
Desenvolvendo um EA multimoeda (Parte 6): Automatizando a seleção de um grupo de instâncias
Introdução
No artigo anterior, demos um passo importante ao implementar um recurso que permite escolher como a estratégia opera: com um tamanho de posição constante ou variável. Com isso, conseguimos ajustar os resultados da estratégia de acordo com o rebaixamento máximo alcançado e agrupar as estratégias dentro dos limites especificados. Para ilustrar, selecionamos manualmente algumas das combinações mais promissoras dos parâmetros de entrada de uma única instância da estratégia e tentamos organizá-las em um grupo, ou até mesmo em um conjunto de três grupos, cada um com três estratégias. Nesse último cenário, obtivemos os melhores resultados.
No entanto, se precisarmos aumentar o número de estratégias em cada grupo e combinar mais grupos diferentes, o trabalho manual vai crescer significativamente.
Primeiro, para cada símbolo, precisamos otimizar uma única instância da estratégia usando diferentes critérios. Em alguns casos, pode ser necessário fazer uma otimização separada para diferentes timeframes. No caso da nossa estratégia modelo, também podemos realizar otimizações distintas para os tipos de ordens abertas (stop, limite ou posições a mercado).
Segundo, precisamos escolher um pequeno número (entre 10 e 20) dos melhores parâmetros dentre os milhares obtidos (cerca de 20 a 50 mil) após as otimizações. No entanto, esses parâmetros devem ser os melhores não apenas individualmente, mas também quando combinados em um grupo. Esse processo de selecionar e adicionar cada instância da estratégia manualmente demanda tempo e paciência.
Terceiro, precisamos combinar os grupos obtidos em grupos maiores usando a normalização. Quando fazemos isso manualmente, conseguimos criar apenas dois ou três níveis. Logo, tentar aumentar o número de níveis de agrupamento já se torna um trabalho bastante árduo.
Por isso, vamos tentar automatizar essa etapa do desenvolvimento do EA.
Traçando um caminho
Infelizmente, fazer tudo de uma vez é quase impossível. A complexidade da tarefa pode desanimar qualquer um que tente resolvê-la de uma só vez. Por isso, vamos abordar o problema por partes. A maior dificuldade para começar a implementação são as questões que permanecem no ar: "Será que isso vai trazer algum benefício? Conseguiremos substituir a seleção manual por uma automática sem perder qualidade (ou, quem sabe, até melhorando)? Esse processo não acabará sendo mais demorado do que a seleção manual?"
Enquanto não tivermos respostas para essas perguntas, é difícil começar a buscar uma solução. Então, faremos o seguinte: a prioridade será testar a hipótese de que a seleção automatizada em grupos pode ser útil. Para isso, vamos pegar um conjunto de resultados da otimização de um EA em um símbolo e escolher manualmente um bom grupo normalizado. Este será nosso modelo de comparação (baseline). Depois, com o mínimo de esforço, vamos implementar uma versão simples da automatização, permitindo a seleção do grupo sem intervenção manual, e comparar o resultado do grupo selecionado automaticamente com o do grupo escolhido manualmente. Se os resultados mostrarem que a automatização é promissora, poderemos seguir para uma implementação mais refinada e adequada.
Preparação dos dados iniciais
Carregaremos os resultados da otimização do EA SimpleVolumesExpertSingle.mq5, obtidos anteriormente durante a elaboração das partes anteriores, e faremos a exportação para XML.
Fig. 1. Exportando os resultados da otimização para processamento futuro
Para facilitar o uso futuro, vamos adicionar algumas colunas extras ao arquivo, com valores de parâmetros que não foram incluídos na otimização. Precisamos adicionar as colunas symbol, timeframe, maxCountOfOrders e, o mais importante, fittedBalance. Este último será calculado com base no rebaixamento máximo relativo do saldo.
Se começarmos com um saldo inicial de $100.000, então o rebaixamento absoluto é aproximadamente 100.000 (relDDpercent / 100). Essa quantidade deve corresponder a 10% do fittedBalance, resultando na fórmula:
fittedBalance = 100000 * (relDDpercent / 100) / 0.1 = relDDpercent * 10000
O valor do timeframe, que no código é definido pela constante PERIOD_H1, será representado pelo seu valor numérico, 16385.
Com essas adições, vamos gerar uma tabela de dados, que será salva no formato CSV. Após a transposição, as primeiras linhas da tabela gerada ficarão assim:
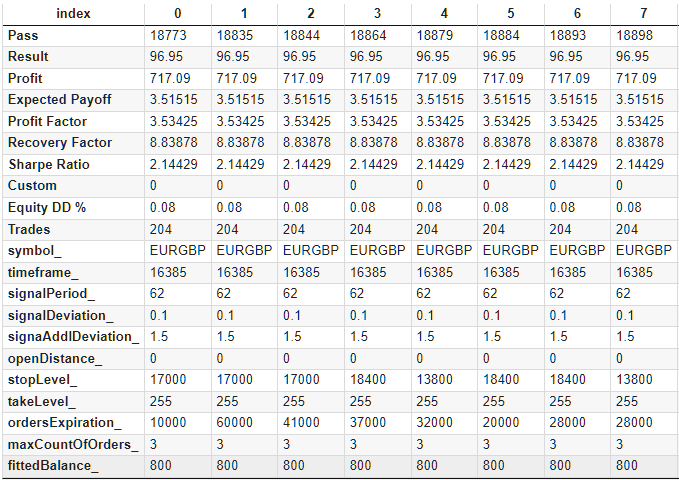
Fig. 2. Tabela de resultados de otimização com colunas adicionais
Idealmente, essa tarefa poderia ser delegada ao computador, usando a biblioteca TesterCache ou alguma outra forma de salvar os dados de cada passagem durante a otimização. Mas, como combinamos, vamos manter as coisas simples. Por isso, por enquanto, faremos isso manualmente.
Nessa tabela, há linhas em que o lucro ficou abaixo de zero (aproximadamente 1.000 linhas de 18.000). Esses resultados certamente não nos interessam, então vamos eliminá-los imediatamente.
Após isso, os dados iniciais estarão prontos para construir a variante básica e para o uso subsequente na seleção de grupos de estratégias que possam competir com a variante básica.
Baseline
Preparar a variante básica é um processo simples, mas repetitivo. Primeiro, precisamos classificar nossas estratégias por ordem decrescente de "qualidade". Para avaliar a qualidade, utilizaremos o seguinte método. Selecionaremos um conjunto de colunas que contém diferentes métricas de resultados nesta tabela: Profit, Expected Payoff, Profit Factor, Recovery Factor, Sharpe Ratio, Equity DD %, Trades. Aplicaremos a cada uma delas uma normalização min-max, trazendo os valores para o intervalo [0; 1]. Vamos obter colunas adicionais com o sufixo '_s', e para cada linha calcularemos a soma da seguinte forma:
0.5 * Profit_s + ExpectedPayoff_s + ProfitFactor_s + RecoveryFactor_s + SharpeRatio_s + (1 - EquityDD_s) + 0.3 * Trades_s,
e a adicionaremos como uma nova coluna na tabela. Faremos a ordenação por essa coluna em ordem decrescente.
Em seguida, começaremos a percorrer a lista de cima para baixo, adicionando ao grupo os candidatos que acharmos interessantes e verificando imediatamente como eles funcionam em conjunto. Vamos nos esforçar para adicionar conjuntos de parâmetros que sejam o mais diferentes possível entre si, tanto nos parâmetros quanto nos resultados.
Por exemplo, entre os conjuntos de parâmetros, pode haver aqueles que diferem apenas pelo nível de SL. No entanto, se esse nível não foi acionado durante o período de teste, os resultados serão idênticos, independentemente do nível de SL. Portanto, não devemos combinar tais configurações, pois elas terão os mesmos horários de abertura e fechamento de posições, o que significa que os momentos de rebaixamento máximo coincidirão. Queremos escolher instâncias que apresentem rebaixamentos em momentos diferentes, o que nos permitirá aumentar a lucratividade ao reduzir os tamanhos das posições, não proporcionalmente ao número de estratégias, mas em uma proporção menor.
Selecionaremos, dessa forma, 16 instâncias normalizadas de estratégias.
Também aplicaremos a negociação utilizando um saldo fixo. Para isso, definiremos o valor FixedBalance = 10000. Com essa escolha, as estratégias normalizadas individualmente gerarão um rebaixamento máximo de 1000. Vamos analisar os resultados dos testes:
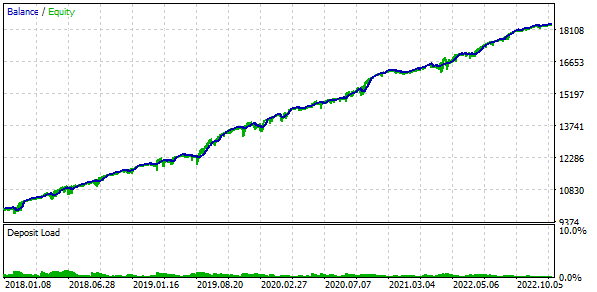
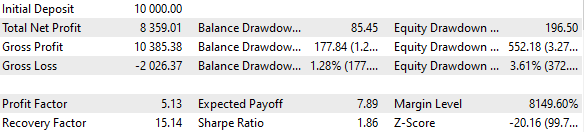
Fig. 3. Resultados da variante básica
Se combinarmos 16 instâncias de estratégias e reduzirmos os tamanhos das posições em 16 vezes, o rebaixamento máximo será de apenas $552 em vez de $1000. Para transformar esse grupo de estratégias em um grupo normalizado, calcularemos que, para manter o rebaixamento em 10%, podemos aplicar um multiplicador de escala Scale igual a 1000 / 552 = 1,81.
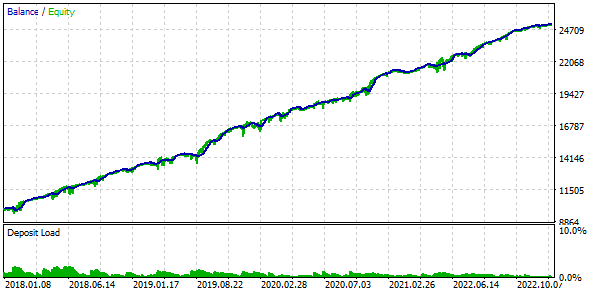

Fig. 4. Resultados da variante básica com o grupo normalizado (Scale=1.81)
Para não esquecer a necessidade de usar FixedBalance = 10000 e Scale = 1,81, definiremos esses números como valores padrão para os parâmetros de entrada correspondentes. Obteremos o seguinte código:
//+------------------------------------------------------------------+ //| Входные параметры | //+------------------------------------------------------------------+ input group "::: Управление капиталом" input double expectedDrawdown_ = 10; // - Максимальный риск (%) input double fixedBalance_ = 10000; // - Используемый депозит (0 - использовать весь) в валюте счета input double scale_ = 1.81; // - Масштабирующий множитель для группы input group "::: Прочие параметры" input ulong magic_ = 27183; // - Magic CVirtualAdvisor *expert; // Объект эксперта //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Устанавливаем параметры в классе управления капиталом CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Создаем эксперта, работающего с виртуальными позициями expert = new CVirtualAdvisor(magic_, "SimpleVolumes_Baseline"); // Создаем и наполняем массив из всех выбранных экземпляров стратегий CVirtualStrategy *strategies[] = { new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 48, 1.6, 0.1, 0, 11200, 1160, 51000, 3, 3000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 156, 0.4, 0.7, 0, 15800, 905, 18000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 156, 1, 0.8, 0, 19000, 680, 41000, 3, 900), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 14, 0.3, 0.8, 0, 19200, 495, 27000, 3, 1100), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 38, 1.4, 0.1, 0, 19600, 690, 60000, 3, 1000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 98, 0.9, 1, 0, 15600, 1850, 7000, 3, 1300), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 44, 1.8, 1.9, 0, 13000, 675, 45000, 3, 600), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 86, 1, 1.7, 0, 17600, 1940, 56000, 3, 1000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 230, 0.7, 1.2, 0, 8800, 1850, 2000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 44, 0.1, 0.6, 0, 10800, 230, 8000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 108, 0.6, 0.9, 0, 12000, 1080, 46000, 3, 800), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 182, 1.8, 1.9, 0, 13000, 675, 33000, 3, 600), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 62, 0.1, 1.5, 0, 16800, 255, 2000, 3, 800), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 12, 1.4, 1.7, 0, 9600, 440, 59000, 3, 700), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 24, 1.7, 2, 0, 11600, 1930, 23000, 3, 700), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 30, 1.1, 0.1, 0, 18400, 1295, 27000, 3, 1500), }; // Добавляем к эксперту группу из выбранных стратегий expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
Salvaremos esse código no arquivo BaselineExpert.mq5 na pasta atual.
A variante básica para comparação está pronta; agora, vamos nos concentrar na implementação da automatização da seleção de instâncias de estratégias em um grupo.
Aprimoramento da estratégia
As combinações de parâmetros de entrada que precisaremos inserir como parâmetros do construtor da estratégia estão atualmente armazenadas em um arquivo CSV, ou seja, ao lê-las de lá, obteremos seus valores no formato string. Seria conveniente que a estratégia tivesse um construtor que aceitasse uma linha única, a partir da qual extrairia todos os parâmetros necessários. No futuro, planejamos implementar exatamente esse método de passagem de parâmetros para o construtor, por exemplo, utilizando a biblioteca Input_Struct. Mas, por enquanto, para simplificar, adicionaremos um segundo construtor desse tipo:
//+------------------------------------------------------------------+ //| Торговая стратегия с использованием тиковых объемов | //+------------------------------------------------------------------+ class CSimpleVolumesStrategy : public CVirtualStrategy { ... public: CSimpleVolumesStrategy(const string &p_params); ... }; //+------------------------------------------------------------------+ //| Конструктор | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(const string &p_params) { string param[]; int total = StringSplit(p_params, ',', param); if(total == 11) { m_symbol = param[0]; m_timeframe = (ENUM_TIMEFRAMES) StringToInteger(param[1]); m_signalPeriod = (int) StringToInteger(param[2]); m_signalDeviation = StringToDouble(param[3]); m_signaAddlDeviation = StringToDouble(param[4]); m_openDistance = (int) StringToInteger(param[5]); m_stopLevel = StringToDouble(param[6]); m_takeLevel = StringToDouble(param[7]); m_ordersExpiration = (int) StringToInteger(param[8]); m_maxCountOfOrders = (int) StringToInteger(param[9]); m_fittedBalance = StringToDouble(param[10]); CVirtualReceiver::Get(GetPointer(this), m_orders, m_maxCountOfOrders); // Загружаем индикатор для получения тиковых объемов m_iVolumesHandle = iVolumes(m_symbol, m_timeframe, VOLUME_TICK); // Устанавливаем размер массива-приемника тиковых объемов и нужную адресацию ArrayResize(m_volumes, m_signalPeriod); ArraySetAsSeries(m_volumes, true); } }
Neste construtor, presume-se que os valores de todos os parâmetros estão embalados em uma única string na ordem correta e separados por vírgulas. Essa string é passada como o único parâmetro do construtor, é dividida em partes pelas vírgulas, e cada parte, após ser convertida para o tipo de dado correspondente, é atribuída à propriedade apropriada da classe.
Salve as alterações no arquivo SimpleVolumesStrategy.mqh na pasta atual.
Aprimoramento do EA
Vamos usar o EA SimpleVolumesExpert.mq5 como base e criar um novo EA, que será responsável pela otimização da seleção de várias instâncias de estratégias a partir do mesmo arquivo CSV que utilizamos na seleção manual anteriormente.
Primeiramente, adicionaremos um grupo de parâmetros de entrada, que permitirá carregar a lista de parâmetros das instâncias de estratégias e selecioná-los para inclusão em um grupo. Para simplificar, limitaremos o número de estratégias que podem ser incluídas simultaneamente no grupo a oito e permitiremos definir um número menor que 8, se necessário.
input group "::: Отбор в группу" sinput string fileName_ = "Params_SV_EURGBP_H1.csv"; // Файл с параметрами стратегий (*.csv) sinput int count_ = 8; // Количество стратегий в группе (1 .. 8) input int i0_ = 0; // Индекс стратегии #1 input int i1_ = 1; // Индекс стратегии #2 input int i2_ = 2; // Индекс стратегии #3 input int i3_ = 3; // Индекс стратегии #4 input int i4_ = 4; // Индекс стратегии #5 input int i5_ = 5; // Индекс стратегии #6 input int i6_ = 6; // Индекс стратегии #7 input int i7_ = 7; // Индекс стратегии #8
Se o parâmetro count_ for menor que 8, apenas o número especificado de parâmetros, que indicam os índices das estratégias, será usado para a seleção.
Aqui, nos deparamos com uma certa complexidade. O problema é que, se colocarmos o arquivo com os parâmetros das estratégias Params_SV_EURGBP_H1.csv no diretório de dados do terminal, ele será lido a partir de lá apenas quando o EA for executado no gráfico do terminal. Se for executado no testador, esse arquivo não será encontrado, pois o testador opera com seu próprio diretório de dados. Claro, poderíamos localizar o diretório de dados do testador e copiar o arquivo para lá, mas isso é inconveniente e não resolve o próximo problema que surge.
O próximo problema é que, ao iniciar a otimização (que é o objetivo deste EA), o arquivo de dados não estará disponível para o cluster de agentes na rede local, sem mencionar os agentes da MQL5 Cloud Network.
Uma solução temporária para esses problemas poderia ser incluir o conteúdo do arquivo de dados no código-fonte do EA. No entanto, tentaremos ainda assim viabilizar o uso de um arquivo CSV externo. Para isso, utilizaremos recursos da linguagem MQL5, como a diretiva de pré-processador tester_file e o manipulador de eventos OnTesterInit(). Também aproveitaremos a existência de uma pasta de dados comum para todos os terminais e agentes de teste no computador local.
Como indicado na documentação, a diretiva tester_file permite especificar o nome de um arquivo para o testador, que será passado ao testador para uso. Isso implica que, mesmo que o testador seja executado em um servidor remoto, esse arquivo será enviado e colocado no diretório de dados do agente de teste. Isso parece ser exatamente o que precisamos. Mas, há um porém! Esse nome de arquivo deve ser uma constante e definido no momento da compilação. Portanto, não é possível inserir um nome de arquivo arbitrário, passado como parâmetro de entrada do EA, durante a execução da otimização.
Teremos que aplicar uma solução alternativa. Escolheremos um nome de arquivo fixo e o definiremos no EA. Podemos construí-lo, por exemplo, a partir do nome do próprio EA. Este nome constante será especificado na diretiva tester_file:
#define PARAMS_FILE __FILE__".params.csv" #property tester_file PARAMS_FILE
Em seguida, adicionaremos uma variável global para o array de conjuntos de parâmetros das estratégias, armazenados como strings. É nesse array que iremos ler os dados do arquivo.
string params[]; // Массив наборов параметров стратегий в виде строк
Escreveremos uma função para carregar os dados do arquivo, que funcionará da seguinte maneira: Primeiro, verificamos se existe um arquivo com o nome especificado na pasta de dados comum do terminal ou na pasta de dados. Se ele estiver lá, copiamos para o arquivo com o nome fixo escolhido na pasta de dados. Depois, abrimos o arquivo com o nome fixo para leitura e carregamos os dados dele.
//+------------------------------------------------------------------+ //| Загрузка наборов параметров стратегий из CSV-файла | //+------------------------------------------------------------------+ int LoadParams(const string fileName, string &p_params[]) { bool res = false; // Проверим существование файла в общей папке и в папке данных if(FileIsExist(fileName, FILE_COMMON)) { // Если он есть в общей папке, то копируем его в папку данных с фиксированным именем res = FileCopy(fileName, FILE_COMMON, PARAMS_FILE, FILE_REWRITE); } else if(FileIsExist(fileName)) { // Если он есть в папке данных, то копируем его сюда же, но с фиксированным именем res = FileCopy(fileName, 0, PARAMS_FILE, FILE_REWRITE); } // Если файл с фиксированным именем есть, то тоже хорошо if(FileIsExist(PARAMS_FILE)) { res = true; } // Если файл обнаружен, то if(res) { // Открываем его int f = FileOpen(PARAMS_FILE, FILE_READ | FILE_TXT | FILE_ANSI); // Если открыли успешно if(f != INVALID_HANDLE) { FileReadString(f); // Игнорируем заголовки столбцов данных // Для всех дальнейших строк файла while(!FileIsEnding(f)) { // Читаем строку и выделяем из неё часть, содержащую входные параметры стратегии string s = CSVStringGet(FileReadString(f), 10, 21); // Добавляем эту часть в массив наборов параметров стратегий APPEND(p_params, s); } FileClose(f); return ArraySize(p_params); } } return 0; }
Dessa forma, se o código for executado em um agente de teste remoto, o arquivo com o nome fixo já terá sido transferido para a pasta de dados a partir do EA principal que iniciou a otimização. Para garantir isso, é necessário adicionar a chamada dessa função de carregamento no manipulador de eventos OnTesterInit().
Nesse mesmo manipulador, configuraremos os valores para os intervalos de varredura dos índices dos conjuntos de parâmetros, para que não precisemos defini-los manualmente na janela de configurações de parâmetros de otimização. Se for necessário selecionar um grupo com menos de 8 conjuntos, também desativaremos automaticamente a varredura dos índices excedentes.
//+------------------------------------------------------------------+ //| Инициализация перед оптимизацией | //+------------------------------------------------------------------+ int OnTesterInit(void) { // Загружаем наборы параметров стратегий int totalParams = LoadParams(fileName_, params); // Если ничего не загрузили, то сообщим об ошибке if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_FAILED); } // Параметру scale_ устанавливаем значение 1 ParameterSetRange("scale_", false, 1, 1, 1, 2); // Параметрам перебора индексов наборов задаём диапазоны изменения for(int i = 0; i < 8; i++) { if(i < count_) { ParameterSetRange("i" + (string) i + "_", true, 0, 0, 1, totalParams - 1); } else { // Для лишних индексов отключаем перебор ParameterSetRange("i" + (string) i + "_", false, 0, 0, 1, totalParams - 1); } } return(INIT_SUCCEEDED); }
Como critério de otimização, escolheremos o lucro máximo que pode ser obtido com um rebaixamento máximo de 10% do saldo inicial fixo. Para isso, adicionaremos ao EA um manipulador OnTester(), no qual calcularemos o valor desse indicador:
//+------------------------------------------------------------------+ //| Результат тестирования | //+------------------------------------------------------------------+ double OnTester(void) { // Максимальная абсолютная просадка double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Прибыль double profit = TesterStatistics(STAT_PROFIT); // Коэффициент возможного увеличения размеров позиций для просадки 10% от fixedBalance_ double coeff = fixedBalance_ * 0.1 / balanceDrawdown; // Пресчитываем прибыль double fittedProfit = profit * coeff; return fittedProfit; }
Com o cálculo desse indicador, obtemos imediatamente, em uma única passagem, a informação sobre o lucro possível, considerando o rebaixamento máximo atingido nessa passagem, ajustando o multiplicador de escala para que ele atinja 10%.
No manipulador de inicialização do EA OnInit(), também devemos carregar os conjuntos de parâmetros das estratégias. Em seguida, pegamos os índices dos parâmetros de entrada e verificamos se não há duplicatas. Se houver duplicatas, a passagem com esses parâmetros de entrada não será iniciada. Se tudo estiver correto, extraímos do array os conjuntos de parâmetros com os índices especificados e os adicionamos ao EA.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Загружаем наборы параметров стратегий int totalParams = LoadParams(fileName_, params); // Если ничего не загрузили, то сообщим об ошибке if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_PARAMETERS_INCORRECT); } // Формируем строку из индексов наборов параметров, разделённых запятыми string strIndexes = (string) i0_ + "," + (string) i1_ + "," + (string) i2_ + "," + (string) i3_ + "," + (string) i4_ + "," + (string) i5_ + "," + (string) i6_ + "," + (string) i7_; // Превращаем эту строку в массив string indexes[]; StringSplit(strIndexes, ',', indexes); // Оставляем в нём только заданное количество экземпляров ArrayResize(indexes, count_); // Множество для индексов наборов параметров CHashSet<string> setIndexes; // Добавляем все индексы во множество FOREACH(indexes, setIndexes.Add(indexes[i])); // Сообщаем об ошибке, если if(count_ < 1 || count_ > 8 // количество экземпляров не в диапазоне 1 .. 8 || setIndexes.Count() != count_ // не все индексы уникальные ) { return INIT_PARAMETERS_INCORRECT; } // Устанавливаем параметры в классе управления капиталом CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Создаем эксперта, работающего с виртуальными позициями expert = new CVirtualAdvisor(magic_, "SimpleVolumes_OptGroup"); // Создаем и наполняем массив из всех экземпляров стратегий CVirtualStrategy *strategies[]; FOREACH(indexes, APPEND(strategies, new CSimpleVolumesStrategy(params[StringToInteger(indexes[i])]))); // Формируем и добавляем к эксперту выбранные группы стратегий expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
Além disso, será necessário adicionar ao EA um manipulador OnTesterDeinit(), mesmo que vazio. Essa é uma exigência do compilador para EAs que possuem o manipulador OnTesterInit().
Salvamos o código gerado no arquivo OptGroupExpert.mq5 na pasta atual.
Simples união
Vamos iniciar a otimização do EA que acabamos de criar, especificando o caminho para o arquivo CSV contendo os conjuntos de parâmetros das estratégias de negociação. Usaremos o algoritmo genético, maximizando o critério do usuário, que é o lucro normalizado para um rebaixamento de 10%. O período de teste para a otimização será o mesmo: de 2018 a 2022, inclusive.
O bloco padrão para otimização genética, com mais de 10.000 execuções, levou cerca de 9 horas usando 13 agentes de teste na rede local. E, surpreendentemente, os resultados realmente superaram os do conjunto básico. Veja como a parte superior da tabela com os resultados da otimização ficou:
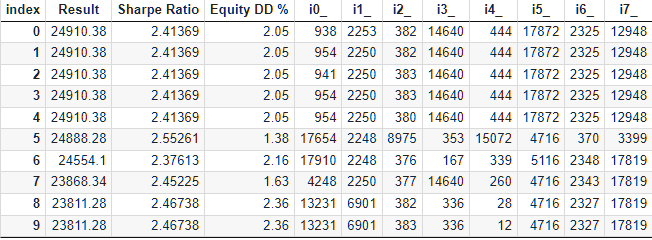
Fig. 6. Tabela com os resultados da otimização da seleção automatizada em grupo
Vamos analisar o melhor dos resultados com mais detalhes. Para obter o lucro calculado, além de especificar todos os índices da primeira linha da tabela, precisaremos definir o parâmetro scale_ como a razão entre o rebaixamento de 10% especificado ($1000 de $10000) e o rebaixamento máximo alcançado no saldo. Na tabela, esse valor está em porcentagem, mas para um cálculo mais preciso, é melhor usar o valor absoluto, não o relativo.
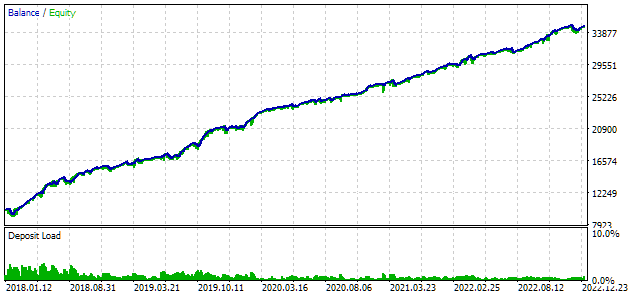
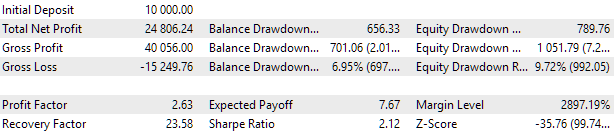
Fig. 7. Resultados do teste do melhor grupo
Os resultados de lucro diferem um pouco dos calculados, mas essa diferença é muito pequena e pode ser ignorada. No entanto, é evidente que a seleção automatizada conseguiu encontrar um grupo melhor do que o que selecionamos manualmente: o lucro foi de $24800, em vez de $15200, mais de uma vez e meia maior. E isso sem necessidade de qualquer intervenção humana, o que já é um resultado bastante encorajador. Podemos respirar aliviados e continuar com mais entusiasmo nesse caminho.
Vamos verificar se é possível melhorar algo no processo de seleção sem grandes esforços. Na tabela com os resultados da seleção de estratégias em grupos, é evidente que os primeiros cinco grupos têm o mesmo resultado, com a diferença estando apenas em um ou dois índices dos conjuntos de parâmetros. Isso ocorre porque no nosso arquivo original de conjuntos de parâmetros de estratégias, havia alguns que também davam resultados idênticos, mas diferiam em algum parâmetro menos significativo. Portanto, se dois conjuntos diferentes, que dão os mesmos resultados, forem incluídos em dois grupos distintos, esses grupos poderão apresentar os mesmos resultados.
Isso também significa que, durante o processo de otimização, vários desses conjuntos "iguais" de parâmetros de estratégias podem ser incluídos em um único grupo. Isso reduz a diversidade no grupo, algo que buscamos para minimizar o rebaixamento. Vamos tentar eliminar as execuções de otimização em que tais conjuntos "iguais" são incluídos no grupo.
União com clusterização
Para eliminar esses grupos, dividiremos todos os conjuntos de parâmetros de estratégias do arquivo CSV original em vários clusters. Em cada cluster, serão reunidos conjuntos de parâmetros que produzem resultados idênticos ou muito semelhantes. Para a clusterização, utilizaremos o algoritmo de k-médias. Como dados de entrada para a clusterização, usaremos as seguintes colunas: signalPeriod_, signalDeviation_, signaAddlDeviation_, openDistance_, stopLevel_, takeLevel_. Vamos tentar dividir todos os nossos conjuntos de parâmetros em 64 clusters usando o seguinte código Python:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df.to_csv('Params_SV_EURGBP_H1-with_cluster.csv', index=False) Agora, nosso arquivo com conjuntos de parâmetros tem uma nova coluna com o número do cluster. Para utilizar esse arquivo, criaremos um novo EA com base no OptGroupExpert.mq5 e faremos pequenas adições.
Vamos adicionar mais um conjunto e, durante a inicialização, preenchê-lo com os números dos clusters com os conjuntos de parâmetros selecionados. Executaremos a passagem apenas se todos os números dos clusters nesses conjuntos de parâmetros forem diferentes. Como agora as linhas lidas do arquivo contêm um número de cluster no final, que não faz parte dos parâmetros da estratégia, precisamos removê-lo da string de parâmetros antes de passá-la para o construtor da estratégia.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ... // Множества для индексов наборов параметров и кластеров CHashSet<string> setIndexes; CHashSet<string> setClusters; // Добавляем все индексы и кластеры во множества FOREACH(indexes, { setIndexes.Add(indexes[i]); string cluster = CSVStringGet(params[StringToInteger(indexes[i])], 11, 12); setClusters.Add(cluster); }); // Сообщаем об ошибке, если if(count_ < 1 || count_ > 8 // количество экземпляров не в диапазоне 1 .. 8 || setIndexes.Count() != count_ // не все индексы уникальные || setClusters.Count() != count_ // не все кластеры уникальные ) { return INIT_PARAMETERS_INCORRECT; } ... FOREACH(indexes, { // Убираем номер кластера из строки набора параметров string param = CSVStringGet(params[StringToInteger(indexes[i])], 0, 11); // Добавляем стратегию с набором параметров с заданным индексом APPEND(strategies, new CSimpleVolumesStrategy(param)) }); // Формируем и добавляем к эксперту группу стратегий expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
Salvamos este código no arquivo OptGroupClusterExpert.mq5 na pasta atual.
Essa otimização também apresentou algumas desvantagens. Se o algoritmo genético incluir muitas instâncias na população inicial com pelo menos dois índices de conjuntos de parâmetros iguais, isso pode levar ao rápido enfraquecimento da população e à interrupção prematura do algoritmo de otimização. No entanto, após uma nova execução, podemos ter mais sorte, e a otimização pode ser concluída, encontrando resultados bastante bons.
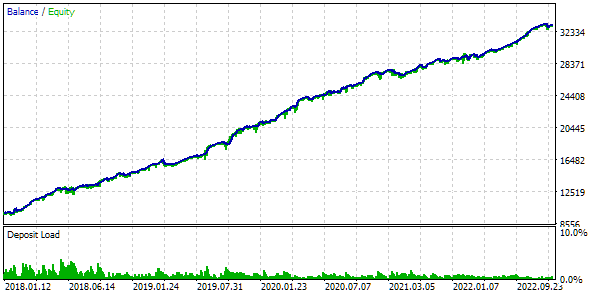
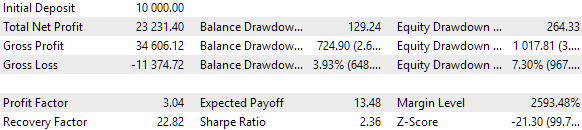
Fig. 8. Resultados do teste do melhor grupo com clusterização
Aumentar a probabilidade de evitar o enfraquecimento da população pode ser feito misturando os conjuntos de parâmetros de entrada ou reduzindo o número de estratégias incluídas no grupo. Em qualquer caso, o tempo gasto na otimização é reduzido em uma vez e meia a duas vezes em comparação com a otimização sem clusterização.
Uma instância por cluster
Existe ainda outra maneira de evitar o enfraquecimento da população: manter no arquivo apenas um conjunto pertencente a cada cluster. Podemos gerar um arquivo com esses dados usando o seguinte código Python:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df = df.sort_values(['cluster', 'Sharpe Ratio']).groupby('cluster').agg('last').reset_index()
clusters = df.cluster
df = df.iloc[:, 1:]
df['cluster'] = clusters
df.to_csv('Params_SV_EURGBP_H1-one_cluster.csv', index=False Podemos usar esse arquivo CSV com dados para otimizar qualquer um dos dois EAs escritos nesta série de artigos.
Se descobrirmos que sobraram poucos conjuntos, podemos aumentar o número de clusters ou incluir vários conjuntos de um mesmo cluster.
Vamos verificar os resultados da otimização desse EA:
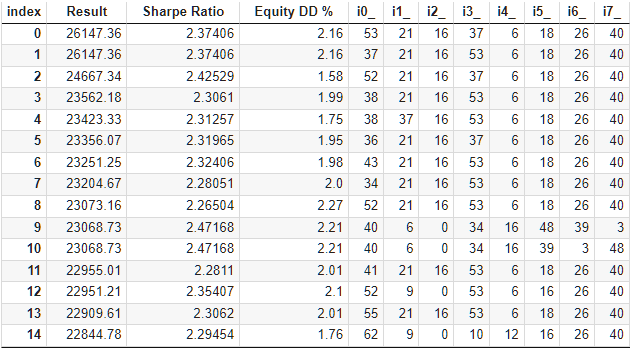
Fig. 9. Tabela com os resultados da otimização da seleção automatizada em grupo por 64 clusters
Eles são aproximadamente os mesmos dos dois métodos anteriores. Foi encontrada uma configuração que supera todas as encontradas anteriormente. Embora isso seja mais uma questão de sorte do que uma vantagem de limitar o número de conjuntos. Aqui estão os resultados de uma única passagem do melhor grupo:
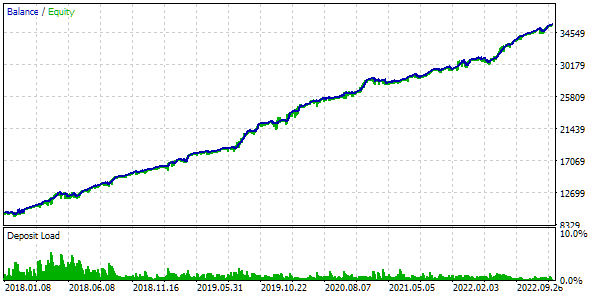
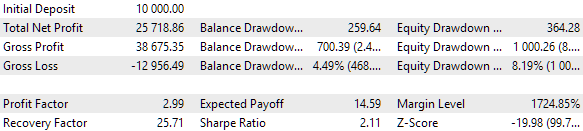
Fig. 10. Resultados do teste do melhor grupo com uma instância por cluster
Na tabela de resultados, é perceptível a repetição de grupos que diferem apenas na ordem dos índices dos conjuntos de parâmetros das estratégias.
Podemos evitar isso adicionando uma verificação ao EA para garantir que a combinação de índices nos parâmetros de entrada forme uma sequência crescente. No entanto, isso leva novamente a problemas com a otimização genética devido ao rápido enfraquecimento da população. E a pesquisa completa, mesmo para a seleção de 8 conjuntos de um grupo de 64, resulta em um número muito grande de execuções. Talvez seja necessário mudar a maneira como os parâmetros de entrada do EA são convertidos em índices de conjuntos de parâmetros de estratégias. Mas isso já são considerações para o futuro.
Vale destacar que resultados comparáveis aos da seleção manual (lucro de aproximadamente $15.000), ao usar um conjunto por cluster, são encontrados literalmente nos primeiros minutos de otimização. Para encontrar os melhores resultados, no entanto, é necessário aguardar quase até o final da otimização.
Considerações finais
Então, vejamos o que conseguimos. Confirmamos que a seleção automática de conjuntos de parâmetros em um grupo pode proporcionar resultados de lucratividade melhores do que a seleção manual. Embora o processo em si leve mais tempo, ele não exige intervenção humana, o que é uma grande vantagem. Além disso, podemos reduzir esse tempo significativamente, se necessário,adicionando mais agentes de teste.
Agora podemos seguir em frente. Se conseguimos selecionar grupos de instâncias de estratégias, podemos pensar em automatizar a composição de novos grupos a partir desses bons grupos que obtivemos. No código do EA, a principal diferença será apenas em como ler corretamente os parâmetros e adicionar não apenas um, mas vários grupos de estratégias ao expert. Nesse contexto, seria interessante considerar um formato unificado para armazenar os conjuntos de parâmetros otimizáveis para estratégias e grupos em um banco de dados, em vez de usar arquivos separados.
Também seria interessante analisar como nossos bons grupos se comportam em um período de teste fora do intervalo em que a otimização dos parâmetros foi realizada. Provavelmente, é isso que vamos explorar no próximo artigo.
Obrigado pela atenção, até a próxima!
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14478
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso