
Разрабатываем мультивалютный советник (Часть 6): Автоматизируем подбор группы экземпляров
Введение
В предыдущей статье мы сделали важный шаг — реализовали возможность выбора варианта работы стратегий: с постоянным размером позиций и с переменным размером позиций. Это позволило нам ввести нормировку результатов работы стратегий по максимальной достигаемой просадке и обеспечило возможность их объединения в группы, для которых максимальная просадка тоже находилась в заданных пределах. Для демонстрации мы вручную отобрали из результатов оптимизации одиночного экземпляра стратегии несколько самых привлекательных комбинаций входных параметров и попробовали их объединить в одну группу или даже в группу из трёх групп по три стратегии. В последнем случае мы получили наилучшие результаты.
Однако если встаёт вопрос об увеличении количества стратегий в группах и количества разных объединяемых групп, то объём рутинной ручной работы сильно возрастает.
Во-первых, на каждом символе надо провести оптимизацию одиночного экземпляра стратегии с разными критериями оптимизации. Причём для каждого символа может понадобиться проводить отдельную оптимизацию для разных таймфреймов. А ещё для конкретно нашей модельной стратегии можно выполнять отдельную оптимизацию по видам открываемых ордеров (стоповые, лимитные или рыночные позиции).
Во-вторых, из полученных в результате оптимизаций наборов параметров, которых получается около 20 - 50 тысяч, необходимо выбрать небольшое количество (10 - 20) самых лучших. Однако лучшими они должны быть не только сами по себе, но и при совместной работе в группе. Процесс отбора и добавления экземпляров стратегий по одному тоже требует времени и терпения.
В-третьих, полученные группы надо в свою очередь объединять в вышестоящие группы, проводя нормировку. Если это делать вручную, то можно себе позволить только два или три уровня. Большее количество уровней группировки представляется уже слишком трудоёмким.
Поэтому попробуем автоматизировать данный этап разработки советника.
Намечаем путь
Сделать всё и сразу, к сожалению, вряд ли получится. Наоборот, сложность поставленной задачи может вызвать нежелание вообще браться за её решение. Поэтому попробуем подступиться к ней хотя бы с какого-нибудь края. Главной трудностью, мешающей приступить к реализации, является висящие в воздухе вопросы: "А будет ли нам с этого какая-то польза? Получится ли заменить ручной отбор на автоматический без потери качества (а желательно и с повышением)? Не окажется ли этот процесс в целом ещё более длительным, чем ручной отбор?"
Пока на них нет ответа, браться за решение тяжело. Поэтому сделаем так: первоочередной задачей поставим задачу проверки гипотезы, что автоматизированный отбор в группы может быть полезен. Для её проверки мы возьмем какой-либо набор результатов оптимизации одного экземпляра на одном символе и вручную отберём хорошую нормированную группу. Это будет наш базовый образец для сравнения результатов (baseline). Затем с минимальными затратами напишем простейшую реализацию автоматизации, позволяющую провести отбор группы не вручную и сравним результат группы, отобранной автоматизировано, с результатом группы, отобранной вручную. Если результаты сравнения покажут перспективность автоматизации, то можно будет заняться уже дальнейшей более красивой и правильной реализацией.
Подготовка исходных данных
Загрузим результаты оптимизации советника SimpleVolumesExpertSingle.mq5, полученные ранее при написании предыдущих частей, и выполним экспорт в XML.
Рис. 1. Экспорт результатов оптимизации для дальнейшей обработки
Для упрощения дальнейшего использования, добавим в этот файл дополнительные столбцы, содержащие значения тех параметров, которые не участвовали в оптимизации. Нам понадобится добавить symbol, timeframe, maxCountOfOrders и, что самое важное, fittedBalance. Значение последнего мы вычислим исходя из известной максимальной относительной просадки по средствам.
Если мы использовали начальный баланс $100000, то абсолютная просадка составила примерно 100000 * (relDDpercent / 100). Эта величина должна составлять 10% от fittedBalance, поэтому получаем:
fittedBalance = 100000 * (relDDpercent / 100) / 0.1 = relDDpercent * 10000
Значение таймфрейма, которое в коде задаётся константой PERIOD_H1, мы представим в виде его числового значения 16385.
В результате дополнений получим таблицу данных, которую сохраним в формате CSV. В транспонированном виде первые строки полученной таблицы выглядят так:
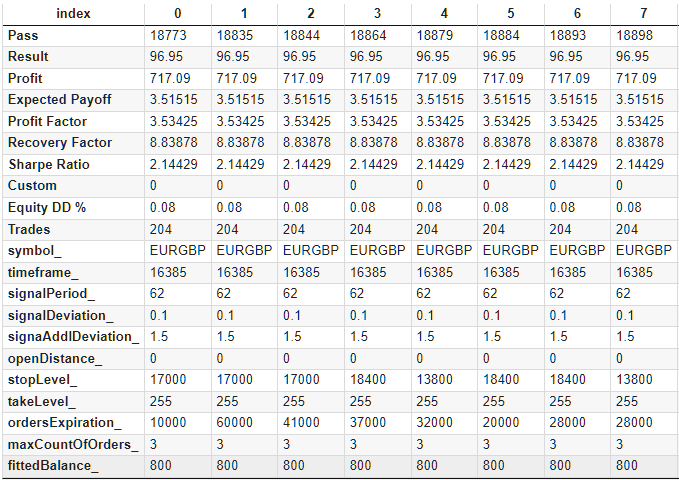
Рис. 2. Дополненная таблица с результатами оптимизации
По-хорошему, эту работу можно поручить компьютеру, например, используя библиотеку TesterCache, или реализовав какой-то ещё способ сохранения данных о каждом проходе при оптимизации. Но мы договорились сначала обойтись минимальными усилиями. Поэтому эту работу проделаем пока что вручную.
В этой таблице содержатся строки, в которых прибыль оказалась меньше нуля (примерно 1000 строк из 18000). Эти результаты нам точно не интересны, поэтому давайте сразу от них избавимся.
После этого исходные данные готовы для построения базового варианта и для последующего использования в подборе групп стратегий, которые смогут потягаться с базовым вариантом.
Baseline
Подготовка базового варианта представляет собой простой, но однообразный процесс. Для начала мы как-то должны отсортировать наши стратегии по убыванию "качества". Для оценки качества воспользуемся таким способом. Выделим набор столбцов, которые в этой таблице содержат различные метрики результатов: Profit, Expected Payoff, Profit Factor, Recovery Factor, Sharpe Ratio, Equity DD %, Trades. К каждому из них применим мин-макс масштабирование, приводящее к диапазону [0; 1]. Получим дополнительные столбцы с суффиксом '_s', по которым посчитаем для каждой строки сумму таким образом:
0.5 * Profit_s + ExpectedPayoff_s + ProfitFactor_s + RecoveryFactor_s + SharpeRatio_s + (1 - EquityDD_s) + 0.3 * Trades_s,
и добавим её как новый столбец таблицы. По нему выполним сортировку по убыванию.
Затем начнем идти по списку сверху вниз, добавляя в группу понравившиеся кандидаты и сразу проверяя, как они работают вместе. Мы будем стараться добавлять такие наборы параметров, которые как можно сильнее отличаются друг от друга и по параметрам, и по результатам.
Например, среди наборов параметров есть такие, которые отличаются только уровнем SL. Но если этот уровень ни разу не срабатывал за период тестирования, то при разных уровнях результаты будут получаться одинаковыми. Поэтому такие комбинации объединять нельзя, так как у них будет совпадать время открытия и закрытия позиций, а значит, и времена максимальных просадок. Мы же хотим подобрать такие экземпляры, чтобы просадки у них возникали в разное время. Это позволит нам увеличить прибыльность за счёт того, что объемы позиций можно будет уменьшить не пропорционально количеству стратегий, а в меньшее число раз.
Отберём таким образом 16 нормированных экземпляров стратегий.
Также мы будем применять торговлю с использованием фиксированного баланса для торговли. Для этого установим значение FixedBalance = 10000. При таком выборе нормированные стратегии по отдельности будут давать максимальную просадку, равную 1000. Посмотрим на результаты тестирования:
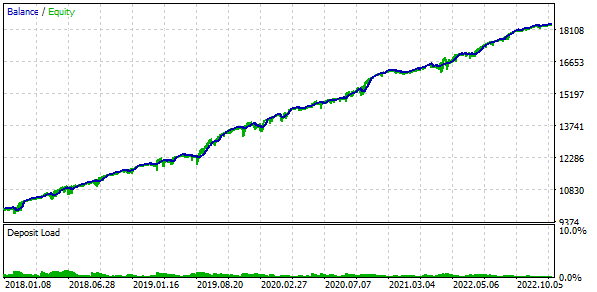
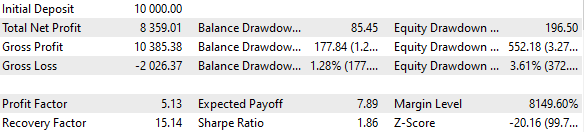
Рис. 3. Результаты базового варианта
Получается, что если мы объединяем 16 экземпляров стратегий и уменьшаем при этом в 16 раз размеры позиций, открываемых каждым экземпляром, то максимальная просадка составляет уже только $552 вместо $1000. Чтобы превратить эту группу стратегий в нормированную группу, рассчитаем, что для сохранения просадки в 10% можно применить масштабирующий множитель Scale равный 1000 / 552 = 1.81.
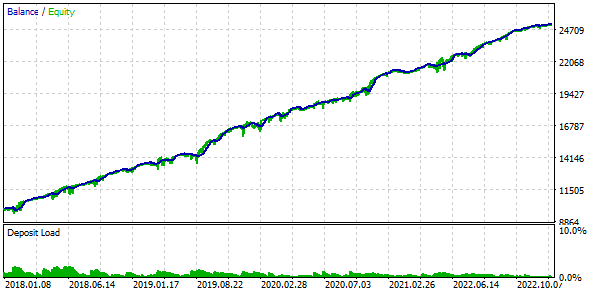

Рис. 4. Результаты базового варианта с нормированной группой (Scale=1.81)
Чтобы не забыть про необходимость использования FixedBalance = 10000 и Scale = 1.81, поставим эти числа в качестве значения по умолчанию для соответствующих входных параметров. Получим следующий код:
//+------------------------------------------------------------------+ //| Входные параметры | //+------------------------------------------------------------------+ input group "::: Управление капиталом" input double expectedDrawdown_ = 10; // - Максимальный риск (%) input double fixedBalance_ = 10000; // - Используемый депозит (0 - использовать весь) в валюте счета input double scale_ = 1.81; // - Масштабирующий множитель для группы input group "::: Прочие параметры" input ulong magic_ = 27183; // - Magic CVirtualAdvisor *expert; // Объект эксперта //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Устанавливаем параметры в классе управления капиталом CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Создаем эксперта, работающего с виртуальными позициями expert = new CVirtualAdvisor(magic_, "SimpleVolumes_Baseline"); // Создаем и наполняем массив из всех выбранных экземпляров стратегий CVirtualStrategy *strategies[] = { new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 48, 1.6, 0.1, 0, 11200, 1160, 51000, 3, 3000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 156, 0.4, 0.7, 0, 15800, 905, 18000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 156, 1, 0.8, 0, 19000, 680, 41000, 3, 900), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 14, 0.3, 0.8, 0, 19200, 495, 27000, 3, 1100), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 38, 1.4, 0.1, 0, 19600, 690, 60000, 3, 1000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 98, 0.9, 1, 0, 15600, 1850, 7000, 3, 1300), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 44, 1.8, 1.9, 0, 13000, 675, 45000, 3, 600), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 86, 1, 1.7, 0, 17600, 1940, 56000, 3, 1000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 230, 0.7, 1.2, 0, 8800, 1850, 2000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 44, 0.1, 0.6, 0, 10800, 230, 8000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 108, 0.6, 0.9, 0, 12000, 1080, 46000, 3, 800), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 182, 1.8, 1.9, 0, 13000, 675, 33000, 3, 600), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 62, 0.1, 1.5, 0, 16800, 255, 2000, 3, 800), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 12, 1.4, 1.7, 0, 9600, 440, 59000, 3, 700), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 24, 1.7, 2, 0, 11600, 1930, 23000, 3, 700), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 30, 1.1, 0.1, 0, 18400, 1295, 27000, 3, 1500), }; // Добавляем к эксперту группу из выбранных стратегий expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
Сохраним его в файле BaselineExpert.mq5 в текущей папке.
Базовый вариант для сравнения готов, теперь займемся реализацией автоматизации подбора экземпляров стратегий в группу.
Доработка стратегии
Комбинации входных параметров, которые мы должны будем подставлять как параметры конструктора стратегии, сейчас у нах хранятся в CSV-файле, то есть при чтении их оттуда мы получим их в виде значений типа string. Было бы удобно, если бы стратегия имела конструктор, принимающий одну строку, из которой он выделял бы все необходимые параметры. В дальнейшем мы планируем сделать именно такой способ передачи параметров в конструктор, например, с использованием библиотеки Input_Struct. Но пока для простоты добавим второй конструктор такого вида:
//+------------------------------------------------------------------+ //| Торговая стратегия с использованием тиковых объемов | //+------------------------------------------------------------------+ class CSimpleVolumesStrategy : public CVirtualStrategy { ... public: CSimpleVolumesStrategy(const string &p_params); ... }; //+------------------------------------------------------------------+ //| Конструктор | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(const string &p_params) { string param[]; int total = StringSplit(p_params, ',', param); if(total == 11) { m_symbol = param[0]; m_timeframe = (ENUM_TIMEFRAMES) StringToInteger(param[1]); m_signalPeriod = (int) StringToInteger(param[2]); m_signalDeviation = StringToDouble(param[3]); m_signaAddlDeviation = StringToDouble(param[4]); m_openDistance = (int) StringToInteger(param[5]); m_stopLevel = StringToDouble(param[6]); m_takeLevel = StringToDouble(param[7]); m_ordersExpiration = (int) StringToInteger(param[8]); m_maxCountOfOrders = (int) StringToInteger(param[9]); m_fittedBalance = StringToDouble(param[10]); CVirtualReceiver::Get(GetPointer(this), m_orders, m_maxCountOfOrders); // Загружаем индикатор для получения тиковых объемов m_iVolumesHandle = iVolumes(m_symbol, m_timeframe, VOLUME_TICK); // Устанавливаем размер массива-приемника тиковых объемов и нужную адресацию ArrayResize(m_volumes, m_signalPeriod); ArraySetAsSeries(m_volumes, true); } }
В этом конструкторе подразумевается, что значения всех параметров упакованы в одну строку в нужном порядке и разделены символом запятой. Такая строка передается в качестве единственного параметра конструктора, делится на части по запятым, и каждая часть, после преобразования в соответствующий тип данных, присваивается нужному свойству класса.
Сохраним изменения в файле SimpleVolumesStrategy.mqh в текущей папке.
Доработка советника
Возьмем в качестве образца советник SimpleVolumesExpert.mq5, и создадим на его основе новый советник, который будет заниматься оптимизацией выбора нескольких экземпляров стратегий из того же CSV-файла, что мы использовали для ручного отбора ранее.
Прежде всего, добавим группу входных параметров, с помощью которых можно будет обеспечить загрузку списка параметров экземпляров стратегий и их выбор в группу. Для простоты ограничим количество одновременно включаемых в группу стратегий восемью штуками и предусмотрим возможность задавать меньшее, чем 8, количество.
input group "::: Отбор в группу" sinput string fileName_ = "Params_SV_EURGBP_H1.csv"; // Файл с параметрами стратегий (*.csv) sinput int count_ = 8; // Количество стратегий в группе (1 .. 8) input int i0_ = 0; // Индекс стратегии #1 input int i1_ = 1; // Индекс стратегии #2 input int i2_ = 2; // Индекс стратегии #3 input int i3_ = 3; // Индекс стратегии #4 input int i4_ = 4; // Индекс стратегии #5 input int i5_ = 5; // Индекс стратегии #6 input int i6_ = 6; // Индекс стратегии #7 input int i7_ = 7; // Индекс стратегии #8
Если параметр count_ будет меньше 8, то для перебора будут использованы только указанное в нём количество параметров, задающих индексы стратегий.
Дальше мы сталкиваемся с некоторой сложностью. Дело в том, что если мы расположим файл с параметрами стратегий Params_SV_EURGBP_H1.csv в каталоге данных терминала, то он будет читаться оттуда только при запуске этого советника на графике терминала. Если запустить его в тестере, то этот файл не будет обнаружен, так как тестер работает со своим каталогом данных. Можно, конечно, найти местоположение каталога данных тестера и скопировать файл туда, но это неудобно и не решает следующую возникающую проблему.
Следующая проблема в том, что при запуске оптимизации (а мы именно для этого разрабатываем данный советник) файл с данными не будет доступен кластеру агентов в локальной сети, не говоря уж об агентах MQL5 Cloud Network.
Временным решением указанных проблем могло быть включение содержимого файла с данными в исходный код советника. Но мы попробуем всё-таки обеспечить возможность использования внешнего CSV-файла. Для этого нам понадобится воспользоваться такими средствами в языке MQL5 как директива препроцессора tester_file и обработчик события OnTesterInit(). Также воспользуемся наличием общей папки данных для всех терминалов и агентов тестирования на локальном компьютере.
Как указано в справке, директива tester_file позволяет задать имя файла для тестера, который будет передан тестеру в работу. Это подразумевает, что даже если тестер выполняется на удалённом сервере, то этот файл будет ему послан и размещён в каталоге данных агента тестирования. Вроде бы это как раз то, что нам нужно. Но не тут-то было! Это имя файла должно быть константой и определяться она должна в момент компиляции. Поэтому подставить в неё произвольной имя файла, передаваемое во входных параметрах советника только при запуске оптимизации, не представляется возможным.
Придётся применить такой обходной манёвр. Мы выберем какое-то фиксированное имя файла и зададим его в советнике. Можно сконструировать его, например, из имени самого советника. Именно это константное имя мы укажем в директиве tester_file:
#define PARAMS_FILE __FILE__".params.csv" #property tester_file PARAMS_FILE
Затем добавим глобальную переменную для массива наборов параметров стратегий в виде строк. Именно в этот массив мы будем читать данные из файла.
string params[]; // Массив наборов параметров стратегий в виде строк
Напишем функцию загрузки данных из файла, которая будет работать следующим образом. Сначала проверим, существует ли файл с указанным именем в общей папке данных терминала или в папке данных. Если он там есть, то мы копируем его в файл с выбранным фиксированным именем в папку данных. А дальше открываем для чтения файл с фиксированным именем, и читаем данные из него.
//+------------------------------------------------------------------+ //| Загрузка наборов параметров стратегий из CSV-файла | //+------------------------------------------------------------------+ int LoadParams(const string fileName, string &p_params[]) { bool res = false; // Проверим существование файла в общей папке и в папке данных if(FileIsExist(fileName, FILE_COMMON)) { // Если он есть в общей папке, то копируем его в папку данных с фиксированным именем res = FileCopy(fileName, FILE_COMMON, PARAMS_FILE, FILE_REWRITE); } else if(FileIsExist(fileName)) { // Если он есть в папке данных, то копируем его сюда же, но с фиксированным именем res = FileCopy(fileName, 0, PARAMS_FILE, FILE_REWRITE); } // Если файл с фиксированным именем есть, то тоже хорошо if(FileIsExist(PARAMS_FILE)) { res = true; } // Если файл обнаружен, то if(res) { // Открываем его int f = FileOpen(PARAMS_FILE, FILE_READ | FILE_TXT | FILE_ANSI); // Если открыли успешно if(f != INVALID_HANDLE) { FileReadString(f); // Игнорируем заголовки столбцов данных // Для всех дальнейших строк файла while(!FileIsEnding(f)) { // Читаем строку и выделяем из неё часть, содержащую входные параметры стратегии string s = CSVStringGet(FileReadString(f), 10, 21); // Добавляем эту часть в массив наборов параметров стратегий APPEND(p_params, s); } FileClose(f); return ArraySize(p_params); } } return 0; }
Таким образом, если данный код будет выполняться на удалённом агенте тестирования, то ему в папку данных уже будет передан файл с фиксированным именем от главного экземпляра советника, который запустил оптимизацию. Чтобы это произошло, необходимо добавить вызов данной функции загрузки в обработчик события OnTesterInit().
В этом же обработчике мы установим значения для диапазонов перебора индексов наборов параметров, чтобы не устанавливать их вручную в окне настроек параметров оптимизации. Если надо подбирать группу из меньшего, чем 8, количества наборов, то здесь мы также автоматически отключим перебор лишних индексов.
//+------------------------------------------------------------------+ //| Инициализация перед оптимизацией | //+------------------------------------------------------------------+ int OnTesterInit(void) { // Загружаем наборы параметров стратегий int totalParams = LoadParams(fileName_, params); // Если ничего не загрузили, то сообщим об ошибке if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_FAILED); } // Параметру scale_ устанавливаем значение 1 ParameterSetRange("scale_", false, 1, 1, 1, 2); // Параметрам перебора индексов наборов задаём диапазоны изменения for(int i = 0; i < 8; i++) { if(i < count_) { ParameterSetRange("i" + (string) i + "_", true, 0, 0, 1, totalParams - 1); } else { // Для лишних индексов отключаем перебор ParameterSetRange("i" + (string) i + "_", false, 0, 0, 1, totalParams - 1); } } return(INIT_SUCCEEDED); }
В качестве критерия оптимизации выберем максимальную прибыль, которую можно было бы получить при максимальной просадке в 10% от начального фиксированного баланса. Для этого добавим в советник обработчик OnTester(), в котором вычислим значение данного показателя:
//+------------------------------------------------------------------+ //| Результат тестирования | //+------------------------------------------------------------------+ double OnTester(void) { // Максимальная абсолютная просадка double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Прибыль double profit = TesterStatistics(STAT_PROFIT); // Коэффициент возможного увеличения размеров позиций для просадки 10% от fixedBalance_ double coeff = fixedBalance_ * 0.1 / balanceDrawdown; // Пресчитываем прибыль double fittedProfit = profit * coeff; return fittedProfit; }
Благодаря расчёту данного показателя мы сразу за один проход получаем информацию о том, какую прибыль можно получить, если учесть максимальную достигнутую просадку на данном проходе, установив масштабирующий множитель так, чтобы она могла достигать 10%.
В обработчике инициализации советника OnInit() мы точно также должны сначала загрузить наборы параметров стратегий. Затем берём индексы из входных параметров и проверяем, что среди них нет повторяющихся. Если это не так, то проход с такими входными параметрами не запускается. Если всё в порядке, то вытаскиваем из массива наборов параметров стратегий наборы с заданными индексами и добавляем их в советник.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Загружаем наборы параметров стратегий int totalParams = LoadParams(fileName_, params); // Если ничего не загрузили, то сообщим об ошибке if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_PARAMETERS_INCORRECT); } // Формируем строку из индексов наборов параметров, разделённых запятыми string strIndexes = (string) i0_ + "," + (string) i1_ + "," + (string) i2_ + "," + (string) i3_ + "," + (string) i4_ + "," + (string) i5_ + "," + (string) i6_ + "," + (string) i7_; // Превращаем эту строку в массив string indexes[]; StringSplit(strIndexes, ',', indexes); // Оставляем в нём только заданное количество экземпляров ArrayResize(indexes, count_); // Множество для индексов наборов параметров CHashSet<string> setIndexes; // Добавляем все индексы во множество FOREACH(indexes, setIndexes.Add(indexes[i])); // Сообщаем об ошибке, если if(count_ < 1 || count_ > 8 // количество экземпляров не в диапазоне 1 .. 8 || setIndexes.Count() != count_ // не все индексы уникальные ) { return INIT_PARAMETERS_INCORRECT; } // Устанавливаем параметры в классе управления капиталом CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Создаем эксперта, работающего с виртуальными позициями expert = new CVirtualAdvisor(magic_, "SimpleVolumes_OptGroup"); // Создаем и наполняем массив из всех экземпляров стратегий CVirtualStrategy *strategies[]; FOREACH(indexes, APPEND(strategies, new CSimpleVolumesStrategy(params[StringToInteger(indexes[i])]))); // Формируем и добавляем к эксперту выбранные группы стратегий expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
Также в данный советник нам понадобится обязательно добавить хотя бы пустой обработчик OnTesterDeinit(). Таково требование компилятора для советников, у которых присутствует обработчик OnTesterInit().
Полученный код сохраним в файле OptGroupExpert.mq5 в текущей папке.
Простое объединение
Запустим оптимизацию написанного советника, указав путь к созданному CSV-файлу с наборами параметров торговых стратегий. Будем использовать генетический алгоритм, максимизирующий пользовательский критерий, в качестве которого выступает нормированная на 10%-ную просадку прибыль. Период тестирования для оптимизации используем тот же самый: с 2018 по 2022 годы включительно.
Стандартный блок для генетической оптимизации из более чем 10000 прогонов занял примерно 9 часов при использовании 13 агентов тестирования в локальной сети. И, как ни странно, результаты действительно превзошли результаты базового набора. Вот как выглядит верх таблицы с результатами оптимизации:
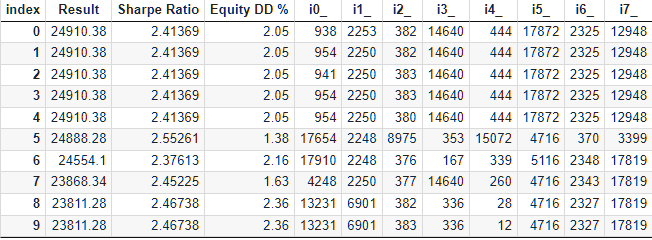
Рис. 6. Таблица с результатами оптимизации автоматизированного отбора в группу
Давайте посмотрим на лучший из результатов подробнее. Для получения расчётной прибыли нам необходимо будет помимо указания всех индексов из первой строки таблицы установить еще параметр scale_ равный отношению заданной 10%-ой просадки ($1000 от $10000) к достигнутой максимальной просадке по средствам. В таблице у нас она есть в процентах, но для более точного расчёта лучше взять её абсолютное, а не относительное значение.
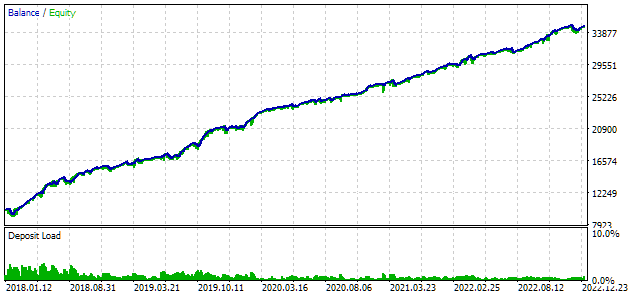
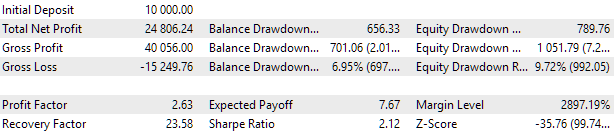
Рис. 7. Результаты тестирования лучшей группы
Результаты по прибыли немного отличаются от расчётных, но это отличие очень незначительное, и им можно пренебречь. Зато видно, что автоматизированный подбор смог найти более хорошую группу, чем мы отобрали вручную: прибыль составила $24800 вместо $15200, более чем в полтора раза больше. При этом процессе не потребовалось никакого человеческого участия. А это уже весьма обнадёживающий результат. Можно выдохнуть и продолжить уже с большим энтузиазмом работу в данном направлении.
Давайте посмотрим, можно ли что-то улучшить в процессе отбора, не прикладывая при этом больших усилий. В таблице с результатами отбора стратегий в группы сразу бросается в глаза, что у первых пяти групп результат одинаковый, а отличие у них только в одном или двух индексах наборов параметров. Это следствие того, что в нашем исходном файле с наборами параметров стратегий были такие, которые тоже давали одинаковый результат, но отличались между собой в каком-нибудь менее значимом параметре. Поэтому если в две группы попадает два разных набора, дающих одинаковые результаты, то такие две группы могут давать одинаковые результаты.
Это также означает, что при процессе оптимизации в одну группу могут браться несколько таких "одинаковых" наборов параметров стратегий. А это приводит к уменьшению разнообразия в группе, к которому мы стремимся для уменьшения просадки. Давайте попробуем как-то избавиться от проходов оптимизации, где в группу попадают такие "одинаковые" наборы.
Объединение с кластеризацией
Для избавления от подобных групп мы разделим все наборы параметров стратегий из исходного CSV-файла на несколько кластеров. В каждом кластере будут собраны наборы параметров, дающие либо полностью одинаковые либо похожие результаты. Для кластеризации воспользуемся готовым алгоритмом кластеризации k-средних. В качестве входных данных для кластеризации возьмём следующие столбцы: signalPeriod_, signalDeviation_, signaAddlDeviation_, openDistance_, stopLevel_, takeLevel_. Попробуем разбить все наши наборы параметров на 64 кластера с помощью такого кода на Python:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df.to_csv('Params_SV_EURGBP_H1-with_cluster.csv', index=False) Теперь в наш файл с наборами параметров добавлен ещё один столбец с номером кластера. Для использования этого файла создадим новый советник на основе OptGroupExpert.mq5 и внесём в него небольшие дополнения.
Добавим ещё одно множество и будем при инициализации заполнять его номерами кластеров, в которые попали выбранные наборы параметров. Запускать такой прогон будем только в том случае, если ещё и номера всех кластеров в этой группе наборов параметров оказались различными. Поскольку теперь в строках, прочитанных из файла, в конце содержится номер кластера, не относящийся к параметрам стратегии, то нам его необходимо убрать из строки параметров перед передачей в конструктор стратегии.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ... // Множества для индексов наборов параметров и кластеров CHashSet<string> setIndexes; CHashSet<string> setClusters; // Добавляем все индексы и кластеры во множества FOREACH(indexes, { setIndexes.Add(indexes[i]); string cluster = CSVStringGet(params[StringToInteger(indexes[i])], 11, 12); setClusters.Add(cluster); }); // Сообщаем об ошибке, если if(count_ < 1 || count_ > 8 // количество экземпляров не в диапазоне 1 .. 8 || setIndexes.Count() != count_ // не все индексы уникальные || setClusters.Count() != count_ // не все кластеры уникальные ) { return INIT_PARAMETERS_INCORRECT; } ... FOREACH(indexes, { // Убираем номер кластера из строки набора параметров string param = CSVStringGet(params[StringToInteger(indexes[i])], 0, 11); // Добавляем стратегию с набором параметров с заданным индексом APPEND(strategies, new CSimpleVolumesStrategy(param)) }); // Формируем и добавляем к эксперту группу стратегий expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
Сохраним этот код в файле OptGroupClusterExpert.mq5 в текущей папке.
При такой организации оптимизации тоже обнаружились свои недостатки. Если в генетическом алгоритме в начальную популяцию попало слишком много особей, у которых хотя бы два индекса наборов параметров одинаковы, то это приводит к быстрому вырождению популяции и преждевременной остановке алгоритма оптимизации. Но при другом запуске нам может повезти больше, и тогда оптимизация доходит до конца и находит достаточно хорошие результаты.
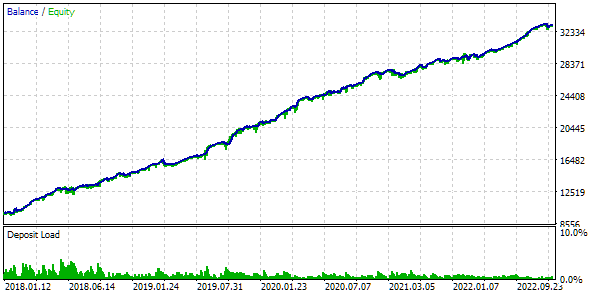
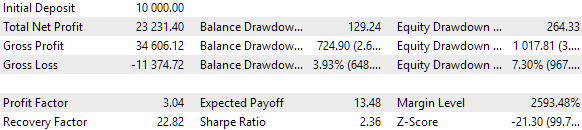
Рис. 8. Результаты тестирования лучшей группы с кластеризацией
Повысить вероятность предотвращения вырождения популяции можно либо перемешав наборы входных параметров или уменьшив количество включаемых в группу стратегий. В любом случае время, затрачиваемое на оптимизацию сокращается в полтора-два раза по сравнению с оптимизацией без кластеризации.
Один экземпляр в кластере
Есть и ещё один способ предотвратить вырождение популяции: оставить в файле только по одному набору, принадлежащему данному кластеру. Сформировать файл с такими данными можно с помощью такого кода на Python:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df = df.sort_values(['cluster', 'Sharpe Ratio']).groupby('cluster').agg('last').reset_index()
clusters = df.cluster
df = df.iloc[:, 1:]
df['cluster'] = clusters
df.to_csv('Params_SV_EURGBP_H1-one_cluster.csv', index=False Для этого CSV-файла с данными мы можем использовать при оптимизации любой из двух написанных в рамках данной статьи советников.
Если окажется, что у нас осталось слишком мало наборов, то можно либо увеличить количество кластеров, либо брать по несколько наборов из одного кластера.
Посмотрим на результаты оптимизации этого советника:
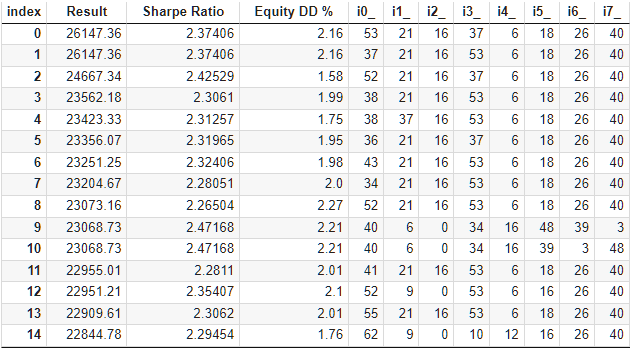
Рис. 9. Таблица с результатами оптимизации автоматизированного отбора в группу по 64 кластерам
Они примерно такие же, как и для двух предыдущих подходов. Была найдена одна группа, превосходящая все, найденные ранее. Хотя это вопрос скорее везения, чем превосходства ограничения количества наборов. Вот результаты одиночного прохода лучшей группы:
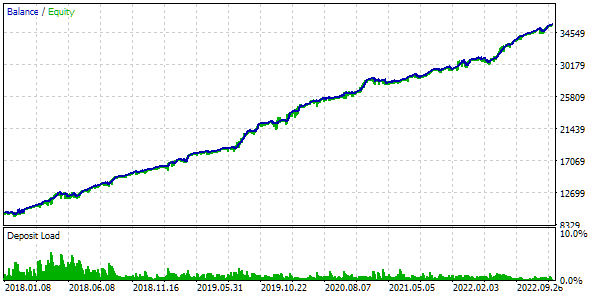
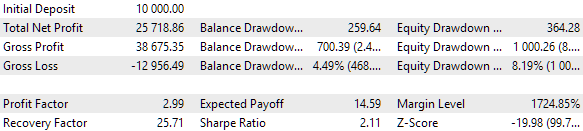
Рис. 10. Результаты тестирования лучшей группы с одним набором в кластере
В таблице результатов заметно повторение групп, отличающихся только порядком индексов наборов параметров стратегий.
От этого можно уйти, если добавить в советников проверку условия, что комбинация индексов во входных параметрах должна образовывать возрастающую последовательность. Но это снова проводит к проблемам с использованием генетической оптимизации из-за очень быстрого вырождения популяции. А для полного перебора даже подбор из 64 наборов одной группы из 8 наборов даёт слишком большое количество проходов. Скорее, надо как-то менять способ преобразования перебираемых входных параметров советника в индексы наборов параметров стратегий. Но это уже заметки на будущее.
Отдельно стоит отметить, что результаты, сравнимые с результатом ручного отбора (прибыль ~$15000), при использовании по одному набору из кластера находятся буквально в первые минуты оптимизации. Это для нахождения самых лучших результатов необходимо дожидаться почти самого конца оптимизации.
Заключение
Итак, посмотрим, что у нас получилось. Мы подтвердили, что автоматический подбор наборов параметров в группу может давать более хорошие результаты по прибыльности, чем подбор, осуществляемый вручную. На сам процесс понадобится больше времени, но это время не требует человеческого участия, что очень хорошо. К тому же мы можем его существенно сократить при необходимости, разменяв на использование большего количества агентов тестирования.
Теперь можем двигаться дальше. Если мы имеем возможность подбирать группы экземпляров стратегий, то можно задуматься и об автоматизации составления групп из полученных хороших групп. С точки зрения кода советника, отличие будет только в том, как правильно прочитать параметры и добавить к эксперту уже не одну, а несколько групп стратегий. Тут можно подумать об унифицированном формате хранения наборов оптимизируемых параметров для стратегий и групп в базе данных, а не в отдельных файлах.
Ещё было бы неплохо посмотреть на поведение наших хороших групп на периоде тестирования, находящегося вне периода, на котором проводилась оптимизация параметров. Наверное, именно это попробуем сделать в следующей статье.
Спасибо за внимание, до новых встреч!
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Отличная статья и система :)
- К каждому из них применим мин-макс масштабирование, приводящее к диапазону [0; 1]. Получим дополнительные столбцы с суффиксом '_s',
Юрий, а как Вы это сделали? Я в exel искал и ничего подобного там не увидел в функциях.
Виктор, спасибо за отзыв!
Специальной функции в Excel я тоже не знаю, делаю примерно так:
Виктор, спасибо за отзыв!
Специальной функции в Excel я тоже не знаю, делаю примерно так:
Спасибо Юрий.
А вот у вас написано про добавление колонок Profit, Expected Payoff, Profit Factor, Recovery Factor, Sharpe Ratio, Equity DD %, Trades, с _s. А их в каком порядке добавлять чтобы работало? Каждый столбик после оригинального столбика или можно все в конце таблицы добавить? Могли бы Вы сделать скриншот названий колонок как у Вы делаете со своей таблицы уже отредактированной, или просто прикрепите файл небольшой уже отредактированный для образца.
Ещё когда Вы оптимизируете советник, ставите по комплексному критерию или просто баланс макс? Я пробовал у меня что-то не очень большое количество трейдов в проходах находит, порядка 100-180 сделок за 5 лет.
И подскажите ещё пожалуйста, а если я хотел бы чтобы ваш советник сигнал считывал и открывал сделки на открытии нового бара на заданном таймфрейме, а вот сопровождал сделки каждый тик как сейчас работает. Куда мне добавить функцию проверки наступления нового бара, чтобы работало вот так?
Порядок добавления имеет значения только с точки зрения, как это сделать быстрее. Мне было быстрее эти столбцы добавить в конце таблицы (столбцы AC:AI), потом по ним посчитать отклонения еще в нескольких новых столбцах (AJ:AP), затем в AQ просуммировать AJ:AP, потом в AR находим максимальный коэффициент масштабирования Scale, и в AS вычисляем отношение Res = AR/AQ. Чтобы по нему отсортировать, надо скопировать из AS в новый столбец AT только значения. Прикрепил пример.
Оптимизацию начинаю с комплексного критерия, а затем по всем остальным. Количество сделок может получаться разным, в том числе и относительно небольшим. Это зависит от размеров уровней SL и TP.
В следующей статье планирую как раз рассказать в том числе и о функции проверки нового бара, и о том, как ее можно там применить.
Порядок добавления имеет значения только с точки зрения, как это сделать быстрее. Мне было быстрее эти столбцы добавить в конце таблицы (столбцы AC:AI), потом по ним посчитать отклонения еще в нескольких новых столбцах (AJ:AP), затем в AQ просуммировать AJ:AP, потом в AR находим максимальный коэффициент масштабирования Scale, и в AS вычисляем отношение Res = AR/AQ. Чтобы по нему отсортировать, надо скопировать из AS в новый столбец AT только значения. Прикрепил пример.
Оптимизацию начинаю с комплексного критерия, а затем по всем остальным. Количество сделок может получаться разным, в том числе и относительно небольшим. Это зависит от размеров уровней SL и TP.
В следующей статье планирую как раз рассказать в том числе и о функции проверки нового бара, и о том, как ее можно там применить.
Юрий спасибо за пример таблицы, Я как понимаю это из последней статьи (7), она тоже пригодится, но я у Вас просил пример таблицы из этой статьи (6), которую Вы подаёте на вход советника OptGroupClusterExpert.mq5. Как я понимаю эта таблица у Вас называется Params_SV_EURGBP_H1-with_cluster.csv и Params_SV_EURGBP_H1.csv . Вот их у Вас я и попросил. Прикрепите пожалуйста эти таблицы как пример.
По поводу следующей статьи круто! Будем ждать:) Если можно было бы неплохо добавить ещё в стратегию возможность временного фильтра для каждой стратегии (указывать чесы начала и конца торгового периода) и какие нибудь фильтры на индикаторах (2-3 штуки). тогда я думаю получится классный советник для торговли всего рынка целиком :)
Виктор, да, действительно, забежал немного вперед с предыдущим примером таблицы.
Прикрепил пример для Params_SV_EURGBP_H1.xlsx, так как в CSV-файле уже не будет формул. Вам надо будет его сохранить в CSV, и если Excel у вас использует в качестве разделителя символ ';', то надо во всём CSV-файле сделать замену ';' на ','. Файл Params_SV_EURGBP_H1-with_cluster.csv получается уже автоматически с использованием приведённого в статье кода на Python из Params_SV_EURGBP_H1.csv.
По поводу добавления временных фильтров и дополнительных индикаторов: используемая архитектура это позволяет - можно создавать новые классы торговых стратегий (наследников CVirtualStrategy) с любыми желаемыми фильтрами и индикаторами. Для себя использовать временные фильтры не планирую, так как ни разу не получалось улучшить торговые результаты путём введения временных ограничений. Использования многих индикаторов в одной стратегии тоже в планах нет, так как сильная фильтрация входных сигналов для меня менее важна. Её можно получить опосредованно через объединение нескольких экземпляров стратегий, использующих по одному разному индикатору, например.