
Developing a multi-currency Expert Advisor (Part 6): Automating the selection of an instance group
Introduction
In the previous article, we have implemented the ability to choose the strategy option - with a constant position size and with a variable position size. This allowed us to introduce normalization of the results of the strategies' work according to the maximum drawdown and provided the possibility of combining them into groups, for which the maximum drawdown was also within the specified limits. For the sake of demonstration, we manually selected several of the most attractive combinations of inputs from the optimization results of a single strategy instance and tried to combine them into one group or even into a group of three groups of three strategies. We got the best results in the latter case.
However, if we need to increase the number of strategies in groups and the number of different groups being combined, then the volume of routine manual work increases greatly.
First, we need to optimize a single instance of the strategy with different optimization criteria on each symbol. Moreover, for each symbol, it may be necessary to carry out separate optimization for different timeframes. For our specific model strategy, we can also perform separate optimization by types of orders opened (stop, limit or market positions).
Second, from the resulting sets of parameters, which amount to about 20-50 thousand, it is necessary to select a small number (10-20) of the best ones. However, they should be the best not only on their own, but also when working together in a group. Selecting and adding strategy instances one by one also takes time and patience.
Third, the obtained groups should in turn be combined into higher groups, carrying out standardization. If you do this manually, you can only afford two or three levels. More levels of grouping seem too labor-intensive.
Therefore, let's try to automate this stage of EA development.
Mapping out the path
Unfortunately, it is unlikely that we will be able to do everything at once. On the contrary, the complexity of the task at hand may cause a reluctance to take on its solution at all. Therefore, let us try to approach it from at least one side. The main difficulty that prevents us from starting implementation is the arising question: "Will this bring us any benefit? Will it be possible to replace manual selection with automatic one without loss of quality (and preferably with an increase)? Wouldn't this process as a whole be even longer than manual selection?"
Until we have answers, it is difficult to take on a solution. So let's do it this way: our current priority will be to test the hypothesis that automated group selection can be useful. To test it, we will take some set of optimization results of one instance on one symbol and manually select a good normalized group. This will be our baseline for comparing results. Then, with minimal costs, write the simplest automation allowing us to select a group. After that, we will compare the result of the group selected automatically with the result of the one selected manually. If the comparison results show the potential of automation, then it will be possible to move on to further, more beautiful and correct implementation.
Preparing initial data
Let's download the SimpleVolumesExpertSingle.mq5 EA optimization results obtained when implementing the previous parts and export to XML.
Fig. 1. Exporting optimization results for further processing
To simplify further use, we will add additional columns containing the values of the parameters not involved in the optimization. We will need to add symbol, timeframe, maxCountOfOrders and, more importantly, fittedBalance. We will calculate the value of the latter based on the known maximum relative drawdown by equity.
If we use the initial balance of USD 100,000, then the absolute drawdown is approximately 100,000 * (relDDpercent / 100). This value should be 10% of fittedBalance, so we get:
fittedBalance = 100000 * (relDDpercent / 100) / 0.1 = relDDpercent * 10000
We will represent the timeframe value specified in the code by the constant PERIOD_H1, as its numerical value of 16385.
As a result of the additions, we get a data table, which we save in CSV format. In transposed form, the first rows of the resulting table look like this:
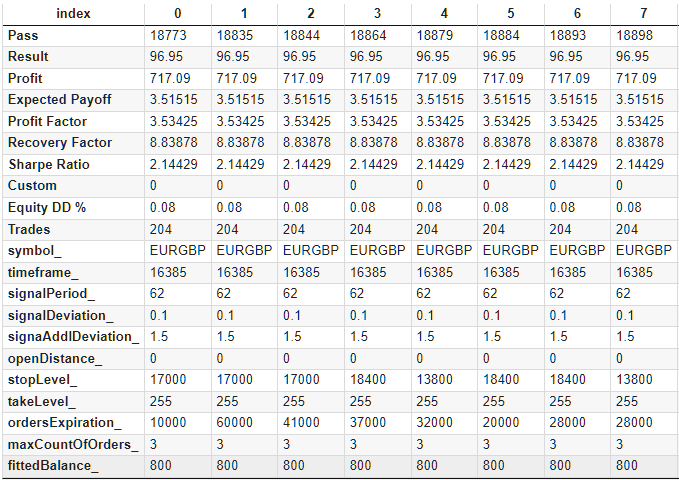
Fig. 2. Supplemented table with optimization results
This work could be delegated to a computer, for example, by using the TesterCache library or by implementing some other way of storing data about each pass during optimization. But I want to do this with minimal effort. Therefore, I will do this work manually for now.
This table contains rows with the profit less than zero (approximately 1000 rows out of 18,000). We are definitely not interested in these results, so let's get rid of them right away.
After this, the initial data is ready for constructing a baseline version and for subsequent use in selecting groups of strategies that can compete with the baseline version.
Baseline
Preparing a basic version is a simple but monotonous process. To begin with, we should somehow sort our strategies in the order of decreasing "quality". Let's use the following method to assess the quality. Highlight the set of columns that contain various performance metrics in this table: Profit, Expected Payoff, Profit Factor, Recovery Factor, Sharpe Ratio, Equity DD % and Trades. Each of them is subject to min-max scaling resulting in the range [0; 1]. Get additional columns with the the '_s' suffix and use them to calculate the sum for each row as follows:
0.5 * Profit_s + ExpectedPayoff_s + ProfitFactor_s + RecoveryFactor_s + SharpeRatio_s + (1 - EquityDD_s) + 0.3 * Trades_s,
and add it as the new table column. Sort it in descending order.
Then we will start going down the list, adding candidates we like to the group and immediately checking how they work together. We will try to add sets of parameters that are as different from each other as possible, both in parameters and in results.
For example, among the sets of parameters there are those that differ only in the SL level. But if this level has never been triggered during the testing period, then the results will be the same at different levels. Therefore, such combinations cannot be combined, since their opening and closing times will coincide, and therefore, the times of maximum drawdowns will coincide as well. We want to select the specimens whose drawdowns occur at different times. This will allow us to increase profitability due to the fact that the volume of positions can be reduced not proportionally to the number of strategies, but by a smaller number of times.
Let us select 16 standardized strategy instances in this way.
We will also trade using a fixed balance for trading. To do this, set FixedBalance = 10000. With this choice, the normalized strategies individually will give a maximum drawdown of 1000. Let's look at the test results:
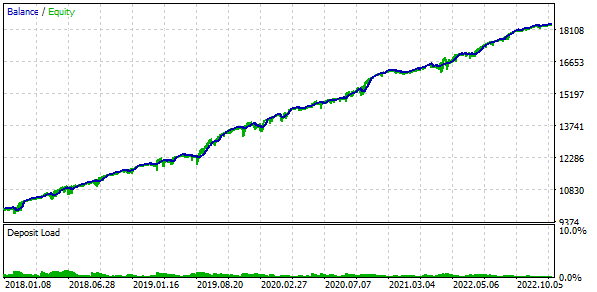
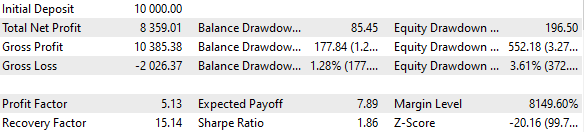
Fig. 3. Base case results
It turns out that if we combine 16 copies of strategies and reduce the size of positions opened by each copy by 16 times, then the maximum drawdown is only USD 552 instead of USD 1000. To turn this group of strategies into a normalized group, we perform calculations so that the scaling factor Scale equal to 1000 / 552 = 1.81 can be applied to maintain the 10% drawdown.
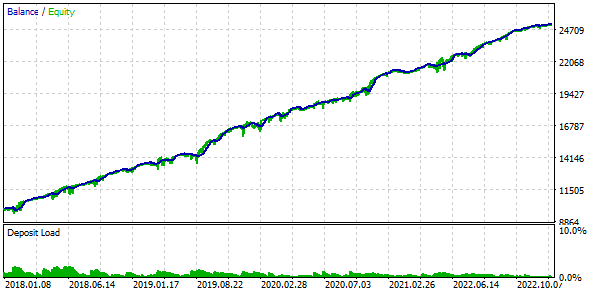

Fig. 4. Base case results with the normalized group (Scale=1.81)
To remember the need to use FixedBalance = 10,000 and Scale = 1.81, set these numbers as the default values for the corresponding inputs. We get the following code:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" input double expectedDrawdown_ = 10; // - Maximum risk (%) input double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency input double scale_ = 1.81; // - Group scaling multiplier input group "::: Other parameters" input ulong magic_ = 27183; // - Magic CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Create an EA handling virtual positions expert = new CVirtualAdvisor(magic_, "SimpleVolumes_Baseline"); // Create and fill the array of all selected strategy instances CVirtualStrategy *strategies[] = { new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 48, 1.6, 0.1, 0, 11200, 1160, 51000, 3, 3000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 156, 0.4, 0.7, 0, 15800, 905, 18000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 156, 1, 0.8, 0, 19000, 680, 41000, 3, 900), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 14, 0.3, 0.8, 0, 19200, 495, 27000, 3, 1100), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 38, 1.4, 0.1, 0, 19600, 690, 60000, 3, 1000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 98, 0.9, 1, 0, 15600, 1850, 7000, 3, 1300), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 44, 1.8, 1.9, 0, 13000, 675, 45000, 3, 600), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 86, 1, 1.7, 0, 17600, 1940, 56000, 3, 1000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 230, 0.7, 1.2, 0, 8800, 1850, 2000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 44, 0.1, 0.6, 0, 10800, 230, 8000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 108, 0.6, 0.9, 0, 12000, 1080, 46000, 3, 800), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 182, 1.8, 1.9, 0, 13000, 675, 33000, 3, 600), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 62, 0.1, 1.5, 0, 16800, 255, 2000, 3, 800), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 12, 1.4, 1.7, 0, 9600, 440, 59000, 3, 700), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 24, 1.7, 2, 0, 11600, 1930, 23000, 3, 700), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 30, 1.1, 0.1, 0, 18400, 1295, 27000, 3, 1500), }; // Add a group of selected strategies to the strategies expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
Save it in the BaselineExpert.mq5 file of the current folder.
The basic version for comparison is ready, now let's get down to implementing the automation of selecting strategy instances into a group.
Refining the strategy
The combinations of inputs that we will have to substitute as parameters of the strategy constructor are currently stored in the CSV file. This means that when reading them from there, we will receive them as values of the string type. It would be convenient if the strategy had a constructor that took a single string, from which it extracted all the necessary parameters. I plan to implement this method of passing parameters to the constructor, for example, using the Input_Struct library. But for now, for simplicity, let's add the second constructor of this type:
//+------------------------------------------------------------------+ //| Trading strategy using tick volumes | //+------------------------------------------------------------------+ class CSimpleVolumesStrategy : public CVirtualStrategy { ... public: CSimpleVolumesStrategy(const string &p_params); ... }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(const string &p_params) { string param[]; int total = StringSplit(p_params, ',', param); if(total == 11) { m_symbol = param[0]; m_timeframe = (ENUM_TIMEFRAMES) StringToInteger(param[1]); m_signalPeriod = (int) StringToInteger(param[2]); m_signalDeviation = StringToDouble(param[3]); m_signaAddlDeviation = StringToDouble(param[4]); m_openDistance = (int) StringToInteger(param[5]); m_stopLevel = StringToDouble(param[6]); m_takeLevel = StringToDouble(param[7]); m_ordersExpiration = (int) StringToInteger(param[8]); m_maxCountOfOrders = (int) StringToInteger(param[9]); m_fittedBalance = StringToDouble(param[10]); CVirtualReceiver::Get(GetPointer(this), m_orders, m_maxCountOfOrders); // Load the indicator to get tick volumes m_iVolumesHandle = iVolumes(m_symbol, m_timeframe, VOLUME_TICK); // Set the size of the tick volume receiving array and the required addressing ArrayResize(m_volumes, m_signalPeriod); ArraySetAsSeries(m_volumes, true); } }
This constructor assumes that the values of all parameters are packed into one string in the correct order and separated by a comma. Such a string is passed as the only parameter of the constructor, divided into parts by commas, and each part, after conversion to the appropriate data type, is assigned to the desired class property.
Let's save the changes to the SimpleVolumesStrategy.mqh file in the current folder.
Refining the EA
Let's take the SimpleVolumesExpert.mq5 EA as an example. We will create a new EA based on it, which will be engaged in optimizing the selection of several strategy instances from the same CSV file we used for manual selection earlier.
First of all, let's add a group of inputs that will allow loading the list of strategy instance parameters and selecting them into the group. For simplicity, we will limit the number of strategies included in a group at the same time to eight and provide the ability to set a number smaller than 8.
input group "::: Selection for the group" sinput string fileName_ = "Params_SV_EURGBP_H1.csv"; // File with strategy parameters (*.csv) sinput int count_ = 8; // Number of strategies in the group (1 .. 8) input int i0_ = 0; // Strategy index #1 input int i1_ = 1; // Strategy index #2 input int i2_ = 2; // Strategy index #3 input int i3_ = 3; // Strategy index #4 input int i4_ = 4; // Strategy index #5 input int i5_ = 5; // Strategy index #6 input int i6_ = 6; // Strategy index #7 input int i7_ = 7; // Strategy index #8
If count_ is less than 8, then only the number of parameters, defining the strategy indices, specified in it will be used for the enumeration.
Next we encounter an issue. If we place a file with the Params_SV_EURGBP_H1.csv strategy parameters in the terminal data directory, then it will be read from there only when this EA is launched on the terminal chart. If we run it in the tester, this file will not be detected, since the tester works with its own data directory. We can, of course, find the location of the tester data directory and copy the file there, but this is inconvenient and does not solve the next problem.
The next problem is that when running optimization (and this is exactly what we are developing this EA for), the data file will not be available to the cluster of agents in the local network, not to mention the MQL5 Cloud Network agents.
A temporary solution to the above problems could be to include the contents of the data file into the EA source code. But we will still try to provide the ability to use an external CSV file. To do this, we will need to use such tools in the MQL5 language as the tester_file preprocessor directive and the OnTesterInit() event handler. We will also take advantage of the presence of a common data folder for all terminals and testing agents on the local computer.
As stated in the MQL5 Reference, the tester_file directive allows specifying the file name for the tester. This means that even if the tester is running on a remote server, this file will be sent to it and placed in the test agent data directory. This seems to be exactly what we need. But that is not the case! This file name should be a constant and should be defined during the compilation. Therefore, it is not possible to substitute an arbitrary file name, passed in the EA inputs only when starting optimization, to it.
We will have to use the following workaround. We will choose some fixed file name and set it in the EA. It can be constructed, for example, from the name of the EA itself. It is this constant name that we will specify in the tester_file directive:
#define PARAMS_FILE __FILE__".params.csv" #property tester_file PARAMS_FILE
Next, we will add a global variable for the array of strategy parameter sets as strings. It is into this array that we will read data from the file.
string params[]; // Array of strategy parameter sets as strings
Let's write a function for loading data from a file, which will work as follows. First, let's check if a file with the specified name exists in the terminal shared data folder or in the data folder. If it is there, then we copy it to the file with a selected fixed name in the data folder. Next, open the file with the fixed name for reading and read data from it.
//+------------------------------------------------------------------+ //| Load strategy parameter sets from a CSV file | //+------------------------------------------------------------------+ int LoadParams(const string fileName, string &p_params[]) { bool res = false; // Check if the file exists in the shared folder and in the data folder if(FileIsExist(fileName, FILE_COMMON)) { // If it is in the shared folder, then copy it to the data folder with a fixed name res = FileCopy(fileName, FILE_COMMON, PARAMS_FILE, FILE_REWRITE); } else if(FileIsExist(fileName)) { // If it is in the data folder, then copy it here, but with a fixed name res = FileCopy(fileName, 0, PARAMS_FILE, FILE_REWRITE); } // If there is a file with a fixed name, that is good as well if(FileIsExist(PARAMS_FILE)) { res = true; } // If the file is found, then if(res) { // Open it int f = FileOpen(PARAMS_FILE, FILE_READ | FILE_TXT | FILE_ANSI); // If opened successfully if(f != INVALID_HANDLE) { FileReadString(f); // Ignore data column headers // For all further file strings while(!FileIsEnding(f)) { // Read the string and extract the part containing the strategy inputs string s = CSVStringGet(FileReadString(f), 10, 21); // Add this part to the array of strategy parameter sets APPEND(p_params, s); } FileClose(f); return ArraySize(p_params); } } return 0; }
Thus, if this code is executed on a remote test agent, then the file with the fixed name from the main EA instance that launched the optimization will already be passed to its data folder. To make this happen, you need to add calling this load function to the OnTesterInit() event handler.
In this same handler, we will set the values for the ranges of the parameter set index iteration so that we do not have to set them manually in the optimization parameter settings window. If we need to select a group from a number of sets smaller than 8, then here we will also automatically disable the enumeration of unnecessary indices.
//+------------------------------------------------------------------+ //| Initialization before optimization | //+------------------------------------------------------------------+ int OnTesterInit(void) { // Load strategy parameter sets int totalParams = LoadParams(fileName_, params); // If nothing is loaded, report an error if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_FAILED); } // Set scale_ to 1 ParameterSetRange("scale_", false, 1, 1, 1, 2); // Set the ranges of change for the parameters of the set index iteration for(int i = 0; i < 8; i++) { if(i < count_) { ParameterSetRange("i" + (string) i + "_", true, 0, 0, 1, totalParams - 1); } else { // Disable the enumeration for extra indices ParameterSetRange("i" + (string) i + "_", false, 0, 0, 1, totalParams - 1); } } return(INIT_SUCCEEDED); }
As an optimization criterion, choose the maximum profit that could be obtained with a maximum drawdown of 10% of the initial fixed balance. To do this, add the OnTester() handler, in which we calculate the parameter value, to the EA:
//+------------------------------------------------------------------+ //| Test results | //+------------------------------------------------------------------+ double OnTester(void) { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = fixedBalance_ * 0.1 / balanceDrawdown; // Recalculate the profit double fittedProfit = profit * coeff; return fittedProfit; }
By calculating this parameter, we immediately receive information in one pass about what profit can be obtained if we take into account the maximum drawdown achieved in this pass, setting the scaling multiplier so that the drawdown can reach 10%.
In the OnInit() EA initialization handler, we also need to load the strategy parameter sets first. Then we take the indices from the inputs and check that there are no duplicates among them. If this is not the case, then the pass with such inputs is not started. If all is well, extract sets with the specified indices from the array of strategy parameter sets and add them to the EA.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Load strategy parameter sets int totalParams = LoadParams(fileName_, params); // If nothing is loaded, report an error if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_PARAMETERS_INCORRECT); } // Form the string from the parameter set indices separated by commas string strIndexes = (string) i0_ + "," + (string) i1_ + "," + (string) i2_ + "," + (string) i3_ + "," + (string) i4_ + "," + (string) i5_ + "," + (string) i6_ + "," + (string) i7_; // Turn the string into the array string indexes[]; StringSplit(strIndexes, ',', indexes); // Leave only the specified number of instances in it ArrayResize(indexes, count_); // Multiplicity for parameter set indices CHashSet<string> setIndexes; // Add all indices to the multiplicity FOREACH(indexes, setIndexes.Add(indexes[i])); // Report an error if if(count_ < 1 || count_ > 8 // number of instances not in the range 1 .. 8 || setIndexes.Count() != count_ // not all indexes are unique ) { return INIT_PARAMETERS_INCORRECT; } // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Create an EA handling virtual positions expert = new CVirtualAdvisor(magic_, "SimpleVolumes_OptGroup"); // Create and fill the array of all strategy instances CVirtualStrategy *strategies[]; FOREACH(indexes, APPEND(strategies, new CSimpleVolumesStrategy(params[StringToInteger(indexes[i])]))); // Create and add selected groups of strategies to the EA expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
We will also need to add at least the OnTesterDeinit() empty handler to the EA. This is a compiler requirement for EAs that have the OnTesterInit() handler.
We will save the obtained code in the OptGroupExpert.mq5 file of the current folder.
Simple composition
Launch optimization of the implemented EA by specifying the path to the created CSV file with sets of trading strategy parameters. We will use a genetic algorithm that maximizes a user criterion, which is the profit normalized to the 10% drawdown. We use the same test period for the optimization - from 2018 to 2022 inclusive.
A standard genetic optimization block of over 10,000 runs took approximately 9 hours to complete using 13 test agents on a local network. Surprisingly, the results actually outperformed the baseline set. This is what the top of the optimization results table looks like:
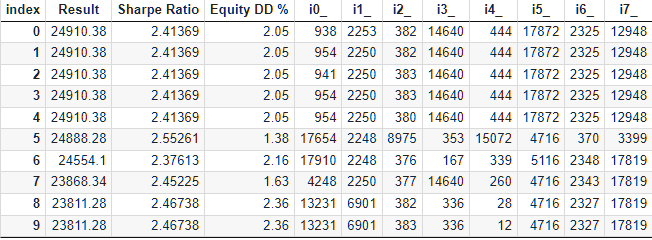
Fig. 6. Results of optimization of automated selection into a group
Let's take a closer look at the best result. To obtain the calculated profit, in addition to specifying all the indices from the first row of the table, we will need to set the scale_ parameter equal to the ratio of the specified 10% drawdown (USD 1000 from USD 10,000) to the achieved maximum drawdown by equity. In the table, we have it as a percentage. However, for a more accurate calculation, it is better to take its absolute rather than relative value.
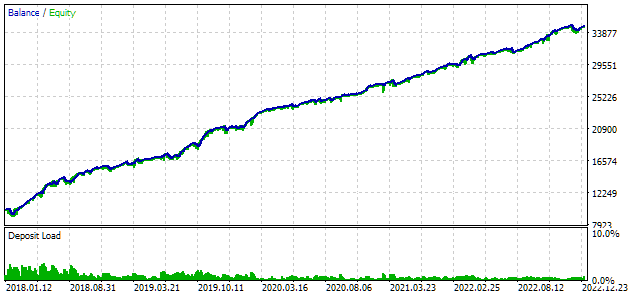
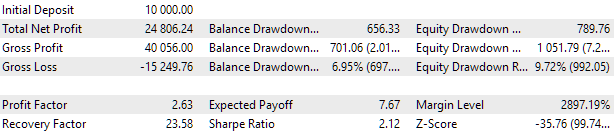
Fig. 7. Test results of the best group
The profit results are slightly different from the calculated ones, but this difference is very insignificant and can be neglected. But it is clear that the automated selection was able to find a better group than the one selected manually: the profit was USD 24,800 instead of USD 15,200 - more than one and a half times better. This process did not require any human intervention. This is already a very encouraging result. We can breathe a sigh of relief and continue working in this direction with greater enthusiasm.
Let's see if there is anything we can improve in the selection process without putting in a lot of effort. In the table containing the results of selecting strategies into groups, we clearly see that the first five groups have the same results, and the difference between them is only in one or two indices of the parameter sets. This happens because in our original file with sets of strategy parameters, there were some that also gave the same result, but differed from each other in some less significant parameter. Therefore, if two different sets of data that give the same results fall into two groups, then these two groups may yield the same results.
This also means that several "identical" sets of strategy parameters can be accepted into one group during the optimization. This causes a decrease in the group diversity we strive for in order to reduce drawdown. Let's try to get rid of optimization passes where such "identical" sets end up in a group.
Composition with clustering
To get rid of such groups, we will divide all sets of strategy parameters from the original CSV file into several clusters. Each cluster will contain sets of parameters that give either completely identical or similar results. For clustering, we will use a ready-made k-means clustering algorithm. We will take the following columns as input data for clustering: signalPeriod_, signalDeviation_, signaAddlDeviation_, openDistance_, stopLevel_ and takeLevel_. Let's try to split all our parameter sets into 64 clusters using the following Python code:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df.to_csv('Params_SV_EURGBP_H1-with_cluster.csv', index=False)
Now our parameter set file has one more column added with the cluster number. To use this file, let's create a new EA based on OptGroupExpert.mq5 and make some small additions to it.
Let's add another set and fill it with the numbers of clusters, that contain the selected sets of parameters, during the initialization. We will launch such a run only if the numbers of all clusters in this group of parameter sets turn out to be different. Since the strings read from the file now contain a cluster number at the end that is not related to the strategy parameters, we need to remove it from the parameter string before passing it to the strategy constructor.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ... // Multiplicities for parameter and cluster set indices CHashSet<string> setIndexes; CHashSet<string> setClusters; // Add all indices and clusters to the multiplicities FOREACH(indexes, { setIndexes.Add(indexes[i]); string cluster = CSVStringGet(params[StringToInteger(indexes[i])], 11, 12); setClusters.Add(cluster); }); // Report an error if if(count_ < 1 || count_ > 8 // number of instances not in the range 1 .. 8 || setIndexes.Count() != count_ // not all indexes are unique || setClusters.Count() != count_ // not all clusters are unique ) { return INIT_PARAMETERS_INCORRECT; } ... FOREACH(indexes, { // Remove the cluster number from the parameter set string string param = CSVStringGet(params[StringToInteger(indexes[i])], 0, 11); // Add a strategy with a set of parameters with a given index APPEND(strategies, new CSimpleVolumesStrategy(param)) }); // Form and add a group of strategies to the EA expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
Save this code in the OptGroupClusterExpert.mq5 file of the current folder.
This type of optimization arrangement has also revealed its own shortcomings. If too many individuals with at least two identical parameter set indices end up in the initial population of a genetic algorithm, this leads to rapid degeneration of the population and premature termination of the optimization algorithm. But with another launch we may be luckier, and then the optimization reaches the end and finds quite good results.
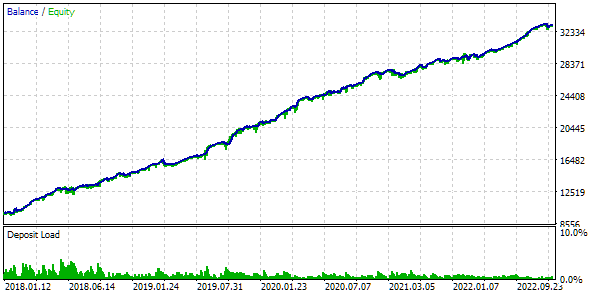
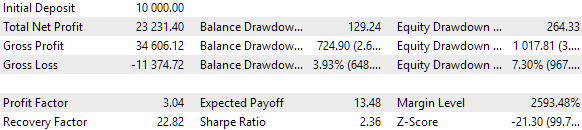
Fig. 8. Test results of the best group with clustering
The probability of preventing population degeneration can be increased either by mixing the sets of inputs or by reducing the number of strategies included in the group. In any case, the time spent on optimization is reduced by one and a half to two times compared to optimization without clustering.
One instance in the cluster
There is another way to prevent population degeneration: leave only one set belonging to a given cluster in the file. We can generate the file with such data using the following Python code:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df = df.sort_values(['cluster', 'Sharpe Ratio']).groupby('cluster').agg('last').reset_index()
clusters = df.cluster
df = df.iloc[:, 1:]
df['cluster'] = clusters
df.to_csv('Params_SV_EURGBP_H1-one_cluster.csv', index=False
For this CSV file with data, we can use any of the two EAs written in this article for optimization.
If it turns out that we have too few sets left, then we can either increase the number of clusters or take several sets from one cluster.
Let's look at the optimization results of this EA:
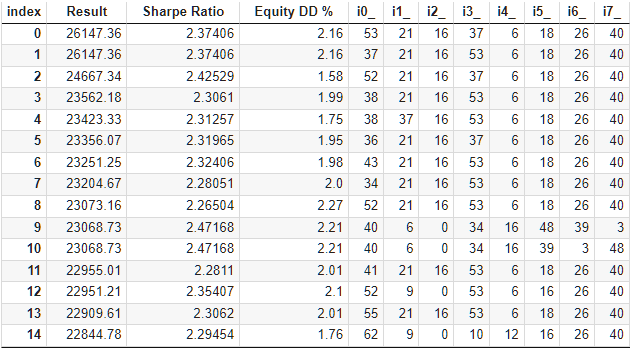
Fig. 9. Results of optimization of automated selection into a group by 64 clusters
They are approximately the same as for the two previous approaches. One group was found that surpassed all previously found ones. Although this is more a matter of luck than the superiority of the set limit. Here are the results of the best group's single pass:
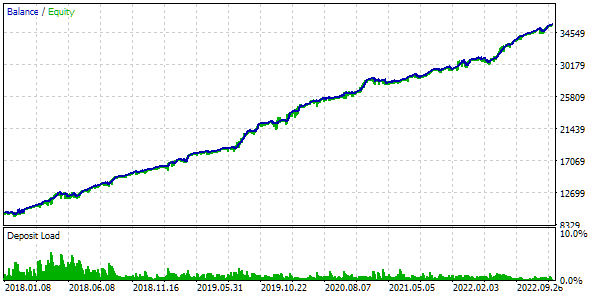
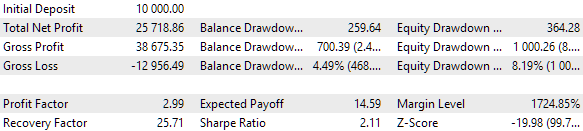
Fig. 10. Test results of the best group with one set in the cluster
In the results table, a repetition of groups is noticeable, differing only in the order of the indices of the strategy parameter sets.
This can be avoided by adding a condition check to the EAs that the combination of indices in the input parameters must form an increasing sequence. But this again leads to problems with the use of genetic optimization due to the very rapid degeneration of the population. For a complete enumeration, even selecting one group of 8 sets from 64 sets gives too many passes. It is necessary to somehow change the method of converting the EA's iterated inputs into indices of strategy parameter sets. But these are already plans for the future.
It is worth noting that results comparable to the manual selection ones (profit ~ USD 15,000), when using one set from the cluster, are found literally in the first minutes of optimization. However, in order to find the best results, we need to wait until almost the very end of the optimization.
Conclusion
Let's see what we got. We have confirmed that auto selection of parameter sets into a group can produce better profitability results than manual selection. The process itself will take more time, but this time does not require human participation, which is very good. Moreover, we can significantly reduce it if necessary by exchanging it for using more test agents.
Now we can move on. If we have the ability to select groups of strategy instances, then we can think about automating the creation of groups from the good groups obtained. In terms of EA code, the difference will only be in how to correctly read the parameters and add to the EA not one, but several groups of strategies. Here we can think about a unified format for storing sets of optimized parameters for strategies and groups in a database, rather than in separate files.
It would also be nice to look at the behavior of our good groups during the test period, which is outside the period, in which the parameter optimization was carried out. This is probably what I will try to do in the next article.
Thank you for your attention! See you soon!
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/14478
 Features of Custom Indicators Creation
Features of Custom Indicators Creation
 Example of Auto Optimized Take Profits and Indicator Parameters with SMA and EMA
Example of Auto Optimized Take Profits and Indicator Parameters with SMA and EMA
 Features of Experts Advisors
Features of Experts Advisors
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Great article and system :)
- We apply a min-max scaling to each of them, leading to the range [0; 1]. We get additional columns with suffix '_s' ,
Yuri, how did you do it? I searched in exel and didn't see anything like that in the functions there.
Victor, thanks for your feedback!
I don't know a special function in Excel either, I do it like this:
Victor, thanks for the feedback!
I don't know any special function in Excel either, I do it like this:
Thanks Yuri.
But you wrote about adding columns Profit,Expected Payoff,Profit Factor,Recovery Factor,Sharpe Ratio,Equity DD %,Trades, with _s. What order should I add them in to make it work? Each column after the original column or can they all be added at the end of the table? Could you make a screenshot of the column names as you do from your table already edited, or just attach a small file already edited for a sample.
Also, when you optimise the Expert Advisor, do you set a complex criterion or just balance max? I tried it and I have something not very large number of trades in the passages finds, about 100-180 trades for 5 years.
And please tell me, if I would like your EA to read the signal and open trades at the opening of a new bar on a given timeframe, but accompanied trades every tick as it works now. Where should I add the function of checking the occurrence of a new bar to work like this?
The order of addition only matters in terms of how to do it faster. It was faster for me to add these columns at the end of the table (columns AC:AI), then calculate the deviations in several new columns (AJ : AP), then sum AJ:AP in A Q , then find the maximum scaling factor Scale in AR, and calculate the ratio Res = AR/AQ in AS. To sort by it, you have to copy only the values from AS to a new AT column. I have attached an example.
I start optimisation with the complex criterion and then all other criteria. The number of deals can be different, including relatively small. It depends on the size of SL and TP levels.
In the next article I plan to tell you about the function of checking a new bar and how it can be applied there.
In the next article I plan to tell you about the function of checking a new bar and how it can be applied there.
Yuri, thank you for the example table, I understand it is from the last article (7), it will also be useful, but I asked you for an example of the table from this article (6), which you feed to the input of the OptGroupClusterExpert.mq5 Expert Advisor . As I understand this table is called Params_SV_EURGBP_H1-with_cluster.csv and Params_SV_EURGBP_H1.csv. That's what I asked you for. Please attach these tables as an example.
About the next article cool! Let's wait:) If it would be nice to add to the strategy the possibility of time filter for each strategy (specify start and end times of the trading period) and some filters on indicators (2-3 pieces). then I think it would be a great EA for trading the whole market :).
Victor, yes indeed, got a bit ahead of myself with the previous table example.
I have attached an example for Params_SV_EURGBP_H1.xlsx, as the CSV file will no longer contain formulas. You will need to save it to CSV, and if Excel uses ';' as a delimiter, you will need to replace ';' with ',' in the entire CSV file. The Params_SV_EURGBP_H1-with_cluster.csv file is obtained automatically using the Python code from Params_SV_EURGBP_H1.csv given in the article.
As for adding time filters and additional indicators: the architecture used allows it - you can create new classes of trading strategies (successors of CVirtualStrategy) with any desired filters and indicators. I do not plan to use time filters for myself, as I have never managed to improve trading results by introducing time constraints. I don't plan to use many indicators in one strategy, because strong filtering of input signals is less important for me. It can be obtained indirectly by combining several instances of strategies that use one different indicator each, for example.