
Ciência de Dados e Aprendizado de Máquina (Parte 15): SVM — uma ferramenta útil no arsenal do trader

Conteúdo:
- Introdução
- O que é um hiperplano?
- Método linear de vetores de suporte
- Método dual de vetores de suporte
- Margem rígida
- Margem suave
- Treinamento do modelo do método linear de vetores de suporte
- Previsões obtidas do modelo de vetor de suporte linear
- Treinamento e teste do modelo de vetor de suporte linear
- Coleta e normalização de dados
- Instância da classe DualSVMONNX. Inicialização da classe
- Treinamento do modelo Dual SVM em Python
- Transformação do modelo de vetor de suporte do sklearn para ONNX
- Pensamentos finais
Introdução
As máquinas de vetores de suporte (Support Vector Machine, SVM) são uma forma de aprendizado supervisionado usada em tarefas de classificação linear e não linear e regressão, e às vezes para detecção de valores atípicos.
Ao contrário dos métodos de classificação bayesiana e regressão logística, que usam modelos matemáticos simples para classificação de informações, SVM utiliza funções matemáticas sofisticadas de treinamento voltadas para encontrar o hiperplano ótimo que separa os dados em um espaço N-dimensional.
O algoritmo SVM é frequentemente usado para tarefas de classificação. Essas são as tarefas que abordaremos neste artigo.

O que é um hiperplano?
Um hiperplano é uma linha usada para separar pontos de dados de diferentes classes.
")
O hiperplano tem as seguintes propriedades:
Dimensão. Em tarefas de classificação binária, o hiperplano é um subespaço (d-1)-dimensional, onde d é a dimensão do espaço de características. Por exemplo, em um espaço bidimensional de características, o hiperplano é uma linha unidimensional.
Matematicamente, o hiperplano pode ser representado por uma equação linear do tipo:
![]()
![]() — vetor ortogonal ao hiperplano e que determina sua orientação.
— vetor ortogonal ao hiperplano e que determina sua orientação.
![]() — vetor de características.
— vetor de características.
b — termo escalar de deslocamento, que move o hiperplano a partir da origem.
Divisão. O hiperplano divide o espaço de características em dois semiespaços:
Área onde ![]() corresponde a uma classe.
corresponde a uma classe.
Área onde ![]() corresponde a outra classe.
corresponde a outra classe.
Margem. No SVM, o objetivo é encontrar um hiperplano que maximize o espaço entre o hiperplano e os pontos de dados mais próximos de qualquer classe. Esses pontos de dados mais próximos são chamados de "vetores de suporte". O SVM busca encontrar um hiperplano que forneça o maior espaço possível enquanto minimiza o erro de classificação.
Classificação. O hiperplano ideal encontrado pode ser usado para classificar novos pontos de dados. Calculando ![]() , pode-se determinar de que lado do hiperplano o ponto de dados está, e assim atribuí-lo a uma das duas classes.
, pode-se determinar de que lado do hiperplano o ponto de dados está, e assim atribuí-lo a uma das duas classes.
O conceito de hiperplano é um elemento chave das máquinas de vetores de suporte, pois forma a base do classificador de margem máxima. O objetivo do método de vetores de suporte é encontrar o hiperplano que melhor separa os dados, mantendo ao mesmo tempo a maior margem possível entre as classes, o que, por sua vez, aumenta a generalização do modelo e sua resistência a dados não vistos.
double CLinearSVM::hyperplane(vector &x) { return x.MatMul(W) - B; }
Como mencionado anteriormente, o termo de deslocamento, denotado por b, é um termo escalar, então tive que declarar uma variável dupla.
class CLinearSVM { protected: CMatrixutils matrix_utils; CMetrics metrics; CPreprocessing<vector, matrix> *normalize_x; vector W; //Weights vector double B; //bias term bool is_fitted_already; struct svm_config { uint batch_size; double alpha; double lambda; uint epochs; }; private: svm_config config;
Aqui, usamos a classe CLinearSVM. Neste artigo, vamos considerar duas versões do método de vetores de suporte — linear e dual.
Método linear de vetores de suporte
O SVM linear é um tipo de vetor de suporte que utiliza um kernel linear, o que significa que ele usa uma fronteira de decisão linear para separar os pontos de dados. No SVM linear, você trabalha diretamente com o espaço de características, e o problema de otimização é frequentemente expresso em sua forma mais simples. O objetivo principal do SVM linear é encontrar o hiperplano linear que melhor separa os dados.
Esse tipo é mais adequado para dados linearmente separáveis.
Método dual de vetores de suporte
A forma dual não é um tipo separado do método de vetores de suporte, mas sim uma representação do problema de otimização do SVM. A forma dual do SVM é uma reformulação matemática da tarefa de otimização original, que permite o uso de métodos de resolução mais eficientes. Os multiplicadores de Lagrange são introduzidos na fórmula para maximizar a função objetivo dual, o que é equivalente à tarefa principal. A solução do problema dual leva à identificação dos vetores de suporte, que são cruciais para a classificação.
Esse tipo é melhor para dados que não são linearmente separáveis.

Além disso, é possível usar margens rígidas ou suaves para tomar decisões sobre o classificador SVM usando um hiperplano.
Margem rígida
Se os dados de treinamento são linearmente separáveis, é possível escolher dois hiperplanos paralelos que separam as duas classes de dados de modo que a distância entre eles seja a maior possível. A área limitada por esses dois hiperplanos é chamada de margem, e o hiperplano com a maior margem é o que fica no meio entre eles. Com um conjunto de dados normalizado ou padronizado, esses hiperplanos podem ser descritos pelas equações
![]() (tudo que está nessa fronteira ou acima pertence a uma classe com o rótulo 1)
(tudo que está nessa fronteira ou acima pertence a uma classe com o rótulo 1)
e
![]() (tudo que está nesta fronteira ou abaixo pertence a outra classe com o rótulo -1).
(tudo que está nesta fronteira ou abaixo pertence a outra classe com o rótulo -1).
A distância entre eles é igual a 2/||w||, e para maximizar a distância, ||w|| deve ser minimizado. Para evitar que qualquer ponto de dados fique dentro da margem, adicionamos a restrição: yi(wTXi -b) >= 1, onde yi = i-ésima linha do objetivo, e Xi = i-ésima linha em X.
Margem suave
Para usar o SVM em casos onde os dados não são linearmente separáveis, a função de perda de articulação foi introduzida.
![]() .
.
Aqui, ![]() é o i-ésimo alvo (ou seja, neste caso 1 ou -1), e
é o i-ésimo alvo (ou seja, neste caso 1 ou -1), e ![]() é o i-ésimo resultado.
é o i-ésimo resultado.
Se o ponto de dados tem classe = 1, então a perda será 0, caso contrário, será a distância entre a fronteira e o ponto de dados. Nosso objetivo é minimizar
![]() onde λ é um compromisso entre o tamanho da margem e xi estar no lado correto desta margem. Se o valor de λ for muito baixo, a equação se torna uma margem rígida.
onde λ é um compromisso entre o tamanho da margem e xi estar no lado correto desta margem. Se o valor de λ for muito baixo, a equação se torna uma margem rígida.
Usaremos margem rígida para a classe Linear SVM. Isso é possível graças à função de sinal, que retorna o sinal de um número real em notação matemática. Expressa como:
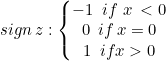
int CLinearSVM::sign(double var) { if (var == 0) return (0); else if (var < 0) return -1; else return 1; }
Treinamento do modelo do método linear de vetores de suporte
O treinamento do método SVM envolve a busca por um hiperplano ótimo que separe os dados enquanto maximiza o aumento da margem. A margem, ou o espaçamento, é a distância entre o hiperplano e os pontos de dados mais próximos de qualquer classe. O objetivo é encontrar um hiperplano que maximize a margem enquanto minimiza os erros de classificação.
Atualização de pesos (w):
a. Primeiro termo. O primeiro termo da função de perda corresponde à perda de articulação, que mede o erro de classificação. Para cada exemplo de treinamento i, calculamos a derivada da função de perda em relação aos pesos w:
- Se
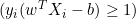 , isso significa que o ponto de dados está corretamente classificado e fora da margem, a derivada é zero.
, isso significa que o ponto de dados está corretamente classificado e fora da margem, a derivada é zero. - Se
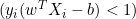 , isso indica que o ponto de dados está dentro da margem ou classificado incorretamente, a derivada é
, isso indica que o ponto de dados está dentro da margem ou classificado incorretamente, a derivada é 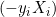 .
.
b. Segundo termo:
O segundo termo é a regularização. Isso fornece uma pequena margem e ajuda a prevenir o sobreajuste. A derivada deste termo em relação aos pesos w é 2λw, onde λ é o parâmetro de regularização.
c. Combinamos as derivadas do primeiro e segundo termos,
Atualizamos os pesos w:
-Quando ![]() os pesos são atualizados assim:
os pesos são atualizados assim: ![]() , e se
, e se ![]() , atualizamos assim:
, atualizamos assim: ![]() . Aqui α é o coeficiente de aprendizado.
. Aqui α é o coeficiente de aprendizado.
Atualização do ponto de interseção (b):
a. Primeiro termo:
A derivada da função de perda de articulação em relação ao ponto de interseção b é calculada de maneira semelhante aos pesos:
- Se
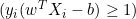 , a derivada é zero.
, a derivada é zero. - Se
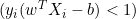 , a derivada é igual a
, a derivada é igual a 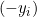 .
.
b. Segundo termo:
O segundo termo não depende do ponto de interseção, então sua derivada em relação a b é zero. c. Atualizamos o ponto de interseção b:
- Se
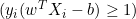 , atualizamos
, atualizamos 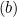 assim:
assim: 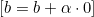
- Se
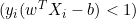 , atualizamos
, atualizamos 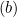 assim:
assim: 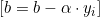
Variável de desvio (ξ):
A variável de desvio (ξ) permite que alguns pontos de dados estejam dentro da margem, o que significa que eles estão mal classificados ou dentro dessa margem. A condição ![]() significa que a fronteira de decisão deve estar pelo menos
significa que a fronteira de decisão deve estar pelo menos ![]() unidades afastada do ponto de dados i.
unidades afastada do ponto de dados i.
Assim, o processo de treinamento do SVM inclui a atualização de pesos e interseções com base na perda de articulação e no termo de regularização. O objetivo é encontrar o hiperplano ótimo que maximize a margem, considerando os possíveis erros de classificação dentro do limite permitidos pela variável de desvio. Esse processo geralmente é resolvido usando métodos de otimização. Neste processo, os vetores de suporte são definidos durante o treinamento. Eles têm como objetivo definir a fronteira de decisão.
void CLinearSVM::fit(matrix &x, vector &y) { matrix X = x; vector Y = y; ulong rows = X.Rows(), cols = X.Cols(); if (X.Rows() != Y.Size()) { Print("Support vector machine Failed | FATAL | X m_rows not same as yvector size"); return; } W.Resize(cols); B = 0; normalize_x = new CPreprocessing<vector, matrix>(X, NORM_STANDARDIZATION); //Normalizing independent variables //--- if (rows < config.batch_size) { Print("The number of samples/rows in the dataset should be less than the batch size"); return; } matrix temp_x; vector temp_y; matrix w, b; vector preds = {}; vector loss(config.epochs); during_training = true; for (uint epoch=0; epoch<config.epochs; epoch++) { for (uint batch=0; batch<=(uint)MathFloor(rows/config.batch_size); batch+=config.batch_size) { temp_x = matrix_utils.Get(X, batch, (config.batch_size+batch)-1); temp_y = matrix_utils.Get(Y, batch, (config.batch_size+batch)-1); #ifdef DEBUG_MODE: Print("X\n",temp_x,"\ny\n",temp_y); #endif for (uint sample=0; sample<temp_x.Rows(); sample++) { // yixiw-b≥1 if (temp_y[sample] * hyperplane(temp_x.Row(sample)) >= 1) { this.W -= config.alpha * (2 * config.lambda * this.W); // w = w + α* (2λw - yixi) } else { this.W -= config.alpha * (2 * config.lambda * this.W - ( temp_x.Row(sample) * temp_y[sample] )); // w = w + α* (2λw - yixi) this.B -= config.alpha * temp_y[sample]; // b = b - α* (yi) } } } //--- Print the loss at the end of an epoch is_fitted_already = true; preds = this.predict(X); loss[epoch] = preds.Loss(Y, LOSS_BCE); printf("---> epoch [%d/%d] Loss = %f Accuracy = %f",epoch+1,config.epochs,loss[epoch],metrics.confusion_matrix(Y, preds, false)); #ifdef DEBUG_MODE: Print("W\n",W," B = ",B); #endif } during_training = false; return; }
Previsões obtidas do modelo de vetor de suporte linear
Para obter previsões do nosso modelo, os dados são passados para a função sinal depois que o hiperplano for estabelecido.
int CLinearSVM::predict(vector &x) { if (!is_fitted_already) { Print("Err | The model is not trained, call the fit method to train the model before you can use it"); return 1000; } vector temp_x = x; if (!during_training) normalize_x.Normalization(temp_x); //Normalize a new input data when we are not running the model in training return sign(hyperplane(temp_x)); }
Treinamento e teste do modelo de vetor de suporte linear
É necessário testar o modelo antes de implementá-lo para fazer quaisquer previsões significativas sobre os dados de mercado. Começamos com a inicialização de uma instância da classe Linear SVM.
#include <MALE5\Support Vector Machine(SVM)\svm.mqh> CLinearSVM *svm; input uint bars = 1000; input uint epochs_ = 1000; input uint batch_size_ = 64; input double alpha__ =0.1; input double lambda_ = 0.01; bool train_once; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- svm = new CLinearSVM(batch_size_, alpha__, epochs_, lambda_); train_once = false; //--- return(INIT_SUCCEEDED); }
Continuamos com a coleta de dados. Usaremos 4 variáveis independentes: RSI, HIGH BANDS BOLLINGER, LOW e MID.
vec_.CopyIndicatorBuffer(rsi_handle, 0, 0, bars); dataset.Col(vec_, 0); vec_.CopyIndicatorBuffer(bb_handle, 0, 0, bars); dataset.Col(vec_, 1); vec_.CopyIndicatorBuffer(bb_handle, 1, 0, bars); dataset.Col(vec_, 2); vec_.CopyIndicatorBuffer(bb_handle, 2, 0, bars); dataset.Col(vec_, 3); open.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_OPEN, 0, bars); close.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_CLOSE, 0, bars); for (ulong i=0; i<vec_.Size(); i++) //preparing the independent variable dataset[i][4] = close[i] > open[i] ? 1 : -1; // if price closed above its opening thats bullish else bearish
Concluímos a coleta de dados, dividindo os dados em conjuntos de treinamento e teste.
matrix_utils.TrainTestSplitMatrices(dataset,train_x,train_y,test_x,test_y,0.7,42); //split the data into training and testing samples
Treinamento/ajuste do modelo
svm.fit(train_x, train_y);
Resultado
0 15:15:42.394 svm test (EURUSD,H1) ---> epoch [1/1000] Loss = 7.539322 Accuracy = 0.489000 IK 0 15:15:42.395 svm test (EURUSD,H1) ---> epoch [2/1000] Loss = 7.499849 Accuracy = 0.491000 EG 0 15:15:42.395 svm test (EURUSD,H1) ---> epoch [3/1000] Loss = 7.499849 Accuracy = 0.494000 .... .... GG 0 15:15:42.537 svm test (EURUSD,H1) ---> epoch [998/1000] Loss = 6.907756 Accuracy = 0.523000 DS 0 15:15:42.537 svm test (EURUSD,H1) ---> epoch [999/1000] Loss = 7.006438 Accuracy = 0.521000 IM 0 15:15:42.537 svm test (EURUSD,H1) ---> epoch [1000/1000] Loss = 6.769601 Accuracy = 0.516000
Observamos a precisão do modelo tanto no treinamento quanto no teste.
vector train_pred = svm.predict(train_x), test_pred = svm.predict(test_x); printf("Train accuracy = %f",metrics.confusion_matrix(train_y, train_pred, true)); printf("Test accuracy = %f ",metrics.confusion_matrix(test_y, test_pred, true));
Resultado
CH 0 15:15:42.538 svm test (EURUSD,H1) Confusion Matrix IQ 0 15:15:42.538 svm test (EURUSD,H1) [[171,175] HE 0 15:15:42.538 svm test (EURUSD,H1) [164,190]] DQ 0 15:15:42.538 svm test (EURUSD,H1) NO 0 15:15:42.538 svm test (EURUSD,H1) Classification Report JD 0 15:15:42.538 svm test (EURUSD,H1) LO 0 15:15:42.538 svm test (EURUSD,H1) _ Precision Recall Specificity F1 score Support JQ 0 15:15:42.538 svm test (EURUSD,H1) -1.0 0.51 0.49 0.54 0.50 346.0 DH 0 15:15:42.538 svm test (EURUSD,H1) 1.0 0.52 0.54 0.49 0.53 354.0 HL 0 15:15:42.538 svm test (EURUSD,H1) FG 0 15:15:42.538 svm test (EURUSD,H1) Accuracy 0.52 PP 0 15:15:42.538 svm test (EURUSD,H1) Average 0.52 0.52 0.52 0.52 700.0 PS 0 15:15:42.538 svm test (EURUSD,H1) W Avg 0.52 0.52 0.52 0.52 700.0 FK 0 15:15:42.538 svm test (EURUSD,H1) Train accuracy = 0.516000 MS 0 15:15:42.538 svm test (EURUSD,H1) Confusion Matrix LI 0 15:15:42.538 svm test (EURUSD,H1) [[79,74] CM 0 15:15:42.538 svm test (EURUSD,H1) [68,79]] FJ 0 15:15:42.538 svm test (EURUSD,H1) HF 0 15:15:42.538 svm test (EURUSD,H1) Classification Report DM 0 15:15:42.538 svm test (EURUSD,H1) NH 0 15:15:42.538 svm test (EURUSD,H1) _ Precision Recall Specificity F1 score Support NN 0 15:15:42.538 svm test (EURUSD,H1) -1.0 0.54 0.52 0.54 0.53 153.0 PQ 0 15:15:42.538 svm test (EURUSD,H1) 1.0 0.52 0.54 0.52 0.53 147.0 JE 0 15:15:42.538 svm test (EURUSD,H1) GP 0 15:15:42.538 svm test (EURUSD,H1) Accuracy 0.53 RI 0 15:15:42.538 svm test (EURUSD,H1) Average 0.53 0.53 0.53 0.53 300.0 JH 0 15:15:42.538 svm test (EURUSD,H1) W Avg 0.53 0.53 0.53 0.53 300.0 DO 0 15:15:42.538 svm test (EURUSD,H1) Test accuracy = 0.527000
O modelo mostrou uma precisão de 53% em previsões fora da amostra. Alguns podem dizer que é um modelo ruim, mas eu diria que é regular. Esses resultados podem estar relacionados a muitos fatores, incluindo erros no modelo, má normalização, critérios de convergência e muitos outros. Você pode experimentar com os parâmetros e tentar melhorar o resultado. No entanto, é mais provável que os dados sejam muito complexos para um modelo linear. Estou quase certo disso, por isso vamos tentar o método dual SVM e ver se ele mostra melhores resultados.
Estudaremos o método SVM duplo no ONXX Python. Não consegui obter um modelo em MQL5 que pudesse se aproximar do desempenho e precisão do modelo sklearn python. É por isso que continuaremos trabalhando no método dual SVM em Python. No entanto, incluí a biblioteca Dual SVM em MQL5 no arquivo principal svm.mqh — ele está anexado a este artigo e também disponível no meu GitHub, cujo link está no final deste artigo.
Para executar o método dual SVM em Python, precisamos coletar dados e normalizá-los usando MQL5. Vamos precisar criar uma nova classe chamada CDualSVMONNX dentro do arquivo svm.mqh. Esta classe será responsável por trabalhar com o modelo ONNX obtido do Python.
class CDualSVMONNX { private: CPreprocessing<vectorf, matrixf> *normalize_x; CMatrixutils matrix_utils; struct data_struct { ulong rows, cols; } df; public: CDualSVMONNX(void); ~CDualSVMONNX(void); long onnx_handle; void SendDataToONNX(matrixf &data, string csv_name = "DualSVMONNX-data.csv", string csv_header=""); bool LoadONNX(const uchar &onnx_buff[], ENUM_ONNX_FLAGS flags=ONNX_NO_CONVERSION); int Predict(vectorf &inputs); vector Predict(matrixf &inputs); };
Aqui está uma visão geral da classe.
Coleta e normalização de dados
Precisamos de dados para o nosso modelo aprender. Esses dados precisam ser limpos para que sejam adequados para o nosso modelo SVM:
void CDualSVMONNX::SendDataToONNX(matrixf &data, string csv_name = "DualSVMONNX-data.csv", string csv_header="") { df.cols = data.Cols(); df.rows = data.Rows(); if (df.cols == 0 || df.rows == 0) { Print(__FUNCTION__," data matrix invalid size "); return; } matrixf split_x; vectorf split_y; matrix_utils.XandYSplitMatrices(data, split_x, split_y); //since we are going to be normalizing the independent variable only we need to split the data into two normalize_x = new CPreprocessing<vectorf,matrixf>(split_x, NORM_MIN_MAX_SCALER); //Normalizing Independent variable only matrixf new_data = split_x; new_data.Resize(data.Rows(), data.Cols()); new_data.Col(split_y, data.Cols()-1); if (csv_header == "") { for (ulong i=0; i<df.cols; i++) csv_header += "COLUMN "+string(i+1) + (i==df.cols-1 ? "" : ","); //do not put delimiter on the last column } //--- Save the Normalization parameters also matrixf params = {}; string sep=","; ushort u_sep; string result[]; u_sep=StringGetCharacter(sep,0); int k=StringSplit(csv_header,u_sep,result); ArrayRemove(result, k-1, 1); //remove the last column header since we do not have normalization parameters for the target variable as it is not normalized normalize_x.min_max_scaler.min.Swap(params); matrix_utils.WriteCsv("min_max_scaler.min.csv",params,result,false,8); normalize_x.min_max_scaler.max.Swap(params); matrix_utils.WriteCsv("min_max_scaler.max.csv",params,result,false,8); //--- matrix_utils.WriteCsv(csv_name, new_data, csv_header, false, 8); //Save dataset to a csv file }
Como a coleta de dados para treinamento precisa ser feita uma vez, usaremos um script para isso.
Script GetDataforONNX.mq5
#include <MALE5\Support Vector Machine(SVM)\svm.mqh> CDualSVMONNX dual_svm; input uint bars = 1000; input uint epochs_ = 1000; input uint batch_size_ = 64; input double alpha__ =0.1; input double lambda_ = 0.01; input int rsi_period = 13; input int bb_period = 20; input double bb_deviation = 2.0; int rsi_handle, bb_handle; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { rsi_handle = iRSI(Symbol(),PERIOD_CURRENT,rsi_period, PRICE_CLOSE); bb_handle = iBands(Symbol(), PERIOD_CURRENT, bb_period,0, bb_deviation, PRICE_CLOSE); //--- matrixf data = GetTrainTestData<float>(); dual_svm.SendDataToONNX(data,"DualSVMONNX-data.csv","rsi,bb-high,bb-low,bb-mid,target"); } //+------------------------------------------------------------------+ //| Getting data for Training and Testing the model | //+------------------------------------------------------------------+ template <typename T> matrix<T> GetTrainTestData() { matrix<T> data(bars, 5); vector<T> v; //Temporary vector for storing Indicator buffers v.CopyIndicatorBuffer(rsi_handle, 0, 0, bars); data.Col(v, 0); v.CopyIndicatorBuffer(bb_handle, 0, 0, bars); data.Col(v, 1); v.CopyIndicatorBuffer(bb_handle, 1, 0, bars); data.Col(v, 2); v.CopyIndicatorBuffer(bb_handle, 2, 0, bars); data.Col(v, 3); vector open, close; open.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_OPEN, 0, bars); close.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_CLOSE, 0, bars); for (ulong i=0; i<v.Size(); i++) //preparing the independent variable data[i][4] = close[i] > open[i] ? 1 : -1; // if price closed above its opening thats bullish else bearish return data; }
Resultado
Um arquivo chamado DualSVMONNX-data.csv foi criado na pasta Files no diretório MQL5.
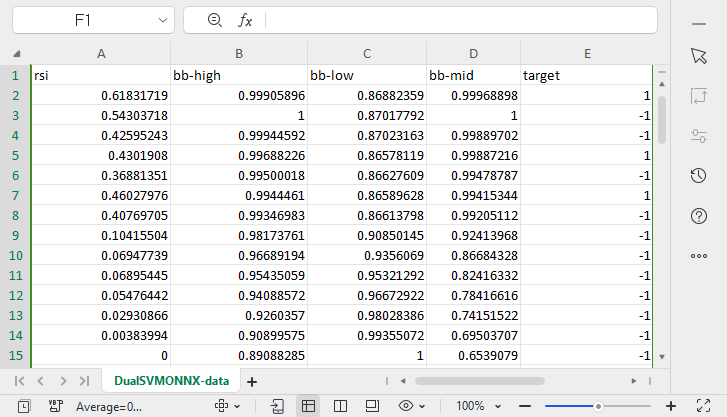
Note o término da função SendDataToONNX .
Também salvei os parâmetros de normalização.
normalize_x.min_max_scaler.min.Swap(params); matrix_utils.WriteCsv("min_max_scaler.min.csv",params,result,false,8); normalize_x.min_max_scaler.max.Swap(params); matrix_utils.WriteCsv("min_max_scaler.max.csv",params,result,false,8);
Usaremos os mesmos parâmetros de normalização novamente para obter as melhores previsões do modelo. Portanto, salvar esses dados ajudará a rastrear os valores dos parâmetros de normalização. Os arquivos CSV estarão na mesma pasta que o conjunto de dados. Também salvaremos o modelo ONNX lá.
Instância da classe DualSVMONNX. Inicialização da classe
class DualSVMONNX: def __init__(self, dataset, c=1.0, kernel='rbf'): data = pd.read_csv(dataset) # reading a csv file np.random.seed(42) self.X = data.drop(columns=['target']).astype(np.float32) # dropping the target column from independent variable self.y = data["target"].astype(int) # storing the target variable in its own vector self.X = self.X.to_numpy() self.y = self.y.to_numpy() # Split the data into training and testing sets self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(self.X, self.y, test_size=0.2, random_state=42) self.onnx_model_name = "DualSVMONNX" #our final onnx model file name for saving purposes really # Create a dual SVM model with a kernel self.svm_model = SVC(kernel=kernel, C=c)
Treinamento do modelo Dual SVM em Python
def fit(self): self.svm_model.fit(self.X_train, self.y_train) # fitting/training the model y_preds = self.svm_model.predict(self.X_train) print("accuracy = ",accuracy_score(self.y_train, y_preds))
Após o treinamento do modelo, vamos ver qual é a precisão após executar este trecho de código.
Resultado

Obtivemos uma precisão de 63%, o que indica que o modelo SVM para classificar este problema específico é, no melhor dos casos, mediano. No entanto, vamos realizar uma validação cruzada para entender se a precisão é a esperada:
scores = cross_val_score(self.svm_model, self.X_train, self.y_train, cv=5) mean_cv_accuracy = np.mean(scores) print(f"\nscores {scores} mean_cv_accuracy {mean_cv_accuracy}")
Resultado

O que significa esse resultado de validação cruzada?
Quando executamos o modelo com diferentes parâmetros, não há uma grande diferença nos resultados. Isso nos diz que nosso modelo está no caminho certo. A precisão média que conseguimos obter foi de 59,875, o que não está muito distante dos 63,3 que alcançamos.
Transformação do modelo de vetor de suporte do sklearn para ONNX
def saveONNX(self):
initial_type = [('float_input', FloatTensorType(shape=[None, 4]))] # None means we don't know the rows but we know the columns for sure, Remember !! we have 4 independent variables
onnx_model = convert_sklearn(self.svm_model, initial_types=initial_type) # Convert the scikit-learn model to ONNX format
onnx.save_model(onnx_model, dataset_path + f"\\{self.onnx_model_name}.onnx") #saving the onnx model
O modelo foi salvo no diretório MQL5/Files.
Abaixo está como o arquivo ONNX parece quando aberto no MetaEditor. Note a explicação do processo. Isso é importante.

Na seção de parâmetros de entrada, temos float_input — um parâmetro do tipo float. A seguir, 'tensor' significa que precisamos passar para a função OnnxRun uma matriz ou vetor, pois ambos são tensores. No final, está indicado (?, 4) — o tamanho das entradas, onde ? significa que o número de linhas é desconhecido; o número de colunas é 4. A seguir está a parte Outputs.
Aqui temos dois nós — um fornece as etiquetas previstas -1 ou 1, que neste caso são do tipo INT64 ou INT em mql5.
O segundo nó com probabilidades é um tensor de tipos float, contendo 2 colunas e um número desconhecido de linhas. Para extrair valores, pode-se usar uma matriz nx2 ou simplesmente um vetor de tamanho >= 2.
Como há dois nós nos dados de saída, podemos extrair os resultados duas vezes:
long outputs_0[] = {1}; if (!OnnxSetOutputShape(onnx_handle, 0, outputs_0)) //giving the onnx handle first node output shape { Print(__FUNCTION__," Failed to set the output shape Err=",GetLastError()); return false; } long outputs_1[] = {1,2}; if (!OnnxSetOutputShape(onnx_handle, 1, outputs_1)) //giving the onnx handle second node output shape { Print(__FUNCTION__," Failed to set the output shape Err=",GetLastError()); return false; }
Por outro lado, podemos extrair um único nó de entrada.
const long inputs[] = {1,4}; if (!OnnxSetInputShape(onnx_handle, 0, inputs)) //Giving the Onnx handle the input shape { Print(__FUNCTION__," Failed to set the input shape Err=",GetLastError()); return false; }
Este código ONNX foi obtido da função LoadONNX, mostrada abaixo:
bool CDualSVMONNX::LoadONNX(const uchar &onnx_buff[], ENUM_ONNX_FLAGS flags=ONNX_NO_CONVERSION) { onnx_handle = OnnxCreateFromBuffer(onnx_buff, flags); //creating onnx handle buffer if (onnx_handle == INVALID_HANDLE) { Print(__FUNCTION__," OnnxCreateFromBuffer Error = ",GetLastError()); return false; } //--- const long inputs[] = {1,4}; if (!OnnxSetInputShape(onnx_handle, 0, inputs)) //Giving the Onnx handle the input shape { Print(__FUNCTION__," Failed to set the input shape Err=",GetLastError()); return false; } long outputs_0[] = {1}; if (!OnnxSetOutputShape(onnx_handle, 0, outputs_0)) //giving the onnx handle first node output shape { Print(__FUNCTION__," Failed to set the output shape Err=",GetLastError()); return false; } long outputs_1[] = {1,2}; if (!OnnxSetOutputShape(onnx_handle, 1, outputs_1)) //giving the onnx handle second node output shape { Print(__FUNCTION__," Failed to set the output shape Err=",GetLastError()); return false; } return true; }
Observe atentamente a função que, como você pode ter adivinhado, nos falta ao carregar os parâmetros de normalização. Esses parâmetros são muito importantes para padronizar novos dados de entrada para que correspondam às dimensões dos dados treinados com os quais o modelo já está familiarizado.
É possível carregar os parâmetros de um arquivo CSV - isso funciona sem problemas em tempo real de negociação. No entanto, esse método pode ser complicado e nem sempre funcionar bem no testador de estratégias. Portanto, por enquanto, vamos copiar os parâmetros de normalização manualmente para o código do nosso EA. Finalmente, teremos os parâmetros de normalização dentro do nosso EA. Primeiro, alteremos a função LoadONNX para que ela aceite vetores de entrada max e min, que são usados no Min Max Scaler.
bool CDualSVMONNX::LoadONNX(const uchar &onnx_buff[], ENUM_ONNX_FLAGS flags, vectorf &norm_max, vectorf &norm_min)
Fim desta função.
normalize_x = new CPreprocessing<vectorf,matrixf>(norm_max, norm_min); //Load min max scaler with parameters
Copiando e colando parâmetros de normalização de arquivos CSV para EAs.
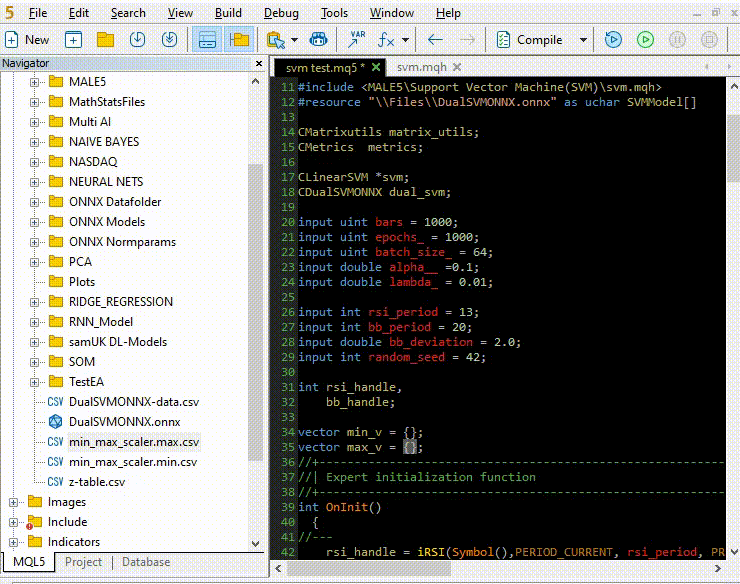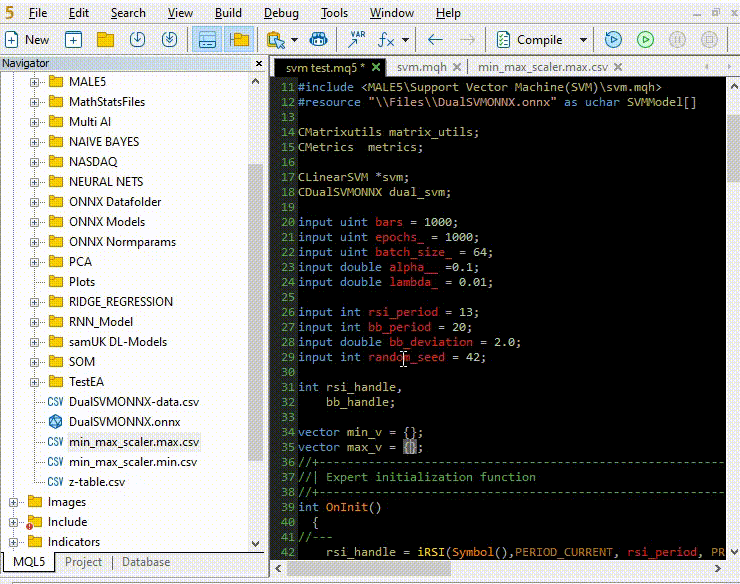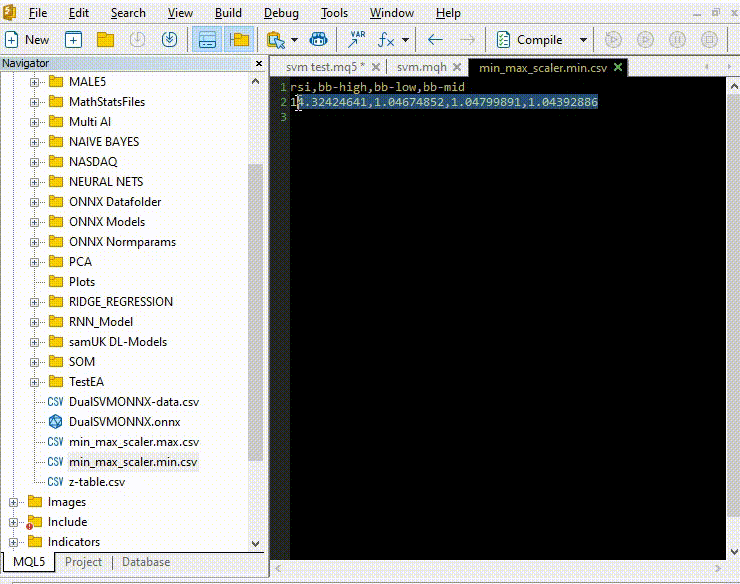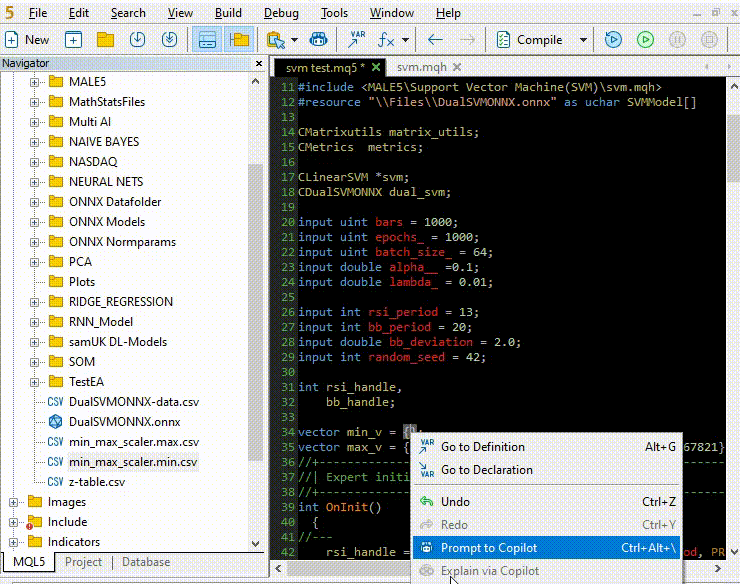
Vamos treinar e tentar testar o modelo da mesma forma que fizemos com Python. Nosso objetivo é garantir que estamos no mesmo caminho em ambas as linguagens.
Função OnInit no EA de teste test.mq5
vector min_v = {14.32424641,1.04674852,1.04799891,1.04392886}; vector max_v = {86.28263092,1.07385755,1.07907069,1.07267821}; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- rsi_handle = iRSI(Symbol(),PERIOD_CURRENT, rsi_period, PRICE_CLOSE); bb_handle = iBands(Symbol(), PERIOD_CURRENT, bb_period, 0 , bb_deviation, PRICE_CLOSE); vector y_train, y_test; // float values matrixf datasetf = GetTrainTestData<float>(); matrixf x_trainf, x_testf; vectorf y_trainf, y_testf; //--- matrix_utils.TrainTestSplitMatrices(datasetf,x_trainf,y_trainf,x_testf,y_testf,0.8,42); //split the data into training and testing samples vectorf max_vf = {}, min_vf = {}; //convertin the parameters into float type max_vf.Assign(max_v); min_vf.Assign(min_v); dual_svm.LoadONNX(SVMModel, ONNX_DEFAULT, max_vf, min_vf); y_train.Assign(y_trainf); y_test.Assign(y_testf); vector train_preds = dual_svm.Predict(x_trainf); vector test_preds = dual_svm.Predict(x_testf); Print("\n<<<<< Train Classification Report >>>>\n"); metrics.confusion_matrix(y_train, train_preds); Print("\n<<<<< Test Classification Report >>>>\n"); metrics.confusion_matrix(y_test, test_preds); return(INIT_SUCCEEDED); }Resultado
RP 0 17:08:53.068 svm test (EURUSD,H1) <<<<< Train Classification Report >>>> HE 0 17:08:53.068 svm test (EURUSD,H1) MR 0 17:08:53.068 svm test (EURUSD,H1) Confusion Matrix IG 0 17:08:53.068 svm test (EURUSD,H1) [[245,148] CO 0 17:08:53.068 svm test (EURUSD,H1) [150,257]] NK 0 17:08:53.068 svm test (EURUSD,H1) DE 0 17:08:53.068 svm test (EURUSD,H1) Classification Report HO 0 17:08:53.068 svm test (EURUSD,H1) FI 0 17:08:53.068 svm test (EURUSD,H1) _ Precision Recall Specificity F1 score Support ON 0 17:08:53.068 svm test (EURUSD,H1) 1.0 0.62 0.62 0.63 0.62 393.0 DP 0 17:08:53.068 svm test (EURUSD,H1) -1.0 0.63 0.63 0.62 0.63 407.0 JG 0 17:08:53.068 svm test (EURUSD,H1) FR 0 17:08:53.068 svm test (EURUSD,H1) Accuracy 0.63 CK 0 17:08:53.068 svm test (EURUSD,H1) Average 0.63 0.63 0.63 0.63 800.0 KI 0 17:08:53.068 svm test (EURUSD,H1) W Avg 0.63 0.63 0.63 0.63 800.0 PP 0 17:08:53.068 svm test (EURUSD,H1) DH 0 17:08:53.068 svm test (EURUSD,H1) <<<<< Test Classification Report >>>> PQ 0 17:08:53.068 svm test (EURUSD,H1) EQ 0 17:08:53.068 svm test (EURUSD,H1) Confusion Matrix HJ 0 17:08:53.068 svm test (EURUSD,H1) [[61,31] MR 0 17:08:53.068 svm test (EURUSD,H1) [40,68]] NH 0 17:08:53.068 svm test (EURUSD,H1) DP 0 17:08:53.068 svm test (EURUSD,H1) Classification Report HL 0 17:08:53.068 svm test (EURUSD,H1) FF 0 17:08:53.068 svm test (EURUSD,H1) _ Precision Recall Specificity F1 score Support GJ 0 17:08:53.068 svm test (EURUSD,H1) -1.0 0.60 0.66 0.63 0.63 92.0 PO 0 17:08:53.068 svm test (EURUSD,H1) 1.0 0.69 0.63 0.66 0.66 108.0 DD 0 17:08:53.068 svm test (EURUSD,H1) JO 0 17:08:53.068 svm test (EURUSD,H1) Accuracy 0.65 LH 0 17:08:53.068 svm test (EURUSD,H1) Average 0.65 0.65 0.65 0.64 200.0 CJ 0 17:08:53.068 svm test (EURUSD,H1) W Avg 0.65 0.65 0.65 0.65 200.0
Nós novamente obtivemos os mesmos 63% de precisão, que obtivemos com o script em Python. Não é maravilhoso?
Aqui está como a função de previsão parece por dentro:
int CDualSVMONNX::Predict(vectorf &inputs) { vectorf outputs(1); //label outputs vectorf x_output(2); //probabilities vectorf temp_inputs = inputs; normalize_x.Normalization(temp_inputs); //Normalize the input features if (!OnnxRun(onnx_handle, ONNX_DEFAULT, temp_inputs, outputs, x_output)) { Print("Failed to get predictions from onnx Err=",GetLastError()); return (int)outputs[0]; } return (int)outputs[0]; }
Ela executa o arquivo ONNX para obter previsões e retorna um inteiro para o rótulo previsto.
Depois, implementamos uma estratégia simples para testar ambos os modelos do método de vetores de suporte no testador de estratégias. A estratégia é simples: se a classe prevista pelo SVM == 1, abrimos uma operação de compra, caso contrário, se a classe prevista == -1, abrimos uma operação de venda.
Resultados no testador de estratégias:
Para o método linear de vetores de suporte
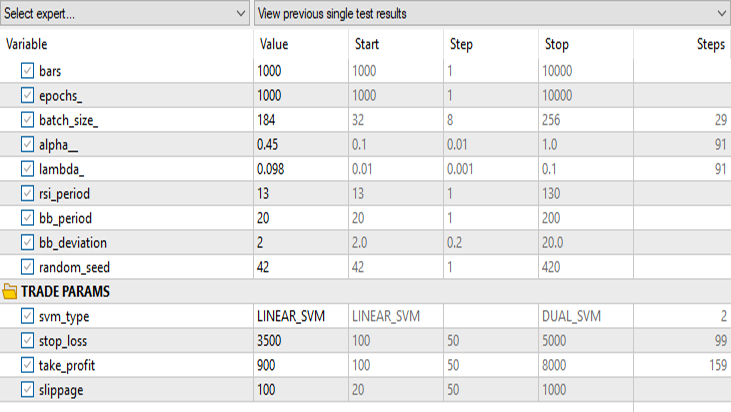
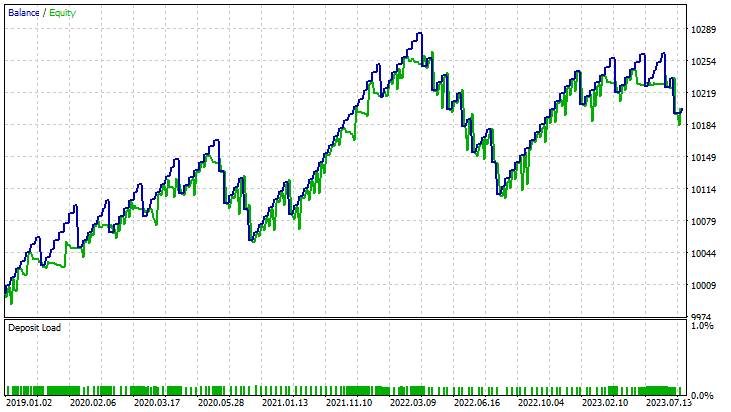
Para a forma dual do método de vetores de suporte:
Mantemos todos os mesmos dados de entrada, exceto svm_type.
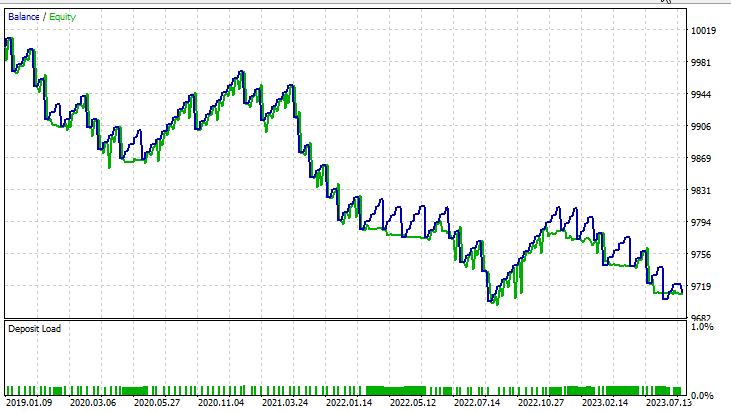
A forma dual do SVM não se saiu muito bem com os dados de entrada que funcionaram para o SVM linear. Talvez seja necessário mais otimização e investigação sobre por que o modelo ONNX não está convergindo, mas isso é assunto para outro artigo.
Pensamentos finais
Vantagens dos modelos de vetores de suporte SVM
- Funciona eficazmente em espaços multidimensionais, ou seja, o método de vetores de suporte é adequado para trabalhar com amostras de dados financeiros com múltiplas funções, indicadores de negociação e variáveis de mercado.
- Os vetores de suporte são menos propensos a sobreajuste, fornecendo uma solução mais generalizada que pode se adaptar melhor às condições de mercado invisíveis.
- Os modelos de SVM oferecem versatilidade graças às diferentes funções de kernel, permitindo que os traders experimentem diferentes estratégias e adaptem o modelo a padrões de mercado específicos.
- Os métodos SVM capturam bem as relações não lineares dentro dos dados, o que é crucial ao lidar com mercados financeiros complexos.
Desvantagens
- SVM podem ser sensíveis a dados ruidosos, o que afeta seus resultados e os torna mais suscetíveis a comportamentos de mercado instáveis.
- O treinamento de modelos SVM pode ser custoso em termos de recursos computacionais, especialmente ao lidar com grandes conjuntos de dados, o que limita sua escalabilidade em certos cenários de negociação em tempo real.
- Vetores de suporte dependem significativamente do desenvolvimento de características, exigindo conhecimento na área de domínio para escolher os indicadores apropriados e o processamento eficaz dos dados.
- Como vimos, os modelos em SVM mostraram uma precisão média de até 63% na forma dual e 59% na linear. Embora esses modelos possam não superar alguns métodos avançados de aprendizado de máquina, eles ainda oferecem um ponto de partida razoável para traders de MQL5.
Declínio da popularidade
Apesar do sucesso no passado, nos últimos anos a popularidade do SVM diminuiu. Isso pode estar relacionado ao seguinte:
- O desenvolvimento de métodos de aprendizado profundo, especialmente redes neurais, suplantou algoritmos tradicionais de machine learning devido à sua capacidade de extrair automaticamente características hierárquicas.
- Conjuntos extensivos de dados financeiros tornaram-se cada vez mais acessíveis, tornando modelos de aprendizado profundo, que funcionam bem com grandes volumes de dados, mais atraentes.
- O surgimento de hardware poderoso e recursos computacionais distribuídos tornou mais viável o treinamento e a implantação de modelos complexos de aprendizado profundo.
Em conclusão, embora os modelos SVM possam não ser a solução de ponta, seu uso em ambientes de negociação MQL5 é justificado. Sua simplicidade, confiabilidade e adaptabilidade os tornam uma ferramenta valiosa, especialmente para traders com dados limitados ou recursos computacionais. Vetores de suporte podem ser vistos como parte de um conjunto de ferramentas mais amplo, potencialmente complementando-os com novos enfoques sobre o aprendizado de máquina conforme a dinâmica do mercado evolui.
Obrigado pela atenção.
| Arquivo | Descrição | Uso |
|---|---|
| dual_svm.py | script python | Implementação do Dual SVM em Python. |
| GetDataforONNX.mq5 | script mql5 | Usado para coletar, normalizar e armazenar dados em um arquivo csv localizado na pasta MQL5/Files. |
| preprocessing.mqh | arquivo include mql5 | Contém a classe e funções para normalização e padronização dos dados de entrada. |
| matrix_utils.mqh | arquivo include mql5 | Biblioteca com operações matriciais adicionais. |
| metrics.mqh | arquivo include mql5 | Biblioteca que contém funções adicionais para análise de desempenho de modelos de aprendizado de máquina. |
| svm test.mq5 | EA | Expert Advisor para testar todo o código que está no artigo. |
O código usado neste artigo também pode ser encontrado no meu repositório no GitHub.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/13395
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso