
Нейросети в трейдинге: Управляемая сегментация (Окончание)

Введение
В предыдущей статье мы познакомились с метод RefMask3D, разработанным для проведения комплексного анализа мультимодального взаимодействия и понимания признаков рассматриваемого облака точек. RefMask3D представляет собой комплексный фреймворк, который включает несколько модулей:
- Энкодер точек с встроенным модулем Geometry-Enhanced Group-Word Attention. В нем осуществляется кросс-модальное внимание между описанием объекта на естественном языке и локальными группами точек (субоблаками) на каждом этапе кодирования их признаков. Предложенная авторами метода архитектура блока позволяет уменьшить влияние шума, присущего прямой корреляции между точками и словами, и преобразует внутренние геометрические отношения в тонкую структуру облака точек. Все это значительно улучшает способность модели взаимодействовать с лингвистическими и геометрическими данными.
- Языковая модель преобразует полученное текстовое описание целевого объекта в структуру токенов, используемых моделью для идентификации объекта.
- Набор обучаемых лингвистических примитивов (Linguistic Primitives Construction — LPC) предназначен для представления различных семантических атрибутов, таких как форма, цвет, размер, отношения, местоположение и т. д. При взаимодействии с определенной лингвистической информацией, эти примитивы способны приобретать соответствующие атрибуты.
- Декодер с использованием архитектуры Transformer усиливает фокус модели на разнообразной семантике облака точек, тем самым значительно улучшая способность точно локализовать и идентифицировать целевой объект.
- Модуль кластера объектов (Object Cluster Module — OCM) выполняет функции сбора целостной информации и генерации эмбедингов объектов.
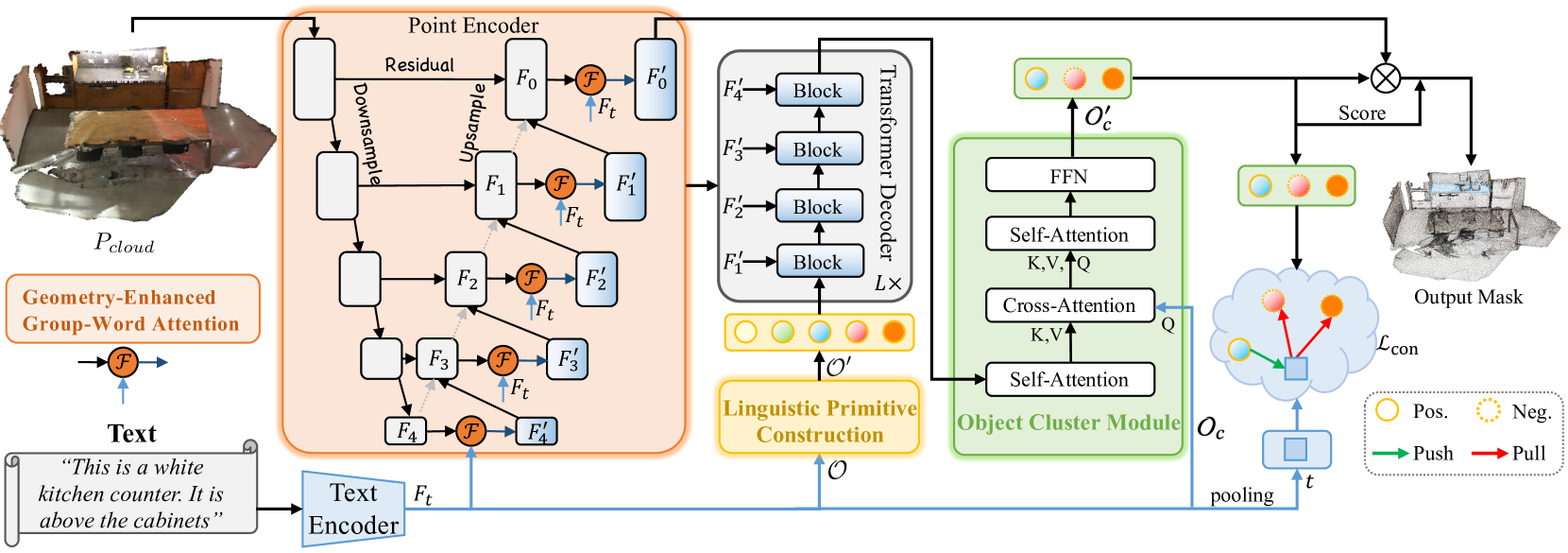
В предыдущей статье мы уже выполнили значительную часть работы по реализации предложенного фреймворка. В частности, мы реализовали алгоритм модулей Geometry-Enhanced Group-Word Attention и Linguistic Primitives Construction в соответствующих классах. Мы так же проговорили, что функционал Декодера можно покрыть уже существующими наработками различных вариантов реализации блоков кросс-вниманиия. И остановились на построении алгоритмов модуля кластера объектов. С этой точки мы и продолжим работу.
1. Реализация модуля кластера объектов
Как уже было сказано выше, модуль кластера объектов предназначен для сбора целостной информации и генерации эмбедингов объектов. Авторская визуализация модуля представлена ниже.
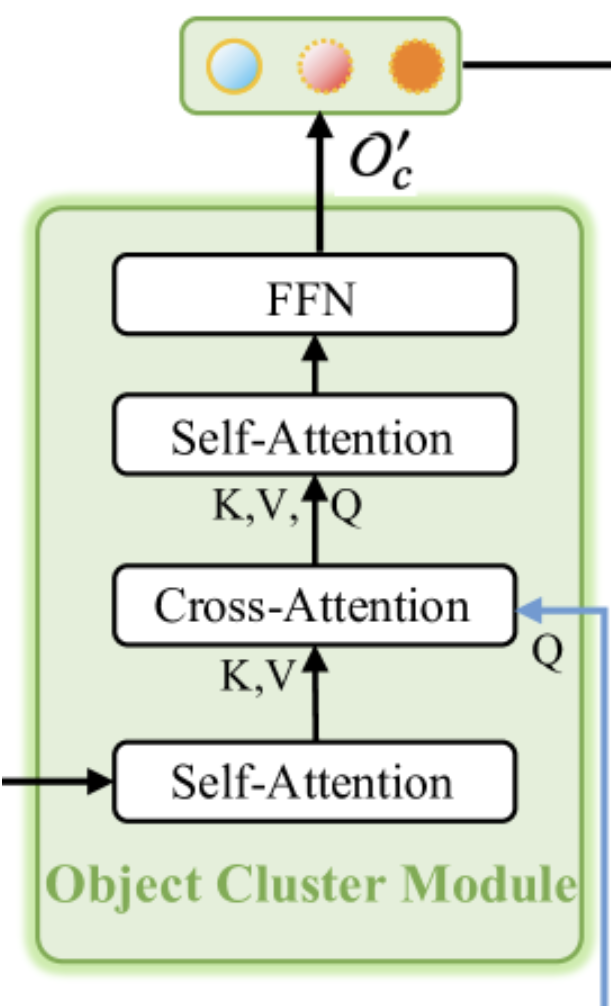
Как можно заметить из представленной визуализации, модуль кластера объектов состоит из двух блоков Self-Attention, одного Cross-Attention между ними и блока FFN на выходе, который является полносвязным MLP. Подобная архитектура модуля может вызывать различные ассоциации. С одной стороны она напоминает ванильный декодер Transformer с дополнительным блоком Self-Attention после Cross-Attention. Но здесь следует обратить внимание на измененный функционал блока кросс-внимания. И тогда на память приходит метод SPFormer. В такой интерпретации первый блок Self-Attention выполняет функционал модуля извлечения признаков точек.
Впрочем, в представленном архитектурном решении можно найти и миниатюрную копию ванильного Transformer. Здесь мы имеем "урезанную" копию энкодера, лишенную блока FeedForward, и декодер с переставленными блоками Cross-Attention и Self-Attention. Это, несомненно, делает данный модуль комплексным и важным в общем фреймворке RefMask3D, что подтверждается экспериментами, проведенными авторами метода. Внедрение модуля кластера объектов позволяет повысить эффективность модели на 1.57%.
На вход модуля кластера объектов поступают данные из 2 источников. Вначале результаты работы Декодера, которые представляют собой эмбединги примитивов, обогащенные информацией об анализируемом облаке точек, проходят через первый блок Self-Attention и служат контекстом для последующего блока кросс-внимания. Основным источником информации для блока кросс-внимания являются эмбединги текстового описания целевого объекта. Именно на их основе формируются сущности Query блока кросс-внимания. И далее, результаты работы блока Cross-Attention подаются на второй Self-Attention и FeedForward.
Описанный выше алгоритм мы реализуем в классе CNeuronOCM, структура которого представлена ниже.
class CNeuronOCM : public CNeuronBaseOCL { protected: uint iPrimWindow; uint iPrimUnits; uint iPrimHeads; uint iContWindow; uint iContUnits; uint iContHeads; uint iWindowKey; //--- CLayer cQuery; CLayer cKey; CLayer cValue; CLayer cMHAttentionOut; CLayer cAttentionOut; CArrayInt cScores; CLayer cResidual; CLayer cFeedForward; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } public: CNeuronOCM(void) {}; ~CNeuronOCM(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronOCM; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool updateInputWeights(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); //--- virtual uint GetPrimitiveWindow(void) const { return iPrimWindow; } virtual uint GetContextWindow(void) const { return iContWindow; } };
Базовый функционал нейронного слоя мы унаследуем от полносвязного CNeuronBaseOCL, который мы используем в качестве родительского класса.
В представленной выше структуре нового класса можно заметить уже знакомый набор переопределяемых методов и целый ряд объявленных внутренних объектов и переменных. С их функционалом мы познакомимся в процессе реализации методов класса. Сейчас же стоит отметить, что все внутренние объекты были объявлены статическими. А значит мы можем оставить пустыми конструктор и деструктор класса. Инициализация всех объявленных и унаследованных внутренних объектов осуществляется в методе Init. Как Вы знаете, в параметрах указанного метода мы получаем набор констант, которые позволяют нам однозначно интерпретировать архитектуру создаваемого объекта.
bool CNeuronOCM::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, cont_window * cont_units, optimization_type, batch)) return false;
В теле метода, по уже сложившейся традиции, мы сначала вызываем одноименный метод родительского класса, в котором уже реализованы алгоритмы минимально-необходимого контроля полученных параметров и инициализация унаследованных объектов. А контроль выполнения операций метода родительского класса мы осуществляем по возвращаемому логическому значению.
После успешного выполнения операций метода родительского класса мы сохраним значения полученных констант во внутренних переменных нашего класса.
iPrimWindow = prim_window; iPrimUnits = prim_units; iPrimHeads = prim_heads; iContWindow = cont_window; iContUnits = cont_units; iContHeads = cont_heads; iWindowKey = window_key;
И очистим динамические массивы внутренних объектов.
cQuery.Clear(); cKey.Clear(); cValue.Clear(); cMHAttentionOut.Clear(); cAttentionOut.Clear(); cResidual.Clear(); cFeedForward.Clear();
А затем мы переходим к инициализации объектов внутренних блоков. Согласно описанному выше алгоритму первым идет блок Self-Attention анализа зависимостей между примитивами.
Здесь я хочу напомнить, что на вход модуля мы получаем примитивы, которые в Декодере были обогащены информацией об анализируемом облаке точек. Следовательно, задача данного блока выявить примитивы, релевантные для анализируемого облака точек.
Вначале мы создаем объекты генерации сущностей Query, Key и Value. Для генерации всех сущностей мы используем сверточные слои с идентичными параметрами. Указатели на инициализированные объекты мы добавляем в динамические массивы, именованные созвучно генерируемым сущностям.
CNeuronBaseOCL *neuron = NULL; CNeuronConvOCL *conv = NULL; //--- Primitives Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 0, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false; //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 1, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 2, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
Далее мы добавим полносвязный слой для записи результатов многоголового внимания.
//--- Multi-Heads Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 3, OpenCL, iPrimHeads * iWindowKey * iPrimUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
И воспользуемся сверточным слоем для масштабирования результатов многоголового внимания до размера тензора исходных данных.
//--- Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 4, OpenCL, iPrimHeads * iWindowKey, iPrimHeads * iWindowKey, iPrimWindow, iPrimUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
А завершает блок Self-Attention полносвязный слой остаточных связей.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 5, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
Легко заметить, что представленная выше структура объектов блока внимания универсальна. И может быть использована как для блока Self-Attention, так и для Cross-Attention. Думаю очевидно, что для реализации алгоритма последующего блока Cross-Attention мы создадим аналогичные объекты и добавим указатели на них в те же динамические массивы. Единственное отличие в источниках данных для формирования сущностей Query, Key и Value. При формировании сущности Query мы используем информацию о контексте в качестве исходных данных.
//--- Cross-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 6, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false;
В то время как для формирования сущностей Key и Value используются результаты предшествующего блока Self-Attention. Здесь мы имеем размер тензора идентичный обучаемым примитивам.
//--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 7, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 8, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
Затем мы добавляем слой результатов многоголового внимания.
//--- Multi-Heads Cross-Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 9, OpenCL, iContHeads * iWindowKey * iContUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
Добавим сверточный слой масштабирования.
//--- Cross-Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 10, OpenCL, iContHeads * iWindowKey, iContHeads * iWindowKey, iContWindow, iContUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
И завершает блок Cross-Attention слой остаточных связей.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 11, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
Следующим шагом мы создаем ещё один блок Self-Attention. На этот раз анализа контекстуальных зависимостей. И здесь мы снова повторяем создание аналогичных объектов блока внимания с добавлением указателей на создаваемые объекты в те же динамические массивы. Только теперь все сущности формируются по результатам работы блока кросс-внимания. Следовательно, тензор исходных данных имеет размерность анализируемого контекста.
//--- Context Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 12, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false; //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 13, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 14, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
Добавляем слой результатов многоголового внимания.
//--- Multi-Heads Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 15, OpenCL, iContHeads * iWindowKey * iContUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
За которым идет сверточный слой масштабирования.
//--- Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 16, OpenCL, iContHeads * iWindowKey, iContHeads * iWindowKey, iContWindow, iContUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
Ну а в завершении блока, как и ранее, используется слой остаточных связей.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 17, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
И теперь нам остается добавить объекты блока FeedForward. По аналогии с ванильным Transformer в данном блоке мы используем 2 сверточных слоя с функцией активации LReLU между ними.
//--- Feed Forward conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 18, OpenCL, iContWindow, iContWindow, 4 * iContWindow, iContUnits, 1, optimization, iBatch) || !cFeedForward.Add(conv) ) return false; conv.SetActivationFunction(LReLU); conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 19, OpenCL, 4*iContWindow, 4*iContWindow, iContWindow, iContUnits, 1, optimization, iBatch) || !cFeedForward.Add(conv) ) return false;
В качестве слоя остаточной связи в данном случае мы будем использовать буфера нашего класса, унаследованные от родительского класса. Однако мы организуем подмену указателей на буфера градиентов ошибки с целью сокращения операций копирования данных.
if(!SetGradient(conv.getGradient())) return false; //--- SetOpenCL(OpenCL); //--- return true; }
И в завершении метода мы вернем логический результат выполнения операций вызывающей программе.
Обратите внимание, что мы не создали объекты буферов данных для записи коэффициентов внимания. Данные буфера будут созданы только в контексте OpenCL. И их создание вынесено в отдельный метод CreateBuffers, с которым я предлагаю Вам ознакомиться самостоятельно во вложении.
После завершения работы над методом инициализации объекта мы переходим к построению алгоритмов прямого прохода. Которые мы реализуем в методе feedForward. И здесь следует обратить внимание, что мы несколько отошли от привычного формата методов прямого прохода, используемых ранее. Если в предыдущих работах мы использовали указатель на объект нейронного слоя в качестве первого источника исходных данных и указатель на буфер данных в качестве второго, то в данном случае мы используем объекты нейронного слоя в обоих случаях. Однако на данном этапе подобная реализация возможна только для внутренних объектов, используемых при построении алгоритмов работы вышестоящего объекта нейронного слоя. Что нас вполне устраивает.
bool CNeuronOCM::feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context) { CNeuronBaseOCL *neuron = NULL, *q = cQuery[0], *k = cKey[0], *v = cValue[0];
В теле метода мы создадим несколько локальных переменных для временного хранения указателей на объекты нейронных слоев. И сразу в них запишем указатели на объекты формирования сущностей для первого блока внимания. После чего проверим актуальность указателей на объекты и сгенерируем необходимые сущности из полученного от внешней программы тензора примитивов.
if(!q || !k || !v) return false; if(!q.FeedForward(Primitives) || !k.FeedForward(Primitives) || !v.FeedForward(Primitives) ) return false;
Полученные сущности мы передадим в блок многоголового внимания для анализа зависимостей.
if(!AttentionOut(q, k, v, cScores[0], cMHAttentionOut[0], iPrimUnits, iPrimHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
Полученные результаты мы масштабируем и суммируем с соответствующими исходными данными. После чего проводим нормализацию результатов.
neuron = cAttentionOut[0]; if(!neuron || !neuron.FeedForward(cMHAttentionOut[0]) ) return false; v = cResidual[0]; if(!v || !SumAndNormilize(Primitives.getOutput(), neuron.getOutput(), v.getOutput(), iPrimWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
На вход первого блока Self-Attention мы подали примитивы, обогащенные информацией об анализируемом облаке точек. И в теле блока добавили внутренних зависимостей. Таким образом мы хотим контрастно выделить примитивы, релевантные анализируемой сцене. По существу, этот этап можно сравнить с выполнением задачи сегментации облака точек. Но в данном случае наша задача заключается в нахождении целевого объекта, описанного текстовым выражением. Поэтому мы переходим к следующему этапу кросс-внимания. Где сопоставляем эмбединги описания целевого объекта и примитивы, присущие анализируемому облаку точек. Для этого мы берем из наших массивов объектов нейронные слои формирования сущностей кросс-внимания. Проверяем актуальность полученных указателей. И генерируем необходимые сущности.
//--- Cross-Attention q = cQuery[1]; k = cKey[1]; v = cValue[1]; if(!q || !k || !v) return false; if(!q.FeedForward(Context) || !k.FeedForward(neuron) || !v.FeedForward(neuron) ) return false;
Напомню, что Query генерируется из эмбедингов описания целевого объекта. А исходными данными для формирования Key и Value служат результаты предыдущего блока Self-Attention. Далее мы воспользуемся механизмом многоголового внимания.
if(!AttentionOut(q, k, v, cScores[1], cMHAttentionOut[1], iContUnits, iContHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
А затем масштабируем полученные результаты и дополним их остаточными связями.
neuron = cAttentionOut[1]; if(!neuron || !neuron.FeedForward(cMHAttentionOut[1]) ) return false; v = cResidual[1]; if(!v || !SumAndNormilize(Context.getOutput(), neuron.getOutput(), v.getOutput(), iContWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
Следует отметить, что в качестве остаточных связей мы используем тензор исходного контекста. Результаты суммирования двух тензоров мы нормализуем в разрезе отдельных элементов последовательности.
На выходе блока Cross-Attention мы ожидаем получить эмбединги описания целевого объекта, обогащенные информацией из анализируемого облака точек. Иными словами мы хотим "подсветить" эмбедиги описания целевого объекта релевантные для анализируемой сцены.
Обратите внимание, что в данном случае мы и не проводим прямого сопоставления анализируемого облака точек с описанием целевого объекта. Однако, на предыдущих этапах фреймворка RefMask3D мы осуществляем выделение примитивов в исходном облаке точек. А в блоке кросс-внимания мы выделили из данного нам описания целевого объекта примитивы, найденные в исходном облаке точек. И далее мы соберем "целостную картину", обогатив выделенные эмбединги взаимными связями в последующем блоке Self-Attention.
Как и ранее, мы изымаем из внутренних динамических массивов следующие слои формирования сущностей и проверяем актуальность полученных указателей.
//--- Context Self-Attention q = cQuery[2]; k = cKey[2]; v = cValue[2]; if(!q || !k || !v) return false;
После чего генерируем сущности Query, Key и Value. В данном случае исходными данными для формирования всех сущностей служат результаты предшествующего блока кросс-внимания.
if(!q.FeedForward(neuron) || !k.FeedForward(neuron) || !v.FeedForward(neuron) ) return false;
Мы так же используем алгоритм многоголового внимания для обнаружения взаимозависимостей в анализируемой последовательности данных.
if(!AttentionOut(q, k, v, cScores[2], cMHAttentionOut[2], iContUnits, iContHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
Полученные результаты масштабируем и добавляем остаточные связи с последующей нормализацией данных.
q = cAttentionOut[1]; if(!q || !q.FeedForward(cMHAttentionOut[2]) ) return false; v = cResidual[2]; if(!v || !SumAndNormilize(q.getOutput(), neuron.getOutput(), v.getOutput(), iContWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
И далее нам предстоит провести через блок FeedForward тензор обогащенного контекста. К полученным результатам мы добавляем остаточные связи и нормализуем данные. Полученные значения записываем в буфер результатов нашего класса CNeuronOCM. Данный объект был унаследован от родительского класса.
//--- Feed Forward q = cFeedForward[0]; k = cFeedForward[1]; if(!q || !k || !q.FeedForward(neuron) || !k.FeedForward(q) || !SumAndNormilize(neuron.getOutput(), k.getOutput(), Output, iContWindow, true, 0, 0, 0, 1) ) return false; //--- return true; }
В завершении работы метода прямого прохода нам остается лишь вернуть логический результат выполнения операций вызывающей программе.
После завершения работы по построению методов прямого прохода мы переходим к организации процессов обратного прохода. Как обычно, функционал обратного прохода мы разделяем на 2 этапа: распределения градиентов ошибки до всех элементов в соответствии с их влиянием на общий результат работы модели и оптимизация обучаемых параметров. Соответственно, для каждого этапа мы построим свой метод: calcInputGradients и updateInputWeights. Первый полностью инверсирует операции прямого прохода. А во втором мы лишь последовательно вызываем одноименные методы внутренних объектов, содержащих обучаемые параметры. С алгоритмами построения указанных методов предлагаю Вам ознакомиться самостоятельно. Полный код данного класса и всех его методов приведен во вложении.
2. Построение фреймворка RefMask3D
Мы провели большую работу по реализации отдельных модулей фреймворка RefMask3D и теперь нам предстоит собрать все в едином объекте, объединив отдельные блоки в четко выстроенную структуру. Для выполнения этой работы мы создадим новый класс CNeuronRefMask, структура которого представлена ниже.
class CNeuronRefMask : public CNeuronBaseOCL { protected: CNeuronGEGWA cGEGWA; CLayer cContentEncoder; CLayer cBackGround; CNeuronLPC cLPC; CLayer cDecoder; CNeuronOCM cOCM; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronRefMask(void) {}; ~CNeuronRefMask(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint content_size, uint content_units, uint primitive_units, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRefMask; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
В представленной выше структуре легко заметить объекты, реализованных нами модулей. Но вместе с ними присутствуют ещё объекты динамических массивов, с функционалом которых мы познакомимся в процессе реализации методов нового класса.
Все внутренние объекты объявлены статично, что позволяет нам оставить "пустыми" конструктор и деструктор класса. А инициализация всех объявленных и унаследованных объектов осуществляется в методе Init.
Как Вы знаете, в параметрах данного метода мы получаем константы, позволяющие однозначно идентифицировать архитектуру создаваемого объекта. Однако большое количество сложных внутренних объектов ведет к сильной вариативности архитектуры объекта. И, как следствие, увеличению параметров описания подобных архитектурных решений. На мой взгляд, излишнее количество параметров лишь усложнит работу с классом. Поэтому было принято решение об унификации параметров внутренних объектов, что позволило значительно сократить количество внешних параметров. Речь идет о том, чтобы в параметрах метода инициализации оставить лишь константы, определяющие параметры исходных данных и результатов. А для внутренних объектов по возможности использовать аналогичные параметры внешних данных. К примеру, размер окна одного элемента последовательности мы указываем лишь для исходных данных. Однако данный параметр мы используем и при генерации эмбедингов обучаемых примитивов, и в качестве размере эмбединга контекста. Таким образом, для построения тензоров примитивов и контекста нам достаточно указать соответствующие размеры последовательностей.
bool CNeuronRefMask::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint content_size, uint content_units, uint primitive_units, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * content_units, optimization_type, batch)) return false;
Первой операцией в теле метода мы, как обычно, вызываем одноименный метод родительского класса, в котором уже реализован функционал минимально-необходимого контроля полученных параметров и инициализация унаследованных объектов. Поле чего переходим к работе по инициализации объявленных объектов. И здесь мы сначала инициализируем энкодер облака точек в виде созданного ранее модуля Geometry-Enhaced Group-Word Attention.
//--- Geometry-Enhaced Group-Word Attention if(!cGEGWA.Init(0, 0, OpenCL, window, window_key, heads, units_count, window, heads, (content_units + 3), 2, layers, optimization, iBatch)) return false; cGEGWA.AddNeckGradient(true);
Здесь следует обратить внимание на 2 момента. Первое, при указании размера последовательности контекста мы добавили 3 элемента к размеру эмбединга описания целевого объекта. Разумеется, как и в предыдущей работе, мы не будем задавать текстовое описание целевого объекта. Вместо этого мы сгенерируем несколько токенов из вектора описания текущего состояния счета и открытых позиций. Здесь мы руководствуемся тем же подходом, что создание нескольких различных токенов описания одного описания состояния счета позволят нам провести всесторонний анализ текущей рыночной ситуации. Однако мы не исключаем наличия шума и выбросов в исходных данных. И для исключения их влияние мы вводим 3 дополнительных обучаемых токена для аккумулирования нерелевантных значений. По существу, это "фоновый" токен, предложенный авторами фреймворка RefMask3D.
Второй момент заключается в том, что в нашем энкодере точек мы используем двухслойные блоки внимания на всех этапах. А параметр внутренних слоев layers, полученный от внешней программы, указывает на количество вложений "шеи" нашего U-образного модуля.
Кроме того мы активируем функционал суммирование градиентов ошибки для объектов шеи.
Далее идет энкодер контекста. Для данного модуля мы не создавали отдельного бока. Тем менее Вы уже знакомы с его архитектурой. Она полностью повторяет энкодер уточняющего выражения метода 3D-GRES. Вначале мы создаем полносвязный слой для записи вектора описания текущего состояния счета.
//--- Content Encoder cContentEncoder.Clear(); cContentEncoder.SetOpenCL(OpenCL); CNeuronBaseOCL *neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(window * content_units, 1, OpenCL, content_size, optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
А затем добавляем полносвязный слой генерации заданного количества эмбедингов требуемого размера.
neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 2, OpenCL, window * content_units, optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
Тут же мы добавим ещё один слой, в который запишем конкатенированный тензор контекста и "фоновых" токенов.
neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 3, OpenCL, window * (content_units + 3), optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
Следующим шагом мы создаем модель генерации тензора обучаемых фоновых токенов. Здесь мы так же используем двухслойную MLP. Её первый слой статичен и содержит "1". А второй генерирует тензор необходимого размера на основании обучаемых параметров.
//--- Background cBackGround.Clear(); cBackGround.SetOpenCL(OpenCL); neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(window * 3, 4, OpenCL, content_size, optimization, iBatch) || !cBackGround.Add(neuron) ) return false; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 5, OpenCL, window * 3, optimization, iBatch) || !cBackGround.Add(neuron) ) return false;
Затем мы добавим модуль лингвистических примитивов.
//--- Linguistic Primitive Construction if(!cLPC.Init(0, 6, OpenCL, window, window_key, heads, heads, primitive_units, content_units, 2, 1, optimization, iBatch)) return false;
За которым следует декодер. Здесь мы сделали небольшое отступление от предложенной авторами метода структуры и заменили слои декодера ванильного Transformer на объекты созданного ранее модуля кластера объектов. Выше мы уже обсуждали сходство и различие в архитектуре указанных модулей. И надеемся, что такой подход позволит нам ещё немного повысить эффективность создаваемой модели.
Так же стоит отметить, что согласно предложенной авторами фреймворка RefMask3D структуре каждый слой декодера проводит анализ зависимостей с отдельным слоем U-образного энкодера точек. Для реализации данного подходам мы организуем цикл с последовательным извлечением соответствующих объектов.
//--- Decoder cDecoder.Clear(); cDecoder.SetOpenCL(OpenCL); CNeuronOCM *ocm = new CNeuronOCM(); if(!ocm || !ocm.Init(0, 7, OpenCL, window, window_key, units_count, heads, window, primitive_units, heads, optimization, iBatch) || !cDecoder.Add(ocm) ) return false; for(uint i = 0; i < layers; i++) { neuron = cGEGWA.GetInsideLayer(i); ocm = new CNeuronOCM(); if(!ocm || !neuron || !ocm.Init(0, i + 8, OpenCL, window, window_key, neuron.Neurons() / window, heads, window, primitive_units, heads, optimization, iBatch) || !cDecoder.Add(ocm) ) return false; }
Нам остается инициализировать модуль кластера объектов.
//--- Object Cluster Module if(!cOCM.Init(0, layers + 8, OpenCL, window, window_key, primitive_units, heads, window, content_units, heads, optimization, iBatch)) return false;
И осуществим подмену указателей на буфера данных, которая позволит нам сократить количества операций копирования значений.
if(!SetOutput(cOCM.getOutput()) || !SetGradient(cOCM.getGradient()) ) return false; //--- return true; }
Ну а в завершении метода мы вернем логический результат выполнения операций вызывающей программе. На этом мы завершаем построение метода инициализации объекта класса и переходим к организации алгоритмов прямого прохода, которые мы реализуем в методе feedForward. В параметрах данного метода мы получаем указатели на два объекта исходных данных. Первый из них представлен в виде указателя на объект нейронного слоя, а второй — буфера данных. Эта та схема, для которой у нас организованы интерфейсы внутри нашей базовой модели.
bool CNeuronRefMask::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
В теле метода мы проверяем актуальность полученного указателя на второй источник исходных данных и, при необходимости, осуществляем подмену указателя на буфер результатов в первом слое Энкодера контекста.
//--- Context Encoder CNeuronBaseOCL *context = cContentEncoder[0]; if(context.getOutput() != SecondInput) { if(!context.SetOutput(SecondInput, true)) return false; }
После чего генерируем эмбединг контекста на основании представленных данных.
int content_total = cContentEncoder.Total(); for(int i = 1; i < content_total - 1; i++) { context = cContentEncoder[i]; if(!context || !context.FeedForward(cContentEncoder[i - 1]) ) return false; }
Обратите внимание на тот факт, что операции прямого прохода начинаются именно с генерации эмбединга контекста. Ведь энкодер точек использует данную информацию в качестве второго источника исходных данных.
Далее мы генерируем тензор фоновых токенов.
//--- Background Encoder CNeuronBaseOCL *background = NULL; if(bTrain) { for(int i = 1; i < cBackGround.Total(); i++) { background = cBackGround[i]; if(!background || !background.FeedForward(cBackGround[i - 1]) ) return false; } } else { background = cBackGround[cBackGround.Total() - 1]; if(!background) return false; }
И конкатенируем его с тензором эмбединга контекста.
CNeuronBaseOCL *neuron = cContentEncoder[content_total - 1]; if(!neuron || !Concat(context.getOutput(), background.getOutput(), neuron.getOutput(), context.Neurons(), background.Neurons(), 1)) return false;
А вот уже конкатенированный тензор вместе с указателем на первый источник исходных данных, полученный от внешней программы, мы передадим в наш энкодер точек.
//--- Geometry-Enhaced Group-Word Attention if(!cGEGWA.FeedForward(NeuronOCL, neuron.getOutput())) return false;
Кроме того, эмбединг контекста мы передаем в модуль генерации лингвистических примитивов. Только в данном случае мы используем тензор без фоновых токенов.
//--- Linguistic Primitive Construction if(!cLPC.FeedForward(context)) return false;
Наверное, надо отметить, что фоновые токены используются только в энкодере точек для фильтрации шума и выбросов.
На данном этапе мы уже сформировали тензоры эмбедингов лингвистических примитивов и исходного облака точек. Следующим шагом мы сопоставим их в нашем декодере, который поможет выявить лингвистические примитивы, присущие анализируемой сцене. Здесь мы сначала сопоставим результаты энкодера точек с нашими примитивами.
//--- Decoder CNeuronOCM *decoder = cDecoder[0]; if(!decoder.feedForward(GetPointer(cGEGWA), GetPointer(cLPC))) return false;
А затем обогатим эмбеденги лингвистических примитивов промежуточными результатами энкодера точек. Для этого организуем цикл, в котором последовательно будем извлекать последующие слои декодера и соответствующие объекты энкодера точек с последующим сопоставлением данных.
for(int i = 1; i < cDecoder.Total(); i++) { decoder = cDecoder[i]; if(!decoder.feedForward(cGEGWA.GetInsideLayer(i - 1), cDecoder[i - 1])) return false; }
Результаты работы декодера мы проведем через модуль кластера объектов.
//--- Object Cluster Module if(!cOCM.feedForward(decoder, context)) return false; //--- return true; }
После чего завершим работу метода прямого прохода, передав логический результат выполнения операций вызывающей программе.
Стоит сказать, что реализованный алгоритм не является полной копией авторского фреймворка RefMask3D. В авторском алгоритме присутствует еще умножение результатов энкодера точек на выход модуля кластера объектов с добавлением головы определения вероятностей отнесения точки к тому или иному объекту. И причиной такому "урезанию" алгоритма служит различие решаемых задач. Нам нет необходимости визуального выделения отдельных объектов на анализируемой сцене. Для принятия решения о совершении торговой операции достаточно знаний о наличии искомых паттернов и их параметров. Поэтому мы приняли решение о реализации предложенного фреймворка в таком виде. А результаты его работы будут проанализированы моделью Актера.
Ну а мы двигаемся дальше. И за реализацией алгоритмов прямого прохода следует построение методов реализации процессов обратного прохода. И в данном случае следует сказать несколько слов о методе распределения градиентов ошибки calcInputGradients. Как всегда, в нем мы полностью инверсируем операции прямого прохода. Но стоит отметить, что в процессе прямого прохода мы генерируем целый ряд сущностей, которые оказывают ключевое влияние на эффективность модели. Среди них можно отметить обучаемые примитивы, эмбединги контекста и фоновых токенов. И разумеется, нам бы хотелось сформировать максимальное разнообразие данных сущностей с целью покрытия наибольшего пространства наблюдаемой сцены рыночной ситуации. И если в модуле генерации лингвистических примитивов мы уже реализовали данный функционал, то для других сущностей нам еще предстоит его создать. Поэтому предлагаю уделить несколько минут рассмотрению алгоритма, используемого для построения метода распределения градиента ошибки.
bool CNeuronRefMask::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) { if(!NeuronOCL || !SecondGradient) return false;
В параметрах метода мы получаем указатели на 3 объекта: один нейронный слой и два буфера данных. Как вы знаете, объект нейронного слоя содержит буферы результатов и градиентов ошибки первого источника. А вот для второго источника данных мы получаем отдельные буфера исходных данных и соответствующих градиентов ошибки. Здесь же присутствует указатель на функцию активации второго исходника данных.
В теле метода мы сразу проверяем актуальность полученных указателей на первый источник данных и градиент ошибки второго. Отсутствие корректного указателя на буфер второго источника исходных данных для нас не критично, так как проверенный указатель мы сохранили при выполнении прямого прохода.
Далее мы, при необходимости, осуществляем подмену на буфер градиентов ошибки в наше внутреннем объекте второго источника исходных данных.
CNeuronBaseOCL *neuron = cContentEncoder[0]; if(!neuron) return false; if(neuron.getGradient() != SecondGradient) { if(!neuron.SetGradient(SecondGradient)) return false; neuron.SetActivationFunction(SecondActivation); }
На этом мы завершаем подготовительную работу и переходим к непосредственным операциям распределения градиента ошибки.
Благодаря подмене указателей на буфера данных, выполненной при инициализации объекта, градиент ошибки, поступающий от последующего, слоя записывается непосредственно в буфер модуля кластера объектов. Поэтому, опуская излишнюю операцию копирования данных, мы начинаем выполнение операций с распределения градиента ошибки через объект OCM.
//--- Object Cluster Module CNeuronBaseOCL *context = cContentEncoder[cContentEncoder.Total() - 2]; if(!cOCM.calcInputGradients(cDecoder[cDecoder.Total() - 1], context)) return false;
Обратите внимание, что в данном случае мы передаем градиент в последний слой декодера и предпоследний слой энкодера контекста. Ведь последний слой энкодера контекста содержит конкатенированный тензор эмбединга контекста и фоновых токенов, который используется только для энкодера точек.
Следующим шагом мы распространим градиент ошибки через декодер. Для этого мы организуем обратный цикл перебора слоев декодера.
//--- Decoder CNeuronOCM *decoder = NULL; for(int i = cDecoder.Total() - 1; i > 0; i--) { decoder = cDecoder[i]; if(!decoder.calcInputGradients(cGEGWA.GetInsideLayer(i - 1), cDecoder[i - 1])) return false; } decoder = cDecoder[0]; if(!decoder.calcInputGradients(GetPointer(cGEGWA), GetPointer(cLPC))) return false;
Обратите внимание, что в процессе распределения градиента ошибки мы передаем его на внутренние слои энкодера точек. Именно для сохранения этих значений мы реализовали ранее алгоритм суммирования градиентов ошибки для объектов шеи.
Вторым источником данных Декодера является модуль генерации примитивов LPC. Полученный на нем градиент ошибки мы распределим до внутреннего модуля генерации примитивов и эмбединга контекста без фоновых токенов. Но последний буфер уже содержит данные от ранее проведенных операций. Поэтому мы временно заменим указатель буфера градиентов эмбединга контекста на неиспользуемый нами буфер, унаследованный от родительского класса. И лишь потом вызовем метод распределения градиента ошибки модуля LPC. А затем суммируем значения двух буферов данных.
//--- Linguistic Primitive Construction CBufferFloat *context_grad = context.getGradient(); if(!context.SetGradient(PrevOutput, false)) return false; if(!cLPC.FeedForward(context) || !SumAndNormilize(context_grad, context.getGradient(), context_grad, 1, false, 0, 0, 0, 1) ) return false;
Далее мы проведем градиент ошибки через энкодер точек. И на это раз мы распределяем градиент ошибки между первым источником исходных данных и эмбедингом контекста с фоновыми токенами.
//--- Geometry-Enhaced Group-Word Attention neuron = cContentEncoder[cContentEncoder.Total() - 1]; if(!neuron || !NeuronOCL.calcHiddenGradients((CObject*)GetPointer(cGEGWA), neuron.getOutput(), neuron.getGradient(), (ENUM_ACTIVATION)neuron.Activation())) return false;
Здесь важно отметить, что нам необходимо осуществлять совместную диверсификацию токеном контекста и фона. Ведь не сложно догадаться, что фоновые токены и контекст принадлежат одному подпространству. Более того, помимо диверсификации токенов контекста и фона, нам необходимо выстроить четкое различие между этими сущностями. Поэтому мы сначала добавим ошибку диверсификации для конкатенированного тензора контекста и фона.
if(!DiversityLoss(neuron, cOCM.GetContextWindow(), neuron.Neurons() / cOCM.GetContextWindow(), true)) return false; CNeuronBaseOCL *background = cBackGround[cBackGround.Total() - 1]; if(!background || !DeConcat(context.getGradient(), background.getGradient(), neuron.getGradient(), context.Neurons(), background.Neurons(), 1) || !DeActivation(context.getOutput(), context.getGradient(), context.getGradient(), context.Activation()) || !SumAndNormilize(context_grad, context.getGradient(), context_grad, 1, false, 0, 0, 0, 1) || !context.SetGradient(context_grad, false) ) return false;
А затем распределим полученный градиент ошибки между соответствующим буферами указанных сущностей. Скорректируем градиент контекста на производную функции активации и добавим полученные значения к ранее накопленным. После чего ввернем указатель на соответствующий буфер данных. Далее мы можем опустить градиент ошибки до уровня второго источника данных.
//--- Context Encoder for(int i = cContentEncoder.Total() - 3; i >= 0; i--) { context = cContentEncoder[i]; if(!context || !context.calcHiddenGradients(cContentEncoder[i + 1]) ) return false; }
Напомню, что указатель на буфер градиентов ошибки мы уже сохранили в соответствующем объекте внутреннего нейронного слоя. Поэтому операция переноса значений между буферами данных становится излишней.
На данном этапе мы распределили градиент ошибки до обоих источников исходных данных и почти всех внутренних объектов. "Почти" потому, что нам осталось распределить градиент ошибки через модель генерации фоновых токенов. Скорректируем полученный выше градиент ошибки на производную функции активации и организуем цикл обратного перебора слоев MLP.
//--- Background if(!DeActivation(background.getOutput(), background.getGradient(), background.getGradient(), background.Activation())) return false; for(int i = cBackGround.Total() - 2; i > 0; i--) { background = cBackGround[i]; if(!background || !background.calcHiddenGradients(cBackGround[i + 1]) ) return false; } //--- return true; }
И в завершении метода распределения градиента ошибки мы вернем вызывающей программе логический результат выполнения операций.
На этом мы завершаем рассмотрение алгоритмов реализации фреймворка RefNask3D. А с полным кодом всех представленных классов и их методов Вы можете ознакомиться во вложении. Там же Вы найдете архитектуру обучаемых моделей и всех программ, используемых при подготовке данной статьи.
В архитектуру обучаемых моделей мы внесли лишь точечные правки, которые заключаются в изменении одного слоя Энкодера описания состояния окружающей среды. Программы же взаимодействия с окружающей средой и обучения моделей были перенесены из предыдущих работ и вовсе без изменений. Поэтому мы не будем останавливаться на их рассмотрении, а перейдем к заключительной части нашей статьи — обучение моделей и тестирование результатов.
3. Тестирование
Как было сказано выше, внесение изменений в архитектуру моделей не повлекло изменения в структуре исходных данных и результатов. А значит для первичного обучения моделей мы можем воспользоваться ранее собранной обучающей выборкой. Напомню, что для обучения моделей мы используем реальные исторические данные инструмента EURUSD за весь 2023 год на таймфрейме H1. Параметры всех анализируемых индикаторов используются по умолчанию.
Обучение моделей осуществляется offline. Однако для подержания обучающей выборки в актуальном состоянии мы проводим периодическое обновление обучающей выборки с добавлением проходов в рамках текущей политики Актера. Итерации обучения моделей и обновления обучающей выборки повторяются до достижения желаемого результата.
В рамках подготовки данной статьи мы получили довольно интересную политику Актера. Результаты её тестирования на исторических данных января 2024 года представлены ниже.
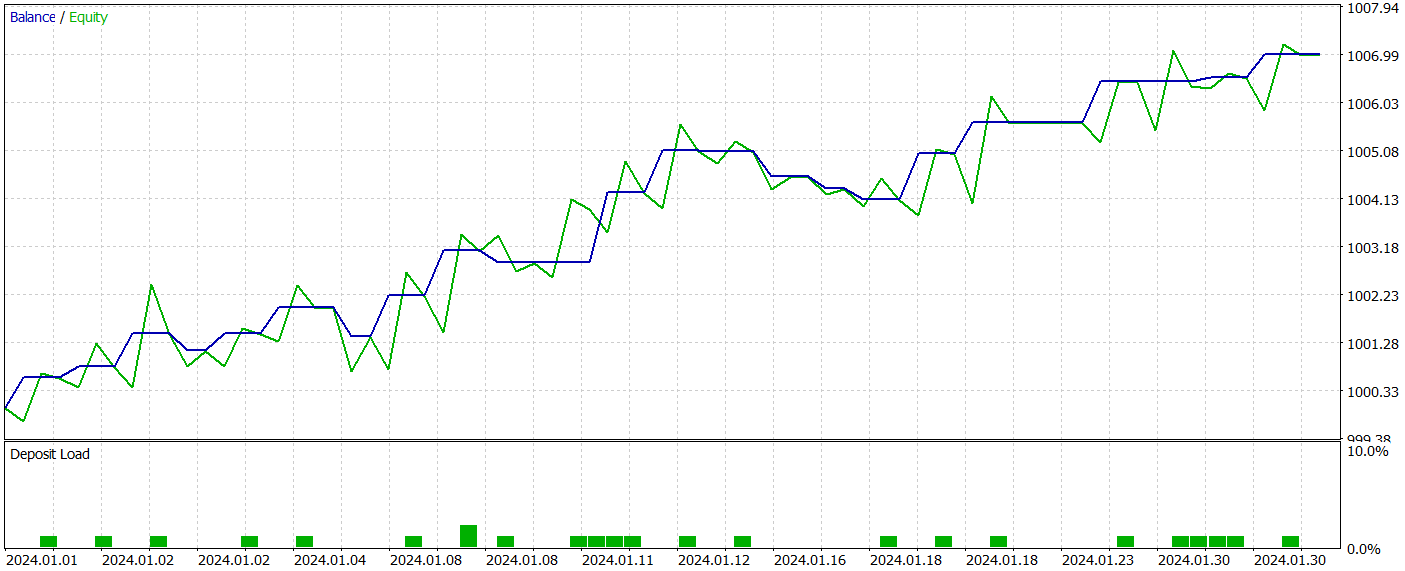
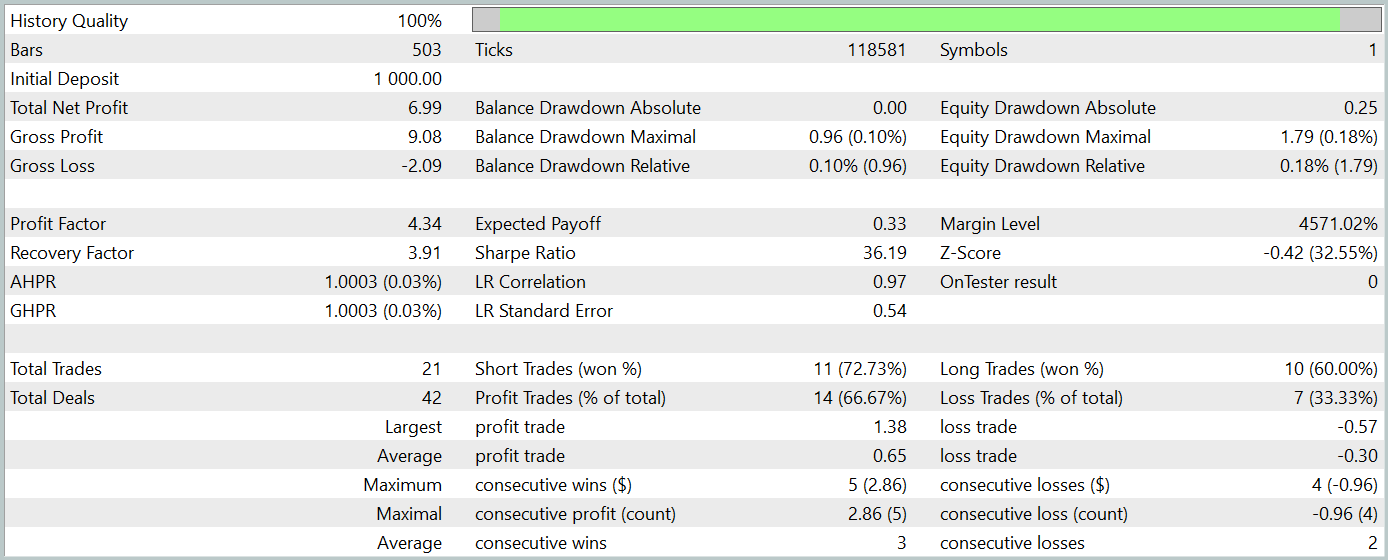
Легко заметить, что период тестирования не входит в обучающую выборку. Такой метод тестирования создает условия, максимально приближенные к реальному использованию модели.
За период тестирования модель совершила 21 торговую операцию и 14 из них было закрыто с прибылью, что составило более 66%. Следует отметить, что доля прибыльных операций превышает убыточные как по коротким, так и по длинным позициям. Более того, средняя прибыльная сделка в 2 раза превышает среднюю убыточную. А аналогичный показатель по максимальной прибыльной сделке приближается к трехкратной отметке. При этом график баланса имеет четко выраженную тенденцию.
Конечно, малое количество совершенных торговых операций не позволяет говорить об эффективности работе модели в долгосрочной перспективе. Тем не менее, предложенный подход явно обладает потенциалом и заслуживает дальнейших исследований.
Заключение
На протяжении двух последних статей мы провели огромную работу по реализации подходов, предложенных авторами метода RefMask3D средствами MQL5. Конечно, представленный вариант реализации имеет некоторые отклонения от авторского фреймворка. Тем не менее, полученные результаты демонстрируют потенциал предложенного подхода.
Однако, обращаю Ваше внимания, что все программы, представленные в данной статье носят демонстрационный характер и не готовы для использования в реальных рыночных условиях.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Дмитрий здравствуйте. Вот при обучении выскочила такая вот ошибка:
Что это значит?
Кстати при компиляции вот такие 2 предупреждения появляются:
Файлы из статьи без изменений.
Отличная статья. Я собираюсь скачать ее и попробовать использовать в эти выходные. Есть две вещи, которые не отображаются в отчете о бэктесте. Используемая валютная пара и таймфрейм. Не могли бы вы предоставить эту информацию или ссылку на предыдущую статью, которая определила это? Я только что нашел ответы. Это EURUSD и H1.
Виктор, у меня была такая же ошибка с мемо на Deprecated behavior. В моем случае я разрабатывал класс и случайно вызвал видимую функцию, которой не хватало параметра, но класс содержал правильные параметры. Добавление параметра решило мою проблему. пробная программа работала правильно, используя deprecated behavior, поэтому это ошибка мемо.