
Do básico ao intermediário: Array e String (III)

Introdução
O conteúdo exposto aqui, visa e tem como objetivo, pura e simplesmente a didática. De modo algum deve ser encarado como uma aplicação final, onde o objetivo não seja o estudo dos conceitos aqui mostrados.
No artigo anterior Do básico ao intermediário: Array e Strings (II), demonstrei de uma maneira bastante simples e de fácil compreensão, como você já conseguiria aplicar o conhecimento mostrado até aquele momento. Isto a fim de conseguir criar dois tipos de soluções bastante simples e que muitos imaginam ser necessário bem mais conhecimento para tal coisa. Porém, tudo que foi visto e implementado naquele artigo, de fato, pode ser feito por qualquer iniciante em programação. Desde é claro ele utilize de um pouco de criatividade e aplique os conceitos mostrados até aquele momento.
Porém, apesar do que foi mostrado ali, de fato funcionar, e sendo perfeitamente possível ser criado sem muitas dificuldades. Existe um pequeno detalhe que pode travar muitos iniciantes. E este detalhe tem tudo a ver com a aplicação mostrada justamente naquele artigo.
Muitos de vocês, devem ter ficado imaginando: Como foi possível gerar uma senha a partir de dois textos, ou frases, aparentemente simples? Não consegui captar o motivo de tal coisa funcionar. Apesar de ter conseguido acompanhar a ideia e compreender o código. Aquele tipo de coisa para mim não fez o menor sentido. De fato, meu caro leitor, existem coisas na programação, ou melhor dizendo, coisas que são feitas pelos programadores, que não fazem muito sentido, quando outras pessoas que não são programadoras a observam. Uma destas coisas é justamente o que foi feito naquele artigo. Onde fizemos uma manipulação de texto, utilizando uma matemática muito simples e básica.
Como aquele tipo de coisa e conceito, é muito utilizado em diversas atividades de programação. Acho valido explicar em mais detalhes, o porquê de aquilo funcionar. Com toda certeza isto irá lhe ajudar a começar a pensar como um programador. E não mais como um mero usuário. Então, muito provavelmente o tema deste artigo, que seria ARRAYS, será levemente adiado. Mas ainda assim, iremos tratar de array neste artigo. Mas de uma forma mais simples. Então vamos iniciar o primeiro tópico, para entender por que aquilo que foi visto no artigo anterior funciona.
Traduzindo valores
Uma das tarefas mais comuns em programação, é a tradução e tratamento de informações ou banco de dados. Programação tem tudo a ver com isto. Se você está pensando em aprender como programar, mas não entende. Ou ainda não compreendeu, que o objetivo de uma aplicação, é criar dados que o computador consiga compreender. E depois traduzir estes valores em uma informação que humanos compreendem. Você está seguindo um caminho totalmente errado. É melhor parar e começar tudo a partir do zero. Pois de fato, programação é totalmente baseada neste simples princípio. Temos uma informação e precisamos fazer com que o computador consiga compreender esta informação. Depois que o computador gerar um resultado, precisamos traduzir este mesmo resultado para algo que consigamos compreender.
Computadores são muitos bons para trabalhar com zeros e uns. Mas são completamente inúteis se precisar trabalhar com qualquer outro tipo de informação. A mesma coisa acontece com os humanos. Eles são horríveis em entender o que um monte de zeros e uns significam. Porém conseguem compreender perfeitamente o significado de uma palavra, ou gráfico.
Agora, podemos falar de maneira mais simples, sobre algumas coisas. No início da era da informática, os primeiros processadores tinham em se OpCode, que é um set de instruções. Códigos para trabalhar com valores decimais. Sim, meu caro leitor, os primeiros processadores conseguiam entender o que era um 8 ou um 5. Estas instruções faziam parte do chamado set BCD. Já que permitiam os processadores usarem números que para nos humanos faziam sentido. Porém usando uma lógica binárias. No entanto, com o passar do tempo, estas instruções BCD, caíram em desuso. Já que era muito mais complicado, ensinar, ou melhor dizendo, criar um circuito, capaz de fazer cálculos decimais do que fazer os cálculos em binário e depois converter em decimal. Assim sendo, passou a ser responsabilidade do programador, criar e efetuar está tradução. Tanto que no início, existia uma verdadeira salada de frutas, quando o assunto era ponto flutuante. Mas isto irá ser explicado em um outro momento. Já que com as atuais ferramentas que formam mostradas e explicadas até este momento, não seria possível explicar como o sistema de ponto flutuante funciona. Preciso explicar mais alguns conceitos antes de explicar como o ponto flutuante funciona.
Um detalhe importante: Este sistema BCD ainda é utilizado, mas não como você possa estar imaginando. Em um próximo artigo, iremos brincar com algo relacionado a este sistema BCD.
Mas vamos voltar a nossa questão. Assim começou a surgir as primeiras bibliotecas de tradução, entre valores decimais, para valores binários. E de valores binários para valores decimais. Podendo inclusive ser utilizado outras bases, como a hexadecimal e a octal, que são as mais comuns. Porém voltadas para aplicações mais especificas.
Ok. Neste ponto chegamos ao que foi visto nos artigos anteriores. Onde mostrei que no MQL5 existem funções que nos permitem fazer esta tradução. E em todos os casos a transformação, se dá tendo como base uma string. Seja ela de entrada, seja ela de saída. Esta string é a informação que humanos compreendem. Já a parte binária é enviada para o computador processar. No entanto, apesar de tais bibliotecas funcionarem muito bem, e serem bastante práticas. As mesmas ocultam grande parte do conhecimento sobre como manipular de fato os dados. Por conta disto, cursos que ensinam certas linguagens, não criam de fato programadores. Mas criam apenas pessoas que se imaginam programadores. Porém não sabem como as coisas funcionam por debaixo dos panos.
Como o MQL5, nos dá alguma liberdade de criação. Podemos, mesmo tendo como objetivo apenas a didática. Criar algo parecido com o que seria uma destas bibliotecas. Porém vale ressaltar o seguinte ponto: Uma biblioteca criada sem o uso de uma linguagem de baixo nível, não será mais rápida ou eficaz que a biblioteca padrão da linguagem. E quando digo linguagem de baixo nível, estou me referindo a programar em C ou C++. E como estas duas linguagens, conseguem criar um código que se a próxima muito do Assembly puro. Nada será mais rápido do que elas. Então o que será visto aqui, tem como objetivo apenas a didática.
Beleza. Tendo dado está explicação inicial. Vamos criar um pequeno tradutor. E com o conhecimento visto até este ponto. Fazer isto será uma tarefa bastante simples. Neste tradutor, primeiramente iremos transformar valores binários em um valor hexadecimal ou octal. Já que estes são mais simples de se fazer a tradução. Não exigindo muitas operações para isto. Desta forma, vamos usar o código visto na sequência, como sendo um ponto de partida.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64i\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. } 15. //+------------------------------------------------------------------+
Código 01
Quando executamos este código 01. Será gerado no terminal, o que você pode ver na imagem 01. Observe quais foram os especificadores de formatos usados aqui. Se forem usados outros, a resposta será diferente do que você pode notar nesta imagem 01. Experimente isto depois para entender melhor como este tipo de coisa funciona.
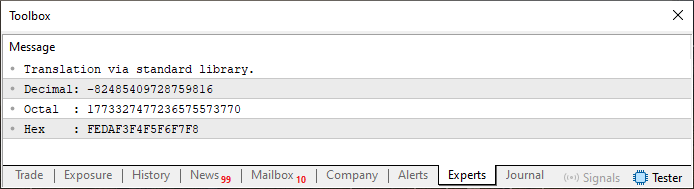
Imagem 01
Note que isto é bem simples, prático e direto. Mas como a biblioteca padrão consegue fazer isto? Bem esta é a mágica que iremos ver agora como fazer meu caro leitor. Mas antes é preciso que você entenda uma outra coisa que é a formatação da informação que será mostrada. E sim, existe uma formatação por de trás destas informações. Para tornar as coisas mais simples e não as complicar neste momento. Quero que você procure uma tabela a WEB. Esta tabela, que é muito fácil de ser encontrada, é conhecida como tabela ASCII. Para facilitar abaixo, mostro um exemplar desta tabela. Existem outros com mais informações. Mas este que é visto na imagem 02 já será o suficiente para entender o que iremos fazer.
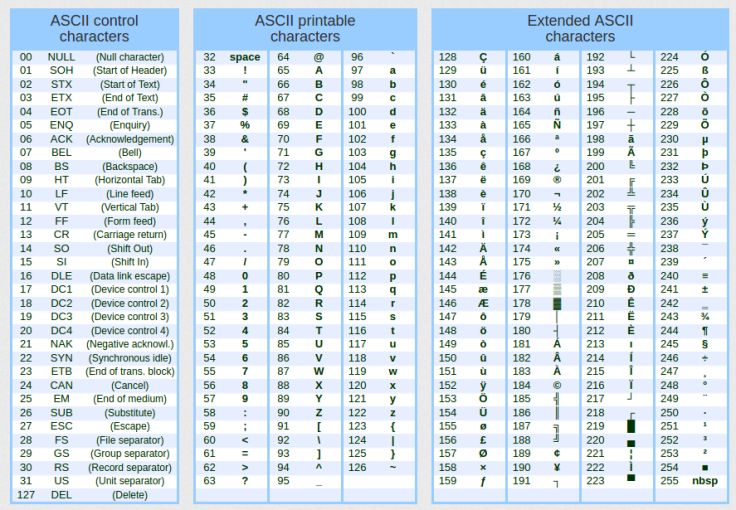
Imagem 02
A tabela que nos interessa é a de caracteres imprimíveis. Ou seja, a que é vista na parte central desta imagem 02. A parte esquerda são caracteres especiais. Já a parte da direita, vária de tabela para tabela. Podendo inclusive ser criada por nossa aplicação. Não neste caso do MQL5, já que para criar esta tabela da direita, é necessário acesso a certas partes do hardware, coisa que não é permitida pelo MQL5, e não é acessível por grande parte das linguagens. Basicamente, este tipo de coisa é feito por quem programa em linguagens de baixo nível, como C ou C++. Porém estou falando isto, apenas para que você saiba, que pode haver diferenças nas figuras vista no lado direito da imagem.
Ok. Mas por que esta tabela ASCII é tão importante para nós, aqui no MQL5? Esta tabela, não é somente importante aqui. Mas é importante para qualquer um que queira manipular dados. Existem outras tabelas, como valores diferentes e símbolos diferentes, como por exemplo a tabela UTF 8, a tabela UTF 16, a tabela ISO 8859 e daí por diante. Cada uma serve para um propósito. Mas aqui no MQL5, normalmente podemos usar a tabela ASCII. Salvo certos casos em que precisaremos de outras tabelas. Mas isto ficará para ser explicado em outro momento no futuro.
Muito bem, meu caro leitor. Agora para que possamos traduzir as informações preciso que você entenda uma coisa. Vamos olhar para a imagem 02. Para podemos traduzir um valor binário, para um valor hexadecimal. Precisamos usar os dígitos de zero a nove, e as letras de A até F. Olhando na tabela, podemos ver que o digito zero é o número 48. Deste ponto em diante, cada número que avançamos corresponde a um digito. Por exemplo, se avançarmos seis posições, o que seria o digito seis, usaremos o valor 54. Entendeu? Bem, a mesma coisa acontece com as letras. Como a letra A, maiúscula, tem o valor de 65. Já temos um ponto de partida. Porém você precisa lembrar que a letra A em hexadecimal indica o valor dez e assim por diante. Sendo que a letra F seria o valor 15. Basicamente é bem simples e prático. O único cuidado a ser tomado neste caso é que entre o digito 9 e a letra A temos alguns símbolos que precisam ser pulados. Isto para evitar que a string hexadecimal, venha a ficar com símbolos estranhos nela. Isto se desejarmos efetuar um acesso direto a tabela ASCII. Porém, apesar de isto ser possível, para nosso objetivo aqui, iremos usar algo um pouco diferente. Isto por que o objetivo aqui, é explicar por que aquele código visto no artigo anterior funciona. Então sendo assim, e para alcançar o objetivo pretendido. Vejamos o código que será utilizado. Este pode ser observado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64i\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s", 18. ValueToString(value, 0), 19. ValueToString(value, 1), 20. ValueToString(value, 2) 21. ); 22. } 23. //+------------------------------------------------------------------+ 24. string ValueToString(ulong arg, char format) 25. { 26. const string szChars = "0123456789ABCDEF"; 27. string sz0 = ""; 28. 29. while (arg) 30. { 31. switch (format) 32. { 33. case 0: 34. arg = 0; 35. break; 36. case 1: 37. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 38. arg >>= 3; 39. break; 40. case 2: 41. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 42. arg >>= 4; 43. break; 44. default: 45. return "Format not implemented."; 46. } 47. } 48. 49. return sz0; 50. } 51. //+------------------------------------------------------------------+
Código 02
Ao executarmos este código 02, o resultado visto no terminal é mostrado logo abaixo.
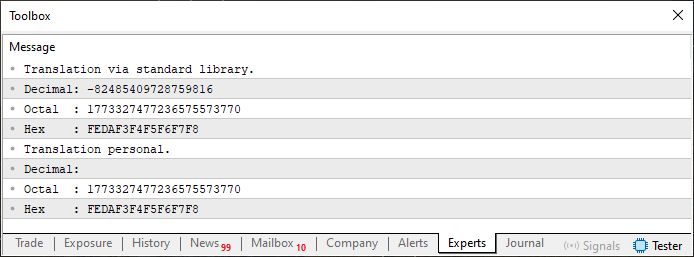
Imagem 03
Como grande parte deste código é fácil de ser compreendido por quem vem acompanhando e estudando o conteúdo dos artigos. Irei dar destaque somente ao que está ocorrendo nas linhas 37 e 41. Isto por conta da questão onde utilizamos um operador AND para isolar alguns bits. Parece ser algo complicado, mas é bem mais simples do que parece. Vamos pensar somente no caso da linha 37. Sabemos que um valor octal, terá apenas dígitos. E estes dígitos irão se zero até sete. Agora em binário este valor sete é representado da seguinte forma 111. Ou seja, se fizermos uma operação AND bit a bit com qualquer valor, teremos um valor que irá de zero até sete. A mesma coisa acontece na linha 41. Só que ali, teremos um valor que irá de zero até quinze. Agora olhe para a linha 26. Ali temos os caracteres que serão utilizados quando a informação estiver sendo criada. Como em MQL5, uma string é um tipo de array especial. Ao acessarmos à string contida na linha 26, da forma como está sendo feita nas linhas 37 e 41. Estaremos na verdade, procurando UM e somente UM daqueles caracteres presentes na string. Então de fato, neste momento, a string, NÃO ESTARÁ SENDO ACESSADA como uma string, e sim, como um array.
Por conta de algumas questões, a contagem dos elementos sempre se inicia em zero. Mas este zero, NÃO REPRESENTA o tamanho da string. Mas sim o primeiro caractere visto ali. Se não existir nenhum, o comprimento da string será de zero. Se existir algum, ele será maior que zero. Porém isto não muda o fato de que a contagem iria iniciar em zero.
Sei, que no primeiro momento, isto parece muito confuso e totalmente sem lógica. Mas conforme você for se familiarizando com o uso de arrays. Este tipo de coisa passará a ser cada vez mais natural para você meu caro leitor.
Mas existe um ponto ainda faltando para ser implementado neste código 02. Este ponto é justamente o que se refere aos valores decimais. Para resolver a questão dos valores decimais, de maneira correta. Precisamos usar um recurso do qual ainda não expliquei, como trabalhar com ele. Porém, para não lhe deixar na mão e sem a devida explicação. Vamos fazer uma pequena suposição aqui. Isto por que não faz sentido complicar o código de maneira inútil apenas para assegurar a correta representação dos dados. Mesmo por que, da forma como ele está implementado. Faltando um recurso que ainda será explicado. Já poderemos converter qualquer valor do tipo inteiro, até a largura de 64 bits. Isto de maneira quase 100% correta. Porém quando este tal recurso, que é a criação de template e typename, for explicado. Poderemos converter qualquer valor sem dores de cabeça. Até lá vamos focar apenas nas questões mais simples.
Então observe que o tipo declarado na linha seis, é um tipo, inteiro com sinal. Por conta disto, teríamos de checar se o tipo pode ou não ser negativo. Mas para não complicar as coisas sem necessidade, vamos supor que todo e qualquer valor será sempre um inteiro sem sinal. Ou seja, não será possível representar valores negativos. Com esta suposição, sendo imposta no nosso código. Podemos mudar ele a fim de verificar se de fato, conseguimos ver os valores corretamente. Isto é feito usando o código implementado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64u\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. } 25. //+------------------------------------------------------------------+ 26. string ValueToString(ulong arg, char format) 27. { 28. const string szChars = "0123456789ABCDEF"; 29. string sz0 = ""; 30. 31. while (arg) 32. switch (format) 33. { 34. case 0: 35. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 36. arg /= 10; 37. break; 38. case 1: 39. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 40. arg >>= 3; 41. break; 42. case 2: 43. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 44. arg >>= 4; 45. break; 46. case 3: 47. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 48. arg >>= 1; 49. break; 50. default: 51. return "Format not implemented."; 52. } 53. 54. return sz0; 55. } 56. //+------------------------------------------------------------------+
Código 03
Como bônus extra. Neste código 03 adicionei também a conversão do valor para sua representação binária. Note que é tão simples quanto nos demais casos. De qualquer maneira, quando executado, o resultado deste código 03 é mostrado logo abaixo.
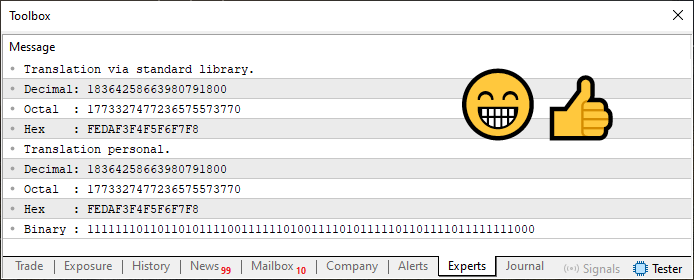
Imagem 04
Agora meu caro leitor, preste muita atenção a uma coisa que está ocorrendo aqui. Talvez seja a coisa mais importante que será dita e mostrada neste artigo. Entre este código 03 e o código 02 quase não existe diferença. Porém se você olhar a imagem 03 e a comparar com a imagem 04 irá notar algo diferente ali.
A diferença está no valor da tradução via biblioteca padrão. Observe o valor DECIMAL. Perceba que ele é diferente. Porém isto não faz sentido. Já a linha seis, tanto do código 03 quanto do código 04 são exatamente iguais. Então onde está a diferença, que fez com que o valor fosse impresso de maneira totalmente distinta, do que era imaginado. Bem, meu caro leitor, a diferença está justamente na linha nove. Observe com muita atenção esta linha nove, no código 03 e depois no código 04. O simples fato, desta mínima diferença faz com que o valor que pela declaração de tipo na linha seis, deveria ser negativo. Passou a ser positivo. Existe uma forma de resolver este tipo de falha. Mas como foi dito. É necessário explicar como utilizar um outro recurso que ainda não foi explicado.
Até lá tome cuidado quando for imprimir valores no terminal. Isto por que, qualquer descuido que por ventura venha a ocorrer, você pode ser levado a cometer um erro de interpretação dos valores calculados. Por isto é importante estudar e praticar o que está sendo mostrado. Não ache que apenas ler a documentação, ou estes artigos será suficiente para lhe tornar um programador de qualidade. É preciso sim praticar e estudar tudo que está sendo mostrado.
Muito bem, apesar deste pequeno detalhe está ocorrendo. Você pode observar que a tradução do valor em sua representação decimal está rigorosamente correta. E note que o cálculo necessário para fazer a conversão é bem simples. Ali na linha 35, usamos aquele símbolo de porcentagem %, para obter o resto da divisão por 10. Este resto, aponta qual deverá ser o símbolo utilizado. Isto entre os presentes em szChars. Logo depois de ter feito isto, na linha 36, pegamos e dizemos qual o novo valor de arg. Para isto, apenas dividimos arg por 10. O resultado é o valor que será utilizado depois. E assim vamos conseguindo transformar um valor binário em um valor legível por um humano.
Com base nesta explicação, acredito que aqueles códigos vistos no artigo anterior, agora de fato poderão ser bem compreendidos. No entanto, podemos melhorar as coisas um pouco mais, além daquilo que foi mostrado no artigo anterior. E para isto, iremos utilizar o último código mostrado naquele artigo. Ou seja, o código que utilizava arrays de maneira mais direta. Porém para fazer isto de maneira adequada, vamos a um novo tópico.
Configurando a largura do password
Ok, para começarmos a falar de algo que podemos fazer no código 06, visto no artigo anterior. Precisamos primeiro ver este código sendo mostrado aqui. Então vamos replicar ele logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg) 12. { 13. const string szCodePhrase = "The quick brown fox jumps over the lazy dog"; 14. 15. uchar psw[], 16. pos; 17. 18. ArrayResize(psw, StringLen(szArg)); 19. for (int c = 0; szArg[c]; c++) 20. { 21. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 22. psw[c] = (uchar)szCodePhrase[pos]; 23. } 24. return CharArrayToString(psw); 25. } 26. //+------------------------------------------------------------------+
Código 04
Agora vamos a uma rápida explicação aqui. Começando pelo seguinte fato. Existem dois tipos de array que podemos utilizar. Um que seria um array estático e o outro que seria um array dinâmico. O que faz um array ser do tipo estático ou dinâmico é a forma como ele é declarado. Esta questão se o array é estático ou dinâmico, nada tem a ver com usar ou não a palavra reservada static na declaração. Como esta questão é muito complicada para ser explicada assim, de supetão. E não quero dar uma explicação meia boca. Vou dar uma leve resumida só para que você entenda o código 04.
Uma array dinâmico, é declarado como mostrado na linha 15. Note que ali temos o nome da variável, que no caso é psw, e logo depois um abre e fecha colchetes. Sem nenhum tipo de informação dentro destes colchetes. Isto é um array dinâmico. E sendo um array dinâmico, podemos em tempo de execução dizer qual deve ser o tamanho do mesmo. Na verdade, precisamos fazer isto. Já que tentar acessar qualquer posição em um array dinâmico NÃO ALOCADO é considerado um erro. E faz com que seu código seja encerrado imediatamente. Por conta deste fato, temos na linha 18, o local onde alocamos memória suficiente para armazenar dados no array.
Lembre-se, uma string é um array especial. E uma string, desde que não seja constante, é um array dinâmico, que não precisamos alocar memória para ela. O próprio compilador adiciona as rotinas necessárias para que isto seja feito. Sem a nossa intervenção direta. Mas como aqui, não estamos usando uma string, e sim um array puro e simples. Precisamos dizer quanto de memória queremos, ou precisamos. E é neste ponto que mora um pequeno segredo.
Se durante a execução desta linha 18, do código 04, informarmos qual o tamanho do password que queremos criar. Podemos limitar as coisas de maneira bem interessante. E ao mesmo tempo trabalhar melhor em cima do password que deverá ser criado. Com isto, já nos vem mente, a necessidade de algumas pequenas mudanças neste código 04. Estas mudanças podem ser vistas logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = "The quick brown fox jumps over the lazy dog"; 14. 15. uchar psw[], 16. pos; 17. 18. ArrayResize(psw, SizePsw); 19. for (int c = 0; szArg[c]; c++) 20. { 21. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 22. psw[c] = (uchar)szCodePhrase[pos]; 23. } 24. return CharArrayToString(psw); 25. } 26. //+------------------------------------------------------------------+
Código 05
Agora muita atenção ao seguinte fato. Na linha oito do código 05, estamos passando um novo argumento para a função da linha 11. Este mesmo argumento está sendo utilizado na linha 18 para dizer quantos caracteres o password irá conter. No caso oito caracteres. Porém se você tentar executar este código 05, o mesmo irá falhar, e o motivo é a linha 22. Isto por que, na linha seis estamos criando uma frase secreta que contém mais de oito caracteres presentes. E como o laço da linha 19 irá ser encerrado somente quando um símbolo NULL for encontrado na string szArg, que no caso é exatamente a string declarada na linha seis. Na linha 22, estaremos tentando acessar uma posição não válida de memória. E como isto é um erro. O código irá falhar.
Porém isto não é de fato um problema aqui. Tudo que precisamos fazer e escolher se queremos usar toda a frase definida na linha seis, ou se queremos usar apenas parte da frase, a fim de completar os oito caracteres que desejamos. Em cada uma destas decisões, teremos um direcionamento levemente diferente no que será o código final. Por isto é bom aprender como programar as coisas. Pois uma solução proposta por um programador, pode não ser a preferida por outro programador. Mas conversando a gente se entende. Porém sem saber programar, você não conseguiria implementar a melhor solução para você. Ficando assim completamente dependente da decisão que alguém irá tomar para você.
Ok, então vamos fazer a seguinte escolha: Vamos utilizar toda a frase secreta. Mas ao mesmo tempo, vamos modificar a string da linha 13, para uma outra vista no artigo anterior. Assim teremos algo um pouco mais interessante.
No entanto, antes de realmente criamos o código, quero que você volte a imagem 02, presente no tópico anterior e observe cada um dos valores presentes naquela tabela e que fazem parte da string declarada na linha seis. Você por um acaso consegue notar algo de interessante nestes dados? Não, sim, talvez? A questão aqui é que quando decidimos usar toda a frase declarada na linha seis, teremos que utilizar algum outro artificio aqui. Isto por que, se a mudança for feita conforme mostrado no código logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. for (int c = 0; szArg[c]; c++) 21. { 22. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] = (uchar)szCodePhrase[pos]; 24. i = (i == SizePsw ? 0 : i); 25. } 26. return CharArrayToString(psw); 27. } 28. //+------------------------------------------------------------------+
Código 06
Não estaremos de fato usando toda a frase, mas somente parte dela. Na verdade, apenas os oito últimos caracteres presentes na frase secreta, que foi definida na linha seis. Isto pode ser comprovado se você executar o código 06 e comparar os resultados com o que é visto no artigo anterior. Onde estamos usando a mesma frase código visto aqui no código 06.
Porém, mesmo sem de fato executar este código 06, você o analisando, conseguirá perceber que apesar da linha 23, não mais fazer o código falhar. Ela terá pouco efeito. Já que a linha 24 estará nos forçando a sempre renovar o valor do password. Na exata posição definida como limite do password. Por isto, mesmo que a frase da linha seis contenha todos aqueles caracteres. No final, seria como se apenas oito deles de fato existissem. E isto nós causa, uma falsa sensação de segurança ao criarmos uma frase secreta. Agora, como sabemos com base na imagem 02, que cada símbolo é definido por um valor, podemos usar este array, para criar um somatório dos valores. Isto fará com que de fato, todos os símbolos sejam utilizados. Porém preste atenção a um detalhe aqui meu caro leitor. O maior valor que podemos colocar no array é definido pelo tipo usado no array. No próximo artigo irei detalhar isto de uma forma melhor. Mas por enquanto, podemos fazer mais algumas mudanças no código como mostrado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. return CharArrayToString(psw); 28. } 29. //+------------------------------------------------------------------+
Código 07
Agora sim, temos algo que utiliza toda a frase secreta. Observe que foi necessário mudar muito pouco o código. Entre as mudanças está o fato de que na linha 20, estamos dizendo para que o array seja inicializado com um determinado valor. No caso o valor é zero. Você pode dizer, caso queira, qual será o valor inicial. Isto irá fazer diferença depois. Principalmente se você tiver uma frase secreta que utiliza o mesmo símbolo mais de uma vez. Para este tipo de problema existem diversos métodos diferentes de se evitar que um mesmo símbolo, atribuía um mesmo valor para diferentes posições. No próximo artigo iremos falar mais sobre isto. Mas a questão aqui é justamente a linha 24. Agora estamos somando os valores, e com isto, utilizando completamente ambas as frases. Porém existe um problema aqui. Este é observado quando executamos o código.
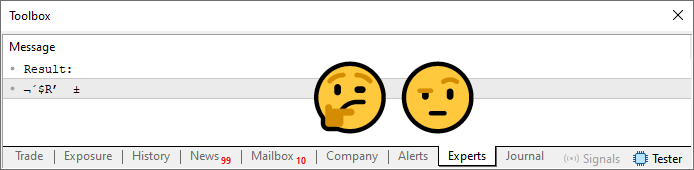
Imagem 05
E então, como você poderá utilizar este password? Difícil não é mesmo. Porém o que aconteceu aqui é que o array, está com os valores que foram calculados pela soma limitada. Precisamos fazer com que os valores que foram calculados apontem de fato para algum dos valores presentes na string declarada na linha 13. E para fazer isto, será necessário utilizarmos um outro laço. Assim o código resultado é mostrado logo na sequência.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. 28. for (uchar c = 0; c < SizePsw; c++) 29. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 30. 31. return CharArrayToString(psw); 32. } 33. //+------------------------------------------------------------------+
Código 08
Agora depois de passar pelo laço visto na linha 28 deste código 08, teremos algo que você pode observar logo abaixo.
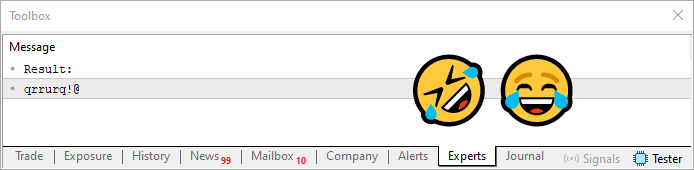
Imagem 06
Isto sim que eu posso chamar de uma feliz coincidência. Eu estava falando de um password que poderia ter caracteres repetidos. E como poderíamos resolver isto. E para nossa felicidade, aconteceu justamente do resultado vir a conter caracteres repetindo. É muita sorte mesmo. (RISOS).
Considerações finais
Neste artigo, foi mostrado de maneira parcial, como a acontece a tradução de valores binários em outros tipos de valores. Trabalhamos também, no que seria os primeiros passos a fim de conseguir compreender como uma string pode ser trabalhada como um array. Além disto, vimos como evitar um tipo de erro muito comum, quando usamos arrays no nosso código. Porém, o que foi visto aqui, acabou em uma feliz coincidência, que será melhor explicada no próximo artigo. Onde iremos entender como evitar coisas deste tipo venham a acontecer. Além disto, iremos nos aprofundar um pouco mais nesta questão sobre tipos de dados em arrays. Então até breve.
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso