
Машинное обучение и Data Science (Часть 20): Выбор между LDA и PCA в задачах алготрейдинга на MQL5

-- Чем больше имеешь, тем меньше замечаешь.
Что такое линейный дискриминантный анализ (Linear Discriminant Analysis, ЛДА)?
ЛДА — обобщающий алгоритм машинного обучения с учителем , целью которого является поиск линейной комбинации признаков, которая наилучшим образом разделяет классы в наборе данных.
Как и Анализ главных компонентов (PCA), это алгоритм уменьшения размерности. Эти алгоритмы часто используют для уменьшения размерности. В этой статье мы сравним их и посмотрим, в какой ситуации каждый из алгоритмов работает лучше всего. Мы уже обсуждали PCA в предыдущих статьях этой серии. Давайте начнем со знакомства с алгоритмом ЛДА, поскольку основной объем статьи будет посвящен этому алгоритму и равнению его с PCA. Мы будем сравнивать производительность этих двух алгоритмов на простом наборе данных и в тестере стратегий.

Цели/теория
Для чего используется метод линейного дискриминантного анализа:
- Улучшение разделимости классов: LDA стремится найти линейные комбинации признаков, с которыми будет максимальное разделение между классами в данных. Проецируя данные на эти дискриминационные измерения, LDA помогает усилить различия между классами, делая классификацию более эффективной.
- Уменьшение размерности: LDA уменьшает размерность пространства признаков, проецируя данные на подпространство меньшей размерности. При этом при уменьшении размерности сохраняется как можно большее количество информации о классовых различиях. Уменьшение пространства признаков может привести к упрощению моделей, ускорению вычислений и повышению производительности.
- Минимизация внутриклассовой вариативности: LDA стремится минимизировать разброс или вариативность внутри класса, гарантируя, что точки данных, принадлежащие одному классу, плотно сгруппированы вместе в преобразованном пространстве. За счет уменьшения внутриклассовой вариативности LDA помогает улучшить разделение между классами и повысить надежность модели классификации.
- Увеличение межклассового расстояния: И наоборот, LDA стремится максимизировать различие между классами за счет установки максимально возможного расстояния между классами в преобразованном пространстве. Таким образом, алгоритм ЛДА позволяет проводить более четкие различия между классами и делать классификацию более точной.
- Возможности мультиклассовой классификации: ЛДА подходит для группировки признаков на более чем два класса. Учитывая отношения между всеми классами одновременно, алгоритм находит общее подпространство, которое оптимально разделяет все классы. При этом мы получаем эффективные границы классификации в многомерных пространствах признаков.
Предположения:
Метод линейного дискриминантного анализа делает несколько предположений. Итак, предполагается, что
- Измерения независимы друг от друга.
- Данные обычно распределяются внутри объектов.
- Классы в наборе данных имеют одинаковую матрицу ковариаций.
Шаги алгоритма ЛДА
1. Расчет матрицы рассеяния внутри класса (SW):
Вычисляем матрицу рассеяния для каждого класса.
matrix SW, SB; //within and between scatter matrices SW.Init(num_features, num_features); SB.Init(num_features, num_features); for (ulong i=0; i<num_classes; i++) { matrix class_samples = {}; for (ulong j=0, count=0; j<x.Rows(); j++) { if (y[j] == classes[i]) //Collect a matrix for samples belonging to a particular class { count++; class_samples.Resize(count, num_features); class_samples.Row(x.Row(j), count-1); } } matrix diff = Base::subtract(class_samples, class_means.Row(i)); //Each row subtracted to the mean if (diff.Rows()==0 && diff.Cols()==0) //if the subtracted matrix is zero stop the program for possible bugs or errors { DebugBreak(); return x_centered; } SW += diff.Transpose().MatMul(diff); //Find within scatter matrix vector mean_diff = class_means.Row(i) - x_centered.Mean(0); SB += class_samples.Rows() * mean_diff.Outer(mean_diff); //compute between scatter matrix }
Суммируем эти отдельные матрицы рассеяния, чтобы получить матрицу рассеяния внутри класса.
2. Вычисление матрицы рассеяния между классами (SB):
Находим средний вектор для каждого класса.
matrix SW, SB; //within and between scatter matrices SW.Init(num_features, num_features); SB.Init(num_features, num_features); for (ulong i=0; i<num_classes; i++) { matrix class_samples = {}; for (ulong j=0, count=0; j<x.Rows(); j++) { if (y[j] == classes[i]) //Collect a matrix for samples belonging to a particular class { count++; class_samples.Resize(count, num_features); class_samples.Row(x.Row(j), count-1); } } matrix diff = Base::subtract(class_samples, class_means.Row(i)); //Each row subtracted to the mean if (diff.Rows()==0 && diff.Cols()==0) //if the subtracted matrix is zero stop the program for possible bugs or errors { DebugBreak(); return x_centered; } SW += diff.Transpose().MatMul(diff); //Find within scatter matrix vector mean_diff = class_means.Row(i) - x_centered.Mean(0); SB += class_samples.Rows() * mean_diff.Outer(mean_diff); //compute between scatter matrix }
Рассчитываем матрицу рассеяния между классами.
SB += class_samples.Rows() * mean_diff.Outer(mean_diff); //compute between scatter matrix
3. Расчет собственных значений и собственных векторов
Решаем обобщенную задачу собственных значений, включающую SW и SB, получаем собственные значения и соответствующие им собственные векторы.
matrix eigen_vectors; vector eigen_values; matrix SBSW = SW.Inv().MatMul(SB); SBSW += this.m_regparam * MatrixExtend::eye((uint)SBSW.Rows()); if (!SBSW.Eig(eigen_vectors, eigen_values)) { Print("%s Failed to calculate eigen values and vectors Err=%d",__FUNCTION__,GetLastError()); DebugBreak(); matrix empty = {}; return empty; }
Выбор отличительных признаков:
Сортируем собственные значения в порядке убывания.
vector args = MatrixExtend::ArgSort(eigen_values);
MatrixExtend::Reverse(args);
eigen_values = Base::Sort(eigen_values, args);
eigen_vectors = Base::Sort(eigen_vectors, args); Выбираем k лучших собственных векторов, чтобы сформировать матрицу преобразования.
this.m_components = extract_components(eigen_values); Поскольку и линейный дискриминантный анализ LDA, и анализ главных компонентов PCA служат одной и той же цели — уменьшить размерность, мы можем использовать аналогичные методы для извлечения компонентов, например дисперсию и график собственных значений Scree Plot. Их же мы использовали в статье про PCA.
Мы можем расширить наш класс алгоритма LDA, чтобы он мог извлекать компоненты для себя, когда по умолчанию количество компонентов равно NULL.
if (this.m_components == NULL) this.m_components = extract_components(eigen_values); else //plot the scree plot extract_components(eigen_values);
Проецирование данных на новое пространство объектов
Умножаем исходные данные на выбранные собственные векторы, чтобы получить новое пространство признаков.
this.projection_matrix = Base::Slice(eigen_vectors, this.m_components); return x_centered.MatMul(projection_matrix.Transpose());
Весь этот код выполняется внутри функции fit_transform. Эта функция отвечает за обучение и подготовку алгоритма линейного дискриминантного анализа. Чтобы наш класс мог обрабатывать новые/невидимые данные, нужно добавить функции для дальнейших преобразований.
matrix CLDA::transform(const matrix &x) { if (this.projection_matrix.Rows() == 0) { printf("%s fit_transform method must be called befor transform",__FUNCTION__); matrix empty = {}; return empty; } matrix x_centered = Base::subtract(x, this.mean); return x_centered.MatMul(this.projection_matrix.Transpose()); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CLDA::transform(const vector &x) { matrix m = MatrixExtend::VectorToMatrix(x, this.num_features); if (m.Rows()==0) { vector empty={}; return empty; //return nothing since there is a failure in converting vector to matrix } m = transform(m); return MatrixExtend::MatrixToVector(m); }
Обзор класса LDA
Общий класс алгоритма ЛДА теперь выглядит так:
enum lda_criterion //selecting best components criteria selection { CRITERION_VARIANCE, CRITERION_KAISER, CRITERION_SCREE_PLOT }; class CLDA { CPlots plt; protected: uint m_components; lda_criterion m_criterion; matrix projection_matrix; ulong num_features; double m_regparam; vector mean; uint CLDA::extract_components(vector &eigen_values, double threshold=0.95); public: CLDA(uint k=NULL, lda_criterion CRITERION_=CRITERION_SCREE_PLOT, double reg_param =1e-6); ~CLDA(void); matrix fit_transform(const matrix &x, const vector &y); matrix transform(const matrix &x); vector transform(const vector &x); };
Параметр регуляризации reg_param имеет меньшее значение, поскольку он используется только для регуляризации матриц SW и SB. Это позволяет избегать ошибок при вычислении собственных значений и векторов.
SW += this.m_regparam * MatrixExtend::eye((uint)num_features); SB += this.m_regparam * MatrixExtend::eye((uint)num_features);
Использование линейного дискриминантного анализа на выборке
Применим наш класс ЛДА на популярной выборке данных Iris-csv и посмотрим, что он сделает.
string headers; matrix data = MatrixExtend::ReadCsv("iris.csv",headers); //Read csv
Напомню, что это метод обучения с учителем. Это означает, что нам нужно собирать независимые и целевые переменные отдельно и передавать их в модель.
matrix x; vector y; MatrixExtend::XandYSplitMatrices(data, x, y);
#include <MALE5\Dimensionality Reduction\LDA.mqh> CLDA *lda; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- string headers; matrix data = MatrixExtend::ReadCsv("iris.csv",headers); //Read csv matrix x; vector y; MatrixExtend::XandYSplitMatrices(data, x, y); Print("Original X\n",x); lda = new CLDA(); matrix transformed_x = lda.fit_transform(x, y); Print("Transformed X\n",transformed_x); return(INIT_SUCCEEDED); }
Результат
HH 0 10:18:21.210 LDA Test (EURUSD,H1) Original X IQ 0 10:18:21.210 LDA Test (EURUSD,H1) [[5.1,3.5,1.4,0.2] HF 0 10:18:21.210 LDA Test (EURUSD,H1) [4.9,3,1.4,0.2] ... ... ES 0 10:18:21.211 LDA Test (EURUSD,H1) [6.5,3,5.2,2] ML 0 10:18:21.211 LDA Test (EURUSD,H1) [6.2,3.4,5.4,2.3] EI 0 10:18:21.211 LDA Test (EURUSD,H1) [5.9,3,5.1,1.8]] IL 0 10:18:21.243 LDA Test (EURUSD,H1) DD 0 10:18:21.243 LDA Test (EURUSD,H1) Transformed X DM 0 10:18:21.243 LDA Test (EURUSD,H1) [[-1.058063221542643,2.676898315513957] JD 0 10:18:21.243 LDA Test (EURUSD,H1) [-1.060778666796316,2.532150351483708] DM 0 10:18:21.243 LDA Test (EURUSD,H1) [-0.9139922886488467,2.777963946569435] ... ... IK 0 10:18:21.244 LDA Test (EURUSD,H1) [1.527279343196588,-2.300606221030168] QN 0 10:18:21.244 LDA Test (EURUSD,H1) [0.9614855249192527,-1.439559895222919] EF 0 10:18:21.244 LDA Test (EURUSD,H1) [0.6420061576026481,-2.511057690832021…]
Получился красивый график:
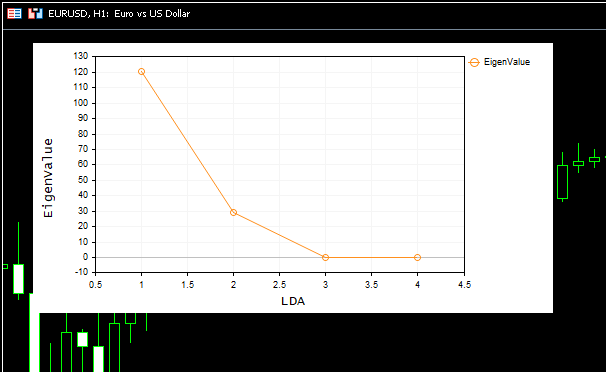
На осыпном графике (Scree Plot) видно, что наилучшее количество компонентов находится в точке изгиба 2, и это именно то количество компонентов, которое вернул наш класс. Теперь давайте визуализируем возвращенные компоненты. Посмотрим, являются ли они отличительными, ведь цель уменьшения измерений состоит в том, чтобы получить минимальное количество компонентов, которое объясняет все различия в исходных данных. Проще говоря, это упрощенная версия наших данных.
Я решил сохранить компоненты нашего советника в файле csv и построить их с помощью Python, используя https://www.kaggle.com/code/omegajoctan/lda-vs-pca-comComponents-iris-data
MatrixExtend::WriteCsv("iris-data lda-components.csv",transformed_x); 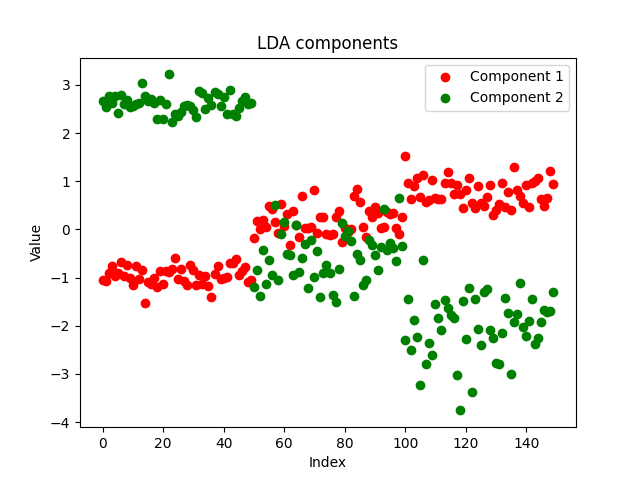
Компоненты выглядят чистыми, что доказывает успешную реализацию. Теперь давайте посмотрим, как выглядят компоненты PCA:
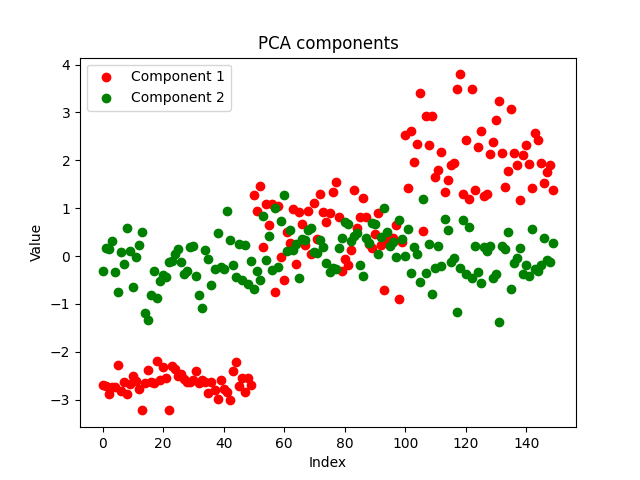
Оба метода хорошо разделили данные. Мы не можем сказать, какой из них работает лучше, глядя только на график. Давайте используем одну и ту же модель с теми же параметрами для одного и того же набора данных и проверим точность обеих моделей как при обучении, так и при тестировании.
Сравнение эффективности алгоритмов LDA и PCA при обучении и тестировании
Используем модели дерева решений с одинаковыми параметрами для отдельных данных, полученных с помощью алгоритмов LDA и PCA соответственно.
#include <MALE5\Dimensionality Reduction\LDA.mqh> #include <MALE5\Dimensionality Reduction\PCA.mqh> #include <MALE5\Decision Tree\tree.mqh> #include <MALE5\Metrics.mqh> CLDA *lda; CPCA *pca; CDecisionTreeClassifier *classifier_tree; input int random_state_ = 42; input double training_sample_size = 0.7; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- string headers; matrix data = MatrixExtend::ReadCsv("iris.csv",headers); //Read csv Print("<<<<<<<< LDA Applied >>>>>>>>>"); matrix x_train, x_test; vector y_train, y_test; MatrixExtend::TrainTestSplitMatrices(data,x_train,y_train,x_test,y_test,training_sample_size,random_state_); lda = new CLDA(NULL); matrix x_transformed = lda.fit_transform(x_train, y_train); //Transform the training data classifier_tree = new CDecisionTreeClassifier(); classifier_tree.fit(x_transformed, y_train); //Train the model using the transformed data vector preds = classifier_tree.predict(x_transformed); //Make predictions using the transformed data Print("Train accuracy: ",Metrics::confusion_matrix(y_train, preds).accuracy); x_transformed = lda.transform(x_test); preds = classifier_tree.predict(x_transformed); Print("Test accuracy: ",Metrics::confusion_matrix(y_test, preds).accuracy); delete (classifier_tree); delete (lda); //--- Print("<<<<<<<< PCA Applied >>>>>>>>>"); pca = new CPCA(NULL); x_transformed = pca.fit_transform(x_train); classifier_tree = new CDecisionTreeClassifier(); classifier_tree.fit(x_transformed, y_train); preds = classifier_tree.predict(x_transformed); //Make predictions using the transformed data Print("Train accuracy: ",Metrics::confusion_matrix(y_train, preds).accuracy); x_transformed = pca.transform(x_test); preds = classifier_tree.predict(x_transformed); Print("Test accuracy: ",Metrics::confusion_matrix(y_test, preds).accuracy); delete (classifier_tree); delete(pca); return(INIT_SUCCEEDED); }
Результаты алгоритма LDA:
GM 0 18:23:18.285 LDA Test (EURUSD,H1) <<<<<<<< LDA Applied >>>>>>>>> MR 0 18:23:18.302 LDA Test (EURUSD,H1) JP 0 18:23:18.344 LDA Test (EURUSD,H1) Confusion Matrix FK 0 18:23:18.344 LDA Test (EURUSD,H1) [[39,0,0] CR 0 18:23:18.344 LDA Test (EURUSD,H1) [0,30,5] QF 0 18:23:18.344 LDA Test (EURUSD,H1) [0,2,29]] IS 0 18:23:18.344 LDA Test (EURUSD,H1) OM 0 18:23:18.344 LDA Test (EURUSD,H1) Classification Report KF 0 18:23:18.344 LDA Test (EURUSD,H1) QQ 0 18:23:18.344 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support FF 0 18:23:18.344 LDA Test (EURUSD,H1) 1.0 1.00 1.00 1.00 1.00 39.0 GI 0 18:23:18.344 LDA Test (EURUSD,H1) 2.0 0.94 0.86 0.97 0.90 35.0 ML 0 18:23:18.344 LDA Test (EURUSD,H1) 3.0 0.85 0.94 0.93 0.89 31.0 OS 0 18:23:18.344 LDA Test (EURUSD,H1) FN 0 18:23:18.344 LDA Test (EURUSD,H1) Accuracy 0.93 JO 0 18:23:18.344 LDA Test (EURUSD,H1) Average 0.93 0.93 0.97 0.93 105.0 KJ 0 18:23:18.344 LDA Test (EURUSD,H1) W Avg 0.94 0.93 0.97 0.93 105.0 EQ 0 18:23:18.344 LDA Test (EURUSD,H1) Train accuracy: 0.933 JH 0 18:23:18.344 LDA Test (EURUSD,H1) Confusion Matrix LS 0 18:23:18.344 LDA Test (EURUSD,H1) [[11,0,0] IJ 0 18:23:18.344 LDA Test (EURUSD,H1) [0,13,2] RN 0 18:23:18.344 LDA Test (EURUSD,H1) [0,1,18]] IK 0 18:23:18.344 LDA Test (EURUSD,H1) OE 0 18:23:18.344 LDA Test (EURUSD,H1) Classification Report KN 0 18:23:18.344 LDA Test (EURUSD,H1) QI 0 18:23:18.344 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support LN 0 18:23:18.344 LDA Test (EURUSD,H1) 1.0 1.00 1.00 1.00 1.00 11.0 CQ 0 18:23:18.344 LDA Test (EURUSD,H1) 2.0 0.93 0.87 0.97 0.90 15.0 QD 0 18:23:18.344 LDA Test (EURUSD,H1) 3.0 0.90 0.95 0.92 0.92 19.0 OK 0 18:23:18.344 LDA Test (EURUSD,H1) FF 0 18:23:18.344 LDA Test (EURUSD,H1) Accuracy 0.93 GD 0 18:23:18.344 LDA Test (EURUSD,H1) Average 0.94 0.94 0.96 0.94 45.0 HQ 0 18:23:18.344 LDA Test (EURUSD,H1) W Avg 0.93 0.93 0.96 0.93 45.0 CF 0 18:23:18.344 LDA Test (EURUSD,H1) Test accuracy: 0.933
LDA создала стабильную модель с точностью 93% как при обучении, так и при тестировании. Теперь посмотрим на работу PCA:
Результаты алгоритма PCA:
MM 0 18:26:40.994 LDA Test (EURUSD,H1) <<<<<<<< PCA Applied >>>>>>>>>
LS 0 18:26:41.071 LDA Test (EURUSD,H1) Confusion Matrix
LJ 0 18:26:41.071 LDA Test (EURUSD,H1) [[39,0,0]
ER 0 18:26:41.071 LDA Test (EURUSD,H1) [0,34,1]
OE 0 18:26:41.071 LDA Test (EURUSD,H1) [0,4,27]]
KD 0 18:26:41.071 LDA Test (EURUSD,H1)
IL 0 18:26:41.071 LDA Test (EURUSD,H1) Classification Report
MG 0 18:26:41.071 LDA Test (EURUSD,H1)
CR 0 18:26:41.071 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support
DE 0 18:26:41.071 LDA Test (EURUSD,H1) 1.0 1.00 1.00 1.00 1.00 39.0
EH 0 18:26:41.071 LDA Test (EURUSD,H1) 2.0 0.89 0.97 0.94 0.93 35.0
KL 0 18:26:41.071 LDA Test (EURUSD,H1) 3.0 0.96 0.87 0.99 0.92 31.0
ID 0 18:26:41.071 LDA Test (EURUSD,H1)
NO 0 18:26:41.071 LDA Test (EURUSD,H1) Accuracy 0.95
CH 0 18:26:41.071 LDA Test (EURUSD,H1) Average 0.95 0.95 0.98 0.95 105.0
KK 0 18:26:41.071 LDA Test (EURUSD,H1) W Avg 0.95 0.95 0.98 0.95 105.0
NR 0 18:26:41.071 LDA Test (EURUSD,H1) Train accuracy: 0.952
LK 0 18:26:41.071 LDA Test (EURUSD,H1) Confusion Matrix
FR 0 18:26:41.071 LDA Test (EURUSD,H1) [[11,0,0]
FJ 0 18:26:41.072 LDA Test (EURUSD,H1) [0,14,1]
MM 0 18:26:41.072 LDA Test (EURUSD,H1) [0,3,16]]
NL 0 18:26:41.072 LDA Test (EURUSD,H1)
HD 0 18:26:41.072 LDA Test (EURUSD,H1) Classification Report
LO 0 18:26:41.072 LDA Test (EURUSD,H1)
FJ 0 18:26:41.072 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support
KM 0 18:26:41.072 LDA Test (EURUSD,H1) 1.0 1.00 1.00 1.00 1.00 11.0
EP 0 18:26:41.072 LDA Test (EURUSD,H1) 2.0 0.82 0.93 0.90 0.88 15.0
HD 0 18:26:41.072 LDA Test (EURUSD,H1) 3.0 0.94 0.84 0.96 0.89 19.0
HL 0 18:26:41.072 LDA Test (EURUSD,H1)
OG 0 18:26:41.072 LDA Test (EURUSD,H1) Accuracy 0.91
PS 0 18:26:41.072 LDA Test (EURUSD,H1) Average 0.92 0.93 0.95 0.92 45.0
IP 0 18:26:41.072 LDA Test (EURUSD,H1) W Avg 0.92 0.91 0.95 0.91 45.0
PE 0 18:26:41.072 LDA Test (EURUSD,H1) Test accuracy: 0.911 Алгоритм PCA дал еще более точную модель, обеспечивающую точность 95% при обучении и точность 91,1% при тестировании.
Преимущества линейного дискриминантного анализа (ЛДА, LDA):
ЛДА имеет несколько преимуществ, благодаря чему алгоритм часто используется в задачах классификации и уменьшения размерности:
- Эффективно уменьшает размерность. LDA уменьшает размерность пространства объектов, преобразуя исходные объекты в пространство меньшей размерности. Такое снижение размерности позволяет получить более простые модели, борется с проклятием размерности и повышает эффективность вычислений.
- Сохраняет информацию о межклассовых различиях. Метод LDA стремится найти линейные комбинации признаков, с которыми будет максимальное разделение между классами. Метод фокусируется на отличиях между классами, чтобы сохранить важные шаблоны и структуры конкретных классов.
- Он извлекает признаки и классифицирует их за один шаг. Метод LDA одновременно выполняет извлечение и классификацию признаков. Он изучает преобразование исходных признаков и улучшает разделимость классов, что делает его по своей сути подходящим для задач классификации. Такой комплексный подход позволяет создавать более эффективные и интерпретируемые модели.
- Устойчив к переобучению. Метод LDA менее склонен к переобучению по сравнению с другими алгоритмами классификации, особенно когда количество выборок невелико по сравнению с количеством признаков. Снижая размерность пространства признаков и концентрируясь на наиболее отличительных признаках, метод может хорошо обобщать невидимые данные.
- Подходит для многоклассовой классификации. Метод хорошо применим для задач классификации с участием более чем двух классов. Он учитывает отношения между всеми классами одновременно, что приводит к созданию эффективных границ разделения в многомерных пространствах объектов.
- Вычислительная эффективность. Внутри метода решаются задачи поиска собственных значений и умножения матриц — это эффективные расчеты, которые можно удобно реализовать с помощью встроенных методов MQL5. Благодаря этому алгоритм ЛДА подходит для крупных наборов данных и приложений реального времени.
- Легко интерпретировать. Преобразованные признаки, полученные с помощью LDA, легко интерпретировать и анализировать, чтобы позволяет лучше понять основные закономерности в данных. Линейные комбинации признаков, полученные с помощью метода LDA, могут дать представление о дискриминационных факторах, влияющих на решение о классификации.
- Его предположения часто оправдываются. Методом LDA предполагается, что данные обычно распределяются внутри каждого класса с равными ковариационными матрицами. Хотя такое не всегда оправдывается на практике, LDA все равно может работать хорошо, даже если такое предположение выполняется частично.
Хотя линейный дискриминантный анализ (LDA) имеет ряд преимуществ, он также имеет некоторые ограничения и недостатки:
Недостатки метода линейного дискриминантного анализа (ЛДА, LDA):
- Он предполагает гауссово распределение внутри объектов. Метод LDA предполагает, что данные внутри каждого класса обычно распределяются с равными ковариационными матрицами. Если это предположение не оправдывается, метод может дать неоптимальные результаты или даже не сойтись. На практике реальные данные могут иметь ненормальное распределение, что может ограничивать эффективность метода.
- Чувствительность к выбросам. Метод чувствителен к выбросам, особенно когда ковариационные матрицы оцениваются на основе ограниченных данных. Выбросы могут существенно повлиять на оценку ковариационных матриц и результирующих дискриминантных направлений, что потенциально может привести к предвзятым или ненадежным результатам классификации.
- Менее гибок при моделировании нелинейных отношений. Метод предполагает, что границы решений между классами линейны. Если же отношения между признаками и классами нелинейны, метод не может эффективно улавливать такие сложные шаблоны. В таких случаях более подходящими могут оказаться методы нелинейного уменьшения размерности или нелинейные классификаторы.
- Проклятие размерности реально. Когда количество признаков намного превышает количество выборок, LDA может пострадать от проклятия размерности. В многомерных пространствах признаков оценка ковариационных матриц становится менее надежной, а дискриминантные направления хуже отражают истинную базовую структуру данных.
- Ограниченные результаты при работе с несбалансированными классами. Метод работает хуже при несбалансированном распределении классов, когда один или несколько классов имеют значительно меньше выборок, чем другие. В таких случаях класс с меньшим количеством выборок может быть плохо представлен при оценке средних значений класса и ковариационных матриц, что приводит к смещению результатов классификации.
- С трудом обрабатывает нечисловые данные. Метод LDA обычно работает с числовыми данными и его сложно применять напрямую к наборам данных, содержащим категориальные или нечисловые переменные. Это может потребовать предварительной обработки, например кодирование категориальных переменных или преобразование нечисловых данных в числовые представления, что может привести к дополнительной сложности и потенциальной потере информации.
LDA против PCA в торговой среде
Чтобы использовать рассматриваемые методы уменьшения размерностей в торговой среде, нам нужно создать функцию для обучения и тестирования модели, после чего мы сможем использовать обученную модель для прогнозирования в тестере стратегий, что поможет нам проанализировать их эффективность.
Мы будем использовать 5 индикаторов в нашем наборе данных, которые будем уменьшать, используя оба этих метода:
int OnInit() { //--- Trend following indicators indicator_handle[0] = iAMA(Symbol(), PERIOD_CURRENT, 9 , 2 , 30, 0, PRICE_OPEN); indicator_handle[1] = iADX(Symbol(), PERIOD_CURRENT, 14); indicator_handle[2] = iADXWilder(Symbol(), PERIOD_CURRENT, 14); indicator_handle[3] = iBands(Symbol(), PERIOD_CURRENT, 20, 0, 2.0, PRICE_OPEN); indicator_handle[4] = iDEMA(Symbol(), PERIOD_CURRENT, 14, 0, PRICE_OPEN); }
void TrainTest() { vector buffer = {}; for (int i=0; i<ArraySize(indicator_handle); i++) { buffer.CopyIndicatorBuffer(indicator_handle[i], 0, 0, bars); //copy indicator buffer dataset.Col(buffer, i); //add the indicator buffer values to the dataset matrix } //--- vector y(bars); MqlRates rates[]; CopyRates(Symbol(), PERIOD_CURRENT,0,bars, rates); for (int i=0; i<bars; i++) //Creating the target variable { if (rates[i].close > rates[i].open) //if bullish candle assign 1 to the y variable else assign the 0 class y[i] = 1; else y[0] = 0; } //--- dataset.Col(y, dataset.Cols()-1); //add the y variable to the last column //--- matrix x_train, x_test; vector y_train, y_test; MatrixExtend::TrainTestSplitMatrices(dataset,x_train,y_train,x_test,y_test,training_sample_size,random_state_); matrix x_transformed = {}; switch(dimension_reduction) { case LDA: lda = new CLDA(NULL); x_transformed = lda.fit_transform(x_train, y_train); //Transform the training data break; case PCA: pca = new CPCA(NULL); x_transformed = pca.fit_transform(x_train); break; } classifier_tree = new CDecisionTreeClassifier(); classifier_tree.fit(x_transformed, y_train); //Train the model using the transformed data vector preds = classifier_tree.predict(x_transformed); //Make predictions using the transformed data Print("Train accuracy: ",Metrics::confusion_matrix(y_train, preds).accuracy); switch(dimension_reduction) { case LDA: x_transformed = lda.transform(x_test); //Transform the testing data break; case PCA: x_transformed = pca.transform(x_test); break; } preds = classifier_tree.predict(x_transformed); Print("Test accuracy: ",Metrics::confusion_matrix(y_test, preds).accuracy); }
После обучения данных их необходимо протестировать. Ниже приведены результаты обоих методов. Первым идет LDA:
JK 0 01:00:24.440 LDA Test (EURUSD,H1) GK 0 01:00:37.442 LDA Test (EURUSD,H1) Confusion Matrix QR 0 01:00:37.442 LDA Test (EURUSD,H1) [[60,266] FF 0 01:00:37.442 LDA Test (EURUSD,H1) [46,328]] DR 0 01:00:37.442 LDA Test (EURUSD,H1) RN 0 01:00:37.442 LDA Test (EURUSD,H1) Classification Report FE 0 01:00:37.442 LDA Test (EURUSD,H1) LP 0 01:00:37.442 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support HD 0 01:00:37.442 LDA Test (EURUSD,H1) 0.0 0.57 0.18 0.88 0.28 326.0 FI 0 01:00:37.442 LDA Test (EURUSD,H1) 1.0 0.55 0.88 0.18 0.68 374.0 RM 0 01:00:37.442 LDA Test (EURUSD,H1) QH 0 01:00:37.442 LDA Test (EURUSD,H1) Accuracy 0.55 KQ 0 01:00:37.442 LDA Test (EURUSD,H1) Average 0.56 0.53 0.53 0.48 700.0 HP 0 01:00:37.442 LDA Test (EURUSD,H1) W Avg 0.56 0.55 0.51 0.49 700.0 KK 0 01:00:37.442 LDA Test (EURUSD,H1) Train accuracy: 0.554 DR 0 01:00:37.443 LDA Test (EURUSD,H1) Confusion Matrix CD 0 01:00:37.443 LDA Test (EURUSD,H1) [[20,126] LO 0 01:00:37.443 LDA Test (EURUSD,H1) [12,142]] OK 0 01:00:37.443 LDA Test (EURUSD,H1) ME 0 01:00:37.443 LDA Test (EURUSD,H1) Classification Report QN 0 01:00:37.443 LDA Test (EURUSD,H1) GI 0 01:00:37.443 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support JM 0 01:00:37.443 LDA Test (EURUSD,H1) 0.0 0.62 0.14 0.92 0.22 146.0 KR 0 01:00:37.443 LDA Test (EURUSD,H1) 1.0 0.53 0.92 0.14 0.67 154.0 MF 0 01:00:37.443 LDA Test (EURUSD,H1) MQ 0 01:00:37.443 LDA Test (EURUSD,H1) Accuracy 0.54 MJ 0 01:00:37.443 LDA Test (EURUSD,H1) Average 0.58 0.53 0.53 0.45 300.0 OI 0 01:00:37.443 LDA Test (EURUSD,H1) W Avg 0.58 0.54 0.52 0.45 300.0 QP 0 01:00:37.443 LDA Test (EURUSD,H1) Test accuracy: 0.54
PCA показал лучшие результаты во время обучения и немного хуже при тестировании:
GE 0 01:01:57.202 LDA Test (EURUSD,H1) MS 0 01:01:57.202 LDA Test (EURUSD,H1) Classification Report IH 0 01:01:57.202 LDA Test (EURUSD,H1) OS 0 01:01:57.202 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support KG 0 01:01:57.202 LDA Test (EURUSD,H1) 0.0 0.62 0.28 0.85 0.39 326.0 GL 0 01:01:57.202 LDA Test (EURUSD,H1) 1.0 0.58 0.85 0.28 0.69 374.0 MP 0 01:01:57.202 LDA Test (EURUSD,H1) JK 0 01:01:57.202 LDA Test (EURUSD,H1) Accuracy 0.59 HL 0 01:01:57.202 LDA Test (EURUSD,H1) Average 0.60 0.57 0.57 0.54 700.0 CG 0 01:01:57.202 LDA Test (EURUSD,H1) W Avg 0.60 0.59 0.55 0.55 700.0 EF 0 01:01:57.202 LDA Test (EURUSD,H1) Train accuracy: 0.586 HO 0 01:01:57.202 LDA Test (EURUSD,H1) Confusion Matrix GG 0 01:01:57.202 LDA Test (EURUSD,H1) [[26,120] GJ 0 01:01:57.202 LDA Test (EURUSD,H1) [29,125]] KN 0 01:01:57.202 LDA Test (EURUSD,H1) QJ 0 01:01:57.202 LDA Test (EURUSD,H1) Classification Report MQ 0 01:01:57.202 LDA Test (EURUSD,H1) CL 0 01:01:57.202 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support QP 0 01:01:57.202 LDA Test (EURUSD,H1) 0.0 0.47 0.18 0.81 0.26 146.0 GE 0 01:01:57.202 LDA Test (EURUSD,H1) 1.0 0.51 0.81 0.18 0.63 154.0 QI 0 01:01:57.202 LDA Test (EURUSD,H1) MD 0 01:01:57.202 LDA Test (EURUSD,H1) Accuracy 0.50 RE 0 01:01:57.202 LDA Test (EURUSD,H1) Average 0.49 0.49 0.49 0.44 300.0 IL 0 01:01:57.202 LDA Test (EURUSD,H1) W Avg 0.49 0.50 0.49 0.45 300.0 PP 0 01:01:57.202 LDA Test (EURUSD,H1) Test accuracy: 0.503
Наконец, мы можем создать простую торговую стратегию на основе сигналов, поставляемых моделью дерева решений.
void OnTick() { //--- if (!train_once) //call the function to train the model once on the program lifetime { TrainTest(); train_once = true; } //--- vector inputs(indicator_handle.Size()); vector buffer; for (uint i=0; i<indicator_handle.Size(); i++) { buffer.CopyIndicatorBuffer(indicator_handle[i], 0, 0, 1); //copy the current indicator value inputs[i] = buffer[0]; //add its value to the inputs vector } //--- SymbolInfoTick(Symbol(), ticks); if (isnewBar(PERIOD_CURRENT)) // We want to trade on the bar opening { vector transformed_inputs = {}; switch(dimension_reduction) //transform every new data to fit the dimensions selected during training { case LDA: transformed_inputs = lda.transform(inputs); //Transform the new data break; case PCA: transformed_inputs = pca.transform(inputs); break; } int signal = (int)classifier_tree.predict(transformed_inputs); double min_lot = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); SymbolInfoTick(Symbol(), ticks); if (signal == -1) { if (!PosExists(MAGICNUMBER, POSITION_TYPE_SELL)) // If a sell trade doesnt exist m_trade.Sell(min_lot, Symbol(), ticks.bid, ticks.bid+stoploss*Point(), ticks.bid - takeprofit*Point()); } else { if (!PosExists(MAGICNUMBER, POSITION_TYPE_BUY)) // If a buy trade doesnt exist m_trade.Buy(min_lot, Symbol(), ticks.ask, ticks.ask-stoploss*Point(), ticks.ask + takeprofit*Point()); } } }
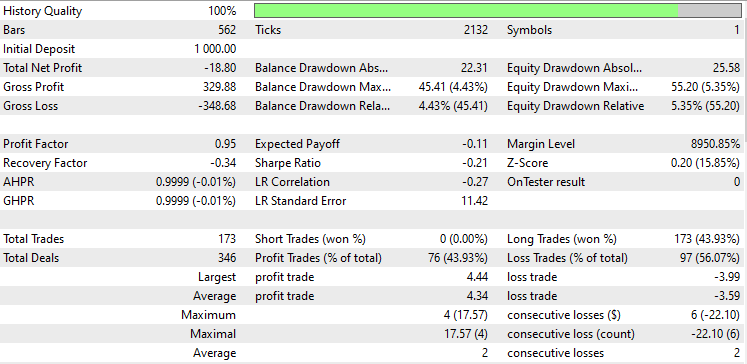
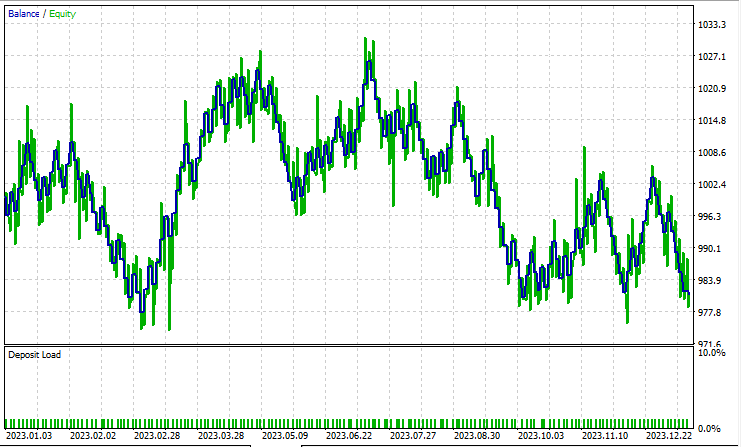
Я тестировал в режиме цен открытия с января 2023 года по февраль 2024 года. Оба метода работали на простой стратегии:
Линейный дискриминантный анализ (LDA):
Тестирование с анализом главных компонентов (PCA):
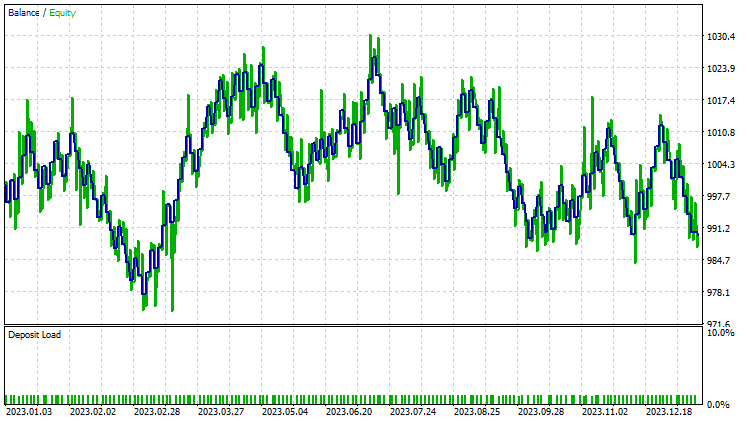
Результаты почти идентичны: модель с LDA принесла убыток на 8 долларов больше, чем PCA. С точки зрения работы с данными, тестер стратегий менее релевантен для методов сокращения размерностей, поскольку их основная задача — для упрощения переменных, особенно при работе с большими данными. Также при запуске этого советника в тестере стратегий я столкнулся с некоторыми несоответствиями в расчетах, вызванными неожиданными ошибками в работе матричных и векторных методов. Я рекомендую запускать программу несколько раз, пока не получите значимый результат, если вдруг столкнетесь с ошибками.
Если вы следили за этой серией статей, возможно, вы задаетесь вопросом почему мы не масштабировали преобразованные данные, полученные с помощью этих двух методов, как мы делали в предыдущей статье.
Необходимость нормализации данных из алгоритмов PCA или LDA для модели машинного обучения зависит от конкретных характеристик вашей выборки, используемого алгоритма и целей. Что нужно учитывать:
- Преобразование — методы работают с ковариационной матрицей исходных признаков и находят ортогональные компоненты (главные компоненты), которые передают максимальную дисперсию данных. Преобразованные данные, полученные этими методами, состоят из этих основных компонентов.
- Нормализация до использования PCA или LDA. Часто нормализуют исходные объектов перед выполнением метода PCA или LDA, особенно если объекты имеют разные масштабы или единицы измерения. Нормализация гарантирует, что все признаки вносят равный вклад в ковариационную матрицу, и предотвращает доминирование признаков с более крупными масштабами над главными компонентами.
- Нормализация после методов PCA или LDA. Необходимость нормализовать преобразованные данные зависит от конкретных требований вашего алгоритма машинного обучения и характеристик преобразованных признаков. Некоторые алгоритмы, такие как логистическая регрессия или k ближайших соседей, чувствительны к различиям в масштабах признаков, для них может быть полезным нормализовать признаки даже после методов PCA или LDA.
- Другие алгоритмы, такие как используемые нами деревья решений, менее чувствительны к масштабам признаков и могут работать без нормализации данных после снижения размерности.
- Влияние нормализации на интерпретируемость. Нормализация после методов LDA и PCA может повлиять на интерпретируемость главных компонентов. Если вам нужно понимать вклад исходных признаков в основные компоненты, нормализация преобразованных данных может скрыть эти взаимосвязи.
- Влияние на производительность. Поэкспериментируйте как с нормализованными, так и с ненормализованными преобразованными данными, чтобы оценить влияние на производительность модели. В некоторых случаях нормализация может привести к лучшей сходимости, улучшению обобщения или более быстрому обучению, тогда как в других случаях она может практически не иметь эффекта.
За развитием этой модели машинного обучения и многого другого из этой серии статей можно следить в моем репозиторий на GitHub.
Содержимое вложения:
| Файл | Описание/назначение |
|---|---|
| tree.mqh | Модель классификатора дерева решений. |
| MatrixExtend.mqh | Дополнительные функции для работы с матрицами. |
| metrics.mqh | Функции и код для измерения производительности моделей машинного обучения. |
| preprocessing.mqh | Библиотека для предварительной обработки необработанных входных данных, чтобы сделать их пригодными для использования в моделях машинного обучения. |
| base.mqh | Базовая библиотека для использования методов PCA и LDA, содержит функции, упрощающие написание кода. |
| pca.mqh | Библиотека метода анализа главных компонентов PCA |
| lda.mqh | Библиотека метода линейного дискриминантного анализа LDA |
| plots.mqh | Библиотека для построения векторов и матриц |
| lda vs pca script.mq5 | Скрипт для демонстрации алгоритмов pca и lda |
| LDA Test.mq5 | Основной советник для тестирования большей части кода |
| iris.csv | Набор данных для проверки модели iris |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/14128

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования