
多通貨エキスパートアドバイザーの開発(第11回):最適化の自動化(最初のステップ)
はじめに
前回の記事では、最適化から得られた結果を活用し、複数の取引戦略インスタンスが連動するレディメイドのEAを構築するための基礎を築きました。これにより、使用するすべてのインスタンスのパラメータを手動でコードやEAの入力に入力する必要がなくなりました。初期化文字列を特定の形式でファイルに保存するか、EAが利用できるようにソースコードにテキストとして挿入するだけで済むのです。
これまでのところ、初期化文字列は手動で生成されてきました。しかし、今こそ、得られた最適化結果に基づいてEAの初期化文字列を自動的に形成する実装に着手する時です。この記事内で完全に自動化されたソリューションを手に入れることは難しいかもしれませんが、少なくとも意図した方向に大きく前進することは間違いありません。
タスクの設定
一般的に、私たちの目的は次のように定義できます。端末で実行され、いくつかの銘柄と時間枠で取引戦略の単一インスタンスを用いたEAの最適化を実行することです。対象銘柄はEURGBP、EURUSD、GBPUSD、時間枠はH1、M30、M15とします。データベースに保存された各最適化パスの結果から、特定の銘柄と時間枠に関連するものを選択できるようにする必要があります(将来的には、他のテストパラメータの組み合わせにも対応する予定です)。
1つの銘柄と時間枠の組み合わせについて、各結果グループから異なる基準に基づいて最良の結果を選びます。選択したすべてのインスタンスは、1つの(今のところ)インスタンスグループにまとめられます。次に、グループの倍率を決定する必要があります。将来的には別のEAがこれを担当する予定ですが、今のところは手動でおこないます。
選択されたグループと倍率に基づいて、最終的なEAで使用される初期化文字列を形成します。
概念
次に、いくつかの新しい概念を紹介します。
- 汎用EAとは、初期化文字列を受信し、取引口座で動作する準備が整ったエキスパートアドバイザー(EA)です。このEAは、inputsで指定された名前のファイルから初期化文字列を読み込むことができるほか、プロジェクト名とバージョンによってデータベースからも取得できます。
- 最適化EAは、プロジェクトの最適化に関するすべてのアクションを実行する責任を持つEAです。このEAをチャート上で実行すると、必要な最適化アクションに関する情報をデータベースから検索し、順次実行します。その結果、汎用EA用に保存された初期化文字列が生成されます。
- ステージEAは、テスターで直接最適化されたEAです。実施されるステージの数によって、いくつかの種類があります。最適化EAは、これらのEAを起動して最適化を行い、その完了を追跡します。
この記事では、1つの取引戦略インスタンスのパラメータを最適化するための1つの段階に限定します。第2段階では、いくつかのベストインスタンスを1つのグループにまとめ、正規化しますが、当面は手動でおこないます。
汎用EAとして、データベースから取引戦略の優れた例に関する情報を選択し、初期化文字列を自ら構築できるEAを作成します。
データベース内の必要な最適化措置に関する情報は、便利な形で保存されるべきです。この種の情報は比較的簡単に作成できるはずです。データベースにこの情報がどのように登録されるのかという疑問は一旦置いておきましょう。ユーザーフレンドリーなインターフェイスは後で実装すればよいので、現在の主な課題は、この情報の構造を理解し、それに対応するテーブル構造をデータベースに作成することです。
まずは、より一般的なエンティティを特定し、徐々に単純なエンティティに降りていきましょう。最終的には、先に作成した1つのテスターパスに関する情報を表すエンティティにたどり着くはずです。
プロジェクト
プロジェクトエンティティはトップレベルの複合体であり、1つのプロジェクトは複数のステージから構成されます。ステージの詳細については後述します。プロジェクトは、名前とバージョンによって特徴づけられ、必要に応じて説明文を含むことがあります。プロジェクトには、「created」、「queued for run」、「running」、「completed」といった状態があります。また、プロジェクト実行の結果得られた汎用EAの初期化文字列を、このエンティティに格納することも論理的です。
将来的には、MQL5のプログラムでデータベースの情報を使用する利便性を高めるために、簡単なORM (Object-Relational Mapping)を実装する予定です。具体的には、データベースに格納するすべてのエンティティを表すクラスをMQL5で作成します。
プロジェクトエンティティのクラスオブジェクトは、データベースに以下の情報を格納します。
- id_project:プロジェクトID
- name:初期化文字列を検索するために汎用EAで使用されるプロジェクト名
- version:取引戦略のインスタンスのバージョンなどによって定義されるプロジェクトのバージョン
- description:プロジェクトの説明、重要な詳細を含む任意のテキスト(空も可)
- params:プロジェクト完了時に入力される汎用EAの初期化文字列(デフォルトは空)
- status:プロジェクトのステータス(Created(デフォルト)、Queued、Processing、Done)
フィールドのリストは後で拡張可能です。
プロジェクトの実行準備が整ったら、次にキュー状態に移行します。この移行は当面手動でおこないます。私たちの最適化EAは、このステータスを持つプロジェクトを検索し、処理ステータスへと移行させます。
各段階の開始時と完了時には、プロジェクトステータスの更新が必要かどうかを確認します。最初のステージが開始されると、プロジェクトは「Processing」状態になります。そして、最後のステージが完了すると、プロジェクトは「Done」状態になります。この時点で、プロジェクト完了時に汎用EAに渡すことができる初期化文字列を受け取るために、paramsフィールドの値が埋められます。
ステージ
前述のように、各プロジェクトは複数の段階に分かれています。ステージの主な特徴は、テスターでの最適化のために、このステージ内で立ち上げられるEA(ステージEA)です。また、各ステージにはテスト間隔が設けられます。この間隔は、その段階で実行されるすべての最適化に対して統一されます。さらに、最適化に関するその他の情報(初期預金、ティックシミュレーションモードなど)も保存できるようにする必要があります。
各ステージは、親(前)ステージを指定することができ、この場合、ステージの実行は親ステージの完了後にのみ開始されます。
このクラスのオブジェクトは、以下の情報をデータベースに保存します。
- id_stage:ステージID
- id_project:ステージが属するプロジェクトID
- id_parent_stage :親(前)ステージのID
- name :ステージ名
- expert:この段階で最適化のために起動されたEAの名前
- from_date:最適化期間の開始日
- to_date:最適化期間の終了日
- forward_date:最適化期間の開始日(フォワードモードが使用されないようにするためには空)
- 最適化パラメータ(初期デポジット、ティックシミュレーションモードなど)のその他のフィールドには、ほとんどの場合変更の必要がないデフォルト値が設定されています。
- status :ステージの状態(Queued(デフォルト)、Processing、Done)
各ステージは、1つまたは複数のジョブで構成されています。最初のジョブが始まると、ステージは「Processing」状態に入ります。そして、すべてのジョブが完了すると、ステージは「Done」状態になります。
ジョブ
各ステージの実装は、そのステージに含まれるすべてのジョブの順次実行で構成されます。ジョブの主な特徴は、銘柄、時間枠、EAの入力であり、このジョブを含む段階で最適化されます。
このクラスのオブジェクトは、以下の情報をデータベースに保存します。
- id_job:ジョブID
- id_stage:ジョブが属するステージのID
- symbol:テスト銘柄(取引商品)
- 期間:テスト期間
- tester_inputs:EA最適化入力の設定
- status :ジョブのステータス(Queued(デフォルト)、Processing、Done)
各ジョブは、1つまたは複数の最適化タスクで構成されます。最初の最適化タスクが開始されると、ジョブは「Processing」状態に入ります。すべての最適化タスクが完了すると、ジョブは「Done」状態になります。
最適化タスク
各タスクの実行は、そのタスクに含まれるすべてのタスクの順次実行で構成されます。この問題の主な特徴は、最適化基準です。テスターの残りの設定はジョブからタスクに継承されます。
このタイプのオブジェクトは、以下の情報をデータベースに保存します。
- id_task :タスクID
- id_job:ジョブが実行されるジョブID
- optimization_criterion:与えられたタスクの最適化基準
- start_date:最適化タスクの開始時刻
- finish_date :最適化タスクの終了時刻
- status:最適化タスクのステータス(Queued(デフォルト)、 Processing、Done)
各タスクは複数の最適化パスで構成されます。最初の最適化パスが開始されると、最適化タスクは「Processing」状態に入ります。すべての最適化パスが完了すると、最適化タスクは「Done」状態になります。
最適化パス
最適化パスは、ストラテジーテスターで最適化中の全パスの結果を自動保存することを追加した以前の記事ですでに検討しました。次に、このパスが実行されたタスクIDを含む新しいフィールドを追加します。
このタイプのオブジェクトは、以下の情報をデータベースに保存します。
- id_pass :パスID
- id_task :パスが実行されるタスクのID
- パス結果フィールド:パスに関する利用可能なすべての統計(パス番号、トランザクション数、利益係数など)のフィールドグループ
- params:パスで使用される戦略インスタンスのパラメータを含む初期化文字列
- inputs :入力値を渡す
- pass_date:パス終了時刻
以前の実装と比較して、各パスで使用される戦略のパラメータに関する保存された情報の構成を変更しました。より一般的には、戦略グループに関する情報を保存する必要があります。したがって、1つの戦略を含む戦略グループでも、必ずその戦略についての情報が保存されるようにします。
また、パスが開始される前ではなく、パスが完了した後にのみテーブルにエントリが追加されるため、パスのステータスフィールドは存在しません。したがって、エントリが存在するということは、すでにそのパスが完了していることを示しています。
私たちのデータベースはすでにその構造を大幅に強化しているため、データベースの作成と作業を担当するプログラムコードにも変更を加える必要があります。
データベースの作成と管理
開発の過程では、データベースの構造を何度も更新し、再作成する必要が生じます。そのため、データベースを再構築し、必要な初期データで満たすためのシンプルな補助スクリプトを作成します。初期データを空のデータベースに入力する方法については、後で検討することにします。
#include "Database.mqh" int OnStart() { DB::Open(); // Open the database // Execute requests for table creation and filling initial data DB::Create(); DB::Close(); // Close the database return INIT_SUCCEEDED; }
現在のフォルダのCleanDatabase.mq5ファイルにコードを保存します。
以前は、CDatabase::Create()メソッド内に、1 つのテーブルを再作成する SQL クエリを含む文字列の配列がありました。しかし、テーブルの数が増えるにつれて、SQL クエリをソースコードに直接格納することは不便になってきました。そこで、すべての SQL リクエストのテキストを別のファイルに移動し、そのファイルから読み込んでCreate()メソッド内で実行することにします。
この変更を実現するためには、ファイルからすべてのリクエストをその名前で読み込み、実行するメソッドが必要です。
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { ... public: ... // Make a request to the database from the file static bool ExecuteFile(string p_fileName); }; ... //+------------------------------------------------------------------+ //| Making a request to the database from the file | //+------------------------------------------------------------------+ bool CDatabase::ExecuteFile(string p_fileName) { // Array for reading characters from the file uchar bytes[]; // Number of characters read long len = 0; // If the file exists in the data folder, then if(FileIsExist(p_fileName)) { // load it from there len = FileLoad(p_fileName, bytes); } else if(FileIsExist(p_fileName, FILE_COMMON)) { // otherwise, if it is in the common data folder, load it from there len = FileLoad(p_fileName, bytes, FILE_COMMON); } else { PrintFormat(__FUNCTION__" | ERROR: File %s is not exists", p_fileName); } // If the file has been loaded, then if(len > 0) { // Convert the array to a query string string query = CharArrayToString(bytes); // Return the query execution result return Execute(query); } return false; }
では、Create()メソッドを変更してみましょう。データベースの構造と初期データを含むファイルは、固定の名前になります。具体的には、.schema.sqlという文字列がデータベース名に追加されます。
//+------------------------------------------------------------------+ //| Create an empty DB | //+------------------------------------------------------------------+ void CDatabase::Create() { string schemaFileName = s_fileName + ".schema.sql"; bool res = ExecuteFile(schemaFileName); if(res) { PrintFormat(__FUNCTION__" | Database successfully created from %s", schemaFileName); } }
これで、どのSQLiteデータベース環境でも、すべてのテーブルを作成し、初期データを投入することができます。その後、作成したデータベースをSQLクエリのセットとしてファイルにエクスポートし、このファイルをMQL5プログラムで使用することが可能です。
この段階でCDatabaseクラスに加えなければならない最後の変更は、データの挿入だけでなく、テーブルからデータを取り出すリクエストも実行できるようにすることです。将来的には、データを取得するためのすべてのコードを、データベースに格納された個々のエンティティを扱う別々のクラスに分散させる予定ですが、これらのクラスが完成するまでは、一時的な回避策を講じる必要があります。
MQL5が提供するツールを使ってデータを読み込むのは、追加するよりも複雑です。リクエスト結果の行を取得するためには、その特定のリクエストのデータを取得するために設計された新しいデータ型(構造体)をMQL5で作成する必要があります。次に、リクエストを送信し、結果のハンドルを取得します。このハンドルを使って、ループ内でリクエスト結果の文字列を一度に一つずつ、同じ以前に作成した構造体の変数に格納できます。
そのため、CDababaseクラス内で、テーブルからデータを取得するリクエストの結果を読み取る汎用メソッドを書くのは実装が難しいため、代わりに上位レベルに任せることにします。そのためには、s_dbフィールドに格納されているデータベース接続ハンドルを上位レベルに提供するだけで済みます。
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { ... public: static int Id(); // Database connection handle ... }; ... //+------------------------------------------------------------------+ //| Database connection handle | //+------------------------------------------------------------------+ int CDatabase::Id() { return s_db; }
取得したコードを現在のフォルダのDatabase.mqhファイルに保存します。
最適化EA
これで最適化EAの作成を開始できます。まず第一に、fxsaberによるテスターで動作するためのライブラリが必要です。
#include <fxsaber/MultiTester/MTTester.mqh> // https://www.mql5.com/ru/code/26132
最適化EAは、タイマーに従って定期的に主要な作業を実行します。そのため、タイマーを作成し、初期化関数の中でそのハンドラを即座に起動して実行することにします。最適化作業には通常数十分かかるため、5秒ごとにタイマーを作動させる設定にします。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Create the timer and start its handler EventSetTimer(5); OnTimer(); return(INIT_SUCCEEDED); }
タイマーハンドラでは、テスターが現在使用中でないかどうかをチェックします。もし使用中でなければ、現在のタスクを完了させるためのアクションを実行する必要があります。その後、次のタスクの最適化IDと入力をデータベースから取得し、StartTask()関数を呼び出して起動します。
//+------------------------------------------------------------------+ //| Expert timer function | //+------------------------------------------------------------------+ void OnTimer() { PrintFormat(__FUNCTION__" | Current Task ID = %d", currentTaskId); // If the EA is stopped, remove the timer and the EA itself from the chart if (IsStopped()) { EventKillTimer(); ExpertRemove(); return; } // If the tester is not in use if (MTTESTER::IsReady()) { // If the current task is not empty, if(currentTaskId) { // Complete the current task FinishTask(currentTaskId); } // Get the number of tasks in the queue totalTasks = TotalTasks(); // If there are tasks, then if(totalTasks) { // Get the ID of the next current task currentTaskId = GetNextTask(currentSetting); // Launch the current task StartTask(currentTaskId, currentSetting); Comment(StringFormat( "Total tasks in queue: %d\n" "Current Task ID: %d", totalTasks, currentTaskId)); } else { // If there are no tasks, remove the EA from the chart PrintFormat(__FUNCTION__" | Finish.", 0); ExpertRemove(); } } }
タスク起動関数内では、MTTESTER クラスのメソッドを使用してテスターに入力を読み込み、最適化モードでテスターを起動します。また、データベースの情報を更新し、現在のタスクの開始時刻とステータスを保存します。
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void StartTask(ulong taskId, string setting) { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", taskId, setting); // Launch a new optimization task in the tester MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(setting); MTTESTER::ClickStart(); // Update the task status in the database DB::Open(); string query = StringFormat( "UPDATE tasks SET " " status='Processing', " " start_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); }
データベースから次のタスクを受け取る関数も非常にシンプルです。基本的には、SQLクエリを実行し、その結果を受け取るだけです。この関数は、次のタスクのIDを結果として返し、最適化入力を含む文字列を、参照引数として渡されたsetting変数に書き込みます。
//+------------------------------------------------------------------+ //| Get the next optimization task from the queue | //+------------------------------------------------------------------+ ulong GetNextTask(string &setting) { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT s.expert," " s.from_date," " s.to_date," " j.symbol," " j.period," " j.tester_inputs," " t.id_task," " t.optimization_criterion" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status = 'Queued'" " ORDER BY s.id_stage, j.id_job LIMIT 1;"; // Open the database DB::Open(); if(DB::IsOpen()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string expert; string from_date; string to_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { setting = StringFormat( "[Tester]\r\n" "Expert=Articles\\2024-04-15.14741\\%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=2\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=0\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d||0||0||0||N\r\n" "%s\r\n", row.expert, row.symbol, row.period, row.from_date, row.to_date, row.optimization_criterion, row.id_task, row.tester_inputs ); res = row.id_task; } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } return res; }
簡略化のため、いくつかの最適化入力の値はコード内で直接指定されています。たとえば、入金額10,000米ドル、レバレッジ1:200、通貨は常に米ドルなどです。これらのパラメータの値は、必要に応じてデータベースから取得することも可能です。
キュー内のタスク数を返すTotalTasks()関数のコードは、前述の関数と非常に似ているため、ここでは省略します。
出来上がったコードを現在のフォルダのOptimization.mq5ファイルに保存します。あとは、最低限自給自足できるシステムを構築するために、以前に作成したファイルに少しだけ編集を加える必要があります。
СVirtualStrategyとСSimpleVolumesStrategy
これらのクラスでは、戦略の正規化残高を設定する機能を削除し、初期値を常に10,000に固定します。この値は、戦略が所定の正規化係数を持つグループに含まれる場合のみ変更されます。たとえ戦略のインスタンスを1つだけ実行する場合でも、そのインスタンスは必ずグループに追加される必要があります。
次に、CVirtualStrategyクラスのオブジェクトのコンストラクタに新しい値を設定します。
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualStrategy::CVirtualStrategy() : m_fittedBalance(10000), m_fixedLot(0.01), m_ordersTotal(0) {}
CSimpleVolumesStrategyクラスのコンストラクタにおいて、初期化文字列から最後のパラメーターの読み取りを削除します。
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(string p_params) { // Save the initialization string m_params = p_params; // Read the parameters from the initialization string m_symbol = ReadString(p_params); m_timeframe = (ENUM_TIMEFRAMES) ReadLong(p_params); m_signalPeriod = (int) ReadLong(p_params); m_signalDeviation = ReadDouble(p_params); m_signaAddlDeviation = ReadDouble(p_params); m_openDistance = (int) ReadLong(p_params); m_stopLevel = ReadDouble(p_params); m_takeLevel = ReadDouble(p_params); m_ordersExpiration = (int) ReadLong(p_params); m_maxCountOfOrders = (int) ReadLong(p_params); m_fittedBalance = ReadDouble(p_params); // If there are no read errors, if(IsValid()) { ... } }
現在のフォルダのVirtualStrategy.mqhファイルとCSimpleVolumesStrategy.mqhファイルに変更を保存します。
СVirtualStrategyGroup
このクラスには、現在のグループの初期化文字列を、異なる正規化係数の代入値で返す機能を持つ新しいメソッドを追加しました。正規化係数の値は、テスターが実行を完了した後に決定されるため、すぐに正しい倍率のグループを作成することはできません。基本的には、引数として渡された数字を、閉じ括弧の前の初期化文字列に代入するだけのシンプルな実装です。
//+------------------------------------------------------------------+ //| Class of trading strategies group(s) | //+------------------------------------------------------------------+ class CVirtualStrategyGroup : public CFactorable { ... public: ... string ToStringNorm(double p_scale); }; ... //+------------------------------------------------------------------+ //| Convert an object to a string with normalization | //+------------------------------------------------------------------+ string CVirtualStrategyGroup::ToStringNorm(double p_scale) { return StringFormat("%s([%s],%f)", typename(this), ReadArrayString(m_params), p_scale); }VirtualStrategyGroup.mqhファイルに加えた変更を現在のフォルダに保存します。
CTesterHandler
最適化パスの結果を格納するクラスに、s_idTask staticプロパティを追加し、現在の最適化タスク ID を代入します。入力されたデータフレームを処理するメソッドでは、結果をデータベースに保存するためのSQLクエリに渡される値のセットに追加します。
//+------------------------------------------------------------------+ //| Optimization event handling class | //+------------------------------------------------------------------+ class CTesterHandler { ... public: ... static ulong s_idTask; }; ... ulong CTesterHandler::s_idTask = 0; ... //+------------------------------------------------------------------+ //| Handling incoming frames | //+------------------------------------------------------------------+ void CTesterHandler::ProcessFrames(void) { // Open the database DB::Open(); ... // Go through frames and read data from them while(FrameNext(pass, name, id, value, data)) { ... // Form an SQL query from the received data query = StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %d, %s,\n'%s',\n'%s');", s_idTask, pass, values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); // Add it to the SQL query array APPEND(queries, query); } // Execute all requests DB::ExecuteTransaction(queries); ... }
得られたコードを現在のフォルダのTesterHandler.mqhファイルに保存します。
СVirtualAdvisor
いよいよ最後の編集に取り掛かります。EAクラスでは、与えられた最適化パスの間にEAで使用された戦略または戦略のグループの自動正規化機能を追加します。このプロセスを実現するために、EAの初期化文字列から使用される戦略のグループを再構築し、さらにこのグループの初期化文字列を、パスにおける現在のドローダウンの結果に基づいて計算された別の正規化乗数で形成します。
//+------------------------------------------------------------------+ //| OnTester event handler | //+------------------------------------------------------------------+ double CVirtualAdvisor::Tester() { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = CMoney::FixedBalance() * 0.1 / balanceDrawdown; // Calculate the profit in annual terms long totalSeconds = TimeCurrent() - m_fromDate; double fittedProfit = profit * coeff * 365 * 24 * 3600 / totalSeconds ; // Re-create the group of used strategies for subsequent normalization CVirtualStrategyGroup* group = NEW(ReadObject(m_params)); // Perform data frame generation on the test agent CTesterHandler::Tester(fittedProfit, // Normalized profit group.ToStringNorm(coeff) // Normalized group initialization string ); delete group; return fittedProfit; }
現在のフォルダのVirtualAdvisor.mqhファイルに変更を保存します。
最適化の開始
最適化を開始する準備が整いました。データベースには合計81のタスク(3つの銘柄 × 3つの時間枠 × 9つの基準)が作成されています。最初は、最適化のインターバルを5ヶ月と短く設定し、選択する最適化されたパラメータの組み合わせも少数に絞りました。これは、作業戦略インスタンスの入力の組み合わせを発見すること自体よりも、自動テストのパフォーマンスに興味があったからです。何度かテストを実行し、細かな欠点を修正した結果、私たちが望んでいたものを得ることができました。パステーブルには、1つの戦略インスタンスを持つ正規化されたグループの初期化文字列を含むパス結果が格納されています。
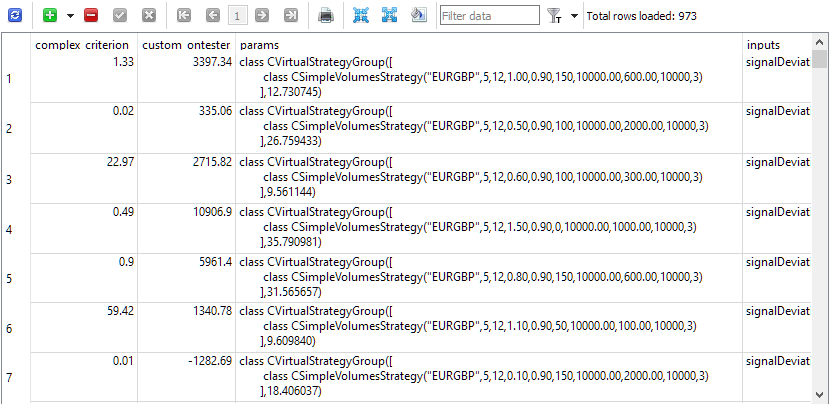
図1:パス結果を伴う「パス」
構造がその価値を証明したら、より複雑な仕事を与えることが可能です。具体的には、同じ81のタスクをより長い間隔で、さらに多くのパラメータの組み合わせを用いて実行してみましょう。この場合、しばらく待たなければなりません。20のエージェントが1つの最適化タスクを約1時間かけて実行するため、つまり、24時間体制で仕事をすれば、すべての仕事を完了させるのに3日ほどかかることになります。
その後、受信した数千のパスから最適なものを手動で選択し、選択基準に基づいた対応するSQLクエリを形成します。最初は、シャープレシオが5を超えたパスのみを選択することにします。次に、新しいEAを作成します。このEAは、初期段階では汎用EAの役割を果たします。その主要部分は初期化関数であり、この関数では、選択したベストパスのパラメータをデータベースから抽出し、それに基づいてEAの初期化文字列を形成します。
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" sinput double expectedDrawdown_ = 10; // - Maximum risk (%) sinput double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency sinput double scale_ = 1.00; // - Group scaling multiplier input group "::: Selection for the group" input int count_ = 1000; // - Number of strategies in the group input group "::: Other parameters" sinput ulong magic_ = 27183; // - Magic input bool useOnlyNewBars_ = true; // - Work only at bar opening CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); string query = StringFormat( "SELECT DISTINCT p.custom_ontester, p.params, j.id_job " " FROM passes p JOIN" " tasks t ON p.id_task = t.id_task" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE p.custom_ontester > 0 AND " " trades > 20 AND " " p.sharpe_ratio > 5" " ORDER BY s.id_stage ASC," " j.id_job ASC," " p.custom_ontester DESC LIMIT %d;", count_); DB::Open(); int request = DatabasePrepare(DB::Id(), query); if(request == INVALID_HANDLE) { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); DB::Close(); return 0; } struct Row { double custom_ontester; string params; int id_job; } row; string strategiesParams = ""; while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } // Prepare the initialization string for an EA with a group of several strategies string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
最適化のために、2021年と2022年の2年間を含む間隔を選びました。この期間での汎用EAの結果を見てみましょう。最大ドローダウンを10%に抑えるため、scale_multiplierに適切な値を選択します。以下は、この期間における汎用EAのテスト結果です。
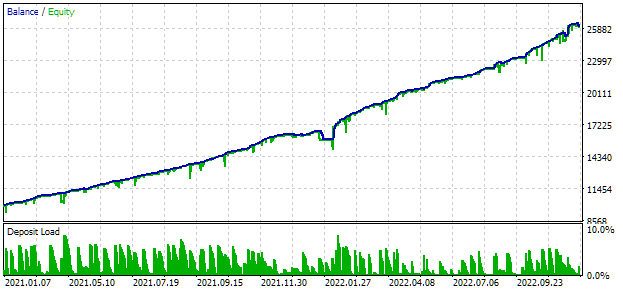
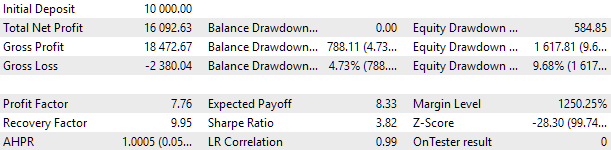
図2:2021~2022年の汎用EAテスト結果(scale_ = 2)
約1000の戦略インスタンスがEA操作に関与しました。結果を改善することを目的としたこれまでに説明したアクションの多くをまだ実行していないため、これらの結果は中間的なものとして扱う必要があります。特に、EURUSD戦略のインスタンス数がEURGBP戦略よりもかなり多くなっていることがわかりました。これにより、複数通貨の利点はまだ最大限に活用されていない状況です。そのため、改善の余地があるという希望があります。この可能性を実現するために、今後の記事で詳しく説明していくつもりです。
結論
意図したゴールに向けて重要な一歩を踏み出しました。さまざまな銘柄、時間枠、その他のパラメータにおける取引戦略のインスタンスの最適化を自動化する能力を得ることができました。これにより、パラメータを変更して次の最適化プロセスを実行するために、実行中の最適化プロセスの終了を追跡する必要がなくなりました。
すべての結果をデータベースに保存することで、最適化EAの再起動を心配する必要がなくなります。何らかの理由で最適化EAの動作が中断された場合、次の起動時にはキュー内の次のタスクから再開されます。また、最適化プロセスにおけるすべてのテストパスの全体像も把握しています。
しかし、まだまだ研究の余地があります。ステージとプロジェクトの状態の更新はまだ実装されていません。現在はタスクの状態を更新しているだけです。複数の段階からなるプロジェクトの最適化についてもまだ考慮されていません。また、データのクラスタリングが必要な場合、データステージの中間処理をどのように実装するのが最適かも不明です。これらすべてを後続の記事でカバーする予定です。
ご清聴ありがとうございました。またすぐにお会いしましょう。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14741
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
そうだね、僕自身もこんなにシンプルだとは思っていなかった。最初はValidateを勉強して、それをベースに自分で何か書かなきゃいけないと思っていたんだけど、もっとシンプルな実装でいけることに気づいたんだ。
素晴らしいライブラリをありがとう!
こんにちは、Yuriy、
UserRoamingAppData...に作成したCleanDatabaseでSQLを作成しましたが、オプティマイザを使おうとしたら、エラーが出ました:IPCサーバーが起動していません。
また、ターミナルとMetaEditorで/portableスイッチを使用していますが、MQLのインストールはすべてC:Forex Program Filesにあります。
MQ4の開発とEAのテスト中に、私はテストに興味のあるすべてのペアのディレクトリを作成しました。私はJOINコマンドを使用して、各テストディレクトリの適切なサブディレクトリを、プロブレムの起動と気配値データの受信のための共通ディレクトリにリダイレクトし、すべての別々のテストが同じデータと実行ファイルを使用していることを確認しました。 さらに、各テストは実行ごとにCVSファイルを書き、私はFile関数のバージョンを使用して、各FilesディレクトリからCVSファイルを読み込んで、共通のCVSファイルに統合しました。 SQLアクセスの代わりにCVSファイルを使用する際に、これがあなたの興味を引くものであれば、私に知らせてください。
取り急ぎ、パート20をダウンロードして、例を見ながらお茶を濁すつもりです。
ケープコッダ