
Нейросети — это просто (Часть 95): Снижение потребления памяти в моделях Transformer

Введение
Появление архитектуры Transformer в 2017 году привело к появлению больших языковых моделей (LLM), которые демонстрируют высокие результаты в решении задач обработки естественного языка. Довольно скоро преимущества подходов Self-Attention были "взяты на вооружение" исследователями практически во всех областях машинного обучения.
Однако из-за своей авторегрессионной природы, Декодер Transformer ограничен пропускной способностью памяти, используемой для загрузки и хранения сущностей Key и Value на каждом временном шаге (так называемое KV-кэширование). Поскольку этот кэш масштабируется линейно, в зависимости от размера модели, размера пакета и длины контекста, он может даже превышать использование памяти весами модели.
Должен сказать, что эта проблема не нова. И есть различные подходы к её решению. Наибольшее распространение получили методы прямого сокращения используемых головок KV. В 2019 году авторы статьи "Fast Transformer Decoding: One Write-Head is All You Need" предложили алгоритм Multi-Query Attention (MQA), который использует только одну проекцию Key и Value для всех голов внимания на уровне одного слоя. Это уменьшает потребление памяти для KV-кэша на 1/heads. Это существенное снижение потребления ресурсов, приводит к некоторой деградации в качестве и стабильности модели.
Авторы метода Grouped-Query Attention (GQA), описанного в статье "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints" (2023), представляют промежуточное решение по разделению нескольких головок KV на несколько групп внимания. Эффективность уменьшения размера кэша KV при использовании GQA составляет groups/heads. При разумном количестве голов, GQA может достичь почти паритета с базовой моделью в различных тестах. Однако, уменьшение размера кэша KV по-прежнему ограничивается 1/heads с помощью MQA, но этого может быть недостаточно для некоторых приложений.
Чтобы выйти за рамки указанного ограничения, авторы статьи "MLKV: Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding" предлагают алгоритм многоуровневого совместного использования Key и Value (MLKV). Они делают еще один шаг вперед по совместному использованию KV. MLKV не только разделяет головы KV между головками внимания одного слоя, но и между головками внимания других уровней. Головки KV можно использовать для групп головок внимания в одном слое и/или для групп головок внимания последующих слоев. В крайнем случае, для всех голов внимания всех слоев можно использовать одну головку KV. Авторы метода экспериментируют с различными конфигурациями, которые используют как сгруппированные Query на одном уровне, так и между разными уровнями. И даже с конфигурациями, в которых количество голов KV меньше количества слоев. Представленные в статье эксперименты демонстрируют, что эти конфигурации обеспечивают разумный компромисс между производительностью и достигнутой экономией памяти. Практическое снижение объема используемой памяти до 2/layers исходного размера кэша KV не приводит к существенному ухудшению качества модели.
1. Метод MLKV
Метод MLKV является логическим продолжением алгоритмов MQA и GQA. В указанных методах размер KV-кэша снижается за счет уменьшения голов KV, которые совместно используются группой голов внимания в рамках одного слоя Self-Attention. Вполне ожидаемый шаг — совместное использование сущностей Key и Value между слоями Self-Attention. Этот шаг может быть обоснован недавними исследованиями роли блока FeedForward в алгоритме Transformer. Предполагается, что указанный блок имитирует память "Key-Value", обрабатывающую разные уровни информации. Однако, наиболее примечательным для нас является замечание, что группы последовательных слоев вычисляют схожие вещи. Точнее, нижние уровни занимаются поверхностными шаблонами, а верхние — более семантическими деталями. Таким образом, можно сделать вывод, что внимание можно делегировать группам слоев, сохраняя при этом необходимые вычисления в блоке FeedForward. Интуитивно понятно, что головки KV могут быть разделены между слоями, которые имеют схожие цели.
Развивая эти идеи, авторы метода MLKV предлагают многоуровневый обмен ключами. MLKV не только разделяет головки KV среди голов внимания к Query на уровне одного слоя Self-Attention, но и среди голов внимания на других уровнях. Это позволяет снизить общее количество KV-голов в Transformer и таким образом обеспечить еще меньший KV-кэш.
MLKV можно записать следующим образом:
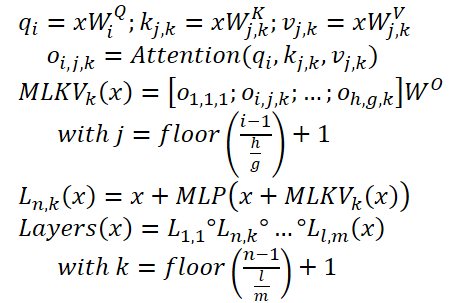
Ниже представлена авторская визуализация сравнения методов снижения размера KV-кэша.

Проведенные авторами метода эксперименты демонстрируют явный компромисс между памятью и точностью. Архитекторам остается выбирать, чем пожертвовать. При этом следует учитывать множество факторов. Для количества голов KV, превышающего или равного числу слоев, все же лучше использовать GQA/MQA вместо MLKV. Авторы метода предполагают, что наличие нескольких голов KV в нескольких слоях более важно, чем наличие нескольких головок KV в одном слое. Другими словами, следует пожертвовать головками KV сначала на уровне слоя (GQA/MQA), а затем на межуровневом уровне (MLKV).
Для случаев работы в условиях более жестких требований к памяти, требующих количество голов KV меньше количества слоев, единственным способом является MLKV. Это дизайнерское решение жизнеспособно. Авторы метода обнаружили, что при снижении голов внимания в 2 раза меньше количества слоев, MLKV работает очень близко к MQA. А значит, это должно быть относительно простым решением, если требуется кэш KV, размер которого вдвое меньше того, что обеспечивает MQA.
Для требований ниже этого значения, можно использовать количество головок KV до 6 раз меньше количества слоев без резкого ухудшения качества. Все, что ниже этого, становится сомнительным.
2. Реализация средствами MQL5
После сравнительно небольшого теоретического описания предложенных подходов, мы переходим к их практической реализации средствами MQL5. И здесь мы реализуем MLKV метод. На мой взгляд, это наиболее общий подход, а MQA и GQA можно представить в качестве частных случаев MLKV.
И наиболее спорный вопрос предстоящей реализации — передача информации между нейронными слоями. В данном случае было принято решение не усложнять существующий алгоритм обмена данными между объектами нейронных слоев, а воспользоваться блоком многослойной последовательности. Что мы уже не раз реализовывали. И в качестве родительского класса для предстоящей реализации был выбран CNeuronMLMHAttentionOCL.
2.1 Реализация на стороне OpenCL
А начнем мы свою работу с подготовки кернелов на стороне OpenCL программы. И здесь сразу стоит обратить внимание, что в выбранном нами родительском классе для параллельной генерации сущностей Query, Key и Value мы использовали один конкатенированный тензор. И на этом был построен весь механизм внимания. Однако использование различного количества голов для Query и Key-Value, а также использование Key-Value с другого уровня, заставляет нас задуматься о разделении указанных сущностей на 2 отдельных тензора. Напомню, что подобное мы уже делали при построении блоков кросс-внимания.
Так почему бы нам не воспользоваться существующими наработками и немного скорректировать алгоритм кернелов кросс-внимания? Все что нам надо, так это добавить ещё один параметр кернела, указывающий на количество KV-голов (выделен красным в коде).
__kernel void MH2AttentionOut(__global float *q, ///<[in] Matrix of Querys __global float *kv, ///<[in] Matrix of Keys __global float *score, ///<[out] Matrix of Scores __global float *out, ///<[out] Matrix of attention int dimension, ///< Dimension of Key int heads_kv )
В теле кернела для определения анализируемой KV-головки нам достаточно взять остаток от деления текущей головы внимания на общее количество KV-голов.
const int h_kv = h % heads_kv;
И сделаем корректировку смещения в буфере тензора Key-Value.
const int shift_k = 2 * dimension * (k + h_kv); const int shift_v = 2 * dimension * (k + heads_kv + h_kv);
Дальнейший код кернела остался без изменений. Аналогичные правки были внесены в код кернела обратного прохода MH2AttentionInsideGradients. А с полным кодом обоих кернелов вы можете самостоятельно ознакомиться во вложении.
На этом мы завершаем работу на стороне OpenCL и переходим к коду основной программы. И здесь нам сначала необходимо восстановить работоспособность созданного ранее кода. Ведь дополнительный параметр в указанных выше кернелах приведет к ошибкам при их вызове. Поэтому мы находим все вызовы этих кернелов и добавляем передачу данных в новый параметр.
Напомню, что ранее мы использовали одинаковое количество голов для Query и Key-Value.
if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_heads_kv, (int)iHeads)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgument(def_k_MH2AttentionInsideGradients, def_k_mh2aig_heads_kv, (int)iHeads)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
2.2 Создание класса MLKV
Продолжаем нашу работу. И на следующем этапе мы создадим класс многослойного блока внимания с использованием подходов MLKV — CNeuronMLMHAttentionMLKV. Как уже было сказано ранее, новый класс будет прямым наследником класса CNeuronMLMHAttentionOCL. Структура нового класса представлена ниже.
class CNeuronMLMHAttentionMLKV : public CNeuronMLMHAttentionOCL { protected: uint iLayersToOneKV; uint iHeadsKV; CCollection KV_Tensors; CCollection KV_Weights; CBufferFloat Temp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool AttentionOut(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *scores, CBufferFloat *out); virtual bool AttentionInsideGradients(CBufferFloat *q, CBufferFloat *q_g, CBufferFloat *kv, CBufferFloat *kv_g, CBufferFloat *scores, CBufferFloat *gradient); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronMLMHAttentionMLKV(void) {}; ~CNeuronMLMHAttentionMLKV(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMLMHAttentionMLKV; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Как можно заметить, в представленной структуре класса мы вводим 2 переменные для хранения количества KV-голов (iHeadsKV) и периодичность обновления тензора Key-Value (iLayersToOneKV).
Мы также добавили коллекции хранения тензоров Key-Value и матрицы весов для их формирования (KV_Tensors и KV_Weights соответственно).
Кроме того, мы добавили буфер Temp для записи промежуточных значений градиентов ошибки.
Набор методов класса довольно стандартный и, думаю, вы уже понимаете их назначение. Ну а более подробно мы познакомимся с ними в процессе реализации.
Все внутренние объекты класса мы объявляем статичными, что позволяет нам оставить "пустыми" конструктор и деструктор класса. А инициализация всех вложенных объектов и переменных осуществляется в методе Init. Как обычно, в параметрах данного метода передается вся информация, необходимая для создания требуемого объекта.
bool CNeuronMLMHAttentionMLKV::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
В теле метода мы сразу вызываем одноименный метод базового класса всех нейронных слоев CNeuronBaseOCL.
Обратите внимание, что мы обращаемся к объекту базового класса, а не прямого родительского. Это связано с разделением сущностей Query. Key и Value на 2 тензора, что ведет к изменению размеров некоторых буферов данных. Однако такой подход заставляет нас инициализировать не только новые объекты, но и унаследованные от родительского класса.
После успешного выполнения метода инициализации базового класса, мы сохраняем полученные параметры класса во внутренние переменные.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(layers, 1); iHeadsKV = fmax(heads_kv, 1); iLayersToOneKV = fmax(layers_to_one_kv, 1);
Следующим шагом мы определим размеры всех создаваемых буферов.
uint num_q = iWindowKey * iHeads * iUnits; //Size of Q tensor uint num_kv = 2 * iWindowKey * iHeadsKV * iUnits; //Size of KV tensor uint q_weights = (iWindow + 1) * iWindowKey * iHeads; //Size of weights' matrix of Q tenzor uint kv_weights = 2 * (iWindow + 1) * iWindowKey * iHeadsKV; //Size of weights' matrix of KV tenzor uint scores = iUnits * iUnits * iHeads; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits; //Size of multi-heads self-attention uint out = iWindow * iUnits; //Size of out tensore uint w0 = (iWindowKey + 1) * iHeads * iWindow; //Size W0 tensor uint ff_1 = 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
И организуем цикл с числом итераций, равным количеству внутренних слоев в создаваемом блоке внимания.
for(uint i = 0; i < iLayers; i++) {
В теле цикла мы создаем ещё один вложенный цикл, в котором сначала создадим буферы для хранения данных. А на второй итерации вложенного цикла создадим буферы для записи соответствующих градиентов ошибки.
CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- Initilize Q tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Здесь мы первыми создадим тензоры сущностей Query. А за ними аналогичные тензоры для записи сущностей Key-Value. Только последние мы будем создавать один раз на iLayersToOneKV итераций цикла.
//--- Initilize KV tensor if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Tensors.Add(temp)) return false; }
Далее, следуя за алгоритмом Transformer, мы создаем буферы для записи тензоров матрицы коэффициентов зависимости, многоголового внимания и его сжатого представления.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
И тут же добавим буферы блока FeedForward.
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
//--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
Обратите внимание, что при создании буферов для сохранения результатов работы и градиентов ошибки 2-го слоя блока FeedForward, мы сначала проверяем номер слоя. Так как для последнего слоя мы не будем создавать новые буферы, то сохраним указатели на уже созданные буферы результатов работы и градиентов ошибки нашего класса CNeuronMLMHAttentionMLKV. Это позволит нам избежать излишнего копирования данных при обмене данными с последующим слоем.
После создания буферов хранения промежуточных результатов и соответствующих градиентов ошибки, мы создадим буфера матриц обучаемых параметров нашего класса. И надо сказать, что их здесь тоже достаточное количество. Первой мы создадим и инициализируем случайными параметрами матрицу весов для генерации сущности Query.
//--- Initilize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(q_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < q_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
Аналогичным образом генерируем параметры генерации тензора Key-Value. Только они создаются один раз на iLayersToOneKV внутренних слоев.
//--- Initilize KV weights if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < kv_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Weights.Add(temp)) return false; }
Далее генерируем параметры сжатия результатов многоголового внимания.
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
И завершают эту работу последние по списку, но не по значению, параметры блока FeedForward.
//--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
В процессе обучения модели нам понадобятся буферы для записи моментов всех вышесозданных параметров. Эти буферы мы создадим во вложенном цикле, число итераций которого зависит от выбранного метода оптимизации.
//--- for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(q_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(kv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Weights.Add(temp)) return false; }
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(w0, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_1, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_2, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } }
После создания всех коллекций буферов нашего блока внимания, мы инициализируем ещё один вспомогательный буфер, который будем использовать для записи промежуточных значений.
if(!Temp.BufferInit(MathMax(num_kv, out), 0)) return false; if(!Temp.BufferCreate(OpenCL)) return false; //--- return true; }
На каждом этапе мы в обязательном порядке контролируем процесс выполнения операций. И в конце работы метода мы возвращаем вызывающей программе логический результат выполнения операций.
В методах AttentionOut и AttentionInsideGradients осуществляется постановка в очередь выполнения скорректированных нами кернелов. Но мы не будем сейчас останавливаться на подробном рассмотрении их алгоритмов. Алгоритм постановки любого кернела в очередь выполнения остается неизменным:
- Определение пространства задач.
- Передача всех необходимых параметров в кернел.
- Постановка кернела в очередь выполнения.
Код данного алгоритма был уже не раз описан в рамках данной серии статей. В том числе методы постановки в очередь исходной версии кернелов, которые мы модифицировали, описаны в статье, посвященной методу ADAPT. А вам я предлагаю самостоятельно ознакомиться с указанными методами во вложении.
А мы переходим к рассмотрению алгоритма метода прямого прохода feedForward. В параметрах метода мы получаем указатель на объект предшествующего слоя, который в данном случае предоставляет нам исходные данные.
bool CNeuronMLMHAttentionMLKV::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
И в теле метода мы первым делом проверяем актуальность полученного указателя. После чего объявим локальный указатель на буфер тензора Key-Value и организовываем цикл перебора всех внутренних слоев нашего блока.
CBufferFloat *kv = NULL; for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(6 * i - 4)); CBufferFloat *q = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, q, iWindow, iWindowKey * iHeads, None)) return false;
В теле цикла мы сначала генерируем тензор сущностей Query. А затем генерируем тензор Key-Value. Но обратите внимание, что последний мы генерируем не на каждой итерации перебора внутренних слоев, а лишь каждые iLayersToOneKV слоев. Математически контроль этого условия довольно прост — нам лишь необходимо, чтобы индекс текущего слоя делился без остатка на количество слоев работы одного тензора Key-Value. И следует отметить, что для первого слоя с индексом "0" остаток от деления тоже отсутствует.
if((i % iLayersToOneKV) == 0) { uint i_kv = i / iLayersToOneKV; kv = KV_Tensors.At(i_kv * 2); if(IsStopped() || !ConvolutionForward(KV_Weights.At(i_kv * (optimization == SGD ? 2 : 3)), inputs, kv, iWindow, 2 * iWindowKey * iHeadsKV, None)) return false; }
Указатель на буфер сгенерированных сущностей мы сохраняем в объявленную нами ранее локальную переменную, что облегчает нам доступ к ним на последующих итерациях цикла.
После генерации всех необходимых сущностей мы выполняем операции прямого прохода кросс-внимания. Результаты которых записываются в буфер выхода многоголового внимания.
//--- Score calculation and Multi-heads attention calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !AttentionOut(q, kv, temp, out)) return false;
Затем мы сжимаем полученные данные до размера исходных данных.
//--- Attention out calculation temp = FF_Tensors.At(i * 6); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9)), out, temp, iWindowKey * iHeads, iWindow, None)) return false;
После чего, согласно алгоритму Transformer, мы суммируем результаты работы блока Self-Attention с исходными данными и нормализуем полученные значения.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow, true)) return false;
Далее мы проводим данные через блок FeedForward.
//--- Feed Forward inputs = temp; temp = FF_Tensors.At(i * 6 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), temp, out, 4 * iWindow, iWindow, activation)) return false;
А затем данные из 2 потоков снова суммируем и нормализуем.
//--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } //--- return true; }
После успешного завершения всех итераций нашего цикла перебора внутренних нейронных слоев, мы возвращаем вызывающей программе логический результат выполненных операций.
За реализацией методов прямого прохода следует построение алгоритмов обратного прохода. Именно здесь осуществляется оптимизация параметров модели с целью нахождения функции максимального правдоподобия на обучающей выборке. Как вы знаете, алгоритм обратного прохода строится в 2 этапа. Сначала мы распространяем градиент ошибки до всех элементов модели с учетом их влияния на общий результат. Этот функционал выполняется в методе calcInputGradients. А на втором этапе (метод updateInputWeights) осуществляется непосредственная оптимизация параметров в сторону антиградиента.
Свою работу по реализации алгоритма обратного прохода мы начнем с метода распространения градиента ошибки calcInputGradients. В параметрах данный метод получает указатель на объект предшествующего нейронного слоя. И если при прямом проходе он выполнял роль исходных данных, то на данном этапе результат выполнения операций метода мы запишем в буфер градиентов ошибки полученного объекта.
bool CNeuronMLMHAttentionMLKV::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
В теле метода мы проверяем актуальность полученного указателя. После чего создадим 2 локальные переменные для хранения указателей на буферы данных, передаваемых между внутренними слоями.
CBufferFloat *out_grad = Gradient;
CBufferFloat *kv_g = KV_Tensors.At(KV_Tensors.Total() - 1);
После проведения небольшой подготовительной работы, мы организовываем цикл внутренних нейронных слоев в обратном порядке.
for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { if(i == int(iLayers - 1) || (i + 1) % iLayersToOneKV == 0) kv_g = KV_Tensors.At((i / iLayersToOneKV) * 2 + 1);
В нем мы сначала определяем необходимость смены буфера градиентов ошибки сущностей Key-Value.
Напомню, что методом MLKV предполагается использование одного тензора сущностей Key-Value для нескольких блоков Self-Attention. При организации прямого прохода мы уже реализовали соответствующие механизмы. Теперь нам предстоит организовать передачу градиента ошибки до соответствующего уровня Key-Value. И конечно, мы будем суммировать градиенты ошибки от различных уровней.
Дальнейшее построение алгоритма метода максимально близко к распределению градиента ошибки в объектах кросс-внимания. Вначале мы проводим градиент ошибки, полученный от последующего слоя, через блок FeedForward.
//--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), out_grad, FF_Tensors.At(i * 6 + 1), FF_Tensors.At(i * 6 + 4), 4 * iWindow, iWindow, None)) return false; CBufferFloat *temp = FF_Tensors.At(i * 6 + 3); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), FF_Tensors.At(i * 6 + 4), FF_Tensors.At(i * 6), temp, iWindow, 4 * iWindow, LReLU)) return false;
Аналогично тому, как мы суммировали данные из 2 потоков при прямом проходе, мы суммируем градиент ошибки по тем же потокам данных в обратном направлении.
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false; out_grad = temp;
На следующем этапе мы осуществляем разделение полученного градиента ошибки по головам внимания.
//--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 6 : 9)), out_grad, AO_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1), iWindowKey * iHeads, iWindow, None)) return false;
И далее мы распределяем градиент ошибки на сущности Query, Key и Value. Здесь мы организуем небольшое разветвление алгоритма. Дело в том, что нам необходимо суммировать градиент ошибки тензора Key-Value от нескольких внутренних слоев. А при прямом выполнении метода распределения градиента ошибки, мы каждый раз будем удалять ранее собранные данные и перезаписывать их новыми. Поэтому напрямую записывать градиент ошибки в буфер тензора Key-Value мы будем только при первом обращении к нему.
//--- Passing gradient to query, key and value if(i == int(iLayers - 1) || (i + 1) % iLayersToOneKV == 0) { if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i * 2), QKV_Tensors.At(i * 2 + 1), KV_Tensors.At((i / iLayersToOneKV) * 2), kv_g, S_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1))) return false; }
В остальных случаях мы сначала запишем градиент ошибки во вспомогательный буфер. А затем прибавим полученные значения к ранее собранным.
else { if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i * 2), QKV_Tensors.At(i * 2 + 1), KV_Tensors.At((i / iLayersToOneKV) * 2), GetPointer(Temp), S_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1))) return false; if(IsStopped() || !SumAndNormilize(kv_g, GetPointer(Temp), kv_g, iWindowKey, false, 0, 0, 0, 1)) return false; }
Далее нам предстоит передать градиент ошибки на уровень предыдущего слоя. И здесь под "предыдущим слоем" мы прежде всего подразумеваем внутренний предыдущий слой. Однако, при обработке самого нижнего уровня, градиент ошибки мы будем передавать в буфер объекта, полученного в параметрах метода.
Вначале мы определяем указатель на объект получения градиента ошибки.
CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 6 - 1); inp = FF_Tensors.At(i * 6 - 4); }
После чего, спускаем градиент ошибки от сущности Query.
if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, iWindowKey * iHeads, None)) return false;
И суммируем градиент ошибки по 2 потокам данных (Query + "сквозной").
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
В описанном выше алгоритме не хватает лишь градиента ошибки от сущностей Key и Value. Как вы помните, данные сущности формируются не от каждого внутреннего слоя. Соответственно и градиент ошибки мы будем передавать только на те данные, которые использовались при их формировании. Но здесь есть один нюанс. Ранее мы уже записали в буфер градиентов исходных данных ошибку от сущности Query и сквозного потока. Поэтому мы сначала запишем градиент ошибки во вспомогательный буфер, а затем прибавим его к ранее собранным данным.
//--- if((i % iLayersToOneKV) == 0) { if(IsStopped() || !ConvolutionInputGradients(KV_Weights.At(i / iLayersToOneKV * (optimization == SGD ? 2 : 3)), kv_g, inp, GetPointer(Temp), iWindow, 2 * iWindowKey * iHeadsKV, None)) return false; if(IsStopped() || !SumAndNormilize(GetPointer(Temp), temp, temp, iWindow, false, 0, 0, 0, 1)) return false; }
В завершении итераций цикла мы передаем указатель на буфер градиентов ошибки для осуществления операций следующей итерации цикла.
if(i > 0) out_grad = temp; } //--- return true; }
Как всегда, мы на каждом шаге контролируем результат выполнения операций. И после успешного прохождения всех итераций цикла, передаем логический результат выполнения операций метода вызывающей программы.
Градиент ошибки мы распределили до всех внутренних объектов и предшествующего слоя. Следующим этапом нам предстоит скорректировать параметры модели. Этот функционал выполняется в методе updateInputWeights. Как и оба рассмотренных выше метода, в параметрах мы получаем указатель на объект предыдущего слоя.
bool CNeuronMLMHAttentionMLKV::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput();
В теле метода мы проверяем актуальность полученного указателя и сразу сохраняем указатель на буфер результатов полученного объекта в локальную переменную.
Далее мы организовываем цикл перебора всех внутренних слоев с обновлением параметров модели.
for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(l * 2 + 1), inputs, (optimization == SGD ? QKV_Weights.At(l * 2 + 1) : QKV_Weights.At(l * 3 + 1)), (optimization == SGD ? NULL : QKV_Weights.At(l * 3 + 2)), iWindow, iWindowKey * iHeads)) return false;
Аналогично методу прямого прохода, сначала мы корректируем параметры формирования тензора Query.
Затем мы обновляем параметры формирования тензора Key-Value. Но стоит отметить, что эти параметры корректируются не на каждой итерации цикла. Однако корректировка параметров тензора Key-Value в общем цикле, облегчает синхронизацию с корректным буфером исходных данных и делает код максимально читабельным.
if(l % iLayersToOneKV == 0) { uint l_kv = l / iLayersToOneKV; if(IsStopped() || !ConvolutuionUpdateWeights(KV_Weights.At(l_kv * (optimization == SGD ? 2 : 3)), KV_Tensors.At(l_kv * 2 + 1), inputs, (optimization == SGD ? KV_Weights.At(l_kv*2 + 1) : KV_Weights.At(l_kv*3 + 1)), (optimization == SGD ? NULL : KV_Weights.At(l_kv * 3 + 2)), iWindow, 2 * iWindowKey * iHeadsKV)) return false; }
Непосредственно блок Self-Attention не содержит обучаемых параметров. Однако они появляются в слое сжатия результатов многоголового внимания до размера исходных данных. И следующим шагом мы корректируем эти параметры.
if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 6 : 9)), FF_Tensors.At(l * 6 + 3), AO_Tensors.At(l * 2), (optimization == SGD ? FF_Weights.At(l * 6 + 3) : FF_Weights.At(l * 9 + 3)), (optimization == SGD ? NULL : FF_Weights.At(l * 9 + 6)), iWindowKey * iHeads, iWindow)) return false;
После чего нам остается лишь скорректировать параметры блока FeedForward.
if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 6 : 9) + 1), FF_Tensors.At(l * 6 + 4), FF_Tensors.At(l * 6), (optimization == SGD ? FF_Weights.At(l * 6 + 4) : FF_Weights.At(l * 9 + 4)), (optimization == SGD ? NULL : FF_Weights.At(l * 9 + 7)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 6 : 9) + 2), FF_Tensors.At(l * 6 + 5), FF_Tensors.At(l * 6 + 1), (optimization == SGD ? FF_Weights.At(l * 6 + 5) : FF_Weights.At(l * 9 + 5)), (optimization == SGD ? NULL : FF_Weights.At(l * 9 + 8)), 4 * iWindow, iWindow)) return false;
Передадим указатель на буфер исходных данных для последующего внутреннего нейронного цикла и перейдем к следующей итерации цикла.
inputs = FF_Tensors.At(l * 6 + 2); } //--- return true; }
После успешного выполнения всех итераций цикла, мы возвращаем логический результат выполняемых операций вызывающей программе.
На этом мы завершаем рассмотрение методов нашего нового класса блока внимания с использованием подходов, предложенных авторами метода MLKV. А с полным кодом данного класса и всех его методов можно ознакомиться во вложении.
Как было сказано ранее, упомянутые методы MQA и GQA являются частными случаями MLKV. И их легко реализовать с использованием созданного класса, указав в параметрах метода инициализации класса "layers_to_one_kv=1". При этом, если значение параметра heads_kv равно количеству голов внимания для сущности Query, мы получаем ванильный Transformer. Если меньше, то — GQA. А при heads_kv равно "1" имеем реализацию MQA.
Должен сказать, что в процессе подготовки данной статьи был создан и класс кросс-внимания с использованием подходов MLKV — CNeuronMLCrossAttentionMLKV. Его структура представлена ниже.
class CNeuronMLCrossAttentionMLKV : public CNeuronMLMHAttentionMLKV { protected: uint iWindowKV; uint iUnitsKV; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); virtual bool AttentionOut(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *scores, CBufferFloat *out); virtual bool AttentionInsideGradients(CBufferFloat *q, CBufferFloat *q_g, CBufferFloat *kv, CBufferFloat *kv_g, CBufferFloat *scores, CBufferFloat *gradient); //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); public: CNeuronMLCrossAttentionMLKV(void) {}; ~CNeuronMLCrossAttentionMLKV(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key,uint heads, uint window_kw, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMLCrossAttentionMLKV; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); };
Данный класс построен наследником вышеописанного класса CNeuronMLMHAttentionMLKV, в алгоритм его методов внесены лишь точечные правки, с которыми я предлагаю вам ознакомиться самостоятельно во вложении.
2.3 Архитектура моделей
Выше мы реализовали подходы, предложенные авторами метода MLKV средствами MQL5, и теперь можем перейти к описанию архитектуры обучаемых моделей. Надо сказать, что в отличие от ряда последних статей, сегодня мы будем корректировать архитектуры не Энкодера состояния окружающей среды. Новые объекты мы добавим в архитектуру моделей Актера и Критика. Напомню, что архитектура указанных моделей задается в методе CreateDescriptions.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
В параметрах метод получает указатели на 2 динамических массива для записи последовательной архитектуры моделей. В теле метода мы проверяем полученные указатели и, при необходимости, создаем новые экземпляры объектов.
Первой мы описываем архитектуру Актера. На вход модели мы планируем подавать описание состояния счета и открытых позиций.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Полученные данные проходят первичную обработку полносвязным слоем.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
А далее мы поставим новый слой многоуровневого кросс-внимания с использование подходов MLKV.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLCrossAttentionMLKV; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); }
Данный слой будет сопоставлять текущее состояние счета с прогнозом предстоящего ценового движения, полученного от Энкодера состояния окружающей среды.
Здесь мы будем использовать 8 голов внимания для Query и только 2 для тензора Key-Value.
{
int temp[] = {8, 2};
ArrayCopy(descr.heads, temp);
}
Всего в нашем блоке мы создадим 9 вложенных слоев, при этом новый тензор Key-Value будем генерировать через каждые 3 слоя.
descr.layers = 9; descr.step = 3;
Для оптимизации параметров модели мы воспользуемся методом Adam.
descr.window_out = 32; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
После блока внимания данные обрабатываются 2 полносвязными слоями.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
И на выходе модели мы создаем стохастическую политику Актера, которая допускает действия в некотором диапазоне оптимальных значений.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Кроме того, мы воспользуемся подходами метода FreDF для согласования действий в частотной области.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.8f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Аналогичным образом мы построим модель Критика. Только вместо состояния счета мы подадим на вход модели вектор действий, сгенерированных политикой Актера.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Они также проходят первичную обработку полносвязным слоем.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
За которым идет блок кросс-внимания.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLCrossAttentionMLKV; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); } { int temp[] = {8, 2}; ArrayCopy(descr.heads, temp); } descr.window_out = 32; descr.step = 3; descr.layers = 9; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Результаты обработки данных в блоке кросс-внимания проходят через 3 полносвязных слоя.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
А на выходе модели формируется вектор ожидаемых вознаграждений.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Мы также добавляем слой FreDF для согласованности вознаграждений в частотной области.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NRewards; descr.count = 1; descr.step = int(false); descr.probability = 0.8f; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
Советники сбора данных и обучения моделей мы оставили без изменений. С их полным кодом вы можете самостоятельно ознакомиться во вложении. Там же вы найдете полный код всех классов и программ, используемых при подготовке этой статьи.
3. Тестирование
После завершения работы по реализации предложенных методов, мы переходим к завершающему этапу нашей работы — проверке эффективности предложенных подходов на реальных данных.
Как всегда, для обучения моделей мы используем реальные исторические данные инструмента EURUSD таймфрейм H1 за весь 2023 год. Сбор данных для обучающей выборки осуществляется путем запуска советников взаимодействия с окружающей средой в тестере стратегий MetaTrader 5.
Не секрет, что при первом запуске наши модели инициализируются случайными параметрами. Как следствие, мы получаем проходы абсолютно случайных политик, которые далеки от оптимальных. Чтобы добавить в обучающую выборку данные прибыльных проходов, я рекомендую при сборе первичных данных использовать подходы метода Real-ORL.
После сбора первичной обучающей выборки, мы сначала осуществляем обучение Энкодера состояния окружающей среды, путем запуска советника ".../MLKV/StudyEncoder.mq5" в режиме реального времени на графике терминала MetaTrader 5. Данный советник работает только с обучающей выборкой, анализируя зависимости в исторических данных ценового движения. И по-существу, для его обучения достаточно даже одного прохода в независимости от результатов торговли. Поэтому мы осуществляем обучение Энкодера состояния счета до остановки снижения ошибки прогнозирования без обновления обучающей выборки.
Здесь надо сказать, что обучаемые затем модели Актера и Критика используют полученные прогнозы опосредствовано. Для достижения максимального результата нам необходимо выделение текущих тенденций состояния окружающей среды и их силы в скрытом состоянии Энкодера, к которому затем обращаются модели Актера и Критика.
Получив желаемый результат в процессе обучения Энкодера состояния окружающей среды мы переходим к обучению политики Актера и точности оценки действий Критиком. Второй этап обучения моделей является итерационным. Все дело в том, что вариативность анализируемой окружающей среды финансовых рынков очень высока. И собрать все возможные варианты взаимодействия Агента с окружающей средой не представляется возможным. Поэтому после нескольких итераций обучения моделей Актера и Критика, мы проводим дополнительную итерацию сбора обучающих данных. Данный процесс призван дополнить собранную ранее обучающую выборку данными взаимодействия с окружающей средой в некой области текущей политики Актера, что позволит уточнить и оптимизировать её.
Как уже было сказано выше, несколько итераций обучения моделей Актера и Критика чередуются с операциями обновления обучающей выборки. И этот процесс повторяется несколько раз до получения желаемой политики Актера.
Тестирование обученных моделей осуществляется на данных Января 2024 года, не входящих в обучающую выборку. Все прочие параметры переносятся без изменений из итераций сбора обучающей выборки.
Должен признаться, что в процессе обучения моделей при подготовке данной статьи мне не удалось получить политику, способную генерировать прибыль на тестовой выборке. Очевидно, это влияние процесса деградации модели, на который было указано в авторской статье.
Результаты тестирования представлены ниже.
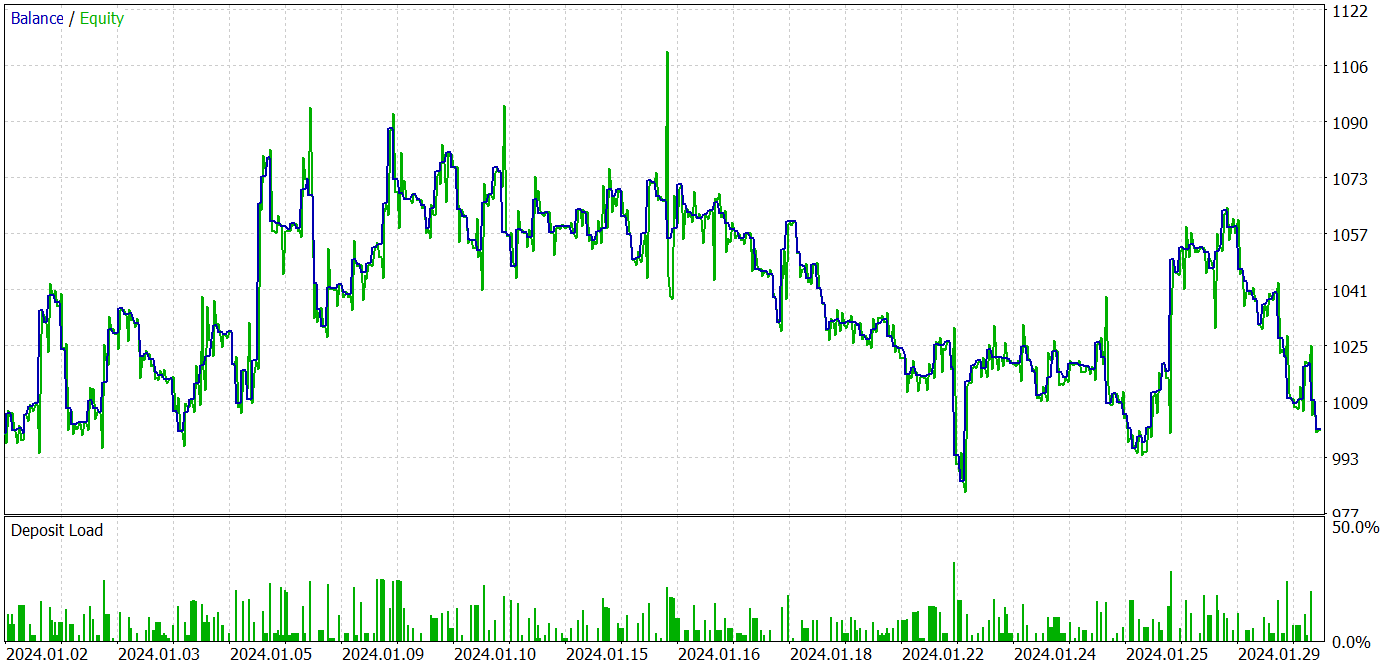
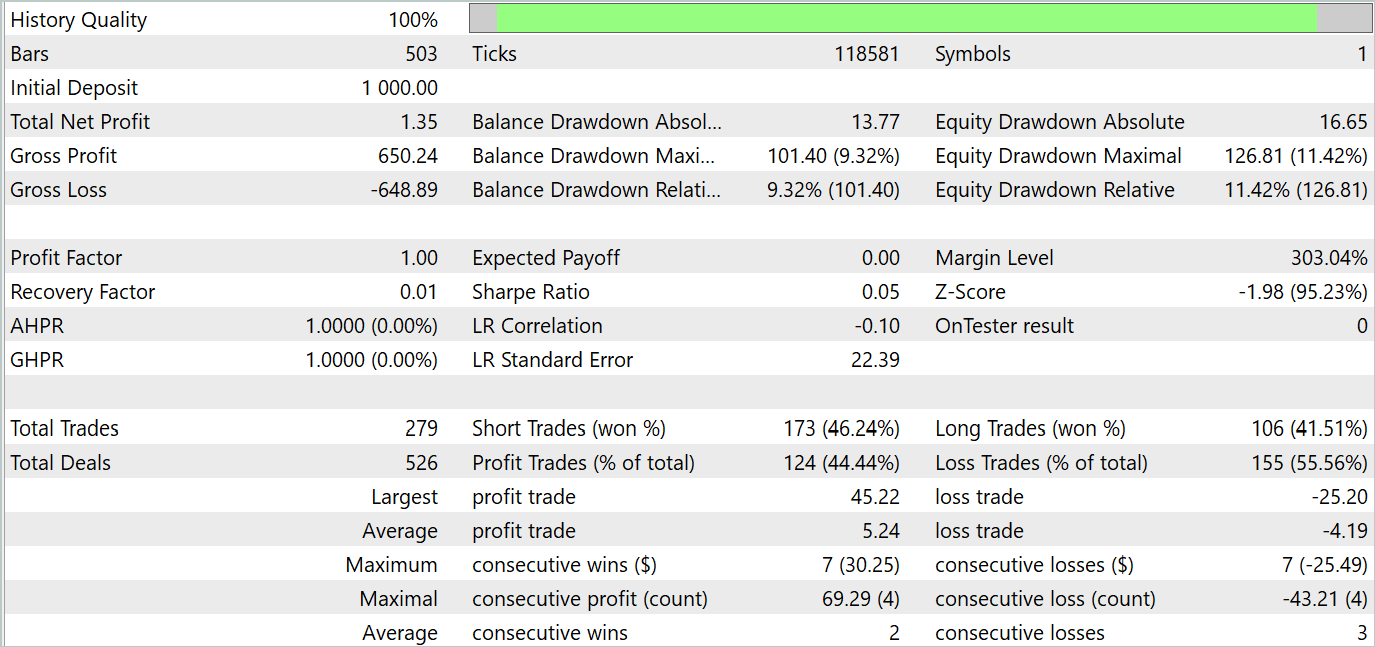
По результатам тестирования мы видим колебания доходности на новых данных близкую к "0". В целом мы имеем максимальную и среднюю прибыль выше аналогичных убыточных показателей. Однако доля в 44.4% прибыльных сделок не позволила получить какую-либо прибыль на протяжении периода тестирования.
Заключение
В данной статье мы познакомились с новым методом MLKV (Multi-Layer Key-Value), который представляет собой инновационный подход для более эффективного использования памяти в Transformers. Основная идея заключается в расширении кэширования KV на несколько слоев, что позволяет значительно уменьшить использование памяти.
В практической части статьи мы реализовали предложенные подходы средствами MQL5. Обучили и протестировали модели на реальных данных. Наши тесты показали, что предложенные подходы позволяют значительно сократить затраты на обучение и эксплуатацию модели. Однако за это приходится платить эффективностью работы модели. И здесь следует подходить взвешенно к поиску компромисса между затратами и эффективностью модели.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
А как вы понимаете, что сеть чему-то научилась, а не генерит рандомные сигналы?
Стохастическая политика Актера предполагает некую рандомность действий. Однако в процессе обучения диапазон разброса рандомных значений сильно сужается. Дело в том, что при организации стохастической политики для каждого действия обучается 2 параметра: среднее значение и дисперсия разброса значений. При обучении политики среднее значения стремится к оптимуму, а дисперсия — к 0.
Чтобы понять насколько рандомные действия Агента я делаю несколько тестовых проходов для одной политики. Если Агент генерирует рандомные действия, то результат всех проходов будет сильно отличаться. Для обученной политики различие в результатах будет несущественное.
Стохастическая политика Актера предполагает некую рандомность действий. Однако в процессе обучения диапазон разброса рандомных значений сильно сужается. Дело в том, что при организации стохастической политики для каждого действия обучается 2 параметра: среднее значение и дисперсия разброса значений. При обучении политики среднее значения стремится к оптимуму, а дисперсия — к 0.
Чтобы понять насколько рандомные действия Агента я делаю несколько тестовых проходов для одной политики. Если Агент генерирует рандомные действия, то результат всех проходов будет сильно отличаться. Для обученной политики различие в результатах будет несущественное.
Понял, спасибо.