
多通貨エキスパートアドバイザーの開発(第6回):インスタンスグループ選択の自動化
はじめに
前回の記事では、戦略のオプションとして、ポジションサイズを一定にする方法と可変にする方法を選択できるようにしました。これによって、戦略の結果を最大ドローダウンに従って正規化することができ、最大ドローダウンも指定された範囲内にあるグループにまとめることができるようになりました。デモンストレーションのために、1つの戦略インスタンスの最適化結果から、最も魅力的な入力の組み合わせを手作業でいくつか選び、それらを1つのグループ、あるいは3つの戦略からなる3つのグループにまとめることを試みました。後者のケースで最高の結果を得ました。
しかし、グループ内の戦略の数を増やし、異なるグループの組み合わせ数を増やす必要がある場合、ルーチンの手作業が大幅に増えます。
まず、各銘柄について異なる最適化基準で戦略の単一インスタンスを最適化する必要があります。さらに、各銘柄について、異なる時間枠に対して個別に最適化をおこなう必要がある場合もあります。私たちの特定のモデル戦略では、出した注文のタイプ(ストップ、リミット、成り行きポジション)別に最適化を実行することもできます。
第二に、結果として得られた約2~5万個のパラメータから、少数(10~20個)の最適なものを選択する必要があります。ただし、これらは単独で最良であるだけではなく、グループで連携されるべきです。戦略のインスタンスを1つずつ選んで追加していくのも、時間と忍耐が必要です。
第三に、得られたグループを順次上位グループに統合し、標準化を実施します。これを手作業でやると、2、3レベルしか出せません。これ以上のグループ分けは手間がかかりすぎるように思えます。
そこで、EA開発のこの段階を自動化してみましょう。
パスのマッピング
残念ながら、一度にすべてをこなすことはできないでしょう。それどころか、目の前の課題が複雑であるために、その解決にまったく取り掛かろうとしないこともあります。したがって、少なくとも片側からアプローチしてみましょう。実装に踏み切れない最大の難点は、これで利益がもたらされるか、品質を落とさずに(できれば向上させて)手動選択を自動選択に置き換えることはできるのか、このプロセス全体に、手作業による選択よりもさらに長くなるのではないかといった疑問です。
答えが出るまでは、解決策に取り込むことは難しくなります。つまり、現在の優先事項は、自動化されたグループ選択が有用であるという仮説を検証することです。これをテストするために、1つの銘柄に対する1つのインスタンスの最適化結果のセットを取り、手動で正規化された良いグループを選択します。これが、結果を比較するためのベースラインとなります。そして、最小限のコストで、グループ選択を可能にする最もシンプルな自動化を作成します。その後、自動的に選択されたグループの結果と、手動で選択されたグループの結果を比較します。比較の結果、自動化の可能性が示されれば、さらに、より美しく正しい実装へと進むことができるでしょう。
初期データの準備
ここまでの実装で得られたSimpleVolumesExpertSingle.mq5 EAの最適化結果をダウンロードし、XMLにエクスポートしてみましょう。
図1:さらなる処理のために最適化結果をエクスポートする
さらに使いやすくするために、最適化に関与しないパラメータの値を含む列を追加します。symbol、timeframe、maxCountOfOrders、そしてより重要なfittedBalanceを追加する必要があります。後者については、既知のエクイティ別相対ドローダウンの最大値に基づいて計算します。
初期残高をUSD 100,000とすると、絶対的なドローダウンは約100,000 * (relDDpercent / 100)となります。この値はfittedBalanceの10%でなければなりません。
fittedBalance = 100000 * (relDDpercent / 100) / 0.1 = relDDpercent * 10000
定数PERIOD_H1によってコードで指定された時間枠値を、その数値16385として表現します。
追加した結果、データ表ができ、CSV形式で保存されます。転置形式では、出来上がった表の最初の行は次のようになります。
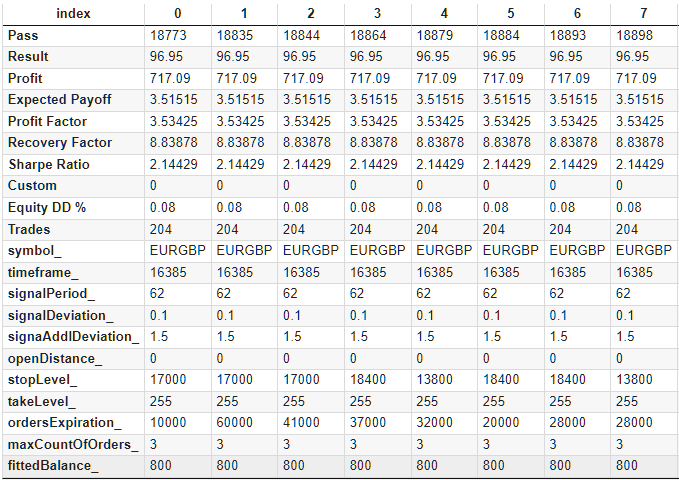
図2:最適化結果の補足表
この作業は、例えばTesterCacheライブラリを使用するか、最適化中の各パスに関するデータを保存する他の方法を実装することによって、コンピュータに委ねることができます。ただし、最小限の努力でおこないたいと思います。従って、この作業はとりあえず手作業でおこなうことにします。
この表には、利益がゼロ未満の行が含まれています(18,000行中約1000行)。このような結果には絶対に興味がないので、すぐに取り除きましょう。
この後、初期データはベースラインバージョンを構築し、ベースラインバージョンと競合する戦略グループを選択するために使用する準備が整います。
ベースライン
基本版の準備は単純ながらも単調な作業です。そもそも、戦略を「質」の低い順に並べ替えるべきです。次の方法で品質を評価しましょう。この表の様々なパフォーマンスメトリクスを含む列のセットを強調表示します。利益、期待ペイオフ、プロフィットファクター、リカバリーファクター、シャープレシオ、エクイティDD%、取引です。それぞれは最小から最大のスケーリングが施され、[0; 1]の範囲となります。接尾辞「_s」を持つ追加の列を取得し、それを使用して各行の合計を以下のように計算します。
0.5 * Profit_s + ExpectedPayoff_s + ProfitFactor_s + RecoveryFactor_s + SharpeRatio_s + (1 - EquityDD_s) + 0.3 * Trades_s,
これを新しい表列として追加して、降順に並べ替えます。
そして、リストを見ながら、気に入った候補をグループに加え、すぐにそれらの相性を確認します。パラメータと結果の両方において、可能な限り互いに異なるパラメータのセットを追加するようにします。
例えば、パラメータのセットの中には、SLレベルだけが異なるものがあります。しかし、もしこのレベルがテスト期間中に一度も発動されたことがなければ、異なるレベルでも結果は同じになります。したがって、このような組み合わせを組み合わせることはできません。なぜなら、両者の始値と終値が一致し、したがって最大ドローダウンの時間も一致するからです。選択したいのはドローダウンが異なる時間に発生するサンプルです。これによって、戦略の数に比例するのではなく、少ない回数でポジション量を減らすことができるため、収益性を高めることができます。
このようにして、16の標準化された戦略インスタンスを選択してみましょう。
また、取引には固定残高を使用します。これをおこなうには、FixedBalance = 10000を設定します。この選択では、正規化された戦略は個々に最大ドローダウンは1000となります。テスト結果を見てみましょう。
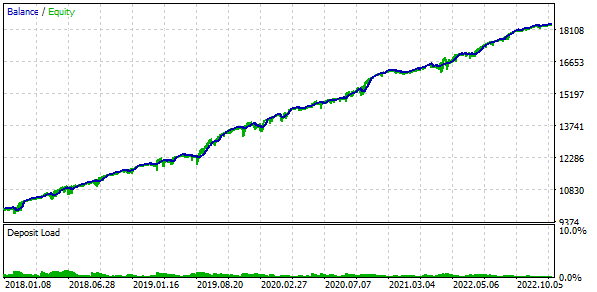
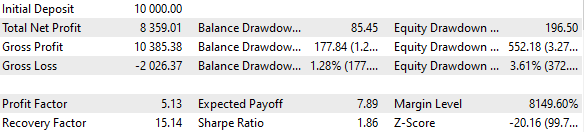
図3:ベースケースの結果
16コピーの戦略を組み合わせ、各コピーが建てるポジションのサイズを16分の1に縮小すれば、最大ドローダウンはUSD 1000ではなく、USD 552で済むことがわかりました。この戦略グループを正規化したグループにするために、1000 / 552 = 1.81に等しいスケーリングファクタScaleを適用できるように計算をおこなって10%のドローダウンを維持します。
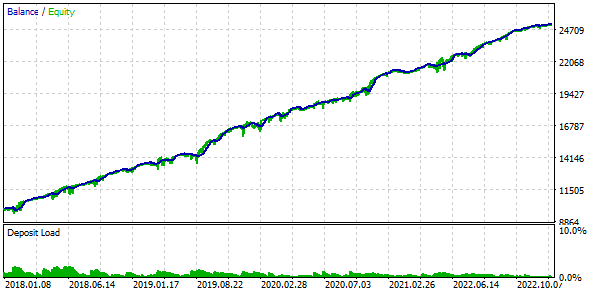

図4: 正規化グループによる基本ケースの結果(Scale=1.81)
FixedBalance= 10,000とScale = 1.81を使用する必要性について忘れないために、これらの数値を対応する入力のデフォルト値として設定します。次のようなコードが得られます。
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" input double expectedDrawdown_ = 10; // - Maximum risk (%) input double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency input double scale_ = 1.81; // - Group scaling multiplier input group "::: Other parameters" input ulong magic_ = 27183; // - Magic CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Create an EA handling virtual positions expert = new CVirtualAdvisor(magic_, "SimpleVolumes_Baseline"); // Create and fill the array of all selected strategy instances CVirtualStrategy *strategies[] = { new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 48, 1.6, 0.1, 0, 11200, 1160, 51000, 3, 3000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 156, 0.4, 0.7, 0, 15800, 905, 18000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 156, 1, 0.8, 0, 19000, 680, 41000, 3, 900), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 14, 0.3, 0.8, 0, 19200, 495, 27000, 3, 1100), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 38, 1.4, 0.1, 0, 19600, 690, 60000, 3, 1000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 98, 0.9, 1, 0, 15600, 1850, 7000, 3, 1300), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 44, 1.8, 1.9, 0, 13000, 675, 45000, 3, 600), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 86, 1, 1.7, 0, 17600, 1940, 56000, 3, 1000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 230, 0.7, 1.2, 0, 8800, 1850, 2000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 44, 0.1, 0.6, 0, 10800, 230, 8000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 108, 0.6, 0.9, 0, 12000, 1080, 46000, 3, 800), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 182, 1.8, 1.9, 0, 13000, 675, 33000, 3, 600), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 62, 0.1, 1.5, 0, 16800, 255, 2000, 3, 800), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 12, 1.4, 1.7, 0, 9600, 440, 59000, 3, 700), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 24, 1.7, 2, 0, 11600, 1930, 23000, 3, 700), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 30, 1.1, 0.1, 0, 18400, 1295, 27000, 3, 1500), }; // Add a group of selected strategies to the strategies expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
それを現在のフォルダのBaselineExpert.mq5ファイルに保存します。
比較のための基本的なバージョンは準備できたので、次は戦略インスタンスをグループに選択する自動化の実装に取りかかりましょう。
戦略の練り直し
戦略のコンストラクタのパラメータとして代用しなければならない入力の組み合わせは、現在CSVファイルに保存されています。つまり、そこから読み込む場合は、文字列型の値として受け取ることになります。戦略のコンストラクタに、文字列を受け取り、そこから必要なパラメータをすべて取り出すものがあれば便利です。コンストラクタにパラメータを渡すこのメソッドは、例えばInput_Structライブラリを使用して実装するつもりですが、当面は、簡単にするために、この型の2番目のコンストラクタを追加しましょう。
//+------------------------------------------------------------------+ //| Trading strategy using tick volumes | //+------------------------------------------------------------------+ class CSimpleVolumesStrategy : public CVirtualStrategy { ... public: CSimpleVolumesStrategy(const string &p_params); ... }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(const string &p_params) { string param[]; int total = StringSplit(p_params, ',', param); if(total == 11) { m_symbol = param[0]; m_timeframe = (ENUM_TIMEFRAMES) StringToInteger(param[1]); m_signalPeriod = (int) StringToInteger(param[2]); m_signalDeviation = StringToDouble(param[3]); m_signaAddlDeviation = StringToDouble(param[4]); m_openDistance = (int) StringToInteger(param[5]); m_stopLevel = StringToDouble(param[6]); m_takeLevel = StringToDouble(param[7]); m_ordersExpiration = (int) StringToInteger(param[8]); m_maxCountOfOrders = (int) StringToInteger(param[9]); m_fittedBalance = StringToDouble(param[10]); CVirtualReceiver::Get(GetPointer(this), m_orders, m_maxCountOfOrders); // Load the indicator to get tick volumes m_iVolumesHandle = iVolumes(m_symbol, m_timeframe, VOLUME_TICK); // Set the size of the tick volume receiving array and the required addressing ArrayResize(m_volumes, m_signalPeriod); ArraySetAsSeries(m_volumes, true); } }
このコンストラクタは、すべてのパラメータの値が正しい順序で1つの文字列にまとめられ、カンマで区切られていることを前提としています。このような文字列は、コンストラクタの唯一のパラメータとして渡され、カンマで分割され、適切なデータ型に変換された後、各部分が目的のクラスプロパティに割り当てられます。
現在のフォルダにあるSimpleVolumesStrategy.mqhファイルに変更を保存しましょう。
EAの改良
SimpleVolumesExpert.mq5 EAを例にとって説明しましょう。このEAを基に新しいEAを作成し、先ほど手動選択に使用したのと同じCSVファイルから複数の戦略インスタンスを選択し、最適化をおこないます。
まず最初に、戦略インスタンスパラメータのリストを読み込み、グループに選択できるように入力グループを追加しましょう。分かりやすくするために、1つのグループに同時に含まれる戦略の数を8つに制限し、8より小さい数を設定できるようにします。
input group "::: Selection for the group" sinput string fileName_ = "Params_SV_EURGBP_H1.csv"; // File with strategy parameters (*.csv) sinput int count_ = 8; // Number of strategies in the group (1 .. 8) input int i0_ = 0; // Strategy index #1 input int i1_ = 1; // Strategy index #2 input int i2_ = 2; // Strategy index #3 input int i3_ = 3; // Strategy index #4 input int i4_ = 4; // Strategy index #5 input int i5_ = 5; // Strategy index #6 input int i6_ = 6; // Strategy index #7 input int i7_ = 7; // Strategy index #8
count_が8より小さい場合、その中で指定された戦略インデックスを定義するパラメータの数だけが、列挙に使用されます。
次に問題に遭遇します。Params_SV_EURGBP_H1.csv戦略パラメータを含むファイルを端末データディレクトリに配置すると、このEAが端末チャート上で起動されたときのみ、そこから読み込まれます。テスターで実行すると、このファイルは検出されません。テスターは独自のデータディレクトリで動作するからです。もちろん、テスターデータディレクトリの場所を探し、そこにファイルをコピーすることはできますが、これは不便であり、次の問題を解決するものではありません。
次の問題は、最適化を実行しているとき(まさにこのためにこのEAを開発しているのです)、MQL5クラウドネットワークのエージェントはもちろん、ローカルネットワークのエージェントクラスタもデータファイルを利用できないことです。
上記の問題に対する一時的な解決策として、データファイルの内容をEAのソースコードに含めることが考えられますが、外部CSVファイルを使用する機能は提供するつもりです。そのためには、tester_fileプリプロセッサディレクティブやOnTesterInit()イベントハンドラなど、MQL5言語のツールを使用する必要があります。また、すべての端末とテストエージェントに共通のデータフォルダがローカルコンピュータにあることを活用します。
MQL5リファレンスに記載されているように、tester_fileディレクティブはテスターのファイル名を指定することができます。つまり、テスターがリモートサーバー上で動作していても、このファイルはリモートサーバーに送られ、テストエージェントのデータディレクトリに配置されます。これはまさに私たちに必要なことのように思えますが、そうではありません。このファイル名は定数とし、コンパイル時に定義します。そのため、最適化開始時にのみEAの入力に渡される任意のファイル名を代入することはできません。
以下の回避策を使用しなければなりません。固定ファイル名を決めてEAに設定します。例えば、これはEAそのものの名前から構築することができます。tester_fileディレクティブで指定するのは、この定数名です。
#define PARAMS_FILE __FILE__".params.csv" #property tester_file PARAMS_FILE
次に、戦略パラメータセットを文字列として配列するグローバル変数を追加します。この配列にファイルからデータを読み込みます。
string params[]; // Array of strategy parameter sets as strings
ファイルからデータを読み込む関数を書いてみましょう。まず、端末の共有データフォルダ、あるいはデータフォルダに指定した名前のファイルが存在するかどうかを確認します。もし存在すれば、データフォルダ内の選択した固定名のファイルにコピーします。次に、読み込み用の固定名のファイルを開き、そこからデータを読み込みます。
//+------------------------------------------------------------------+ //| Load strategy parameter sets from a CSV file | //+------------------------------------------------------------------+ int LoadParams(const string fileName, string &p_params[]) { bool res = false; // Check if the file exists in the shared folder and in the data folder if(FileIsExist(fileName, FILE_COMMON)) { // If it is in the shared folder, then copy it to the data folder with a fixed name res = FileCopy(fileName, FILE_COMMON, PARAMS_FILE, FILE_REWRITE); } else if(FileIsExist(fileName)) { // If it is in the data folder, then copy it here, but with a fixed name res = FileCopy(fileName, 0, PARAMS_FILE, FILE_REWRITE); } // If there is a file with a fixed name, that is good as well if(FileIsExist(PARAMS_FILE)) { res = true; } // If the file is found, then if(res) { // Open it int f = FileOpen(PARAMS_FILE, FILE_READ | FILE_TXT | FILE_ANSI); // If opened successfully if(f != INVALID_HANDLE) { FileReadString(f); // Ignore data column headers // For all further file strings while(!FileIsEnding(f)) { // Read the string and extract the part containing the strategy inputs string s = CSVStringGet(FileReadString(f), 10, 21); // Add this part to the array of strategy parameter sets APPEND(p_params, s); } FileClose(f); return ArraySize(p_params); } } return 0; }
したがって、このコードがリモートのテストエージェントで実行された場合、最適化を開始したメインのEAインスタンスから固定名のファイルが、すでにそのデータフォルダに渡されます。これを実現するには、OnTesterInit()イベントハンドラに、この読み込み関数の呼び出しを追加する必要があります。
この同じハンドラで、最適化パラメータ設定ウィンドウで手動で設定する必要がないように、パラメータセットインデックス反復の範囲の値を設定します。8より小さい数の集合からグループを選択する必要がある場合、ここでは不要なインデックスの列挙も自動的に無効にします。
//+------------------------------------------------------------------+ //| Initialization before optimization | //+------------------------------------------------------------------+ int OnTesterInit(void) { // Load strategy parameter sets int totalParams = LoadParams(fileName_, params); // If nothing is loaded, report an error if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_FAILED); } // Set scale_ to 1 ParameterSetRange("scale_", false, 1, 1, 1, 2); // Set the ranges of change for the parameters of the set index iteration for(int i = 0; i < 8; i++) { if(i < count_) { ParameterSetRange("i" + (string) i + "_", true, 0, 0, 1, totalParams - 1); } else { // Disable the enumeration for extra indices ParameterSetRange("i" + (string) i + "_", false, 0, 0, 1, totalParams - 1); } } return(INIT_SUCCEEDED); }
最適化の基準として、最大ドローダウンが初期固定残高の10%で得られる最大利益を選択します。これをおこなうには、パラメータ値を計算するOnTester()ハンドラを EA に追加します。
//+------------------------------------------------------------------+ //| Test results | //+------------------------------------------------------------------+ double OnTester(void) { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = fixedBalance_ * 0.1 / balanceDrawdown; // Recalculate the profit double fittedProfit = profit * coeff; return fittedProfit; }
このパラメータを計算することで、このパスで達成された最大ドローダウンを考慮に入れ、ドローダウンが10%に達するようにスケーリング乗数を設定した場合、どの程度の利益が得られるかという情報を1パスで即座に得ることができます。
OnInit()EA初期化ハンドラでは、最初に戦略のパラメータセットを読み込む必要もあります。次に、入力からインデックスを取り出し、その中に重複がないことを確認します。そうでない場合、そのような入力を持つパスは開始されません。問題がなければ、戦略パラメータセットの配列から指定したインデックスを持つセットを抽出し、EAに追加します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Load strategy parameter sets int totalParams = LoadParams(fileName_, params); // If nothing is loaded, report an error if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_PARAMETERS_INCORRECT); } // Form the string from the parameter set indices separated by commas string strIndexes = (string) i0_ + "," + (string) i1_ + "," + (string) i2_ + "," + (string) i3_ + "," + (string) i4_ + "," + (string) i5_ + "," + (string) i6_ + "," + (string) i7_; // Turn the string into the array string indexes[]; StringSplit(strIndexes, ',', indexes); // Leave only the specified number of instances in it ArrayResize(indexes, count_); // Multiplicity for parameter set indices CHashSet<string> setIndexes; // Add all indices to the multiplicity FOREACH(indexes, setIndexes.Add(indexes[i])); // Report an error if if(count_ < 1 || count_ > 8 // number of instances not in the range 1 .. 8 || setIndexes.Count() != count_ // not all indexes are unique ) { return INIT_PARAMETERS_INCORRECT; } // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Create an EA handling virtual positions expert = new CVirtualAdvisor(magic_, "SimpleVolumes_OptGroup"); // Create and fill the array of all strategy instances CVirtualStrategy *strategies[]; FOREACH(indexes, APPEND(strategies, new CSimpleVolumesStrategy(params[StringToInteger(indexes[i])]))); // Create and add selected groups of strategies to the EA expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
また、少なくともOnTesterDeinit() の空のハンドラをEAに追加する必要があります。これはOnTesterInit()ハンドラを持つEAのコンパイラ要件です。
得られたコードを現在のフォルダのOptGroupExpert.mq5ファイルに保存します。
シンプルな構成
取引戦略パラメータのセットを含む作成された CSV ファイルへのパスを指定して、実装されたEAの最適化を開始します。10%のドローダウンに対して正規化された利益であるユーザー基準を最大化する遺伝的アルゴリズムを使用します。最適化には同じテスト期間(2018年から2022年まで)を使用します。
ローカルネットワーク上で13のテストエージェントを使用し、10,000回を超える標準的な遺伝的最適化ブロックを完了するのに約9時間を要しました。驚くべきことに、結果はベースラインセットを上回りました。最適化結果表のトップはこのようになっています。
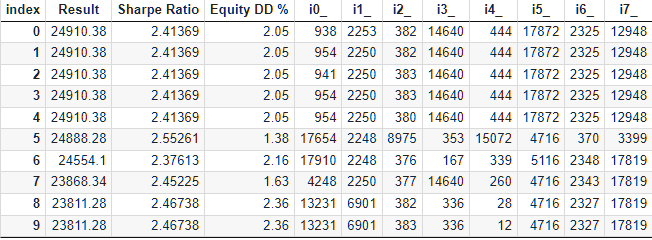
図6:グループへの自動選択の最適化の結果
最上位の結果を詳しく見てみましょう。計算された利益を得るには、表の最初の行からすべての指数を指定することに加えて、scale_パラメータを、指定された10%のドローダウン(USD 10,000からUSD 1000)の、株式によって達成された最大ドローダウンに対する比率に等しく設定する必要があります。表ではパーセンテージで表示しています。しかし、より正確な計算のためには、相対値ではなく絶対値を取る方がよいです。
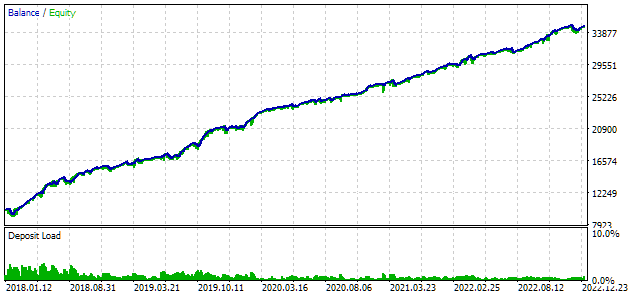
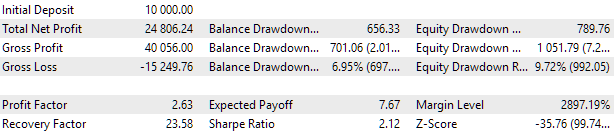
図7:最上位グループのテスト結果
利益結果は計算結果とわずかに異なりますが、この差は非常に些細なものであり、無視できます。しかし、自動選択によって手動で選択したグループよりも優れたグループを見つけることができたのは明らかです。利益はUSD 15,200ではなくUSD 24,800となり、1.5倍以上も向上しました。このプロセスには人間の介入は必要ありませんでした。これはすでに非常に心強い結果です。安心して息をつき、より熱意をもってこの方向に取り組み続けることができます。
選考プロセスにおいて、労力をかけずに改善できることがあるかどうか見てみましょう。戦略をグループ分けした結果を表にすると、最初の5つのグループは同じ結果であり、その差はパラメータセットの1つか2つの指標にしかないことがよくわかります。これは、戦略パラメータのセットを含む元のファイルには、同じ結果を与えるものもあったが、あまり重要でないパラメータで互いに異なっていたためです。したがって、同じ結果を与える2つの異なるデータセットが2つのグループに分類される場合、これら2つのグループは同じ結果をもたらす可能性があります。
これはまた、最適化の際に、複数の「同一の」戦略パラメータセットを1つのグループに受け入れることができることを意味します。これでは、ドローダウンを減らすために努力しているグループの多様性が低下してしまいます。このような「同じ」セットがグループになってしまうような最適化パスをなくすようにしましょう。
クラスタリングによる構成
このようなグループを取り除くために、元のCSVファイルから戦略パラメータのすべてのセットをいくつかのクラスタに分割します。各クラスタには、完全に同じか、似たような結果を与えるパラメータのセットが含まれます。クラスタリングには、既製のk平均クラスタリングアルゴリズムを使用します。signalPeriod_、signalDeviation_、signaAddlDeviation_、openDistance_、stopLevel_、takeLevel_の列をクラスタリングの入力データとします。以下のPythonコードを使用して、すべてのパラメータセットを64クラスタに分割してみましょう。
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df.to_csv('Params_SV_EURGBP_H1-with_cluster.csv', index=False)
これでパラメータセットファイルにクラスタ番号の列が1つ追加されました。このファイルを使用するために、OptGroupExpert.mq5を基に新しいEAを作成し、それに少し追加してみましょう。
別のセットを追加して、初期化時に選択されたパラメータのセットを含むクラスタの数で埋めてみましょう。これは、パラメータセット群の全クラスタ数が異なることが判明した場合にのみ実行します。ファイルから読み込まれた文字列の最後には、戦略のパラメータとは関係のないクラスタ番号が含まれているため、戦略のコンストラクタに渡す前に、パラメータ文字列から取り除く必要があります。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ... // Multiplicities for parameter and cluster set indices CHashSet<string> setIndexes; CHashSet<string> setClusters; // Add all indices and clusters to the multiplicities FOREACH(indexes, { setIndexes.Add(indexes[i]); string cluster = CSVStringGet(params[StringToInteger(indexes[i])], 11, 12); setClusters.Add(cluster); }); // Report an error if if(count_ < 1 || count_ > 8 // number of instances not in the range 1 .. 8 || setIndexes.Count() != count_ // not all indexes are unique || setClusters.Count() != count_ // not all clusters are unique ) { return INIT_PARAMETERS_INCORRECT; } ... FOREACH(indexes, { // Remove the cluster number from the parameter set string string param = CSVStringGet(params[StringToInteger(indexes[i])], 0, 11); // Add a strategy with a set of parameters with a given index APPEND(strategies, new CSimpleVolumesStrategy(param)) }); // Form and add a group of strategies to the EA expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
このコードを現在のフォルダのOptGroupClusterExpert.mq5ファイルに保存します。
この種の最適化の配置は、それ自身の欠点も明らかにしています。遺伝的アルゴリズムの初期母集団に、少なくとも2つの同じパラメータセット指標を持つ個体が多すぎると、母集団が急速に退化し、最適化アルゴリズムが早期に終了してしまいます。しかし、もう一回起動すれば、もっと運がよくなるかもしれません。そして最適化は最後まで進み、非常に良い結果が得られます。
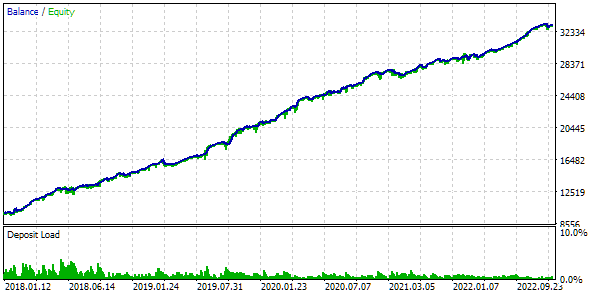
図8:クラスタリングによる最上位グループのテスト結果
集団の退化を防ぐ確率は、入力のセットを混ぜ合わせるか、グループに含まれる戦略の数を減らすことで高めることができます。いずれにせよ、最適化に費やす時間は、クラスタリングなしの最適化に比べて1.5倍から2倍短縮されます。
クラスタ内の1つのインスタンス
母集団の退化を防ぐもうひとつの方法があります。与えられたクラスタに属するセットをひとつだけファイルに残すことです。以下のPythonコードを使用して、このようなデータを含むファイルを生成することができます。
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df = df.sort_values(['cluster', 'Sharpe Ratio']).groupby('cluster').agg('last').reset_index()
clusters = df.cluster
df = df.iloc[:, 1:]
df['cluster'] = clusters
df.to_csv('Params_SV_EURGBP_H1-one_cluster.csv', index=False
このCSVファイルには、この記事で書いた2つのEAのいずれかを使用して最適化することができます。
もし残りのセットが少なすぎることがわかったら、クラスタの数を増やすか、1つのクラスタからいくつかのセットを取り出します。
このEAの最適化結果を見てみましょう。
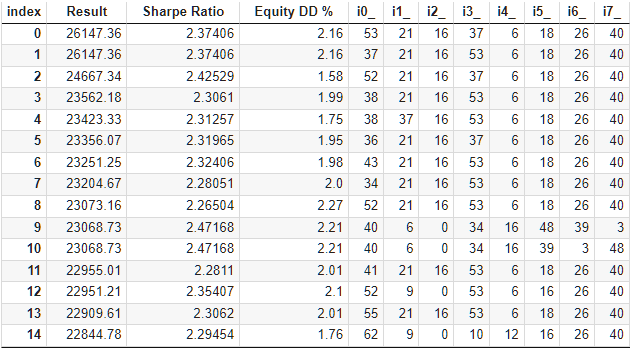
図9:64クラスタによるグループへの自動選択の最適化結果
これらは前の2つのアプローチとほぼ同じです。以前発見されたものを凌駕する1つのグループが発見されました。しかし、これは設定されたリミットの優劣というよりも、運の問題です。以下は、最上位グループのシングルパスの結果です。
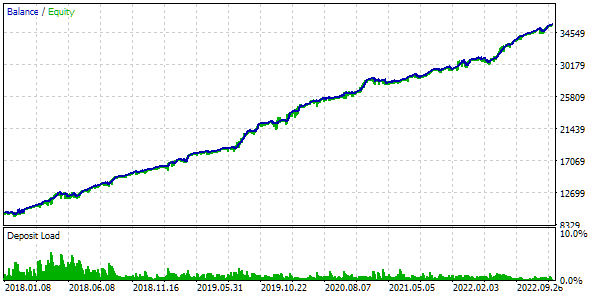
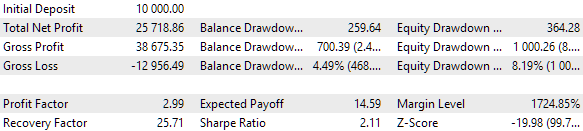
図10:クラスタ内の1セットでの最上位グループのテスト結果
結果表では、戦略パラメータセットのインデックスの順番が異なるだけで、グループの繰り返しが目立ちます。
これは、入力パラメータのインデックスの組み合わせが増加シーケンスを形成しなければならないという条件チェックをEAに追加することで回避できます。しかし、これもまた、集団の退化が非常に速いため、遺伝的最適化の使用に問題が生じます。完全な列挙のためには、64セットから8セットのグループを1つ選択するだけでも、パス数が多すぎます。EAの反復入力を戦略パラメータセットのインデックスに変換する方法を、何らかの方法で変更する必要がありますが、これらはすでに将来の計画に入っています。
注目すべきは、クラスタから1セットを使用した場合、手動選択と同等の結果(約USD 15,000の利益)が、文字通り最適化の最初の数分で得られることです。ただし、最良の結果を見つけるためには、最適化のほぼ最後まで待つ必要があります。
結論
さて何があるでしょうか。パラメータセットをグループに自動選択することで、手動選択よりも収益性の高い結果が得られることを確認しました。プロセス自体にはもっと時間がかかるでしょうが、今回は人間が参加する必要がありません。さらに、必要であれば、より多くのテストエージェントと交換することで大幅に削減することもできます。
これで次に進むことができます。戦略インスタンスのグループを選択する機能ができれば、得られた良いグループからグループを自動作成することを考えることができます。EAのコードに関しては、パラメータを正しく読み取る方法と、EAに1つだけでなく複数の戦略グループを追加する方法の違いだけでしょう。ここでは、戦略とグループの最適化されたパラメータセットを、別々のファイルではなくデータベースに保存するための統一フォーマットについて考えることができます。
また、パラメータ最適化がおこなわれた期間以外のテスト期間中に、優秀なグループの振る舞いを確認するのもいいでしょう。これはおそらく、次回の記事で試みます。
ご清聴ありがとうございました。またすぐにお会いしましょう。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14478
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ビクター、フィードバックありがとう!
私もエクセルの特別な関数は知りません:
ユーリ、ありがとう。
でも、Profit、Expected Payoff、Profit Factor、Recovery Factor、Sharpe Ratio、Equity DD%、Trades、に_を付けて列を追加すると書いてありましたね。どのような順序で追加すればうまくいくのでしょうか?元の列の後にそれぞれの列を追加するのか、それともテーブルの最後にすべて追加するのか。既に編集されたテーブルから行うように、列名のスクリーンショットを作成するか、サンプルとして既に編集された小さなファイルを添付してください。
また、Expert Advisorを最適化する際、複雑な基準を設定するのでしょうか、それとも単にバランス最大値を設定するのでしょうか?試してみたところ、5年間で100-180トレード程度と、あまり多くないトレード数が見つかりました。
また、EAがシグナルを読み取り、指定されたタイムフレームで新しいバーのオープニングで取引を開始するようにしたいのですが、現在動作しているようにティックごとに取引を伴います。このように動作させるには、新しいバーの発生をチェックする機能をどこに追加すればよいでしょうか?
足し算の順序が重要なのは、いかに速く行うかという点だけである。表の最後にこれらの列を追加し(AC:AI列)、次にいくつかの新しい列で偏差を計算し(AJ: AP)、AQでAJ:APを 合計し、ARで最大スケーリングファクターScaleを求め、ASで比率Res = AR/AQを計算 する方が早かった。これでソートするには、ASの値のみを新しいAT列にコピーする必要があります。例を添付します。
複雑な基準で最適化を開始し、次に他のすべての基準で最適化を行う。案件の数は、比較的少ないものも含め、さまざまです。それはSLとTPレベルの大きさによります。
次回は、新しいバーをチェックする機能と、そこでの適用方法についてお話しする予定です。
次回は、新しいバーをチェックする機能と、そこでの適用方法についてお話しする予定です。
ユーリさん、テーブルの例をありがとうございます。前回の記事(7)のものだと理解していますので、それも役に立つと思いますが、この記事(6)のOptGroupClusterExpert.mq5 Expert Advisorの入力にフィードするテーブルの例をお聞きしました。私の理解では、このテーブルは Params_SV_EURGBP_H1-with_cluster.csv と Params_SV_EURGBP_H1.csv と呼ばれています。それが私がお尋ねしたものです。例としてこれらのテーブルを添付してください。
次の記事について!待ちましょう:)もしストラテジーに、各ストラテジーの時間フィルター(取引期間の開始時間と終了時間を指定)とインジケーターのフィルター(2-3個)を追加できたら、市場全体を取引するための素晴らしいEAになると思います :).
ビクター、確かに、前のテーブルの例では少し先走りすぎた。
CSVファイルに数式が含まれなくなるので、Params_SV_EURGBP_H1.xlsxの 例を添付しました。CSVファイルに保存する必要がありますが、Excelが区切り文字として';'を使用している場合は、CSVファイル全体で';'を','に置き換える必要があります。Params_SV_EURGBP_H1-with_cluster.csv ファイルは、記事中にあるParams_SV_EURGBP_H1.csv から Python コードを使用して自動的に取得されます。
時間フィルタ と追加指標を追加することに関して:使用されているアーキテクチャはそれを可能にします - あなたは任意のフィルタと指標を持つ取引戦略の新しいクラス(CVirtualStrategyの後継)を作成することができます。私自身は時間フィルターを使うつもりはありません。時間制約を導入することで取引結果を改善できたことがないからです。一つのストラテジーで多くのインディケータを使うつもりはありません。なぜなら、入力シグナルの強力なフィルタリングは私にとってそれほど重要ではないからです。例えば、1つずつ異なるインディケータを使用するストラテジーのインスタンスをいくつか組み合わせることで、間接的に得ることができます。
新しい記事「 多通貨EAトレードの開発(第6回):インスタンスグループを自動的に選択する」が公開されました:
ByYuriy Bykov