Redes neurais de maneira fácil (Parte 45): Ensinando habilidades para investigar estados

Introdução
Algoritmos de aprendizado hierárquico por reforço permitem resolver tarefas bastante complexas com sucesso. Isso é alcançado dividindo o problema geral em tarefas menores. Uma das principais questões nesse contexto é a escolha adequada e o treinamento de habilidades que permitam ao agente agir eficazmente e, sempre que possível, controlar ao máximo o ambiente para alcançar seus objetivos.
Anteriormente, já nos familiarizamos com dois algoritmos de aprendizado de habilidades: DIAYN e DADS. No primeiro caso, treinamos habilidades com a máxima diversidade de comportamento, buscando assim garantir a exploração máxima do ambiente. Nesse processo, estávamos dispostos a treinar habilidades que seriam inúteis para a resolução de nossa tarefa atual.
No segundo algoritmo (DADS), abordamos o treinamento de habilidades do ponto de vista de como elas afetam o ambiente circundante. Aqui, buscamos prever a dinâmica do ambiente e utilizar habilidades que permitam obter o máximo benefício das mudanças.
Em ambos os casos, as habilidades da distribuição a priori foram usadas como dados iniciais para o agente e foram exploradas durante o treinamento. A aplicação prática desse tipo de abordagem demonstra uma cobertura insuficiente do espaço de estados. Consequentemente, as habilidades treinadas não são capazes de interagir eficazmente com todos os estados possíveis do ambiente circundante.
Neste artigo, proponho apresentar um método alternativo de ensino de habilidades denominado Explore, Discover and Learn (EDL). O método EDL aborda o problema de maneira diferente, superando o problema da cobertura limitada de estados e oferecendo um comportamento mais flexível e adaptável ao agente.
1. Algoritmo "Explore, Discover and Learn" (explorar, descobrir e aprender)
O método de Exploração, Descoberta e Aprendizado (EDL) foi apresentado em um artigo científico intitulado "Explore, Discover and Learn: Unsupervised Discovery of State-Covering Skills" em agosto de 2020. Ele propõe uma abordagem que permite ao agente descobrir e aprender a usar várias habilidades em um ambiente sem qualquer conhecimento prévio sobre estados e habilidades. Também permite treinar habilidades diversas que abrangem diferentes estados, contribuindo para uma exploração e treinamento mais eficazes do agente em um ambiente desconhecido.
O método EDL tem uma estrutura fixa e consiste em 3 etapas principais: exploração, descoberta e aprendizado de habilidades.
Na ausência de qualquer conhecimento prévio sobre o ambiente circundante e as habilidades necessárias, iniciamos nossa pesquisa. Nesta fase, teremos que criar um conjunto de treinamento de estados iniciais abrangendo uma ampla variedade de estados que correspondem a todos os comportamentos possíveis do ambiente circundante. Em nosso trabalho, usaremos uma amostra uniforme de estados do sistema durante o período de treinamento. No entanto, outras abordagens são possíveis, especialmente quando se trata de treinar modos específicos de comportamento do agente. É importante observar que o método EDL não requer acesso às trajetórias ou ações realizadas por uma estratégia de EA, embora não exclua o uso delas.
Na segunda etapa, realizamos a busca por habilidades que estão ocultas em estados específicos do ambiente circundante. A ideia fundamental deste método é que existe alguma conexão entre o estado (ou espaço de estados) do ambiente e a habilidade específica que o agente deve utilizar. Nossa tarefa é identificar essas dependências.
É importante destacar que, nesta fase, não temos nenhum conhecimento sobre os estados do ambiente circundante, apenas uma amostra desses estados. Além disso, não temos conhecimento das habilidades necessárias. No entanto, como mencionado anteriormente, o método EDL prevê a descoberta de habilidades sem supervisão. Para procurar essas dependências, usamos um autocodificador variacional. Nas entradas e saídas do modelo, temos estados do ambiente circundante, enquanto no estado latente do autocodificador, esperamos obter a identificação da habilidade oculta que deriva do estado atual do ambiente circundante. Nesta abordagem, o codificador do nosso autocodificador constrói uma função de dependência da habilidade com base no estado atual do ambiente circundante, e o decodificador do modelo realiza a função inversa, estabelecendo a relação entre o estado e a habilidade utilizada. O uso do autocodificador variacional permite a transição de uma correspondência clara entre "estado-habilidade" para uma distribuição probabilística, aumentando assim a estabilidade do modelo em um ambiente estocástico complexo.
Assim, na ausência de conhecimento adicional sobre estados e habilidades, o uso do autocodificador variacional no método EDL nos proporciona a capacidade de explorar e descobrir habilidades ocultas relacionadas a diferentes estados do ambiente circundante. Estabelecer a função de dependência entre o estado do ambiente circundante e a habilidade necessária nos permitirá, no futuro, interpretar novos estados do ambiente circundante como uma combinação das habilidades mais relevantes.
Observe que nos métodos previamente discutidos, primeiro treinávamos as habilidades. Em seguida, o planejador buscava a estratégia para usar essas habilidades prontas para atingir o objetivo. No método EDL, o enfoque é inverso. Primeiro, estabelecemos as relações entre o estado e as habilidades. Somente depois disso treinamos as habilidades. Isso permite relacionar as habilidades de forma mais precisa com estados específicos do ambiente e determinar quais habilidades são mais eficazes em situações específicas.
A etapa final do algoritmo é o treinamento do modelo de habilidades (Agente). Aqui, treinamos a estratégia do agente, que maximiza a informação mútua entre os estados e as variáveis ocultas. O treinamento do agente é realizado por métodos de aprendizado por reforço. A formação da recompensa segue uma abordagem semelhante ao método DADS, mas os autores do método fizeram uma pequena simplificação na fórmula. Lembremos que, no DADS, a recompensa interna do agente era formada pela fórmula:
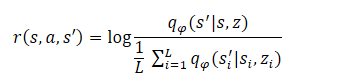
A partir do curso de matemática, sabemos que:
![]()
Logo:
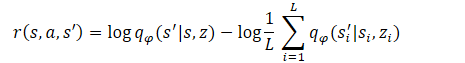
Como pode ser observado, o subtraendo é uma constante para todas as habilidades usadas. Portanto, para otimizar a política, só podemos usar o minuendo. Essa abordagem permite reduzir o volume de cálculos sem perda na qualidade do treinamento do modelo.
![]()
Esta etapa final pode ser considerada como o treinamento de uma estratégia que imita o decodificador em um processo de tomada de decisões de Markov, ou seja, uma estratégia que visitará estados que o decodificador gerará para cada habilidade oculta z. É importante notar que a função de recompensa é fixa, ao contrário dos métodos anteriores, nos quais ela varia continuamente com base no comportamento da estratégia. Isso torna o processo de treinamento mais estável e aumenta a convergência dos modelos.
2. Implementação em MQL5
Após explorarmos os aspectos teóricos do método Exploração, Descoberta e Aprendizado (EDL), passamos para a parte prática do nosso artigo. Antes de começarmos a implementar o método usando MQL5, é importante compartilhar algumas características da nossa implementação.
Na seção de Testes do artigo anterior, demonstrou-se a semelhança entre os resultados do uso do vetor one-hot e da distribuição completa para identificar a habilidade utilizada nos dados iniciais do Agente. Isso nos permite escolher a abordagem adequada com base nos dados disponíveis, reduzindo assim as operações matemáticas. Isso, em geral, nos dá a possibilidade de reduzir o número de operações executadas, bem como aumentar a velocidade de treinamento e desempenho do modelo.
Um segundo ponto a ser observado é que estamos fornecendo os mesmos dados de entrada (dados históricos de movimento de preços, indicadores e saldo) tanto para o Planejador quanto para o Agente. No entanto, o Agente também recebe um identificador de habilidade junto a esses dados.
Por outro lado, quando estudamos autocodificadores, mencionamos que o estado latente do autocodificador é uma representação comprimida de seus dados de entrada. Isso significa que, concatenando o vetor de dados de entrada com o vetor de dados latentes do autocodificador variacional, estamos passando os mesmos dados em sua representação completa e compacta.
No caso de usar blocos de pré-processamento de dados semelhantes, essa abordagem pode ser redundante. Nesta implementação, estaremos fornecendo apenas o estado latente do autocodificador como entrada para o Agente, que já contém essencialmente todas as informações necessárias. Isso nos permitirá reduzir significativamente a quantidade de operações realizadas, bem como o tempo total de treinamento dos modelos.
Claro, esse método é viável apenas quando se usam dados de entrada semelhantes para o Planejador e o Agente. Em princípio, outras abordagens também são possíveis. Por exemplo, o autocodificador pode estabelecer relações apenas entre os dados históricos e a habilidade, sem considerar o estado da conta. E, na entrada do Agente, concatenar o vetor de estado latente do autocodificador com o vetor de descrição do estado da conta. Não seria um erro usar todos os dados, como fizemos na implementação dos métodos previamente discutidos. Em sua própria implementação, você pode experimentar com diferentes abordagens.
Todas essas decisões são refletidas na arquitetura dos modelos, que especificamos na função CreateDescriptions. Nos parâmetros deste método, passamos ponteiros para dois arrays dinâmicos que descrevem os modelos do Planejador e do Agente. Observe que, na implementação do método EDL, não estamos criando um Discriminador, pois essa função é desempenhada pelo decodificador do autocodificador (Planejador).
bool CreateDescriptions(CArrayObj *actor, CArrayObj *scheduler) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; }
Primeiro, criaremos o autocodificador variacional do Planejador. Os dados históricos e o estado da conta são fornecidos como entrada para este modelo, refletindo-se no tamanho da camada de dados de entrada. Como de costume, os dados de entrada passam por um pré-processamento na camada de normalização em lote.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Em seguida, há um bloco convolucional para reduzir a dimensionalidade dos dados e extrair características específicas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!scheduler.Add(descr)) { delete descr; return false; }
Em seguida, temos três camadas totalmente conectadas com uma redução gradual na dimensionalidade. Note que o tamanho da última camada é duas vezes maior do que o número de habilidades treináveis. Isso é uma característica distintiva do autocodificador variacional. Ao contrário do autocodificador clássico, no autocodificador variacional, cada recurso é representado por dois parâmetros: o valor médio e a dispersão da distribuição.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NSkills; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
O truque de reparametrização é realizado na camada seguinte, criada especialmente para a implementação do autocodificador variacional. Aqui também realizamos a amostragem dos parâmetros a partir da distribuição definida. O tamanho dessa camada corresponde ao número de habilidades treináveis.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NSkills; if(!scheduler.Add(descr)) { delete descr; return false; }
O decodificador é implementado com três camadas totalmente conectadas. A última camada não possui uma função de ativação, pois é difícil determinar uma função de ativação para dados não normalizados.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.optimization = ADAM; descr.activation = None; if(!scheduler.Add(descr)) { delete descr; return false; }
É importante observar que, assim como na implementação do método anterior, não restauraremos completamente os dados de entrada. Isso ocorre porque a influência das ações do Agente sobre o preço de mercado do instrumento é insignificante. Em contrapartida, o estado do saldo está diretamente relacionado à estratégia usada pelo Agente. Portanto, na saída do autocodificador, restauraremos apenas a descrição do estado da conta.
Após o Planejador, criamos a descrição da arquitetura do Agente. Como mencionado anteriormente, a camada de dados de entrada do Agente é reduzida ao número de habilidades treináveis.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
O uso do estado latente de outro modelo nos permite dispensar o bloco de pré-processamento de dados. Portanto, imediatamente após a camada de dados de entrada, temos um bloco de tomada de decisões composto por três camadas totalmente conectadas.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Na saída do modelo, usamos um bloco de função quantil totalmente parametrizado, o que nos permite estudar mais detalhadamente a distribuição das recompensas.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- return true; }
Como antes, a função de descrição da arquitetura dos modelos foi colocada em um arquivo de inclusão chamado "\EDL\Trajectory.mqh". Isso nos permite usar uma arquitetura de modelo unificada em todas as etapas do método EDL.
Após a criação das arquiteturas dos modelos, avançamos para o trabalho com os especialistas para implementar o método em estudo. Primeiro, criamos o Expert Advisor (EA) da primeira etapa - Pesquisa. Essa funcionalidade é realizada no EA "EDL\Research.mq5". Devo dizer imediatamente que o algoritmo deste EA é quase idêntico aos EAs homônimos das edições anteriores. No entanto, existem algumas diferenças devido à arquitetura dos modelos. Especificamente, nas implementações anteriores, o algoritmo deste EA usava apenas o modelo do Agente, com dados de entrada e um identificador de habilidade gerado aleatoriamente. Nesta implementação, fornecemos os dados históricos como entrada para o Planejador. Após sua propagação, extraímos o estado latente, que é fornecido como entrada para o Agente para tomar decisões. Você pode ver o código completo do EA e todas as suas funções no anexo.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ........ //--- if(!Scheduler.feedForward(GetPointer(State1), 1, false)) return; if(!Scheduler.GetLayerOutput(LatentLayer, Result)) return; //--- if(!Actor.feedForward(Result, 1, false)) return; int act = Actor.getSample(); //--- ........ ........ //--- }
A segunda etapa do método EDL envolve a definição de habilidades. Como mencionado na parte teórica, nesta fase, estaremos treinando o autocodificador variacional. Esta funcionalidade será executada no EA "StudyModel.mq5". O EA foi desenvolvido com base nos Expert Advisors de treinamento de modelos de artigos anteriores. Foram feitas apenas alterações relacionadas ao algoritmo deste método.
Na função OnInit, apenas uma modelo de Planejador é inicializado. No entanto, as principais mudanças foram feitas na função de treinamento do modelo Train. No início da função, como antes, declaramos variáveis internas.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); vector<float> account, reward; int bar, action;
Em seguida, organizamos um laço de treinamento com o número de iterações definido nos parâmetros externos do EA.
//--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
Dentro do laço, escolhemos aleatoriamente um passe da amostra de treinamento e, em seguida, um dos estados do passe selecionado. As informações sobre o estado selecionado são transferidas para o buffer de dados de entrada para a propagação do nosso modelo. Essas iterações não diferem das realizadas anteriormente. Lembro que preenchemos as informações do estado da conta em termos relativos.
State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i].account[1] / PrevBalance); State.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i].account[2] / PrevBalance); State.Add(Buffer[tr].States[i].account[4] / PrevBalance); State.Add(Buffer[tr].States[i].account[5]); State.Add(Buffer[tr].States[i].account[6]); State.Add(Buffer[tr].States[i].account[7] / PrevBalance); State.Add(Buffer[tr].States[i].account[8] / PrevBalance);
Em seguida, determinamos o lucro por lote com base na mudança de preço da próxima vela e salvamos os indicadores de saldo e patrimônio em variáveis locais para cálculos posteriores.
//--- bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1];
Após a conclusão da preparação, realizamos a propagação do nosso modelo.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Após o sucesso na propagação, precisamos organizar a retropropagação do nosso modelo. Aqui, precisamos preparar os valores alvo do nosso modelo. Seguindo a lógica de treinamento de autocodificadores, normalmente usaríamos o buffer de dados de entrada como valores alvo. Mas, fizemos alterações na arquitetura e na lógica de treinamento. Primeiro, na saída, não geramos o conjunto completo de recursos dos dados de entrada, mas apenas os parâmetros de descrição do estado da conta.
Segundo, demos um passo adiante e gostaríamos de treinar o modelo para gerar um estado de conta previsto subsequente. Nesse caso, não geraremos o estado da conta para todas as ações possíveis do agente. Durante a fase de treinamento dos modelos, podemos "olhar" para a próxima vela nos dados de treinamento e realizar a ação que maximizaria nosso lucro. Portanto, formamos o estado de conta previsto desejado e o usamos como valores alvo para a retropropagação do modelo.
if(prof_1l > 5 ) action = (prof_1l < 10 || Buffer[tr].States[i].account[6] > 0 ? 2 : 0); else { if(prof_1l < -5) action = (prof_1l > -10 || Buffer[tr].States[i].account[5] > 0 ? 2 : 1); else action = 3; } account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); Result.Clear(); Result.Add((account[0] - PrevBalance) / PrevBalance); Result.Add(account[1] / PrevBalance); Result.Add((account[1] - PrevEquity) / PrevEquity); Result.Add(account[2] / PrevBalance); Result.Add(account[4] / PrevBalance); Result.Add(account[5]); Result.Add(account[6]); Result.Add(account[7] / PrevBalance); Result.Add(account[8] / PrevBalance);
Observe que, ao determinarmos a ação desejada, estamos impondo algumas restrições:
- lucro mínimo para abrir uma operação,
- movimento mínimo para fechar a operação (esperamos pequenas oscilações),
- Antes de abrir uma nova posição, fechamos todas as operações opostas.
Desta forma, estamos buscando criar um modelo de previsão com o comportamento desejado.
A previsão do estado da conta gerado é transformada em unidades relativas e transferida para o buffer de dados. Em seguida, realizamos o processo de retropropagação do nosso modelo.
if(!Scheduler.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Como antes, ao concluir as iterações do ciclo, exibimos uma mensagem informativa para que o usuário acompanhe visualmente o processo de treinamento do modelo.
Após a conclusão de todas as iterações do ciclo de treinamento do modelo, limpamos o bloco de comentários no gráfico e inicializamos o processo de encerramento do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); ExpertRemove(); //--- }
Você pode consultar o código completo do EA de treinamento do autocodificador variacional do planejador no anexo.
Após estabelecer as relações entre os estados do ambiente e as habilidades, é hora de treinar nosso Agente nas habilidades necessárias. Essa funcionalidade será implementada no EA "EDL\StudyActor.mq5". Devo mencionar que neste EA, estamos usando duas modelos (Planejador e Agente), mas estaremos treinando apenas uma (Agente). Portanto, na inicialização do EA, carregamos previamente as duas modelos. Mas, uma falha crítica na execução do programa ocorre apenas se não for possível carregar o Planejador, que deve estar previamente treinado.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true)) { PrintFormat("Error of load scheduler model: %d", GetLastError()); return INIT_FAILED; }
Quando ocorre um erro ao carregar o modelo do Agente, inicializamos a criação de um novo modelo.
if(!Actor.Load(FileName + "Act.nnw", dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *scheduler = new CArrayObj(); if(!CreateDescriptions(actor, scheduler)) { delete actor; delete scheduler; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete scheduler; return INIT_FAILED; } delete actor; delete scheduler; //--- }
E, é claro, após o carregamento bem-sucedido ou a criação de novos modelos, verificamos se os tamanhos das camadas neurais dos dados de entrada correspondem aos resultados das operações executadas pelos modelos.
//--- Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } Actor.SetOpenCL(Scheduler.GetOpenCL()); Actor.SetUpdateTarget(MathMax(Iterations / 100, 10000)); //--- Scheduler.getResults(Result); if(Result.Total() != AccountDescr) { PrintFormat("The scope of the scheduler does not match the account description (%d <> %d)", AccountDescr, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); int inputs = Result.Total(); if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("Error of load latent layer %d", LatentLayer); return INIT_FAILED; } if(inputs != Result.Total()) { PrintFormat("Size of latent layer does not match input size of Actor (%d <> %d)", Result.Total(), inputs); return INIT_FAILED; }
Após o carregamento e a inicialização bem-sucedidos dos modelos, bem como após passar por todos os controles, inicializamos o evento de início do processo de treinamento do modelo e concluímos a função de inicialização do EA.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
O processo de treinamento do Agente é realizado no método Train. A primeira parte do método inclui a seleção do passe, estado e organização da propagação do planejador, conforme descrito anteriormente, e transferido sem alterações para este EA. Portanto, pularemos essa seção e iremos diretamente para a organização da propagação do nosso Agente. Aqui, tudo é bastante simples. Nós apenas extraímos o estado latente do autocodificador e passamos os dados obtidos como entrada para o nosso Agente. Certificamo-nos de acompanhar o processo de execução das operações.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { ........ ........ //--- if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!Actor.feedForward(Result, 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Após a conclusão bem-sucedida das operações de propagação, devemos realizar o processo de retropropagação do nosso modelo Agente. Como mencionado na seção teórica, o treinamento do Agente é realizado usando métodos de aprendizado por reforço. Agora, precisamos criar recompensas para as ações geradas durante a propagação. O método EDL pressupõe que o Agente seja treinado com base nas recompensas geradas pelo Discriminador. Neste caso, o papel do Discriminador é desempenhado pelo decodificador do autocodificador do planejador. No entanto, fizemos uma pequena alteração no método proposto pelos autores para a formação de recompensas, o que em geral não contradiz a ideologia do método.
Como mencionado anteriormente, durante o treinamento do autocodificador, usamos o estado calculado desejado da nossa conta, levando em consideração as restrições impostas. Agora, vamos recompensar o comportamento do Agente que nos aproxima o máximo possível do resultado desejado. Usaremos a métrica de distância euclidiana entre dois vetores como medida entre o estado desejado e o estado previsto do nosso saldo. Para que a ação que mais nos aproxime do estado desejado receba a recompensa máxima, multiplicaremos a distância obtida por "-1".
Esse método nos permite realizar um ciclo e calcular recompensas para todas as ações possíveis do Agente, e não apenas para uma ação isolada. Isso, em geral, aumenta a estabilidade e o desempenho do processo de treinamento do modelo.
Scheduler.getResults(SchedulerResult); ActorResult = vector<float>::Zeros(NActions); for(action = 0; action < NActions; action++) { reward = GetNewState(Buffer[tr].States[i].account, action, prof_1l); reward[0] = reward[0] / PrevBalance - 1.0f; reward[3] = reward[2] / PrevBalance; reward[2] = reward[1] / PrevEquity - 1.0f; reward[1] /= PrevBalance; reward[4] /= PrevBalance; reward[7] /= PrevBalance; reward[8] /= PrevBalance; reward=MathPow(SchedulerResult - reward, 2.0); ActorResult[action] = -reward.Sum(); }
Após concluir o ciclo de avaliação de todas as ações possíveis do Agente, obtemos um vetor de distâncias dos estados calculados após cada ação possível do Agente até o estado desejado previsto pelo nosso autocodificador. Lembre-se de que as distâncias estão registradas com um sinal negativo, logo, a distância máxima é a mais negativa, ou simplesmente o valor mínimo. Ao subtrair esse valor mínimo de cada elemento do vetor, zeramos a recompensa para a ação que nos afasta ao máximo do resultado desejado. Todas as outras recompensas são convertidas para valores positivos sem alterar sua estrutura.
ActorResult = ActorResult - ActorResult.Min();
Neste caso, intencionalmente, não usamos o SoftMax. Isso ocorre porque a conversão para a faixa de probabilidades preservaria apenas a estrutura e diminuiria a influência do afastamento máximo do resultado desejado. No entanto, essa influência é altamente significativa no processo de construção de uma estratégia geral.
Além disso, é importante observar que os estados previstos pelo autocodificador não correspondem completamente à real estocasticidade do ambiente circundante. Portanto, avaliar a qualidade das previsões do autocodificador é crucial. A qualidade do treinamento do agente, em última análise, depende da correspondência entre os estados previstos pelo autocodificador e os estados reais do ambiente com os quais o agente interage.
Também gostaria de lembrar que, ao construir sua estratégia, o Agente leva em consideração não apenas as recompensas imediatas, mas também a possibilidade acumulada de recompensas até o final do episódio. Neste caso, usaremos o modelo alvo (Target Net) para determinar o valor do próximo estado. Esse recurso já está implementado no modelo da função quantil completamente parametrizada. No entanto, para seu funcionamento adequado, precisamos passar o próximo estado do sistema no processo de retrocesso.
Nesse cenário, primeiro precisamos realizar uma propagação do autocodificador usando o próximo estado do sistema do buffer de reprodução de experiência.
State.AssignArray(Buffer[tr].States[i+1].state); State.Add((Buffer[tr].States[i+1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i+1].account[1] / PrevBalance); State.Add((Buffer[tr].States[i+1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i+1].account[2] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[4] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[5]); State.Add(Buffer[tr].States[i+1].account[6]); State.Add(Buffer[tr].States[i+1].account[7] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[8] / PrevBalance); //--- if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Somente então podemos extrair a representação comprimida do próximo estado do sistema do estado latente do autocodificador. Em seguida, realizamos a retropropagação do nosso Agente.
if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } State.AssignArray(Result); Result.AssignArray(ActorResult); if(!Actor.backProp(Result,DiscountFactor,GetPointer(State),1,false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Em seguida, informamos o usuário sobre o progresso do processo de treinamento do Agente e passamos para a próxima iteração do ciclo.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
pós a conclusão do processo de treinamento do Agente, limpamos o campo de comentários e inicializamos o processo de encerramento do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
Você pode consultar o código completo do EA no anexo.
3. Teste
Testamos a eficácia desse método em dados históricos dos primeiros 4 meses de 2023 do par de moedas EURUSD, no gráfico H1, usando os parâmetros padrão de todos os indicadores. Começamos reunindo um conjunto de exemplos a partir de 50 passagens, incluindo tanto passagens lucrativas quanto não lucrativas. Lembre-se de que anteriormente procurávamos usar apenas passagens lucrativas para treinar habilidades capazes de gerar lucros. Neste caso, adicionamos algumas passagens não lucrativas ao conjunto de exemplos para demonstrar estados não lucrativos às modelos. Na negociação real, corremos o risco de sofrer perdas, mas gostaríamos de ter uma estratégia para minimizar essas perdas.
Em seguida, procedemos ao treinamento dos modelos, primeiro do autocodificador e depois do agente.
Testamos o desempenho dos modelos treinados no testador de estratégias, usando dados históricos de maio de 2023. Esses dados não foram incluídos no conjunto de treinamento e permitem verificar o funcionamento dos modelos em novos dados.
É preciso mencionar que os primeiros resultados ficaram aquém das nossas expectativas. Entre os resultados positivos, podemos citar a distribuição relativamente uniforme das habilidades utilizadas no conjunto de testes. No entanto, isso é tudo o que podemos destacar como positivo em nossos testes. Após várias iterações de treinamento do autocodificador e do agente, não conseguimos desenvolver um modelo capaz de gerar lucro no conjunto de treinamento. Evidentemente, o problema estava na incapacidade do autocodificador em prever estados com precisão suficiente. Como resultado, a curva de balanço está longe do resultado desejado.
Para verificar nossa suposição, criamos um EA alternativo de treinamento do agente, chamado "EDL\StudyActor2.mq5". A única diferença entre a versão alternativa e a anterior reside no algoritmo de geração de recompensas. Usamos um ciclo novamente para prever as mudanças no estado da conta. No entanto, desta vez, usamos o indicador de mudança relativa no saldo como recompensa.
ActorResult = vector<float>::Zeros(NActions); for(action = 0; action < NActions; action++) { reward = GetNewState(Buffer[tr].States[i].account, action, prof_1l); ActorResult[action] = reward[0]/PrevBalance-1.0f; }
O Agente treinado com a função de recompensa modificada apresentou um aumento bastante uniforme no rendimento durante todo o período de teste.


É importante destacar que o treinamento do Agente com uma abordagem modificada para a geração de recompensas foi realizado sem re-treinar o autocodificador ou alterar a arquitetura do Agente em si. Ou seja, o treinamento de ambos os agentes ocorreu em condições totalmente comparáveis. Apenas a revisão das abordagens para a geração de recompensas permitiu melhorar o desempenho do modelo. Isso mais uma vez confirma a importância da escolha adequada da função de recompensa, que desempenha um papel fundamental nos métodos de aprendizado por reforço.

Considerações finais
Neste artigo, conhecemos mais um método de treinamento de habilidades chamado Explore, Discover and Learn (EDL). O algoritmo apresentado permite que o agente explore o ambiente circundante e adquira novas habilidades sem conhecimento prévio dos estados ou habilidades necessárias. Isso se torna possível graças ao uso de um autocodificador variacional para descobrir as relações entre os estados do ambiente circundante e as habilidades necessárias.
Na primeira etapa do método, a exploração do ambiente é realizada. Um conjunto de treinamento de estados com uma ampla gama de estados diferentes, correspondentes a diferentes comportamentos, é formado. Em seguida, usando um autocodificador variacional, são encontradas relações entre os estados e as habilidades. O estado latente do autocodificador serve como uma representação compacta dos estados e uma espécie de identificador das habilidades necessárias. O decodificador e o codificador do modelo formam as funções que relacionam os estados e as habilidades.
O treinamento do agente é realizado com o objetivo de adquirir um estado previsto pelo autocodificador. Os estados previstos fornecidos pelo autocodificador são livres da estocasticidade presente no ambiente real, o que aumenta a estabilidade e a velocidade de treinamento do agente. No entanto, ao mesmo tempo, esta é uma limitação do método, pois a eficácia do modelo depende muito da qualidade das previsões dos estados pelo autocodificador, como foi demonstrado durante os testes.
Atualmente, os mercados financeiros são ambientes bastante complexos e estocásticos, difíceis de prever. Investir neles continua sendo de alto risco. Obter resultados positivos na negociação só é possível através da estrita observância de uma estratégia ponderada e equilibrada.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | StudyModel.mq5 | EA | EA de treinamento de modelo do autocodificador |
| 3 | StudyActor.mq5 | EA | EA de treinamento do agente |
| 4 | StudyActor2.mq5 | EA | EA alternativo de treinamento de agente (função de recompensa alterada) |
| 5 | Test.mq5 | EA | EA para teste do modelo |
| 6 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 7 | FQF.mqh | Biblioteca de classe | Biblioteca de classes de preparação de modelos totalmente parametrizada |
| 8 | NeuroNet.mqh | Biblioteca de classe | Biblioteca das classes para criar uma rede neural |
| 9 | NeuroNet.cl | Biblioteca | Biblioteca do código do programa OpenCL |
| 10 | VAE.mqh | Biblioteca de classe | Biblioteca da classe de camada latente de autocodificador variacional |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/12783
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso