
Redes neurais de maneira fácil (Parte 89): Transformador de decomposição por frequência do sinal (FEDformer)

Introdução
A previsão de longo prazo de séries temporais é um problema antigo ao resolver diversas tarefas aplicadas. Modelos baseados em Transformer demonstram resultados promissores. No entanto, a alta complexidade computacional e os requisitos de memória dificultam o uso de Transformer para modelar sequências longas. Isso impulsionou diversas pesquisas voltadas para a redução dos custos computacionais do Transformer.
Apesar dos avanços alcançados pelos métodos de previsão de séries temporais baseados em Transformer, em alguns casos, eles não conseguem capturar as características gerais da distribuição da série temporal. A tentativa de resolver esse problema foi feita pelos autores do artigo "FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting". Eles comparam dados reais da série temporal com os valores previstos, obtidos pelo Transformer padrão. Uma captura de tela do artigo dos autores é apresentada abaixo.
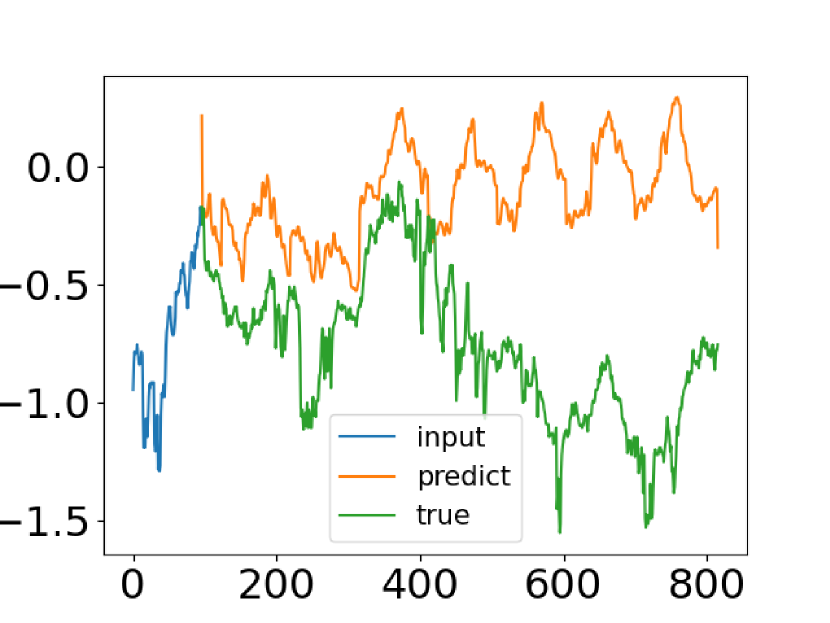
É fácil perceber que a distribuição da série temporal prevista difere significativamente da verdadeira. A discrepância entre os valores esperados e previstos pode ser explicada pela atenção pontual no Transformer. Como a previsão para cada etapa temporal é feita individualmente e de forma independente, é provável que o modelo não consiga manter as propriedades globais e as estatísticas das séries temporais na totalidade. Para resolver esse problema, os autores do artigo exploram duas ideias.
A primeira é usar a abordagem de decomposição de tendências sazonais, amplamente utilizada na análise de séries temporais. Os autores do artigo apresentam uma arquitetura especial de modelo que aproxima eficientemente a distribuição das previsões à realidade.
A segunda ideia é incorporar a análise de Fourier no algoritmo Transformer. Em vez de aplicar o Transformer à dimensão temporal da sequência, eles propõem analisar suas características de frequência, o que ajuda o Transformer a capturar melhor as propriedades globais das séries temporais.
A combinação das ideias propostas é implementada no modelo Frequency Enhanced Decomposition Transformer, ou abreviado, FEDformer.
Uma das questões mais importantes relacionadas ao FEDformer é qual subconjunto de componentes de frequência deve ser utilizado na análise de Fourier para representar as séries temporais. Em análises semelhantes, normalmente preservam-se os componentes de baixa frequência e descartam-se as componentes de alta frequência. No entanto, isso pode não ser apropriado para a previsão de séries temporais, pois algumas mudanças nas tendências das séries estão ligadas a eventos importantes. Essa parte da informação pode ser perdida ao simplesmente remover todos os componentes de alta frequência do sinal. Os autores do método aceitam que as séries temporais geralmente possuem representações esparsas desconhecidas com base no conjunto de Fourier. Sua análise teórica mostrou que um subconjunto aleatório de componentes de frequência, incluindo tanto baixas quanto altas frequências, fornece uma melhor representação das séries temporais. Esta observação foi confirmada por extensos estudos empíricos.
Além de aumentar a eficiência para previsão de longo prazo, a combinação do Transformer com a análise de frequência permite reduzir os custos computacionais de complexidade quadrática para linear.
Os autores do artigo resumem suas conquistas da seguinte maneira:
1. Foi proposta uma arquitetura de Transformer para decomposição de sinais com características de frequência aprimoradas, utilizando especialistas para a decomposição de tendências sazonais, o que melhora a capacidade de capturar as propriedades globais das séries temporais.
2. Foram propostos blocos Fourier expandidos e blocos wavelet aprimorados na arquitetura Transformer, que permitem identificar importantes estruturas nas séries temporais através do estudo das características de frequência. Esses blocos substituem tanto os blocos de atenção interna quanto de atenção cruzada.
3. Através da escolha aleatória de um número fixo de componentes Fourier, o modelo proposto alcança complexidade computacional linear e otimiza o uso de memória. A eficiência desse método de seleção foi comprovada teorica e empiricamente.
4. Experimentos realizados em seis conjuntos de dados básicos de diversas áreas mostram que o modelo proposto melhora a eficiência dos métodos modernos em 14,8% para previsão multivariada e em 22,6% para previsão univariada.
1. Algoritmo FEDformer
Vale mencionar que os autores apresentaram duas variantes do modelo FEDformer. Um utiliza a base Fourier para análise das características de frequência da série temporal, e o outro se baseia no uso de wavelets, que permitem combinar a análise tanto no tempo quanto no domínio da frequência.
A previsão de séries temporais de longo prazo representa um problema sequence-to-sequence. Denotamos o tamanho da sequência de dados de entrada como I e a sequência prevista como O. Seja D o tamanho do vetor que descreve um estado da série. Assim, a entrada do Codificador é um tensor de tamanho I*D, e o Decodificador recebe uma matriz de tamanho (I/2+O)*D.
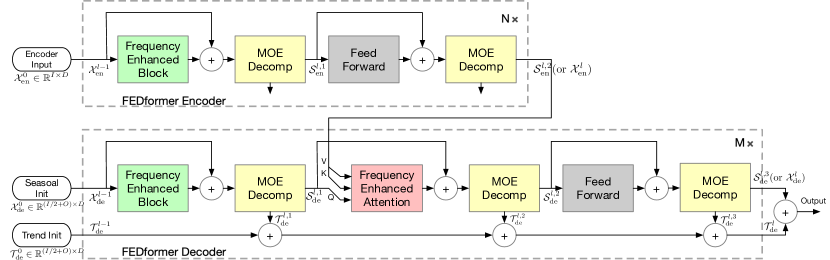
Como mencionado anteriormente, os autores aprimoram a arquitetura Transformer ao incorporar a decomposição e a distribuição de tendências sazonais. O Transformer atualizado apresenta uma arquitetura de decomposição profunda e inclui o bloco de análise de características de frequência (FEB), o bloco de atenção a características de frequência (FEA) e os blocos de decomposição Mixture Of Experts (MOEDecomp).
O Codificador do FEDformer utiliza uma estrutura em vários níveis, semelhante ao Codificador do Transformer. Um bloco individual pode ser representado pelas seguintes expressões matemáticas:
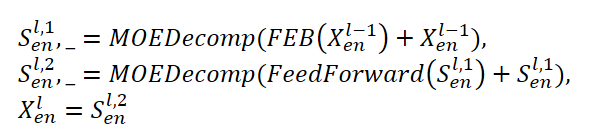
Aqui, Sen representa a componente sazonal extraída dos dados de entrada no bloco de decomposição MOEDecomp.
Para o módulo FEB, os autores do método propõem 2 versões diferentes (FEB-f e FEB-w), que são implementadas através do mecanismo de Transformada Discreta de Fourier (DFT) e da Transformada Discreta Wavelet (DWT), respectivamente. Nessa implementação, eles substituem o bloco Self-Attention.
O Decodificador também usa uma estrutura em múltiplos níveis, assim como o Codificador. No entanto, a arquitetura de seus blocos componentes é muito mais ampla e descrita pelas fórmulas:
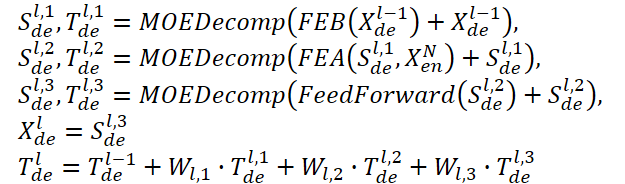
Sde e Tde representam as componentes sazonal e de tendência após o bloco de decomposição MOEDecomp. E Wl desempenha o papel de projeção da tendência extraída. Assim como FEB, FEA tem duas versões diferentes (FEA-f e FEA-w), implementadas por projeções DFT e DWT, respectivamente. O FEA é projetado com um mecanismo de atenção e substitui o bloco de atenção cruzada do Transformer padrão.
A previsão final é a soma de duas componentes refinadas decompostas. A componente sazonal é projetada por meio de uma matriz WS até a dimensão alvo.
![]()
O modelo FEDformer proposto usa a Transformada Discreta de Fourier (DFT), que permite decompor a sequência analisada em suas componentes harmônicas (componentes sinusoidais). Para aumentar a eficiência do modelo, os autores do FEDformer utilizam a Transformada Rápida de Fourier (FFT).
Como mencionado anteriormente, o método usa um subconjunto aleatório da base de Fourier, e a escala do subconjunto é limitada por um escalar. A escolha do índice de modo antes das operações DFT e da DFT (IDFT) inversa permite regular ainda mais a complexidade computacional.
O bloco com faixa de frequência expandida e Transformada de Fourier (FEB-f) é usado tanto no Codificador quanto no Decodificador. Os dados de entrada do bloco FEB-f são primeiro projetados linearmente e, em seguida, transformados do domínio temporal para as características de frequência. Das características de frequência obtidas, M harmônicos são amostrados aleatoriamente. Em seguida, as características de frequência selecionadas são multiplicadas por uma matriz de núcleo parametrizada, que é inicializada com parâmetros aleatórios e ajustada durante o treinamento do modelo. O resultado é complementado com zeros até a dimensão total das características de frequência antes de executar a transformada inversa de Fourier, que retorna a sequência analisada ao domínio temporal. A visualização do bloco FEB-f fornecida pelos autores está abaixo.
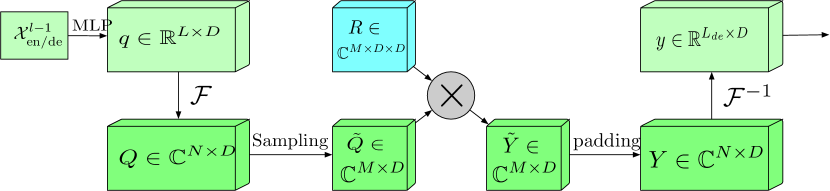
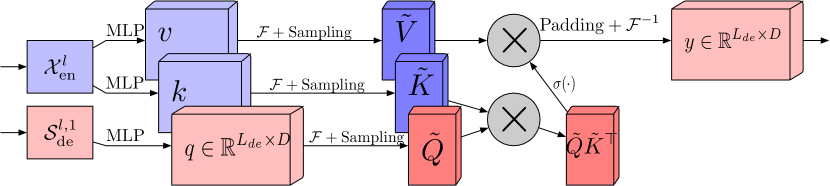
No bloco de atenção de características de frequência usando a Transformada Discreta de Fourier (FEA-f), o mecanismo canônico do Transformer é mantido com pequenas modificações. Os dados de entrada são transformados nas representações Query, Key e Value. No caso de atenção cruzada, as Queries vêm do Decodificador, enquanto as Keys e Values são obtidas do Codificador. No entanto, no FEA-f, transformamos as Queries, Keys e Values usando a Transformada de Fourier e executamos um mecanismo de atenção semelhante ao canônico no domínio das características de frequência. Aqui, assim como no bloco FEB-f, para a análise nós amostramos aleatoriamente M harmônicos. O resultado da operação de atenção é complementado com zeros até o tamanho da sequência original, e é realizada a transformada inversa de Fourier. A estrutura do FEA-f está mostrada abaixo na visualização dos autores.
Enquanto a Transformada de Fourier cria uma representação do sinal em termos de suas características de frequência, a Transformada Wavelet permite representar o sinal tanto no domínio temporal quanto no de frequência, proporcionando acesso eficiente a informações localizadas sobre o sinal original. A Transformada Multi-Wavelet combina as vantagens dos polinômios ortogonais e das wavelets. A representação multi-wavelet do sinal pode ser obtida através do produto tensorial entre as bases multi-escala e multi-wavelet. Note que as bases em diferentes escalas estão conectadas pelo produto tensorial. Os autores do FEDformer adaptam uma representação wavelet não convencional para reduzir a complexidade do modelo.
A arquitetura FEB-w difere da FEB-f pelo seu mecanismo recursivo: os dados de entrada são decompostos recursivamente em 3 partes, e cada uma delas é processada individualmente. Para a decomposição wavelet, os autores propõem uma matriz fixa de decomposição baseada nas wavelets de Legendre. Três módulos FEB-f são usados para processar a parte de alta frequência resultante, a parte de baixa frequência e a parte remanescente da decomposição wavelet, respectivamente. A cada iteração, é gerado um tensor processado de alta frequência, um tensor processado de baixa frequência e um tensor não processado de baixa frequência. Este é um método descendente, e na etapa de decomposição o sinal é reduzido pela metade a cada iteração. Três conjuntos de blocos FEB-f são usados em conjunto durante diferentes iterações da decomposição. Quanto à reconstrução wavelet, os autores do método também geram recursivamente o tensor de saída.
O FEA-w contém uma etapa de decomposição e uma etapa de reconstrução, semelhante ao FEB-w. Aqui, os autores do FEDformer mantêm a etapa de reconstrução inalterada. A única diferença está na fase de decomposição. A mesma matriz é usada para decompor o sinal nas entidades Query, Key e Value. Como mostrado anteriormente, o bloco FEB-w contém três blocos FEB-f para processar o sinal. O FEB-f pode ser visto como uma substituição para o mecanismo de Self-Attention. Os autores usam uma forma simples de criar atenção cruzada com o reforço de frequência via decomposição wavelet, substituindo cada FEB-f por um módulo FEA-f. Além disso, outro módulo FEA-f é adicionado para processar os resíduos mais grosseiros.
Devido aos padrões periódicos complexos frequentemente observados em conjunto com componentes de tendência nos dados reais, a extração de tendências pode ser difícil quando se combina médias móveis com uma janela fixa. Para superar esse problema,foi desenvolvido o bloco de decomposição Mixture Of Experts (MOEDecomp). Ele contém um conjunto de filtros com médias de tamanhos diferentes para extrair múltiplos componentes de tendência do sinal original, além de um conjunto de pesos dependentes dos dados para combiná-los na tendência final.
O algoritmo completo do método FEDformer é apresentado na visualização dos autores abaixo.
2. Implementação com MQL5
Após revisar os aspectos teóricos do método FEDformer proposto, é necessário dizer de imediato que nossa implementação estará longe da original. Utilizaremos as abordagens sugeridas, mas não implementaremos completamente o algoritmo proposto. E isso se deve a algumas de minhas convicções pessoais.
Para começar, precisamos decidir qual base vamos utilizar, DFT ou DWT. A questão é bastante complexa e ambígua, sobre a qual se pode "quebrar a cabeça" por muito tempo. No entanto, faremos algo muito mais simples. Consultaremos os resultados dos testes do método, que estão apresentados no artigo dos autores.

Preste atenção na coluna "Exchange". Não entraremos em detalhes sobre quais dados específicos foram utilizados para testar o modelo, mas é evidente a superioridade do modelo com o uso de DWT. Provavelmente, devido à ausência de periodicidade claramente expressa nos dados de entrada, DFT não consegue identificar o momento de mudança nas tendências. Pois ele ignora a dimensão temporal dos dados de entrada. Ao mesmo tempo, DWT, que analisa o sinal em ambas as dimensões, pode fornecer dados preditivos mais precisos. Acredito que, em tal situação, nossa escolha em favor do DWT seja óbvia.
2.1 Implementação de DWT
Tendo decidido a base da implementação, a primeira coisa que faremos é implementar a capacidade de decomposição wavelet em nossa biblioteca. Para isso, criaremos um novo objeto CNeuronLegendreWavelets.
Vamos pensar um pouco sobre a arquitetura do objeto que estamos criando. Como já foi mencionado anteriormente, para a decomposição wavelet, os autores do método sugerem utilizar uma matriz fixa de decomposição da base das wavelets de Legendre. Em outras palavras, para decompor o sinal, basta multiplicar o vetor do sinal pela matriz da base das wavelets.
Em nossa sequência de dados de entrada, precisaremos analisar vários sinais paralelos de uma série temporal multimodal. Nesse caso, para cada série temporal unidimensional, utilizaremos a mesma matriz base.
Este processo é muito semelhante à convolução com vários filtros. No entanto, neste caso, o papel da matriz de filtros é desempenhado pela matriz base das wavelets. Portanto, faz sentido criar um novo objeto que herde nosso bloco convolucional. Com uma abordagem bem pensada, podemos utilizar ao máximo os métodos herdados, reescrevendo apenas alguns deles.
class CNeuronLegendreWavelets : public CNeuronConvOCL { protected: virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronLegendreWavelets(void) {}; ~CNeuronLegendreWavelets(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronLegendreWavelets; } };
Na estrutura apresentada acima da nova classe CNeuronLegendreWavelets, é possível ver apenas três métodos reescritos, um dos quais é o identificador da classe Type, que retorna uma constante predefinida.
O segundo ponto, que já foi mencionado anteriormente, é que utilizamos uma matriz fixa da base de wavelets. Portanto, nossa classe não terá parâmetros treináveis, e o método updateInputWeights será sobrescrito como uma "função vazia".
Basicamente, temos que trabalhar apenas com o método de inicialização do objeto da classe Init. No novo método, não declaramos quaisquer variáveis ou objetos locais. E no método de inicialização, apenas precisamos preencher a matriz de base das wavelets.
Os autores do método propõem usar polinômios de Legendre como wavelets. Eu escolhi 9 desses polinômios, cuja visualização é apresentada abaixo.

Como pode ser observado, os polinômios apresentados no gráfico permitem descrever um espectro bastante amplo de frequências.
Também vale a pena notar que o intervalo de valores permitidos para os polinômios apresentados é [0, 1]. Isso é bastante conveniente. Definimos o comprimento da janela da sequência analisada como 1. E dividimos o intervalo pelo número de elementos na sequência. Assim, determinamos o passo temporal entre dois elementos consecutivos da sequência, que formamos inicialmente com um passo fixo. E aqui não importa o time frame dos dados de entrada coletados. Analisamos as características de frequência do sinal dentro da janela visível da sequência original.
Neste ponto, surge o problema de determinar o número de elementos na sequência durante a fase de projeto do modelo. Antes de criar a matriz base, precisamos especificar suas dimensões. Nesta etapa, temos apenas o número de filtros que selecionamos. Mas o tamanho da janela da sequência analisada só será conhecido na inicialização do modelo. Na verdade, temos duas opções para resolver essa situação:
- 1. Definir dimensões fixas para a matriz de base das wavelets e preencher imediatamente seus valores. O uso de uma camada convolucional treinável antes da matriz nos permitirá trabalhar com qualquer tamanho de sequência original.
- 2. Criar um algoritmo universal para preencher a matriz de base das wavelets na fase de inicialização do modelo, para qualquer tamanho de dados de entrada.
A primeira opção nos permite preencher a matriz com valores fixos de qualquer maneira disponível. Podemos até encontrar na internet os coeficientes das wavelets base que nos interessam. Mas como podemos encontrar esse "meio-termo" entre precisão e desempenho? Além disso, as exigências de precisão das previsões podem variar bastante em diferentes tarefas.
Aqui, na minha opinião, a segunda opção parece mais otimizada. Para implementá-la, criaremos as fórmulas dos polinômios selecionados como macros. Aqui estão algumas (a lista completa está disponível em anexo):
#define Legendre4(x) (70*pow(x,4) - 140*pow(x,3) + 90*pow(x,2) - 20*x + 1) #define Legendre6(x) (924*pow(x,6) - 2772*pow(x,5) + 3150*pow(x,4) - 1680*pow(x,3) + \ 420*pow(x,2) - 42*x + 1) #define Legendre8(x) (12870*pow(x,8) - 51480*pow(x,7) + 84084*pow(x,6) - 72072*pow(x,5) + \ 34650*pow(x,4) - 9240*pow(x,3) + 1260*pow(x,2) - 72*x + 1)
Com essas macros, podemos obter o valor do polinômio para qualquer valor discreto. E, após concluir o trabalho preparatório, podemos passar diretamente para a descrição do algoritmo de inicialização do objeto de nossa nova classe CNeuronLegendreWavelets::Init.
Nos parâmetros do método, passamos os parâmetros-chave da arquitetura do objeto:
bool CNeuronLegendreWavelets::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, window, step, 9, units_count, optimization_type, batch)) return false;
E no corpo do método, chamamos primeiro o método de mesmo nome da classe-mãe.
Observe que, nos parâmetros do método de inicialização da nova classe, recebemos apenas o tamanho da janela da sequência analisada e o número de elementos na sequência. E ao chamar o método equivalente da classe-mãe, precisamos adicionar o passo da janela e o número de filtros. Já decidimos sobre o número de filtros, que são 9. E o passo da janela analisada será igual à janela analisada.
Após a execução bem-sucedida do método de inicialização da classe-mãe, nossa matriz de parâmetros de convolução é preenchida com valores aleatórios. Precisamos preenchê-la com os parâmetros da base wavelet. Para isso, primeiro, preenchermos a matriz de pesos com valores nulos. Este é um ponto muito importante, pois precisamos zerar os parâmetros de bias definidos.
WeightsConv.BufferInit(WeightsConv.Total(), 0);
Em seguida, no loop, preenchemos a matriz com os valores da base wavelet:
for(uint i = 0; i < iWindow; i++) { uint shift = i; float k = float(i) / iWindow; if(!WeightsConv.Update(shift, Legendre4(k))) return false; shift += iWindow + 1; if(!WeightsConv.Update(shift, Legendre6(k))) return false; shift += iWindow + 1; if(!WeightsConv.Update(shift, Legendre8(k))) return false; shift += iWindow + 1; if(!WeightsConv.Update(shift, Legendre10(k))) return false; shift += iWindow + 1; if(!WeightsConv.Update(shift, Legendre12(k))) return false; shift += iWindow + 1; if(!WeightsConv.Update(shift, Legendre16(k))) return false; shift += iWindow + 1; if(!WeightsConv.Update(shift, Legendre18(k))) return false; shift += iWindow + 1; if(!WeightsConv.Update(shift, Legendre20(k))) return false; }
A matriz preenchida será transferida para a memória do contexto OpenCL:
if(!!OpenCL) if(!WeightsConv.BufferWrite()) return false; //--- return true; }
E finalizamos o trabalho do método.
Aqui é importante mencionar que, nessa implementação, o restante do funcional necessário para o funcionamento correto do objeto foi herdado da classe-mãe. Portanto, finalizamos o trabalho com essa classe e seguimos em frente.
2.2 Bloco FED-w
Na próxima etapa de nosso trabalho, podemos dizer que subimos um degrau, criando nossa visão do bloco FED-w, cuja funcionalidade é implementada na classe CNeuronFEDW. A estrutura dessa classe está apresentada abaixo.
class CNeuronFEDW : public CNeuronBaseOCL { protected: //--- uint iWindow; uint iCount; //--- CNeuronLegendreWavelets cWavlets; CNeuronBatchNormOCL cNorm; CNeuronSoftMaxOCL cSoftMax; CNeuronConvOCL cFF[2]; CNeuronBaseOCL cReconstruct; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Reconsruct(CBufferFloat* inputs, CBufferFloat *outputs); public: CNeuronFEDW(void) {}; ~CNeuronFEDW(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronFEDW; } virtual void SetOpenCL(COpenCLMy *obj); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); };
Pode-se notar que essa classe possui uma arquitetura mais complexa em comparação com a anterior. Nela, são declaradas duas variáveis locais para armazenar os parâmetros-chave. Além disso, uma série de objetos internos é declarada, cujas funções conheceremos no processo de implementação. Todos os objetos são declarados como estáticos, o que nos permite deixar o construtor e o destrutor da classe "vazios".
A inicialização direta de todos os objetos internos, como sempre, ocorre no método CNeuronFEDW::Init. Nos parâmetros do método, passamos os principais parâmetros da arquitetura do objeto. Entre eles, destacam-se os parâmetros fundamentais do tamanho da janela visível dos dados (window) e do número de sequências unitárias analisadas (count).
bool CNeuronFEDW::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * count, optimization_type, batch)) return false;
No corpo do método, primeiro chamamos o método de mesmo nome da classe-mãe, o que, pode-se dizer, é uma regra na implementação de nossos objetos. Em seguida, salvamos nas variáveis locais os parâmetros da arquitetura do objeto que está sendo inicializado:
iWindow = window; iCount = count;
E então inicializamos os objetos internos na ordem de seu uso subsequente.
Primeiramente, planejamos extrair as características de frequência dos dados de entrada recebidos. Para isso, usamos a instância da classe CNeuronLegendreWavelets:
if(!cWavlets.Init(0, 0, OpenCL, iWindow, iWindow, iCount, optimization, iBatch)) return false; cWavlets.SetActivationFunction(None);
Devo dizer que o bloco FED-w que estamos criando é significativamente simplificado em comparação com o proposto pelos autores do método. Decidi não usar blocos DFT. Acho que a análise das características de frequência sem levar em conta a dimensão temporal pode jogar contra nós e reduzir a qualidade das previsões. Isso, no mínimo, coloca em dúvida a viabilidade do uso de DFT. Mas essa é minha opinião, e ela pode estar errada.
Além disso, a exclusão do processo relativamente trabalhoso de FFT reduzirá significativamente o custo dos recursos computacionais durante o treinamento e a operação do modelo.
Com base no que foi mencionado anteriormente, decidi seguir pelo caminho de aumentar o desempenho do modelo, assumindo os riscos de possível degradação na qualidade da previsão.
Os dados obtidos após a decomposição wavelet eu inicialmente normalizo usando uma camada de normalização em lote:
if(!cNorm.Init(0, 1, OpenCL, 9 * iCount, 1000,optimization)) return false; cNorm.SetActivationFunction(None);
Em seguida, avalio a participação de cada um dos filtros utilizados. Para isso, traduzo os dados obtidos para um subespaço de probabilidades utilizando a função SoftMax.
if(!cSoftMax.Init(0, 1, OpenCL, 9 * iCount, optimization, iBatch)) return false; cSoftMax.SetHeads(iCount); cSoftMax.SetActivationFunction(None);
Note que avaliamos cada canal unitário separadamente.
Depois disso, restauramos a série temporal original a partir da representação probabilística por meio da convolução inversa com nossa matriz de bases wavelet. O resultado será armazenado em uma camada básica aninhada recém-criada:
if(!cReconstruct.Init(0, 2, OpenCL, iWindow, optimization, iBatch)) return false; cReconstruct.SetActivationFunction(None);
Pode-se observar que as operações mencionadas acima formam um ciclo fechado: série temporal → decomposição wavelet → normalização → representação probabilística → série temporal. No entanto, ao final, obtemos uma representação bastante suavizada da série temporal original, que passou por uma espécie de filtro digital. Como resultado, conseguimos uma filtragem eficiente dos dados com um mínimo de parâmetros treináveis, que estão presentes apenas na camada de normalização em lote. E esse bloco substitui o Self-Attention na nossa implementação.
Aqui, é importante notar que, essencialmente, estamos trocando os parâmetros treináveis do modelo por wavelets pré-definidos. Isso torna o modelo mais compreensível, diferentemente da "caixa-preta" de parâmetros treináveis, mas menos flexível. E impõe uma carga adicional sobre o arquiteto do modelo na busca pelos wavelets ideais para resolver a tarefa. Não por acaso, coloquei os polinômios wavelet em um bloco separado de macro substituições. Essa abordagem nos permitirá experimentar facilmente com diferentes wavelets na busca pelos mais adequados.
Mas voltemos ao nosso método de inicialização da classe. E após o bloco de filtro digital, vem o bloco FeedForward típico da arquitetura Transformer. Aqui usamos sem modificações uma MLP de 2 camadas com LReLU entre elas. Como anteriormente, usamos objetos de camada convolucional para implementar o processamento independente dos canais:
if(!cFF[0].Init(0, 3, OpenCL, iWindow, iWindow, 4 * iWindow, iCount, optimization, iBatch)) return false; cFF[0].SetActivationFunction(LReLU); if(!cFF[1].Init(0, 4, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iCount, optimization, iBatch)) return false; SetActivationFunction(None);
Ao finalizar o método de inicialização, organizamos a substituição do buffer de gradiente de erro para minimizar operações desnecessárias de cópia de dados:
if(Gradient != cFF[1].getGradient()) SetGradient(cFF[1].getGradient()); //--- return true; }
Após concluir o trabalho de inicialização do nosso objeto, passamos à implementação da propagação para frente do modelo proposto. Do processo planejado descrito acima, vale destacar a convolução inversa das probabilidades obtidas na série temporal.
"Convolução inversa" soa como algo novo em nossa implementação. No entanto, já realizamos esse processo há muito tempo. É com a convolução inversa que distribuímos o gradiente de erro na camada convolucional. Mas agora precisamos implementar esse processo no âmbito da propagação para frente.
A dificuldade está no fato de que todos os métodos das nossas classes trabalham com uma lista fixa de buffers de dados. Isso nos permite não nos preocuparmos com os buffers de dados durante a criação dos modelos. Basta fornecer um ponteiro para o objeto, e todos os buffers já estão definidos no método. "A outra face da moeda" é que não podemos usar o método de propagação reversa para implementar o algoritmo dentro da propagação para frente. Mas podemos criar um novo método, no qual usaremos o kernel previamente criado, passando-lhe os buffers e parâmetros corretos.
Vamos proceder dessa forma. Criaremos o método CNeuronFEDW::Reconsruct, em cujos parâmetros passaremos os ponteiros para os buffers das probabilidades obtidas e da sequência que será restaurada:
bool CNeuronFEDW::Reconsruct(CBufferFloat *sequence, CBufferFloat *probability) { uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = sequence.Total();
No corpo do método, definiremos o espaço de trabalho e passaremos todos os parâmetros necessários para o kernel:
if(!OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv, def_k_chgc_matrix_w, cWavlets.GetWeightsConv().GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv, def_k_chgc_matrix_g, probability.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv, def_k_chgc_matrix_o, probability.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv, def_k_chgc_matrix_ig, sequence.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CalcHiddenGradientConv, def_k_chgc_outputs, probability.Total())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CalcHiddenGradientConv, def_k_chgc_step, (int)iWindow)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CalcHiddenGradientConv, def_k_chgc_window_in, (int)iWindow)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CalcHiddenGradientConv, def_k_chgc_window_out, (int)9)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CalcHiddenGradientConv, def_k_chgc_activation, (int)None)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CalcHiddenGradientConv, def_k_chgc_shift_out, (int)0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Depois disso, colocaremos o kernel na fila de execução:
if(!OpenCL.Execute(def_k_CalcHiddenGradientConv, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Com isso, o trabalho preparatório está concluído, e podemos começar a descrição do método de propagação para frente da nossa classe CNeuronFEDW::feedForward. Como de costume, nos parâmetros do método de propagação para frente, passamos um ponteiro para o objeto da camada anterior do nosso modelo, que contém os dados de entrada necessários:
bool CNeuronFEDW::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cWavlets.FeedForward(NeuronOCL.AsObject())) return false;
No corpo do método, primeiro decompomos a sequência recebida em suas características de frequência. Para isso, chamamos o método de propagação para frente do objeto aninhado cWavlets.
Em seguida, conforme o algoritmo proposto, normalizamos os dados obtidos e os convertimos para um subespaço probabilístico:
if(!cNorm.FeedForward(cWavlets.AsObject())) return false; if(!cSoftMax.FeedForward(cNorm.AsObject())) return false;
Depois, restauramos a sequência temporal:
if(!Reconsruct(cReconstruct.getOutput(), cSoftMax.getOutput())) return false;
O restante do algoritmo é semelhante ao do Transformer clássico. Somamos e normalizamos as sequências temporais original e restaurada:
if(!SumAndNormilize(NeuronOCL.getOutput(), cReconstruct.getOutput(), cReconstruct.getOutput(), iWindow, true, 0, 0, 0, 1)) return false;
Passamos os dados pelo bloco FeedForward:
if(!cFF[0].FeedForward(cReconstruct.AsObject())) return false; if(!cFF[1].FeedForward(cFF[0].AsObject())) return false;
Em seguida, somamos e normalizamos novamente as sequências temporais dos dois fluxos de dados:
if(!SumAndNormilize(cFF[1].getOutput(), cReconstruct.getOutput(), getOutput(), iWindow, true, 0, 0, 0, 1)) return false; //--- return true; }
A propagação para frente está implementada, e passamos agora à construção dos métodos de retropropagação. Primeiro, criaremos o método de distribuição de gradiente de erro CNeuronFEDW::calcInputGradients:
bool CNeuronFEDW::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
No corpo do método, primeiro verificamos a validade do ponteiro para o objeto da camada anterior passado como parâmetro. Afinal, na ausência dele, as operações do método perdem sentido.
Como você deve lembrar, no método de inicialização da classe, realizamos a substituição dos buffers de dados de gradiente de erro. Agora podemos trabalhar diretamente com o bloco FeedForward.
if(!cFF[0].calcHiddenGradients(cFF[1].AsObject())) return false; if(!cReconstruct.calcHiddenGradients(cFF[0].AsObject())) return false;
Assim como no fluxo de dados da propagação para frente, na retropropagação também distribuímos o gradiente de erro por dois fluxos de dados paralelos. E nesta etapa, somamos o gradiente de erro de ambos os fluxos.
if(!SumAndNormilize(Gradient, cReconstruct.getGradient(), cReconstruct.getGradient(), iWindow, false)) return false;
Depois, devemos passar o gradiente de erro pela operação de convolução inversa. Obviamente, esta é uma operação comum de convolução. Mas temos um problema: O método de propagação para frente da camada convolucional não trabalha com buffers de gradiente de erro. Desta vez, vamos usar um pequeno truque — substituímos temporariamente os buffers de resultados dos layers pelos buffers de seus gradientes. Para isso, cuidadosamente salvamos os ponteiros para os buffers de dados que serão substituídos:
CBufferFloat *temp_r = cReconstruct.getOutput(); if(!cReconstruct.SetOutput(cReconstruct.getGradient(), false)) return false; CBufferFloat *temp_w = cWavlets.getOutput(); if(!cWavlets.SetOutput(cSoftMax.getGradient(), false)) return false;
Realizamos a propagação para frente da camada convolucional:
if(!cWavlets.FeedForward(cReconstruct.AsObject())) return false;
E restauramos os buffers de dados para seu estado original:
if(!cWavlets.SetOutput(temp_w, false)) return false; if(!cReconstruct.SetOutput(temp_r, false)) return false;
Depois, passamos o gradiente de erro para a camada anterior:
if(!cNorm.calcHiddenGradients(cSoftMax.AsObject())) return false; if(!cWavlets.calcHiddenGradients(cNorm.AsObject())) return false; if(!NeuronOCL.calcHiddenGradients(cWavlets.AsObject())) return false;
E somamos o gradiente de erro dos dois fluxos de dados:
if(!SumAndNormilize(NeuronOCL.getGradient(), cReconstruct.getGradient(), NeuronOCL.getGradient(), iWindow, false)) return false; //--- return true; }
Não nos esqueçamos de controlar a execução de todas as operações. Depois disso, concluímos o método.
Após a distribuição do gradiente de erro para todos os elementos de nosso modelo, segue-se a otimização dos parâmetros treináveis do modelo. A funcionalidade de otimização dos parâmetros deste objeto é implementada no método CNeuronFEDW::updateInputWeights. O algoritmo do método é bastante simples: apenas chamamos os métodos com o mesmo nome dos objetos aninhados e verificamos o resultado das operações pelo resultado lógico do funcionamento dos métodos chamados.
bool CNeuronFEDW::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cFF[0].UpdateInputWeights(cReconstruct.AsObject())) return false; if(!cFF[1].UpdateInputWeights(cFF[0].AsObject())) return false; if(!cNorm.UpdateInputWeights(cWavlets.AsObject())) return false; //--- return true; }
Observe que, neste método, trabalhamos apenas com aqueles objetos que contêm parâmetros treináveis.
Com isso, concluímos a análise dos algoritmos de construção dos métodos das novas classes. O código completo das classes e métodos analisados pode ser encontrado no anexo. Lá você também encontrará o código completo de todos os programas utilizados na preparação deste artigo.
Vale ressaltar que criamos apenas nossa própria visão do Codificador de estado do algoritmo FEDformer proposto. No entanto, deixamos de lado o Decodificador. Essa foi uma decisão consciente, relacionada à abordagem fundamental da tarefa de criar uma estratégia de trading lucrativa. O fato é que, por mais estranho que possa parecer, não buscamos prever com a maior precisão possível os estados futuros do ambiente. Isso porque eles influenciam de forma indireta o funcionamento do nosso Agente. Se estivéssemos construindo um algoritmo preciso com regras para o estado futuro, precisaríamos de uma previsão extremamente exata do movimento de preços futuro. Porém, nossa abordagem para a política do Agente é diferente.
Treinamos o Codificador para prever os estados futuros do ambiente para obter um estado oculto do Codificador o mais informativo possível. O Ator, por sua vez, extrai o estado oculto do Codificador, que, na verdade, é parte integrante do Ator e desempenha a função de analisar o estado atual do ambiente. E, com base na análise realizada do estado atual do ambiente pelo Ator, ele constrói sua política de comportamento.
Existe uma linha tênue aqui que precisamos entender. E é por isso que não gastamos recursos excessivos na decomposição do estado oculto do Codificador para obter a previsão mais precisa dos estados futuros do ambiente.
2.3 Arquitetura dos modelos
Após construir os objetos que são os "blocos de construção" do nosso modelo, passamos à descrição da arquitetura completa dos modelos treináveis. Devo dizer que, neste trabalho, decidi combinar abordagens que parecem completamente distintas, ou até concorrentes. Até mesmo concorrentes. Decidi utilizar a abordagem proposta de decomposição wavelet da série temporal como processamento primário dos dados antes de aplicar o método TiDE, discutido no artigo anterior. Como resultado, houve alterações na arquitetura do Codificador do estado do ambiente, que está implementada no método CreateEncoderDescriptions.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
No corpo do método, como de costume, primeiro verificamos a validade do ponteiro obtido para o array dinâmico para registrar a arquitetura do modelo e, se necessário, criamos uma nova instância do objeto.
Para obter os dados de entrada, utilizamos um objeto da camada neural totalmente conectada básica.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
O modelo, como sempre, recebe os dados "brutos" iniciais, e o processamento primário deles é realizado na camada de normalização em lote dos dados:
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 10000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, transpomos os dados iniciais para que, nas operações subsequentes, seja realizada uma análise independente das sequências unitárias dos indicadores usados:
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; }
Depois, utilizamos um bloco de 10 camadas FED-w:
//--- layer 3-12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFEDW; descr.count = BarDescr; descr.window = HistoryBars; descr.activation = None; for(int i = 0; i < 10; i++) if(!encoder.Add(descr)) { delete descr; return false; }
Logo após o bloco, inserimos um Codificador totalmente conectado para séries temporais:
//--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTiDEOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.window_out = NForecast; descr.step = 4; { int windows[] = {HistoryBars, 2 * EmbeddingSize, EmbeddingSize, 2 * EmbeddingSize, NForecast}; if(ArrayCopy(descr.windows, windows) <= 0) return false; } descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, assim como anteriormente, é utilizada uma camada convolucional para correção do desvio dos valores previstos:
//--- layer 14 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = NForecast; descr.step = NForecast; descr.window_out = NForecast; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Transpomos os valores previstos para a representação dos dados iniciais:
//--- layer 15 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
E retornamos os parâmetros estatísticos da sequência temporal original:
//--- layer 16 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Como se pode notar, as mudanças afetaram apenas a arquitetura interna do Codificador. Portanto, basta apenas alterar o ponteiro para a camada de estado latente do Codificador para extrair os dados. A arquitetura do Ator e do Crítico permanece inalterada.
#define LatentLayer 14
Além disso, não há necessidade de fazer alterações nem nos EAs de interação com o ambiente, nem nos EAs de treinamento das modelos. O código completo deles está no anexo, e a descrição dos algoritmos pode ser encontrada no artigo anterior.
3. Testes
Neste artigo, conhecemos o método FEDformer, que traduz a análise de séries temporais para o domínio das características de frequência. Um método bastante interessante e promissor. E realizamos um trabalho significativo na implementação dos métodos propostos com os recursos do MQL5.
Gostaria de destacar mais uma vez que este artigo apresenta nossa própria visão da implementação dos métodos propostos, que difere significativamente da descrição do método apresentada no artigo original. Portanto, as conclusões feitas com base nos resultados do teste do modelo se referem apenas a esta implementação e não podem ser extrapoladas integralmente para o método original.
Como mencionado anteriormente, as mudanças afetaram apenas a arquitetura interna do Codificador. Isso significa que podemos usar os conjuntos de treinamento previamente coletados para treinar as modelos.
Lembro que, para o treinamento offline das modelos, usamos trajetórias previamente coletadas de interação com o ambiente. A coleta de dados foi realizada com base em dados históricos reais de todo o ano de 2023. O ativo utilizado foi EURUSD, e o intervalo de tempo foi H1. O teste do modelo treinada é realizado no testador de estratégias do MetaTrader 5 com dados históricos de janeiro de 2024.
Na primeira etapa, treinamos o Codificador do estado do ambiente minimizando o erro entre os valores reais de descrição dos estados futuros do ambiente e seus valores previstos. No Codificador, apenas os estados do ambiente que não dependem das ações do Agente são analisados e previstos. Portanto, realizamos o treinamento completo do Codificador sem atualizar o conjunto de treinamento.
Na minha opinião subjetiva, nesta etapa, a qualidade da previsão dos estados futuros do ambiente melhorou. Isso é evidenciado pela redução do erro durante o processo de treinamento. No entanto, não fiz uma comparação gráfica entre os valores reais e previstos para uma análise detalhada da qualidade deles.
Na segunda etapa iterativa, realizamos o treinamento da política do Ator, que ocorre paralelamente ao modelo do Crítico, o qual fornece a avaliação provável das ações do Ator. Nesta etapa, é fundamental garantir a precisão na avaliação das ações do Ator. Por isso, alternamos o processo de treinamento das modelos com a atualização dos dados do conjunto de treinamento, levando em consideração a política atual do Ator.
Após uma série de iterações indicadas, consegui treinar a política de comportamento do Ator para gerar lucro tanto no intervalo de tempo de treinamento quanto no intervalo de tempo de teste. Os resultados dos testes estão apresentados abaixo.

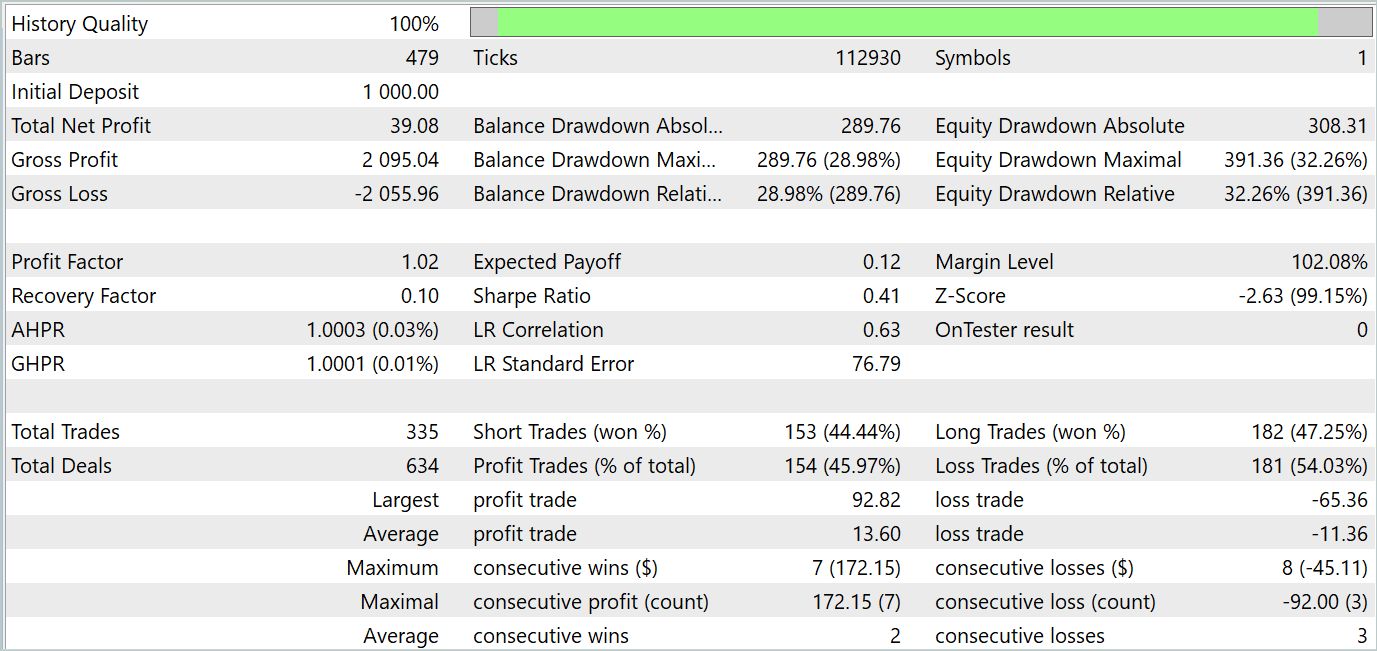
Como se pode observar, o gráfico de saldo mantém uma tendência geral de crescimento. No entanto, é possível identificar claramente quatro tendências no gráfico: duas lucrativas e duas com prejuízo. O ponto positivo é que as tendências lucrativas têm um potencial maior. Isso permite acumular lucro suficiente para evitar a perda do depósito durante os períodos de perda. No entanto, há um equilíbrio delicado sendo mantido. Durante o período de teste, o fator de lucro foi de apenas 1,02, e a porcentagem de operações lucrativas ficou ligeiramente abaixo de 46%.
Em geral, o modelo demonstra potencial, mas ainda é necessário trabalho adicional para minimizar os períodos de perda.
Considerações finais
Neste artigo, conhecemos o método FEDformer, que foi proposto para previsão de longo prazo de séries temporais. O método sugere um mecanismo de atenção com aproximação de baixa ordem por frequência e decomposição mista para lidar com o deslocamento da distribuição.
Na parte prática, implementamos nossa visão dos métodos propostos utilizando MQL5. Treinamos e testamos o modelo com base em dados históricos reais. Os resultados dos testes demonstram o potencial do modelo discutido. No entanto, há aspectos que exigem maior atenção.
Referências
- FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | EA | EA para coleta de exemplos usando o método Real-ORL |
| 3 | Study.mq5 | EA | EA para treinamento das modelos |
| 4 | StudyEncoder.mq5 | EA | EA para treinamento do codificador |
| 5 | Test.mq5 | EA | EA para teste do modelo |
| 6 | Trajectory.mqh | Biblioteca de classe | Estrutura para descrever o estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código para o programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14858
 Está chegando o novo MetaTrader 5 e MQL5
Está chegando o novo MetaTrader 5 e MQL5
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso