ニューラルネットワークが簡単に(第45回):状態探索スキルの訓練

はじめに
階層的強化学習アルゴリズムは、非常に複雑な問題をうまく解くことができます。これは、問題をより小さなサブタスクに分割することによって達成されます。この文脈における主な問題のひとつは、エージェントが効果的に行動し、可能であれば目標を達成するために可能な限り環境を管理できるような、スキルの正しい選択と訓練です。
前回までに、DIAYNとDADSのスキル訓練アルゴリズムを紹介しました。最初のケースでは、環境を最大限に探索できるように、最大限の多様な行動でスキルを教えました。同時に、現在の仕事に役立たないスキルの訓練も厭いませんでした。
2つ目のアルゴリズム(DADS)では、環境への影響という観点から学習スキルにアプローチしました。ここでは、環境のダイナミクスを予測し、変化から最大限の利益を得ることができるスキルを使うことを目指しました。
どちらの場合も、事前分布のスキルがエージェントへの入力として使用され、訓練プロセスで探索されました。この方法を実際に使用すると、状態空間を十分に網羅していないことがわかります。その結果、訓練されたスキルは、起こりうるすべての環境状態と効果的に相互作用することができません。
この記事では、EDL (Explore, Discover and Learn、探索、発見、学習)という代替的なスキルの教授法について知ることを提案します。EDLは異なる角度からこの問題にアプローチすることで、限られた状態カバレッジの問題を克服し、より柔軟で適応的なエージェント動作を提供することができます。
1.「EDL (Explore, Discover and Learn)」アルゴリズム
EDL (Explore, Discover and Learn)法は、2020年8月に科学論文「Explore, Discover and Learn:Unsupervised Discovery of State-Covering Skills」で発表されました。これは、エージェントが、状態やスキルに関する事前知識なしに、環境におけるさまざまなスキルを発見し、使用することを学習することを可能にするアプローチを提案するものです。また、異なる状態にまたがる様々なスキルの訓練が可能で、未知の環境におけるエージェントの探索と学習をより効率的におこなうことができます。
EDLメソッドには決まった構造があり、「探索」「発見」「スキル訓練」の3つの主要な段階から構成されています。
探検は、環境についての予備知識も必要なスキルもないまま始まります。この段階では、ありとあらゆる環境行動に対応する様々な状態を最大限にカバーした初期状態の学習セットを作成しなければなりません。私たちの研究では、訓練期間中のシステム状態の均一なサンプリングを使用します。ただし、特にエージェントの特定の行動様式を訓練する場合には、他のアプローチも可能です。EDLは、専門家戦略によって作られた軌道や行動にアクセスする必要はないことに留意すべきです。しかし、その使用を排除するものでもありません。
第2段階では、特定の環境条件に隠されたスキルを探します。この方法の基本的な考え方は、環境の状態(または状態空間)とエージェントが使用すべき特定のスキルとの間に何らかの関連があるということです。そのような依存関係を見極めなければなりません。
なお、現段階では環境条件についての知識はありません。そのような状態はほんの一例です。さらに、必要なスキルについての知識も不足しています。同時に、EDLメソッドは教師なしでスキルを発見するものであることも指摘しました。このアルゴリズムは、変分オートエンコーダを使用して、指定された依存関係を探索します。モデルの入力と出力には環境状態が存在します。オートエンコーダの潜在的な状態では、現在の環境状態から導かれる潜在的なスキルの識別が得られると期待されます。このアプローチでは、オートエンコーダのエンコーダは、スキルが環境の現在の状態にどのように依存するかの関数を構築します。モデルデコーダは逆関数を実行し、使用するスキルに対する状態の依存性を構築します。変分オートエンコーダを使うことで、明確な「状態とスキル」の対応から、ある確率分布に移行することができます。これは一般的に、複雑な確率的環境におけるモデルの安定性を高めます。
このように、状態やスキルに関する付加的な知識がない場合、EDL法で変分オートエンコーダを使用することで、さまざまな環境状態に関連する隠れたスキルを探索発見する機会が得られます。環境の状態と必要とされるスキルの関係を表す関数を構築することで、環境の新しい状態を、将来的に最も関連性の高いスキルのセットに解釈できるようになります。
先に説明した方法では、まずスキルを訓練しました。そこでスケジューラは、既成のスキルを使って目標を達成する戦略を探しました。EDL方式は逆のアプローチをとります。まずステートとスキルの間に依存関係を構築します。その後、技術を教えます。 これにより、特定の環境条件にスキルをより正確に適合させ、特定の状況でどのスキルを使用するのが最も効果的かを判断することができます。
アルゴリズムの最終段階は、スキルモデル(エージェント)の訓練です。ここでエージェントは、状態と隠れ変数の相互情報を最大化する戦略を学習します。エージェントは強化学習法を用いて訓練されます。報酬の構成はDADSメソッドと似ていますが、メソッドの著者は方程式を少し簡略化しています。覚えておいでかもしれませんが、DADSのエージェント内部報酬は、方程式に従って形成されています。
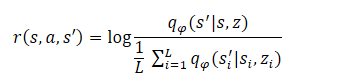
数学の授業では、次のように学びます。
![]()
したがって
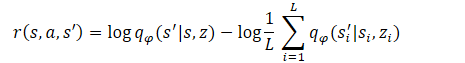
おわかりのように、減数はすべてのスキルにおいて一定です。従って、ポリシーの最適化には最小値しか使えません。このアプローチにより、モデル訓練の質を落とすことなく、計算量を減らすことができます。
![]()
この最終段階は、マルコフ決定過程の下でデコーダを模倣する戦略、つまり、デコーダが各隠れzスキルに対して生成する状態を訪れる戦略の訓練と考えることができます。報酬関数は、戦略の行動によって連続的に変化する従来の方法とは異なり、固定されていることに注意すべきです。これにより、訓練がより安定し、モデルの収束性が高まります。
2.MQL5を使用した実装
EDL (Exploration, Discovery and Learning)メソッドの理論的側面を考察した後は、実践的な部分に話を移しましょう。MQL5を使ってメソッドを実装する前に、実装機能を見ておく必要があります。
前回の記事の検証セクションでは、エージェントのソースデータで使用されているスキルを特定するためにワンホットベクトルと完全分布を使用した結果の類似性を実証しました。これによって、手持ちのデータに応じてどちらかのアプローチを使うことができ、計算量を減らすことができます。これは一般的に、手術の回数を減らす可能性を与えてくれます。同時に、モデルの訓練や操作のスピードも上げることができます。
2つ目の注意点は、スケジューラとエージェントの入力に同じ初期データ(価格の動き、パラメータ値、バランス状態の履歴データ)を提出することです。このデータには、エージェント入力時にスキルIDも追加されます。
一方、オートエンコーダを研究する際、オートエンコーダの潜在的な状態は元のデータの圧縮表現であると述べました。言い換えれば、ソースデータのベクトルと変分オートエンコーダの潜在データのベクトルを連結することで、同じデータを完全な表現と圧縮された表現で2回渡すことになります。
同じようなブロックの予備的なソースデータの取り扱いが使用される場合、このアプローチは冗長になる可能性があります。そこで、この実装では、オートエンコーダの潜在的な状態をエージェントの入力に送るだけです。これにより、モデルの訓練にかかる総時間だけでなく、実行される操作の量も大幅に減らすことができます。
もちろん、このアプローチは、スケジューラとエージェントの入力に同様の初期データを使用する場合にのみ可能です。その他のオプションも可能です。例えば、オートエンコーダは、口座の状態を考慮することなく、過去のデータとスキルの間の依存関係のみを構築することができます。エージェントの入力では、オートエンコーダの潜在状態のベクトルと計数状態の記述のベクトルを連結することができます。先に説明したメソッドを実装したときのように、すべてのデータを使用することは間違いではありません。実装にあたっては、さまざまなアプローチを試すことができます。
このような決定はすべて、CreateDescriptions関数で指定するモデルアーキテクチャに必ず反映されます。メソッドのパラメータには、スケジューラとエージェントのモデルを記述する2つの動的配列へのポインタを渡します。EDLメソッドを実装する際に識別器は作成しないことに注意してください。識別器の役割はオートエンコーダ(スケジューラ)デコーダが担うからです。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *scheduler) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; }
スケジューラ用の変分オートエンコーダが最初に作られます。このモデルには、過去のデータと口座ステータスを入力しており、これはソースデータレイヤーのサイズに反映されています。いつものように、生データはバッチ正規化層で前処理されます。
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
次に、データの次元を減らし、特定の特徴を抽出するための畳み込みブロックが来ます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!scheduler.Add(descr)) { delete descr; return false; }
次に、3つの全結合層があり、徐々に次元が下がっていきます。最終層のサイズは、訓練されるスキルの数の2倍であることに注意してください。これが変分オートエンコーダの特徴です。古典的なオートエンコーダとは異なり、変分オートエンコーダでは、各特徴は、平均値と分布の分散という2つのパラメータで表されます。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NSkills; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
パラメータ再変換のトリックは、変分オートエンコーダを実装するために特別に作られた次の層で実行されます。ここで、パラメータも与えられた分布からサンプリングされます。この層のサイズは、訓練されるスキルの数に対応しています。
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NSkills; if(!scheduler.Add(descr)) { delete descr; return false; }
デコーダは3つの全結合層の形で実装されています。非正規化データに対する活性化関数を決定することは困難であるため、後者は活性化関数なしです。
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.optimization = ADAM; descr.activation = None; if(!scheduler.Add(descr)) { delete descr; return false; }
以前の方法と同様に、元のデータは完全には復元しません。結局のところ、エージェントの行動が金融商品の市場価格に与える影響はごくわずかです。逆に、バランスの状態はエージェントの戦略に直接左右されます。したがって、オートエンコーダの出力では、口座状態の記述のみを復元します。
スケジューラの次に、エージェントアーキテクチャの記述を作成します。前述したように、エージェントのソースデータ層は、訓練されるスキルの数まで削減されます。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
異なるモデルの隠れ状態を使うことで、データの前処理ブロックを省くことができます。このように、ソースデータ層の直後には、3つの全結合層からなる意思決定ブロックが存在します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
モデルの出力では、完全にパラメータ化された分位関数のブロックを使用し、報酬の分布をより詳細に調べることができます。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- return true; }
前回と同様、インクルードファイル「EDLTrajectory.mqh」にモデル構造を記述する機能を入れました。これにより、EDL手法の全段階を通じて単一のモデルアーキテクチャを使用することができます。
モデルアーキテクチャを作成した後、研究対象のメソッドを実装するためのEAの作成に移ります。まず、第1段階のEAである「Research」を作成します。この機能は、EDLResearch.mq5 EAで実行されます。このEAのアルゴリズムは、以前の記事で紹介した同名のEAをほぼ完全にコピーしています。しかし、モデルのアーキテクチャによる違いもあります。特に、以前の実装では、このEAのアルゴリズムはエージェントモデルのみを使用し、その入力には初期データとランダムに生成されたスキルIDが供給されていました。この実装では、スケジューラの入力に過去のデータを提供します。そのダイレクトパスの後、隠された状態を抽出し、それをエージェント入力に提出して行動を決定します。EAの完全なコードとすべての関数は添付ファイルにあります。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ........ //--- if(!Scheduler.feedForward(GetPointer(State1), 1, false)) return; if(!Scheduler.GetLayerOutput(LatentLayer, Result)) return; //--- if(!Actor.feedForward(Result, 1, false)) return; int act = Actor.getSample(); //--- ........ ........ //--- }
EDL法の第2段階は、スキルを特定することです。理論的な部分で述べたように、この段階では変分オートエンコーダを訓練します。この機能は「StudyModel.mq5」EAで実行されます。このEAは、過去の記事で紹介したモデル訓練EAに基づいて作成されました。唯一の変更は、メソッドのアルゴリズムに関するものです。
OnInit関数では、1つのスケジューラモデルだけが初期化されます。ただし、主な変更はTrainモデルの訓練機能に加えられました。前回同様、関数の冒頭で内部変数を宣言します。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); vector<float> account, reward; int bar, action;
次に、EAの外部パラメータで指定された反復回数で訓練サイクルを準備します。
//--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
ループの本体では、ランダムにパスを選択し、選択されたパスの状態の1つを訓練セットから選択します。選択された状態の記述データは、このモデルのフォワードパス用のソースデータバッファに転送されます。これらの反復は、以前におこなったものと変わらありません。覚えておいでかもしれませんが、相対的に見れば口座状況に関する情報を記入します。
State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i].account[1] / PrevBalance); State.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i].account[2] / PrevBalance); State.Add(Buffer[tr].States[i].account[4] / PrevBalance); State.Add(Buffer[tr].States[i].account[5]); State.Add(Buffer[tr].States[i].account[6]); State.Add(Buffer[tr].States[i].account[7] / PrevBalance); State.Add(Buffer[tr].States[i].account[8] / PrevBalance);
次に、次のローソク足の価格変化量から1ロットあたりの利益を求め、その後の計算のために残高と資本をローカル変数に保存します。
//--- bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1];
準備作業を終えたら、モデルのフォワードパスを実行します。
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
フォワードパスが成功したら、次はリバースパスを準備しなければなりません。ここでは、モデルの目標値を準備する必要があります。オートエンコーダの訓練のロジックに従えば、ソースデータバッファをターゲット値として使用しなければなりませんが、アーキテクチャーと訓練ロジックに変更を加えました。第一に、ソースデータの属性の完全なセットを出力するのではなく、口座の状態を記述するためのパラメータのみを生成します。
次に、私たちは小さな一歩を踏み出しました。モデルを訓練して、その後の口座状態を予測できるようにしたいと思います。しかし、エージェントのすべての可能な行動に対して口座状態を生成するわけではありません。モデルの訓練段階で、訓練サンプルの次のローソクを判断し、最も有益な行動を取ることができます。このようにして、口座の望ましい予測状態を形成し、それをモデルのバックワードパスの目標値として使用します。
if(prof_1l > 5 ) action = (prof_1l < 10 || Buffer[tr].States[i].account[6] > 0 ? 2 : 0); else { if(prof_1l < -5) action = (prof_1l > -10 || Buffer[tr].States[i].account[5] > 0 ? 2 : 1); else action = 3; } account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); Result.Clear(); Result.Add((account[0] - PrevBalance) / PrevBalance); Result.Add(account[1] / PrevBalance); Result.Add((account[1] - PrevEquity) / PrevEquity); Result.Add(account[2] / PrevBalance); Result.Add(account[4] / PrevBalance); Result.Add(account[5]); Result.Add(account[6]); Result.Add(account[7] / PrevBalance); Result.Add(account[8] / PrevBalance);
希望する行動を定義する際に、次の制限を導入します。
- 取引を開始するための最低利益
- 取引を終了するための最小限の動き(小さな変動を待つ)
- 新規ポジションを建てる前に、反対売買をすべて決済する
これで、望ましい振る舞いをする予測モデルを作ります。
生成された口座の予測状態を相対単位の平面に移し、データバッファに転送します。その後、モデルのリバースパスをおこないます。
if(!Scheduler.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
前回と同様、ループの繰り返し終了時に、ユーザーがモデルの訓練過程を視覚的に監視できるよう、情報メッセージを表示します。
モデル訓練サイクルのすべての反復が完了したら、チャート上のコメントブロックを消去し、EAを終了するプロセスを開始します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); ExpertRemove(); //--- }
スケジューラ変分オートエンコーダの訓練EAの完全なコードは添付ファイルにあります。
環境状態とスキルの依存関係を決定した後、必要なスキルを持つエージェントを訓練する必要があります。EDL\StudyActor.mq5 EAで機能を準備します。このEAでは、スケジューラとエージェントの2つのモデルを使用します。ただし、訓練するのはエージェント1つだけです。そのため、EA初期化メソッドでは2つのモデルをプリロードします。しかし、プログラムの致命的な終了は、すでに訓練されているはずのスケジューラを読み込めなくするだけです。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true)) { PrintFormat("Error of load scheduler model: %d", GetLastError()); return INIT_FAILED; }
エージェントモデルの読み込み中にエラーが発生した場合、新しいモデルの作成を開始します。
if(!Actor.Load(FileName + "Act.nnw", dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *scheduler = new CArrayObj(); if(!CreateDescriptions(actor, scheduler)) { delete actor; delete scheduler; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete scheduler; return INIT_FAILED; } delete actor; delete scheduler; //--- }
モデルを読み込むまたは新規作成した後、ソースデータのニューラル層のサイズと結果が機能に対応していることを確認します。
//--- Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } Actor.SetOpenCL(Scheduler.GetOpenCL()); Actor.SetUpdateTarget(MathMax(Iterations / 100, 10000)); //--- Scheduler.getResults(Result); if(Result.Total() != AccountDescr) { PrintFormat("The scope of the scheduler does not match the account description (%d <> %d)", AccountDescr, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); int inputs = Result.Total(); if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("Error of load latent layer %d", LatentLayer); return INIT_FAILED; } if(inputs != Result.Total()) { PrintFormat("Size of latent layer does not match input size of Actor (%d <> %d)", Result.Total(), inputs); return INIT_FAILED; }
モデルの読み込みと初期化に成功し、さらにすべてのコントロールをパスした後、モデル訓練開始のイベントを初期化し、EA初期化関数の動作を完了します。
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
エージェントの訓練プロセスはTrainメソッドで構成されます。このメソッドの最初の部分には、パスを選択することが含まれる。スケジューラのダイレクトパスの状態と構成は前述の通りであり、変更することなくこのEAに引き継がれています。従って、このブロックはスキップして、すぐにエージェントのダイレクトパスの手配に移ります。ここではすべてが非常に簡潔です。オートエンコーダの潜在的な状態を抽出し、受信したデータをエージェントの入力に渡すだけです。操作の実行を制御することを忘れないでください。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { ........ ........ //--- if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!Actor.feedForward(Result, 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
フォワードパスの操作が成功したら、エージェントモデルを通してリバースパスを準備する必要があります。理論ブロックでも述べたように、エージェントの訓練は強化訓練法を用いておこなわれます。ダイレクトパスの間に発生する行動に対する報酬の形成を準備しなければなりません。EDL法では、識別器によって生成された報酬に基づいてエージェントを訓練します。この場合、その役割はスケジューラオートエンコーダーデコーダが担います。ただし、著者らが提案した報酬形成の原則から少し逸脱しました。これは一般的に、メソッドのイデオロギーと矛盾するものではありません。
前述したように、オートエンコーダの訓練では、導入された制限を考慮した上で、口座の望ましい計算状態を使用しました。これで、望ましい結果に可能な限り近づけるエージェントの行動に報酬を与えるようになります。バランスの望ましい状態と予測状態の間の尺度として、2つのベクトル間の距離のユークリッドメトリックを使用します。その結果得られた距離に報酬として「-1」を乗じることで、望ましい状態に可能な限り近づける行動が最大の報酬を受け取るようにします。
このアプローチにより、サイクルを準備し、1つの個別の行動だけでなく、エージェントのすべての可能な行動に対して報酬を記入することができます。これにより、一般的にモデル学習プロセスの安定性とパフォーマンスが向上します。
Scheduler.getResults(SchedulerResult); ActorResult = vector<float>::Zeros(NActions); for(action = 0; action < NActions; action++) { reward = GetNewState(Buffer[tr].States[i].account, action, prof_1l); reward[0] = reward[0] / PrevBalance - 1.0f; reward[3] = reward[2] / PrevBalance; reward[2] = reward[1] / PrevEquity - 1.0f; reward[1] /= PrevBalance; reward[4] /= PrevBalance; reward[7] /= PrevBalance; reward[8] /= PrevBalance; reward=MathPow(SchedulerResult - reward, 2.0); ActorResult[action] = -reward.Sum(); }
すべての可能なエージェントの行動を列挙するサイクルを完了した後、エージェントの各可能な行動の後に計算された状態から、オートエンコーダによって予測された所望の状態までの距離のベクトルを得ます。覚えておいでかもしれませんが、距離は反対の記号で書きました。従って、最大距離は最大マイナス、あるいは単に最小となります。ベクトルの各要素からこの最小値を差し引けば、望ましい結果から遠ざかる行動の報酬はゼロになります。他のすべての報酬は、その構造を変えることなく、プラス値の領域に移されます。
ActorResult = ActorResult - ActorResult.Min();
この場合、SoftMaxはあえて使いません。結局のところ、確率の領域に移行することで、構造のみが保存され、望ましい結果からの距離の影響は中和されます。この影響力は、全体的な戦略を構築する上で非常に重要です。
加えて、オートエンコーダの予測された状態は、環境の実際の確率性に完全には対応していません。したがって、オートエンコーダの予測品質を評価することは重要です。エージェント訓練の質は、最終的にはオートエンコーダが予測した状態と、エージェントが相互作用する実際の環境状態との対応に依存します。
また、戦略を構築する際、エージェントは現在の報酬だけでなく、エピソード終了までに報酬を受け取る可能性を総合的に考慮することも忘れてはいけません。この場合、ターゲットモデル(ターゲットネット)を使って、次の状態のコストを決定します。この機能は、完全にパラメータ化された分位関数モデルにすでに実装されていますが、正常に機能させるためには、システムの次の状態を反転メソッドに渡す必要があります。
この場合、まず、経験値再生バッファから次のシステム状態を使用して、オートエンコーダのフォワードパスを実行する必要があります。
State.AssignArray(Buffer[tr].States[i+1].state); State.Add((Buffer[tr].States[i+1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i+1].account[1] / PrevBalance); State.Add((Buffer[tr].States[i+1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i+1].account[2] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[4] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[5]); State.Add(Buffer[tr].States[i+1].account[6]); State.Add(Buffer[tr].States[i+1].account[7] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[8] / PrevBalance); //--- if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
次に、オートエンコーダの潜在状態から、システムの次の状態の圧縮表現を抽出することができます。次に、エージェントのリバースパスを実行します。
if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } State.AssignArray(Result); Result.AssignArray(ActorResult); if(!Actor.backProp(Result,DiscountFactor,GetPointer(State),1,false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
次に、エージェント訓練プロセスの進捗状況をユーザに通知し、次の反復サイクルに移ります。
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
エージェント訓練プロセスを完了した後、コメントフィールドをクリアし、EAのシャットダウンを開始します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
完全なEAコードは添付ファイルにあります。
3.検証
2023年の最初の4ヶ月間のEURUSDの履歴データでアプローチの効率を検証しました。いつものように、H1時間枠を使用しました。指標はデフォルトのパラメータで使用しました。まず、採算の取れるパスと採算の取れないパスの両方が存在する50のパスの事例をデータベースとして収集しました。以前は収益性の高いパスだけを使おうとしていました。そうすることで、利益を生み出せる技術を教えたいと考えたのです。この場合、採算の取れない状態をモデルに示すために、例のデータベースに採算の取れないパスをいくつか追加しました。結局のところ、実際の取引ではドローダウンのリスクを受け入れますが、最小限の損失でそこから脱出する戦略は持っていたいのです。
まずオートエンコーダを、次にエージェントを訓練しました。
訓練されたモデルは、2023年5月の履歴データを使ってストラテジーテスターでテストされました。このデータは訓練セットには含まれておらず、新しいデータでモデルの性能をテストすることができます。
最初の結果は予想以上に悪くなりました。好結果では、テストサンプルで使用されたスキルの分布がかなり均一です。テストの好結果はここで終わりました。オートエンコーダとエージェントの訓練を何度も繰り返しましたが、訓練セットで利益を生み出すモデルを得ることはできませんでした。どうやら、オートエンコーダが十分な精度で状態を予測できないことが問題だったようです。その結果、残高の曲線は望ましい結果からはほど遠いものとなってしまいました。
この仮定を検証するために、代替エージェント訓練EA EDLStudyActor2.mq5を作成しました。代替オプションと、以前に検討されたオプションの唯一の違いは、報酬を生成するアルゴリズムです。また、このサイクルを使って口座状況の変化を予測しました。今回は、報酬として相対的残高変化指標を使用した。
ActorResult = vector<float>::Zeros(NActions); for(action = 0; action < NActions; action++) { reward = GetNewState(Buffer[tr].States[i].account, action, prof_1l); ActorResult[action] = reward[0]/PrevBalance-1.0f; }
修正された報酬関数を用いて訓練されたエージェントは、テスト期間中、収益性の上昇がほぼ横ばいでした。


エージェントは、オートエンコーダの再訓練やエージェント自体のアーキテクチャを変更することなく、報酬生成のための修正されたアプローチで訓練されました。両エージェントの訓練は、完全に同等の条件下でおこなわれました。報酬形成のアプローチを見直しただけで、モデルの効率を上げることが可能になりました。このことは、強化訓練法において重要な役割を果たす報酬関数を正しく選択することの重要性を改めて裏付けています。

結論
今回は、もうひとつのスキル訓練法であるEDL (Explore, Discover and Learn)を紹介しました。このアルゴリズムは、エージェントが環境を探索し、条件や必要なスキルの事前知識なしに新しいスキルを発見することを可能にします。これは、変分オートエンコーダを使用して、環境状態と必要なスキルの間の依存関係を見つけることによって可能になります。
この方法の最初の段階では、環境調査がおこなわれます。状態の訓練サンプルは、様々な行動に対応する様々な状態を最大限カバーするように形成されます。その後、変分オートエンコーダを用いて、状態とスキルの依存関係を探索します。オートエンコーダの潜在的な状態は、状態の圧縮された表現であり、必要なスキルの識別子のような役割を果たします。モデルデコーダとエンコーダーは、状態とスキルの間に依存関数を形成します。
エージェントは、オートエンコーダによって予測された状態を取得しようとすることによって、フレームワークで学習されます。オートエンコーダが提供する予測状態には、実環境に内在する確率性がないため、エージェントの訓練の安定性とスピードが向上します。同時に、モデルの性能はオートエンコーダによる状態予測の質に強く依存するため、これはアプローチのボトルネックでもあります。これがテストで実証されたことです。
現在、金融市場は非常に複雑で確率的な環境であり、予測は困難です。それらに投資することは、依然としてリスクが高くなります。取引で好結果を出すには、慎重かつバランスの取れた戦略を厳守する必要があります。
参考文献リスト
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | StudyModel.mq5 | EA | オートエンコーダーモデルの訓練EA |
| 3 | StudyActor.mq5 | EA | エージェント訓練 EA |
| 4 | StudyActor2.mq5 | EA | 代替エージェント訓練EA(異なる報酬関数) |
| 5 | Test.mq5 | EA | モデルテストEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述構造 |
| 7 | FQF.mqh | クラスライブラリ | 完全にパラメータ化されたモデルの作業を整理するためのクラスライブラリ |
| 8 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 9 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
| 10 | VAE.mqh | クラスライブラリ | 変分オートエンコーダ潜在層クラスライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/12783
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索