Artículos sobre aprendizaje automático en el trading
Creación de robots comerciales basados en inteligencia artificial: integración nativa con Python, operaciones con matrices y vectores, bibliotecas de matemáticas y estadística y mucho más.
Aprenda a usar el aprendizaje automático en el trading. Neuronas, perceptrones, redes convolucionales y recurrentes, modelos predictivos: parta de lo básico y avance hasta construir su propia IA. Aprenderá a entrenar y aplicar redes neuronales para el comercio algorítmico en los mercados financieros.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Redes neuronales: así de sencillo (Parte 28): Algoritmo de gradiente de políticas
Continuamos analizando los métodos de aprendizaje por refuerzo. En el artículo anterior, nos familiarizamos con el método de aprendizaje Q profundo, en el que entrenamos un modelo para predecir la próxima recompensa dependiendo de la acción realizada en una situación particular. Luego realizamos una acción según nuestra política y la recompensa esperada, pero no siempre es posible aproximar la función Q, o su aproximación no ofrece el resultado deseado. En estos casos, los métodos de aproximación no se utilizan para funciones de utilidad, sino para una política (estrategia) de acciones directa. Precisamente a tales métodos pertenece el gradiente de políticas o policy gradient.

Aprendizaje automático y data science (Parte 06): Descenso de gradiente
El descenso de gradiente juega un papel importante en el entrenamiento de redes neuronales y diversos algoritmos de aprendizaje automático: es un algoritmo rápido e inteligente. Sin embargo, a pesar de su impresionante funcionamiento, muchos científicos de datos todavía lo malinterpretan. Veamos sobre qué tratará este artículo.
Redes neuronales: así de sencillo (Parte 5): Cálculos multihilo en OpenCL
Ya hemos analizado algunos tipos de implementación de redes neuronales. Podemos ver con facilidad que se repiten las mismas operaciones para cada neurona de la red. Y aquí sentimos el legítimo deseo de aprovechar las posibilidades que ofrece la computación multihilo de la tecnología moderna para acelerar el proceso de aprendizaje de una red neuronal. En el presente artículo, analizaremos una de las opciones para tal implementación.

Redes neuronales: así de sencillo (Parte 9): Documentamos el trabajo realizado
Ya hemos recorrido un largo camino y el código de nuestra biblioteca ha crecido de manera considerable. Resulta difícil monitorear todas las conexiones y dependencias. Y, obviamente, antes de proseguir con el desarrollo del proyecto, necesitaremos documentar el trabajo ya realizado y actualizar la documentación en cada paso posterior. Una documentación debidamente redactada nos ayudará a ver la integridad de nuestro trabajo.

Gradient boosting (CatBoost) en las tareas de construcción de sistemas comerciales. Un enfoque ingenuo
Entrenamiento del clasificador CatBoost en el lenguaje Python, exportación al formato mql5; análisis de los parámetros del modelo y simulador de estrategias personalizado. Para preparar los datos y entrenar el modelo, se usan el lenguaje de programación Python y la biblioteca MetaTrader5.

Remuestreo avanzado y selección de modelos CatBoost con el método de fuerza bruta
Este artículo describe uno de los posibles enfoques respecto a la transformación de datos para mejorar las capacidades generalizadoras del modelo, y también analiza la iteración sobre los modelos CatBoost y la elección del mejor de ellos.

Algoritmos de optimización de la población: Evolución diferencial (Differential Evolution, DE)
En este artículo, hablaremos del algoritmo que muestra los resultados más controvertidos entre todos los anteriormente analizados, el algoritmo de Evolución Diferencial (DE).

Aprendizaje de máquinas en sistemas comerciales con cuadrícula y martingale. ¿Apostaría por ello?
En este artículo, presentaremos al lector la técnica del aprendizaje automático para el comercio con martingale y cuadrícula. Para nuestra sorpresa, este enfoque, por algún motivo, no se ha tratado en absoluto en la red global. Después de leer el artículo, podremos crear nuestros propios bots.

Algoritmos de optimización de la población: Algoritmo de murciélago (Bat algorithm - BA)
Hoy analizaremos el algoritmo de murciélago (Bat algorithm - BA), que posee una sorprendente convergencia en funciones suaves.

Algoritmos de optimización de la población: Algoritmo de optimización de cuco (Cuckoo Optimization Algorithm — COA)
El siguiente algoritmo que analizaremos será la optimización de la búsqueda de cuco usando los vuelos de Levy. Este es uno de los últimos algoritmos de optimización, así como el nuevo líder en la clasificación.
Aprendizaje automático y Data Science (Parte 02): Regresión logística
La clasificación de los datos es un punto crucial para los tráders algorítmicos y los programadores. En este artículo, nos centraremos en uno de los algoritmos logísticos de clasificación que podría ayudarnos a identificar los síes o los noes, las subidas y bajadas, las compras y las ventas.

Aprendizaje automático y data science (Parte 05): Árboles de decisión usando como ejemplo las condiciones meteorológicas para jugar al tenis
Los árboles de decisión clasifican los datos imitando la forma de pensar de los seres humanos. En este artículo, veremos cómo construir árboles de decisión y usar estos para clasificar y predecir datos. El objetivo principal del algoritmo del árbol de decisión es dividir la muestra en datos con "impurezas" y en datos "limpios" o próximos a los nodos.

Algoritmos de optimización de la población: Optimización de malas hierbas invasoras (IWO)
La asombrosa capacidad de las malas hierbas para sobrevivir en una gran variedad de condiciones inspiró la idea de un potente algoritmo de optimización. El IWO es uno de los mejores entre los analizados anteriormente.
Aprendizaje automático y Data Science (Parte 11): Clasificador bayesiano ingenuo y teoría de la probabilidad en el trading
Comerciar con probabilidades es como caminar por la cuerda floja: requiere precisión, equilibrio y una clara comprensión del riesgo. En el mundo del trading, la probabilidad lo es todo: es lo que determina el resultado, el éxito o el fracaso, los beneficios o las pérdidas. Usando el poder de la probabilidad, los tráders pueden tomar decisiones mejor informadas, gestionar el riesgo con mayor eficacia y alcanzar sus objetivos financieros. Tanto si es usted un inversor experimentado como un tráder principiante, comprender las probabilidades puede ser la clave para liberar su potencial comercial. En este artículo, analizaremos el fascinante mundo del trading probabilístico y le mostraremos cómo llevar su modo de comerciar al siguiente nivel.
Aprendizaje automático y data science (Parte 03): Regresión matricial
En esta ocasión, vamos a crear modelos usando matrices: estas ofrecen una gran flexibilidad y permiten crear modelos potentes que pueden manejar no solo cinco variables independientes, sino muchas otras, tantas como los límites computacionales de nuestro ordenador nos permitan. El presente artículo será muy interesante, eso seguro.

Experimentos con redes neuronales (Parte 2): Optimización inteligente de una red neuronal
Las redes neuronales lo son todo. Vamos a comprobar en la práctica si esto es así. MetaTrader 5 como herramienta autosuficiente para el uso de redes neuronales en el trading. Una explicación sencilla.

Algoritmos de optimización de la población: Optimización de colonias de hormigas (ACO)
En esta ocasión, analizaremos el algoritmo de optimización de colonias de hormigas (ACO). El algoritmo es bastante interesante y ambiguo al mismo tiempo. Intentaremos crear un nuevo tipo de ACO.

Redes neuronales: así de sencillo (Parte 26): Aprendizaje por refuerzo
Continuamos estudiando los métodos de aprendizaje automático. En este artículo, iniciaremos otro gran tema llamado «Aprendizaje por refuerzo». Este enfoque permite a los modelos establecer ciertas estrategias para resolver las tareas. Esperamos que esta propiedad del aprendizaje por refuerzo abra nuevos horizontes para la construcción de estrategias comerciales.

Redes neuronales: así de sencillo (Parte 31): Algoritmos evolutivos
En el artículo anterior, comenzamos a analizar los métodos de optimización sin gradiente, y también nos familiarizamos con el algoritmo genético. Hoy continuaremos con el tema iniciado, y estudiaremos otra clase de algoritmos evolutivos.

Experimentos con redes neuronales (Parte 1): Recordando la geometría
Las redes neuronales lo son todo. En este artículo, usaremos la experimentación y enfoques no estándar para desarrollar un sistema comercial rentable y comprobaremos si las redes neuronales pueden ser de alguna ayuda para los comerciantes.
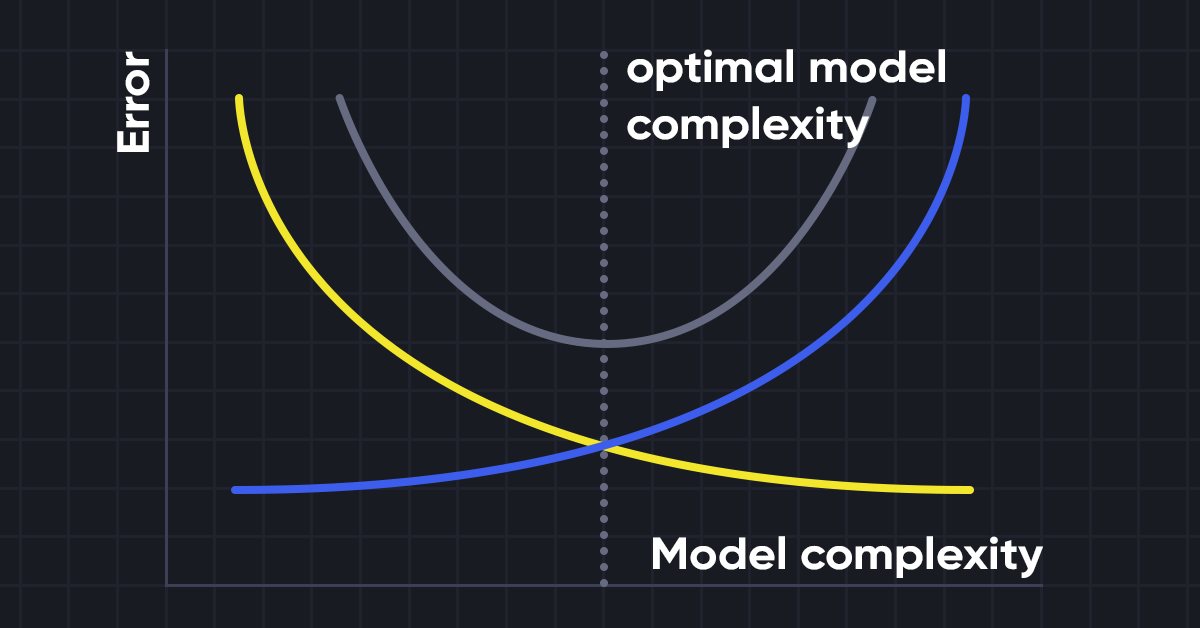
Aprendizaje automático y Data Science (Parte 10): Regresión de cresta
La regresión de cresta (Ridge Regression) es una técnica simple para reducir la complejidad del modelo y combatir el ajuste que puede derivar de una regresión lineal simple.

Redes neuronales: así de sencillo (Parte 32): Aprendizaje Q distribuido
En uno de los artículos de esta serie, nos familiarizamos con el método de aprendizaje Q. Este método promedia las recompensas de cada acción. En 2017 se presentaron dos trabajos que muestran un mayor éxito al estudiar la función de distribución de recompensas. Vamos a analizar la posibilidad de utilizar esta tecnología para resolver nuestros problemas.

Redes neuronales: así de sencillo (Parte 65): Aprendizaje supervisado ponderado por distancia (DWSL)
En este artículo, le presentaremos un interesante algoritmo que se basa en la intersección de los métodos de aprendizaje supervisado y por refuerzo.
Aprendizaje automático y Data Science (Parte 07): Regresión polinomial
La regresión polinomial es un modelo flexible diseñado para resolver de forma eficiente problemas que un modelo de regresión lineal no puede gestionar. En este artículo, aprenderemos a crear modelos polinómicos en MQL5 y a sacar provecho de ellos.

Redes neuronales: así de sencillo (Parte 14): Clusterización de datos
Lo confieso: ha pasado más de un año desde que publiqué el último artículo. En tanto tiempo, me ha sido posible repensar mucho, desarrollar nuevos enfoques. Y en este nuevo artículo, me gustaría alejarme un poco del método anteriormente usado de aprendizaje supervisado, y sugerir una pequeña inmersión en los algoritmos de aprendizaje no supervisado. En particular, vamos a analizar uno de los algoritmos de clusterización, las k-medias.
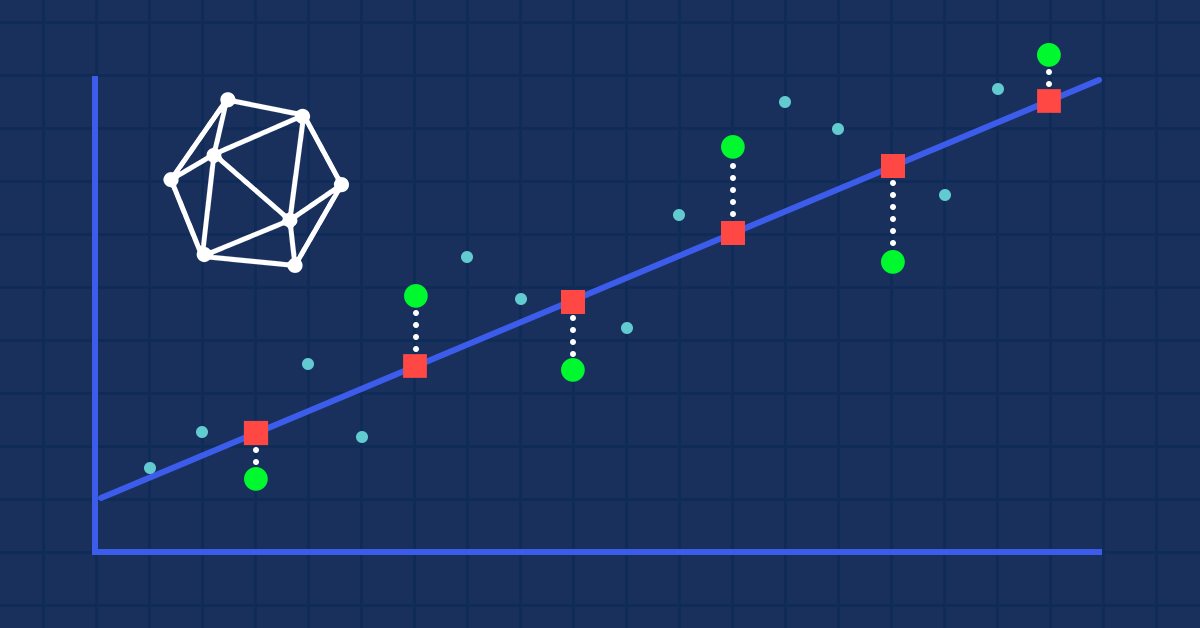
Evaluación de modelos ONNX usando métricas de regresión
La regresión es una tarea que consiste en predecir un valor real a partir de un ejemplo sin etiquetar. Para evaluar la precisión de las predicciones de los modelos de regresión, se usan las llamadas métricas de regresión.

Redes neuronales de propagación inversa del error en matrices MQL5
El artículo describe la teoría y la práctica de la aplicación del algoritmo de propagación inversa del error en MQL5 con la ayuda de matrices. Asimismo, incluye clases y ejemplos preparados del script, el indicador y el asesor.

Redes neuronales: así de sencillo (Parte 27): Aprendizaje Q profundo (DQN)
Seguimos explorando el aprendizaje por refuerzo. En este artículo, hablaremos del método de aprendizaje Q profundo o deep Q-learning. El uso de este método permitió al equipo de DeepMind crear un modelo capaz de superar a los humanos jugando a los videojuegos de ordenador de Atari. Nos parece útil evaluar el potencial de esta tecnología para las tareas comerciales.

Redes neuronales: así de sencillo (Parte 29): Algoritmo actor-crítico con ventaja (Advantage actor-critic)
En los artículos anteriores de esta serie, nos familiarizamos con dos algoritmos de aprendizaje por refuerzo. Obviamente, cada uno de ellos tiene sus propias ventajas y desventajas. Como suele suceder en estos casos, se nos ocurre combinar ambos métodos en un algoritmo que incorporaría lo mejor de los dos, y así compensar las carencias de cada uno de ellos. En este artículo, hablaremos de dicho método.

Algoritmos de optimización de la población: Algoritmo de luciérnagas (Firefly Algorithm - FA)
Hoy analizaremos el método de optimización «Búsqueda con ayuda del algoritmo de luciérnagas» 'Firefly Algorithm Search' (FA). Tras modificar el algoritmo, este ha pasado de ocupar un lugar marginal a convertirse en un verdadero líder en la tabla de calificación.
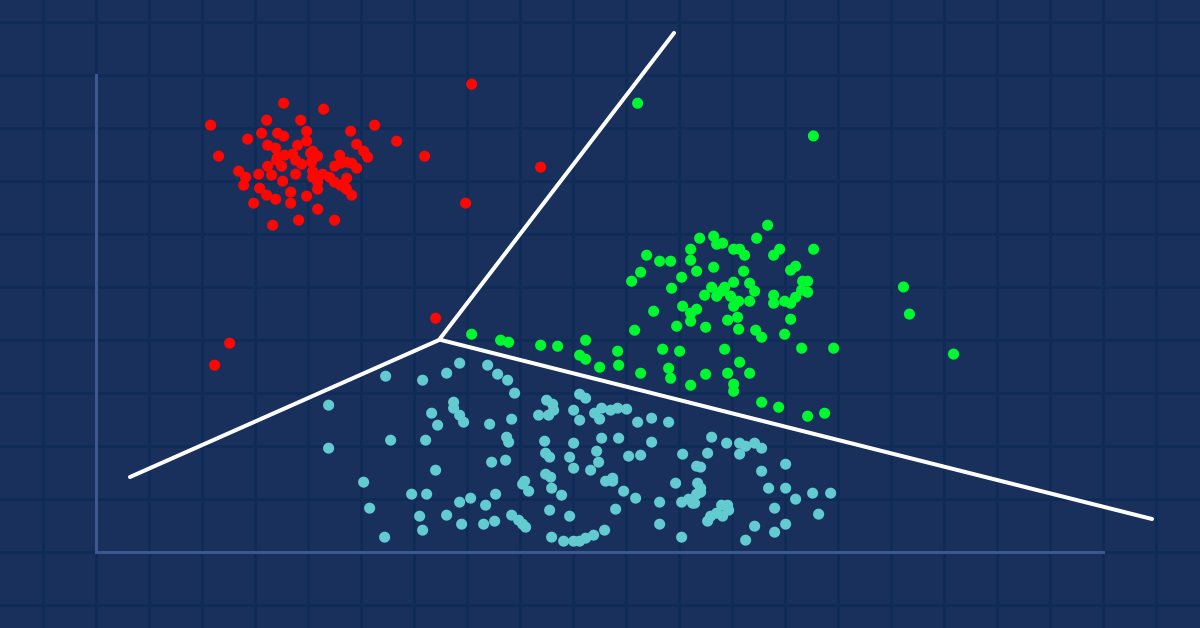
Aprendizaje automático y Data Science (Parte 8): Clusterización con el método de k-medias en MQL5
Para todos los que trabajan con datos, incluidos los tráders, la minería de datos puede descubrir posibilidades completamente nuevas, porque a menudo los datos no son tan simples como parecen. Resulta difícil para el ojo humano ver patrones y relaciones profundas en un conjunto de datos. Una solución sería el algoritmo de k-medias o k-means. Veamos si resulta útil.

Aprendizaje automático y data science (Parte 04): Predicción de una caída bursátil
En este artículo, intentaremos usar nuestro modelo logístico para predecir una caída del mercado de valores según las principales acciones de la economía estadounidense: NETFLIX y APPLE. Analizaremos estas acciones, y también usaremos la información sobre las anteriores caídas del mercado en 2019 y 2020. Veamos cómo funcionará nuestro modelo en las poco favorables condiciones actuales.

Redes neuronales: así de sencillo (Parte 33): Regresión cuantílica en el aprendizaje Q distribuido
Continuamos explorando el aprendizaje Q distribuido. Hoy analizaremos este enfoque desde un ángulo diferente. Vamos a hablar de la posibilidad de utilizar la regresión cuantílica para resolver el problema de la previsión de los movimientos de precio.

Aprendizaje automático y Data Science (Parte 16): Una nueva mirada a los árboles de decisión
En la última parte de nuestra serie sobre aprendizaje automático y trabajo con big data, vamos a volver a los árboles de decisión. Este artículo va dirigido a los tráders que desean comprender el papel de los árboles de decisión en el análisis de las tendencias del mercado. Asimismo, contiene toda la información básica sobre la estructura, la finalidad y el uso de estos árboles. Hoy analizaremos las raíces y ramas de los árboles algorítmicos y veremos cuál es su potencial en relación con las decisiones comerciales. También echaremos juntos un nuevo vistazo a los árboles de decisión y veremos cómo pueden ayudarnos a superar los retos de los mercados financieros.

Redes neuronales: así de sencillo (Parte 16): Uso práctico de la clusterización
En el artículo anterior, creamos una clase para la clusterización de datos. En este artículo, queremos compartir con el lector diferentes opciones de uso de los resultados obtenidos para resolver problemas prácticos en el trading.

Algoritmos de optimización de la población: Búsqueda armónica (HS)
Hoy estudiaremos y pondremos a prueba un algoritmo de optimización muy potente, la búsqueda armónica (HS), que se inspira en el proceso de búsqueda de la armonía sonora perfecta. ¿Qué algoritmo lidera ahora mismo nuestra clasificación?

Redes neuronales: así de sencillo (Parte 19): Reglas asociativas usando MQL5
Continuamos con el tema de la búsqueda de reglas asociativas. En el artículo anterior, vimos los aspectos teóricos de este tipo de problemas. En el presente artículo, mostraremos la implementación del método FP-Growth usando MQL5. Y también pondremos a prueba nuestra aplicación con datos reales.

Metamodelos en el aprendizaje automático y el trading: Timing original de las órdenes comerciales
Metamodelos en el aprendizaje automático: Creación automática de sistemas comerciales sin apenas intervención humana: el Modelo decide por sí mismo cómo y cuándo comerciar.
Gradient boosting en el aprendizaje de máquinas transductivo y activo
En este artículo, el lector podrá familiarizarse con los métodos de aprendizaje automático activo basados en datos reales, descubriendo además cuáles son sus ventajas y desventajas. Puede que estos métodos terminen por ocupar un lugar en su arsenal de modelos de aprendizaje automático. El término transducción fue introducido por Vladímir Naúmovich Vápnik, el inventor de la máquina de vectores de soporte (SVM).

Redes neuronales: así de sencillo (Parte 20): Autocodificadores
Continuamos analizando los algoritmos de aprendizaje no supervisado. El lector podría preguntarse sobre la relevancia de las publicaciones recientes en el tema de las redes neuronales. En este nuevo artículo, retomaremos el uso de las redes neuronales.