сохраненных данных, после чего переносим информацию из обучающей выборки в буфер данных.
state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum()==0) { iter--; continue; } bState.AssignArray(state);
На основании подготовленных данных мы осуществляем прямой проход обучаемой модели.
//--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Однако мы не загружаем полученные прогнозные значения. На данном этапе нас не столько интересуют результаты прогнозирования, сколько их отклонение от реальных последующих значений, которые сохранены в обучающей выборке. Поэтому мы загружаем последующие состояния из обучающей выборки.
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
И подготовим истинные значения, с которыми нам предстоит сравнить полученные прогнозы. Эти данные мы подадим в параметры метода обратного прохода нашей модели. Именно в нем осуществляется оптимизация параметров модели с целью минимизации ошибки прогнозирования.
if(!Encoder.backProp(Result,(CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
После успешного выполнения прямого и обратного проходов нашей модели нам остается лишь проинформировать пользователя о ходе процесса обучения и перейти к следующей итерации цикла.
if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Должен признать, что процесс обучения построен максимально просто и без излишеств. Длительность обучения определяется только количеством итераций обучения, которое указывается пользователем во внешних параметрах при запуске советника. Ранний выход из процесса обучения возможет только при возникновении ошибки или принудительном закрытии программы пользователем в терминале.
После завершения процесса обучения мы очищаем поле комментариев на графике программы, в которое мы ранее выводили информацию о ходе обучения.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
Результаты обучения выводим в журнал MetaTrader 5 и инициализируем завершение работы текущей программы. Сохранение обученной модели осуществляется в методе OnDeinit. С полным кодом советника Вы можете ознакомиться во вложении.
2.2 Алгоритм обучения Актера
Второй советник "Study.mq5" предназначен для обучения политики Актера. При этом, в рамках данной программы происходит и обучение модели Критика.
Здесь надо сказать, что роль Критика довольно специфична — он должен направить Актера действовать в нужном направлении. Однако сам Критик не используется в процессе эксплуатации модели. Иными словами, как бы это парадоксально не звучало, мы обучаем Критика, чтобы обучить Актера.
Структура советника обучения Актера аналогична рассмотренной выше программе обучения Энкодера. И в рамках данной статьи мы лишь остановимся на методе обучения моделей Train.
Как и в выше рассмотренной программе, в теле метода мы сначала генерируем вектор вероятностей выбора траекторий из обучающей выборки и объявляем локальные переменные.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
После чего объявляем цикл обучения, в теле которого сэмплируем траекторию из обучающей выборки и состояние на ней.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i <= 0) { iter--; continue; } state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum()==0) { iter--; continue; } bState.AssignArray(state);
Тут же мы закодируем метку времени, которую представим в виде вектора синусоидальных гармоник различной частоты.
bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Собранными данными мы воспользуемся для генерирования прогнозных значений предстоящего ценового движения. Эта операция выполняется путем вызова метода прямого прохода ранее обученного Энкодера.
//--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false,(CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Как было сказано выше, для обучения Актера нам нужно обучить Критика. Мы извлекаем из обучающей выборки действия, совершенные Актером при сборе обучающей выборки.
//--- Critic bActions.AssignArray(Buffer[tr].States[i].action); if(bActions.GetIndex() >= 0) bActions.BufferWrite();
И подаем их на вход нашей модели Критика вместе с прогнозным состоянием окружающей среды.
Critic.TrainMode(true); if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Здесь стоит обратить внимание, что на вход Критика мы подаем скрытое состояние Энкодера вместо данных прогноза предстоящего ценового движения и будущих показателей индикаторов, которые сформировались на выходе модели. Это связано с тем, что на выходе Энкодера мы добавили к прогнозным значениям статистические параметры исходного временного ряда. И следовательно, перед обработкой таких данных в модели Критика нам необходимо их нормализовать. Но вместо этого, мы берем скрытое состояние Энкодера, в котором прогнозные значения содержатся без смещений, свойственных исходным данным.
По результатам прямого прохода Критик сформировал некоторую оценку действий Актера. Которая, очевидно, на первых итерациях обучения будет далека от реального вознаграждения, полученного Актером в ходе взаимодействия с окружающей средой. Мы извлекаем из обучающей выборки реальное вознаграждение, которое было получено за предпринятое действие.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
И осуществляем обратный проход Критика с целью минимизации ошибки оценки действий.
Следующим шагом мы осуществляем обучение политики Актера. Для осуществления его прямого прохода нам предстоит сначала подготовить тензор описания состояния счета, который мы извлекаем из обучающей выборки.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
А затем осуществим прямой проход модели, передав в параметрах метода вектор описания состояния счета и скрытое состояние Энкодера.
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Очевидно, что по результатам прямого прохода Актера сформировался некоторый вектор действий. Его мы вместе с латентным состоянием Энкодера подаем на вход Критика.
Critic.TrainMode(false); if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Обратите внимание, что на данном этапе мы отключаем режим обучения Критика. Так как в данном случае модель Критика будет использоваться только для передачи градиента ошибки Актеру.
Оптимизацию параметров Актера мы будем осуществлять, так сказать, в 2 направлениях. Во-первых, ожидается, что в нашей обучающей выборке есть успешные проходы, по результатам которых была получена прибыль за период обучения. Мы возьмем такие проходы в качестве эталонных и методами обучения с учителем подтянем политику нашего Актера к таким действиям.
if(Buffer[tr].States[0].rewards[0] > 0) if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
С другой стороны, мы понимаем, что прибыльных проходов будет значительно меньше убыточных. И, конечно, мы не будем игнорировать информацию, которую они несут. Согласитесь, в процессе обучения политики Актера убыточные проходы не менее полезны, чем прибыльные. Если к прибыльным проходом мы подтягиваем политику Актера, то от убыточных нужно отталкиваться. Но насколько и в какую сторону? Кроме того, даже в убыточных проходах могут быть прибыльные сделки. И нам желательно сохранить эту информацию. Именно здесь и проявляется роль Критика в процессе обучения политики Актера.
Предполагается, что в процессе обучения Критика, его параметры оптимизируют некую функцию зависимости между действием Актера, состоянием окружающей среды и вознаграждением. Следовательно, если при неизменности состояния окружающей среды мы будем двигаться в сторону максимизации вознаграждения, то градиент ошибки нам укажет направление корректировки действий Агента для повышения ожидаемого вознаграждения. Этим свойством мы и воспользуемся.
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); }
Мы извлекаем текущую оценку действий Критиком. Увеличим в ней прибыль на 1% и на столько же уменьшим убыток. Это и будут наши целевые значения на данном этапе. Их мы передадим для проведения операций обратного прохода Критика, а затем и Актера.
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), LatentLayer, -1, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Хочу напомнить, что на данном этапе для Критика мы отключили режим обучения. А значит он используется только для передачи градиента ошибки Актеру. И данный обратный проход не корректирует параметры Критика. Актер же корректирует параметры модели в сторону максимизации ожидаемого вознаграждения.
Далее нам остается лишь проинформировать пользователя о ходе обучения моделей и перейти к следующей итерации цикла.
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После завершения процесса обучения мы очищаем поле комментариев на графике инструмента. Результаты обучения выводим в журнал и инициализируем процесс завершения работы программы.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
На этом мы завершаем рассмотрение алгоритмов программ обучения моделей. А с полным кодом всех программ, используемых при подготовке статьи, Вы можете самостоятельно ознакомиться во вложении.
3. Сбор обучающей выборки
Следующий, не мене важный этап — сбор данных для обучающей выборки. Здесь надо сказать, что для получения реальных данных о взаимодействии с окружающей средой мы используем тестер стратегий MetaTrader 5. В нем мы осуществляем проходы на исторических данных. А полученные результаты записываем в файл обучающей выборки.
И вполне естественно, что перед началом обучения становится вопрос — где взять успешные проходы по обучающей выборке. И должен сказать здесь есть несколько вариантов. Наверное, самый очевидный, это взять историю и вручную "накидать" идеальные сделки. Бесспорно, такой подход имеет место быть. Но это ручной труд. И с ростом обучающей выборки кратно растут и затраты труда. А вместе с тем время на подготовку обучающей выборки. Кроме того, использование ручного труда всегда ведет к появлению различного рода ошибок, которые списываются на "человеческий фактор". Я же в своей работе для сбора первичных данных использую фреймворк Real-ORL, который уже был подробно описан в данной серии статей. Там же приведен код программы, который продублирован во вложении. И мы не будем на нем подробно останавливаться.
Собранная первичная обучающая выборка позволяет дать модели первое представление об окружающей среде. Но мир финансовых рынков настолько многогранен, что полностью его повторить не может ни одна обучающая выборка. Кроме того, зависимости, которые модель построила между анализируемыми индикаторами и прибыльными сделками могут оказаться ложными или неполными, так как в представленной обучающей выборке отсутствовали примеры, способные выявить подобные несоответствия. Поэтому в процессе обучения нам потребуется уточнение обучающей выборки. И на этот раз подход к сбору дополнительной информации будет уже отличаться.
Дело в том, что на данном этапе перед нами стоит задача оптимизация выученной политики Актера. И для выполнения поставленной задачи нам необходимы данные достаточно близкие к траектории текущей политики Актера, которые позволяют понять направление вектора изменения вознаграждения при некотором отклонений действий от текущей политики. Имея такую информацию, мы можем увеличить доходность текущей политики, двигаясь в направлении увеличения вознаграждения.
Здесь так же возможны варианты. И подходы могут меняться по разным факторам. В том числе и в зависимости от архитектуры модели. К примеру, при использовании стохастической политики мы можем просто запустить несколько проходов Актера с использованием текущей политики в тестере стратегий. Стохастическая голова все сделает за нас. Разброс случайных действий актера покроет интересующее нас пространство действий, и мы сможем провести дообучение модели с учетом обновленных данных. В случае же использования строгой политики Актера, когда модель выстраивает однозначные связи между состоянием окружающей среды и действием, мы можем воспользоваться добавлением некоторого шума к действиям Агента, чтобы создать некое облако действий вокруг текущей политики Актера.
В обоих случаях для сбора дополнительных данных обучающей выборки удобно использовать режим медленной оптимизации тестера стратегий.
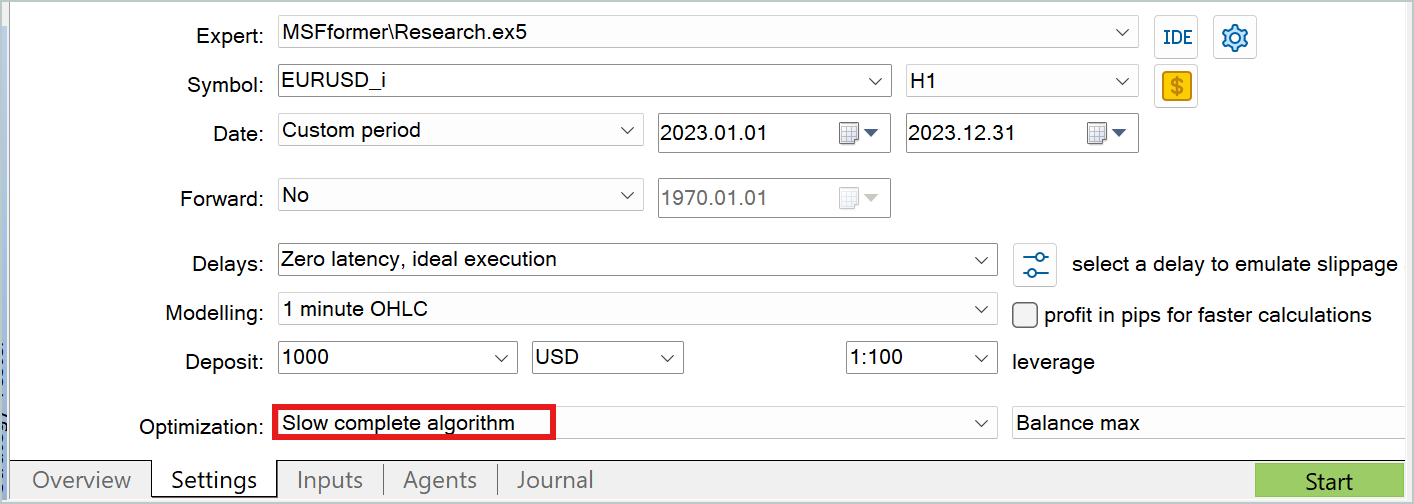
Позвольте не останавливаться на подробном рассмотрении программ взаимодействия с окружающей средой. Они уже не раз были рассмотрены в рамках данной серии статей. А полный код всех программ, используемых при подготовке данной статьи, представлен во вложении. Там же есть код программ взаимодействия с окружающей средой для вашего самостоятельного ознакомления.
4. Обучение и тестирование моделей
После рассмотрения алгоритмов всех программ, используемых при обучении моделей мы переходим непосредственно к самому процессу. Обучать представленные модели мы будем на реальных исторических данных инструмента EURUSD таймфрейм H1. В качестве периода обучения мы используем весь 2023 год.
На указанном историческом интервале мы собираем первичную обучающую выборку, как это обсуждалось выше. И на ней мы проводим обучение Энкодера состояния окружающей среды. Как уже было сказано, модель Энкодера в процессе обучения использует только исторические данные ценового движения и показателей анализируемых индикаторов. Думаю очевидно, что указанные данные идентичны для всех проходов на неизменном интервале исторических данных. Поэтому нам нет смысла на данном этапе проводить уточнение обучающей выборки. И мы обучаем модель Энкодера на первичной обучающей выборке до получения желаемого результата.
В процессе обучения мы следим за ошибкой прогнозирования. Останавливаем обучение модели, когда ошибка прогнозирования перестает снижаться и её колебания держатся в небольшом диапазоне.
Разумеется, нам интересно, что же смогла выучить модель. Несмотря на то, что наша цель — это обучение прибыльной политики Актера. Я все же утолил свое любопытство и сравнил прогнозное и фактическое изменение цены на наборе случайно выбранных данных из обучающей выборки.
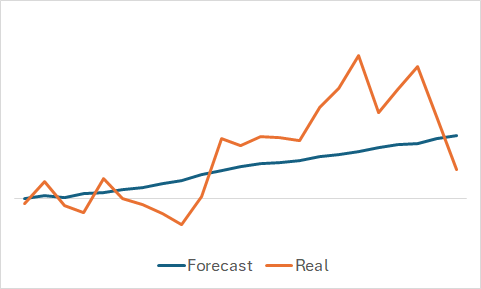
Как можно заметить на представленном графике модель смогла уловить основную тенденцию предстоящего ценового движения.
Довольно ровный график прогнозного ценового движения с незначительными колебаниями может натолкнуть на мысль, что возможно модель уловила общий тренд обучающей выборки и для всех состояний будет демонстрировать похожую картину вне зависимости от реальных данных. Чтобы подтвердить или опровергнуть такое предположение мы сэмплируем еще одно состояние из обучающей выборки и строим аналогичное сравнение прогнозного и фактического ценового движения.
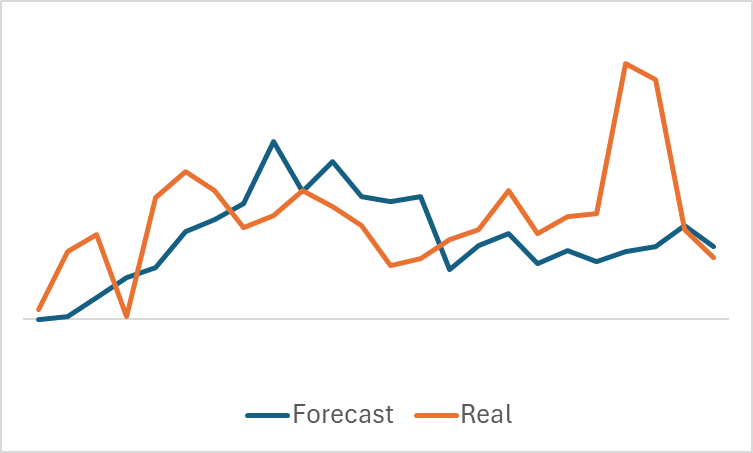
Здесь мы видим уже более значительные колебания прогнозных значений ценового движения. Тем не менее, они расположены довольно близко к реальным данным.
После обучения модели Энкодера состояний окружающей среды мы переходим ко второму этапу — обучению политики Актера. И этот процесс уже носит итерационный характер. Первую итерацию обучения мы проводим на данных первичной обучающей выборке. На этом этапе мы даем модели некое первичное представление об окружающей среде. А благодаря прибыльным проходом, которые нам удалось собрать с помощью метода Real-ORL, мы закладываем базис нашей будущей политики.
В процессе обучения моделей мы, как и на первом этапе, ориентируемся по показаниям ошибки моделей. И на первом этапе я бы рекомендовал ориентироваться на значения ошибки Критика. Да, нам необходима политика Актера, способная генерировать прибыль. Но вспомните наше обсуждение выше: для обучения Актера нам нужно обучить Критика. Именно выстраивание правильных зависимостей внутри Критика поможет нам скорректировать политику Актера в нужном направлении.
Когда ошибка Критика остановится на одном уровне без признаков дальнейшего снижения, необходимо перейти в тестер стратегий и собрать дополнительные данные с помощью советника "Research.mq5", который я рекомендую запустить в режиме медленной оптимизации.
Затем мы проводим дообучение моделей Актера и Критика. Вначале процесса дообучения моделей можно наблюдать некоторое повышение ошибки обоих моделей, которое связано с обработкой новых данных. Однако вскоре Вы заметете постепенное снижение ошибки и выход на новые минимумы.
Таким образом мы повторяем итерации уточнения обучающей выборки и дообучение моделей.
Так же хочу напомнить, что в представленной архитектуре Актера используется стохастическая голова, которая характеризуется некоторой случайностью действий. Поэтому при тестировании обученной политики Актера рекомендуется проводить несколько проходов на тестовом временном отрезке. Политику Актера можно считать обученной, если отклонениями в проходах можно пренебречь.
При подготовке данной статьи тестирование обученной модели осуществлялось на исторических данных Января 2024 года. Данный временной интервал не входил в обучающую выборку, а значит для модели это новые данные. А близость интервалов обучающей выборки и тестирования позволяет говорить о сопоставимости данных.
В процессе обучения нами была получена модель, способная генерировать прибыль как на данных обучающей выборки, так и на тестовом периоде.
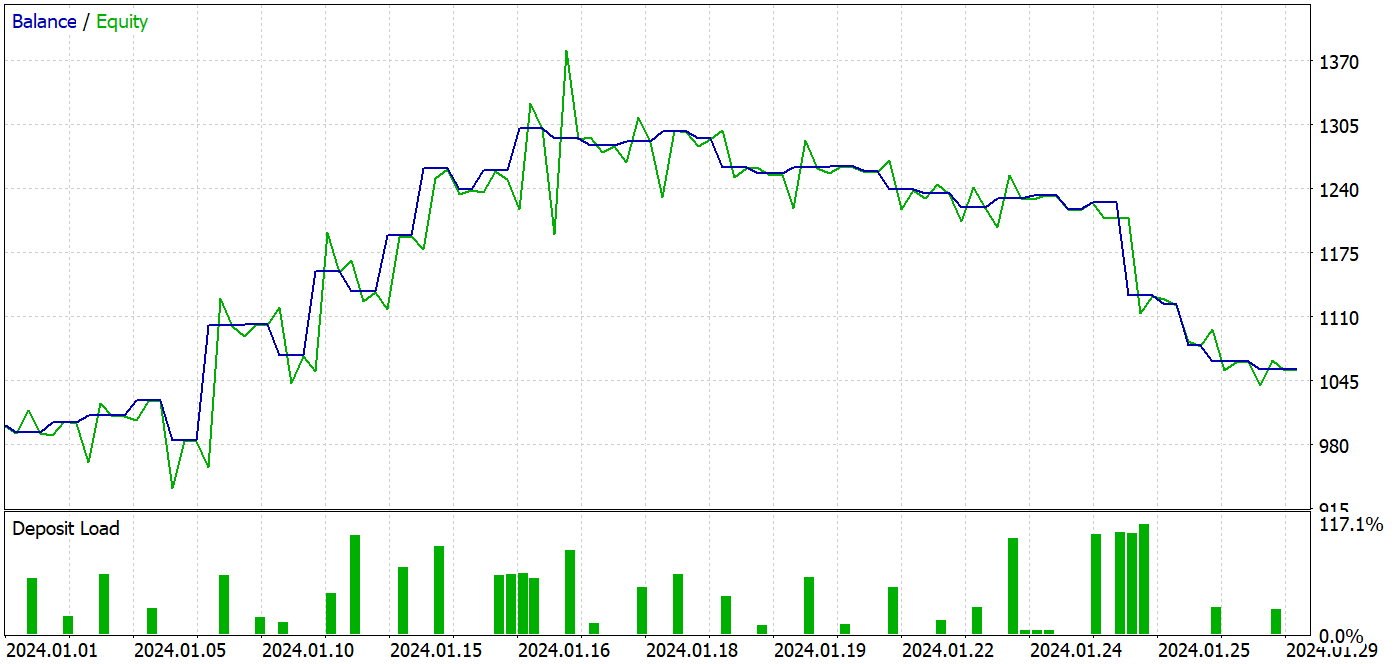
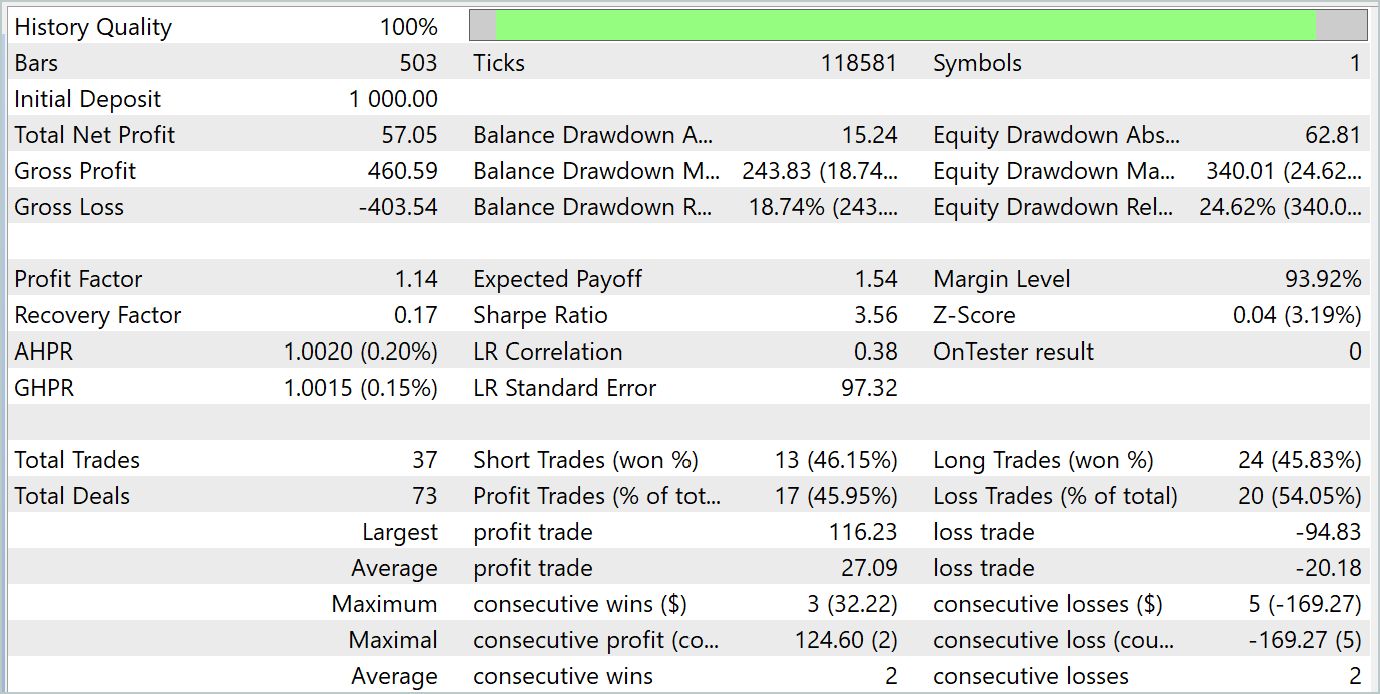
За период тестирования модель совершила 37 сделок, 17 из которых было закрыто с прибылью. Что составило почти 46%. Примечательно, что доля прибыльных сделок среди длинных и коротких позиций практически равны. Отклонение составляет только 0.32%, что может быть лишь погрешностью вычислений, связанной с малым количеством сделок. Максимальная и средняя прибыльная сделка выше соответствующих показателей убыточных сделок. Это позволило закрыть период тестирования с прибылью. А профит фактор составил 1.14. Однако настораживает, что прибыль была получена в первой половине месяца. Далее наблюдается боковое движение баланса. А последняя неделя месяца отметилась просадкой.
Заключение
В данной статье мы провели обучение и тестирование модели с использованием подходов метода MSFformer. По результатам тестирования мы получили неплохие результаты, позволяющие говорить о перспективности предложенных подходов. Однако обращает внимание просадка баланса в последней неделе тестового периода, что может свидетельствовать о необходимости дополнительных этапов обучения модели.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования