
Нейросети — это просто (Часть 93): Адаптивное прогнозирование в частотной и временной областях (Окончание)

Введение
В предыдущей статье мы познакомились с алгоритмом ATFNet, который представляет собой ансамбль из 2 моделей прогнозирования временных рядов. Одна из них работает во временной области и строит прогнозные значения изучаемого временного ряда на основе анализа амплитуд сигнала. Вторая модель работает с частотными характеристиками анализируемого временного ряда и фиксирует его глобальные зависимости, их периодичность и спектр. Адаптивное объединение двух независимых прогнозов, по словам автором метода, позволяет достичь впечатляющих результатов.
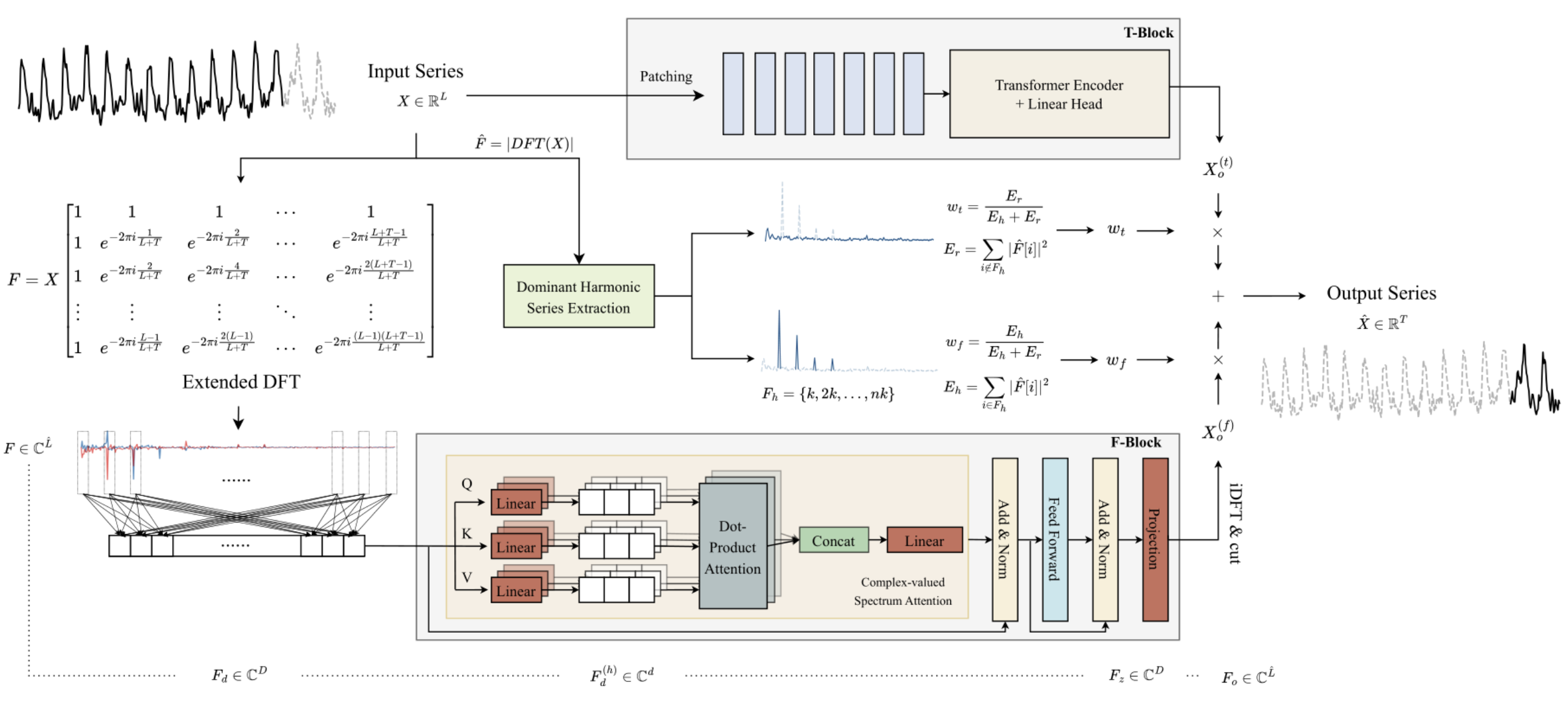
Ключевой особенностью частотного F-блока является полное построение алгоритма с использованием математики комплексных чисел. Для выполнения данного требования в предыдущей статье мы построили класс CNeuronComplexMLMHAttention, в котором полностью повторили алгоритм многослойного Энкодера Transformer с элементами многоголового Self-Attention. Построенный нами класс комплексного внимания является основой F-блока. И в данной статье мы продолжим реализацию подходов, предложенных авторами метода ATFNet.
1. Создание класса ATFNet
После реализации, можно сказать, фундамента частотного F-блока — класса комплексного внимания CNeuronComplexMLMHAttention, мы поднимаемся на уровень вверх и создаем класс CNeuronATFNetOCL, в котором по существу и будет реализован весь алгоритм ATFNet.
Должен признаться, что реализация столь комплексного алгоритма, как ATFNet, в рамках одного класса нейронного слоя, возможно, не самое оптимальное решение. Но построенная нами ранее последовательная модель нейронной сети не предусматривает возможность организации работы нескольких различных параллельных процессов, как T-блок и F-блок в данном случае. А реализация подобного функционала потребует более глобальных изменений. Было принято решение идти по пути минимальных затрат и реализовать весь алгоритм в виде класса одного нейронного слоя. Структура класса CNeuronATFNetOCL представлена ниже.
class CNeuronATFNetOCL : public CNeuronBaseOCL { protected: uint iHistory; uint iForecast; uint iVariables; uint iFFT; //--- T-Block CNeuronBatchNormOCL cNorm; CNeuronTransposeOCL cTranspose; CNeuronPositionEncoder cPositionEncoder; CNeuronPatching cPatching; CLayer caAttention; CLayer caProjection; CNeuronRevINDenormOCL cRevIN; //--- F-Block CBufferFloat *cInputs; CBufferFloat cInputFreqRe; CBufferFloat cInputFreqIm; CNeuronBaseOCL cInputFreqComplex; CBufferFloat cMainFreqWeights; CNeuronBaseOCL cNormFreqComplex; CBufferFloat cMeans; CBufferFloat cVariances; CNeuronComplexMLMHAttention cFreqAtteention; CNeuronBaseOCL cUnNormFreqComplex; CBufferFloat cOutputFreqRe; CBufferFloat cOutputFreqIm; CBufferFloat cOutputTimeSeriasRe; CBufferFloat cOutputTimeSeriasIm; CBufferFloat cOutputTimeSeriasReGrad; CBufferFloat cReconstructInput; CBufferFloat cForecast; CBufferFloat cReconstructInputGrad; CBufferFloat cForecastGrad; CBufferFloat cZero; //--- virtual bool FFT(CBufferFloat *inp_re, CBufferFloat *inp_im, CBufferFloat *out_re, CBufferFloat *out_im, bool reverse = false); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); virtual bool ComplexNormalize(void); virtual bool ComplexUnNormalize(void); virtual bool ComplexNormalizeGradient(void); virtual bool ComplexUnNormalizeGradient(void); virtual bool MainFreqWeights(void); virtual bool WeightedSum(void); virtual bool WeightedSumGradient(void); virtual bool calcReconstructGradient(void); public: CNeuronATFNetOCL(void) {}; ~CNeuronATFNetOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint history, uint forecast, uint variables, uint heads, uint layers, uint &patch[], ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronATFNetOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *net, float tau); virtual void SetOpenCL(COpenCLMy *obj); virtual CBufferFloat *getWeights(void); };
В представленной структуре класса CNeuronATFNetOCL можно выделить 4 внутренние переменные:
- iHistory — глубина анализируемой истории;
- iForecast — горизонт планирования;
- iVariables — количество анализируемых переменных (унитарных временных рядов);
- iFFT — размер тензора быстрого разложения Фурье (DFT).
Напомню, что алгоритм DFT требует размер вектор исходных данных равным одной из степеней "2". Поэтому мы тензор исходных данных дополняем нулевыми значениями до требуемого размера.
Внутренние объекты метода разделены на два блока в соответствии с их принадлежностью к блокам алгоритма ATFNet. С их назначением, как и функционалом методов класса, мы познакомимся в процессе реализации алгоритма.
Все внутренние объекты объявлены статично, что позволяет нам оставить конструктор и деструктор класса CNeuronATFNetOCL пустыми.
1.1 Инициализация объекта
Инициализация внутренних объектов нашего нового класса осуществляется в методе Init. И здесь нас ожидает первое следствие решения реализация всего алгоритма ATFNet в рамках одного класса — необходимость передачи большого количества параметров от вызывающей программы.
По существу, внутри класса CNeuronATFNetOCL нам предстоит построить две параллельные многослойные модели с использованием механизмов внимания как во временном T-блоке, так и в частотном F-блоке. И для каждой модели нам необходимо указать архитектуру.
Для решения этой проблемы мы решили по возможности использовать "универсальные" параметры — когда параметр одинаково используется обеими моделями. Ведь без сомнения у нас есть параметры описания тензора исходных данных и результатов: глубина анализируемой истории, количество унитарных временных рядов и горизонт планирования. Думаю, ни у кого не вызывает сомнения, что указанные параметры одинаково используются в T-блоке и F-блоке.
Кроме того, обе модели построены вокруг Энкодера Transformer и эксплуатируют архитектуру многоголового Self-Attention с несколькими слоями. Мы решили в обоих блоках использовать одинаковое количество голов внимания и слоев Энкодера.
Однако для слоя сегментации данных, который используется в T-блоке и не имеет аналога в F-блоке, нам предстоит передать дополнительные параметры. И здесь, чтобы не сильно увеличивать количество параметров метода, мы решили воспользоваться массивом их 3-х элементов. Первый элемент данного массива содержит размер окна одного сегмента, а второй — шаг этого окна в буфере исходных данных. В последний элемент массива мы запишем размер одного патча на выходе слоя сегментации данных.
bool CNeuronATFNetOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint history, uint forecast, uint variables, uint heads, uint layers, uint &patch[], ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, forecast * variables, optimization_type, batch)) return false;
В теле метода мы, как обычно, вызываем одноименный метод инициализации родительского класса. И здесь стоит обратить внимание, что для метода родительского класса мы указываем размер слоя как произведение количества анализируемых переменных (унитарных временных рядов) на горизонт планирования. Иными словами, мы планируем на выходе слоя CNeuronATFNetOCL получить готовый результат прогнозируемого продолжения анализируемого временного ряда.
После успешной инициализации унаследованных объектов, мы сохраняем в переменные ключевые параметры архитектуры.
iHistory = MathMax(history, 1); iForecast = forecast; iVariables = variables;
И рассчитаем размер тензора для быстрого разложения Фурье. Здесь я хочу напомнить, что авторы ATFNet предлагают расширенное разложение Фурье, которое определяет частотные характеристики полного временного ряда с учетом исторических и прогнозируемых данных.
uint size = iHistory + iForecast; int power = int(MathLog(size) / M_LN2); if(MathPow(2, power) < size) power++; iFFT = uint(MathPow(2, power));
Следующим этапом нам предстоит инициализировать внутренние объекты нашего класса. И тут надо немного начать с ожидаемого представления исходных данных. Так как наша модель предполагает анализ унитарных временных рядов во временной и частотной областях, то мы ожидаем на вход нашего слоя получить уже картеж из унитарных временных рядов. И на выходе CNeuronATFNetOCL вернет аналогичный картеж прогнозных значений.
Ещё один момент — нормализация данных. Оба блока модели используют нормализацию исходных данных. Только T-блок нормализует данные во временной области, а F-блок — в частотной. Поэтому в данной реализации было принято решение подавать на вход слоя ненормализованные данные. А нормализация и обратное добавление стохастических характеристик осуществляется внутри отдельных блоков по соответствующим измерениям.
Для удобства чтения и прозрачности кода, инициализировать внутренние объекты мы будем по блокам их использования и в порядке выстраиваемого алгоритма. Начнем мы с T-блока.
Как уже было сказано выше, на вход слоя подаются ненормализованные данные. Следовательно, нам предстоит сначала привести полученные данные к сопоставимому виду.
//--- T-Block if(!cNorm.Init(0, 0, OpenCL, iHistory * iVariables, batch, optimization)) return false;
Авторы ATFNet не используют позиционное кодирование данных в частотной области, но оставили его при анализе данных во временной области. Добавим слой позиционного кодирования.
if(!cPositionEncoder.Init(0, 1, OpenCL, iVariables, iHistory, optimization, batch)) return false;
Далее надо сказать, что при построении слоя сегментации данных в его алгоритм мы встроили своеобразное транспонирование данных. И теперь нам необходимо подготовить исходные данные перед подачей на вход слоя CNeuronPatching. Для выполнения этой операции был добавлен слой транспонирования данных.
if(!cTranspose.Init(0, 2, OpenCL, iHistory, iVariables, optimization, batch)) return false; cTranspose.SetActivationFunction(None);
Теперь нам необходимо рассчитать количество патчей на выходе слоя сегментации исходя из размера окна одного сегмента и его шага, полученных в параметрах метода от внешней программы.
uint count = (iHistory - patch[0] + 2 * patch[1] - 1) / patch[1];
После проведения необходимой подготовительной работы мы осуществляем инициализацию слоя сегментации данных.
if(!cPatching.Init(0, 3, OpenCL, patch[0], patch[1], patch[2], count, iVariables, optimization, batch)) return false;
При построении метода PatchTST в качестве блока внимания мы использовали Conformer. Здесь мы воспользуемся тем же решением. И следующим шагом создадим требуемое количество вложенных слоев CNeuronConformer.
caAttention.SetOpenCL(OpenCL); for(uint l = 0; l < layers; l++) { CNeuronConformer *temp = new CNeuronConformer(); if(!temp) return false; if(!temp.Init(0, 4 + l, OpenCL, patch[2], 32, heads, iVariables, count, optimization, batch)) { delete temp; return false; } if(!caAttention.Add(temp)) { delete temp; return false; } }
За блоком внимания, анализирующего исходный временной ряд, мы поставим блок из 3-х сверточных слоев, который будет осуществлять прогнозирование последующих данных на всю глубину планирования в разрезе отдельных унитарных временных рядов.
int total = 3; caProjection.SetOpenCL(OpenCL); uint window = patch[2] * count; for(int l = 0; l < total; l++) { CNeuronConvOCL *temp = new CNeuronConvOCL(); if(!temp) return false; if(!temp.Init(0, 4+layers+l, OpenCL, window, window, (total-l)*iForecast, iVariables, optimization, batch)) { delete temp; return false; } temp.SetActivationFunction(TANH); if(!caProjection.Add(temp)) { delete temp; return false; } window = (total - l) * iForecast; }
Обратите внимание, что в каждом слое мы указываем одинаковое количество элементов последовательности, равное количеству унитарных временных рядов в анализируемом временном ряде. При этом в каждом последующем слое уменьшается количество фильтров на выходе нейронного слоя, которое в последнем слое равно заданной глубине прогнозирования.
На выходе T-блока мы будем добавлять к прогнозным значениям статистические параметры исходного временного ряда с помощью слоя CNeuronRevINDenormOCL.
if(!cRevIN.Init(0, 4 + layers + total, OpenCL, iForecast * iVariables, 1, cNorm.AsObject())) return false;
На этом этапе мы инициализировали все внутренние объекты, относящиеся к T-блоку прогнозирования во временной области. И далее мы переходим к работе с объектами частотного F-блока.
Согласно алгоритму ATFNet, полученные на вход F-блока исходные данные мы переводим в частотную область с помощью быстрого разложения Фурье (DFT). Как вы помните, построенная нами ранее реализация алгоритма DFT записывает частотный спектр в два буфера данных. Один для вещественной части спектра, второй — для мнимой.
//--- F-Block if(!cInputFreqRe.BufferInit(iFFT * iVariables, 0) || !cInputFreqRe.BufferCreate(OpenCL)) return false; if(!cInputFreqIm.BufferInit(iFFT * iVariables, 0) || !cInputFreqIm.BufferCreate(OpenCL)) return false;
Для удобства последующей обработки мы объединим информацию о спектре в один буфер.
if(!cInputFreqComplex.Init(0, 0, OpenCL, iFFT * iVariables * 2, optimization, batch)) return false;
И тут же мы подготовим буфер для записи доли доминирующей частоты. Здесь следует отметить, что доминирующую частоту мы определяем отдельно для каждого унитарного временного ряда.
if(!cMainFreqWeights.BufferInit(iVariables, 0) || !cMainFreqWeights.BufferCreate(OpenCL)) return false;
И тут надо вспомнить, что на вход нашего слоя подаются необработанные исходные данные, которые генерируют довольно различные спектры унитарных временных рядов. Для приведения спектров в сопоставимый вид перед последующей обработкой, авторы метода рекомендуют провести нормализацию частотных характеристик. Нормализованные данные мы будем сохранять в буферах слоя cNormFreqComplex.
if(!cNormFreqComplex.Init(0, 1, OpenCL, iFFT * iVariables * 2, optimization, batch)) return false;
При этом статистические характеристики исходного спектра мы сохраним в соответствующие буферы данных.
if(!cMeans.BufferInit(iVariables, 0) || !cMeans.BufferCreate(OpenCL)) return false; if(!cVariances.BufferInit(iVariables, 0) || !cVariances.BufferCreate(OpenCL)) return false;
Подготовленные таким образом частотные характеристики исходных данных мы будем обрабатывать с помощью блока комплексного внимания. В предыдущей статье мы провели большую реализацию по реализации класса CNeuronComplexMLMHAttention. И теперь нам остается лишь инициализировать внутренний объект указанного класса.
if(!cFreqAtteention.Init(0, 2, OpenCL, iFFT, 32, heads, iVariables, layers, optimization, batch)) return false;
После обработки спектра исходных данных в блоке комплексного внимания, алгоритмом предусмотрено выполнение обратных процедур. Сначала мы добавляем к обработанному спектру статистические показатели исходных частотных характеристик.
if(!cUnNormFreqComplex.Init(0, 1, OpenCL, iFFT * iVariables * 2, optimization, batch)) return false;
Выделим отдельно вещественную и мнимую часть спектра.
if(!cOutputFreqRe.BufferInit(iFFT*iVariables, 0) || !cOutputFreqRe.BufferCreate(OpenCL)) return false; if(!cOutputFreqIm.BufferInit(iFFT*iVariables, 0) || !cOutputFreqIm.BufferCreate(OpenCL)) return false;
И вернем данные во временную область.
if(!cOutputTimeSeriasRe.BufferInit(iFFT*iVariables, 0) || !cOutputTimeSeriasRe.BufferCreate(OpenCL)) return false; if(!cOutputTimeSeriasIm.BufferInit(iFFT*iVariables, 0) || !cOutputTimeSeriasIm.BufferCreate(OpenCL)) return false;
Для целей обратного прохода мы создадим буфер градиентов для вещественной части временного ряда.
if(!cOutputTimeSeriasReGrad.BufferInit(iFFT*iVariables, 0) || !cOutputTimeSeriasReGrad.BufferCreate(OpenCL)) return false;
Здесь стоит обратить внимание, что мы не создаем буфер градиентов для мнимой части временного ряда. Суть в том, что для временного ряда целевые значения мнимой части равны "0". Следовательно, градиент ошибки мнимой части равен значениям мнимой части с обратным знаком. И при обратном проходе мы можем воспользоваться буфером результатов прямого прохода для мнимой части обработанного временного ряда.
Обратите внимание, что после обратного DFT (iDFT) мы планируем получать обработанный полный временной ряд, состоящий из реконструкции исходных данных и прогнозных значений на заданный горизонт планирования. Для выделения требуемой части прогнозных значений мы разделим полный временной ряд на два буфера: восстановленных данных и прогнозных значений.
if(!cReconstructInput.BufferInit(iHistory*iVariables, 0) || !cReconstructInput.BufferCreate(OpenCL)) return false; if(!cForecast.BufferInit(iForecast*iVariables, 0) || !cForecast.BufferCreate(OpenCL)) return false;
И добавим буферы для соответствующих градиентов ошибки.
if(!cReconstructInputGrad.BufferInit(iHistory*iVariables, 0) || !cReconstructInputGrad.BufferCreate(OpenCL)) return false; if(!cForecastGrad.BufferInit(iForecast*iVariables, 0) || !cForecastGrad.BufferCreate(OpenCL)) return false;
Необходимо обратить внимание, что в предложенном автором методе ATFNet не предусмотрен анализ отклонений восстановленных данных от исходных значений анализируемого временного ряда. Мы же добавляем данный функционал в попытке осуществить более тонкую настройку блока комплексного внимания. Потенциально, лучшее понимание анализируемых данных позволит повысить качество прогнозов нашей модели.
Дополнительно мы создадим буфер нулевых значений, который будет использовать при заполнении недостающих значений в исходных данных и градиентах ошибки.
if(!cZero.BufferInit(iFFT*iVariables, 0) || !cZero.BufferCreate(OpenCL)) return false; //--- return true; }
Не забываем на каждом этапе контролировать процесс выполнения операций. И по завершении инициализации всех объявленных объектов, мы возвращаем логическое значение выполнения операций метода вызывающей программе.
1.2 Прямой проход
После завершения работы по инициализации объектов класса, мы переходим к построению алгоритма прямого прохода. И начнем мы работу с построения дополнительных кернелов в программе OpenCL.
Вначале мы вспомним о нормализации спектров частотных характеристик унитарных временных рядов. Использование ранее реализованных алгоритмов нормализации вещественных данных в данном случае может сильно исказить данные. Поэтому нам необходимы средства нормализации данных в комплексной области. Этот функционал мы реализуем в кернеле ComplexNormalize. В параметрах кернела мы передадим указатели на 4 буфера данных и размерность унитарной последовательности. Мы планируем использовать данный кернел в одномерном пространстве задач в разрезе спектров унитарных временных рядов.
__kernel void ComplexNormalize(__global float2 *inputs, __global float2 *outputs, __global float2 *means, __global float *vars, int dimension) { if(dimension <= 0) return;
Обратите внимание на объявление буферов данных. Буферы исходных данных, результатов и средних имеют векторный тип float2. Именно такой тип данных мы решили использовать на стороне OpenCL для работы с комплексными величинами. И на их фоне выделяется буфер дисперсий, который объявлен с вещественным типом float. Здесь следует вспомнить, что дисперсии показывают среднеквадратическое отклонение величины от средней. А расстояние между двумя точками является вещественной величиной.
В теле метода мы проверяем полученную размерность нормализируемого вектора. Очевидно, что она должна быть больше "0". А затем идентифицируем текущий поток в пространстве задач, определим смещение в буферах данных и создадим комплексное представление размерности анализируемой последовательности.
size_t n = get_global_id(0); const int shift = n * dimension; const float2 dim = (float2)(dimension, 0);
Далее мы организуем цикл, в котором определим среднее значение анализируемого спектра.
float2 mean = 0; for(int i = 0; i < dimension; i++) { float2 val = inputs[shift + i]; if(isnan(val.x) || isinf(val.x) || isnan(val.y) || isinf(val.y)) inputs[shift + i] = (float2)0; else mean += val; } means[n] = mean = ComplexDiv(mean, dim);
Полученный результат мы сразу сохраняем в соответствующий элемент буфера средних значений.
На следующем этапе организуем цикл определения дисперсии анализируемой последовательности.
float variance = 0; for(int i = 0; i < dimension; i++) variance += pow(ComplexAbs(inputs[shift + i] - mean), 2); vars[n] = variance = sqrt((isnan(variance) || isinf(variance) ? 1.0f : variance / dimension));
Здесь следует обратить внимание на два момента. Первое: несмотря на сохранение среднего значения в буфер внешних данных, при выполнении операций мы используем значение локальной переменной, так как доступ к элементу буфера, находящегося в глобальной памяти контекста, значительно медленнее обращения к локальной переменной кернела.
Второй момент — методический: при вычислении дисперсии последовательности комплексных чисел, в отличие от вещественных, в квадрат мы возводим абсолютно значение отклонения элемента комплексной последовательности от среднего значения. Именно абсолютное значение комплексной величины покажет расстояние между точками в 2-мерном пространстве вещественной и мнимой частей. В то время как простая разница комплексных величин нам покажет лишь смещение координат.
И на последнем этапе работы кернела мы организуем последний цикл, в котором нормализуем данные исходного спектра. Полученные значения запишем в соответствующие элементы буфера результатов.
float2 v=(float2)(variance, 0); for(int i = 0; i < dimension; i++) { float2 val = ComplexDiv((inputs[shift + i] - mean), v); if(isnan(val.x) || isinf(val.x) || isnan(val.y) || isinf(val.y)) val = (float2)0; outputs[shift + i] = val; } }
Здесь мы также работаем с локальными переменными среднего значения и среднеквадратического отклонения.
И сразу создадим кернел обратной нормализации ComplexUnNormalize, в котором мы вернем извлеченные статистические показатели исходного спектра.
__kernel void ComplexUnNormalize(__global float2 *inputs, __global float2 *outputs, __global float2 *means, __global float *vars, int dimension) { if(dimension <= 0) return;
Легко заметить, что данный кернел получает тот же набор параметров из 4-х указателей на буферы данных и одной переменной. Мы также планируем запускать кернел в 1-мерном пространстве задач по числу унитарных временных рядов.
В теле кернела мы идентифицируем поток в пространстве задач и определяем смещения в буферах данных.
size_t n = get_global_id(0); const int shift = n * dimension;
Загрузим из буферов статистические показатели и сразу преобразуем среднеквадратическое отклонение в комплексную величину.
float v= vars[n]; float2 variance=(float2)((v > 0 ? v : 1.0f), 0) float2 mean = means[n];
После чего организуем единственный в данном кернеле цикл преобразования данных.
for(int i = 0; i < dimension; i++) { float2 val = ComplexMul(inputs[shift + i], variance) + mean; if(isnan(val.x) || isinf(val.x) || isnan(val.y) || isinf(val.y)) val = (float2)0; outputs[shift + i] = val; } }
Полученные значения записываем в соответствующие элементы буфера результатов.
Для вызова вышесозданных кернелов на стороне основной программы используются методы ComplexNormalize и ComplexUnNormalize. Алгоритм их построения не отличается от рассмотренных ранее методов постановки кернелов OpenCL программы в очередь выполнения. Поэтому мы не будем сейчас и далее останавливаться на рассмотрении кода подобных методов. Но вы всегда можете самостоятельно ознакомиться с ним во вложении.
Кроме того, для адаптивного слияния результатов временного и частотного прогнозирования нам потребуются коэффициенты влияния, которые авторы метода ATFNet предлагают определять по доли доминирующей частоты в общем спектре. Соответственно, на стороне OpenCL программы мы создадим два кернела:
- MainFreqWeight — определения доли доминирующей частоты;
- WeightedSum — вычисление взвешенной суммы прогнозов в частотной и временной областях.
Оба кернела мы планируем в 1-мерном пространстве задач по числу анализируемых унитарных временных рядов.
В параметрах кернела MainFreqWeight мы передаем указатели на два буфера данных (частотных характеристик и результатов) и размерность анализируемого ряда.
__kernel void MainFreqWeight(__global float2 *freq, __global float *weight, int dimension ) { if(dimension <= 0) return; //--- size_t n = get_global_id(0); const int shift = n * dimension;
В теле кернела мы идентифицируем текущий поток выполнения операций в пространстве задач и определяем смещение в буферах данных. После чего подготавливаем локальные переменные.
float max_f = 0; float total = 0; float energy;
Далее мы организуем цикл, в котором определим энергию доминирующей частоты и всего спектра.
for(int i = 0; i < dimension; i++) { energy = ComplexAbs(freq[shift + i]); total += energy; max_f = fmax(max_f, energy); }
В завершение операций кернела мы разделим энергию доминирующей частоты на общую энергию спектра. Полученное значение сохраним в соответствующий элемент буфера результатов.
weight[n] = max_f / (total > 0 ? total : 1); }
Алгоритм кернела определения взвешенной суммы прогнозов временной и частотной областей WeightedSum довольно прост. В параметрах кернел получает 4 указателя на буферы данных и размерность вектора одной последовательности (в нашем случае, глубина прогнозирования).
__kernel void WeightedSum(__global float *inputs1, __global float *inputs2, __global float *outputs, __global float *weight, int dimension ) { if(dimension <= 0) return; //--- size_t n = get_global_id(0); const int shift = n * dimension;
В теле кернела мы идентифицируем текущий поток в 1-мерном пространстве задач и определяем смещение в буферах данных. И затем организовываем цикл взвешенного суммирования элементов. Результаты операций сразу записываются в соответствующий элемент буфера результатов.
float w = weight[n]; for(int i = 0; i < dimension; i++) outputs[shift + i] = inputs1[shift + i] * w + inputs2[shift + i] * (1 - w); }
Для постановки кернелов в очередь выполнения на стороне основной программы были созданы одноименные методы, с кодом которых вы можете самостоятельно ознакомиться во вложении.
После завершения подготовительной работы мы переходим к построению метода прямого прохода feedForward нашего класса CNeuronATFNetOCL. В параметрах данного метода, как и аналогичного метода родительского класса, мы получаем указатель на объект предшествующего нейронного слоя, который в данном случае выступает в роли исходных данных для последующих операций.
bool CNeuronATFNetOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !NeuronOCL.getOutput()) return false;
В теле метода мы сначала проверяем актуальность полученного указателя. И сохраняем во внутреннюю переменную текущего объекта указатель на буфер результатов полученного нейронного слоя.
if(cInputs != NeuronOCL.getOutput())
cInputs = NeuronOCL.getOutput();
Далее мы сначала выполняем операции прогнозирования последующих данных анализируемого временного ряда во временной области. Здесь мы нормализуем полученные данные.
//--- T-Block if(!cNorm.FeedForward(NeuronOCL)) return false;;
После чего добавляем к ним позиционное кодирование.
if(!cPositionEncoder.FeedForward(cNorm.AsObject())) return false;
Транспонируем полученный тензор и разбиваем данные на патчи.
if(!cTranspose.FeedForward(cPositionEncoder.AsObject())) return false; if(!cPatching.FeedForward(cTranspose.AsObject())) return false;
Подготовленные таким образом данные проходят через блок внимания.
int total = caAttention.Total(); CNeuronBaseOCL *prev = cPatching.AsObject(); for(int i = 0; i < total; i++) { CNeuronBaseOCL *att = caAttention.At(i); if(!att.FeedForward(prev)) return false; prev = att; }
И осуществляется прогнозирование последующих значений.
total = caProjection.Total(); for(int i = 0; i < total; i++) { CNeuronBaseOCL *proj = caProjection.At(i); if(!proj.FeedForward(prev)) return false; prev = proj; }
И на выходе T-блока мы добавляем статистические показатели исходного временного ряда к прогнозным значениям.
if(!cRevIN.FeedForward(prev)) return false;
После получения прогнозных значений во временной области, мы переходим к работе с частотной областью. И здесь, первым делом, мы преобразуем полученный временной ряд в спектр частотных характеристик. Для этого мы используем алгоритм FFT.
//--- F-Block if(!FFT(cInputs, cInputs, GetPointer(cInputFreqRe), GetPointer(cInputFreqIm), false)) return false;
После получения двух буферов вещественной и мнимой части частотного спектра мы объединяем их в единый тензор.
if(!Concat(GetPointer(cInputFreqRe), GetPointer(cInputFreqIm), cInputFreqComplex.getOutput(), 1, 1, iFFT * iVariables)) return false;
Обратите внимание, что при конкатенации для обоих буферов данных мы используем размер окна, равный 1 элементу. Таким образом, мы получаем тензор, в котором вещественная и мнимая часть соответствующей частотной характеристики находятся рядом.
Полученный тензор частотных характеристик исходных данных мы нормализуем.
if(!ComplexNormalize()) return false;
И определяем долю доминирующей частоты.
if(!MainFreqWeights()) return false;
Подготовленные данные частотных характеристик мы пропускаем через блок внимания. Для этого нам достаточно лишь вызвать метод прямого прохода, созданного в предыдущей статье класса многослойного комплексного внимания.
if(!cFreqAtteention.FeedForward(cNormFreqComplex.AsObject())) return false;
После успешного выполнения операций блока внимания, мы возвращаем статистические параметры частотных характеристик исходного ряда в обработанные данные.
if(!ComplexUnNormalize()) return false;
Разделяем тензор частотного спектра на составляющие его вещественную и мнимую части.
if(!DeConcat(GetPointer(cOutputFreqRe), GetPointer(cOutputFreqIm), cUnNormFreqComplex.getOutput(), 1, 1, iFFT * iVariables)) return false;
И преобразуем спектр частотных характеристик обратно во временной ряд.
if(!FFT(GetPointer(cOutputFreqRe), GetPointer(cOutputFreqIm), GetPointer(cOutputTimeSeriasRe), GetPointer(cOutputTimeSeriasIm), true)) return false;
Думаю, здесь надо дать некоторые пояснения к указанным выше операциям F-блока. На первый взгляд может показаться странным выполнение большого количества преобразований временного ряда в частотные характеристики, их нормализация и последующие обратные операции, возвращающие данные в тот же временной ряд, только для выполнения операций внимания. Тем более, что все эти операции, кроме внимания, не имеют обучаемых параметров и теоретически должны вернуть нам исходный временной ряд. Но все дело именно в блоке внимания.
Напомню, что авторы метода предложили использовать расширенное дискретное преобразование Фурье. На практике мы просто используем комплексный экспоненциальный базис DFT полного временного ряда. Но при преобразовании исходного временного ряда в его частотные характеристики, мы не имеем прогнозных значений и просто заменяем их нулевыми значениями. Следовательно, выполнение обратного DFT вполне ожидаемо вернет нам прогнозные значения близкие к "0", что не устраивает нас. Поэтому мы приводим спектры унитарных временных рядов в сопоставимый вид путем их нормализации. И сопоставляя их между собой в блоке внимания мы пытаемся научить модель восстанавливать недостающие данные анализируемых частотных характеристик.
Таким образом, на выходе комплексного блока внимания мы ожидаем получить измененные и согласованные между собой спектры частотных характеристик унитарных полных временных рядов с восстановленными пропущенными (недостающими) данными. А восстановление временного ряда из измененных спектров позволит нам получить отличные от "0" прогнозные значения анализируемых временных рядов.
Для завершения операций прямого прохода нам остается лишь выделить прогнозируемые значения из полного временного ряда.
if(!DeConcat(GetPointer(cReconstructInput), GetPointer(cForecast), GetPointer(cOutputTimeSeriasReGrad), GetPointer(cOutputTimeSeriasRe), iHistory, iForecast, iFFT - iHistory - iForecast, iVariables)) return false;
И сложить прогнозы, сделанные во временной и частотной областях, с учетом коэффициента значимости.
//--- Output if(!WeightedSum()) return false; //--- return true; }
Не забываем на каждом этапе контролировать результат выполнения операций. А по завершении операций метода, мы возвращаем логический результат всех операций вызывающей программе.
1.3 Распределение градиента ошибки
После выполнения прямого прохода, нам предстоит распределить градиент ошибки до всех обучающих параметров модели. В нашем новом классе они есть как в T-блоке, так и в F-блоке. Поэтому нам необходимо реализовать механизм передачи градиента ошибки сквозь T и F блоки. А затем объединить градиент ошибки из двух потоков и передать суммарный градиент не уровень предыдущего слоя.
Как и при прямом проходе, перед построением метода calcInputGradients нам необходимо провести некоторую подготовительную работу. При прямом проходе на стороне OpenCL программы мы создали кернелы нормализации и обратного возвращения статистических показателей распределения ComplexNormalize и ComplexUnNormalize, соответственно. При обратном проходе нам предстоит создать кернелы распределения градиента ошибки через указанные операции ComplexNormalizeGradient и ComplexUnNormalizeGradient, соответственно.
В кернеле распределения градиента ошибки через блок нормализации частотных характеристик мы лишь разделим полученный градиент ошибки на среднеквадратическое отклонение соответствующего спектра.
__kernel void ComplexNormalizeGradient(__global float2 *inputs_gr, __global float2 *outputs_gr, __global float *vars, int dimension) { if(dimension <= 0) return; //--- size_t n = get_global_id(0); const int shift = n * dimension; //--- float v = vars[n]; float2 variance = (float2)((v > 0 ? v : 1.0f), 0); for(int i = 0; i < dimension; i++) { float2 val = ComplexDiv(outputs_gr[shift + i], variance); if(isnan(val.x) || isinf(val.x) || isnan(val.y) || isinf(val.y)) val = (float2)0; inputs_gr[shift + i] = val; } }
Должен сказать, что это довольно упрощенный подход к решению данной задачи. Здесь мы среднее значение и среднеквадратическое отклонение принимаем как константы. Хотя на самом деле они являются функциями, и по правилам градиентного спуска нам также необходимо скорректировать их влияние и передать градиент ошибки на влияющие элементы модели. Но как показывает практика, влияние этих элементов на исходные данные достаточно мало. И для снижения затрат на обучение моделей, мы опустим эти операции.
Кернел распределения градиента через операции денормализации данных построен по аналогичной схеме, только здесь мы умножаем полученный градиент ошибки на среднеквадратическое отклонение.
__kernel void ComplexUnNormalizeGradient(__global float2 *inputs_gr, __global float2 *outputs_gr, __global float *vars, int dimension) { if(dimension <= 0) return; //--- size_t n = get_global_id(0); const int shift = n * dimension; //--- float v = vars[n]; float2 variance = (float2)((v > 0 ? v : 1.0f), 0); for(int i = 0; i < dimension; i++) { float2 val = ComplexMul(outputs_gr[shift + i], variance); if(isnan(val.x) || isinf(val.x) || isnan(val.y) || isinf(val.y)) val = (float2)0; inputs_gr[shift + i] = val; } }
Далее нам необходимо ещё реализовать кернел для распределения суммарного градиента ошибки между блоками прогнозирования во временной и частотной области. Этот функционал мы реализуем в кернеле WeightedSumGradient. В параметрах данный кернел получает указатели на 4 буфера данных и 1 параметр, аналогично соответствующему кернелу прямого прохода.
__kernel void WeightedSumGradient(__global float *inputs_gr1, __global float *inputs_gr2, __global float *outputs_gr, __global float *weight, int dimension ) { if(dimension <= 0) return; //--- size_t n = get_global_id(0); const int shift = n * dimension;
В теле кернела мы, как обычно, идентифицируем текущий поток в 1-мерном пространстве задач и определяем смещение в буферах данных. После чего подготовим локальные переменные весов прогнозов частотного и временного ряда.
float w = weight[n]; float w1 = 1 - weight[n];
А затем организуем цикл распределения градиента ошибки по соответствующим буферам данным.
for(int i = 0; i < dimension; i++) { float grad = outputs_gr[shift + i]; inputs_gr1[shift + i] = grad * w; inputs_gr2[shift + i] = grad * w1; } }
Постановка вышеприведенных кернелов распределения градиента ошибки в очередь выполнения осуществляется в одноименных методах на стороне основной программы. С кодом этих методов вы можете самостоятельно ознакомиться во вложении.
Ещё один момент, на который нам следует обратить внимание, это вычисление градиента ошибки восстановленного временного ряда исторических значений. Данный функционал мы будем выполнять в методе calcReconstructGradient.
Здесь надо сказать, что несмотря на выполнение операций на стороне OpenCL контекста, для выполнения указанных операций мы не создаем новый кернел. Вместо этого мы воспользуемся уже готовым кернелом определения градиента ошибки по целевым значениям. Нам лишь необходимо создать метод постановки кернела в очередь выполнения с использование буферов данных нашего F-блока.
Используемый нами кернел запускается в одномерном пространстве задач по числу элементов в тензоре. В нашем случае размер анализируемого вектора равен произведению глубины анализируемой истории на количество унитарных временных рядов.
bool CNeuronATFNetOCL::calcReconstructGradient(void) { uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = iHistory * iVariables;
В качестве целевых данных у нас выступают значения исходных данных, которые мы получили при прямом проходе от предшествующего нейронного слоя. При прямом проходе мы предусмотрительно сохранили указатель на необходимый нам буфер данных.
if(!OpenCL.SetArgumentBuffer(def_k_CalcOutputGradient, def_k_cog_matrix_t, cInputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Градиент ошибки мы определяем для восстановленных данных из обработанного спектра.
if(!OpenCL.SetArgumentBuffer(def_k_CalcOutputGradient, def_k_cog_matrix_o, cReconstructInput.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Результаты операций мы будем записывать в буфер градиентов восстановленных данных.
if(!OpenCL.SetArgumentBuffer(def_k_CalcOutputGradient, def_k_cog_matrix_ig, cReconstructInputGrad.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И при прямом проходе мы не использовали функций активации.
if(!OpenCL.SetArgument(def_k_CalcOutputGradient, def_k_cog_activation, (int)None)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Ставим кернел в очередь выполнения, проверяем результат операций и завершаем работу метода, возвращая вызывающей программе логический результат выполненных операций.
if(!OpenCL.SetArgument(def_k_CalcOutputGradient, def_k_cog_error, 1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } ResetLastError(); if(!OpenCL.Execute(def_k_CalcOutputGradient, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel CalcOutputGradient: %d", GetLastError()); return false; } //--- return true; }
После завершения подготовительной работы, мы переходим непосредственно к построению метода распределения градиентов ошибки calcInputGradients.
В параметрах данного метода, аналогично одноименному методу родительского класса, мы получаем указатель на объект предыдущего нейронного слоя, которому нам предстоит передать градиент ошибки.
bool CNeuronATFNetOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !NeuronOCL.getGradient() || !cInputs) return false;
В теле метода мы сразу проверяем актуальность полученного указателя. После чего распределяем градиент ошибки, полученный от последующего слоя на 2 потока между блоками прогнозирования во временной и частотной областях.
//--- Output if(!WeightedSumGradient()) return false;
Первым мы проведем градиент ошибки через T-блок прогнозирования во временной области. Здесь в обратном порядке прямого прохода вызываем одноименные методы вложенных объектов.
//--- T-Block if(cRevIN.Activation() != None && !DeActivation(cRevIN.getOutput(), cRevIN.getGradient(), cRevIN.getGradient(), cRevIN.Activation())) return false; CNeuronBaseOCL *next = cRevIN.AsObject(); for(int i = caProjection.Total() - 1; i >= 0; i--) { CNeuronBaseOCL *proj = caProjection.At(i); if(!proj || !proj.calcHiddenGradients((CObject *)next)) return false; next = proj; } for(int i = caAttention.Total() - 1; i >= 0; i--) { CNeuronBaseOCL *att = caAttention.At(i); if(!att || !att.calcHiddenGradients((CObject *)next)) return false; next = att; } if(!cPatching.calcHiddenGradients((CObject*)next)) return false; if(!cTranspose.calcHiddenGradients(cPatching.AsObject())) return false; if(!cPositionEncoder.calcHiddenGradients(cTranspose.AsObject())) return false; if(!cNorm.calcHiddenGradients(cPositionEncoder.AsObject())) return false; if(!NeuronOCL.calcHiddenGradients(cNorm.AsObject())) return false;
Алгоритм распределения градиента в блоке частотного прогнозирования немного сложнее. Здесь мы сначала определим градиент ошибки для мнимой части восстановленного временного ряда. Как уже было сказано ранее, целевым значением для мнимой части временного ряда является "0". Поэтому для определения градиента ошибки мы просто изменим знак для результатов прямого прохода.
//--- F-Block if(!CNeuronBaseOCL::SumAndNormilize(GetPointer(cOutputTimeSeriasIm), GetPointer(cOutputTimeSeriasIm), GetPointer(cOutputTimeSeriasIm), iFFT*iVariables, false, 0, 0, 0, -0.5)) return false;
Далее мы определим градиент ошибки восстановления исторических данных.
if(!calcReconstructGradient()) return false;
После чего мы объединим тензоры градиентов ошибки восстановления исторических данных (определили в методе calcReconstructGradient), градиент ошибки прогнозирования временного ряда (получили при разделении градиента ошибки последующего слоя на два потока) и дополним нулевыми значениями до размера спектра полного ряда.
if(!Concat(GetPointer(cReconstructInputGrad), GetPointer(cForecastGrad), GetPointer(cZero), GetPointer(cOutputTimeSeriasReGrad), iHistory, iForecast, iFFT - iHistory - iForecast, iVariables)) return false;
Мы дописываем нулевые значения в конец тензора градиентов ошибки полного временного ряда, так как у нас нет данных о целевых значениях за пределами горизонта планирования. А значит, мы их просто не корректируем.
Полученный градиент ошибки для полного временного ряда, построенного по данным блока частотного прогнозирования, мы переводим в частотную область путем применения FFT.
if(!FFT(GetPointer(cOutputTimeSeriasReGrad), GetPointer(cOutputTimeSeriasIm), GetPointer(cOutputFreqRe), GetPointer(cOutputFreqIm), false)) return false;
Полученные данные вещественной и мнимой части частотного спектра градиента ошибки мы объединяем в единый тензор.
if(!Concat(GetPointer(cOutputFreqRe), GetPointer(cOutputFreqIm), cUnNormFreqComplex.getGradient(), 1, 1, iFFT * iVariables)) return false;
Корректируем градиент ошибки на производную операций денормализации данных.
if(!ComplexUnNormalizeGradient()) return false;
И проводим градиент ошибки через блок комплексного внимания.
if(!cNormFreqComplex.calcHiddenGradients(cFreqAtteention.AsObject())) return false;
Затем мы корректируем градиент ошибки на производную функции нормализации данных.
if(!ComplexNormalizeGradient()) return false;
Разделяем вещественную и мнимую части спектра.
if(!DeConcat(GetPointer(cInputFreqRe), GetPointer(cInputFreqIm), cInputFreqComplex.getGradient(), 1, 1, iFFT * iVariables)) return false;
И возвращаем градиент ошибки во временную область с помощью IFFT.
if(!FFT(GetPointer(cInputFreqRe), GetPointer(cInputFreqIm), GetPointer(cOutputTimeSeriasRe), GetPointer(cOutputTimeSeriasIm), false)) return false;
Здесь стоит обратить внимание, что мы получили градиент ошибки для полного временного ряда. На предыдущий слой нам необходимо передать только градиент ошибки исторических данных. Поэтому мы сначала выделим данные для анализируемого горизонта истории.
if(!DeConcat(GetPointer(cInputFreqRe), GetPointer(cOutputTimeSeriasIm), GetPointer(cOutputTimeSeriasRe), iHistory, iFFT-iHistory, iVariables)) return false;
А затем добавим полученные значения к результатам распределения градиента ошибки T-блока.
if(!CNeuronBaseOCL::SumAndNormilize(NeuronOCL.getGradient(), GetPointer(cInputFreqRe), NeuronOCL.getGradient(), iHistory*iVariables, false, 0, 0, 0, 0.5)) return false; //--- return true; }
Напомню, что на каждой итерации мы контролируем процесс выполнения операций. И после успешного завершения всех операций, мы возвращаем логический результат работы метода вызывающей программе.
1.4 Обновление параметров модели
Градиент ошибки каждого обучаемого параметра модели определяет его влияние на общий результат. И следующим этапом нам предстоит скорректировать параметры модели для минимизации ошибки. Данный функционал выполняется в методе updateInputWeights. В рамках реализации нашего класса обновление параметров сводится к вызову одноименных методов вложенных объектов, содержащих обучаемые параметры. В F-блоке это только класс комплексного внимания.
bool CNeuronATFNetOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { //--- F-Block if(!cFreqAtteention.UpdateInputWeights(cNormFreqComplex.AsObject())) return false;
В T-блоке таких объектов больше.
//--- T-Block if(!cPatching.UpdateInputWeights(cPositionEncoder.AsObject())) return false; int total = caAttention.Total(); CNeuronBaseOCL *prev = cPatching.AsObject(); for(int i = 0; i < total; i++) { CNeuronBaseOCL *att = caAttention.At(i); if(!att.UpdateInputWeights(prev)) return false; prev = att; } total = caProjection.Total(); for(int i = 0; i < total; i++) { CNeuronBaseOCL *proj = caProjection.At(i); if(!proj.UpdateInputWeights(prev)) return false; prev = proj; } //--- return true; }
На этом мы завершаем рассмотрение алгоритмов реализации подходов, предложенных авторами ATFNet. А с полным кодом класса CNeuronATFNetOCL и вех его методов вы можете ознакомиться во вложении.
2. Архитектура модели
После завершения работы с нашим новым классом реализации подходов метода ATFNet, мы переходим к построению архитектуры наших моделей. Как вы уже, наверное, догадались, внедрять новый нейронный слой мы будем в Энкодер состояния окружающей среды. Конечно, сложно назвать класс CNeuronATFNetOCL нейронным слоем. В нем реализована довольно сложная архитектура построения комплексной модели.
На вход нашего энкодера мы будем подавать набор необработанных исходных данных, такой же как мы подавали на вход построенных ранее моделей.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } //--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Однако, в данном случае мы не нормализуем полученные данные. Напомню, что и T-блок, и F-блок в своей архитектуре имеют нормализацию данных. Поэтому мы опускаем этот шаг. Однако наши исходные данные сформированы по векторам описания отдельных состояний окружающей среды. Перед дальнейшей обработкой мы транспонируем исходные данные для возможности анализа в разрезе унитарных временных рядов.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; }
И далее мы воспользуемся нашим новым классом для прогнозирования последующих данных анализируемого временного ряда.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronATFNetOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.window_out = NForecast; descr.step = 8; descr.layers = 4; { int temp[] = {5, 1, 16}; ArrayCopy(descr.windows, temp); } descr.activation = None; descr.batch = 10000; if(!encoder.Add(descr)) { delete descr; return false; }
По существу, в данном слое заключена вся наша модель. На его выходе мы получаем нужные нам прогнозные значения на всю глубину планирования. Нам остается лишь транспонировать их до требуемой размерности.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
И для согласованности спектра прогнозных значений мы воспользуемся подходами метода FreDF.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(false); descr.probability = 0.8f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Модели Актера и Критика мы оставили без изменений.
Программы обучения и тестирования обученных моделей были так же перенесены без изменений из предыдущих статей. С их кодом вы можете самостоятельно ознакомиться во вложении.
3. Тестирование
Нами была проведена большая работа по реализации подходов, предложенных авторами метода ATFNet средствами MQL5. Объем проделанной работы даже вышел за рамки одной статьи. И наконец, мы переходим к заключительному этапу нашей работы — обучению и тестированию моделей.
Для обучения моделей мы будем использовать ранее созданный советник для обучения предыдущих моделей. Следовательно, можно воспользоваться и ранее собранными обучающими данными.
Напомню, что обучение моделей осуществляется на исторических данных инструмента EURUSD тайм-фрейм H1 за весь 2023 год.
На первом этапе мы обучаем модель Энкодера прогнозированию последующих состояний окружающей среды на горизонт планирования, который определяется константой NForecast.
Как и ранее, модель Энкодера анализирует только ценовое движение, поэтому в процессе первого этапа обучения нам нет необходимости обновлять обучающую выборку.
На втором этапе нашего процесса обучения мы осуществляем поиск наиболее оптимальной политики действий нашего Актера. И здесь мы уже осуществляем итерационное обучение моделей Актера и Критика, которое чередуется с обновлением обучающей выборки. Процесс обновления обучающей выборки позволяет нам уточнить вознаграждения окружающей среды в области текущей политики Актера, что в свою очередь поможет произвести более тонкую настройку искомой политики.
В процессе обучения нам удалось получить политику Актера, способную генерировать прибыль как на обучающих, так и на тестовых данных. Результаты тестирования модели представлены ниже.
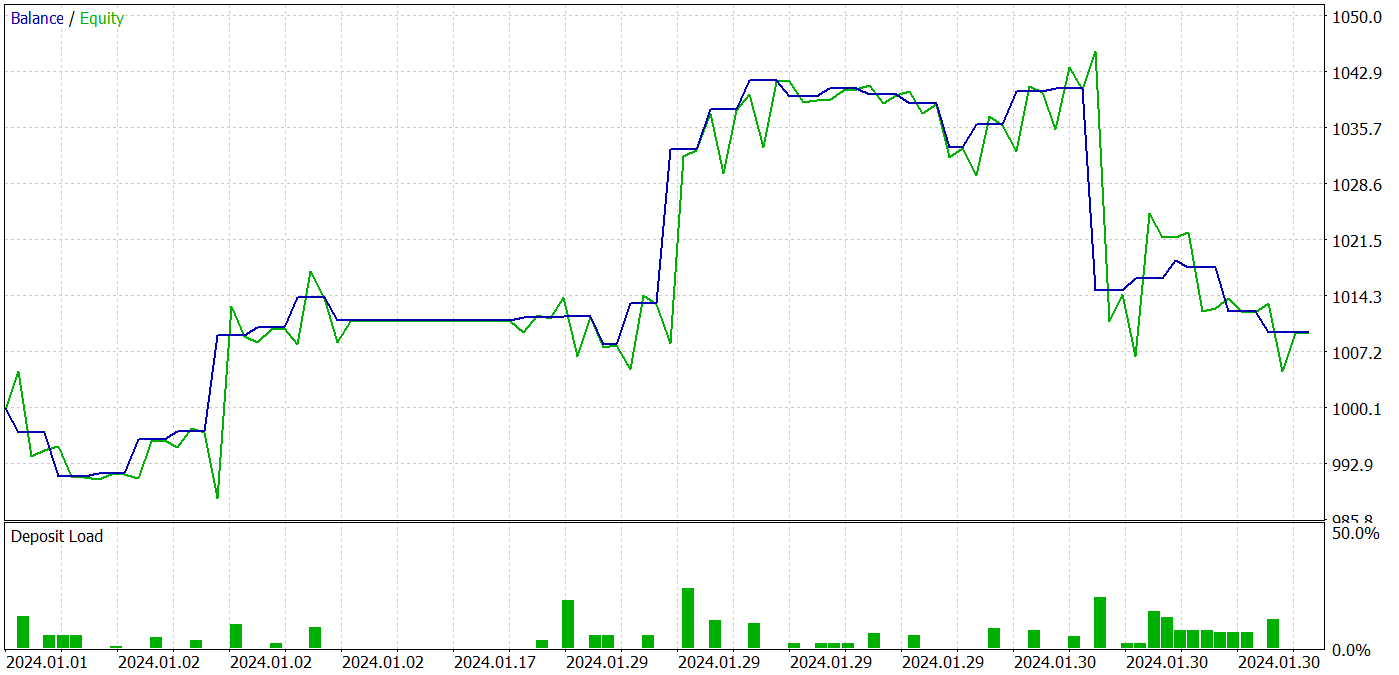
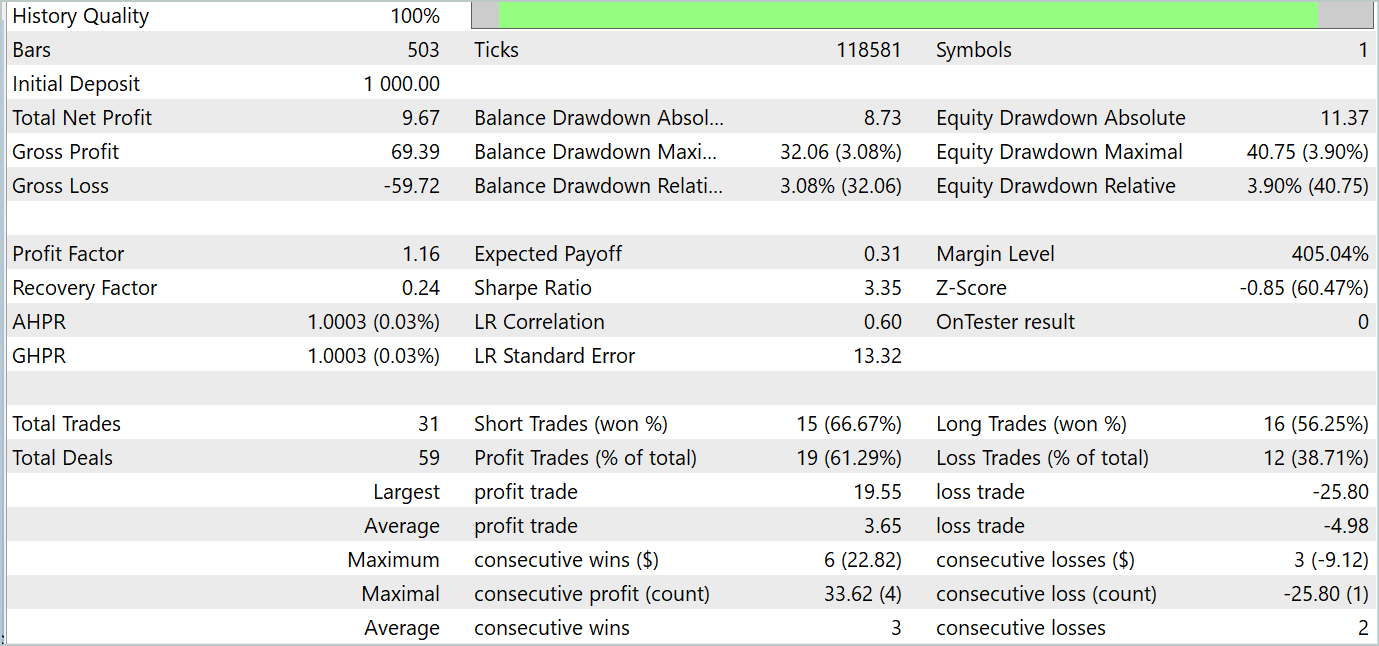
За период тестирования модель совершила 31 сделку, 19 из которых было закрыто с прибылью. Доля прибыльных сделок составила более 61%. Примечательно, что модель совершила практически равное количество длинных и коротких позиций (15 против 16).
Заключение
Последние две статьи были посвящены методу ATFNet, предложенному в статье "ATFNet: Adaptive Time-Frequency Ensembled Network for Long-term Time Series Forecasting" для прогнозирования многомерных временных рядов. Модель ATFNet объединяет модули временной и частотной областей для анализа зависимостей в данных временных рядов. Она использует T-Block для захвата локальных зависимостей во временной области и F-Block для анализа цикличностей временного ряда в частотной области.
ATFNet применяет взвешивание энергии доминирующей гармонической серии, расширенное преобразование Фурье и внимание к комплексному спектру для адаптации к периодичности и смещению частот во входных временных рядах.
В практической части нашей работы мы реализовали свое видение предложенных подходов средствами MQL5. Провели обучение и тестирование моделей на реальных данных. Результаты тестирования свидетельствуют о перспективности предложенных подходов для использования в построении прибыльных торговых стратегий.
Ссылки
- ATFNet: Adaptive Time-Frequency Ensembled Network for Long-term Time Series Forecasting
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Дмитрий здравствуйте!
Подскажите а как Вы производите обучение и пополнение базы примеров за год истории? У меня в Ваших советниках из последних статей (где используете год истории) наблюдается проблема с пополнением новых примеров в файл bd. Дело в том что когда этот файл доходит до размера 2 Гб, он видимо как то криво начинает сохранятся и потом советник обучения моделей не может его прочитать и выдаёт ошибку. Либо у файла bd резко начинает падать размер, с каждым новым пополнением примерами в плоть до нескольких мегабайт и потом советник обучения всё равно выдаёт ошибку. Данная проблема возникает до 150 траеторий если за год брать историю и примерно до 250 если за 7 месяцев. Размер файла bd растёт очень быстро. К примеру 18 траекторий весят почти 500 Мб. 30 траекторий 700 Мб.
В результате чтобы обучать приходится данный файл при наборе за 7 месяцев где-то 230 траеторий по просту удалять и создавать его заново предобученным советником. Но при таком режиме механизм обновления траеторий при пополнении базы данный по просту не работает. Я предполагаю что это связано с ограничением в 4 Гб ОЗУ на один поток в МТ5. Где-то в справке про это писали.
Что интересно в ранних статьях (где история была за 7 месяцев, и база на 500 траекторий весила примерно 1 Гб) такой проблемы не было. Ресурсами пк у меня это не ограничено тк ОЗУ более 32 Гб и на видеокарте памяти достаточно.
Дмитрий как Вы обучаете с учётом данного момента или может быть Вы как либо настроили МТ5 предварительно?
Файлы использую из статей без какой либо модификации.
Дмитрий здравствуйте!
Подскажите а как Вы производите обучение и пополнение базы примеров за год истории? У меня в Ваших советниках из последних статей (где используете год истории) наблюдается проблема с пополнением новых примеров в файл bd. Дело в том что когда этот файл доходит до размера 2 Гб, он видимо как то криво начинает сохранятся и потом советник обучения моделей не может его прочитать и выдаёт ошибку. Либо у файла bd резко начинает падать размер, с каждым новым пополнением примерами в плоть до нескольких мегабайт и потом советник обучения всё равно выдаёт ошибку. Данная проблема возникает до 150 траеторий если за год брать историю и примерно до 250 если за 7 месяцев. Размер файла bd растёт очень быстро. К примеру 18 траекторий весят почти 500 Мб. 30 траекторий 700 Мб.
В результате чтобы обучать приходится данный файл при наборе за 7 месяцев где-то 230 траеторий по просту удалять и создавать его заново предобученным советником. Но при таком режиме механизм обновления траеторий при пополнении базы данный по просту не работает. Я предполагаю что это связано с ограничением в 4 Гб ОЗУ на один поток в МТ5. Где-то в справке про это писали.
Что интересно в ранних статьях (где история была за 7 месяцев, и база на 500 траекторий весила примерно 1 Гб) такой проблемы не было. Ресурсами пк у меня это не ограничено тк ОЗУ более 32 Гб и на видеокарте памяти достаточно.
Дмитрий как Вы обучаете с учётом данного момента или может быть Вы как либо настроили МТ5 предварительно?
Файлы использую из статей без какой либо модификации.
Виктор,

Даже не знаю, что Вам ответить. У меня работают и файлы большего размера.
Привет, прочитал эту статью, интересно. Немного понял, буду просматривать еще раз после прочтения оригинальной статьи.
Я наткнулся на эту статью https://www.mdpi.com/2076-3417/14/9/3797#
В ней утверждается, что они достигли 94% в классификации изображений биткоинов, действительно ли это возможно?